#kubernetes cluster installation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Install Canonical Kubernetes on Linux | Snap Store
Fast, secure & automated application deployment, everywhere Canonical Kubernetes is the fastest, easiest way to deploy a fully-conformant Kubernetes cluster. Harnessing pure upstream Kubernetes, this distribution adds the missing pieces (e.g. ingress, dns, networking) for a zero-ops experience. Get started in just two commands: sudo snap install k8s –classic sudo k8s bootstrap — Read on…
View On WordPress
#dns#easiest way to deploy a fully-conformant Kubernetes cluster. Harnessing pure upstream Kubernetes#everywhere Canonical Kubernetes is the fastest#Fast#networking) for a zero-ops experience. Get started in just two commands: sudo snap install k8s --classic sudo k8s bootstrap#secure & automated application deployment#this distribution adds the missing pieces (e.g. ingress
1 note
·
View note
Text
Microk8s vs k3s: Lightweight Kubernetes distribution showdown
Microk8s vs k3s: Lightweight Kubernetes distribution showdown #homelab #kubernetes #microk8svsk3scomparison #lightweightkubernetesdistributions #k3sinstallationguide #microk8ssnappackagetutorial #highavailabilityinkubernetes #k3s #microk8s #portainer
Especially if you are into running Kubernetes in the home lab, you may look for a lightweight Kubernetes distribution. Two distributions that stand out are Microk8s and k3s. Let’s take a look at Microk8s vs k3s and discover the main differences between these two options, focusing on various aspects like memory usage, high availability, and k3s and microk8s compatibility. Table of contentsWhat is…

View On WordPress
#container runtimes and configurations#edge computing with k3s and microk8s#High Availability in Kubernetes#k3s installation guide#kubernetes cluster resources#Kubernetes on IoT devices#lightweight kubernetes distributions#memory usage optimization#microk8s snap package tutorial#microk8s vs k3s comparison
0 notes
Video
youtube
Session 5 Kubernetes 3 Node Cluster and Dashboard Installation and Confi...
#youtube#Kubernetes 3 Node Cluster and Dashboard Installation and Configuration with Podman 🚀 In this exciting video tutorial we dive into the worl
1 note
·
View note
Text
#spotify#kubernetes cluster setup#kubernetes#kubernetes cluster#kubernetes interview questions#kubernetes installation
0 notes
Text
A3 Ultra VMs With NVIDIA H200 GPUs Pre-launch This Month

Strong infrastructure advancements for your future that prioritizes AI
To increase customer performance, usability, and cost-effectiveness, Google Cloud implemented improvements throughout the AI Hypercomputer stack this year. Google Cloud at the App Dev & Infrastructure Summit:
Trillium, Google’s sixth-generation TPU, is currently available for preview.
Next month, A3 Ultra VMs with NVIDIA H200 Tensor Core GPUs will be available for preview.
Google’s new, highly scalable clustering system, Hypercompute Cluster, will be accessible beginning with A3 Ultra VMs.
Based on Axion, Google’s proprietary Arm processors, C4A virtual machines (VMs) are now widely accessible
AI workload-focused additions to Titanium, Google Cloud’s host offload capability, and Jupiter, its data center network.
Google Cloud’s AI/ML-focused block storage service, Hyperdisk ML, is widely accessible.
Trillium A new era of TPU performance
Trillium A new era of TPU performance is being ushered in by TPUs, which power Google’s most sophisticated models like Gemini, well-known Google services like Maps, Photos, and Search, as well as scientific innovations like AlphaFold 2, which was just awarded a Nobel Prize! We are happy to inform that Google Cloud users can now preview Trillium, our sixth-generation TPU.
Taking advantage of NVIDIA Accelerated Computing to broaden perspectives
By fusing the best of Google Cloud’s data center, infrastructure, and software skills with the NVIDIA AI platform which is exemplified by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs it also keeps investing in its partnership and capabilities with NVIDIA.
Google Cloud announced that the new A3 Ultra VMs featuring NVIDIA H200 Tensor Core GPUs will be available on Google Cloud starting next month.
Compared to earlier versions, A3 Ultra VMs offer a notable performance improvement. Their foundation is NVIDIA ConnectX-7 network interface cards (NICs) and servers equipped with new Titanium ML network adapter, which is tailored to provide a safe, high-performance cloud experience for AI workloads. A3 Ultra VMs provide non-blocking 3.2 Tbps of GPU-to-GPU traffic using RDMA over Converged Ethernet (RoCE) when paired with our datacenter-wide 4-way rail-aligned network.
In contrast to A3 Mega, A3 Ultra provides:
With the support of Google’s Jupiter data center network and Google Cloud’s Titanium ML network adapter, double the GPU-to-GPU networking bandwidth
With almost twice the memory capacity and 1.4 times the memory bandwidth, LLM inferencing performance can increase by up to 2 times.
Capacity to expand to tens of thousands of GPUs in a dense cluster with performance optimization for heavy workloads in HPC and AI.
Google Kubernetes Engine (GKE), which offers an open, portable, extensible, and highly scalable platform for large-scale training and AI workloads, will also offer A3 Ultra VMs.
Hypercompute Cluster: Simplify and expand clusters of AI accelerators
It’s not just about individual accelerators or virtual machines, though; when dealing with AI and HPC workloads, you have to deploy, maintain, and optimize a huge number of AI accelerators along with the networking and storage that go along with them. This may be difficult and time-consuming. For this reason, Google Cloud is introducing Hypercompute Cluster, which simplifies the provisioning of workloads and infrastructure as well as the continuous operations of AI supercomputers with tens of thousands of accelerators.
Fundamentally, Hypercompute Cluster integrates the most advanced AI infrastructure technologies from Google Cloud, enabling you to install and operate several accelerators as a single, seamless unit. You can run your most demanding AI and HPC workloads with confidence thanks to Hypercompute Cluster’s exceptional performance and resilience, which includes features like targeted workload placement, dense resource co-location with ultra-low latency networking, and sophisticated maintenance controls to reduce workload disruptions.
For dependable and repeatable deployments, you can use pre-configured and validated templates to build up a Hypercompute Cluster with just one API call. This include containerized software with orchestration (e.g., GKE, Slurm), framework and reference implementations (e.g., JAX, PyTorch, MaxText), and well-known open models like Gemma2 and Llama3. As part of the AI Hypercomputer architecture, each pre-configured template is available and has been verified for effectiveness and performance, allowing you to concentrate on business innovation.
A3 Ultra VMs will be the first Hypercompute Cluster to be made available next month.
An early look at the NVIDIA GB200 NVL72
Google Cloud is also awaiting the developments made possible by NVIDIA GB200 NVL72 GPUs, and we’ll be providing more information about this fascinating improvement soon. Here is a preview of the racks Google constructing in the meantime to deliver the NVIDIA Blackwell platform’s performance advantages to Google Cloud’s cutting-edge, environmentally friendly data centers in the early months of next year.
