#preprints
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Text
MIT libraries are thriving without Elsevier

I'm coming to BURNING MAN! On TUESDAY (Aug 27) at 1PM, I'm giving a talk called "DISENSHITTIFY OR DIE!" at PALENQUE NORTE (7&E). On WEDNESDAY (Aug 28) at NOON, I'm doing a "Talking Caterpillar" Q&A at LIMINAL LABS (830&C).

Once you learn about the "collective action problem," you start seeing it everywhere. Democrats – including elected officials – all wanted Biden to step down, but none of them wanted to be the first one to take a firm stand, so for months, his campaign limped on: a collective action problem.
Patent trolls use bullshit patents to shake down small businesses, demanding "license fees" that are high, but much lower than the cost of challenging the patent and getting it revoked. Collectively, it would be much cheaper for all the victims to band together and hire a fancy law firm to invalidate the patent, but individually, it makes sense for them all to pay. A collective action problem:
https://locusmag.com/2013/11/cory-doctorow-collective-action/
Musicians get royally screwed by Spotify. Collectively, it would make sense for all of them to boycott the platform, which would bring it to its knees and either make it pay more or put it out of business. Individually, any musician who pulls out of Spotify disappears from the horizon of most music fans, so they all hang in – a collective action problem:
https://pluralistic.net/2024/06/21/off-the-menu/#universally-loathed
Same goes for the businesses that get fucked out of 30% of their app revenues by Apple and Google's mobile business. Without all those apps, Apple and Google wouldn't have a business, but any single app that pulls out commits commercial suicide, so they all hang in there, paying a 30% vig:
https://pluralistic.net/2024/08/15/private-law/#thirty-percent-vig
That's also the case with Amazon sellers, who get rooked for 45-51 cents out of every dollar in platform junk fees, and whose prize for succeeding despite this is to have their product cloned by Amazon, which underprices them because it doesn't have to pay a 51% rake on every sale. Without third-party sellers there'd be no Amazon, but it's impossible to get millions of sellers to all pull out at once, so the Bezos crime family scoops up half of the ecommerce economy in bullshit fees:
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens
This is why one definition of "corruption" is a system with "concentrated gains and diffuse losses." The company that dumps toxic waste in your water supply reaps all the profits of externalizing its waste disposal costs. The people it poisons each bear a fraction of the cost of being poisoned. The environmental criminal has a fat warchest of ill-gotten gains to use to bribe officials and pay fancy lawyers to defend it in court. Its victims are each struggling with the health effects of the crimes, and even without that, they can't possibly match the polluter's resources. Eventually, the polluter spends enough money to convince the Supreme Court to overturn "Chevron deference" and makes it effectively impossible to win the right to clean water and air (or a planet that's not on fire):
https://www.cfr.org/expert-brief/us-supreme-courts-chevron-deference-ruling-will-disrupt-climate-policy
Any time you encounter a shitty, outrageous racket that's stable over long timescales, chances are you're looking at a collective action problem. Certainly, that's the underlying pathology that preserves the scholarly publishing scam, which is one of the most grotesque, wasteful, disgusting frauds in our modern world (and that's saying something, because the field is crowded with many contenders).
Here's how the scholarly publishing scam works: academics do original scholarly research, funded by a mix of private grants, public funding, funding from their universities and other institutions, and private funds. These academics write up their funding and send it to a scholarly journal, usually one that's owned by a small number of firms that formed a scholarly publishing cartel by buying all the smaller publishers in a string of anticompetitive acquisitions. Then, other scholars review the submission, for free. More unpaid scholars do the work of editing the paper. The paper's author is sent a non-negotiable contract that requires them to permanently assign their copyright to the journal, again, for free. Finally, the paper is published, and the institution that paid the researcher to do the original research has to pay again – sometimes tens of thousands of dollars per year! – for the journal in which it appears.
