#Kubernetes cluster management tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Best Kubernetes Management Tools in 2023
Best Kubernetes Management Tools in 2023 #homelab #vmwarecommunities #Kubernetesmanagementtools2023 #bestKubernetescommandlinetools #managingKubernetesclusters #Kubernetesdashboardinterfaces #kubernetesmanagementtools #Kubernetesdashboard
Kubernetes is everywhere these days. It is used in the enterprise and even in many home labs. It’s a skill that’s sought after, especially with today’s push for app modernization. Many tools help you manage things in Kubernetes, like clusters, pods, services, and apps. Here’s my list of the best Kubernetes management tools in 2023. Table of contentsWhat is Kubernetes?Understanding Kubernetes and…

View On WordPress
#best Kubernetes command line tools#containerized applications management#Kubernetes cluster management tools#Kubernetes cost monitoring#Kubernetes dashboard interfaces#Kubernetes deployment solutions#Kubernetes management tools 2023#large Kubernetes deployments#managing Kubernetes clusters#open-source Kubernetes tools
0 notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Modern Tools Enhance Data Governance and PII Management Compliance

Modern data governance focuses on effectively managing Personally Identifiable Information (PII). Tools like IBM Cloud Pak for Data (CP4D), Red Hat OpenShift, and Kubernetes provide organizations with comprehensive solutions to navigate complex regulatory requirements, including GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). These platforms offer secure data handling, lineage tracking, and governance automation, helping businesses stay compliant while deriving value from their data.
PII management involves identifying, protecting, and ensuring the lawful use of sensitive data. Key requirements such as transparency, consent, and safeguards are essential to mitigate risks like breaches or misuse. IBM Cloud Pak for Data integrates governance, lineage tracking, and AI-driven insights into a unified framework, simplifying metadata management and ensuring compliance. It also enables self-service access to data catalogs, making it easier for authorized users to access and manage sensitive data securely.
Advanced IBM Cloud Pak for Data features include automated policy reinforcement and role-based access that ensure that PII remains protected while supporting analytics and machine learning applications. This approach simplifies compliance, minimizing the manual workload typically associated with regulatory adherence.
The growing adoption of multi-cloud environments has necessitated the development of platforms such as Informatica and Collibra to offer complementary governance tools that enhance PII protection. These solutions use AI-supported insights, automated data lineage, and centralized policy management to help organizations seeking to improve their data governance frameworks.
Mr. Valihora has extensive experience with IBM InfoSphere Information Server “MicroServices” products (which are built upon Red Hat Enterprise Linux Technology – in conjunction with Docker\Kubernetes.) Tim Valihora - President of TVMG Consulting Inc. - has extensive experience with respect to:
IBM InfoSphere Information Server “Traditional” (IIS v11.7.x)
IBM Cloud PAK for Data (CP4D)
IBM “DataStage Anywhere”
Mr. Valihora is a US based (Vero Beach, FL) Data Governance specialist within the IBM InfoSphere Information Server (IIS) software suite and is also Cloud Certified on Collibra Data Governance Center.
Career Highlights Include: Technical Architecture, IIS installations, post-install-configuration, SDLC mentoring, ETL programming, performance-tuning, client-side training (including administrators, developers or business analysis) on all of the over 15 out-of-the-box IBM IIS products Over 180 Successful IBM IIS installs - Including the GRID Tool-Kit for DataStage (GTK), MPP, SMP, Multiple-Engines, Clustered Xmeta, Clustered WAS, Active-Passive Mirroring and Oracle Real Application Clustered “IADB” or “Xmeta” configurations. Tim Valihora has been credited with performance tuning the words fastest DataStage job which clocked in at 1.27 Billion rows of inserts\updates every 12 minutes (using the Dynamic Grid ToolKit (GTK) for DataStage (DS) with a configuration file that utilized 8 compute-nodes - each with 12 CPU cores and 64 GB of RAM.)
0 notes
Text
Integrating ROSA Applications with AWS Services (CS221)
As cloud-native architectures become the backbone of modern application deployments, combining the power of Red Hat OpenShift Service on AWS (ROSA) with native AWS services unlocks immense value for developers and DevOps teams alike. In this blog post, we explore how to integrate ROSA-hosted applications with AWS services to build scalable, secure, and cloud-optimized solutions — a key skill set emphasized in the CS221 course.
🚀 What is ROSA?
Red Hat OpenShift Service on AWS (ROSA) is a managed OpenShift platform that runs natively on AWS. It allows organizations to deploy Kubernetes-based applications while leveraging the scalability and global reach of AWS, without managing the underlying infrastructure.
With ROSA, you get:
Fully managed OpenShift clusters
Integrated with AWS IAM and billing
Access to AWS services like RDS, S3, DynamoDB, Lambda, etc.
Native CI/CD, container orchestration, and operator support
🧩 Why Integrate ROSA with AWS Services?
ROSA applications often need to interact with services like:
Amazon S3 for object storage
Amazon RDS or DynamoDB for database integration
Amazon SNS/SQS for messaging and queuing
AWS Secrets Manager or SSM Parameter Store for secrets management
Amazon CloudWatch for monitoring and logging
Integration enhances your application’s:
Scalability — Offload data, caching, messaging to AWS-native services
Security — Use IAM roles and policies for fine-grained access control
Resilience — Rely on AWS SLAs for critical components
Observability — Monitor and trace hybrid workloads via CloudWatch and X-Ray
🔐 IAM and Permissions: Secure Integration First
A crucial part of ROSA-AWS integration is managing IAM roles and policies securely.
