#DataSketches
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Photo

Overview of immigration in five countries
by u/DataSketches
16 notes
·
View notes
Text
Apache Data Sketches in BigQuery: Quick Analytics at scale

Fast, approximate, large-scale analytics: BigQuery supports Apache Data Sketches.
Understanding large datasets in today's data-driven environment sometimes requires complex non-additive aggregation methods. As data grows to large sizes, conventional methods become computationally expensive and time-consuming. Apache DataSketches can assist. Apache Data Sketches functions are now accessible in BigQuery, providing powerful tools for large-scale approximation analytics.
Apache Data Sketches What?
Software library Apache DataSketches is open-source. Its sketches are probabilistic data structures or streaming algorithms. These sketches effectively summarise large datasets. It is a "required toolkit" for systems that must extract useful information from massive amounts of data. Yahoo started working on the project in 2011, released it in 2015, and still uses it.
Essential Features and Goals:
Apache Data Sketches aims to provide fast, approximate analytics on massive datasets at scale. Conventional approaches for count distinct, quantiles, and most-frequent item queries in big data analysis take a lot of time and computational resources, especially when the data is large (typically more than random-access memory can hold).
DataSketches helps users quickly extract knowledge from enormous datasets, especially when accurate computations are not possible. If imprecise results are acceptable, sketches can produce results orders of magnitude faster. Sketches may be the sole response for interactive, real-time enquiries.
It works:
Big data is summarised well by sketches. One data pass and low memory and computational cost are typical. These tiny probabilistic data structures enable accurate estimations.
Merging sketches, which makes them additive and parallelizable, is essential. Combining drawings from many databases allows for further analysis. The combination of compact size and mergeability can boost computing task speed by orders of magnitude compared to conventional approaches.
Important features and benefits include:
Fast: Sketches can batch and real-time process data in one pass. Data sketching reduces big data processing times from days to minutes or seconds.
Efficiency: Low memory and computational overhead. They save resources by reducing query and storage costs compared to raw data. Sketching-focused systems feature simpler architectures and use less computer power.
Accuracy: Sketches accurately approximate histograms, quantiles, and distinct counts. The biggest potential difference between an actual value and its estimated value is reflected by mathematically specified error bounds in all but a few sketches. The user can adjust these error limitations to balance sketch size and error bounds; larger sketches have smaller error bounds.
Scalability: The library is designed for large-data production systems. It helps analyse massive volumes of data that random-access memory cannot hold.
Interoperability: Apache Data Sketches may be transported between systems and interpreted by Java, C++, and Python without losing accuracy because to their explicitly defined binary representations.
Theta Sketch's built-in set operators (Union, Intersection, and Difference) enable set expressions like ((A ∪ B) ∩ (C ∪ D)) \ (E ∪ F) that yield sketches. For rapid queries, this function gives unprecedented analytical choices.
Important Sketch Types (BigQuery-Integrated Examples):
The library contains analytical sketches of several types:
Cardidality Sketches: Estimate count variations. Theta Sketch for distinct counting and set expressions, Hyper Log Log Sketch (HLL) for simple distinct counting, CPC Sketch for accuracy per stored size, and Tuple Sketch, which builds on Theta Sketch to link additional values to distinct items for complex analysis.
Quantile sketches evaluate values at percentiles or rankings like the median. REQ Sketch is designed for higher accuracy at the rank domain's ends, KLL Sketch is known for statistically optimal quantile approximation accuracy for a given size and insensitivity to input data distribution, and T-Digest Sketch is a quick, compact heuristic sketch (without mathematically proven error bounds) for strictly numeric data.
Frequency drawings identify events that occur more often than a threshold. The Frequent Things Sketch, also known as the Heavy-Hitter sketch, may detect frequent items in one pass for static analysis or real-time monitoring.
Apache Data Sketches is a strong collection of specialised algorithms that enable fast, accurate, and exact approximate analysis on massive datasets in big data environments such cloud platforms like Google Cloud BigQuery.
#ApacheDataSketches#DataSketches#bigdatasets#BigQuery#randomaccessmemory#ApacheData#technology#technews#technologynews#news#govindhtech
0 notes
Text



Design Tips #2: How to Align Graphs in your Designs
#designtips#datavisualization#graph#data#statistics#analytics#dataisbeautiful#chart#dashboard#datagram#dataart#infographic#informationisbeautiful#datatellingstories#datadesign#ddj#datasketch#dataviz
3 notes
·
View notes
Link
0 notes
Photo

