#postgres in ec2
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
#aws cloud#aws ec2#aws s3#aws serverless#aws ecs fargate tutorial#aws tutorial#aws cloud tutorial#aws course#aws cloud services#aws apprunner#aws rds postgres
0 notes
Text
Hosting Options for Full Stack Applications: AWS, Azure, and Heroku

Introduction
When deploying a full-stack application, choosing the right hosting provider is crucial. AWS, Azure, and Heroku offer different hosting solutions tailored to various needs. This guide compares these platforms to help you decide which one is best for your project.
1. Key Considerations for Hosting
Before selecting a hosting provider, consider: ✅ Scalability — Can the platform handle growth? ✅ Ease of Deployment — How simple is it to deploy and manage apps? ✅ Cost — What is the pricing structure? ✅ Integration — Does it support your technology stack? ✅ Performance & Security — Does it offer global availability and robust security?
2. AWS (Amazon Web Services)
Overview
AWS is a cloud computing giant that offers extensive services for hosting and managing applications.
Key Hosting Services
🚀 EC2 (Elastic Compute Cloud) — Virtual servers for hosting web apps 🚀 Elastic Beanstalk — PaaS for easy deployment 🚀 AWS Lambda — Serverless computing 🚀 RDS (Relational Database Service) — Managed databases (MySQL, PostgreSQL, etc.) 🚀 S3 (Simple Storage Service) — File storage for web apps
Pros & Cons
✔️ Highly scalable and flexible ✔️ Pay-as-you-go pricing ✔️ Integration with DevOps tools ❌ Can be complex for beginners ❌ Requires manual configuration
Best For: Large-scale applications, enterprises, and DevOps teams.
3. Azure (Microsoft Azure)
Overview
Azure provides cloud services with seamless integration for Microsoft-based applications.
Key Hosting Services
🚀 Azure Virtual Machines — Virtual servers for custom setups 🚀 Azure App Service — PaaS for easy app deployment 🚀 Azure Functions — Serverless computing 🚀 Azure SQL Database — Managed database solutions 🚀 Azure Blob Storage — Cloud storage for apps
Pros & Cons
✔️ Strong integration with Microsoft tools (e.g., VS Code, .NET) ✔️ High availability with global data centers ✔️ Enterprise-grade security ❌ Can be expensive for small projects ❌ Learning curve for advanced features
Best For: Enterprise applications, .NET-based applications, and Microsoft-centric teams.
4. Heroku
Overview
Heroku is a developer-friendly PaaS that simplifies app deployment and management.
Key Hosting Features
🚀 Heroku Dynos — Containers that run applications 🚀 Heroku Postgres — Managed PostgreSQL databases 🚀 Heroku Redis — In-memory caching 🚀 Add-ons Marketplace — Extensions for monitoring, security, and more
Pros & Cons
✔️ Easy to use and deploy applications ✔️ Managed infrastructure (scaling, security, monitoring) ✔️ Free tier available for small projects ❌ Limited customization compared to AWS & Azure ❌ Can get expensive for large-scale apps
Best For: Startups, small-to-medium applications, and developers looking for quick deployment.
5. Comparison Table
FeatureAWSAzureHerokuScalabilityHighHighMediumEase of UseComplexModerateEasyPricingPay-as-you-goPay-as-you-goFixed plansBest ForLarge-scale apps, enterprisesEnterprise apps, Microsoft usersStartups, small appsDeploymentManual setup, automated pipelinesIntegrated DevOpsOne-click deploy
6. Choosing the Right Hosting Provider
✅ Choose AWS for large-scale, high-performance applications.
✅ Choose Azure for Microsoft-centric projects.
✅ Choose Heroku for quick, hassle-free deployments.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
Sonarqube Setup with Postgresql
sonarqube installation along with java 17 Postgresql Database Prerequisites Need an AWS EC2 instance (min t2.small) Install Java 17 (openjdk-17) apt-get update apt list | grep openjdk-17 apt-get install openjdk-17-jdk -y Install & Setup Postgres Database for SonarQube Source: https://www.postgresql.org/download/linux/ubuntu/ Install Postgresql database Import the repository signing…
0 notes
Text
Veeam backup for aws Processing postgres rds failed: No valid combination of the network settings was found for the worker configuration
In this article, we shall discuss various errors you can encounter when implementing “Veeam Backup for AWS to protect RDS, EC2 and VPC“. Specifically, the following error “veeam backup for aws Processing postgres rds failed: No valid combination of the network settings was found for the worker configuration” will be discussed. A configuration is a group of network settings that Veeam Backup for…

View On WordPress
#AWS#AWS SSM Service#AWS System State Manager#Backup#Backup and Recovery#Create Production Worker Node#EC2#Enable Auto Assign Public IP Address on AWS#rds#The Worker Node for region is not set#VBAWS#VBAWS Session Status#Veeam Backup for AWS#Veeam backup for AWS Errors
0 notes
Link
Job summaryThis is an excellent opportunity to join one of Amazon’s world-class team of engineers, and work with some of the best and brightest while also developing your skills and career within one of the most dynamic, innovative and progressive te …
#devops#cicd#cloud#engineering#career#jobs#jobsearch#recruiting#hiring#TechTalent#AWS#Bash#CloudFormation#Docker#EC2#Kubernetes#Linux#Postgres#Python#Redis#Ruby#S3#Terraform#Go#Java#Lambda#Node
0 notes
Text
Importing geo-partitioned data... the easy way
Importing geo-partitioned data… the easy way

setting the stage
I started at Cockroach labs back in June 2019 to help others learn how to architect and develop applications using a geo-distributed database. There has been a resurgence in distributed database technology, but the focus on geo-distributed is quite unique to CockroachDB. While the underlying technology is unique, developers and DBAs that come with a wealth of experience, need…
View On WordPress
0 notes
Text
Fullstack Engineer - Remote Anywhere

Software Engineering at B12 B12's engineering team views software as a craft, but improving the world as the reason to practice it. Our engineers are responsible for prioritizing, conceptualizing, co-designing, building, testing, and engaging users for any concept we are building out. We’re generalists in encouraging each other to experience the full stack, but we’re also aware of each other’s preferences in the stack. We mentor and teach where we can, both inside and outside of the company. We value sharing our work with the outside world. Our team has published papers on forming expert flash teams and machine-mediated worker hierarchies. We’ve baked our research into Orchestra, the system that coordinates our expert and machine teams, and released Orchestra into open source to contribute our software back to the community. We hope our engineers have more longevity than any one tool we use, but here is a sampling of our current thoughts about technology: - We live on Python/Django and JavaScript/React. - We store blobs in Amazon’s S3, munch on them in Amazon’s EC2, develop in Docker, and deploy containers to Amazon’s Elastic Beanstalk. - We believe Postgres should be the first system you consider when you think about persisting structured data. - We religiously clean and centralize data in Amazon’s Redshift, and are able to answer most any question in SQL. - We have near-full test coverage on the backend, and are making progress on our frontend and integration tests. - We set up continuous integration and deployment because, while this model comes with its own pains, we’ve disliked being on fixed release schedules on previous projects. - We like to move fast and support point-in-time recovery :). You’d be a good fit if - You have at least 2 years of experience building products and systems in production. - You are an amazing communicator. - You feel comfortable managing your time and deciding amongst competing priorities. - You are passionate about the future of work. - You enjoy learning and teaching. - You have some mobile experience. - You care about and want to contribute to our mission of helping people do meaningful work. Don’t fear: - We highly favor talent and interest. - B12 is a safe place for human beings. We particularly encourage you to apply if you identify as a woman, are a person of color or other underrepresented minority, or are a member of the LGBTQIA community. How to apply Please provide: - A pointer to your CV, resume, LinkedIn profile, or any other summary of your career so far. - Some informal text introducing yourself and what you are excited about. - If you have a profile on websites like GitHub or other repositories of open source software, you can provide that as well. If you don’t have one, it’s still very possible for us to get along just fine! APPLY ON COMPANY WEBSITE Disclaimer: - This job opening is available on the respective company website as of 15th May 2023. The job openings may get expired by the time you check the post. - Candidates are requested to study and verify all the job details before applying and contact the respective company representative in case they have any queries. - The owner of this site has provided all the available information regarding the location of the job i.e. work from anywhere, work from home, fully remote, remote, etc. However, if you would like to have any clarification regarding the location of the job or have any further queries or doubts; please contact the respective company representative. Viewers are advised to do full requisite enquiries regarding job location before applying for each job. - Authentic companies never ask for payments for any job-related processes. Please carry out financial transactions (if any) at your own risk. - All the information and logos are taken from the respective company website. Read the full article
0 notes
Text
Bạn đã biết AWS Free Tier hay chưa?