Redefining CPU efficiency and performance with Google Axion Processors
CPUs are a cost-effective solution for a variety of general-purpose workloads, and they are frequently utilized in combination with AI workloads to produce complicated applications, even if TPUs and GPUs are superior at specialized jobs. Google Axion Processors, its first specially made Arm-based CPUs for the data center, at Google Cloud Next ’24. Customers using Google Cloud may now benefit from C4A virtual machines, the first Axion-based VM series, which offer up to 10% better price-performance compared to the newest Arm-based instances offered by other top cloud providers.
Additionally, compared to comparable current-generation x86-based instances, C4A offers up to 60% more energy efficiency and up to 65% better price performance for general-purpose workloads such as media processing, AI inferencing applications, web and app servers, containerized microservices, open-source databases, in-memory caches, and data analytics engines.
Titanium and Jupiter Network: Making AI possible at the speed of light
Titanium, the offload technology system that supports Google’s infrastructure, has been improved to accommodate workloads related to artificial intelligence. Titanium provides greater compute and memory resources for your applications by lowering the host’s processing overhead through a combination of on-host and off-host offloads. Furthermore, although Titanium’s fundamental features can be applied to AI infrastructure, the accelerator-to-accelerator performance needs of AI workloads are distinct.
Google has released a new Titanium ML network adapter to address these demands, which incorporates and expands upon NVIDIA ConnectX-7 NICs to provide further support for virtualization, traffic encryption, and VPCs. The system offers best-in-class security and infrastructure management along with non-blocking 3.2 Tbps of GPU-to-GPU traffic across RoCE when combined with its data center’s 4-way rail-aligned network.
Google’s Jupiter optical circuit switching network fabric and its updated data center network significantly expand Titanium’s capabilities. With native 400 Gb/s link rates and a total bisection bandwidth of 13.1 Pb/s (a practical bandwidth metric that reflects how one half of the network can connect to the other), Jupiter could handle a video conversation for every person on Earth at the same time. In order to meet the increasing demands of AI computation, this enormous scale is essential.
Hyperdisk ML is widely accessible
For computing resources to continue to be effectively utilized, system-level performance maximized, and economical, high-performance storage is essential. Google launched its AI-powered block storage solution, Hyperdisk ML, in April 2024. Now widely accessible, it adds dedicated storage for AI and HPC workloads to the networking and computing advancements.
Hyperdisk ML efficiently speeds up data load times. It drives up to 11.9x faster model load time for inference workloads and up to 4.3x quicker training time for training workloads.
With 1.2 TB/s of aggregate throughput per volume, you may attach 2500 instances to the same volume. This is more than 100 times more than what big block storage competitors are giving.
Reduced accelerator idle time and increased cost efficiency are the results of shorter data load times.
Multi-zone volumes are now automatically created for your data by GKE. In addition to quicker model loading with Hyperdisk ML, this enables you to run across zones for more computing flexibility (such as lowering Spot preemption).
Developing AI’s future
Google Cloud enables companies and researchers to push the limits of AI innovation with these developments in AI infrastructure. It anticipates that this strong foundation will give rise to revolutionary new AI applications.
Read more on Govindhtech.com
#A3UltraVMs#NVIDIAH200#AI#Trillium#HypercomputeCluster#GoogleAxionProcessors#Titanium#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
2 notes
·
View notes
Text
Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
In the era of cloud-native transformation, data is the fuel powering everything from mission-critical enterprise apps to real-time analytics platforms. However, as Kubernetes adoption grows, many organizations face a new set of challenges: how to manage persistent storage efficiently, reliably, and securely across distributed environments.
To solve this, Red Hat OpenShift Data Foundation (ODF) emerges as a powerful solution — and the DO370 training course is designed to equip professionals with the skills to deploy and manage this enterprise-grade storage platform.
🔍 What is Red Hat OpenShift Data Foundation?
OpenShift Data Foundation is an integrated, software-defined storage solution that delivers scalable, resilient, and cloud-native storage for Kubernetes workloads. Built on Ceph and Rook, ODF supports block, file, and object storage within OpenShift, making it an ideal choice for stateful applications like databases, CI/CD systems, AI/ML pipelines, and analytics engines.
🎯 Why Learn DO370?
The DO370: Red Hat OpenShift Data Foundation course is specifically designed for storage administrators, infrastructure architects, and OpenShift professionals who want to:
✅ Deploy ODF on OpenShift clusters using best practices.
✅ Understand the architecture and internal components of Ceph-based storage.
✅ Manage persistent volumes (PVs), storage classes, and dynamic provisioning.
✅ Monitor, scale, and secure Kubernetes storage environments.
✅ Troubleshoot common storage-related issues in production.
🛠️ Key Features of ODF for Enterprise Workloads
1. Unified Storage (Block, File, Object)
Eliminate silos with a single platform that supports diverse workloads.
2. High Availability & Resilience
ODF is designed for fault tolerance and self-healing, ensuring business continuity.
3. Integrated with OpenShift
Full integration with the OpenShift Console, Operators, and CLI for seamless Day 1 and Day 2 operations.
4. Dynamic Provisioning
Simplifies persistent storage allocation, reducing manual intervention.
5. Multi-Cloud & Hybrid Cloud Ready
Store and manage data across on-prem, public cloud, and edge environments.
📘 What You Will Learn in DO370
Installing and configuring ODF in an OpenShift environment.
Creating and managing storage resources using the OpenShift Console and CLI.
Implementing security and encryption for data at rest.
Monitoring ODF health with Prometheus and Grafana.
Scaling the storage cluster to meet growing demands.
🧠 Real-World Use Cases
Databases: PostgreSQL, MySQL, MongoDB with persistent volumes.
CI/CD: Jenkins with persistent pipelines and storage for artifacts.
AI/ML: Store and manage large datasets for training models.
Kafka & Logging: High-throughput storage for real-time data ingestion.
👨🏫 Who Should Enroll?
This course is ideal for:
Storage Administrators
Kubernetes Engineers
DevOps & SRE teams
Enterprise Architects
OpenShift Administrators aiming to become RHCA in Infrastructure or OpenShift
🚀 Takeaway
If you’re serious about building resilient, performant, and scalable storage for your Kubernetes applications, DO370 is the must-have training. With ODF becoming a core component of modern OpenShift deployments, understanding it deeply positions you as a valuable asset in any hybrid cloud team.
