#High Availability in Kubernetes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Microk8s vs k3s: Lightweight Kubernetes distribution showdown
Microk8s vs k3s: Lightweight Kubernetes distribution showdown #homelab #kubernetes #microk8svsk3scomparison #lightweightkubernetesdistributions #k3sinstallationguide #microk8ssnappackagetutorial #highavailabilityinkubernetes #k3s #microk8s #portainer
Especially if you are into running Kubernetes in the home lab, you may look for a lightweight Kubernetes distribution. Two distributions that stand out are Microk8s and k3s. Let’s take a look at Microk8s vs k3s and discover the main differences between these two options, focusing on various aspects like memory usage, high availability, and k3s and microk8s compatibility. Table of contentsWhat is…

View On WordPress
#container runtimes and configurations#edge computing with k3s and microk8s#High Availability in Kubernetes#k3s installation guide#kubernetes cluster resources#Kubernetes on IoT devices#lightweight kubernetes distributions#memory usage optimization#microk8s snap package tutorial#microk8s vs k3s comparison
0 notes
Text
A3 Ultra VMs With NVIDIA H200 GPUs Pre-launch This Month

Strong infrastructure advancements for your future that prioritizes AI
To increase customer performance, usability, and cost-effectiveness, Google Cloud implemented improvements throughout the AI Hypercomputer stack this year. Google Cloud at the App Dev & Infrastructure Summit:
Trillium, Google’s sixth-generation TPU, is currently available for preview.
Next month, A3 Ultra VMs with NVIDIA H200 Tensor Core GPUs will be available for preview.
Google’s new, highly scalable clustering system, Hypercompute Cluster, will be accessible beginning with A3 Ultra VMs.
Based on Axion, Google’s proprietary Arm processors, C4A virtual machines (VMs) are now widely accessible
AI workload-focused additions to Titanium, Google Cloud’s host offload capability, and Jupiter, its data center network.
Google Cloud’s AI/ML-focused block storage service, Hyperdisk ML, is widely accessible.
Trillium A new era of TPU performance
Trillium A new era of TPU performance is being ushered in by TPUs, which power Google’s most sophisticated models like Gemini, well-known Google services like Maps, Photos, and Search, as well as scientific innovations like AlphaFold 2, which was just awarded a Nobel Prize! We are happy to inform that Google Cloud users can now preview Trillium, our sixth-generation TPU.
Taking advantage of NVIDIA Accelerated Computing to broaden perspectives
By fusing the best of Google Cloud’s data center, infrastructure, and software skills with the NVIDIA AI platform which is exemplified by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs it also keeps investing in its partnership and capabilities with NVIDIA.
Google Cloud announced that the new A3 Ultra VMs featuring NVIDIA H200 Tensor Core GPUs will be available on Google Cloud starting next month.
Compared to earlier versions, A3 Ultra VMs offer a notable performance improvement. Their foundation is NVIDIA ConnectX-7 network interface cards (NICs) and servers equipped with new Titanium ML network adapter, which is tailored to provide a safe, high-performance cloud experience for AI workloads. A3 Ultra VMs provide non-blocking 3.2 Tbps of GPU-to-GPU traffic using RDMA over Converged Ethernet (RoCE) when paired with our datacenter-wide 4-way rail-aligned network.
In contrast to A3 Mega, A3 Ultra provides:
With the support of Google’s Jupiter data center network and Google Cloud’s Titanium ML network adapter, double the GPU-to-GPU networking bandwidth
With almost twice the memory capacity and 1.4 times the memory bandwidth, LLM inferencing performance can increase by up to 2 times.
Capacity to expand to tens of thousands of GPUs in a dense cluster with performance optimization for heavy workloads in HPC and AI.
Google Kubernetes Engine (GKE), which offers an open, portable, extensible, and highly scalable platform for large-scale training and AI workloads, will also offer A3 Ultra VMs.
Hypercompute Cluster: Simplify and expand clusters of AI accelerators
It’s not just about individual accelerators or virtual machines, though; when dealing with AI and HPC workloads, you have to deploy, maintain, and optimize a huge number of AI accelerators along with the networking and storage that go along with them. This may be difficult and time-consuming. For this reason, Google Cloud is introducing Hypercompute Cluster, which simplifies the provisioning of workloads and infrastructure as well as the continuous operations of AI supercomputers with tens of thousands of accelerators.
Fundamentally, Hypercompute Cluster integrates the most advanced AI infrastructure technologies from Google Cloud, enabling you to install and operate several accelerators as a single, seamless unit. You can run your most demanding AI and HPC workloads with confidence thanks to Hypercompute Cluster’s exceptional performance and resilience, which includes features like targeted workload placement, dense resource co-location with ultra-low latency networking, and sophisticated maintenance controls to reduce workload disruptions.
For dependable and repeatable deployments, you can use pre-configured and validated templates to build up a Hypercompute Cluster with just one API call. This include containerized software with orchestration (e.g., GKE, Slurm), framework and reference implementations (e.g., JAX, PyTorch, MaxText), and well-known open models like Gemma2 and Llama3. As part of the AI Hypercomputer architecture, each pre-configured template is available and has been verified for effectiveness and performance, allowing you to concentrate on business innovation.
A3 Ultra VMs will be the first Hypercompute Cluster to be made available next month.
An early look at the NVIDIA GB200 NVL72
Google Cloud is also awaiting the developments made possible by NVIDIA GB200 NVL72 GPUs, and we’ll be providing more information about this fascinating improvement soon. Here is a preview of the racks Google constructing in the meantime to deliver the NVIDIA Blackwell platform’s performance advantages to Google Cloud’s cutting-edge, environmentally friendly data centers in the early months of next year.
Redefining CPU efficiency and performance with Google Axion Processors
CPUs are a cost-effective solution for a variety of general-purpose workloads, and they are frequently utilized in combination with AI workloads to produce complicated applications, even if TPUs and GPUs are superior at specialized jobs. Google Axion Processors, its first specially made Arm-based CPUs for the data center, at Google Cloud Next ’24. Customers using Google Cloud may now benefit from C4A virtual machines, the first Axion-based VM series, which offer up to 10% better price-performance compared to the newest Arm-based instances offered by other top cloud providers.