Steps:
Create IAM Roles for Service Accounts (IRSA):
ROSA supports IAM Roles for Service Accounts, allowing pods to securely access AWS services without hardcoding credentials.
Attach IAM Policy to the Role:
Example: An application that uploads files to S3 will need the following permissions:{ "Effect": "Allow", "Action": ["s3:PutObject", "s3:GetObject"], "Resource": "arn:aws:s3:::my-bucket-name/*" }
Annotate OpenShift Service Account:
Use oc annotate to associate your OpenShift service account with the IAM role.
📦 Common Integration Use Cases
1. Storing App Logs in S3
Use a Fluentd or Loki pipeline to export logs from OpenShift to Amazon S3.
2. Connecting ROSA Apps to RDS
Applications can use standard drivers (PostgreSQL, MySQL) to connect to RDS endpoints — make sure to configure VPC and security groups appropriately.
3. Triggering AWS Lambda from ROSA
Set up an API Gateway or SNS topic to allow OpenShift applications to invoke serverless functions in AWS for batch processing or asynchronous tasks.
4. Using AWS Secrets Manager
Mount secrets securely in pods using CSI drivers or inject them using operators.
🛠 Hands-On Example: Accessing S3 from ROSA Pod
Here’s a quick walkthrough:
Create an IAM Role with S3 permissions.
Associate the role with a Kubernetes service account.
Deploy your pod using that service account.
Use AWS SDK (e.g., boto3 for Python) inside your app to access S3.
oc create sa s3-access oc annotate sa s3-access eks.amazonaws.com/role-arn=arn:aws:iam::<account-id>:role/S3AccessRole
Then reference s3-access in your pod’s YAML.
📚 ROSA CS221 Course Highlights
The CS221 course from Red Hat focuses on:
Configuring service accounts and roles
Setting up secure access to AWS services
Using OpenShift tools and operators to manage external integrations
Best practices for hybrid cloud observability and logging
It’s a great choice for developers, cloud engineers, and architects aiming to harness the full potential of ROSA + AWS.
✅ Final Thoughts
Integrating ROSA with AWS services enables teams to build robust, cloud-native applications using best-in-class tools from both Red Hat and AWS. Whether it's persistent storage, messaging, serverless computing, or monitoring — AWS services complement ROSA perfectly.
Mastering these integrations through real-world use cases or formal training (like CS221) can significantly uplift your DevOps capabilities in hybrid cloud environments.
Looking to Learn or Deploy ROSA with AWS?
HawkStack Technologies offers hands-on training, consulting, and ROSA deployment support. For more details www.hawkstack.com
0 notes
Text
From Code to Production: Streamlining the ML Lifecycle with Kubernetes and Kubeflow
In today’s AI-driven landscape, organizations are increasingly looking to scale their machine learning (ML) initiatives from isolated experiments to production-grade deployments. However, operationalizing ML is not trivial—it involves a complex set of challenges including infrastructure management, workflow automation, reproducibility, and deployment governance.
To address these, industry leaders are turning to Kubernetes and Kubeflow—tools that bring DevOps best practices to the ML lifecycle, enabling scalable, reliable, and maintainable ML workflows across teams and environments.
The Complexity of Operationalizing Machine Learning
While data scientists often begin with model development in local environments or notebooks, this initial experimentation phase represents only a fraction of the full ML lifecycle. Moving from prototype to production requires:
Coordinating multi-step workflows (e.g., preprocessing, training, validation, deployment)
Managing compute-intensive tasks and scaling across GPUs or distributed environments
Ensuring reproducibility across versions, datasets, and model iterations
Enabling continuous integration and delivery (CI/CD) for ML pipelines
Monitoring model performance and retraining when necessary
Without the right infrastructure, these steps become manual, error-prone, and difficult to maintain at scale.
Kubernetes: The Infrastructure Backbone
Kubernetes has emerged as the de facto standard for container orchestration and infrastructure automation. Its relevance in ML stems from its ability to:
Dynamically allocate compute resources based on workload requirements
Standardize deployment environments across cloud and on-premise infrastructure
Provide high availability, fault tolerance, and scalability for training and serving
Enable microservices-based architecture for modular, maintainable ML pipelines
By containerizing ML workloads and running them on Kubernetes, teams gain consistency, flexibility, and control—essential attributes for production-grade ML.
Kubeflow: Machine Learning at Scale
Kubeflow, built on Kubernetes, is a dedicated platform for managing the entire ML lifecycle. It abstracts the complexities of infrastructure, allowing teams to focus on modeling and experimentation while automating the rest. Key features include:
Kubeflow Pipelines: Define and orchestrate repeatable, modular ML workflows
Training Operators: Support for distributed training frameworks (e.g., TensorFlow, PyTorch)
Katib: Automated hyperparameter tuning at scale
KFServing (KServe): Scalable, serverless model serving
Centralized Notebook Environments: Managed Jupyter notebooks running securely within the cluster
Kubeflow enables organizations to enforce consistency, governance, and observability across all stages of ML development and deployment.
Business Impact and Technical Advantages
Implementing Kubernetes and Kubeflow in ML operations delivers tangible benefits:
Increased Operational Efficiency: Reduced manual effort through automation and CI/CD for ML
Scalability and Flexibility: Easily scale workloads to meet demand, across any cloud or hybrid environment
Improved Reproducibility and Compliance: Version control for datasets, code, and model artifacts
Accelerated Time-to-Value: Faster transition from model experimentation to business impact
These platforms also support better collaboration between data science, engineering, and DevOps teams, driving organizational alignment and reducing friction in model deployment processes.
