#scrape data from Amazon
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Amazon Best Seller: Top 7 Tools To Scrape Data From Amazon

In the realm of e-commerce, data reigns supreme. The ability to gather and analyze data is key to understanding market trends, consumer behavior, and gaining a competitive edge. Amazon, being the e-commerce giant it is, holds a treasure trove of valuable data that businesses can leverage for insights and decision-making. However, manually extracting this data can be a daunting task, which is where web scraping tools come into play. Here, we unveil the top seven tools to scrape data from Amazon efficiently and effectively.
Scrapy: As one of the most powerful and flexible web scraping frameworks, Scrapy offers robust features for extracting data from websites, including Amazon. Its modular design and extensive documentation make it a favorite among developers for building scalable web crawlers. With Scrapy, you can navigate through Amazon's pages, extract product details, reviews, prices, and more with ease.
Octoparse: Ideal for non-programmers, Octoparse provides a user-friendly interface for creating web scraping workflows. Its point-and-click operation allows users to easily set up tasks to extract data from Amazon without writing a single line of code. Whether you need to scrape product listings, images, or seller information, Octoparse simplifies the process with its intuitive visual operation.
ParseHub: Another user-friendly web scraping tool, ParseHub, empowers users to turn any website, including Amazon, into structured data. Its advanced features, such as the ability to handle JavaScript-heavy sites and pagination, make it well-suited for scraping complex web pages. ParseHub's point-and-click interface and automatic data extraction make it a valuable asset for businesses looking to gather insights from Amazon.
Beautiful Soup: For Python enthusiasts, Beautiful Soup is a popular choice for parsing HTML and XML documents. Combined with Python's requests library, Beautiful Soup enables developers to scrape data from Amazon with ease. Its simplicity and flexibility make it an excellent choice for extracting specific information, such as product titles, descriptions, and prices, from Amazon's web pages.
Apify: As a cloud-based platform for web scraping and automation, Apify offers a convenient solution for extracting data from Amazon at scale. With its ready-made scrapers called "actors," Apify simplifies the process of scraping Amazon's product listings, reviews, and other valuable information. Moreover, Apify's scheduling and monitoring features make it easy to keep your data up-to-date with Amazon's ever-changing content.
WebHarvy: Specifically designed for scraping data from web pages, WebHarvy excels at extracting structured data from Amazon and other e-commerce sites. Its point-and-click interface allows users to create scraping tasks effortlessly, even for dynamic websites like Amazon. Whether you need to scrape product details, images, or prices, WebHarvy provides a straightforward solution for extracting data in various formats.
Mechanical Turk: Unlike the other tools mentioned, Mechanical Turk takes a different approach to data extraction by leveraging human intelligence. Powered by Amazon's crowdsourcing platform, Mechanical Turk allows businesses to outsource repetitive tasks, such as data scraping and data validation, to a distributed workforce. While it may not be as automated as other tools, Mechanical Turk offers unparalleled flexibility and accuracy in handling complex data extraction tasks from Amazon.
In conclusion, the ability to scrape data from Amazon is essential for businesses looking to gain insights into market trends, competitor strategies, and consumer behavior. With the right tools at your disposal, such as Scrapy, Octoparse, ParseHub, Beautiful Soup, Apify, WebHarvy, and Mechanical Turk, you can extract valuable data from Amazon efficiently and effectively. Whether you're a developer, data analyst, or business owner, these tools empower you to unlock the wealth of information that Amazon has to offer, giving you a competitive edge in the ever-evolving e-commerce landscape.
0 notes
Text

The ASIN (Amazon Standard Identification Identifier) is a ten-digit number that is used to identify products on Amazon. This is unique to each product and is assigned when a new item is added to Amazon's stock. Except for books, which have an ISBN (International Standard Book Number) instead of an ASIN, almost every product on Amazon has an ASIN code. This Amazon product identifier is required before you may sell on Amazon. To achieve the best and most precise results, you can use an Amazon scraping tool to scrape Amazon product data.
