#semantic graph model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
Revolutionizing Digital Marketing with Quantum SEO

In a world where algorithms evolve by the minute and competition for digital visibility is fiercer than ever, traditional SEO tactics are no longer enough. Enter Quantum SEO—a next-gen approach to search engine optimization that combines artificial intelligence, data science, and advanced semantic understanding to unlock unseen ranking potential. At Thatware LLP, we're leading the charge with cutting-edge Quantum SEO services designed to future-proof your online presence.
What Is Quantum SEO?
Quantum SEO is not just another buzzword in the digital marketing realm. It represents a paradigm shift in how search engines are understood and optimized for. Unlike conventional SEO, which relies heavily on keywords, backlinks, and content updates, Quantum SEO leverages:
AI-driven algorithms
Natural Language Processing (NLP)
Predictive user behavior analytics
Knowledge graphs and entity-based SEO
Machine learning for real-time SERP adaptation
It’s about understanding not just what users search for, but why they search—making your content smarter, faster, and more contextually relevant.
Why Quantum SEO Matters in 2025 and Beyond
Search engines like Google are becoming increasingly context-aware and user-intent focused. The rise of semantic search, voice assistants, and conversational AI means SEO strategies must evolve. Quantum SEO ensures your brand stays ahead by:
Enhancing search intent matching
Aligning content with Google’s E-E-A-T principles
Improving core web vitals and user experience
Utilizing AI predictions to preemptively optimize content
These innovations allow businesses to gain an unfair advantage in high-competition niches.
Quantum SEO Services at Thatware LLP
At Thatware, we’ve pioneered Quantum SEO services tailored to today’s advanced search environment. Our process includes:
AI-powered audit tools to scan and analyze your website's SEO health
Custom NLP-based content optimization
Entity-based schema markup to align with search engine knowledge graphs
Advanced competitor analysis using data modeling and reverse engineering
Semantic content clusters for topical authority building
Our approach is scientific, data-driven, and custom-tailored to each client’s industry and goals.
Real Results, Scientifically Engineered
Unlike conventional SEO providers that rely on generic packages, Thatware’s Quantum SEO services are grounded in data science and proprietary AI models. Our clients have seen dramatic increases in keyword rankings, traffic quality, and conversions—especially in highly competitive industries like finance, health, and tech.
Final Thoughts: Embrace the Quantum Leap
SEO is no longer just about keywords—it's about intelligence. By adopting Quantum SEO, your brand can step into the future of search optimization, leveraging science-backed techniques to dominate SERPs like never before.
0 notes
Text
IEEE Transactions on Fuzzy Systems, Volume 33, Issue 6, June 2025
1) Brain-Inspired Fuzzy Graph Convolution Network for Alzheimer's Disease Diagnosis Based on Imaging Genetics Data
Author(s): Xia-An Bi, Yangjun Huang, Wenzhuo Shen, Zicheng Yang, Yuhua Mao, Luyun Xu, Zhonghua Liu
Pages: 1698 - 1712
2) Adaptive Incremental Broad Learning System Based on Interval Type-2 Fuzzy Set With Automatic Determination of Hyperparameters
Author(s): Haijie Wu, Weiwei Lin, Yuehong Chen, Fang Shi, Wangbo Shen, C. L. Philip Chen
Pages: 1713 - 1725
3) A Novel Reliable Three-Way Multiclassification Model Under Intuitionistic Fuzzy Environment
Author(s): Libo Zhang, Cong Guo, Tianxing Wang, Dun Liu, Huaxiong Li
Pages: 1726 - 1739
4) Guaranteed State Estimation for H−/L∞ Fault Detection of Uncertain Takagi–Sugeno Fuzzy Systems With Unmeasured Nonlinear Consequents
Author(s): Masoud Pourasghar, Anh-Tu Nguyen, Thierry-Marie Guerra
Pages: 1740 - 1752
5) Online Self-Learning Fuzzy Recurrent Stochastic Configuration Networks for Modeling Nonstationary Dynamics
Author(s): Gang Dang, Dianhui Wang
Pages: 1753 - 1766
6) ADMTSK: A High-Dimensional Takagi–Sugeno–Kang Fuzzy System Based on Adaptive Dombi T-Norm
Author(s): Guangdong Xue, Liangjian Hu, Jian Wang, Sergey Ablameyko
Pages: 1767 - 1780
7) Constructing Three-Way Decision With Fuzzy Granular-Ball Rough Sets Based on Uncertainty Invariance
Author(s): Jie Yang, Zhuangzhuang Liu, Guoyin Wang, Qinghua Zhang, Shuyin Xia, Di Wu, Yanmin Liu
Pages: 1781 - 1792
8) TOGA-Based Fuzzy Grey Cognitive Map for Spacecraft Debris Avoidance
Author(s): Chenhui Qin, Yuanshi Liu, Tong Wang, Jianbin Qiu, Min Li
Pages: 1793 - 1802
9) Reinforcement Learning-Based Fault-Tolerant Control for Semiactive Air Suspension Based on Generalized Fuzzy Hysteresis Model
Author(s): Pak Kin Wong, Zhijiang Gao, Jing Zhao
Pages: 1803 - 1814
10) Adaptive Fuzzy Attention Inference to Control a Microgrid Under Extreme Fault on Grid Bus
Author(s): Tanvir M. Mahim, A.H.M.A. Rahim, M. Mosaddequr Rahman
Pages: 1815 - 1824
11) Semisupervised Feature Selection With Multiscale Fuzzy Information Fusion: From Both Global and Local Perspectives
Author(s): Nan Zhou, Shujiao Liao, Hongmei Chen, Weiping Ding, Yaqian Lu
Pages: 1825 - 1839
12) Fuzzy Domain Adaptation From Heterogeneous Source Teacher Models
Author(s): Keqiuyin Li, Jie Lu, Hua Zuo, Guangquan Zhang
Pages: 1840 - 1852
13) Differentially Private Distributed Nash Equilibrium Seeking for Aggregative Games With Linear Convergence
Author(s): Ying Chen, Qian Ma, Peng Jin, Shengyuan Xu
Pages: 1853 - 1863
14) Robust Divide-and-Conquer Multiple Importance Kalman Filtering via Fuzzy Measure for Multipassive-Sensor Target Tracking
Author(s): Hongwei Zhang
Pages: 1864 - 1875
15) Fully Informed Fuzzy Logic System Assisted Adaptive Differential Evolution Algorithm for Noisy Optimization
Author(s): Sheng Xin Zhang, Yu Hong Liu, Xin Rou Hu, Li Ming Zheng, Shao Yong Zheng
Pages: 1876 - 1888
16) Impulsive Control of Nonlinear Multiagent Systems: A Hybrid Fuzzy Adaptive and Event-Triggered Strategy
Author(s): Fang Han, Hai Jin
Pages: 1889 - 1898
17) Uncertainty-Aware Superpoint Graph Transformer for Weakly Supervised 3-D Semantic Segmentation
Author(s): Yan Fan, Yu Wang, Pengfei Zhu, Le Hui, Jin Xie, Qinghua Hu
Pages: 1899 - 1912
18) Observer-Based SMC for Discrete Interval Type-2 Fuzzy Semi-Markov Jump Models
Author(s): Wenhai Qi, Runkun Li, Peng Shi, Guangdeng Zong
Pages: 1913 - 1925
19) Network Security Scheme for Discrete-Time T-S Fuzzy Nonlinear Active Suspension Systems Based on Multiswitching Control Mechanism
Author(s): Jiaming Shen, Yang Liu, Mohammed Chadli
Pages: 1926 - 1936
20) Fuzzy Multivariate Variational Mode Decomposition With Applications in EEG Analysis
Author(s): Hongkai Tang, Xun Yang, Yixuan Yuan, Pierre-Paul Vidal, Danping Wang, Jiuwen Cao, Duanpo Wu
Pages: 1937 - 1948
21) Adaptive Broad Network With Graph-Fuzzy Embedding for Imbalanced Noise Data
Author(s): Wuxing Chen, Kaixiang Yang, Zhiwen Yu, Feiping Nie, C. L. Philip Chen
Pages: 1949 - 1962
22) Average Filtering Error-Based Event-Triggered Fuzzy Filter Design With Adjustable Gains for Networked Control Systems
Author(s): Yingnan Pan, Fan Huang, Tieshan Li, Hak-Keung Lam
Pages: 1963 - 1976
23) Fuzzy and Crisp Gaussian Kernel-Based Co-Clustering With Automatic Width Computation
Author(s): José Nataniel A. de Sá, Marcelo R.P. Ferreira, Francisco de A.T. de Carvalho
Pages: 1977 - 1991
24) A Biselection Method Based on Consistent Matrix for Large-Scale Datasets
Author(s): Jinsheng Quan, Fengcai Qiao, Tian Yang, Shuo Shen, Yuhua Qian
Pages: 1992 - 2005
25) Nash Equilibrium Solutions for Switched Nonlinear Systems: A Fuzzy-Based Dynamic Game Method
Author(s): Yan Zhang, Zhengrong Xiang
Pages: 2006 - 2015
26) Active Domain Adaptation Based on Probabilistic Fuzzy C-Means Clustering for Pancreatic Tumor Segmentation
Author(s): Chendong Qin, Yongxiong Wang, Fubin Zeng, Jiapeng Zhang, Yangsen Cao, Xiaolan Yin, Shuai Huang, Di Chen, Huojun Zhang, Zhiyong Ju
Pages: 2016 - 2026
0 notes
Text
Power BI Trends 2025: AI Assist, Mobile Layouts & Semantic Model Advances
Microsoft Power BI continues to evolve with feature-rich updates aimed at improving analytics, user experience, and reporting flexibility. The latest updates in 2025 are geared toward making data visualization more accessible, intelligent, and mobile-responsive.
