#large Kubernetes deployments
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
Best Kubernetes Management Tools in 2023
Best Kubernetes Management Tools in 2023 #homelab #vmwarecommunities #Kubernetesmanagementtools2023 #bestKubernetescommandlinetools #managingKubernetesclusters #Kubernetesdashboardinterfaces #kubernetesmanagementtools #Kubernetesdashboard
Kubernetes is everywhere these days. It is used in the enterprise and even in many home labs. It’s a skill that’s sought after, especially with today’s push for app modernization. Many tools help you manage things in Kubernetes, like clusters, pods, services, and apps. Here’s my list of the best Kubernetes management tools in 2023. Table of contentsWhat is Kubernetes?Understanding Kubernetes and…

View On WordPress
#best Kubernetes command line tools#containerized applications management#Kubernetes cluster management tools#Kubernetes cost monitoring#Kubernetes dashboard interfaces#Kubernetes deployment solutions#Kubernetes management tools 2023#large Kubernetes deployments#managing Kubernetes clusters#open-source Kubernetes tools
0 notes
Text
Top 10 In- Demand Tech Jobs in 2025

Technology is growing faster than ever, and so is the need for skilled professionals in the field. From artificial intelligence to cloud computing, businesses are looking for experts who can keep up with the latest advancements. These tech jobs not only pay well but also offer great career growth and exciting challenges.
In this blog, we’ll look at the top 10 tech jobs that are in high demand today. Whether you’re starting your career or thinking of learning new skills, these jobs can help you plan a bright future in the tech world.
1. AI and Machine Learning Specialists
Artificial Intelligence (AI) and Machine Learning are changing the game by helping machines learn and improve on their own without needing step-by-step instructions. They’re being used in many areas, like chatbots, spotting fraud, and predicting trends.
Key Skills: Python, TensorFlow, PyTorch, data analysis, deep learning, and natural language processing (NLP).
Industries Hiring: Healthcare, finance, retail, and manufacturing.
Career Tip: Keep up with AI and machine learning by working on projects and getting an AI certification. Joining AI hackathons helps you learn and meet others in the field.
2. Data Scientists
Data scientists work with large sets of data to find patterns, trends, and useful insights that help businesses make smart decisions. They play a key role in everything from personalized marketing to predicting health outcomes.
Key Skills: Data visualization, statistical analysis, R, Python, SQL, and data mining.
Industries Hiring: E-commerce, telecommunications, and pharmaceuticals.
Career Tip: Work with real-world data and build a strong portfolio to showcase your skills. Earning certifications in data science tools can help you stand out.
3. Cloud Computing Engineers: These professionals create and manage cloud systems that allow businesses to store data and run apps without needing physical servers, making operations more efficient.
Key Skills: AWS, Azure, Google Cloud Platform (GCP), DevOps, and containerization (Docker, Kubernetes).
Industries Hiring: IT services, startups, and enterprises undergoing digital transformation.
Career Tip: Get certified in cloud platforms like AWS (e.g., AWS Certified Solutions Architect).
4. Cybersecurity Experts
Cybersecurity professionals protect companies from data breaches, malware, and other online threats. As remote work grows, keeping digital information safe is more crucial than ever.
Key Skills: Ethical hacking, penetration testing, risk management, and cybersecurity tools.
Industries Hiring: Banking, IT, and government agencies.
Career Tip: Stay updated on new cybersecurity threats and trends. Certifications like CEH (Certified Ethical Hacker) or CISSP (Certified Information Systems Security Professional) can help you advance in your career.
5. Full-Stack Developers
Full-stack developers are skilled programmers who can work on both the front-end (what users see) and the back-end (server and database) of web applications.
Key Skills: JavaScript, React, Node.js, HTML/CSS, and APIs.
Industries Hiring: Tech startups, e-commerce, and digital media.
Career Tip: Create a strong GitHub profile with projects that highlight your full-stack skills. Learn popular frameworks like React Native to expand into mobile app development.
6. DevOps Engineers
DevOps engineers help make software faster and more reliable by connecting development and operations teams. They streamline the process for quicker deployments.
Key Skills: CI/CD pipelines, automation tools, scripting, and system administration.
Industries Hiring: SaaS companies, cloud service providers, and enterprise IT.
Career Tip: Earn key tools like Jenkins, Ansible, and Kubernetes, and develop scripting skills in languages like Bash or Python. Earning a DevOps certification is a plus and can enhance your expertise in the field.
7. Blockchain Developers
They build secure, transparent, and unchangeable systems. Blockchain is not just for cryptocurrencies; it’s also used in tracking supply chains, managing healthcare records, and even in voting systems.
Key Skills: Solidity, Ethereum, smart contracts, cryptography, and DApp development.
Industries Hiring: Fintech, logistics, and healthcare.
Career Tip: Create and share your own blockchain projects to show your skills. Joining blockchain communities can help you learn more and connect with others in the field.
8. Robotics Engineers
Robotics engineers design, build, and program robots to do tasks faster or safer than humans. Their work is especially important in industries like manufacturing and healthcare.
Key Skills: Programming (C++, Python), robotics process automation (RPA), and mechanical engineering.
Industries Hiring: Automotive, healthcare, and logistics.
Career Tip: Stay updated on new trends like self-driving cars and AI in robotics.
9. Internet of Things (IoT) Specialists
IoT specialists work on systems that connect devices to the internet, allowing them to communicate and be controlled easily. This is crucial for creating smart cities, homes, and industries.
Key Skills: Embedded systems, wireless communication protocols, data analytics, and IoT platforms.
Industries Hiring: Consumer electronics, automotive, and smart city projects.
Career Tip: Create IoT prototypes and learn to use platforms like AWS IoT or Microsoft Azure IoT. Stay updated on 5G technology and edge computing trends.
10. Product Managers
Product managers oversee the development of products, from idea to launch, making sure they are both technically possible and meet market demands. They connect technical teams with business stakeholders.
Key Skills: Agile methodologies, market research, UX design, and project management.
Industries Hiring: Software development, e-commerce, and SaaS companies.
Career Tip: Work on improving your communication and leadership skills. Getting certifications like PMP (Project Management Professional) or CSPO (Certified Scrum Product Owner) can help you advance.
Importance of Upskilling in the Tech Industry
Stay Up-to-Date: Technology changes fast, and learning new skills helps you keep up with the latest trends and tools.
Grow in Your Career: By learning new skills, you open doors to better job opportunities and promotions.
Earn a Higher Salary: The more skills you have, the more valuable you are to employers, which can lead to higher-paying jobs.
Feel More Confident: Learning new things makes you feel more prepared and ready to take on tougher tasks.
Adapt to Changes: Technology keeps evolving, and upskilling helps you stay flexible and ready for any new changes in the industry.
Top Companies Hiring for These Roles
Global Tech Giants: Google, Microsoft, Amazon, and IBM.
Startups: Fintech, health tech, and AI-based startups are often at the forefront of innovation.
Consulting Firms: Companies like Accenture, Deloitte, and PwC increasingly seek tech talent.