Conclusion
As enterprises continue to invest in AI/ML, the need for robust, scalable, and repeatable operational practices has never been greater. Kubernetes and Kubeflow provide a powerful foundation to manage the end-to-end ML lifecycle—from code to production.
Organizations that adopt these tools are better positioned to drive innovation, reduce operational overhead, and realize the full potential of their machine learning initiatives.
0 notes
Text
Why Should your GPU cloud management software be Kubernetes agnostic?
As organizations, including Neoclouds and sovereign entities, develop GPU cloud infrastructures to support AI workloads, many cloud management solutions come bundled with a specific Kubernetes distribution. While this bundling might appear convenient initially, it often leads to significant long-term challenges, primarily due to vendor lock-in.
Such tightly integrated solutions can become inflexible, incompatible with existing enterprise IT environments, and difficult to scale across diverse infrastructures. In contrast, modern GPU cloud management software should be Kubernetes-aware—capable of integrating seamlessly with any CNCF-compliant Kubernetes cluster—rather than being bound to a particular distribution.
Challenges with Bundled Kubernetes Distributions
One of the most pressing issues with bundled Kubernetes solutions is vendor lock-in. When GPU cloud management software is tightly coupled with a specific Kubernetes distribution, it restricts the freedom to adopt or integrate with existing or preferred Kubernetes environments already deployed within the organization. This limits flexibility and often forces organizations into long-term dependencies on a single vendor.
Another concern is operational rigidity. These bundled solutions typically offer limited support for third-party monitoring, alerting, and optimization tools, thereby hampering operational visibility and performance tuning. They also constrain customization options, making it harder to adapt the platform to specific infrastructure or workload needs.
The lack of advanced multi-tenancy features further compounds the problem. While many of these platforms offer basic role-based access control (RBAC) and namespace isolation, they fall short when it comes to supporting complex, enterprise-grade multi-tenant environments that require deeper isolation of resources and policies.
Furthermore, hybrid cloud support is often inadequate in such stacks. Portability between on-premises, hybrid, or edge environments is either limited or non-existent, making it difficult to extend workloads across multiple infrastructures or federate across clouds.
Lastly, there's a frequent misalignment with enterprise DevOps practices. Enterprises often have standardized Kubernetes distributions and established CI/CD pipelines. Introducing a new, tightly-coupled distribution disrupts these processes, requiring lengthy certification cycles and integration efforts to bring the new solution in line with internal systems.
Defining Kubernetes-Aware Management
A Kubernetes-aware GPU cloud management solution should:
Operate across multiple clusters, accommodating various tenants, regions, or environments.
Be deployable atop any Kubernetes distribution without enforcing a specific one.
Integrate with existing Kubernetes-native tools like Prometheus, Grafana, Istio, and cert-manager.
Support GPU-aware scheduling frameworks such as Run:AI, Ray, and SLURM as optional plugins, not mandatory dependencies.
The aarna.ml GPU CMS Advantage
The aarna.ml GPU Cloud Management Software (CMS) exemplifies a platform-agnostic approach, designed for cloud providers and enterprise AI platforms. Its key features include:
Compatibility with any CNCF-compliant Kubernetes cluster, including Upstream Kubernetes, OpenShift, EKS, AKS, and SUSE Rancher/RKE.
Unified management of multiple clusters through a centralized control plane.
Robust multi-tenancy support via per-tenant namespaces, RBAC policies, and storage/network isolation, independent of the underlying Kubernetes distribution.
Integration with GPU scheduling frameworks like Ray, Run:AI, and SLURM, tailored to specific workload requirements.
Orchestration capabilities for bare-metal, virtual machine, and container workloads across both Kubernetes and non-Kubernetes environments.
Emphasis on automation, abstraction, and policy-driven management to avoid distribution lock-in.
This approach ensures maximum flexibility, alignment with enterprise architectures, and the freedom to evolve underlying platforms, catering to Neoclouds, sovereign clouds, and private GPU cloud providers alike.
Comparative Overview
Unlike bundled GPU orchestration platforms that come tied to specific Kubernetes distributions, aarna.ml GPU CMS offers a completely vendor-neutral approach. Most tightly integrated solutions rely on their own Kubernetes versions, making them incompatible with broader IT environments. In contrast, aarna.ml is fully compatible with any CNCF-compliant Kubernetes, giving enterprises the freedom to choose what works best for them.
Additionally, multi-cluster support is often limited or non-existent in coupled stacks, while aarna.ml provides robust multi-cluster capabilities out of the box. In terms of multi-tenancy, traditional stacks may offer only basic role-based access and namespace management. Aarna.ml, however, delivers full tenant isolation and policy controls designed for enterprise-grade environments.
Support for external infrastructure is another differentiator. Coupled stacks generally do not support hybrid or external deployments effectively, whereas aarna.ml is built to span on-prem, cloud, and edge. And when it comes to GPU scheduler support, many locked-in systems provide limited or no integration, while aarna.ml allows for flexible, pluggable integration with popular frameworks such as Run:AI, Ray, and SLURM.
Overall, aarna.ml’s compatibility with existing Kubernetes clusters, advanced features, and flexible architecture make it a forward-looking choice for modern AI infrastructure.
Conclusion
While bundled GPU orchestration platforms may offer initial convenience, they often impede scalability, integration, and agility in the long run. Embracing a Kubernetes-agnostic approach with solutions like aarna.ml GPU CMS provides the flexibility and compatibility essential for modern AI cloud infrastructures.
