#managing Kubernetes clusters
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Best Kubernetes Management Tools in 2023
Best Kubernetes Management Tools in 2023 #homelab #vmwarecommunities #Kubernetesmanagementtools2023 #bestKubernetescommandlinetools #managingKubernetesclusters #Kubernetesdashboardinterfaces #kubernetesmanagementtools #Kubernetesdashboard
Kubernetes is everywhere these days. It is used in the enterprise and even in many home labs. It’s a skill that’s sought after, especially with today’s push for app modernization. Many tools help you manage things in Kubernetes, like clusters, pods, services, and apps. Here’s my list of the best Kubernetes management tools in 2023. Table of contentsWhat is Kubernetes?Understanding Kubernetes and…

View On WordPress
#best Kubernetes command line tools#containerized applications management#Kubernetes cluster management tools#Kubernetes cost monitoring#Kubernetes dashboard interfaces#Kubernetes deployment solutions#Kubernetes management tools 2023#large Kubernetes deployments#managing Kubernetes clusters#open-source Kubernetes tools
0 notes
Text
Certified Kubernetes Administrator (CKA)

Material Includes
Kubernetes Lab Access
Mock Tests for Certification
Certificate of Completion
Requirements
Basic knowledge of Linux and containers
Quick Enquiry
About Course
Master Kubernetes, the leading container orchestration platform, with hands-on training. This course covers cluster setup, management, and troubleshooting, aligning with CKA certification.
What I will learn?
Deploy Kubernetes clusters
Manage applications in Kubernetes
Prepare for CKA certification
Course Curriculum
Lesson 1: Introduction to Containers and Kubernetes
Lesson 2: Setting Up a Cluster
Certified Kubernetes Administrator (CKA) Online Exam & Certification
Get in Touch
Founded in 2004, COSSINDIA (Prodevans wing) is an ISO 9001:2008 certified a global IT training and company. Created with vision to offer high quality training services to individuals and the corporate, in the field of ‘IT Infrastructure Management’, we scaled new heights with every passing year.
Quick Links
Webinar
Privacy Policy
Terms of Use
Blogs
About Us
Contact Us
Follow Us
Facebook
Instagram
Youtube
LinkedIn
Contact Info
Monday - Sunday: 7:30 – 21:00 hrs.
Hyderabad Office: +91 7799 351 640
Bangalore Office: +91 72044 31703 / +91 8139 990 051
#Certified Kubernetes Administrator#CKA Course India#Kubernetes Training#Cloud Native Computing#Container Orchestration#DevOps Certification#COSS India CKA#Kubernetes Certification Course#Kubernetes Hands‑On Training#Infrastructure Automation#Kubernetes Cluster Management
0 notes
Text
A Comprehensive Guide to Deploy Azure Kubernetes Service with Azure Pipelines

A powerful orchestration tool for containerized applications is one such solution that Azure Kubernetes Service (AKS) has offered in the continuously evolving environment of cloud-native technologies. Associate this with Azure Pipelines for consistent CI CD workflows that aid in accelerating the DevOps process. This guide will dive into the deep understanding of Azure Kubernetes Service deployment with Azure Pipelines and give you tips that will enable engineers to build container deployments that work. Also, discuss how DevOps consulting services will help you automate this process.
Understanding the Foundations
Nowadays, Kubernetes is the preferred tool for running and deploying containerized apps in the modern high-speed software development environment. Together with AKS, it provides a high-performance scale and monitors and orchestrates containerized workloads in the environment. However, before anything, let’s deep dive to understand the fundamentals.
Azure Kubernetes Service: A managed Kubernetes platform that is useful for simplifying container orchestration. It deconstructs the Kubernetes cluster management hassles so that developers can build applications instead of infrastructure. By leveraging AKS, organizations can:
Deploy and scale containerized applications on demand.
Implement robust infrastructure management
Reduce operational overhead
Ensure high availability and fault tolerance.
Azure Pipelines: The CI/CD Backbone
The automated code building, testing, and disposition tool, combined with Azure Kubernetes Service, helps teams build high-end deployment pipelines in line with the modern DevOps mindset. Then you have Azure Pipelines for easily integrating with repositories (GitHub, Repos, etc.) and automating the application build and deployment.
Spiral Mantra DevOps Consulting Services
So, if you’re a beginner in DevOps or want to scale your organization’s capabilities, then DevOps consulting services by Spiral Mantra can be a game changer. The skilled professionals working here can help businesses implement CI CD pipelines along with guidance regarding containerization and cloud-native development.
Now let’s move on to creating a deployment pipeline for Azure Kubernetes Service.
Prerequisites you would require
Before initiating the process, ensure you fulfill the prerequisite criteria:
Service Subscription: To run an AKS cluster, you require an Azure subscription. Do create one if you don’t already.
CLI: The Azure CLI will let you administer resources such as AKS clusters from the command line.