In conclusion, the tech world is constantly changing, and staying updated is key to having a successful career. In 2025, jobs in fields like AI, cybersecurity, data science, and software development will be in high demand. By learning the right skills and keeping up with new trends, you can prepare yourself for these exciting roles. Whether you're just starting or looking to improve your skills, the tech industry offers many opportunities for growth and success.
#Top 10 Tech Jobs in 2025#In- Demand Tech Jobs#High paying Tech Jobs#artificial intelligence#datascience#cybersecurity
2 notes
·
View notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Embarking on a Digital Journey: Your Guide to Learning Coding
In today's fast-paced and ever-evolving technology landscape, DevOps has emerged as a crucial and transformative field that bridges the gap between software development and IT operations. The term "DevOps" is a portmanteau of "Development" and "Operations," emphasizing the importance of collaboration, automation, and efficiency in the software delivery process. DevOps practices have gained widespread adoption across industries, revolutionizing the way organizations develop, deploy, and maintain software. This paradigm shift has led to a surging demand for skilled DevOps professionals who can navigate the complex and multifaceted DevOps landscape.

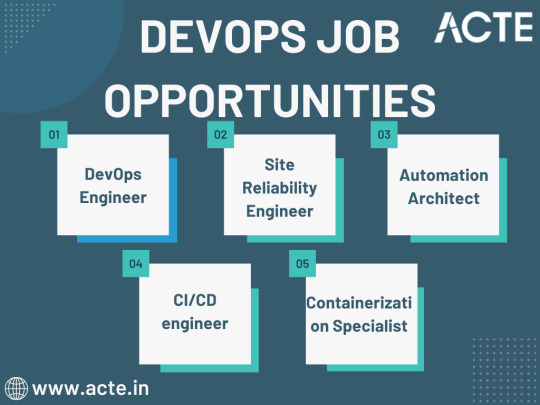
Exploring DevOps Job Opportunities
DevOps has given rise to a spectrum of job opportunities, each with its unique focus and responsibilities. Let's delve into some of the key DevOps roles that are in high demand:
1. DevOps Engineer
At the heart of DevOps lies the DevOps engineer, responsible for automating and streamlining IT operations and processes. DevOps engineers are the architects of efficient software delivery pipelines, collaborating closely with development and IT teams. Their mission is to accelerate the software delivery process while ensuring the reliability and stability of systems.
2. Site Reliability Engineer (SRE)
Site Reliability Engineers, or SREs, are a subset of DevOps engineers who specialize in maintaining large-scale, highly reliable software systems. They focus on critical aspects such as availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning. SREs play a pivotal role in ensuring that applications and services remain dependable and performant.
3. Automation Architect
Automation is a cornerstone of DevOps, and automation architects are experts in this domain. These professionals design and implement automation solutions that optimize software development and delivery processes. By automating repetitive and manual tasks, they enhance efficiency and reduce the risk of human error.
4. Continuous Integration/Continuous Deployment (CI/CD) Engineer
CI/CD engineers specialize in creating, maintaining, and optimizing CI/CD pipelines. The CI/CD pipeline is the backbone of DevOps, enabling the automated building, testing, and deployment of code. CI/CD engineers ensure that the pipeline operates seamlessly, enabling rapid and reliable software delivery.
5. Containerization Specialist
The rise of containerization technologies like Docker and orchestration tools such as Kubernetes has revolutionized software deployment. Containerization specialists focus on managing and scaling containerized applications, making them an integral part of DevOps teams.
Navigating the DevOps Learning Journey
To embark on a successful DevOps career, individuals often turn to comprehensive training programs and courses that equip them with the necessary skills and knowledge. The DevOps learning journey typically involves the following courses:
1. DevOps Foundation
A foundational DevOps course covers the basics of DevOps practices, principles, and tools. It serves as an excellent starting point for beginners, providing a solid understanding of the DevOps mindset and practices.
2. DevOps Certification
Advanced certification courses are designed for those who wish to delve deeper into DevOps methodologies, CI/CD pipelines, and various tools like Jenkins, Ansible, and Terraform. These certifications validate your expertise and enhance your job prospects.
3. Docker and Kubernetes Training
Containerization and container orchestration are two essential skills in the DevOps toolkit. Courses focused on Docker and Kubernetes provide in-depth knowledge of these technologies, enabling professionals to effectively manage containerized applications.
4. AWS or Azure DevOps Training
Specialized DevOps courses tailored to cloud platforms like AWS or Azure are essential for those working in a cloud-centric environment. These courses teach how to leverage cloud services in a DevOps context, further streamlining software development and deployment.
5. Advanced DevOps Courses
For those looking to specialize in specific areas, advanced DevOps courses cover topics like DevOps security, DevOps practices for mobile app development, and more. These courses cater to professionals who seek to expand their expertise in specific domains.
As the DevOps landscape continues to evolve, the need for high-quality training and education becomes increasingly critical. This is where ACTE Technologies steps into the spotlight as a reputable choice for comprehensive DevOps training.
They offer carefully thought-out courses that are intended to impart both foundational information and real-world, practical experience. Under the direction of knowledgeable educators, students can quickly advance on their path to become skilled DevOps engineers. They provide practical insights into industrial practises and issues, going beyond theory.
Your journey toward mastering DevOps practices and pursuing a successful career begins here. In the digital realm, where possibilities are limitless and innovation knows no bounds, ACTE Technologies serves as a gateway to a thriving DevOps career. With a diverse array of courses and expert instruction, you'll find the resources you need to thrive in this ever-evolving domain.
3 notes
·
View notes
Text
The Cost of Hiring a Microservices Engineer: What to Expect

Many tech businesses are switching from monolithic programs to microservices-based architectures as software systems get more complicated. More flexibility, scalability, and deployment speed are brought about by this change, but it also calls for specialized talent. Knowing how much hiring a microservices engineer would cost is essential to making an informed decision.
Understanding the factors that affect costs can help you better plan your budget and draw in the best personnel, whether you're developing a new product or updating outdated systems.
Budgeting for Specialized Talent in a Modern Cloud Architecture
Applications composed of tiny, loosely linked services are designed, developed, and maintained by microservices engineers. These services are frequently implemented separately and communicate via APIs. When you hire a microservices engineer they should have extensive experience with distributed systems, API design, service orchestration, and containerization.
They frequently work with cloud platforms like AWS, Azure, or GCP as well as tools like Docker, Kubernetes, and Spring Boot. They play a crucial part in maintaining the scalability, modularity, and maintainability of your application.
What Influences the Cost?
The following variables affect the cost of hiring a microservices engineer:
1. Level of Experience
Although they might charge less, junior engineers will probably require supervision. Because they can independently design and implement reliable solutions, mid-level and senior engineers with practical experience in large-scale microservices projects attract higher rates.
2. Place
Geography has a major impact on salaries. Hiring in North America or Western Europe, for instance, is usually more expensive than hiring in Southeast Asia, Eastern Europe, or Latin America.
3. Type of Employment
Are you hiring contract, freelance, or full-time employees? For short-term work, freelancers may charge higher hourly rates, but the total project cost may be less.