0 notes
Text
Amazon Product Data Scraping Services - Scrape Amazon Product Data
Leverage the benefit of our Amazon product data scraping services to efficiently scrape Amazon product data, encompassing essential details such as ASIN, product titles, pricing information, and more.
know more:
#Amazon Product Data Scraping Services#Scrape Amazon Product Data#Scrape Images Data from Amazon#Scrape Product Review Data from Amazon
0 notes
Text
i decided to upload my little baby svt file collection for everyone. its rly just a small random grab bag but i have access to some source files (basically meaning ts files so not screen recorded or watermarked, i will mark these as "source quality") + ive collected some concert recordings as well. enjoy.
!!! dont forget youre helping hybe finance the killing of palestinians when you give them money. consider donating to a palestinian child here. thank you
the links are hosted on gofile and WILL EXPIRE in about 2 weeks! you can send me an anon any time if you need me to reupload something, i want to share these files with as many people as possible! the only reason they'll expire is bc i can't afford permanent storage right now.
full list and links under the cut~ includes nana tour in the soup a selection of concerts some caratlands yadda yadda
❣️ stuff that will be added as soon as i get it: caratland 2025 both days no watermark + dokyeom focus cam, follow to japan fukuoka source quality
NANA TOUR source quality, 1080p, this is the full non-shortened weverse release!
IN THE SOOP Season 1 - source quality, 1080p, eng & spanish subs, this is the amazon version meaning it's shorter than the weverse release by 2 episodes. i don't have the full version in proper quality, if you do PLEASE dm me Season 2 - source quality, 1080p, eng subs, this is the full weverse release / ‼️ ATTENTION: for this one the audio and video streams are split but when you open the video file in VLC player you can simply add the audio stream in the settings. send me an ask if you need help with that!
CARATLAND 2024 - source quality, weverse release! 2024 - both days, both with multi and single cam each
CONCERTS
Right Here in Goyang - both days Right Here in Osaka - day 1 Follow Again Osaka - day 1 Follow Again to Incheon - day 2 CONCERT FILMS Follow Again to Cinemas 2024 - source quality Power of Love: The Movie 2023 - source quality Follow to Fukuoka 2023, source quality Ode to You in Seoul 2019 - source quality
OTHER PLACES TO DOWNLOAD FILES: therosebay 3cmgoogie dadeuthannie svt vlive archive
if you don't care about downloading files you can check out svtflix. it's an archive of almost every show, concert, documentary etc free to stream. and then there's also this old archive.
if you have high quality files you want to share please dm me!! i can store, upload & maintain links
some other resources: jdownloader - this program is the best for youtube downloads, not 4kdownloader!!! jdownloader also lets you download from a million other sites.. no limit no ads no scraping your data weversetools - to download wv lives
ok bye~

#seventeen#svtcreations#svtedit#bellamyblakru#chwedoutbox#heysol#cheytermelon#usersemily#annietrack#u dont have to rb just tagging in case yr interested :3#*#dl
318 notes
·
View notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about “AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
This day in history

On SEPTEMBER 24th, I'll be speaking IN PERSON at the BOSTON PUBLIC LIBRARY!

#20yrsago AnarchistU, Toronto’s wiki-based free school https://web.archive.org/web/20040911010603/http://anarchistu.org/bin/view/Anarchistu
#20yrsago Fair use is a right AND a defense https://memex.craphound.com/2004/09/09/fair-use-is-a-right-and-a-defense/
#20yrsago Bounty for asking “How many times have you been arrested, Mr. President?” https://web.archive.org/web/20040918115027/https://onesimplequestion.blogspot.com/
#20yrsago What yesterday’s terrible music https://www.loweringthebar.net/2009/09/open-mike-likely-to-close-out-legislators-career.htmlsampling ruling means https://web.archive.org/web/20040910095029/http://www.lessig.org/blog/archives/002153.shtml
#15yrsago Conservative California legislator gives pornographic account of his multiple affairs (including a lobbyist) into open mic https://www.loweringthebar.net/2009/09/open-mike-likely-to-close-out-legislators-career.html