A Professional Team: You will need to have a professional team with technical knowledge to set up the pipeline. Hire DevOps developers from us if you don’t have one yet.
Kubernetes Cluster: Deploy an AKS cluster with Azure Portal or ARM template. This will be the cluster that you run your pipeline on.
Docker: Since you’re deploying containers, you need Docker installed on your machine locally for container image generation and push.
Step-by-Step Deployment Process
Step 1: Begin with Creating an AKS Cluster
Simply begin the process by setting up an AKS cluster with CLI or Azure Portal. Once the process is completed, navigate further to execute the process of application containerization, and for that, you would need to create a Docker file with the specification of your application runtime environment. This step is needed to execute the same code for different environments.
Step 2: Setting Up Your Pipelines
Now, the process can be executed for new projects and for already created pipelines, and that’s how you can go further.
Create a New Project
Begin with launching the Azure DevOps account; from the screen available, select the drop-down icon.
Now, tap on the Create New Project icon or navigate further to use an existing one.
In the final step, add all the required repositories (you can select them either from GitHub or from Azure Repos) containing your application code.
For Already Existing Pipeline
Now, from your existing project, tap to navigate the option mentioning Pipelines, and then open Create Pipeline.
From the next available screen, select the repository containing the code of the application.
Navigate further to opt for either the YAML pipeline or the starter pipeline. (Note: The YAML pipeline is a flexible environment and is best recommended for advanced workflows.).
Further, define pipeline configuration by accessing your YAML file in Azure DevOps.
Step 3: Set Up Your Automatic Continuous Deployment (CD)
Further, in the next step, you would be required to automate the deployment process to fasten the CI CD workflows. Within the process, the easiest and most common approach to execute the task is to develop a YAML file mentioning deployment.yaml. This step is helpful to identify and define the major Kubernetes resources, including deployments, pods, and services.
After the successful creation of the YAML deployment, the pipeline will start to trigger the Kubernetes deployment automatically once the code is pushed.
Step 4: Automate the Workflow of CI CD
Now that we have landed in the final step, it complies with the smooth running of the pipelines every time the new code is pushed. With the right CI CD integration, the workflow allows for the execution of continuous testing and building with the right set of deployments, ensuring that the applications are updated in every AKS environment.
Best Practices for AKS and Azure Pipelines Integration
1. Infrastructure as Code (IaC)
- Utilize Terraform or Azure Resource Manager templates
- Version control infrastructure configurations
- Ensure consistent and reproducible deployments
2. Security Considerations
- Implement container scanning
- Use private container registries
- Regular security patch management
- Network policy configuration
3. Performance Optimization
- Implement horizontal pod autoscaling
- Configure resource quotas
- Use node pool strategies
- Optimize container image sizes
Common Challenges and Solutions
Network Complexity
Utilize Azure CNI for advanced networking
Implement network policies
Configure service mesh for complex microservices
Persistent Storage
Use Azure Disk or Files
Configure persistent volume claims
Implement storage classes for dynamic provisioning
Conclusion
Deploying the Azure Kubernetes Service with effective pipelines represents an explicit approach to the final application delivery. By embracing these practices, DevOps consulting companies like Spiral Mantra offer transformative solutions that foster agile and scalable approaches. Our expert DevOps consulting services redefine technological infrastructure by offering comprehensive cloud strategies and Kubernetes containerization with advanced CI CD integration.
Let’s connect and talk about your cloud migration needs
2 notes
·
View notes
Text
GitOps: Automating Infrastructure with Git-Based Workflows

In today’s cloud-native era, automation is not just a convenience—it’s a necessity. As development teams strive for faster, more reliable software delivery, GitOps has emerged as a game-changing methodology. By using Git as the single source of truth for infrastructure and application configurations, GitOps enables teams to automate deployments, manage environments, and scale effortlessly. This approach is quickly being integrated into modern DevOps services and solutions, especially as the demand for seamless operations grows.
What is GitOps?
GitOps is a set of practices that use Git repositories as the source of truth for declarative infrastructure and applications. Any change to the system—whether a configuration update or a new deployment—is made by modifying Git, which then triggers an automated process to apply the change in the production environment. This methodology bridges the gap between development and operations, allowing teams to collaborate using the same version control system they already rely on.
With GitOps, infrastructure becomes code, and managing environments becomes as easy as managing your codebase. Rollbacks, audits, and deployments are all handled through Git, ensuring consistency and visibility.
Real-World Example of GitOps in Action
Consider a SaaS company that manages multiple Kubernetes clusters across environments. Before adopting GitOps, the operations team manually deployed updates, which led to inconsistencies and delays. By shifting to GitOps, the team now updates configurations in a Git repo, which triggers automated pipelines that sync the changes across environments. This transition reduced deployment errors by 70% and improved release velocity by 40%.