🧭 Ready to transform your Kubernetes storage strategy? Enroll in DO370 and master Red Hat OpenShift Data Foundation today with HawkStack Technologies – your trusted Red Hat Certified Training Partner. For more details www.hawkstack.com
0 notes
Text
Is ChatGPT Easy to Use? Here’s What You Need to Know
Introduction: A Curious Beginning I still remember the first time I stumbled upon ChatGPT my heart raced at the thought of talking to an AI. I was a fresh-faced IT enthusiast, eager to explore how a “gpt chat” interface could transform my workflow. Yet, as excited as I was, I also felt a tinge of apprehension: Would I need to learn a new programming language? Would I have to navigate countless settings? Spoiler alert: Not at all. In this article, I’m going to walk you through my journey and show you why ChatGPT is as straightforward as chatting with a friend. By the end, you’ll know exactly “how to use ChatGPT” in your day-to-day IT endeavors whether you’re exploring the “chatgpt app” on your phone or logging into “ChatGPT online” from your laptop.
What Is ChatGPT, Anyway?
If you’ve heard of “chat openai,” “chat gbt ai,” or “chatgpt openai,” you already know that OpenAI built this tool to mimic human-like conversation. ChatGPT sometimes written as “Chat gpt”—is an AI-powered chatbot that understands natural language and responds with surprisingly coherent answers. With each new release remember buzz around “chatgpt 4��? OpenAI has refined its approach, making the bot smarter at understanding context, coding queries, creative brainstorming, and more.
GPT Chat: A shorthand term some people use, but it really means the same as ChatGPT just another way to search or tag the service.
ChatGPT Online vs. App: Although many refer to “chatgpt online,” you can also download the “chatgpt app” on iOS or Android for on-the-go access.
Free vs. Paid: There’s even a “chatgpt gratis” option for users who want to try without commitment, while premium plans unlock advanced features.
Getting Started: Signing Up for ChatGPT Online
1. Creating Your Account
First things first head over to the ChatGPT website. You’ll see a prompt to sign up or log in. If you’re wondering about “chat gpt free,” you’re in luck: OpenAI offers a free tier that anyone can access (though it has usage limits). Here’s how I did it:
Enter your email (or use Google/Microsoft single sign-on).
Verify your email with the link they send usually within seconds.
Log in, and voila, you’re in!
No complex setup, no plugin installations just a quick email verification and you’re ready to talk to your new AI buddy. Once you’re “ChatGPT online,” you’ll land on a simple chat window: type a question, press Enter, and watch GPT 4 respond.
Navigating the ChatGPT App
While “ChatGPT online” is perfect for desktop browsing, I quickly discovered the “chatgpt app” on my phone. Here’s what stood out:
Intuitive Interface: A text box at the bottom, a menu for adjusting settings, and conversation history links on the side.
Voice Input: On some versions, you can tap the microphone icon—no need to type every query.
Seamless Sync: Whatever you do on mobile shows up in your chat history on desktop.
For example, one night I was troubleshooting a server config while waiting for a train. Instead of squinting at the station’s Wi-Fi, I opened the “chat gpt free” app on my phone, asked how to tweak a Dockerfile, and got a working snippet in seconds. That moment convinced me: whether you’re using “chatgpt online” or the “chatgpt app,” the learning curve is minimal.
Key Features of ChatGPT 4
You might have seen “chatgpt 4” trending this iteration boasts numerous improvements over earlier versions. Here’s why it feels so effortless to use:
Better Context Understanding: Unlike older “gpt chat” bots, ChatGPT 4 remembers what you asked earlier in the same session. If you say, “Explain SQL joins,” and then ask, “How does that apply to Postgres?”, it knows you’re still talking about joins.
Multi-Turn Conversations: Complex troubleshooting often requires back-and-forth questions. I once spent 20 minutes configuring a Kubernetes cluster entirely through a multi-turn conversation.
Code Snippet Generation: Want Ruby on Rails boilerplate or a Python function? ChatGPT 4 can generate working code that requires only minor tweaks. Even if you make a mistake, simply pasting your error output back into the chat usually gets you an explanation.
These features mean that even non-developers say, a project manager looking to automate simple Excel tasks can learn “how to use ChatGPT” with just a few chats. And if you’re curious about “chat gbt ai” in data analytics, hop on and ask ChatGPT can translate your plain-English requests into practical scripts.
Tips for First-Time Users
I’ve coached colleagues on “how to use ChatGPT” in the last year, and these small tips always come in handy:
Be Specific: Instead of “Write a Python script,” try “Write a Python 3.9 script that reads a CSV file and prints row sums.” The more detail, the more precise the answer.
Ask Follow-Up Questions: Stuck on part of the response? Simply type, “Can you explain line 3 in more detail?” This keeps the flow natural—just like talking to a friend.
Use System Prompts: At the very start, you can say, “You are an IT mentor. Explain in beginner terms.” That “meta” instruction shapes the tone of every response.
Save Your Favorite Replies: If you stumble on a gem—say, a shell command sequence—star it or copy it to a personal notes file so you can reference it later.
When a coworker asked me how to connect a React frontend to a Flask API, I typed exactly that into the chat. Within seconds, I had boilerplate code, NPM install commands, and even a short security note: “Don’t forget to add CORS headers.” That level of assistance took just three minutes, demonstrating why “gpt chat” can feel like having a personal assistant.
Common Challenges and How to Overcome Them
No tool is perfect, and ChatGPT is no exception. Here are a few hiccups you might face and how to fix them:
Occasional Inaccuracies: Sometimes, ChatGPT can confidently state something that’s outdated or just plain wrong. My trick? Cross-check any critical output. If it’s a code snippet, run it; if it’s a conceptual explanation, ask follow-up questions like, “Is this still true for Python 3.11?”
Token Limits: On the “chatgpt gratis” tier, you might hit usage caps or get slower response times. If you encounter this, try simplifying your prompt or wait a few minutes for your quota to reset. If you need more, consider upgrading to a paid plan.
Overly Verbose Answers: ChatGPT sometimes loves to explain every little detail. If that happens, just say, “Can you give me a concise version?” and it will trim down its response.
Over time, you learn how to phrase questions so that ChatGPT delivers exactly what you need quickly—no fluff, just the essentials. Think of it as learning the “secret handshake” to get premium insights from your digital buddy.
Comparing Free and Premium Options
If you search “chat gpt free” or “chatgpt gratis,” you’ll see that OpenAI’s free plan offers basic access to ChatGPT 3.5. It’s great for light users students looking for homework help, writers brainstorming ideas, or aspiring IT pros tinkering with small scripts. Here’s a quick breakdown: FeatureFree Tier (ChatGPT 3.5)Paid Tier (ChatGPT 4)Response SpeedStandardFaster (priority access)Daily Usage LimitsLowerHigherAccess to Latest ModelChatGPT 3.5ChatGPT 4 (and beyond)Advanced Features (e.g., Code)LimitedFull accessChat History StorageShorter retentionLonger session memory
For someone just dipping toes into “chat openai,” the free tier is perfect. But if you’re an IT professional juggling multiple tasks and you want the speed and accuracy of “chatgpt 4” the upgrade is usually worth it. I switched to a paid plan within two weeks of experimenting because my productivity jumped tenfold.
