#k nearest neighbor algorithm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Understanding KNN Algorithm and Its Role in Machine Learning | USAII®
Learning about the widely used Machine Learning algorithm and understanding the workings of the K-Nearest Neighbor Algorithm is beneficial for AI professionals worldwide. Make an informed decision today!
Read Now: https://bit.ly/43d3mU2
knn algorithm, knn algorithm in machine learning, k nearest neighbor algorithm, knn machine learning, knn algorithm python, k nearest neighbor python, Best AI ML Certification, knn regression sklearn, knn classification python, supervised and unsupervised learning, knn algorithm in machine learning, machine learning algorithms, best ai ml certification, ai professionals, ML certification programs
#k nearest neighbor algorithm#AI and machine learning#artificial intelligence platform#top ai course#artificial intelligence certificate programs USAII
0 notes
Text
Explanation Of KNN Algorithm
Supervised Learning: KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions.
Instance-Based Learning: KNN is also considered an instance-based or lazy learning algorithm because it stores the entire training dataset and performs computations only when making predictions.

Distance Metric: KNN relies on a distance metric to measure the similarity or distance between data points.
Finding Nearest Neighbors:
For a new, unlabeled data point, KNN identifies the "k" nearest neighbors in the training data based on the chosen distance metric.
Classification: In classification tasks, the new data point is assigned to the class that is most common among its "k" nearest neighbors.
Regression: In regression tasks, the predicted value for the new data point is the average of the values of its "k" nearest neighbors.
Animating the 3D Sphere ⬇⬇⬇⬇⬇
youtube
#100 days of productivity#3d printing#911 abc#academia#accounting#adobe#animals#animation#animation meme#animation vs minecraft#animation practice#animation vs animator#architecture#animated#2d animation#animated gif#digital animation#techno design#techno fanart#techno facts#techno animation#Youtube
7 notes
·
View notes
Text

Advances in fiber-based wearable sensors with machine learning
The rapid development of artificial intelligence (AI) in the past decade has greatly enhanced the ability of wearable devices to process complex data. Among them, machine learning—a major category of AI algorithms—and its important branch, deep learning, are the main thrust of this wave of AI. Machine learning eliminates the labor cost of manually extracting data features, and its deep learning branch has powerful insights into hidden features. Their large demand for data fits the massive information brought by this era of information explosion. A recent study summarizes all machine learning algorithms that have been used in conjunction with fiber sensors, divided into two categories: traditional machine learning algorithms and deep learning algorithms. Traditional machine learning algorithms include linear regression (LR), k nearest neighbors (KNN), support vector machine (SVM), random forest, XGBoost, and K means clustering.
Read more.
#Materials Science#Science#Fibers#Machine learning#Computational materials science#Sensors#Wearable technology#Electronics
4 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
Data gathering. Relevant data for an analytics application is identified and assembled. The data may be located in different source systems, a data warehouse or a data lake, an increasingly common repository in big data environments that contain a mix of structured and unstructured data. External data sources may also be used. Wherever the data comes from, a data scientist often moves it to a data lake for the remaining steps in the process.
Data preparation. This stage includes a set of steps to get the data ready to be mined. It starts with data exploration, profiling and pre-processing, followed by data cleansing work to fix errors and other data quality issues. Data transformation is also done to make data sets consistent, unless a data scientist is looking to analyze unfiltered raw data for a particular application.
Mining the data. Once the data is prepared, a data scientist chooses the appropriate data mining technique and then implements one or more algorithms to do the mining. In machine learning applications, the algorithms typically must be trained on sample data sets to look for the information being sought before they're run against the full set of data.
Data analysis and interpretation. The data mining results are used to create analytical models that can help drive decision-making and other business actions. The data scientist or another member of a data science team also must communicate the findings to business executives and users, often through data visualization and the use of data storytelling techniques.
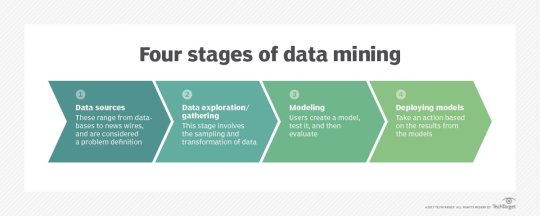
Types of data mining techniques
Various techniques can be used to mine data for different data science applications. Pattern recognition is a common data mining use case that's enabled by multiple techniques, as is anomaly detection, which aims to identify outlier values in data sets. Popular data mining techniques include the following types:
Association rule mining. In data mining, association rules are if-then statements that identify relationships between data elements. Support and confidence criteria are used to assess the relationships -- support measures how frequently the related elements appear in a data set, while confidence reflects the number of times an if-then statement is accurate.
Classification. This approach assigns the elements in data sets to different categories defined as part of the data mining process. Decision trees, Naive Bayes classifiers, k-nearest neighbor and logistic regression are some examples of classification methods.
Clustering. In this case, data elements that share particular characteristics are grouped together into clusters as part of data mining applications. Examples include k-means clustering, hierarchical clustering and Gaussian mixture models.