4. Specialization and the Tech Stack
Because of their specialised knowledge, engineers who are familiar with niche stacks or tools (such as event-driven architecture, Istio, or advanced Kubernetes usage) frequently charge extra.
Use a salary benchmarking tool to ensure that your pay is competitive. This helps you set expectations and prevent overpaying or underbidding by providing you with up-to-date market data based on role, region, and experience.
Hidden Costs to Consider
In addition to the base pay or rate, you need account for:
Time spent onboarding and training
Time devoted to applicant evaluation and interviews
The price of bad hires (in terms of rework or delays)
Continuous assistance and upkeep if you're starting from scratch
These elements highlight how crucial it is to make a thoughtful, knowledgeable hiring choice.
Complementary Roles to Consider
Working alone is not how a microservices engineer operates. Several tech organizations also hire cloud engineers to oversee deployment pipelines, networking, and infrastructure. Improved production performance and easier scaling are guaranteed when these positions work closely together.
Summing Up
Hiring a microservices engineer is a strategic investment rather than merely a cost. These engineers with the appropriate training and resources lays the groundwork for long-term agility and scalability.
Make smart financial decisions by using tools such as a pay benchmarking tool, and think about combining your hire with cloud or DevOps support. The correct engineer can improve your architecture's speed, stability, and long-term value for tech businesses updating their apps.
0 notes
Text
Hybrid Cloud Application: The Smart Future of Business IT

Introduction
In today’s digital-first environment, businesses are constantly seeking scalable, flexible, and cost-effective solutions to stay competitive. One solution that is gaining rapid traction is the hybrid cloud application model. Combining the best of public and private cloud environments, hybrid cloud applications enable businesses to maximize performance while maintaining control and security.
This 2000-word comprehensive article on hybrid cloud applications explains what they are, why they matter, how they work, their benefits, and how businesses can use them effectively. We also include real-user reviews, expert insights, and FAQs to help guide your cloud journey.
What is a Hybrid Cloud Application?
A hybrid cloud application is a software solution that operates across both public and private cloud environments. It enables data, services, and workflows to move seamlessly between the two, offering flexibility and optimization in terms of cost, performance, and security.
For example, a business might host sensitive customer data in a private cloud while running less critical workloads on a public cloud like AWS, Azure, or Google Cloud Platform.
Key Components of Hybrid Cloud Applications
Public Cloud Services – Scalable and cost-effective compute and storage offered by providers like AWS, Azure, and GCP.
Private Cloud Infrastructure – More secure environments, either on-premises or managed by a third-party.
Middleware/Integration Tools – Platforms that ensure communication and data sharing between cloud environments.
Application Orchestration – Manages application deployment and performance across both clouds.
Why Choose a Hybrid Cloud Application Model?
1. Flexibility
Run workloads where they make the most sense, optimizing both performance and cost.
2. Security and Compliance
Sensitive data can remain in a private cloud to meet regulatory requirements.
3. Scalability
Burst into public cloud resources when private cloud capacity is reached.
4. Business Continuity
Maintain uptime and minimize downtime with distributed architecture.
5. Cost Efficiency
Avoid overprovisioning private infrastructure while still meeting demand spikes.
Real-World Use Cases of Hybrid Cloud Applications
1. Healthcare
Protect sensitive patient data in a private cloud while using public cloud resources for analytics and AI.
2. Finance
Securely handle customer transactions and compliance data, while leveraging the cloud for large-scale computations.
3. Retail and E-Commerce
Manage customer interactions and seasonal traffic spikes efficiently.
4. Manufacturing
Enable remote monitoring and IoT integrations across factory units using hybrid cloud applications.
5. Education
Store student records securely while using cloud platforms for learning management systems.
Benefits of Hybrid Cloud Applications
Enhanced Agility
Better Resource Utilization
Reduced Latency
Compliance Made Easier
Risk Mitigation
Simplified Workload Management
Tools and Platforms Supporting Hybrid Cloud
Microsoft Azure Arc – Extends Azure services and management to any infrastructure.
AWS Outposts – Run AWS infrastructure and services on-premises.
Google Anthos – Manage applications across multiple clouds.
VMware Cloud Foundation – Hybrid solution for virtual machines and containers.
Red Hat OpenShift – Kubernetes-based platform for hybrid deployment.
Best Practices for Developing Hybrid Cloud Applications
Design for Portability Use containers and microservices to enable seamless movement between clouds.
Ensure Security Implement zero-trust architectures, encryption, and access control.
Automate and Monitor Use DevOps and continuous monitoring tools to maintain performance and compliance.
Choose the Right Partner Work with experienced providers who understand hybrid cloud deployment strategies.
Regular Testing and Backup Test failover scenarios and ensure robust backup solutions are in place.
Reviews from Industry Professionals
Amrita Singh, Cloud Engineer at FinCloud Solutions:
"Implementing hybrid cloud applications helped us reduce latency by 40% and improve client satisfaction."
John Meadows, CTO at EdTechNext:
"Our LMS platform runs on a hybrid model. We’ve achieved excellent uptime and student experience during peak loads."
Rahul Varma, Data Security Specialist:
"For compliance-heavy environments like finance and healthcare, hybrid cloud is a no-brainer."
Challenges and How to Overcome Them
1. Complex Architecture
Solution: Simplify with orchestration tools and automation.
2. Integration Difficulties
Solution: Use APIs and middleware platforms for seamless data exchange.
3. Cost Overruns
Solution: Use cloud cost optimization tools like Azure Advisor, AWS Cost Explorer.
4. Security Risks
Solution: Implement multi-layered security protocols and conduct regular audits.
FAQ: Hybrid Cloud Application
Q1: What is the main advantage of a hybrid cloud application?
A: It combines the strengths of public and private clouds for flexibility, scalability, and security.
Q2: Is hybrid cloud suitable for small businesses?
A: Yes, especially those with fluctuating workloads or compliance needs.
Q3: How secure is a hybrid cloud application?
A: When properly configured, hybrid cloud applications can be as secure as traditional setups.
Q4: Can hybrid cloud reduce IT costs?
A: Yes. By only paying for public cloud usage as needed, and avoiding overprovisioning private servers.
Q5: How do you monitor a hybrid cloud application?
A: With cloud management platforms and monitoring tools like Datadog, Splunk, or Prometheus.
Q6: What are the best platforms for hybrid deployment?
A: Azure Arc, Google Anthos, AWS Outposts, and Red Hat OpenShift are top choices.
Conclusion: Hybrid Cloud is the New Normal
The hybrid cloud application model is more than a trend—it’s a strategic evolution that empowers organizations to balance innovation with control. It offers the agility of the cloud without sacrificing the oversight and security of on-premises systems.
If your organization is looking to modernize its IT infrastructure while staying compliant, resilient, and efficient, then hybrid cloud application development is the way forward.
At diglip7.com, we help businesses build scalable, secure, and agile hybrid cloud solutions tailored to their unique needs. Ready to unlock the future? Contact us today to get started.