The academic publishing cartel insists that the millions it extracts from academic institutions and the billions it reaps in profit are all in service to serving as neutral, rigorous gatekeepers who ensure that only the best scholarship makes it into print. This is flatly untrue. The "editorial process" the academic publishers take credit for is virtually nonexistent: almost everything they publish is virtually unchanged from the final submission format. They're not even typesetting the paper:
https://link.springer.com/article/10.1007/s00799-018-0234-1
The vetting process for peer-review is a joke. Literally: an Australian academic managed to get his dog appointed to the editorial boards of seven journals:
https://www.atlasobscura.com/articles/olivia-doll-predatory-journals
Far from guarding scientific publishing from scams and nonsense, the major journal publishers have stood up entire divisions devoted to pay-to-publish junk science. Elsevier – the largest scholarly publisher – operated a business unit that offered to publish fake journals full of unreveiwed "advertorial" papers written by pharma companies, packaged to look like a real journal:
https://web.archive.org/web/20090504075453/http://blog.bioethics.net/2009/05/merck-makes-phony-peerreview-journal/
Naturally, academics and their institutions hate this system. Not only is it purely parasitic on their labor, it also serves as a massive brake on scholarly progress, by excluding independent researchers, academics at small institutions, and scholars living in the global south from accessing the work of their peers. The publishers enforce this exclusion without mercy or proportion. Take Diego Gomez, a Colombian Masters candidate who faced eight years in prison for accessing a single paywalled academic paper:
https://www.eff.org/deeplinks/2014/07/colombian-student-faces-prison-charges-sharing-academic-article-online
And of course, there's Aaron Swartz, the young activist and Harvard-affiliated computer scientist who was hounded to death after he accessed – but did not publish – papers from MIT's JSTOR library. Aaron had permission to access these papers, but JSTOR, MIT, and the prosecutors Stephen Heymann and Carmen Ortiz argued that because he used a small computer program to access the papers (rather than clicking on each link by hand) he had committed 13 felonies. They threatened him with more than 30 years in prison, and drew out the proceedings until Aaron was out of funds. Aaron hanged himself in 2013:
https://en.wikipedia.org/wiki/Aaron_Swartz
Academics know all this terrible stuff is going on, but they are trapped in a collective action problem. For an academic to advance in their field, they have to publish, and they have to get their work cited. Academics all try to publish in the big prestige journals – which also come with the highest price-tag for their institutions – because those are the journals other academics read, which means that getting published is top journal increases the likelihood that another academic will find and cite your work.
If academics could all agree to prioritize other journals for reading, then they could also prioritize other journals for submissions. If they could all prioritize other journals for submissions, they could all prioritize other journals for reading. Instead, they all hold one another hostage, through a wicked collective action problem that holds back science, starves their institutions of funding, and puts their colleagues at risk of imprisonment.
Despite this structural barrier, academics have fought tirelessly to escape the event horizon of scholarly publishing's monopoly black hole. They avidly supported "open access" publishers (most notably PLoS), and while these publishers carved out pockets for free-to-access, high quality work, the scholarly publishing cartel struck back with package deals that bundled their predatory "open access" journals in with their traditional journals. Academics had to pay twice for these journals: first, their institutions paid for the package that included them, then the scholars had to pay open access submission fees meant to cover the costs of editing, formatting, etc – all that stuff that basically doesn't exist.