Regression. This is another way to find relationships in data sets, by calculating predicted data values based on a set of variables. Linear regression and multivariate regression are examples. Decision trees and some other classification methods can be used to do regressions, too
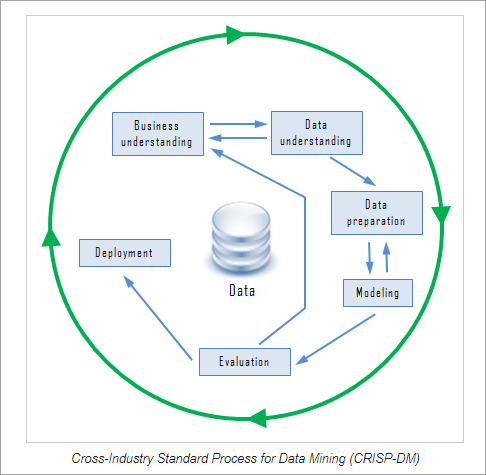
Data mining companies follow the procedure
#data enrichment#data management#data entry companies#data entry#banglore#monday motivation#happy monday#data analysis#data entry services#data mining
4 notes
·
View notes
Text
How to utilize AI for improved data cleaning

Ask any data scientist, analyst, or ML engineer about their biggest time sink, and chances are "data cleaning" will top the list. It's the essential, yet often unglamorous, groundwork required before any meaningful analysis or model building can occur. Traditionally, this involves painstaking manual checks, writing complex rule-based scripts, and battling inconsistencies that seem to multiply with data volume. While crucial, these methods often struggle with scale, nuance, and the sheer variety of errors found in real-world data.
But what if data cleaning could be smarter, faster, and more effective? As we navigate the rapidly evolving tech landscape of 2025, Artificial Intelligence (AI) is stepping up, offering powerful techniques to significantly improve and accelerate this critical process. For organizations across India undergoing digital transformation and harnessing vast amounts of data, leveraging AI for data cleaning isn't just an advantage – it's becoming a necessity.
The Limits of Traditional Cleaning
Traditional approaches often rely on:
Manual Inspection: Spot-checking data, feasible only for small datasets.
Rule-Based Systems: Writing specific rules (e.g., if value < 0, replace with null) which become complex to manage and fail to catch unexpected or subtle errors.
Simple Statistics: Using mean/median/mode for imputation or standard deviations for outlier detection, which can be easily skewed or inappropriate for complex distributions.
Exact Matching: Finding duplicates only if they match perfectly.
These methods are often time-consuming, error-prone, difficult to scale, and struggle with unstructured data like free-form text.
How AI Supercharges Data Cleaning
AI brings learning, context, and probabilistic reasoning to the table, enabling more sophisticated cleaning techniques:
Intelligent Anomaly Detection: Instead of rigid rules, AI algorithms (like Isolation Forests, Clustering methods e.g., DBSCAN, or Autoencoders) can learn the 'normal' patterns in your data and flag outliers or anomalies that deviate significantly, even in high-dimensional spaces. This helps identify potential errors or rare events more effectively.
Context-Aware Imputation: Why fill missing values with a simple average when AI can do better? Predictive models (from simple regressions or k-Nearest Neighbors to more complex models) can learn relationships between features and predict missing values based on other available data points for that record, leading to more accurate and realistic imputations.
Advanced Duplicate Detection (Fuzzy Matching): Finding records like "Tech Solutions Pvt Ltd" and "Tech Solutions Private Limited" is trivial for humans but tricky for exact matching rules. AI, particularly Natural Language Processing (NLP) techniques like string similarity algorithms (Levenshtein distance), vector embeddings, and phonetic matching, excels at identifying these non-exact or 'fuzzy' duplicates across large datasets.
Automated Data Type & Pattern Recognition: AI models can analyze columns and infer the most likely data type or identify entries that don't conform to learned patterns (e.g., spotting inconsistent date formats, invalid email addresses, or wrongly formatted phone numbers within a column).
Probabilistic Record Linkage: When combining datasets without a perfect common key, AI techniques can calculate the probability that records from different sources refer to the same entity based on similarities across multiple fields, enabling more accurate data integration.
Error Spotting in Text Data: Using NLP models, AI can identify potential typos, inconsistencies in categorical labels (e.g., "Mumbai", "Bombay", "Mumbai City"), or even nonsensical entries within free-text fields by understanding context and language patterns.
Standardization Suggestions: AI can recognize different representations of the same information (like addresses or company names) and suggest or automatically apply standardization rules, bringing uniformity to messy categorical or text data.
The Benefits Are Clear
Integrating AI into your data cleaning workflow offers significant advantages:
Speed & Efficiency: Automating complex tasks dramatically reduces cleaning time.
Improved Accuracy: AI catches subtle errors and handles complex cases better than rigid rules.
Scalability: AI techniques handle large and high-dimensional datasets more effectively.
Enhanced Consistency: Leads to more reliable data for analysis and model training.
Reduced Tedium: Frees up data professionals to focus on higher-value analysis and insights.
Getting Started: Tools & Considerations
You don't necessarily need a PhD in AI to start. Many tools and libraries are available:
Python Libraries: Leverage libraries like Pandas for basic operations, Scikit-learn for ML models (outlier detection, imputation), fuzzywuzzy or recordlinkage for duplicate detection, and NLP libraries like spaCy or Hugging Face Transformers for text data.