Real-World Use Cases for IT Careers
As an IT blogger, I’ve seen ChatGPT bridge gaps in various IT roles. Here are some examples that might resonate with you:
Software Development: Generating boilerplate code, debugging error messages, or even explaining complex algorithms in simple terms. When I first learned Docker, ChatGPT walked me through building an image, step by step.
System Administration: Writing shell scripts, explaining how to configure servers, or outlining best security practices. One colleague used ChatGPT to set up an Nginx reverse proxy without fumbling through documentation.
Data Analysis: Crafting SQL queries, parsing data using Python pandas, or suggesting visualization libraries. I once asked, “How to use chatgpt for data cleaning?” and got a concise pandas script that saved hours of work.
Project Management: Drafting Jira tickets, summarizing technical requirements, or even generating risk-assessment templates. If you ever struggled to translate technical jargon into plain English for stakeholders, ChatGPT can be your translator.
In every scenario, I’ve found that the real magic isn’t just the AI’s knowledge, but how quickly it can prototype solutions. Instead of spending hours googling or sifting through Stack Overflow, you can ask a direct question and get an actionable answer in seconds.
Security and Privacy Considerations
Of course, when dealing with AI, it’s wise to think about security. Here’s what you need to know:
Data Retention: OpenAI may retain conversation data to improve their models. Don’t paste sensitive tokens, passwords, or proprietary code you can’t risk sharing.
Internal Policies: If you work for a company with strict data guidelines, check whether sending internal data to a third-party service complies with your policy.
Public Availability: Remember that anyone else could ask ChatGPT similar questions. If you need unique, private solutions, consult official documentation or consider an on-premises AI solution.
I routinely use ChatGPT for brainstorming and general code snippets, but for production credentials or internal proprietary logic, I keep those aspects offline. That balance lets me benefit from “chatgpt openai” guidance without compromising security.
Is ChatGPT Right for You?
At this point, you might be wondering, “Okay, but is it really easy enough for me?” Here’s my honest take:
Beginners who have never written a line of code can still ask ChatGPT to explain basic IT concepts no jargon needed.
Intermediate users can leverage the “chatgpt app” on mobile to troubleshoot on the go, turning commute time into learning time.
Advanced professionals will appreciate how ChatGPT 4 handles multi-step instructions and complex code logic.
If you’re seriously exploring a career in IT, learning “how to use ChatGPT” is almost like learning to use Google in 2005: essential. Sure, there’s a short learning curve to phrasing your prompts for maximum efficiency, but once you get the hang of it, it becomes second nature just like typing “ls -la” into a terminal.
Conclusion: Your Next Steps
So, is ChatGPT easy to use? Absolutely. Between the intuitive “chatgpt app,” the streamlined “chatgpt online” interface, and the powerful capabilities of “chatgpt 4,” most users find themselves up and running within minutes. If you haven’t already, head over to the ChatGPT website and create your free account. Experiment with a few prompts maybe ask it to explain “how to use chatgpt” and see how it fits into your daily routine.
Remember:
Start simple. Ask basic questions, then gradually dive deeper.
Don’t be afraid to iterate. If an answer isn’t quite right, refine your prompt.
Keep security in mind. Never share passwords or sensitive data.
Whether you’re writing your first “gpt chat” script, drafting project documentation, or just curious how “chat gbt ai” can spice up your presentations, ChatGPT is here to help. Give it a try, and in no time, you’ll wonder how you ever managed without your AI sidekick.
1 note
·
View note
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
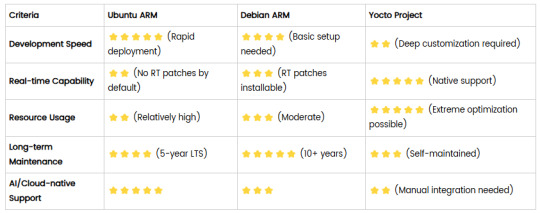
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
Effective Kubernetes cluster monitoring simplifies containerized workload management by measuring uptime, resource use (such as memory, CPU, and storage), and interaction between cluster components. It also enables cluster managers to monitor the cluster and discover issues such as inadequate resources, errors, pods that fail to start, and nodes that cannot join the cluster. Essentially, Kubernetes monitoring enables you to discover issues and manage Kubernetes clusters more proactively. What Kubernetes Metrics Should You Measure? Monitoring Kubernetes metrics is critical for ensuring the reliability, performance, and efficiency of applications in a Kubernetes cluster. Because Kubernetes constantly expands and maintains containers, measuring critical metrics allows you to spot issues early on, optimize resource allocation, and preserve overall system integrity. Several factors are critical to watch with Kubernetes: Cluster monitoring - Monitors the health of the whole Kubernetes cluster. It helps you find out how many apps are running on a node, if it is performing efficiently and at the right capacity, and how much resource the cluster requires overall. Pod monitoring - Tracks issues impacting individual pods, including resource use, application metrics, and pod replication or auto scaling metrics. Ingress metrics - Monitoring ingress traffic can help in discovering and managing a variety of issues. Using controller-specific methods, ingress controllers can be set up to track network traffic information and workload health. Persistent storage - Monitoring volume health allows Kubernetes to implement CSI. You can also use the external health monitor controller to track node failures. Control plane metrics - With control plane metrics we can track and visualize cluster performance while troubleshooting by keeping an eye on schedulers, controllers, and API servers. Node metrics - Keeping an eye on each Kubernetes node's CPU and memory usage might help ensure that they never run out. A running node's status can be defined by a number of conditions, such as Ready, MemoryPressure, DiskPressure, OutOfDisk, and NetworkUnavailable. Monitoring and Troubleshooting Kubernetes Clusters Using the Kubernetes Dashboard The Kubernetes dashboard is a web-based user interface for Kubernetes. It allows you to deploy containerized apps to a Kubernetes cluster, see an overview of the applications operating on the cluster, and manage cluster resources. Additionally, it enables you to: Debug containerized applications by examining data on the health of your Kubernetes cluster's resources, as well as any anomalies that have occurred. Create and modify individual Kubernetes resources, including deployments, jobs, DaemonSets, and StatefulSets. Have direct control over your Kubernetes environment using the Kubernetes dashboard. The Kubernetes dashboard is built into Kubernetes by default and can be installed and viewed from the Kubernetes master node. Once deployed, you can visit the dashboard via a web browser to examine extensive information about your Kubernetes cluster and conduct different operations like scaling deployments, establishing new resources, and updating application configurations. Kubernetes Dashboard Essential Features Kubernetes Dashboard comes with some essential features that help manage and monitor your Kubernetes clusters efficiently: Cluster overview: The dashboard displays information about your Kubernetes cluster, including the number of nodes, pods, and services, as well as the current CPU and memory use. Resource management: The dashboard allows you to manage Kubernetes resources, including deployments, services, and pods. You can add, update, and delete resources while also seeing extensive information about them. Application monitoring: The dashboard allows you to monitor the status and performance of Kubernetes-based apps. You may see logs and stats, fix issues, and set alarms.
