#llama api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
#Meta y su Aplicación de AI + LlamaCon
El pasado martes 29 de abril, Meta lanzo la primera versión de la aplicación Meta AI: el asistente que conoce tus preferencias, recuerda el contexto y está personalizado para ti. Además, se realizo la LlamaCon, siendo esta la primera edición del evento que celebra la tecnología, el enfoque abierto y donde se compartió nuevas herramientas (Fuente Meta Argentina). A continuación, más…
0 notes
Text
#DeepSeek V3#الذكاء الاصطناعي الصيني#نماذج الذكاء الاصطناعي#سرعة المعالجة#خوارزميات الذكاء الاصطناعي#API DeepSeek#تحسينات DeepSeek V3#مقارنة النماذج#GPT-4#Llama 3.1#Cloud 3.5#معالجة البيانات#تقنيات الذكاء الاصطناعي#تطبيقات DeepSeek#مفتوح المصد��
3 notes
·
View notes
Text
Ubuntu 安裝 ollama 在本地執行 Llama 3.2 推論模型與 API 服務
Ollama 介紹 Ollama 是一個專注於大語言模型(LLM, Large Language Models)應用的開源專案,旨在幫助開發者輕鬆部署和使用私有的大型語言模型,而無需依賴外部的雲端服務或外部 API,這些模型不僅僅只有包括 Meta Llama Model,也提供其他一些 Open LLM Model,像是 Llama 3.3, Phi 3, Mistral, Gemma 2。該專案的核心目的是提供高效、安全、可控的 LLM 推論環境建制。大致上有以下特性: 採用本地機器運行 Ollama 支援在自己的設備上載入模型,無需將數據上傳至雲端,確保數據隱私與安全。通過優化模型運行效率,即使在資源有限的設備上也能流暢進行推論。 開源與可客製化 Ollama 是一個採用 MIT License…
0 notes
Text

Создано в рамках проекта SimsLab "Офисы в каждый город"
Это здание стало местом силы для местных IT-гениев. В офисах кипит настоящая магия: тестировщики ругают новые уровни, а аналитики раскручивают вирусные тренды. На первом этаже пахнет крепким эспрессо из коворкинга, где за круглыми столами программисты на ходу правят баги, а стартаперы спорят о блокчейне. Но будьте осторожны, ведь бариста уже наверняка знает ваш API.
В пустующем офисе раньше давали симолеоны под проценты, а теперь вы можете взять его в аренду, но уже без скрытых комиссий!

🟣boosty️ (free) 🟢NO CC 🟢Lot: 40×30 🟢Lot type: Basic 🟢Newcrest, Llama Lagune 👋🏻 telegram @s4realtor @publicvanillabuilds @maxismatchccworld ❤️
















ВИД СВЕРХУ:



#ts4#ts4 download#ts4 lot#ts4 community lot#show us your builds#ts4 build#ts4 building#sims 4 build#ts4 speed build#ts4 nocc#sims 4#build sims#sims 4 download#speed build#speedbuild#sims 4 speed build#no cc lot#no cc#симс 4 строительство#maxis match#симс 4#build_lilu
33 notes
·
View notes
Note
Hey! Hi. Pretty quick question. I've been half messing around with setting up a Tumblr bot of my own, probably using llama 3 or something. A pretty major issue that I've ran into though is that, as far as I can tell, the tumblr API has no way for bots to respond to asks automatically? But this clearly wasn't an issue for Frank so could I just ask like, how did you do it? Did you use puppeteer or something to like directly interface with a browser? Or is there another way that I'm missing
In the API, an not-yet-answered ask is just a post in the "submission" state. (You can fetch these with the submissions endpoint.)
You can answer an ask through the API by editing it so that its state is something other than "submission."
Typically you would want the state to be "published", though you can also use "draft" to save the response post to drafts or "queue" to queue it.
Just changing the state alone will cause the ask to be published (or drafted/queued) with an empty answer. To supply an answer, what you need to do depends on whether you're using NPF or legacy:
With the legacy edit endpoint, you pass a parameter called "answer".
With the NPF edit endpoint, (IIRC) you append additional blocks to the "content" field containing the answer, and leave the "layout" field as-is to specify that the added blocks are not part of the ask (cf. the NPF layout spec).
I think this should all be possible in pytumblr2. The reason I'm not sure is that Frank never actually used pytumblr2, she just used pytumblr plus a bunch of workarounds and stuff that I eventually split off into pytumblr2.
