#scrape unstructured data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
What is data mining? How is it different from data scraping?
Data mining converts data into accurate insights. Gather knowledge from unstructured data using advanced data mining techniques. Read more https://scrape.works/blog/what-is-data-mining-how-is-it-different-from-data-scraping/

0 notes
Text
In the subject of data analytics, this is the most important concept that everyone needs to understand. The capacity to draw insightful conclusions from data is a highly sought-after talent in today's data-driven environment. In this process, data analytics is essential because it gives businesses the competitive edge by enabling them to find hidden patterns, make informed decisions, and acquire insight. This thorough guide will take you step-by-step through the fundamentals of data analytics, whether you're a business professional trying to improve your decision-making or a data enthusiast eager to explore the world of analytics.
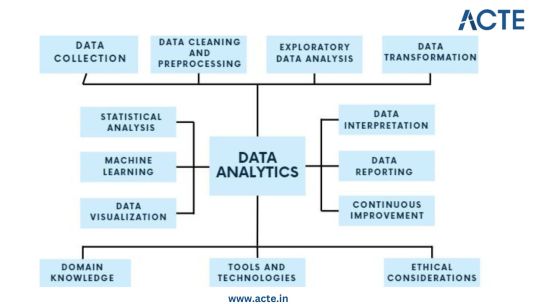
Step 1: Data Collection - Building the Foundation
Identify Data Sources: Begin by pinpointing the relevant sources of data, which could include databases, surveys, web scraping, or IoT devices, aligning them with your analysis objectives. Define Clear Objectives: Clearly articulate the goals and objectives of your analysis to ensure that the collected data serves a specific purpose. Include Structured and Unstructured Data: Collect both structured data, such as databases and spreadsheets, and unstructured data like text documents or images to gain a comprehensive view. Establish Data Collection Protocols: Develop protocols and procedures for data collection to maintain consistency and reliability. Ensure Data Quality and Integrity: Implement measures to ensure the quality and integrity of your data throughout the collection process.
Step 2: Data Cleaning and Preprocessing - Purifying the Raw Material
Handle Missing Values: Address missing data through techniques like imputation to ensure your dataset is complete. Remove Duplicates: Identify and eliminate duplicate entries to maintain data accuracy. Address Outliers: Detect and manage outliers using statistical methods to prevent them from skewing your analysis. Standardize and Normalize Data: Bring data to a common scale, making it easier to compare and analyze. Ensure Data Integrity: Ensure that data remains accurate and consistent during the cleaning and preprocessing phase.
Step 3: Exploratory Data Analysis (EDA) - Understanding the Data
Visualize Data with Histograms, Scatter Plots, etc.: Use visualization tools like histograms, scatter plots, and box plots to gain insights into data distributions and patterns. Calculate Summary Statistics: Compute summary statistics such as means, medians, and standard deviations to understand central tendencies. Identify Patterns and Trends: Uncover underlying patterns, trends, or anomalies that can inform subsequent analysis. Explore Relationships Between Variables: Investigate correlations and dependencies between variables to inform hypothesis testing. Guide Subsequent Analysis Steps: The insights gained from EDA serve as a foundation for guiding the remainder of your analytical journey.
Step 4: Data Transformation - Shaping the Data for Analysis
Aggregate Data (e.g., Averages, Sums): Aggregate data points to create higher-level summaries, such as calculating averages or sums. Create New Features: Generate new features or variables that provide additional context or insights. Encode Categorical Variables: Convert categorical variables into numerical representations to make them compatible with analytical techniques. Maintain Data Relevance: Ensure that data transformations align with your analysis objectives and domain knowledge.
Step 5: Statistical Analysis - Quantifying Relationships
Hypothesis Testing: Conduct hypothesis tests to determine the significance of relationships or differences within the data. Correlation Analysis: Measure correlations between variables to identify how they are related. Regression Analysis: Apply regression techniques to model and predict relationships between variables. Descriptive Statistics: Employ descriptive statistics to summarize data and provide context for your analysis. Inferential Statistics: Make inferences about populations based on sample data to draw meaningful conclusions.
Step 6: Machine Learning - Predictive Analytics
Algorithm Selection: Choose suitable machine learning algorithms based on your analysis goals and data characteristics. Model Training: Train machine learning models using historical data to learn patterns. Validation and Testing: Evaluate model performance using validation and testing datasets to ensure reliability. Prediction and Classification: Apply trained models to make predictions or classify new data. Model Interpretation: Understand and interpret machine learning model outputs to extract insights.
Step 7: Data Visualization - Communicating Insights
Chart and Graph Creation: Create various types of charts, graphs, and visualizations to represent data effectively. Dashboard Development: Build interactive dashboards to provide stakeholders with dynamic views of insights. Visual Storytelling: Use data visualization to tell a compelling and coherent story that communicates findings clearly. Audience Consideration: Tailor visualizations to suit the needs of both technical and non-technical stakeholders. Enhance Decision-Making: Visualization aids decision-makers in understanding complex data and making informed choices.
Step 8: Data Interpretation - Drawing Conclusions and Recommendations
Recommendations: Provide actionable recommendations based on your conclusions and their implications. Stakeholder Communication: Communicate analysis results effectively to decision-makers and stakeholders. Domain Expertise: Apply domain knowledge to ensure that conclusions align with the context of the problem.
Step 9: Continuous Improvement - The Iterative Process
Monitoring Outcomes: Continuously monitor the real-world outcomes of your decisions and predictions. Model Refinement: Adapt and refine models based on new data and changing circumstances. Iterative Analysis: Embrace an iterative approach to data analysis to maintain relevance and effectiveness. Feedback Loop: Incorporate feedback from stakeholders and users to improve analytical processes and models.
Step 10: Ethical Considerations - Data Integrity and Responsibility
Data Privacy: Ensure that data handling respects individuals' privacy rights and complies with data protection regulations. Bias Detection and Mitigation: Identify and mitigate bias in data and algorithms to ensure fairness. Fairness: Strive for fairness and equitable outcomes in decision-making processes influenced by data. Ethical Guidelines: Adhere to ethical and legal guidelines in all aspects of data analytics to maintain trust and credibility.
Data analytics is an exciting and profitable field that enables people and companies to use data to make wise decisions. You'll be prepared to start your data analytics journey by understanding the fundamentals described in this guide. To become a skilled data analyst, keep in mind that practice and ongoing learning are essential. If you need help implementing data analytics in your organization or if you want to learn more, you should consult professionals or sign up for specialized courses. The ACTE Institute offers comprehensive data analytics training courses that can provide you the knowledge and skills necessary to excel in this field, along with job placement and certification. So put on your work boots, investigate the resources, and begin transforming.
24 notes
·
View notes
Text
Healthcare Market Research: Why Does It Matter?
Healthcare market research (MR) providers interact with several stakeholders to discover and learn about in-demand treatment strategies and patients’ requirements. Their insightful reports empower medical professionals, insurance companies, and pharma businesses to engage with patients in more fulfilling ways. This post will elaborate on the growing importance of healthcare market research.
What is Healthcare Market Research?
Market research describes consumer and competitor behaviors using first-hand or public data collection methods, like surveys and web scraping. In medicine and life sciences, clinicians and accessibility device developers can leverage it to improve patient outcomes. They grow faster by enhancing their approaches as validated MR reports recommend.
Finding key opinion leaders (KOL), predicting demand dynamics, or evaluating brand recognition efforts becomes more manageable thanks to domain-relevant healthcare market research consulting. Although primary MR helps with authority-building, monitoring how others in the target field innovate their business models is also essential. So, global health and life science enterprises value secondary market research as much as primary data-gathering procedures.
The Importance of Modern Healthcare Market Research
1| Learning What Competitors Might Do Next
Businesses must beware of market share fluctuations due to competitors’ expansion strategies. If your clients are more likely to seek help from rival brands, this situation suggests failure to compete.