Additionally, compared to comparable current-generation x86-based instances, C4A offers up to 60% more energy efficiency and up to 65% better price performance for general-purpose workloads such as media processing, AI inferencing applications, web and app servers, containerized microservices, open-source databases, in-memory caches, and data analytics engines.
Titanium and Jupiter Network: Making AI possible at the speed of light
Titanium, the offload technology system that supports Google’s infrastructure, has been improved to accommodate workloads related to artificial intelligence. Titanium provides greater compute and memory resources for your applications by lowering the host’s processing overhead through a combination of on-host and off-host offloads. Furthermore, although Titanium’s fundamental features can be applied to AI infrastructure, the accelerator-to-accelerator performance needs of AI workloads are distinct.
Google has released a new Titanium ML network adapter to address these demands, which incorporates and expands upon NVIDIA ConnectX-7 NICs to provide further support for virtualization, traffic encryption, and VPCs. The system offers best-in-class security and infrastructure management along with non-blocking 3.2 Tbps of GPU-to-GPU traffic across RoCE when combined with its data center’s 4-way rail-aligned network.
Google’s Jupiter optical circuit switching network fabric and its updated data center network significantly expand Titanium’s capabilities. With native 400 Gb/s link rates and a total bisection bandwidth of 13.1 Pb/s (a practical bandwidth metric that reflects how one half of the network can connect to the other), Jupiter could handle a video conversation for every person on Earth at the same time. In order to meet the increasing demands of AI computation, this enormous scale is essential.
Hyperdisk ML is widely accessible
For computing resources to continue to be effectively utilized, system-level performance maximized, and economical, high-performance storage is essential. Google launched its AI-powered block storage solution, Hyperdisk ML, in April 2024. Now widely accessible, it adds dedicated storage for AI and HPC workloads to the networking and computing advancements.
Hyperdisk ML efficiently speeds up data load times. It drives up to 11.9x faster model load time for inference workloads and up to 4.3x quicker training time for training workloads.
With 1.2 TB/s of aggregate throughput per volume, you may attach 2500 instances to the same volume. This is more than 100 times more than what big block storage competitors are giving.
Reduced accelerator idle time and increased cost efficiency are the results of shorter data load times.
Multi-zone volumes are now automatically created for your data by GKE. In addition to quicker model loading with Hyperdisk ML, this enables you to run across zones for more computing flexibility (such as lowering Spot preemption).
Developing AI’s future
Google Cloud enables companies and researchers to push the limits of AI innovation with these developments in AI infrastructure. It anticipates that this strong foundation will give rise to revolutionary new AI applications.
Read more on Govindhtech.com
#A3UltraVMs#NVIDIAH200#AI#Trillium#HypercomputeCluster#GoogleAxionProcessors#Titanium#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
2 notes
·
View notes
Text
Cloud Agnostic: Achieving Flexibility and Independence in Cloud Management
As businesses increasingly migrate to the cloud, they face a critical decision: which cloud provider to choose? While AWS, Microsoft Azure, and Google Cloud offer powerful platforms, the concept of "cloud agnostic" is gaining traction. Cloud agnosticism refers to a strategy where businesses avoid vendor lock-in by designing applications and infrastructure that work across multiple cloud providers. This approach provides flexibility, independence, and resilience, allowing organizations to adapt to changing needs and avoid reliance on a single provider.

What Does It Mean to Be Cloud Agnostic?
Being cloud agnostic means creating and managing systems, applications, and services that can run on any cloud platform. Instead of committing to a single cloud provider, businesses design their architecture to function seamlessly across multiple platforms. This flexibility is achieved by using open standards, containerization technologies like Docker, and orchestration tools such as Kubernetes.
Key features of a cloud agnostic approach include:
Interoperability: Applications must be able to operate across different cloud environments.
Portability: The ability to migrate workloads between different providers without significant reconfiguration.
Standardization: Using common frameworks, APIs, and languages that work universally across platforms.
Benefits of Cloud Agnostic Strategies
Avoiding Vendor Lock-InThe primary benefit of being cloud agnostic is avoiding vendor lock-in. Once a business builds its entire infrastructure around a single cloud provider, it can be challenging to switch or expand to other platforms. This could lead to increased costs and limited innovation. With a cloud agnostic strategy, businesses can choose the best services from multiple providers, optimizing both performance and costs.
Cost OptimizationCloud agnosticism allows companies to choose the most cost-effective solutions across providers. As cloud pricing models are complex and vary by region and usage, a cloud agnostic system enables businesses to leverage competitive pricing and minimize expenses by shifting workloads to different providers when necessary.
Greater Resilience and UptimeBy operating across multiple cloud platforms, organizations reduce the risk of downtime. If one provider experiences an outage, the business can shift workloads to another platform, ensuring continuous service availability. This redundancy builds resilience, ensuring high availability in critical systems.
Flexibility and ScalabilityA cloud agnostic approach gives companies the freedom to adjust resources based on current business needs. This means scaling applications horizontally or vertically across different providers without being restricted by the limits or offerings of a single cloud vendor.
Global ReachDifferent cloud providers have varying levels of presence across geographic regions. With a cloud agnostic approach, businesses can leverage the strengths of various providers in different areas, ensuring better latency, performance, and compliance with local regulations.
Challenges of Cloud Agnosticism
Despite the advantages, adopting a cloud agnostic approach comes with its own set of challenges:
Increased ComplexityManaging and orchestrating services across multiple cloud providers is more complex than relying on a single vendor. Businesses need robust management tools, monitoring systems, and teams with expertise in multiple cloud environments to ensure smooth operations.
Higher Initial CostsThe upfront costs of designing a cloud agnostic architecture can be higher than those of a single-provider system. Developing portable applications and investing in technologies like Kubernetes or Terraform requires significant time and resources.
Limited Use of Provider-Specific ServicesCloud providers often offer unique, advanced services—such as machine learning tools, proprietary databases, and analytics platforms—that may not be easily portable to other clouds. Being cloud agnostic could mean missing out on some of these specialized services, which may limit innovation in certain areas.
Tools and Technologies for Cloud Agnostic Strategies
Several tools and technologies make cloud agnosticism more accessible for businesses:
Containerization: Docker and similar containerization tools allow businesses to encapsulate applications in lightweight, portable containers that run consistently across various environments.
Orchestration: Kubernetes is a leading tool for orchestrating containers across multiple cloud platforms. It ensures scalability, load balancing, and failover capabilities, regardless of the underlying cloud infrastructure.