30 notes
·
View notes
Quote
カーパシー氏は、ソフトウェアというものが過去2回にわたって急速に変化したものと考えています。最初に登場したのがソフトウェア 1.0です。ソフトウェア1.0は誰もがイメージするような基本的なソフトウェアのことです。 ソフトウェア1.0がコンピュータ向けに書くコードであるのに対し、ソフトウェア2.0は基本的にニューラルネットワークであり、特に「重み」のことを指します。開発者はコードを直接書くのではなく、データセットを調整し、最適化アルゴリズ���を実行してこのニューラルネットワークのパラメーターを生成するのです。 ソフトウェア 1.0に当たるGitHub上のプロジェクトは、それぞれを集約して関係のあるプロジェクトを線で結んだ「Map of GitHub」で表せます。 ソフトウェア 2.0は同様に「Model Atlas」で表されます。巨大な円の中心にOpenAIやMetaのベースとなるモデルが存在し、そのフォークがつながっています。 生成AIが洗練されるにつれ、ニューラルネットワークの調整すらAIの助けを得て行えるようになりました。これらは専門的なプログラミング言語ではなく、「自然言語」で実行できるのが特徴です。自然言語、特に英語で大規模言語モデル(LLM)をプログラミング可能になった状態を、カーパシー氏は「ソフトウェア 3.0」と呼んでいます。 まとめると、コードでコンピューターをプログラムするのがソフトウェア 1.0、重みでニューラルネットワークをプログラムするのがソフトウェア 2.0、自然言語のプロンプトでLLMをプログラムするのがソフトウェア 3.0です。 カーパシー氏は「おそらくGitHubのコードはもはや単なるコードではなく、コードと英語が混在した新しい種類のコードのカテゴリーが拡大していると思います。これは単に新しいプログラミングパラダイムであるだけでなく、私たちの母国語である英語でプログラミングしている点も驚くべきことです。私たちは3つの完全に異なるプログラミングパラダイムを有しており、業界に参入するならば、これらすべてに精通していることが非常に重要です。なぜなら、それぞれに微妙な長所と短所があり、特定の機能は1.0や2.0、3.0でプログラミングする必要があるかもしれません。ニューラルネットワークをトレーニングするべきか、LLMにプロンプトを送信するべきか。指示は明示的なコードであるべきでしょうか?つまり、私たちは皆、こうした決定を下し、実際にこれらのパラダイム間を流動的に移行できる可能性を秘めているのです」と述べました。 ◆AIは「電気」である カーパシー氏は「AIは新しい電気である」と捉えています。OpenAI、Google、Anthropic などのLLMラボはトレーニングのために設備投資を行っていて、これは電気のグリッドを構築することとよく似ています。企業はAPIを通じてAIを提供するための運用コストもかかります。通常、100万件など一定単位ごとに料金を請求する仕組みです。このAPIには、低遅延、高稼働率、安定した品質などさまざまなバリューがあります。これらの点に加え、過去に多くのLLMがダウンした影響で人々が作業不能に陥った現象も鑑みると、AIは電気のようななくてはならないインフラに当たるというのがカーパシー氏の考えです。 しかし、LLMは単なる電気や水のようなものではなく、もっと複雑なエコシステムが構築されています。OSだとWindowsやMacのようなクローズドソースのプロバイダーがいくつかあり、Linuxのようなオープンソースの代替案があります。LLMにおいても同様の構造が形成されつつあり、クローズドソースのプロバイダーが競合している中、LlamaのようなオープンソースがLLM界におけるLinuxのようなものへと成長するかもしれません。 カーパシー氏は「LLMは新しい種類のOSのようなものだと感じました。CPUの役割を果たすような存在で、LLMが処理できるトークンの長さ(コンテキストウィンドウ)はメモリに相当し、メモリと計算リソースを調整して問題解決を行うのです。これらの機能をすべて活用しているため、客観的に見ると、まさにOSに非常に似ています。OSだとソフトウェアをダウンロードして実行できますが、LLMでも同様の操作ができるものもあります」と述べました。 ◆AIは発展途中 LLMの計算リソースはコンピューターにとってまだ非常に高価であり、性能の良いLLMはほとんどクラウドサーバーで動作しています。ローカルで実行できるDeepSeek-R1のようなモデルも出てきていますが、やはり何百万円もするような機器を何百台とつなげて動かしているようなクラウドサーバーと個人のPCでは出力結果に大きな差が現れます。 カーパシー氏は「個人用コンピューター革命はまだ起こっていません。経済的ではないからです。意味がありません。しかし、一部の人々は試みているかもしれません。例えば、Mac miniは一部のLLMに非常に適しています。将来的にどのような形になるかは不明です。もしかしたら、皆さんがこの形や仕組みを発明するかもしれません」と述べました。 また、PCでは当たり前に使われているグラフィカルユーザーインターフェース(GUI)がLLMには中途半端にしか導入されていないという点も特徴です。ChatGPTなどのチャットボットは、基本的にテキスト入力欄を提供しているだけです。カーパシー氏は「まだ一般的な意味でのGUIが発明されていないと思います」と話しています。 ◆AIは技術拡散の方向が逆 これまでのPCは、政府が軍事用に開発し、企業などがそれを利用し、その後広くユーザーに使われるという歴史をたどってきました。一方でAIは政府や企業ではなくユーザーが広く利用し、その集合知が体系化され、企業が利用するようになります。カーパシー氏は「実際、企業や政府は、私たちが技術を採用するような速度に追いついていません。これは逆行していると言えるでしょう。新しい点であり前例がないといえるのは、LLMが少数の人々や企業の手中にあるのではなく、私たち全員の手中にあることです。なぜなら、私たちは皆コンピュータを持っており、それはすべてソフトウェアであり、ChatGPTは数十億の人々に瞬時に、一夜にしてコンピュータに配信されたからです。これは信じられないことです」と語りました。 ◆人類はAIと協力関係にある AIが利用されるときは、通常、AIが生成を行い、人間である私たちが検証を行うという作業が繰り返されます。このループをできるだけ高速化することは人間にとってもAIにとってもメリットがあります。 これを実現する方法としてカーパシー氏が挙げるのが、1つは検証を大幅にスピードアップすることです。これはGUIを導入することで実現できる可能性があります。長いテキストだけを読むことは労力がかかりますが、絵など文字以外の物を見ることで容易になります。 2つ目は、AIを制御下に置く必要がある点です。カーパシー氏は「多くの人々がAIエージェントに過剰に興奮している」と指摘しており、AIの出力すべてを信じるのではなく、AIが正しいことを行っているか、セキュリティ上の問題がないかなどを確かめることが重要だと述べています。LLMは基本的にもっともらしい言葉をもっともらしく並べるだけの機械であり、出力結果が必ずしも正しいとは限りません。結果を常に検証することが大切です。 この記事のタイトルとURLをコピーする ・関連記事 Metaが既存の生成AIにあるトークン制限をはるかに上回る100万トークン超のコンテンツ生成を可能にする次世代AIアーキテクチャ「Megabyte」を発表 - GIGAZINE 世界最長のコンテキストウィンドウ100万トークン入力・8万トークン出力対応にもかかわらずたった7800万円でトレーニングされたAIモデル「MiniMax-M1」がオープンソースで公開され誰でもダウンロード可能に - GIGAZINE AppleがXcodeにAIでのコーディング補助機能を追加&Apple Intelligenceの基盤モデルフレームワークが利用可能に - GIGAZINE AnthropicがAIモデルの思考内容を可視化できるオープンソースツール「circuit-tracer」を公開 - GIGAZINE DeepSeekと清華大学の研究者がLLMの推論能力を強化する新しい手法を発表 - GIGAZINE 「現在のAIをスケールアップしても汎用人工知能は開発できない」と考える科学者の割合は76% - GIGAZINE ・関連コンテンツ TwitterやFacebookで使われている「Apache Hadoop」のメリットや歴史を作者自らが語る 仮想通貨暴落などで苦境に立たされたマイニング業者は余ったGPUを「AIトレーニング用のリソース」として提供している 「AI懐疑論者の友人はみんな頭がおかしい」というブログが登場、賛否両論さまざまなコメントが寄せられる 私たちが何気なく使っているソフトウェアはどのように開発されているのか? グラフをはみ出した点と線が世界に広がっていく手描きアニメ「Extrapolate」が圧巻 「アルゴリズムって何?」を専門家が分かりやすく解説 機械学習でコンピューターが音楽を理解することが容易ではない理由 生きてるだけでお金がもらえるベーシックインカムこそ「資本主義2.0」だとの主張、その理由とは?