Academics started putting "preprints" of their work on the web, and for a while, it looked like the big preprint archive sites could mount a credible challenge to the scholarly publishing cartel. So the cartel members bought the preprint sites, as when Elsevier bought out SSRN:
https://www.techdirt.com/2016/05/17/disappointing-elsevier-buys-open-access-academic-pre-publisher-ssrn/
Academics were elated in 2011, when Alexandra Elbakyan founded Sci-Hub, a shadow library that aims to make the entire corpus of scholarly work available without barrier, fear or favor:
https://sci-hub.ru/alexandra
Sci-Hub neutralized much of the collective action trap: once an article was available on Sci-Hub, it became much easier for other scholars to locate and cite, which reduced the case for paying for, or publishing in, the cartel's journals:
https://arxiv.org/pdf/2006.14979
The scholarly publishing cartel fought back viciously, suing Elbakyan and Sci-Hub for tens of millions of dollars. Elsevier targeted prepress sites like academia.edu with copyright threats, ordering them to remove scholarly papers that linked to Sci-Hub:
https://svpow.com/2013/12/06/elsevier-is-taking-down-papers-from-academia-edu/
This was extremely (if darkly) funny, because Elsevier's own publications are full of citations to Sci-Hub:
https://eve.gd/2019/08/03/elsevier-threatens-others-for-linking-to-sci-hub-but-does-it-itself/
Meanwhile, scholars kept the pressure up. Tens of thousands of scholars pledged to stop submitting their work to Elsevier:
http://thecostofknowledge.com/
Academics at the very tops of their fields publicly resigned from the editorial board of leading Elsevier journals, and published editorials calling the Elsevier model unethical:
https://www.theguardian.com/science/blog/2012/may/16/system-profit-access-research
And the New Scientist called the racket "indefensible," decrying the it as an industry that made restricting access to knowledge "more profitable than oil":
https://www.newscientist.com/article/mg24032052-900-time-to-break-academic-publishings-stranglehold-on-research/
But the real progress came when academics convinced their institutions, rather than one another, to do something about these predator publishers. First came funders, private and public, who announced that they would only fund open access work:
https://www.nature.com/articles/d41586-018-06178-7
Winning over major funders cleared the way for open access advocates worked both the supply-side and the buy-side. In 2019, the entire University of California system announced it would be cutting all of its Elsevier subscriptions:
https://www.science.org/content/article/university-california-boycotts-publishing-giant-elsevier-over-journal-costs-and-open
Emboldened by the UC system's principled action, MIT followed suit in 2020, announcing that it would no longer send $2m every year to Elsevier:
https://pluralistic.net/2020/06/12/digital-feudalism/#nerdfight
It's been four years since MIT's decision to boycott Elsevier, and things are going great. The open access consortium SPARC just published a stocktaking of MIT libraries without Elsevier:
https://sparcopen.org/our-work/big-deal-knowledge-base/unbundling-profiles/mit-libraries/
How are MIT's academics getting by without Elsevier in the stacks? Just fine. If someone at MIT needs access to an Elsevier paper, they can usually access it by asking the researchers to email it to them, or by downloading it from the researcher's site or a prepress archive. When that fails, there's interlibrary loan, whereby other libraries will send articles to MIT's libraries within a day or two. For more pressing needs, the library buys access to individual papers through an on-demand service.
This is how things were predicted to go. The libraries used their own circulation data and the webservice Unsub to figure out what they were likely to lose by dropping Elsevier – it wasn't much!
https://unsub.org/
The MIT story shows how to break a collective action problem – through collective action! Individual scholarly boycotts did little to hurt Elsevier. Large-scale organized boycotts raised awareness, but Elsevier trundled on. Sci-Hub scared the shit out of Elsevier and raised awareness even further, but Elsevier had untold millions to spend on a campaign of legal terror against Sci-Hub and Elbakyan. But all of that, combined with high-profile defections, made it impossible for the big institutions to ignore the issue, and the funders joined the fight. Once the funders were on-side, the academic institutions could be dragged into the fight, too.
Now, Elsevier – and the cartel – is in serious danger. Automated tools – like the Authors Alliance termination of transfer tool – lets academics get the copyright to their papers back from the big journals so they can make them open access:
https://pluralistic.net/2021/09/26/take-it-back/
Unimaginably vast indices of all scholarly publishing serve as important adjuncts to direct access shadow libraries like Sci-Hub:
https://pluralistic.net/2021/10/28/clintons-ghost/#cornucopia-concordance
Collective action problems are never easy to solve, but they're impossible to address through atomized, individual action. It's only when we act as a collective that we can defeat the corruption – the concentrated gains and diffuse losses – that allow greedy, unscrupulous corporations to steal from us, wreck our lives and even imprison us.