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aws-free-tier/ - Cloudemind.com
Bạn đã biết AWS Free Tier hay chưa?
Sử dụng Cloud nói chung và AWS Cloud nói riêng các bạn sẽ nghe cứ nghe hoài là nó rẻ, nó ổn định. Câu trả lời của Kevin là nó còn tùy thuộc vào tình huống sử dụng và trình độ của người sử dụng nữa. Cloud giống như cung cấp cho các bạn một chiếc xe xịn, các bạn ko biết lái (sử dụng) nó đúng nhu cầu đúng mục đích bạn có thể sẽ gây họa cho bản thân và tổ chức. Vậy làm sao để giảm thiểu tai họa, rủi ro khi sử dụng cloud?
Chỉ có một cách duy nhất là các bạn cần phải biết cách sử dụng Cloud. Ah thì có thể học các khóa học, các hướng dẫn trên internet, may mắn hơn thì tổ chức các bạn có các hoạt động liên quan đào tạo. Nhưng đào tạo thì nó cũng chỉ đáp ứng phần nhỏ thôi, cái chính các bạn cần phải làm thực (hands-on) trên các hệ thống thật mới đem lại sự tin cậy nhất định.
Đôi lúc đọc tài liệu mà ko có thời gian thao tác hệ thống dịch vụ thật có thể đem lại cho các bạn tư duy ko chính xác về thực tế, dễ dẫn đến cách nghĩ, cách tư vấn sai cho tổ chức hay thậm chí khách hàng của các bạn. Bản thân Kevin thấy sử dụng Cloud đã rất dễ so với cách làm truyền thống, tập trung tối đa thời gian vào innovation ứng dụng và business của các bạn, nhưng cũng có cái khó là Cloud là một mảng rất rộng, các bạn cần chọn một hướng nào đó mà mình thích thú và đào sâu thì mới có “đẳng” để làm chứ ko chỉ để nói. Lúc này thì gọi là Experienced!
Chúc các bạn ngày càng Experienced với AWS Cloud.
Well Done is better than Well Said!
Unknown
AWS Free Tier
AWS cung cấp hơn 175 dịch vụ trong đó có hơn 85 cho phép bạn dùng miễn phí. Có 03 loại miễn phí bạn có thể có là:
12 months free – Sử dụng miễn phí trong 12 tháng. ��ây có lẽ là loại phổ biến nhất.
Always free – Miễn phí suốt đời. Quá tuyệt vời.
Trials – thông thường có một giới hạn nhất định dùng thử. Ví dụ: 2 tháng.
Chúng ta hãy cùng điểm qua một số dịch vụ chính mà ban đầu các bạn có thể gặp phải phổ biến. Đây là cách sắp xếp các nhân của Kevin để dễ nhớ hơn, bạn có thể group các services theo cách bạn nhớ nhé:
Bộ ba Amazon EC2, S3 và RDS
Đây có lẽ là bộ phổ biến nhất mà dường như ai khi bắt đầu cũng có làm qua.
EC2: compute cung cấp các virtual machine trên nền tảng AWS Cloud.
S3: storage service. Cung cấp dịch vụ lưu trữ đối tượng. S3 cũng là dịch vụ serverless hỗ trợ lưu trữ không giới hạn trong mỗi bucket.
RDS – Relational Database Service – dịch vụ CSDL.
Với AWS free tier bạn có thể dùng như sau: Amazon EC2 Free tier:
Resizable compute capacity in the Cloud.
12 months free
750 hours t2.micro or t3.micro (depends on region available)
OS: Linux, RHEL, SLES, Windows
Amazon S3 Free Tier:
Secure, durable, and scalable object storage infrastructure.
12 months free
5GB storage
20K Read requests
2K Put requests
Amazon RDS Free Tier:
12 months free
750 hours
Instance type: db.t2.micro
Storage: 20GB gp
Backup Storage: 20GB
Engine: mysql, postgres, mariadb, mssql, oracle BYOL
Bộ AWS Serverless
Nằm trong bộ này Kevin sắp xếp đó là Amazon DynamoDB, AWS Lambda, API Gateway, Step Functions.
Amazon DynamoDB Free Tier:
Fast and flexible NoSQL database with seamless scalability.
Always free
Storage: 25GB
WCU: 25
RCU: 25
AWS Lambda Free Tier
Compute service that runs your code in response to events and automatically manages the compute resources.
Always free
1M requests per month
3.2M seconds of compute time
Amazon API Gateway Free Tier
Publish, maintain, monitor, and secure APIs at any scale.
12 months free
1M received api per month
AWS Step Functions Free Tier
Coordinate components of distributed applications.
Always free
4K state transition per month
Amazon SQS Free Tier
Scalable queue for storing messages as they travel between computers.
Always free
1M requests
Amazon SNS Free Tier
Fast, flexible, fully managed push messaging service.
Always free
1M publics
100K HTTP/S deliveries
1K email deliveries
AWS AppSync Free Tier
Develop, secure and run GraphQL APIs at any scale.
12 months free
250K query or data modification
250K real time updates
600K connection minutes
Bộ Data Science
Bộ này bao gồm các dịch vụ liên quan Data Analys, Data Visualization, Machine Learning, AI.
Amazon SageMaker Free Tier
Machine learning for every data scientist and developer.
2 months free trial
Studio notebooks: 250 hours per month ml.t3.medium or
SageMaker Data Wrangler: 25 hours per month ml.m5.4xlarge
Storage: 25GB per month, 10M write units
Training: 50 hours per month m4.xlarge or m5.xlarge
Inference: 125 hours per month of m4.xlarge or m5.xlarge
Amazon SageMaker GroundTruth Free Tier
Build highly-accurate training datasets quickly, while reducing data labeling costs by up to 70% .
2 months free trials
500 objects labeled per month
Amazon Forecast Free Tier
Amazon Forecast is a fully managed service that uses machine learning (ML) to deliver highly accurate forecasts.