講演「ソフトウェアは再び変化している」が海外で大反響、その衝撃的な内容とは? - GIGAZINE
5 notes
·
View notes
Text
Elon Musk’s so-called Department of Government Efficiency (DOGE) used artificial intelligence from Meta’s Llama model to comb through and analyze emails from federal workers.
Materials viewed by WIRED show that DOGE affiliates within the Office of Personnel Management (OPM) tested and used Meta’s Llama 2 model to review and classify responses from federal workers to the infamous “Fork in the Road” email that was sent across the government in late January.
The email offered deferred resignation to anyone opposed to changes the Trump administration was making to its federal workforce, including an enforced return-to-office policy, downsizing, and a requirement to be “loyal.” To leave their position, recipients merely needed to reply with the word “resign.” This email closely mirrored one that Musk sent to Twitter employees shortly after he took over the company in 2022.
Records show that Llama was deployed to sort through email responses from federal workers to determine how many accepted the offer. The model appears to have run locally, according to materials viewed by WIRED, meaning it’s unlikely to have sent data over the internet.
Meta and OPM did not respond to requests for comment from WIRED.
Meta CEO Mark Zuckerberg appeared alongside other Silicon Valley tech leaders like Musk and Amazon founder Jeff Bezos at Trump’s inauguration in January, but little has been publicly known about his company’s tech being used in government. Because of Llama’s open-source nature, the tool can easily be used by the government to support Musk’s goals without the company’s explicit consent.
Soon after Trump took office in January, DOGE operatives burrowed into OPM, an independent agency that essentially serves as the human resources department for the federal government. The new administration’s first big goal for the agency was to create a government-wide email service, according to current and former OPM employees. Riccardo Biasini, a former Tesla engineer, was involved in building the infrastructure for the service that would send out the original “Fork in the Road” email, according to material viewed by WIRED and reviewed by two government tech workers.
In late February, weeks after the Fork email, OPM sent out another request to all government workers and asked them to submit five bullet points outlining what they accomplished each week. These emails threw a number of agencies into chaos, with workers unsure how to manage email responses that had to be mindful of security clearances and sensitive information. (Adding to the confusion, it has been reported that some workers who turned on read receipts say they found that the responses weren’t actually being opened.) In February, NBC News reported that these emails were expected to go into an AI system for analysis. While the materials seen by WIRED do not explicitly show DOGE affiliates analyzing these weekly “five points” emails with Meta’s Llama models, the way they did with the Fork emails, it wouldn’t be difficult for them to do so, two federal workers tell WIRED.
“We don’t know for sure,” says one federal worker on whether DOGE used Meta’s Llama to review the “five points” emails. “Though if they were smart they’d reuse their code.”
DOGE did not appear to use Musk’s own AI model, Grok, when it set out to build the government-wide email system in the first few weeks of the Trump administration. At the time, Grok was a proprietary model belonging to xAI, and access to its API was limited. But earlier this week, Microsoft announced that it would begin hosting xAi’s Grok 3 models as options in its Azure AI Foundry, making the xAI models more accessible in Microsoft environments like the one used at OPM. This potentially, should they want it, would enable Grok as an option as an AI system going forward. In February, Palantir struck a deal to include Grok as an AI option in the company’s software, which is frequently used in government.
Over the past few months, DOGE has rolled out and used a variety of AI-based tools at government agencies. In March, WIRED reported that the US Army was using a tool called CamoGPT to remove DEI-related language from training materials. The General Services Administration rolled out “GSAi” earlier this year, a chatbot aimed at boosting overall agency productivity. OPM has also accessed software called AutoRIF that could assist in the mass firing of federal workers.
4 notes
·
View notes
Note
Hi, I saw your project dissecting the lore of Bloodborne. It is very, very impressive, and has rekindled something that I had thought dead. LLAMA-3, a ground-breaking release in LLM technology, has been made available to the public. Noteworthy is that it is quite good at impartial translations. You may access this for free, with an api, on the frontends "Together ai" or "Perplexity labs" (they're site names). Text dumps in JP are surely available. I pray that this may assist you.