0 notes
Text
Red Hat OpenShift Administration III: Scaling Deployments in the Enterprise
In the world of modern enterprise IT, scalability is not just a desirable trait—it's a mission-critical requirement. As organizations continue to adopt containerized applications and microservices architectures, the ability to seamlessly scale infrastructure and workloads becomes essential. That’s where Red Hat OpenShift Administration III comes into play, focusing on the advanced capabilities needed to manage and scale OpenShift clusters in large-scale production environments.
Why Scaling Matters in OpenShift
OpenShift, Red Hat’s Kubernetes-powered container platform, empowers DevOps teams to build, deploy, and manage applications at scale. But managing scalability isn’t just about increasing pod replicas or adding more nodes—it’s about making strategic, automated, and resilient decisions to meet dynamic demand, ensure availability, and optimize resource usage.
OpenShift Administration III (DO380) is the course designed to help administrators go beyond day-to-day operations and develop the skills needed to ensure enterprise-grade scalability and performance.
Key Takeaways from OpenShift Administration III
1. Advanced Cluster Management
The course teaches administrators how to manage large OpenShift clusters with hundreds or even thousands of nodes. Topics include:
Advanced node management
Infrastructure node roles
Cluster operators and custom resources
2. Automated Scaling Techniques
Learn how to configure and manage:
Horizontal Pod Autoscalers (HPA)
Vertical Pod Autoscalers (VPA)
Cluster Autoscalers These tools allow the platform to intelligently adjust resource consumption based on workload demands.
3. Optimizing Resource Utilization
One of the biggest challenges in scaling is maintaining cost-efficiency. OpenShift Administration III helps you fine-tune quotas, limits, and requests to avoid over-provisioning while ensuring optimal performance.
4. Managing Multitenancy at Scale
The course delves into managing enterprise workloads in a secure and multi-tenant environment. This includes:
Project-level isolation
Role-based access control (RBAC)
Secure networking policies
5. High Availability and Disaster Recovery
Scaling isn't just about growing—it’s about being resilient. Learn how to:
Configure etcd backup and restore
Maintain control plane and application availability
Build disaster recovery strategies
Who Should Take This Course?
This course is ideal for:
OpenShift administrators responsible for large-scale deployments
DevOps engineers managing Kubernetes-based platforms
System architects looking to standardize on Red Hat OpenShift across enterprise environments
Final Thoughts
As enterprises push towards digital transformation, the demand for scalable, resilient, and automated platforms continues to grow. Red Hat OpenShift Administration III equips IT professionals with the skills and strategies to confidently scale deployments, handle complex workloads, and maintain robust system performance across the enterprise.
Whether you're operating in a hybrid cloud, multi-cloud, or on-premises environment, mastering OpenShift scalability ensures your infrastructure can grow with your business.
Ready to take your OpenShift skills to the next level? Contact HawkStack Technologies today to learn about our Red Hat Learning Subscription (RHLS) and instructor-led training options for DO380 – Red Hat OpenShift Administration III. For more details www.hawkstack.com
0 notes
Text
Why Full-Stack Web Development Skills Are in High Demand in 2025
In today’s fast-paced digital world, the way we build, access, and interact with technology is evolving rapidly. Companies are racing to create seamless, scalable, and efficient digital solutions—and at the heart of this movement lies full-stack web development. If you've been exploring career options in tech or wondering what skills will truly pay off in 2025, the answer is clear: full-stack web development is one of the hottest and most valuable skill sets on the market.
But why exactly are full-stack web development skills in high demand in 2025? Let’s break it down in a way that’s easy to understand and relevant, whether you're a student, a working professional looking to upskill, or a business owner trying to stay ahead of the curve.
The Versatility of Full-Stack Developers
Full-stack web developers are often called the "Swiss Army knives" of the tech industry. Why? Because they can work across the entire web development process—from designing user-friendly interfaces (front end) to managing databases and servers (back end).
This versatility is extremely valuable for several reasons:
Cost-efficiency: Companies can hire one skilled developer instead of multiple specialists.
Faster development cycles: Full-stack developers can manage the entire pipeline, resulting in quicker launches.
Better project understanding: With a view of the whole system, these developers can troubleshoot and optimise more effectively.
Strong collaboration: Their ability to bridge front-end and back-end teams enhances communication and project execution.
In 2025, as companies look for more agility and speed, hiring full-stack developers has become a strategic move.
Startups and SMEs Are Driving the Demand
One of the biggest contributors to this rising demand is the startup ecosystem. Small and medium enterprises (SMEs), especially in tech-driven sectors, rely heavily on lean teams and flexible development strategies.
For them, hiring a full-stack developer means:
Getting more done with fewer people
Accelerating time-to-market for their products
Reducing the dependency on multiple external vendors
Even large corporations are adapting this mindset, often building smaller agile squads where each member is cross-functional. In such setups, full-stack web development skills are a goldmine.
Evolution of Tech Stacks
As technology evolves, so do the tools and frameworks used to build digital applications. In 2025, popular stacks like MERN (MongoDB, Express, React, Node.js), MEAN (MongoDB, Express, Angular, Node.js), and even serverless architecture are becoming industry standards.
Being proficient in full-stack web development means you’re equipped to work with:
Front-end technologies (React, Angular, Vue)
Back-end frameworks (Node.js, Django, Ruby on Rails)
Databases (MySQL, MongoDB, PostgreSQL)
Deployment and DevOps tools (Docker, Kubernetes, AWS)
This knowledge gives developers the ability to build complete, production-ready applications from scratch, which is a massive competitive advantage.
Remote Work and Freelancing Boom
The rise of remote work has opened up global opportunities for developers. Employers no longer prioritise geography—they want skills. And full-stack developers, being multi-skilled and independent, are ideal candidates for remote positions and freelance contracts.
Whether you want to work for a U.S.-based tech startup from your home in India or build your own freelance web development business, having full-stack skills is your passport.
Key benefits include:
Higher freelance rates
Flexible work schedules
Access to global job markets
The ability to manage solo projects end-to-end
AI & Automation: Full-Stack Developers Are Adapting
You might wonder—won’t AI and automation replace developers? The truth is, full-stack developers are adapting to this wave by learning how to integrate AI tools and automation into their projects. They're not being replaced; they're evolving.
Skills in full-stack development now often include:
API integration with AI models
Building intelligent web apps
Automating development processes with CI/CD tools
This adaptability makes full-stack developers even more indispensable in 2025.
Conclusion: The Future Is Full-Stack
The digital transformation era isn't slowing down. Businesses of all sizes need agile, skilled professionals who can wear multiple hats. That’s why full-stack web development skills are not just a nice-to-have—they’re a must-have in 2025.
To summarise, here’s why full-stack web development is in high demand:
It offers cost-effectiveness and faster delivery for companies.
Startups and SMEs rely on full-stack developers to scale quickly.
It covers all essential layers of modern tech stacks.
Freelancers and remote workers benefit immensely from this skill.
Developers can stay relevant by integrating AI and automation.
If you’re considering a career in tech or wondering how to future-proof your skill set, learning full-stack web development could be the smartest move you make this year.
0 notes
Text
Choosing the Right Tech Stack for Your SaaS Startup in 2025

Launching a SaaS startup in 2025 presents incredible opportunities—but also steep competition and technical complexity. At the core of every successful SaaS product lies one critical decision: choosing the right tech stack. This choice directly impacts your application's scalability, performance, development speed, and long-term maintainability. As innovation accelerates and user expectations grow, aligning with the right tools and technologies becomes even more crucial. That's why leading SaaS software development companies are focusing on modern, flexible, and efficient stacks to help startups future-proof their products.
In this blog, we’ll break down what a tech stack is, key considerations for making the right choice in 2025, and which stacks are trending. Whether you're bootstrapping or seeking funding, understanding your tech foundation is essential for long-term success.
What Is a Tech Stack?
A tech stack refers to the set of technologies used to build and run a software application. It typically includes:
Frontend technologies: What users interact with (e.g., React, Vue, Angular)
Backend technologies: Handles logic, database operations, and APIs (e.g., Node.js, Django, Ruby on Rails)
Database systems: Where data is stored and managed (e.g., PostgreSQL, MongoDB, MySQL)
DevOps tools: For deployment, monitoring, and scaling (e.g., Docker, Kubernetes, Jenkins)
Your stack choices affect everything from development speed to product performance and even your team's ability to scale quickly.
Key Factors to Consider When Choosing a SaaS Tech Stack
Choosing a tech stack isn’t just a matter of picking popular frameworks. It requires a strategic approach that factors in both your short-term goals and long-term product roadmap.
1. Scalability
Can your stack handle increased load as your user base grows? Scalability must be baked in from the beginning. Cloud-native stacks and microservices architecture are popular choices in 2025 for their ability to scale horizontally with ease.
2. Time to Market
Speed is everything for SaaS startups. Tech stacks with extensive libraries, rich documentation, and large developer communities (like JavaScript frameworks or Python-based platforms) enable faster MVP development and iteration.
3. Developer Availability
Choosing niche languages or frameworks may limit your hiring pool. Opt for technologies with a large, active community to make future hiring and team expansion easier.
4. Security
Security is non-negotiable in SaaS. Your stack should support encryption, secure APIs, and compliance with standards like GDPR, HIPAA, or SOC 2—depending on your target market.
5. Cost
The total cost of ownership includes not only development but also hosting, scaling, and maintenance. Some platforms (e.g., Firebase) offer great starter plans, but may become expensive at scale. Use tools like a SaaS cost calculator to estimate long-term infrastructure and development costs.
Popular Tech Stacks for SaaS Startups in 2025
Here's a breakdown of some modern stacks popular among high-performing SaaS startups in 2025:
1. MERN Stack (MongoDB, Express, React, Node.js)
Strengths: Full JavaScript stack, large community, great for real-time apps
Best for: Single-page applications, fast MVPs
2. Jamstack (JavaScript, APIs, Markup)
Strengths: Fast, secure, and SEO-friendly
Best for: Static sites, headless CMS, marketing-heavy SaaS platforms
3. Serverless Architecture (AWS Lambda, Azure Functions, Google Cloud Functions)
Strengths: Minimal server management, pay-per-use
Best for: Startups focused on reducing infrastructure costs and scaling automatically
4. Python + Django + PostgreSQL
Strengths: Quick prototyping, clean code, robust ORM
Best for: SaaS tools needing strong data integrity, admin dashboards
5. Go (Golang) + React + Kubernetes
Strengths: High performance, great concurrency, scalable microservices
Best for: SaaS platforms with high-performance requirements or complex workflows
Need Expert Help Choosing Your Tech Stack?
👉 Book an Appointment Get tailored advice from our SaaS tech architects. Whether you're starting from scratch or revamping your current product, we can help align your business goals with the most efficient stack.
Mistakes to Avoid When Choosing Your Tech Stack
❌ Over-Engineering the MVP
It’s tempting to build for scale from day one, but doing so can delay your time to market. Focus on the fastest path to MVP with scalability in mind—but don’t overcomplicate.
❌ Following Hype, Not Need
Just because a new framework is trending doesn’t mean it’s right for your product. Assess each tool’s pros and cons in the context of your specific needs.
❌ Ignoring Team Expertise
Your current team's skills are a major asset. Choosing a stack outside their expertise can result in delays, bugs, and unnecessary training costs.
The Role of SaaS Software Development Companies
Choosing your stack is just the beginning. The real value lies in how efficiently you can execute your product vision using those technologies. SaaS software development companies specialize in helping startups navigate the tech landscape by:
Offering experienced developers familiar with modern SaaS architecture
Providing strategic consulting for scalability, security, and integrations
Accelerating MVP launches with tried-and-tested frameworks
Delivering full-cycle development from ideation to post-launch support
In 2025, agility and technological precision are the keys to success in the SaaS world. By partnering with the right development team and selecting a well-aligned tech stack, you can focus on what matters most—solving real problems for your users.
Final Thoughts
Your tech stack will shape the trajectory of your SaaS startup. It affects how fast you ship features, how your app performs under load, and how easily you can scale your team and product. Don’t rush the decision. Take a holistic view—factor in development speed, security, hiring flexibility, and long-term cost implications.
Whether you choose the classic MERN stack or go serverless with cutting-edge tools, what matters most is making an informed, forward-looking decision. With guidance from experienced partners and a clear vision of your product roadmap, you can confidently set your SaaS business up for long-term success.
To do it right, consider working with top-tier SaaS software development firms that not only understand code but also the business logic behind building scalable, resilient, and profitable SaaS platforms.
0 notes
Text
Inside the Development Cycle: Editors, Runtimes, and Notebooks
In the evolving world of data science, knowing algorithms and models is only part of the story. To truly become proficient, it’s equally important to understand the development cycle that supports data science projects from start to finish. This includes using the right editors, managing efficient runtimes, and working with interactive notebooks—each of which plays a vital role in shaping the outcome of any data-driven solution.
If you’re beginning your journey into this exciting field, enrolling in a structured and comprehensive data science course in Hyderabad can give you both theoretical knowledge and practical experience with these essential tools.
What Is the Development Cycle in Data Science?
The data science development cycle is a structured workflow that guides the process of turning raw data into actionable insights. It typically includes:
Data Collection & Preprocessing
Exploratory Data Analysis (EDA)
Model Building & Evaluation
Deployment & Monitoring
Throughout these stages, data scientists rely on various tools to write code, visualise data, test algorithms, and deploy solutions. Understanding the development environments—specifically editors, runtimes, and notebooks—can make this process more streamlined and efficient.
Code Editors: Writing the Blueprint
A code editor is where much of the data science magic begins. Editors are software environments where developers and data scientists write and manage their code. These tools help format code, highlight syntax, and even provide autocomplete features to speed up development.
Popular Editors in Data Science:
VS Code (Visual Studio Code): Lightweight, customisable, and supports multiple programming languages.
PyCharm: Feature-rich editor tailored for Python, which is widely used in data science.
Sublime Text: Fast and flexible, good for quick scripting or data wrangling tasks.
In most data science classes, learners start by practising in basic editors before moving on to integrated environments that combine editing with runtime and visualisation features.
Runtimes: Where Code Comes to Life
A runtime is the engine that executes your code. It's the environment where your script is interpreted or compiled and where it interacts with data and produces results. Choosing the right runtime environment is crucial for performance, compatibility, and scalability.
Types of Runtimes:
Local Runtime: Code runs directly on your computer. Good for development and testing, but limited by hardware.
Cloud-Based Runtime: Services like Google Colab or AWS SageMaker provide powerful cloud runtimes, which are ideal for large datasets and complex models.
Containerised Runtimes: Using Docker or Kubernetes, these environments are portable and scalable, making them popular in enterprise settings.
In a professional data science course in Hyderabad, students often gain experience working with both local and cloud runtimes. This prepares them for real-world scenarios, where switching between environments is common.
Notebooks: The Interactive Canvas
Perhaps the most iconic tool in a data scientist's toolkit is the notebook interface. Notebooks like Jupyter and Google Colab allow users to combine live code, visualisations, and explanatory text in a single document. This format is ideal for storytelling, collaboration, and experimentation.
Why Notebooks Matter:
Interactivity: You can run code in segments (cells), making it easy to test and modify individual parts of a script.
Visualisation: Direct integration with libraries like Matplotlib and Seaborn enables real-time plotting and analysis.
Documentation: Notebooks support markdown, making it simple to annotate your work and explain results clearly.
These features make notebooks indispensable in both academic learning and professional development. Many data science courses now revolve around notebook-based assignments, allowing students to document and share their learning process effectively.
Putting It All Together
When working on a data science project, you’ll often move fluidly between these tools:
Start in an editor to set up your script or function.
Run your code in a suitable runtime—either local for small tasks or cloud-based for heavier jobs.
Switch to notebooks for analysis, visualisation, and sharing results with stakeholders or collaborators.
Understanding this workflow is just as important as mastering Python syntax or machine learning libraries. In fact, many hiring managers look for candidates who can not only build models but also present them effectively and manage their development environments efficiently.
Why Choose a Data Science Course in Hyderabad?
Hyderabad has quickly emerged as a tech hub in India, offering a vibrant ecosystem for aspiring data professionals. Opting for data science courses in Hyderabad provides several advantages:
Industry Exposure: Access to companies and startups using cutting-edge technologies.
Expert Faculty: Learn from instructors with real-world experience.
Career Support: Resume building, mock interviews, and job placement assistance.
Modern Curriculum: Courses that include the latest tools like Jupyter notebooks, cloud runtimes, and modern editors.
Such programs help bridge the gap between classroom learning and real-world application, equipping students with practical skills that employers truly value.
Conclusion
The success of any data science project depends not only on the strength of your algorithms but also on the tools you use to develop, test, and present your work. Understanding the role of editors, runtimes, and notebooks in the development cycle is essential for efficient and effective problem-solving.
Whether you’re an aspiring data scientist or a professional looking to upskill, the right training environment can make a big difference. Structured data science classes can provide the guidance, practice, and support you need to master these tools and become job-ready.
Data Science, Data Analyst and Business Analyst Course in Hyderabad
Address: 8th Floor, Quadrant-2, Cyber Towers, Phase 2, HITEC City, Hyderabad, Telangana 500081
Ph: 09513258911
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] DESCRIPTIONAs AI-driven systems evolve, robust backends are vital for managing large-scale data. This book explores backend principles, focusing on Go (Golang) for scalable, cloud-native development. It highlights Go's readability, concurrency, and open-source support. Step-by-step guidance, design patterns, and examples help developers and architects create resilient systems for modern software applications.It starts with the basics of backend development, covering programming, databases, APIs, and cloud services. You will learn Go fundamentals like data structures, packages, and testing, followed by using frameworks like Gin and Echo for web servers. It introduces microservices, Docker, Kubernetes, and concepts like concurrency and fault tolerance. You will explore inter-service communication (REST, gRPC, GraphQL), data modeling with relational and NoSQL databases, and scalability. The book also dives into CI/CD, cloud deployment, monitoring, security best practices, and strategies for maintaining backend systems efficiently.By mastering the concepts and practices covered in this book, you will be well-equipped to design, develop, and deploy secure, scalable, and maintainable backend systems using Golang. You will gain the confidence to tackle complex backend challenges and contribute to the development of high-performance applications.WHAT YOU WILL LEARN● Core Go language constructs and concurrency patterns for efficient programming.● Building high-performance web servers using popular Go frameworks.● Designing microservices and orchestrating containers with Kubernetes for scalability.● Creating secure and scalable APIs with RESTful, gRPC, and GraphQL.● Best practices for CI/CD pipelines and robust backend system optimization.● Use industry standard techniques that can instill confidence in stakeholders as well as users/customers.WHO THIS BOOK IS FORThis book is for beginners in computer science, those preparing for competitive exams and interviews, seasoned engineers, and software professionals seeking insights into designing, building, and maintaining large-scale backend systems. Publisher : Bpb Publications (20 January 2025) Language : English Paperback : 322 pages ISBN-10 : 9365893550 ISBN-13 : 978-9365893557 Item Weight : 553 g Dimensions : 19.05 x 1.85 x 23.5 cm Country of Origin : India [ad_2]
0 notes
Text
Understanding the Role of an AWS Solutions Architect in Modern Cloud Infrastructure

As the new technology era evolved, cloud computing revolutionized how organizations deploy, manage, and scale their IT infrastructure. Among the front-runners of cloud platforms is Amazon Web Services (AWS), a giant of a player with a gigantic portfolio of services spanning from simple web hosting to sophisticated machine learning and data analytics. At the fulcrum of utilizing AWS effectively is the central position of an AWS Solutions Architect—a professional who designs secure, scalable, high-performance, and trusted cloud solutions. With enterprises rapidly transferring their workloads to the cloud, the need for skilled AWS Solutions Architects has grown, and the profession is now among the most crucial in the field of cloud computing.
What Does an AWS Solutions Architect Do?
An AWS Solutions Architect is tasked with converting technical specifications into architecture designs that dictate how cloud infrastructure and applications should be designed and deployed. The experts collaborate with IT operations teams, developers, project managers, and business stakeholders to determine business requirements and design cloud systems that are scalable, cost-saving, and reliable. Whether assisting an emerging startup roll out a new application or a large corporation migrate legacy systems to the cloud, an AWS Solutions Architect ensures architecture is meeting needs current and future. They specialize in a wide array of AWS services such as EC2 for compute, S3 for storage, RDS for databases, VPC for networking, and Lambda for serverless computing and understand how to use these tools to build efficient systems that add value.
Key Work of an AWS Solutions Architect
Being an AWS Solutions Architect is all about a lot more than designing out systems. They are generally doing end-to-end project delivery, from planning to deployment and optimization. Any given day could find them attending technical reviews, demoing solutions to stakeholders, determining the most optimal AWS services to use, and making sure the architecture aligns with AWS's well-architected framework, with an emphasis on operational excellence, security, reliability, performance efficiency, and cost optimization. Most of the time, AWS Solutions Architect is also an ambassador to non-technical and technical staff, decoding arcane technical words into easy-to-understand actionable strategies for business leaders. They may also have to apply DevOps patterns to enable continuous integration and delivery pipelines, handle Infrastructure as Code (IaC) using products such as AWS CloudFormation or Terraform, and monitor system performance through AWS CloudWatch and X-Ray.
Skills and Certifications Required for AWS Solutions Architects
To be successful as an AWS Solutions Architect, one should have a good grasp of cloud computing principles and a good grasp of IT infrastructure such as networking, databases, storage devices, and security. One should be skilled in designing distributed systems and should also have a good grasp of how AWS services integrate with one another. Although practical experience cannot be replaced, getting the relevant certifications can authenticate your knowledge and improve your credibility. The most suitable certifications are the AWS Certified Solutions Architect – Associate and the AWS Certified Solutions Architect – Professional. These are designed to assess your skill in designing and deploying dynamic scalable, fault-tolerant, highly available, and reliable applications on AWS. Apart from that, programming language knowledge such as Python, Java, or Node.js, as well as DevOps tools like Jenkins, Docker, and Kubernetes, will provide you with a competitive advantage.
Why AWS Solutions Architect Career is in Hot Demand
Greater usage of cloud services across industries—such as healthcare, banking, entertainment, and education—has witnessed a sudden boom in the demand for AWS Solutions Architects with skills.
With increasingly larger numbers of firms attempting to bring their workloads on AWS or expand their cloud infrastructure, they need skilled specialists to lead them through this procedure, reduce potential risks, and make sure they are leveraging all the features AWS has to provide. Based on job market trends, the AWS Solutions Architect position is one of the most rewarding and in-demand IT careers, with average salaries between $120,000 and more than $160,000 per year, depending on experience and location. Furthermore, remote work innovations have optimized the potential for AWS Solutions Architects worldwide to work with best-in-class companies anywhere globally.
Real-World Impact: How AWS Solutions Architects Drive Innovation
AWS Solutions Architects are not only system architects but also innovation enablers.
Through designing flexible, secure, and elastic cloud solutions, they enable companies to get products to market quicker, reach customers globally, and adapt to shifting market needs in a matter of days. For instance, an e-commerce company collaborating with an AWS Solutions Architect would be able to accommodate a last-minute spike in website traffic for a holiday sale without interruption. A healthcare business would be able to securely store and process patient data in compliance with regulations through AWS's HIPAA-compliant solutions. A new media company would be able to deliver high-quality video with low latency through AWS's global content delivery network. These are just a few among several ways in which AWS Solutions Architects make a tremendous contribution in terms of fitting cloud technology in accordance with business objectives.
Conclusion: Why Every Cloud Strategy Needs an AWS Solutions Architect
There are several paths to the cloud, and if not guided correctly, there can be problems like unnecessary expenses, loopholes in security, and inefficiencies in the system.
The AWS Solutions Architect is where all these issues stop.
With extensive AWS technology knowledge and a vision, these experts make sure that companies not only move to the cloud securely but flourish there. Whether you are an executive charting your cloud course or a future cloud expert hoping to develop a fulfilling career, it is crucial that you know the importance of an AWS Solutions Architect. While cloud adoption accelerates, these architects will be at the forefront of digital change—designing the systems driving the future.
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text
Microservices Programming

Microservices architecture is revolutionizing the way modern software is built. Instead of a single monolithic application, microservices break down functionality into small, independent services that communicate over a network. This approach brings flexibility, scalability, and easier maintenance. In this post, we’ll explore the core concepts of microservices and how to start programming with them.
What Are Microservices?
Microservices are a software development technique where an application is composed of loosely coupled, independently deployable services. Each service focuses on a specific business capability and communicates with others through lightweight APIs, usually over HTTP or messaging queues.
Why Use Microservices?
Scalability: Scale services independently based on load.
Flexibility: Use different languages or technologies for different services.
Faster Development: Small teams can build, test, and deploy services independently.
Resilience: Failure in one service doesn't crash the entire system.
Better Maintainability: Easier to manage, update, and test smaller codebases.
Key Components of Microservices Architecture
Services: Individual, self-contained units with specific functionality.
API Gateway: Central access point that routes requests to appropriate services.
Service Discovery: Automatically locates services within the system (e.g., Eureka, Consul).
Load Balancing: Distributes incoming traffic across instances (e.g., Nginx, HAProxy).
Containerization: Deploy services in isolated environments (e.g., Docker, Kubernetes).
Messaging Systems: Allow asynchronous communication (e.g., RabbitMQ, Apache Kafka).
Popular Tools and Frameworks
Spring Boot + Spring Cloud (Java): Full-stack support for microservices.
Express.js (Node.js): Lightweight framework for building RESTful services.
FastAPI (Python): High-performance framework ideal for microservices.
Docker: Container platform for packaging and running services.
Kubernetes: Orchestrates and manages containerized microservices.
Example: A Simple Microservices Architecture
User Service: Manages user registration and authentication.
Product Service: Handles product listings and inventory.
Order Service: Manages order placement and status.
Each service runs on its own server or container, communicates through REST APIs, and has its own database to avoid tight coupling.
Best Practices for Microservices Programming
Keep services small and focused on a single responsibility.
Use versioned APIs to ensure backward compatibility.
Centralize logging and monitoring using tools like ELK Stack or Prometheus + Grafana.
Secure your APIs using tokens (JWT, OAuth2).
Automate deployments and CI/CD pipelines with tools like Jenkins, GitHub Actions, or GitLab CI.
Avoid shared databases between services — use event-driven architecture for coordination.
Challenges in Microservices
Managing communication and data consistency across services.
Increased complexity in deployment and monitoring.
Ensuring security between service endpoints.
Conclusion
Microservices programming is a powerful approach to building modern, scalable applications. While it introduces architectural complexity, the benefits in flexibility, deployment, and team autonomy make it an ideal choice for many large-scale projects. With the right tools and design patterns, you can unlock the full potential of microservices for your applications.
0 notes
Text
Service Mesh with Istio and Linkerd: A Practical Overview
As microservices architectures continue to dominate modern application development, managing service-to-service communication has become increasingly complex. Service meshes have emerged as a solution to address these complexities — offering enhanced security, observability, and traffic management between services.
Two of the most popular service mesh solutions today are Istio and Linkerd. In this blog post, we'll explore what a service mesh is, why it's important, and how Istio and Linkerd compare in real-world use cases.
What is a Service Mesh?
A service mesh is a dedicated infrastructure layer that controls communication between services in a distributed application. Instead of hardcoding service-to-service communication logic (like retries, failovers, and security policies) into your application code, a service mesh handles these concerns externally.
Key features typically provided by a service mesh include:
Traffic management: Fine-grained control over service traffic (routing, load balancing, fault injection)
Observability: Metrics, logs, and traces that give insights into service behavior
Security: Encryption, authentication, and authorization between services (often using mutual TLS)
Reliability: Retries, timeouts, and circuit breaking to improve service resilience
Why Do You Need a Service Mesh?
