#merge database software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
Merge Database Software: Streamlining Data Integration for Enhanced Efficiency
In today's data-driven world, businesses and organizations rely heavily on efficient data management to make informed decisions, improve operations, and drive growth. One critical aspect of data management is the ability to merge multiple databases seamlessly. Merge database software is designed to address this need, offering tools to combine data from different sources into a cohesive and accessible format. This article explores the benefits, features, and considerations when choosing merge database software.
Benefits of Merge Database Software
Improved Data Consistency: Merging databases ensures that data from various sources is consistent and up-to-date. This reduces discrepancies and ensures that all users are working with the same information.
Enhanced Data Accessibility: By combining multiple databases into a single, unified system, users can access all relevant data from one location. This improves efficiency and makes it easier to retrieve and analyze information.
Streamlined Operations: Merge database software automates the process of integrating data, saving time and reducing the risk of human error. This allows IT teams to focus on more strategic tasks.
Better Decision-Making: With a unified database, decision-makers have a comprehensive view of the organization's data. This enables more accurate analysis and better-informed decisions.
Cost Savings: Efficient data integration can reduce the need for multiple data storage solutions and minimize maintenance costs. This can lead to significant savings over time.
Key Features of Merge Database Software
Data Mapping and Transformation: The software should offer tools to map data fields from different databases and transform data into a consistent format. This ensures that merged data is accurate and usable.
Conflict Resolution: When merging databases, conflicts can arise due to duplicate records or differing data formats. Advanced conflict resolution features help identify and resolve these issues automatically.
Support for Multiple Data Sources: The software should be compatible with various database types and formats, such as SQL, NoSQL, and cloud-based databases. This flexibility allows for seamless integration across different platforms.
Scalability: As organizations grow, their data integration needs will evolve. The software should be scalable to accommodate increasing data volumes and complexity.
Real-Time Synchronization: For businesses that require up-to-the-minute data, real-time synchronization ensures that merged databases are always current.
Security and Compliance: The software should provide robust security features to protect sensitive data during the merge process. Compliance with industry standards and regulations is also crucial.
Considerations When Choosing Merge Database Software
Ease of Use: The software should have an intuitive interface and straightforward setup process. This ensures that users can quickly learn and effectively utilize the tool.
Customizability: Different organizations have unique data integration needs. The ability to customize the software to fit specific requirements is a valuable feature.
Vendor Support and Training: Reliable customer support and training resources can help users maximize the software's potential and address any issues that arise.
Cost: Consider the total cost of ownership, including licensing fees, implementation costs, and ongoing maintenance. Choose a solution that offers the best value for your organization.
Integration with Existing Systems: Ensure that the merge database software can seamlessly integrate with your current IT infrastructure and other software applications.
Conclusion
Merge database software is an essential tool for organizations seeking to streamline their data integration processes. By providing a unified and consistent view of data, these tools enhance accessibility, improve decision-making, and drive operational efficiency. When selecting merge database software, consider factors such as ease of use, customizability, vendor support, cost, and compatibility with existing systems. Investing in the right software can significantly improve your organization's data management capabilities and support long-term growth.
For more info click here:- data cleansing deduplication
0 notes
Text
This Week in Rust 577
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on X (formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
Official
This Month in Our Test Infra: November 2024
December 2024 Leadership Council Update
Newsletters
The Embedded Rustacean Issue #34
Rust Trends Issue #55
Project/Tooling Updates
Dioxus 0.6
Flawless Replay
Rust9x update: Rust 1.84.0-beta
What's new in SeaQuery 0.32.x
Observations/Thoughts
Rust Macros: A Cautionary Tale
Running teloxide bots cheaply on Fly.io
Speeding up Ruby by rewriting C… in Ruby
Memory-safe PNG decoders now vastly outperform C PNG libraries
State of the Crates 2025
Comparing Rust Database Crates
Rust Walkthroughs
Parsing MIDI messages in Rust
Drag & Drop Images into Bevy 0.15 on the web
Missing iterable traits and how to introduce them effortlessly
EuroRust: Introduction to Diesel: basic and advanced concepts in practice
Miscellaneous
My Rust Story
November 2024 Rust Jobs Report
[video] How to Integrate C++ and Rust
[video] 2024 LLVM Developers' Meeting - Rust ❤️ LLVM
Crate of the Week
This week's crate is include-utils, a more powerful replacement for the standard library's include_str macro.
Thanks to Aleksey Sidorov for the self-suggestion!
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
RFCs
No calls for testing were issued this week.
Rust
No calls for testing were issued this week.
Rustup
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Rustup
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No Calls for participation were submitted this week.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
No Calls for papers or presentations were submitted this week.x
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
Updates from the Rust Project
462 pull requests were merged in the last week
dataflow_const_prop: do not eval a ptr address in SwitchInt
fn_sig_for_fn_abi should return a ty::FnSig, no need for a binder
rust_for_linux: -Zreg-struct-return commandline flag for X86
actually walk into lifetimes and attrs in EarlyContextAndPass
add allocate_bytes and refactor allocate_str in InterpCx for raw byte…
add context to "const in pattern" errors
add lint against function pointer comparisons
add more info on type/trait mismatches for different crate versions
avoid opaque type not constrained errors in the presence of other errors
avoid fetching the anon const hir node that is already available
deeply normalize when computing implied outlives bounds
do not implement unsafe auto traits for types with unsafe fields
don't suggest restricting bound with unstable traits on stable and mention it's unstable on nightly
don't use a SyntheticProvider for literally every type
fix MutVisitor's default implementations to visit Stmt's and BinOp's spans
fix suggestion when shorthand self has erroneous type
gate async fn trait bound modifier on async_trait_bounds
handle --json-output properly
hide errors whose suggestions would contain error constants or types
implement checks for tail calls
improve TagEncoding::Niche docs, sanity check, and UB checks
include LLDB and GDB visualizers in MSVC distribution
introduce default_field_values feature
lint against Symbol::intern on a string literal
lint: change help for pointers to dyn types in FFI
make CoercePointee errors translatable
make sure to record deps from cached task in new solver on first run
move most tests for -l and #[link(..)] into tests/ui/link-native-libs
no need to create placeholders for GAT args in confirm_object_candidate
only allow PassMode::Direct for aggregates on wasm when using the C ABI
parse guard patterns
reduce false positives on some common cases from if-let-rescope lint
reimplement ~const trait specialization
structurally resolve in adjust_for_branches
structurally resolve in probe_adt
unify sysroot_target_{bin,lib}dir handling
use correct hir_id for array const arg infers
miri: cleanup: avoid passing byte slice to anonsocket_read
miri: fix SC fence logic
miri: fix weak memory emulation to avoid generating behaviors that are forbidden under C++ 20
miri: implement simd_relaxed_fma
extend Miri to correctly pass mutable pointers through FFI
remove polymorphization
introduce MixedBitSet
stabilize const_collections_with_hasher and build_hasher_default_const_new
stabilize const_{size,align}_of_val
stabilize noop_waker
stabilize std::io::ErrorKind::CrossesDevices
stabilize std::io::ErrorKind::QuotaExceeded
add core::arch::breakpoint and test
implementation of fmt::FormattingOptions
add Extend impls for tuples of arity 1 through 12
cargo: docs(fingerprint): cargo-rustc extra flags do not affect the metadata
cargo: feat(build-rs): Add the 'error' directive
cargo: fix(add): Don't select yanked versions when normalizing names
cargo: fix(build-rs): Correctly refer to the item in assert
cargo: fix(build-std): determine root crates by target spec std:bool
cargo: fix(fingerprint): Don't throwaway the cache on RUSTFLAGS changes
cargo: fix(fix): Migrate workspace dependencies
cargo: test(build-std): make mock-std closer to real world
cargo: fix(build-rs)!: remove meaningless 'cargo_cfg_debug_assertions'
cargo: refactor: use Path::push to construct remap-path-prefix
cargo: semVer: add section on RPIT capturing
rustdoc: remove eq for clean::Attributes
rustdoc: rename issue-\d+.rs tests to have meaningful names (part 10)
rustdoc: rename set_back_info to restore_module_data
rustdoc: always display first line of impl blocks even when collapsed
improve code for FileName retrieval in rustdoc
clippy: doc_lazy_continuation: Correctly count indent with backslashes
clippy: extend precedence for bitmasking and shift
clippy: new lint for as *const _ and as *mut _ pointer casts
rust-analyzer: add Configurable Option to Exclude Trigger Characters for Typing Assists
rust-analyzer: add implict unsafety inlay hints for extern blocks
rust-analyzer: add typing handler for param list pipe
rust-analyzer: complete derive helper attributes
rust-analyzer: complete diagnostics in ty lowering groundwork and serve a first diagnostic 🎉
rust-analyzer: extend reported unsafe operations
rust-analyzer: support AsyncFnX traits
rust-analyzer: fix parsing of parenthesized type args and RTN
rust-analyzer: better parser recovery for paths
rust-analyzer: coerce two FnDefs to fn pointers even if they are the same, if they are subtypes
rust-analyzer: disable < typing handler again
rust-analyzer: do not report warnings from proc macros, ever
rust-analyzer: fix a bug when synthetic AST node were searched in the AST ID map and caused panics
rust-analyzer: fix parser getting stuck for bad asm expressions
rust-analyzer: fix parsing of dyn T in generic arg on 2015 edition
rust-analyzer: fix parsing of integer/keyword name refs in various places
rust-analyzer: fix shadowing of record enum variant in patterns
rust-analyzer: fixed another bug with glob imports
rust-analyzer: map new replacement nodes to their mutable equivalents in SyntaxEditor
rust-analyzer: non-exhaustive structs may be empty
rust-analyzer: panic when displaying generic params with defaults
rust-analyzer: parse lifetime bounds in lifetime param into TypeBoundList
rust-analyzer: resolve generic parameters within use captures
rust-analyzer: temporarily disable completion resolve support for helix and neovim
rust-analyzer: improve heuristics for on typing semicolon insertion
rust-analyzer: make bracket typing handler work on more things
rust-analyzer: migrate add_turbo_fish to SyntaxEditor
rust-analyzer: migrate introduce_named_generic Assist to Use SyntaxFactory
rust-analyzer: migrate sort_items Assist to Use SyntaxFactory
rust-analyzer: vscode: only show status bar item in relevant files
Rust Compiler Performance Triage
A pretty quiet week, with both few PRs landed and no large changes in performance.