Customizable views: The dashboard allows you to create and preserve bespoke dashboards with the metrics and information that are most essential to you. Kubernetes Monitoring Best Practices Here are some recommended practices to help you properly monitor and debug Kubernetes installations: 1. Monitor Kubernetes Metrics Kubernetes microservices require understanding granular resource data like memory, CPU, and load. However, these metrics may be complex and challenging to leverage. API indicators such as request rate, call error, and latency are the most effective KPIs for identifying service faults. These metrics can immediately identify degradations in a microservices application's components. 2. Ensure Monitoring Systems Have Enough Data Retention Having scalable monitoring solutions helps you to efficiently monitor your Kubernetes cluster as it grows and evolves over time. As your Kubernetes cluster expands, so will the quantity of data it creates, and your monitoring systems must be capable of handling this rise. If your systems are not scalable, they may get overwhelmed by the volume of data and be unable to offer accurate or relevant results. 3. Integrate Monitoring Systems Into Your CI/CD Pipeline Source Integrating Kubernetes monitoring solutions with CI/CD pipelines enables you to monitor your apps and infrastructure as they are deployed, rather than afterward. By connecting your monitoring systems to your pipeline for continuous integration and delivery (CI/CD), you can automatically collect and process data from your infrastructure and applications as it is delivered. This enables you to identify potential issues early on and take action to stop them from getting worse. 4. Create Alerts You may identify the problems with your Kubernetes cluster early on and take action to fix them before they get worse by setting up the right alerts. For example, if you configure alerts for crucial metrics like CPU or memory use, you will be informed when those metrics hit specific thresholds, allowing you to take action before your cluster gets overwhelmed. Conclusion Kubernetes allows for the deployment of a large number of containerized applications within its clusters, each of which has nodes that manage the containers. Efficient observability across various machines and components is critical for successful Kubernetes container orchestration. Kubernetes has built-in monitoring facilities for its control plane, but they may not be sufficient for thorough analysis and granular insight into application workloads, event logging, and other microservice metrics within Kubernetes clusters.
0 notes
Text
Getting Started with Kubeflow: Machine Learning on Kubernetes Made Easy
In today’s data-driven world, organizations are increasingly investing in scalable, reproducible, and automated machine learning (ML) workflows. But deploying ML models from research to production remains a complex, resource-intensive challenge. Enter Kubeflow, a powerful open-source platform designed to streamline machine learning operations (MLOps) on Kubernetes. Kubeflow abstracts much of the complexity involved in orchestrating ML workflows, bringing DevOps best practices to the ML lifecycle.
Whether you're a data scientist, ML engineer, or DevOps professional, this guide will help you understand Kubeflow’s architecture, key components, and how to get started.
What is Kubeflow?
Kubeflow is an end-to-end machine learning toolkit built on top of Kubernetes, the de facto container orchestration system. Originally developed by Google, Kubeflow was designed to support ML workflows that run on Kubernetes, making it easy to deploy scalable and portable ML pipelines.
At its core, Kubeflow offers a collection of interoperable components covering the full ML lifecycle:
Data exploration
Model training and tuning
Pipeline orchestration
Model serving
Monitoring and metadata tracking
By leveraging Kubernetes, Kubeflow ensures your ML workloads are portable, scalable, and cloud-agnostic.
Why Use Kubeflow?
Traditional ML workflows often involve disparate tools and manual handoffs, making them hard to scale, reproduce, or deploy. Kubeflow simplifies this by:
Standardizing ML workflows across teams
Automating pipeline execution and parameter tuning
Scaling training jobs dynamically on Kubernetes clusters
Monitoring model performance with integrated logging and metrics
Supporting hybrid and multi-cloud environments
Essentially, Kubeflow brings the principles of CI/CD and infrastructure-as-code into the ML domain—enabling robust MLOps.
Key Components of Kubeflow
Kubeflow’s modular architecture allows you to use only the components you need. Here are the most critical ones to know:
1. Kubeflow Pipelines
This is the heart of Kubeflow. It allows you to define, schedule, and monitor complex ML workflows as Directed Acyclic Graphs (DAGs). Pipelines support versioning, experiment tracking, and visualization of workflow runs.
2. Katib
An AutoML component that handles hyperparameter tuning using state-of-the-art algorithms like Bayesian optimization, grid search, and more. Katib can run large-scale tuning jobs across clusters.
3. KFServing (now KServe)
A robust model serving component for deploying trained models with support for REST/gRPC, autoscaling (including scale-to-zero), and multi-framework compatibility (TensorFlow, PyTorch, ONNX, XGBoost, etc.).
4. JupyterHub
Provides multi-user Jupyter notebooks directly within your Kubernetes environment. Great for data exploration, feature engineering, and prototyping.
5. ML Metadata (MLMD)
Tracks lineage and metadata about datasets, models, pipeline runs, and experiments, enabling reproducibility and governance.
Setting Up Kubeflow: A High-Level Walkthrough
Getting Kubeflow up and running can be daunting due to its complexity and the requirements of Kubernetes infrastructure. Here’s a high-level roadmap to guide your setup.
Step 1: Prepare Your Kubernetes Cluster
Kubeflow runs on Kubernetes, so you’ll need a Kubernetes cluster ready—either locally (via Minikube or KIND), on-premises, or in the cloud (GKE, EKS, AKS, etc.). Ensure you have:
Kubernetes ≥ v1.21
Sufficient CPU/memory resources
kubectl CLI configured
Step 2: Choose a Kubeflow Distribution
You can install Kubeflow using one of the following options:
Kubeflow Manifests: Official YAML manifests for production-grade installs
MiniKF: A local, single-node VM version ideal for development
Kfctl: Deprecated but still used in legacy environments
Kubeflow Operator: For declarative installs using CRDs
For most users, Kubeflow Manifests or MiniKF are the best starting points.
Step 3: Deploy Kubeflow
Assuming you’re using Kubeflow Manifests:
# Clone the manifests repo
git clone https://github.com/kubeflow/manifests.git
cd manifests
# Deploy using kustomize
while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
The installation process may take several minutes. Once complete, access the dashboard via a port-forward or ingress route.
The installation process may take several minutes. Once complete, access the dashboard via a port-forward or ingress route.