#15yrsago Shel Silverstein’s UNCLE SHELBY, not exactly a kids’ book https://memex.craphound.com/2009/09/09/shel-silversteins-uncle-shelby-not-exactly-a-kids-book/
#10yrsago Seemingly intoxicated Rob Ford gives subway press-conference https://www.youtube.com/watch?v=WbcETJRoNCs
#10yrsago Amazon vs Hachette is nothing: just WAIT for the audiobook wars! https://locusmag.com/2014/09/cory-doctorow-audible-comixology-amazon-and-doctorows-first-law/
#10yrsago Dietary supplement company sues website for providing a forum for dissatisfied customers https://www.techdirt.com/2014/09/08/dietary-supplement-company-tries-suing-pissedconsumer-citing-buyers-agreement-to-never-say-anything-negative-about-roca/
#10yrsago New wind-tunnel tests find surprising gains in cycling efficiency from leg-shaving https://www.theglobeandmail.com/life/health-and-fitness/health/the-curious-case-of-the-cyclists-unshaved-legs/article20370814/
#10yrsago Behind the scenes look at Canada’s Harper government gagging scientists https://www.cbc.ca/news/science/federal-scientist-media-request-generates-email-frenzy-but-no-interview-1.2759300
#10yrsago Starred review in Kirkus for INFORMATION DOESN’T WANT TO BE FREE https://www.kirkusreviews.com/book-reviews/cory-doctorow/information-doesnt-want-to-be-free/
#10yrsago Steven Gould’s “Exo,” a Jumper novel by way of Heinlein’s “Have Spacesuit, Will Travel” https://memex.craphound.com/2014/09/09/steven-goulds-exo-a-jumper-novel-by-way-of-heinleins-have-spacesuit-will-travel/
#5yrsago Important legal victory in web-scraping case https://arstechnica.com/tech-policy/2019/09/web-scraping-doesnt-violate-anti-hacking-law-appeals-court-rules/
#5yrsago Whistleblowers out Falwell’s Liberty University as a grifty, multibillion-dollar personality cult https://web.archive.org/web/20190910000528/https://www.politico.com/magazine/amp/story/2019/09/09/jerry-falwell-liberty-university-loans-227914
#5yrsago Pinduoduo: China’s “Groupon on steroids” https://www.wired.com/story/china-ecommerce-giant-never-heard/
#5yrsago Notpetya: the incredible story of an escaped US cyberweapon, Russian state hackers, and Ukraine’s cyberwar https://www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/
#5yrsago NYT calls for an end to legacy college admissions https://www.nytimes.com/2019/09/07/opinion/sunday/end-legacy-college-admissions.html
#5yrsago Purdue’s court filings understate its role in the opioid epidemic by 80% https://www.propublica.org/article/data-touted-by-oxycontin-maker-to-fight-lawsuits-doesnt-tell-the-whole-story
#1yrago Saturday linkdump, part the sixth https://pluralistic.net/2023/09/09/nein-nein/#everything-is-miscellaneous
The paperback edition of The Lost Cause, my nationally bestselling, hopeful solarpunk novel is out this month!
9 notes
·
View notes
Text
@cutestkilla

OKAY DRE THE AI THING IS WILD. And I don't know how I would write a shippy fic about it, because I hate everything about it. Basically, my paper is about AI deathbots, which are "re-creation services", aka generative AI that brings people back from the dead by using the deceased person's writing, voice clips and photo and video footage. This way you can have an chatbox where you can chat with the deceased, or even a phone call to talk with the deceased, or even a video call with the deceased.
Yeah.
Basically, imagine I die tomorrow, unexpectedly. Then y'all can put everything I wrote on this blog and my main, plus my papers and assignments, and my fics, and my messages with friends on WhatsApp and whatever into a large language model and that AI will then generate "text responses that I would say" in circumstances. It will mimic my writing style and it will probably not shut the fuck about glee.
And bla, bla, bla, affective scaffolding and grief processing. It can help people. It HAS helped people. Imagine that my sudden death leaves my parents feeling empty. This way they can say goodbye to "me" by chatting with AI-me. BUT there are definitely issues about how a bereaved person can get too reliant on them. What if it prevents my parents from moving on? And there's of course the issue of consent. You now have it in writing: I do not consent to being turned into a deathbot. But many do not give consent. How could they? Especially people who died earlier. Of course my family didn't ask my grandpa for permission when he was dying in 2002. How could we?
