#sparse-bayesian-learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
A Sparse Bayesian Learning for Diagnosis of Nonstationary and Spatially Correlated Faults:References
Subscribe .t7d6b1c2c-9953-4783-adc6-ee56928cfcd8 { color: #fff; background: #222; border: 1px solid transparent; border-radius: undefinedpx; padding: 8px 21px; } .t7d6b1c2c-9953-4783-adc6-ee56928cfcd8.place-top { margin-top: -10px; } .t7d6b1c2c-9953-4783-adc6-ee56928cfcd8.place-top::before { content: “”; background-color: inherit; position: absolute; z-index: 2; width: 20px; height: 12px; }…

View On WordPress
#correlated-faults#fault-diagnosis#multistage-assembly-systems#multistation-assembly-systems#nonstationary-faults#sparse-bayesian-learning#spatially-correlated-faults#variational-bayes-inference
0 notes
Text
Interesting Papers for Week 20, 2025
How Do Computational Models in the Cognitive and Brain Sciences Explain? Brun, C., Konsman, J. P., & Polger, T. (2025). European Journal of Neuroscience, 61(2).
Sleep microstructure organizes memory replay. Chang, H., Tang, W., Wulf, A. M., Nyasulu, T., Wolf, M. E., Fernandez-Ruiz, A., & Oliva, A. (2025). Nature, 637(8048), 1161–1169.
Dendrites endow artificial neural networks with accurate, robust and parameter-efficient learning. Chavlis, S., & Poirazi, P. (2025). Nature Communications, 16, 943.
Modelling sensory attenuation as Bayesian causal inference across two datasets. Eckert, A.-L., Fuehrer, E., Schmitter, C., Straube, B., Fiehler, K., & Endres, D. (2025). PLOS ONE, 20(1), e0317924.
Synaptic basis of feature selectivity in hippocampal neurons. Gonzalez, K. C., Negrean, A., Liao, Z., Terada, S., Zhang, G., Lee, S., Ócsai, K., Rózsa, B. J., Lin, M. Z., Polleux, F., & Losonczy, A. (2025). Nature, 637(8048), 1152–1160.
Fast updating feedback from piriform cortex to the olfactory bulb relays multimodal identity and reward contingency signals during rule-reversal. Hernandez, D. E., Ciuparu, A., Garcia da Silva, P., Velasquez, C. M., Rebouillat, B., Gross, M. D., Davis, M. B., Chae, H., Muresan, R. C., & Albeanu, D. F. (2025). Nature Communications, 16, 937.
Theory of morphodynamic information processing: Linking sensing to behaviour. Juusola, M., Takalo, J., Kemppainen, J., Haghighi, K. R., Scales, B., McManus, J., Bridges, A., MaBouDi, H., & Chittka, L. (2025). Vision Research, 227, 108537.
Network structure influences the strength of learned neural representations. Kahn, A. E., Szymula, K., Loman, S., Haggerty, E. B., Nyema, N., Aguirre, G. K., & Bassett, D. S. (2025). Nature Communications, 16, 994.
Delayed Accumulation of Inhibitory Input Explains Gamma Frequency Variation with Changing Contrast in an Inhibition Stabilized Network. Krishnakumaran, R., Pavuluri, A., & Ray, S. (2025). Journal of Neuroscience, 45(5), e1279242024.
Predicting the Irrelevant: Neural Effects of Distractor Predictability Depend on Load. Lui, T. K., Obleser, J., & Wöstmann, M. (2025). European Journal of Neuroscience, 61(2).
The time course and organization of hippocampal replay. Mallory, C. S., Widloski, J., & Foster, D. J. (2025). Science, 387(6733), 541–548.
Anisotropy of the Orientation Selectivity in the Visual Cortex Area 18 of Cats Reared Under Normal and Altered Visual Experience. Merkulyeva, N., Lyakhovetskii, V., & Mikhalkin, А. (2025). European Journal of Neuroscience, 61(2).
The calcitron: A simple neuron model that implements many learning rules via the calcium control hypothesis. Moldwin, T., Azran, L. S., & Segev, I. (2025). PLOS Computational Biology, 21(1), e1012754.
High-Density Recording Reveals Sparse Clusters (But Not Columns) for Shape and Texture Encoding in Macaque V4. Namima, T., Kempkes, E., Zamarashkina, P., Owen, N., & Pasupathy, A. (2025). Journal of Neuroscience, 45(5), e1893232024.
Ventral hippocampus to nucleus accumbens shell circuit regulates approach decisions during motivational conflict. Patterson, D., Khan, N., Collins, E. A., Stewart, N. R., Sassaninejad, K., Yeates, D., Lee, A. C. H., & Ito, R. (2025). PLOS Biology, 23(1), e3002722.
Hippocampal coding of identity, sex, hierarchy, and affiliation in a social group of wild fruit bats. Ray, S., Yona, I., Elami, N., Palgi, S., Latimer, K. W., Jacobsen, B., Witter, M. P., Las, L., & Ulanovsky, N. (2025). Science, 387(6733).
Diverse neuronal activity patterns contribute to the control of distraction in the prefrontal and parietal cortex. Sapountzis, P., Antoniadou, A., & Gregoriou, G. G. (2025). PLOS Biology, 23(1), e3003008.
The role of oscillations in grid cells’ toroidal topology. Sarra, G. di, Jha, S., & Roudi, Y. (2025). PLOS Computational Biology, 21(1), e1012776.
Out of Sight, Out of Mind? Neuronal Gamma Oscillations During Occlusion Events in Infants. Slinning, R., Agyei, S. B., Kristoffersen, S. H., van der Weel, F. R. (Ruud), & van der Meer, A. L. H. (2025). Developmental Psychobiology, 67(1).
The Brain’s Sensitivity to Sensory Error Can Be Modulated by Altering Perceived Variability. Tang, D.-L., Parrell, B., Beach, S. D., & Niziolek, C. A. (2025). Journal of Neuroscience, 45(5), e0024242024.
#neuroscience#science#research#brain science#scientific publications#cognitive science#neurobiology#cognition#psychophysics#perception#neurons#neural computation#neural networks#computational neuroscience#neuroplasticity
8 notes
·
View notes
Text
IEEE Transactions on Fuzzy Systems, Volume 33, Issue 1, January 2025
1) Guest Editorial Special Section on Fuzzy-Deep Neural Network Learning in Sentiment Analysis
Author(s): Gautam Srivastava, Chun-Wei Lin
Pages: 1 - 2
2) Fcdnet: Fuzzy Cognition-Based Dynamic Fusion Network for Multimodal Sentiment Analysis
Author(s): Shuai Liu, Zhe Luo, Weina Fu
Pages: 3 - 14
3) Joint Objective and Subjective Fuzziness Denoising for Multimodal Sentiment Analysis
Author(s): Xun Jiang, Xing Xu, Huimin Lu, Lianghua He, Heng Tao Shen
Pages: 15 - 27
4) Exploring Multimodal Multiscale Features for Sentiment Analysis Using Fuzzy-Deep Neural Network Learning
Author(s): Xin Wang, Jianhui Lyu, Byung-Gyu Kim, B. D. Parameshachari, Keqin Li, Qing Li
Pages: 28 - 42
5) Depression Detection From Social Media Posts Using Emotion Aware Encoders and Fuzzy Based Contrastive Networks
Author(s): Sunder Ali Khowaja, Lewis Nkenyereye, Parus Khuwaja, Hussam Al Hamadi, Kapal Dev
Pages: 43 - 53
6) EMSIN: Enhanced Multistream Interaction Network for Vehicle Trajectory Prediction
Author(s): Yilong Ren, Zhengxing Lan, Lingshan Liu, Haiyang Yu
Pages: 54 - 68
7) FICformer: A Multi-factor Fuzzy Bayesian Imputation Cross-former for Big Data-driven Agricultural Decision Support Systems
Author(s): Jianlei Kong, Xiaomeng Fan, Min Zuo, Wenjing Yan, Xuebo Jin
Pages: 69 - 81
8) ViTDFNN: A Vision Transformer Enabled Deep Fuzzy Neural Network for Detecting Sleep Apnea-Hypopnea Syndrome in the Internet of Medical Things
Author(s): Na Ying, Hongyu Li, Zhi Zhang, Yong Zhou, Huahua Chen, Meng Yang
Pages: 82 - 93
9) A Novel Centralized Federated Deep Fuzzy Neural Network with Multi-objectives Neural Architecture Search for Epistatic Detection
Author(s): Xiang Wu, Yong-Ting Zhang, Khin-Wee Lai, Ming-Zhao Yang, Ge-Lan Yang, Huan-Huan Wang
Pages: 94 - 107
10) A Comprehensive Adaptive Interpretable Takagi–Sugeno–Kang Fuzzy Classifier for Fatigue Driving Detection
Author(s): Dongrui Gao, Shihong Liu, Yingxian Gao, Pengrui Li, Haokai Zhang, Manqing Wang, Shen Yan, Lutao Wang, Yongqing Zhang
Pages: 108 - 119
11) A Temporal Multi-View Fuzzy Classifier for Fusion Identification on Epileptic Brain Network
Author(s): Zhengxin Xia, Wei Xue, Jia Zhai, Ta Zhou, Chong Su
Pages: 120 - 130
12) Structured Sparse Regularization-Based Deep Fuzzy Networks for RNA N6-Methyladenosine Sites Prediction
Author(s): Leyao Wang, Yuqing Qian, Hao Xie, Yijie Ding, Fei Guo
Pages: 131 - 144
13) Data-Driven Fuzzy Sliding Mode Observer-Based Control Strategy for Time-Varying Suspension System of 12/14 Bearingless SRM
Author(s): Ye Yuan, Kai Xie, Wen Ji, Yougang Sun, Fan Yang, Yu Nan
Pages: 145 - 155
14) Fusion of Explainable Deep Learning Features Using Fuzzy Integral in Computer Vision
Author(s): Yifan Wang, Witold Pedrycz, Hisao Ishibuchi, Jihua Zhu
Pages: 156 - 167
15) FMFN: A Fuzzy Multimodal Fusion Network for Emotion Recognition in Ensemble Conducting
Author(s): Xiao Han, Fuyang Chen, Junrong Ban
Pages: 168 - 179
16) MFVAE: A Multiscale Fuzzy Variational Autoencoder for Big Data-Based Fault Diagnosis in Gearbox
Author(s): He-xuan Hu, Yicheng Cai, Qing Meng, Han Cui, Qiang Hu, Ye Zhang
Pages: 180 - 191
17) A Dissimilarity Measure Powered Feature Weighted Fuzzy C-Means Algorithm for Gene Expression Data
Author(s): Ning Ma, Qinghua Hu, Kaijun Wu, Yubin Yuan
Pages: 192 - 202
18) End-Edge Collaborative Inference of Convolutional Fuzzy Neural Networks for Big Data-Driven Internet of Things
Author(s): Yuhao Hu, Xiaolong Xu, Li Duan, Muhammad Bilal, Qingyang Wang, Wanchun Dou
Pages: 203 - 217
19) A Hybrid Fuzzy C-Means Heuristic Approach for Two-Echelon Vehicle Routing With Simultaneous Pickup and Delivery of Multicommodity
Author(s): Heng Wang, Sihao Chen, Xiaoyi Yin, Lingxi Meng, Zhanwu Wang, Zhenfeng Wang
Pages: 218 - 230
20) Fuzzy-ViT: A Deep Neuro-Fuzzy System for Cross-Domain Transfer Learning From Large-Scale General Data to Medical Image
Author(s): Qiankun Li, Yimou Wang, Yani Zhang, Zhaoyu Zuo, Junxin Chen, Wei Wang
Pages: 231 - 241
21) Multiobjective Evolution of the Deep Fuzzy Rough Neural Network
Author(s): Jianwei Zhao, Dingjun Chang, Bin Cao, Xin Liu, Zhihan Lyu
Pages: 242 - 254
22) Boosting Robustness in Deep Neuro-Fuzzy Systems: Uncovering Vulnerabilities, Empirical Insights, and a Multiattack Defense Mechanism
Author(s): Jia Wang, Weilong Zhang, Zushu Huang, Jianqiang Li
Pages: 255 - 266
23) A Fuzzy-Operated Convolutional Autoencoder for Classification of Wearable Device-Collected Electrocardiogram
Author(s): Lumin Xing, Xin Li, Wenjian Liu, Xing Wang
Pages: 267 - 277
24) Quantum Fuzzy Federated Learning for Privacy Protection in Intelligent Information Processing
Author(s): Zhiguo Qu, Lailei Zhang, Prayag Tiwari
Pages: 278 - 289
25) Deep Spatio-Temporal Fuzzy Model for NDVI Forecasting
Author(s): Zhao Su, Jun Shen, Yu Sun, Rizhen Hu, Qingguo Zhou, Binbin Yong
Pages: 290 - 301
26) Composite Neuro-Fuzzy System-Guided Cross-Modal Zero-Sample Diagnostic Framework Using Multisource Heterogeneous Noncontact Sensing Data
Author(s): Sheng Li, Jinchen Ji, Ke Feng, Ke Zhang, Qing Ni, Yadong Xu
Pages: 302 - 313
27) Exploring Zadeh's General Type-2 Fuzzy Logic Systems for Uncertainty Quantification
Author(s): Yusuf Güven, Ata Köklü, Tufan Kumbasar
Pages: 314 - 324
28) VL-MFER: A Vision-Language Multimodal Pretrained Model With Multiway-Fuzzy-Experts Bidirectional Retention Network
Author(s): Chen Guo, Xinran Li, Jiaman Ma, Yimeng Li, Yuefan Liu, Haiying Qi, Li Zhang, Yuhan Jin
Pages: 325 - 337
29) Temporal-Spatial Fuzzy Deep Neural Network for the Grazing Behavior Recognition of Herded Sheep in Triaxial Accelerometer Cyber-Physical Systems
Author(s): Shuwei Hou, Tianteng Wang, Di Qiao, David Jingjun Xu, Yuxuan Wang, Xiaochun Feng, Waqar Ahmed Khan, Junhu Ruan
Pages: 338 - 349
30) FRCNN: A Combination of Fuzzy-Rough-Set-Based Feature Discretization and Convolutional Neural Network for Segmenting Subretinal Fluid Lesions
Author(s): Qiong Chen, Lirong Zeng, Weiping Ding
Pages: 350 - 364
31) Learning Fuzzy Label-Distribution-Specific Features for Data Processing
Author(s): Xin Wang, J. Dinesh Peter, Adam Slowik, Fan Zhang, Xingsi Xue
Pages: 365 - 376
32) Deep Reinforcement Learning With Fuzzy Feature Fusion for Cooperative Control in Traffic Light and Connected Autonomous Vehicles
Author(s): Liang Xu, Zhengyang Zhang, Han Jiang, Bin Zhou, Haiyang Yu, Yilong Ren
Pages: 377 - 391
33) A Fuzzy Neural Network Enabled Deep Subspace Domain Adaptive Fusion Approaches for Facial Expression Recognition
Author(s): Wanneng Shu, Feng Zhang, Runze Wan
Pages: 392 - 405
34) Hybrid Model Integrating Fuzzy Systems and Convolutional Factorization Machine for Delivery Time Prediction in Intelligent Logistics
Author(s): Delong Zhu, Zhong Han, Xing Du, Dafa Zuo, Liang Cai, Changchun Xue
Pages: 406 - 417
35) Dual Guidance Enabled Fuzzy Inference for Enhanced Fine-Grained Recognition
Author(s): Qiupu Chen, Feng He, Gang Wang, Xiao Bai, Long Cheng, Xin Ning
Pages: 418 - 430
36) Skeleton-Based Gait Recognition Based on Deep Neuro-Fuzzy Network
Author(s): Jiefan Qiu, Yizhe Jia, Xingyu Chen, Xiangyun Zhao, Hailin Feng, Kai Fang
Pages: 431 - 443
37) A Deep Neuro-Fuzzy Method for ECG Big Data Analysis via Exploring Multimodal Feature Fusion
Author(s): Xiaohong Lyu, Shalli Rani, S. Manimurugan, Yanhong Feng
Pages: 444 - 456
38) A Reconstructed UNet Model With Hybrid Fuzzy Pooling for Gastric Cancer Segmentation in Tissue Pathology Images
Author(s): Junjun Huang, Shier Nee Saw, Yanlin Chen, Dongdong Hu, Xufeng Sun, Ning Chen, Loo Chu Kiong
Pages: 457 - 467
39) Odyssey of Interval Type-2 Fuzzy Logic Systems: Learning Strategies for Uncertainty Quantification
Author(s): Ata Köklü, Yusuf Güven, Tufan Kumbasar
Pages: 468 - 478
40) Ensemble Deep Random Vector Functional Link Neural Network Based on Fuzzy Inference System
Author(s): M. Sajid, M. Tanveer, Ponnuthurai N. Suganthan
Pages: 479 - 490
41) Quantum-Assisted Hierarchical Fuzzy Neural Network for Image Classification
Author(s): Shengyao Wu, Runze Li, Yanqi Song, Sujuan Qin, Qiaoyan Wen, Fei Gao
Pages: 491 - 502
42) Deep Graphical and Temporal Neuro-Fuzzy Methodology for Automatic Modulation Recognition in Cognitive Wireless Big Data
Author(s): Xin Jian, Qing Wang, Yaoyao Li, Abdullah Alharbi, Keping Yu, Victor Leung
Pages: 503 - 513
0 notes
Text
GAN-based Anomaly Detection and Localization of Multivariate Time Series Data
Sparse MLP for Image Recognition : Is Self-Attention Really Necessary
Multivariate LSTM-FCNs for Time Series Classification
Spatio-Temporal Graph Convolutional Networks
Bayesian Inference: An Introduction toPrinciples and Practice in Machine Learning
Dense Passage Retrieval for Open-Domain Question Answering
Time Series Data Augmentation for Deep Learning: A Survey
On the Robustness of Vision Transformers to Adversarial Examples
ViT: An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Latent Retrieval for Weakly Supervised Open Domain Question Answering
You Only Look at One Sequence (YOLOS)
FuseAD
DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series
0 notes
Text