AI Assist Enhancements
Power BI now supports ad hoc calculations in read mode using Copilot. Users can ask questions and generate calculations directly from reports without entering edit mode. This expands the use of AI across all user levels.
Copilot is also now available on mobile devices, making insights accessible on the go. This helps business users interact with data and get answers from dashboards using natural language, no matter where they are.
Mobile Layout Auto-Creation
Creating mobile-friendly dashboards is now easier. Power BI automatically generates mobile layouts for desktop reports, which can be previewed and adjusted before publishing. This ensures reports are effective across both desktop and mobile interfaces without requiring extra effort from developers.
Semantic Model Enhancements
Developers now have the ability to edit semantic models live in Direct Lake mode. Changes sync seamlessly between Power BI Desktop and Power BI Service, supporting smoother collaboration across teams.
TMDL (Text Model Definition Language) view is also now available, allowing developers to compare and manage changes with better version control. These updates offer improved precision and flexibility for modeling complex data relationships.
New Visual Features
Power BI has expanded its visual options, including support for table headers with groupings, new chart types like Lollipop and Graph PRO, and updated mapping visuals. These provide better data presentation while allowing deeper interaction with insights.
Interface updates like Dark Mode and an improved metrics hub make navigating dashboards easier, faster, and more visually comfortable.
Expanded Data Connectivity
Power BI now offers broader data connectivity, including improved integration with platforms like Oracle, Vertica, and Snowflake. This makes it easier to centralize insights from multiple sources and reduces the need for complex data engineering.
Collaboration and Workflow Integration
Power BI continues to introduce features that enable interaction beyond just data consumption. With translytical flows and writeback support, users can now take actions directly from dashboards — such as approvals or updating entries — which enhances workflow automation and real-time decision-making.
These features position Power BI as more than just a reporting tool; it becomes a critical part of daily operations.
How VBeyond Digital Adds Value
VBeyond Digital helps organizations implement Power BI in ways that match their business goals. Their team offers full-service support covering:
Power BI integration with Azure, Dynamics 365, and third-party platforms
Power BI consulting services for strategy and solution design
A team of experienced Power BI experts and certified Power BI consultants
End-to-end Power BI services from data modeling to dashboard rollout
Support for Power Platform developers embedding Power BI into broader applications
VBeyond Digital ensures businesses get more from their data by implementing meaningful dashboards, training users, and supporting long-term optimization.
Final Thoughts
The 2025 updates to Power BI mark a shift toward smarter, mobile-ready, and action-oriented analytics. AI-assisted features, auto-generated mobile layouts, semantic modeling control, and real-time collaboration tools help users work more efficiently with data.
Organizations looking to adopt or upgrade their analytics should explore these new features and consider working with trusted partners like VBeyond Digital to implement them successfully.
#power bi integration#power bi consulting#power bi consulting services#power bi#microsoft#microsoft power automate
0 notes
Text
Hybrid AI Systems: Combining Symbolic and Statistical Approaches
Artificial Intelligence (AI) over the last few years has been driven primarily by two distinct methodologies: symbolic AI and statistical (or connectionist) AI. While both have achieved substantial results in isolation, the limitations of each approach have prompted researchers and organisations to explore hybrid AI systems—an integration of symbolic reasoning with statistical learning.
This hybrid model is reshaping the AI landscape by combining the strengths of both paradigms, leading to more robust, interpretable, and adaptable systems. In this blog, we’ll dive into how hybrid AI systems work, why they matter, and where they are being applied.
Understanding the Two Pillars: Symbolic vs. Statistical AI
Symbolic AI, also known as good old-fashioned AI (GOFAI), relies on explicit rules and logic. It represents knowledge in a human-readable form, such as ontologies and decision trees, and applies inference engines to reason through problems.
Example: Expert systems like MYCIN (used in medical diagnosis) operate on a set of "if-then" rules curated by domain experts.
Statistical AI, on the other hand, involves learning from data—primarily through machine learning models, especially neural networks. These models can recognise complex patterns and make predictions, but often lack transparency and interpretability.
Example: Deep learning models used in image and speech recognition can process vast datasets to identify subtle correlations but can be seen as "black boxes" in terms of reasoning.
The Need for Hybrid AI Systems
Each approach has its own set of strengths and weaknesses. Symbolic AI is interpretable and excellent for incorporating domain knowledge, but it struggles with ambiguity and scalability. Statistical AI excels at learning from large volumes of data but falters when it comes to reasoning, abstraction, and generalisation from few examples.
Hybrid AI systems aim to combine the strengths of both:
Interpretability from symbolic reasoning
Adaptability and scalability from statistical models
This fusion allows AI to handle both the structure and nuance of real-world problems more effectively.
Key Components of Hybrid AI
Knowledge Graphs: These are structured symbolic representations of relationships between entities. They provide context and semantic understanding to machine learning models. Google’s search engine is a prime example, where a knowledge graph enhances search intent detection.
Neuro-symbolic Systems: These models integrate neural networks with logic-based reasoning. A notable initiative is IBM’s Project Neuro-Symbolic AI, which combines deep learning with logic programming to improve visual question answering tasks.
Explainability Modules: By merging symbolic explanations with statistical outcomes, hybrid AI can provide users with clearer justifications for its decisions—crucial in regulated industries like healthcare and finance.
Real-world Applications of Hybrid AI
Healthcare: Diagnosing diseases often requires pattern recognition (statistical AI) and domain knowledge (symbolic AI). Hybrid systems are being developed to integrate patient history, medical literature, and real-time data for better diagnostics and treatment recommendations.
Autonomous Systems: Self-driving cars need to learn from sensor data (statistical) while following traffic laws and ethical considerations (symbolic). Hybrid AI helps in balancing these needs effectively.
Legal Tech: Legal document analysis benefits from NLP-based models combined with rule-based systems that understand jurisdictional nuances and precedents.
The Role of Hybrid AI in Data Science Education
As hybrid AI gains traction, it’s becoming a core topic in advanced AI and data science training. Enrolling in a Data Science Course that includes modules on symbolic logic, machine learning, and hybrid models can provide you with a distinct edge in the job market.
Especially for learners based in India, a Data Science Course in Mumbai often offers a diverse curriculum that bridges foundational AI concepts with cutting-edge developments like hybrid systems. Mumbai, being a major tech and financial hub, provides access to industry collaborations, real-world projects, and expert faculty—making it an ideal location to grasp the practical applications of hybrid AI.
Challenges and Future Outlook
Despite its promise, hybrid AI faces several challenges:
Integration Complexity: Merging symbolic and statistical approaches requires deep expertise across different AI domains.
Data and Knowledge Curation: Building and maintaining symbolic knowledge bases (e.g., ontologies) is resource-intensive.
Scalability: Hybrid systems must be engineered to perform efficiently at scale, especially in dynamic environments.
However, ongoing research is rapidly addressing these concerns. For instance, tools like Logic Tensor Networks (LTNs) and Probabilistic Soft Logic (PSL) are providing frameworks to facilitate hybrid modelling. Major tech companies like IBM, Microsoft, and Google are heavily investing in this space, indicating that hybrid AI is more than just a passing trend—it’s the future of intelligent systems.
Conclusion
Hybrid AI systems represent a promising convergence of logic-based reasoning and data-driven learning. By combining the explainability of symbolic AI with the predictive power of statistical models, these systems offer a more complete and reliable approach to solving complex problems.
For aspiring professionals, mastering this integrated approach is key to staying ahead in the evolving AI ecosystem. Whether through a Data Science Course online or an in-person Data Science Course in Mumbai, building expertise in hybrid AI will open doors to advanced roles in AI development, research, and strategic decision-making.
Business name: ExcelR- Data Science, Data Analytics, Business Analytics Course Training Mumbai
Address: 304, 3rd Floor, Pratibha Building. Three Petrol pump, Lal Bahadur Shastri Rd, opposite Manas Tower, Pakhdi, Thane West, Thane, Maharashtra 400602
Phone: 09108238354
Email: [email protected]
0 notes
Text
qKnow Platform – A Fusion Platform of Knowledge Graph and Large Language Models
qKnow Platform is an open-source knowledge management system designed for enterprise-level applications. It deeply integrates core capabilities such as knowledge extraction, knowledge fusion, knowledge reasoning, and knowledge graph construction.