Triage done by @simulacrum. Revision range: 490b2cc0..1b3fb316
0 Regressions, 0 Improvements, 7 Mixed; 4 of them in rollups 25 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
Rust
[disposition: merge] Add --doctest-compilation-args option to add compilation flags to doctest compilation
Cargo
[disposition: merge] fix(cargo-rustc): stabilize higher precedence trailing flags
Language Team
No Language Team Proposals entered Final Comment Period this week.
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline Tracking Issues or PRs entered Final Comment Period this week.
New and Updated RFCs
[new] Drop type destructuring
[new] #[must_use = false]
[new] RFC: Partial Types (v3)
Upcoming Events
Rusty Events between 2024-12-11 - 2025-01-08 🦀
Virtual
2024-12-11 | Virtual (Vancouver, BC, CA) | Vancouver Rust
egui
2024-12-12 | Hybrid: In-Person and Virtual (Seattle, WA, US) | Seattle Rust Meetup
December Meetup
2024-12-12 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-12-12 | Virtual (Nürnberg, DE) | Rust Nuremberg
Rust Nürnberg online
2024-12-13 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-12-17 | Virtual (San Francisco, CA, US) | Blockchain Center SF
Rust in Web3: Developer Series
2024-12-17 | Virtual (Tel Aviv-Yafo, IL) | Code Mavens 🦀 - 🐍 - 🐪
Rust Source Code Reading: The thousands crate (Virtual, English)
2024-12-17 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2024-12-19 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-12-19 | Virtual (Mexico City, DF, MX) | Rust MX
Posada 2024
2024-12-20 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-12-24 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-12-26 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-01-02| Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2025-01-04 | Virtual (Kampala, UG) | Rust Circle Kampala
Rust Circle Meetup
Asia
2024-12-14 | Bangalore/Bengaluru, IN | Rust Bangalore
December 2024 Rustacean meetup/workshop
Europe
2024-12-11 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup
2024-12-12 | Amsterdam, NL | Rust Developers Amsterdam Group
Rust Meetup @ JetBrains
2024-12-12 | München, DE | Rust Munich
Rust Munich 2024 / 4 - Hacking Evening
2024-12-12 | Vienna, AT | Rust Vienna
Rust Vienna - December | at Sentry.io 🦀
2024-12-17 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
Secret Santa in Rust: Unwrapping Property Testing
2024-12-18 | Ghent, BE | Systems Programming Ghent
Launch of new community for Rust and C++ developers
North America
2024-12-12 | Hybrid: In-Person and Virtual (Seattle, WA, US) | Seattle Rust User Group
December Meetup
2024-12-12 | Mountain View, CA, US | Hacker Dojo
RUST MEETUP at HACKER DOJO
2024-12-16 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2024-12-17 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-12-26 | Mountain View, CA, US | Hacker Dojo
RUST MEETUP at HACKER DOJO
Oceania
2024-12-16 | Collingwood, AU | Rust Melbourne
December 2024 Rust Melbourne Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Memory-safe implementations of PNG (png, zune-png, wuffs) now dramatically outperform memory-unsafe ones (libpng, spng, stb_image) when decoding images.
Rust png crate that tops our benchmark shows 1.8x improvement over libpng on x86 and 1.5x improvement on ARM.
– Shnatsel on /r/rust
Thanks to Anton Fetisov for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
3 notes
·
View notes
Text
The Role of Machine Learning Engineer: Combining Technology and Artificial Intelligence

Artificial intelligence has transformed our daily lives in a greater way than we can’t imagine over the past year, Impacting how we work, communicate, and solve problems. Today, Artificial intelligence furiously drives the world in all sectors from daily life to the healthcare industry. In this blog we will learn how machine learning engineer build systems that learn from data and get better over time, playing a huge part in the development of artificial intelligence (AI). Artificial intelligence is an important field, making it more innovative in every industry. In the blog, we will look career in Machine learning in the field of engineering.
What is Machine Learning Engineering?
Machine Learning engineer is a specialist who designs and builds AI models to make complex challenges easy. The role in this field merges data science and software engineering making both fields important in this field. The main role of a Machine learning engineer is to build and design software that can automate AI models. The demand for this field has grown in recent years. As Artificial intelligence is a driving force in our daily needs, it become important to run the AI in a clear and automated way.
A machine learning engineer creates systems that help computers to learn and make decisions, similar to human tasks like recognizing voices, identifying images, or predicting results. Not similar to regular programming, which follows strict rules, machine learning focuses on teaching computers to find patterns in data and improve their predictions over time.
Responsibility of a Machine Learning Engineer:
Collecting and Preparing Data
Machine learning needs a lot of data to work well. These engineers spend a lot of time finding and organizing data. That means looking for useful data sources and fixing any missing information. Good data preparation is essential because it sets the foundation for building successful models.
Building and Training Models
The main task of Machine learning engineer is creating models that learn from data. Using tools like TensorFlow, PyTorch, and many more, they build proper algorithms for specific tasks. Training a model is challenging and requires careful adjustments and monitoring to ensure it’s accurate and useful.
Checking Model Performance
When a model is trained, then it is important to check how well it works. Machine learning engineers use scores like accuracy to see model performance. They usually test the model with separate data to see how it performs in real-world situations and make improvements as needed.
Arranging and Maintaining the Model
After testing, ML engineers put the model into action so it can work with real-time data. They monitor the model to make sure it stays accurate over time, as data can change and affect results. Regular updates help keep the model effective.
Working with Other Teams
ML engineers often work closely with data scientists, software engineers, and experts in the field. This teamwork ensures that the machine learning solution fits the business goals and integrates smoothly with other systems.
Important skill that should have to become Machine Learning Engineer:
Programming Languages
Python and R are popular options in machine learning, also other languages like Java or C++ can also help, especially for projects needing high performance.
Data Handling and Processing
Working with large datasets is necessary in Machine Learning. ML engineers should know how to use SQL and other database tools and be skilled in preparing and cleaning data before using it in models.
Machine Learning Structure
ML engineers need to know structure like TensorFlow, Keras, PyTorch, and sci-kit-learn. Each of these tools has unique strengths for building and training models, so choosing the right one depends on the project.
Mathematics and Statistics
A strong background in math, including calculus, linear algebra, probability, and statistics, helps ML engineers understand how algorithms work and make accurate predictions.
Why to become a Machine Learning engineer?
A career as a machine learning engineer is both challenging and creative, allowing you to work with the latest technology. This field is always changing, with new tools and ideas coming up every year. If you like to enjoy solving complex problems and want to make a real impact, ML engineering offers an exciting path.
Conclusion
Machine learning engineer plays an important role in AI and data science, turning data into useful insights and creating systems that learn on their own. This career is great for people who love technology, enjoy learning, and want to make a difference in their lives. With many opportunities and uses, Artificial intelligence is a growing field that promises exciting innovations that will shape our future. Artificial Intelligence is changing the world and we should also keep updated our knowledge in this field, Read AI related latest blogs here.
2 notes
·
View notes
Text
Mastering Web Development: A Comprehensive Guide for Beginners
In the vast landscape of technology, web development stands as a crucial cornerstone. It encompasses the art and science of building websites, ranging from simple static pages to complex web applications. Whether you're aiming to pursue a career in software development or seeking to enhance your digital presence, understanding web development is essential.
In this comprehensive guide, we'll take you through the fundamental concepts and practical skills needed to master web development from scratch. Let's dive in!
1. Understanding HTML (Hypertext Markup Language)
HTML serves as the backbone of every web page, providing the structure and content. It uses tags to define different elements such as headings, paragraphs, images, and links. By mastering HTML, you'll be able to create well-structured and semantically meaningful web documents.
2. Exploring CSS (Cascading Style Sheets)
CSS is the language used to style HTML elements, enhancing their appearance and layout. With CSS, you can customize colors, fonts, spacing, and more, giving your website a polished and professional look. Understanding CSS selectors and properties is essential for effective styling.
3. Introduction to JavaScript
JavaScript is a versatile programming language that adds interactivity and dynamic behavior to web pages. From simple animations to complex web applications, JavaScript powers a wide range of functionalities. Learning JavaScript fundamentals such as variables, functions, and events is crucial for web development.
4. Building Responsive Websites
In today's mobile-centric world, it's essential to create websites that adapt seamlessly to various screen sizes and devices. Responsive web design achieves this by using fluid grids, flexible images, and media queries. Mastering responsive design principles ensures that your websites look great on desktops, tablets, and smartphones.
5. Introduction to Version Control with Git
Git is a powerful tool for tracking changes in your codebase and collaborating with other developers. By learning Git basics such as branching, merging, and committing, you can streamline your development workflow and effectively manage project versions.
6. Introduction to Front-End Frameworks
Front-end frameworks like Bootstrap, Foundation, and Materialise provide pre-designed components and stylesheets to expedite web development. By leveraging these frameworks, you can create responsive and visually appealing websites with less effort and code.
7. Introduction to Back-End Development
While front-end development focuses on the user interface, back-end development deals with server-side logic and database management. Learning back-end languages such as Node.js, Python, or PHP enables you to build dynamic web applications and handle user interactions efficiently.
8. Deploying Your Website
Once you've developed your website, it's time to make it accessible to the world. Deploying a website involves selecting a web hosting provider, uploading your files, and configuring domain settings. Understanding the deployment process ensures that your website goes live smoothly.
9. Conclusion and Next Steps
Congratulations on completing this comprehensive guide to mastering web development! By now, you've gained a solid understanding of HTML, CSS, JavaScript, version control, frameworks, and deployment. As you continue your journey in web development, remember to stay curious, practice regularly, and explore advanced topics to further refine your skills.
Resources for Further Learning:
Online tutorials and documentation
Interactive coding platforms
Community forums and discussion groups
Next Steps:
Explore advanced topics such as web performance optimization, server-side rendering, and progressive web apps.
Build real-world projects to apply your skills and showcase your portfolio.
Stay updated with the latest trends and technologies in web development through blogs, podcasts, and conferences.
With dedication and perseverance, you'll continue to evolve as a proficient web developer, creating innovative solutions and contributing to the ever-changing digital landscape . Happy coding!
4 notes
·
View notes
Text
The Versatile Role of a DevOps Engineer: Navigating the Convergence of Dev and Ops
The world of technology is in a state of constant evolution, and as businesses increasingly rely on software-driven solutions, the role of a DevOps engineer has become pivotal. DevOps engineers are the unsung heroes who seamlessly merge the worlds of software development and IT operations to ensure the efficiency, security, and automation of the software development lifecycle. Their work is like the unseen wiring in a well-orchestrated symphony, making sure that every note is played in harmony. This blog will delve into the world of DevOps engineering, exploring the intricacies of their responsibilities, the skills they wield, and the dynamic nature of their day-to-day work.