Step 4: Access the Kubeflow Central Dashboard
You can now access the Kubeflow UI, where you can create experiments, launch notebooks, manage pipelines, and deploy models—all from a unified interface.
Best Practices for Working with Kubeflow
To make the most of Kubeflow in production, consider the following:
Namespace Isolation: Use namespaces to separate teams and workflows securely.
Pipeline Versioning: Always version your pipeline components for reproducibility.
Storage Integration: Integrate with cloud-native or on-prem storage solutions (e.g., S3, GCS, NFS).
Security: Configure Role-Based Access Control (RBAC) and authentication using Istio and Dex.
Monitoring: Use Prometheus, Grafana, and ELK for observability and logging.
Common Challenges and How to Overcome Them
Kubeflow is powerful, but it comes with its share of complexity:
Challenge
Solution
Steep learning curve
Start with MiniKF or managed services like GCP Vertex AI Pipelines
Complex deployment
Use Helm charts or managed Kubernetes to abstract infra setup
RBAC and security
Leverage Kubeflow Profiles and Istio AuthPolicies for fine-grained control
Storage configuration
Use pre-integrated cloud-native storage classes or persistent volumes
Final Thoughts
Kubeflow brings enterprise-grade scalability, reproducibility, and automation to the machine learning lifecycle by marrying ML workflows with Kubernetes infrastructure. While it can be challenging to deploy and manage, the long-term benefits for production-grade MLOps are substantial.
For teams serious about operationalizing machine learning, Kubeflow is not just a tool—it’s a paradigm shift.
0 notes
Text
Modern Tools Enhance Data Governance and PII Management Compliance

Modern data governance focuses on effectively managing Personally Identifiable Information (PII). Tools like IBM Cloud Pak for Data (CP4D), Red Hat OpenShift, and Kubernetes provide organizations with comprehensive solutions to navigate complex regulatory requirements, including GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). These platforms offer secure data handling, lineage tracking, and governance automation, helping businesses stay compliant while deriving value from their data.
PII management involves identifying, protecting, and ensuring the lawful use of sensitive data. Key requirements such as transparency, consent, and safeguards are essential to mitigate risks like breaches or misuse. IBM Cloud Pak for Data integrates governance, lineage tracking, and AI-driven insights into a unified framework, simplifying metadata management and ensuring compliance. It also enables self-service access to data catalogs, making it easier for authorized users to access and manage sensitive data securely.
Advanced IBM Cloud Pak for Data features include automated policy reinforcement and role-based access that ensure that PII remains protected while supporting analytics and machine learning applications. This approach simplifies compliance, minimizing the manual workload typically associated with regulatory adherence.
The growing adoption of multi-cloud environments has necessitated the development of platforms such as Informatica and Collibra to offer complementary governance tools that enhance PII protection. These solutions use AI-supported insights, automated data lineage, and centralized policy management to help organizations seeking to improve their data governance frameworks.
Mr. Valihora has extensive experience with IBM InfoSphere Information Server “MicroServices” products (which are built upon Red Hat Enterprise Linux Technology – in conjunction with Docker\Kubernetes.) Tim Valihora - President of TVMG Consulting Inc. - has extensive experience with respect to:
IBM InfoSphere Information Server “Traditional” (IIS v11.7.x)
IBM Cloud PAK for Data (CP4D)
IBM “DataStage Anywhere”
Mr. Valihora is a US based (Vero Beach, FL) Data Governance specialist within the IBM InfoSphere Information Server (IIS) software suite and is also Cloud Certified on Collibra Data Governance Center.
Career Highlights Include: Technical Architecture, IIS installations, post-install-configuration, SDLC mentoring, ETL programming, performance-tuning, client-side training (including administrators, developers or business analysis) on all of the over 15 out-of-the-box IBM IIS products Over 180 Successful IBM IIS installs - Including the GRID Tool-Kit for DataStage (GTK), MPP, SMP, Multiple-Engines, Clustered Xmeta, Clustered WAS, Active-Passive Mirroring and Oracle Real Application Clustered “IADB” or “Xmeta” configurations. Tim Valihora has been credited with performance tuning the words fastest DataStage job which clocked in at 1.27 Billion rows of inserts\updates every 12 minutes (using the Dynamic Grid ToolKit (GTK) for DataStage (DS) with a configuration file that utilized 8 compute-nodes - each with 12 CPU cores and 64 GB of RAM.)
0 notes
Text
The Unseen Power of Linux System Infrastructure: Beyond the Conventional Wisdom
Introduction: Not Just Another Server
When people talk about Linux servers, the conversation often revolves around the obvious. They mention reliability, open-source flexibility, security, and cost-efficiency. But the true essence of Linux servers goes far deeper than just technical specifications and traditional arguments. To understand Linux servers is to understand a philosophy, a movement, and a way of rethinking digital sovereignty. It's not just about running code; it's about choosing freedom, performance, and evolution.
A Living, Breathing Ecosystem
Unlike static operating systems that are updated occasionally by monolithic corporations, Linux servers are part of a vibrant, dynamic, and self-healing ecosystem. Each distribution is a living entity, shaped by communities across the globe, evolving with the needs of real users, developers, and businesses. It is not just software installed on a machine; it is a living organism constantly adapting, optimizing, and innovating. Linux servers do not wait for permission from a central authority to grow; they evolve organically, driven by necessity and passion.
The Philosophy of Choice and Control
Linux servers offer a depth of customization and control that no proprietary system can match. Every decision, from the kernel level to the user space, is yours to make. It forces you to engage with your infrastructure on a deeper level. This engagement creates a symbiotic relationship between the user and the machine. Running a Linux server is not merely about deploying an application; it's about architecting an environment tailored to your precise needs. This level of granular control cultivates a mindset of precision, intentionality, and mastery.
Security Through Transparency
While other systems rely heavily on obscurity and corporate security teams, Linux servers achieve unparalleled security through radical transparency. Every line of code is available for inspection, every vulnerability can be scrutinized by thousands of independent eyes. This isn't just about patching CVEs faster; it's about creating a fundamentally more secure environment through collective vigilance. A Linux server is not a black box; it’s an open book written in real-time by the world’s finest minds.
Resilience in the Face of Adversity
There is a reason why the world’s most critical infrastructure — from financial markets to space exploration — trusts Linux servers. It’s not just about uptime; it’s about resilience. When chaos hits, when unexpected failures cascade, Linux servers offer the kind of composure and recoverability that closed systems simply cannot. Thanks to tools like system snapshots, redundant configurations, and scriptable recovery processes, Linux servers embody a philosophy of survival, adaptability, and engineering for the worst-case scenario.
The True Cost of Ownership
It's easy to highlight that Linux is "free," but that's a shallow way to view its economic advantage. The true cost of a server lies in maintenance, downtime, scalability, and flexibility over time. Linux servers win because they minimize these hidden costs. Their modularity means you can optimize precisely what you need, without paying for bloated software features. Their massive global community means faster troubleshooting and innovation. In the long run, Linux servers don’t just save money — they enable you to reinvest in growth rather than firefighting.