Infrastructure as Code (IaC): Tools like Terraform and Ansible enable businesses to define cloud infrastructure using code. This makes it easier to manage, replicate, and migrate infrastructure across different providers.
APIs and Abstraction Layers: Using APIs and abstraction layers helps standardize interactions between applications and different cloud platforms, enabling smooth interoperability.
When Should You Consider a Cloud Agnostic Approach?
A cloud agnostic approach is not always necessary for every business. Here are a few scenarios where adopting cloud agnosticism makes sense:
Businesses operating in regulated industries that need to maintain compliance across multiple regions.
Companies require high availability and fault tolerance across different cloud platforms for mission-critical applications.
Organizations with global operations that need to optimize performance and cost across multiple cloud regions.
Businesses aim to avoid long-term vendor lock-in and maintain flexibility for future growth and scaling needs.
Conclusion
Adopting a cloud agnostic strategy offers businesses unparalleled flexibility, independence, and resilience in cloud management. While the approach comes with challenges such as increased complexity and higher upfront costs, the long-term benefits of avoiding vendor lock-in, optimizing costs, and enhancing scalability are significant. By leveraging the right tools and technologies, businesses can achieve a truly cloud-agnostic architecture that supports innovation and growth in a competitive landscape.
Embrace the cloud agnostic approach to future-proof your business operations and stay ahead in the ever-evolving digital world.
2 notes
·
View notes
Text
Journey to Devops
The concept of “DevOps” has been gaining traction in the IT sector for a couple of years. It involves promoting teamwork and interaction, between software developers and IT operations groups to enhance the speed and reliability of software delivery. This strategy has become widely accepted as companies strive to provide software to meet customer needs and maintain an edge, in the industry. In this article we will explore the elements of becoming a DevOps Engineer.
Step 1: Get familiar with the basics of Software Development and IT Operations:
In order to pursue a career as a DevOps Engineer it is crucial to possess a grasp of software development and IT operations. Familiarity with programming languages like Python, Java, Ruby or PHP is essential. Additionally, having knowledge about operating systems, databases and networking is vital.
Step 2: Learn the principles of DevOps:
It is crucial to comprehend and apply the principles of DevOps. Automation, continuous integration, continuous deployment and continuous monitoring are aspects that need to be understood and implemented. It is vital to learn how these principles function and how to carry them out efficiently.
Step 3: Familiarize yourself with the DevOps toolchain:
Git: Git, a distributed version control system is extensively utilized by DevOps teams, for code repository management. It aids in monitoring code alterations facilitating collaboration, among team members and preserving a record of modifications made to the codebase.
Ansible: Ansible is an open source tool used for managing configurations deploying applications and automating tasks. It simplifies infrastructure management. Saves time when performing tasks.
Docker: Docker, on the other hand is a platform for containerization that allows DevOps engineers to bundle applications and dependencies into containers. This ensures consistency and compatibility across environments from development, to production.
Kubernetes: Kubernetes is an open-source container orchestration platform that helps manage and scale containers. It helps automate the deployment, scaling, and management of applications and micro-services.
Jenkins: Jenkins is an open-source automation server that helps automate the process of building, testing, and deploying software. It helps to automate repetitive tasks and improve the speed and efficiency of the software delivery process.
Nagios: Nagios is an open-source monitoring tool that helps us monitor the health and performance of our IT infrastructure. It also helps us to identify and resolve issues in real-time and ensure the high availability and reliability of IT systems as well.
Terraform: Terraform is an infrastructure as code (IAC) tool that helps manage and provision IT infrastructure. It helps us automate the process of provisioning and configuring IT resources and ensures consistency between development and production environments.
Step 4: Gain practical experience:
The best way to gain practical experience is by working on real projects and bootcamps. You can start by contributing to open-source projects or participating in coding challenges and hackathons. You can also attend workshops and online courses to improve your skills.
Step 5: Get certified:
Getting certified in DevOps can help you stand out from the crowd and showcase your expertise to various people. Some of the most popular certifications are:
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Microsoft Certified: Azure DevOps Engineer Expert
AWS Certified Cloud Practitioner
Step 6: Build a strong professional network:
Networking is one of the most important parts of becoming a DevOps Engineer. You can join online communities, attend conferences, join webinars and connect with other professionals in the field. This will help you stay up-to-date with the latest developments and also help you find job opportunities and success.
Conclusion:
You can start your journey towards a successful career in DevOps. The most important thing is to be passionate about your work and continuously learn and improve your skills. With the right skills, experience, and network, you can achieve great success in this field and earn valuable experience.
2 notes
·
View notes
Text
Embarking on a Digital Journey: Your Guide to Learning Coding
In today's fast-paced and ever-evolving technology landscape, DevOps has emerged as a crucial and transformative field that bridges the gap between software development and IT operations. The term "DevOps" is a portmanteau of "Development" and "Operations," emphasizing the importance of collaboration, automation, and efficiency in the software delivery process. DevOps practices have gained widespread adoption across industries, revolutionizing the way organizations develop, deploy, and maintain software. This paradigm shift has led to a surging demand for skilled DevOps professionals who can navigate the complex and multifaceted DevOps landscape.

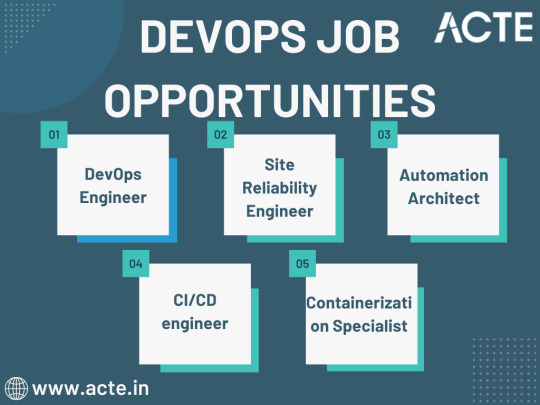
Exploring DevOps Job Opportunities
DevOps has given rise to a spectrum of job opportunities, each with its unique focus and responsibilities. Let's delve into some of the key DevOps roles that are in high demand:
1. DevOps Engineer
At the heart of DevOps lies the DevOps engineer, responsible for automating and streamlining IT operations and processes. DevOps engineers are the architects of efficient software delivery pipelines, collaborating closely with development and IT teams. Their mission is to accelerate the software delivery process while ensuring the reliability and stability of systems.