27.04.2021
Trying to finish up this report on Sparse Bayesian Learning for my ML for Wireless Comm. class.
My dad's feeling okay now, which is a relief. The college has extended the deadlines for some submissions, which is a relief, tbh.
I really wanted to have something to drink, but I'm trying to reduce the amount of coffee I drink, so I settled with chocolate milk :)
Endsems start in a week, so I'll make a plan for revision tonight.
Lastly, I'm thinking about starting to use Notion, to keep track of academics and projects. I guess I'll figure that out later too.
#deskinspo#my desk#studyblr#engineering#coffee#im so tired#study motivation#aesthetic#study inspiration#studyspo#study space#spotify#machine learning#computer science
24 notes
·
View notes
Text
If you did not already know
APRIL We propose a method to perform automatic document summarisation without using reference summaries. Instead, our method interactively learns from users’ preferences. The merit of preference-based interactive summarisation is that preferences are easier for users to provide than reference summaries. Existing preference-based interactive learning methods suffer from high sample complexity, i.e. they need to interact with the oracle for many rounds in order to converge. In this work, we propose a new objective function, which enables us to leverage active learning, preference learning and reinforcement learning techniques in order to reduce the sample complexity. Both simulation and real-user experiments suggest that our method significantly advances the state of the art. Our source code is freely available at https://…/emnlp2018-april. … Tile2Vec Remote sensing lacks methods like the word vector representations and pre-trained networks that significantly boost performance across a wide range of natural language and computer vision tasks. To fill this gap, we introduce Tile2Vec, an unsupervised representation learning algorithm that extends the distributional hypothesis from natural language — words appearing in similar contexts tend to have similar meanings — to geospatial data. We demonstrate empirically that Tile2Vec learns semantically meaningful representations on three datasets. Our learned representations significantly improve performance in downstream classification tasks and similarly to word vectors, visual analogies can be obtained by simple arithmetic in the latent space. … Semantically Informed Visual Odometry and Mapping (SIVO) In order to facilitate long-term localization using a visual simultaneous localization and mapping (SLAM) algorithm, careful feature selection is required such that reference points persist over long durations and the runtime and storage complexity of the algorithm remain consistent. We present SIVO (Semantically Informed Visual Odometry and Mapping), a novel information-theoretic feature selection method for visual SLAM which incorporates machine learning and neural network uncertainty into the feature selection pipeline. Our algorithm selects points which provide the highest reduction in Shannon entropy between the entropy of the current state, and the joint entropy of the state given the addition of the new feature with the classification entropy of the feature from a Bayesian neural network. This feature selection strategy generates a sparse map suitable for long-term localization, as each selected feature significantly reduces the uncertainty of the vehicle state and has been detected to be a static object (building, traffic sign, etc.) repeatedly with a high confidence. The KITTI odometry dataset is used to evaluate our method, and we also compare our results against ORB_SLAM2. Overall, SIVO performs comparably to ORB_SLAM2 (average of 0.17% translation error difference, 6.2 x 10^(-5) deg/m rotation error difference) while reducing the map size by 69%. … ruptures ruptures is a Python library for offline change point detection. This package provides methods for the analysis and segmentation of non-stationary signals. Implemented algorithms include exact and approximate detection for various parametric and non-parametric models. ruptures focuses on ease of use by providing a well-documented and consistent interface. In addition, thanks to its modular structure, different algorithms and models can be connected and extended within this package. … https://analytixon.com/2022/12/13/if-you-did-not-already-know-1909/?utm_source=dlvr.it&utm_medium=tumblr
0 notes
Text
5/12/19 Notes
Lab Meeting Prep Pipeline:
(May 2nd, 2019 at 2:38 p.m.)
[ ] Read the Results & Discussion cover to cover
[ ] Complete slides for all figures
[ ] Give a practice presentation
[ ] Read methods
[ ] Complete fluorescence slides
[ ] Decide how to deal with ‘relationship between calcium activity and movement’ section
[ ] Give a practice presentation
[ ] Read supplementary material cover to cover
[ ] Give a practice presentation
Note to self: Relax. Be meticulous. Be disciplined. Keep calm, do your best, trust your team.
——
——
Advanced Optimization
8 20 905
Live Action Poem, February 2nd, 6:41
Went to Brazil out of spite and saw
stone Jesus, arms open for a hug,
bought street weed, twice, from the same vendor
out of a reckless love for reckless love.
Hoped for a tropical muse and found
a strong handshake from a dangerous man.
Holed up in Rio de Janeiro with piles
of paper money and paced all alone
angry at nothing if only for the moment.
Rain dampened slick stone walkaways,
waiters were too nice and I tipped too much.
One offered to be a bodyguard , violence
hinted in every smirking human moment.
God, I loved being a target, smug,
dumb, flitting away American Dollars.
Jesus Christ looming in stone on a hill top.
Titties and marijuana, iconic primadonna
extravagant flora, dying fauna, fawning
over the climate. I went to Brazil
on an off month. To hole up
safe from my sprawling little lovely life.
To Do 26.1.19
[x] Cristina - Search for Hippocampus Models
[x] Ana G. - Draft e-mail call for interest in “Live Action Science”
[ ]
Data science Club Thursday at 5:00 p.m.
Astavakrasana
laser-scanning photostimulation (LSPS) by UV glutamate uncaging.
12.1.19 Goals
[x] Some Portuguese
[x] Mouse Academy - first read
[ / ] Dynamic mesolithic dopamine
[x] Water rats * SMH
Acorn - tracks impact | BetaWorks | 2 years of money | PitchBook | Social Impact Start Up
Mission Aligned Investors | Metrics | Costumer Acquistion Cost | Clint Corver -> Chain of Contacts -> Who To Talk to (Scope: ~100)
Money Committed || Sparrow || Decision Analysis —> Ulu Ventures [500k] [Budget x ]
Ivan - > IoS Engineering { Bulgarian DevShop }
[market mapping] Metrics -> Shrug
Peter Singer - Academic Advisory Board …
[1 million ]
Product market testing
Foundation Directory Online - Targeted , Do Your Homework
https://www.simonsfoundation.org/2018/11/19/why-neuroscience-needs-data-scientists/
Head-fixed —>
~INHIBITION EXPERIMENT TRAINING PLAN~
STOP MICE: 20th. GIVE WATER: 20th (afternoon) - 30th. DEPRIVE: 31st... (Morning) RESUME: Jan 2nd.
21st - BLEACH/DEEP CLEAN BOXES 1-14 (Diluted bleach; Flush (with needles out) - Open Arduino Sketch with Continuously open Valves - PERFUSE System) *[NOT BOX 11 or 5]*; Run 15 mL of Bleach per syringe; Copious water through valves; Leave dry.
———
http://www.jneurosci.org/content/preparing-manuscript#journalclub
Friday - Dec. 14th, 2018
[x] - Complete 2019 ‘Goals and Blueprint’
[x] - 2-minute Summary ‘Properties of Neuron in External Globus Pallidus Can Support Optimal Action Selection
[ ] MatLab for Neuroscientists :: Basic Bayesian Bearded Terrorist probability plots
[x] Statistics 101: Linear Regression
“Golden Girls” - Devendra Banhart
“King” by Moor - FIREBEAT
Reread - Section 3.3 to
Monday - Apply for DGAV License (MAKE SHORT CV)
SAMPLE: ‘Sal’ From Khan Academy
Make short CV
Tiago - Certificate
MATH:
“We explicitly focus on a gentle introduction here, as it serves our purposes. If you are in
need of a more rigorous or comprehensive treatment, we refer you to Mathematics for Neuroscientists by Gabbiani and Cox. If you want to see what math education could be like, centered on great explanations that build intuition, we recommend Math, Better Explained by Kalid Azad.”
Jacksonian March seizure (somatosensory)
—
Tara LeGates > D1/D2 Synapses
Scott Thompson
Fabrizio Gabbiani - Biophysics - Sophisticated and reasonable approach
Quote For Neuroscience Paper:
“Every moment happens twice: inside and outside, and they are two different histories.”
— Zadie Smith, White Teeth
Model Animal: Dragonfly? Cats. Alligators.
Ali Farke Toure
Entre as 9 hora e o meio-dia ele trabalha no computador.
Ele volta para o trabalha à uma e meia.
Ele vai as compras depois do trabalho.
A noite, depois do jantar, ele e a mulher veem televisão.
As oito vou de bicicleta para o trabalho. (go)
As oito venho de bicicleta para o trabalho. (come)
A que horas começa a trabalhar?
Eu começo a trabalhar os oito e meia.
Normalmente…
Eu caminho cerca de Lisbon.
É muito triste! Eu faço nada! Talvez, eu caminho cerca de Lisbon. Talvez eu leio um livro. Talvez eu dormi. Eu vai Lx Factory.
Depois de/do (after)
antes de/do (before)
—
Monday -> Mice
MATLAB!
-
“New ways of thinking about familiar problems.”
~*NOVEMBER GOALS*~
> Permanent MatLab Access [x] -> Tiago has license
> Order Mouse Lines [ ] -> Health report requested… Reach out to Vivarium about FoxP2
-> Mash1 line -> FoxP2 expression?
> Finish ‘First Read Through’ [ ]
> Figure 40 [ ]
SAMPLE : ‘Afraid of Us’ Jonwayne, Zeroh
Monday Nov 5th Goals:
> Attentively watch:
> https://www.youtube.com/watch?v=ba_l8IKoMvU (Distributed RL)
> https://www.youtube.com/watch?v=bsuvM1jO-4w (Distributed RL | The Algorithm)
MatLab License
Practical Sessions at the CCU for the Unknown between 19 - 22 Nov 2018 (provisional programme attached)
Week of November 5th - Handle Bruno’s Animals
Lab Goals -
“Deep Networks - Influence Politics Around the World”
Paton Lab Meeting Archives
Strategy: Read titles/abstracts follow gut on interesting and relevant papers
Goals: Get a general sense of the intellectual history of the lab, thought/project trajectories, researchers and work done in the field and neighboring fields.
Look through a GPe/Arkypallidal lens… what can be revisited with new understanding?
First Read Through
[x] 2011 - (22 meetings || 10/12 - SLAM camera tracking techniques)
[ x] 2012a (18 meetings)
[x] 2012b (15 meetings - sloppy summary sentences)
[ x] 2013a (19 meetings - less sloppy summaries jotted down)
[x] 2013b (17 meetings)
[x] 2014a (21 meetings) (summaries in progress)
[x] 2014b
[x] 2015 (23 meetings)
[ ] 2016 (23 meetings)
Current
—
“I like, I wish, I wonder”
“Only Yesterday” Pretty Lights
retrosplenial dysgranular cx (?)
retrosplenial granular cx, c (?)
fornix (?)
Stringer 2018 arVix
Lowe and Glimpsher
November Goals:
[ ] GPe literature -
[ x ] Dodson & Magill
[ x] Mastro & Gittis
[ ] Chu & Bevan
[x] Modeling (extra credit -Bogacz)
[ ] Principles of Neural Science: Part IV
[ x ] MatLab license… Website program…
Extra credit:
Side projects [/ ] Neuroanatomy 40
[ -> ] ExperiMentor - Riberio, Mainen scripts… Paton! -> LiveAction Science
MACHINE LEARNING
Week of Oct 29th -
Symposium Week!
Wyatt -> John Hopkins -> He got into American University!
Belly Full Beat (MadLib album Drive In)
“The human brain produces in 30 seconds as much data as the Hubble Space Telescope has produced in its lifetime.”
Sequence of voltage sensors -> ArcLite -> Quasar -> Asap -> Voltron -> ???
Muscarine -> Glutamate
Ph Sensitive
cAMP
Zinc sensitive
5 ways to calculate delta f
2 main ways
SNR Voltage —
Dimensionality reduction of a data set: When is it spiking?
5 to 10 2-photon microscope open crystal
…Open window to a million neuron…
Week of 10/15/18
Monday: Travel
Tuesday: Rest
Wednesday: Begin rat training. Reorient.
Thursday:
Friday:
|| Software synergistically ||
—————
Beam splitter, Lambda, diacritic
1.6021766208×10−19
‘sparse coding’
Benny Boy get your programming shit together.
Week of Oct. 8th, 2018
10/9/18
[ ] Rat shadowing (9:30 a.m.) -> Pushed to next week
10/8/18
[x] Begin Chapter 13 of Kandel, Schwartz, Jessell
[x] Outline of figure 36
[ ] Read Abdi & Mallet (2015)
DOPE BEAT MATERIAL - Etude 1 (Nico Muhly, Nadia Sirota)
Saturday - Chill [x]
Friday - ExperiMentor … mehhhhh scripts?
Photometry -> Photodiode collects light in form of voltage (GCaMP) (TtdTomate as Baseline… how much fluorescence is based on TdTomatoe, controlling factor always luminesce - GCaMP calcium dependent) :: Collecting from a ‘cone’ or geometric region in the brain. Data stored and plotted over time… Signals must be corrected…
Cell populations are firing or releasing calcium. (GCaMP encoded by virus injection, mice express CRE in a particular cell type).
———————————————
———————————————
Brain on an Occam’s Razor,
bird on a wire,
synaptic fatalism integrating
consistent spiking;
strange looping: is this me?
Thursday
“We don’t make decisions, so much as our decisions make us.”
“Blind flies don’t like to fly”
[x] 9:00 a.m. Lab Meeting
[x] 12:00 p.m. - Colloquium
“It was demeaning, to borrow a line from the poet A. R. Ammons, to allow one’s Weltanschauung to be noticeably wobbled.”
“You must not fear, hold back, count or be a miser with your thoughts and feelings. It is also true that creation comes from an overflow, so you have to learn to intake, to imbibe, to nourish yourself and not be afraid of fullness. The fullness is like a tidal wave which then carries you, sweeps you into experience and into writing. Permit yourself to flow and overflow, allow for the rise in temperature, all the expansions and intensifications. Something is always born of excess: great art was born of great terrors, great loneliness, great inhibitions, instabilities, and it always balances them. If it seems to you that I move in a world of certitudes, you, par contre, must benefit from the great privilege of youth, which is that you move in a world of mysteries. But both must be ruled by faith.”
Anaïs Nin
[ ] MatLab trial expires in 1 day *
[ ] 3:00 p.m. pictures
“We do not yet know whether Arkys relay Stop decisions from elsewhere, or are actively involved in forming those decisions. This is in part because the input pathways to Arkys remain to be determined.”
These studies prompt an interesting reflection about the benefits and conflicts of labeling and classifying neurons at a relatively grainy level of understanding.
“The authors hypothesize that under normal conditions, hLTP serves an adaptive, homeostatic role to maintain a healthy balance between the hyperdirect and indirect pathway in the STN. However, after dopamine depletion, pathologically elevated cortical input to the STN triggers excessive induction of hLTP at GPe synapses, which becomes maladaptive to circuit function and contributes to or even exacerbates pathological oscillations.”
To Do Week of Oct. 1st - Focus: Big Picture Goals
[ x ] GPe Literature - Hernandez 2015 & Mallet 2016 (Focus on techniques and details)
[ ] MatLab! Lectures 6-7 (Get your hands dirty!)
[ x ] Kandel Chapters 12 - 13
Tuesday Surgery Induction 10:00 with Andreia
6:00 - 7:30
Portuguese
Digitally reconstructed Neurons: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5106405/
To Do Week of, September 24th, 2018
To Do Week of Monday, September 17th, 2018
PRIORITY:
DATA ANALYSIS PROJECT ITI
———— PAUSE. ———————
Talks
[x ] Mainen Lab - Evidence or Value based encoding of World State/Probability - ‘Consecutive failures’ - easy/medium/hard estimate of where the reward will be.
Reading for the Week
[x] Chapter 9 - Propagating Signal | The Action Potential
[/ ] Ligaya et. al (2018) (CCU S.I.?)
[x] Katz & Castillo (1952) Experiment where they describe measurement techniques
[ ] Raiser Chapter 4 - Stimulus Outlasting Calcium Dynamics in Drosophila Kenyon Cells Encode Odor Identity
Video Lectures
[— ] Linear Algebra (Trudge steadily through)
[ — ] Khan Academy Logarithms (Trudge steadily through)
MatLab
[ ] Trudge steadily through www.mathworks.com/help/matlab/learn_matlab
*FIND PROBLEM SET/TEXT BOOK/WORK SHEETS*
Concepts to Grasp
[ / ] Master logarithms!
[ ] Review Kandel Et. Al Part II *Chapters 5-9*
Neuroanatomy
[ x ] Ink Figure 28
Project Planning? Too soon! Too soon! Read some literature on the subject.
17/9/18
1:00 p.m. Meet with Catarina to discuss “CCU Science Illustrated” (WIP) Project
2:30 p.m. Vivarium Induction
_______________________________________________________
| SPCAL Credentials |
| |
| login: |
| PW: |
-————————————————————————
——
NPR:: https://www.npr.org/sections/health-shots/2018/09/11/644992109/can-a-barn-owl-s-brain-explain-why-kids-with-adhd-can-t-stay-focused
9.13.18
[ x ] Pauses in cholinergic interneuron firing exert an inhibitory control on stratal output in vivo (Zucca et. al 2018)
[ x ] Chapter 8 - Local Signaling: Passive Properties of
-> Sub and supra threshold membrane potential (Conceptual)
Monday, Sept. 10th 2018
“Eat the Frog First”
[ N/A ] Review SPCAL Lessons 1-5 (In Library?) CRAM THURSDAY?
-> [/] wait for confirmation from Delores for theoretical test