Repost from @mona_chalabi using @RepostRegramApp - Today is Equal Pay Day 💵💵💵 On average, women earn 80¢ for every dollar a man makes. But that average varies a whole lot depending on what race you are. Source: US Census Bureau, 2015 #datasketch
1 note
·
View note
Text
Shared Verizon Media’s AI Solutions at the AI Accelerator Summit - Automobile Traffic Flow Monitoring, Cellular Network Performance Prediction, IoT Analytics, and Threat Detection
Chetan Trivedi, Head of Technical Program Management (Verizon Solutions Team), Verizon Media
I recently spoke at the AI Accelerator Summit in San Jose. During my presentation, I shared a few of Verizon Media’s AI Solutions via four machine learning use cases, including:
Cellular Network Performance Prediction
Our team implemented a time series prediction model for the performance of base station parameters such as bearer drop, SIP, and handover failure.
Threat Detection System
DDoS (Distributed Denial of Service) use case where we implemented a real-time threat detection capability using time series data.
Automobile Traffic Flow Monitoring
A collaboration with a city to identify traffic patterns at certain traffic junctions and streets to provide insights so they can improve traffic patterns and also address safety concerns.
IoT Analytics
Detecting vending machine anomalies and addressing them before dispatching the service vehicle with personnel to fix the problem which is very costly for the businesses.
youtube
During the conference, I heard many talks that reinforced common machine learning and AI industry themes. These included:
Key factors to consider when selecting the right use cases for your AI/ML efforts include understanding your error tolerance and ensuring you have sufficient training data.
Implementing AI/ML at scale (with a high volume of data) and moving towards deep learning for supported use cases, where data is highly dimensional and/or higher prediction accuracy is required with enough data to train deep learning models.
Using ensemble learning techniques such as bagging, boosting or other variants of these methods.
At Verizon Media, we’ve built and open sourced several helpful tools that are focused on big data, machine learning, and AI, including:
DataSketches - high-performance library of stochastic streaming algorithms commonly called "sketches" in the data sciences.
TensorFlowOnSpark - brings TensorFlow programs to Apache Spark clusters.
Trapezium - framework to build batch, streaming and API services to deploy machine learning models using Spark and Akka compute.
Vespa - big data serving engine.
If you’d like to discuss any of the above use cases or open source projects, feel free to email me.
4 notes
·
View notes
Text
A tweet
@alfredovelazco @moecolombia No está fácil, pero alguna compañía de Big Data,IA y Analítica podría intentar comparar 1)noticias falsas en medios y en redes, 2)tendencias de odio, 3) acciones de campaña sucia entre la campaña actual, la de 2018 y otras. cc @DatalyticsBI @linterna @datasketch @whaleandjaguar_
— Mauricio Jaramillo Marín, Impacto TIC (@MauricioJaramil) May 19, 2022
0 notes
Text
DataSketches zum Top-Level-Projekt der Apache Software Foundation gekürt
Die Big-Data-Analysebibliothek für Näherungsalgorithmen ist nach knapp zwei Jahren im Incubator nun ein vollwertiges Projekt der Open-Source-Organisation. Read more www.heise.de/news/…... www.digital-dynasty.net/de/teamblogs/…