2. Site Reliability Engineer (SRE)
Site Reliability Engineers, or SREs, are a subset of DevOps engineers who specialize in maintaining large-scale, highly reliable software systems. They focus on critical aspects such as availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning. SREs play a pivotal role in ensuring that applications and services remain dependable and performant.
3. Automation Architect
Automation is a cornerstone of DevOps, and automation architects are experts in this domain. These professionals design and implement automation solutions that optimize software development and delivery processes. By automating repetitive and manual tasks, they enhance efficiency and reduce the risk of human error.
4. Continuous Integration/Continuous Deployment (CI/CD) Engineer
CI/CD engineers specialize in creating, maintaining, and optimizing CI/CD pipelines. The CI/CD pipeline is the backbone of DevOps, enabling the automated building, testing, and deployment of code. CI/CD engineers ensure that the pipeline operates seamlessly, enabling rapid and reliable software delivery.
5. Containerization Specialist
The rise of containerization technologies like Docker and orchestration tools such as Kubernetes has revolutionized software deployment. Containerization specialists focus on managing and scaling containerized applications, making them an integral part of DevOps teams.
Navigating the DevOps Learning Journey
To embark on a successful DevOps career, individuals often turn to comprehensive training programs and courses that equip them with the necessary skills and knowledge. The DevOps learning journey typically involves the following courses:
1. DevOps Foundation
A foundational DevOps course covers the basics of DevOps practices, principles, and tools. It serves as an excellent starting point for beginners, providing a solid understanding of the DevOps mindset and practices.
2. DevOps Certification
Advanced certification courses are designed for those who wish to delve deeper into DevOps methodologies, CI/CD pipelines, and various tools like Jenkins, Ansible, and Terraform. These certifications validate your expertise and enhance your job prospects.
3. Docker and Kubernetes Training
Containerization and container orchestration are two essential skills in the DevOps toolkit. Courses focused on Docker and Kubernetes provide in-depth knowledge of these technologies, enabling professionals to effectively manage containerized applications.
4. AWS or Azure DevOps Training
Specialized DevOps courses tailored to cloud platforms like AWS or Azure are essential for those working in a cloud-centric environment. These courses teach how to leverage cloud services in a DevOps context, further streamlining software development and deployment.
5. Advanced DevOps Courses
For those looking to specialize in specific areas, advanced DevOps courses cover topics like DevOps security, DevOps practices for mobile app development, and more. These courses cater to professionals who seek to expand their expertise in specific domains.
As the DevOps landscape continues to evolve, the need for high-quality training and education becomes increasingly critical. This is where ACTE Technologies steps into the spotlight as a reputable choice for comprehensive DevOps training.
They offer carefully thought-out courses that are intended to impart both foundational information and real-world, practical experience. Under the direction of knowledgeable educators, students can quickly advance on their path to become skilled DevOps engineers. They provide practical insights into industrial practises and issues, going beyond theory.
Your journey toward mastering DevOps practices and pursuing a successful career begins here. In the digital realm, where possibilities are limitless and innovation knows no bounds, ACTE Technologies serves as a gateway to a thriving DevOps career. With a diverse array of courses and expert instruction, you'll find the resources you need to thrive in this ever-evolving domain.
3 notes
·
View notes
Text
Demystifying Microsoft Azure Cloud Hosting and PaaS Services: A Comprehensive Guide
In the rapidly evolving landscape of cloud computing, Microsoft Azure has emerged as a powerful player, offering a wide range of services to help businesses build, deploy, and manage applications and infrastructure. One of the standout features of Azure is its Cloud Hosting and Platform-as-a-Service (PaaS) offerings, which enable organizations to harness the benefits of the cloud while minimizing the complexities of infrastructure management. In this comprehensive guide, we'll dive deep into Microsoft Azure Cloud Hosting and PaaS Services, demystifying their features, benefits, and use cases.
Understanding Microsoft Azure Cloud Hosting
Cloud hosting, as the name suggests, involves hosting applications and services on virtual servers that are accessed over the internet. Microsoft Azure provides a robust cloud hosting environment, allowing businesses to scale up or down as needed, pay for only the resources they consume, and reduce the burden of maintaining physical hardware. Here are some key components of Azure Cloud Hosting:
Virtual Machines (VMs): Azure offers a variety of pre-configured virtual machine sizes that cater to different workloads. These VMs can run Windows or Linux operating systems and can be easily scaled to meet changing demands.
Azure App Service: This PaaS offering allows developers to build, deploy, and manage web applications without dealing with the underlying infrastructure. It supports various programming languages and frameworks, making it suitable for a wide range of applications.
Azure Kubernetes Service (AKS): For containerized applications, AKS provides a managed Kubernetes service. Kubernetes simplifies the deployment and management of containerized applications, and AKS further streamlines this process.
Exploring Azure Platform-as-a-Service (PaaS) Services
Platform-as-a-Service (PaaS) takes cloud hosting a step further by abstracting away even more of the infrastructure management, allowing developers to focus primarily on building and deploying applications. Azure offers an array of PaaS services that cater to different needs:
Azure SQL Database: This fully managed relational database service eliminates the need for database administration tasks such as patching and backups. It offers high availability, security, and scalability for your data.
Azure Cosmos DB: For globally distributed, highly responsive applications, Azure Cosmos DB is a NoSQL database service that guarantees low-latency access and automatic scaling.
Azure Functions: A serverless compute service, Azure Functions allows you to run code in response to events without provisioning or managing servers. It's ideal for event-driven architectures.
Azure Logic Apps: This service enables you to automate workflows and integrate various applications and services without writing extensive code. It's great for orchestrating complex business processes.
Benefits of Azure Cloud Hosting and PaaS Services
Scalability: Azure's elasticity allows you to scale resources up or down based on demand. This ensures optimal performance and cost efficiency.
Cost Management: With pay-as-you-go pricing, you only pay for the resources you use. Azure also provides cost management tools to monitor and optimize spending.
High Availability: Azure's data centers are distributed globally, providing redundancy and ensuring high availability for your applications.
Security and Compliance: Azure offers robust security features and compliance certifications, helping you meet industry standards and regulations.
Developer Productivity: PaaS services like Azure App Service and Azure Functions streamline development by handling infrastructure tasks, allowing developers to focus on writing code.