Community voting for SXSW is live! If you wanna hear RIDA QADRI and me talk about how GIG WORKERS can DISENSHITTIFY their jobs with INTEROPERABILITY, VOTE FOR THIS ONE!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/08/16/the-public-sphere/#not-the-elsevier
#pluralistic#libraries#glam#elsevier#monopolies#antitrust#scams#open access#scholarship#education#lis#oa#publishing#scholarly publishing#sci-hub#preprints#interlibrary loan#aaron swartz#aaronsw#collective action problems
632 notes
·
View notes
Text
Chirping With Glee from The Shimmering Voyage Vol. 3 Yijun Jiang, HOYO-MiX
#genshin#genshin impact#the shimmering voyage vol. 3#overworld#veluriyam mirage#preprints#pavilion of hermits#plays in preprints and the pavilion of hermits#yijun jiang
8 notes
·
View notes
Text
La fuerza muscular.
Nuestro presidente, Miguel Rodal, ha realizado un estudio sobre la fuerza muscular, la cual ha sido recomendada para su pre-publicación por una de las revistas científicas más prestigiosas (bioengineering). Esto quiere decir que el artículo espera tener bastante impacto de interés entre la comunidad deportiva y de investigación, aún sin las pertinentes revisiones. Tras la recomendación de…
#Bioengineering#Exercise Biomechanics#Half squat#Mechanical power#Miguel Rodal#PBT Framework#Power-based training#Preprints#Universidad de Extremadura
0 notes
Text
Because this just came up in my professional life and it drives me mad when journalists don't make it clear:
Articles on preprint servers are not generally peer-reviewed
If you want something peer-reviewed, you're looking for the Version of Record (published article complete with journal formatting) or the Author's Accepted Manuscript (unformatted final version, generally found in open-access repositories*).
The whole point of a preprint server (SSRN, arXiv, etc) is to share and discuss research in its early stages with colleagues. It's not just pre-print; it's generally pre-entire-publication-process. It's not supposed to be the final version.
(Confusingly, there's also a thing called "ahead-of-print", when a research article is published on the journal website after it's passed peer review but before it's been officially assigned to an issue of the journal. That's completely different.)
*This doesn't mean SciHub. It usually means university websites. At least in the UK, the Author's Accepted Manuscript of most articles should be placed in the author's university repository. This is called Green Open Access. You can search these via core dot ac dot uk.
#Research#Open access#Librarian#Scholarly publishing#Preprints#Open research#Getting articles for free is often legal and straightforward#But you do have to know what you're looking at
1 note
·
View note
Text



Behold the magnificent walrus fairy!
#sewing#handmade#plushie#walrus plushie#walrus fairy#walrus fairy plushie#easily one of my favorite things I’ve made it’s absurd and delightful#if I hadn’t already promised this one to a neighbor kid I’d keep this one#like. I don’t keep most of my plushies but I’d keep it lol#oh well! the kid will love it#I’m going to give more plushies butterfly wings#I used preprinted spoonflower fabric for it and I have enough for a few more pairs
955 notes
·
View notes
Text
Reference saved in our archive
Just an interesting preprint. Your body's immune response to a tattoo was the thing that got me reading about the complement system back in the day.
Abstract Despite safety concerns regarding the toxicity of tattoo ink, no studies have reported the consequences of tattooing on the immune response. In this work, we have characterized the transport and accumulation of different tattoo inks in the lymphatic system using a murine model. Upon quick lymphatic drainage, we observed that macrophages mainly capture the ink in the lymph node (LN). An initial inflammatory reaction at local and systemic levels follows ink capture. Notably, the inflammatory process is maintained over time as we observed clear signs of inflammation in the draining LN two months following tattooing. In addition, the capture of ink by macrophages was associated with the induction of apoptosis in both human and murine models. Furthermore, the ink accumulated in the LN altered the immune response against a COVID-19 vaccine. We observed a reduced antibody response following vaccination with a mRNA-based SARS-CoV-2 vaccine, which was associated with a decreased expression of the Spike protein in macrophages in the draining LN. Considering the unstoppable trend of tattooing in the population, our results are crucial in informing the toxicology programs, policymakers, and the general public regarding the potential risk of the tattooing practice associated with an altered immune response.