1 note
·
View note
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring #homelab #kubernetes #KubernetesManagement #LensKubernetesDesktop #KubernetesClusterManagement #MultiClusterManagement #KubernetesSecurityFeatures #KubernetesUI #kubernetesmonitoring
Kubernetes is a well-known container orchestration platform. It allows admins and organizations to operate their containers and support modern applications in the enterprise. Kubernetes management is not for the “faint of heart.” It requires the right skill set and tools. Lens Kubernetes desktop is an app that enables managing Kubernetes clusters on Windows and Linux devices. Table of…

View On WordPress
#Kubernetes cluster management#Kubernetes collaboration tools#Kubernetes management#Kubernetes performance improvements#Kubernetes real-time monitoring#Kubernetes security features#Kubernetes user interface#Lens Kubernetes 2023.10#Lens Kubernetes Desktop#multi-cluster management
0 notes
Text
Apigee APIM Operator for API Administration On Any Gateway

We now provide the Apigee APIM Operator, a lightweight Application Programming Interface Management and API Gateway tool for GKE environments. This release is a critical step towards making Apigee API management available on every gateway, anywhere.
The Kubernetes-based Apigee APIM Operator allows you build and manage API offerings. Cloud-native developers benefit from its command-line interface for Kubernetes tools like kubectl. APIM resources help the operator sync your Google Kubernetes Engine cluster with Apigee.
Advantages
For your business, the APIM Operator offers:
With the APIM Operator, API producers may manage and protect their APIs using Kubernetes resource definitions. Same tools and methods for managing other Kubernetes resources can be used for APIs.
Load balancer-level API regulation streamlines networking configuration and API security and access for the operator.
Kubernetes' role-based access control (RBAC) and Apigee custom resource definitions enable fine-grained access control for platform administrators, infrastructure administrators, and API developers.
Integration with Kubernetes: The operator integrates Helm charts and Custom Resource Definitions to make cloud-native development easy.
Reduced Context Switching: The APIM Operator lets developers administer APIs from Kubernetes, eliminating the need to switch tools.
Use APIM Operator when
API producers who want Kubernetes API management should utilise APIM Operator. It's especially useful for cloud-native Kubernetes developers who want to manage their APIs using the same tools and methods. Our APIM Operator lets Apigee clients add Cloud Native Computing Foundation (CNCF)-based API management features.
limitations
The APIM Operator's Public Preview has certain restrictions:
Support is limited to REST APIs. Public Preview doesn't support GraphQL or gRPC.
The Public Preview edition supports 25 regional or global GKE Gateway resources and API management policies.
A single environment can have 25 APIM extension policies. Add extra APIM extension policies by creating a new environment.
Gateway resources can have API management policies, but not HTTPRoutes.
Public Preview does not support region extension. A setup APIM Operator cannot be moved to different regions.
Meaning for you?
With Kubernetes-like YAML, you can configure API management for many cloud-native enterprises that use CNCF-standardized tooling without switching tools.
APIM integration with Kubernetes and CNCF toolchains reduces conceptual and operational complexity for platform managers and service developers on Google Cloud.
Policy Management: RBAC administrators can create APIM template rules to let groups use different policies based on their needs. Add Apigee rules to APIM templates to give users and administrators similar capabilities as Apigee Hybrid.
Key Features and Capabilities
The GA version lets users set up a GKE cluster and GKE Gateway to use an Apigee Hybrid instance for API management via a traffic extension (ext-proc callout). It supports factory-built Day-Zero settings with workload modification and maintains API lifespan with Kubernetes/CNCF toolchain YAML rules.
Meeting Customer Needs
This functionality addresses the growing requirement for developer-friendly API management solutions. Apigee was considered less agile owing to its complexity and the necessity to shift from Kubectl to other tools. In response to this feedback, Google Cloud created the APIM Operator, which simplifies and improves API management.
Looking Ahead
It is exploring gRPC and GraphQL support to support more API types, building on current GA version's robust foundation. As features and support are added, it will notify the community. Google Cloud is also considering changing Gateway resource and policy attachment limits.
The APIM Operator will improve developer experience and simplify API management for clients, they believe. It looks forward to seeing how creatively you use this functionality in your apps.
#APIMOperator#ApigeeAPIMOperator#APIGateway#APIAdministration#APIManagement#Apigee#CustomResourceDefinitions#technology#technews#news#technologynews#technologytrends
0 notes
Text
Security and Compliance in Cloud Deployments: A Proactive DevOps Approach
As cloud computing becomes the backbone of modern digital infrastructure, organizations are increasingly migrating applications and data to the cloud for agility, scalability, and cost-efficiency. However, this shift also brings elevated risks around security and compliance. To ensure safety and regulatory alignment, companies must adopt a proactive DevOps approach that integrates security into every stage of the development lifecycle—commonly referred to as DevSecOps.
Why Security and Compliance Matter in the Cloud
Cloud environments are dynamic and complex. Without the proper controls in place, they can easily become vulnerable to data breaches, configuration errors, insider threats, and compliance violations. Unlike traditional infrastructure, cloud-native deployments are continuously evolving, which requires real-time security measures and automated compliance enforcement.
Neglecting these areas can lead to:
Financial penalties for regulatory violations (GDPR, HIPAA, SOC 2, etc.)
Data loss and reputation damage
Business continuity risks due to breaches or downtime
The Role of DevOps in Cloud Security
DevOps is built around principles of automation, collaboration, and continuous delivery. By extending these principles to include security (DevSecOps), teams can ensure that infrastructure and applications are secure from the ground up, rather than bolted on as an afterthought.