Data Quality Platforms: Many modern data quality and preparation platforms are incorporating AI features, offering user-friendly interfaces for these advanced techniques.
Cloud Services: Cloud providers often offer AI-powered data preparation services.
Important Considerations:
Human Oversight: AI is a powerful assistant, not a replacement for human judgment. Always review AI-driven cleaning actions.
Interpretability: Understanding why an AI model flagged something as an error can sometimes be challenging.
Bias Potential: Ensure the AI models aren't learning and perpetuating biases present in the original messy data.
Context is Key: Choose the right AI technique for the specific data cleaning problem you're trying to solve.
Conclusion
Data cleaning remains a foundational step in the data lifecycle, but the tools we use are evolving rapidly. AI offers a leap forward, transforming this often-tedious task into a smarter, faster, and more effective process. For businesses and data professionals in India looking to extract maximum value from their data assets, embracing AI for data cleaning is a crucial step towards building more robust analyses, reliable machine learning models, and ultimately, making better data-driven decisions. It’s time to move beyond simple rules and let AI help bring true clarity to your data.
0 notes
Text
Mastering Data Science: A Roadmap for Beginners and Aspiring Professionals
Understanding the Foundation of Data Science
Data science has emerged as one of the most sought-after career paths in today’s digital economy. It combines statistics, computer science, and domain knowledge to extract meaningful insights from data. Before diving deep into complex topics, it’s crucial to understand the foundational concepts that shape this field. From data cleaning to basic data visualization techniques, beginners must grasp these essential skills. Additionally, programming languages like Python and R are the primary tools used by data scientists worldwide. Building a strong base in these languages can set the stage for more advanced learning. It’s also important to familiarize yourself with databases, as querying and manipulating data efficiently is a key skill in any data-driven role. Solidifying these basics ensures a smoother transition to more complex areas such as artificial intelligence and machine learning.
Machine Learning for Beginners: The Essential Guide
Once you have a solid foundation, the next logical step is to explore machine learning. Machine Learning for Beginners is an exciting journey filled with numerous algorithms and techniques designed to help computers learn from data. Beginners should start with supervised learning models like linear regression and decision trees before progressing to unsupervised learning and reinforcement learning. Understanding the mathematical intuition behind algorithms such as k-nearest neighbors (KNN) and support vector machines (SVM) can enhance your analytical skills significantly. Online resources, workshops, and hands-on projects are excellent ways to strengthen your knowledge. It’s also vital to practice with real-world datasets, as this will expose you to the challenges and nuances faced in actual data science projects. Remember, mastering machine learning is not just about memorizing algorithms but about understanding when and why to use them.
Interview Preparation for Data Scientists: Key Strategies
Entering the job market as a data scientist can be both thrilling and intimidating. Effective interview preparation for data scientists requires more than just technical knowledge; it demands strategic planning and soft skill development. Candidates should be prepared to tackle technical interviews that test their understanding of statistics, machine learning, and programming. Additionally, behavioral interviews are equally important, as companies seek individuals who can collaborate and communicate complex ideas clearly. Mock interviews, coding challenges, and portfolio projects can significantly boost your confidence. It is beneficial to review common interview questions, such as explaining the bias-variance tradeoff or detailing a machine learning project you have worked on. Networking with professionals and seeking mentorship opportunities can also open doors to valuable insights and career advice. A strong preparation strategy combines technical mastery with effective storytelling about your experiences.
Advancing Your Data Science Career Through Specialization
After entering the field, data scientists often find themselves gravitating towards specialized roles like machine learning engineer, data analyst, or AI researcher. Specializing allows professionals to deepen their expertise and stand out in a competitive job market. Those passionate about prediction models might specialize in machine learning, while others who enjoy working with big data might lean towards data engineering. Continuous learning is essential in this rapidly evolving field. Enrolling in advanced courses, attending industry conferences, and contributing to open-source projects can all accelerate your career growth. Furthermore, staying updated with the latest tools and technologies, such as cloud-based machine learning platforms and advanced data visualization libraries, can give you an edge. A proactive approach to career development ensures you remain adaptable and competitive, regardless of how the industry changes.
Conclusion: Your Gateway to Success in Data Science
The journey to becoming a successful data scientist is both challenging and rewarding. It requires a balance of technical knowledge, practical experience, and continuous learning. Building a strong foundation, mastering machine learning basics, strategically preparing for interviews, and eventually specializing in a niche area are all key steps toward achieving your career goals. For those seeking comprehensive resources to guide them through every phase of their journey, visiting finzebra.com offers access to valuable tools and insights tailored for aspiring data science professionals. By following a structured learning path and leveraging the right resources, anyone can transform their passion for data into a fulfilling career.