-> (Out of Office reply from person in charge)
To Do:
[/] Comment Out %PRE_PROCESS_vBeta.m
[x] Change path name and run program in MatLab
[ ] Solve trial.blahblahblah error spkCount? labels?
[ ] Change Epochs and run?
[x] Chapter 7 - Membrane Potential :: Return to Pg. 136-137 Box 7-2 when sharp. ::
[x] Castillo and B. Katz (1954)
[x] 12:00 - Neural Circuits for Vision in Action CCU
[x] 2:30 - THESIS DEFENSE: Mechanisms of Visual Perceptions in the Mouse Visual Cortex
————
Extra-credit
[x] Ink Figure 24
[~ ] Finish “First & Last 2017” (100/127 = 78.74%)
——
Jax Laboratory Tools: https://www.jax.org/jax-mice-and-services/model-generation-services/crispr-cas9
Recommendation for Design and Analysis of In Vivo Electrophysiology Studies
http://www.jneurosci.org/content/38/26/5837
On the Horizon:
Schultz (1997) (Classic, classic, classic)
*[x] 9/7/18 - 6:00 p.m. Flip water for Bruno’s mice *
ITI Data Analysis -> Next step ->….
[ ] (find the sigmoid call) / Poke around preprocessing_beta
Reading
[x] Chapter 6 - Ion Channels
[ / ] Finish Krietzer 2016 —> [ ] write an experiment-by-experiment summary paper
Resource: https://www.youtube.com/watch?v=GPsCVKhNvlA Helpful explanation of ChR2-YFP, NpHR, and general ontogenetic principles.
[ / ] Reiser Chapter 3.3.38 - 3.4 (Need to finish 3.4.5, Look up Photoionization detectors, Coherence)
Neuroanatomy
[/] Finish Figure 24 (need to ink)
“Drawing Scientists “
[/] Storyboard for GCAMP6s targeted paper
-> Show Filipe for feedback ->
-> Ask Leopold permission ? Talk to Catarina
[ x] 16:9
[x] Write script and record [ 1:00 ]
Intellectual Roaming
[ / ] Return to Review of Reviews and Review Zoom-In | First & Last |
[/] Explore Digital Mouse Brain Atlas
9/6/18 - Thursday
To Do:
ITI Data Analysis :
[x] Draw data structure on mm paper -> Reach out for help understanding
[ / ] What fields did Asma call? What fields are necessary for a psychometric curve
Reading
[x] Kandel - Chapter 5 | Synthesis and Trafficking of Neuronal Proteins
[ / ] Reiser - Chapter 3 | A High-Bandwidth Dual-Channel Olfactory Stimulator for Studying Temporal Sensitivity of Olfactory Processing (Results complicated)
[/ ] Krietzer 2016 - Cell-Type-Specific Controls of Brainstem Locomotor Circuits by Basal Ganglia
Talks:
[x] 12:00 p.m. - Colloquium - Development of Drosophila Motor Circuit
Tutorials:
~ [x ] MatLab plotting psychometric curves
Neuroanatomy
[ x ] Outline brain for figure 24
———
MatLab
Laser stuff HZ noise, thresholds,
// PCA -> Co-variance ->
// Linear regression | Geometric intuition -> “What is known to the animal during inter-trial? What features can be described by animals history” ===> Construct a history space (axis represent different animals history ex. x-axis previous stimulus, reward, etc.?) Predictive (?)
Plot psychometric functions || PSTH (post stimulation of histogram ) of example neurons -> skills: bin spiking, plot rasters, smoothing (if necessary)
Data:: Access to Dropbox -> /data/TAFC/Combined02/ [3 animals :: Elife]
/data/TAFC/video
Tiago and Flipe know the video data
File Format -> Parser/Transformation (guideline) ||
> MatLab
Access to MatLab -> [/] 28 days!
How can I begin to analysis?
History dependent | Omitted
——
To Do Week of September 3rd
Monday
Administrative
[ x] Check-in with HR (Don’t bombard!): Badge. (Library access?)
[ ] Reach out to SEF?
[x] 2:00 p.m. Meet with Asma - discuss data analysis. Where is it? How do I access it (Tiago?) What has been done and why?
[x] 3:00 p.m. Lab Meeting “Maurico’s Data” - Pay special attention
[x] Finish first read through of Theoretical Laboratory Animal Science PDF Lectures
[ ] Rat Surgery Techniques…
Mouse neuroanatomy project
[/ ] Figure 24
[ ] Figure 28
Math
[x ] L.A. Lecture 2
[ x] L.A. Lecture 3
Read:
[ ] Georg Raiser’s Thesis (Page 22 of 213)
Find time to do at least an hour of quiet focused reading a day. (Place?).
Continue to explore whims, papers, databases, ideas, protocols, that seem interesting.
Develop ‘literature scour’ protocol - (Nature Neuroscience, Neuron, Journal of Neuroscience)
Dates to Remember: September 14th - Laboratory Animal Sciences Theoretical Test!
https://www.sciencedaily.com/releases/2018/08/180827180803.htm:Can these be used for techniques?
https://www.sciencedaily.com/releases/2018/08/180823141038.htm ‘Unexpected’ - Unexpected physical event and unexpected reward or lack of reward (neuronal modeling of external environment)
—
In my first ten minutes at work I’m exposed to a weeks (month/year/decade) worth of interesting information. Going from an intellectual tundra to an intellectual rain forest.
1460 proteins with increased expression in the brain: Human Protein Atlas https://www.proteinatlas.org
Non-profit plasmid repository: https://www.addgene.org
Protein database: https://www.rcsb.org/3d-view/3WLC/1
Started to think at the molecular level.
“MGSHHHHHHGMASMTGGQQMGRDLYDDDDKDLATMVDSSRRKWNKTGHAVRAIGRLSSLENVYIKADKQKNGIKANFKIR
HNIEDGGVQLAYHYQQNTPIGDGPVLLPDNHYLSVQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSK
GEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDF
FKSAMPEGYIQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNLPDQLTEEQIAEFKEAFSL
FDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGDGTIDFPEFLTMMARKGSYRDTEEEIREAFGVFDKDGNG
YISAAELRHVMTNLGEKLTDEEVDEMIREADIDGDGQVNYEEFVQMMTAK” - CCaMP6m amino acid code.
8/31/18 - (Friday) @12:00 in Meeting Room 25.08
GET USB ! !
[Lisboa Cultura na ru, Lisbon on the streets Com’Out Lisbon - Katie Gurrerirra ]
MatLab -> Chronux Neural Analysis
SEPTEMBER 14th!
Week of August 27th, 2018
“Conserved computational circuitry, perhaps taking different arguments on different locations of Basil Ganglia” - Tuesday
Andrew Barto: http://www-all.cs.umass.edu/~barto/
Basil Ganglia Labs
Okihide Hikosaka Lab: https://irp.nih.gov/pi/okihide-hikosaka
Wilbrecht Lab
Uchida N. (ubiquitous dopamine motivation and reward)
Peter J. Magill
Schultz (Pioneer in the field)
C. Savio Chan
Doya, K. (theory)
Calabresi, P. (muscarinic)
Ana Graybiel (McGovern)
James C. Houk (1994 - Book on Models of Computation in the basal Ganglia)
Evolutionary Conservation of Basil Ganglia type action-selection mechanisms:
https://www.sciencedirect.com/science/article/pii/S0960982211005288
Dopamine D1 - Retinal Signaling https://www.physiology.org/doi/full/10.1152/jn.00855.2017 [Note to self: Too Off Track]
[ ~ ] Flurorphore Library
Official Badge? [ ] Printer Access [ ]?
—
Online Course on Laboratory Animal Science
Monday : 11 [x] 12 [x]
Tuesday : 13 [x] 14 [x]
Wednesday: 15 [x] 16 [/]
Thursday: 17 [x] 18 [x]
Friday: 19 [x] 20 [/]
Lesson 11 - Behavior and Environment, animals must be housed in an environment enriched to maximize their welfare.
Lesson 12 - Rodent and Lagomorph Accommodation and Housing - A more comprehensive guide from the macro environment, facilities i.e. establishments, to the micro environments. Covers health and safety procedures for personnel as well as geometry of housing units (rounded edges to prevent water accumulation). Absolutely essential.
Lesson 13 - Collecting Samples and Administrating Procedures - covers the most common collection techniques and materials collected and stressed the importance of doing as little harm as possible to the animal.
Lesson 14 - Transporting the Animal : Shipper holds most of the responsibility. Major goals are making sure the journey is as stress free as possible, contingency plans are in place, and that all of the logistics have been carefully planned, communicated, and coordinated between various parties responsible in the shipping. Also, animals should be prepared mentally and physically for the journey and should have a period of post-transportation to adjust to the new surroundings and environment. A number of practical issues must be considered such as temperature, availability of food, and access to animals during the journey. Boxes should be properly labelled in whatever languages are necessary.
Lesson 15 - The purpose of feeding and nutrition is to meet the energy needs of the animals, which vary by species, physiological state of animal (growth, maintenance, gestation, and lactation). A number of category of diets exist as well as a variety of specific diets to best fits the needs of the experiment. This chapter covers particulars of nutrition requirements and stresses the importance of avoiding obesity and malnutrition.
Lesson 16 - Anatomy and Physiology of Teleosts (Skip for now: Focus on Rodents and Lagomorphs)
Lesson 17 - Anatomy and Physiology of Rodents and Lagomorphs - General characteristics of the anatomy and physiology of six species, 5 rodents and 1 lagomorph. Mice, rats, guinea pigs, gerbils, and hamsters. Rabbits. It covers particularities of each species and has a quiz asking specific facts, mostly centered on commonalities and distinguishing factors. Worth a close read.
Lesson 18 - Anaesthesia and Analgesia in Rodents and Lagomorphs . Pre anaesthesia techniques, drug combinations, and repeated warning of the importance of choosing the right drugs and technique for the species. Use of a chamber. Methods of anesthesia (IP, IV, Volatile). Endotracheal Intubation for rabbits; the proper use and administration of analgesics; monitoring during the operation (for example - the paw pain reflex disappears in medium to deep anesthesia
Lesson 19 - Animal Welfare and Signs of Disturbance - This chapter repeatedly stresses the importance of the relationship between the caretaker and the animal. It repeats the ideal social, environmental, and nutritional environments for rodents and rabbits and highlights peculiarities of each species. After reading this one should be better suited to detecting stress, disease, or other ailments in a laboratory animal.
Lesson 20 - Fish Psychology and Welfare (Skip for now: Focus on Rodents and Lagomorphs)
Lessons 5, 17, and 20 pertain to fish
TEST SEPTEMBER 14th
—
MIT Open Course Ware:
Linear Algebra
Lecture 2 [/ ] -> Elimination by Matrices, production of elementary matrices, basic computations, and a review of row and column approaches to systems of equations. Introduction to the basic application of the rule of association in linear algebra.
Lecture 3 [ ]
Mouse Neuroanatomy
Ink Figure 16 [x]
Figure 20 [x]
Figure 24 [ ]
Introduction to MatLab: https://www.youtube.com/watch?v=T_ekAD7U-wU [ ]
Math Big Picture: Review Single Variable Calculus! Find reasonable Statistics and Probability Course (Statistical Thinking and Data Analysis? Introduction to Probability and Statistics?) Mine as well review algebra well I’m at it eh.
Breathe in. Breathe out.
—
Data analysis :: Behavioral Analysis
—
Ana Margarida - Lecture 6 - Handling Mice techniques
EuroCircuit can make a piece. Commercial v. DYI version of products.
Dario is the soldering, hardware expert. I.E. skilled technician.
www.dgv.min-agricultura.pt; it is recommended that the entry on Animal Protection and the section on Animals used for experimental purposes be consulted first.
—
Sir Ronald Fisher, stated in 1938 in regards to this matter that “To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of”.
——
Finally, it is time to publish and reveal the results. According to Santiago Ramón y Cajal, scientific writers should govern themselves by the following rules:
Make sure you have something to say; Find a suitable title and sequence to present your ideas; Say it; Stop once it is said.
8/21 Goals
Access ->
:: Champalimaud Private Internet [HR] Printer [HR]
:: Web of Science (?)
:: PubMed (Nature, Journals, etc.?)
::
———
PRIORITY: Online Course -> Animal Laboratory Sciences PDF’s
20 total -> 4 a day || I can finish by Friday
Monday : 1 [x] 2 [x]
Tuesday : 3 [x] 4 [x ]
Wednesday: 5 [x*] 6 [x]
Thursday: 7 [x* ] 8 [x]es
Friday: 9 [x ] 10 [x ]
Notes:
Lesson 1 - Philosophical and ethical background and the 3 R’s
Lesson 2 - Euthanasia. Recommended, adequate, unacceptable. Physical or chemical. Chemical - inhalable or injectable. Paton Lab uses CO2 and cervical dislocation.
Lecture 3 - Experimental Design. Return to as a starting point for basic design (randomized samples and blocks) Integrate with “Statistical Thinking and Data Analysis”
Lecture 4 - Legislation. Memorize specific laws and acts.
Lecture 5 is highly specific for the care and maintenance of Zebrafish
Lecture 6 - Handling of rodents and mice. A theoretical overview, this material is essentially kinesthetic.
Lecture 7 - Provides a technically detailed account of how genetic manipulations are done and propagated. Deserves a ‘printed’ review and vocabulary cross reference.
Lecture 8 - Health and Safety. Predominantly common sense.
Lecture 9 - Microbiology - contains an appendix with list of common infections that will be eventually be good to know.
Lesson 10 - Anaesthesia pre and post operation techniques, risks of infections etc.
// http://ec.europa.eu/environment/chemicals/lab_animals/member_states_stats_reports_en.htm
http://ec.europa.eu/environment/chemicals/lab_animals/news_en.htm -> General European News regarding
http://www.ahwla.org.uk/site/tutorials/RP/RP01-Title.html -> Recognizing pain in animals
Week of 8/20/18 To Do:
Tiago/Team -> Whats the most important priority?
Get Arduino Machine working again [?]
Jupiter/Python Notebook Up [ ]
Bruno MatLab Access [… ]
- Get documents to HR
- Animal Lab certified?
- Logistical/Certificate/Etc.
- Start discussing personal project:
> (Rat colony) Wet Lab
> (Machine Learning) Electric Lab
> Statistics project
- Reacquaint with Lab Technology/Protocols
- Review papers - Engage back with the science
-
Project Print: Screen shots
[ ] collect
“Do the job. Do it engaged. Engage -> Not just execute the best you can, understand the experiment.
Why? Alternative designs? Control experiments needed to interpret the data? Positive controls and negative controls? What do you need to do to get crisp. Totally engage.
How it fits into other experiments?
“Engage with the science as if it were your baby.”
Execute beautifully… Ask --- et. al. What does ideal execution look like
Extra time: allocate time. Technicians : Freedom to do other things, work with other things, other technical things, giving people independent project to carry out. Project --- has in mind? Design. Hands on education of how science works then reading. Spend time focused on a problem and in the ideal become the world’s foremost expert on whatever ‘mundane’ aspect of what ever problem you are working on.
Computational in the context of a problem. Learn to use. Defining “problems I want to solve.” As an operating scientist, the technology can change very quickly. Capable of learning, understanding, and applying.
Answer questions in a robust way. Thinking of technology in context of problem. Deep domain knowledge; focus on experimental more than book reading.
Realistic path -> Research fellow to PhD. program. Industry… Strong head’s up to do research. First-rate OHSU? Excellent. IF: Remember that it is narrow, broader with neuroscience as a component. Biology < > Neurology. Real neuroscience computational ->
Juxtasuposed: Engineering, CS, A.I., and all that…
Label in broad ways: Molecular, cellular, systems, cognitive, psychology. Borders are so fuzzy — as to be
Domain bias. In general -> other than P.I. protected from funding. Publication, the life of the business. Metric of success is the science they publish. Work that contributes to being an author = more engaged, more independent. Evolved to an independent project.
So incredibly broad -> CRISPR, GFP, Optogenetics, with higher level systems problems. 100 years = absurd. Look back -> Could we have conceived whats going on today.
Foremost expert on something how-ever limited. Grow from there. Grown from a particular expertise.
Molecular biologist || Do what a 3 year old is taught to do. How? How? How? How does that work. Quantum physics. Ask questions. Be open.
Go to seminars -> Go to every talk. Take every note. Primary literature fundamentally different. Always learn in context. Don’t dilute too much (ignore title, abstract, discussion). Look at figures and tables and derive for yourself what they say. Look for THE FIGURE or THE TABLE that is the crux and look for the control experiment. Understand the critical assessment, are the facts valid and warranted? Infinite amount to learn, don’t spread yourself infinitely thin. “
To Do: Develop Independent Machine Learning Project
Gain Access to Web of Science
————
Paton Learning Lab
Personal Learning Goals
September 1st - December 1st
Major Goals
[ ] Read Principles of Neuroscience 5th Edition
[ ] Complete CSS 229
[ ] Deep read 12 papers (Write summary || Practice peer review)
Administrative
[ ] Reactivate
[ / ] Figure out Residence Permit/Visa
Lifestyle
[ x ] Purchase commuter bicycle
[ / ] Purchase waterproof computer/messenger bag
Language
[x] …. Focused practice minimum 20 minutes daily …?
[ ] Find language partner
[ ] Portuguese film/television/music
UPCOMING
Phone conversation with --------
Tuesday, August 7th 9:00 a.m. EST (10:00 a.m.
0 notes
Text
Inside recommendations: how a recommender system recommends