while i appreciate the kind words, machine translation has always sucked big ones and is incapable of picking up on the information that a human is capable of, such as puns, double meanings, innuendo, etc. it's not an impartial text and trying to derive a "pure" meaning from computer translation ignores the overt and purposeful human elements in the language arts
22 notes
·
View notes
Text

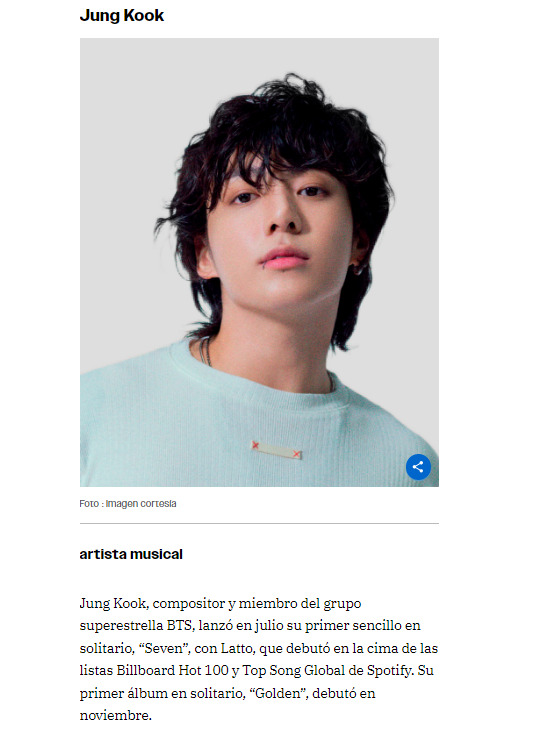

Jungkook se encuentran entre los honrados en la lista A100 de los asiáticos más impactantes de 2024 de Gold House
Keanu Reeves, Jungkook y Hayao Miyazaki se encuentran entre los honrados en la lista A100 de los asiáticos más impactantes de 2024 de Gold House .
La lista A100 de Gold House honra a los pioneros de la industria que están a la vanguardia de lo que la organización llama la "nueva era del oro". Gold House celebrará a estos homenajeados y anunciará varias iniciativas nuevas en la Gala de Oro el 11 de mayo en el centro de Los Ángeles.
Gold House también reconocerá al ejecutivo discográfico, productor y presidente de HYBE Corporation, Bang Si-Hyuk, al presentarle al fundador de BTS el premio Gold Legend.
Jung Kook
artista musical
Jung Kook, compositor y miembro del grupo superestrella BTS, lanzó en julio su primer sencillo en solitario, “Seven”, con Latto, que debutó en la cima de las listas Billboard Hot 100 y Top Song Global de Spotify. Su primer álbum en solitario, “Golden”, debutó en noviembre.
Variety X 1Mayo 2024
Keanu Reeves, Jung Kook, Hayao Miyazaki Among Gold House’s A100 Honorees
(https://x.com/Variety/status/1785658118434705885)
GoldHouseCo X 2 may.
Jung Kook (Music Artist) Learn more about all the Honorees at http://goldhouse.org/A100. #A100 #APAHM #APIHM #GoldNewWorld #GoldExcellence #API #JungKook
#jeon jungkook#jungkook#kookie#galletita#cr. a Variety en X#congratulations jungkook#cr. a GoldHouseCo en X#felicidades jungkook#Jungkook se encuentran entre los honrados en la lista A100 de los asiáticos más impactantes de 2024 de Gold House
8 notes
·
View notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Critical Vulnerability (CVE-2024-37032) in Ollama

Researchers have discovered a critical vulnerability in Ollama, a widely used open-source project for running Large Language Models (LLMs). The flaw, dubbed "Probllama" and tracked as CVE-2024-37032, could potentially lead to remote code execution, putting thousands of users at risk.
What is Ollama?
Ollama has gained popularity among AI enthusiasts and developers for its ability to perform inference with compatible neural networks, including Meta's Llama family, Microsoft's Phi clan, and models from Mistral. The software can be used via a command line or through a REST API, making it versatile for various applications. With hundreds of thousands of monthly pulls on Docker Hub, Ollama's widespread adoption underscores the potential impact of this vulnerability.
The Nature of the Vulnerability
The Wiz Research team, led by Sagi Tzadik, uncovered the flaw, which stems from insufficient validation on the server side of Ollama's REST API. An attacker could exploit this vulnerability by sending a specially crafted HTTP request to the Ollama API server. The risk is particularly high in Docker installations, where the API server is often publicly exposed. Technical Details of the Exploit The vulnerability specifically affects the `/api/pull` endpoint, which allows users to download models from the Ollama registry and private registries. Researchers found that when pulling a model from a private registry, it's possible to supply a malicious manifest file containing a path traversal payload in the digest field. This payload can be used to: - Corrupt files on the system - Achieve arbitrary file read - Execute remote code, potentially hijacking the system The issue is particularly severe in Docker installations, where the server runs with root privileges and listens on 0.0.0.0 by default, enabling remote exploitation. As of June 10, despite a patched version being available for over a month, more than 1,000 vulnerable Ollama server instances remained exposed to the internet.
Mitigation Strategies
To protect AI applications using Ollama, users should: - Update instances to version 0.1.34 or newer immediately - Implement authentication measures, such as using a reverse proxy, as Ollama doesn't inherently support authentication - Avoid exposing installations to the internet - Place servers behind firewalls and only allow authorized internal applications and users to access them
Broader Implications for AI and Cybersecurity
This vulnerability highlights ongoing challenges in the rapidly evolving field of AI tools and infrastructure. Tzadik noted that the critical issue extends beyond individual vulnerabilities to the inherent lack of authentication support in many new AI tools. He referenced similar remote code execution vulnerabilities found in other LLM deployment tools like TorchServe and Ray Anyscale. Moreover, despite these tools often being written in modern, safety-first programming languages, classic vulnerabilities such as path traversal remain a persistent threat. This underscores the need for continued vigilance and robust security practices in the development and deployment of AI technologies. Read the full article
2 notes
·
View notes
Text

ZOHO
¿Qué es? es un software de gestión de relaciones con clientes a pedido (CRM) que permite gestionar las relaciones con los clientes de una manera eficiente.
Es eficiente porque Zoho CRM lo ayuda a optimizar sus funciones de ventas a nivel de organización, marketing, asistencia al cliente y gestión de inventario en un solo sistema.
¿Cómo se utiliza?
Comenzar a usar Zoho CRM es sencillo.
Configure su cuenta ingresando los detalles personales y los de la organización.
Personalice el producto conforme a sus necesidades y descubra más sobre las operaciones realizadas con más frecuencia en Zoho CRM.
1. Configuración de la cuenta
2. Personalización de productos
3. Operaciones comunes
4. Obtención de productos listos para empresas.
Zoho Projects: ventajas
Automatización de flujo de trabajo con Blueprints.