A proactive DevOps approach focuses on:
Shift-Left Security: Security checks are moved earlier in the development process to catch issues before deployment.
Continuous Compliance: Policies are codified and integrated into CI/CD pipelines to maintain adherence to industry standards automatically.
Automated Risk Detection: Real-time scanning tools identify vulnerabilities, misconfigurations, and policy violations continuously.
Infrastructure as Code (IaC) Security: IaC templates are scanned for compliance and security flaws before provisioning cloud infrastructure.
Key Components of a Proactive Cloud Security Strategy
Identity and Access Management (IAM): Ensure least-privilege access using role-based policies and multi-factor authentication.
Encryption: Enforce encryption of data both at rest and in transit using cloud-native tools and third-party integrations.
Vulnerability Scanning: Use automated scanners to check applications, containers, and VMs for known security flaws.
Compliance Monitoring: Track compliance posture continuously against frameworks such as ISO 27001, PCI-DSS, and NIST.
Logging and Monitoring: Centralized logging and anomaly detection help detect threats early and support forensic investigations.
Secrets Management: Store and manage credentials, tokens, and keys using secure vaults.
Best Practices for DevSecOps in the Cloud
Integrate Security into CI/CD Pipelines: Use tools like Snyk, Aqua, and Checkov to run security checks automatically.
Perform Regular Threat Modeling: Continuously assess evolving attack surfaces and prioritize high-impact risks.
Automate Patch Management: Ensure all components are regularly updated and unpatched vulnerabilities are minimized.
Enable Policy as Code: Define and enforce compliance rules through version-controlled code in your DevOps pipeline.
Train Developers and Engineers: Security is everyone’s responsibility—conduct regular security training and awareness sessions.
How Salzen Cloud Ensures Secure Cloud Deployments
At Salzen Cloud, we embed security and compliance at the core of our cloud solutions. Our team works with clients to develop secure-by-design architectures that incorporate DevSecOps principles from planning to production. Whether it's automating compliance reports, hardening Kubernetes clusters, or configuring IAM policies, we ensure cloud operations are secure, scalable, and audit-ready.
Conclusion
In the era of cloud-native applications, security and compliance can no longer be reactive. A proactive DevOps approach ensures that every component of your cloud environment is secure, compliant, and continuously monitored. By embedding security into CI/CD workflows and automating compliance checks, organizations can mitigate risks while maintaining development speed.
Partner with Salzen Cloud to build secure and compliant cloud infrastructures with confidence.
0 notes
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
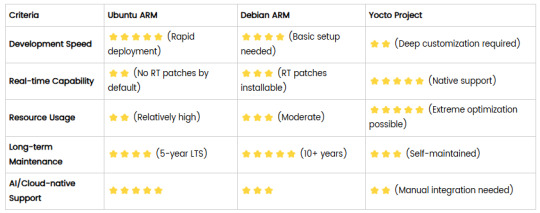
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
Unlocking Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
In today’s cloud-native world, Kubernetes has become the de facto platform for orchestrating containerized applications. However, with this rise comes the critical need for persistent, reliable, and scalable storage solutions that can keep up with dynamic workloads. This is where Red Hat OpenShift Data Foundation (ODF) steps in as a powerful storage layer for OpenShift clusters.
In this blog post, we explore how the DO370 training course—Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation—equips IT professionals with the skills to deploy and manage advanced Kubernetes storage solutions in an enterprise environment.
What is OpenShift Data Foundation?
Red Hat OpenShift Data Foundation (formerly OpenShift Container Storage) is an integrated, software-defined storage solution for containers. It provides a unified platform to manage block, file, and object storage directly within your OpenShift cluster. Built on Ceph and Rook, ODF is designed for high availability, scalability, and performance—making it ideal for enterprise applications.
Key Features of ODF:
Seamless integration with Red Hat OpenShift
Dynamic provisioning of persistent volumes
Support for multi-cloud and hybrid storage scenarios
Built-in data replication, encryption, and disaster recovery
Monitoring and management through the OpenShift console
About the DO370 Course
The DO370 course is designed for infrastructure administrators, storage engineers, and DevOps professionals who want to master enterprise-grade storage in OpenShift environments.
Course Highlights:
Install and configure OpenShift Data Foundation on OpenShift clusters
Manage storage classes, persistent volume claims (PVCs), and object storage
Implement monitoring and troubleshooting for storage resources
Secure data at rest and in motion
Explore advanced topics like snapshotting, data resilience, and performance tuning
Hands-On Labs:
Red Hat’s training emphasizes practical, real-world labs. In DO370, learners get hands-on experience setting up ODF, deploying workloads, managing storage resources, and performing disaster recovery simulations—all within a controlled OpenShift environment.
Why DO370 Matters for Enterprises
As enterprises transition from legacy systems to cloud-native platforms, managing stateful workloads on Kubernetes becomes a top priority. DO370 equips your team with the tools to:
Deliver high-performance storage for databases and big data applications
Ensure business continuity with built-in data protection features
Optimize storage usage across hybrid and multi-cloud environments
Reduce infrastructure complexity by consolidating storage on OpenShift
Ideal Audience
This course is ideal for:
Red Hat Certified System Administrators (RHCSA)
OpenShift administrators and site reliability engineers (SREs)
Architects designing storage for containerized applications
Teams adopting DevOps and CI/CD practices with stateful apps
Conclusion
If your organization is embracing Kubernetes at scale, you cannot afford to overlook storage. DO370: Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation gives your teams the knowledge and confidence to deploy resilient, scalable, and secure storage in OpenShift environments.