Empowering Innovation and Experimentation
A Linux server is not just a platform for hosting websites or applications. It is a playground for innovation. Want to build a Kubernetes cluster from scratch? Set up a cutting-edge AI environment? Automate complex data pipelines? With Linux, the only limit is your ambition. The open nature of the ecosystem encourages experimentation without penalty. Mistakes are learning opportunities, not costly failures. Every reboot, every configuration tweak, every successful deployment turns you from a consumer of technology into a creator.
The Silent Backbone of the Internet
Every day, billions of people interact with Linux servers without even knowing it. They browse websites, stream videos, communicate across continents — all thanks to infrastructures powered invisibly by Linux. It's the silent workhorse that holds up the modern digital world. Even companies that build proprietary platforms often rely on Linux servers at their core. They don't advertise it, but behind every major cloud provider, every massive database, every seamless user experience, there is likely a Linux box humming quietly in a data center.
Cultural Movement, Not Just Technology
To run Linux servers is to align yourself with a culture that values openness, community, and empowerment. This is a culture that believes in giving back, in documenting knowledge, in challenging monopolies, and in pushing the boundaries of what’s possible. Using Linux is not just a technical choice; it is a philosophical one. It says that you value collaboration over competition, transparency over secrecy, and innovation over stagnation.
From Hobbyist to Enterprise: A Universal Language
What’s fascinating about Linux servers rackset is their universal appeal. A teenager learning to code in their bedroom and a Fortune 500 company building multi-region high-availability clusters are both speaking the same language. The barrier to entry is low, but the ceiling for growth is limitless. You can start with a simple VPS and end up architecting complex, distributed systems that span continents — all within the same ecosystem. Linux grows with you, matching your pace, your curiosity, and your ambition.
Future-Proofing Your Career and Your Business
Betting on Linux is betting on the future. With the explosion of cloud computing, DevOps, AI, blockchain, and edge computing, Linux expertise is becoming not just valuable but essential. Businesses that invest in Linux-based infrastructures future-proof themselves against technological obsolescence. Professionals who master Linux servers position themselves at the bleeding edge of innovation, equipped to handle the next generation of technological challenges with confidence.
Conclusion: The Choice That Defines You
Choosing to run Linux servers is not just a technical decision. It is a declaration of independence, a commitment to mastery, a vote for a better digital world. It is a journey from user to creator, from consumer to architect. In a world increasingly defined by opaque systems and centralized control, Linux servers offer a rare gift: transparency, autonomy, and limitless potential. To choose Linux is to choose to stand on the shoulders of giants — and to build something even greater.
0 notes
Text
Kubernetes Dashboard Tutorial: Visualize & Manage Your Cluster Like a Pro! 🔍📊
✔️ Learn how to install and launch the Kubernetes Dashboard ✔️ View real-time CPU & memory usage using Metrics Server 📈 ✔️ Navigate through Workloads, Services, Configs, and Storage ✔️ Create and manage deployments using YAML or the UI 💻 ✔️ Edit live resources and explore namespaces visually 🧭 ✔️ Understand how access methods differ in local vs production clusters 🔐 ✔️ Great for beginners, visual learners, or collaborative teams 🤝
👉 Whether you're debugging, deploying, or just learning Kubernetes, this dashboard gives you a GUI-first approach to mastering clusters!
youtube
0 notes
Text
AWS Introduces AWS MCP Servers for Serverless, ECS, & EKS

MCP AWS server
The AWS Labs GitHub repository now has Model Context Protocol (MCP) servers for AWS Serverless, Amazon ECS, and Amazon Elastic Kubernetes Service. Real-time contextual responses from open-source solutions trump AI development assistants' pre-trained knowledge. MCP servers provide current context and service-specific information to help you avoid deployment issues and improve service interactions, while AI assistant Large Language Models (LLM) use public documentation.
These open source solutions can help you design and deploy apps faster by using Amazon Web Services (AWS) features and configurations. These MCP servers enable AI code assistants with deep understanding of Amazon ECS, Amazon EKS, and AWS Serverless capabilities, speeding up the code-to-production process in your IDE or debugging production issues. They integrate with popular AI-enabled IDEs like Amazon Q Developer on the command line to allow you design and deploy apps using natural language commands.
Specialist MCP servers' functions:
With Amazon ECS MCP Server, applications can be deployed and containerised quickly. It helps configure AWS networking, load balancers, auto-scaling, task definitions, monitoring, and services. Real-time troubleshooting can fix deployment difficulties, manage cluster operations, and apply auto-scaling using natural language.
Amazon EKS MCP Server gives AI helpers contextual, up-to-date information for Kubernetes EKS environments. By providing the latest EKS features, knowledge base, and cluster state data, it enables AI code assistants more exact, customised aid throughout the application lifecycle.
The AWS Serverless MCP Server enhances serverless development. AI coding helpers learn AWS services, serverless patterns, and best practices. Integrating with the AWS Serverless Application Model Command Line Interface (AWS SAM CLI) to manage events and deploy infrastructure using tried-and-true architectural patterns streamlines function lifecycles, service integrations, and operational requirements. It also advises on event structures, AWS Lambda best practices, and code.
Users are directed to the AWS Labs GitHub repository for installation instructions, example settings, and other specialist servers, such as Amazon Bedrock Knowledge Bases Retrieval and AWS Lambda function transformation servers.
AWS MCP server operation
Giving Context: The MCP servers give AI assistants current context and knowledge about specific AWS capabilities, configurations, and even your surroundings (such as the EKS cluster state), eliminating the need for broad or outdated knowledge. For more accurate service interactions and fewer deployment errors, this is crucial.
They enable AI code assistance deep service understanding of AWS Serverless, ECS, and EKS. This allows the AI to make more accurate and tailored recommendations from code development to production issues.
The servers allow developers to construct and deploy apps using natural language commands using AI-enabled IDEs and tools like Amazon Q Developer on the command line. The AI assistant can use the relevant MCP server to get context or do tasks after processing the natural language query.
Aiding Troubleshooting and Service Actions: Servers provide tools and functionality for their AWS services. As an example:
Amazon ECS MCP Server helps configure load balancers and auto-scaling. Real-time debugging tools like fetch_task_logs can help the AI assistant spot issues in natural language queries.
The Amazon EKS MCP Server provides cluster status data and utilities like search_eks_troubleshoot_guide to fix EKS issues and generate_app_manifests to build Kubernetes clusters.
In addition to contextualising serverless patterns, best practices, infrastructure as code decisions, and event schemas, the AWS Serverless MCP Server communicates with the AWS SAM CLI. An example shows how it can help the AI helper discover best practices and architectural demands.