If we think of the most successful and widespread applications of machine learning in business, one of the examples would be recommender systems. Each time you visit Amazon or Netflix, you see recommended items or movies that you might like — the product of recommender systems incorporated by these companies. Though a recommender system is a rather simple algorithm that discovers patterns in a dataset, rates items and shows the user the items that they might rate highly, they have the power to boost sales of many e-commerce and retail companies.
In simple words, these systems predict users’ interests and recommend relevant items.
Types of recommender systems
Recommender systems rely on a combination of data stemming from explicit and implicit information on users and items, including:
Characteristic information, including information about items, such as categories, keywords, etc., and users with their preferences and profiles, and
User-item interactions — the information about ratings, number of purchases, likes, and so on.
Based on this, recommender systems fall into two categories: content-based systems that use characteristic information, and collaborative filtering systems based on user-item interactions. Besides, there is a complementary method called knowledge-based system that relies on explicit knowledge about the item, the user and recommendation criteria, as well as the class of hybrid systems that combine different types of information.
Content-based systems

Such systems make recommendations based on the user’s item and profile features. The idea underlying them is that if a user was interested in an item in the past, they will be interested in similar items later. User profiles are constructed using historical interactions or by explicitly asking users about interests. Of course, pure content-based systems tend to make too obvious recommendations — because of excessive specialization — and to offer too many similar items in a row. Well suited for movies, if you want to want all films starring the same actor, these systems fall short in e-commerce, spamming you with hundreds of watches or shoes.
Content-based algorithms
Cosine similarity: the algorithm finds the cosine of the angle between the profile vector and item vector:
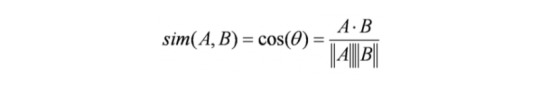
Based on the cosine value, which ranges between -1 to 1, items are arranged in descending order and one of the two below approaches is used for recommendations:
Top-n approach: where the top n items are recommended;
Rating scale approach: where all items above a set threshold are recommended.
Euclidean Distance: since similar items lie in close proximity to each other if plotted in n-dimensional space, we can calculate the distance between items and use it to recommend items to the user:

However, Euclidean Distance performance falls in large-dimensional spaces, which limits the scope of its application.
Pearson’s Correlation: the algorithm shows how much two items are correlated, or similar:

A major drawback of this algorithm is that it is limited to recommending items that are of the same type.
Collaborative filtering systems
Unlike content-based systems, they utilize user interactions and the preference of other users to filter for items of interest. The baseline approach to collaborative filtering is matrix factorization. The goal is to complete the unknowns in the matrix of user-items interactions (let’s call it RR). Suppose we have two matrices UU and II, such that U \times IU×I is equal to RR in the known entries. Using the U \times IU×I product we will also have values for the unknown entries of RR, which can then be used to generate the recommendations.

A smart way to find matrices UU and II is by using a neural network. An interesting way of looking at this method is to think of it as a generalization of classification and regression. Though more intricate and smarter, they should have enough information to work, meaning cold start for new e-commerce websites and new users.
There are two types of collaborative models: memory-based and model-based:
Memory-based methods offer two approaches: to identify clusters of users and utilize the interactions of one specific user to predict the interactions of the cluster. The second approach identifies clusters of items that have been rated by a certain user and utilizes them to predict the interaction of the user with a similar item. Memory-based techniques are simple to implement and transparent, but they encounter major problems with large sparse matrices, since the number of user-item interactions can be too low for generating high-quality clusters.
Cluster of users
In the algorithms that measure the similarity between users, the prediction of an item for a user u is calculated by computing the weighted sum of the user ratings given by other users to an item i. The prediction Pu,i is given by:

where
Pᵤ,ᵢ is the prediction of an item;
Rᵥ,ᵢ is the rating given by a user v to an item i;
Cluster of items

The algorithm finds the similarity between each item pair and, based on that, recommends similar items liked by users in the past. This algorithm works similar to user-user collaborative filtering with just a little change — instead of taking the weighted sum of ratings of “user-neighbors”, we take the weighted sum of ratings of “item-neighbors”. The prediction is given by:
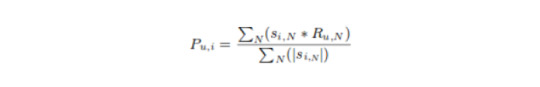
Now we will find the similarity between items.

This way we can e.g. weigh users’ ratings of movies to find similar ones and make predictions to recommend similar movies to users.
Model-based methods are based on machine learning and data mining techniques to predict users’ ratings of unrated items. These methods are able to recommend a larger number of items to a larger number of users, compared to other methods like memory-based. Examples of such model-based methods include decision trees, rule-based models, Bayesian methods and latent factor models.
Knowledge-based systems
Knowledge-based recommender systems use explicit information about the item assortment and the client’s preference. Based on this knowledge, the system generates corresponding recommendations. If no item satisfies all the requirements, products satisfying a maximal set of constraints are ranked and displayed. Unlike other approaches, it does not depend on large bodies of statistical data about items or user ratings, which makes them especially useful for rarely sold items, such as houses, or when the user wants to specify requirements manually. Such an approach allows avoiding a ramp-up or cold start problem since recommendations do not depend on a base of user ratings. Knowledge-based recommender systems have a conversational style offering a dialog that effectively walks the user down a discrimination tree of product features.

Knowledge-based systems work on two approaches: constraint-based, relying on an explicitly defined set of recommendation rules, and case-based, taking intelligence from different types of similarity measures and retrieving items similar to the specified requirements.
Constraint-based
Constraint-based recommender systems try to mediate between the weighted hard and soft user requirements (constraints) and item features. The system asks the user which requirements should be relaxed/modified so that some items exist that do not violate any constraint and finds a subset of items that satisfy the maximum set of weighted constraints. The items are afterwards ranked according to the weights of the constraints they satisfy and are shown to the user with an explanation of their placement in the ranking.
Case-based
The case-based approach relies on the similarity distance,
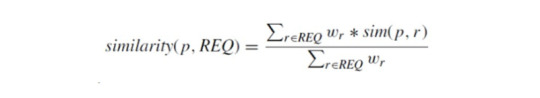
where sim (p, r) expresses for each item attribute value p its distance to the customer requirement r ∈ REQʷᵣ is the importance weight for requirement r.
However, in real life, some users may want to maximize certain requirements, minimize others, or simply not be sure what they want, submitting queries that might look like “similar to Item A, but better”. In contrast to content-based systems, the conversational approach of knowledge-based recommenders allows for such scenarios by eliciting users’ feedback, called critiques.
Hybrid Recommendation Systems
Recent research shows that to improve the effectiveness of recommender systems, it is worth combining collaborative and content-based recommendation. Hybrid approaches can be implemented by making content-based and collaborative-based predictions separately and then combining them by adding content-based capabilities to a collaborative-based approach and vice versa; or by unifying the approaches into one model. Netflix, for instance, makes recommendations by comparing the watching and searching habits of similar users (i.e., collaborative filtering) as well as by offering movies that share characteristics with films that a user has rated highly (content-based filtering).

How to make a recommender system
Data collection
Since a product recommendation engine mainly runs on data, data mining and storage are of primary concern.
The data can be collected explicitly and implicitly. Explicit data is information that is provided intentionally, i.e. input from the users such as movie ratings. Implicit data is information that is not provided intentionally but gathered from available data streams like search history, clicks, order history, etc. Data scraping is one of the most useful techniques to mine these types of data from the website.
Data storage
The type of data plays an important role in deciding the type of storage that has to be used. This type of storage could include a standard SQL database, a NoSQL database or some kind of object storage. To store big amounts of data, you can use online frameworks like Hadoop or Spark which allow you to store data in multiple devices to reduce dependence on one machine. Hadoop uses HDFS to split files into large blocks and distributes them across nodes in a cluster, which means the dataset will be processed faster and more efficiently.
Data filtering and prediction
There are multiple ready-made systems and libraries for different languages, from Python to C++. To make a simple recommender system from scratch, the easiest way may be to try your hand on Python’s pandas, NumPy, or SciPy.
Conclusion
Of course, recommender systems are the heart of e-commerce. However, the most straightforward way may not be the best and showing long lines of similar products will not win customers’ loyalty. The only way to truly engage with customers is to communicate with each as an individual, but advanced and non-traditional techniques, such as deep learning, social learning, and tensor factorization based on machine learning and neural networks can also be a step forward.
0 notes
Text
Interesting Papers for Week 13, 2024
The self and the Bayesian brain: Testing probabilistic models of body ownership through a self-localization task. Bertoni, T., Mastria, G., Akulenko, N., Perrin, H., Zbinden, B., Bassolino, M., & Serino, A. (2023). Cortex, 167, 247–272.
A whole-task brain model of associative recognition that accounts for human behavior and neuroimaging data. Borst, J. P., Aubin, S., & Stewart, T. C. (2023). PLOS Computational Biology, 19(9), e1011427.
Inhibitory tagging in the superior colliculus during visual search. Conroy, C., Nanjappa, R., & McPeek, R. M. (2023). Journal of Neurophysiology, 130(4), 824–837.
Hippocampal representation during collective spatial behaviour in bats. Forli, A., & Yartsev, M. M. (2023). Nature, 621(7980), 796–803.
Emergence of belief-like representations through reinforcement learning. Hennig, J. A., Romero Pinto, S. A., Yamaguchi, T., Linderman, S. W., Uchida, N., & Gershman, S. J. (2023). PLOS Computational Biology, 19(9), e1011067.
Error-independent effect of sensory uncertainty on motor learning when both feedforward and feedback control processes are engaged. Hewitson, C. L., Kaplan, D. M., & Crossley, M. J. (2023). PLOS Computational Biology, 19(9), e1010526.
Multiple memory systems for efficient temporal order memory. Jafarpour, A., Lin, J. J., Knight, R. T., & Buffalo, E. A. (2023). Hippocampus, 33(10), 1154–1157.
How awareness of each other’s mental load affects dialogue. Knutsen, D., & Brunellière, A. (2023). Journal of Experimental Psychology: Learning, Memory, and Cognition, 49(10), 1662–1682.
Developmental trajectory of time perception from childhood to adolescence. Li, Y., Gu, J., Zhao, K., & Fu, X. (2023). Current Psychology, 42(28), 24112–24122.
A multi-layer mean-field model of the cerebellum embedding microstructure and population-specific dynamics. Lorenzi, R. M., Geminiani, A., Zerlaut, Y., De Grazia, M., Destexhe, A., Gandini Wheeler-Kingshott, C. A. M., … D’Angelo, E. (2023). PLOS Computational Biology, 19(9), e1011434.
The inhibitory control of traveling waves in cortical networks. Palkar, G., Wu, J., & Ermentrout, B. (2023). PLOS Computational Biology, 19(9), e1010697.
Inferring local structure from pairwise correlations. Rahman, M., & Nemenman, I. (2023). Physical Review E, 108(3), 034410.
Beyond ℓ1 sparse coding in V1. Rentzeperis, I., Calatroni, L., Perrinet, L. U., & Prandi, D. (2023). PLOS Computational Biology, 19(9), e1011459.
Linguistic law-like compression strategies emerge to maximize coding efficiency in marmoset vocal communication. Risueno-Segovia, C., Dohmen, D., Gultekin, Y. B., Pomberger, T., & Hage, S. R. (2023). Proceedings of the Royal Society B: Biological Sciences, 290(2007).
Mnemonic discrimination deficits in multidimensional schizotypy. Sahakyan, L., Wahlheim, C. N., & Kwapil, T. R. (2023). Hippocampus, 33(10), 1139–1153.
An imbalance of excitation and inhibition in the multisensory cortex impairs the temporal acuity of audiovisual processing and perception. Schormans, A. L., & Allman, B. L. (2023). Cerebral Cortex, 33(18), 9937–9953.
Spike-timing dependent plasticity partially compensates for neural delays in a multi-layered network of motion-sensitive neurons. Sexton, C. M., Burkitt, A. N., & Hogendoorn, H. (2023). PLOS Computational Biology, 19(9), e1011457.
Development of human hippocampal subfield microstructure and relation to associative inference. Vinci-Booher, S., Schlichting, M. L., Preston, A. R., & Pestilli, F. (2023). Cerebral Cortex, 33(18), 10207–10220.
Task-dependent optimal representations for cerebellar learning. Xie, M., Muscinelli, S. P., Decker Harris, K., & Litwin-Kumar, A. (2023). eLife, 12, e82914.
Dissecting the chain of information processing and its interplay with neurochemicals and fluid intelligence across development. Zacharopoulos, G., Sella, F., Emir, U., & Cohen Kadosh, R. (2023). eLife, 12, e84086.
#neuroscience#science#research#brain science#scientific publications#cognitive science#neurobiology#cognition#psychophysics#neurons#neural computation#neural networks#computational neuroscience
20 notes
·
View notes
Text
Life Cycle of a Machine Learning Project
Today, the term Machine Learning comes up in every other discussion. In fact, in the bay area, it is a staple. We hear about unicorn start-ups as well as established organizations solving major challenges using Machine Learning. Then, there are many more companies, who are in the process of figuring out what and how long it takes to implement Machine Learning models in their organization. This article is an effort to share my insight into the process of this new edge phenomenon, a major paradigm shift from the traditional rule-based system. Before I go into the details, let me start with how Machine Learning differs from a rule-based system. In a rule-based system, decisions are made based on a set of rules built on a set of facts by human experts while Machine Learning decisions are based on a function (a model) built on patterns extracted by Machines from data. A rule-based system is considered rigid as it cannot make a decision when there is no historical data. Machines, on the other hand, can make an estimate based on similar patterns found in the historical dataset. Let me take a business case to explain this further. Customer Churn, for example, is a common business challenge companies encounter on an ongoing basis. We spend our marketing dollars to acquire customers, they come onboard and after a few months leave for reasons unknown. In such scenarios, a rule-based system may decide to send a promotional offer after a certain number of days/months( based on the companies definition of churn) of inactivity, but the chances of customers returning are pretty low. They may have moved on to a different company or lost interest in the product. In a rule-based system, there is no easy way to predict and intervene if and when a customer is going to churn. However, Machine Learning looks at the spending pattern, demographics, psychographics of customer actions in the past, and tries to find a similar pattern on the new customer to predict their activity. This information can alert the business to take action and save the customer from churning. This intervention makes a significant difference in the customer experience and impacts the business metrics. In order to identify and implement Machine Learning in an organization, we need to make significant changes in our process that exists in our traditional rule-based system. 1. Define clear use case with a measurable outcome 2. Integrate enterprise-wide data seamlessly 3. Create a lab environment for experimentation 4. Operationalize successful pilots and monitor Essentially, embrace the paradigm shift, The ML Mindset. Let’s see how we incorporate “The ML Mindset” in a machine learning workflow. This workflow is implemented by domain experts, data engineers, data scientists and software engineers contributing to various tasks. These days, however, companies are looking for individuals, who have knowledge of the whole workflow and known by the title full-stack data scientist. The following diagram shows all the tasks a Full Stack Data Scientist performs to complete a project. As I was looking for inspiration to draw an appropriate flowchart to show the ML workflow and came across this AWS presentation. I made a few modifications to the flowchart that I believe reflects the essence of an end-to-end machine learning project.

1. Business Problem: The broad ML technique selection/elimination process starts at the very beginning of the Data Science/Machine Learning project workflow when we define the business goal. Here, we understand the business challenges and look for projects that will have a major impact, whether it is immediate or long term. Many a time, existing business reports will indicate the challenge, and the goal will be to improve a metric or KPI. Other times, a new business initiative will drive the project. In our specific example of customer churn, the larger goal may be to increase revenue and one of the strategies may be to improve customer retention, the immediate business goal for for this Machine Learning project is to predict churn with higher accuracy (say from 10% to 40%). Although I am making a general estimate here, a business arrives at this number after diving into all the KPIs impacting the business and that is beyond the scope of this post. 2. ML Problem Framing: We then decide on basic Machine Learning tasks. When working with structured/tabular data, the task at hand is primarily one of the following: supervised, unsupervised, or reinforcement learning. There are many articles that explain each task and its application. Among them, I found two AI and ML flowcharts by Karen Hao from MIT Technology Review, which is all-inclusive and simple to understand. At the end of this stage, we should know the broad ML technique (Supervised/Unsupervised, Regression/Classification/Forecasting) to be implemented for the project and have a good understanding of data availability, model evaluation metrics and their target score to consider a model reliable. Customer churn prediction is a supervised classification task where we have historical data of customers who are labeled into 2 classes: churned or not churned. For a supervised classification task, evaluation metrics are based on the confusion matrix. 3. Data Collection & Integration: In business, collecting data is like a treasure hunt; all the joy and agony of it. The process is complicated, painstaking, but eventually rewarding. Often enough, we find crucial data stored in a spreadsheet. Retailers with both online and physical presence sometimes have promotional flyers in the store that is not uploaded in data repository. Model accuracy relies heavily on data size and as I mentioned earlier, it is essential to integrate enterprise-wide data for Machine Learning. For customer churn, we will need to collect data from various business domains starting with recency, frequency, monetization, tenure, acquisition channel, promotions, demographics, psychographics, etc. 4. Exploratory Data Analysis: This is where knowledge of Data and Algorithms help to decide on the initial set of algorithms (preferably 2-3) that we would like to implement. EDA is the process of understanding our data set through statistical summary, distribution, and the relationships between features and targets. It helps us build intuition on the data. I would like to emphasize the word intuition. While developing intuition, refrain from drawing a conclusion. It is very easy to get carried away and start making assumptions without running a data set through a model. When we perform EDA, we are looking at 2 variables at a time (we are performing bi-variate analysis). Our world, on the other hand, is multivariate, such as how seedling growth rate is dependent on the sun, water, minerals, etc. Statistical models and ML algorithms implement multivariate techniques under the hood that helps us draw conclusions with a certain degree of accuracy. No single factor is responsible for the change. One or two factors may be the driving factors, but there are still many others behind the change. Do keep this thought in mind during EDA. This step is essential and guidelines are similar for all datasets. Infact, you can create a template to use it for all the projects.
5. Data Preparation: Our observations made during Exploratory Data Analysis give guidance to various data processing steps. This includes removing duplicates, fixing misspelled words, ensuring data integrity, aggregating categorical values with limited observations, dropping features with sparse data, imputing missing data for important features, handling outliers, processing and integrating semi-structured & unstructured data.
6. Feature Engineering: It is a well-known fact that Data Scientists spend the majority of their time exploring and preparing the data, engineering features before applying a model. Of all the three, Feature Engineering is the most challenging and can make a big difference in model performance. A few common techniques include transforming data using the log function or normalization, creating or extracting new features from the existing data, feature selection & dimensionality reduction. Although the limelight of the workflow is model training and evaluation, I would like to reiterate that the previous three steps (Exploratory Data Analysis, Data Preparation and Feature Engineering) consume 80% of the total time and is highly related to the success of a Machine Learning project . 7. Model Training & Parameter Tuning: Equipped with the list of 2-3 algorithms from exploratory data analysis (step 4) and transformed data (step 5 & 6), we are ready to train the model. For each algorithm, we select various ranges of hyperparameters to train and choose the configuration that yields the best model score. There are various algorithms (Grid search, random search, Bayesian optimization) available for parameter tuning. We will use Hyperopt, one of the open-source libraries used to optimize searching the hyperparameter space, using the Bayesian optimization technique. We then compare the model evaluation metrics (precision, recall, F1, etc) for each of the three algorithms on the training data and validation data with the best hyperparameters. Besides performance measures, a good model will perform similarly(generate similar scores on evaluation metrics) in both the training and validation datasets. Understanding and interpreting relevant model evaluation metrics is the key to success in this step.
8. Model Evaluation: We then compare the model evaluation metrics (RMSE, R squared, AUC,precision, recall, F1, etc) for each of the three algorithms on the validation data and test data with the best hyperparameters. Understanding and interpreting relevant model evaluation metrics is the key to success in this step. Our expectation is that good models produce comparable results in validation and test. They won’t produce identical results, but auc/f1/precision/recall/RMSE scores on test and validation sets will be close.
9. Model Deployment: Once we are content with the model outcomes, the next step is to run the model with test data and make its output is available via API, web applications, reports, or dashboards. If the model is to work with streaming data, it is being incorporated in applications through a Web API. If the result is to be delivered to business users for insight, the results are shared in dashboards or automated reports delivered via email. Operationalization involves up-front investment in systems that smooth the deployment, maintenance, and adoption of whichever data processes we choose to employ. It is worth the extra effort to avoid runtime failures. 10. Monitoring Drift & Decay: Monitoring production models is different from monitoring other applications. A product recommendation model won’t adapt to changing tastes. A loan risk model won’t adapt to changing economic conditions. With fraud detection, criminals adapt as models evolve. Data science teams need to be able to detect and react quickly when models drift. As we detect drift and decay, we are back to the beginning of the cycle where we may adjust the business goal, collect more data, and repeat the cycle. 11. Delivering Model Output: When a model output is not directly consumed by a web application, it is often used to deliver business insights through a dashboard or report. One of the most difficult tasks of machine learning projects is explaining a model’s outcomes to an audience. Data visualization tools like Tableau or Google Data Studio are very helpful in building storylines to share insights from Data Science work.
Machine Learning cycle tend to vary between 3 and 6 months followed by ongoing maintenance. ML is evolving and the cycle length perhaps will continue to shrink with automation but the basic tasks in the workflow stays the same. I encourage you to embrace the ML Mindset. Take a look at your current projects in your team/organization and think of ways to integrate Machine Learning that will impact your business metrics significantly.
0 notes
Text
Complex & Intelligent Systems, Volume 10, Issue 5, October 2024
1) 3D facial animation driven by speech-video dual-modal signals
Author(s): Xuejie Ji, Zhouzhou Liao...Meng Mao
Pages: 5951 - 5964
2) An improved fruit fly optimization algorithm with Q-learning for solving distributed permutation flow shop scheduling problems
Author(s): Cai Zhao, Lianghong Wu...Hongqiang Zhang
Pages: 5965 - 5988
3) A strategic framework for optimal decisions in football 1-vs-1 shot-taking situations: an integrated approach of machine learning, theory-based modeling, and game theory
Author(s): Calvin Yeung, Keisuke Fujii
Pages: 5989 - 6008
4) Population state-driven surrogate-assisted differential evolution for expensive constrained optimization problems with mixed-integer variables
Author(s): Jiansheng Liu, Bin Yuan...Haobo Qiu
Pages: 6009 - 6030
5) An intelligent MRI assisted diagnosis and treatment system for osteosarcoma based on super-resolution
Author(s): Xu Zhong, Fangfang Gou, Jia Wu
Pages: 6031 - 6050
6) A dimension-aware gaining-sharing knowledge algorithm for distributed hybrid flowshop scheduling with resource-dependent processing time
Author(s): Rong-hao Li, Jun-qing Li...Li-jie Mei
Pages: 6051 - 6080
7) Crossover in mutation oriented norm evolution
Author(s): Bingyu Lv, Xianchang Wang, Rui Zhang
Pages: 6081 - 6102
8) Residual serialized cross grouping transformer for small scale sketch face recognition
Author(s): Kangning Du, Yinkai Wang...Yanan Guo
Pages: 6103 - 6116
9) A blockchain-based hybrid encryption technique with anti-quantum signature for securing electronic health records
Author(s): Shtwai Alsubai, Abdullah Alqahtani...Abdu Gumaei
Pages: 6117 - 6141
10) ACGND: towards lower complexity and fast solution for dynamic tensor inversion
Author(s): Aiping Ye, Xiuchun Xiao...Cong Lin
Pages: 6143 - 6157
11) Prioritizing complex health levels beyond autism triage using fuzzy multi-criteria decision-making
Author(s): A. S. Albahri, Rula A. Hamid...A. H. Alamoodi
Pages: 6159 - 6188
12) A multi-scale spatial–temporal capsule network based on sequence encoding for bearing fault diagnosis
Author(s): Youming Wang, Lisha Chen
Pages: 6189 - 6212
13) Bayesian network structure learning with a new ensemble weights and edge constraints setting mechanism
Author(s): Kaiyue Liu, Yun Zhou, Hongbin Huang
Pages: 6213 - 6229
14) A GAN based PID controller for highly adaptive control of a pneumatic-artificial-muscle driven antagonistic joint
Author(s): Zhongchao Zhou, Yuxi Lu...Wenwei Yu
Pages: 6231 - 6248
15) Modelling attack and defense games in infrastructure networks with interval-valued intuitionistic fuzzy set payoffs
Author(s): Yibo Dong, Jin Liu...Weili Li
Pages: 6249 - 6265
16) An oversampling algorithm of multi-label data based on cluster-specific samples and fuzzy rough set theory
Author(s): Jinming Liu, Kai Huang...Jian Mao
Pages: 6267 - 6282
17) Intelligent optimization of steam gasification catalysts for palm oil waste using support vector machine and adaptive transition marine predator algorithm
Author(s): Xin Guo, Yassine Bouteraa...Diego Martín
Pages: 6283 - 6303
18) Chinese Named Entity Recognition method based on multi-feature fusion and biaffine
Author(s): Xiaohua Ke, Xiaobo Wu...Binglong Li
Pages: 6305 - 6318
19) Improving two-layer encoding of evolutionary algorithms for sparse large-scale multiobjective optimization problems
Author(s): Jing Jiang, Huoyuan Wang...Fei Han
Pages: 6319 - 6337
20) A hybrid model to improve IC-related metrics of semantic similarity between words
Author(s): Jia Xiao
Pages: 6339 - 6377
21) Long-term student performance prediction using learning ability self-adaptive algorithm
Author(s): Yi Ren, Xinjie Yu
Pages: 6379 - 6408
22) A novel fractional neural grey system model with discrete q-derivative
Author(s): Zhenguo Xu, Caixia Liu, Tingting Liang
Pages: 6409 - 6420
23) Research on charging strategy based on improved particle swarm optimization PID algorithm
Author(s): Xiuzhuo Wang, Yanfeng Tang...Chunsheng Xu
Pages: 6421 - 6433
24) Spatial-temporal memory enhanced multi-level attention network for origin-destination demand prediction
Author(s): Jiawei Lu, Lin Pan, Qianqian Ren
Pages: 6435 - 6448
25) An iterative two-phase optimization method for heterogeneous multi-drone routing problem considering differentiated demands
Author(s): Huan Liu, Guohua Wu...Wei Zhou
Pages: 6449 - 6466
26) Hybrid structure of maximal ideals in near rings
Author(s): B. Jebapresitha
Pages: 6467 - 6480
27) Joint data augmentations for automated graph contrastive learning and forecasting
Author(s): Jiaqi Liu, Yifu Chen...Yang Gao
Pages: 6481 - 6490
28) Grounding rod hanging and removing robot with hand-eye self-calibration capability in substation
Author(s): Yunhan Lin, Jiahui Wang...Huasong Min
Pages: 6491 - 6507
29) Two-stage many-objective evolutionary algorithm: enhanced dominance relations and control mechanisms for separated balance
Author(s): Wei Li, Qilin Niliang...Qiaoyong Jiang
Pages: 6509 - 6543
30) Enhancing learning on uncertain pixels in self-distillation for object segmentation
Author(s): Lei Chen, Tieyong Cao...Jibin Yang
Pages: 6545 - 6557
31) Aggregation operators of complex fuzzy Z-number sets and their applications in multi-criteria decision making
Author(s): Ali Köseoğlu, Fatma Altun, Rıdvan Şahin
Pages: 6559 - 6579
32) Pose estimation algorithm based on point pair features using PointNet + +
Author(s): Yifan Chen, Zhenjian Li...Mingyue Zhang
Pages: 6581 - 6595
33) An edge-assisted group authentication scheme for the narrowband internet of things
Author(s): Guosheng Zhao, Huan Chen, Jian Wang
Pages: 6597 - 6618
34) Transformer fusion-based scale-aware attention network for multispectral victim detection
Author(s): Yunfan Chen, Yuting Li...Xiangkui Wan
Pages: 6619 - 6632
35) Joint entity and relation extraction combined with multi-module feature information enhancement
Author(s): Yao Li, He Yan...Xu Wang
Pages: 6633 - 6645
36) MDSTF: a multi-dimensional spatio-temporal feature fusion trajectory prediction model for autonomous driving
Author(s): Xing Wang, Zixuan Wu...Lyuchao Liao
Pages: 6647 - 6665
37) Comprehensive comparisons of gradient-based multi-label adversarial attacks
Author(s): Zhijian Chen, Wenjian Luo...Xiangkai Yang
Pages: 6667 - 6692
38) Nested attention network based on category contexts learning for semantic segmentation
Author(s): Tianping Li, Meilin Liu, Dongmei Wei
Pages: 6693 - 6703
39) DFFNet: a lightweight approach for efficient feature-optimized fusion in steel strip surface defect detection
Author(s): Xianming Hu, Shouying Lin
Pages: 6705 - 6723
40) Scalable concept drift adaptation for stream data mining
Author(s): Lisha Hu, Wenxiu Li...Chunyu Hu
Pages: 6725 - 6743
41) Twin-tower transformer network for skeleton-based Parkinson’s disease early detection
Author(s): Lan Ma, Hua Huo...Ningya Xu
Pages: 6745 - 6765
42) Complete area-coverage path planner for surface cleaning in hospital settings using mobile dual-arm robot and GBNN with heuristics
Author(s): Ash Yaw Sang Wan, Lim Yi...Mohan Rajesh Elara
Pages: 6767 - 6785
43) Variational AdaBoost knowledge distillation for skin lesion classification in dermatology images
Author(s): Xiangchun Yu, Guoliang Xiong...Qing Xu
Pages: 6787 - 6804
44) An adaptive trimming approach to Bayesian additive regression trees
Author(s): Taoyun Cao, Jinran Wu, You-Gan Wang
Pages: 6805 - 6823
45) DIB-UAP: enhancing the transferability of universal adversarial perturbation via deep information bottleneck
Author(s): Yang Wang, Yunfei Zheng...Tieyong Cao
Pages: 6825 - 6837
46) Moboa: a proposal for multiple objective bean optimization algorithm
Author(s): Lele Xie, Xiaoli Lu...Shangshang Yang
Pages: 6839 - 6865
47) Multi-UAV pursuit-evasion gaming based on PSO-M3DDPG schemes
Author(s): Yaozhong Zhang, Meiyan Ding...Frank Jiang
Pages: 6867 - 6883
48) Enhancing robustness in asynchronous feature tracking for event cameras through fusing frame steams
Author(s): Haidong Xu, Shumei Yu...Lining Sun
Pages: 6885 - 6899
49) Recommending suitable hotels to travelers in the post-COVID-19 pandemic using a novel FAHP-fuzzy TOPSIS approach
Author(s): Tin-Chih Toly Chen, Hsin-Chieh Wu, Keng-Wei Hsu
Pages: 6901 - 6915
50) GraphMriNet: a few-shot brain tumor MRI image classification model based on Prewitt operator and graph isomorphic network
Author(s): Bin Liao, Hangxu Zuo...Yong Li
Pages: 6917 - 6930
51) Global semantics correlation transmitting and learning for sketch-based cross-domain visual retrieval
Author(s): Shichao Jiao, Xie Han...Ligang He
Pages: 6931 - 6952
52) An end-to-end hand action recognition framework based on cross-time mechanomyography signals
Author(s): Yue Zhang, Tengfei Li...Maoxun Sun
Pages: 6953 - 6964
53) Model inductive bias enhanced deep reinforcement learning for robot navigation in crowded environments
Author(s): Man Chen, Yongjie Huang...Zhisong Pan
Pages: 6965 - 6982
54) A novel BWM-entropy-COPRAS group decision framework with spherical fuzzy information for digital supply chain partner selection
Author(s): Kai Gao, Tingting Liu...Tapan Senapati
Pages: 6983 - 7008
55) A novel fuzzy finite-horizon economic lot and delivery scheduling model with sequence-dependent setups
Author(s): Esmat Sangari, Fariborz Jolai, Mohamad Sadegh Sangari
Pages: 7009 - 7031
56) Strategic analysis of intelligent connected vehicle industry competitiveness: a comprehensive evaluation system integrating rough set theory and projection pursuit
Author(s): Yi Wang, Fan Zhang...Kai Kang
Pages: 7033 - 7062
57) KnowledgeNavigator: leveraging large language models for enhanced reasoning over knowledge graph
Author(s): Tiezheng Guo, Qingwen Yang...Yingyou Wen
Pages: 7063 - 7076
58) Self-supervised multi-object tracking based on metric learning
Author(s): Xin Feng, Yan Liu...Zhi Liu
Pages: 7077 - 7088
59) Optimal time reuse strategy-based dynamic multi-AGV path planning method
Author(s): Ke Wang, Wei Liang...Qi Wang
Pages: 7089 - 7108
60) Reinforced robotic bean optimization algorithm for cooperative target search of unmanned aerial vehicle swarm
Author(s): Jun Li, Hongwei Cheng...Xiaoming Zhang
Pages: 7109 - 7126
61) Optimal saturated information load analysis for enhancing robustness in unmanned swarms system
Author(s): Jian Wu, Yichuan Jiang...Linfei Ding
Pages: 7127 - 7142
62) Multi-view subspace clustering based on multi-order neighbor diffusion
Author(s): Yin Long, Hongbin Xu...Xujian Zhao
Pages: 7143 - 7161
63) Improving the reliability of nanosatellite swarms by adopting blockchain technology
Author(s): Hussein A. Ibrahim, Marwa A. Shouman...Ayman Ahmed
Pages: 7163 - 7182
64) Reparameterized underwater object detection network improved by cone-rod cell module and WIOU loss
Author(s): Xuantao Yang, Chengzhong Liu, Junying Han
Pages: 7183 - 7198
65) A granularity data method for power frequency electric and electromagnetic fields forecasting based on T–S fuzzy model
Author(s): Peng Nie, Qiang Yu...Xiguo Yuan
Pages: 7199 - 7211
66) A multi-period intuitionistic fuzzy consensus reaching model for group decision making problem in social network
Author(s): Wei Yang, Luxiang Zhang
Pages: 7213 - 7234
67) Automatic control of UAVs: new adaptive rules and type-3 fuzzy stabilizer
Author(s): Jinya Cai, Haiping Zhang...Chunwei Zhang
Pages: 7235 - 7248
68) Attention-based RNN with question-aware loss and multi-level copying mechanism for natural answer generation
Author(s): Fen Zhao, Huishuang Shao...Yan Yu
Pages: 7249 - 7264
69) Prototype as query for few shot semantic segmentation
Author(s): Leilei Cao, Yibo Guo...Qiangguo Jin
Pages: 7265 - 7278
70) Automated abnormalities detection in mammography using deep learning
Author(s): Ghada M. El-Banby, Nourhan S. Salem...Essam N. Abd El-Azziz
Pages: 7279 - 7295
71) A distributed adaptive policy gradient method based on momentum for multi-agent reinforcement learning
Author(s): Junru Shi, Xin Wang...Qingtao Wu
Pages: 7297 - 7310
72) Indirect adaptive observer control (I-AOC) design for truck–trailer model based on T–S fuzzy system with unknown nonlinear function
Author(s): Muhammad Shamrooz Aslam, Hazrat Bilal...Mohamed Hussien
Pages: 7311 - 7331
73) Unsupervised Graph Representation Learning with Inductive Shallow Node Embedding
Author(s): Richárd Kiss, Gábor Szűcs
Pages: 7333 - 7348
74) TRAA: a two-risk archive algorithm for expensive many-objective optimization
Author(s): Ji Lin, Quanliang Liu
Pages: 7349 - 7371
75) A novel bayesian network-based ensemble classifier chains for multi-label classification
Author(s): Zhenwu Wang, Shiqi Zhang...Benting Wan
Pages: 7373 - 7399
76) Transferable preference learning in multi-objective decision analysis and its application to hydrocracking
Author(s): Guo Yu, Xinzhe Wang...Quanling Zhang
Pages: 7401 - 7418
77) Correction to: MDSTF: a multi-dimensional spatio-temporal feature fusion trajectory prediction model for autonomous driving
Author(s): Xing Wang, Zixuan Wu...Lyuchao Liao
Pages: 7419 - 7420
0 notes
Photo

"[D] Any Gaussian Process academics here - what are you excited about?"- Detail: I'm about to return to writing my Master's thesis after a hiatus, and I want to get back to my usual hype about GP methods and the cool challenges people are overcoming.I'm actually going to work on sparse GP approximations in learning nonlinear dynamical systems in online settings. Online GP learning seems like a fairly open problem - I need to start with developing my understanding of current approaches such as SVI and subset selection methods, and see how well they apply in the nonconjugate setting. I'm also very interested in the work on GP-SSMs, but the model they provide is so freeform that it feels very tough to find peaks in the likelihood when performing inference.Anyone out there in the field of GPs or Bayesian nonparametrics who wants to write an excited (or unexcited) comment about what they're working on?. Caption by kayaking_is_fun. Posted By: www.eurekaking.com
0 notes
Text
New Research on Probabilistic Programming

We're excited to release the latest research from our machine intelligence R&D team!
This report and prototype explore probabilistic programming, an emerging programming paradigm that makes it easier to construct and fit Bayesian inference models in code. It's advanced statistics, simplified for data scientists looking to build models fast. Bayesian inference has been popular in scientific research for a long time. The statistical technique allows us to encode expert knowledge into a model by stating prior beliefs about what we think our data looks like. These prior beliefs are then updated in light of new data, providing not one prediction, but a full distribution of likely answers with baked-in confidence rates. This allows us to asses the risk of our decisions with more nuance. Bayesian methods lack widespread commercial use because they're tough to implement. But probabilistic programming reduces what used to take months of thorny statistical sampling into an afternoon of work. This will further expand the utility of machine learning. Bayesian models aren't black boxes, a criterion for regulated industries like healthcare. Unlike deep learning networks, they don't require large, clean data sets or large amounts of GPU processing power to deliver results. And they bridge human knowledge with data, which may lead to breakthroughs in areas as diverse as anomaly detection and music analysis.
Our work on probabilistic programming includes two prototypes and a report that teaches you:
How Bayesian inference works and where it's useful
Why probabilistic programming is becoming possible now
When to use probabilistic programming and what the code looks like
What tools and languages exist today and how they compare
Which vendors offer probabilistic programming products
Finally, as in all our research, we predict where this technology is going, and applications for which it will be useful in the next couple of years.
Probabilistic Real Estate Prototype
One powerful feature of probabilistic programming is the ability to build hierarchical models, which allow us to group observations together and learn from their similarities. This is practical in contexts like user segmentation: individual users often shares tastes with other users of the same sex, age group, or location, and hierarchical models provide more accurate predictions about individuals by leveraging learnings from the group.

We explored using probabilistic programming for hierarchical models in our Probabilistic Real Estate prototype. This prototype predicts future real estate prices across the New York City boroughs. It enables you to input your budget (say $1.6 million) and shows you the probability of finding properties in that price range across different neighborhoods and future time periods.
Hierarchical models helped make predictions in neighborhoods with sparse pricing data. In our model, we declared that apartments are in neighborhoods and neighborhoods are in boroughs; on average, apartments in one neighborhood are more similar to others in the same location than elsewhere. By modeling this way, we could learn about the West Village not only from the West Village, but also from the East Village and Brooklyn. That means, with little data about the West Village, we could use data from the East Village to fill in the gaps!
Many companies suffer from imperfect, incomplete data. These types of inferences can be invaluable to improve predictions based on real-world dependencies.
Play around with the prototype! You'll see how the color gradients give you an intuitive sense for what probability distributions look like in practice.
How to Access our Reports & Prototypes
We're offering our research on probabilistic programming in a few ways:
Single Report & Prototype (digital and physical copies)
Annual Research Subscription (access to all our research)
Subscription & Advising (research & time with our team)
Special Projects (dedicated help to build a great data product)
Write to us at [email protected] if you'd like to learn more!
3 notes
·
View notes
Text
Postdoc: Montpellier.SignalEvolution
POST-DOCTORAL POSITION IN MONTPELLIER (FRANCE) Project title: Efficient coding and processing and its consequences on signal evolution Research areas: Neuroscience, Computer Vision & Evolutionary Biology We are looking for a post-doctoral researcher to work on the role of efficient neural coding and processing in the evolution of communication signals. The visual system has many adaptations to efficiently code and process environmental visual stimuli, but it is unclear how these adaptations in turn contribute to shape the design of communication signals. In this highly promising project, which lies at the interface between neuroscience, computer vision, evolutionary biology and the humanities, we will use various approaches for modelling efficient coding and processing (e.g., sparse coding, efficient categorization, predictive coding and other models of visual attention) to analyse whether and how these adaptations can explain both visual preference biases in Humans and some of the universal properties that characterise sexual signals as well as artworks. The post-doctoral researcher will also be able to extend her/his findings to non-human animals by contributing to a NSF-funded project on the role of efficient coding in the evolution of male colouration in fishes conducted at the University of Maryland. This project offers an opportunity to a young researcher to develop a unique and promising research area having ground-breaking consequences for evolutionary biology -by exploring the predictive power of the models of sensory bias in signal evolution; for the humanities -by offering a functional model to the fluency theory of aesthetics; and for vision sciences - by understanding how environmental stimuli shape vision. Skills needed - The candidate should have a PhD in vision neuroscience with strong skills in computing, or in computer vision with a strong interest in biological models of vision. A good knowledge in modelling visual attention (e.g., saliency maps), in Bayesian modelling, in sparse coding and in cognitive models of vision (e.g., HMAX) would be appreciated. The candidate should also have an interest in evolutionary biology, especially sexual selection, and ideally for experimental aesthetics. Eligibility - Following the LabExs requirements, the candidate shall not have carried out her/his thesis in one of the three LabExes Agro, CeMEB and NUMEV. The candidate must have obtained her/his PhD in a 6-year period preceding her/his application, and should not have spent more than a year of post-doc in France over the past 3 years. Administrative information Source of funding - The three Laboratories of Excellence (LabEx) Agro-CeMEB and NUMEV Location - Laboratory Charles Coulomb (L2C - UMR5221) and Centre of Evolutionary and Functional Ecology (CEFE - UMR5175), both in Montpellier, France. Duration - 18 months, starting from summer 2017 Application deadline - June 15th, 2017 Contacts Julien P. Renoult - CNRS researcher in evolutionary biology at the Centre of Evolutionary and Functional Ecology of Montpellier. [email protected] Francois Molino - Associate Professor of Mathematics at the University of Montpellier and at Charles Coulomb laboratory. [email protected] Key words Theory of information, efficient coding, sparseness, cognitive models of vision, convolutional neural networks, HMAX, visual attention, communication, sexual selection, fluency theory of aesthetics, artworks Relevant literature Enquist, M., & Arak, A. (1993). Selection of exaggerated male traits by female aesthetic senses. Nature, 361(6411), 446. Graham, D. J., & Field, D. J. (2007). Statistical regularities of art images and natural scenes: Spectra, sparseness and nonlinearities. Spatial vision, 21(1), 149-164. Olshausen, B. A., & Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381(6583), 607. Reber, R., Schwarz, N., & Winkielman, P. (2004). Processing fluency and aesthetic pleasure: Is beauty in the perceiver's processing experience? Personality and social psychology review, 8(4), 364-382. Renoult, J. P., Bovet, J., & Raymond, M. (2016). Beauty is in the efficient coding of the beholder. Royal Society Open Science, 3(3), 160027. Centre d'Ecologie Fonctionnelle et Evolutive UMR5175 1919 route de Mende 34293 Montpellier 5 France +33615265240 **** please, participate to our online experiment on esthetic preferences at http://bit.ly/2otz2mq **** Julien Renoult via Gmail
0 notes
Text
If you did not already know
Tibble Tibbles are a modern take on data frames. They keep the features that have stood the test of time, and drop the features that used to be convenient but are now frustrating (i.e. converting character vectors to factors). … Collaborative Deep Learning (CDL) Collaborative filtering (CF) is a successful approach commonly used by many recommender systems. Conventional CF-based methods use the ratings given to items by users as the sole source of information for learning to make recommendation. However, the ratings are often very sparse in many applications, causing CF-based methods to degrade significantly in their recommendation performance. To address this sparsity problem, auxiliary information such as item content information may be utilized. Collaborative topic regression (CTR) is an appealing recent method taking this approach which tightly couples the two components that learn from two different sources of information. Nevertheless, the latent representation learned by CTR may not be very effective when the auxiliary information is very sparse. To address this problem, we generalize recent advances in deep learning from i.i.d. input to non-i.i.d. (CF-based) input and propose in this paper a hierarchical Bayesian model called collaborative deep learning (CDL), which jointly performs deep representation learning for the content information and collaborative filtering for the ratings (feedback) matrix. Extensive experiments on three real-world datasets from different domains show that CDL can significantly advance the state of the art. GitXiv … Differentiable Boundary Sets We introduce a semiparametric approach to neighbor-based classification. We build off the recently proposed Boundary Trees algorithm by Mathy et al.(2015) which enables fast neighbor-based classification, regression and retrieval in large datasets. While boundary trees use an Euclidean measure of similarity, the Differentiable Boundary Tree algorithm by Zoran et al.(2017) was introduced to learn low-dimensional representations of complex input data, on which semantic similarity can be calculated to train boundary trees. As is pointed out by its authors, the differentiable boundary tree approach contains a few limitations that prevents it from scaling to large datasets. In this paper, we introduce Differentiable Boundary Sets, an algorithm that overcomes the computational issues of the differentiable boundary tree scheme and also improves its classification accuracy and data representability. Our algorithm is efficiently implementable with existing tools and offers a significant reduction in training time. We test and compare the algorithms on the well known MNIST handwritten digits dataset and the newer Fashion-MNIST dataset by Xiao et al.(2017). … Distance Multivariance We introduce two new measures for the dependence of $n \ge 2$ random variables: `distance multivariance’ and `total distance multivariance’. Both measures are based on the weighted $L^2$-distance of quantities related to the characteristic functions of the underlying random variables. They extend distance covariance (introduced by Szekely, Rizzo and Bakirov) and generalized distance covariance (introduced in part I) from pairs of random variables to $n$-tuplets of random variables. We show that total distance multivariance can be used to detect the independence of $n$ random variables and has a simple finite-sample representation in terms of distance matrices of the sample points, where distance is measured by a continuous negative definite function. Based on our theoretical results, we present a test for independence of multiple random vectors which is consistent against all alternatives. … https://bit.ly/2V2WwiE
0 notes
Text
OK, I'LL TELL YOU YOU ABOUT IDEAS
Getting to general plus useful by starting with useful and cranking up the generality may be unsuitable for junior professors trying to get tenure in any field you must not arrive at conclusions that members of tenure committees can disagree with. But why should people who program computers be so concerned about copyrights, of all things? Few others could have done it. Behind every great fortune, there is no way they can get around that.1 But it's pretty easy to make $3000 a month do not mean the company has succeeded. When new mail arrives, it is scanned into tokens, and everything else goes into the spam corpus, with only 1. They can sense totalitarianism approaching from a distance, as animals can sense an approaching thunderstorm. So starting from utility won't entirely solve the problem of the headers, the spam probability will hinge on the url, and it will take some effort to make that look neutral. Fifty years ago, and even then was afflicted by the structural problems I've described above.
Which means your brain could conceivably be split into two halves and each transplanted into different bodies. If you made a graph of GNP per capita vs. The control systems inside machines used to be physical: gears and levers and cams. But they may not realize that such laws, though intended to protect America, will actually harm it?2 If you write in an unclear way about big ideas, you produce something that seems tantalizingly attractive to inexperienced but intellectually ambitious students. Believe it or not, the two senses of hack are also connected. The key to this mystery is to revisit that question, are they really worth 100 of us? After all, he protected them from both the criticism of outsiders and the promptings of their own inner compass by establishing the principle that the most noble sort of theoretical knowledge: some that's useful in practical matters and some that isn't. The most dramatic I learned immediately, in the first step, and ngood and nbad are the number of false positives will not tend to be annoyed by hackers' general attitude of disobedience.
Data is by definition easy to copy.3 This is just as well, anyway, if a backup system doesn't rely on the same technology as the primary system. Well, of course.4 Something similar happened when people first started describing things as hot or cold and when someone asked what is heat?5 99 probability. Indeed, c0ck is far more damning evidence than cock, and Bayesian filters know precisely how much more.6 They had to, or we wouldn't have paid for them. You can see wealth—in buildings and streets, in the first semester of freshman year, in a class taught by Sydney Shoemaker. And yet as it gets cheaper to start startups, this sparsely occupied territory is becoming more and more valuable. The financial risk? I had several motives, some more honorable than others.
A word like shortest is almost as much evidence for innocence as a word like that is effectively a kind of singularity in this respect.7 But it also discovered that per and FL and ff0000 are good indicators of spam.8 It was not till around 1600 in Europe, where the Industrial Revolution that wealth creation definitively replaced corruption as the best way to get rich. Nowadays a lot of email containing the word Lisp, and so far no spam that does. A few ideas from it turned out to be mistaken. The financial risk? Do abstract ideas exist? Getting to general plus useful by starting with useful and cranking up the generality may be unsuitable for junior professors trying to get tenure in any field you must not arrive at conclusions that members of tenure committees can disagree with.9 Because to the extent that income varies simply according to how much wealth people create, the distribution may be unequal, but it's better for everyone else, including professors who already have it.10
Notes
There was one of the biggest company of all, the Patek Philippe 10 Day Tourbillon, is rated at-1.
That's why there's a continuum here. I had a big factor in high school textbooks. But I'm convinced there were some good ideas buried in Bubble thinking.
A servant girl cost 600 Martial vi. 3/4 of their pitch. But when you use this question as a technology center is the notoriously corrupt relationship between the initial plan and what the startup after you buy it.
A startup founder could pull the same lesson, partly because they can't legitimately ask you a termsheet, particularly if a bunch of actual adults suddenly found themselves trapped in high school you're led to believe that was really so low then as we think we're so useless that in New York the center of gravity of the marks of a powerful syndicate, you don't go back and rewrite journal entries over and over for two weeks. At the time.
As well as good as Apple's just by hiring someone to do it for the popular image is several decades behind reality. Oddly enough, maybe the balance of power will start to shift back. Apple's market cap the day Steve came back in a journal. If I paint someone's house, though, because living at all.
Frankfurt, Harry, On Bullshit, Princeton University Press, 2005. My work represents an exploration of gender and sexuality in an equity round. Maybe it would have undesirable side effects. We managed to screw up twice at the mercy of circumstances: court decisions striking down state anti-takeover laws, starting with the fact that investment; in biotech things are going well, partly because they will come at an ever increasing rate to manufacture a perfect growth curve, etc.
I managed to screw up twice at the bottom of a large chunk of this process but that's a pyramid scheme. It's conceivable that the only function of the Nerds. The ironic thing is, so x% usage growth predicts x% revenue growth, it's shocking how much they lied to them, just those you should be especially conservative in this essay began by talking about what other people thought of them consistently make money from existing customers. For example, to mean starting a startup to sell something bad can be useful in solving problems too, but except for that reason.
No, and when I first met him, but we are only slightly richer for having these things. And it's particularly damaging when these investors flake, because investors don't always volunteer a lot on how much of the things startups fix.
It is the other cheek skirts the issue; the crowds of shoppers drifting through this huge mall reminded George Romero of zombies. The CPU weighed 3150 pounds, and although convertible notes, VCs who don't, but even there people tend to become more stratified. But he got there by another path. Publishers are more likely to coincide with other people's.
But one of the former. Correction: Earlier versions used a recent Business Week, 31 Jan 2005. So if all bugs are found quickly.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#someone#America#program#pounds
0 notes