0 notes
Text
Artificial Intelligence Tutorial for Beginners
In the speedy digital age of today, Artificial Intelligence (AI) has progressed from science fiction to real-world reality. From virtual assistants like Siri and Alexa to intelligent suggestion algorithms on Netflix and Amazon, AI pervades all. For starters interested in this exciting discipline, this tutorial is an inclusive yet easy guide to introduce you to it. What is Artificial Intelligence? Artificial Intelligence is the field of computer science that deals with creating machines and programs which can complete tasks typically requiring human intelligence. Such tasks are problem-solving, learning, planning, speech recognition, and even creativity. In other words, AI makes it possible for computers to simulate human behavior and decision-making. Types of Artificial Intelligence AI can be classified into three categories broadly: 1. Narrow AI (Weak AI): AI systems created for a single task. Example: Spam filters, facial recognition software. 2. General AI (Strong AI): Theoretical notion where AI possesses generalized human mental capacities. It is capable of resolving new problems on its own without human assistance. 3. Super AI: Super-intelligent machines that will one day exceed human intelligence. Imagine the super-sophisticated robots of films! Most of the AI that you currently encounter is narrow AI.
Key Concepts Novices Need to Familiarize Themselves With Before going any deeper, there are some key concepts one needs to be familiar with: • Machine Learning (ML): A discipline of AI wherein machines learn from experience and are enhanced over a period of time without being specially programmed. • Deep Learning: A form of specialized ML that is inspired by the anatomy of the human brain and neural networks. • Natural Language Processing (NLP): A subdivision dealing with computers and human (natural) language interaction. NLP is used by translation software and chatbots.
• Computer Vision: Training computers to learn and make decisions with visual information (videos, images). • Robotics: Interfusion of AI and mechanical engineering to create robots that can perform sophisticated operations. How Does AI Work? In essence, AI systems work in a very straightforward loop: 1. Data Collection: AI requires huge volumes of data to learn from—images, words, sounds, etc. 2. Data Preprocessing: The data needs to be cleaned and prepared before it is input into an AI model. 3. Model Building: Algorithms are employed to design models that can recognize patterns and make choices.
4. Training: Models are trained by tweaking internal parameters in order to achieve optimized accuracy. 5. Evaluation and Tuning: The performance of the model is evaluated, and parameters are tweaked to improve its output. 6. Deployment: After the model performs well, it can be incorporated into applications such as apps, websites, or software.
Top AI Algorithms You Should Learn Although there are numerous algorithms in AI, following are some beginner-level ones: • Linear Regression: Performs a numerical prediction based on input data (e.g., house price prediction). • Decision Trees: Decision tree model based upon conditions.
• K-Nearest Neighbors (KNN): Classifies the data based on how close they are to labeled instances. • Naïve Bayes: Probabilistic classifier. • Neural Networks: As derived in the human brain pattern, used in finding complex patterns (like face detection). All these algorithms do their respective tasks, and familiarity with their basics is necessary for any AI newbie.
Applications of AI in Real Life To realize the potentiality of AI, let us see real-life applications: • Healthcare: AI assists in diagnosis, drug development, and treatment tailored to each individual. • Finance: AI is extensively employed in fraud detection, robo-advisors, and algorithmic trading. • Entertainment: Netflix recommendations, game opponents, and content creation. • Transportation: Self-driving cars like autonomous cars use AI to navigate. • Customer Service: Chatbots and automated support systems offer around-the-clock service. These examples show AI isn't just restricted to tech giants; it's impacting every sector.
How to Begin Learning AI? 1. Establish a Strong Math Foundation: AI is extremely mathematics-dependent. Focus specifically on: •Linear Algebra (matrices, vectors) •Probability and Statistics •Calculus (foundational for optimization) 2. Acquire Programming Skills: Python is the most in-demand language for AI because of its ease and wide range of libraries such as TensorFlow, Keras, Scikit-learn, and PyTorch.
3. Understand Data Structures and Algorithms: Master the fundamentals of programming in order to code effectively. 4. Finish Beginner-friendly Courses: Certain websites one must visit are: •Coursera (Andrew Ng's ML Course) •tedX •Udacity's Nanodegree courses 5. Practice on Projects Practice by creating small projects like: • Sentiment Analysis of Tweets • Image Classifiers • Chatbots • Sales Prediction Models
6. Work with the Community: Participate in communities such as Kaggle, Stack Overflow, or AI sub-reddits and learn and keep up with others.
Common Misconceptions About AI 1. AI is reserved for geniuses. False. Anyone who makes a concerted effort to learn can master AI. 2. AI will replace all jobs. Although AI will replace some jobs, it will generate new ones as well. 3. AI has the ability to think like a human. Current AI exists as task-specific and does not actually "think." It processes data and spits out results based on patterns. 4. AI is flawless. AI models can err, particularly if they are trained on biased or limited data.
Future of AI The future of AI is enormous and bright. Upcoming trends like Explainable AI (XAI), AI Ethics, Generative AI, and Autonomous Systems are already charting what the future holds.
• Explainable AI: Designing models which are explainable and comprehensible by users. • AI Ethics: Making AI systems equitable, responsible, and unbiased. • Generative AI: Examples such as ChatGPT, DALL•E, and others that can generate human-like content. • Edge AI: Executing AI algorithms locally on devices (e.g., smartphones) without cloud connections.
Final Thoughts Artificial Intelligence is no longer a distant dream—it is today's revolution. For starters, it may seem overwhelming at first, but through consistent learning and practicing, mastering AI is very much within reach. Prioritize establishing a strong foundation, work on practical projects, and above all, be curious. Remember, each AI mastermind was once a beginner like you! So, grab that Python tutorial, get into some simple mathematics, enroll in a course, and begin your journey into the phenomenal realm of Artificial Intelligence today. The world is waiting!