Use Cases for Azure Cloud Hosting and PaaS
Web Applications: Azure App Service is ideal for hosting web applications, enabling easy deployment and scaling without managing the underlying servers.
Microservices: Azure Kubernetes Service supports the deployment and orchestration of microservices, making it suitable for complex applications with multiple components.
Data-Driven Applications: Azure's PaaS offerings like Azure SQL Database and Azure Cosmos DB are well-suited for applications that rely heavily on data storage and processing.
Serverless Architecture: Azure Functions and Logic Apps are perfect for building serverless applications that respond to events in real-time.
In conclusion, Microsoft Azure's Cloud Hosting and PaaS Services provide businesses with the tools they need to harness the power of the cloud while minimizing the complexities of infrastructure management. With scalability, cost-efficiency, and a wide array of services, Azure empowers developers and organizations to innovate and deliver impactful applications. Whether you're hosting a web application, managing data, or adopting a serverless approach, Azure has the tools to support your journey into the cloud.
#Microsoft Azure#Internet of Things#Azure AI#Azure Analytics#Azure IoT Services#Azure Applications#Microsoft Azure PaaS
2 notes
·
View notes
Text
Best Software Development Company in Chennai | Leading Software Solutions

When searching for the best software development company in Chennai, businesses of all sizes look for a partner who combines technical expertise, a customer-centric approach, and proven delivery. A leading Software Development Company in Chennai offers end-to-end solutions—from ideation and design to development, testing, deployment, and maintenance—ensuring your software is scalable, secure, and aligned with your strategic goals.
Why Choose the Best Software Development Company in Chennai?
Local Expertise, Global Standards Chennai has emerged as a thriving IT hub, home to talented engineers fluent in cutting-edge technologies. By selecting the best software development company in Chennai, you tap into deep local expertise guided by global best practices, ensuring your project stays on time and within budget.
Proven Track Record The top Software Development Company in Chennai showcases a rich portfolio of successful projects across industries—finance, healthcare, e-commerce, education, and more. Their case studies demonstrate on-point requirements gathering, agile delivery, and robust support.
Cost-Effective Solutions Chennai offers competitive rates without compromising quality. The best software development company in Chennai provides flexible engagement models—fixed price, time & materials, or dedicated teams—so you can choose the structure that best fits your budget and timeline.
Cultural Alignment & Communication Teams in Chennai often work in overlapping time zones with North America, Europe, and Australia, enabling real-time collaboration. A leading Software Development Company in Chennai emphasizes transparent communication, regular status updates, and seamless integration with your in-house team.
Core Services Offered
A comprehensive Software Development Company in Chennai typically delivers:
Custom Software Development Tailor-made applications built from the ground up to address unique business challenges—whether it’s a CRM, ERP, inventory system, or specialized B2B software.
Mobile App Development Native and cross-platform iOS/Android apps designed for performance, usability, and engagement. Ideal for startups and enterprises aiming to reach customers on the go.
Web Application Development Responsive, SEO-friendly, and secure web apps using frameworks like React, Angular, and Vue.js, backed by scalable back-end systems in Node.js, .NET, Java, or Python.
UI/UX Design User-centered design that drives adoption. Wireframes, prototypes, and high-fidelity designs ensure an intuitive interface that delights end users.
Quality Assurance & Testing Automated and manual testing—functional, performance, security, and usability—to deliver a bug-free product that scales under real-world conditions.
DevOps & Cloud Services CI/CD pipelines, containerization with Docker/Kubernetes, and deployments on AWS, Azure, or Google Cloud for high availability and rapid release cycles.
Maintenance & Support Post-launch monitoring, feature enhancements, and 24/7 support to keep your software running smoothly and securely.
The Development Process
Discovery & Planning Workshops and stakeholder interviews to define scope, objectives, and success metrics.
Design & Prototyping Rapid prototyping of wireframes and UI mockups for early feedback and iterative refinement.
Agile Development Two-week sprints with sprint demos, ensuring transparency and adaptability to changing requirements.
Testing & QA Continuous testing throughout development to catch issues early and deliver a stable release.
Deployment & Go-Live Seamless rollout with thorough planning, user training, and post-deployment support.
Maintenance & Evolution Ongoing enhancements, performance tuning, and security updates to keep your application competitive.
Benefits of Partnering Locally
Speedy Onboarding: Proximity to Chennai’s tech ecosystem speeds up recruitment of additional talent.
Cultural Synergy: Shared cultural context helps in understanding your business nuances faster.
Time-Zone Overlap: Real-time collaboration during key business hours reduces turnaround times.
Networking & Events: Access to local tech meetups, hackathons, and startup incubators for continuous innovation.
Conclusion
Choosing the best software development company in Chennai means entrusting your digital transformation to a partner with deep technical skills, transparent processes, and a client-first ethos. Whether you’re a startup looking to disrupt the market or a large enterprise aiming to modernize legacy systems, the right Software Development Company in Chennai will guide you from concept to success—delivering high-quality software on schedule and within budget. Start your journey today and experience why Chennai stands out as a premier destination for software development excellence.
0 notes
Text
Master Multicluster Kubernetes with DO480: Red Hat OpenShift Platform Plus Training
In today’s enterprise landscape, managing multiple Kubernetes clusters across hybrid or multi-cloud environments is no longer optional — it’s essential. Whether you’re scaling applications globally, ensuring high availability, or meeting regulatory compliance, multicluster management is the key to consistent, secure, and efficient operations.
That’s where Red Hat OpenShift Platform Plus and the DO480 course come in.
🔍 What is DO480?
DO480: Multicluster Management with Red Hat OpenShift Platform Plus is an advanced, hands-on course designed for platform engineers, cluster admins, and DevOps teams. It teaches how to manage and secure Kubernetes clusters at scale using Red Hat’s enterprise-grade tools like:
Red Hat Advanced Cluster Management (ACM) for Kubernetes
Red Hat Advanced Cluster Security (ACS) for Kubernetes
OpenShift GitOps and Pipelines
Multi-cluster observability
📌 Why Should You Learn DO480?
As enterprises adopt hybrid and multi-cloud strategies, the complexity of managing Kubernetes clusters increases. DO480 equips you with the skills to:
✅ Deploy, govern, and automate multiple clusters ✅ Apply security policies consistently across all clusters ✅ Gain centralized visibility into workloads, security posture, and compliance ✅ Use GitOps workflows to streamline multicluster deployments ✅ Automate Day-2 operations like backup, disaster recovery, and patch management
👨💻 What Will You Learn?