As applications grow more complex, maintaining reliable and secure communication between services becomes critical. A service mesh abstracts this complexity, allowing teams to:
Deploy features faster without worrying about cross-service communication challenges
Increase application reliability and uptime
Gain full visibility into service behavior without modifying application code
Enforce security policies consistently across the environment
Introducing Istio
Istio is one of the most feature-rich service meshes available today. Originally developed by Google, IBM, and Lyft, Istio offers deep integration with Kubernetes but can also support hybrid cloud environments.
Key Features of Istio:
Advanced traffic management: Canary deployments, A/B testing, traffic shifting
Comprehensive security: Mutual TLS, policy enforcement, and RBAC (Role-Based Access Control)
Extensive observability: Integrates with Prometheus, Grafana, Jaeger, and Kiali for metrics and tracing
Extensibility: Supports custom plugins through WebAssembly (Wasm)
Ingress/Egress gateways: Manage inbound and outbound traffic effectively
Pros of Istio:
Rich feature set suitable for complex enterprise use cases
Strong integration with Kubernetes and cloud-native ecosystems
Active community and broad industry adoption
Cons of Istio:
Can be resource-heavy and complex to set up and manage
Steeper learning curve compared to lighter service meshes
Introducing Linkerd
Linkerd is often considered the original service mesh and is known for its simplicity, performance, and focus on the core essentials.
Key Features of Linkerd:
Lightweight and fast: Designed to be resource-efficient
Simple setup: Easy to install, configure, and operate
Security-first: Automatic mutual TLS between services
Observability out of the box: Includes metrics, tap (live traffic inspection), and dashboards
Kubernetes-native: Deeply integrated with Kubernetes
Pros of Linkerd:
Minimal operational complexity
Lower resource usage
Easier learning curve for teams starting with service mesh
High performance and low latency
Cons of Linkerd:
Fewer advanced traffic management features compared to Istio
Less customizable for complex use cases
Choosing the Right Service Mesh
Choosing between Istio and Linkerd largely depends on your needs:
Choose Istio if you require advanced traffic management, complex security policies, and extensive customization — typically in larger, enterprise-grade environments.
Choose Linkerd if you value simplicity, low overhead, and rapid deployment — especially in smaller teams or organizations where ease of use is critical.
Ultimately, both Istio and Linkerd are excellent choices — it’s about finding the best fit for your application landscape and operational capabilities.
Final Thoughts
Service meshes are no longer just "nice to have" for microservices — they are increasingly a necessity for ensuring resilience, security, and observability at scale. Whether you pick Istio for its powerful feature set or Linkerd for its lightweight design, implementing a service mesh can greatly enhance your service architecture.
Stay tuned — in upcoming posts, we'll dive deeper into setting up Istio and Linkerd with hands-on labs and real-world use cases!
Would you also like me to include a hands-on quickstart guide (like "how to install Istio and Linkerd on a local Kubernetes cluster")? 🚀
For more details www.hawkstack.com
0 notes
Text
Site Reliability Engineering: Tools, Techniques & Responsibilities
Introduction to Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) is a modern approach to managing large-scale systems by applying software engineering principles to IT operations. Originally developed by Google, SRE focuses on improving system reliability, scalability, and performance through automation and data-driven decision-making.

At its core, SRE bridges the gap between development and operations teams. Rather than relying solely on manual interventions, SRE encourages building robust systems with self-healing capabilities. SRE teams are responsible for maintaining uptime, monitoring system health, automating repetitive tasks, and handling incident response.
A key concept in SRETraining is the use of Service Level Objectives (SLOs) and Error Budgets. These help organizations balance the need for innovation and reliability by defining acceptable levels of failure. SRE also emphasizes observability—the ability to understand what's happening inside a system using metrics, logs, and traces.
By embracing automation, continuous improvement, and a blameless culture, SRE enables teams to reduce downtime, scale efficiently, and deliver high-quality digital services. As businesses increasingly depend on digital infrastructure, the demand for SRE practices and professionals continues to grow. Whether you're in development, operations, or IT leadership, understanding SRE can greatly enhance your approach to building resilient systems.
Tools Commonly Used in SRE
Monitoring & Observability
Prometheus – Open-source monitoring system with time-series data and alerting.
Grafana – Visualization and dashboard tool, often used with Prometheus.
Datadog – Cloud-based monitoring platform for infrastructure, applications, and logs.
New Relic – Full-stack observability with APM and performance monitoring.
ELK Stack (Elasticsearch, Logstash, Kibana) – Log analysis and visualization.
Incident Management & Alerting
PagerDuty – Real-time incident alerting, on-call scheduling, and response automation.
Opsgenie – Alerting and incident response tool integrated with monitoring systems.
VictorOps (now Splunk On-Call) – Streamlines incident resolution with automated workflows.
Automation & Configuration Management
Ansible – Simple automation tool for configuration and deployment.
Terraform – Infrastructure as Code (IaC) for provisioning cloud resources.
Chef / Puppet – Configuration management tools for system automation.
CI/CD Pipelines
Jenkins – Widely used automation server for building, testing, and deploying code.
GitLab CI/CD – Integrated CI/CD pipelines with source control.
Spinnaker – Multi-cloud continuous delivery platform.
Cloud & Container Orchestration
Kubernetes – Container orchestration for scaling and managing applications.
Docker – Containerization tool for packaging applications.
AWS CloudWatch / GCP Stackdriver / Azure Monitor – Native cloud monitoring tools.
Best Practices in Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) promotes a disciplined approach to building and operating reliable systems. Adopting best practices in SRE helps organizations reduce downtime, manage complexity, and scale efficiently.
A foundational practice is defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs) to measure and set targets for performance and availability. These metrics ensure teams understand what reliability means for users and how to prioritize improvements.
Error budgets are another critical concept, allowing controlled failure to balance innovation with stability. If a system exceeds its error budget, development slows to focus on reliability enhancements.
SRE also emphasizes automation. Automating repetitive tasks like deployments, monitoring setups, and incident responses reduces human error and improves speed. Minimizing toil—manual, repetitive work that doesn’t add long-term value—is essential for team efficiency.
Observability is key. Systems should be designed with visibility in mind using logs, metrics, and traces to quickly detect and resolve issues.
Finally, a blameless post mortem culture fosters continuous learning. After incidents, teams analyze what went wrong without pointing fingers, focusing instead on preventing future issues.
Together, these practices create a culture of reliability, efficiency, and resilience—core goals of any successful SRE team.
Top 5 Responsibilities of a Site Reliability Engineer (SRE)
Maintain System Reliability and Uptime
Ensure services are available, performant, and meet defined availability targets.
Automate Operational Tasks
Build tools and scripts to automate deployments, monitoring, and incident response.
Monitor and Improve System Health
Set up observability tools (metrics, logs, traces) to detect and fix issues proactively.
Incident Management and Root Cause Analysis
Respond to incidents, minimize downtime, and conduct postmortems to learn from failures.
Define and Track SLOs/SLIs
Establish reliability goals and measure system performance against them.
Know More: Site Reliability Engineering (SRE) Foundation Training and Certification.
0 notes