And yada yada, the usual data issues when it comes to companies, cause yes, companies are hawking. Microsoft has already been granted a patent for the chatbox and visual recreation of the dead and Amazon is also working on it through AI voice for Alexa. And there are also a bunch of (sketchy) start-ups that are eerily like the NowNext. Sillicone Valley techbros like Braden would gobble this shit up. Digital immortality! But yes, so far these deathbots are paid services. What happens if someone cannot afford to keep the subscription going? Will the deathbot suddenly start advertising Uber Eats using a deceased person's voice and face? Probably. Once profit is part of it, all morality leaves. This AI version of me needs to be profitable, so companies might actually be interested in altering "me" to fit my parents' wishes to encourage them to keep using their services. Is that still a representation of me?
And what happens to the data of the deceased, even if the deathbot ceases to exist? AI is notorious for using data that is obtained under questionable circumstances. My parents move on and decide to terminate my deathbot, but then my data is still in the hands of good ole Jeff Bezos who will use it to further train the deathbot AI. My data will also be blended with other people's data, or data from 3rd parties that were possibly scraped for other purposes. Is it a representation of "me" if it's my data, other dead people's data and, I dunno, scraped data from an article on the invasion of Ukraine from the New York Times or a great Drarry erotic fanfic scraped from AO3?
I realise I just basically summarised my paper in this post BUT I FIND THIS EXTREMELY FASCINATING AND FUCKED UP AND YES, BLACK MIRROR ALREADY DID AN EPISODE ON THIS IN 2013.
Basically:

6 notes
·
View notes
Text
Grindr’s AI wingman, currently in beta testing with around 10,000 users, arrives at a pivotal moment for the software company. With its iconic notification chirp and ominous mask logo, the app is known culturally as a digital bathhouse for gay and bisexual men to swap nudes and meet with nearby users for sex, but Grindr CEO George Arison sees the addition of a generative AI assistant and machine intelligence tools as an opportunity for expansion.
“This is not just a hookup product anymore,” he says. “There's obviously no question that it started out as a hookup product, but the fact that it's become a lot more over time is something people don't fully appreciate.” Grindr’s product road map for 2025 spotlights multiple AI features aimed at current power users, like chat summaries, as well as dating and travel-focused tools.
Whether users want them or not, it’s all part of a continuing barrage of AI features being added by developers to most dating apps, from Hinge deciding whether profile answers are a slog using AI, to Tinder soon rolling out AI-powered matches. Wanting to better understand how AI fits into Grindr's future, I experimented with a beta version of Grindr's AI wingman for this hands-on report.
First Impressions of Grindr’s AI Wingman
In interviews over the past few months, Arison has laid out a consistent vision for Grindr’s AI wingman as the ultimate dating tool—a digital helper that can write witty responses for users as they chat with matches, help pick guys worth messaging, and even plan the perfect night out.
“It's been surprisingly flirtatious,” he says about the chatbot. “Which is good.”
Once enabled, the AI wingman appeared as another faceless Grindr profile in my message inbox. Despite grand visions for the tool, the current iteration I tested was a simple, text-only chatbot tuned for queer audiences.
First, I wanted to test the chatbot’s limits. Unlike the more prudish outputs from OpenAI’s ChatGPT and Anthropic’s Claude, Grindr’s AI wingman was willing to be direct. I asked it to share fisting tips for beginners, and after stating that fisting is not for newcomers, the AI wingman encouraged me to start slow, use tons of lube, explore smaller toys first, and always have a safe word ready to go. “Most importantly, do your research and maybe chat with experienced folks in the community,” the bot said. ChatGPT flagged similar questions as going against its guidelines, and Claude refused to even broach the subject.
Although the wingman was down to talk through other kinks—like watersports and pup play—with a focus on education, the app rebuked my advances for any kind of erotic role-play. “How about we keep things playful but PG-13?” said Grindr’s AI wingman. “I’d be happy to chat about dating tips, flirting strategies, or fun ways to spice up your profile instead.” The bot also refused to explore kinks based on race or religion, warning me that these are likely harmful forms of fetishization.
Processing data through Amazon Web Service’s Bedrock system, the chatbot does include some details scraped from the web, but it can’t go out and find new information in real time. Since the current version doesn't actively search the internet for answers, the wingman provided more general advice than specifics when asked to plan a date for me in San Francisco. “How about checking out a local queer-owned restaurant or bar?” it said. “Or maybe plan a picnic in a park and people-watch together?” Pressed for specifics, the AI wingman did name a few relevant locations for date nights in the city but couldn’t provide operating hours. In this instance, posing a similar question to ChatGPT produced a better date night itinerary, thanks to that chatbot’s ability to search the open web.