http://www.digital-dynasty.net/de/teamblogs/datasketches-zum-top-level-projekt-der-apache-software-foundation-gekurt
0 notes
Photo
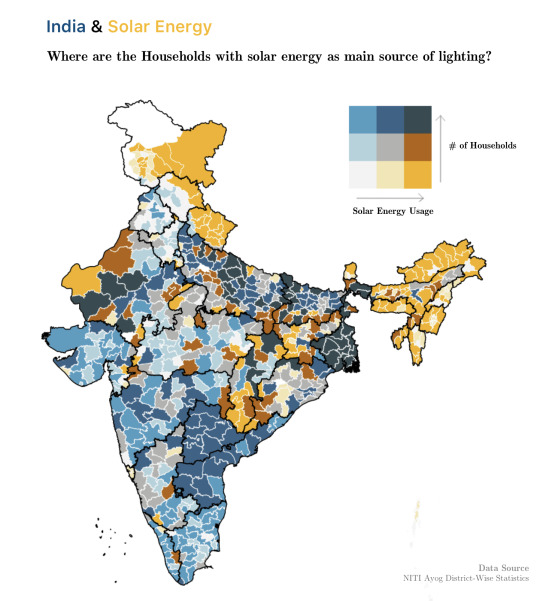
"[OC] Distribution of Indian Households with solar energy as main source of lighting."- Caption by DataSketcher - Detail: https://ift.tt/2OclCcF. Filed Under: 1,000 ways to visualize Data. Curated by: www.eurekaking.com
0 notes
Text
[OC] Distribution of Indian Households with solar energy as main source of lighting.
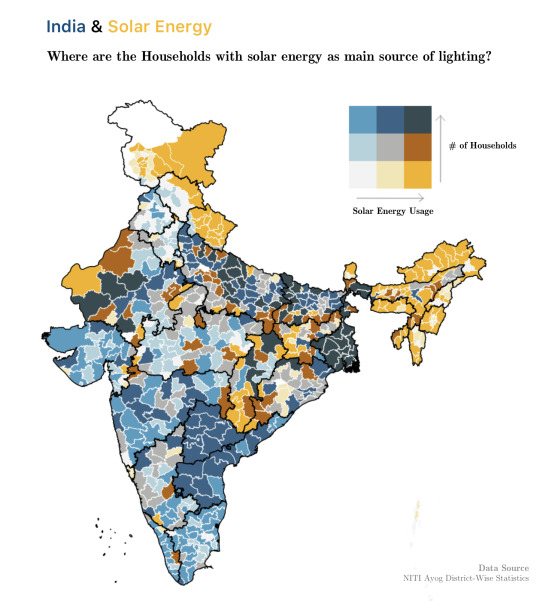
by DataSketcher See more http://bit.ly/34US0pJ
0 notes
Text
Open Sourcing Bullet, Yahoo’s Forward-Looking Query Engine for Streaming Data

By Michael Natkovich, Akshai Sarma, Nathan Speidel, Marcus Svedman, and Cat Utah
Big Data is no longer just Apache server logs. Nowadays, the data may be user engagement data, performance metrics, IoT (Internet of Things) data, or something else completely atypical. Regardless of the size of the data, or the type of querying patterns on it (exploratory, ad-hoc, periodic, long-term, etc.), everyone wants queries to be as fast as possible and cheap to run in terms of resources. Data can be broadly split into two kinds: the streaming (generally real-time) kind or the batched-up-over-a-time-interval (e.g., hourly or daily) kind. The batch version is typically easier to query since it is stored somewhere like a data warehouse that has nice SQL-like interfaces or an easy to use UI provided by tools such as Tableau, Looker, or Superset. Running arbitrary queries on streaming data quickly and cheaply though, is generally much harder… until now. Today, we are pleased to share our newly open sourced, forward-looking general purpose query engine, called Bullet, with the community on GitHub.
With Bullet, you can:
Powerful and nested filtering
Fetching raw data records
Aggregating data using Group Bys (Sum, Count, Average, etc.), Count Distincts, Top Ks
Getting distributions of fields like Percentiles or Frequency histograms
One of the key differences between how Bullet queries data and the standard querying paradigm is that Bullet does not store any data. In most other systems where you have a persistence layer (including in-memory storage), you are doing a look-back when you query the layer. Instead, Bullet operates on data flowing through the system after the query is started – it’s a look-forward system that doesn’t need persistence. On a real-time data stream, this means that Bullet is querying data after the query is submitted. This also means that Bullet does not query any data that has already passed through the stream. The fact that Bullet does not rely on a persistence layer is exactly what makes it extremely lightweight and cheap to run.
To see why this is better for the kinds of use cases Bullet is meant for – such as quickly looking at some metric, checking some assumption, iterating on a query, checking the status of something right now, etc. – consider the following: if you had a 1000 queries in a traditional query system that operated on the same data, these query systems would most likely scan the data 1000 times each. By the very virtue of it being forward looking, 1000 queries in Bullet scan the data only once because the arrival of the query determines and fixes the data that it will see. Essentially, the data is coming to the queries instead of the queries being farmed out to where the data is. When the conditions of the query are satisfied (usually a time window or a number of events), the query terminates and returns you the result.
A Brief Architecture Overview