The DO480 course covers key topics, including:
Installing and configuring Red Hat ACM
Creating and managing cluster sets, placement rules, and application lifecycle
Using OpenShift GitOps for declarative deployment
Integrating ACS for runtime and build-time security
Enforcing policies and handling compliance at scale
All these are practiced through hands-on labs in a real-world environment.
🎯 Who Should Attend?
This course is ideal for:
Platform engineers managing multiple clusters
DevOps professionals building GitOps-based automation
Security teams enforcing policies across cloud-native environments
Anyone aiming to become a Red Hat Certified Specialist in Multicluster Management
🔒 Certification Path
Completing DO480 helps prepare you for the Red Hat Certified Specialist in Multicluster Management exam — a valuable addition to your Red Hat Certified Architect (RHCA) journey.
🚀 Ready to Master Multicluster Kubernetes? Enroll in DO480 – Multicluster Management with Red Hat OpenShift Platform Plus and gain the skills needed to control, secure, and scale your OpenShift environment like a pro.
🔗 Talk to HawkStack today to schedule your corporate or individual training. 🌐 www.hawkstack.com
0 notes
Text
Unlocking SRE Success: Roles and Responsibilities That Matter
In today’s digitally driven world, ensuring the reliability and performance of applications and systems is more critical than ever. This is where Site Reliability Engineering (SRE) plays a pivotal role. Originally developed by Google, SRE is a modern approach to IT operations that focuses strongly on automation, scalability, and reliability.

But what exactly do SREs do? Let’s explore the key roles and responsibilities of a Site Reliability Engineer and how they drive reliability, performance, and efficiency in modern IT environments.
🔹 What is a Site Reliability Engineer (SRE)?
A Site Reliability Engineer is a professional who applies software engineering principles to system administration and operations tasks. The main goal is to build scalable and highly reliable systems that function smoothly even during high demand or failure scenarios.
🔹 Core SRE Roles
SREs act as a bridge between development and operations teams. Their core responsibilities are usually grouped under these key roles:
1. Reliability Advocate
Ensures high availability and performance of services
Implements Service Level Objectives (SLOs), Service Level Indicators (SLIs), and Service Level Agreements (SLAs)
Identifies and removes reliability bottlenecks
2. Automation Engineer
Automates repetitive manual tasks using tools and scripts
Builds CI/CD pipelines for smoother deployments
Reduces human error and increases deployment speed
3. Monitoring & Observability Expert
Sets up real-time monitoring tools like Prometheus, Grafana, and Datadog
Implements logging, tracing, and alerting systems
Proactively detects issues before they impact users
4. Incident Responder
Handles outages and critical incidents
Leads root cause analysis (RCA) and postmortems
Builds incident playbooks for faster recovery
5. Performance Optimizer
Analyzes system performance metrics
Conducts load and stress testing
Optimizes infrastructure for cost and performance
6. Security and Compliance Enforcer
Implements security best practices in infrastructure
Ensures compliance with industry standards (e.g., ISO, GDPR)
Coordinates with security teams for audits and risk management
7. Capacity Planner
Forecasts traffic and resource needs
Plans for scaling infrastructure ahead of demand
Uses tools for autoscaling and load balancing
🔹 Day-to-Day Responsibilities of an SRE
Here are some common tasks SREs handle daily:
Deploying code with zero downtime
Troubleshooting production issues
Writing automation scripts to streamline operations
Reviewing infrastructure changes
Managing Kubernetes clusters or cloud services (AWS, GCP, Azure)
Performing system upgrades and patches
Running game days or chaos engineering practices to test resilience
🔹 Tools & Technologies Commonly Used by SREs
Monitoring: Prometheus, Grafana, ELK Stack, Datadog
Automation: Terraform, Ansible, Chef, Puppet
CI/CD: Jenkins, GitLab CI, ArgoCD
Containers & Orchestration: Docker, Kubernetes
Cloud Platforms: AWS, Google Cloud, Microsoft Azure
Incident Management: PagerDuty, Opsgenie, VictorOps
🔹 Why SRE Matters for Modern Businesses
Reduces system downtime and increases user satisfaction
Improves deployment speed without compromising reliability
Enables proactive problem solving through observability
Bridges the gap between developers and operations
Drives cost-effective scaling and infrastructure optimization
🔹 Final Thoughts
Site Reliability Engineering roles and responsibilities are more than just monitoring systems—it’s about building a resilient, scalable, and efficient infrastructure that keeps digital services running smoothly. With a blend of coding, systems knowledge, and problem-solving skills, SREs play a crucial role in modern DevOps and cloud-native environments.
📥 Click Here: Site Reliability Engineering certification training program
0 notes
Text
K3s vs K8s: The Best Kubernetes Home Lab Distribution
K3s vs K8s: The Best Home Lab Kubernetes Distribution @vexpert #vmwarecommunities #100daysofhomelab #homelab #KubernetesHomeLab #k3svsk8s #LightweightKubernetes #KubernetesDistributions #EdgeComputing #HighAvailabilityinKubernetes #KubernetesScalability
Kubernetes, a project under the Cloud Native Computing Foundation, is a popular container orchestration platform for managing distributed systems. Many who are running home labs or want to get into running Kubernetes in their home lab to get experience with modern applications may wonder which Kubernetes distribution is best to use. Today, we will compare the certified Kubernetes distribution…

View On WordPress
#Certified Kubernetes Distribution#edge computing#High Availability in Kubernetes#K3s for Local Development#k3s vs k8s#Kubernetes distributions#Kubernetes home lab#Kubernetes Scalability#Lightweight Kubernetes#Resource-Constrained Environments
0 notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
The Technology Stack Behind a Fast Cryptocurrency Exchange Script

In the fast-paced world of crypto trading, speed, security, and scalability are everything. Whether you're launching a new platform or upgrading an existing one, the technology stack behind your cryptocurrency exchange script plays a crucial role in user experience and platform success.
Let’s break down what goes into building a lightning-fast and secure crypto exchange.
🔹 Frontend Technologies
Speedy UI/UX is critical. Most modern exchanges use React.js or Vue.js to build interactive, responsive interfaces. These frameworks ensure real-time updates for charts, orders, and wallets without page reloads.