The DevOps Engineer: Bridging the Gap
DevOps engineers are the bridge builders in the realm of software development. They champion collaboration between development and operations teams, promoting faster development cycles and more reliable software. These professionals are well-versed in scripting, automation, containerization, and continuous integration/continuous deployment (CI/CD) tools. Their mission is to streamline processes, enhance system reliability, and contribute to the overall success of software projects.
The Skill Set of a DevOps Engineer
A DevOps engineer's skill set is a versatile mix of technical and soft skills. They must excel in coding and scripting, system administration, and automation tools, creating efficient pipelines with CI/CD integration. Proficiency in containerization and orchestration, cloud computing, and security is crucial. DevOps engineers are excellent collaborators with strong communication skills and a knack for problem-solving. They prioritize documentation and are committed to continuous professional development, ensuring they remain invaluable in the dynamic landscape of modern IT operations..
What a DevOps Engineer Does Throughout the Day
A typical day for a DevOps engineer is dynamic and multifaceted, reflecting the varied responsibilities in this role. They focus on collaboration, automation, and efficiency, aiming to ensure that the software development lifecycle is smooth. Their day often begins with a deep dive into infrastructure management, where they meticulously check the health of servers, networks, and databases, ensuring that all systems are up and running smoothly. One of the main priorities is minimising disruptions and downtime.
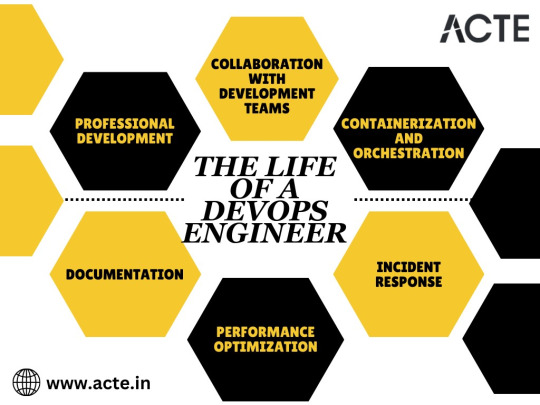
Here's a closer look at the intricate web of tasks that DevOps engineers expertly navigate throughout the day:
1. Collaboration with Development Teams: DevOps engineers embark on a journey of collaboration, working closely with software development teams. They strive to comprehend the intricacies of new features and applications, ensuring that these seamlessly integrate with the existing infrastructure and are deployable.
2. Containerization and Orchestration: In the ever-evolving world of DevOps, the use of containerization technologies like Docker and orchestration tools such as Kubernetes is a common practice. DevOps engineers dedicate their time to efficiently manage containerized applications and scale them according to varying workloads.
3. Incident Response: In the dynamic realm of IT, unpredictability is the norm. Issues and incidents can rear their heads at any moment. DevOps engineers stand as the first line of defense, responsible for rapid incident response. They delve into issues, relentlessly searching for root causes, and swiftly implement solutions to restore service and ensure a seamless user experience.
4. Performance Optimization: Continuous performance optimization is the name of the game. DevOps engineers diligently analyze system performance data, pinpointing bottlenecks, and proactively applying enhancements to boost application speed and efficiency. Their commitment to optimizing performance ensures a responsive and agile digital ecosystem.
5. Documentation: Behind the scenes, DevOps engineers meticulously maintain comprehensive documentation. This vital documentation encompasses infrastructure configurations and standard operating procedures. Its purpose is to ensure that processes are repeatable, transparent, and easily accessible to the entire team.
6. Professional Development: The world of DevOps is in constant flux, with new technologies and trends emerging regularly. To stay ahead of the curve, DevOps engineers are committed to ongoing professional development. This entails self-guided learning, attendance at workshops, and, in many cases, achieving additional certifications to deepen their expertise.
In conclusion, the role of a DevOps engineer is one of great significance in today's tech-driven world. These professionals are the linchpins that keep the machinery of software development and IT operations running smoothly. With their diverse skill set, they streamline processes, enhance efficiency, and ensure the reliability and security of applications. The dynamic nature of their work, encompassing collaboration, automation, and infrastructure management, makes them indispensable.
For those considering a career in DevOps, the opportunities are vast, and the demand for skilled professionals continues to grow. ACTE Technologies stands as a valuable partner on your journey to mastering DevOps. Their comprehensive training programs provide the knowledge and expertise needed to excel in this ever-evolving field. Your path to becoming a proficient DevOps engineer starts here, with a world of possibilities awaiting you.
3 notes
·
View notes
Text
202310271453
In the wondrous realm of the mind, where neurons dance to the tune of thoughts, we embark on a journey through the cosmos of knowledge.
Our quest delves deep into the heart of cognition, where neuroscience unlocks the mysteries of our mental symphony. But this is no solitary exploration; it's a waltz of interconnected ideas.
Imagine, if you will, a thought in motion, a neuron firing, setting the stage for what we call the mind. It's a captivating performance, an intricate ballet where every step taken by your thoughts orchestrates the dance of consciousness. As thought evolves, so does the mind, a conductor of the body's orchestra, directing each note with precision.
But what lies beyond the confines of the self? As the mind extends its reach, we glimpse the vast outer-firmament, a macrocosm awaiting exploration. It's a canvas for us to paint our thoughts and emotions, where inner meets outer, and microcosm embraces macrocosm.
Now, let's transition to the world of programming, where functional reactive programming becomes our musical score. Like a grand symphony, it harmonizes data and actions, creating an enchanting melody of software development. As we delve into the intricacies of code, we find beauty in the logic of systems.
Ancient Hebrew and Koine Greek, languages steeped in history, guide us through the wisdom of antiquity. Their words resonate like ancient incantations, connecting us to the past. A linguistic bridge to forgotten eras.
Paracelsus, the alchemical maestro, takes us on an alchemical journey where matter and spirit converge. The essence of transformation, both in the laboratory and the soul, unfolds before us. His teachings serve as our guide.
And in the digital realm, we meet Philip Wadler, a luminary in the world of programming languages. His insights into functional programming provide the tools to craft elegant and efficient software. Unix, the operating system that powers the digital world, becomes our playground.
Quareia Josephine McCarthy invites us into the mystical world of magic, where intention and ritual become catalysts for change. Her teachings merge with the essence of our thoughts and actions, empowering our rituals for transformation.
Now, let's shift our focus to the realm of data, where vector databases store knowledge like ancient scrolls in a library of the mind. This modern-age wisdom repository becomes a vessel for our quest.Venture into the digital landscapes of MUDs, where storytelling takes a digital form. It's a place where we merge the ancient art of storytelling with the modern realms of code and creativity.
As we seek the alchemical parallels in the Hebrew language to the periodic table of elements, we unravel the hidden mysteries of creation. The building blocks of matter interweave with the essence of ancient language.
Our fingers dance on mechanical keyboards, each keypress a tactile pleasure, like a musician playing an instrument. The choice of keycaps becomes our artistic expression, a tactile symphony of keystrokes.
Dr. Joe Dispenza guides us into the territory of the mind's potential. With every thought and intention, we mold our reality. It's a powerful reminder that we are the architects of our destinies.
Vim, the text editor, becomes our quill, crafting the narratives of code. It's a tool for those who understand that precision and efficiency are the keystones of programming.
In the realm of productivity and flow, we journey with the Flow Research Collective. Their wisdom helps us unlock our peak performance and harness the tides of creativity.
Now, let's embark on epic adventures in the world of RPGs, where stories and characters are woven with code. Sublime Text becomes our spellbook, casting enchantments of efficiency over our code.
As we dive deeper into the labyrinth of the self, we realize that the ego is but a shadow, a character we control in the grand narrative of existence. We transcend definitions and become the authors of our own stories.
Sam Ovens, the master of entrepreneurship, shares his insights on building businesses. It's a journey where we blend creativity and strategy, forging empires in the digital age.
Carlo Suares takes us into the world of mystical symbolism, where every letter holds a universe of meaning. We decipher the secrets encoded in the very fabric of reality.
Eric Elliott's expertise in JavaScript shines as we navigate the digital landscape. It's a world where code becomes the paintbrush, and the canvas is the browser.
Kyle M. Yates invites us to explore the philosophy of consciousness. It's a journey into the depths of the mind, a quest to understand the essence of being.
J. Gresham Machen and Page H. Kelley lead us through the pages of academia, where knowledge is both the key and the door to understanding. It's a place where ideas are born and nurtured.
John J. Owens shares his wisdom on intention, catalysts, and the art of ritual rehearsal. It's a magical journey where we learn to wield the power of intention to shape our reality.
Connoisseur Nic Vapes introduces us to the world of e-liquids and vaporizers. It's a sensory experience where flavors and aromas dance on our taste buds, a symphony of vapor.
Mikhaila Peterson, the advocate of a holistic approach to health, guides us through the world of adaptogens and natural remedies. It's a journey of vitality and well-being.
Green coffee, a treasure trove of antioxidants and energy, fuels our quest for health and vitality. It's a brew that awakens our senses and energizes our minds.
Analog technology, a realm of nostalgia and craftsmanship, takes us back to a time when machines were tangible and repairable. It's a world where we appreciate the art of the mechanical.
Cannabis, a plant with a history as rich as it is controversial, becomes a canvas for exploration. It's a journey into the depths of herbal wisdom and the science of cannabinoids.
And in the digital world, Redux.js, a state management library, becomes our companion as we navigate the intricate dance of data flow. It's a tool that empowers us to create robust web applications.
These are the passions that fuel our journey, the pillars of our education. We are both the teachers and the students, on a perpetual quest for knowledge, self-improvement, and mastery. As we continue to explore this tapestry of passions, we invite you to join us on this extraordinary odyssey.
2 notes
·
View notes
Text

There are different various types of trends in ICT (Information and Communication Technology) So what is ICT? ICT is an extensional term for information technology (IT) that stresses the role of unified communications and the integration of telecommunications.
In recent years, Information and Communication Technology (ICT) has become increasingly prevalent in our society. Without further ado, here are the different trends in ICT:
Convergence: Convergence in technology refers to the combining or integration of different services or technologies into a single platform or system. In a technological context, this could refer to the blending of different types of technologies, such as cloud computing, artificial intelligence, Internet of Things, virtual reality, augmented reality, and more. This could also include the merging of different services from different providers, such as combining a music streaming service with a fitness tracking app to create a single platform for fitness and entertainment.