An AI assistant like Amazon Q can communicate with the right AWS MCP server for ECS, EKS, or Serverless development or deployment questions. This server can activate service-specific tools or provide specialised, current, or real-time information to help the AI assistant reply more effectively and accurately. This connection accelerates coding-to-production.
#AWSMCPserver#AmazonElasticContainerService#ModelContextProtocol#integrateddevelopmentenvironment#commandline#AmazonECS#technology#technews#technologynews#news#govindhtech
0 notes
Text
Master Multicluster Kubernetes with DO480: Red Hat OpenShift Platform Plus Training
In today’s enterprise landscape, managing multiple Kubernetes clusters across hybrid or multi-cloud environments is no longer optional — it’s essential. Whether you’re scaling applications globally, ensuring high availability, or meeting regulatory compliance, multicluster management is the key to consistent, secure, and efficient operations.
That’s where Red Hat OpenShift Platform Plus and the DO480 course come in.
🔍 What is DO480?
DO480: Multicluster Management with Red Hat OpenShift Platform Plus is an advanced, hands-on course designed for platform engineers, cluster admins, and DevOps teams. It teaches how to manage and secure Kubernetes clusters at scale using Red Hat’s enterprise-grade tools like:
Red Hat Advanced Cluster Management (ACM) for Kubernetes
Red Hat Advanced Cluster Security (ACS) for Kubernetes
OpenShift GitOps and Pipelines
Multi-cluster observability
📌 Why Should You Learn DO480?
As enterprises adopt hybrid and multi-cloud strategies, the complexity of managing Kubernetes clusters increases. DO480 equips you with the skills to:
✅ Deploy, govern, and automate multiple clusters ✅ Apply security policies consistently across all clusters ✅ Gain centralized visibility into workloads, security posture, and compliance ✅ Use GitOps workflows to streamline multicluster deployments ✅ Automate Day-2 operations like backup, disaster recovery, and patch management
👨💻 What Will You Learn?
The DO480 course covers key topics, including:
Installing and configuring Red Hat ACM
Creating and managing cluster sets, placement rules, and application lifecycle
Using OpenShift GitOps for declarative deployment
Integrating ACS for runtime and build-time security
Enforcing policies and handling compliance at scale
All these are practiced through hands-on labs in a real-world environment.
🎯 Who Should Attend?
This course is ideal for:
Platform engineers managing multiple clusters
DevOps professionals building GitOps-based automation
Security teams enforcing policies across cloud-native environments
Anyone aiming to become a Red Hat Certified Specialist in Multicluster Management
🔒 Certification Path
Completing DO480 helps prepare you for the Red Hat Certified Specialist in Multicluster Management exam — a valuable addition to your Red Hat Certified Architect (RHCA) journey.
🚀 Ready to Master Multicluster Kubernetes? Enroll in DO480 – Multicluster Management with Red Hat OpenShift Platform Plus and gain the skills needed to control, secure, and scale your OpenShift environment like a pro.
🔗 Talk to HawkStack today to schedule your corporate or individual training. 🌐 www.hawkstack.com
0 notes
Text
Getting Started with Google Kubernetes Engine: Your Gateway to Cloud-Native Greatness
After spending over 8 years deep in the trenches of cloud engineering and DevOps, I can tell you one thing for sure: if you're serious about scalability, flexibility, and real cloud-native application deployment, Google Kubernetes Engine (GKE) is where the magic happens.
Whether you’re new to Kubernetes or just exploring managed container platforms, getting started with Google Kubernetes Engine is one of the smartest moves you can make in your cloud journey.
"Containers are cool. Orchestrated containers? Game-changing."
🚀 What is Google Kubernetes Engine (GKE)?
Google Kubernetes Engine is a fully managed Kubernetes platform that runs on top of Google Cloud. GKE simplifies deploying, managing, and scaling containerized apps using Kubernetes—without the overhead of maintaining the control plane.
Why is this a big deal?
Because Kubernetes is notoriously powerful and notoriously complex. With GKE, Google handles all the heavy lifting—from cluster provisioning to upgrades, logging, and security.
"GKE takes the complexity out of Kubernetes so you can focus on building, not babysitting clusters."
🧭 Why Start with GKE?
If you're a developer, DevOps engineer, or cloud architect looking to:
Deploy scalable apps across hybrid/multi-cloud
Automate CI/CD workflows
Optimize infrastructure with autoscaling & spot instances
Run stateless or stateful microservices seamlessly
Then GKE is your launchpad.
Here’s what makes GKE shine:
Auto-upgrades & auto-repair for your clusters
Built-in security with Shielded GKE Nodes and Binary Authorization
Deep integration with Google Cloud IAM, VPC, and Logging
Autopilot mode for hands-off resource management
Native support for Anthos, Istio, and service meshes
"With GKE, it's not about managing containers—it's about unlocking agility at scale."
🔧 Getting Started with Google Kubernetes Engine
Ready to dive in? Here's a simple flow to kick things off:
Set up your Google Cloud project
Enable Kubernetes Engine API
Install gcloud CLI and Kubernetes command-line tool (kubectl)
Create a GKE cluster via console or command line
Deploy your app using Kubernetes manifests or Helm
Monitor, scale, and manage using GKE dashboard, Cloud Monitoring, and Cloud Logging
If you're using GKE Autopilot, Google manages your node infrastructure automatically—so you only manage your apps.
“Don’t let infrastructure slow your growth. Let GKE scale as you scale.”
🔗 Must-Read Resources to Kickstart GKE
👉 GKE Quickstart Guide – Google Cloud
👉 Best Practices for GKE – Google Cloud
👉 Anthos and GKE Integration
👉 GKE Autopilot vs Standard Clusters
👉 Google Cloud Kubernetes Learning Path – NetCom Learning
🧠 Real-World GKE Success Stories
A FinTech startup used GKE Autopilot to run microservices with zero infrastructure overhead
A global media company scaled video streaming workloads across continents in hours
A university deployed its LMS using GKE and reduced downtime by 80% during peak exam seasons
"You don’t need a huge ops team to build a global app. You just need GKE."
🎯 Final Thoughts
Getting started with Google Kubernetes Engine is like unlocking a fast track to modern app delivery. Whether you're running 10 containers or 10,000, GKE gives you the tools, automation, and scale to do it right.
With Google Cloud’s ecosystem—from Cloud Build to Artifact Registry to operations suite—GKE is more than just Kubernetes. It’s your platform for innovation.
“Containers are the future. GKE is the now.”
So fire up your first cluster. Launch your app. And let GKE do the heavy lifting while you focus on what really matters—shipping great software.
Let me know if you’d like this formatted into a visual infographic or checklist to go along with the blog!
1 note
·
View note