🔹 Backend Frameworks
A high-performance backend is the engine. Node.js, Go, or Python (Django) are popular choices thanks to their scalability and non-blocking architecture. These handle everything from API requests to order matching engines efficiently.
🔹 Database Layer
Handling massive transactional data? Robust databases like PostgreSQL, MongoDB, or Redis are often used for storing trade history, user data, and wallet balances. Some platforms use a hybrid structure to combine speed and consistency.
🔹 Blockchain Integration
A core component of any cryptocurrency exchange script is wallet integration. Secure APIs connect your platform to major blockchains like Bitcoin, Ethereum, BNB Chain, and others for deposits, withdrawals, and transaction tracking.
🔹 Security Stack
Cyber threats are real. A solid exchange script includes 2FA, anti-DDoS protection, KYC/AML modules, and encrypted wallets to ensure compliance and protect user funds.
🔹 Real-Time Engines
For instant order execution and price updates, technologies like WebSockets and Kafka enable real-time data flow, critical for high-frequency traders.
🔹 DevOps & Deployment
Using Docker, Kubernetes, and cloud platforms like AWS or Azure ensures that your exchange is scalable, highly available, and easy to maintain. A solid cryptocurrency exchange script backed by this stack not only performs faster but also earns user trust. Are you using the right stack to build your crypto platform?
0 notes
Text
Cloud-Native Application Development: Why It’s the Future of Product Engineering
As businesses accelerate their digital transformation, cloud-native application development is emerging as the new standard for scalable, agile, and resilient software delivery. Unlike traditional monolithic architectures, cloud-native applications are designed specifically to leverage the full potential of cloud computing, allowing organizations to innovate faster and serve customers better.
What is Cloud-Native Application Development?
Cloud-native application development refers to building and running applications that fully exploit the benefits of the cloud delivery model. This involves:
Microservices architecture
Containerization (e.g., Docker)
Orchestration (e.g., Kubernetes)
Continuous integration and continuous delivery (CI/CD)
DevOps and DevSecOps practices
Cloud-native is not just about where applications run—it's about how they are designed, developed, and operated.
Benefits of Developing Applications Natively for the Cloud
1. Scalability – Cloud-native apps scale effortlessly to handle increased workloads using auto-scaling features and managed services.
2. Resilience – With built-in fault tolerance and redundancy, these applications maintain high availability and recover quickly from failures.
3. Faster Time-to-Market – Microservices and CI/CD pipelines allow for rapid iterations and deployments.
4. Cost Efficiency – Pay-as-you-go models and the ability to scale down reduce infrastructure costs.
5. Portability – Containerized applications can run across multiple cloud providers and environments with minimal changes.
6. Improved Developer Productivity – Developers can work independently on different services without being bottlenecked by other teams.
Choosing the Right Cloud Provider: AWS, Azure, or GCP?
Selecting a cloud provider depends on your specific business needs, application architecture, and ecosystem compatibility. Here’s a quick breakdown of the top three providers:
Read more
0 notes
Text
Cloud Database and DBaaS Market in the United States entering an era of unstoppable scalability
Cloud Database And DBaaS Market was valued at USD 17.51 billion in 2023 and is expected to reach USD 77.65 billion by 2032, growing at a CAGR of 18.07% from 2024-2032.
Cloud Database and DBaaS Market is experiencing robust expansion as enterprises prioritize scalability, real-time access, and cost-efficiency in data management. Organizations across industries are shifting from traditional databases to cloud-native environments to streamline operations and enhance agility, creating substantial growth opportunities for vendors in the USA and beyond.
U.S. Market Sees High Demand for Scalable, Secure Cloud Database Solutions
Cloud Database and DBaaS Market continues to evolve with increasing demand for managed services, driven by the proliferation of data-intensive applications, remote work trends, and the need for zero-downtime infrastructures. As digital transformation accelerates, businesses are choosing DBaaS platforms for seamless deployment, integrated security, and faster time to market.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6586
Market Keyplayers:
Google LLC (Cloud SQL, BigQuery)
Nutanix (Era, Nutanix Database Service)
Oracle Corporation (Autonomous Database, Exadata Cloud Service)
IBM Corporation (Db2 on Cloud, Cloudant)
SAP SE (HANA Cloud, Data Intelligence)
Amazon Web Services, Inc. (RDS, Aurora)
Alibaba Cloud (ApsaraDB for RDS, ApsaraDB for MongoDB)
MongoDB, Inc. (Atlas, Enterprise Advanced)
Microsoft Corporation (Azure SQL Database, Cosmos DB)
Teradata (VantageCloud, ClearScape Analytics)
Ninox (Cloud Database, App Builder)
DataStax (Astra DB, Enterprise)
EnterpriseDB Corporation (Postgres Cloud Database, BigAnimal)
Rackspace Technology, Inc. (Managed Database Services, Cloud Databases for MySQL)
DigitalOcean, Inc. (Managed Databases, App Platform)
IDEMIA (IDway Cloud Services, Digital Identity Platform)
NEC Corporation (Cloud IaaS, the WISE Data Platform)
Thales Group (CipherTrust Cloud Key Manager, Data Protection on Demand)
Market Analysis
The Cloud Database and DBaaS Market is being shaped by rising enterprise adoption of hybrid and multi-cloud strategies, growing volumes of unstructured data, and the rising need for flexible storage models. The shift toward as-a-service platforms enables organizations to offload infrastructure management while maintaining high availability and disaster recovery capabilities.
Key players in the U.S. are focusing on vertical-specific offerings and tighter integrations with AI/ML tools to remain competitive. In parallel, European markets are adopting DBaaS solutions with a strong emphasis on data residency, GDPR compliance, and open-source compatibility.
Market Trends
Growing adoption of NoSQL and multi-model databases for unstructured data
Integration with AI and analytics platforms for enhanced decision-making
Surge in demand for Kubernetes-native databases and serverless DBaaS
Heightened focus on security, encryption, and data governance
Open-source DBaaS gaining traction for cost control and flexibility
Vendor competition intensifying with new pricing and performance models
Rise in usage across fintech, healthcare, and e-commerce verticals
Market Scope
The Cloud Database and DBaaS Market offers broad utility across organizations seeking flexibility, resilience, and performance in data infrastructure. From real-time applications to large-scale analytics, the scope of adoption is wide and growing.