Social Media: refers to online platforms or applications that allow users to connect, share, and communicate with others. These platforms or applications use a variety of tools or technologies, such as web servers, software, databases, and networking equipment, to facilitate social interaction. Social media platforms can range from simple messaging apps to complex social networks with hundreds of thousands or even millions of users.
-Different types of social media(sample):
Social media platforms can be classified into a few major categories based on their functions, features, or target audience:
General social networks: These platforms are typically designed for open communication between users with a broad range of interests, relationships, and backgrounds. They provide communication and interaction tools such as messaging, shared content, and events, and often encourage connections between users who may not know each other in person. Examples of these types of social media platforms include Facebook, Instagram, Twitter, and TikTok.
Bookmarking Site: is an online service that allows users to save or "bookmark" web pages and other content, usually with tags or categories for easy organization. These sites often allow users to organize their bookmarks into collections, share their bookmarks with others, and search and discover new content through other users' bookmarks. Popular examples of bookmarking sites include Google Bookmarks, Evernote, and Pinterest.
Social news is a variation of social media that focuses on sharing and discussing news and current events. These platforms or services often allow users to create and engage in communities around related topics, submit and discover links to news and articles, discuss and debate these topics, and share their thoughts and opinions. Popular examples of social news platforms include Google News, Feedly, and Flipboard.
Media sharing refers to the process of sharing media files, such as photos, videos, music, and documents, between users via online platforms or applications. This can be done through direct messaging or in dedicated groups or communities. Popular examples of media sharing platforms include file-sharing services such as Dropbox, media hosting services such as Flickr and YouTube, and social media platforms such as Facebook and Instagram.
Microblogging refers to the practice of publishing short, frequent updates or "tweets" on social media platforms. These updates are made to public feeds or user profiles, allowing followers or other users to easily access and stay up to date on new content.
Blogs and forums are both online platforms where users can share and engage in discussions or conversations with others, but they are not the same. Blogs are often created by individual authors to share and express their personal thoughts and opinions with others, while forums are structured more as online discussion boards or communities, where multiple users can contribute and engage in the conversation as a group. Blogs typically offer a more one-way communication, where authors create articles and readers comment and interact, while forums allow for a more open dialogue and back-and-forth interaction between multiple users.
☆
☆
☆
mobile technologies:
refers to the use of computing and communication technology that is accessed through mobile devices, such as smartphones, tablets, and smartwatches. This technology allows users to stay connected to the internet and easily access a wide range of services and applications even when on-the-go, including social networking, gaming, web browsing, messaging, communication, navigation, and more. In recent years, mobile technology has become increasingly dominant in our society, with most people now having access to multiple mobile devices and using them for a wide range of activities throughout their daily lives.
mobile operating devices
iOS is the operating system developed by Apple for its iPhones, iPads, and other mobile devices. iOS is specifically designed for mobile devices and provides a user-friendly interface and a vast selection of apps and services on the App Store. Features include advanced camera capabilities, support for different languages, access to cloud storage and services, and more. The latest version of iOS is iOS 16, released in September 18, 2023(iOS 17).
Android is the operating system developed by Google for mobile devices, including smartphones and tablets. It's used on a wide range of Android-based devices, including those made by Samsung, LG, OnePlus, Google, Asus, and more. Android is designed for ease of use and offers features such as a personalized user interface, access to the Google Play Store, and compatibility with a wide range of apps and services. The latest version of Android is Android 14, released in September 2023.
BlackBerry OS is the operating system developed by BlackBerry Limited and used on their BlackBerry smartphones, tablets, and other devices. It is designed specifically for these devices and provides various features, functions, and capabilities, including access to apps, email, and text messaging. The latest version of BlackBerry OS is 10.3.3, released in June 2020.
Windows Phone OS is an operating system developed by Microsoft for its Windows Phone devices, which include smartphones and tablets. It is based on the Windows kernel and designed specifically for these devices, providing features such as a user-friendly interface, access to apps and services from the Windows Store, and deep integration with Microsoft's cloud-based services, such as OneDrive and Bing. The latest version of Windows Phone OS is 8.1, released in 2014. However, Microsoft discontinued development of Windows Phone OS in 2016 and shifted its focus toward other platforms, such as Windows 10.
Windows Mobile is the operating system developed by Microsoft for its Windows Mobile-based devices, which include smartphones, tablets, and other devices. It is based on the Windows kernel and designed specifically for Windows Mobile devices, providing features such as a user-friendly interface, support for various apps and services, and deep integration with Microsoft's cloud-based services, such as OneDrive and Bing. However, Windows Mobile was discontinued in 2016 and Microsoft shifted its focus to Windows 10.
Symbian is a mobile operating system developed by Nokia for its Symbian-based devices, which include smartphones, tablets, and other devices. It was the dominant operating system for mobile devices for many years, until it was discontinued in 2014 and replaced by the newer Android-based Nokia X platform. Symbian was known for its user-friendly interface and wide range of features, including internet connectivity, advanced messaging and email features, and access to a variety of apps and services. Nokia was a key player in the development of the mobile phone and has since shifted its focus toward other platforms, such as Android and Windows.
WebOS is the operating system developed by LG for its line of WebOS-based smart TVs and other devices. It provides a user-friendly interface with access to various features and functionality, including streaming media services, online content and services, and integration with smart home devices. It can also be used with LG smart watches and smartphones. The latest version of WebOS is WebOS 6.0, released in 2022.
Windows Mobile is the operating system developed by Microsoft for its Windows Mobile-based devices, which include smartphones, tablets, and other devices. It is based on the Windows kernel and designed specifically for Windows Mobile devices, providing features such as a user-friendly interface, support for various apps and services, and deep integration with Microsoft's cloud-based services, such as OneDrive and Bing. However, Windows Mobile was discontinued in 2016 and Microsoft shifted its focus to Windows 10 Mobile instead.
ASSISTIVE MEDIA: assistive media refers to media and technology that is designed to assist or enable communication and access for people with special needs or disabilities. This can include products such as assistive listening devices or software, assistive technologies for blind or low-vision individuals, and communication aids or support services for individuals with physical, cognitive, or psychological disabilities. Assistive media helps to reduce communication barriers for these individuals and provide them with access to education, employment, and social activities.
three components:
1. Client computers – also known as end-user computers or client stations, are individual devices that are used to access and interact with a larger network or system. These devices are often connected to a server or mainframe, where the processing and storage of data and information take place. The client computer then receives and displays the information, providing a user interface and allowing for user interaction. In a corporate or enterprise setting, client computers are typically provided by the organization to their employees or users, who connect to the network and use the software and services provided by the organization. 2. Distributed Servers – refer to a network of connected servers that are spread across a geographic region or multiple locations. This allows for sharing of resources, such as data, application and storage, over a large area and the ability to access and utilize information quickly and effectively. Distributed servers can also improve system performance, reliability, and scalability, as well as providing failover capabilities and redundancy in case of server failure. The use of distributed servers is prominent in cloud computing and related technologies, as it allows for remote access, storage, and computing of data without the need for physical servers in each location. 3. Datacenters – A datacenter is a facility dedicated to the housing, operation, and management of computer systems and data. These facilities usually contain servers, storage systems, networking equipment, and other information technology components, as well as environmental controls to maintain an optimal operating temperature and humidity for the equipment. Datacenters are fundamental for organizations and businesses that rely on large amounts of data and technology for their operations, and allow for secure and reliable storage and management of data. They can also provide services such as cloud computing, storage, and network connections for other companies or organizations.
Cloud Computing:
Cloud computing is a computing model in which data and applications are stored and processed in remote servers or data centers, rather than on local devices or systems. This allows for the sharing of resources and data among multiple users and devices, improved scalability and flexibility, and access to data and applications from anywhere with an internet connection. Cloud computing can be provided through a variety of models, such as Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS).
Types of Clouds
1.Public Cloud -is an internet-based cloud computing service that is provided by a third-party provider and is accessible to the general public. Users access the Public Cloud through a subscription or pay-as-you-go model, allowing them to use its capabilities and resources as needed, without having to build and manage their own infrastructure or hardware. The Public Cloud provides a range of services, such as computing power, storage, networking, application and database hosting, analytics, and artificial intelligence. It is often used by organizations and individuals to reduce the cost and complexity of building and managing their own IT infrastructure. 2.Private Cloud - is an internal or privately hosted cloud computing environment, controlled and managed by a single organization or individual. Unlike the Public Cloud, which is accessible to anyone with an internet connection, the Private Cloud is restricted to a limited number of users, often within the same organization or network. Private Clouds provide many of the same capabilities and services as Public Clouds, but with higher security and control over data and resources. They also offer the flexibility to manage and support applications and workloads in a customized environment, without the need for large capital investments in data center equipment and infrastructure. 3.Community Cloud - is a type of cloud computing environment that is shared among a group of organizations or entities within a specific geographical, industrial, or academic community. It allows these organizations to utilize a shared cloud structure, resources, and tools while maintaining control and governance over their own data and systems. In contrast to a Public Cloud, which is operated by a third-party provider and accessible to anyone with an internet connection, a Community Cloud is typically owned and managed by a governing body or consortium of participating organizations. This governance allows for more control over data, security, and other considerations, while still providing the benefits of cloud computing. 4.Hybrid Cloud-is a cloud computing environment that combines the use of both Private and Public Clouds. This approach allows organizations to leverage the advantages and capabilities of each cloud model, while also reducing the drawbacks and risks associated with relying entirely on one type of cloud. In a Hybrid Cloud, some data, systems, or applications may be hosted on a Private Cloud, while other data or more demanding workloads may be hosted on a Public Cloud. This approach provides the option to move workloads between clouds based on the specific requirements or performance needs. Hybrid Clouds are becoming increasingly popular as a way to optimize cost, flexibility, and performance in cloud computing deployments.
PS: this is made by a student and with no professional assistance, so if there are any incorrect statement, please do correct me, thanks<3
also, some of my sources are a bit outdated, so i have to change some details, if my grammars seems off, please do point it out so i can correct it<3
#technology#empowerment technology#knowledge#understanding#learn#ict#ice related#student#school project#homework#learn with me
0 notes
Text
The Role of DevOps in Modern Web Development Projects
In today's fast-paced digital landscape, building a great website is only half the battle. The other half is ensuring that it runs smoothly, scales efficiently, and delivers continuous value to users without disruption. This is where DevOps plays a vital role in modern web development projects.