Despite my lingering skepticism about the wingman tool potentially being more of an AI fad than the actual future of dating, I do see immediate value in a chatbot that can help users come to terms with their sexuality and start the coming out process. Many Grindr users, including myself, become users of the app before telling anyone about their desires, and a kind, encouraging chatbot would have been more helpful to me than the “Am I Gay?” quiz I resorted to as a teenager.
Out With the Bugs, In With the AI
When he took the top job at Grindr before the company’s public listing in 2022, Arison prioritized zapping bugs and fixing app glitches over new feature releases. “We got a lot of bugs out of the way last year,” he says. “Until now, we didn't really have an opportunity to be able to build a lot of new features.”
Despite getting investors hot and bothered, it’s hard to tell how daily Grindr users will respond to this new injection of AI into the app. While some may embrace the suggested matches and the more personalized experience, generative AI is now more culturally polarizing than ever as people complain about its oversaturation, lack of usefulness, and invasion of privacy. Grindr users will be presented with the option to allow their sensitive data, such as the contents of their conversations and precise location, to be used to train the company’s AI tools. Users can go into their account’s privacy settings to opt out if they change their mind.
Arison is convinced in-app conversations reveal a more authentic version of users than what's filled out on any profile, and the next generation of recommendations will be stronger by focusing on that data. “It's one thing what you say in your profile,” he says. “But, it's another thing what you say in your messages—how real that might be.” Though on apps like Grindr, where the conversations often contain explicit, intimate details, some users will be uncomfortable with an AI model reading their private chats to learn more about them, choosing to avoid those features.
Potentially, one of the most helpful AI tools for overly active Grindr users who are open to their data being processed by AI models could be the chat summaries recapping recent interactions with some talking points thrown in to keep conversations going.
“It's really about reminding you what type of connection you might have had with this user, and what might be good topics that could be worth picking back up on,” says A. J. Balance, Grindr’s chief product officer.
Then there’s the model’s ability to highlight the profiles of users it thinks you’re most compatible with. Say you’ve matched with another user and chatted a bit, but that’s as far as things went in the app. Grindr’s AI model will be able to summarize details about that conversation and, using what it has learned about you both, highlight those profiles as part of an “A-List” and offer some ways to rekindle the connection, widening the door you’ve already opened.
“This ‘A-List’ product actually goes through your inbox with folks you've spoken with, pulls out the folks where you've had some good connections,” Balance says. “And it uses that summary to remind you why it could be good to pick back up the conversation.”
Slow Roll
As a gaybie, my first interactions on Grindr were liberating and constricting at the same time. It was the first time I saw casual racism, like “No fats. No fems. No Asians,” blasted across multiple online profiles. And even at my fittest, there always seemed to be some headless torso more in shape than me right around the corner and ready to mock my belly. Based on past experiences, AI features that could detect addiction to the app and encourage healthier habits and boundaries would be a welcome addition.
While Grindr’s other, AI-focused tools are planned for more immediate releases throughout this year, the app’s generative AI assistant isn’t projected to have a complete rollout until 2027. Arison doesn’t want to rush a full release to Grindr’s millions of global users. “These are also expensive products to run,” he says. “So, we want to be kind of careful with that as well.” Innovations in generative AI, like DeepSeek’s R1 model, may eventually reduce the cost to run it on the backend.
Will he be able to navigate adding these experimental, and sometimes controversial, AI tools to the app as part of a push to become more welcoming for users looking to find long-term relationships or queer travel advice, in addition to hookups? For now, Arison appears optimistic, albeit cautious. “We don't expect all of these things to take off,” he says. “Some of them will and some won't.”