Companies might provide fitness products, over-the-counter (OTC) medicines, or childcare facilities. However, they will always lose to a competitor who can satisfy the stakeholders’ demands more efficiently. These developments evolve over the years, during which you can study and estimate business rivals’ future vision.
You want to track competing businesses’ press releases, public announcements, new product launches, and marketing efforts. You must also analyze their quarter-on-quarter market performance. If the data processing scope exceeds your tech capabilities, consider using healthcare data management services offering competitive intelligence integrations.
2| Understanding Patients and Their Needs for Unique Treatment
Patients can experience unwanted bodily changes upon consuming a medicine improperly. Otherwise, they might struggle to use your accessibility technology. If healthcare providers implement a user-friendly feedback and complaint collection system, they can reduce delays. As a result, patients will find a cure for their discomfort more efficiently.
However, processing descriptive responses through manual means is no longer necessary. Most market research teams have embraced automated unstructured data processing breakthroughs. They can guess a customer’s emotions and intentions from submitted texts without frequent human intervention. This era of machine learning (ML) offers ample opportunities to train ML systems to sort patients’ responses quickly.
So, life science companies can increase their employees’ productivity if their healthcare market research providers support ML-based feedback sorting and automation strategies.
Besides, hospitals, rehabilitation centers, and animal care facilities can incorporate virtual or physical robots powered by conversational artificial intelligence (AI). Doing so is one of the potential approaches to addressing certain patients’ loneliness problems throughout hospitalization. Utilize MR to ask your stakeholders whether such integrations improve their living standards.
3| Improving Marketing and Sales
Healthcare market research aids pharma and biotechnology corporations to categorize customer preferences according to their impact on sales. It also reveals how brands can appeal to more people when introducing a new product or service. One approach is to shut down or downscale poorly performing ideas.
If a healthcare facility can reduce resources spent on underperforming promotions, it can redirect them to more engaging campaigns. Likewise, MR specialists let patients and doctors directly communicate their misgivings about such a medicine or treatment via online channels. The scale of these surveys can extend to national, continental, or global markets. It is more accessible as cloud platforms flexibly adjust the resources a market research project may need.
With consistent communication involving doctors, patients, equipment vendors, and pharmaceutical brands, the healthcare industry will be more accountable. It will thrive sustainably.
Healthcare Market Research: Is It Ethical?
Market researchers in healthcare and life sciences will rely more on data-led planning as competition increases and customers demand richer experiences like telemedicine. Remember, it is not surprising how awareness regarding healthcare infrastructure has skyrocketed since 2020. At the same time, life science companies must proceed with caution when handling sensitive data in a patient’s clinical history.
On one hand, universities and private research projects need more healthcare data. Meanwhile, threats of clinical record misuse are real, having irreparable financial and psychological damage potential.
Ideally, hospitals, laboratories, and pharmaceutical firms must inform patients about the use of health records for research or treatment intervention. Today, reputed data providers often conduct MR surveys, use focus groups, and scan scholarly research publications. They want to respect patients’ choice in who gets to store, modify, and share the data.
Best Practices for Healthcare Market Research Projects
Legal requirements affecting healthcare data analysis, market research, finance, and ethics vary worldwide. Your data providers must recognize and respect this reality. Otherwise, gathering, storing, analyzing, sharing, or deleting a patient’s clinical records can increase legal risks.
Even if a healthcare business has no malicious intention behind extracting insights, cybercriminals can steal healthcare data. Therefore, invest in robust IT infrastructure, partner with experts, and prioritize data governance.
Like customer-centricity in commercial market research applications, dedicate your design philosophy to patient-centricity.
Incorporating health economics and outcomes research (HEOR) will depend on real-world evidence (RWE). Therefore, protect data integrity and increase quality management standards. If required, find automated data validation assistance and develop or rent big data facilities.
Capture data on present industry trends while maintaining a grasp on long-term objectives. After all, a lot of data is excellent for accuracy, but relevance is the backbone of analytical excellence and business focus.
Conclusion
Given this situation, transparency is the key to protecting stakeholder faith in healthcare data management. As such, MR consultants must act accordingly. Healthcare market research is not unethical. Yet, this statement stays valid only if a standardized framework specifies when patients’ consent trumps medical researchers’ data requirements. Healthcare market research is not unethical. Yet, this statement stays valid only if a standardized framework specifies when patients’ consent trumps medical researchers’ data requirements.
Market research techniques can help fix the long-standing communication and ethics issues in doctor-patient relationships if appropriately configured, highlighting their importance in the healthcare industry’s progress. When patients willingly cooperate with MR specialists, identifying recovery challenges or clinical devices’ ergonomic failures is quick. No wonder that health and life sciences organizations want to optimize their offerings by using market research.
3 notes
·
View notes
Text
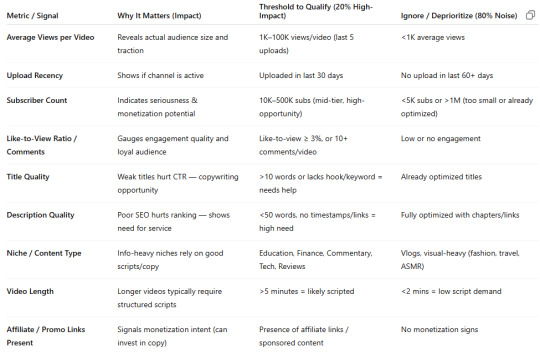
Metrics for analyzing
Providing copywriting services to YouTube channels is a smart niche—many creators need help with titles, descriptions, hooks, scripts, and even SEO optimization. To assess whether a channel qualifies for your service (and what kind of service they might need), your scraper should collect both quantitative and qualitative data points.
Here’s a detailed breakdown of key metrics and inferences you can build:
1. Basic Channel Information
Channel Name
Channel URL
Channel Description: Helps identify niche/genre (e.g., tech, beauty, education).
Country (if available)
2. Engagement & Reach
These indicate whether the channel is active, growing, and potentially monetized (i.e., worth investing in copywriting).
Subscriber Count
Total Video Count
Total Views
Average Views per Video
View-to-subscriber ratio (helps assess engagement)
Upload Frequency (e.g., X videos/week or month)
Recent Upload Dates (to confirm activity)
Video Age Analysis: Are they consistently posting for 6+ months?
3. Content Performance (Recent 5–10 Videos)
Scrape video-level metadata to infer how content performs and how optimized it is:
Title Length and Structure
Presence of Keywords in Title/Description
Clickbait vs. Informational Titles
Average Views per Recent Video
Like-to-View Ratio
Comment Count
Video Duration Trends
Scripted Content? (Inferred from style/genre—e.g., educational likely is)
Thumbnail Quality (optional, using image recognition or tagging)
4. SEO and Copy Optimization Check
Scrape and analyze:
Video Descriptions: Are they SEO-friendly, engaging, or just minimal?
Use of Tags: How many and which ones? Relevant or generic?
Chapters/Timestamps in Description
Hashtags Used
External Links (e.g., affiliate, social, Patreon)
5. Channel Niche / Target Market
Use the scraped channel and video descriptions, titles, and tags to cluster:
Topic Categories: Tech, Gaming, Beauty, Education, Vlogging, Finance, etc.
Content Type: Entertainment, tutorials, storytelling, reviews, commentary
Target Audience: Kids, general, professionals, niche communities
6. Monetization Signals
Sponsorship Mentions
Affiliate Links
Merch Store / Patreon / Memberships
Professional Thumbnails, Intro, Branding (suggests budget + seriousness)
7. Pain Point Signals for Copywriting
These can help your system prioritize channels that likely need help:
Poor Titles (vague, long, unstructured)
Empty or weak Descriptions
Low engagement despite high subs
Inconsistent uploads despite decent views
No timestamps or SEO optimization
Channels with good visuals but bad copy
Bonus: Score & Segment Channels
You can use the above to compute a lead score for each channel:
Activity Score: Upload frequency + recent activity
Engagement Score: View-to-sub ratio + like/comment ratios
Optimization Score: Title/desc quality + tag usage + SEO elements
Copywriting Need Score: Signs of poor copy vs. high potential
Segment them into:
High-need, high-potential: Poor copy, decent reach
High-performing but scalable: Good copy, could scale with help
Low engagement or inactive: Not qualified now
Would you like help creating the scraper logic or a scoring algorithm?