Zoho usa la misma herramienta para la automatización en todas sus aplicaciones.
Esta herramienta se llama " Blueprints" Su objetivo principal es ayudar a los usuarios a crear flujos de trabajo personalizados que básicamente ilustran ciertos procesos de una manera sistemática y organizada.
Una vez configurado, Blueprint guiará a los usuarios a través de la ejecución del proceso sabiendo qué acciones deben realizarse y en qué orden.
Estos pueden incluir notificaciones y actualizaciones automáticas para miembros del equipo y colaboradores, actualizaciones de facturas con nuevas horas facturables, etc.
También es posible crear procesos de automatización complicados y utilizar la API para obtener más posibilidades.
Zoho Projects: desventajas
Falta de plantillas preconfiguradas
Actualmente casi todos los software de gestión de proyectos ofrecen plantillas preconfiguradas para diferentes industrias. No es el caso de Zoho Projects. Se puede crear plantillas personalizadas a base de sus proyectos existentes para no tener que repetir la misma información una y otra vez en casos similares.
Pero si es principiante, las plantillas pueden ser una buena base para entender cómo hacer el plan de proyecto y usar el software.
Metodología
La mejora continua es un indicador distintivo de los equipos ágiles exitosos.
El cronograma de estado ayuda a su equipo a identificar los cuellos de botella y descubrir maneras de generar el mayor valor mientras elimina tantas actividades improductivas como sea posible.
Zoho en la educación
El software de gestión de proyectos de educación es una herramienta que ayuda a los usuarios a planificar todos sus proyectos académicos, realizar seguimientos de estos y colaborar. Lleva a los profesores, estudiantes, administradores y padres a una sola plataforma para que puedan colaborar sin esfuerzo, aprender y tomar decisiones colectivamente.
youtube
2 notes
·
View notes
Text
Traducir de español a ingles.
En AO3 soy mapache_opache.
One Piece, Familia AU.
Apis conoció a Luffy cuando tenía 8 años y escapaba de la marina, después de su aventura con los Sombrero de paja los sigue en el periódico mientras aprende todo sobre su historia familiar de su abuelo, sufriendo de siestas involuntarias durante todo el proceso, Bokuden, su abuelo, muere cuando ella cumple 14 años. Sabía que este día llegaría pero aún está triste y desolada.
Un día un marine llamado Nezumi viene a su isla preguntando por el elixir de la vida eterna, buscándola a ella, decidida a no hablar y sabiendo que no tenía forma o tiempo para escapar, deja que se la lleven no queriendo tener a los aldeanos en el fuego cruzado.
Antes de que saque uno de sus viejos trucos y escape durante una tormenta como en los viejos tiempos, se encuentran con uno de los almirantes, Koby durante sus vacaciones en el East Blue.
Koby salva a Apis y arresta a Nezumi por abuso de poder, como primero tiene que llevar a Nezumi a Loguetwon y desde ahí será llevado ante la justicia en el Marineford del Nuevo Mundo promete regresar a Apis a su casa cuando termine, la lleva con él mientras tanto.
En alguna parte del camino se topan con Luffy en sus propias vacaciones personales quien decide unirse a ellos.
En el camino ganan una relación de padres e hija, aunque Apis ve a Koby más como una mamá (mamá gallina).
Koby aún está enamorado de Luffy pero a aceptado hace años que sus sentimientos no son ni serán correspondidos y está decidido a no malinterpretar a Luffy ( lo malinterpretar de todos modos de la manera incorrecta) y también piensa que Luffy está saliendo con Hancook.
Luffy recién está dándose cuenta de sus sentimientos hacia Koby e intenta actuar sobre ellos, Koby no lo está entendiendo y eso lo está frustrando ¿Que tan más obvio tiene que ser?
Apis nota todo y ayuda a sus padres con diferentes niveles de éxito.
Detalles:
Nezumi se enteró del elixir de la vida de los antiguos reportes (notas personales) del difuntos comodoro Nelson Royale.
Nezumi tenía a Apis en una celda cuando Koby hizo su inspección sorpresa.
Los sombreros de paja se toman unas pequeñas vacaciones para visitar sus islas natales y a sus seres queridos (medio spoiler: Robin visita a Jaguar en Elbaf).
Luffy va a visitar al hijo de Shanks y Makino en Dawn.
Apis todavía está un poco triste por su abuelo, cuando aterrizan en la isla Mirrorball se encuentran Jango y Fullbody en un concurso de baile, Koby y Luffy se unen con Apis para intentar animar a la pequeña, funciona mejor de lo que pensaron para todas las partes involucradas, al final pura diversión.
Nami y Sanji salen juntos románticamente, visitan el Baratie y Cocoyashi Village.
Nami y Sanji se unen a las vacaciones familiares, de todos modos, Luffy necesita su ayuda en el romance.
Tajio es uno de los mejores cocineros de la marina por eso fue asignado al barco de Koby, termina siendo adoptado por Sanji y Nami.
Sanji reconoce a Tajio como ese niño que ayudó en la cocina de la marina años atrás.
Luffy le pide ayuda a Nami y Sanji sobre Koby.
Apis pide la ayuda de Tajio con sus nuevos padres.
Se pueden ver los comienzos de un romance en ciernes entre Apis y Tajio.
Apis y Teijio tienen la misma edad.
Luffy llama a Apis su pequeña campeona y Apis lo llama Pa.
Koby llama a Apis miel o su pequeña aventurera y Apis lo llama Papá.
Las islas que Koby, Apis y Luffy visitan o pasan son: Loguetwon, Cocoyashi, Baratie, Ciudad Orange, Villa Syrup (Apis y Tajio tienen una pequeña aventura con los antiguos piratas de Usopp), la isla de los animales raros, Dawn y Mirrorball (entre otras)
Así es como veo a la familia:
Luffy el papá.
Koby la mamá.
Apis la hija.
Sabo el tío.
Dragón el abuelo.
Garp el ¿bisabuelo? ¿Tatara abuelo?.
Sanji el papá.
Nami la mamá.
Tajio el hijo.
Nojiko la tía.
Genzo el abuelo.
Reiju la tía.
Zeff el abuelo.
(¿soy la única que ve a Apis como la hija adoptiva perfecta para Luffy y Koby? es aventurera (como Luffy),comió una fruta del diablo (como Luffy) y se preocupa por los demás (el viejo Ryu y como Koby) ¿O a Tajio como el hijo adoptivo perfecto para Nami y Sanji? Porque Tajio es pelirrojo, parece que le gusta navegar y es cocinero, el también cree en el Gran Azul como Sanji).
Pareja principal: Luffy x Koby
Pareja secundaria: Sanji x Nami
Cualquiera puede hacer lo que quiera con este AU.
#straw hat pirates#coby one piece#kobylu#koby#lukoby#luffy x koby#one piece#luffy#coby#koby one piece
2 notes
·
View notes
Text
It's worse.
The glasses Meta built come with language translation features -- meaning it becomes harder for bilingual families to speak privately without being overheard.
No it's even worse.
Because someone has developed an app (I-XRAY) that scans and detects who people are in real-time.
No even worse.
Because I-XRAY accesses all kinds of public data about that person.
Wait is it so bad?
I-XRAY is not publicly usable and was only built to show what a privacy nightmare Meta is creating. Here's a 2-minute video of the creators doing a experiment how quickly people on the street's trust can be exploited. It's chilling because the interactions are kind and heartwarming but obviously the people are being tricked in the most uncomfortable way.
Yes it is so bad:
Because as satirical IT News channel Fireship demonstrated, if you combine a few easily available technologies, you can reproduce I-XRAYs results easily.
Hook up an open source vision model (for face detection). This model gives us the coordinates to a human face. Then tools like PimEyes or FaceCheck.ID -- uh, both of those are free as well... put a name to that face. Then phone book websites like fastpeoplesearch.com or Instant Checkmate let us look up lots of details about those names (date of birth, phone #, address, traffic and criminal records, social media accounts, known aliases, photos & videos, email addresses, friends and relatives, location history, assets & financial info). Now you can use webscrapers (the little programs Google uses to index the entire internet and feed it to you) or APIs (programs that let us interface with, for example, open data sets by the government) -> these scraping methods will, for many targeted people, provide the perpetrators with a bulk of information. And if that sounds impractical, well, the perpetrators can use a open source, free-to-use large language model like LLaMa (also developed by Meta, oh the irony) to get a summary (or get ChatGPT style answers) of all that data.
Fireship points out that people can opt out of most of these data brokers by contacting them ("the right to be forgotten" has been successfully enforced by European courts and applies globally to people that make use of our data). Apparently the New York Times has compiled an extensive list of such sites and services.
But this is definitely dystopian. And individual opt-outs exploit that many people don't even know that this is a thing and that place the entire responsibility on the individual. And to be honest, I don't trust the New York Times and almost feel I'm drawing attention to myself if I opt out. It really leaves me personally uncertain what is the smarter move. I hope this tech is like Google's smartglasses and becomes extinct.
i hate the "meta glasses" with their invisible cameras i hate when people record strangers just-living-their-lives i hate the culture of "it's not illegal so it's fine". people deserve to walk around the city without some nameless freak recording their faces and putting them up on the internet. like dude you don't show your own face how's that for irony huh.
i hate those "testing strangers to see if they're friendly and kind! kindness wins! kindness pays!" clickbait recordings where overwhelmingly it is young, attractive people (largely women) who are being scouted for views and free advertising . they're making you model for them and they reap the benefits. they profit now off of testing you while you fucking exist. i do not want to be fucking tested. i hate the commodification of "kindness" like dude just give random people the money, not because they fucking smiled for it. none of the people recording has any idea about the origin of the term "emotional labor" and none of us could get them to even think about it. i did not apply for this job! and you know what! i actually super am a nice person! i still don't want to be fucking recorded!
& it's so normalized that the comments are always so fucking ignorant like wow the brunette is so evil so mean so twisted just because she didn't smile at a random guy in an intersection. god forbid any person is in hiding due to an abusive situation. no, we need to see if they'll say good morning to a stranger approaching them. i am trying to walk towards my job i am not "unkind" just because i didn't notice your fucked up "social experiment". you fucking weirdo. stop doing this.
19K notes
·
View notes
Text
من Scale AI إلى NFDG ، كيف تقوم Meta بإعادة بناء قدرتها التنافسية في السوق من خلال عمليات استحواذ ضخمة لشركات الذكاء الاصطناعى؟
في ساحة معركة الذكاء الاصطناعى من الذكاء الاصطناعى في Openai و Google و Anthropic ، غالبًا ما تظهر Meta منخفضة المفتاح والهامش. على الرغم من أن لديها نموذج مفتوح المصدر الخاص به ، إلا أنه يفتقر دائمًا إلى تطبيقات أو ابتكارات اختراق. في الوقت الحاضر ، تُظهر عمليات الدمج والاستحواذات الكبرى وأفعال الصيد الجائر أن Meta يبدو أنه تحول من التركيز على البحث والتطوير إلى استخدام تخطيط رأس المال والبيئة للتعويض عن وجود السوق المتخلف ، على أمل إعادة تنظيم سرد الذكاء الاصطناعي. من R&D LLM إلى M&A على نطاق واسع: بدوره استراتيجية META في العامين الماضيين ، كرست Meta نفسها لتطوير سلسلة Llama نموذج اللغة. على الرغم من إطلاق Llama 4 ، إلا أن السوق كان غير مبال. قالت صحيفة وول ستريت جورنال (WSJ) إن المطورين يعتقدون عمومًا أن النماذج المتنافسة مثل Gemini 2.5 Pro و Claude 4 و GPT-4O أقوى ، وليس فقط وظائف الاستدلال القوية ، ولكن أيضًا مثل البشر. بالإضافة إلى ذلك ، تسبب تغيير الوظائف المتتالي للأعضاء الأساسيين أيضًا في مخاوف بشأن تنمية آفاق Meta AI. (Meta AI Boss Lecun يفتح رأيه: AI ليس ذكيًا على الإطلاق ، وقد انفجر فريق Llama أيضًا) بالمقارنة مع المنافسين في السوق ، ما الفرق بين لاما؟ يعتقد المؤلف أن المشكلة الرئيسية هي أن "التكنولوجيا الجيدة لا تعني منتجات جيدة ، ولا يعني أنها تلبي الطلب على السوق". يفتقر النموذج الممتاز ذي الأداء الممتاز والمصدر المجاني إلى إنشاء عادات وتبعيات المستخدم ، ويتكامل مع منتج عملي. يعتمد Openai على ChatGpt لإنشاء بوابات المستخدمين ؛ تستخدم Google Gemini لتخطيط نظام Android البيئي ؛ يركز الإنسان على خدمات أمن المؤسسات و API. والميتا يصنعون لاما بالفعل اندماجفي برنامج Social Software Empire Instagram أو WhatsApp ، من الواضح أن استخدام المستخدم وشعبية السوق منخفضة نسبيًا. (هل يمكن أن تقوم AI بمهام ضارة سراً؟ من الواضح أن المدير التنفيذي لشركة Meta Mark Zuckerberg أدرك أن أبحاث المنتجات وتطويرها وحدها لا يمكنها دعم المنافسة الشاملة للنظام الإيكولوجي لمنظمة العفو الدولية. ونتيجة لذلك ، فإن التصميم الجديد متصل بالعمليات الدموية والاستحواذ والاستثمارات تكشف تدريجياً. انضم إذا لم تتمكن منذ عام 2024 ، بدأت META سلسلة من الهجمات الاستباقية ، حيث استثمرت أولاً بقيمة 14.3 مليار دولار من بيانات الاستثمار التي تحمل علامة AI Giant Scale ، التي حصلت على ما يقرب من نصف حقوق الملكية وتجنيد مؤسسها Alexandr Wang للانضمام إلى قسم "Superintelligence" الذي تم تأسيسه حديثًا. (Openai Disconnects Scale AI التعاون! Meta تنفق المال على صيد الناس ويسبب الصدمة ، كما أن Google شائعات لخفضها) في وقت لاحق ، حاول الحصول على Safe Superintelligence (SSI) ، وهي شركة منظمة العفو الدولية التي أسسها مؤسس شركة Openai Elya Sutskever. على الرغم من أنه تم رفضه ، فقد نجح في مسار الرئيس التنفيذي لشركة SSI دانييل جروس والرئيس التنفيذي السابق لـ Github نات فريدمان ، وحمل أسهم في صندوق رأس المال الاستثماري الذي أنشأوه بشكل مشترك. NFDG。 لم يعد هذا مجرد اكتساب موهبة ، ولكن أيضًا اختراقًا بيئيًا استراتيجيًا. أهداف الاستثمار في NFDG لا تعمل بشكل جيد الآن ولكن لديها أيضًا مستقبل واعد ، بما في ذلك Figma و Stripe و Perplexity و Eleven Labs. تتيح هذه الصفقة الحصول على هذه الموارد الفنية المبتكرة وفرص الاستثمار ومسارات الاستحواذ بشكل غير مباشر ، ويمكنها إدخال سيناريوهات التطبيق الرئيسية بتكلفة أقل في المستقبل. MAGNET MAGNET + جمع البيانات: تصميم AI المتعدد من ZuckerBet نشر مستثمر اليعسوب عمره عمرانقر فوقمفتاح هذه الصفقة: يستخدم Zuck استثمارًا مختلطًا لفهم الذكاء الصناعي ، والتخطيط الاستراتيجي ، وتعزيز العلامات التجارية ، وامتصاص المواهب. Gross و Friedman ليسا كبار رواد الأعمال ، ولكن أيضًا "مغناطيس المواهب" في دائرة ريادة الأعمال. يرمز انضمامهم إلى أن Meta ستجذب بسهولة أكبر مهندسي الذكاء الاصطناعي ومصممي المنتجات وفرق المغامرة الجديدة. ببساطة ، يتيح الاستثمار في Scale AI Meta تقوية التحكم في البيانات وربط NFDG لملء فجوة المواهب في طبقة التطبيق. (قام Openai بمنع الصيد الجائر لمئات الملايين من المغنيسيوم ، واستدار للتوقيع على عقد الدفاع الأمريكي 200 مليون المغنيسيوم) من كونه وحيدًا إلى التحالف ، يستخدم Meta المال لاختراق النظام البيئي لمنظمة العفو الدولية يبدو أن Meta و Zuckerberg قد تحولوا الآن من الحضانة الداخلية الأصلية للنظام
الإيكولوجي لمنظمة العفو الدولية لتشكيل خريطة الذكاء الاصطناعى من خلال رأس المال والاتصالات لتشكيل منتجات متعددة المتقاطعات وخريطة الذكاء الاصطناعى المتقاطع. سواء أكان نموذجًا مفتوح المصدر ، أو يمسك بالأشخاص أو الاستثمار أو الاستحواذ ، فإن Zuckerberg يملأ "فجوة الوجود" للشركة في سوق الذكاء الاصطناعي مع استراتيجية هجينة. عندما يواصل عمالقة التكنولوجيا الآخرين تعزيز التحكم في التطبيق وحصته في السوق ، اختار Meta إنفاق الأموال لتشكيل تحالف ، على أمل الفوز بمفتاح مسابقة AI هذه. تحذير المخاطراستثمارات العملة المشفرة محفوفة بالمخاطر للغاية ، وقد تتقلب أسعارها بشكل كبير وقد تفقد كل مديرك. يرجى تقييم المخاطر بحذر.
0 notes
Text
How Generative AI Training in Bengaluru Can Boost Your Tech Career?
In recent years, Generative AI has emerged as one of the most disruptive technologies transforming industries across the globe. From personalized content creation to AI-driven design, code generation, and even advanced medical imaging—Generative AI is revolutionizing how we work, interact, and innovate.
And if you are a tech enthusiast or working professional based in India’s Silicon Valley, you’re in the perfect place to jump into this exciting field. Generative AI Training in Bengaluru offers a unique blend of industry exposure, expert-led education, and career acceleration opportunities. This blog will guide you through the benefits of pursuing generative AI training in Bengaluru and how it can supercharge your career in the tech domain.
What is Generative AI?
Before diving into the career benefits, let’s define what Generative AI actually is. Generative AI refers to a class of artificial intelligence models capable of generating new content—text, images, audio, video, or code—based on patterns learned from existing data.
Popular tools and models include:
ChatGPT (OpenAI) – for conversational AI and text generation
DALL·E & Midjourney – for AI-generated images
Codex & GitHub Copilot – for AI-assisted programming
Runway ML & Sora – for generative video
Stable Diffusion – for open-source creative tasks
Industries are actively seeking professionals who can understand, implement, and innovate with these tools. That’s where Generative AI training comes in.
Why Choose Bengaluru for Generative AI Training?
Bengaluru is more than just a city—it’s the beating heart of India’s tech ecosystem. Here’s why enrolling in a Generative AI training in Bengaluru program can be a game-changer:
1. Home to India’s Leading Tech Companies
From Infosys and Wipro to Google, Microsoft, and OpenAI-partnered startups—Bengaluru hosts a vast number of AI-focused organizations. Training in the city means you’re close to the action, with easier access to internships, workshops, and networking events.
2. Cutting-Edge Training Institutes
Bengaluru boasts some of the top AI and ML training providers in India. These institutions offer hands-on experience with real-world projects, industry mentorship, and certifications that are recognized globally.
3. Startup Ecosystem
With a thriving startup culture, Bengaluru is a breeding ground for innovation. After completing your training, you’ll find ample opportunities in early-stage ventures working on next-gen generative AI products.
4. Tech Community and Events
The city is buzzing with meetups, hackathons, AI summits, and conferences. This vibrant tech community provides a great platform to learn, collaborate, and grow.
What Does Generative AI Training in Bengaluru Include?
Most leading programs in Bengaluru offer comprehensive coverage of the following:
✅ Core AI and ML Concepts
Understanding the foundational building blocks—supervised/unsupervised learning, deep learning, and neural networks.
✅ Generative Models
Focused training on GANs (Generative Adversarial Networks), VAEs (Variational Autoencoders), and Diffusion Models.
✅ Large Language Models (LLMs)
Working with GPT-3.5, GPT-4, Claude, LLaMA, and other state-of-the-art transformer-based models.
✅ Prompt Engineering
Learning the art and science of crafting prompts to generate better, controlled outputs from AI models.
✅ Toolkits and Platforms
Hands-on experience with tools like OpenAI APIs, Hugging Face, TensorFlow, PyTorch, GitHub Copilot, and LangChain.
✅ Capstone Projects
End-to-end implementation of real-world generative AI projects in areas like healthcare, e-commerce, finance, and creative media.
How Generative AI Training in Bengaluru Can Boost Your Tech Career?
Let’s get to the heart of it—how can this training actually boost your career?
1. Future-Proof Your Skill Set
As automation and AI continue to evolve, companies are constantly seeking professionals with AI-forward skills. Generative AI is at the forefront, and training in it makes you an in-demand candidate across industries.
2. Land High-Paying Roles
According to industry data, professionals with Generative AI skills are commanding salaries 20-30% higher than traditional tech roles. Roles such as:
AI Product Engineer
Prompt Engineer
Machine Learning Scientist
Generative AI Researcher
AI Consultant
LLM Application Developer
are on the rise.
3. Open Doors to Global Opportunities
With Bengaluru's global tech footprint, professionals trained here can easily transition to remote roles, international placements, or work with multinational companies using generative AI.
4. Enhance Your Innovation Quotient
Generative AI unlocks creativity in code, design, storytelling, and more. Whether you're building an app, automating a workflow, or launching a startup, these skills amplify your ability to innovate.
5. Accelerate Your Freelancing or Startup Journey
Many tech professionals in Bengaluru are turning into solopreneurs and startup founders. With generative AI, you can quickly prototype MVPs, create content, or offer freelance services in writing, video creation, or coding—all powered by AI.
Who Should Enroll in a Generative AI Training Program?
A Generative AI training in Bengaluru is ideal for:
Software Developers & Engineers – who want to transition into AI-focused roles.
Data Scientists – looking to expand their capabilities in creative and generative models.
Students & Graduates – aiming for a future-proof tech career.
Designers & Content Creators – interested in AI-assisted creation.
Entrepreneurs & Product Managers – who wish to integrate AI into their offerings.
IT Professionals – looking to reskill or upskill for better job roles.
Why Choose a Professional Institute?
While there are many online courses available, a classroom or hybrid program in Bengaluru often provides:
Mentorship from industry experts
Collaborative learning environment
Real-time feedback and doubt-solving
Placement support and career counseling
Live projects using real-world datasets
One such reputed name is the Boston Institute of Analytics, which offers industry-relevant, project-based Generative AI training programs in Bengaluru. Their curriculum is tailored to meet evolving market demands, ensuring students graduate job-ready.
Final Thoughts
In today’s fast-evolving tech landscape, staying ahead means staying adaptable—and Generative AI is the perfect skill to future-proof your career. Whether you want to break into AI development, build cutting-edge products, or simply enhance your tech toolkit, enrolling in a Generative AI Training in Bengaluru can set you on a path of accelerated growth and innovation.
Bengaluru’s thriving tech ecosystem, access to global companies, and expert-led training institutions make it the ideal place to begin your generative AI journey. Don’t wait for the future—start building it now with the right training, tools, and support.
#Generative AI courses in Bengaluru#Generative AI training in Bengaluru#Agentic AI Course in Bengaluru#Agentic AI Training in Bengaluru
0 notes