3 notes
·
View notes
Text
Okay, so I just wanna bring something up regarding YouTube (and Google by extension, as they fully own YouTube, and also Google [and Amazon] are currently being sued for being illegal monopolies)
So YouTube's bad updates have officially pushed me to Firefox, but I wanna break down some of their recent updates
The first thing they did was removing people's ability to watch videos if adblockers were present, which is borderline legal
There is no law in the US, where Google is hosted, that requires a user to disable adblockers on certain websites, meaning that YouTube blocking people from using adblockers and paying for their product/watching extensive ads instead isn't technically legal, but also isn't technically illegal
This is also the Adpocalypse 2, with ads being anywhere from 10 seconds to a full minute, and ads also run at the beginning of videos, the end of videos, as midrolls, as the starts of every chapter, and when you move your location in the video -
even on some videos that've disabled ads and use sponsorships - and these also run occasionally on videos marked for sleep-aids such as ASMR videos and on unmonetized videos that shouldn't have ads as the person who put up the video doesn't get paid
The next problematic update they put up was creating an artificial 5-second delay for Firefox users (this can be remedied with www.youtube.com##+js(nano-stb, resolve(1), 5000, 0.001) in uBO), which is in violation of antitrust law
What pushed me to Firefox is that the new update for Chrome (and all Chrome-based browsers), Manifest v3 will completely disable any extensions not directly authorized by Google, and this includes completely disabling uBlock Origin, which forces people not on Firefox or TorBrowser to be bombarded with ads and data scraping.
After moving to Firefox, I've noticed another thing that I'm 90% sure is another violation of antitrust law: In Chrome, there's 1080p. In Firefox, it's split into 1080p and 1080p Premium, reducing the intended bitrate and making videos visibly lower quality - requiring people to pay for YouTube Premium in order to use YouTube as intended.
What the fuck is happening?
18 notes
·
View notes
Text
This guide will teach you about the top 7 tools for scraping data from Amazon. These tools will help you gather all kinds of information about your product.
For More Information:-
0 notes
Text
Astrophysicists may have solved the mystery of Uranus’s unusual radiation belts

- By Nuadox Crew -
The weak radiation belts around Uranus, observed by Voyager 2 nearly 50 years ago, may actually be due to changes in particle speed caused by the planet’s asymmetric magnetic field.
Uranus's magnetic field is tilted 60° from its spin axis, creating an unusual magnetic environment.
Researchers, including Acevski et al., used new modeling incorporating a quadrupole field to simulate this asymmetry and found that particle speeds vary in different parts of their orbits.
This variation spreads particles out, decreasing their density by up to 20%, which could explain Voyager 2's observations.
Although this does not completely account for the weaker radiation belts, it offers insights into Uranus's magnetic anomalies. NASA’s proposed mission to the ice giants may provide further data to understand these mechanisms.
Header image: The planet Uranus, depicted in this James Webb Space Telescope image, features a tilted magnetic field and unusual radiation belts. Future missions to this icy giant may uncover more details. Credit: NASA, ESA, CSA, STScI.
Read more at Eos
Scientific paper: M. Acevski et al, Asymmetry in Uranus' High Energy Proton Radiation Belt, Geophysical Research Letters (2024). DOI: 10.1029/2024GL108961
--
Other recent news
Google is investigating claims of AI-generated content scraping, which affects search result rankings.
Amazon is reviewing whether Perplexity AI improperly scraped online content.
A bone analysis provides new insights into the Denisovans, an ancient human species, and their survival in extreme environments.
#astronomy#ai#space#uranus#planets#physics#google#big tech#search#generative ai#amazon#Perplexity AI#copyright#bone#paleontology#Denisovans#dna#genomics
5 notes
·
View notes
Text
elsewhere on the internet: AI and advertising
Bubble Trouble (about AIs trained on AI output and the impending model collapse) (Ed Zitron, Mar 2024)
A Wall Street Journal piece from this week has sounded the alarm that some believe AI models will run out of "high-quality text-based data" within the next two years in what an AI researcher called "a frontier research problem." Modern AI models are trained by feeding them "publicly-available" text from the internet, scraped from billions of websites (everything from Wikipedia to Tumblr, to Reddit), which the model then uses to discern patterns and, in turn, answer questions based on the probability of an answer being correct. Theoretically, the more training data that these models receive, the more accurate their responses will be, or at least that's what the major AI companies would have you believe. Yet AI researcher Pablo Villalobos told the Journal that he believes that GPT-5 (OpenAI's next model) will require at least five times the training data of GPT-4. In layman's terms, these machines require tons of information to discern what the "right" answer to a prompt is, and "rightness" can only be derived from seeing lots of examples of what "right" looks like. ... One (very) funny idea posed by the Journal's piece is that AI companies are creating their own "synthetic" data to train their models, a "computer-science version of inbreeding" that Jathan Sadowski calls Habsburg AI. This is, of course, a terrible idea. A research paper from last year found that feeding model-generated data to models creates "model collapse" — a "degenerative learning process where models start forgetting improbable events over time as the model becomes poisoned with its own projection of reality."
...
The AI boom has driven global stock markets to their best first quarter in 5 years, yet I fear that said boom is driven by a terrifyingly specious and unstable hype cycle. The companies benefitting from AI aren't the ones integrating it or even selling it, but those powering the means to use it — and while "demand" is allegedly up for cloud-based AI services, every major cloud provider is building out massive data center efforts to capture further demand for a technology yet to prove its necessity, all while saying that AI isn't actually contributing much revenue at all. Amazon is spending nearly $150 billion in the next 15 years on data centers to, and I quote Bloomberg, "handle an expected explosion in demand for artificial intelligence applications" as it tells its salespeople to temper their expectations of what AI can actually do. I feel like a crazy person every time I read glossy pieces about AI "shaking up" industries only for the substance of the story to be "we use a coding copilot and our HR team uses it to generate emails." I feel like I'm going insane when I read about the billions of dollars being sunk into data centers, or another headline about how AI will change everything that is mostly made up of the reporter guessing what it could do.
They're Looting the Internet (Ed Zitron, Apr 2024)
An investigation from late last year found that a third of advertisements on Facebook Marketplace in the UK were scams, and earlier in the year UK financial services authorities said it had banned more than 10,000 illegal investment ads across Instagram, Facebook, YouTube and TikTok in 2022 — a 1,500% increase over the previous year. Last week, Meta revealed that Instagram made an astonishing $32.4 billion in advertising revenue in 2021. That figure becomes even more shocking when you consider Google's YouTube made $28.8 billion in the same period . Even the giants haven’t resisted the temptation to screw their users. CNN, one of the most influential news publications in the world, hosts both its own journalism and spammy content from "chum box" companies that make hundreds of millions of dollars driving clicks to everything from scams to outright disinformation. And you'll find them on CNN, NBC and other major news outlets, which by proxy endorse stories like "2 Steps To Tell When A Slot Is Close To Hitting The Jackpot." These “chum box” companies are ubiquitous because they pay well, making them an attractive proposition for cash-strapped media entities that have seen their fortunes decline as print revenues evaporated. But they’re just so incredibly awful. In 2018, the (late, great) podcast Reply All had an episode that centered around a widower whose wife’s death had been hijacked by one of these chum box advertisers to push content that, using stolen family photos, heavily implied she had been unfaithful to him. The title of the episode — An Ad for the Worst Day of your Life — was fitting, and it was only until a massively popular podcast intervened did these networks ban the advert. These networks are harmful to the user experience, and they’re arguably harmful to the news brands that host them. If I was working for a major news company, I’d be humiliated to see my work juxtaposed with specious celebrity bilge, diet scams, and get-rich-quick schemes.
...
While OpenAI, Google and Meta would like to claim that these are "publicly-available" works that they are "training on," the actual word for what they're doing is "stealing." These models are not "learning" or, let's be honest, "training" on this data, because that's not how they work — they're using mathematics to plagiarize it based on the likelihood that somebody else's answer is the correct one. If we did this as a human being — authoritatively quoting somebody else's figures without quoting them — this would be considered plagiarism, especially if we represented the information as our own. Generative AI allows you to generate lots of stuff from a prompt, allowing you to pretend to do the research much like LLMs pretend to know stuff. It's good for cheating at papers, or generating lots of mediocre stuff LLMs also tend to hallucinate, a virtually-unsolvable problem where they authoritatively make incorrect statements that creates horrifying results in generative art and renders them too unreliable for any kind of mission critical work. Like I’ve said previously, this is a feature, not a bug. These models don’t know anything — they’re guessing, based on mathematical calculations, as to the right answer. And that means they’ll present something that feels right, even though it has no basis in reality. LLMs are the poster child for Stephen Colbert’s concept of truthiness.