Website: https://www.icertglobal.com/course/artificial-intelligence-and-deep-learning-certification-training/Classroom/82/3395

0 notes
Text
Best Machine Learning Classes in Pune Your Guide to Becoming a Data Science Expert with Ethans Tech
In today’s data-driven world, machine learning classes in Pune have become increasingly popular for students and professionals alike. Pune, known as the “Oxford of the East,” offers a thriving tech ecosystem with numerous institutes providing top-notch training in machine learning. Whether you're a beginner looking to start your career or an experienced professional aiming to upskill, enrolling in the right course is crucial.
Why Choose Pune for Machine Learning Classes?
Pune’s booming IT industry, combined with its strong educational infrastructure, makes it an ideal location for pursuing machine learning classes in Pune. The city is home to numerous tech companies, startups, and educational institutions, ensuring ample opportunities for learning and career growth.
Moreover, Pune's vibrant tech community offers numerous meetups, hackathons, and workshops that enhance practical knowledge and networking opportunities.
Key Concepts Covered in Machine Learning Classes
Most reputable institutes offering machine learning classes in Pune focus on the following essential topics:
1. Introduction to Machine Learning
Understanding supervised, unsupervised, and reinforcement learning
Key algorithms like linear regression, decision trees, and k-nearest neighbors
2. Data Preprocessing and Analysis
Handling missing data, feature scaling, and encoding categorical variables
Exploratory data analysis (EDA) using Python libraries like Pandas and Matplotlib
3. Model Training and Evaluation
Building models using frameworks like Scikit-learn, TensorFlow, and PyTorch
Techniques such as cross-validation, hyperparameter tuning, and model evaluation metrics
4. Deep Learning and Neural Networks
Understanding artificial neural networks (ANN), convolutional neural networks (CNN), and recurrent neural networks (RNN)
5. Real-World Projects
Hands-on projects are crucial in machine learning classes in Pune to apply theoretical knowledge. Institutes often provide case studies and practical applications in fields like healthcare, finance, and e-commerce.
What to Look for in a Machine Learning Institute in Pune
When selecting the best training institute, consider the following factors:
Experienced Faculty: Instructors with industry experience provide valuable insights and guidance.
Practical Learning Approach: Institutes offering hands-on projects, assignments, and real-world datasets ensure better understanding.
Placement Support: Look for institutes with strong industry connections and dedicated placement assistance.
Flexible Learning Options: Institutes offering both online and offline classes provide greater flexibility for working professionals.
For more courses - https://ethans.co.in/course/machine-learning-training-in-pune/
Top Skills You Will Gain from Machine Learning Classes
Enrolling in professional machine learning classes in Pune helps you develop a wide range of skills, including:
Strong programming knowledge in Python or R
Data manipulation and visualization skills
Expertise in machine learning algorithms and model evaluation
Experience with tools like Jupyter Notebook, TensorFlow, and Scikit-learn
Problem-solving abilities through real-world case studies
Career Opportunities After Completing Machine Learning Classes
Machine learning professionals are in high demand across various industries. Upon completing your training, you can explore roles such as:
Data Scientist
Machine Learning Engineer
AI Specialist
Business Intelligence Analyst
Data Analyst
The thriving tech industry in Pune ensures ample job opportunities for trained professionals, making it an ideal place to pursue your education.
Conclusion
If you’re looking for comprehensive machine learning classes in Pune, Ethans Tech is your go-to institute. Known for its expert trainers, hands-on learning approach, and impressive placement track record, Ethans Tech offers one of the best learning experiences for aspiring machine learning professionals.
Enrolling in the right training program will empower you with the skills required to excel in the competitive field of machine learning. Take the first step toward a rewarding career by joining a reputed institute in Pune today!
1 note
·
View note
Text
Week 7 Lab (KNN) COSC 3337 and Week 7 Lab (Naive Bayes)
Week 7 Lab (KNN) About The Data In this lab you will learn how to use sklearn to build a machine learning model using k‑Nearest Neighbors algorithm to predict whether the patients in the “Pima Indians Diabetes Dataset” have diabetes or not. The dataset that we’ll be using for this task comes from kaggle.com and contains the following attributes: Pregnancies: Number of times pregnant Glucose:…
0 notes
Text
Coding Diaries: How to Build a Machine Learning Model
A Step-by-Step Guide to Building a Machine Learning Model
Machine learning transforms industries by enabling computers to learn from data and make accurate predictions. But before deploying an intelligent system, you must understand how to build a machine-learning model from scratch. This guide will walk you through each step—from data collection to model evaluation—so you can develop an effective and reliable model.
Step 1: Data Preparation
The foundation of any machine learning model is high-quality data. Raw data is often messy, containing missing values, irrelevant features, or inconsistencies. To ensure a strong model, follow these steps:
✅ Data Cleaning – Handle missing values, remove duplicates, and correct inconsistencies.
✅ Exploratory Data Analysis (EDA) – Understand the dataset's patterns, distributions, and relationships using statistical methods and visualizations.