Simplified provisioning and automated scaling
Cross-region replication and backup
High-availability architecture with minimal downtime
Customizable storage and compute configurations
Built-in compliance with regional data laws
Suitable for startups to large enterprises
Forecast Outlook
The market is poised for strong and sustained growth as enterprises increasingly value agility, automation, and intelligent data management. Continued investment in cloud-native applications and data-intensive use cases like AI, IoT, and real-time analytics will drive broader DBaaS adoption. Both U.S. and European markets are expected to lead in innovation, with enhanced support for multicloud deployments and industry-specific use cases pushing the market forward.
Access Complete Report: https://www.snsinsider.com/reports/cloud-database-and-dbaas-market-6586
Conclusion
The future of enterprise data lies in the cloud, and the Cloud Database and DBaaS Market is at the heart of this transformation. As organizations demand faster, smarter, and more secure ways to manage data, DBaaS is becoming a strategic enabler of digital success. With the convergence of scalability, automation, and compliance, the market promises exciting opportunities for providers and unmatched value for businesses navigating a data-driven world.
Related reports:
U.S.A leads the surge in advanced IoT Integration Market innovations across industries
U.S.A drives secure online authentication across the Certificate Authority Market
U.S.A drives innovation with rapid adoption of graph database technologies
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
Mail us: [email protected]
#Cloud Database and DBaaS Market#Cloud Database and DBaaS Market Growth#Cloud Database and DBaaS Market Scope
0 notes
Text
How Can You Build a Scalable Fintech Software Platform?

The fintech revolution is redefining the way individuals and businesses manage money. From mobile banking and peer-to-peer payments to wealth management and insurance tech, financial technology is driving innovation across all sectors. However, as customer bases grow and user demands increase, the need for scalable fintech software becomes critical.
Building a robust and scalable platform is not only about accommodating growth—it's about doing so efficiently, securely, and with the flexibility to evolve. In this guide, we’ll explore the essential steps and components required to build a scalable fintech software platform that can meet modern expectations and future demands.
1. Start with a Modular Architecture
Scalability starts at the architectural level. A monolithic structure may be easier to launch initially, but it can quickly become a bottleneck as your fintech services grow. Instead, opt for a modular or microservices architecture. This design principle allows each component (e.g., payments, authentication, user profiles) to function independently.
By using this structure, updates and scaling can be performed on specific services without affecting the entire platform. This modularity enhances agility, accelerates development, and minimizes downtime during maintenance or upgrades.
2. Leverage Cloud Infrastructure
Cloud computing has transformed the way fintech companies build and scale their platforms. Cloud providers offer flexible, on-demand resources that can grow with your needs. Instead of investing heavily in physical servers, you can scale horizontally by adding more virtual machines or containers during peak usage.
Cloud-native technologies like Kubernetes, Docker, and serverless computing allow for:
Auto-scaling of resources
Global accessibility
Faster deployment cycles
Cost optimization based on usage
A cloud-first approach ensures that your fintech software remains responsive, even under heavy load.
3. Implement API-First Design
Integration is a key element in delivering comprehensive fintech services. Whether you're connecting with payment gateways, third-party tools, or external data providers, an API-first strategy makes this process seamless.
APIs enable interoperability and extend the value of your platform. By designing your fintech software with well-documented, secure, and version-controlled APIs, you not only simplify integration but also empower partners, developers, and clients to innovate around your platform.
4. Ensure Security and Compliance from Day One
Security is not optional—it's foundational. Scalable fintech platforms must be built with data protection and compliance in mind from the outset. As your user base grows, so does the risk surface. Poor security can lead to data breaches, legal penalties, and damage to your brand.
Key security practices include:
End-to-end encryption
Role-based access control
Multi-factor authentication
Real-time monitoring and anomaly detection
Additionally, compliance with regulations such as GDPR, KYC, and AML must be embedded within your processes. Automating compliance through built-in regulatory frameworks saves time and ensures consistency as your platform scales.
5. Optimize for Performance and Reliability
No one wants to use a fintech app that crashes during a transaction. Performance and reliability are vital for user trust and retention. A scalable fintech software platform must maintain low latency and high availability, regardless of the number of users.
To achieve this:
Use content delivery networks (CDNs) to serve static assets faster
Implement load balancing to distribute traffic evenly
Monitor infrastructure with real-time analytics and alerts
Conduct performance and stress testing regularly
High availability ensures that your fintech services are accessible 24/7 without disruption, fostering user confidence.
6. Design for a Seamless User Experience
As your platform grows, so will the diversity of your user base. A scalable fintech software solution must accommodate varying user behaviors, device types, and accessibility needs. That means designing intuitive, mobile-first interfaces and providing responsive support features.
Key UX principles include:
Simple onboarding flows
Personalized dashboards
Fast and easy transaction processes
Interactive support (e.g., chatbots or AI assistants)
Consistent and thoughtful design improves usability and helps drive customer satisfaction, which is essential for long-term growth.
7. Adopt Agile and DevOps Practices
Building a scalable platform requires continuous improvement. By adopting Agile methodologies and DevOps practices, development and operations teams can collaborate more effectively. Continuous integration and continuous deployment (CI/CD) pipelines allow for faster updates, quicker bug fixes, and more frequent releases without compromising quality.
These practices also support automation in testing, monitoring, and deployment, reducing human error and speeding up development cycles.
8. Plan for Data Scalability and Advanced Analytics
Data is the backbone of any fintech platform. From transaction history to user behavior, every interaction generates valuable information. Your software must be able to store, manage, and analyze growing volumes of data efficiently.
Scalable fintech services should include:
Distributed databases
Real-time analytics engines
AI-powered decision-making tools
Data warehousing for long-term storage
With the right data strategy, you can gain actionable insights, optimize performance, and offer personalized financial experiences to users.
Final Thoughts
Scalability is not an afterthought—it’s a design requirement from the beginning. To build a fintech software platform that stands the test of time, companies must focus on modular architecture, robust security, seamless integration, and a user-first approach. Cloud-native development, data analytics, and continuous delivery practices are also key enablers of long-term growth.
Organizations like Xettle Technologies specialize in crafting scalable, secure, and future-ready fintech software platforms tailored to the specific needs of financial service providers. By embracing the right technologies and methodologies, you can ensure your fintech solution not only grows with demand but leads in innovation.
0 notes