#mask up#public health#wear a mask#wear a respirator#pandemic#covid#still coviding#covid 19#coronavirus#sars cov 2#preprint
86 notes
·
View notes
Text
The best way to understand tumblr's strain of antipsychiatry is the many, many times I have seen Freud quotes tagged antipsych
#i dont think there are more than 20 or 30 people on this website who have actually read any anti psychiatry literature#bc literally all the antipsych posts on here i see were critiques of psychiatry BY psychiatrists from the fucking early 1900s#when your definition of anti psychiatry is less radical than freuds you need to not be calling yourself that#not that im anti psychiatry. i like the theory and find it interesting#but it's just something that informs my practice of psychology#bc a lot of the critiques are valid and can be worked into practice. theres a good preprint article i read that basically fixed one#of the big critiques of psychiatry too i can send it to anyone whos interested
48 notes
·
View notes
Text
.....did... did stoned me spend an entire evening constructing a complex mathematical model of request directness as a way of explaining why people who self estimate reduced success probability not only do make requests more indirectly, but also why this is a rational strategy?
I. What.
....I bet I could write that up somewhere and submit it for publication...
#day job#what the fuck brain#there are one paper and one preprint on the theme that i can find and both are 2018 or more recent#maybe if i want an absolutely unhinged side project
40 notes
·
View notes
Text
I really love that given the invention of a magical recording device, Rozemyne’s use of it is to create a cute stuffed animal with quotes from someone you love who is far away
And Ferdinand’s was to start recording incriminating evidence
And yet Rozemyne is the one who used it to justify a little light coup
#preprint spoilers#part5vol8#ascendance of a bookworm spoilers#spoilers#本���きの下剋上#ascendance of a bookworm
49 notes
·
View notes
Text
Read an AI hype preprint because apparently I am not very discerning with my time. There's a lot that's kinda funny about it.
So the title of this paper is "People cannot distinguish GPT-4 from a human in a Turing test". The purpose of the title is evidently not to provide a clear reference for other researchers, but rather to produce AI hype and be reproduced in credulous headlines, as we'll see shortly.
The paper opens with a brief history and presentation of the Turing test. The important features are that the interrogator questions an AI and a human and is tasked with identifying the AI and has 5 minutes to do so. Then it presents the testing setup they used. 500 people are recruited, they are split into five categories of 100 each (making the percentage signs redundant), 400 interrogators, who talk to GPT-4, GPT-3.5, ELIZA, or a human (from the remaining 100) for five minutes and then are asked to determine if they talked to a human or not. It is a two-player setup. Why, though? You just explained that the Turing test was formulated on the premise of three participants, what is the reasoning for departing from that? Oh, ok, here it is:
We used a two-player formulation of the game, where a single human interrogator conversed with a single witness who was either a human or a machine. While this differs from Turing’s original three-player formulation, it has become a standard operationalisation of the test because it eliminates the confound of the third player’s humanlikeness and is easier to implement
WHAT? The "confound" of the third player's humanlikeness is the point! That is part of the premise of the test, it's trying to test/compare humanlikeness. Margarine marketers are more honest than this. By the end of the Introduction section of this paper titled "People cannot distinguish GPT-4 from a human in a Turing test" the authors have explained that they did not administer a Turing test because they were pretty sure that if they did GPT-4 would fail and they wanted a positive result so they designed their own test it could succeed instead. This is just outright fraud!
It's also kind of weird to talk about "GPT-4" succeeding at the test, because it was in fact a specific elaborate prompt of GPT-4, selected on the basis of prior research that had found it the most effective strategy. I mean, it needs to be prompted with something and it's not entirely clear to me why I think something more neutral without specific listed strategies would be a more honest implementation but I do. I guess it's because the way this finding is presented it's claiming that the AI is good at deception, and I mean it just really isn't. The AI didn't come up with the idea of doing an exploratory study with a wide variety of prompts (or for that matter, come up with the prompts themselves) and then using the ones that worked best, that was the researchers. The researchers who have pretty obviously rigged the whole study, in fact.