2 months free trials
10K time series forecasts per month
Storage: 10GB per month
Training hours: 10h per month
Amazon Personalize Free Tier
Amazon Personalize enables developers to build applications with the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations.
2 months free trials
Data processing & storage: 20GB per month
Training: 100 hours per month
Recommendation: 50 TPS hours of real time recommendations / month
Amazon Rekognition Free Tier
Deep learning-based image recognition service.
12 months free
5,000 images per month
Store: 1,000 face metadata per month
Amazon Augmented AI
Amazon Augmented AI (Amazon A2I) makes it easy to build the workflows required for human review of ML predictions.
12 months free
42 objects per month (500 human reviews per year)
AWS Deepracer Free Tier
DeepRacer is an autonomous 1/18th scale race car designed to test RL models by racing on a physical track.
30 days free trials
10 hours for 30 days
Free storage: 5GB
Amazon Fraud Detector
Amazon Fraud Detector uses machine learning (ML)to identify potentially fraudulent activity so customers can catch more online fraud faster.
2 months free
model training per month: 50 compute hours
model hosting per month: 500 compute hours
fraud detection: 30K real time online fraud insight predictions & 30K real time rules based fraud predictions per month
Nhóm dịch vụ lưu trữ AWS
AWS cung cấp nhiều loại hình lưu trữ từ file, object đến cả block storage. Tùy loại dữ liệu và cách sử dụng dữ liệu mà chọn loại hình lưu trữ phù hợp. Một số dịch vụ lưu trữ phổ biến như: S3 (đã nói ở trên), EFS, EBS, Storage Gateway, CloudFront… Hãy cùng xem qua các dịch vụ chính nhé.
Amazon Elastic Block Store (EBS) Free Tier
Persistent, durable, low-latency block-level storage volumes for EC2 instances.
12 months free
Storage: 30GB (gp or magnetic)
2M IOPS với EBS Magnetic
Snapshot storage: 1GB
Amazon Elastic File Service (EFS) Free Tier
Simple, scalable, shared file storage service for Amazon EC2 instances.
Storage: 5GB
Amazon CloudFront Free Tier
Web service to distribute content to end users with low latency and high data transfer speeds.
12 months free
Data Transfer out: 50GB per month
HTTP / HTTPS requests: 2M per month
AWS Storage Gateway Free Tier
Hybrid cloud storage with seamless local integration and optimized data transfer.
Always free
First 100GB
Conclusion
AWS cung cấp rất nhiều dịch vụ miễn phí để các bạn có thể vọc trước khi triển khai ra môi trường production. Thậm chí nếu các bạn biết cách tận dụng thì hàng tháng sẽ ko tốn phí cho các website nho nhỏ phục vụ em yêu khoa học AWS.
Lưu ý khi các bạn sử dụng vượt quá free tier thì bạn sẽ trả giá theo từng loại dịch vụ quy định.
Bài này Kevin chỉ điểm qua các dịch chính hay ho mà có thể phổ biến cho các bạn sử dụng. Còn dịch vụ nào hay ho thì bạn chia sẻ chúng ta cùng học nhé.
Have fun!
Tham khảo: https://aws.amazon.com/free/
Xem thêm: https://cloudemind.com/aws-free-tier/
0 notes
Text
https://codeonedigest.blogspot.com/2023/07/create-aws-ec2-instance-install.html
#youtube#video#codeonedigest#aws#postgres db#postgres tutorial#postgres installation#postgres database#postgresql#postgres#aws ec2 server#aws ec2 instance#aws ec2 service#ec2#aws ec2
0 notes
Text
How we scaled data streaming at Coinbase using AWS MSK

By: Dan Moore, Eric Sun, LV Lu, Xinyu Liu
Tl;dr: Coinbase is leveraging AWS’ Managed Streaming for Kafka (MSK) for ultra low latency, seamless service-to-service communication, data ETLs, and database Change Data Capture (CDC). Engineers from our Data Platform team will further present this work at AWS’ November 2021 Re:Invent conference.
Abstract
At Coinbase, we ingest billions of events daily from user, application, and crypto sources across our products. Clickstream data is collected via web and mobile clients and ingested into Kafka using a home-grown Ruby and Golang SDK. In addition, Change Data Capture (CDC) streams from a variety of databases are powered via Kafka Connect. One major consumer of these Kafka messages is our data ETL pipeline, which transmits data to our data warehouse (Snowflake) for further analysis by our Data Science and Data Analyst teams. Moreover, internal services across the company (like our Prime Brokerage and real time Inventory Drift products) rely on our Kafka cluster for running mission-critical, low-latency (sub 10 msec) applications.
With AWS-managed Kafka (MSK), our team has mitigated the day-to-day Kafka operational overhead of broker maintenance and recovery, allowing us to concentrate our engineering time on core business demands. We have found scaling up/out Kafka clusters and upgrading brokers to the latest Kafka version simple and safe with MSK. This post outlines our core architecture and the complete tooling ecosystem we’ve developed around MSK.

Configuration and Benefits of MSK
Config:
TLS authenticated cluster
30 broker nodes across multiple AZs to protect against full AZ outage
Multi-cluster support
~17TB storage/broker
99.9% monthly uptime SLA from AWS
Benefits:
Since MSK is AWS managed, one of the biggest benefits is that we’re able to avoid having internal engineers actively maintain ZooKeeper / broker nodes. This has saved us 100+ hours of engineering work as AWS handles all broker security patch updates, node recovery, and Kafka version upgrades in a seamless manner. All broker updates are done in a rolling fashion (one broker node is updated at a time), so no user read/write operations are impacted.
Moreover, MSK offers flexible networking configurations. Our cluster has tight security group ingress rules around which services can communicate directly with ZooKeeper or MSK broker node ports. Integration with Terraform allows for seamless broker addition, disk space increases, configuration updates to our cluster without any downtime.
Finally, AWS has offered excellent MSK Enterprise support, meeting with us on several occasions to answer thorny networking and cluster auth questions.
Performance:
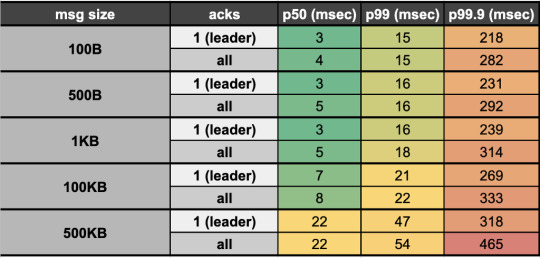
We reduced our end-to-end (e2e) latency (time taken to produce, store, and consume an event) by ~95% when switching from Kinesis (~200 msec e2e latency) to Kafka (<10msec e2e latency). Our Kafka stack’s p50 e2e latency for payloads up to 100KB averages <10 msec (in-line with LinkedIn as a benchmark, the company originally behind Kafka). This opens doors for ultra low latency applications like our Prime Brokerage service. Full latency breakdown from stress tests on our prod cluster, by payload size, presented below:
Proprietary Kafka Security Service (KSS)
What is it?
Our Kafka Security Service (KSS) houses all topic Access Control Lists (ACLs). On deploy, it automatically syncs all topic read/write ACL changes with MSK’s ZooKeeper nodes; effectively, this is how we’re able to control read/write access to individual Kafka topics at the service level.