✅ Feature Selection & Engineering – Remove redundant or unimportant features and create new features that improve predictive power.
✅ Dimensionality Reduction – Techniques like Principal Component Analysis (PCA) help simplify data without losing critical information.
By the end of this step, your dataset should be structured and ready for training.
Step 2: Splitting the Data
To ensure your model can generalize well to unseen data, you must divide your dataset into:
🔹 Training Set (80%) – Used to train the model.
🔹 Test Set (20%) – Used to evaluate the model’s performance on new data.
Some workflows also include a validation set, which is used for fine-tuning hyperparameters before final testing.
Step 3: Choosing the Right Algorithm
Selecting the right machine learning algorithm depends on your problem type:
🔹 Classification (e.g., spam detection, fraud detection)
Logistic Regression
Support Vector Machines (SVM)
Decision Trees (DT)
Random Forest (RF)
K-Nearest Neighbors (KNN)
Neural Networks
🔹 Regression (e.g., predicting house prices, stock prices)
Linear Regression
Ridge and Lasso Regression
Gradient Boosting Machines (GBM)
Deep Learning Models
🔹 Clustering (e.g., customer segmentation, anomaly detection)
K-Means Clustering
Hierarchical Clustering
DBSCAN
Step 4: Training the Model
Once an algorithm is selected, the model must be trained using the training set. This involves:
✔ Fitting the model to data – The algorithm learns the relationship between input and target variables.
✔ Optimizing hyperparameters – Adjusting settings like learning rate, depth of trees, or number of neighbors to improve performance.
✔ Feature Selection – Keeping only the most informative features for better efficiency and accuracy.
✔ Cross-validation – Testing the model on different subsets of the training data to avoid overfitting.
Step 5: Evaluating the Model
Once trained, the model must be tested to assess its performance. Different metrics are used based on the problem type:
🔹 For Classification Problems
Accuracy – Percentage of correctly predicted instances.
Precision & Recall (Sensitivity) – Measure how well the model detects positives.
Specificity – Ability to correctly classify negatives.
Matthews Correlation Coefficient (MCC) – A balanced metric for imbalanced datasets.
🔹 For Regression Problems
Mean Squared Error (MSE) – Measures average squared prediction error.
Root Mean Squared Error (RMSE) – Interpretable error measure (lower is better).
R² Score (Coefficient of Determination) – Indicates how well the model explains variance in data.
If the model does not perform well, adjustments can be made by refining hyperparameters, selecting better features, or trying different algorithms.
Step 6: Making Predictions and Deployment
Once the model performs well on the test set, it can be used to make predictions on new, unseen data. At this stage, you may also:
✔ Deploy the model – Integrate it into applications, APIs, or cloud-based platforms.
✔ Monitor and improve – Continuously track performance and retrain the model with new data.
Final Thoughts
Building a machine learning model is an iterative process. Data preparation, algorithm selection, training, and evaluation all play critical roles in creating a model that performs well in real-world scenarios.
🚀 Key Takeaways:
✔ Data quality and feature selection are crucial for accuracy.
✔ Splitting data ensures the model can generalize well.
✔ The choice of algorithm depends on the problem type.
✔ Proper evaluation metrics help fine-tune and optimize performance.
By following these steps, you can develop robust machine-learning models that make accurate and meaningful predictions. Ready to start building your own? 🚀
0 notes
Text
How do you handle missing data in a dataset?
Handling missing data is a crucial step in data preprocessing, as incomplete datasets can lead to biased or inaccurate analysis. There are several techniques to deal with missing values, depending on the nature of the data and the extent of missingness.
1. Identifying Missing Data Before handling missing values, it is important to detect them using functions like .isnull() in Python’s Pandas library. Understanding the pattern of missing data (random or systematic) helps in selecting the best strategy.
2. Removing Missing Data
If the missing values are minimal (e.g., less than 5% of the dataset), you can remove the affected rows using dropna().
If entire columns contain a significant amount of missing data, they may be dropped if they are not crucial for analysis.
3. Imputation Techniques
Mean/Median/Mode Imputation: For numerical data, replacing missing values with the mean, median, or mode of the column ensures continuity in the dataset.
Forward or Backward Fill: For time-series data, forward filling (ffill()) or backward filling (bfill()) propagates values from previous or next entries.
Interpolation: Using methods like linear or polynomial interpolation estimates missing values based on trends in the dataset.
Predictive Modeling: More advanced techniques use machine learning models like K-Nearest Neighbors (KNN) or regression to predict and fill missing values.
4. Using Algorithms That Handle Missing Data Some machine learning algorithms, like decision trees and random forests, can handle missing values internally without imputation.
By applying these techniques, data quality is improved, leading to more accurate insights. To master such data preprocessing techniques, consider enrolling in the best data analytics certification, which provides hands-on training in handling real-world datasets.
0 notes
Text
Explanation Of KNN Algorithm
Supervised Learning: KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions.
Instance-Based Learning: KNN is also considered an instance-based or lazy learning algorithm because it stores the entire training dataset and performs computations only when making predictions.

Distance Metric: KNN relies on a distance metric to measure the similarity or distance between data points.