Whether you're modernizing legacy applications or building new cloud-native solutions, OpenShift Data Foundation is your answer for enterprise-grade Kubernetes storage—and DO370 is the path to mastering it.
Interested in enrolling in DO370 for your team? At HawkStack Technologies, we offer Red Hat official training and corporate packages, including access to Red Hat Learning Subscription (RHLS). Contact us today to learn more! 🌐 www.hawkstack.com
0 notes
Text
Understanding Kubernetes Architecture: Building Blocks of Cloud-Native Infrastructure
In the era of rapid digital transformation, Kubernetes has emerged as the de facto standard for orchestrating containerized workloads across diverse infrastructure environments. For DevOps professionals, cloud architects, and platform engineers, a nuanced understanding of Kubernetes architecture is essential—not only for operational excellence but also for architecting resilient, scalable, and portable applications in production-grade environments.
Core Components of Kubernetes Architecture
1. Control Plane Components (Master Node)
The Kubernetes control plane orchestrates the entire cluster and ensures that the system’s desired state matches the actual state.
API Server: Serves as the gateway to the cluster. It handles RESTful communication, validates requests, and updates cluster state via etcd.
etcd: A distributed, highly available key-value store that acts as the single source of truth for all cluster metadata.
Controller Manager: Runs various control loops to ensure the desired state of resources (e.g., replicaset, endpoints).
Scheduler: Intelligently places Pods on nodes by evaluating resource requirements and affinity rules.
2. Worker Node Components
Worker nodes host the actual containerized applications and execute instructions sent from the control plane.
Kubelet: Ensures the specified containers are running correctly in a pod.
Kube-proxy: Implements network rules, handling service discovery and load balancing within the cluster.
Container Runtime: Abstracts container operations and supports image execution (e.g., containerd, CRI-O).
3. Pods
The pod is the smallest unit in the Kubernetes ecosystem. It encapsulates one or more containers, shared storage volumes, and networking settings, enabling co-located and co-managed execution.
Kubernetes in Production: Cloud-Native Enablement
Kubernetes is a cornerstone of modern DevOps practices, offering robust capabilities like:
Declarative configuration and automation
Horizontal pod autoscaling
Rolling updates and canary deployments
Self-healing through automated pod rescheduling
Its modular, pluggable design supports service meshes (e.g., Istio), observability tools (e.g., Prometheus), and GitOps workflows, making it the foundation of cloud-native platforms.
Conclusion
Kubernetes is more than a container orchestrator—it's a sophisticated platform for building distributed systems at scale. Mastering its architecture equips professionals with the tools to deliver highly available, fault-tolerant, and agile applications in today’s multi-cloud and hybrid environments.
0 notes
Text
Getting Started with Google Kubernetes Engine: Your Gateway to Cloud-Native Greatness
After spending over 8 years deep in the trenches of cloud engineering and DevOps, I can tell you one thing for sure: if you're serious about scalability, flexibility, and real cloud-native application deployment, Google Kubernetes Engine (GKE) is where the magic happens.
Whether you’re new to Kubernetes or just exploring managed container platforms, getting started with Google Kubernetes Engine is one of the smartest moves you can make in your cloud journey.
"Containers are cool. Orchestrated containers? Game-changing."
🚀 What is Google Kubernetes Engine (GKE)?
Google Kubernetes Engine is a fully managed Kubernetes platform that runs on top of Google Cloud. GKE simplifies deploying, managing, and scaling containerized apps using Kubernetes—without the overhead of maintaining the control plane.
Why is this a big deal?
Because Kubernetes is notoriously powerful and notoriously complex. With GKE, Google handles all the heavy lifting—from cluster provisioning to upgrades, logging, and security.
"GKE takes the complexity out of Kubernetes so you can focus on building, not babysitting clusters."
🧭 Why Start with GKE?
If you're a developer, DevOps engineer, or cloud architect looking to:
Deploy scalable apps across hybrid/multi-cloud
Automate CI/CD workflows
Optimize infrastructure with autoscaling & spot instances
Run stateless or stateful microservices seamlessly
Then GKE is your launchpad.
Here’s what makes GKE shine:
Auto-upgrades & auto-repair for your clusters
Built-in security with Shielded GKE Nodes and Binary Authorization
Deep integration with Google Cloud IAM, VPC, and Logging
Autopilot mode for hands-off resource management
Native support for Anthos, Istio, and service meshes
"With GKE, it's not about managing containers—it's about unlocking agility at scale."
🔧 Getting Started with Google Kubernetes Engine
Ready to dive in? Here's a simple flow to kick things off:
Set up your Google Cloud project
Enable Kubernetes Engine API
Install gcloud CLI and Kubernetes command-line tool (kubectl)
Create a GKE cluster via console or command line
Deploy your app using Kubernetes manifests or Helm
Monitor, scale, and manage using GKE dashboard, Cloud Monitoring, and Cloud Logging
If you're using GKE Autopilot, Google manages your node infrastructure automatically—so you only manage your apps.
“Don’t let infrastructure slow your growth. Let GKE scale as you scale.”
🔗 Must-Read Resources to Kickstart GKE
👉 GKE Quickstart Guide – Google Cloud
👉 Best Practices for GKE – Google Cloud
👉 Anthos and GKE Integration
👉 GKE Autopilot vs Standard Clusters
👉 Google Cloud Kubernetes Learning Path – NetCom Learning
🧠 Real-World GKE Success Stories
A FinTech startup used GKE Autopilot to run microservices with zero infrastructure overhead
A global media company scaled video streaming workloads across continents in hours
A university deployed its LMS using GKE and reduced downtime by 80% during peak exam seasons
"You don’t need a huge ops team to build a global app. You just need GKE."