There is also some possible arguable dishonesty in the way the situation was presented to the human participants. They say the participants were told they would be put in conversation with either a human or a machine. Now, unless they were told more than is mentioned, I contend those people would have been entitled to treat this as an implication that those were equally likely possibilities, especially given the analogy with the actual Turing test, in which the population sizes of humans and machines are necessarily identical. Note also that all in all the interrogators turned out just a little under 50% human verdicts. In fact, the probability that they would be assigned to speak to a machine was 75%. If the interrogators had been told that there was only a 25% probability they would be assigned to speak to a human, would they have been more critical? Would they have assigned closer to 25% human verdicts? Even if it weren't that much closer, I suspect it would bring the GPT-4 success rate below 50%, which was treated as an important benchmark for god knows what reason. It might also bring the human success rate below 50%, of course. All of this could have been avoided by simply running the actual Turing test, but again, GPT-4 would have failed so they couldn't do that.
I wouldn't be too surprised if this paper did get accepted without major revisions, science is as vulnerable to hype cycles as everyone else, but if it does then what an indictment of the field (hm, actually, what field, I don't think "dicking around with GPT" has really been standardized yet).
#paper was coauthored by a PhD student (who should know better) and his thesis adviser (who should REALLY know better)#hopefully the preprint status will make the media feel weird about pushing this “result” too hard for now#but some of the less discerning sources have already run with it
9 notes
·
View notes
Text

why the fuck have they censored the word 'killed' on a real life sheet of paper at an actual fucking protest??? hello???
#what the fuck#how can you complain about media censorship if you too won't even say what was done to them#capitulating to marketing based social media algorithms in Real Life???? why do you refuse to speak plainly???? to use actual words???#to lend this the gravity it actually fucking deserves?#these are preprinted and mass produced posters they make for the protest every sunday. sometimes they come out with some absolute fucking#bullshit but i literally can't believe this#palestine
2 notes
·
View notes
Text
Blissful Little Ditty from The Shimmering Voyage Vol. 3 Peijia You, HOYO-MiX
#genshin#genshin impact#the shimmering voyage vol. 3#overworld#veluriyam mirage#pavilion of hermits#preprints#plays in preprints and the pavilion of hermits#peijia you
7 notes
·
View notes
Text
i hope we get the skin revamp in the new year
#instant reprints is gonna be SUCH a gamechanger#esp for ppl who preprint one copy before opening preorders#i don't do that but its a valid strategy
5 notes
·
View notes
Link
I always advise reading the whole thing, but here are excerpts.
(Although this post is a response to one pre-print, it matches up with hordes of data / research we’ve seen since 2020 — at this point it’s not in question that this virus affects the entire vascular system, and can cause heart attacks and strokes even in younger people.)
The short version is that even among those who had COVID but no symptoms, there is tissue damage.
When cells die, their contents are released into the surrounding tissue. Parts of the DNA of the cell are also released and can be detected in the bloodstream. That’s what is meant by cell-free DNA (cfDNA). Epigenetic liquid biopsies study the cfDNA and can determine the type of cells that it came from, based on characteristic molecular structures. The authors state “Patients with severe COVID-19 had a massive elevation of circulating cell-free DNA (cfDNA) levels, which originated in lung epithelial cells, cardiomyocytes, vascular endothelial cells and erythroblasts, suggesting increased cell death or turnover in these tissues.”
Cardiomyocytes are the muscle cells of the heart that contract to provide the heartbeat. When a large area of these become damaged, it is called a myocardial infarction, or commonly called a heart attack.
...
The damage to the vascular endothelium is really one of the most critical things to understand about COVID. It is the layer of cells lining blood vessels.
... When that occurs, capillaries can be occluded, which would lead to reduced (or no) oxygen flow to the tissue supplied by the capillary.
... “Patients with severe COVID-19 have a higher concentration of cfDNA, originating in affected tissues.” When endothelial damage occurs and microthrombi form on a large scale, such as in severe COVID, it leads to acute organ damage and potentially organ failure.The damage of clot formation is evident in a stroke.
... Endothelial damage is not only dangerous due to clot formation, but also because the endothelial cells are responsible for the transfer of oxygen from red blood cells into the surrounding tissue, which can also lead to that tissue being starved of oxygen and potential death of those cells, which is called ischemia.
I suspect that part of the reason that COVID seems less damaging in younger or healthier populations is that they can more easily handle some tissue damage since the surrounding unaffected tissue can take on some of the load of the damaged tissue. However, as that unaffected tissue ages, it won’t work quite as efficiently as when it was young and healthy, and the impacts of the COVID infection will start manifesting themselves as a number of chronic diseases. The fact that we are seeing many of these in such a short time is extremely concerning. It suggests that we will see massive amounts of chronic diseases among people who had COVID infections in the future. You can find information on some of these broken down by organ system on this page. Click the link of the system to see some of the studies.
#covid#long covid#heart attack#heart disease#chronic illness#stroke#mild covid#covid is not mild#blog#study#preprint
4 notes
·
View notes
Text
An interesting preprint: Reversible Transcriptomic Age Shifts from Physiological Stress in Whole Blood - Preprint posted Sept 9, 2024
Abstract We develop a genome-wide transcriptomic clock for predicting chronological age using whole blood samples from 463 healthy individuals. Our findings reveal profound age acceleration, up to 24.47 years, under perturbed homeostasis in COVID-19 patients, which reverted to baseline upon recovery. This study demonstrates that the whole blood transcriptome can track reversible changes in biological age induced by stressors in real physiological time, suggesting a potential role for anti-aging interventions in disease management.
#mask up#covid#pandemic#covid 19#wear a mask#public health#coronavirus#sars cov 2#still coviding#wear a respirator#long covid#preprint
48 notes
·
View notes
Text
Make sure to use the IRS website above to choose where you're filing! (It's not yet updated though.)
I've heard of companies being vague so it sounds like it's free, but nope. Only after you've spent so much time putting in info do you find out it's not free after all.
Note: IRS lists places where federal filing is free, but state taxes are not necessarily. I'm under the impression it's very hard to find places with free state taxes but please correct me if I'm wrong (please. I think I have to file in two states this year).
Also, at companies like HR block, most employees aren't full time tax accountants. They're usually temp workers. I assume they get some training and they certainly have way more experience than most people, but let's just say I wasn't impressed either time I filed with them. I've preemptively insisted that I'll do my brother's taxes while he's in college.
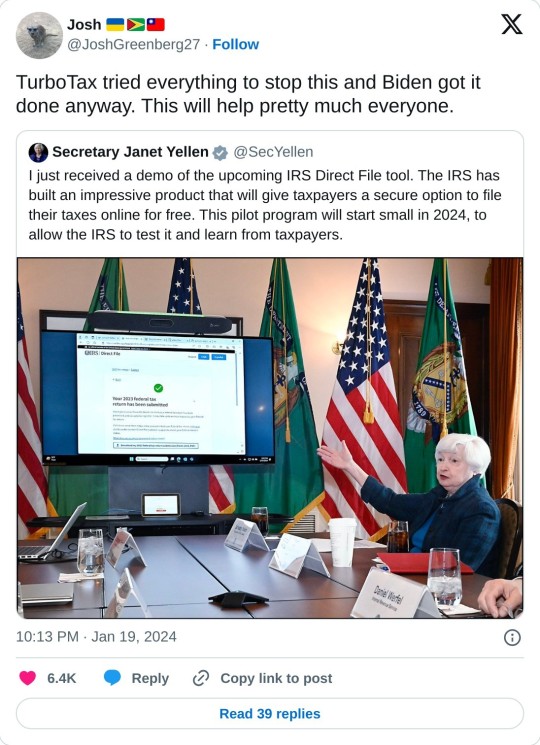
#in the past you could file taxes on paper on your own for the cost of some envelopes and stamps (so like $2-3)#but thats not even possible any more. my mom was very anxious about filing online for the first time. i had to help her#i remember when i was little she'd get the forms from the public library. there was a big display of them preprinted near the entrance#eventually we started printing them ourselves#im also absolutely willing to rant about my bad hr block experiences but felt like they werent really useful in the post
128K notes
·
View notes