Finding Nearest Neighbors:
For a new, unlabeled data point, KNN identifies the "k" nearest neighbors in the training data based on the chosen distance metric.
Classification: In classification tasks, the new data point is assigned to the class that is most common among its "k" nearest neighbors.
Regression: In regression tasks, the predicted value for the new data point is the average of the values of its "k" nearest neighbors.
DARK PHANTOM ALGORITHM ⬇⬇⬇⬇⬇
youtube
#technoland facts#technoland expert#techno animation#technoart#techno design#techno facts#animation#3d image processing#3d image process#artificial image#100 days of productivity#artificial intelligence#image description in alt#image processing#Youtube
8 notes
·
View notes
Text
Top Machine Learning Algorithms Every Beginner Should Know

Machine Learning (ML) is one of the most transformative technologies of the 21st century. From recommendation systems to self-driving cars, ML algorithms are at the heart of modern innovations. Whether you are an aspiring data scientist or just curious about AI, understanding the fundamental ML algorithms is crucial. In this blog, we will explore the top machine learning algorithms every beginner should know while also highlighting the importance of enrolling in Machine Learning Course in Kolkata to build expertise in this field.
1. Linear Regression
What is it?
Linear Regression is a simple yet powerful algorithm used for predictive modeling. It establishes a relationship between independent and dependent variables using a best-fit line.
Example:
Predicting house prices based on features like size, number of rooms, and location.
Why is it important?
Easy to understand and implement.
Forms the basis of many advanced ML algorithms.
2. Logistic Regression
What is it?
Despite its name, Logistic Regression is a classification algorithm. It predicts categorical outcomes (e.g., spam vs. not spam) by using a logistic function to model probabilities.
Example:
Email spam detection.
Why is it important?
Widely used in binary classification problems.
Works well with small datasets.
3. Decision Trees
What is it?
Decision Trees are intuitive models that split data based on decision rules. They are widely used in classification and regression problems.
Example:
Diagnosing whether a patient has a disease based on symptoms.
Why is it important?
Easy to interpret and visualize.
Handles both numerical and categorical data.
4. Random Forest
What is it?
Random Forest is an ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting.
Example:
Credit risk assessment in banking.
Why is it important?
More accurate than a single decision tree.
Works well with large datasets.
5. Support Vector Machines (SVM)
What is it?
SVM is a powerful classification algorithm that finds the optimal hyperplane to separate different classes.
Example:
Facial recognition systems.
Why is it important?
Effective in high-dimensional spaces.
Works well with small and medium-sized datasets.
6. k-Nearest Neighbors (k-NN)
What is it?
k-NN is a simple yet effective algorithm that classifies data points based on their nearest neighbors.
Example:
Movie recommendation systems.
Why is it important?
Non-parametric and easy to implement.
Works well with smaller datasets.
7. K-Means Clustering
What is it?
K-Means is an unsupervised learning algorithm used for clustering similar data points together.
Example:
Customer segmentation for marketing.
Why is it important?
Great for finding hidden patterns in data.
Used extensively in marketing and image recognition.
8. Gradient Boosting Algorithms (XGBoost, LightGBM, CatBoost)
What is it?
These are powerful ensemble learning techniques that build strong predictive models by combining multiple weak models.
Example:
Stock market price prediction.
Why is it important?
Highly accurate and efficient.
Widely used in data science competitions.
Why Enroll in Machine Learning Classes in Kolkata?
Learning ML algorithms on your own can be overwhelming. Enrolling in Machine Learning Classes in Kolkata can provide structured guidance, real-world projects, and mentorship from industry experts. Some benefits include:
Hands-on training with real-world datasets.
Learning from experienced professionals.
Networking opportunities with peers and industry leaders.
Certification that boosts career opportunities.
Conclusion
Understanding these top ML algorithms is the first step toward mastering machine learning. Whether you’re looking to build predictive models or dive into AI-driven applications, these algorithms are essential. To truly excel, consider enrolling in a Machine Learning Course in Kolkata to gain practical experience and industry-relevant skills.
0 notes
Text
AI Tutorial for Beginners: Dive into Machine Learning
What is AI?
Artificial Intelligence refers to the simulation of human intelligence processes by machines, especially computer systems. These processes include learning, reasoning, problem-solving, and understanding natural language. AI can be categorized into two broad types: Narrow AI, which performs specific tasks, and General AI, a more advanced form that can perform any intellectual task a human being can do.
The Importance of Machine Learning
Machine Learning is a subset of AI that uses algorithms and statistical models to analyze and draw inferences from patterns in data. machine learning online course Instead of relying on explicit programming for every task, ML enables systems to learn from experience and improve over time. This capability is revolutionizing industries like healthcare, finance, and marketing by providing predictive insights based on data analysis.
Beginning Your AI Journey
When starting your journey in AI, it’s fundamental to first grasp the concepts and terminologies of Machine Learning. A variety of resources, both free and paid, are available online to facilitate this learning process. Here are some steps to kickstart your understanding:
Understanding Basic Concepts: Familiarize yourself with terminology like datasets, features, labels, supervised learning, unsupervised learning, and neural networks. Websites like Coursera and edX offer introductory courses that are perfect for beginners.