By combining development and operations into a unified workflow, DevOps enables faster delivery, better quality, and greater reliability. For any business working with a Web Development Company, understanding the impact of DevOps is crucial to building and maintaining a competitive digital presence.
What Is DevOps?
DevOps is a cultural and technical approach that integrates software development (Dev) with IT operations (Ops). It focuses on automating processes, improving collaboration between teams, and enabling continuous integration and continuous delivery (CI/CD) pipelines.
The primary goals of DevOps include:
Faster development cycles
Automated testing and deployment
Greater deployment reliability
Rapid issue detection and resolution
Continuous improvement of digital infrastructure
In web development, DevOps isn't just a technical concept—it's a workflow philosophy that streamlines how websites and applications are built, deployed, and maintained.
Faster and More Reliable Deployments
Before DevOps, web development often involved manual deployments, slow update cycles, and siloed teams. This led to delays, miscommunications, and higher chances of errors during deployment.
With DevOps, modern development companies automate build processes, testing, and deployments through tools like Jenkins, GitLab CI, and GitHub Actions. This means updates can be pushed to production quickly and reliably, ensuring:
Faster feature releases
Reduced time to market
Lower risk of downtime
Whether you’re updating a landing page, rolling out a new feature, or deploying an entire web application, DevOps practices make the process seamless and predictable.
Improved Collaboration Between Development and Operations
Traditionally, development teams focused on building features, while operations teams were responsible for maintaining infrastructure. This disconnect often caused friction, especially when issues arose in production.
DevOps eliminates that divide by encouraging a shared responsibility model. Developers think about infrastructure, performance, and reliability from the beginning, while operations teams are involved earlier in the development cycle.
This collaborative mindset results in:
Fewer bugs and incidents
Better understanding of user and infrastructure needs
Faster problem resolution
Stronger alignment between business goals and technical delivery
Continuous Integration and Continuous Delivery (CI/CD)
At the heart of DevOps is the CI/CD pipeline. Continuous Integration ensures that code changes are automatically tested and merged, while Continuous Delivery automates deployment to production or staging environments.
Benefits of CI/CD in web development include:
Early bug detection
Reduced integration issues
Quicker rollbacks when needed
Easier feature experimentation (A/B testing, beta releases)
These pipelines help teams iterate faster, release new features regularly, and respond quickly to user feedback—an essential capability for growing brands and digital products.
Infrastructure as Code (IaC) for Scalability
As websites grow, so do their infrastructure needs. DevOps teams use Infrastructure as Code to automate and manage servers, databases, and networks using tools like Terraform, AWS CloudFormation, and Ansible.
Instead of manually configuring servers, everything is codified and version-controlled, making it easy to:
Scale infrastructure on demand
Replicate environments across staging and production
Recover quickly from failures
Maintain consistency across deployments
IaC brings flexibility and efficiency, especially for web platforms expecting rapid traffic growth or frequent feature updates.
Enhanced Monitoring and Feedback Loops
A critical part of DevOps is monitoring application performance and gathering feedback to drive improvements. Web development teams implement real-time monitoring using tools like Prometheus, Grafana, Datadog, or New Relic.
This allows for:
Early detection of performance bottlenecks
Real-time alerts and automatic scaling
Informed decision-making based on usage analytics
Better customer experience through proactive issue resolution
Monitoring ensures that websites don’t just work at launch—but continue to perform under pressure.
Security Integration (DevSecOps)
Modern DevOps also includes a security layer, often referred to as DevSecOps. Rather than treating security as a final check, it’s integrated into every step—from coding and testing to deployment.
With DevSecOps, web development companies:
Run automated security scans during builds
Use container security tools like Docker Scan or Aqua Security
Ensure secure access controls and data encryption
Maintain compliance with industry regulations
This shift-left approach to security minimizes vulnerabilities and makes your website resilient from the start.
Conclusion
DevOps is no longer optional—it’s essential. In modern web development projects, DevOps ensures that your site is not only built efficiently but also deployed quickly, runs reliably, and scales effortlessly. It reduces friction between teams, speeds up release cycles, and enables businesses to deliver better user experiences, faster.
If you're planning a high-performance website or digital product, working with a Web Development Company that embraces DevOps practices is a strategic advantage. It means fewer delays, fewer bugs, and a web presence that evolves as fast as your business does.
0 notes
Text
Next-Gen Security Testing Services Using AI: A Deep Dive

In the ever-evolving landscape of software development, security breaches have grown more frequent and sophisticated. Traditional testing methods, though foundational, are no longer sufficient in identifying and addressing the fast-moving threats facing modern systems. This is where Next-Gen Security Testing Services come into play, blending AI innovation with robust testing protocols.
At Robotico Digital, we’ve redefined how security integrates into software engineering by embedding Artificial Intelligence (AI) into our advanced Security Testing Services. This deep dive explores how AI transforms Security Testing in Software Testing, enabling faster detection, smarter remediation, and continuous protection across development pipelines.
The Shift Toward AI in Security Testing
Historically, Security Testing Services were heavily reliant on manual reviews, rule-based scanners, and time-intensive penetration testing. While still valuable, these methods struggle to keep up with:
lRapid DevOps cycles
lEvolving attack vectors
lIncreasing application complexity
lHybrid cloud and microservices infrastructure
AI, specifically through machine learning (ML), Natural Language Processing (NLP), and behavioral analytics, has introduced a transformative layer of intelligence to these services. It allows security testers and developers to go beyond reactive defenses—identifying risks proactively and at scale.
How AI Enhances Security Testing in Software Testing
Incorporating AI into Security Testing in Software Testing provides multi-dimensional improvements across efficiency, accuracy, and adaptability. Let’s break down the core components.
1. Automated Vulnerability Detection
AI-powered scanners can crawl source code, binary files, API endpoints, and web interfaces to detect anomalies that indicate vulnerabilities. Unlike traditional scanners, AI engines learn from past vulnerabilities and global threat databases to continually improve detection precision.
Key Features:
lPattern recognition across massive codebases
lZero-day threat detection using anomaly detection models
lAuto-mapping of application attack surfaces
2. Adaptive Risk Prioritization
One major challenge in Security Testing Services is managing false positives and prioritizing true threats. AI models rank vulnerabilities based on:
lExploitability
lBusiness impact
lData sensitivity
lThreat intelligence feeds
This reduces alert fatigue and ensures engineering teams focus on high-priority issues first.
3. Dynamic Threat Modeling
AI systems can automatically generate and update threat models for evolving software architectures. By simulating attacker behavior, AI enables predictive testing—discovering how vulnerabilities might be chained or escalated.
4. Self-Learning Penetration Testing
AI agents mimic ethical hackers using reinforcement learning. These bots evolve through trial and error, discovering unconventional paths to exploitation and mimicking real-world attack tactics.
Robotico Digital’s AI-Powered Security Testing Stack
At Robotico Digital, we’ve built a proprietary AI-enhanced testing framework designed to deliver intelligent, continuous, and scalable security coverage. Here's what powers our next-gen Security Testing Services:
AI-Powered SAST & DAST Engines
SAST (Static Application Security Testing): Our AI models review code for insecure functions, misconfigurations, and data flow leaks at the source level.
DAST (Dynamic Application Security Testing): AI crawlers test running applications by simulating user behavior and injecting payloads to trigger security vulnerabilities.
Machine-Learning Vulnerability Correlation
We reduce redundant findings by merging results from multiple tools and identifying duplicate alerts. ML models group similar issues, track them across builds, and learn from developer remediation behavior.
AI-Based Compliance Validation
Robotico Digital uses AI to ensure compliance with:
lOWASP Top 10
lGDPR / HIPAA / PCI DSS
lNIST and ISO 27001 We map discovered vulnerabilities to these frameworks, highlighting gaps in your security and compliance posture.
Use Cases of AI in Security Testing Services
Web & Mobile Application Testing
AI identifies issues such as insecure authentication, broken access controls, and injection attacks. It tests logic errors and parameter tampering based on how real users interact with the app.
API Security Testing
APIs are high-value targets. Our AI models analyze OpenAPI/Swagger specs, apply fuzzing techniques, and test for broken object-level authorization (BOLA) and mass assignment vulnerabilities.
Cloud & Infrastructure Testing
For cloud-native applications, AI detects misconfigurations in IAM roles, storage permissions, and network security groups—especially in multi-cloud environments like AWS, Azure, and GCP.
DevSecOps Pipeline Integration
Robotico Digital integrates AI-based scanning tools directly into CI/CD platforms like GitLab, Jenkins, and Azure DevOps. This ensures shift-left security with automated gates at every build stage.
Implementation Challenges & Considerations
While the benefits are substantial, integrating AI into Security Testing Services is not without hurdles:
1. Data Quality & Training Bias
AI models require high-quality, labeled data to function accurately. Poor or biased training datasets can lead to both false positives and false negatives.
2. Explainability & Developer Trust
“Black-box” decisions from AI can frustrate developers. Robotico Digital addresses this by using explainable AI (XAI) models that provide root cause analysis and remediation context.
3. AI Model Drift
Security threats evolve. AI models must be updated regularly to avoid “drift” that could miss emerging threats. We maintain continuous model updates with feedback loops from threat intelligence systems.
Future of AI in Security Testing Services
AI in Security Testing Services is still in its growth phase. Here’s what’s on the horizon:
lGenerative AI for Test Case Creation: Using models like GPT-4 to simulate attacks and generate intelligent test scripts.
lAutonomous Remediation Agents: AI that not only finds issues but can propose or apply secure code fixes autonomously.
lFederated Threat Learning: Secure sharing of anonymized threat data across organizations to train more resilient models.
lAI-Powered Red Teaming: Simulated human-like attackers that learn and evolve to breach complex systems.
Conclusion
Security is not a checkbox; it’s a continuous journey. As applications grow more complex and the cyber threat landscape expands, relying on traditional methods alone is no longer enough. AI enables Security Testing Services to become proactive, intelligent, and deeply integrated into the development lifecycle.
At Robotico Digital, we’re proud to lead the next generation of Security Testing in Software Testing by harnessing the power of artificial intelligence. Our AI-enhanced services empower organizations to detect vulnerabilities faster, respond more intelligently, and scale their cybersecurity operations with confidence.
