#Databricks CLI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
Boost Productivity with Databricks CLI: A Comprehensive Guide
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type.
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type. The best part? Windows users can join in on the exhilarating journey and install the new CLI with Homebrew, just like macOS and Linux users. This blog aims to provide comprehensive…

View On WordPress
#API#Authentication#Azure Databricks#Azure Databricks Cluster#Azure SQL Database#Cluster#Command prompt#data#Data Analytics#data engineering#Data management#Database#Databricks#Databricks CLI#Databricks CLI commands#Homebrew#JSON#Linux#MacOS#REST API#SQL#SQL database#Windows
0 notes
Text
Databricks Certified Data Engineer Professional Practice Exam For Best Preparation
Are you aspiring to become a certified data engineer with Databricks? Passing the Databricks Certified Data Engineer Professional exam is a significant step in proving your advanced data engineering skills. To simplify your preparation, the latest Databricks Certified Data Engineer Professional Practice Exam from Cert007 is an invaluable resource. Designed to mimic the real exam, it provides comprehensive practice questions that will help you master the topics and build confidence. With Cert007’s reliable preparation material, you can approach the exam with ease and increase your chances of success.
Overview of the Databricks Certified Data Engineer Professional Exam
The Databricks Certified Data Engineer Professional exam evaluates your ability to leverage the Databricks platform for advanced data engineering tasks. You will be tested on a range of skills, including:
Utilizing Apache Spark, Delta Lake, and MLflow to manage and process large datasets.
Building and optimizing ETL pipelines.
Applying data modeling principles to structure data in a Lakehouse architecture.
Using developer tools such as the Databricks CLI and REST API.
Ensuring data pipeline security, reliability, and performance through monitoring, testing, and governance.
Successful candidates will demonstrate a solid understanding of Databricks tools and the capability to design secure, efficient, and robust pipelines for data engineering.
Exam Details
Number of Questions: 60 multiple-choice questions
Duration: 120 minutes
Cost: $200 per attempt
Primary Coding Language: Python (Delta Lake functionality references are in SQL)
Certification Validity: 2 years from the date of passing
Exam Objectives and Weightage
The exam content is divided into six key objectives:
Databricks Tooling (20%) Proficiency in Databricks developer tools, including the CLI, REST API, and notebooks.
Data Processing (30%) Deep understanding of data transformation, optimization, and real-time streaming tasks using Databricks.
Data Modeling (20%) Knowledge of structuring data effectively for analysis and reporting in a Lakehouse architecture.
Security and Governance (10%) Implementation of secure practices for managing data access, encryption, and auditing.
Monitoring and Logging (10%) Ability to use tools and techniques to monitor pipeline performance and troubleshoot issues.
Testing and Deployment (10%) Knowledge of building, testing, and deploying reliable data engineering solutions.
Preparation Tips for Databricks Certified Data Engineer Professional Exam
1. Leverage Cert007 Practice Exams
The Databricks Certified Data Engineer Professional Practice Exam by Cert007 is tailored to provide a hands-on simulation of the real exam. Practicing with these questions will sharpen your understanding of the key concepts and help you identify areas where additional study is needed.
2. Understand the Databricks Ecosystem
Develop a strong understanding of the core components of the Databricks platform, including Apache Spark, Delta Lake, and MLflow. Focus on how these tools integrate to create seamless data engineering workflows.
3. Study the Official Databricks Learning Pathway
Follow the official Data Engineer learning pathway provided by Databricks. This pathway offers structured courses and materials designed to prepare candidates for the certification exam.
4. Hands-On Practice
Set up your own Databricks environment and practice creating ETL pipelines, managing data in Delta Lake, and deploying models with MLflow. This hands-on experience will enhance your skills and reinforce theoretical knowledge.
5. Review Security and Governance Best Practices
Pay attention to secure data practices, including access control, encryption, and compliance requirements. Understanding governance within the Databricks platform is essential for this exam.
6. Time Management for the Exam
Since you’ll have 120 minutes to answer 60 questions, practice pacing yourself during the exam. Aim to spend no more than 2 minutes per question, leaving time to review your answers.