3 notes
·
View notes
Text
How I'm Tracking My Manga Reading Backlog
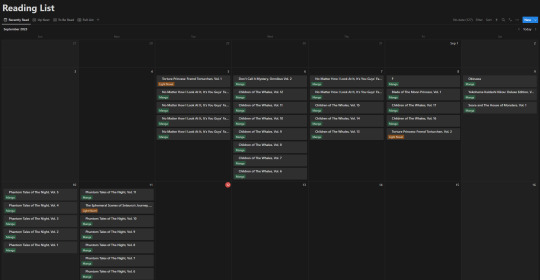
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
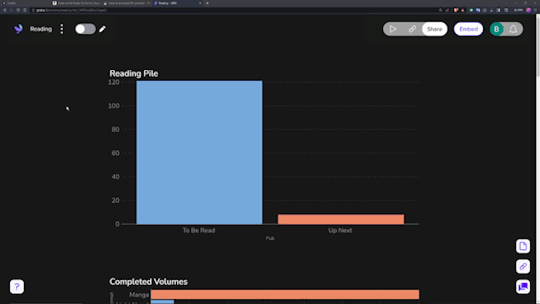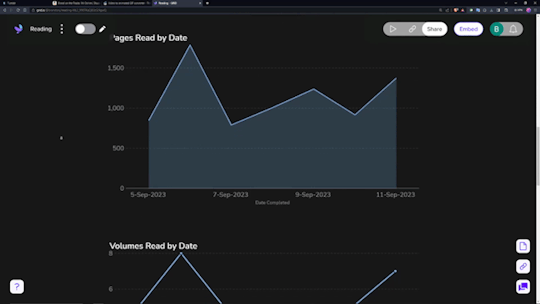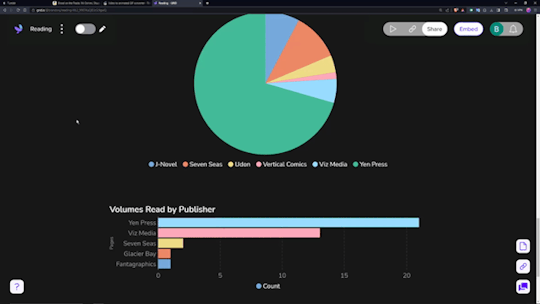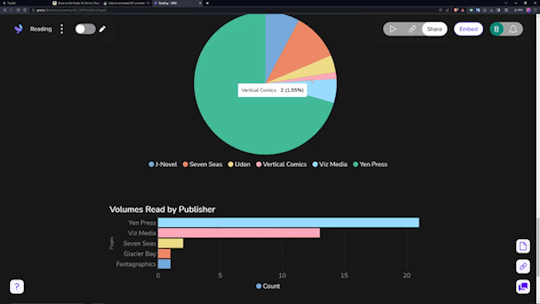
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
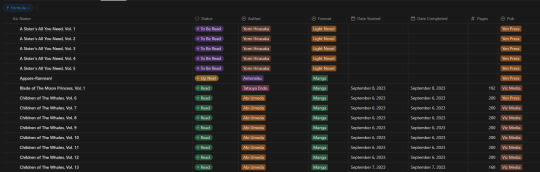
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
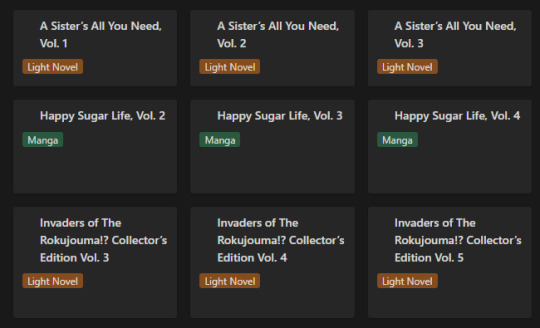
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes
Text
How to Extract Amazon Product Prices Data with Python 3
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Use Amazon Review Scraping Services To Boost The Pricing Strategies
Use data extraction services to gather detailed insights from customer reviews. Our advanced web scraping services provide a comprehensive analysis of product feedback, ratings, and comments. Make informed decisions, understand market trends, and refine your business strategies with precision. Stay ahead of the competition by utilizing Amazon review scraping services, ensuring your brand remains attuned to customer sentiments and preferences for strategic growth.
2 notes
·
View notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes