#Azure Databricks Cluster
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
Unlocking the Full Power of Apache Spark 3.4 for Databricks Runtime!
You've dabbled in the magic of Apache Spark 3.4 with my previous blog "Exploring Apache Spark 3.4 Features for Databricks Runtime", where we journeyed through 8 game-changing features
You’ve dabbled in the magic of Apache Spark 3.4 with my previous blog “Exploring Apache Spark 3.4 Features for Databricks Runtime“, where we journeyed through 8 game-changing features—from the revolutionary Spark Connect to the nifty tricks of constructing parameterized SQL queries. But guess what? We’ve only scratched the surface! In this sequel, we’re diving deeper into the treasure trove of…

View On WordPress
#Apache Spark#Azure Databricks#Azure Databricks Cluster#Data Frame#Databricks#databricks apache spark#Databricks SQL#Memory Profiler#NumPy#performance#Pivot#pyspark#PySpark UDFs#SQL#SQL queries#SQL SELECT#SQL Server
0 notes
Text
youtube
Databricks: what’s new in May 2025? Updates & Features Explained! #databricks Databricks, What’s New in Databricks? May 2025 Updates & Features Explained! In May 2025, Databricks added several key features. 📌 Key Highlights for This Month: - *0:16* 16.4 LTS - *0:28* Autoloader auto cleaner - *2:28* Lakeflow UI connectors - *3:01* Workflow run with different settings - *4:27* ETL/DLT editor - *5:30* PRIVATE materialised views and streaming tables - *6:48* Delta share materialised views and streaming tables - *7:27* Clean rooms up to 10 collaborators - *7:57* Predictive optimisation for all - *8:45* Just-in-time user provisioning - *10:04* Cluster logs - *11:13* Run the code inside the assistant - *13:22* Query snippets - *14:34* New charts - *15:43* Run apps locally - *16:51* Custom data sources - *18:01* Syntax highlighter - *19:25* String aggregation ============================= 📚 *Notebooks from the video:* 🔗 [GitHub Repository](https://ift.tt/aJpTNju) 🔔𝐃𝐨𝐧'𝐭 𝐟𝐨𝐫𝐠𝐞𝐭 𝐭𝐨 𝐬𝐮𝐛𝐬𝐜𝐫𝐢𝐛𝐞 𝐭𝐨 𝐦𝐲 𝐜𝐡𝐚𝐧𝐧𝐞𝐥 𝐟𝐨𝐫 𝐦𝐨𝐫𝐞 𝐮𝐩𝐝𝐚𝐭𝐞𝐬. https://www.youtube.com/@databricks_hubert_dudek/?sub_confirmation=1 🔗 Support Me Here! ☕Buy me a coffee: https://ift.tt/nlEDgNR ✨ Explore Databricks AI insights and workflows—read more: https://ift.tt/hUeGRFE ============================= 🎬Suggested videos for you: ▶️ [What’s new in January 2025](https://www.youtube.com/watch?v=JJiwSplZmfk) ▶️ [What’s new in February 2025](https://www.youtube.com/watch?v=tuKI0sBNbmg) ▶️ [What’s new in March 2025](https://youtu.be/hJD7KoNq-uE) ▶️ [What’s new in April 2025](https://youtu.be/FDgtNVeLTc8) ============================= 📚 **New Articles for Further Reading:** - 📝 *Clean Landing Zone — autoloader cleanSource:* 🔗 [Read the full article](https://ift.tt/gS2h1s3) - 📝 *Nested groups in databricks:* 🔗 [Read the full article](https://ift.tt/TileUHn) - 📝 *Cost Benchmark: 2 billion records from bronze to silver on serverless:* 🔗 [Read the full article](https://ift.tt/WUnICfR) - 📝 *Logs to Volumes and to Dataframe:* 🔗 [Read the full article](https://ift.tt/Reya0pJ) ============================= 🔎 Related Phrases: #databricks #bigdata #dataengineering #machinelearning #sql #cloudcomputing #dataanalytics #ai #azure #googlecloud #aws #etl #python #data #database #datawarehouse via databricks by Hubert Dudek https://www.youtube.com/channel/UCR99H9eib5MOHEhapg4kkaQ May 19, 2025 at 03:07AM
#databricks#dataengineering#machinelearning#sql#dataanalytics#ai#databrickstutorial#databrickssql#databricksai#Youtube
0 notes
Text
Data Science Tutorial for 2025: Tools, Trends, and Techniques
Data science continues to be one of the most dynamic and high-impact fields in technology, with new tools and methodologies evolving rapidly. As we enter 2025, data science is more than just crunching numbers—it's about building intelligent systems, automating decision-making, and unlocking insights from complex data at scale.
Whether you're a beginner or a working professional looking to sharpen your skills, this tutorial will guide you through the essential tools, the latest trends, and the most effective techniques shaping data science in 2025.
What is Data Science?
At its core, data science is the interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing patterns, and building predictive or explanatory models.
Data scientists are problem-solvers, storytellers, and innovators. Their work influences business strategies, public policy, healthcare solutions, and even climate models.

Essential Tools for Data Science in 2025
The data science toolkit has matured significantly, with tools becoming more powerful, user-friendly, and integrated with AI. Here are the must-know tools for 2025:
1. Python 3.12+
Python remains the most widely used language in data science due to its simplicity and vast ecosystem. In 2025, the latest Python versions offer faster performance and better support for concurrency—making large-scale data operations smoother.
Popular Libraries:
Pandas: For data manipulation
NumPy: For numerical computing
Matplotlib / Seaborn / Plotly: For data visualization
Scikit-learn: For traditional machine learning
XGBoost / LightGBM: For gradient boosting models
2. JupyterLab
The evolution of the classic Jupyter Notebook, JupyterLab, is now the default environment for exploratory data analysis, allowing a modular, tabbed interface with support for terminals, text editors, and rich output.
3. Apache Spark with PySpark
Handling massive datasets? PySpark—Python’s interface to Apache Spark—is ideal for distributed data processing across clusters, now deeply integrated with cloud platforms like Databricks and Snowflake.
4. Cloud Platforms (AWS, Azure, Google Cloud)
In 2025, most data science workloads run on the cloud. Services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI simplify model training, deployment, and monitoring.
5. AutoML & No-Code Tools
Tools like DataRobot, Google AutoML, and H2O.ai now offer drag-and-drop model building and optimization. These are powerful for non-coders and help accelerate workflows for pros.
Top Data Science Trends in 2025
1. Generative AI for Data Science
With the rise of large language models (LLMs), generative AI now assists data scientists in code generation, data exploration, and feature engineering. Tools like OpenAI's ChatGPT for Code and GitHub Copilot help automate repetitive tasks.
2. Data-Centric AI
Rather than obsessing over model architecture, 2025’s best practices focus on improving the quality of data—through labeling, augmentation, and domain understanding. Clean data beats complex models.
3. MLOps Maturity
MLOps—machine learning operations—is no longer optional. In 2025, companies treat ML models like software, with versioning, monitoring, CI/CD pipelines, and reproducibility built-in from the start.
4. Explainable AI (XAI)
As AI impacts sensitive areas like finance and healthcare, transparency is crucial. Tools like SHAP, LIME, and InterpretML help data scientists explain model predictions to stakeholders and regulators.
5. Edge Data Science
With IoT devices and on-device AI becoming the norm, edge computing allows models to run in real-time on smartphones, sensors, and drones—opening new use cases from agriculture to autonomous vehicles.
Core Techniques Every Data Scientist Should Know in 2025
Whether you’re starting out or upskilling, mastering these foundational techniques is critical:
1. Data Wrangling
Before any analysis begins, data must be cleaned and reshaped. Techniques include:
Handling missing values
Normalization and standardization
Encoding categorical variables
Time series transformation
2. Exploratory Data Analysis (EDA)
EDA is about understanding your dataset through visualization and summary statistics. Use histograms, scatter plots, correlation heatmaps, and boxplots to uncover trends and outliers.
3. Machine Learning Basics
Classification (e.g., predicting if a customer will churn)
Regression (e.g., predicting house prices)
Clustering (e.g., customer segmentation)
Dimensionality Reduction (e.g., PCA, t-SNE for visualization)
4. Deep Learning (Optional but Useful)
If you're working with images, text, or audio, deep learning with TensorFlow, PyTorch, or Keras can be invaluable. Hugging Face’s transformers make it easier than ever to work with large models.
5. Model Evaluation
Learn how to assess model performance with:
Accuracy, Precision, Recall, F1 Score
ROC-AUC Curve
Cross-validation
Confusion Matrix
Final Thoughts
As we move deeper into 2025, data science tutorial continues to be an exciting blend of math, coding, and real-world impact. Whether you're analyzing customer behavior, improving healthcare diagnostics, or predicting financial markets, your toolkit and mindset will be your most valuable assets.
Start by learning the fundamentals, keep experimenting with new tools, and stay updated with emerging trends. The best data scientists aren’t just great with code—they’re lifelong learners who turn data into decisions.
0 notes
Text
Explore Apache Spark structured streaming
Apache Spark is a distributed processing framework for large scale data analytics. You can use Spark on Microsoft Azure in the following services: Microsoft Fabric Azure Databricks Spark can be used to run code (usually written in Python, Scala, or Java) in parallel across multiple cluster nodes, enabling it to process very large volumes of data efficiently. Spark can be used for both batch…

View On WordPress
0 notes
Text
Optimizing Data Operations with Databricks Services
Introduction
In today’s data-driven world, businesses generate vast amounts of information that must be processed, analyzed, and stored efficiently. Managing such complex data environments requires advanced tools and expert guidance. Databricks Services offer comprehensive solutions to streamline data operations, enhance analytics, and drive AI-powered decision-making.
This article explores how Databricks Services accelerate data operations, their key benefits, and best practices for maximizing their potential.
What are Databricks Services?
Databricks Services encompass a suite of cloud-based solutions and consulting offerings that help organizations optimize their data processing, machine learning, and analytics workflows. These services include:
Data Engineering and ETL: Automating data ingestion, transformation, and storage.
Big Data Processing with Apache Spark: Optimizing large-scale distributed computing.
Machine Learning and AI Integration: Leveraging Databricks for predictive analytics.
Data Governance and Security: Implementing policies to ensure data integrity and compliance.
Cloud Migration and Optimization: Transitioning from legacy systems to modern Databricks environments on AWS, Azure, or Google Cloud.
How Databricks Services Enhance Data Operations
Organizations that leverage Databricks Services benefit from a unified platform designed for scalability, efficiency, and AI-driven insights.
1. Efficient Data Ingestion and Integration
Seamless data integration is essential for real-time analytics and business intelligence. Databricks Services help organizations:
Automate ETL pipelines using Databricks Auto Loader.
Integrate data from multiple sources, including cloud storage, on-premise databases, and streaming data.
Improve data reliability with Delta Lake, ensuring consistency and schema evolution.
2. Accelerating Data Processing and Performance
Handling massive data volumes efficiently requires optimized computing resources. Databricks Services enable businesses to:
Utilize Apache Spark clusters for distributed data processing.
Improve query speed with Photon Engine, designed for high-performance analytics.
Implement caching, indexing, and query optimization techniques for better efficiency.
3. Scaling AI and Machine Learning Capabilities
Databricks Services provide the infrastructure and expertise to develop, train, and deploy machine learning models. These services include:
MLflow for end-to-end model lifecycle management.
AutoML capabilities for automated model tuning and selection.
Deep learning frameworks like TensorFlow and PyTorch for advanced AI applications.
4. Enhancing Security and Compliance
Data security and regulatory compliance are critical concerns for enterprises. Databricks Services ensure:
Role-based access control (RBAC) with Unity Catalog for data governance.
Encryption and data masking to protect sensitive information.
Compliance with GDPR, HIPAA, CCPA, and other industry regulations.
5. Cloud Migration and Modernization
Transitioning from legacy databases to modern cloud platforms can be complex. Databricks Services assist organizations with:
Seamless migration from Hadoop, Oracle, and Teradata to Databricks.
Cloud-native architecture design tailored for AWS, Azure, and Google Cloud.
Performance tuning and cost optimization for cloud computing environments.
Key Benefits of Databricks Services
Organizations that invest in Databricks Services unlock several advantages, including:
1. Faster Time-to-Insight
Pre-built data engineering templates accelerate deployment.
Real-time analytics improve decision-making and operational efficiency.
2. Cost Efficiency and Resource Optimization
Serverless compute options minimize infrastructure costs.
Automated scaling optimizes resource utilization based on workload demand.
3. Scalability and Flexibility
Cloud-native architecture ensures businesses can scale operations effortlessly.
Multi-cloud and hybrid cloud support enable flexibility in deployment.
4. AI-Driven Business Intelligence
Advanced analytics and AI models uncover hidden patterns in data.
Predictive insights improve forecasting and business strategy.
5. Robust Security and Governance
Enforces best-in-class data governance frameworks.
Ensures compliance with industry-specific regulatory requirements.
Industry Use Cases for Databricks Services
Many industries leverage Databricks Services to drive innovation and operational efficiency. Below are some key applications:
1. Financial Services
Fraud detection using AI-powered transaction analysis.
Regulatory compliance automation for banking and fintech.
Real-time risk assessment for investment portfolios.
2. Healthcare & Life Sciences
Predictive analytics for patient care optimization.
Drug discovery acceleration through genomic research.
HIPAA-compliant data handling for secure medical records.
3. Retail & E-Commerce
Personalized customer recommendations using AI.
Supply chain optimization with predictive analytics.
Demand forecasting to improve inventory management.
4. Manufacturing & IoT
Anomaly detection in IoT sensor data for predictive maintenance.
AI-enhanced quality control systems to reduce defects.
Real-time analytics for production line efficiency.
Best Practices for Implementing Databricks Services
To maximize the value of Databricks Services, organizations should follow these best practices:
1. Define Clear Objectives
Set measurable KPIs to track data operation improvements.
Align data strategies with business goals and revenue targets.
2. Prioritize Data Governance and Quality
Implement data validation and cleansing processes.
Leverage Unity Catalog for centralized metadata management.
3. Automate for Efficiency
Use Databricks automation tools to streamline ETL and machine learning workflows.
Implement real-time data streaming for faster insights.
4. Strengthen Security Measures
Enforce multi-layered security policies for data access control.
Conduct regular audits and compliance assessments.
5. Invest in Continuous Optimization
Update data pipelines and ML models to maintain peak performance.
Provide ongoing training for data engineers and analysts.
Conclusion
Databricks Services provide businesses with the expertise, tools, and technology needed to accelerate data operations, enhance AI-driven insights, and improve overall efficiency. Whether an organization is modernizing its infrastructure, implementing real-time analytics, or strengthening data governance, Databricks Services offer tailored solutions to meet these challenges.
By partnering with Databricks experts, companies can unlock the full potential of big data, AI, and cloud-based analytics, ensuring they stay ahead in today’s competitive digital landscape.
0 notes
Text
Building Complex Data Workflows with Azure Data Factory Mapping Data Flows

Building Complex Data Workflows with Azure Data Factory Mapping Data Flows
Azure Data Factory (ADF) Mapping Data Flows allows users to build scalable and complex data transformation workflows using a no-code or low-code approach.
This is ideal for ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) scenarios where large datasets need processing efficiently.
1. Understanding Mapping Data Flows
Mapping Data Flows in ADF provide a graphical interface for defining data transformations without writing complex code. The backend execution leverages Azure Databricks, making it highly scalable.
Key Features
✅ Drag-and-drop transformations — No need for complex scripting. ✅ Scalability with Spark — Uses Azure-managed Spark clusters for execution. ✅ Optimized data movement — Push-down optimization for SQL-based sources. ✅ Schema drift handling — Auto-adjusts to changes in source schema. ✅ Incremental data processing — Supports delta loads to process only new or changed data.
2. Designing a Complex Data Workflow
A well-structured data workflow typically involves:
📌 Step 1: Ingest Data from Multiple Sources
Connect to Azure Blob Storage, Data Lake, SQL Server, Snowflake, SAP, REST APIs, etc.
Use Self-Hosted Integration Runtime if data is on-premises.
Optimize data movement with parallel copy.
📌 Step 2: Perform Data Transformations
Join, Filter, Aggregate, and Pivot operations.
Derived columns for computed values.
Surrogate keys for primary key generation.
Flatten hierarchical data (JSON, XML).
📌 Step 3: Implement Incremental Data Processing
Use watermark columns (e.g., last updated timestamp).
Leverage Change Data Capture (CDC) for tracking updates.
Implement lookup transformations to merge new records efficiently.
📌 Step 4: Optimize Performance
Use Partitioning Strategies: Hash, Round Robin, Range-based.
Enable staging before transformations to reduce processing time.
Choose the right compute scale (low, medium, high).
Monitor debug mode to analyze execution plans.
📌 Step 5: Load Transformed Data to the Destination
Write data to Azure SQL, Synapse Analytics, Data Lake, Snowflake, Cosmos DB, etc.
Optimize data sinks by batching inserts and using PolyBase for bulk loads.
3. Best Practices for Efficient Workflows
✅ Reduce the number of transformations — Push down operations to source SQL engine when possible. ✅ Use partitioning to distribute workload across multiple nodes. ✅ Avoid unnecessary data movement — Stage data in Azure Blob instead of frequent reads/writes. ✅ Monitor with Azure Monitor — Identify bottlenecks and tune performance. ✅ Automate execution with triggers, event-driven execution, and metadata-driven pipelines.
Conclusion
Azure Data Factory Mapping Data Flows simplifies the development of complex ETL workflows with a scalable, graphical, and optimized approach.
By leveraging best practices, organizations can streamline data pipelines, reduce costs, and improve performance.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Azure Databricks: Unleashing the Power of Big Data and AI
Introduction to Azure Databricks
In a world where data is considered the new oil, managing and analyzing vast amounts of information is critical. Enter Azure Databricks, a unified analytics platform designed to simplify big data and artificial intelligence (AI) workflows. Developed in partnership between Microsoft and Databricks, this tool is transforming how businesses leverage data to make smarter decisions.
Azure Databricks combines the power of Apache Spark with Azure’s robust ecosystem, making it an essential resource for businesses aiming to harness the potential of data and AI.
Core Features of Azure Databricks
Unified Analytics Platform
Azure Databricks brings together data engineering, data science, and business analytics in one environment. It supports end-to-end workflows, from data ingestion to model deployment.
Support for Multiple Languages
Whether you’re proficient in Python, SQL, Scala, R, or Java, Azure Databricks has you covered. Its flexibility makes it a preferred choice for diverse teams.
Seamless Integration with Azure Services
Azure Databricks integrates effortlessly with Azure’s suite of services, including Azure Data Lake, Azure Synapse Analytics, and Power BI, streamlining data pipelines and analysis.

How Azure Databricks Works
Architecture Overview
At its core, Azure Databricks leverages Apache Spark’s distributed computing capabilities. This ensures high-speed data processing and scalability.
Collaboration in a Shared Workspace
Teams can collaborate in real-time using shared notebooks, fostering a culture of innovation and efficiency.
Automated Cluster Management
Azure Databricks simplifies cluster creation and management, allowing users to focus on analytics rather than infrastructure.
Advantages of Using Azure Databricks
Scalability and Flexibility
Azure Databricks automatically scales resources based on workload requirements, ensuring optimal performance.
Cost Efficiency
Pay-as-you-go pricing and resource optimization help businesses save on operational costs.
Enterprise-Grade Security
With features like role-based access control (RBAC) and integration with Azure Active Directory, Azure Databricks ensures data security and compliance.
Comparing Azure Databricks with Other Platforms
Azure Databricks vs. Apache Spark
While Apache Spark is the foundation, Azure Databricks enhances it with a user-friendly interface, better integration, and managed services.
Azure Databricks vs. AWS Glue
Azure Databricks offers superior performance and scalability for machine learning workloads compared to AWS Glue, which is primarily an ETL service.
Key Use Cases for Azure Databricks
Data Engineering and ETL Processes
Azure Databricks simplifies Extract, Transform, Load (ETL) processes, enabling businesses to cleanse and prepare data efficiently.
Machine Learning Model Development
Data scientists can use Azure Databricks to train, test, and deploy machine learning models with ease.
Real-Time Analytics
From monitoring social media trends to analyzing IoT data, Azure Databricks supports real-time analytics for actionable insights.
Industries Benefiting from Azure Databricks
Healthcare
By enabling predictive analytics, Azure Databricks helps healthcare providers improve patient outcomes and optimize operations.
Retail and E-Commerce
Retailers leverage Azure Databricks for demand forecasting, customer segmentation, and personalized marketing.
Financial Services
Banks and financial institutions use Azure Databricks for fraud detection, risk assessment, and portfolio optimization.

Getting Started with Azure Databricks
Setting Up an Azure Databricks Workspace
Begin by creating an Azure Databricks workspace through the Azure portal. This serves as the foundation for your analytics projects.
Creating Clusters
Clusters are the computational backbone. Azure Databricks makes it easy to create and configure clusters tailored to your workload.
Writing and Executing Notebooks
Use notebooks to write, debug, and execute your code. Azure Databricks’ notebook interface is intuitive and collaborative.
Best Practices for Using Azure Databricks
Optimizing Cluster Performance
Select the appropriate cluster size and configurations to balance cost and performance.
Managing Data Storage Effectively
Integrate with Azure Data Lake for efficient and scalable data storage solutions.
Ensuring Data Security and Compliance Implement RBAC, encrypt data at rest, and adhere to industry-specific compliance standards.
Challenges and Solutions in Using Azure Databricks
Managing Costs
Monitor resource usage and terminate idle clusters to avoid unnecessary expenses.
Handling Large Datasets Efficiently
Leverage partitioning and caching to process large datasets effectively.
Debugging and Error Resolution
Azure Databricks provides detailed logs and error reports, simplifying the debugging process.
Future Trends in Azure Databricks
Enhanced AI Capabilities
Expect more advanced AI tools and features to be integrated, empowering businesses to solve complex problems.
Increased Automation
Automation will play a bigger role in streamlining workflows, from data ingestion to model deployment.
Real-Life Success Stories
Case Study: How a Retail Giant Scaled with Azure Databricks
A leading retailer improved inventory management and personalized customer experiences by utilizing Azure Databricks for real-time analytics.
Case Study: Healthcare Advancements with Predictive Analytics
A healthcare provider reduced readmission rates and enhanced patient care through predictive modeling in Azure Databricks.
Learning Resources and Support
Official Microsoft Documentation
Access in-depth guides and tutorials on the Microsoft Azure Databricks documentation.
Online Courses and Certifications
Platforms like Coursera, Udemy, and LinkedIn Learning offer courses to enhance your skills.
Community Forums and Events
Join the Databricks and Azure communities to share knowledge and learn from experts.
Conclusion
Azure Databricks is revolutionizing the way organizations handle big data and AI. Its robust features, seamless integrations, and cost efficiency make it a top choice for businesses of all sizes. Whether you’re looking to improve decision-making, streamline processes, or innovate with AI, Azure Databricks has the tools to help you succeed.
FAQs
1. What is the difference between Azure Databricks and Azure Synapse Analytics?
Azure Databricks focuses on big data analytics and AI, while Azure Synapse Analytics is geared toward data warehousing and business intelligence.
2. Can Azure Databricks handle real-time data processing?
Yes, Azure Databricks supports real-time data processing through its integration with streaming tools like Azure Event Hubs.
3. What skills are needed to work with Azure Databricks?
Knowledge of data engineering, programming languages like Python or Scala, and familiarity with Azure services is beneficial.
4. How secure is Azure Databricks for sensitive data?
Azure Databricks offers enterprise-grade security, including encryption, RBAC, and compliance with standards like GDPR and HIPAA.
5. What is the pricing model for Azure Databricks?
Azure Databricks uses a pay-as-you-go model, with costs based on the compute and storage resources used.
0 notes
Text
How Azure Databricks & Data Factory Aid Modern Data Strategy

For all analytics and AI use cases, maximize data value with Azure Databricks.
What is Azure Databricks?
A completely managed first-party service, Azure Databricks, allows an open data lakehouse in Azure. Build a lakehouse on top of an open data lake to quickly light up analytical workloads and enable data estate governance. Support data science, engineering, machine learning, AI, and SQL-based analytics.
First-party Azure service coupled with additional Azure services and support.
Analytics for your latest, comprehensive data for actionable insights.
A data lakehouse foundation on an open data lake unifies and governs data.
Trustworthy data engineering and large-scale batch and streaming processing.
Get one seamless experience
Microsoft sells and supports Azure Databricks, a fully managed first-party service. Azure Databricks is natively connected with Azure services and starts with a single click in the Azure portal. Without integration, a full variety of analytics and AI use cases may be enabled quickly.
Eliminate data silos and responsibly democratise data to enable scientists, data engineers, and data analysts to collaborate on well-governed datasets.
Use an open and flexible framework
Use an optimised lakehouse architecture on open data lake to process all data types and quickly light up Azure analytics and AI workloads.
Use Apache Spark on Azure Databricks, Azure Synapse Analytics, Azure Machine Learning, and Power BI depending on the workload.
Choose from Python, Scala, R, Java, SQL, TensorFlow, PyTorch, and SciKit Learn data science frameworks and libraries.
Build effective Azure analytics
From the Azure interface, create Apache Spark clusters in minutes.
Photon provides rapid query speed, serverless compute simplifies maintenance, and Delta Live Tables delivers high-quality data with reliable pipelines.
Azure Databricks Architecture
Companies have long collected data from multiple sources, creating data lakes for scale. Quality data was lacking in data lakes. To overcome data warehouse and data lake restrictions, the Lakehouse design arose. Lakehouse, a comprehensive enterprise data infrastructure platform, uses Delta Lake, a popular storage layer. Databricks, a pioneer of the Data Lakehouse, offers Azure Databricks, a fully managed first-party Data and AI solution on Microsoft Azure, making Azure the best cloud for Databricks workloads. This blog article details it’s benefits:
Seamless Azure integration.
Regional performance and availability.
Compliance, security.
Unique Microsoft-Databricks relationship.
1.Seamless Azure integration
Azure Databricks, a first-party service on Microsoft Azure, integrates natively with valuable Azure Services and workloads, enabling speedy onboarding with a few clicks.
Native integration-first-party service
Microsoft Entra ID (previously Azure Active Directory): It seamlessly connects with Microsoft Entra ID for controlled access control and authentication. Instead of building this integration themselves, Microsoft and Databricks engineering teams have natively incorporated it with Azure Databricks.
Azure Data Lake Storage (ADLS Gen2): Databricks can natively read and write data from ADLS Gen2, which has been collaboratively optimised for quick data access, enabling efficient data processing and analytics. Data tasks are simplified by integrating Azure Databricks with Data Lake and Blob Storage.
Azure Monitor and Log Analytics: Azure Monitor and Log Analytics provide insights into it’s clusters and jobs.
The Databricks addon for Visual Studio Code connects the local development environment to Azure Databricks workspace directly.
Integrated, valuable services
Power BI: Power BI offers interactive visualization’s and self-service business insight. All business customers can benefit from it’s performance and technology when used with Power BI. Power BI Desktop connects to Azure Databricks clusters and SQL warehouses. Power BI’s enterprise semantic modelling and calculation features enable customer-relevant computations, hierarchies, and business logic, and Azure Databricks Lakehouse orchestrates data flows into the model.
Publishers can publish Power BI reports to the Power BI service and allow users to access Azure Databricks data using SSO with the same Microsoft Entra ID credentials. Direct Lake mode is a unique feature of Power BI Premium and Microsoft Fabric FSKU (Fabric Capacity/SKU) capacity that works with it. With a Premium Power BI licence, you can Direct Publish from Azure Databricks to create Power BI datasets from Unity Catalogue tables and schemas. Loading parquet-formatted files from a data lake lets it analyse enormous data sets. This capability is beneficial for analysing large models quickly and models with frequent data source updates.
Azure Data Factory (ADF): ADF natively imports data from over 100 sources into Azure. Easy to build, configure, deploy, and monitor in production, it offers graphical data orchestration and monitoring. ADF can execute notebooks, Java Archive file format (JARs), and Python code activities and integrates with Azure Databricks via the linked service to enable scalable data orchestration pipelines that ingest data from various sources and curate it in the Lakehouse.
Azure Open AI: It features AI Functions, a built-in DB SQL function, to access Large Language Models (LLMs) straight from SQL. With this rollout, users can immediately test LLMs on their company data via a familiar SQL interface. A production pipeline can be created rapidly utilising Databricks capabilities like Delta Live Tables or scheduled Jobs after developing the right LLM prompt.
Microsoft Purview: Microsoft Azure’s data governance solution interfaces with Azure Databricks Unity Catalog’s catalogue, lineage, and policy APIs. This lets Microsoft Purview discover and request access while Unity Catalogue remains Azure Databricks’ operational catalogue. Microsoft Purview syncs metadata with it Unity Catalogue, including metastore catalogues, schemas, tables, and views. This connection also discovers Lakehouse data and brings its metadata into Data Map, allowing scanning the Unity Catalogue metastore or selective catalogues. The combination of Microsoft Purview data governance policies with Databricks Unity Catalogue creates a single window for data and analytics governance.
The best of Azure Databricks and Microsoft Fabric
Microsoft Fabric is a complete data and analytics platform for organization’s. It effortlessly integrates Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Intelligence, and Power BI on a SaaS foundation. Microsoft Fabric includes OneLake, an open, controlled, unified SaaS data lake for organizational data. Microsoft Fabric creates Delta-Parquet shortcuts to files, folders, and tables in OneLake to simplify data access. These shortcuts allow all Microsoft Fabric engines to act on data without moving or copying it, without disrupting host engine utilization.
Creating a shortcut to Azure Databricks Delta-Lake tables lets clients easily send Lakehouse data to Power BI using Direct Lake mode. Power BI Premium, a core component of Microsoft Fabric, offers Direct Lake mode to serve data directly from OneLake without querying an Azure Databricks Lakehouse or warehouse endpoint, eliminating the need for data duplication or import into a Power BI model and enabling blazing fast performance directly over OneLake data instead of ADLS Gen2. Microsoft Azure clients can use Azure Databricks or Microsoft Fabric, built on the Lakehouse architecture, to maximise their data, unlike other public clouds. With better development pipeline connectivity, Azure Databricks and Microsoft Fabric may simplify organisations’ data journeys.
2.Regional performance and availability
Scalability and performance are strong for Azure Databricks:
Azure Databricks compute optimisation: GPU-enabled instances speed machine learning and deep learning workloads cooperatively optimised by Databricks engineering. Azure Databricks creates about 10 million VMs daily.
Azure Databricks is supported by 43 areas worldwide and expanding.
3.Secure and compliant
Prioritising customer needs, it uses Azure’s enterprise-grade security and compliance:
Azure Security Centre monitors and protects this bricks. Microsoft Azure Security Centre automatically collects, analyses, and integrates log data from several resources. Security Centre displays prioritised security alerts, together with information to swiftly examine and attack remediation options. Data can be encrypted with Azure Databricks.
It workloads fulfil regulatory standards thanks to Azure’s industry-leading compliance certifications. PCI-DSS (Classic) and HIPAA-certified Azure Databricks SQL Serverless, Model Serving.
Only Azure offers Confidential Compute (ACC). End-to-end data encryption is possible with Azure Databricks secret computing. AMD-based Azure Confidential Virtual Machines (VMs) provide comprehensive VM encryption with no performance impact, while Hardware-based Trusted Execution Environments (TEEs) encrypt data in use.
Encryption: Azure Databricks natively supports customer-managed Azure Key Vault and Managed HSM keys. This function enhances encryption security and control.
4.Unusual partnership: Databricks and Microsoft
It’s unique connection with Microsoft is a highlight. Why is it special?
Joint engineering: Databricks and Microsoft create products together for optimal integration and performance. This includes increased Azure Databricks engineering investments and dedicated Microsoft technical resources for resource providers, workspace, and Azure Infra integrations, as well as customer support escalation management.
Operations and support: Azure Databricks, a first-party solution, is only available in the Azure portal, simplifying deployment and management. Microsoft supports this under the same SLAs, security rules, and support contracts as other Azure services, ensuring speedy ticket resolution in coordination with Databricks support teams.
It prices may be managed transparently alongside other Azure services with unified billing.
Go-To-Market and marketing: Events, funding programmes, marketing campaigns, joint customer testimonials, account-planning, and co-marketing, GTM collaboration, and co-sell activities between both organisations improve customer care and support throughout their data journey.
Commercial: Large strategic organization’s select Microsoft for Azure Databricks sales, technical support, and partner enablement. Microsoft offers specialized sales, business development, and planning teams for Azure Databricks to suit all clients’ needs globally.
Use Azure Databricks to enhance productivity
Selecting the correct data analytics platform is critical. Data professionals can boost productivity, cost savings, and ROI with Azure Databricks, a sophisticated data analytics and AI platform, which is well-integrated, maintained, and secure. It is an attractive option for organisations seeking efficiency, creativity, and intelligence from their data estate because to Azure’s global presence, workload integration, security, compliance, and unique connection with Microsoft.
Read more on Govindhtech.com
#microsoft#azure#azuredatabricks#MicrosoftAzure#MicrosoftFabric#OneLake#DataFactory#lakehouse#ai#technology#technews#news
0 notes
Text
Boost Productivity with Databricks CLI: A Comprehensive Guide
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type.
Exciting news! The Databricks CLI has undergone a remarkable transformation, becoming a full-blown revolution. Now, it covers all Databricks REST API operations and supports every Databricks authentication type. The best part? Windows users can join in on the exhilarating journey and install the new CLI with Homebrew, just like macOS and Linux users. This blog aims to provide comprehensive…

View On WordPress
#API#Authentication#Azure Databricks#Azure Databricks Cluster#Azure SQL Database#Cluster#Command prompt#data#Data Analytics#data engineering#Data management#Database#Databricks#Databricks CLI#Databricks CLI commands#Homebrew#JSON#Linux#MacOS#REST API#SQL#SQL database#Windows
0 notes
Text
youtube
What’s New in Databricks? March 2025 Updates & Features Explained! ### *🚀 What’s New in Databricks? March 2025 Updates & Features Explained!* #databricks #spark #dataengineering #ai #sql #llm Stay ahead with the *latest Databricks updates* for *March 2025.* This month introduces powerful features like: *SQL scripting enhancements, Calling Agents, Genie Files, Lakeflow, Streaming from Views, Secure Access Tokens, Binds, JSON Metadata Exploration, and Automatic Liquid Clustering.* 📌 *Watch the complete breakdown and see how these updates impact your data workflows!* ✨ *🔍 Key Highlights in This Update:* - *0:10* – SQL Scripting Enhancements: More advanced scripting with `BEGIN...END`, `CASE`, and control flow structures - *0:58* – Tabs: Soft tabs for notebooks and files have landed - *1:38* – MLFlow Trae UI: Debug agents with improved tracking - *2:27* – Calling Agents in Databricks: Connect Databricks to external services (e.g., Jira) using *http_request()* function - *5:50* – Volume File Previews: Seamlessly *preview files in volumes* - *6:15* – Genie Files: Easily *join files in Genie conversations* - *7:57* – Genie REST API: Develop your own app using *out-of-the-box Genie capabilities* - *9:15* – Lakeflow Enhancements: New ingestion pipelines, including *Workday & ServiceNow integrations* - *10:40* – Streaming from Views: Learn how to *stream data from SQL views* into live data pipelines - *11:45* – Secure Access Tokens: Manage Databricks *API tokens securely* - *12:24* – Binds: Improve workspace management with *Databricks workspace bindings* for external locations and credentials - *14:22* – DESCRIBE AS JSON: Explore metadata *directly in JSON format* for *more straightforward automation* - *15:50* – Automatic Liquid Clustering: Boost *query performance* with predictive clustering 📚 *Notebooks from the video:* 🔗 [GitHub Repository](https://ift.tt/c3dZYQh) 📝 *More on SQL Enhancements:* 🔗 [Read the full article](https://ift.tt/n9VX6dq) 📝 *More on DESCRIBE AS JSON:* 🔗 [Read the full article](https://ift.tt/sRPU3ik) 📝 *More on Calling GENIE API:* 🔗 [Read the full article](https://ift.tt/6D5fJrQ) ☕ *Enjoyed the video? Could you support me with a coffee?:* 🔗 [Buy Me a Coffee](https://ift.tt/Xv9AmPY) 💡 Whether you're a *data engineer, analyst, or Databricks enthusiast,* these updates will *enhance your workflows* and boost productivity! 🔔 *Subscribe for more Databricks insights & updates:* 📢 [YouTube Channel](https://www.youtube.com/@hubert_dudek/?sub_confirmation=1) 📢 *Stay Connected:* 🔗 [Medium Blog](https://ift.tt/cpeVd0J) --- ### 🎬 *Recommended Videos:* ▶️ [What’s new in January 2025](https://www.youtube.com/watch?v=JJiwSplZmfk)\ ▶️ [What’s new in February 2025](https://www.youtube.com/watch?v=tuKI0sBNbmg) --- ### *🔎 Related Phrases & Keywords:* What’s New In Databricks, March 2025 Updates, Databricks Latest Features, SQL Scripting in Databricks, Calling Agents with HTTP, Genie File Previews, Lakeflow Pipelines, Streaming from Views, Databricks Access Tokens, Databricks Binds, Metadata in JSON, Automatic Liquid Clustering \#databricks #bigdata #dataengineering #machinelearning #sql #cloudcomputing #dataanalytics #ai #azure #googlecloud #aws #etl #python #data #database #datawarehouse via Hubert Dudek https://www.youtube.com/channel/UCR99H9eib5MOHEhapg4kkaQ March 16, 2025 at 09:55PM
#databricks#dataengineering#machinelearning#sql#dataanalytics#ai#databrickstutorial#databrickssql#databricksai#Youtube
0 notes
Text
Microsoft Azure Online Data Engineering | Azure Databricks Training
Azure Databricks Connectivity with Power BI Cloud
Azure Databricks can be connected to Power BI Cloud to leverage the capabilities of both platforms for data processing, analysis, and visualization. - Azure Databricks Training
Here are the general steps to establish connectivity between Azure Databricks and Power BI Cloud:
1. Set up Azure Databricks:
- Make sure you have an Azure Databricks workspace provisioned in your Azure subscription.
- Create a cluster within Databricks to process your data.
2. Configure Databricks JDBC/ODBC Endpoints:
- Open your Azure Databricks workspace.
- Go to the "Clusters" tab and select your cluster.
- Under the "Advanced Options," enable JDBC/ODBC.
3. Get JDBC/ODBC Connection Information:
- Note down the JDBC or ODBC connection details provided in the Databricks workspace. This includes the JDBC/ODBC URL, username, and password. - Azure Data Engineering Training in Ameerpet
4. Power BI Desktop:
- Open Power BI Desktop.
5. Get Data:
- In Power BI Desktop, go to the "Home" tab and select "Get Data."
6. Choose Databricks Connector:
- In the "Get Data" window, select "More..." to open the Get Data window.
- Search for "Databricks" and select the appropriate Databricks connector.
7. Enter Connection Details:
- Enter the JDBC or ODBC connection details obtained from the Databricks workspace.
- Provide the necessary authentication details. - Azure Data Engineering Training
8. Access Data:
- After successful connection, you can access tables, views, or custom queries in Azure Databricks from Power BI.
9. Load Data into Power BI:
- Once connected, you can preview and select the data you want to import into Power BI.
10. Create Visualizations:
- Use Power BI to create visualizations, reports, and dashboards based on the data from Azure Databricks.
11. Refresh Data:
- Set up data refresh schedules in Power BI Service to keep your reports up to date.
Additional Considerations:
- Ensure that the Databricks cluster firewall settings allow connectivity from the Power BI service.
- The Databricks JDBC/ODBC connection may require specific libraries or drivers; make sure to install them if needed.
Keep in mind that the exact steps and options might vary based on updates to Azure Databricks, Power BI, or related components. Always refer to the official documentation for the most accurate and up-to-date information. - Microsoft Azure Online Data Engineering Training
Visualpath is the Leading and Best Institute for learning Azure Data Engineering Training. We provide Azure Databricks Training, you will get the best course at an affordable cost.
Attend Free Demo Call on - +91-9989971070.
Visit Our Blog: https://azuredatabricksonlinetraining.blogspot.com/
Visit: https://www.visualpath.in/azure-data-engineering-with-databricks-and-powerbi-training.html
#azuredataengineertraining#powerbionlinetraining#azuredataengineertraininghyderabad#azuredataengineer#azuredatabrickstraining
0 notes
Text
Key Features of Azure Databricks
Unified Analytics: Single platform for data engineering, data science, and analytics tasks.
Scalability: Efficiently scales to handle large datasets and varying workloads.
Performance Optimization: Optimized for high-performance data processing and analytics.
Integration with Azure Services: Seamless integration with various Azure services.
Collaboration: Shared notebooks, version control, and collaborative coding features.
Built-in Libraries: Includes libraries for machine learning, graph processing, and stream processing.
Security and Compliance: Implements security measures and complies with industry standards.
Automated Cluster Management: Streamlines cluster provisioning and management.
Azure Databricks is a powerful tool for organizations looking to streamline and optimize their big data analytics, data engineering, and machine learning workflows in the cloud.
#magistersign#onlinetraining#support#usa#AzureDatabricks#BigDataTraining#DataAnalytics#CloudTraining#DatabricksLearning#AzureTraining
0 notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
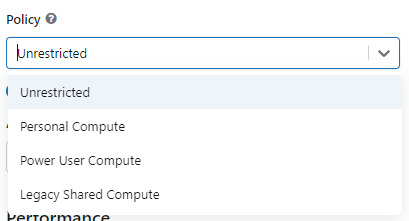
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
Utilizar un policy "unrestricted" o "power user compute"
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
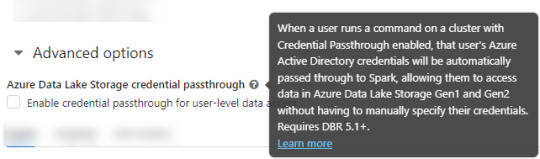
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
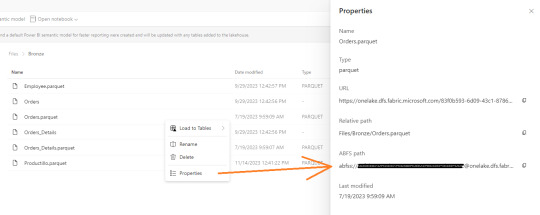
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
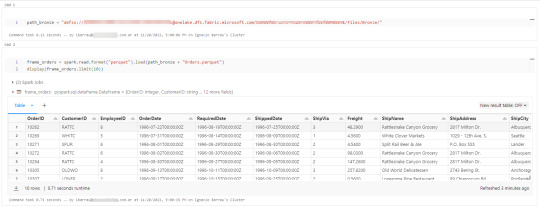
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
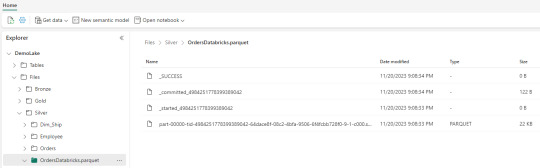
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
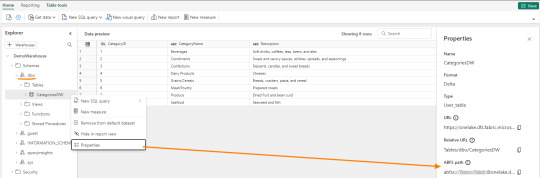
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
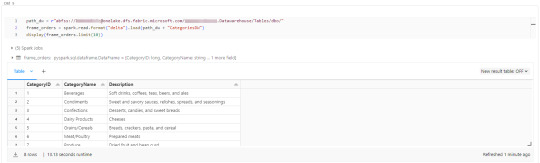
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
Hadoop Migration
Hadoop migration involves the process of transferring data, applications, and resources from legacy Hadoop clusters to modern infrastructure, often involving cloud-native stacks like AWS, Azure, Databricks, GCP, Snowflake, etc. With Hadoop migration, enterprises can streamline data management, enhance analytics capabilities, and optimize resource allocation. Some of the main benefits of Hadoop migration include improved data accessibility, scalability, and cost-efficiency. By adopting Hadoop migration, enterprises can tackle the limitations posed by legacy systems, ensuring compatibility with evolving technological landscapes. In addition, it helps to gain actionable insights from their data and foster data-driven innovation while maintaining data governance and security.
0 notes
Video
youtube
Azure Data Enginer Training with Real-time Project From #SQLSchool
> End to End Implementation. > Concept wise FAQs, Solutions. > Real-time Project with Solution, Project FAQs.
Course Details, Free Demo at: https://sqlschool.com/Azure-DataEngineer-Online-Training.html
#SQLSchool Training Institute offers 100% Real-time, Practical Trainings and Projects on Azure Data Engineer. Course Includes Basic to Advanced Azure ETL Components including one Real-time Project. Azure Data Engineer course from SQL School includes: 1 AZURE RESOURCES 2 AZURE FIREWALL 3 AZURE ACTIVE DIRECTORY 4 AZURE MONITOR 5 AZURE STORAGE 6 AZURE DATA LAKE STORAGE 7 AZURE SYNAPSE POOL 8 AZURE DATABRICKS 9 AZURE DATA FACTORY 10 AZURE SYNAPSE ANALYTICS 11 AZURE STREAM ANALYTICS 12 IOT HUBS 13 EVENT HUBS 14 END TO END IMPLEMENTATION WITH STORAGE + ETL + SPARK CLUSTERS + POWER BI
Details at: www.sqlschool.com
Reach Us (24x7) [email protected] +91 9666 44 0801 (India) +1 (956) 825-0401 (USA)
You can reach your trainer directly at: https://wa.me/+919030040801
#azurecloud #AzureDataFactory #AzureDataLake #AzureDatabricks #DeltaLake #AzureDataEngineering #AzureBI #AzureAnalytics #AzureTraining #DataEngineerProjects #sqlschool
0 notes