GitOps and DevOps Consulting Services
For companies seeking to modernize their infrastructure, DevOps consulting services provide the strategic roadmap to implement GitOps successfully. Consultants analyze your existing systems, assess readiness for GitOps practices, and help create the CI/CD pipelines that connect Git with your deployment tools. They ensure that GitOps is tailored to your workflows and compliance needs.
To explore how experts are enabling seamless GitOps adoption, visit DevOps consulting services offered by Cloudastra.
GitOps in Managed Cloud Environments
GitOps fits perfectly into devops consulting and managed cloud services, where consistency, security, and scalability are top priorities. Managed cloud providers use GitOps to ensure that infrastructure remains in a desired state, detect drifts automatically, and restore environments quickly when needed. With GitOps, they can roll out configuration changes across thousands of instances in minutes—without manual intervention.
Understand why businesses are increasingly turning to devops consulting and managed cloud services to adopt modern deployment strategies like GitOps.
GitOps and DevOps Managed Services: Driving Operational Excellence
DevOps managed services teams are leveraging GitOps to bring predictability and traceability into their operations. Since all infrastructure definitions and changes are stored in Git, teams can easily track who made a change, when it was made, and why. This kind of transparency reduces risk and improves collaboration between developers and operations.
Additionally, GitOps enables managed service providers to implement automated recovery solutions. For example, if a critical microservice is accidentally deleted, the Git-based controller recognizes the drift and automatically re-deploys the missing component to match the declared state.
Learn how DevOps managed services are evolving with GitOps to support enterprise-grade reliability and control.
GitOps in DevOps Services and Solutions
Modern devops services and solutions are embracing GitOps as a core practice for infrastructure automation. Whether managing multi-cloud environments or microservices architectures, GitOps helps teams streamline deployments, improve compliance, and accelerate recovery. It provides a consistent framework for both infrastructure as code (IaC) and continuous delivery, making it ideal for scaling DevOps in complex ecosystems.
As organizations aim to reduce deployment risks and downtime, GitOps offers a predictable and auditable solution. It is no surprise that GitOps has become an essential part of cutting-edge devops services and solutions.
As Alexis Richardson, founder of Weaveworks (the team that coined GitOps), once said:
"GitOps is Git plus automation—together they bring reliability and speed to software delivery."
Why GitOps Matters More Than Ever
The increasing complexity of cloud-native applications and infrastructure demands a method that ensures precision, repeatability, and control. GitOps brings all of that and more by shifting infrastructure management into the hands of developers, using tools they already understand. It reduces errors, boosts productivity, and aligns development and operations like never before.
As Kelsey Hightower, a renowned DevOps advocate, puts it:
"GitOps takes the guesswork out of deployments. Your environment is only as good as what’s declared in Git."
Final Thoughts
GitOps isn’t just about using Git for configuration—it’s about redefining how teams manage and automate infrastructure at scale. By integrating GitOps with your DevOps strategy, your organization can gain better control, faster releases, and stronger collaboration across the board.
Ready to modernize your infrastructure with GitOps workflows?Please visit Cloudastra DevOps as a Services if you are interested to study more content or explore our services. Our team of experienced devops services is here to help you turn innovation into reality—faster, smarter, and with measurable outcomes.
1 note
·
View note
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Perform Safe & Automatic Node Reboots on Kubernetes with Kured

One of the most important tasks of a system administrator is to ensure that the system and all the available packages are updated to their latest versions. Even after adding the nodes to a Kubernetes cluster, we still need to manage the node updates. In most situations, once the updates(e.g., kernel updates, system maintenance, or hardware changes) have been obtained, you need to reboot the node for the changes to apply. This might be even hard on Kubernetes because you need to ensure that the running applications are gracefully terminated or migrated to other nodes before the reboot. Kured (KUbernetes […]
0 notes
Text
Master Infra Monitoring & Alerting with This Prometheus MasterClass

In today’s fast-paced tech world, keeping an eye on your systems is not optional — it's critical. Whether you're managing a handful of microservices or scaling a complex infrastructure, one tool continues to shine: Prometheus. And if you’re serious about learning it the right way, the Prometheus MasterClass: Infra Monitoring & Alerting is exactly what you need.
Why Prometheus Is the Gold Standard in Monitoring
Prometheus isn’t just another monitoring tool — it’s the backbone of modern cloud-native monitoring. It gives you deep insights, alerting capabilities, and real-time observability over your infrastructure. From Kubernetes clusters to legacy systems, Prometheus tracks everything through powerful time-series data collection.
But here’s the catch: it’s incredibly powerful, if you know how to use it.
That’s where the Prometheus MasterClass steps in.
What Makes This Prometheus MasterClass Stand Out?
Let’s be honest. There are tons of tutorials online. Some are free, some outdated, and most barely scratch the surface. This MasterClass is different. It’s built for real-world engineers — people who want to build, deploy, and monitor robust systems without guessing their way through half-baked guides.
Here’s what you’ll gain:
✅ Hands-On Learning: Dive into live projects that simulate actual infrastructure environments. You won’t just watch — you’ll do.
✅ Alerting Systems That Work: Learn to build smart alerting systems that tell you what you need to know before things go south.
✅ Scalable Monitoring Techniques: Whether it’s a single server or a Kubernetes cluster, you’ll master scalable Prometheus setups.
✅ Grafana Integration: Turn raw metrics into meaningful dashboards with beautiful visualizations.
✅ Zero to Advanced: Start from scratch or sharpen your existing skills — this course fits both beginners and experienced professionals.
Who Is This Course For?
This isn’t just for DevOps engineers. If you're a:
Software Developer looking to understand what’s happening behind the scenes…
System Admin who wants smarter monitoring tools…
Cloud Engineer managing scalable infrastructures…
SRE or DevOps Pro looking for an edge…
…then this course is tailor-made for you.
And if you're someone preparing for a real-world DevOps job or a career upgrade? Even better.
Monitoring Isn’t Just a “Nice to Have”
Too many teams treat monitoring as an afterthought — until something breaks. Then it’s chaos.
With Prometheus, you shift from being reactive to proactive. And when you take the Prometheus MasterClass, you’ll understand how to:
Set up automatic alerts before outages hit
Collect real-time performance metrics
Detect slowdowns and performance bottlenecks
Reduce MTTR (Mean Time to Recovery)
This isn’t just knowledge — it’s job-saving, career-accelerating expertise.
Real-World Monitoring, Real-World Tools
The Prometheus MasterClass is packed with tools and integrations professionals use every day. You'll not only learn Prometheus but also how it connects with:
Grafana: Create real-time dashboards with precision.
Alertmanager: Manage all your alerts with control and visibility.
Docker & Kubernetes: Learn how Prometheus works in containerized environments.
Blackbox Exporter, Node Exporter & Custom Exporters: Monitor everything from hardware metrics to custom applications.
Whether it’s latency, memory usage, server health, or request failures — you’ll learn how to monitor it all.
Learn to Set Up Monitoring in Hours, Not Weeks
One of the biggest challenges in learning a complex tool like Prometheus is the time investment. This course respects your time. Each module is focused, practical, and designed to help you get results fast.
By the end of the Prometheus MasterClass, you’ll be able to:
Set up Prometheus in any environment
Monitor distributed systems with ease
Handle alerts and incidents with confidence
Visualize data and performance metrics clearly
And the best part? You’ll actually enjoy the learning journey.
Why Now Is the Right Time to Learn Prometheus
Infrastructure and DevOps skills are in huge demand. Prometheus is used by some of the biggest companies — from startups to giants like Google and SoundCloud.
As more companies embrace cloud-native infrastructure, tools like Prometheus are no longer optional — they’re essential. If you're not adding these skills to your toolbox, you're falling behind.
This MasterClass helps you stay ahead.
You’ll build in-demand monitoring skills, backed by one of the most powerful tools in the DevOps ecosystem. Whether you're aiming for a promotion, a new job, or leveling up your tech stack — this course is your launchpad.
Course Highlights Recap:
🚀 Full Prometheus setup from scratch
📡 Create powerful alerts using Alertmanager
📊 Build interactive dashboards with Grafana
🐳 Monitor Docker & Kubernetes environments
⚙️ Collect metrics using exporters
🛠️ Build real-world monitoring pipelines
All of this, bundled into the Prometheus MasterClass: Infra Monitoring & Alerting that’s designed to empower, not overwhelm.
Start Your Monitoring Journey Today
You don’t need to be a Prometheus expert to start. You just need the right guidance — and this course gives it to you.
Whether you’re monitoring your first server or managing an enterprise-grade cluster, the Prometheus MasterClass gives you everything you need to succeed.
👉 Ready to take control of your infrastructure monitoring?
Click here to enroll in Prometheus MasterClass: Infra Monitoring & Alerting and take the first step toward mastering system visibility.
0 notes
Text
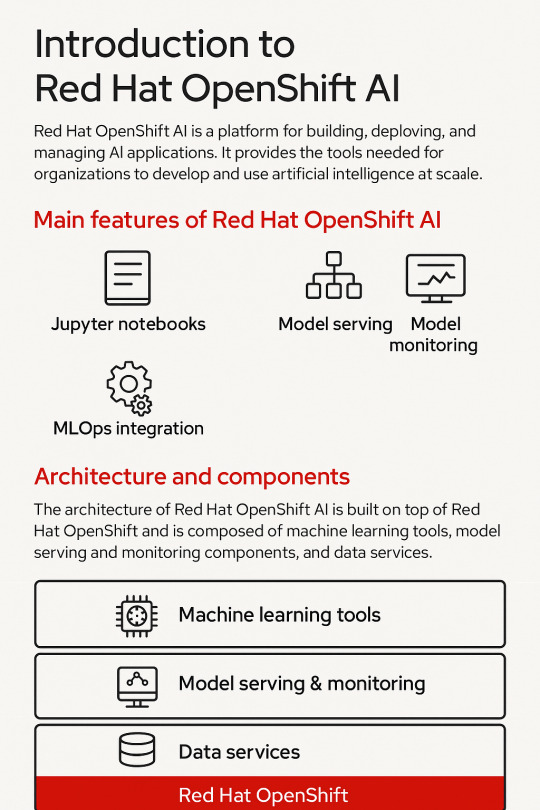
Introduction to Red Hat OpenShift AI: Features, Architecture & Components
In today’s data-driven world, organizations need a scalable, secure, and flexible platform to build, deploy, and manage artificial intelligence (AI) and machine learning (ML) models. Red Hat OpenShift AI is built precisely for that. It provides a consistent, Kubernetes-native platform for MLOps, integrating open-source tools, enterprise-grade support, and cloud-native flexibility.
Let’s break down the key features, architecture, and components that make OpenShift AI a powerful platform for AI innovation.
🔍 What is Red Hat OpenShift AI?
Red Hat OpenShift AI (formerly known as OpenShift Data Science) is a fully supported, enterprise-ready platform that brings together tools for data scientists, ML engineers, and DevOps teams. It enables rapid model development, training, and deployment on the Red Hat OpenShift Container Platform.
🚀 Key Features of OpenShift AI
1. Built for MLOps
OpenShift AI supports the entire ML lifecycle—from experimentation to deployment—within a consistent, containerized environment.
2. Integrated Jupyter Notebooks
Data scientists can use Jupyter notebooks pre-integrated into the platform, allowing quick experimentation with data and models.
3. Model Training and Serving
Use Kubernetes to scale model training jobs and deploy inference services using tools like KServe and Seldon Core.
4. Security and Governance
OpenShift AI integrates enterprise-grade security, role-based access controls (RBAC), and policy enforcement using OpenShift’s built-in features.
5. Support for Open Source Tools
Seamless integration with open-source frameworks like TensorFlow, PyTorch, Scikit-learn, and ONNX for maximum flexibility.
6. Hybrid and Multicloud Ready
You can run OpenShift AI on any OpenShift cluster—on-premise or across cloud providers like AWS, Azure, and GCP.
🧠 OpenShift AI Architecture Overview
Red Hat OpenShift AI builds upon OpenShift’s robust Kubernetes platform, adding specific components to support the AI/ML workflows. The architecture broadly consists of:
1. User Interface Layer
JupyterHub: Multi-user Jupyter notebook support.
Dashboard: UI for managing projects, models, and pipelines.
2. Model Development Layer
Notebooks: Containerized environments with GPU/CPU options.
Data Connectors: Access to S3, Ceph, or other object storage for datasets.
3. Training and Pipeline Layer
Open Data Hub and Kubeflow Pipelines: Automate ML workflows.
Ray, MPI, and Horovod: For distributed training jobs.
4. Inference Layer
KServe/Seldon: Model serving at scale with REST and gRPC endpoints.
Model Monitoring: Metrics and performance tracking for live models.
5. Storage and Resource Management
Ceph / OpenShift Data Foundation: Persistent storage for model artifacts and datasets.
GPU Scheduling and Node Management: Leverages OpenShift for optimized hardware utilization.
🧩 Core Components of OpenShift AI
ComponentDescriptionJupyterHubWeb-based development interface for notebooksKServe/SeldonInference serving engines with auto-scalingOpen Data HubML platform tools including Kafka, Spark, and moreKubeflow PipelinesWorkflow orchestration for training pipelinesModelMeshScalable, multi-model servingPrometheus + GrafanaMonitoring and dashboarding for models and infrastructureOpenShift PipelinesCI/CD for ML workflows using Tekton
🌎 Use Cases
Financial Services: Fraud detection using real-time ML models
Healthcare: Predictive diagnostics and patient risk models
Retail: Personalized recommendations powered by AI
Manufacturing: Predictive maintenance and quality control
🏁 Final Thoughts
Red Hat OpenShift AI brings together the best of Kubernetes, open-source innovation, and enterprise-level security to enable real-world AI at scale. Whether you’re building a simple classifier or deploying a complex deep learning pipeline, OpenShift AI provides a unified, scalable, and production-grade platform.
For more info, Kindly follow: Hawkstack Technologies
0 notes
Text
Senior Software Engineer- Azure Arc team
Azure Arc is connecting the rest of the world’s computing power to Azure. As Azure Arc team, we extend Azure’s cloud capabilities to on-premises, multi-cloud, and edge environments, simplifying the management of servers and Kubernetes environments. By projecting servers and Kubernetes clusters into Azure Resource Manager, customers can easily manage configurations and applications, enable…
0 notes
Text
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring #homelab #kubernetes #KubernetesManagement #LensKubernetesDesktop #KubernetesClusterManagement #MultiClusterManagement #KubernetesSecurityFeatures #KubernetesUI #kubernetesmonitoring
Kubernetes is a well-known container orchestration platform. It allows admins and organizations to operate their containers and support modern applications in the enterprise. Kubernetes management is not for the “faint of heart.” It requires the right skill set and tools. Lens Kubernetes desktop is an app that enables managing Kubernetes clusters on Windows and Linux devices. Table of…

View On WordPress
#Kubernetes cluster management#Kubernetes collaboration tools#Kubernetes management#Kubernetes performance improvements#Kubernetes real-time monitoring#Kubernetes security features#Kubernetes user interface#Lens Kubernetes 2023.10#Lens Kubernetes Desktop#multi-cluster management
0 notes
Text
Master Production-Grade Kubernetes with Red Hat OpenShift Administration III (DO380)
When you're ready to take your OpenShift skills to the next level, Red Hat OpenShift Administration III (DO380) is the course that delivers. It’s designed for system administrators and DevOps professionals who want to master managing and scaling OpenShift clusters in production environments.
At HawkStack, we’ve seen first-hand how this course transforms tech teams—helping them build scalable, secure, and resilient applications using Red Hat’s most powerful platform.
Why DO380 Matters OpenShift isn’t just another Kubernetes distribution. It’s an enterprise-ready platform built by Red Hat, trusted by some of the biggest organizations around the world.
But managing OpenShift in a live production environment requires more than just basic knowledge. That's where DO380 steps in. This course gives you the skills to:
Configure cluster scaling
Automate management tasks
Secure and monitor applications
Handle multi-tenant workloads
Optimize performance and availability
In short, it equips you to keep production clusters running smoothly under pressure.
What You’ll Learn in DO380 Red Hat OpenShift Administration III dives deep into advanced cluster operations, covering:
✅ Day 2 Operations Learn to troubleshoot and tune OpenShift clusters for maximum reliability.
✅ Performance Optimization Get hands-on with tuning resource limits, autoscaling, and load balancing.
✅ Monitoring & Logging Set up Prometheus, Grafana, and EFK (Elasticsearch, Fluentd, Kibana) stacks for full-stack observability.
✅ Security Best Practices Configure role-based access control (RBAC), network policies, and more to protect sensitive workloads.
Who Should Take DO380? This course is ideal for:
Red Hat Certified System Administrators (RHCSAs)
OpenShift administrators with real-world experience
DevOps professionals managing container workloads
Anyone aiming for Red Hat Certified Specialist in OpenShift Administration
If you're managing containerized applications and want to run them securely and at scale—DO380 is for you.
Learn with HawkStack At HawkStack Technologies, we offer expert-led training for DO380, along with access to Red Hat Learning Subscription (RHLS), hands-on labs, and mentoring from certified professionals.
Why choose us?
🔴 Red Hat Certified Instructors
📘 Tailored learning plans
💼 Real-world project exposure
🎓 100% exam-focused support
Our students don’t just pass exams - they build real skills.
Final Thoughts Red Hat OpenShift Administration III (DO380) is more than just a training course—it’s a gateway to high-performance DevOps and production-grade Kubernetes. If you're serious about advancing your career in cloud-native technologies, this is the course that sets you apart.
Let HawkStack guide your journey with Red Hat. Book your seat today and start building the future of enterprise IT.
For more details www.hawkstack.com
0 notes
Text

Kubernetes is a platform for managing apps in containers. Many jobs use it to keep apps running smoothly. It’s popular in modern tech setups called tech stacks.
DevOps engineers use Kubernetes to automate app launches. They set up clusters, which are groups of computers working together to run apps. These computers, called nodes, share tasks to keep apps stable. They write YAML files to define app setups. They check clusters to keep apps fast. DevOps engineers combine development and operations to streamline app deployment and maintenance.
Site reliability engineers care about system stability. They use Kubernetes to make apps self-fix. They set up health checks. They handle upgrades and node groups. They back up clusters and keep systems strong. Site reliability engineers ensure systems run reliably and recover quickly from issues.
Cloud architects build scalable systems. They use Kubernetes for flexible setups in the cloud, which is a network of remote computers that store and run apps, not the fluffy clouds in the sky—no chance of rain here, just data! They launch clusters with Kubernetes services. They use code to build infrastructure. They focus on security and easy moves between clouds. Cloud architects design the big-picture tech infrastructure for organizations.
Software developers use Kubernetes for microservices. They test apps with Minikube, a tool that runs a small Kubernetes cluster on their own computer for testing, like a tiny sandbox for apps—way less scary than a big cluster! They write code for containers. They roll out apps and fix problems in clusters. Software developers create and test the code that makes apps work.
Security engineers protect Kubernetes setups. They set rules to limit access. They check container images for safety. They manage network access. They watch for risks in clusters. Security engineers safeguard systems from threats and vulnerabilities.
Data engineers run data pipelines on Kubernetes. Machine learning engineers use it for AI models. They work with big data tasks. Kubernetes handles heavy workloads. Data engineers and machine learning engineers manage and process large datasets for insights and AI.
Kubernetes helps all these jobs. It simplifies tech challenges. It speeds up app launches and keeps systems steady. It’s like a super easy tool that makes apps work great for everyone.
1 note
·
View note
Text
Why You Need DevOps Consulting for Kubernetes Scaling

With today’s technological advances and fast-moving landscape, scaling Kubernetes clusters has become troublesome for almost every organization. The more companies are moving towards containerized applications, the harder it gets to scale multiple Kubernetes clusters. In this article, you’ll learn the exponential challenges along with the best ways and practices of scaling Kubernetes deployments successfully by seeking expert guidance.
The open-source platform K8s, used to deploy and manage applications, is now the norm in containerized environments. Since businesses are adopting DevOps services in USA due to their flexibility and scalability, cluster management for Kubernetes at scale is now a fundamental part of the business.
Understanding Kubernetes Clusters
Before moving ahead with the challenges along with its best practices, let’s start with an introduction to what Kubernetes clusters are and why they are necessary for modern app deployments. To be precise, it is a set of nodes (physical or virtual machines) connected and running containerized software. K8’s clusters are very scalable and dynamic and are ideal for big applications accessible via multiple locations.
The Growing Complexity Organizations Must Address
Kubernetes is becoming the default container orchestration solution for many companies. But the complexity resides with its scaling, as it is challenging to keep them in working order. Kubernetes developers are thrown many problems with consistency, security, and performance, and below are the most common challenges.
Key Challenges in Managing Large-Scale K8s Deployments
Configuration Management: Configuring many different Kubernetes clusters can be a nightmare. Enterprises need to have uniform policies, security, and allocations with flexibility for unique workloads.
Resource Optimization: As a matter of course, the DevOps consulting services would often emphasize that resources should be properly distributed so that overprovisioning doesn’t happen and the application can run smoothly.
Security and Compliance: Security on distributed Kubernetes clusters needs solid policies and monitoring. Companies have to use standard security controls with different compliance standards.
Monitoring and Observability: You’ll need advanced monitoring solutions to see how many clusters are performing health-wise. DevOps services in USA focus on the complete observability instruments for efficient cluster management.
Best Practices for Scaling Kubernetes
Implement Infrastructure as Code (IaC)
Apply GitOps processes to configure
Reuse version control for all cluster settings.
Automate cluster creation and administration
Adopt Multi-Cluster Management Tools
Modern organizations should:
Set up cluster management tools in dedicated software.
Utilize centralized control planes.
Optimize CI CD Pipelines
Using K8s is perfect for automating CI CD pipelines, but you want the pipelines optimized. By using a technique like blue-green deployments or canary releases, you can roll out updates one by one and not push the whole system. This reduces downtime and makes sure only stable releases get into production.
Also, containerization using Kubernetes can enable faster and better builds since developers can build and test apps in separate environments. This should be very tightly coupled with Kubernetes clusters for updates to flow properly.
Establish Standardization
When you hire DevOps developers, always make sure they:
Create standardized templates
Implement consistent naming conventions.
Develop reusable deployment patterns.
Optimize Resource Management
Effective resource management includes:
Implementing auto-scaling policies
Adopting quotas and limits on resource allocations.
Accessing cluster auto scale for node management
Enhance Security Measures
Security best practices involve:
Role-based access control (RBAC)—Aim to restrict users by role
Network policy isolation based on isolation policy in the network
Updates and security audits: Ongoing security audits and upgrades
Leverage DevOps Services and Expertise
Hire dedicated DevOps developers or take advantage of DevOps consulting services like Spiral Mantra to get the best of services under one roof. The company comprehends the team of experts who have set up, operated, and optimized Kubernetes on an enterprise scale. By employing DevOps developers or DevOps services in USA, organizations can be sure that they are prepared to address Kubernetes issues efficiently. DevOps consultants can also help automate and standardize K8s with the existing workflows and processes.
Spiral Mantra DevOps Consulting Services
Spiral Mantra is a DevOps consulting service in USA specializing in Azure, Google Cloud Platform, and AWS. We are CI/CD integration experts for automated deployment pipelines and containerization with Kubernetes developers for automated container orchestration. We offer all the services from the first evaluation through deployment and management, with skilled experts to make sure your organizations achieve the best performance.
Frequently Asked Questions (FAQs)
Q. How can businesses manage security on different K8s clusters?
Businesses can implement security by following annual security audits and security scanners, along with going through network policies. With the right DevOps consulting services, you can develop and establish robust security plans.
Q. What is DevOps in Kubernetes management?
For Kubernetes management, it is important to implement DevOps practices like automation, infrastructure as code, continuous integration and deployment, security, compliance, etc.
Q. What are the major challenges developers face when managing clusters at scale?
Challenges like security concerns, resource management, and complexity are the most common ones. In addition to this, CI CD pipeline management is another major complexity that developers face.
Conclusion
Scaling Kubernetes clusters takes an integrated strategy with the right tools, methods, and knowledge. Automation, standardization, and security should be the main objectives of organizations that need to take advantage of professional DevOps consulting services to get the most out of K8s implementations. If companies follow these best practices and partner with skilled Kubernetes developers, they can run containerized applications efficiently and reliably on a large scale.
1 note
·
View note
Text
How to Set up Kubernetes Ingress with MicroK8s

Contents What Is Kubernetes Ingress? How to Set Up Kubernetes Ingress? Step 1: Enable Ingress in MicroK8s Step 2: Test Connection with Nginx Step 3: Edit ConfigMap Step 4: Confirm Ingress Setup Step 5: Test Ingress Setup Introduction Kubernetes provides a secure, efficient, and reliable way to exchange data between microservices and resources outside the cluster. By utilizing the concept of Ingress, Kubernetes enables more straightforward load balancing, service discovery, and external connectivity management. This article explains how to set up Ingress in a MicroK8s Kubernetes cluster. Testing in MicroK8s lets you understand how Ingress works and how to apply […]
0 notes
Text
Load Balancing and High Availability for Full-Stack Applications
In a modern web development landscape where users expect 24/7 accessibility and rapid performance, full-stack applications must be designed for both scalability and resilience. Two critical components that ensure this reliability are load balancing and high availability (HA). Comprehending and applying these concepts is essential for any developer, and they form a vital part of the curriculum in a full-stack developer course, especially a full-stack developer course in Mumbai.
What is Load Balancing?
This is the process of distributing incoming network traffic across multiple servers or services to prevent any one component from becoming a bottleneck. When properly implemented, it ensures that:
No single server becomes overwhelmed
Resources are used efficiently
Applications remain responsive even under high traffic
Load balancers can operate at different layers:
Layer 4 (Transport Layer): Balances traffic based on IP address and port.
Layer 7 (Application Layer): Makes decisions based on content like URL paths, cookies, or headers.
Why Load Balancing is Important for Full-Stack Applications
A typical full-stack application includes a frontend (React, Angular), a backend (Node.js, Django), and a database. If the backend becomes overwhelmed due to increased requests—say, during a product launch or seasonal sale—users might face delays or errors.
A load balancer sits between users and the backend servers, routing requests intelligently and ensuring no single server fails under pressure. This approach improves both performance and reliability.
For frontend traffic, Content Delivery Networks (CDNs) also act as a form of load balancer, serving static files, for e.g. HTML, CSS, and JavaScript from geographically closer nodes.
What is High Availability (HA)?
This refers to systems designed to be operational and accessible without interruption for a very high percentage of time. It typically involves:
Redundancy: Multiple instances of services running across different nodes.
Failover Mechanisms: Automatic rerouting of traffic if a service or server fails.
Health Checks: Regular checks to ensure servers are active and responsive.
Scalability: Auto-scaling services to meet increased demand.
Incorporating HA means building systems that can survive server crashes, network failures, or even regional outages without affecting the end-user experience.
Tools and Techniques
Here are key technologies that support load balancing and high availability in a full-stack setup:
NGINX or HAProxy: Commonly used software load balancers that distribute requests across backend servers.
Cloud Load Balancers: AWS Elastic Load Balancer (ELB), Google Cloud Load Balancing, and Azure Load Balancer offer managed solutions.
Docker and Kubernetes: Deploy applications in container clusters that support automatic scaling, failover, and service discovery.
Database Replication and Clustering: Ensures data availability even if one database node goes down.
Auto Scaling Groups: In cloud environments, automatically launch or terminate instances based on demand.
Real-World Application for Developers
Imagine an e-commerce platform where the homepage, product pages, and checkout system are all part of a full-stack application. During a major sale event:
The frontend receives heavy traffic, served efficiently through a CDN.
Backend servers handle search, cart, and payment APIs.
A load balancer routes incoming requests evenly among multiple backend servers.
Kubernetes or cloud instances scale up automatically as traffic increases.
In the event that a server fails for any reason, the load balancer automatically directs traffic to functioning servers, guaranteeing high availability..
This kind of architecture is precisely what students learn to build in a full-stack developer course in Mumbai, where practical exposure to cloud platforms and containerisation technologies is emphasised.
Conclusion
Load balancing and high availability are no longer optional—they're essential for any production-ready full-stack application. These strategies help prevent downtime, improve user experience, and ensure scalability under real-world conditions. For learners enrolled in a java full stack developer course, especially those in dynamic tech hubs like Mumbai, mastering these concepts ensures they’re well-prepared to build and deploy applications that meet the performance and reliability demands of today’s digital economy.
Business Name: Full Stack Developer Course In Mumbai Address: Tulasi Chambers, 601, Lal Bahadur Shastri Marg, near by Three Petrol Pump, opp. to Manas Tower, Panch Pakhdi, Thane West, Mumbai, Thane, Maharashtra 400602, Phone: 09513262822
0 notes