🎯 Final Thoughts
Getting started with Google Kubernetes Engine is like unlocking a fast track to modern app delivery. Whether you're running 10 containers or 10,000, GKE gives you the tools, automation, and scale to do it right.
With Google Cloud’s ecosystem—from Cloud Build to Artifact Registry to operations suite—GKE is more than just Kubernetes. It’s your platform for innovation.
“Containers are the future. GKE is the now.”
So fire up your first cluster. Launch your app. And let GKE do the heavy lifting while you focus on what really matters—shipping great software.
Let me know if you’d like this formatted into a visual infographic or checklist to go along with the blog!
1 note
·
View note
Text
EX280: Red Hat OpenShift Administration
Red Hat OpenShift Administration is a vital skill for IT professionals interested in managing containerized applications, simplifying Kubernetes, and leveraging enterprise cloud solutions. If you’re looking to excel in OpenShift technology, this guide covers everything from its core concepts and prerequisites to advanced certification and career benefits.
1. What is Red Hat OpenShift?
Red Hat OpenShift is a robust, enterprise-grade Kubernetes platform designed to help developers build, deploy, and scale applications across hybrid and multi-cloud environments. It offers a simplified, consistent approach to managing Kubernetes, with added security, automation, and developer tools, making it ideal for enterprise use.
Key Components of OpenShift:
OpenShift Platform: The foundation for scalable applications with simplified Kubernetes integration.
OpenShift Containers: Allows seamless container orchestration for optimized application deployment.
OpenShift Cluster: Manages workload distribution, ensuring application availability across multiple nodes.
OpenShift Networking: Provides efficient network configuration, allowing applications to communicate securely.
OpenShift Security: Integrates built-in security features to manage access, policies, and compliance seamlessly.
2. Why Choose Red Hat OpenShift?
OpenShift provides unparalleled advantages for organizations seeking a Kubernetes-based platform tailored to complex, cloud-native environments. Here’s why OpenShift stands out among container orchestration solutions:
Enterprise-Grade Security: OpenShift Security layers, such as role-based access control (RBAC) and automated security policies, secure every component of the OpenShift environment.
Enhanced Automation: OpenShift Automation enables efficient deployment, management, and scaling, allowing businesses to speed up their continuous integration and continuous delivery (CI/CD) pipelines.
Streamlined Deployment: OpenShift Deployment features enable quick, efficient, and predictable deployments that are ideal for enterprise environments.
Scalability & Flexibility: With OpenShift Scaling, administrators can adjust resources dynamically based on application requirements, maintaining optimal performance even under fluctuating loads.
Simplified Kubernetes with OpenShift: OpenShift builds upon Kubernetes, simplifying its management while adding comprehensive enterprise features for operational efficiency.
3. Who Should Pursue Red Hat OpenShift Administration?
A career in Red Hat OpenShift Administration is suitable for professionals in several IT roles. Here’s who can benefit:
System Administrators: Those managing infrastructure and seeking to expand their expertise in container orchestration and multi-cloud deployments.
DevOps Engineers: OpenShift’s integrated tools support automated workflows, CI/CD pipelines, and application scaling for DevOps operations.
Cloud Architects: OpenShift’s robust capabilities make it ideal for architects designing scalable, secure, and portable applications across cloud environments.
Software Engineers: Developers who want to build and manage containerized applications using tools optimized for development workflows.
4. Who May Not Benefit from OpenShift?
While OpenShift provides valuable enterprise features, it may not be necessary for everyone:
Small Businesses or Startups: OpenShift may be more advanced than required for smaller, less complex projects or organizations with a limited budget.
Beginner IT Professionals: For those new to IT or with minimal cloud experience, starting with foundational cloud or Linux skills may be a better path before moving to OpenShift.
5. Prerequisites for Success in OpenShift Administration
Before diving into Red Hat OpenShift Administration, ensure you have the following foundational knowledge:
Linux Proficiency: Linux forms the backbone of OpenShift, so understanding Linux commands and administration is essential.
Basic Kubernetes Knowledge: Familiarity with Kubernetes concepts helps as OpenShift is built on Kubernetes.
Networking Fundamentals: OpenShift Networking leverages container networks, so knowledge of basic networking is important.
Hands-On OpenShift Training: Comprehensive OpenShift training, such as the OpenShift Administration Training and Red Hat OpenShift Training, is crucial for hands-on learning.
Read About Ethical Hacking
6. Key Benefits of OpenShift Certification
The Red Hat OpenShift Certification validates skills in container and application management using OpenShift, enhancing career growth prospects significantly. Here are some advantages:
EX280 Certification: This prestigious certification verifies your expertise in OpenShift cluster management, automation, and security.
Job-Ready Skills: You’ll develop advanced skills in OpenShift deployment, storage, scaling, and troubleshooting, making you an asset to any IT team.
Career Mobility: Certified professionals are sought after for roles in OpenShift Administration, cloud architecture, DevOps, and systems engineering.
7. Important Features of OpenShift for Administrators
As an OpenShift administrator, mastering certain key features will enhance your ability to manage applications effectively and securely:
OpenShift Operator Framework: This framework simplifies application lifecycle management by allowing users to automate deployment and scaling.
OpenShift Storage: Offers reliable, persistent storage solutions critical for stateful applications and complex deployments.
OpenShift Automation: Automates manual tasks, making CI/CD pipelines and application scaling efficiently.
OpenShift Scaling: Allows administrators to manage resources dynamically, ensuring applications perform optimally under various load conditions.
Monitoring & Logging: Comprehensive tools that allow administrators to keep an eye on applications and container environments, ensuring system health and reliability.
8. Steps to Begin Your OpenShift Training and Certification
For those seeking to gain Red Hat OpenShift Certification and advance their expertise in OpenShift administration, here’s how to get started:
Enroll in OpenShift Administration Training: Structured OpenShift training programs provide foundational and advanced knowledge, essential for handling OpenShift environments.
Practice in Realistic Environments: Hands-on practice through lab simulators or practice clusters ensures real-world application of skills.
Prepare for the EX280 Exam: Comprehensive EX280 Exam Preparation through guided practice will help you acquire the knowledge and confidence to succeed.
9. What to Do After OpenShift DO280?
After completing the DO280 (Red Hat OpenShift Administration) certification, you can further enhance your expertise with advanced Red Hat training programs:
a) Red Hat OpenShift Virtualization Training (DO316)
Learn how to integrate and manage virtual machines (VMs) alongside containers in OpenShift.
Gain expertise in deploying, managing, and troubleshooting virtualized workloads in a Kubernetes-native environment.
b) Red Hat OpenShift AI Training (AI267)
Master the deployment and management of AI/ML workloads on OpenShift.
Learn how to use OpenShift Data Science and MLOps tools for scalable machine learning pipelines.
c) Red Hat Satellite Training (RH403)
Expand your skills in managing OpenShift and other Red Hat infrastructure on a scale.
Learn how to automate patch management, provisioning, and configuration using Red Hat Satellite.
These advanced courses will make you a well-rounded OpenShift expert, capable of handling complex enterprise deployments in virtualization, AI/ML, and infrastructure automation.
Conclusion: Is Red Hat OpenShift the Right Path for You?
Red Hat OpenShift Administration is a valuable career path for IT professionals dedicated to mastering enterprise Kubernetes and containerized application management. With skills in OpenShift Cluster management, OpenShift Automation, and secure OpenShift Networking, you will become an indispensable asset in modern, cloud-centric organizations.
KR Network Cloud is a trusted provider of comprehensive OpenShift training, preparing you with the skills required to achieve success in EX280 Certification and beyond.
Why Join KR Network Cloud?
With expert-led training, practical labs, and career-focused guidance, KR Network Cloud empowers you to excel in Red Hat OpenShift Administration and achieve your professional goals.
https://creativeceo.mn.co/posts/the-ultimate-guide-to-red-hat-openshift-administration
https://bogonetwork.mn.co/posts/the-ultimate-guide-to-red-hat-openshift-administration
#openshiftadmin#redhatopenshift#openshiftvirtualization#DO280#DO316#openshiftai#ai267#redhattraining#krnetworkcloud#redhatexam#redhatcertification#ittraining
0 notes
Text
Learn HashiCorp Vault in Kubernetes Using KubeVault

In today's cloud-native world, securing secrets, credentials, and sensitive configurations is more important than ever. That’s where Vault in Kubernetes becomes a game-changer — especially when combined with KubeVault, a powerful operator for managing HashiCorp Vault within Kubernetes clusters.
🔐 What is Vault in Kubernetes?
Vault in Kubernetes refers to the integration of HashiCorp Vault with Kubernetes to manage secrets dynamically, securely, and at scale. Vault provides features like secrets storage, access control, dynamic secrets, and secrets rotation — essential tools for modern DevOps and cloud security.
🚀 Why Use KubeVault?
KubeVault is an open-source Kubernetes operator developed to simplify Vault deployment and management inside Kubernetes environments. Whether you’re new to Vault or running production workloads, KubeVault automates:
Deployment and lifecycle management of Vault
Auto-unsealing using cloud KMS providers
Seamless integration with Kubernetes RBAC and CRDs
Secure injection of secrets into workloads
🛠️ Getting Started with KubeVault
Here's a high-level guide on how to deploy Vault in Kubernetes using KubeVault:
Install the KubeVault Operator Use Helm or YAML manifests to install the operator in your cluster. helm repo add appscode https://charts.appscode.com/stable/
helm install kubevault-operator appscode/kubevault --namespace kubevault --create-namespace
Deploy a Vault Server Define a custom resource (VaultServer) to spin up a Vault instance.
Configure Storage and Unsealer Use backends like GCS, S3, or Azure Blob for Vault storage and unseal via cloud KMS.
Inject Secrets into Workloads Automatically mount secrets into pods using Kubernetes-native integrations.
💡 Benefits of Using Vault in Kubernetes with KubeVault
✅ Automated Vault lifecycle management
✅ Native Kubernetes authentication
✅ Secret rotation without downtime
✅ Easy policy management via CRDs
✅ Enterprise-level security with minimal overhead
🔄 Real Use Case: Dynamic Secrets for Databases
Imagine your app requires database credentials. Instead of hardcoding secrets or storing them in plain YAML files, you can use KubeVault to dynamically generate and inject secrets directly into pods — with rotation and revocation handled automatically.
🌐 Final Thoughts
If you're deploying applications in Kubernetes, integrating Vault in Kubernetes using KubeVault isn't just a best practice — it's a security necessity. KubeVault makes it easy to run Vault at scale, without the hassle of manual configuration and operations.
Want to learn more? Check out KubeVault.com — the ultimate toolkit for managing secrets in Kubernetes using HashiCorp Vault.
1 note
·
View note