Conclusion
Becoming a Databricks Certified Data Engineer Professional validates your expertise in advanced data engineering using the Databricks platform. By leveraging high-quality resources like the Cert007 practice exams and committing to hands-on practice, you can confidently approach the exam and achieve certification. Remember to stay consistent with your preparation and focus on mastering the six key objectives to ensure your success.
Good luck on your journey to becoming a certified data engineering professional!
0 notes
Link
0 notes
Text
Databricks Certified Data Engineer Professional Exam Questions
Are you planning to go for Databricks Certified Data Engineer Professional Certification Exam? PassQuestion can offer you the best Databricks Certified Data Engineer Professional Exam Questions which can help you to prepare Databricks Certified Professional Data Engineer Exam smoothly and efficiently. you may get the right Databricks Certified Data Engineer Professional Exam Questions that provide all the important features to clear the Databricks Certified Data Engineer Professional Exam. candidate can learn with Databricks Certified Data Engineer Professional Exam Questions according to the latest syllabus and achieve excellent grades in Databricks Certified Data Engineer Professional Exam.
Databricks Certified Data Engineer Professional Certification Exam
The Databricks Certified Data Engineer Professional certification exam assesses an individual's ability to use Databricks to perform advanced data engineering tasks. This includes an understanding of the Databricks platform and developer tools like Apache Spark, Delta Lake, MLflow, and the Databricks CLI and REST API. It also assesses the ability to build optimized and cleaned ETL pipelines. Additionally, modeling data into a Lakehouse using knowledge of general data modeling concepts will also be assessed. Finally, ensuring that data pipelines are secure, reliable, monitored, and tested before deployment will also be included in this exam. Individuals who pass this certification exam can be expected to complete advanced data engineering tasks using Databricks and its associated tools.
There are 60 multiple-choice questions on the Databricks Certified Data Engineer Professional certification exam. Testers will have 120 minutes to complete the certification exam. Each attempt of the certification exam will cost the tester $200. This certification exam's code examples will primarily be in Python. However, any and all references to Delta Lake functionality will be made in SQL. This certification is valid for 2 years following the date on which each tester passes the certification exam.
Exam Content
Databricks Tooling – 20% Data Processing – 30% Data Modeling – 20% Security and Governance – 10% Monitoring and Logging – 10% Testing and Deployment – 10%
View Online Databricks Certified Data Engineer Professional Free Questions
A data engineering team has been using a Databricks SQL query to monitor the performance of an ELT job. The ELT job is triggered by a specific number of input records being ready to process. The Databricks SQL query returns the number of minutes since the job's most recent runtime. Which of the following approaches can enable the data engineering team to be notified if the ELT job has not been run in an hour? A. This type of alerting is not possible in Databricks B. They can set up an Alert for the query to notify them if the returned value is greater than 60 C. They can set up an Alert for the accompanying dashboard to notify when it has not re-freshed in 60minutes D. They can set up an Alert for the accompanying dashboard to notify them if the returned value is greaterthan 60 E. They can set up an Alert for the query to notify when the ELT job fails Answer: B
A data engineer wants to combine two tables as a part of a query horizontally. They want to use a shared column as a key column, and they only want the query result to contain rows whose value in the key column is present in both tables. Which of the following SQL commands can they use to accomplish this task? A. LEFT JOIN B. INNER JOIN C. MERGE D. OUTER JOIN E. UNION Answer: B
Which of the following data workloads will utilize a Bronze table as its source? A. A job that queries aggregated data to publish key insights into a dashboard B. A job that enriches data by parsing its timestamps into a human-readable format C. A job that ingests raw data from a streaming source into the Lakehouse D. A job that develops a feature set for a machine learning application E. A job that aggregates cleaned data to create standard summary statistics Answer: B