1 note
·
View note
Text
Impact of AI on Web Scraping Practices

Introduction
Owing to advancements in artificial intelligence (AI), the history of web scraping is a story of evolution towards efficiency in recent times. With an increasing number of enterprises and researchers relying on data extraction in deriving insights and making decisions, AI-enabled web scraping methods have transformed some of the traditional techniques into newer methods that are more efficient, more scalable, and more resistant to anti-scraping measures.
This blog discusses the effects of AI on web scraping, how AI-powered automation is changing the web scraping industry, the challenges being faced, and, ultimately, the road ahead for web scraping with AI.
How AI is Transforming Web Scraping
1. Enhanced Data Extraction Efficiency
Standard methods of scraping websites and information are rule-based extraction and rely on the script that anybody has created for that particular site, and it is hard-coded for that site and set of extraction rules. But in the case of web scraping using AI, such complexities are avoided, wherein the adaptation of the script happens automatically with a change in the structure of the websites, thus ensuring the same data extraction without rewriting the script constantly.
2. AI-Powered Web Crawlers
Machine learning algorithms enable web crawlers to mimic human browsing behavior, reducing the risk of detection. These AI-driven crawlers can:
Identify patterns in website layouts.
Adapt to dynamic content.
Handle complex JavaScript-rendered pages with ease.
3. Natural Language Processing (NLP) for Data Structuring
NLP helps in:
Extracting meaningful insights from unstructured text.
Categorizing and classifying data based on context.
Understanding sentiment and contextual relevance in customer reviews and news articles.
4. Automated CAPTCHA Solving
Many websites use CAPTCHAs to block bots. AI models, especially deep learning-based Optical Character Recognition (OCR) techniques, help bypass these challenges by simulating human-like responses.
5. AI in Anti-Detection Mechanisms
AI-powered web scraping integrates:
User-agent rotation to simulate diverse browsing behaviors.
IP Rotation & Proxies to prevent blocking.
Headless Browsers & Human-Like Interaction for bypassing bot detection.
Applications of AI in Web Scraping
1. E-Commerce Price Monitoring
AI scrapers help businesses track competitors' pricing, stock availability, and discounts in real-time, enabling dynamic pricing strategies.
2. Financial & Market Intelligence
AI-powered web scraping extracts financial reports, news articles, and stock market data for predictive analytics and trend forecasting.
3. Lead Generation & Business Intelligence
Automating the collection of business contact details, customer feedback, and sales leads through AI-driven scraping solutions.
4. Social Media & Sentiment Analysis
Extracting social media conversations, hashtags, and sentiment trends to analyze brand reputation and customer perception.
5. Healthcare & Pharmaceutical Data Extraction
AI scrapers retrieve medical research, drug prices, and clinical trial data, aiding healthcare professionals in decision-making.
Challenges in AI-Based Web Scraping
1. Advanced Anti-Scraping Technologies
Websites employ sophisticated detection methods, including fingerprinting and behavioral analysis.
AI mitigates these by mimicking real user interactions.
2. Data Privacy & Legal Considerations
Compliance with data regulations like GDPR and CCPA is essential.
Ethical web scraping practices ensure responsible data usage.
3. High Computational Costs
AI-based web scrapers require GPU-intensive resources, leading to higher operational costs.
Optimization techniques, such as cloud-based scraping, help reduce costs.
Future Trends in AI for Web Scraping
1. AI-Driven Adaptive Scrapers
Scrapers that self-learn and adjust to new website structures without human intervention.
2. Integration with Machine Learning Pipelines
Combining AI scrapers with data analytics tools for real-time insights.
3. AI-Powered Data Anonymization
Protecting user privacy by automating data masking and filtering.
4. Blockchain-Based Data Validation
Ensuring authenticity and reliability of extracted data using blockchain verification.
Conclusion
The addition of AI to the web scrape has made it smarter, flexible, and scalable as far as data extraction is concerned. The use of AIs for web scraping will help organizations navigate through anti-bot mechanisms, dynamic changes in websites, and unstructured data processing. Indeed, in the future, web scraping with AI will only be enhanced and more advanced to contribute further innovations in sectors across industries.
For organizations willing to embrace the power of data extraction with AI, CrawlXpert brings you state-of-the-art solutions designed for the present-day web scraping task. Get working with CrawlXpert right now in order to gain from AI-enabled quality automated web scraping solutions!
Know More : https://www.crawlxpert.com/blog/ai-on-web-scraping-practices
0 notes
Text
Top 7 Use Cases of Web Scraping in E-commerce
In the fast-paced world of online retail, data is more than just numbers; it's a powerful asset that fuels smarter decisions and competitive growth. With thousands of products, fluctuating prices, evolving customer behaviors, and intense competition, having access to real-time, accurate data is essential. This is where internet scraping comes in.
Internet scraping (also known as web scraping) is the process of automatically extracting data from websites. In the e-commerce industry, it enables businesses to collect actionable insights to optimize product listings, monitor prices, analyze trends, and much more.

In this blog, we’ll explore the top 7 use cases of internet scraping, detailing how each works, their benefits, and why more companies are investing in scraping solutions for growth and competitive advantage.
What is Internet Scraping?
Internet scraping is the process of using bots or scripts to collect data from web pages. This includes prices, product descriptions, reviews, inventory status, and other structured or unstructured data from various websites. Scraping can be used once or scheduled periodically to ensure continuous monitoring. It’s important to adhere to data guidelines, terms of service, and ethical practices. Tools and platforms like TagX ensure compliance and efficiency while delivering high-quality data.
In e-commerce, this practice becomes essential for businesses aiming to stay agile in a saturated and highly competitive market. Instead of manually gathering data, which is time-consuming and prone to errors, internet scraping automates this process and provides scalable, consistent insights at scale.
Before diving into the specific use cases, it's important to understand why so many successful e-commerce companies rely on internet scraping. From competitive pricing to customer satisfaction, scraping empowers businesses to make informed decisions quickly and stay one step ahead in the fast-paced digital landscape.
Below are the top 7 Use cases of internet scraping.
1. Price Monitoring
Online retailers scrape competitor sites to monitor prices in real-time, enabling dynamic pricing strategies and maintaining competitiveness. This allows brands to react quickly to price changes.
How It Works
It is programmed to extract pricing details for identical or similar SKUs across competitor sites. The data is compared to your product catalog, and dashboards or alerts are generated to notify you of changes. The scraper checks prices across various time intervals, such as hourly, daily, or weekly, depending on the market's volatility. This ensures businesses remain up-to-date with any price fluctuations that could impact their sales or profit margins.
Benefits of Price Monitoring
Competitive edge in pricing
Avoids underpricing or overpricing
Enhances profit margins while remaining attractive to customers
Helps with automatic repricing tools
Allows better seasonal pricing strategies
2. Product Catalog Optimization
Scraping competitor and marketplace listings helps optimize your product catalog by identifying missing information, keyword trends, or layout strategies that convert better.
How It Works
Scrapers collect product titles, images, descriptions, tags, and feature lists. The data is analyzed to identify gaps and opportunities in your listings. AI-driven catalog optimization tools use this scraped data to recommend ideal product titles, meta tags, and visual placements. Combining this with A/B testing can significantly improve your conversion rates.