KSS also signs Certificate Signing Requests (CSRs) using the AWS ACM API. To do this, we leverage our internal Service-to-Service authentication (S2S) framework, which gives us a trustworthy service_id from the client; We then use that service_id and add it as the Distinguished Name in the signed certificate we return to the user.
With a signed certificate, having the Distinguished Name matching one’s service_id, MSK can easily detect via TLS auth whether a given service should be allowed to read/write from a particular topic. If the service is not allowed (according to our acl.yml file and ACLs set in ZooKeeper) to perform a given action, an error will occur on the client side and no Kafka read/write operations will occur.
Also Required
Parallel to KSS, we built a custom Kafka sidecar Docker container that: 1) Plugs simply into one’s existing docker-compose file 2) Auto-generates CSRs on bootup and calls KSS to get signed certs, and 3) Stores credentials in a Docker shared volume on user’s service, which can be used when instantiating a Kafka producer / consumer client so TLS auth can occur.
Rich Data Stream Tooling
We’ve extended our core Kafka cluster with the following powerful tools:
Kafka Connect
This is a distributed cluster of EC2 nodes (AWS autoscaling group) that performs Change Data Capture (CDC) on a variety of database systems. Currently, we’re leveraging the MongoDB, Snowflake, S3, and Postgres source/sink connectors. Many other connectors are available open-source through Confluent here
Kafdrop
We’re leveraging the open-source Kafdrop product for first-class topic/partition offset monitoring and inspecting user consumer lags: source code here
Cruise Control
This is another open-source project, which provides automatic partition rebalancing to keep our cluster load / disk space even across all broker nodes: source code here
Confluent Schema Registry
We use Confluent’s open-source Schema Registry to store versioned proto definitions (widely used along Coinbase gRPC): source code here
Internal Kafka SDK
Critical to our streaming stack is a custom Golang Kafka SDK developed internally, based on the segmentio/kafka release. The internal SDK is integrated with our Schema Registry so that proto definitions are automatically registered / updated on producer writes. Moreover, the SDK gives users the following benefits out of the box:
Consumer can automatically deserialize based on magic byte and matching SR record
Message provenance headers (such as service_id, event_time, event_type) which help conduct end-to-end audits of event stream completeness and latency metrics
These headers also accelerate message filtering and routing by avoiding the penalty of deserializing the entire payload

Streaming SDK
Beyond Kafka, we may still need to make use of other streaming solutions, including Kinesis, SNS, and SQS. We introduced a unified Streaming-SDK to address the following requirements:
Delivering a single event to multiple destinations, often described as ‘fanout’ or ‘mirroring’. For instance, sending the same message simultaneously to a Kafka topic and an SQS queue
Receiving messages from one Kafka topic, emitting new messages to another topic or even a Kinesis stream as the result of data processing
Supporting dynamic message routing, for example, messages can failover across multiple Kafka clusters or AWS regions
Offering optimized configurations for each streaming platform to minimize human mistakes, maximize throughput and performance, and alert users of misconfigurations
Upcoming
On the horizon is integration with our Delta Lake which will fuel more performant, timely data ETLs for our data analyst and data science teams. Beyond that, we have the capacity to 3x the number of broker nodes in our prod cluster (30 -> 90 nodes) as internal demand increases — that is a soft limit which can be increased via an AWS support ticket.
Takeaways
Overall, we’ve been quite pleased with AWS MSK. The automatic broker recovery during security patches, maintenance, and Kafka version upgrades along with the advanced broker / topic level monitoring metrics around disk space usage / broker CPU, have saved us hundreds of hours provisioning and maintaining broker and ZooKeeper nodes on our own. Integration with Terraform has made initial cluster configuration, deployment, and configuration updates relatively painless (use 3AZs for your cluster to make it more resilient and prevent impact from a full-AZ outage).
Performance has exceeded expectations, with sub 10msec latencies opening doors for ultra high-speed applications. Uptime of the cluster has been sound, surpassing the 99.9% SLA given by AWS. Moreover, when any security patches take place, it’s always done in a rolling broker fashion, so no read/write operations are impacted (set default topic replication factor to 3, so that min in-sync replicas is 2 even with node failure).
We’ve found building on top of MSK highly extensible having integrated Kafka Connect, Confluent Schema Registry, Kafdrop, Cruise Control, and more without issue. Ultimately, MSK has been beneficial for both our engineers maintaining the system (less overhead maintaining nodes) and unlocking our internal users and services with the power of ultra-low latency data streaming.
If you’re excited about designing and building highly-scalable data platform systems or working with cutting-edge blockchain data sets (data science, data analytics, ML), come join us on our mission building the world’s open financial system: careers page.
How we scaled data streaming at Coinbase using AWS MSK was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Money 101 https://blog.coinbase.com/how-we-scaled-data-streaming-at-coinbase-using-aws-msk-4595f171266c?source=rss----c114225aeaf7---4 via http://www.rssmix.com/
0 notes
Link
About BettworksBetterWorks provides enterprise software to easily manage strategic plans, collaborative goals (OKR’s) and ongoing performance conversations. Betterworks software helps high-performing companies get aligned, and execute more effective …
#devops#cicd#cloud#engineering#career#jobs#jobsearch#recruiting#hiring#TechTalent#AWS#Bash#CloudFormation#Docker#EC2#Kubernetes#Linux#Postgres#Python#Redis#Ruby#S3#Terraform
0 notes
Text
Options for legacy application modernization with Amazon Aurora and Amazon DynamoDB
Legacy application modernization can be complex. To reduce complexity and risk, you can choose an iterative approach by first replatforming the workload to Amazon Aurora. Then you can use the cloud-native integrations in Aurora to introduce other AWS services around the edges of the workload, often without changes to the application itself. This approach allows teams to experiment, iterate, and modernize legacy workloads iteratively. Modern cloud applications often use several database types working in unison, creating rich experiences for customers. To that end, the AWS database portfolio consists of multiple purpose-built database services that allow you to use the right tool for the right job based on the nature of the data, access patterns, and scalability requirements. For example, a modern cloud-native ecommerce solution can use a relational database for customer transactions and a nonrelational document database for product catalog and marketing promotions. If you’re migrating a legacy on-premises application to AWS, it can be challenging to identify the right purpose-built approach. Furthermore, introducing purpose-built databases to an application that runs on an old-guard commercial database might require extensive rearchitecture. In this post, I propose a modernization approach for legacy applications that make extensive use of semistructured data such as XML in a relational database. Starting in the mid-90s, developers began experimenting with storing XML in relational databases. Although commercial and open-source databases have since introduced native support for nonrelational data types, an impedance mismatch still exists between the relational SQL query language and access methods that may introduce data integrity and scalability challenges for your application. Retrieval of rows based on the value of an XML attribute