A data engineering team has created a series of tables using Parquet data stored in an external sys-tem. The team is noticing that after appending new rows to the data in the external system, their queries within Databricks are not returning the new rows. They identify the caching of the previous data as the cause of this issue. Which of the following approaches will ensure that the data returned by queries is always up-to-date? A. The tables should be stored in a cloud-based external system B. The tables should be converted to the Delta format C. The tables should be updated before the next query is run D. The tables should be refreshed in the writing cluster before the next query is run E. The tables should be altered to include metadata to not cache Answer: B
A data analyst has noticed that their Databricks SQL queries are running too slowly. They claim that this issue is affecting all of their sequentially run queries. They ask the data engineering team for help. The data engineering team notices that each of the queries uses the same SQL endpoint, but any other user does not use the SQL endpoint. Which of the following approaches can the data engineering team use to improve the latency of the data analyst's queries? A. They can turn on the Serverless feature for the SQL endpoint and change the Spot In-stance Policy to "Reliability Optimized" B. They can increase the maximum bound of the SQL endpoint's scaling range C. They can turn on the Auto Stop feature for the SQL endpoint D. They can increase the cluster size of the SQL endpoint E. They can turn on the Serverless feature for the SQL endpoint Answer: D
0 notes
Text
How to Pass Microsoft Azure Foundation Exam AZ-900 (Part 2 of 3)
The Microsoft Azure Foundation Exam AZ-900 or the equivalent from AWS are usually the first cloud certificates that someone new to the cloud starts with. Both cover basic cloud concepts and ensure that you gain a profound understanding of the respective services. As the passing grade of 80% for the AZ-900 is quite high, it is advisable to thoroughly study for the exam. This is the first of three posts that will provide you with all key information about the Azure services that you need to pass the Azure Foundation Exam AZ-900.
The following structure is taken from the latest exam syllabus for the Azure Foundation 2021 and indicates the weight of each chapter in the exam. For each chapter, I have written down a very brief summary of key concepts and information that are typically asked for during the exam. The summary is a great resource to check and finalize your studies for the exam. However, if you are new to the topic, you should first start by going through the official Microsoft Azure training materials.
This is part 2 of the three-parts series regarding the Microsoft Azure Foundation exam AZ-900 and it will cover the third and fourth topic from the content below:
1. Describe Cloud Concepts (20-25%)
2. Describe Core Azure Services (15-20%)
3. Describe core solutions and management tools on Azure (10-15%)
3.1 Describe core solutions available in Azure
3.2 Describe Azure management tools
4. Describe general security and network security features (10-15%)
4.1 Describe Azure security features
4.2 Describe Azure network security
5. Describe identity, governance, privacy, and compliance features (20- 25%)
6. Describe Azure cost management and Service Level Agreements (10- 15%)
3. Describe core solutions and management tools on Azure (10-15%)
3.1 Describe core solutions available in Azure
Virtual Machines
A virtual machine is an IaaS service. Administrators from a company would have full control over the operating system and be able to install all applications on it. For example, Virtual machines can have a VPN installed that encrypts all traffic from the virtual machine itself to a host on the Internet. They can also transfer a virtual machine between different subscriptions.
Scale sets help to manage increased demands, load balancer help to distribute user traffic among identical virtual machines. Azure Virtual Machine Scale Sets are used to host and manage a group of identical Virtual Machines.
To avoid failure in case that a data center fails, you need to deploy across multiple availability zones. At least two virtual machines are needed to ensure 99.99% up time. If a virtual machine is switched off, there are no costs for processing, but still for storage services.
Containers
Containers are more lightweight than virtual machines. Instead of virtualizing the complete operating system, they only need the images and libraries and access the underlying operating system from the host environment. Multiple containers are managed with Azure Kubernetes, which is an IaaS solution.
Storage
Data disks for virtual machines are available through blob storage. Blob storage costs depend on the region. Storage costs depend on the amount of stored data, but also on the amount of read and write operations. Transfers between different regions also costs.
An Azure Storage account – file service – can be used to map a network drive from on premise computers to a Microsoft Azure storage.
Cool storage and archive storage can be used for data that is infrequently accessed.
Further Azure Services
Azure SQL database is a PaaS service. Companies buying the service would not have control over the underlying server hosting in Azure
Azure Web App is a PaaS solution, accessible via https://portal.azure.com. One would not have full access on the underlying machine hosting the web application
Azure DevOps is an integration solution for the deployment of code. It provides a continuous integration and delivery toolset
Azure DevTestLabs quickly provides development and test environments, such as 50 customized virtual machines per week
Azure Event Grid can collect events from multiple sources and process them to an application
Azure Databricks is a big data analysis service for machine learning
Azure Machine Learning Studio can be used to build, test, and deploy predictive analytics solutions
Azure Logic Apps is a platform to create workflows
Azure Data Lakes is a storage repository holding large amounts of data in its native, raw format
Azure Data Lake Analytics helps to transform data and provide valuable insights on the data itself
Azure SQL Data Warehouse is a centralized repository of integrated data from one or more sources. It requires zero administration of the underlying infrastructure and provides low latency access to the data
Cosmos DB Service is a globally distributed, multimodal database service. It can host tables and json documents in Azure without required administration of the underlying infrastructure
Azure Synapse Analytics is an analytics service that brings together enterprise data ware housing and Big Data Analytics
Azure HD Insight is a managed, full-spectrum, open-source analytics service. It can be used for frameworks such as Hadoop, Apache etc
Azure Functions App and Azure Logic App are platforms for serverless code. Azure Logic focuses on workflows, automation, integration, and orchestration, while Azure Functions merely executes code
Azure App Services hosts web apps / web-based applications. It requires to manage the infrastructure
Azure Marketplace is an online store that offers applications and services either built on or designed to integrate with Azure
IoT Central provides a fully managed SaaS solution that makes it easy to connect, monitor, and manage IoT assets at scale
IoT Hub can be used to monitor and control billions of Internet of Things assets
IoT Edge is an IoT solution that can be used to analyze data on end user devices
Azure Time Series Insights provides data exploration and telemetry tools to help refine operational analysis
Azure Cognitive Services is a simplified tool to build intelligent Artificial Intelligence applications
3.2 Describe Azure management tools
Azure Applications Insights monitors web applications and detects and diagnoses anomalies in web apps
The Azure CLI, Azure Powershell, and Azure Portal can be used on Windows 10, Ubuntu, and macOS machines
Cloud Shell works on Android or MacOS that has Powershell Core 6.0 installed
Windows PowerShell and Command Prompt can be used to install the CLI on a computer
4. Describe general security and network security features (10-15%)
4.1 Describe Azure security features
The Azure Firewall protects the network infrastructure
The Azure DDoS Protection provides protection against distributed denial of service attacks
Network Security Groups restrict inbound and outbound traffic. They are used to secure Azure environments
Azure Multi-Factor Authentication provides an extra level of security when users log into the Azure Portal. It is available for administrative and non-administrative user accounts
The Azure Key Vault can be used to store secrets, certificates, or database passwords etc.
Azure Information Protection encrypts documents and email messages
Azure AD Identity Protection can make users that try to login from an anonymous IT address to need to change their password
Authentication is the process of verifying a user´s credentials
4.2 Describe Azure network security
A Network Security Group can filter network traffic to and from Azure resources in an Azure virtual network. They can also ensure that traffic restrictions are in place so that a database server can only communicate with the web browser
An Azure Virtual Network can provide an isolated environment for hosting of virtual machines
A Virtual Network Gateway is needed to connect an on-premise data center to an Azure Virtual Network using a Site-to-Site connection
A Local Network Gateway can represent a VPN device in the cloud context
0 notes
Link
Hi HN,
We’re JY & Julien, co-founders of Data Mechanics (https://www.datamechanics.co), a big data platform striving to offer the simplest way to run Apache Spark.
Apache Spark is an open-source distributed computing engine. It’s the most used technology in big data. First, because it’s fast (10-100x faster than Hadoop MapReduce). Second, because it offers simple, high-level APIs in Scala, Python, SQL, and R. In a few lines of code, data scientists and engineers can explore data, train machine learning models, and build batch or streaming pipelines over very large datasets (size ranging from 10GBs to PBs).
While writing Spark applications is pretty easy, managing their infrastructure, deploying them and keeping them performant and stable in production over time is hard. You need to learn how Apache Spark works under the hood, become an expert with YARN and the JVM, manually choose dozens of infrastructure parameters and Spark configurations, and go through painfully slow iteration cycles to develop, debug, and productionize your app.
As you can tell, before starting Data Mechanics, we were frustrated Spark developers. Julien was a data scientist and data engineer at BlaBlaCar and ContentSquare. JY was the Spark infrastructure team lead at Databricks, the data science platform founded by the creators of Spark. We’ve designed Data Mechanics so that our peer data scientists and engineers can focus on their core mission - building models and pipelines - while the platform handles the mechanical DevOps work.
To realize this goal, we needed a way to tune infrastructure parameters and Spark configurations automatically. There are dozens of such parameters but the most critical ones are the amount of memory and cpu allocated to each node, the degree of parallelism of Spark, and the way Spark handles all-to-all data transfer stages (called shuffles). It takes a lot of expertise and trial-and-error loops to manually tune those parameters. To do it automatically, we first run the logs and metadata produced by Spark through a set of heuristics that determines if the application is stable and performant. A Bayesian optimization algorithm uses this analysis as well as data from past recent runs to choose a set of parameters to use on the next run. It’s not perfect - it needs a few iterations like an engineer would. But the impact is huge because this happens automatically for each application running on the platform (which would be too time-consuming for an engineer). Take the example of an application gradually going unstable as the input data grows over time. Without us, the application crashes on a random day, and an engineer must spend a day remediating the impact of the outage and debugging the app. Our platform can often anticipate and avoid the outage altogether.
The other way we differentiate is by integrating with the popular tools from the data stack. Enterprise data science platforms tend to require their users to abandon their tools to adopt their own end-to-end suite of proprietary solutions: their hosted notebooks, their scheduler, their way of packaging dependencies and version-controlling your code. Instead, our users can connect their Jupyter notebook, their Airflow scheduler, and their favourite IDE directly to the platform. This enables a seamless transition from local development to running at scale on the platform.
We also deploy Spark directly on Kubernetes, which wasn’t possible until recently (Spark version 2.3) - most Spark platforms run on YARN instead. This means our users can package their code dependencies on a Docker image and use a lot of k8s-compatible projects for free (for example around secrets management and monitoring). Kubernetes does have its inherent complexity. We hide it from our users by deploying Data Mechanics in their cloud account on a Kubernetes cluster that we manage for them. Our users can simply interact with our web UI and our API/CLI - they don’t need to poke around Kubernetes unless they really want to.
The platform is available on AWS, GCP, and Azure. Many of our customers use us for their ETL pipelines, they appreciate the ease of use of the platform and the performance boost from automated tuning. We’ve also helped companies start their first Spark project: a startup is using us to parallelize chemistry computations and accelerate the discovery of drugs. This is our ultimate goal - to make distributed data processing accessible to all.
Of course, we share this mission with many companies out there, but we hope you’ll find our angle interesting! We’re excited to share our story with the HN community today and we look forward to hearing about your experience in the data engineering and data science spaces. Have you used Spark and did you feel the frustrations we talked about? If you consider Spark for your next project, does our platform look appealing? We don’t offer self-service deployment yet, but you can schedule a demo with us from the website and we’ll be happy to give you a free trial access in exchange for your feedback.
Thank you!
Comments URL: https://news.ycombinator.com/item?id=23142831
Points: 13
# Comments: 0
0 notes
Text
Empower Data Analysis with Materialized Views in Databricks SQL
Envision a realm where your data is always ready for querying, with intricate queries stored in a format primed for swift retrieval and analysis. Picture a world where time is no longer a constraint, where data handling is both rapid and efficient.
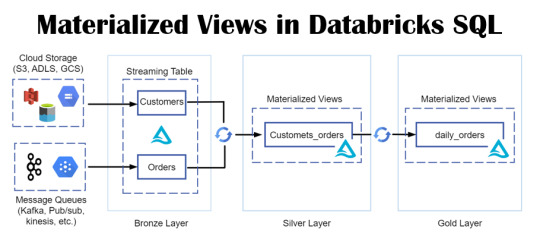
View On WordPress
#Azure#Azure SQL Database#data#Database#Database Management#Databricks#Databricks CLI#Databricks Delta Live Table#Databricks SQL#Databricks Unity catalog#Delta Live#Materialized Views#Microsoft#microsoft azure#Optimization#Performance Optimization#queries#SQL#SQL database#Streaming tables#tables#Unity Catalog#views
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
0 notes