By incorporating advanced large language model (LLM) technology, the platform significantly enhances the understanding and processing of both structured and unstructured data, enabling more intelligent and efficient knowledge extraction and semantic integration.
Leveraging the powerful reasoning and expression capabilities of LLMs, qKnow empowers organizations to rapidly build high-quality, actionable knowledge graph systems—driving intelligent decision-making and business innovation.
Gitee: https://gitee.com/qiantongtech/qKnow
GitHub: https://github.com/qiantongtech/qKnow







0 notes
Text
\documentclass[11pt]{article} \usepackage{amsmath, amssymb, amsfonts} \usepackage{geometry} \usepackage{graphicx} \usepackage{hyperref} \geometry{margin=1in} \title{Spectral Foundations for Hybrid Optoelectronic Computing Architectures: From Riemann Zeros to Physical AI Hardware} \author{Renato Ferreira da Silva \ \texttt{[email protected]} \ ORCID: \href{https://orcid.org/0009-0003-8908-481X}{0009-0003-8908-481X}} \date{\today}
\begin{document}
\maketitle
\begin{abstract} This article establishes a theoretical bridge between spectral models of the Riemann zeta zeros and the design principles of hybrid optoelectronic computing architectures. By interpreting data flow and signal processing as spectral phenomena, we draw on Schr\"odinger operators with machine-learned potentials to inform the structural logic of neuromorphic chips. Our approach uses the Gaussian Unitary Ensemble (GUE) as a universal benchmark for both numerical accuracy and hardware robustness. We argue that such architectures are not merely computational devices, but physical realizations of spectral operators whose eigenvalues encode semantic and functional states. This spectral paradigm enables scalable, reconfigurable, and energetically efficient AI hardware that emulates fundamental structures from number theory and quantum mechanics. \end{abstract}
\section{Introduction} The convergence of high-performance computing, artificial intelligence, and photonics demands a foundational rethinking of how computation is physically realized. While Moore's Law slows, spectral methods rooted in mathematical physics offer a new direction. In particular, the Hilbert--P\'olya conjecture---which suggests that the nontrivial zeros of the Riemann zeta function correspond to the eigenvalues of a self-adjoint operator---invites a reinterpretation of computation as a spectral phenomenon. This work connects spectral operator modeling with hardware design, offering a principled framework for constructing optoelectronic systems whose logic is derived from eigenvalue dynamics.
\section{Spectral Operator Framework} We consider operators of the form: [ \mathcal{L} = -\frac{d^2}{dx^2} + V(x), ] with Dirichlet boundary conditions and potentials of the form: [ V(x) = \sum_{n=0}^K c_n H_n(x) e^{-x^2/2}, ] where $H_n(x)$ are Hermite polynomials and $c_n$ are trainable parameters. The eigenvalues of $\mathcal{L}$, computed numerically, align with the statistical properties of the nontrivial zeros of the Riemann zeta function. We leverage neural networks to learn mappings $c_n \mapsto \lambda_j$, interpreting these as functional transformations from hardware configurations to observable spectral states.
\section{GUE as Design Metric} The Gaussian Unitary Ensemble provides a statistical benchmark for spectral rigidity and eigenvalue spacing. In our context, it serves dual roles: \begin{itemize} \item In simulation: to validate the fidelity of the learned operator. \item In hardware: to ensure robust optical communication, minimal crosstalk, and consistent signal coherence across filaments. \end{itemize} Designing hardware whose delay paths, optical resonances, and thermal fluctuations approximate GUE behavior results in physical stability under computational load.
\section{Hardware Realization of Spectral Paradigms} Each computational unit (UC) in the hybrid optoelectronic architecture is interpreted as a physical realization of a node in a spectral graph: \begin{itemize} \item Optical interconnects act as eigenmode couplings. \item Modulation depths and frequencies correspond to potential configurations. \item Thermal gradients and electromagnetic fields define boundary conditions. \end{itemize} Hence, computation is no longer symbolic but spectral---defined by eigenvalue distributions and dynamic wave propagation.
\section{Spectral Learning and Inference} Using physics-informed neural networks (PINNs), we train the system to infer potential shapes from target spectral outputs. This establishes a feedback loop where: \begin{enumerate} \item Input data modulates physical parameters. \item Spectral output is measured optically. \item Machine learning adjusts the configuration for optimal response. \end{enumerate} This feedback aligns with biological principles of neural plasticity, offering a pathway to hardware-level learning.
\section{Conclusion and Outlook} We propose a new paradigm in AI hardware design rooted in spectral operator theory. By grounding hardware architectures in the spectral behavior of Schr\"odinger-type systems, validated through GUE statistics and machine learning, we lay the foundation for scalable, efficient, and intelligent photonic computing. Future work will explore: \begin{itemize} \item Topological extensions to noncommutative geometries. \item Quantum analogs with entangled photonic states. \item Integration with health diagnostics and real-time physical simulation. \end{itemize}
\end{document}
0 notes
Text
Semantic Knowledge Graphing Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: Transforming Data into Knowledge at Scale
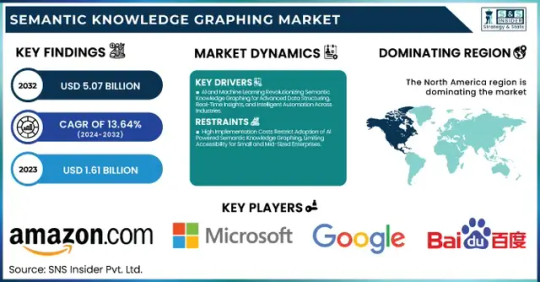
The Semantic Knowledge Graphing Market was valued at USD 1.61 billion in 2023 and is expected to reach USD 5.07 billion by 2032, growing at a CAGR of 13.64% from 2024-2032.
The Semantic Knowledge Graphing Market is rapidly evolving as organizations increasingly seek intelligent data integration and real-time insights. With the growing need to link structured and unstructured data for better decision-making, semantic technologies are becoming essential tools across sectors like healthcare, finance, e-commerce, and IT. This market is seeing a surge in demand driven by the rise of AI, machine learning, and big data analytics, as enterprises aim for context-aware computing and smarter data architectures.
Semantic Knowledge Graphing Market Poised for Strategic Transformation this evolving landscape is being shaped by an urgent need to solve complex data challenges with semantic understanding. Companies are leveraging semantic graphs to build context-rich models, enhance search capabilities, and create more intuitive AI experiences. As the digital economy thrives, semantic graphing offers a foundation for scalable, intelligent data ecosystems, allowing seamless connections between disparate data sources.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6040
Market Keyplayers:
Amazon.com Inc. (Amazon Neptune, AWS Graph Database)
Baidu, Inc. (Baidu Knowledge Graph, PaddlePaddle)
Facebook Inc. (Facebook Graph API, DeepText)
Google LLC (Google Knowledge Graph, Google Cloud Dataproc)
Microsoft Corporation (Azure Cosmos DB, Microsoft Graph)
Mitsubishi Electric Corporation (Maisart AI, MELFA Smart Plus)
NELL (Never-Ending Language Learner, NELL Knowledge Graph)
Semantic Web Company (PoolParty Semantic Suite, Semantic Middleware)
YAGO (YAGO Knowledge Base, YAGO Ontology)
Yandex (Yandex Knowledge Graph, Yandex Cloud ML)
IBM Corporation (IBM Watson Discovery, IBM Graph)
Oracle Corporation (Oracle Spatial and Graph, Oracle Cloud AI)
SAP SE (SAP HANA Graph, SAP Data Intelligence)
Neo4j Inc. (Neo4j Graph Database, Neo4j Bloom)
Databricks Inc. (Databricks GraphFrames, Databricks Delta Lake)
Stardog Union (Stardog Knowledge Graph, Stardog Studio)
OpenAI (GPT-based Knowledge Graphs, OpenAI Embeddings)
Franz Inc. (AllegroGraph, Allegro CL)
Ontotext AD (GraphDB, Ontotext Platform)
Glean (Glean Knowledge Graph, Glean AI Search)
Market Analysis
The Semantic Knowledge Graphing Market is transitioning from a niche segment to a critical component of enterprise IT strategy. Integration with AI/ML models has shifted semantic graphs from backend enablers to core strategic assets. With open data initiatives, industry-standard ontologies, and a push for explainable AI, enterprises are aggressively adopting semantic solutions to uncover hidden patterns, support predictive analytics, and enhance data interoperability. Vendors are focusing on APIs, graph visualization tools, and cloud-native deployments to streamline adoption and scalability.
Market Trends
AI-Powered Semantics: Use of NLP and machine learning in semantic graphing is automating knowledge extraction and relationship mapping.
Graph-Based Search Evolution: Businesses are prioritizing semantic search engines to offer context-aware, precise results.
Industry-Specific Graphs: Tailored graphs are emerging in healthcare (clinical data mapping), finance (fraud detection), and e-commerce (product recommendation).
Integration with LLMs: Semantic graphs are increasingly being used to ground large language models with factual, structured data.
Open Source Momentum: Tools like RDF4J, Neo4j, and GraphDB are gaining traction for community-led innovation.
Real-Time Applications: Event-driven semantic graphs are now enabling real-time analytics in domains like cybersecurity and logistics.
Cross-Platform Compatibility: Vendors are prioritizing seamless integration with existing data lakes, APIs, and enterprise knowledge bases.
Market Scope
Semantic knowledge graphing holds vast potential across industries:
Healthcare: Improves patient data mapping, drug discovery, and clinical decision support.
Finance: Enhances fraud detection, compliance tracking, and investment analysis.
Retail & E-Commerce: Powers hyper-personalized recommendations and dynamic customer journeys.
Manufacturing: Enables digital twins and intelligent supply chain management.
Government & Public Sector: Supports policy modeling, public data transparency, and inter-agency collaboration.
These use cases represent only the surface of a deeper transformation, where data is no longer isolated but intelligently interconnected.
Market Forecast
As AI continues to integrate deeper into enterprise functions, semantic knowledge graphs will play a central role in enabling contextual AI systems. Rather than just storing relationships, future graphing solutions will actively drive insight generation, data governance, and operational automation. Strategic investments by leading tech firms, coupled with the rise of vertical-specific graphing platforms, suggest that semantic knowledge graphing will become a staple of digital infrastructure. Market maturity is expected to rise rapidly, with early adopters gaining a significant edge in predictive capability, data agility, and innovation speed.
Access Complete Report: https://www.snsinsider.com/reports/semantic-knowledge-graphing-market-6040
Conclusion
The Semantic Knowledge Graphing Market is no longer just a futuristic concept—it's the connective tissue of modern data ecosystems. As industries grapple with increasingly complex information landscapes, the ability to harness semantic relationships is emerging as a decisive factor in digital competitiveness.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Semantic Knowledge Graphing Market#Semantic Knowledge Graphing Market Share#Semantic Knowledge Graphing Market Scope#Semantic Knowledge Graphing Market Trends
1 note
·
View note
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
Ravi Bommakanti, CTO of App Orchid – Interview Series
New Post has been published on https://thedigitalinsider.com/ravi-bommakanti-cto-of-app-orchid-interview-series/
Ravi Bommakanti, CTO of App Orchid – Interview Series

Ravi Bommakanti, Chief Technology Officer at App Orchid, leads the company’s mission to help enterprises operationalize AI across applications and decision-making processes. App Orchid’s flagship product, Easy Answers™, enables users to interact with data using natural language to generate AI-powered dashboards, insights, and recommended actions.
The platform integrates structured and unstructured data—including real-time inputs and employee knowledge—into a predictive data fabric that supports strategic and operational decisions. With in-memory Big Data technology and a user-friendly interface, App Orchid streamlines AI adoption through rapid deployment, low-cost implementation, and minimal disruption to existing systems.
Let’s start with the big picture—what does “agentic AI” mean to you, and how is it different from traditional AI systems?
Agentic AI represents a fundamental shift from the static execution typical of traditional AI systems to dynamic orchestration. To me, it’s about moving from rigid, pre-programmed systems to autonomous, adaptable problem-solvers that can reason, plan, and collaborate.
What truly sets agentic AI apart is its ability to leverage the distributed nature of knowledge and expertise. Traditional AI often operates within fixed boundaries, following predetermined paths. Agentic systems, however, can decompose complex tasks, identify the right specialized agents for sub-tasks—potentially discovering and leveraging them through agent registries—and orchestrate their interaction to synthesize a solution. This concept of agent registries allows organizations to effectively ‘rent’ specialized capabilities as needed, mirroring how human expert teams are assembled, rather than being forced to build or own every AI function internally.
So, instead of monolithic systems, the future lies in creating ecosystems where specialized agents can be dynamically composed and coordinated – much like a skilled project manager leading a team – to address complex and evolving business challenges effectively.
How is Google Agentspace accelerating the adoption of agentic AI across enterprises, and what’s App Orchid’s role in this ecosystem?
Google Agentspace is a significant accelerator for enterprise AI adoption. By providing a unified foundation to deploy and manage intelligent agents connected to various work applications, and leveraging Google’s powerful search and models like Gemini, Agentspace enables companies to transform siloed information into actionable intelligence through a common interface.
App Orchid acts as a vital semantic enablement layer within this ecosystem. While Agentspace provides the agent infrastructure and orchestration framework, our Easy Answers platform tackles the critical enterprise challenge of making complex data understandable and accessible to agents. We use an ontology-driven approach to build rich knowledge graphs from enterprise data, complete with business context and relationships – precisely the understanding agents need.
This creates a powerful synergy: Agentspace provides the robust agent infrastructure and orchestration capabilities, while App Orchid provides the deep semantic understanding of complex enterprise data that these agents require to operate effectively and deliver meaningful business insights. Our collaboration with the Google Cloud Cortex Framework is a prime example, helping customers drastically reduce data preparation time (up to 85%) while leveraging our platform’s industry-leading 99.8% text-to-SQL accuracy for natural language querying. Together, we empower organizations to deploy agentic AI solutions that truly grasp their business language and data intricacies, accelerating time-to-value.
What are real-world barriers companies face when adopting agentic AI, and how does App Orchid help them overcome these?
The primary barriers we see revolve around data quality, the challenge of evolving security standards – particularly ensuring agent-to-agent trust – and managing the distributed nature of enterprise knowledge and agent capabilities.
Data quality remains the bedrock issue. Agentic AI, like any AI, provides unreliable outputs if fed poor data. App Orchid tackles this foundationally by creating a semantic layer that contextualizes disparate data sources. Building on this, our unique crowdsourcing features within Easy Answers engage business users across the organization—those who understand the data’s meaning best—to collaboratively identify and address data gaps and inconsistencies, significantly improving reliability.
Security presents another critical hurdle, especially as agent-to-agent communication becomes common, potentially spanning internal and external systems. Establishing robust mechanisms for agent-to-agent trust and maintaining governance without stifling necessary interaction is key. Our platform focuses on implementing security frameworks designed for these dynamic interactions.
Finally, harnessing distributed knowledge and capabilities effectively requires advanced orchestration. App Orchid leverages concepts like the Model Context Protocol (MCP), which is increasingly pivotal. This enables the dynamic sourcing of specialized agents from repositories based on contextual needs, facilitating fluid, adaptable workflows rather than rigid, pre-defined processes. This approach aligns with emerging standards, such as Google’s Agent2Agent protocol, designed to standardize communication in multi-agent systems. We help organizations build trusted and effective agentic AI solutions by addressing these barriers.
Can you walk us through how Easy Answers™ works—from natural language query to insight generation?
Easy Answers transforms how users interact with enterprise data, making sophisticated analysis accessible through natural language. Here’s how it works:
Connectivity: We start by connecting to the enterprise’s data sources – we support over 200 common databases and systems. Crucially, this often happens without requiring data movement or replication, connecting securely to data where it resides.
Ontology Creation: Our platform automatically analyzes the connected data and builds a comprehensive knowledge graph. This structures the data into business-centric entities we call Managed Semantic Objects (MSOs), capturing the relationships between them.
Metadata Enrichment: This ontology is enriched with metadata. Users provide high-level descriptions, and our AI generates detailed descriptions for each MSO and its attributes (fields). This combined metadata provides deep context about the data’s meaning and structure.
Natural Language Query: A user asks a question in plain business language, like “Show me sales trends for product X in the western region compared to last quarter.”
Interpretation & SQL Generation: Our NLP engine uses the rich metadata in the knowledge graph to understand the user’s intent, identify the relevant MSOs and relationships, and translate the question into precise data queries (like SQL). We achieve an industry-leading 99.8% text-to-SQL accuracy here.
Insight Generation (Curations): The system retrieves the data and determines the most effective way to present the answer visually. In our platform, these interactive visualizations are called ‘curations’. Users can automatically generate or pre-configure them to align with specific needs or standards.
Deeper Analysis (Quick Insights): For more complex questions or proactive discovery, users can leverage Quick Insights. This feature allows them to easily apply ML algorithms shipped with the platform to specified data fields to automatically detect patterns, identify anomalies, or validate hypotheses without needing data science expertise.
This entire process, often completed in seconds, democratizes data access and analysis, turning complex data exploration into a simple conversation.
How does Easy Answers bridge siloed data in large enterprises and ensure insights are explainable and traceable?
Data silos are a major impediment in large enterprises. Easy Answers addresses this fundamental challenge through our unique semantic layer approach.
Instead of costly and complex physical data consolidation, we create a virtual semantic layer. Our platform builds a unified logical view by connecting to diverse data sources where they reside. This layer is powered by our knowledge graph technology, which maps data into Managed Semantic Objects (MSOs), defines their relationships, and enriches them with contextual metadata. This creates a common business language understandable by both humans and AI, effectively bridging technical data structures (tables, columns) with business meaning (customers, products, sales), regardless of where the data physically lives.
Ensuring insights are trustworthy requires both traceability and explainability:
Traceability: We provide comprehensive data lineage tracking. Users can drill down from any curations or insights back to the source data, viewing all applied transformations, filters, and calculations. This provides full transparency and auditability, crucial for validation and compliance.
Explainability: Insights are accompanied by natural language explanations. These summaries articulate what the data shows and why it’s significant in business terms, translating complex findings into actionable understanding for a broad audience.
This combination bridges silos by creating a unified semantic view and builds trust through clear traceability and explainability.
How does your system ensure transparency in insights, especially in regulated industries where data lineage is critical?
Transparency is absolutely non-negotiable for AI-driven insights, especially in regulated industries where auditability and defensibility are paramount. Our approach ensures transparency across three key dimensions:
Data Lineage: This is foundational. As mentioned, Easy Answers provides end-to-end data lineage tracking. Every insight, visualization, or number can be traced back meticulously through its entire lifecycle—from the original data sources, through any joins, transformations, aggregations, or filters applied—providing the verifiable data provenance required by regulators.
Methodology Visibility: We avoid the ‘black box’ problem. When analytical or ML models are used (e.g., via Quick Insights), the platform clearly documents the methodology employed, the parameters used, and relevant evaluation metrics. This ensures the ‘how’ behind the insight is as transparent as the ‘what’.
Natural Language Explanation: Translating technical outputs into understandable business context is crucial for transparency. Every insight is paired with plain-language explanations describing the findings, their significance, and potentially their limitations, ensuring clarity for all stakeholders, including compliance officers and auditors.
Furthermore, we incorporate additional governance features for industries with specific compliance needs like role-based access controls, approval workflows for certain actions or reports, and comprehensive audit logs tracking user activity and system operations. This multi-layered approach ensures insights are accurate, fully transparent, explainable, and defensible.
How is App Orchid turning AI-generated insights into action with features like Generative Actions?
Generating insights is valuable, but the real goal is driving business outcomes. With the correct data and context, an agentic ecosystem can drive actions to bridge the critical gap between insight discovery and tangible action, moving analytics from a passive reporting function to an active driver of improvement.
Here’s how it works: When the Easy Answers platform identifies a significant pattern, trend, anomaly, or opportunity through its analysis, it leverages AI to propose specific, contextually relevant actions that could be taken in response.
These aren’t vague suggestions; they are concrete recommendations. For instance, instead of just flagging customers at high risk of churn, it might recommend specific retention offers tailored to different segments, potentially calculating the expected impact or ROI, and even drafting communication templates. When generating these recommendations, the system considers business rules, constraints, historical data, and objectives.
Crucially, this maintains human oversight. Recommended actions are presented to the appropriate users for review, modification, approval, or rejection. This ensures business judgment remains central to the decision-making process while AI handles the heavy lifting of identifying opportunities and formulating potential responses.
Once an action is approved, we can trigger an agentic flow for seamless execution through integrations with operational systems. This could mean triggering a workflow in a CRM, updating a forecast in an ERP system, launching a targeted marketing task, or initiating another relevant business process – thus closing the loop from insight directly to outcome.
How are knowledge graphs and semantic data models central to your platform’s success?
Knowledge graphs and semantic data models are the absolute core of the Easy Answers platform; they elevate it beyond traditional BI tools that often treat data as disconnected tables and columns devoid of real-world business context. Our platform uses them to build an intelligent semantic layer over enterprise data.
This semantic foundation is central to our success for several key reasons:
Enables True Natural Language Interaction: The semantic model, structured as a knowledge graph with Managed Semantic Objects (MSOs), properties, and defined relationships, acts as a ‘Rosetta Stone’. It translates the nuances of human language and business terminology into the precise queries needed to retrieve data, allowing users to ask questions naturally without knowing underlying schemas. This is key to our high text-to-SQL accuracy.
Preserves Critical Business Context: Unlike simple relational joins, our knowledge graph explicitly captures the rich, complex web of relationships between business entities (e.g., how customers interact with products through support tickets and purchase orders). This allows for deeper, more contextual analysis reflecting how the business operates.
Provides Adaptability and Scalability: Semantic models are more flexible than rigid schemas. As business needs evolve or new data sources are added, the knowledge graph can be extended and modified incrementally without requiring a complete overhaul, maintaining consistency while adapting to change.
This deep understanding of data context provided by our semantic layer is fundamental to everything Easy Answers does, from basic Q&A to advanced pattern detection with Quick Insights, and it forms the essential foundation for our future agentic AI capabilities, ensuring agents can reason over data meaningfully.
What foundational models do you support, and how do you allow organizations to bring their own AI/ML models into the workflow?
We believe in an open and flexible approach, recognizing the rapid evolution of AI and respecting organizations’ existing investments.
For foundational models, we maintain integrations with leading options from multiple providers, including Google’s Gemini family, OpenAI’s GPT models, and prominent open-source alternatives like Llama. This allows organizations to choose models that best fit their performance, cost, governance, or specific capability needs. These models power various platform features, including natural language understanding for queries, SQL generation, insight summarization, and metadata generation.
Beyond these, we provide robust pathways for organizations to bring their own custom AI/ML models into the Easy Answers workflow:
Models developed in Python can often be integrated directly via our AI Engine.
We offer seamless integration capabilities with major cloud ML platforms such as Google Vertex AI and Amazon SageMaker, allowing models trained and hosted there to be invoked.
Critically, our semantic layer plays a key role in making these potentially complex custom models accessible. By linking model inputs and outputs to the business concepts defined in our knowledge graph (MSOs and properties), we allow non-technical business users to leverage advanced predictive, classification or causal models (e.g., through Quick Insights) without needing to understand the underlying data science – they interact with familiar business terms, and the platform handles the technical translation. This truly democratizes access to sophisticated AI/ML capabilities.
Looking ahead, what trends do you see shaping the next wave of enterprise AI—particularly in agent marketplaces and no-code agent design?
The next wave of enterprise AI is moving towards highly dynamic, composable, and collaborative ecosystems. Several converging trends are driving this:
Agent Marketplaces and Registries: We’ll see a significant rise in agent marketplaces functioning alongside internal agent registries. This facilitates a shift from monolithic builds to a ‘rent and compose’ model, where organizations can dynamically discover and integrate specialized agents—internal or external—with specific capabilities as needed, dramatically accelerating solution deployment.
Standardized Agent Communication: For these ecosystems to function, agents need common languages. Standardized agent-to-agent communication protocols, such as MCP (Model Context Protocol), which we leverage, and initiatives like Google’s Agent2Agent protocol, are becoming essential for enabling seamless collaboration, context sharing, and task delegation between agents, regardless of who built them or where they run.
Dynamic Orchestration: Static, pre-defined workflows will give way to dynamic orchestration. Intelligent orchestration layers will select, configure, and coordinate agents at runtime based on the specific problem context, leading to far more adaptable and resilient systems.
No-Code/Low-Code Agent Design: Democratization will extend to agent creation. No-code and low-code platforms will empower business experts, not just AI specialists, to design and build agents that encapsulate specific domain knowledge and business logic, further enriching the pool of available specialized capabilities.
App Orchid’s role is providing the critical semantic foundation for this future. For agents in these dynamic ecosystems to collaborate effectively and perform meaningful tasks, they need to understand the enterprise data. Our knowledge graph and semantic layer provide exactly that contextual understanding, enabling agents to reason and act upon data in relevant business terms.
How do you envision the role of the CTO evolving in a future where decision intelligence is democratized through agentic AI?
The democratization of decision intelligence via agentic AI fundamentally elevates the role of the CTO. It shifts from being primarily a steward of technology infrastructure to becoming a strategic orchestrator of organizational intelligence.
Key evolutions include:
From Systems Manager to Ecosystem Architect: The focus moves beyond managing siloed applications to designing, curating, and governing dynamic ecosystems of interacting agents, data sources, and analytical capabilities. This involves leveraging agent marketplaces and registries effectively.
Data Strategy as Core Business Strategy: Ensuring data is not just available but semantically rich, reliable, and accessible becomes paramount. The CTO will be central in building the knowledge graph foundation that powers intelligent systems across the enterprise.
Evolving Governance Paradigms: New governance models will be needed for agentic AI – addressing agent trust, security, ethical AI use, auditability of automated decisions, and managing emergent behaviors within agent collaborations.
Championing Adaptability: The CTO will be crucial in embedding adaptability into the organization’s technical and operational fabric, creating environments where AI-driven insights lead to rapid responses and continuous learning.
Fostering Human-AI Collaboration: A key aspect will be cultivating a culture and designing systems where humans and AI agents work synergistically, augmenting each other’s strengths.
Ultimately, the CTO becomes less about managing IT costs and more about maximizing the organization’s ‘intelligence potential’. It’s a shift towards being a true strategic partner, enabling the entire business to operate more intelligently and adaptively in an increasingly complex world.
Thank you for the great interview, readers who wish to learn more should visit App Orchid.
#adoption#agent#Agentic AI#agents#ai#AI adoption#AI AGENTS#AI systems#AI-powered#AI/ML#Algorithms#Amazon#amp#Analysis#Analytics#anomalies#anomaly#app#App Orchid#applications#approach#attributes#audit#autonomous#bedrock#bi#bi tools#Big Data#black box#box
0 notes
Text
LeanVec Improves Out-of-Distribution Vector Search Accuracy

Intel LeanVec Conquer Vector Search with Smart Dimensionality Reduction
The last essay in this series highlighted how vector search is essential in many applications that need precise and fast replies. Vector search systems often perform poorly due to memory and computation strain from large vector dimensionality. Also common are cross-modal retrieval tasks, such as those in which a user provides a text query to find the most relevant photographs.
These searches often have statistical distributions that differ from database embeddings, making accuracy problematic. Intel's LeanVec integrates dimensionality reduction and vector quantisation to speed up vector search on huge vectors while retaining accuracy in out-of-distribution queries.
Introduction
Recently, deep learning models have enhanced their capacity to construct high-dimensional embedding vectors whose spatial similarities match inputs including pictures, music, video, text, genomics, and computer code. This capability allows programs to explore massive vector collections for semantically meaningful results by finding the closest neighbours to a query vector. Even though similarity search has improved, modern vector indices perform poorly as dimensionality increases.
The most frequent are graph indices, which are directed graphs with edges indicating vector neighbor-relationships and vertices representing dataset vectors. Graph traversal is effective to find nearest neighbours in sub-linear time.
Graph-based indices excel at small dimensionalities (D = 100) but struggle with deep learning model dimensionalities (D ≈ 512, 768, 1536). If deep learning model-derived vectors dominate similarity search deployments, eliminating this performance gap is crucial.
This graph search speed drop is caused by the system's memory latency and bandwidth, which are largely utilised to fetch database vectors from memory randomly. Vector compression sounds like a decent technique to minimise memory strain, however PQ and SCANN either don't compress sufficiently or perform poorly due to irregular memory access patterns.
The Out-of-Distribution Queries Challenge
The queries are out-of-distribution (OOD) when the database and query vector statistical distributions diverge, making vector compression harder. Unfortunately, two modern programs often do this. The first is cross-modal searching, when a user queries one modality to return relevant elements from another. Word searches help text2image find thematically similar pictures. Second, many models, including question-answering ones, may create queries and database vectors.
A two-dimensional example shows the importance of query-aware dimensionality reduction for maximum inner product search. For a query-agnostic method like PCA, projecting the database (𝒳) and query (Q) vectors onto the first main axis (large green arrow) is recommended. This selection will lower inner product resolution since this path is opposing Q's principal axis (orange arrow). Furthermore, the helpful direction (the second primary axis of 𝒳) is gone.
A Lightweight Dimensionality Reduction Method
To speed up similarity search for deep learning embedding vectors, LeanVec approximates the inner product of a database vector x and a query q.
How projection works LVQ reduces the number of bits per entry, whereas DRquery and DRDB reduce vector dimensionality. As shown in Figure, LeanVec down-projects query and database vectors using linear functions DRquery and DRDB.
Each database vector x is compressed twice via LeanVec:
First vector LVQ(DRDB(x)). Inner-product approximation is semi-accurate.
LVQ(x), secondary vector. An appropriate description is the inner-product approximation.
The graph is built and searched using main vectors. Intel experiments show that the graph construction resists LVQ quantisation and dimensionality reduction. Only secondary vectors are searched.
The graph index is searched using main vectors. Less memory footprint reduces vector retrieval time. Due to its decreased dimensionality, the approach requires fewer fused multiply-add operations, reducing processing effort. This approximation is ideal for graph search's random memory-access pattern because it permits inner product calculations with individual database vectors without batch processing.
Intel compensates for inner-product approximation errors by collecting additional candidates and reranking them using secondary vectors to return the top-k. Because query dimensionality reduction (i.e., computing f(q)) is only done once per search, there is some runtime overhead.
Searches are essential to graph formation. Intel's search acceleration directly affects graph construction.
LeanVec learns DRquery and DRDB from data using novel mathematical optimisation algorithms. Because these methods are computationally efficient, their execution time depends on the number of dimensions, not vectors. The approaches additionally consider the statistical distributions of a small sample of typical query vectors and database vectors.
Findings
The results are obvious. LeanVec improves SVS performance, exceeding the top open-source version of a top-performing algorithm (HNSWlib). The reduction in per-query memory capacity increases query speed approximately 4-fold with the same recall (95% 10 recall@10).
Conclusion
LeanVec uses linear dimensionality reduction and vector quantisation to speed up similarity searches on modern embedding models' high-dimensional vectors. As with text2image and question-answering systems, LeanVec excels when enquiries are out of distribution.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#LeanVec#Intel LeanVec#Vector Search#Out-of-Distribution Queries#Dimensionality Reduction
0 notes
Text
The Rise of Generative AI SEO Strategies: Future-Proofing Search with GEO Techniques

In the ever-evolving world of digital marketing, one trend stands above the rest in 2025—Generative AI SEO strategies. At ThatWare LLP , we’ve always been at the forefront of SEO innovation, and today, the fusion of generative artificial intelligence with semantic search and GEO techniques (Generative Entity Optimization) marks a turning point.
Understanding Generative AI SEO Strategies
Generative AI is more than just content creation. It's the engine powering smarter, scalable SEO solutions across technical, on-page, and off-page domains. Generative AI SEO strategies involve using tools like GPT models, diffusion-based image generators, and structured data training to optimize content for both users and search engines. This includes:
Creating hyper-relevant, intent-based content clusters
Auto-generating schema-rich entities for advanced indexing
Predicting search trends and tailoring content proactively
Building semantic relationships between keywords and concepts
These strategies not only reduce manual workloads but also elevate content precision in highly competitive niches.
GEO Techniques: The Backbone of Semantic SEO
One of the most powerful applications of generative AI in SEO is GEO techniques—short for Generative Entity Optimization. This involves refining and contextualizing entities within a digital ecosystem to match Google's Knowledge Graph expectations.
At ThatWare, GEO techniques focus on:
Structuring entities around intent-specific knowledge domains
Enhancing entity salience through NLP-based enrichment
Linking entities using intelligent interlinking strategies
Leveraging AI to simulate and reverse-engineer SERP behavior
This allows websites to dominate featured snippets, People Also Ask (PAA), and even voice search results.
The Generative AI Impact on SEO
Let’s address the elephant in the room: What is the real generative AI impact on SEO?
Here’s what we’re witnessing:
Shift from Keywords to Concepts: Search is becoming more conversational. Generative AI understands user queries better and optimizes content around topics, not just terms.
Massive Content Scalability: Brands can now scale high-quality, niche-specific content in days, not months.
SERP Disruption: AI-generated content affects how SERPs are ranked and evaluated. Quality, E-E-A-T, and relevance have become more important than ever.
Rise of AI-Driven Personalization: Search engines prioritize hyper-personalized results, which AI can simulate and optimize for.
Why ThatWare Is Leading the Charge
At ThatWare LLP , we integrate Generative AI SEO strategies and GEO techniques into every campaign. Our proprietary systems go beyond tools and templates—we custom-train AI on semantic patterns, user psychology, and intent forecasting.
Whether you’re a local business aiming to dominate your region or an enterprise looking to win global SERPs, our AI-first SEO solutions are designed to deliver results that traditional methods simply can’t match.
Final Thoughts
The Generative AI impact on SEO is not just a trend—it’s a revolution. As Google and other search engines evolve, so must your SEO approach. By embracing GEO techniques and cutting-edge Generative AI SEO strategies, you position your business at the top of the digital food chain.
0 notes
Text
IEEE Transactions on Emerging Topics in Computational Intelligence Volume 9, Issue 3, June 2025
1) An Efficient Sampling Approach to Offspring Generation for Evolutionary Large-Scale Constrained Multi-Objective Optimization
Author(s): Langchun Si, Xingyi Zhang, Yajie Zhang, Shangshang Yang, Ye Tian
Pages: 2080 - 2092
2) Long-Tailed Classification Based on Coarse-Grained Leading Forest and Multi-Center Loss
Author(s): Jinye Yang, Ji Xu, Di Wu, Jianhang Tang, Shaobo Li, Guoyin Wang
Pages: 2093 - 2107
3) Two ZNN-Based Unified SMC Schemes for Finite/Fixed/Preassigned-Time Synchronization of Chaotic Systems
Author(s): Yongjun He, Lin Xiao, Linju Li, Qiuyue Zuo, Yaonan Wang
Pages: 2108 - 2121
4) Solving Multiobjective Combinatorial Optimization via Learning to Improve Method
Author(s): Te Ye, Zizhen Zhang, Qingfu Zhang, Jinbiao Chen, Jiahai Wang
Pages: 2122 - 2136
5) Multi-Objective Integrated Energy-Efficient Scheduling of Distributed Flexible Job Shop and Vehicle Routing by Knowledge-and-Learning-Based Hyper-Heuristics
Author(s): YaPing Fu, ZhengPei Zhang, Min Huang, XiWang Guo, Liang Qi
Pages: 2137 - 2150
6) MTMD: Multi-Scale Temporal Memory Learning and Efficient Debiasing Framework for Stock Trend Forecasting
Author(s): Mingjie Wang, Juanxi Tian, Mingze Zhang, Jianxiong Guo, Weijia Jia
Pages: 2151 - 2163
7) Cross-Scale Fuzzy Holistic Attention Network for Diabetic Retinopathy Grading From Fundus Images
Author(s): Zhijie Lin, Zhaoshui He, Xu Wang, Wenqing Su, Ji Tan, Yamei Deng, Shengli Xie
Pages: 2164 - 2178
8) Leveraging Neural Networks and Calibration Measures for Confident Feature Selection
Author(s): Hassan Gharoun, Navid Yazdanjue, Mohammad Sadegh Khorshidi, Fang Chen, Amir H. Gandomi
Pages: 2179 - 2193
9) Modeling of Spiking Neural Network With Optimal Hidden Layer via Spatiotemporal Orthogonal Encoding for Patterns Recognition
Author(s): Zenan Huang, Yinghui Chang, Weikang Wu, Chenhui Zhao, Hongyan Luo, Shan He, Donghui Guo
Pages: 2194 - 2207
10) A Learning-Based Two-Stage Multi-Thread Iterated Greedy Algorithm for Co-Scheduling of Distributed Factories and Automated Guided Vehicles With Sequence-Dependent Setup Times
Author(s): Zijiang Liu, Hongyan Sang, Biao Zhang, Leilei Meng, Tao Meng
Pages: 2208 - 2218
11) A Novel Hierarchical Generative Model for Semi-Supervised Semantic Segmentation of Biomedical Images
Author(s): Lu Chai, Zidong Wang, Yuheng Shao, Qinyuan Liu
Pages: 2219 - 2231
12) PurifyFL: Non-Interactive Privacy-Preserving Federated Learning Against Poisoning Attacks Based on Single Server
Author(s): Yanli Ren, Zhe Yang, Guorui Feng, Xinpeng Zhang
Pages: 2232 - 2243
13) Learning Uniform Latent Representation via Alternating Adversarial Network for Multi-View Clustering
Author(s): Yue Zhang, Weitian Huang, Xiaoxue Zhang, Sirui Yang, Fa Zhang, Xin Gao, Hongmin Cai
Pages: 2244 - 2255
14) Harnessing the Power of Knowledge Graphs to Improve Causal Discovery
Author(s): Taiyu Ban, Xiangyu Wang, Lyuzhou Chen, Derui Lyu, Xi Fan, Huanhuan Chen
Pages: 2256 - 2268
15) MSDT: Multiscale Diffusion Transformer for Multimodality Image Fusion
Author(s): Caifeng Xia, Hongwei Gao, Wei Yang, Jiahui Yu
Pages: 2269 - 2283
16) Adaptive Feature Transfer for Light Field Super-Resolution With Hybrid Lenses
Author(s): Gaosheng Liu, Huanjing Yue, Xin Luo, Jingyu Yang
Pages: 2284 - 2295
17) Broad Graph Attention Network With Multiple Kernel Mechanism
Author(s): Qingwang Wang, Pengcheng Jin, Hao Xiong, Yuhang Wu, Xu Lin, Tao Shen, Jiangbo Huang, Jun Cheng, Yanfeng Gu
Pages: 2296 - 2307
18) Dual-Branch Semantic Enhancement Network Joint With Iterative Self-Matching Training Strategy for Semi-Supervised Semantic Segmentation
Author(s): Feng Xiao, Ruyu Liu, Xu Cheng, Haoyu Zhang, Jianhua Zhang, Yaochu Jin
Pages: 2308 - 2320
19) CVRSF-Net: Image Emotion Recognition by Combining Visual Relationship Features and Scene Features
Author(s): Yutong Luo, Xinyue Zhong, Jialan Xie, Guangyuan Liu
Pages: 2321 - 2333
20) Generative Network Correction to Promote Incremental Learning
Author(s): Justin Leo, Jugal Kalita
Pages: 2334 - 2343
21) A Cross-Domain Recommendation Model Based on Asymmetric Vertical Federated Learning and Heterogeneous Representation
Author(s): Wanjing Zhao, Yunpeng Xiao, Tun Li, Rong Wang, Qian Li, Guoyin Wang
Pages: 2344 - 2358
22) HGRL-S: Towards Heterogeneous Graph Representation Learning With Optimized Structures
Author(s): Shanfeng Wang, Dong Wang, Xiaona Ruan, Xiaolong Fan, Maoguo Gong, He Zhang
Pages: 2359 - 2370
23) Prompt-Based Out-of-Distribution Intent Detection
Author(s): Rudolf Chow, Albert Y. S. Lam
Pages: 2371 - 2382
24) Multi-Graph Contrastive Learning for Community Detection in Multi-Layer Networks
Author(s): Songen Cao, Xiaoyi Lv, Yaxiong Ma, Xiaoke Ma
Pages: 2383 - 2397
25) Observer-Based Event-Triggered Optimal Control for Nonlinear Multiagent Systems With Input Delay via Reinforcement Learning Strategy
Author(s): Xin Wang, Yujie Liao, Lihua Tan, Wei Zhang, Huaqing Li
Pages: 2398 - 2409
26) SODSR: A Three-Stage Small Object Detection via Super-Resolution Using Optimizing Combination
Author(s): Xiaoyong Mei, Kejin Zhang, Changqin Huang, Xiao Chen, Ming Li, Zhao Li, Weiping Ding, Xindong Wu
Pages: 2410 - 2426
27) Toward Automatic Market Making: An Imitative Reinforcement Learning Approach With Predictive Representation Learning
Author(s): Siyuan Li, Yafei Chen, Hui Niu, Jiahao Zheng, Zhouchi Lin, Jian Li, Jian Guo, Zhen Wang
Pages: 2427 - 2439
28) CIGF-Net: Cross-Modality Interaction and Global-Feature Fusion for RGB-T Semantic Segmentation
Author(s): Zhiwei Zhang, Yisha Liu, Weimin Xue, Yan Zhuang
Pages: 2440 - 2451
29) BAUODNET for Class Imbalance Learning in Underwater Object Detection
Author(s): Long Chen, Haohan Yu, Xirui Dong, Yaxin Li, Jialie Shen, Jiangrong Shen, Qi Xu
Pages: 2452 - 2461
30) DFEN: A Dual-Feature Extraction Network-Based Open-Set Domain Adaptation Method for Optical Remote Sensing Image Scene Classification
Author(s): Zhunga Liu, Xinran Ji, Zuowei Zhang, Yimin Fu
Pages: 2462 - 2473
31) Distillation-Based Domain Generalization for Cross-Dataset EEG-Based Emotion Recognition
Author(s): Wei Li, Siyi Wang, Shitong Shao, Kaizhu Huang
Pages: 2474 - 2490
32) NeuronsGym: A Hybrid Framework and Benchmark for Robot Navigation With Sim2Real Policy Learning
Author(s): Haoran Li, Guangzheng Hu, Shasha Liu, Mingjun Ma, Yaran Chen, Dongbin Zhao
Pages: 2491 - 2505
33) Adaptive Constrained IVAMGGMM: Application to Mental Disorders Detection
Author(s): Ali Algumaei, Muhammad Azam, Nizar Bouguila
Pages: 2506 - 2530
34) Visual IoT Sensing Based on Robust Multilabel Discrete Signatures With Self-Topological Regularized Half Quadratic Lifting Functions
Author(s): Bo-Wei Chen, Ying-Hsuan Wu
Pages: 2531 - 2544
35) Heterogeneity-Aware Clustering and Intra-Cluster Uniform Data Sampling for Federated Learning
Author(s): Jian Chen, Peifeng Zhang, Jiahui Chen, Terry Shue Chien Lau
Pages: 2545 - 2556
36) Model-Data Jointly Driven Method for Airborne Particulate Matter Monitoring
Author(s): Ke Gu, Yuchen Liu, Hongyan Liu, Bo Liu, Lai-Kuan Wong, Weisi Lin, Junfei Qiao
Pages: 2557 - 2571
37) Personalized Exercise Group Assembly Using a Two Archive Evolutionary Algorithm
Author(s): Yifei Sun, Yifei Cao, Ziang Wang, Sicheng Hou, Weifeng Gao, Zhi-Hui Zhan
Pages: 2572 - 2583
38) PFPS: Polymerized Feature Panoptic Segmentation Based on Fully Convolutional Networks
Author(s): Shucheng Ji, Xiaochen Yuan, Junqi Bao, Tong Liu, Yang Lian, Guoheng Huang, Guo Zhong
Pages: 2584 - 2596
39) Low-Bit Mixed-Precision Quantization and Acceleration of CNN for FPGA Deployment
Author(s): JianRong Wang, Zhijun He, Hongbo Zhao, Rongke Liu
Pages: 2597 - 2617
40) Bayesian Inference of Hidden Markov Models Through Probabilistic Boolean Operations in Spiking Neuronal Networks
Author(s): Ayan Chakraborty, Saswat Chakrabarti
Pages: 2618 - 2632
0 notes
Text
AI Agent Development: A Complete Guide to Building Smart, Autonomous Systems in 2025
Artificial Intelligence (AI) has undergone an extraordinary transformation in recent years, and 2025 is shaping up to be a defining year for AI agent development. The rise of smart, autonomous systems is no longer confined to research labs or science fiction — it's happening in real-world businesses, homes, and even your smartphone.
In this guide, we’ll walk you through everything you need to know about AI Agent Development in 2025 — what AI agents are, how they’re built, their capabilities, the tools you need, and why your business should consider adopting them today.

What Are AI Agents?
AI agents are software entities that perceive their environment, reason over data, and take autonomous actions to achieve specific goals. These agents can range from simple chatbots to advanced multi-agent systems coordinating supply chains, running simulations, or managing financial portfolios.
In 2025, AI agents are powered by large language models (LLMs), multi-modal inputs, agentic memory, and real-time decision-making, making them far more intelligent and adaptive than their predecessors.
Key Components of a Smart AI Agent
To build a robust AI agent, the following components are essential:
1. Perception Layer
This layer enables the agent to gather data from various sources — text, voice, images, sensors, or APIs.
NLP for understanding commands
Computer vision for visual data
Voice recognition for spoken inputs
2. Cognitive Core (Reasoning Engine)
The brain of the agent where LLMs like GPT-4, Claude, or custom-trained models are used to:
Interpret data
Plan tasks
Generate responses
Make decisions
3. Memory and Context
Modern AI agents need to remember past actions, preferences, and interactions to offer continuity.
Vector databases
Long-term memory graphs
Episodic and semantic memory layers
4. Action Layer
Once decisions are made, the agent must act. This could be sending an email, triggering workflows, updating databases, or even controlling hardware.
5. Autonomy Layer
This defines the level of independence. Agents can be:
Reactive: Respond to stimuli
Proactive: Take initiative based on context
Collaborative: Work with other agents or humans
Use Cases of AI Agents in 2025
From automating tasks to delivering personalized user experiences, here’s where AI agents are creating impact:
1. Customer Support
AI agents act as 24/7 intelligent service reps that resolve queries, escalate issues, and learn from every interaction.
2. Sales & Marketing
Agents autonomously nurture leads, run A/B tests, and generate tailored outreach campaigns.
3. Healthcare
Smart agents monitor patient vitals, provide virtual consultations, and ensure timely medication reminders.
4. Finance & Trading
Autonomous agents perform real-time trading, risk analysis, and fraud detection without human intervention.
5. Enterprise Operations
Internal copilots assist employees in booking meetings, generating reports, and automating workflows.
Step-by-Step Process to Build an AI Agent in 2025
Step 1: Define Purpose and Scope
Identify the goals your agent must accomplish. This defines the data it needs, actions it should take, and performance metrics.
Step 2: Choose the Right Model
Leverage:
GPT-4 Turbo or Claude for text-based agents
Gemini or multimodal models for agents requiring image, video, or audio processing
Step 3: Design the Agent Architecture
Include layers for:
Input (API, voice, etc.)
LLM reasoning
External tool integration
Feedback loop and memory
Step 4: Train with Domain-Specific Knowledge
Integrate private datasets, knowledge bases, and policies relevant to your industry.
Step 5: Integrate with APIs and Tools
Use plugins or tools like LangChain, AutoGen, CrewAI, and RAG pipelines to connect agents with real-world applications and knowledge.
Step 6: Test and Simulate
Simulate environments where your agent will operate. Test how it handles corner cases, errors, and long-term memory retention.
Step 7: Deploy and Monitor
Run your agent in production, track KPIs, gather user feedback, and fine-tune the agent continuously.
Top Tools and Frameworks for AI Agent Development in 2025
LangChain – Chain multiple LLM calls and actions
AutoGen by Microsoft – For multi-agent collaboration
CrewAI – Team-based autonomous agent frameworks
OpenAgents – Prebuilt agents for productivity
Vector Databases – Pinecone, Weaviate, Chroma for long-term memory
LLMs – OpenAI, Anthropic, Mistral, Google Gemini
RAG Pipelines – Retrieval-Augmented Generation for knowledge integration
Challenges in Building AI Agents
Even with all this progress, there are hurdles to be aware of:
Hallucination: Agents may generate inaccurate information.
Context loss: Long conversations may lose relevancy without strong memory.
Security: Agents with action privileges must be protected from misuse.
Ethical boundaries: Agents must be aligned with company values and legal standards.
The Future of AI Agents: What’s Coming Next?
2025 marks a turning point where AI agents move from experimental to mission-critical systems. Expect to see:
Personalized AI Assistants for every employee
Decentralized Agent Networks (Autonomous DAOs)
AI Agents with Emotional Intelligence
Cross-agent Collaboration in real-time enterprise ecosystems
Final Thoughts
AI agent development in 2025 isn’t just about automating tasks — it’s about designing intelligent entities that can think, act, and grow autonomously in dynamic environments. As tools mature and real-time data becomes more accessible, your organization can harness AI agents to unlock unprecedented productivity and innovation.
Whether you’re building an internal operations copilot, a trading agent, or a personalized shopping assistant, the key lies in choosing the right architecture, grounding the agent in reliable data, and ensuring it evolves with your needs.
1 note
·
View note
Text
Semantic Entropy

Semantic entropy is a way to describe how varied or rich the meanings are in a collection of ideas. Imagine you’re having a conversation with someone who jumps between very different topics—talking about music, then philosophy, then cooking, then physics. That conversation would feel wide-ranging and full of variety. In contrast, a conversation that stays strictly within one topic, like only discussing the rules of chess, would feel more narrow and predictable. Semantic entropy tries to capture this difference, not in conversations, but in how an artificial system handles concepts.
In the context of AI and knowledge graphs, each idea or “node” in the graph has a meaning. These meanings are not just labels like “apple” or “planet”—they are embedded in a multidimensional space based on how a language model understands relationships between words and concepts. Two concepts that are similar in meaning are close together in this space; very different concepts are far apart. If an AI system builds a network where all the concepts are similar and close together, it doesn’t take much mental effort to connect them. That’s low semantic entropy. But if the system draws from a wide range of meanings—linking distant and unexpected ideas—then the overall richness increases. That’s high semantic entropy.
To make this measurable, the system first places each node in this meaning space using a language model. Then, it builds a “semantic adjacency matrix” that records how close in meaning each pair of nodes is. It’s like a giant table where each entry shows how much two concepts have in common. From this matrix, the system creates a simplified map of how meanings are distributed overall—similar to how a weather map shows where it's hot or cold. The diversity in this distribution is what semantic entropy reflects.
What makes semantic entropy interesting is that it doesn’t describe structure—it describes possibility. It tells us about the mental or conceptual landscape available to the system, not how the system has chosen to connect things. The system may still be very selective and only build a few connections, but if the concepts it’s working with come from all over the idea space, then there’s a lot of untapped potential. That potential is the core of what semantic entropy measures.
In the study of creative AI systems, semantic entropy plays a special role. It turns out that when semantic entropy is slightly higher than structural order, the system stays in a sweet spot. It keeps discovering new and interesting relationships without falling into total randomness. This balance supports continuous exploration. It’s as if the system is always surrounded by meaningful possibilities, even though it only builds a few new connections at each step. And because it’s always surrounded by these varied options, it never runs out of creative directions to go in.
1 note
·
View note
Text
Unifying Text Semantics and Graph Structures for Temporal Text-attributed
Excerpt from PDF: Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models Siwei Zhang 1 Yun Xiong 1 Yateng Tang 2 Xi Chen 1 Zian Jia 1 Zehao Gu 1 Jiarong Xu 1 Jiawei Zhang 3 Abstract Temporal graph neural networks (TGNNs) have shown remarkable performance in temporal graph modeling. However, real-world temporal graphs often possess rich textual…
1 note
·
View note