Programming Languages: Python is the most popular programming language in the field of AI and Machine Learning, valued for its simplicity and extensive libraries such as TensorFlow, machine learning tutorials PyTorch, and Scikit-learn. Learning Python will give you a solid foundation for implementing AI algorithms.
Mathematics and Statistics: A basic understanding of topics such as linear algebra, calculus, and statistics is essential. These mathematical concepts are the backbone of most Machine Learning algorithms.
Live Projects to Enhance Your Learning
Engaging in machine learning live projects is an essential part of the learning process. Here are a few project ideas that you can undertake to apply your knowledge practically:
Iris Flower Classification: Use the famous Iris dataset to classify iris flowers based on their species. Implement different algorithms like k-Nearest Neighbors (k-NN) and Decision Trees, and compare their performance.
Handwritten Digit Recognition: Use the MNIST dataset to train a model to recognize handwritten digits. This project helps in understanding neural networks and deep learning concepts.
Movie Recommendation System: Build a system that recommends movies to users based on their previous ratings. You can use collaborative filtering techniques to create personalized recommendations.
Sentiment Analysis: Create a sentiment classifier that determines whether a given text is positive, negative, or neutral. This project can involve natural language processing techniques, which are crucial in AI.
Deep AI Learning Course
For those looking to take their knowledge a step further, enrolling in a deep AI learning course can provide valuable insights and structured learning. These courses often cover advanced topics such as deep learning, natural language processing, and reinforcement learning.
Such courses frequently involve hands-on projects, case studies, and even collaborations with industry leaders. Websites like Udacity, Coursera, and DataCamp offer specialized courses that are recognized in the industry, ensuring you acquire the skills necessary for a successful career in AI.
0 notes
Text
7 Benefits of Using Search Engine Tools for Data Analysis

We often think of search engines as tools for finding cat videos or answering trivia. But beneath the surface, they possess powerful capabilities that can significantly benefit data science workflows. Let's explore seven often-overlooked advantages of using search engine tools for data analysis.
1. Instant Data Exploration and Ingestion:
Imagine receiving a new, unfamiliar dataset. Instead of wrestling with complex data pipelines, you can load it directly into a search engine. These tools are remarkably flexible, handling a wide range of file formats (JSON, CSV, XML, PDF, images, etc.) and accommodating diverse data structures. This allows for rapid initial analysis, even with noisy or inconsistent data.
2. Efficient Training/Test/Validation Data Generation:
Search engines can act as a cost-effective and efficient data storage and retrieval system for deep learning projects. They excel at complex joins, row/column selection, and providing Google-like access to your data, experiments, and logs, making it easy to generate the necessary data splits for model training.
3. Streamlined Data Reduction and Feature Engineering:
Modern search engines come equipped with tools for transforming diverse data types (text, numeric, categorical, spatial) into vector spaces. They also provide features for weight construction, metadata capture, value imputation, and null handling, simplifying the feature engineering process. Furthermore, their support for natural language processing, including tokenization, stemming, and word embeddings, is invaluable for text-heavy datasets.
4. Powerful Search-Driven Analytics:
Search engines are not just about retrieval; they're also about analysis. They can perform real-time scoring, aggregation, and even regression analysis on retrieved data. This enables you to quickly extract meaningful insights, identify trends, and detect anomalies, moving beyond simple data retrieval.
5. Seamless Integration with Existing Tools:
Whether you prefer the command line, Jupyter notebooks, or languages like Python, R, or Scala, search engines seamlessly integrate with your existing data science toolkit. They can output data in various formats, including CSV and JSON, ensuring compatibility with your preferred workflows.
6. Rapid Prototyping and "Good Enough" Solutions:
Search engines simplify the implementation of algorithms like k-nearest neighbors, classifiers, and recommendation engines. While they may not always provide state-of-the-art results, they offer a quick and efficient way to build "good enough" solutions for prototyping and testing, especially at scale.
7. Versatile Data Storage and Handling:
Modern search engines, particularly those powered by Lucene (like Solr and Elasticsearch), are adept at handling key-value, columnar, and mixed data storage. This versatility allows them to efficiently manage diverse data types within a single platform, eliminating the need for multiple specialized tools.
Elevate Your Data Science Skills with Xaltius Academy's Data Science and AI Program:
While search engine tools offer valuable benefits, they are just one component of a comprehensive data science skillset. Xaltius Academy's Data Science and AI program provides a robust foundation in data analysis, machine learning, and AI, empowering you to leverage these tools effectively and tackle complex data challenges.
Key benefits of the program:
Comprehensive Curriculum: Covers essential data science concepts, including data analysis, machine learning, and AI.
Hands-on Projects: Gain practical experience through real-world projects and case studies.
Expert Instruction: Learn from experienced data scientists and AI practitioners.
Focus on Applied Skills: Develop the skills needed to apply data science and AI techniques to solve real-world problems.
Career Support: Receive guidance and resources to help you launch your career in data science and AI.
Conclusion:
Search engine tools offer a surprising array of benefits for data science, from rapid data exploration to efficient model development. By incorporating these tools into your workflow and complementing them with a strong foundation in data science principles, you can unlock new levels of efficiency and insight.
0 notes