High Level Bullet Architecture
The Bullet architecture is multi-tenant, can scale linearly for more queries and/or more data, and has been tested to handle 700+ simultaneous queries on a data stream that had up to 1.5 million records per second, or 5-6 GB/s. Bullet is currently implemented on top of Storm and can be extended to support other stream processing engines as well, like Spark Streaming or Flink. Bullet is pluggable, so you can plug in any source of data that can be read in Storm by implementing a simple data container interface to let Bullet work with it.
The UI, web service, and the backend layers constitute your standard three-tier architecture. The Bullet backend can be split into three main subsystems:
Request Processor – receives queries, adds metadata, and sends it to the rest of the system
Data Processor – reads data from an input stream, converts it to a unified data format, and matches it against queries
Combiner – combines results for different queries, performs final aggregations, and returns results
The web service can be deployed on any servlet container, like Jetty. The UI is a Node-based Ember application that runs in the client browser. Our full documentation contains all the details on exactly how we perform computationally-intractable queries like Count Distincts on fields with cardinality in the millions, etc. (DataSketches).
Usage at Yahoo
An instance of Bullet is currently running at Yahoo in production against a small subset of Yahoo’s user engagement data stream. This data is roughly 100,000 records per second and is about 130 MB/s compressed. Bullet queries this with about 100 CPU Virtual Cores and 120 GB of RAM. This fits on less than 2 of our (64 Virtual Cores, 256 GB RAM each) test Storm cluster machines.
One of the most popular use cases at Yahoo is to use Bullet to manually validate the instrumentation of an app or web application. Instrumentation produces user engagement data like clicks, views, swipes, etc. Since this data powers everything we do from analytics to personalization to targeting, it is absolutely critical that the data is correct. The usage pattern is generally to:
Submit a Bullet query to obtain data associated with your mobile device or browser (filter on a cookie value or mobile device ID)
Open and use the application to generate the data while the Bullet query is running
Go back to Bullet and inspect the data
In addition, Bullet is also used programmatically in continuous delivery pipelines for functional testing instrumentation on product releases. Product usage is simulated, then data is generated and validated in seconds using Bullet. Bullet is orders of magnitude faster to use for this kind of validation and for general data exploration use cases, as opposed to waiting for the data to be available in Hive or other systems. The Bullet UI supports pivot tables and a multitude of charting options that may speed up analysis further compared to other querying options.
We also use Bullet to do a bunch of other interesting things, including instances where we dynamically compute cardinalities (using a Count Distinct Bullet query) of fields as a check to protect systems that can’t support extremely high cardinalities for fields like Druid.
What you do with Bullet is entirely determined by the data you put it on. If you put it on data that is essentially some set of performance metrics (data center statistics for example), you could be running a lot of queries that find the 95th and 99th percentile of a metric. If you put it on user engagement data, you could be validating instrumentation and mostly looking at raw data.
We hope you will find Bullet interesting and tell us how you use it. If you find something you want to change, improve, or fix, your contributions and ideas are always welcome! You can contact us here.
Helpful Links
Quick Start
UI Querying Demo
Full Documentation
GitHub Links
DataSketches
13 notes
·
View notes
Photo

There are profits to be made from pain. In addition to the $0.25m illustrated here, GEO also spent $1.7m on lobbying government in 2017 (more than any other private prison contractor) and gave $0.225m to a pro-Trump super PAC during the election. Sources: USA Spending.gov - June 2018, US Department of Health and Human Services - May 2018 #datasketch #immigration . . [source: @monachalabi]
0 notes
Photo

Arnaud Esquerre, ethnologist, on his research into beliefs in supernatural phenomena: “With this kind of investigation, there’s no dead body. It’s not a murder inquiry. There is only the witness.” — « Il n’y a pas de cadavre. Ce n’est pas une enquête policière. Il n’y a que le témoin. » — Some UFOs I drew whilst listening to him. — #cnrs #ufo #objetnonidentifié #speap #datasketch #clairobscur #ethnology #supernatural #aliens
0 notes
Quote
We spoke with @datasketch founder @jpmarindiaz about making data visualization more accessible for Latin American newsrooms #datasketchapps https://t.co/DjniCRoLNL
http://twitter.com/storybench
0 notes
Link
0 notes
Link
#IODC18 estamos en #AbreLatam18 hablando sobre los retos de derechos digitales. ¡Qué bueno verlos por acá! @socialtic @R3Dmx @Karisma @Ojo_Publico @TEDICpy @DATAuy @idatosabiertos @datalat @FeelingMetodo @yeekomx @derechosdigital @ciudadanoi @CodingRights pic.twitter.com/6Sw5C1ZahA
— Datasketch (@datasketch) September 26, 2018
0 notes