can involve a resource-consuming full table scan, which may result in performance bottlenecks. Because enforcing accuracy and consistency of relationships between tables, or referential integrity, on nonrelational data types in a relational database isn’t possible, it may lead to orphaned records and data quality challenges. For such scenarios, I demonstrate a way to introduce Amazon DynamoDB alongside Amazon Aurora PostgreSQL-compatible edition, using the native integration of AWS Lambda with Aurora, without any modifications to your application’s code. DynamoDB is a fully managed key-value and document database with single-millisecond query performance, which makes it ideal to store and query nonrelational data at any scale. This approach paves the way to gradual rearchitecture, whereby new code paths can start to query DynamoDB following the Command-Query Responsibility Segregation pattern. When your applications are ready to cut over reads and writes to DynamoDB, you can remove XML from Aurora tables entirely. Solution overview The solution mirrors XML data stored in an Aurora PostgreSQL table to DynamoDB documents in an event-driven and durable way by using the Aurora integration with Lambda. Because of this integration, Lambda functions can be called directly from within an Aurora database instance by using stored procedures or user-defined functions. The following diagram details the solution architecture and event flows. The solution deploys the following resources and configurations: Amazon Virtual Private Cloud (Amazon VPC) with two public and private subnets across two AWS Availability Zones An Aurora PostgreSQL cluster in the private subnets, encrypted by an AWS KMS managed customer master key (CMK), and bootstrapped with a orders table with sample XML A pgAdmin Amazon Elastic Compute Cloud (Amazon EC2) instance deployed in the public subnet to access the Aurora cluster A DynamoDB table with on-demand capacity mode A Lambda function to transform XML payloads to DynamoDB documents and translate INSERT, UPDATE, and DELETE operations from Aurora PostgreSQL to DynamoDB An Amazon Simple Queue Service (Amazon SQS) queue serving as a dead-letter queue for the Lambda function A secret in AWS Secrets Manager to securely store Aurora admin account credentials AWS Identity and Access Management (IAM) roles granting required permissions to the Aurora cluster, Lambda function and pgAdmin EC2 instance The solution registers the Lambda function with the Aurora cluster to enable event-driven offloading of data from the postgres.orders table to DynamoDB, as numbered in the preceding diagram: When an INSERT, UPDATE, or DELETE statement is run on the Aurora orders table, the PostgreSQL trigger function invokes the Lambda function asynchronously for each row, after it’s committed. Every function invocation receives the operation code (TG_OP), and—as applicable—the new row (NEW) and the old row (OLD) as payload. The Lambda function parses the payload, converts XML to JSON, and performs the DynamoDB PutItem action in case of INSERT or UPDATE and the DeleteItem action in case of DELETE. If an INSERT, UPDATE or DELETE event fails all processing attempts or expires without being processed, it’s stored in the SQS dead-letter queue for further processing. The source postgres.orders table stores generated order data combining XML with relational attributes (see the following example of a table row with id = 1). You can choose which columns or XML attributes get offloaded to DynamoDB by modifying the Lambda function code. In this solution, the whole table row, including XML, gets offloaded to simplify querying and enforce data integrity (see the following example of a corresponding DynamoDB item with id = 1). Prerequisites Before deploying this solution, make sure that you have access to an AWS account with permissions to deploy the AWS services used in this post through AWS CloudFormation. Costs are associated with using these resources. See AWS Pricing for details. To minimize costs, I demonstrate how to clean up the AWS resources at the end of this post. Deploy the solution To deploy the solution with CloudFormation, complete the following steps: Choose Launch Stack. By default, the solution deploys to the AWS Region, us-east-2, but you can change this Region. Make sure you deploy to a Region where Aurora PostgreSQL is available. For AuroraAdminPassword, enter an admin account password for your Aurora cluster, keeping the defaults for other parameters. Acknowledge that CloudFormation might create AWS Identity and Access Management (IAM) resources. Choose Create stack. The deployment takes around 20 minutes. When the deployment has completed, note the provisioned stack’s outputs on the Outputs The outputs are as follows: LambdaConsoleLink and DynamoDBTableConsoleLink contain AWS Management Console links to the provisioned Lambda function and DynamoDB table, respectively. You can follow these links to explore the function’s code and review the DynamoDB table items. EC2InstanceConnectURI contains a deep link to connect to the pgAdmin EC2 instance using SSH via EC2 Instance Connect. The EC2 instance has PostgreSQL tooling installed; you can log in and use psql to run queries from the command line. AuroraPrivateEndpointAddress and AuroraPrivateEndpointPort contain the writer endpoint address and port for the Aurora cluster. This is a private endpoint only accessible from the pgAdmin EC2 instance. pgAdminURL is the internet-facing link to access the pgAdmin instance. Test the solution To test the solution, complete the following steps: Open the DynamoDB table by using the DynamoDBTableConsoleLink link from the stack outputs. Some data is already in the DynamoDB table because we ran INSERT operations on the Aurora database instance as part of bootstrapping. Open a new browser tab and navigate to the pgAdminURL link to access the pgAdmin instance. The Aurora database instance should already be registered. To connect to the Aurora database instance, expand the Servers tree and enter the AuroraAdminPassword you used to create the stack. Choose the postgres database and on the Tools menu, and then choose Query Tool to start a SQL session. Run the following INSERT, UPDATE, and DELETE statements one by one, and return to the DynamoDB browser tab to observe how changes in the Aurora postgres.orders table are reflected in the DynamoDB table. -- UPDATE example UPDATE orders SET order_status = 'pending' WHERE id < 5; -- DELETE example DELETE FROM orders WHERE id > 10; -- INSERT example INSERT INTO orders (order_status, order_data) VALUES ('malformed_order', ' error retrieving kindle id '); The resulting set of items in the DynamoDB table reflects the changes in the postgres.orders table. You can further explore the two triggers (sync_insert_update_delete_to_dynamodb and sync_truncate_to_dynamodb) and the trigger function sync_to_dynamodb() that makes calls to the Lambda function. In the pgAdmin browser tab, on the Tools menu, choose Search Objects. Search for sync. Choose (double-click) a search result to reveal it in the pgAdmin object hierarchy. To review the underlying statements, choose an object (right-click) and choose CREATE Script. Security of the solution The solution incorporates the following AWS security best practices: Encryption at rest – The Aurora cluster is encrypted by using an AWS KMS managed customer master key (CMK). Security – AWS Secrets Manager is used to store and manage Aurora admin account credentials. Identity and access management – The least privilege principle is followed when creating IAM policies. Network isolation – For additional network access control, the Aurora cluster is deployed to two private subnets with a security group permitting traffic only from the pgAdmin EC2 instance. To further harden this solution, you can introduce VPC endpoints to ensure private connectivity between the Lambda function, Amazon SQS, and DynamoDB. Reliability of the solution Aurora is designed to be reliable, durable, and fault tolerant. The Aurora cluster in this solution is deployed across two Availability Zones, with the primary instance in Availability Zone 1 and a replica in Availability Zone 2. In case of a failure event, the replica is promoted to the primary, the cluster DNS endpoint continues to serve connection requests, and the calls to the Lambda function continue in Availability Zone 2 (refer to the solution architecture earlier in this post). Aurora asynchronous calls to Lambda retry on errors, and when a function returns an error after running, Lambda by default retries two more times by using exponential backoff. With the maximum retry attempts parameter, you can configure the maximum number of retries between 0 and 2. Moreover, if a Lambda function returns an error before running (for example, due to lack of available concurrency), Lambda by default keeps retrying for up to 6 hours. With the maximum event age parameter, you can configure this duration between 60 seconds and 6 hours. When the maximum retry attempts or the maximum event age is reached, an event is discarded and persisted in the SQS dead-letter queue for reprocessing. It’s important to ensure that the code of the Lambda function is idempotent. For example, you can use optimistic locking with version number in DynamoDB by ensuring the OLD value matches the document stored in DynamoDB and rejecting the modification otherwise. Reprocessing of the SQS dead-letter queue is beyond the scope of this solution, and its implementation varies between use cases. It’s important to ensure that the reprocessing logic performs timestamp or version checks to prevent a newer item in DynamoDB from being overwritten by an older item from the SQS dead-letter queue. This solution preserves the atomicity of a SQL transaction as a single, all-or-nothing operation. Lambda calls are deferred until a SQL transaction has been successfully committed by using INITIALLY DEFERRED PostgreSQL triggers. Performance efficiency of the solution Aurora integration with Lambda can introduce performance overhead. The amount of overhead depends on the complexity of the PostgreSQL trigger function and the Lambda function itself, and I recommend establishing a performance baseline by benchmarking your workload with Lambda integration disabled. Upon reenabling the Lambda integration, use Amazon CloudWatch and PostgreSQL Statistics Collector to analyze the following: Aurora CPU and memory metrics, and resize the Aurora cluster accordingly Lambda concurrency metrics, requesting a quota increase if you require more than 1,000 concurrent requests Lambda duration and success rate metrics, allocating more memory if necessary DynamoDB metrics to ensure no throttling is taking place on the DynamoDB side PostgreSQL sustained and peak throughput in rows or transactions per second If your Aurora workload is bursty, consider Lambda provisioned concurrency to avoid throttling To illustrate the performance impact of enabling Lambda integration, I provisioned two identical environments in us-east-2 with the following parameters: AuroraDBInstanceClass – db.r5.xlarge pgAdminEC2InstanceType – m5.xlarge AuroraEngineVersion – 12.4 Both environments ran a simulation of a write-heavy workload with 100 INSERT, 20 SELECT, 200 UPDATE, and 20 DELETE threads running queries in a tight loop on the Aurora postgres.orders table. One of the environments had Lambda integration disabled. After 24 hours of stress testing, I collected the metrics using CloudWatch metrics, PostgreSQL Statistics Collector, and Amazon RDS Performance Insights. From an Aurora throughput perspective, enabling Lambda integration on the postgres.orders table reduces the peak read and write throughput to 69% of the baseline measurement (see rows 1 and 2 in the following table). # Throughput measurement INSERT/sec UPDATE/sec DELETE/sec SELECT/sec % of baseline throughput 1 db.r5.xlarge without Lambda integration 772 1,472 159 10,084 100% (baseline) 2 db.r5.xlarge with Lambda integration 576 887 99 7,032 69% 3 db.r5.2xlarge with Lambda integration 729 1,443 152 10,513 103% 4 db.r6g.xlarge with Lambda integration 641 1,148 128 8,203 81% To fully compensate for the reduction in throughput, one option is to double the vCPU count and memory size and change to the higher db.r5.2xlarge Aurora instance class at an increase in on-demand cost (row 3 in the preceding table). Alternatively, you can choose to retain the vCPU count and memory size, and move to the AWS Graviton2 processor-based db.r6g.xlarge Aurora instance class. Because of Graviton’s better price/performance for Aurora, the peak read and write throughput is at 81% of the baseline measurement (row 4 in the preceding table), at a 10% reduction in on-demand cost in us-east-2. As shown in the following graph, the DynamoDB table consumed between 2,630 and 2,855 write capacity units, and Lambda concurrency fluctuated between 259 and 292. No throttling was detected. You can reproduce these results by running a load generator script located in /tmp/perf.py on the pgAdmin EC2 instance. # Lambda integration on /tmp/perf.py 100 20 200 20 true # Lambda integration off /tmp/perf.py 100 20 200 20 false Additional considerations This solution doesn’t cover the initial population of DynamoDB with XML data from Aurora. To achieve this, you can use AWS Database Migration Service (AWS DMS) or CREATE TABLE AS. Be aware of certain service limits before using this solution. The Lambda payload limit is 256 KB for asynchronous invocation, and the DynamoDB maximum item size limit is 400 KB. If your Aurora table stores more than 256 KB of XML data per row, an alternative approach is to use Amazon DocumentDB (with MongoDB compatibility), which can store up to 16 MB per document, or offload XML to Amazon Simple Storage Service (Amazon S3). Clean up To avoid incurring future charges, delete the CloudFormation stack. In the CloudFormation console, change the Region if necessary, choose the stack, and then choose Delete. It can take up to 20 minutes for the clean up to complete. Summary In this post, I proposed a modernization approach for legacy applications that make extensive use of XML in a relational database. Heavy use of nonrelational objects in a relational database can lead to scalability issues, orphaned records, and data quality challenges. By introducing DynamoDB alongside Aurora via native Lambda integration, you can gradually rearchitect legacy applications to query DynamoDB following the Command-Query Responsibility Segregation pattern. When your applications are ready to cut over reads and writes to DynamoDB, you can remove XML from Aurora tables entirely. You can extend this approach to offload JSON, YAML, and other nonrelational object types. As next steps, I recommend reviewing the Lambda function code and exploring the multitude of ways Lambda can be invoked from Aurora, such as synchronously; before, after, and instead of a row being committed; per SQL statement; or per row. About the author Igor is an AWS enterprise solutions architect, and he works closely with Australia’s largest financial services organizations. Prior to AWS, Igor held solution architecture and engineering roles with tier-1 consultancies and software vendors. Igor is passionate about all things data and modern software engineering. Outside of work, he enjoys writing and performing music, a good audiobook, or a jog, often combining the latter two. https://aws.amazon.com/blogs/database/options-for-legacy-application-modernization-with-amazon-aurora-and-amazon-dynamodb/
0 notes
Text
Software Engineer – Machine Learning Platform (E3) – Remote from USA
At Applied Materials, we are building the next generation fab productivity solutions using Artificial Intelligence and Machine Learning.
Our AI/ML team is looking for a Full Stack Engineer who will be responsible for expanding and optimizing APF data and data pipeline architecture, as well as optimizing data flow and collection for cross functional teams.
The Full Stack Engineer will support our data scientists and machine learning engineers on data and machine learning initiatives and will ensure optimal data delivery architecture is consistent throughout ongoing projects.
They must be self-directed and comfortable supporting the data needs of multiple teams, systems and products.
The right candidate will be excited by the prospect of optimizing or even re-designing our companys data architecture to support our next generation of products and data initiatives.This position can be located anywhere in USA.**Responsibilities**+ Create and maintain optimal data pipeline architecture+ Assemble large, complex data sets that meet functional / non-functional business requirements.+ Build the infrastructure required for optimal extraction, transformation, and loading of data from a wide variety of data sources using SQL and big data technologies+ Build analytics tools that utilize the data pipeline to provide actionable insights into customer acquisition, operational efficiency and other key business performance metrics.+ Work with stakeholders including the Product management, Data and Design teams to assist with data-related technical issues and support their data infrastructure needs.+ Create data tools for analytics, data scientist and machine learning team members that assist them in building and optimizing our product into an innovative industry leader.+ Work with data and analytics experts to strive for greater functionality in our data systems.**Qualifications**+ Advanced working knowledge of object-oriented/object function scripting languages: Python, Java, C++, Scala, etc.+ Advanced working SQL knowledge and experience working with relational databases, query authoring (SQL) as well as working familiarity with a variety of databases.+ Experience building and optimizing big data data pipelines, architectures and data sets.+ Experience performing root cause analysis on internal and external data and processes to answer specific business questions and identify opportunities for improvement.+ Strong analytic skills related to working with unstructured datasets.+ Build processes supporting data transformation, data structures, metadata, dependency and workload management.+ A successful history of manipulating, processing and extracting value from large disconnected datasets.+ Working knowledge of message queuing, stream processing, and highly scalable big data data stores.+ Strong project management and organizational skills.+ Experience with machine learning related libraries, such as scikit-learn, pandas, TensorFlow, Keras, etc.+ Experience supporting and working with cross-functional teams in a dynamic environment.+ Experience with big data tools: Hadoop, Spark, Kafka, etc.+ Experience with relational SQL and NoSQL databases, including Postgres, Cassandra, MongoDB, ClickHouse+ Experience with data pipeline and workflow management tools: Azkaban, Luigi, Airflow, etc.+ Experience with cloud services: such as EC2, EMR, RDS, Redshift, Azure services+ Experience with stream-processing systems: Storm, Spark-Streaming, etc.**Education/Experience**+ Candidate with 5+ years of experience in a Full Stack Engineer, Data Engineer, Data Science Developer or Machine Learning Engineer role, who has attained a Graduate degree in Computer Science, Statistics, Informatics, Information Systems, Engineering or another quantitative field.#LI**Qualifications****Education:**Bachelor’s Degree**Skills****Certifications:****Languages:****Years of Experience:**4 – 7 Years**Work Experience:****Additional Information****Travel:**Yes, 10% of the Time**Relocation Eligible:**NoApplied Materials is committed to diversity in its workforce including Equal Employment Opportunity for Minorities, Females, Protected Veterans and Individuals with Disabilities.
The post Software Engineer – Machine Learning Platform (E3) – Remote from USA first appeared on Remote Careers.
from Remote Careers https://ift.tt/3nVDmef via IFTTT
0 notes
Text
Serverless SQL Database - Aurora
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/aurora-serverless-intro/ - Cloudemind.com
Serverless SQL Database - Aurora
Như các bạn đã biết Aurora là AWS fully managed service đưa ra thuộc nhóm dịch vụ RDS (Relational Database Service), hay còn gọi là dịch vụ cơ sở dữ liệu có quan hệ (khóa chính, khóa ngoại). Aurora là loại hình dịch vụ mà mình yêu thích nhất, thú thật ban đầu là vì cái tên, cách mà AWS đặt tên các loại hình dịch vụ của mình rất dễ thương và personalize.
Aurora dịch ra tiếng Việt có nghĩa là ánh bình minh buổi sớm hay còn có thể hiểu là Nữ thần Rạng Đông.
Refresher: RDS viết tắt của Relational Database Service. Hiện tại Amazon RDS hỗ trợ 06 loại engines: MySQL, MSSQL, PostgreSQL, Oracle, MariaDB, và Aurora.
Riêng với Aurora hỗ trợ hai loại engines: Aurora for MySQL, và Aurora for Postgres.
Về phía sử dụng, khách hàng có rất nhiều option chuyển đổi CSDL từ on-prem lên AWS cloud như sau:
Cách 01: Khách hàng chuyển DB theo dạng lift and shift bộ combo EC2 và EBS. Đây là cách KH vẫn cài đặt OS, DB service và chuyển đổi dữ liệu lên AWS. Option này giúp bạn có độ tùy chỉnh cao nhưng bù lại bạn cần manage về mặt hạ tầng nhiều hơn.
Cách 02: Replatform chuyển đổi CSDL ở on-premise lên AWS Cloud thông qua RDS MSSQL, MySQL, PostgreSQL, Oracle. Riêng Oracle có hai loại là BYOL (Bring Your Own License) và licensed instance. Chuyển đổi CSDL lên cloud ở mức độ chỉn chu hơn, tận dụng sức mạnh AWS RDS, auto scaling, multi-az…
Cách 03: Chuyển đổi CSDL lên Native Cloud Service như Aurora. Tận dụng sức mạnh triệt để của Cloud Native Service. Bù lại ứng dụng có thể phải xem xét refactor, cần xem xét sự tương thích giữa App và DB.
Theo kinh nghiệm cá nhân những bạn làm product mới, nên xem xét sử dụng các dịch vụ native của AWS để tận dụng sức mạnh của cloud về khả năng scalability, elasticity và easy of use. Aurora là một trong những dịch vụ mình thấy rất đáng để dùng. Strong Recommended!
Samsung cũng đã migrate hơn 1 tỷ người dùng của họ lên AWS và CSDL họ dùng chính là Aurora. Và hiệu quả giúp Samsung giảm 44% chi phí Database hàng tháng.
Samsung AWS Migration Use Case – 1 Billion Users – https://aws.amazon.com/solutions/case-studies/samsung-migrates-off-oracle-to-amazon-aurora/
Lưu ý: Không phải loại engine hay version nào cũng hỗ trợ Serverless, nên nếu bạn chọn engine Aurora (Postgres hay MySQL) mà không thấy option lựa chọn Serverless thì bạn chọn version khác nhé.
Ví dụ hiện tại phiên bản mới nhất hỗ trợ Serverless là Aurora PostgreSQL version 10.7
Ý tưởng của Aurora Serverless là Pay as you Go, có nghĩa là CSDL có thể scale theo ACU (Aurora Capacity Unit) là tỷ lệ giữa CPU và RAM. Bình thường các bạn khởi tạo Aurora Standard bạn sẽ chọn instance Type (Ví dụ: T3), còn ở đây bạn khởi tạo min và max của ACU.
Hiện tại Aurora Serverless ACU tối thiểu là 02 (Tương đương 04 GB RAM, cấu hình của t3.medium) và tối đa là 384 (tương đương 768GB RAM). Khi khai báo này thì ứng dụng có khả năng scale tự động giãn nở (elasticity) trong khoảng này, khi thấp tải hệ thống consume ít ACU, khi cao tải sẽ cần cao ACU hơn.
Về mặt tính tiền, Aurora Serverless sẽ có 03 tiêu chí: storage, capacity và IO. Điều này cũng rất hợp lý. Căn bản về mặt dev hay phát triển ứng dụng rất đơn giản trong khi phát triển hay cả production. Lợi ích Aurora Serverless có thể gom thành một số ý chính sau:
Đơn giản Simpler – Đỡ phải quản lý về nhiều instances, hay năng lực xử lý capacity của DB.
2. Mở rộng Scalability – DB Có thể giãn nở cả CPU và RAM không ảnh hưởng đến gián đoạn. Điều này là tuyệt vời, bạn không phải dự đoán năng lực cần phải cấp phát cho DB nữa.
3. Cost effective – thay vì bạn phải provision cả một con DB to đùng, bạn có thể provision nhỏ thôi, và tự động nở theo tải sử dụng. Nghe rất xịn xò phải không?
4. HA Storage – Lưu trữ có tính sẵn sàng cao, hệ thống hiện tại Aurora hỗ trợ 06 bản replications để chống data loss.
Đây là một cải tiến rất xịn xò cho các nhà phát triển và cả doanh nghiệp khi sử dụng. Một số use cases phổ biến sử dụng Aurora Serverless đó là:
Ứng dụng có truy xuất đột biến và tải không ổn định (lúc truy xuất nhiều, lúc lại ít).
Ứng dụng mới phát triển mà bạn chưa thể tiên đoán sizing.
Phát triển cho môi trường Dev Test biến thiên về mặt workload. Thường nếu phát triển cho môi trường dev hệ thống sẽ không sử dụng vào ngoài giờ làm việc chẳng hạn, Aurora Serverless có thể tự động shutdown khi nó không được sử dụng.
Multi TenantTenant applications khi triển khai ứng dụng dạng SaaS. Aurora Serverless có thể hỗ trợ quản lý DB Capacity từng ứng dụng truy xuất. Aurora Serverless có thể quản lý từng db capacity.
Tiết kiệm chi phí, vận hành giản đơn.
Các bạn có dùng Aurora Serverless chia sẻ kinh nghiệm với nhau nhé ^^
Thân,
Kevin
Xem thêm: https://cloudemind.com/aurora-serverless-intro/
0 notes
Text
#youtube#video#codeonedigest#microservices#aws#microservice#springboot#spring boot#aws ec2 service#aws ec2 instance#aws ec2 server#ec2#aws ec2
0 notes
Text
Как упростить работу с DWH и Data Lake: DBT + Apache Spark в AWS

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера рассмотрим кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS S3.
ETL/ELT В ЭПОХУ BIG DATA: ЧТО ТАКОЕ DATA BUILD TOOL И КАК ЭТО РАБОТАЕТ
ETL-процессы являются неотъемлемой частью построения корпоративного хранилища или озера данных (Data Lake). Из всех этапов Extract – Transform – Load, именно преобразования являются наиболее нетривиальными, а потому трудозатратными операциями, т.к. здесь с извлеченными данными выполняется целый ряд действий: преобразование структуры; агрегирование; перевод значений; создание новых данных; очистка. Для автоматизации всех этих работ используются специальные инструменты, например, Data Build Tool (DBT). DBT обеспечивает общую основу для аналитиков и дата-инженеров, позволяя строить конвейеры преобразования данных со встроенной CI/CD-поддержкой и обеспечением качества (data quality) [1]. При том, что DBT не выгружает данные из источников, он предоставляет широкие возможности по работе с теми данными, которые уже загружены в хранилище, компилируя код в SQL-запросы. Так можно организовать различные задачи преобразования данных в проекты, чтобы запланировать их для запуска в автоматизированном и структурированном порядке. DBT-проект состоит из директорий и файлов следующих типов: файл модели (.sql) — единица трансформации в виде SELECT-запроса; файл конфигурации (.yml) — параметры, настройки, тесты и документация. Работа DBT-фреймворка устроена так [2]: пользователь создает код моделей в среде разработки; модели запускаются через CLI-интерфейс; DBT компилирует код моделей в SQL-запросы, абстрагируя материализацию в команды CREATE, INSERT, UPDATE, DELETE ALTER, GRANT и пр.; каждая SQL-модель включает SELECT-запрос, определяющий результат – итоговый набор данных; код модели — это смесь SQL и языка шаблонов Jinja; скомпилированный SQL-код исполняется в хранилище в виде графа задач или дерева зависимостей модели, DAG (Directed Acyclic Graph – направленный ациклический граф); DBT строит граф по конфигурациям всех моделей проекта, с учетом их ссылок (ref) друг на друга, чтобы запускать модели в нужной последовательности и параллельно формировать витрины данных. Кроме формирования самих моделей, DBT позволяет протестировать предположения о результирующем наборе данных, включая проверку уникальность, ссылочной целостности, соответствия списку допустимых значений и Not Null. Также возможно добавление пользовательских тестов (custom data tests) в виде SQL-запросов, например, для отслеживания % отклонения фактических показателей от заданных за день, неделю, месяц и прочие периоды. Это позволяет найти в витринах данных нежелательные отклонения и ошибки.Благодаря адаптерам, DBT поддерживает работу со следующими базами и хранилищами данных: Postgres, Redshift, BigQuery, Snowflake, Presto, Apache Spark SQL, Databrics, MS SQL Serves, ClickHouse, Dremio, Oracle Database, MS Azure Synapse DW. Также можно создать собственный адаптер для интеграции с другим хранилищем, используя стратегию материализации. Этот подход сохранения результирующего набора данных модели в хранилище основан на следующих понятиях [2]: Table — физическая таблица в хранилище; View — представление, виртуальная таблица в хранилище. Кроме того, DBT предоставляет механизмы для добавления, версионирования и распространения метаданных и комментариев на уровне моделей и даже отдельных атрибутов. А макросы в виде набора конструкций и выражений, которые могут быть вызваны как функции внутри моделей, позволяют повторно использовать SQL-код между моделями и проектами. Встроенный в DBT менеджер пакетов позволяет пользователям публиковать и повторно использовать отдельные модули и макросы [2].

В качестве практического примера использования DBT рассмотрим кейс со Spark SQL, развернутом в облачных сервисах AWS.
АГРЕГАЦИЯ ЖУРНАЛОВ AWS CLOUDTRAIL В SPARK SQL
Предположим, требуется считать логи AWS CloudTrail, извлекая из них некоторые поля данных, чтобы создать новую таблицу и агрегировать некоторые данные для простого отчета. Источником является существующая таблица AWS Glue, созданная поверх журналов AWS CloudTrail, хранящихся в S3. Эти файлы имеют формат JSON, причем каждый файл содержит один массив или записи CloudTrail. Таблица Spark SQL на самом деле является таблицей Glue, которая представляет собой схему, помещенную поверх набора файлов в S3. Альтернативой каталога хранения метаданных Hive Catalog выступает Glue Catalog – реализация от AWS с S3 вместо HDFS. В качестве кластера Hadoop выступает AWS EMR с установленным Apache Spark под управлением. DBT, установленный на небольшом экземпляре AWS EC2 за пределами кластера EMR, будет использоваться для выполнения последовательных преобразований, создания и заполнения данных в таблицах. Подробные примеры реализации SQL-запросов представлены в источнике [1], а здесь мы перечислим некоторые важные особенности интеграции DBT с Apache Spark, развернутом в AWS: для подключения DBT к Spark с помощью модуля dbt-spark требуется сервер Spark Thrift; DBT и dbt-spark не накладывают ограничений на преобразование данных, позволяя использовать в моделях Data Build Tool любые SQL-запросы, поддерживаемые Spark; стратегия материализации DBT поддерживает базовые оптимизации Spark SQL, в частности, разбиение на разделы/сегменты Hive и разделение вывода Spark с помощью Spark SQL hints; доступ к порту 10001 сервера Thrift позволяет получить доступ ко всем авторизациям Spark SQL в AWS Обойти эту уязвимость можно, ограничив доступ к порту 10001 в кластере EMR только сервером, на котором запущен DBT. Самый простой вариант – ручная настройка с явным указанием IP-адреса главного узла. В production для EMR рекомендуется создать запись Route53. при невысокой загрузке можно запускать DBT в управляемом сервисе ор��естрации контейнеров Amazon Elastic Container Service (ECS), отключив отключить кластер EMR, чтобы сократить расходы на аналитику больших данных.

Узнайте больше про практическое применение Apache Spark для разработки распределенных приложений аналитики больших данных и построения эффективных конвейеров обработки информации на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: Основы Apache Spark для разработчиков Анализ данных с Apache Spark Потоковая обработка в Apache Spark Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop Data Pipeline на Apache Airflow и Apache Hadoop Источники 1. https://medium.com/slalom-australia/aggregate-cloudtrail-logs-with-dbt-and-spark-d3196248d2d4 2. https://habr.com/ru/company/otus/blog/501380/ Read the full article
0 notes