0 notes
Text
Understanding the Full Stack Developer Role
A Full Stack Developer is an individual who possesses the skills and proficiency to handle both the front-end and back-end development aspects of a web application or software project. This means that as a Full Stack Developer at Merge Computers, you will be responsible for designing, developing, and maintaining the entire software and ensuring all components work seamlessly together.
The Importance of Full Stack Developer Courses
To thrive as a Full Stack Developer, it is crucial to receive comprehensive education and training through Full Stack Developer courses. These courses equip individuals with a holistic understanding of various programming languages, web development frameworks, and industry-standard tools. By enrolling in a Full Stack Developer course, such as the Java Full Stack Developer course offered by Merge Computers, you can acquire a solid skill set that prepares you for the practical challenges of the job.
Career Growth as a Full-Stack Developer
The career growth potential for Full Stack Developers is immense, especially in today's digital-centric world. With the demand for skilled professionals at an all-time high, the career prospects in full-stack development are abundant. Merge Computers is committed to helping you realize your career goals, offering a conducive and growth-oriented work environment, professional development programs, and ample opportunities for industry exposure.
Excel as a Java Full Stack Developer
Java is one of the most widely used programming languages in the world, and proficiency in Java Full Stack Development can significantly amplify your career prospects. Merge Computers provides a specialized Java Full Stack Developer course that equips you with the necessary skills to excel in this field. By mastering Java Full Stack Development, you can develop robust web applications and leverage the power of Java's vast ecosystem.
Recommended Full Stack Web Development Courses
To provide a comprehensive education, Merge Computers offers Full Stack Web Development courses tailored to aspiring developers. These courses include a wide range of topics, including front-end development using HTML, CSS, and JavaScript, back-end development using frameworks like Node.js or Django, and database management. These courses will enable you to build end-to-end web applications confidently, broadening your career options significantly.
Conclusion
Evolving technology demands versatile professionals, and a Full Stack Developer career at Merge Computers can position you as one. With a solid foundation gained through Full Stack Developer courses, particularly in Java Full Stack Development, you can embark on a rewarding career path. The Full Stack Web Development courses offered by Merge Computers will equip you with the necessary skills to excel in the industry. So, take the leap and join Merge Computers to become a Full Stack Developer, where endless opportunities await you.
youtube
0 notes
Text
Streamlining Development with Software Configuration Management and DevOps.
In today’s quick-moving software world, managing how code changes are handled is vital. Software configuration management (SCM) helps keep projects stable, track modifications, and make the process more efficient. At CloudKodeForm Technologies, we assist companies in combining SCM methods with DevOps tools to ensure smooth, scalable, and dependable software release.

What is software configuration management?
SCM involves controlling and tracking all changes made to software over its lifespan. It includes managing different versions, handling change requests, and planning releases. For large teams, SCM makes sure everyone can work together without overwriting each other’s work or losing data.
Source control management is a key part of SCM. It focuses on tracking changes in source code. Many teams use tools like Git, SVN, or Mercurial to monitor versions, combine code from different branches, and revert changes if needed. At CloudKodeForm Technologies, we set up these tools within a DevOps pipeline. This allows teams to automate building, testing, and launching software more easily.
Adding source control to DevOps improves transparency and speeds up fixing issues. It also reduces mistakes when merging new code, leading to better quality products and faster releases.
Another important tool is the configuration management database (CMDB). It stores details about hardware, software, and how they connect. When linked to a DevOps setup, CMDB gives clear insight into your IT setup. It helps teams predict the effects of changes, discover dependencies, and plan better.
CloudKodeForm Technologies helps businesses set up and manage CMDBs that work with tools like ServiceNow or BMC. We also create custom solutions, keeping your data accurate and easy to access.
Why work with DevOps consultants?
Setting up SCM and DevOps tools takes skill and careful planning. That’s where companies like CloudKodeForm Technologies step in. We evaluate your current setup and workflows. Then we design a solid plan to improve your configuration management and DevOps processes.
Our services include:
Building CI/CD pipelines
Automating change tracking
Setting up Infrastructure as Code (IaC)
Connecting version control systems
Customizing and deploying CMDBs
We create solutions suitable for startups or big firms that want to grow confidently.
In short, managing software changes now goes hand in hand with DevOps. Growing software systems need good processes, reliable source control, and a strong CMDB to stay stable and flexible.
At CloudKodeForm, we help companies use SCM properly within a modern DevOps setup. We offer expert advice and tailored solutions.
Let us help improve your development cycle—faster rollouts, fewer bugs, and more confidence in your software.
#devops consulting#build android app#lambda cloud#ios development#app development service#node js microservices
0 notes
Text
How Address Matching and Entity Resolution Software Is Revolutionizing Modern Data Management
In today’s data-centric economy, businesses must deal with a flood of information from various sources — customer databases, CRM systems, marketing tools, and more. However, when this data is inconsistent, duplicated, or misaligned, it can disrupt operations, cause compliance issues, and negatively affect customer experiences. That’s where advanced tools like Address Matching Software, Entity Resolution Software, and Data Management Software come into play.
Match Data Pro LLC is at the forefront of data integration and quality, offering intelligent tools that help organizations turn fragmented data into unified, reliable information. Let’s explore how these solutions work and why they are crucial for any business that relies on clean, actionable data.
The Challenge of Dirty and Disconnected Data
Data quality problems often stem from:
Typographical errors in names or addresses
Variations in data formats across systems
Duplicate entries for the same customer or entity
Incomplete or outdated records
These challenges lead to confusion, wasted resources, poor customer service, and flawed analytics. Moreover, regulatory compliance and data governance become nearly impossible when data integrity is compromised.
The Role of Address Matching Software
Address Matching Software is a specialized tool that standardizes, validates, and matches address data across multiple records or databases. For example, “123 Main Street Apt. 5” and “123 Main St #5” may refer to the same location but appear differently in systems. This software ensures that all variations are recognized as a single, accurate address.
Key Features:
Standardization: Formats addresses according to local postal guidelines.
Validation: Verifies addresses using official postal data.
Geocoding: Converts addresses into geographic coordinates for advanced mapping.
Deduplication: Identifies and merges duplicate address records.
For businesses in logistics, e-commerce, and finance, address matching is essential for timely deliveries, targeted marketing, and fraud prevention.
What is Entity Resolution Software?
While address matching focuses on physical locations, Entity Resolution Software (ERS) deals with identifying and linking different records that refer to the same real-world entity — such as a person, company, or product — even when the data doesn’t match exactly.
For instance, the records “Jon A. Smith,” “J. Smith,” and “Jonathan Smith” might all represent the same individual. ERS uses advanced algorithms to detect these connections based on attributes like name, address, email, phone number, and more.
Core Capabilities:
Fuzzy Matching Algorithms: Detects variations and misspellings.
Custom Matching Rules: Adjusted to your specific industry or dataset.
Confidence Scoring: Assigns match probability to suggest potential duplicates.
Golden Record Creation: Generates a single, trusted version of an entity.
By eliminating redundancies and resolving identity conflicts, entity resolution software enables more accurate reporting, better customer experiences, and streamlined operations.
Why Data Management Software Matters
While address and entity resolution tools solve specific data quality issues, Data Management Software provides a comprehensive approach to maintaining and leveraging high-quality data.
This software acts as a central hub where businesses can:
Import and unify data from multiple systems
Clean, standardize, and validate datasets
Track data changes and maintain audit logs
Monitor data quality with real-time dashboards
Enforce governance policies and ensure regulatory compliance
Match Data Pro LLC’s data management platform integrates seamlessly with other enterprise tools and APIs, offering scalable solutions tailored to your industry needs.
Use Cases Across Industries
Retail & E-commerce
Ensure consistent customer profiles across platforms, personalize offers, and reduce cart abandonment with accurate address and identity data.
Financial Services
Identify fraudulent activity by resolving identity mismatches and ensure compliance with KYC (Know Your Customer) regulations.
Healthcare
Consolidate patient records across hospitals, labs, and clinics to improve care coordination and reduce billing errors.
Government
Link citizen records from various departments to deliver efficient public services and prevent identity duplication.
Benefits of Using Match Data Pro LLC’s Solutions
Improved Accuracy: Say goodbye to duplicate records and inconsistent data.
Better Decision-Making: Reliable data leads to smarter, more confident decisions.
Enhanced Customer Experience: Deliver personalized, error-free service.
Regulatory Compliance: Meet GDPR, HIPAA, and other global data regulations.
Cost Savings: Reduce waste caused by errors and duplicated efforts.
Whether you’re a growing startup or a large enterprise, investing in intelligent data tools pays off in operational efficiency and business growth.
Final Thoughts
In an increasingly digital and data-dependent world, organizations must go beyond basic data entry and embrace smart tools like Address Matching Software, Entity Resolution Software, and Data Management Software to maintain a competitive edge.
Match Data Pro LLC delivers state-of-the-art solutions that make your data smarter, cleaner, and more valuable. It’s time to unlock the full potential of your business data and make informed decisions with confidence.
Ready to upgrade your data strategy? Contact Match Data Pro LLC today and see how accurate data can transform your business performance.
0 notes
Text
This Week in Rust 510
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.72.0
Change in Guidance on Committing Lockfiles
Cargo changes how arrays in config are merged
Seeking help for initial Leadership Council initiatives
Leadership Council Membership Changes
Newsletters
This Week in Ars Militaris VIII
Project/Tooling Updates
rust-analyzer changelog #196
The First Stable Release of a Memory Safe sudo Implementation
We're open-sourcing the library that powers 1Password's ability to log in with a passkey
ratatui 0.23.0 is released! (official successor of tui-rs)
Zellij 0.38.0: session-manager, plugin infra, and no more offensive session names
Observations/Thoughts
The fastest WebSocket implementation
Rust Malware Staged on Crates.io
ESP32 Standard Library Embedded Rust: SPI with the MAX7219 LED Dot Matrix
A JVM in Rust part 5 - Executing instructions
Compiling Rust for .NET, using only tea and stubbornness!
Ad-hoc polymorphism erodes type-safety
How to speed up the Rust compiler in August 2023
This isn't the way to speed up Rust compile times
Rust Cryptography Should be Written in Rust
Dependency injection in Axum handlers. A quick tour
Best Rust Web Frameworks to Use in 2023
From tui-rs to Ratatui: 6 Months of Cooking Up Rust TUIs
[video] Rust 1.72.0
[video] Rust 1.72 Release Train
Rust Walkthroughs
[series] Distributed Tracing in Rust, Episode 3: tracing basics
Use Rust in shell scripts
A Simple CRUD API in Rust with Cloudflare Workers, Cloudflare KV, and the Rust Router
[video] base64 crate: code walkthrough
Miscellaneous
Interview with Rust and operating system Developer Andy Python
Leveraging Rust in our high-performance Java database
Rust error message to fix a typo
[video] The Builder Pattern and Typestate Programming - Stefan Baumgartner - Rust Linz January 2023
[video] CI with Rust and Gitlab Selfhosting - Stefan Schindler - Rust Linz July 2023
Crate of the Week
This week's crate is dprint, a fast code formatter that formats Markdown, TypeScript, JavaScript, JSON, TOML and many other types natively via Wasm plugins.
Thanks to Martin Geisler for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Hyperswitch - add domain type for client secret
Hyperswitch - deserialization error exposes sensitive values in the logs
Hyperswitch - move redis key creation to a common module
mdbook-i18n-helpers - Write tool which can convert translated files back to PO
mdbook-i18n-helpers - Package a language selector
mdbook-i18n-helpers - Add links between translations
Comprehensive Rust - Link to correct line when editing a translation
Comprehensive Rust - Track the number of times the redirect pages are visited
RustQuant - Jacobian and Hessian matrices support.
RustQuant - improve Graphviz plotting of autodiff computational graphs.
RustQuant - bond pricing implementation.
RustQuant - implement cap/floor pricers.
RustQuant - Implement Asian option pricers.
RustQuant - Implement American option pricers.
release-plz - add ability to mark Gitea/GitHub release as draft
zerocopy - CI step "Set toolchain version" is flaky due to network timeouts
zerocopy - Implement traits for tuple types (and maybe other container types?)
zerocopy - Prevent panics statically
zerocopy - Add positive and negative trait impl tests for SIMD types
zerocopy - Inline many trait methods (in zerocopy and in derive-generated code)
datatest-stable - Fix quadratic performance with nextest
Ockam - Use a user-friendly name for the shared services to show it in the tray menu
Ockam - Rename the Port to Address and support such format
Ockam - Ockam CLI should gracefully handle invalid state when initializing
css-inline - Update cssparser & selectors
css-inline - Non-blocking stylesheet resolving
css-inline - Optionally remove all class attributes
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
366 pull requests were merged in the last week
reassign sparc-unknown-none-elf to tier 3
wasi: round up the size for aligned_alloc
allow MaybeUninit in input and output of inline assembly
allow explicit #[repr(Rust)]
fix CFI: f32 and f64 are encoded incorrectly for cross-language CFI
add suggestion for some #[deprecated] items
add an (perma-)unstable option to disable vtable vptr
add comment to the push_trailing function
add note when matching on tuples/ADTs containing non-exhaustive types
add support for ptr::writes for the invalid_reference_casting lint
allow overwriting ExpnId for concurrent decoding
avoid duplicate large_assignments lints
contents of reachable statics is reachable
do not emit invalid suggestion in E0191 when spans overlap
do not forget to pass DWARF fragment information to LLVM
ensure that THIR unsafety check is done before stealing it
emit a proper diagnostic message for unstable lints passed from CLI
fix races conditions with SyntaxContext decoding
fix waiting on a query that panicked
improve note for the invalid_reference_casting lint
include compiler flags when you break rust;
load include_bytes! directly into an Lrc
make Sharded an enum and specialize it for the single thread case
make rustc_on_unimplemented std-agnostic for alloc::rc
more precisely detect cycle errors from type_of on opaque
point at type parameter that introduced unmet bound instead of full HIR node
record allocation spans inside force_allocation
suggest mutable borrow on read only for-loop that should be mutable
tweak output of to_pretty_impl_header involving only anon lifetimes
use the same DISubprogram for each instance of the same inlined function within a caller
walk through full path in point_at_path_if_possible
warn on elided lifetimes in associated constants (ELIDED_LIFETIMES_IN_ASSOCIATED_CONSTANT)
make RPITITs capture all in-scope lifetimes
add stable for Constant in smir
add generics_of to smir
add smir predicates_of
treat StatementKind::Coverage as completely opaque for SMIR purposes
do not convert copies of packed projections to moves
don't do intra-pass validation on MIR shims
MIR validation: reject in-place argument/return for packed fields
disable MIR SROA optimization by default
miri: automatically start and stop josh in rustc-pull/push
miri: fix some bad regex capture group references in test normalization
stop emitting non-power-of-two vectors in (non-portable-SIMD) codegen
resolve: stop creating NameBindings on every use, create them once per definition instead
fix a pthread_t handle leak
when terminating during unwinding, show the reason why
avoid triple-backtrace due to panic-during-cleanup
add additional float constants
add ability to spawn Windows process with Proc Thread Attributes | Take 2
fix implementation of Duration::checked_div
hashbrown: allow serializing HashMaps that use a custom allocator
hashbrown: change & to &mut where applicable
hashbrown: simplify Clone by removing redundant guards
regex-automata: fix incorrect use of Aho-Corasick's "standard" semantics
cargo: Very preliminary MSRV resolver support
cargo: Use a more compact relative-time format
cargo: Improve TOML parse errors
cargo: add support for target.'cfg(..)'.linker
cargo: config: merge lists in precedence order
cargo: create dedicated unstable flag for asymmetric-token
cargo: set MSRV for internal packages
cargo: improve deserialization errors of untagged enums
cargo: improve resolver version mismatch warning
cargo: stabilize --keep-going
cargo: support dependencies from registries for artifact dependencies, take 2
cargo: use AND search when having multiple terms
rustdoc: add unstable --no-html-source flag
rustdoc: rename typedef to type alias
rustdoc: use unicode-aware checks for redundant explicit link fastpath
clippy: new lint: implied_bounds_in_impls
clippy: new lint: reserve_after_initialization
clippy: arithmetic_side_effects: detect division by zero for Wrapping and Saturating
clippy: if_then_some_else_none: look into local initializers for early returns
clippy: iter_overeager_cloned: detect .cloned().all() and .cloned().any()
clippy: unnecessary_unwrap: lint on .as_ref().unwrap()
clippy: allow trait alias DefIds in implements_trait_with_env_from_iter
clippy: fix "derivable_impls: attributes are ignored"
clippy: fix tuple_array_conversions lint on nightly
clippy: skip float_cmp check if lhs is a custom type
rust-analyzer: diagnostics for 'while let' loop with label in condition
rust-analyzer: respect #[allow(unused_braces)]
Rust Compiler Performance Triage
A fairly quiet week, with improvements exceeding a small scattering of regressions. Memory usage and artifact size held fairly steady across the week, with no regressions or improvements.
Triage done by @simulacrum. Revision range: d4a881e..cedbe5c
2 Regressions, 3 Improvements, 2 Mixed; 0 of them in rollups 108 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create a Testing sub-team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize PATH option for --print KIND=PATH
[disposition: merge] Add alignment to the NPO guarantee
New and Updated RFCs
[new] Special-cased performance improvement for Iterator::sum on Range<u*> and RangeInclusive<u*>
[new] Cargo Check T-lang Policy
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-08-30 - 2023-09-27 🦀
Virtual
2023-09-05 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-09-05 | Virtual (Munich, DE) | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-09-12 - 2023-09-15 | Virtual (Albuquerque, NM, US) | RustConf
RustConf 2023
2023-09-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-09-13 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-09-13 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
The unreasonable power of combinator APIs
2023-09-14 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-09-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-09-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-09-21 | Lehi, UT, US | Utah Rust
Real Time Multiplayer Game Server in Rust
2023-09-21 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 33rd Edition
2023-09-25 | Virtual (Dublin, IE) | Rust Dublin
How we built the SurrealDB Python client in Rust.
Asia
2023-09-06 | Tel Aviv, IL | Rust TLV
RustTLV @ Final - September Edition
Europe
2023-08-30 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #39 sponsored by Fermyon
2023-08-31 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #2
2023-09-05 | Munich, DE + Virtual | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-14 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-09-19 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Logging and tracing in Rust
2023-09-20 | Aarhus, DK | Rust Aarhus
Rust Aarhus - Rust and Talk at Concordium
2023-09-21 | Bern, CH | Rust Bern
Third Rust Bern Meetup
North America
2023-09-05 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-09-06 | Bellevue, WA, US | The Linux Foundation
Rust Global
2023-09-12 - 2023-09-15 | Albuquerque, NM, US + Virtual | RustConf
RustConf 2023
2023-09-12 | New York, NY, US | Rust NYC
A Panel Discussion on Thriving in a Rust-Driven Workplace
2023-09-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2023-09-14 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
2023-09-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-09-21 | Nashville, TN, US | Music City Rust Developers
Rust on the web! Get started with Leptos
2023-09-26 | Pasadena, CA, US | Pasadena Thursday Go/Rust
Monthly Rust group
2023-09-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-09-13 | Perth, WA, AU | Rust Perth
Rust Meetup 2: Lunch & Learn
2023-09-19 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
2023-09-26 | Canberra, ACT, AU | Rust Canberra
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
In [other languages], I could end up chasing silly bugs and waste time debugging and tracing to find that I made a typo or ran into a language quirk that gave me an unexpected nil pointer. That situation is almost non-existent in Rust, it's just me and the problem. Rust is honest and upfront about its quirks and will yell at you about it before you have a hard to find bug in production.
– dannersy on Hacker News
Thanks to Kyle Strand for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Maximize the Value of Your Data with Master Data Management

Improve Data Quality with MDM
In today’s competitive business landscape, data has become one of the most valuable assets for any organization. However, data that is inaccurate, incomplete, or inconsistent can cause more harm than good. To harness the full potential of data, enterprises must focus on one critical area: improving data quality with Master Data Management (MDM).
From enabling data-driven decision-making to ensuring compliance and operational efficiency, Master Data Management offers a centralized and consistent view of enterprise data. In this blog, we explore how MDM helps organizations improve data quality, the broader benefits of master data management, and how it integrates with ERP systems for sustainable business outcomes.
Why Data Quality Matters in Today’s Enterprise
Data quality is the foundation of efficient business operations, strategic decisions, and superior customer experiences. Poor data quality leads to revenue loss, reduced productivity, compliance issues, and reputational damage.
For example, duplicate customer records can result in missed sales opportunities or marketing errors. Incorrect product master data may cause supply chain disruptions. The solution? A robust MDM strategy designed to improve data quality across the organization.
How Does MDM Improve Data Quality?
The core objective of MDM is to establish a single, authoritative source of truth for critical data entities—such as customers, products, suppliers, employees, and assets. By centralizing the management of this master data, businesses can:
1. Eliminate Duplicates and Redundancies
MDM tools use matching algorithms and validation rules to identify and merge duplicate records. This ensures that every entity—be it a customer or product—has a single, unified record across all systems.
2. Standardize Data Formats
MDM ensures that data is entered and stored in a consistent format. Whether it's address formats, phone numbers, or part numbers, standardization minimizes discrepancies and makes data easier to interpret and analyze.
3. Enforce Business Rules
MDM platforms allow organizations to define and enforce data entry rules. This includes mandatory fields, data validation checks, and hierarchical relationships between data points. These rules enhance consistency and accuracy.
4. Automate Data Cleansing
Modern MDM solutions offer data cleansing functionalities that correct spelling mistakes, normalize values, and enrich records using internal or external data sources—ensuring high-quality master data at all times.
5. Establish Ownership and Accountability
Through role-based access and workflows, MDM enables data stewardship. Data owners and stewards are responsible for managing the quality, integrity, and lifecycle of master data entities.
By incorporating these functionalities, enterprises can improve data quality with MDM—laying the groundwork for reliable reporting, compliance, and customer satisfaction.
The Broader Benefits of Master Data Management
Beyond improving data quality, there are several other compelling benefits of master data management:
Enhanced Operational Efficiency: Unified data eliminates repetitive manual work and speeds up business processes.
Regulatory Compliance: Accurate and traceable data supports adherence to regulations such as GDPR, HIPAA, and SOX.
Improved Customer Experience: A complete and accurate customer profile enables personalized interactions.
Strategic Decision-Making: Clean, consolidated data improves the reliability of analytics and forecasting.
Cost Reduction: Minimizing errors, rework, and redundant software or database usage leads to significant cost savings.
How to Implement MDM in ERP Systems
One of the most common challenges organizations face is integrating MDM within their existing ERP systems. A successful implementation requires a strategic and phased approach. Here's a high-level guide on how to implement MDM in ERP systems:
Step 1: Identify Master Data Domains
Begin by identifying which data domains (e.g., customer, material, vendor) are most critical to your business processes. Prioritize based on volume, usage, and impact on operations.
Step 2: Conduct a Data Assessment
Profile existing data to assess quality, completeness, and redundancy. Understanding current issues helps in defining cleansing and standardization goals.
Step 3: Select an MDM Platform
Choose a platform that integrates well with your ERP system. For SAP environments, solutions like SAP Master Data Governance (SAP MDG) are ideal. These tools offer pre-built data models and workflows tailored for ERP systems.
Step 4: Define Governance Policies
Establish clear data governance policies, including naming conventions, validation rules, ownership, and data lifecycle management. Assign roles such as data stewards to manage accountability.
Step 5: Cleanse and Migrate Data
Before activating the MDM platform, clean and validate all legacy data. Apply transformation and enrichment rules to standardize records across systems.
Step 6: Enable Ongoing Monitoring
Post-implementation, monitor data quality using KPIs and dashboards. Refine rules and governance policies continuously to ensure ongoing data integrity.
This structured approach helps enterprises effectively integrate MDM into their ERP workflows and maintain data quality over time.
Enterprise MDM Best Practices
To ensure long-term success and scalability, businesses must follow enterprise MDM best practices:
Secure Executive Sponsorship: MDM projects require strong leadership backing and cross-functional involvement.
Align with Business Objectives: MDM should support broader business goals like digital transformation, compliance, or customer 360 initiatives.
Start Small, Scale Fast: Begin with one data domain or business unit. Use early wins to fuel momentum.
Automate Governance: Use workflows, alerts, and approval processes to ensure data accuracy and compliance.
Measure and Improve Continuously: Track improvements in data quality, decision-making speed, and system performance to showcase ROI.
Implementing these practices leads to higher adoption rates, lower resistance to change, and maximum business impact.
SAP MDM Implementation Guide
Organizations using SAP ERP systems have access to one of the most powerful MDM solutions available—SAP Master Data Governance (SAP MDG). Here’s a quick SAP MDM implementation guide to get started:
1. Assess Current Master Data
Understand the data models and usage across your SAP S/4HANA or ECC environment. Identify inconsistencies and opportunities for consolidation.
2. Deploy SAP MDG Modules
SAP MDG offers preconfigured modules for various domains—such as customer, material, and vendor data. Choose modules based on your immediate priorities.
3. Configure Data Models and Workflows
Customize data fields, validation rules, and approval workflows as per business needs. Use SAP Fiori apps for intuitive user experiences.
4. Integrate with SAP BTP
Leverage SAP Business Technology Platform (SAP BTP) for cross-system data orchestration, analytics, and machine learning-based data quality monitoring.
5. Train Teams and Monitor
Ensure all users—from business users to data stewards—are trained on the new data processes. Use built-in analytics to measure data quality improvements over time.
SAP MDG empowers enterprises to manage their master data with transparency, efficiency, and control—leading to better quality data and greater business agility.
Conclusion
Organizations that want to stay ahead in a competitive, data-driven market must make data quality a strategic priority. The ability to improve data quality with MDM is no longer just a technical upgrade—it’s a business imperative.
By implementing a robust MDM solution, aligning it with ERP systems, and following enterprise-grade best practices, businesses can unlock significant value. From better decision-making to smoother operations and enhanced customer satisfaction, the ROI of Master Data Management is undeniable.
At McKinsol, we help enterprises deploy, integrate, and scale MDM solutions—especially in SAP landscapes. Whether you're just starting your MDM journey or seeking to refine your data governance framework, our team offers end-to-end guidance and implementation support.
Let your data work smarter. Contact McKinsol today to maximize the value of your master data.
#master data management#sap mdm#sap solutions#benefits of master data management#sap master data management
0 notes
Text
How to Merge PST Files Using an Expert Application?
Merging PST files has always been tough, especially combining large PST files manually through Outlook can be inconvenient and time-consuming.
BitRecover PST Merge is an ultimate tool to merge multiple PST files automatically in just 5-6 steps in no time. It offers users an easy-to-use interface, merging options, advanced filters, etc.
This offline software merges large PST files in bulk. Due to its offline proccessing, it is the safest and 100% secure software for crucial data. It merges the data files including the entire database without any duplicates or data loss.
There is no chance of human error as the wizard is automated and easy to use. The destination path, remove duplicates, and recovery mode options make this software more convenient and professional.
Try out this amazing and powerful tool's Free Demo Version to merge your multiple PST files easily in no time.

1 note
·
View note
Text
Apache Data Sketches in BigQuery: Quick Analytics at scale

Fast, approximate, large-scale analytics: BigQuery supports Apache Data Sketches.
Understanding large datasets in today's data-driven environment sometimes requires complex non-additive aggregation methods. As data grows to large sizes, conventional methods become computationally expensive and time-consuming. Apache DataSketches can assist. Apache Data Sketches functions are now accessible in BigQuery, providing powerful tools for large-scale approximation analytics.
Apache Data Sketches What?
Software library Apache DataSketches is open-source. Its sketches are probabilistic data structures or streaming algorithms. These sketches effectively summarise large datasets. It is a "required toolkit" for systems that must extract useful information from massive amounts of data. Yahoo started working on the project in 2011, released it in 2015, and still uses it.
Essential Features and Goals:
Apache Data Sketches aims to provide fast, approximate analytics on massive datasets at scale. Conventional approaches for count distinct, quantiles, and most-frequent item queries in big data analysis take a lot of time and computational resources, especially when the data is large (typically more than random-access memory can hold).
DataSketches helps users quickly extract knowledge from enormous datasets, especially when accurate computations are not possible. If imprecise results are acceptable, sketches can produce results orders of magnitude faster. Sketches may be the sole response for interactive, real-time enquiries.
It works:
Big data is summarised well by sketches. One data pass and low memory and computational cost are typical. These tiny probabilistic data structures enable accurate estimations.
Merging sketches, which makes them additive and parallelizable, is essential. Combining drawings from many databases allows for further analysis. The combination of compact size and mergeability can boost computing task speed by orders of magnitude compared to conventional approaches.
Important features and benefits include:
Fast: Sketches can batch and real-time process data in one pass. Data sketching reduces big data processing times from days to minutes or seconds.
Efficiency: Low memory and computational overhead. They save resources by reducing query and storage costs compared to raw data. Sketching-focused systems feature simpler architectures and use less computer power.
Accuracy: Sketches accurately approximate histograms, quantiles, and distinct counts. The biggest potential difference between an actual value and its estimated value is reflected by mathematically specified error bounds in all but a few sketches. The user can adjust these error limitations to balance sketch size and error bounds; larger sketches have smaller error bounds.
Scalability: The library is designed for large-data production systems. It helps analyse massive volumes of data that random-access memory cannot hold.
Interoperability: Apache Data Sketches may be transported between systems and interpreted by Java, C++, and Python without losing accuracy because to their explicitly defined binary representations.
Theta Sketch's built-in set operators (Union, Intersection, and Difference) enable set expressions like ((A ∪ B) ∩ (C ∪ D)) \ (E ∪ F) that yield sketches. For rapid queries, this function gives unprecedented analytical choices.
Important Sketch Types (BigQuery-Integrated Examples):
The library contains analytical sketches of several types:
Cardidality Sketches: Estimate count variations. Theta Sketch for distinct counting and set expressions, Hyper Log Log Sketch (HLL) for simple distinct counting, CPC Sketch for accuracy per stored size, and Tuple Sketch, which builds on Theta Sketch to link additional values to distinct items for complex analysis.
Quantile sketches evaluate values at percentiles or rankings like the median. REQ Sketch is designed for higher accuracy at the rank domain's ends, KLL Sketch is known for statistically optimal quantile approximation accuracy for a given size and insensitivity to input data distribution, and T-Digest Sketch is a quick, compact heuristic sketch (without mathematically proven error bounds) for strictly numeric data.
Frequency drawings identify events that occur more often than a threshold. The Frequent Things Sketch, also known as the Heavy-Hitter sketch, may detect frequent items in one pass for static analysis or real-time monitoring.
Apache Data Sketches is a strong collection of specialised algorithms that enable fast, accurate, and exact approximate analysis on massive datasets in big data environments such cloud platforms like Google Cloud BigQuery.
#ApacheDataSketches#DataSketches#bigdatasets#BigQuery#randomaccessmemory#ApacheData#technology#technews#technologynews#news#govindhtech
0 notes