Benefits
Better product visibility
Enhanced user experience and conversion rates
Identifies underperforming listings
Helps curate high-performing metadata templates
3. Competitor Analysis
Internet scraping provides detailed insights into your competitors’ strategies, such as pricing, promotions, product launches, and customer feedback, helping to shape your business approach.
How It Works
Scraped data from competitor websites and social platforms is organized and visualized for comparison. It includes pricing, stock levels, and promotional tactics. You can monitor their advertising frequency, ad types, pricing structure, customer engagement strategies, and feedback patterns. This creates a 360-degree understanding of what works in your industry.
Benefits
Uncover competitive trends
Benchmark product performance
Inform marketing and product strategy
Identify gaps in your offerings
Respond quickly to new product launches
4. Customer Sentiment Analysis
By scraping reviews and ratings from marketplaces and product pages, businesses can evaluate customer sentiment, discover pain points, and improve service quality.
How It Works
Natural language processing (NLP) is applied to scraped review content. Positive, negative, and neutral sentiments are categorized, and common themes are highlighted. Text analysis on these reviews helps detect not just satisfaction levels but also recurring quality issues or logistics complaints. This can guide product improvements and operational refinements.
Benefits
Improve product and customer experience
Monitor brand reputation
Address negative feedback proactively
Build trust and transparency
Adapt to changing customer preferences
5. Inventory and Availability Tracking
Track your competitors' stock levels and restocking schedules to predict demand and plan your inventory efficiently.
How It Works
Scrapers monitor product availability indicators (like "In Stock", "Out of Stock") and gather timestamps to track restocking frequency. This enables brands to respond quickly to opportunities when competitors go out of stock. It also supports real-time alerts for critical stock thresholds.
Benefits
Avoid overstocking or stockouts
Align promotions with competitor shortages
Streamline supply chain decisions
Improve vendor negotiation strategies
Forecast demand more accurately
6. Market Trend Identification
Scraping data from marketplaces and social commerce platforms helps identify trending products, search terms, and buyer behaviors.
How It Works
Scraped data from platforms like Amazon, eBay, or Etsy is analyzed for keyword frequency, popularity scores, and rising product categories. Trends can also be extracted from user-generated content and influencer reviews, giving your brand insights before a product goes mainstream.
Benefits
Stay ahead of consumer demand
Launch timely product lines
Align campaigns with seasonal or viral trends
Prevent dead inventory
Invest confidently in new product development
7. Lead Generation and Business Intelligence
Gather contact details, seller profiles, or niche market data from directories and B2B marketplaces to fuel outreach campaigns and business development.
How It Works
Scrapers extract publicly available email IDs, company names, product listings, and seller ratings. The data is filtered based on industry and size. Lead qualification becomes faster when you pre-analyze industry relevance, product categories, or market presence through scraped metadata.
Benefits
Expand B2B networks
Targeted marketing efforts
Increase qualified leads and partnerships
Boost outreach accuracy
Customize proposals based on scraped insights
How Does Internet Scraping Work in E-commerce?
Target Identification: Identify the websites and data types you want to scrape, such as pricing, product details, or reviews.
Bot Development: Create or configure a scraper bot using tools like Python, BeautifulSoup, or Scrapy, or use advanced scraping platforms like TagX.
Data Extraction: Bots navigate web pages, extract required data fields, and store them in structured formats (CSV, JSON, etc.).
Data Cleaning: Filter, de-duplicate, and normalize scraped data for analysis.
Data Analysis: Feed clean data into dashboards, CRMs, or analytics platforms for decision-making.
Automation and Scheduling: Set scraping frequency based on how dynamic the target sites are.
Integration: Sync data with internal tools like ERP, inventory systems, or marketing automation platforms.
Key Benefits of Internet Scraping for E-commerce
Scalable Insights: Access large volumes of data from multiple sources in real time
Improved Decision Making: Real-time data fuels smarter, faster decisions
Cost Efficiency: Reduces the need for manual research and data entry
Strategic Advantage: Gives brands an edge over slower-moving competitors
Enhanced Customer Experience: Drives better content, service, and personalization
Automation: Reduces human effort and speeds up analysis
Personalization: Tailor offers and messaging based on real-world competitor and customer data
Why Businesses Trust TagX for Internet Scraping
TagX offers enterprise-grade, customizable internet scraping solutions specifically designed for e-commerce businesses. With compliance-first approaches and powerful automation, TagX transforms raw online data into refined insights. Whether you're monitoring competitors, optimizing product pages, or discovering market trends, TagX helps you stay agile and informed.
Their team of data engineers and domain experts ensures that each scraping task is accurate, efficient, and aligned with your business goals. Plus, their built-in analytics dashboards reduce the time from data collection to actionable decision-making.
Final Thoughts
E-commerce success today is tied directly to how well you understand and react to market data. With internet scraping, brands can unlock insights that drive pricing, inventory, customer satisfaction, and competitive advantage. Whether you're a startup or a scaled enterprise, the smart use of scraping technology can set you apart.
Ready to outsmart the competition? Partner with TagX to start scraping smarter.
0 notes
Text
Data Science Trending in 2025
What is Data Science?
Data Science is an interdisciplinary field that combines scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It is a blend of various tools, algorithms, and machine learning principles with the goal to discover hidden patterns from raw data.
Introduction to Data Science
In the digital era, data is being generated at an unprecedented scale—from social media interactions and financial transactions to IoT sensors and scientific research. This massive amount of data is often referred to as "Big Data." Making sense of this data requires specialized techniques and expertise, which is where Data Science comes into play.
Data Science enables organizations and researchers to transform raw data into meaningful information that can help make informed decisions, predict trends, and solve complex problems.
History and Evolution
The term "Data Science" was first coined in the 1960s, but the field has evolved significantly over the past few decades, particularly with the rise of big data and advancements in computing power.
Early days: Initially, data analysis was limited to simple statistical methods.
Growth of databases: With the emergence of databases, data management and retrieval improved.
Rise of machine learning: The integration of algorithms that can learn from data added a predictive dimension.
Big Data Era: Modern data science deals with massive volumes, velocity, and variety of data, leveraging distributed computing frameworks like Hadoop and Spark.
Components of Data Science
1. Data Collection and Storage
Data can come from multiple sources:
Databases (SQL, NoSQL)
APIs
Web scraping
Sensors and IoT devices
Social media platforms
The collected data is often stored in data warehouses or data lakes.
2. Data Cleaning and Preparation
Raw data is often messy—containing missing values, inconsistencies, and errors. Data cleaning involves:
Handling missing or corrupted data
Removing duplicates
Normalizing and transforming data into usable formats
3. Exploratory Data Analysis (EDA)
Before modeling, data scientists explore data visually and statistically to understand its main characteristics. Techniques include:
Summary statistics (mean, median, mode)
Data visualization (histograms, scatter plots)
Correlation analysis
4. Data Modeling and Machine Learning
Data scientists apply statistical models and machine learning algorithms to:
Identify patterns
Make predictions
Classify data into categories
Common models include regression, decision trees, clustering, and neural networks.
5. Interpretation and Communication
The results need to be interpreted and communicated clearly to stakeholders. Visualization tools like Tableau, Power BI, or matplotlib in Python help convey insights effectively.
Techniques and Tools in Data Science
Statistical Analysis
Foundational for understanding data properties and relationships.
Machine Learning
Supervised and unsupervised learning for predictions and pattern recognition.
Deep Learning
Advanced neural networks for complex tasks like image and speech recognition.
Natural Language Processing (NLP)
Techniques to analyze and generate human language.
Big Data Technologies
Hadoop, Spark, Kafka for handling massive datasets.
Programming Languages
Python: The most popular language due to its libraries like pandas, NumPy, scikit-learn.
R: Preferred for statistical analysis.
SQL: For database querying.
Applications of Data Science
Data Science is used across industries:
Healthcare: Predicting disease outbreaks, personalized medicine, medical image analysis.
Finance: Fraud detection, credit scoring, algorithmic trading.
Marketing: Customer segmentation, recommendation systems, sentiment analysis.
Manufacturing: Predictive maintenance, supply chain optimization.
Transportation: Route optimization, autonomous vehicles.
Entertainment: Content recommendation on platforms like Netflix and Spotify.
Challenges in Data Science
Data Quality: Poor data can lead to inaccurate results.
Data Privacy and Ethics: Ensuring responsible use of data and compliance with regulations.
Skill Gap: Requires multidisciplinary knowledge in statistics, programming, and domain expertise.
Scalability: Handling and processing vast amounts of data efficiently.
Future of Data Science
The future promises further integration of artificial intelligence and automation in data science workflows. Explainable AI, augmented analytics, and real-time data processing are areas of rapid growth.
As data continues to grow exponentially, the importance of data science in guiding strategic decisions and innovation across sectors will only increase.
Conclusion
Data Science is a transformative field that unlocks the power of data to solve real-world problems. Through a combination of techniques from statistics, computer science, and domain knowledge, data scientists help organizations make smarter decisions, innovate, and gain a competitive edge.
Whether you are a student, professional, or business leader, understanding data science and its potential can open doors to exciting opportunities and advancements in technology and society.
0 notes
Text
How to reduce product returns with Digital shelf analytics
Discover how Digital shelf analytics can help minimize product returns to transform your retail success. Dive in for actionable strategies. Read more https://xtract.io/blog/how-to-reduce-product-returns-with-digital-shelf-analytics/
0 notes
Text

🚀 Unlock the Power of Enterprise-Grade Web Scraping for Smarter Business Decisions
In today’s data-driven ecosystem, enterprises need real-time, scalable, and custom web scraping solutions to stay competitive, adapt to market shifts, and fuel strategic decision-making. 🌐
🔍 Here’s what enterprise web scraping can help you achieve:
📊 Automate large-scale data collection across industries
📈 Monitor competitors, pricing, trends, and reviews in real-time
🛒 Extract eCommerce, real estate, travel, finance, and job data with precision
🔐 Ensure secure, compliant, and reliable data pipelines
🤖 Enable AI and analytics models with structured, high-quality datasets
💡 “Data is no longer just an asset—it's the competitive advantage.” Enterprise scraping helps turn unstructured web data into actionable intelligence.
0 notes
Text
The Role of Custom Web Data Extraction: Enhancing Business Intelligence and Competitive Advantage
Your off-the-shelf scraping tool worked perfectly last month. Then your target website updated their layout. Everything broke.
Your data pipeline stopped. Your competitive intelligence disappeared. Your team scrambled to fix scripts that couldn’t handle the new structure.
This scenario repeats across thousands of businesses using off-the-shelf extraction tools. Here’s the problem: 89% of leaders recognize web data’s importance. But standardized solutions fail when websites fight back with anti-bot defenses, dynamic content, or simple redesigns.
Custom extraction solves these problems. AI-powered systems see websites like humans do. They adapt automatically when things change.
This article reveals how custom web data extraction delivers reliable intelligence where off-the-shelf tools fail. You’ll discover why tailored solutions outperform one-size-fits-all approaches. You’ll also get to see a detailed industry-specific guide showing how business leaders solve their most complex data challenges.
Beyond Basic Scraping: What Makes Custom Web Data Extraction Different
Basic tools rely on rigid scripts. They expect websites to stay frozen in time. That’s simply not how the modern web works.
Today’s websites use sophisticated blocking techniques:
Rotating CAPTCHA challenges.
Browser fingerprinting.
IP rate limiting.
Complex JavaScript frameworks that render content client-side.
Custom solutions overcome these barriers. They use advanced capabilities you won’t find in basic tools.
Here’s what sets custom web data extraction apart:
Tailored architecture designed for your specific needs and target sources.
AI-powered browsers that render pages exactly as humans see them.
Intelligent IP rotation through thousands of addresses to avoid detection.
Automatic adaptation when target websites change their structure.
Enterprise-grade scale monitoring millions of pages across thousands of sources.
Basic tools might handle dozens of sites with hundreds of results. But they require constant babysitting from your team. Every website redesign breaks your scripts. Every new blocking technique stops your data flow.
On the other hand, enterprise-grade custom solutions monitor thousands of sources simultaneously. Their scrapers extract millions of data points with pinpoint accuracy and adapt automatically when sites change structure.
But here’s what really matters: intelligent data processing.
Raw scraped data is messy and inconsistent. Tailored solutions transform this chaos into structured intelligence by:
Cleaning and standardizing information automatically.
Matching products across different retailers despite varying naming conventions.
Identifying and flagging anomalies that could indicate data quality issues.
Structuring unstructured data into analysis-ready formats.
Industry research reveals that the technical barriers are real. 82% of organizations need help overcoming data collection challenges:
55% face IP blocking.
52% struggle with CAPTCHAs.
56% deal with dynamic content that traditional tools can’t handle.
This is why sophisticated businesses partner with experienced providers like Forage AI. We’ve perfected these capabilities over decades of experience and provide you with enterprise-grade capabilities without the headaches of maintaining complex infrastructure.
Now that you understand what makes custom extraction powerful, let’s see how this capability transforms the core business functions that drive competitive advantage.
Transforming Business Intelligence Across Key Functions
Custom web data extraction doesn’t just collect information. It revolutionizes how organizations understand their markets, customers, and competitive landscape.
Here’s how it transforms three critical business intelligence areas:
Real-Time Competitive Analysis
Forget checking competitor websites once a week. Custom extraction provides continuous competitive surveillance. It captures changes the moment they happen.
Your system monitors:
Pricing changes and product launches across competitor portfolios.
Executive appointments and organizational restructuring at target companies.
Regulatory filings and compliance updates from government sources.
Market expansion and strategic partnerships across your industry.
The competitive advantage:
Shift from reactive to proactive strategic positioning.
Respond within hours instead of days when competitors make a move.
Anticipate market shifts before other players spot them.
Position strategically based on live competitive intelligence.
Customer Intelligence & Market Insights
Understanding your customers means looking beyond your own data. You need to see how they behave across the entire market.
Custom extraction aggregates customer sentiment, preferences, and feedback from every relevant touchpoint online.
Comprehensive customer intelligence includes:
Review patterns across all major platforms to identify valued features.
Social media conversations to spot emerging trends before mainstream awareness.
Forum discussions to understand unmet needs representing new opportunities.
Purchase behavior signals across competitor platforms and review sites.
Strategic insights you gain:
Why customers choose competitors over you.
What actually drives their purchase decisions.
How their preferences evolve over time.
Which features and benefits resonate most strongly with your target market.
Operational Intelligence
Smart organizations use web data to optimize operations beyond marketing and sales. Custom extraction provides the external intelligence that makes internal operations more efficient and strategic.
Supply chain optimization through:
Supplier monitoring of websites, industry news, and regulatory announcements.
Commodity price tracking and shipping delay alerts.
Geopolitical event monitoring that could affect procurement strategies.
Risk management enhancement via:
Early warning signals from news sources and regulatory sites.
Compliance issue identification before they impact operations.
Reputation threat monitoring across digital channels.
Strategic planning support including:
Competitor expansion intelligence and market opportunity identification.
Industry trend analysis that shapes future strategy.
Market condition assessment for long-term decision-making.
This operational intelligence enables informed strategic planning. You gain comprehensive context for critical business decisions.
With these transformed business functions providing superior market intelligence, you’re positioned to create sustainable competitive advantages. But how exactly does this intelligence translate into lasting business benefits? Let’s examine the specific advantages that compound over time.
Creating Sustainable Competitive Advantages
The real power of custom web data extraction isn’t just better information. It’s the systematic advantages that compound over time. Your organization becomes increasingly difficult for competitors to match.
Speed and Agility
Research shows that 73% of organizations achieve quicker decision-making through systematic web data collection. But speed isn’t just about faster decisions. It’s about being first to market opportunities.
Immediate competitive benefits:
Capitalize on competitor pricing errors immediately rather than discovering them days later.
Adjust strategy while competitors are still gathering information.
Position yourself for new opportunities while others are still analyzing.
Compounding speed advantages:
Each quick response strengthens your market position. Customers associate your brand with market leadership. New opportunities become easier to capture.
Consider dynamic pricing strategies. They adjust in real-time based on competitor actions, inventory levels, and demand signals. Organizations using this approach report revenue increases of 5-25% compared to static pricing models.
Complete Market Coverage
While competitors rely on off-the-shelf tools that have limited coverage, custom extraction provides 360-degree market visibility. Industry research indicates that 98% of organizations need more data of at least one type. Tailored solutions eliminate this limitation entirely.
Your monitoring advantage includes:
Direct competitors and adjacent markets that could affect your business.
Pricing, inventory, promotions plus customer sentiment and regulatory changes.
Primary markets plus possibilities of international expansion.
Current conditions and emerging trends before they become obvious.
The scale difference is striking. Simple extraction tools can only handle dozens of products from a few sites before breaking down. Custom extraction monitors thousands of sources continuously with high accuracy. This creates market intelligence that’s simply impossible with off-the-shelf solutions.
Predictive Analytics Capability
With comprehensive, real-time data flowing systematically, you can build predictive capabilities. You anticipate market changes rather than just responding to them.
This is where Forage AI’s expertise becomes critical. We process data from 500M+ websites with AI-powered techniques, transforming raw information into strategic insights. 53% of organizations use public web data specifically to build the AI models that power these predictive insights.
Predictive intelligence detects:
Customer churn signals weeks before accounts show obvious warning signs.
Supply chain disruptions preventing inventory shortages before they impact operations.
Fraud detection patterns identifying suspicious activities before financial losses occur.
Lead scoring optimization predicting which prospects convert before competitors spot them.
The combination of speed, coverage, and prediction creates competitive advantages that are difficult for rivals to replicate. They’d need to invest in similar systematic data capabilities to match your market intelligence. By that time, you’ve gained additional advantages through earlier implementation.
These competitive benefits become even more powerful when applied to specific industry challenges. Let’s take a look at how different sectors leverage these capabilities for measurable ROI.
Industry-Specific Applications That Drive ROI
Different industries face unique competitive challenges. Custom web data extraction solves these in specific, measurable ways.
E-commerce & Retail
Retail operates in the most price-transparent market in history. 75% of retail organizations collect market data systematically while 51% use it specifically for brand health monitoring across multiple channels.
But here’s what sets custom extraction apart from basic extraction tools:
Visual Intelligence Engines: Extract and analyze product images across 1000+ competitor sites to identify color trends, style patterns, and merchandising strategies. Spot emerging visual trends 48 hours before they go mainstream by handling JavaScript-heavy product galleries that load dynamically as users scroll – something basic tools simply can’t manage.
Review Feature Mining: Go beyond sentiment scores. Extract unstructured review data to identify specific product features customers mention that aren’t in your specs. When customers repeatedly request “pockets” in competitor dress reviews, you’ll know before your next design cycle.
Micro-Influencer Discovery: Scrape social media platforms to find micro-influencers already organically mentioning your product category. Identify authentic voices with engaged audiences before they’re on anyone’s radar.
Stock Pattern Prediction: Monitor availability patterns across competitor sites to predict stockouts 7-10 days in advance. This isn’t just checking “in stock” labels – it’s analyzing restocking frequencies, quantity limits, and shipping delays.
Financial Services
Financial institutions face unique challenges around risk assessment, regulatory compliance, and market intelligence.
Custom extraction delivers capabilities impossible with standard tools:
Alternative Data Signals: Extract job postings, online company reviews, and web traffic patterns to assess company health 90 days before earnings reports. When a tech company suddenly posts 50 new sales positions while their engineering hiring freezes, you’ll spot the pivot early.
Multi-Language Regulatory Intelligence: Monitor 200+ regulatory websites across dozens of languages simultaneously for policy changes. Detect subtle shifts in compliance requirements weeks before official translations appear. This requires sophisticated language processing beyond basic translation.
ESG Risk Detection: Scrape news sites, NGO reports, and social media for real-time Environmental, Social, and Governance risk indicators. Identify supply chain controversies or environmental violations before they impact investment portfolios.
High-Frequency Data Extraction: Handle encrypted financial documents and real-time feeds from trading platforms. Process complex data structures that update milliseconds apart while maintaining accuracy.
Healthcare
Healthcare organizations need extraction capabilities that handle complex medical data and compliance requirements:
Clinical Trial Competition Intelligence: Extract real-time patient enrollment numbers and protocol changes from ClinicalTrials.gov and competitor sites. Know when rivals struggle with recruitment or modify trial endpoints. This means parsing complex medical documents and research papers.
Physician Opinion Tracking: Monitor medical forums and conference abstracts for emerging treatment preferences. Detect when specialists start discussing off-label uses or combination therapies 6 months before publication.
Drug Shortage Prediction: Combine Food and Drug Administration databases with pharmacy inventory signals to predict shortages 2-3 weeks early. Extract data from multiple formats while handling medical terminology variations.
Patient Journey Mapping: Analyze anonymized patient experiences from health forums to understand real treatment pathways. Navigate HIPAA-compliant extraction while capturing meaningful insights.
Manufacturing
Manufacturing requires extraction solutions that handle technical complexity across global supply chains:
Component Crisis Detection: Monitor 500+ distributor websites globally for lead time changes on critical components. Detect when a key supplier extends delivery from 8 to 12 weeks before it impacts your production line.
Patent Innovation Tracking: Extract and analyze competitor patent filings to identify technology directions 18 months before product launches. Parse technical specifications and CAD file references to understand true innovation patterns.
Quality Signal Detection: Mine consumer forums and review sites for early product defect patterns. Identify quality issues weeks before they escalate to recalls. This requires understanding technical language across multiple industries.
Sustainability Compliance Monitoring: Extract supplier ESG certifications, audit results, and environmental data from diverse sources. Track your entire supply chain’s compliance status in real-time across different reporting standards.
The Bottom Line: Measurable Impact Across Your Business
When you add it all up, custom web data extraction delivers three types of measurable value:
Immediate efficiency gains through automated intelligence gathering, reducing data processing time by 30-40% while improving decision speed and accuracy.
Revenue acceleration via dynamic pricing optimization (5-25% increases), market timing advantages, and strategic positioning based on comprehensive market understanding.
Risk reduction through early warning systems that spot threats before they impact operations, enabling proactive responses rather than costly reactive measures.
Organizations implementing these capabilities systematically are 57% more likely to expect significant revenue growth. The compound effect means early adopters gain advantages that become increasingly difficult for competitors to match.
These industry applications prove a key point. Sophisticated web data extraction isn’t just a technical capability. It’s a strategic business tool that drives measurable edge across diverse sectors and use cases.
Conclusion: Custom Data Extraction as Competitive Necessity
The evidence is clear. Organizations that systematically leverage web data consistently outperform those relying on manual methods or standard extraction techniques.
89% of business leaders recognize data’s importance. But only those implementing custom extraction solutions capture its full competitive potential.
This isn’t about having better tools. It’s about fundamentally transforming how you understand and respond to market dynamics. Custom web data extraction provides the systematic intelligence foundation that modern competitive strategy requires.
The question isn’t whether to invest in these capabilities. It’s how quickly you can implement them before competitors gain similar advantages.
Ready to stop guessing and start knowing? Contact Forage AI to discover how custom web data extraction can transform your competitive positioning and business intelligence capabilities.
0 notes
Text
Boost Your Retail Strategy with Quick Commerce Data Scraping in 2025
Introduction
The retail landscape is evolving rapidly, with Quick Commerce (Q-Commerce) driving instant deliveries across groceries, FMCG, and essential products. Platforms like Blinkit, Instacart, Getir, Gorillas, Swiggy Instamart, and Zapp dominate the space, offering ultra-fast deliveries. However, for retailers to stay competitive, optimize pricing, and track inventory, real-time data insights are crucial.
Quick Commerce Data Scraping has become a game-changer in 2025, enabling retailers to extract, analyze, and act on live market data. Retail Scrape, a leader in AI-powered data extraction, helps businesses track pricing trends, stock levels, promotions, and competitor strategies.
Why Quick Commerce Data Scraping is Essential for Retailers?
Optimize Pricing Strategies – Track real-time competitor prices & adjust dynamically.
Monitor Inventory Trends – Avoid overstocking or stockouts with demand forecasting.
Analyze Promotions & Discounts – Identify top deals & seasonal price drops.
Understand Consumer Behavior – Extract insights from customer reviews & preferences.
Improve Supply Chain Management – Align logistics with real-time demand analysis.
How Quick Commerce Data Scraping Enhances Retail Strategies?
1. Real-Time Competitor Price Monitoring
2. Inventory Optimization & Demand Forecasting
3. Tracking Promotions & Discounts
4. AI-Driven Consumer Behavior Analysis
Challenges in Quick Commerce Scraping & How to Overcome Them
Frequent Website Structure Changes Use AI-driven scrapers that automatically adapt to dynamic HTML structures and website updates.
Anti-Scraping Technologies (CAPTCHAs, Bot Detection, IP Bans) Deploy rotating proxies, headless browsers, and CAPTCHA-solving techniques to bypass restrictions.
Real-Time Price & Stock Changes Implement real-time web scraping APIs to fetch updated pricing, discounts, and inventory availability.
Geo-Restricted Content & Location-Based Offers Use geo-targeted proxies and VPNs to access region-specific data and ensure accuracy.
High Request Volume Leading to Bans Optimize request intervals, use distributed scraping, and implement smart throttling to prevent getting blocked.
Unstructured Data & Parsing Complexities Utilize AI-based data parsing tools to convert raw HTML into structured formats like JSON, CSV, or databases.
Multiple Platforms with Different Data Formats Standardize data collection from apps, websites, and APIs into a unified format for seamless analysis.
Industries Benefiting from Quick Commerce Data Scraping
1. eCommerce & Online Retailers
2. FMCG & Grocery Brands
3. Market Research & Analytics Firms
4. Logistics & Supply Chain Companies
How Retail Scrape Can Help Businesses in 2025
Retail Scrape provides customized Quick Commerce Data Scraping Services to help businesses gain actionable insights. Our solutions include:
Automated Web & Mobile App Scraping for Q-Commerce Data.
Competitor Price & Inventory Tracking with AI-Powered Analysis.
Real-Time Data Extraction with API Integration.
Custom Dashboards for Data Visualization & Predictive Insights.
Conclusion
In 2025, Quick Commerce Data Scraping is an essential tool for retailers looking to optimize pricing, track inventory, and gain competitive intelligence. With platforms like Blinkit, Getir, Instacart, and Swiggy Instamart shaping the future of instant commerce, data-driven strategies are the key to success.
Retail Scrape’s AI-powered solutions help businesses extract, analyze, and leverage real-time pricing, stock, and consumer insights for maximum profitability.
Want to enhance your retail strategy with real-time Q-Commerce insights? Contact Retail Scrape today!
Read more >>https://www.retailscrape.com/fnac-data-scraping-retail-market-intelligence.php
officially published by https://www.retailscrape.com/.
#QuickCommerceDataScraping#RealTimeDataExtraction#AIPoweredDataExtraction#RealTimeCompetitorPriceMonitoring#MobileAppScraping#QCommerceData#QCommerceInsights#BlinkitDataScraping#RealTimeQCommerceInsights#RetailScrape#EcommerceAnalytics#InstantDeliveryData#OnDemandCommerceData#QuickCommerceTrends
0 notes
Text
Smart Retail Decisions Start with AI-Powered Data Scraping

In a world where consumer preferences change overnight and pricing wars escalate in real time, making smart retail decisions is no longer about instincts—it's about data. And not just any data. Retailers need fresh, accurate, and actionable insights drawn from a vast and competitive digital landscape.
That’s where AI-powered data scraping steps in.
Historically, traditional data scraping has been used to gather ecommerce data. But by leveraging artificial intelligence (AI) in scraping processes, companies can gain real-time, scalable, and predictive intelligence to make informed decisions in retailing.
Here, we detail how data scraping using AI is revolutionizing retailing, its advantages, what kind of data you can scrape, and why it enables high-impact decisions in terms of pricing, inventory, customer behavior, and market trends.
What Is AI-Powered Data Scraping?
Data scraping is an operation of pulling structured data from online and digital channels, particularly websites that do not support public APIs. In retail, these can range from product offerings and price data to customer reviews and availability of items in stock.
AI-driven data scraping goes one step further by employing artificial intelligence such as machine learning, natural language processing (NLP), and predictive algorithms to:
Clean and structure unstructured data
Interpret customer sentiment from reviews
Detect anomalies in prices
Predict market trends
Based on data collected, provide strategic proposals
It's not just about data-gathering—it’s about knowing and taking wise action based on it.
Why Retail Requires Smarter Data Solutions
The contemporary retail sector is sophisticated and dynamic. This is why AI-powered scraping is more important than ever:
Market Changes Never Cease to Occur Prices, demand, and product availability can alter multiple times each day—particularly on marketplaces such as Amazon or Walmart. AI scrapers can monitor and study these changes round-the-clock.
Manual Decision-Making is Too Slow Human analysts can process only so much data. AI accelerates decision-making by processing millions of pieces of data within seconds and highlighting what's significant.
The Competition is Tough Retailers are in a race to offer the best prices, maintain optimal inventory, and deliver exceptional customer experiences. Data scraping allows companies to monitor competitors in real time.
Types of Retail Data You Can Scrape with AI
AI-powered scraping tools can extract and analyze the following retail data from ecommerce sites, review platforms, competitor websites, and search engines:
Product Information
Titles, descriptions, images
Product variants (size, color, model)
Brand and manufacturer details
Availability (in stock/out of stock)
Pricing & Promotions
Real-time price tracking
Historical pricing trends
Discount and offer patterns
Dynamic pricing triggers
Inventory & Supply
Stock levels
Delivery timelines
Warehouse locations
SKU movement tracking
Reviews & Ratings
NLP-based sentiment analysis
Star ratings and text content
Trending complaints or praise
Verified purchase filtering
Market Demand & Sales Rank
Bestsellers by category
Category saturation metrics
Sales velocity signals
New or emerging product trends
Logistics & Shipping
Delivery options and timeframes
Free shipping thresholds
Return policies and costs
Benefits of AI-Powered Data Scraping in Retail
So what happens when you combine powerful scraping capabilities with AI intelligence? Retailers unlock a new dimension of performance and strategy.
1. Real-Time Competitive Intelligence
With AI-enhanced scraping, retailers can monitor:
Price changes across hundreds of competitor SKUs
Promotional campaigns
Inventory status of competitor bestsellers
AI models can predict when a competitor may launch a flash sale or run low on inventory—giving you an opportunity to win customers.
2. Smarter Dynamic Pricing
Machine learning algorithms can:
Analyze competitor pricing history
Forecast demand elasticity
Recommend optimal pricing
Retailers can automatically adjust prices to stay competitive while maximizing margins.
3. Enhanced Product Positioning
By analyzing product reviews and ratings using NLP, you can:
Identify common customer concerns
Improve product descriptions
Make data-driven merchandising decisions
For example, if customers frequently mention packaging issues, that feedback can be looped directly to product development.
4. Improved Inventory Planning
AI-scraped data helps detect:
Which items are trending up or down
Seasonality patterns
Regional demand variations
This enables smarter stocking, reduced overstock, and faster response to emerging trends.
5. Superior Customer Experience
Insights from reviews and competitor platforms help you:
Optimize support responses
Highlight popular product features
Personalize marketing campaigns
Use Cases: How Retailers Are Winning with AI Scraping
DTC Ecommerce Brands
Use AI to monitor pricing and product availability across marketplaces. React to changes in real time and adjust pricing or run campaigns accordingly.
Multichannel Retailers
Track performance and pricing across online and offline channels to maintain brand consistency and pricing competitiveness.
Consumer Insights Teams
Analyze thousands of reviews to spot unmet needs or new use cases—fueling product innovation and positioning.
Marketing and SEO Analysts
Scrape metadata, titles, and keyword rankings to optimize product listings and outperform competitors in search results.
Choosing the Right AI-Powered Scraping Partner
Whether building your own tool or hiring a scraping agency, here’s what to look for:
Scalable Infrastructure
The tool should handle scraping thousands of pages per hour, with robust error handling and proxy support.
Intelligent Data Processing
Look for integrated machine learning and NLP models that analyze and enrich the data in real time.
Customization and Flexibility
Ensure the solution can adapt to your specific data fields, scheduling, and delivery format (JSON, CSV, API).
Legal and Ethical Compliance
A reliable partner will adhere to anti-bot regulations, avoid scraping personal data, and respect site terms of service.
Challenges and How to Overcome Them
While AI-powered scraping is powerful, it’s not without hurdles:
Website Structure Changes
Ecommerce platforms often update their layouts. This can break traditional scraping scripts.
Solution: AI-based scrapers with adaptive learning can adjust without manual reprogramming.
Anti-Bot Measures
Websites deploy CAPTCHAs, IP blocks, and rate limiters.
Solution: Use rotating proxies, headless browsers, and CAPTCHA solvers.
Data Noise
Unclean or irrelevant data can lead to false conclusions.
Solution: Leverage AI for data cleaning, anomaly detection, and duplicate removal.
Final Thoughts
In today's ecommerce disruption, retailers that utilize real-time, smart data will be victorious. AI-driven data scraping solutions no longer represent an indulgence but rather an imperative to remain competitive.
By facilitating data capture and smarter insights, these services support improved customer experience, pricing, marketing, and inventory decisions.
No matter whether you’re introducing a new product, measuring your market, or streamlining your supply chain—smart retailing begins with smart data.
0 notes
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text
Five Things You Didn’t Know About Unstructured Web
Get the most out of web data with our custom web scraping and crawling solutions. Our intelligent data extraction capabilities help in fetching data from complex websites with ease. Read more https://www.scrape.works/infographics/BigData/five-things-you-didnt-know-about-unstructured-web
0 notes
Link
[ad_1] Web scraping and data extraction are crucial for transforming unstructured web content into actionable insights. Firecrawl Playground streamlines this process with a user-friendly interface, enabling developers and data practitioners to explore and preview API responses through various extraction methods easily. In this tutorial, we walk through the four primary features of Firecrawl Playground: Single URL (Scrape), Crawl, Map, and Extract, highlighting their unique functionalities. Single URL Scrape In the Single URL mode, users can extract structured content from individual web pages by providing a specific URL. The response preview within the Firecrawl Playground offers a concise JSON representation, including essential metadata such as page title, description, main content, images, and publication dates. The user can easily evaluate the structure and quality of data returned by this single-page scraping method. This feature is useful for cases where focused, precise data from individual pages, such as news articles, product pages, or blog posts, is required. The user accesses the Firecrawl Playground and enters the URL www.marktechpost.com under the Single URL (/scrape) tab. They select the FIRE-1 model and write the prompt: “Get me all the articles on the homepage.” This sets up Firecrawl’s agent to retrieve structured content from the MarkTechPost homepage using an LLM-powered extraction approach. The result of the single-page scrape is displayed in a Markdown view. It successfully extracts links to various sections, such as “Natural Language Processing,” “AI Agents,” “New Releases,” and more, from the homepage of MarkTechPost. Below these links, a sample article headline with introductory text is also displayed, indicating accurate content parsing. Crawl The Crawl mode significantly expands extraction capabilities by allowing automated traversal through multiple interconnected web pages starting from a given URL. Within the Playground’s preview, users can quickly examine responses from the initial crawl, observing JSON-formatted summaries of page content alongside URLs discovered during crawling. The Crawl feature effectively handles broader extraction tasks, including retrieving comprehensive content from entire websites, category pages, or multi-part articles. Users benefit from the ability to assess crawl depth, page limits, and response details through this preview functionality. In the Crawl (/crawl) tab, the same site ( www.marktechpost.com ) is used. The user sets a crawl limit of 10 pages and configures path filters to exclude pages such as “blog” or “about,” while including only URLs under the “/articles/” path. Page options are customized to extract only the main content, avoiding tags such as scripts, ads, and footers, thereby optimizing the crawl for relevant information. The platform shows results for 10 pages scraped from MarkTechPost. Each tile in the results grid presents content extracted from different sections, such as “Sponsored Content,” “SLD Dashboard,” and “Embed Link.” Each page has both Markdown and JSON response tabs, offering flexibility in how the extracted content is viewed or processed. Map The Map feature introduces an advanced extraction mechanism by applying user-defined mappings across crawled data. It enables users to specify custom schema structures, such as extracting particular text snippets, authors’ names, or detailed product descriptions from multiple pages simultaneously. The Playground preview clearly illustrates how mapping rules are applied, presenting extracted data in a neatly structured JSON format. Users can quickly confirm the accuracy of their mappings and ensure that the extracted content aligns precisely with their analytical requirements. This feature significantly streamlines complex data extraction workflows requiring consistency across multiple webpages. In the Map (/map) tab, the user again targets www.marktechpost.com but this time uses the Search (Beta) feature with the keyword “blog.” Additional options include enabling subdomain searches and respecting the site’s sitemap. This mode aims to retrieve a large number of relevant URLs that match the search pattern. The mapping operation returns a total of 5000 matched URLs from the MarkTechPost website. These include links to categories and articles under themes such as AI, machine learning, knowledge graphs, and others. The links are displayed in a structured list, with the option to view results as JSON or download them for further processing. Currently available in Beta, the Extract feature further refines Firecrawl’s capabilities by facilitating tailored data retrieval through advanced extraction schemas. With Extract, users design highly granular extraction patterns, such as isolating specific data points, including author metadata, detailed product specifications, pricing information, or publication timestamps. The Playground’s Extract preview displays real-time API responses that reflect user-defined schemas, providing immediate feedback on the accuracy and completeness of the extraction. As a result, users can iterate and fine-tune extraction rules seamlessly, ensuring data precision and relevance. Under the Extract (/extract) tab (Beta), the user enters the URL and defines a custom extraction schema. Two fields are specified: company_mission as a string and is_open_source as a boolean. The prompt guides the extraction to ignore details such as partners or integrations, focusing instead on the company’s mission and whether it is open-source. The final formatted JSON output shows that MarkTechPost is identified as an open-source platform, and its mission is accurately extracted: “To provide the latest news and insights in the field of Artificial Intelligence and technology, focusing on research, tutorials, and industry developments.” In conclusion, Firecrawl Playground provides a robust and user-friendly environment that significantly simplifies the complexities of web data extraction. Through intuitive previews of API responses across Single URL, Crawl, Map, and Extract modes, users can effortlessly validate and optimize their extraction strategies. Whether working with isolated web pages or executing intricate, multi-layered extraction schemas across entire sites, Firecrawl Playground empowers data professionals with powerful, versatile tools essential for effective and accurate web data retrieval. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit. 🔥 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes