#the main character's name is spelled two different ways within the same paragraph
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
me rn because Powerless has so many consistency errors and nonsensical conversations I genuinely feel like I am losing my ability to read

#they keep saying one thing and then the exact opposite within the same conversation#the main character's name is spelled two different ways within the same paragraph#online guides and summaries claim the event that the plotline surrounds is different from what is described in the book#fighting for my life as we speak. this is what i get for paying attention to what i read#eernatalk#kai: you are a prize i am trying to win#paedyn: WHAT THE FUCK??? I AM A TROPHY???#kai: no??? what'???' what are you saying right now??????? you are not something i can win?????????? you have to choose me <3 i am a good gu
71 notes
·
View notes
Text
writing a series: the story so far ...
As much as authors hope that our readers remember every single detail from our books, the truth is that most SFF fans will read anywhere between ten to twenty-five books in a year. Keeping up with characters, themes, and stories from one book to another can be daunting, to say the least.
While writing the Los Nefilim series, I wanted to devise a way in which readers didn’t have to struggle to remember who was who and what they were trying to accomplish. I’d tested the method with the Los Nefilim novellas by writing a very short summary of what had happened in the previous novella (or episode) at the beginning of each new novella, and the readers seemed to like it.
Since we wanted Where Oblivion Lives to stand apart from the novellas, I only wrote a note about the various spellings of nefilim and the different divisions of the Inner Guard in the foreword. However, the sequel to Where Oblivion Lives, Carved from Stone and Dream, brought forward a complex set of problems.
I wanted each of the novels to work as stand-alone stories that achieved a sense of closure at the end of each book. I personally hate cliff-hanger endings, and I’ve heard a lot of readers state the same. However, when I enjoy a series, I like a quick refresher to the preceding stories so I don’t have to reread the previous edition before moving to the current book.
At the same time, I want to keep that refresher as non-spoilery as possible in case someone is picking up the second book as their introduction to the series. I need those blurbs to be as enticing as possible so that if the reader enjoys, for example, Carved from Stone and Dream, they might go back and read Where Oblivion Lives.
That was the first problem. The second was more complex and more of a structural issue that I created while planning the events of the series.
Where Oblivion Lives takes place in 1932, and Carved from Stone and Dream takes place in 1939. That is a seven year gap between the events in the first novel and the second.
I also knew my American readers had little exposure to the events leading up to the Spanish Civil War, but at the same time, I wanted to jump readers straight into the action. At the same time, I needed to recap the events succinctly so readers weren’t spending five pages orienting themselves to current events.
Since I’d envisioned the Los Nefilim series as spy/war stories very similar to the old Shadow series, the first problem was fairly easy to fix. I included an author’s note at the beginning of each novel, and beginning with Carved from Stone and Dream, I included a brief refresher that looked like this:
To remedy any memory gaps the reader might have, I’m also including a very brief, spoiler-free synopsis of the events from previous episodes. To be clear: each of the novellas and novels can be read as stand-alone works.
However, I always imagined Los Nefilim as a serial, much like the old Shadow radio serials. In keeping with that tone, here is the story so far . . .
1931 (The Los Nefilim omnibus contains the novellas In Midnight’s Silence, Without Light or Guide, and The Second Death)
Diago Alvarez, a rarity among the nefilim in that his mother was an angel and his father was a daimon-born nefil, discovers that he has a six-year-old son named Rafael. Having never officially joined Los Nefilim, the Spanish Inner Guard, Diago has always lived as a rogue. He maintains a superficial connection to Los Nefilim through his husband, Miquel de Torrellas, who is Guillermo Ramírez’s second-in-command.
Rafael’s presence changes Diago’s priorities. The only way he can protect his son from his daimonic kin is by joining Los Nefilim. Diago swears an oath to Guillermo Ramírez, the king of Los Nefilim, who wants Diago to try and compose the Key—the song that will enable the nefilim to open the realms as the angels do.
1932 (Where Oblivion Lives)
Now a member of Los Nefilim, Diago leaves Spain in order to solve the mystery of his missing violin, which torments his dreams. It’s his first official mission as a member of the Inner Guard, and he succeeds in both solving the mystery and in confronting his PTSD from the Great War. During the course of these events, Guillermo discovers traitors within his own ranks that belong to his brother, Jordi Abelló, who has returned to undermine Guillermo’s right to command Los Nefilim. At the end of 1932, Diago and Guillermo work together and finally compose the first notes to the Key.
Our story begins in 1939. . .
I did the same for A Song with Teeth, and simply added a very short spoiler-free synopsis of Carved from Stone and Dream.
A few tips for writing these summaries:
Focus on one character’s story arc. There are a lot of awesome characters in Los Nefilim, or at least, I like to think so, and while there is room to elaborate on all these characters, remember the purpose behind the refresher: to jog your reader’s memory. Design your blurbs around your protagonist’s character arc and be as precise as possible.
Remind the reader why the protagonist is special. I did this in the first summary of the novellas and continued it throughout the series: Diago Alvarez, a rarity among the nefilim in that his mother was an angel and his father was a daimon-born nefil, discovers that he has a six-year-old son named Rafael. It’s also the first sentence of the first summary. For those who have read the books, they remember Diago. For those new to the series, they know which character is the protagonist and what makes them special to the story.
Stick to the most important plot points. This isn’t the place to go into characterization arcs. The reader will remember those. Ask yourself: What is the series’ main objective? For Los Nefilim, it is the search for the Key. So I designed each blurb to focus on what led them to the next step in finding the Key.
KISS it. Keep it short, sweetheart, from beginning to end. You want to design it so that someone can scan the whole summary in less than a minute. Hit the highlights in as few sentences as possible and then move to the story. In the Los Nefilim series, the novella summaries were two paragraphs only because they were covering the events of three separate stories. I kept each novel’s summary to a short paragraph.
The second problem required a more creative solution. How was I going to skim through seven years of events and keep it entertaining?
The answer was through a prologue, but I didn’t want to do a standard recap.
I thought about how the various divisions of the Inner Guard would communicate during the 1930s: memos and telegrams. So I devised several very brief memos and telegrams that established the backstory as if it were happening in real time. I also developed a catch-phrase that the readers immediately associated with the stories (watch for me).
Because this post has grown a bit, I’m not going to post the entire prologue. It’s comprised of several very short memos and telegrams, but so you can see how I handled the situation, this is the final one before the story begins:
INNER GUARD DIVISION: LOS NEFILIM General Miquel de Torrellas Servicio de Investigación Militar
10 February 1939 SIM Report No. 49785
To the Honorable Madame Sabine Rousseau, Capitaine Général, Les Néphilim:
Catalonia has fallen. Los Nefilim is in retreat.
Our intelligence has uncovered Jordi’s plot to send assassins after Don Guillermo and his daughter, Ysabel. Diago Alvarez, Carme Gebara, and Feran Perez are assigned to escort Don Guillermo to the French border via an undisclosed route. We severed communications with Don Guillermo on 5 February 1939 for his own safety. His whereabouts are currently unknown.
Even in retreat, our unit remains under heavy artillery fire. The Germans and Italians bomb civilians as they flee the Nationalist advance.
My unit will continue to provide support to the mortal refugees in the eastern sector as they cross the Pyrenees. We will approach the border at Le Perthus.
Watch for us.
And this is how you can make a prologue work for you in a series. The prologue is essentially a backstory infodump—the trick is to keep it entertaining.
Be creative. Think about how your characters communicate. Is it through text messages, ravens, coded letters? Then work that into a prologue that will bring your reader quickly up to speed.
If you can skip the prologue and bring your reader into the story in the first paragraph, then by all means, do so. Toss the rules into the fire and do what works best for your readers and your story.
Use beta readers and listen to their input as to what works for them and what doesn’t. One beta reader suggested that I add a glossary to the series, and I did. I don’t know if the readers ever needed it, but it certainly proved invaluable to me a couple of times.
So remember the main rule: keep your reader in the loop at all times. Everything else can handled creatively.
That’s about all I have for now. I’ll be around.
Watch for me.
5 notes
·
View notes
Text
On Drafting
How I draft, an instruction-introduction.
I am aware this might have actually proven more useful at the start of November, for the NANOWRIMO crowd. Sorry!
Today, you need worry about nothing but 30 minutes. That's it. Just 30.
Set everything up beforehand: cup of tea or a cafetière of coffee sitting beside you within easy reaching range; have a bottle of water on hand — always, always have water. Then open up whatever digital draft software you find best/have been persuaded to part with cash for, or a notebook and pen (have a spare pen on hand too — and do also consider pencil, it writes faster in some circumstances...).
All these things happen first. Then you set the timer.
30 minutes.
Did I mention it will only be for 30 minutes?
Of course, by the time you sit there (or stand - standing can be much better for your body) you already have an idea of what you wish to write, even if it is a very basic one. This is not the time for planning, that comes before and is a whole other subject (yes, one day I'll write about my process too, if you’d like?).
30 minutes on the timer.
Go.
Now you write. Simple, yes? Well, no.
For a start, this is the hardest bit for those unaccustomed to writing drafts — they panic. Hopefully, in order to help, here is what I do — those little tricks that enable me to write swiftly and even, at times, furiously.
I type.
I use Scrivener.
I switch to distraction-free mode, with the size of the screen and the opacity of the background already dialled in.
I write.
However, I make mistakes. Perhaps I miss a leter, or aspace. Perhaps i don't capitalise or I spell someting incorectly.
Doesn't matter. Just LEAVE it. Do NOT pause and add the letter, space, capital, or spell it right. That's REDRAFTING and, later, EDITING, not drafting. We’re drafting, remember?
I plough on (or plow — have no fear about your version of English at this stage either, write in the words and spelling you feel most comfortable with).
I write.
There will come a point where I will realise I've missed something out earlier, or I change a name, or I create a name in the first place.
Side note — names, whether people, places, things. They will change. Start with a TK, for example, tkname for the main character, or tkbestfriend for her best friend. You get the idea. At this stage you are drawing out the story, later, things-magical occur and you invariably reach a point in your draft or, sometimes, redraft, where these tks resolve themselves as your subconscious continues to work on the problem of nomenclature.
Back to the missed-out bit, or the mistake.
Don't fix it! Don't you dare move that cursor or the pencil!
Leave it where it is.
Do not worry.
Hit the caps lock. Add in TKIDEA, then record that thought.
Get back to the draft.
It's a mess.
Good.
Have you ever dug clay to make pottery in the wilderness? Or have you ever needed a new spoon carved in order to eat your dinner? No, just me then, ok, sorry, personal example, but still. The clay is a mess. It has roots in it. Soil. Leaves. Small rocks. You need to know how to edit it. The branch of the tree has bark, maybe moss, the spoon wrapped within wooden fibres, hidden from view.
Same with writing.
This is a draft.
Not a polished edit, or even a redraft.
A draft.
Write.
30 minutes.
See how many words you can do. If you already have a good idea of how many — on the worst of days, not the best — use that as your minimum.
On days where words are like hen's teeth or unicorn horns, I can write as few as 500. So that is my minimum target.
BUT it's a target. When you are learning to fire an arrow or hit something with a sling, you DO NOT always hit the target. That's life. That's where practice comes in.
Keep practising.
30 minutes at a time.
Then, invariably, the timer goes off.
You stop writing NOW.
No, you STOP. You DO NOT finish the word, let alone the sentence or paragraph, no no no.
This way, you see, you are left with a loose thread to weave the next time. You won't waste any of those precious 30 minutes, because you know exactly where you are going, what comes next.
Sometimes, and this is rare, your timer will go off just as you finish a paragraph or, even rarer, a scene or chapter. In this case, switch your timer to either 2 or 3 minutes and keep going. Much better to have that thread the next day. If you think that's too short a time, you are wrong. 3 minutes is 10% of your 30 — you should be able to write the next bit in that time, surely?
That's it. You're done. You can reach for the rapidly cooling tea or coffee you forgot.
And then you count.
Obviously, this is easier in Scrivener or another word processor than it is by hand.
Then you record this number somewhere (I currently use tumblr, backed up in Scrivener and Onedrive, but I've also used spreadsheets and hand-written the results too). This is important — you need to look at the factors that curtail your drafts. Hence you'll see notes on my tumblr, where I explain how, for example, I started later in the day, or a record of illness. This gives you (me) a much better idea of what you are capable of — even under less-than-ideal circumstances.
Done.
At this point you can stop for the day, or plan another 30-minute session. If the latter, you get up now and do something else. Never, ever, ever do two 30 minute drafting sessions back-to-back without something different in between. That rarely works and when it does (yeah, I was once young, foolish, and hopeful), it is a statistical abnormality — not the norm. This is why you keep a record and notes, so you can tell future-you not to make mistakes like that.
Done. Done.
Congratulations, you've drafted words. Messy, beautiful words.
Somewhere in that coal is a diamond. Somewhere, amidst the mass you’ve just collected from a riverbank, is the clay you will use to make a cup. Your branch is whispering to you, showing you where to lay axe and knife. That is the next thing. For now, keep collecting the raw materials and, make no mistake, when you draft, those raw materials are simply a volume of words.
Easy yes?
Go try.
This is what works for me. It might not for you, but it is advice/description culled from a long period of practice (and reading about the processes of others, something it seems all writers and artists love to do).
Good luck — but do please remember — in writing as in anything — you make your own luck through discipline, hard work, and practice.
30 minutes.
Draft.
#writing#amwriting#drafting#draft#drafts#on drafting#nanowrimo#nano 2018#words#story#author#writer#practice#advice#messy words#30 minutes
6 notes
·
View notes
Note
Hey there! We were wondering if you would be interested in giving us a full review (We're okay with public). Also sidebar, I love what you're doing here. This is really a great idea.
DISCLAIMER: this review is only reflective of my own opinions and is intended to provide constructive criticism. there is no obligation to listen to or agree with anything said.
OVERALL:
from the colour scheme to the fonts and graphics, everything feels so– thematically similar and visually pleasing. i’m incredibly impressed with how everything turned out, even if i’m not exactly convinced that i would apply. thank you so much for your hard work and love for this rp, because it clearly shows. that being said, there’s still a few things that i would like to see changed or improved upon, mostly to aid clarification.
i’ve done my best to give my honest review and opinion on your rp. i tend to be a bit wordy, so there is also a TLDR at the very bottom of the page. as always, i am here to elaborate on any of my critiques if asked. thanks for coming by!
.
ACCESSIBILITY:
this is not my favorite fansite theme, mostly because it is so commonly used, but you guys have done a really good job of making it your own. the links you’ve chosen to highlight on the main page very helpful and i’m happy that you’ve included so much information about the world you’ve created in the navigation.
unfortunately, i also feel that most of your writing is incredibly dense. as a newcomer to your universe and the concepts you have presented, it takes more than one read in order to understand what is being presented to me and that’s a bit of a turn-off.
i see the most problem in pages such as your rules– which, as an ooc page, should be very easy to navigate, but instead is organized in a way that I don’t feel encourages people to actually read your guidelines. this wordiness combined with the placement of your password, leads me to believe that most would just skip to the end and not read what you’ve written. i’ve suggested changes that i would make in the ‘RULES page’ section down below.
as a general structure, accessibility is great. however, for people wanting to discover more about your world, i think there must be a better way to organize the details of your story.
.
PLOT:
I really do think that this is an original and lovely plot idea, but I stayed on this page for a very long time and I’m still not sure I understood the whole concept. Though this plot is not particularly very long, it feels that way.
The very first sentence does not grab your attention and the first paragraph is a lot of exposition for an audience that is not quite invested yet in your RP. In particular, the first two sentences introduce three completely new concepts and terms to potential applicants, and it feels a bit sprung unto you.
It is just dense and hard to understand. I’ve done a bit of retooling of the first section that I feel better conveys the idea of your RP. I am not saying that it is better or that your writing is not Amazing (bc I firmly believe that it is), but I want to give you an option. .
A centuryago, Sector Zero of the American Government began work on PROJECT GENESIS, aclassified experiment that resulted in the creation of supersoldiers.
These supersoldiers,known as Novas, were a subspecies of humanity gifted with extraordinaryabilities. Though they looked and behaved just like any other humans, theirpowers made them more valuable and more dangerous than any human could ever be.And thus, though they had been exploited by their creators for decades, their veryexistence was kept a secret for the public.
It wasonly in 2015 when the world found out about Novakind.
And it wasthen, that the world changed for good.
Within three years, Novakind were forced to registerthemselves or be imprisoned. For the next decade, Novas and Humans would waragainst each other, attempting to find the delicate equilibrium that wouldallow both sides to coexist. When the acts of terrorism from both sides grewmore and more violent, the government was forced to step in, passing the Nova Protection Act of 2026— a piece of legislationthat saw to the imprisonment of all Nova kind under the guise of“protecting” both them and the humans.
Toavoid being forced to live in the walled-off camps and be subject to the crueltythat the Protection Act established, many Novas became fugitives. There, they seek refuge in abandoned neighborhoods, hoping tooutrun the reach of the government until the horrible injustice comes toend.
In general, I advise that your plot
relies less on terminology (Sector Zero, Project Genesis, Nova, Novakind, Novum districts,..etc. are all words we have never heard before and thus we need a slow introduction to them.
tries to be more immediately attention-grabbing rather than expository
++ there’s a few grammatical and spelling errors in your plot and extra information pages and that’s a big turnoff for me. i would read through your plot one more time and proofread.
I wish the summary and notes section was separated from the rest visually (perhaps with a few line breaks?) rather than indicated under another subheader. It makes more sense to me to have it stand apart from the rest of the plot as it can be and should be read on its own, rather than as a continuation of the more detailed plot.
Though the READ MORE section is helpful and should be included in your rp, it does look a little bit out-of-place on this page, especially directly after the summary. I would rather see a READ MORE link that directs to a page with all 5 separate links right after your detailed plot.

.
AESTHETIC/GRAPHICS:.
I have genuinely nothing bad to say about your fonts or your layout. I wish I could write as long a section on how much I appreciate the colour scheme you’ve chosen and how consistent it is as I wrote about your plot.
You’ve made everything work for you and I’m really impressed.
I wish I had your eye for colour and your ability to pick pictures. Good job!
.
SKELETONS:
I love the diversity in your skeletons and the ideas behind them. The freedom of choice in the faceclaims and the unique connections are really appreciated.
However, none of the skeletons really stand out to me. A lot of the skeletons feel like bullet points, rather than like a quick look into their lives.
I love the graphics associated with each skeleton and think each of the blurbs on the skeletons are perfectly adequate, but none of them really come to life for me. Lupus and Leo are, in my opinion, the best of the batch, but I want more–
I’m sorry that I can’t really elaborate on what I’m looking for, but, in the future, I hope that you can try for a less expository description and something more imbued with animation and emotion. When skeletons are written livelily, it really does allow potential applicants to connect more with your vision of the character.
At this point, I wouldn’t change anything, but I hope that you keep this in mind for the future.
.
THE PAGES:
—– THE ‘RULES’ PAGE
If I would change one thing about your entire RP, it would be the rules. This page is hard to read through. Some of it feels repetitive and, at points, it even directly contradicts itself (no age limit, but also strongly recommended age limit).
I understand the need for all these rules, and, actually believe that most of them need to be there. However, the presentation could just be a little different.
For example, IV, V, IX are all the same topic with slight variations and can be summed up into
OOC Drama and Bullying will not tolerated in this RP. This includes forcing of ‘ships’ or ‘plots’ on other players without consent. If you feel uncomfortable of have any problems with any players, please contact us and we will resolve the issue. If found to be instigating the drama, you will have two warnings before you will be removed from the RP.
And instead of
We(as admins) promise to try and accept applications in a timely manner. We willtry to do acceptances every Wednesday and Sunday, however due to life outsideof tumblr things may change. We promise to make announcements regarding anychanges in acceptance dates/times as soon as possible.
Wedo reserve the right to deny applications, though it is a very rare occurrence.If we do deny an application, it will be for one of three reasons: 1. We feelyou do not understand the skeleton for which you’re applying. 2. Someone elseapplied, and even if your app was spectacular, we felt that the other applicantunderstood the character more, and you chose not to have a secondary optionwhen applying. 3. You failed to use spellcheck or other grammar resources whenwriting your app, to the extreme that it was very hard to read. If you weredenied and would like the reason why, just let us know and we’ll gladly talk itover with you. That being said, even if you’re denied, we would absolutely loveto see you apply again.
I would simply put
Acceptances are every Wednesday and Thursday. If conflicts arise, we will make an announcement regarding any changes in acceptance dates/times.
We reserve the right to deny applications. If you were denied and would like the reason why, please feel free to message us. Regardless of the reason why you were rejected, we will be happy to see you reapply.
As you can see, this is far less wordy and still conveys the same message.
I also firmly believe you should never have a TLDR on your rules page, because well… the players Should read your rules.
.
—– THE EXTRA INFORMATION PAGES
There a few spelling and grammatical errors on these pages and it continues to be a little bit hard to understand.
I would read over these and try to edit them in a way that is more concise.
—– RANDOM COMMENTS
The Dinah Drake name throws me off a little bit, as there is a popular superhero character by that name. It shouldn’t be important, but it just took me out of it.
I highly suggest that you stylize the title of your RP when it shows up (ie DEFIANCE vs Defiance.) It helps distinguish that this is the name of your RP rather than just a noun. It also looks a lot more dynamic.
I would avoid using slang and other colloquialisms when answering asks (ooh, oh, lol..etc.) as usually you are explaining more about your universe and your vision. You want to answer asks clearly and portray your professionalism. Otherwise, I really like the vibes you give off! You seem welcoming and I’m really glad about that.
.
.
.
TLDR; what i would like to see changed
EDIT your Rules & Plot so that they are less wordy and more engaging (also reread for grammatical errors).
I genuinely found your plot hard to get through because it was a lot of ‘telling’ (rather than showing) and it felt a little bit dry. When introducing so many new concepts to potential applicants, you have to ease them into it and sort of sweeten the waters by using a little (but not too much) purple prose and description. It gives life and atmosphere to your RP.
Your rules are just too long and, if I were applying, I would just avoid reading them if possible. I also don’t like the use of a TLDR at the end as it feels unprofessional and implies that one can skip over your rules.
Stylize the word DEFIANCE when you are referring to your RP, so we are aware that it is the title of your RP, rather than just a word.
Really not much else! I like this RP a lot! It is truly beautiful and I wish the best for you.
as a last note and reminder, YOU DO NOT HAVE TO TAKE ANY OF MY SUGGESTIONS AND I WILL NOT CARE if you have not taken any of them. There is no ill-will from me to you. As always, this is not intended to be hate and I genuinely want the best for you guys. I’ve done my very best to make sure my advice is constructive, but please call me out if you find any of this offensive or crude.
Thank you and have a nice day. Good luck!
1 note
·
View note
Text
A deep dive into BERT: How BERT launched a rocket into natural language understanding
by Dawn Anderson Editor’s Note: This deep dive companion to our high-level FAQ piece is a 30-minute read so get comfortable! You’ll learn the backstory and nuances of BERT’s evolution, how the algorithm works to improve human language understanding for machines and what it means for SEO and the work we do every day.

If you have been keeping an eye on Twitter SEO over the past week you’ll have likely noticed an uptick in the number of gifs and images featuring the character Bert (and sometimes Ernie) from Sesame Street. This is because, last week Google announced an imminent algorithmic update would be rolling out, impacting 10% of queries in search results, and also affect featured snippet results in countries where they were present; which is not trivial. The update is named Google BERT (Hence the Sesame Street connection – and the gifs). Google describes BERT as the largest change to its search system since the company introduced RankBrain, almost five years ago, and probably one of the largest changes in search ever. The news of BERT’s arrival and its impending impact has caused a stir in the SEO community, along with some confusion as to what BERT does, and what it means for the industry overall. With this in mind, let’s take a look at what BERT is, BERT’s background, the need for BERT and the challenges it aims to resolve, the current situation (i.e. what it means for SEO), and where things might be headed.
Quick links to subsections within this guide The BERT backstory | How search engines learn language | Problems with language learning methods | How BERT improves search engine language understanding | What does BERT mean for SEO?
What is BERT?
BERT is a technologically ground-breaking natural language processing model/framework which has taken the machine learning world by storm since its release as an academic research paper. The research paper is entitled BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018). Following paper publication Google AI Research team announced BERT as an open source contribution. A year later, Google announced a Google BERT algorithmic update rolling out in production search. Google linked the BERT algorithmic update to the BERT research paper, emphasizing BERT’s importance for contextual language understanding in content and queries, and therefore intent, particularly for conversational search.
So, just what is BERT really?
BERT is described as a pre-trained deep learning natural language framework that has given state-of-the-art results on a wide variety of natural language processing tasks. Whilst in the research stages, and prior to being added to production search systems, BERT achieved state-of-the-art results on 11 different natural language processing tasks. These natural language processing tasks include, amongst others, sentiment analysis, named entity determination, textual entailment (aka next sentence prediction), semantic role labeling, text classification and coreference resolution. BERT also helps with the disambiguation of words with multiple meanings known as polysemous words, in context. BERT is referred to as a model in many articles, however, it is more of a framework, since it provides the basis for machine learning practitioners to build their own fine-tuned BERT-like versions to meet a wealth of different tasks, and this is likely how Google is implementing it too. BERT was originally pre-trained on the whole of the English Wikipedia and Brown Corpus and is fine-tuned on downstream natural language processing tasks like question and answering sentence pairs. So, it is not so much a one-time algorithmic change, but rather a fundamental layer which seeks to help with understanding and disambiguating the linguistic nuances in sentences and phrases, continually fine-tuning itself and adjusting to improve.
The BERT backstory
To begin to realize the value BERT brings we need to take a look at prior developments.
The natural language challenge
Understanding the way words fit together with structure and meaning is a field of study connected to linguistics. Natural language understanding (NLU), or NLP, as it is otherwise known, dates back over 60 years, to the original Turing Test paper and definitions of what constitutes AI, and possibly earlier. This compelling field faces unsolved problems, many relating to the ambiguous nature of language (lexical ambiguity). Almost every other word in the English language has multiple meanings. These challenges naturally extend to a web of ever-increasing content as search engines try to interpret intent to meet informational needs expressed by users in written and spoken queries.
Lexical ambiguity
In linguistics, ambiguity is at the sentence rather than word level. Words with multiple meanings combine to make ambiguous sentences and phrases become increasingly difficult to understand. According to Stephen Clark, formerly of Cambridge University, and now a full-time research scientist at Deepmind:
“Ambiguity is the greatest bottleneck to computational knowledge acquisition, the killer problem of all natural language processing.”
In the example below, taken from WordNet (a lexical database which groups English words into synsets (sets of synonyms)), we see the word “bass” has multiple meanings, with several relating to music and tone, and some relating to fish. Furthermore, the word “bass” in a musical context can be both a noun part-of-speech or an adjective part-of-speech, confusing matters further. Noun
S: (n) bass (the lowest part of the musical range)
S: (n) bass, bass part (the lowest part in polyphonic music)
S: (n) bass, basso (an adult male singer with the lowest voice)
S: (n) sea bass, bass (the lean flesh of a saltwater fish of the family Serranidae)
S: (n) freshwater bass, bass (any of various North American freshwater fish with lean flesh (especially of the genus Micropterus))
S: (n) bass, bass voice, basso (the lowest adult male singing voice)
S: (n) bass (the member with the lowest range of a family of musical instruments)
S: (n) bass (nontechnical name for any of numerous edible marine and freshwater spiny-finned fishes)
Adjective
S: (adj) bass, deep (having or denoting a low vocal or instrumental range) “a deep voice”; “a bass voice is lower than a baritone voice”; “a bass clarinet”
Polysemy and homonymy
Words with multiple meanings are considered polysemous or homonymous.
Polysemy
Polysemous words are words with two or more meanings, with roots in the same origin, and are extremely subtle and nuanced. The verb ‘get’, a polysemous word, for example, could mean ‘to procure’,’ to acquire’, or ‘to understand’. Another verb, ‘run’ is polysemous and is the largest entry in the Oxford English Dictionary with 606 different meanings.
Homonymy
Homonyms are the other main type of word with multiple meanings, but homonyms are less nuanced than polysemous words since their meanings are often very different. For example, “rose,” which is a homonym, could mean to “rise up” or it could be a flower. These two-word meanings are not related at all.
Homographs and homophones
Types of homonyms can be even more granular too. ‘Rose’ and ‘Bass’ (from the earlier example), are considered homographs because they are spelled the same and have different meanings, whereas homophones are spelled differently, but sound the same. The English language is particularly problematic for homophones. You can find a list over over 400 English homophone examples here, but just a few examples of homophones include:
Draft, draught
Dual, duel
Made, maid
For, fore, four
To, too, two
There, their
Where, wear, were
At a spoken phrase-level word when combined can suddenly become ambiguous phrases even when the words themselves are not homophones. For example, the phrases “four candles” and “fork handles” when splitting into separate words have no confusing qualities and are not homophones, but when combined they sound almost identical. Suddenly these spoken words could be confused as having the same meaning as each other whilst having entirely different meanings. Even humans can confuse the meaning of phrases like these since humans are not perfect after all. Hence, the many comedy shows feature “play on words” and linguistic nuances. These spoken nuances have the potential to be particularly problematic for conversational search.
Synonymy is different
To clarify, synonyms are different from polysemy and homonymy, since synonymous words mean the same as each other (or very similar), but are different words. An example of synonymous words would be the adjectives “tiny,” “little” and “mini” as synonyms of “small.”
Coreference resolution
Pronouns like “they,” “he,” “it,” “them,” “she” can be a troublesome challenge too in natural language understanding, and even more so, third-person pronouns, since it is easy to lose track of who is being referred to in sentences and paragraphs. The language challenge presented by pronouns is referred to as coreference resolution, with particular nuances of coreference resolution being an anaphoric or cataphoric resolution. You can consider this simply “being able to keep track” of what, or who, is being talked about, or written about, but here the challenge is explained further.
Anaphora and cataphora resolution
Anaphora resolution is the problem of trying to tie mentions of items as pronouns or noun phrases from earlier in a piece of text (such as people, places, things). Cataphora resolution, which is less common than anaphora resolution, is the challenge of understanding what is being referred to as a pronoun or noun phrase before the “thing” (person, place, thing) is mentioned later in a sentence or phrase. Here is an example of anaphoric resolution:
“John helped Mary. He was kind.”
Where “he” is the pronoun (anaphora) to resolve back to “John.” And another:
The car is falling apart, but it still works.
Here is an example of cataphora, which also contains anaphora too:
“She was at NYU when Mary realized she had lost her keys.”
The first “she” in the example above is cataphora because it relates to Mary who has not yet been mentioned in the sentence. The second “she” is an anaphora since that “she” relates also to Mary, who has been mentioned previously in the sentence.
Multi-sentential resolution
As phrases and sentences combine referring to people, places and things (entities) as pronouns, these references become increasingly complicated to separate. This is particularly so if multiple entities resolve to begin to be added to the text, as well as the growing number of sentences. Here is an example from this Cornell explanation of coreference resolution and anaphora:
a) John took two trips around France. b) They were both wonderful.
Humans and ambiguity
Although imperfect, humans are mostly unconcerned by these lexical challenges of coreference resolution and polysemy since we have a notion of common-sense understanding. We understand what “she” or “they” refer to when reading multiple sentences and paragraphs or hearing back and forth conversation since we can keep track of who is the subject focus of attention. We automatically realize, for example, when a sentence contains other related words, like “deposit,” or “cheque / check” and “cash,” since this all relates to “bank” as a financial institute, rather than a river “bank.” In order words, we are aware of the context within which the words and sentences are uttered or written; and it makes sense to us. We are therefore able to deal with ambiguity and nuance relatively easily.
Machines and ambiguity
Machines do not automatically understand the contextual word connections needed to disambiguate “bank” (river) and “bank” (financial institute). Even less so, polysemous words with nuanced multiple meanings, like “get” and “run.” Machines lose track of who is being spoken about in sentences easily as well, so coreference resolution is a major challenge too. When the spoken word such as conversational search (and homophones), enters the mix, all of these become even more difficult, particularly when you start to add sentences and phrases together.
How search engines learn language
So just how have linguists and search engine researchers enabling machines to understand the disambiguated meaning of words, sentences and phrases in natural language? “Wouldn’t it be nice if Google understood the meaning of your phrase, rather than just the words that are in the phrase?” said Google’s Eric Schmidt back in March 2009, just before the company announced rolling out their first semantic offerings. This signaled one of the first moves away from “strings to things,” and is perhaps the advent of entity-oriented search implementation by Google. One of the products mentioned in Eric Schmidt’s post was ‘related things’ displayed in search results pages. An example of “angular momentum,” “special relativity,” “big bang” and “quantum mechanic” as related items, was provided. These items could be considered co-occurring items that live near each other in natural language through ‘relatedness’. The connections are relatively loose but you might expect to find them co-existing in web page content together. So how do search engines map these “related things” together?
Co-occurrence and distributional similarity
In computational linguistics, co-occurrence holds true the idea that words with similar meanings or related words tend to live very near each other in natural language. In other words, they tend to be in close proximity in sentences and paragraphs or bodies of text overall (sometimes referred to as corpora). This field of studying word relationships and co-occurrence is called Firthian Linguistics, and its roots are usually connected with 1950s linguist John Firth, who famously said:
“You shall know a word by the company it keeps.” (Firth, J.R. 1957)
Similarity and relatedness
In Firthian linguistics, words and concepts living together in nearby spaces in text are either similar or related. Words which are similar “types of things” are thought to have semantic similarity. This is based upon measures of distance between “isA” concepts which are concepts that are types of a “thing.” For example, a car and a bus have semantic similarity because they are both types of vehicles. Both car and bus could fill the gap in a sentence such as: “A ____ is a vehicle,” since both cars and buses are vehicles. Relatedness is different from semantic similarity. Relatedness is considered ‘distributional similarity’ since words related to isA entities can provide clear cues as to what the entity is. For example, a car is similar to a bus since they are both vehicles, but a car is related to concepts of “road” and “driving.” You might expect to find a car mentioned in amongst a page about road and driving, or in a page sitting nearby (linked or in the section – category or subcategory) a page about a car. This is a very good video on the notions of similarity and relatedness as scaffolding for natural language. Humans naturally understand this co-occurrence as part of common sense understanding, and it was used in the example mentioned earlier around “bank” (river) and “bank” (financial institute). Content around a bank topic as a financial institute will likely contain words about the topic of finance, rather than the topic of rivers, or fishing, or be linked to a page about finance. Therefore, “bank’s” company are “finance,” “cash,” “cheque” and so forth.
Knowledge graphs and repositories
Whenever semantic search and entities are mentioned we probably think immediately of search engine knowledge graphs and structured data, but natural language understanding is not structured data. However, structured data makes natural language understanding easier for search engines through disambiguation via distributional similarity since the ‘company’ of a word gives an indication as to topics in the content. Connections between entities and their relations mapped to a knowledge graph and tied to unique concept ids are strong (e.g. schema and structured data). Furthermore, some parts of entity understanding are made possible as a result of natural language processing, in the form of entity determination (deciding in a body of text which of two or more entities of the same name are being referred to), since entity recognition is not automatically unambiguous. Mention of the word “Mozart” in a piece of text might well mean “Mozart,” the composer, “Mozart” cafe, “Mozart” street, and there are umpteen people and places with the same name as each other. The majority of the web is not structured at all. When considering the whole web, even semi-structured data such as semantic headings, bullet and numbered lists and tabular data make up only a very small part of it. There are lots of gaps of loose ambiguous text in sentences, phrases and paragraphs. Natural language processing is about understanding the loose unstructured text in sentences, phrases and paragraphs between all of those “things” which are “known of” (the entities). A form of “gap filling” in the hot mess between entities. Similarity and relatedness, and distributional similarity) help with this.
Relatedness can be weak or strong
Whilst data connections between the nodes and edges of entities and their relations are strong, the similarity is arguably weaker, and relatedness weaker still. Relatedness may even be considered vague. The similarity connection between apples and pears as “isA” things is stronger than a relatedness connection of “peel,” “eat,” “core” to apple, since this could easily be another fruit which is peeled and with a core. An apple is not really identified as being a clear “thing” here simply by seeing the words “peel,” “eat” and “core.” However, relatedness does provide hints to narrow down the types of “things” nearby in content.
Computational linguistics
Much “gap filling” natural language research could be considered computational linguistics; a field that combines maths, physics and language, particularly linear algebra and vectors and power laws. Natural language and distributional frequencies overall have a number of unexplained phenomena (for example, the Zipf Mystery), and there are several papers about the “strangeness” of words and use of language. On the whole, however, much of language can be resolved by mathematical computations around where words live together (the company they keep), and this forms a large part of how search engines are beginning to resolve natural language challenges (including the BERT update).
Word embeddings and co-occurrence vectors
Simply put, word embeddings are a mathematical way to identify and cluster in a mathematical space, words which “live” nearby each other in a real-world collection of text, otherwise known as a text corpus. For example, the book “War and Peace” is an example of a large text corpus, as is Wikipedia. Word embeddings are merely mathematical representations of words that typically live near each other whenever they are found in a body of text, mapped to vectors (mathematical spaces) using real numbers. These word embeddings take the notions of co-occurrence, relatedness and distributional similarity, with words simply mapped to their company and stored in co-occurrence vector spaces. The vector ‘numbers’ are then used by computational linguists across a wide range of natural language understanding tasks to try to teach machines how humans use language based on the words that live near each other.
WordSim353 Dataset examples
We know that approaches around similarity and relatedness with these co-occurrence vectors and word embeddings have been part of research by members of Google’s conversational search research team to learn word’s meaning. For example, “A study on similarity and relatedness using distributional and WordNet-based approaches,” which utilizes the Wordsim353 Dataset to understand distributional similarity. This type of similarity and relatedness in datasets is used to build out “word embeddings” mapped to mathematical spaces (vectors) in bodies of text. Here is a very small example of words that commonly occur together in content from the Wordsim353 Dataset, which is downloadable as a Zip format for further exploration too. Provided by human graders, the score in the right-hand column is based on how similar the two words in the left-hand and middle columns are.
money cash 9.15 coast shore 9.1 money cash 9.08 money currency 9.04 football soccer 9.03 magician wizard 9.02
Word2Vec
Semi-supervised and unsupervised machine learning approaches are now part of this natural language learning process too, which has turbo-charged computational linguistics. Neural nets are trained to understand the words that live near each other to gain similarity and relatedness measures and build word embeddings. These are then used in more specific natural language understanding tasks to teach machines how humans understand language. A popular tool to create these mathematical co-occurrence vector spaces using text as input and vectors as output is Google’s Word2Vec. The output of Word2Vec can create a vector file that can be utilized on many different types of natural language processing tasks. The two main Word2Vec machine learning methods are Skip-gram and Continuous Bag of Words. The Skip-gram model predicts the words (context) around the target word (target), whereas the Continuous Bag of Words model predicts the target word from the words around the target (context). These unsupervised learning models are fed word pairs through a moving “context window” with a number of words around a target word. The target word does not have to be in the center of the “context window” which is made up of a given number of surrounding words but can be to the left or right side of the context window. An important point to note is moving context windows are uni-directional. I.e. the window moves over the words in only one direction, from either left to right or right to left.
Part-of-speech tagging
Another important part of computational linguistics designed to teach neural nets human language concerns mapping words in training documents to different parts-of-speech. These parts of speech include the likes of nouns, adjectives, verbs and pronouns. Linguists have extended the many parts-of-speech to be increasingly fine-grained too, going well beyond common parts of speech we all know of, such as nouns, verbs and adjectives, These extended parts of speech include the likes of VBP (Verb, non-3rd person singular present), VBZ (Verb, 3rd person singular present) and PRP$ (Possessive pronoun). Word’s meaning in part-of-speech form can be tagged up as parts of speech using a number of taggers with a varying granularity of word’s meaning, for example, The Penn Treebank Tagger has 36 different parts of speech tags and the CLAWS7 part of speech tagger has a whopping 146 different parts of speech tags. Google Pygmalion, for example, which is Google’s team of linguists, who work on conversational search and assistant, used part of speech tagging as part of training neural nets for answer generation in featured snippets and sentence compression. Understanding parts-of-speech in a given sentence allows machines to begin to gain an understanding of how human language works, particularly for the purposes of conversational search, and conversational context. To illustrate, we can see from the example “Part of Speech” tagger below, the sentence:
“Search Engine Land is an online search industry news publication.”
This is tagged as “Noun / noun / noun / verb / determiner / adjective / noun / noun / noun / noun” when highlighted as different parts of speech.

Problems with language learning methods
Despite all of the progress search engines and computational linguists had made, unsupervised and semi-supervised approaches like Word2Vec and Google Pygmalion have a number of shortcomings preventing scaled human language understanding. It is easy to see how these were certainly holding back progress in conversational search.
Pygmalion is unscalable for internationalization
Labeling training datasets with parts-of-speech tagged annotations can be both time-consuming and expensive for any organization. Furthermore, humans are not perfect and there is room for error and disagreement. The part of speech a particular word belongs to in a given context can keep linguists debating amongst themselves for hours. Google’s team of linguists (Google Pygmalion) working on Google Assistant, for example, in 2016 was made up of around 100 Ph.D. linguists. In an interview with Wired Magazine, Google Product Manager, David Orr explained how the company still needed its team of Ph.D. linguists who label parts of speech (referring to this as the ‘gold’ data), in ways that help neural nets understand how human language works. Orr said of Pygmalion:
“The team spans between 20 and 30 languages. But the hope is that companies like Google can eventually move to a more automated form of AI called ‘unsupervised learning.'”
By 2019, the Pygmalion team was an army of 200 linguists around the globe made up of a mixture of both permanent and agency staff, but was not without its challenges due to the laborious and disheartening nature of manual tagging work, and the long hours involved. In the same Wired article, Chris Nicholson, who is the founder of a deep learning company called Skymind commented about the un-scaleable nature of projects like Google Pygmalion, particularly from an internationalisation perspective, since part of speech tagging would need to be carried out by linguists across all the languages of the world to be truly multilingual.
Internationalization of conversational search
The manual tagging involved in Pygmalion does not appear to take into consideration any transferable natural phenomenons of computational linguistics. For example, Zipfs Law, a distributional frequency power law, dictates that in any given language the distributional frequency of a word is proportional to one over its rank, and this holds true even for languages not yet translated.
Uni-directional nature of ‘context windows’ in RNNs (Recurrent Neural Networks)
Training models in the likes of Skip-gram and Continuous Bag of Words are Uni-Directional in that the context-window containing the target word and the context words around it to the left and to the right only go in one direction. The words after the target word are not yet seen so the whole context of the sentence is incomplete until the very last word, which carries the risk of some contextual patterns being missed. A good example is provided of the challenge of uni-directional moving context-windows by Jacob Uszkoreit on the Google AI blog when talking about the transformer architecture. Deciding on the most likely meaning and appropriate representation of the word “bank” in the sentence: “I arrived at the bank after crossing the…” requires knowing if the sentence ends in “… road.” or “… river.”

Text cohesion missing
The uni-directional training approaches prevent the presence of text cohesion. Like Ludwig Wittgenstein, a philosopher famously said in 1953:
“The meaning of a word is its use in the language.” (Wittgenstein, 1953)
Often the tiny words and the way words are held together are the ‘glue’ which bring common sense in language. This ‘glue’ overall is called ‘text cohesion’. It’s the combination of entities and the different parts-of-speech around them formulated together in a particular order which makes a sentence have structure and meaning. The order in which a word sits in a sentence or phrase too also adds to this context. Without this contextual glue of these surrounding words in the right order, the word itself simply has no meaning. The meaning of the same word can change too as a sentence or phrase develops due to dependencies on co-existing sentence or phrase members, changing context with it. Furthermore, linguists may disagree over which particular part-of-speech in a given context a word belongs to in the first place. Let us take the example word “bucket.” As humans we can automatically visualize a bucket that can be filled with water as a “thing,” but there are nuances everywhere. What if the word bucket word were in the sentence ���He kicked the bucket,” or “I have yet to cross that off my bucket list?” Suddenly the word takes on a whole new meaning. Without the text-cohesion of the accompanying and often tiny words around “bucket” we cannot know whether bucket refers to a water-carrying implement or a list of life goals.
Word embeddings are context-free
The word embedding model provided by the likes of Word2Vec knows the words somehow live together but does not understand in what context they should be used. True context is only possible when all of the words in a sentence are taken into consideration. For example, Word2Vec does not know when river (bank) is the right context, or bank (deposit). Whilst later models such as ELMo trained on both the left side and right side of a target word, these were carried out separately rather than looking at all of the words (to the left and the right) simultaneously, and still did not provide true context.
Polysemy and homonymy handled incorrectly
Word embeddings like Word2Vec do not handle polysemy and homonyms correctly. As a single word with multiple meanings is mapped to just one single vector. Therefore there is a need to disambiguate further. We know there are many words with the same meaning (for example, ‘run’ with 606 different meanings), so this was a shortcoming. As illustrated earlier polysemy is particularly problematic since polysemous words have the same root origins and are extremely nuanced.
Coreference resolution still problematic
Search engines were still struggling with the challenging problem of anaphora and cataphora resolution, which was particularly problematic for conversational search and assistant which may have back and forth multi-turn questions and answers. Being able to track which entities are being referred to is critical for these types of spoken queries.
Shortage of training data
Modern deep learning-based NLP models learn best when they are trained on huge amounts of annotated training examples, and a lack of training data was a common problem holding back the research field overall.
So, how does BERT help improve search engine language understanding?
With these short-comings above in mind, how has BERT helped search engines (and other researchers) to understand language?
What makes BERT so special?
There are several elements that make BERT so special for search and beyond (the World – yes, it is that big as a research foundation for natural language processing). Several of the special features can be found in BERT’s paper title – BERT: Bi-directional Encoder Representations from Transformers. B – Bi-Directional E – Encoder R – Representations T – Transformers But there are other exciting developments BERT brings to the field of natural language understanding too. These include:
Pre-training from unlabelled text
Bi-directional contextual models
The use of a transformer architecture
Masked language modeling
Focused attention
Textual entailment (next sentence prediction)
Disambiguation through context open-sourced
Pre-training from unlabeled text
The ‘magic’ of BERT is its implementation of bi-directional training on an unlabelled corpus of text since for many years in the field of natural language understanding, text collections had been manually tagged up by teams of linguists assigning various parts of speech to each word. BERT was the first natural language framework/architecture to be pre-trained using unsupervised learning on pure plain text (2.5 billion words+ from English Wikipedia) rather than labeled corpora. Prior models had required manual labeling and the building of distributed representations of words (word embeddings and word vectors), or needed part of speech taggers to identify the different types of words present in a body of text. These past approaches are similar to the tagging we mentioned earlier by Google Pygmalion. BERT learns language from understanding text cohesion from this large body of content in plain text and is then educated further by fine-tuning on smaller, more specific natural language tasks. BERT also self-learns over time too.
Bi-directional contextual models
BERT is the first deeply bi-directional natural language model, but what does this mean?
Bi-directional and uni-directional modeling
True contextual understanding comes from being able to see all the words in a sentence at the same time and understand how all of the words impact the context of the other words in the sentence too. The part of speech a particular word belongs to can literally change as the sentence develops. For example, although unlikely to be a query, if we take a spoken sentence which might well appear in natural conversation (albeit rarely):
“I like how you like that he likes that.”
as the sentence develops the part of speech which the word “like” relates to as the context builds around each mention of the word changes so that the word “like,” although textually is the same word, contextually is different parts of speech dependent upon its place in the sentence or phrase. Past natural language training models were trained in a uni-directional manner. Word’s meaning in a context window moved along from either left to right or right to left with a given number of words around the target word (the word’s context or “it’s company”). This meant words not yet seen in context cannot be taken into consideration in a sentence and they might actually change the meaning of other words in natural language. Uni-directional moving context windows, therefore, have the potential to miss some important changing contexts. For example, in the sentence:
“Dawn, how are you?”
The word “are” might be the target word and the left context of “are” is “Dawn, how.” The right context of the word is “you.” BERT is able to look at both sides of a target word and the whole sentence simultaneously in the way that humans look at the whole context of a sentence rather than looking at only a part of it. The whole sentence, both left and right of a target word can be considered in the context simultaneously.
Transformers / Transformer architecture
Most tasks in natural language understanding are built on probability predictions. What is the likelihood that this sentence relates to the next sentence, or what is the likelihood that this word is part of that sentence? BERT’s architecture and masked language modeling prediction systems are partly designed to identify ambiguous words that change the meanings of sentences and phrases and identify the correct one. Learnings are carried forward increasingly by BERT’s systems. The Transformer uses fixation on words in the context of all of the other words in sentences or phrases without which the sentence could be ambiguous. This fixated attention comes from a paper called ‘Attention is all you need’ (Vaswani et al, 2017), published a year earlier than the BERT research paper, with the transformer application then built into the BERT research. Essentially, BERT is able to look at all the context in text-cohesion by focusing attention on a given word in a sentence whilst also identifying all of the context of the other words in relation to the word. This is achieved simultaneously using transformers combined with bi-directional pre-training. This helps with a number of long-standing linguistic challenges for natural language understanding, including coreference resolution. This is because entities can be focused on in a sentence as a target word and their pronouns or the noun-phrases referencing them resolved back to the entity or entities in the sentence or phrase. In this way the concepts and context of who, or what, a particular sentence is relating to specifically, is not lost along the way. Furthermore, the focused attention also helps with the disambiguation of polysemous words and homonyms by utilizing a probability prediction / weight based on the whole context of the word in context with all of the other words in the sentence. The other words are given a weighted attention score to indicate how much each adds to the context of the target word as a representation of “meaning.” Words in a sentence about the “bank” which add strong disambiguating context such as “deposit” would be given more weight in a sentence about the “bank” (financial institute) to resolve the representational context to that of a financial institute. The encoder representations part of the BERT name is part of the transformer architecture. The encoder is the sentence input translated to representations of words meaning and the decoder is the processed text output in a contextualized form. In the image below we can see that ‘it’ is strongly being connected with “the” and “animal” to resolve back the reference to “the animal” as “it” as a resolution of anaphora.

This fixation also helps with the changing “part of speech” a word’s order in a sentence could have since we know that the same word can be different parts of speech depending upon its context. The example provided by Google below illustrates the importance of different parts of speech and word category disambiguation. Whilst a tiny word, the word ‘to’ here changes the meaning of the query altogether once it is taken into consideration in the full context of the phrase or sentence.

Masked Language Modelling (MLM Training)
Also known as “the Cloze Procedure,” which has been around for a very long time. The BERT architecture analyzes sentences with some words randomly masked out and attempts to correctly predict what the “hidden” word is. The purpose of this is to prevent target words in the training process passing through the BERT transformer architecture from inadvertently seeing themselves during bi-directional training when all of the words are looked at together for combined context. Ie. it avoids a type of erroneous infinite loop in natural language machine learning, which would skew word’s meaning.
Textual entailment (next sentence prediction)
One of the major innovations of BERT is that it is supposed to be able to predict what you’re going to say next, or as the New York Times phrased it in Oct 2018, “Finally, a machine that can finish your sentences.” BERT is trained to predict from pairs of sentences whether the second sentence provided is the right fit from a corpus of text. NB: It seems this feature during the past year was deemed as unreliable in the original BERT model and other open-source offerings have been built to resolve this weakness. Google’s ALBERT resolves this issue. Textual entailment is a type of “what comes next?” in a body of text. In addition to textual entailment, the concept is also known as ‘next sentence prediction’. Textual entailment is a natural language processing task involving pairs of sentences. The first sentence is analyzed and then a level of confidence determined to predict whether a given second hypothesized sentence in the pair “fits” logically as the suitable next sentence, or not, with either a positive, negative, or neutral prediction, from a text collection under scrutiny. Three examples from Wikipedia of each type of textual entailment prediction (neutral / positive / negative) are below. Textual Entailment Examples (Source: Wikipedia) An example of a positive TE (text entails hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has good consequences.
An example of a negative TE (text contradicts hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has no consequences.
An example of a non-TE (text does not entail nor contradict) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man will make you a better person.
Disambiguation breakthroughs from open-sourced contributions
BERT has not just appeared from thin air, and BERT is no ordinary algorithmic update either since BERT is also an open-source natural language understanding framework as well. Ground-breaking “disambiguation from context empowered by open-sourced contributions,” could be used to summarise BERT’s main value add to natural language understanding. In addition to being the biggest change to Google’s search system in five years (or ever), BERT also represents probably the biggest leap forward in growing contextual understanding of natural language by computers of all time. Whilst Google BERT may be new to the SEO world it is well known in the NLU world generally and has caused much excitement over the past 12 months. BERT has provided a hockey stick improvement across many types of natural language understanding tasks not just for Google, but a myriad of both industrial and academic researchers seeking to utilize language understanding in their work, and even commercial applications. After the publication of the BERT research paper, Google announced they would be open-sourcing vanilla BERT. In the 12 months since publication alone, the original BERT paper has been cited in further research 1,997 times at the date of writing. There are many different types of BERT models now in existence, going well beyond the confines of Google Search. A search for Google BERT in Google Scholar returns hundreds of 2019 published research paper entries extending on BERT in a myriad of ways, with BERT now being used in all manner of research into natural language. Research papers traverse an eclectic mix of language tasks, domain verticals (for example clinical fields), media types (video, images) and across multiple languages. BERT’s use cases are far-reaching, from identifying offensive tweets using BERT and SVMs to using BERT and CNNs for Russian Troll Detection on Reddit, to categorizing via prediction movies according to sentiment analysis from IMDB, or predicting the next sentence in a question and answer pair as part of a dataset. Through this open-source approach, BERT goes a long way toward solving some long-standing linguistic problems in research, by simply providing a strong foundation to fine-tune from for anyone with a mind to do so. The codebase is downloadable from the Google Research Team’s Github page. By providing Vanilla BERT as a great ‘starter for ten’ springboard for machine learning enthusiasts to build upon, Google has helped to push the boundaries of State of the art (SOTA) natural language understanding tasks. Vanilla BERT can be likened to a CMS plugins, theme, or module which provides a strong foundation for a particular functionality but can then be developed further. Another simpler similarity might be likening the pre-training and fine-tuning parts of BERT for machine learning engineers to buying an off-the-peg suit from a high street store then visiting a tailor to turn up the hems so it is fit for purpose at a more unique needs level. As Vanilla BERT comes pre-trained (on Wikipedia and Brown corpus), researchers need only fine-tune their own models and additional parameters on top of the already trained model in just a few epochs (loops / iterations through the training model with the new fine-tuned elements included). At the time of BERT’s October 2018, paper publication BERT beat state of the art (SOTA) benchmarks across 11 different types of natural language understanding tasks, including question and answering, sentiment analysis, named entity determination, sentiment classification and analysis, sentence pair-matching and natural language inference. Furthermore, BERT may have started as the state-of-the-art natural language framework but very quickly other researchers, including some from other huge AI-focused companies such as Microsoft, IBM and Facebook, have taken BERT and extended upon it to produce their own record-beating open-source contributions. Subsequently, models other than BERT have become state of the art since BERT’s release. Facebook’s Liu et al entered the BERTathon with their own version extending upon BERT – RoBERTa. claiming the original BERT was significantly undertrained and professing to have improved upon, and beaten, any other model versions of BERT up to that point. Microsoft also beat the original BERT with MT-DNN, extending upon a model they proposed in 2015 but adding on the bi-directional pre-training architecture of BERT to improve further.

There are many other BERT-based models too, including Google’s own XLNet and ALBERT (Toyota and Google), IBM’s BERT-mtl, and even now Google T5 emerging.

The field is fiercely competitive and NLU machine learning engineer teams compete with both each other and non-expert human understanding benchmarks on public leaderboards, adding an element of gamification to the field. Amongst the most popular leaderboards are the very competitive SQuAD, and GLUE. SQuAD stands for The Stanford Question and Answering Dataset which is built from questions based on Wikipedia articles with answers provided by crowdworkers. The current SQuAD 2.0 version of the dataset is the second iteration created because SQuAD 1.1 was all but beaten by natural language researchers. The second-generation dataset, SQuAD 2.0 represented a harder dataset of questions, and also contained an intentional number of adversarial questions in the dataset (questions for which there was no answer). The logic behind this adversarial question inclusion is intentional and designed to train models to learn to know what they do not know (i.e an unanswerable question). GLUE is the General Language Understanding Evaluation dataset and leaderboard. SuperGLUE is the second generation of GLUE created because GLUE again became too easy for machine learning models to beat.

Most of the public leaderboards across the machine learning field double up as academic papers accompanied by rich question and answer datasets for competitors to fine-tune their models on. MS MARCO, for example, is an academic paper, dataset and accompanying leaderboard published by Microsoft; AKA Microsoft MAchine Reaching COmprehension Dataset. The MSMARCO dataset is made up of over a million real Bing user queries and over 180,000 natural language answers. Any researchers can utilize this dataset to fine-tune models.

Efficiency and computational expense
Late 2018 through 2019 can be remembered as a year of furious public leaderboard leap-frogging to create the current state of the art natural language machine learning model. As the race to reach the top of the various state of the art leaderboards heated up, so too did the size of the model’s machine learning engineers built and the number of parameters added based on the belief that more data increases the likelihood for more accuracy. However as model sizes grew so did the size of resources needed for fine-tuning and further training, which was clearly an unsustainable open-source path. Victor Sanh, of Hugging Face (an organization seeking to promote the continuing democracy of AI) writes, on the subject of the drastically increasing sizes of new models:
“The latest model from Nvidia has 8.3 billion parameters: 24 times larger than BERT-large, 5 times larger than GPT-2, while RoBERTa, the latest work from Facebook AI, was trained on 160GB of text 😵”
To illustrate the original BERT sizes – BERT-Base and BERT-Large, with 3 times the number of parameters of BERT-Base. BERT–Base, Cased : 12-layer, 768-hidden, 12-heads , 110M parameters. BERT–Large, Cased : 24-layer, 1024-hidden, 16-heads, 340M parameters. Escalating costs and data sizes meant some more efficient, less computationally and financially expensive models needed to be built.
Welcome Google ALBERT, Hugging Face DistilBERT and FastBERT
Google’s ALBERT, was released in September 2019 and is a joint work between Google AI and Toyota’s research team. ALBERT is considered BERT’s natural successor since it also achieves state of the art scores across a number of natural language processing tasks but is able to achieve these in a much more efficient and less computationally expensive manner. Large ALBERT has 18 times fewer parameters than BERT-Large. One of the main standout innovations with ALBERT over BERT is also a fix of a next-sentence prediction task which proved to be unreliable as BERT came under scrutiny in the open-source space throughout the course of the year. We can see here at the time of writing, on SQuAD 2.0 that ALBERT is the current SOTA model leading the way. ALBERT is faster and leaner than the original BERT and also achieves State of the Art (SOTA) on a number of natural language processing tasks.
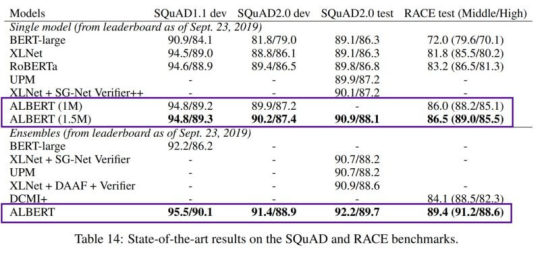
Other efficiency and budget focused, scaled-down BERT type models recently introduced are DistilBERT, purporting to be smaller, lighter, cheaper and faster, and FastBERT.
So, what does BERT mean for SEO?
BERT may be known among SEOs as an algorithmic update, but in reality, it is more “the application” of a multi-layer system that understands polysemous nuance and is better able to resolve co-references about “things” in natural language continually fine-tuning through self-learning. The whole purpose of BERT is to improve human language understanding for machines. In a search perspective this could be in written or spoken queries issued by search engine users, and in the content search engines gather and index. BERT in search is mostly about resolving linguistic ambiguity in natural language. BERT provides text-cohesion which comes from often the small details in a sentence that provides structure and meaning. BERT is not an algorithmic update like Penguin or Panda since BERT does not judge web pages either negatively or positively, but more improves the understanding of human language for Google search. As a result, Google understands much more about the meaning of content on pages it comes across and also the queries users issue taking word’s full context into consideration.

BERT is about sentences and phrases
Ambiguity is not at a word level, but at a sentence level, since it is about the combination of words with multiple meanings which cause ambiguity.

BERT helps with polysemic resolution
Google BERT helps Google search to understand “text-cohesion” and disambiguate in phrases and sentences, particularly where polysemic nuances could change the contextual meaning of words. In particular, the nuance of polysemous words and homonyms with multiple meanings, such as ‘to’, ‘two’, ‘to’, and ‘stand’ and ‘stand’, as provided in the Google examples, illustrate the nuance which had previously been missed, or misinterpreted, in search.
Ambiguous and nuanced queries impacted
The 10% of search queries which BERT will impact may be very nuanced ones impacted by the improved contextual glue of text cohesion and disambiguation. Furthermore, this might well impact understanding even more of the 15% of new queries which Google sees every day, many of which relate to real-world events and burstiness / temporal queries rather than simply long-tailed queries.
Recall and precision impacted (impressions?)
Precision in ambiguous query meeting will likely be greatly improved which may mean query expansion and relaxation to include more results (recall) may be reduced. Precision is a measure of result quality, whereas recall simply relates to return any pages which may be relevant to a query. We may see this reduction in recall reflected in the number of impressions we see in Google Search Console, particularly for pages with long-form content which might currently be in recall for queries they are not particularly relevant for.
BERT will help with coreference resolution
BERT(the research paper and language model)’s capabilities with coreference resolution means the Google algorithm likely helps Google Search to keep track of entities when pronouns and noun-phrases refer to them. BERT’s attention mechanism is able to focus on the entity under focus and resolve all references in sentences and phrases back to that using a probability determination / score. Pronouns of “he,” “she,” “they,” “it” and so forth will be much easier for Google to map back in both content and queries, spoken and in written text. This may be particularly important for longer paragraphs with multiple entities referenced in text for featured snippet generation and voice search answer extraction / conversational search.
BERT serves a multitude of purposes
Google BERT is probably what could be considered a Swiss army knife type of tool for Google Search. BERT provides a solid linguistic foundation for Google search to continually tweak and adjust weights and parameters since there are many different types of natural language understanding tasks that could be undertaken. Tasks may include:
Coreference resolution (keeping track of who, or what, a sentence or phrase refers to in context or an extensive conversational query)
Polysemy resolution (dealing with ambiguous nuance)
Homonym resolution (dealing with understanding words which sound the same, but mean different things
Named entity determination (understanding which, from a number of named entities, text relates to since named entity recognition is not named entity determination or disambiguation), or one of many other tasks.
Textual entailment (next sentence prediction)
BERT will be huge for conversational search and assistant
Expect a quantum leap forward in terms of relevance matching to conversational search as Google’s in-practice model continues to teach itself with more queries and sentence pairs. It’s likely these quantum leaps will not just be in the English language, but very soon, in international languages too since there is a feed-forward learning element within BERT that seems to transfer to other languages.
BERT will likely help Google to scale conversational search
Expect over the short to medium term a quantum leap forward in application to voice search however since the heavy lifting of building out the language understanding held back by Pygmalion’s manual process could be no more. The earlier referenced 2016 Wired article concluded with a definition of AI automated, unsupervised learning which might replace Google Pygmalion and create a scalable approach to train neural nets:
“This is when machines learn from unlabeled data – massive amounts of digital information culled from the internet and other sources.” (Wired, 2016)
This sounds like Google BERT. We also know featured snippets were being created by Pygmalion too. While it is unclear whether BERT will have an impact on Pygmalion’s presence and workload, nor if featured snippets will be generated in the same way as previously, Google has announced BERT will be used for featured snippets and is pre-trained on purely a large text corpus. Furthermore, the self-learning nature of a BERT type foundation continually fed queries and retrieving responses and featured snippets will naturally pass the learnings forward and become even more fine-tuned. BERT, therefore, could provide a potentially, hugely scalable alternative to the laborious work of Pygmalion.
International SEO may benefit dramatically too
One of the major impacts of BERT could be in the area of international search since the learnings BERT picks up in one language seem to have some transferable value to other languages and domains too. Out of the box, BERT appears to have some multi-lingual properties somehow derived from a monolingual (single language understanding) corpora and then extended to 104 languages, in the form of M-BERT (Multilingual BERT). A paper by Pires, Schlinger & Garrette tested the multilingual capabilities of Multilingual BERT and found that it “surprisingly good at zero-shot cross-lingual model transfer.” (Pires, Schlinger & Garrette, 2019). This is almost akin to being able to understand a language you have never seen before since zero-shot learning aims to help machines categorize objects that they have never seen before.
Questions and answers
Question and answering directly in SERPs will likely continue to get more accurate which could lead to a further reduction in click through to sites. In the same way MSMARCO is used for fine-tuning and is a real dataset of human questions and answers from Bing users, Google will likely continue to fine-tune its model in real-life search over time through real user human queries and answers feeding forward learnings. As language continues to be understood paraphrase understanding improved by Google BERT might also impact related queries in “People Also Ask.”
Textual entailment (next sentence prediction)
The back and forth of conversational search, and multi-turn question and answering for assistant will also likely benefit considerably from BERT’s ‘textual entailment’ (next sentence prediction) feature, particularly the ability to predict “what comes next” in a query exchange scenario. However, this might not seem apparent as quickly as some of the initial BERT impacts. Furthermore, since BERT can understand different meanings for the same things in sentences, aligning queries formulated in one way and resolving them to answers which amount to the same thing will be much easier. I asked Dr. Mohammad Aliannejadi about the value BERT provides for conversational search research. Dr. Aliannejadi is an information retrieval researcher who recently defended his Ph.D. research work on conversational search, supervised by Professor Fabio Crestani, one of the authors of “Mobile information retrieval.” Part of Dr. Aliannejadi’s research work explored the effects of asking clarifying questions for conversational assistants, and utilized BERT within its methodology. Dr. Aliannejadi spoke of BERT’s value:
“BERT represents the whole sentence, and so it is representing the context of the sentence and can model the semantic relationship between two sentences. The other powerful feature is the ability to fine-tune it in just a few epochs. So, you have a general tool and then make it specific to your problem.”
Named entity determination
One of the natural language processing tasks undertaken by the likes of a fine-tuned BERT model could be entity determination. Entity determination is deciding the probability that a particular named entity is being referred to from more than one choice of named entity with the same name. Named entity recognition is not named entity disambiguation nor named entity determination. In an AMA on Reddit Google’s Gary Illyes confirmed that unlinked mentions of brand names can be used for this named entity determination purpose currently.

BERT will assist with understanding when a named entity is recognized but could be one of a number of named entities with the same name as each other. An example of multiple named entities with the same name is in the example below. Whilst these entities may be recognized by their name they need to be disambiguated one from the other. Potentially an area BERT can help with. We can see from a search in Wikipedia below the word “Harris” returns many named entities called “Harris.”

BERT could be BERT by name, but not by nature
It is not clear whether the Google BERT update uses the original BERT or the much leaner and inexpensive ALBERT, or another hybrid variant of the many models now available, but since ALBERT can be fine-tuned with far fewer parameters than BERT this might make sense. This could well mean the algorithm BERT in practice may not look very much at all like the original BERT in the first published paper, but a more recent improved version which looks much more like the (also open-sourced) engineering efforts of others aiming to build the latest SOTA models. BERT may be a completely re-engineered large scale production version, or a more computationally inexpensive and improved version of BERT, such as the joint work of Toyota and Google, ALBERT. Furthermore, BERT may continue to evolve into other models since Google T5 Team also now has a model on the public SuperGLUE leaderboards called simply T5. BERT may be BERT in name, but not in nature.
Can you optimize your SEO for BERT?
Probably not. The inner workings of BERT are complex and multi-layered. So much so, there is now even a field of study called “Bertology” which has been created by the team at Hugging Face. It is highly unlikely any search engineer questioned could explain the reasons why something like BERT would make the decisions it does with regards to rankings (or anything). Furthermore, since BERT can be fine-tuned across parameters and multiple weights then self-learns in an unsupervised feed-forward fashion, in a continual loop, it is considered a black-box algorithm. A form of unexplainable AI. BERT is thought to not always know why it makes decisions itself. How are SEOs then expected to try to “optimize” for it? BERT is designed to understand natural language so keep it natural. We should continue to create compelling, engaging, informative and well-structured content and website architectures in the same way you would write, and build sites, for humans. The improvements are on the search engine side of things and are a positive rather than a negative. Google simply got better at understanding the contextual glue provided by text cohesion in sentences and phrases combined and will become increasingly better at understanding the nuances as BERT self-learns.
Search engines still have a long way to go
Search engines still have a long way to go and BERT is only a part of that improvement along the way, particularly since a word’s context is not the same as search engine user’s context, or sequential informational needs which are infinitely more challenging problems. SEOs still have a lot of work to do to help search engine users find their way and help to meet the right informational need at the right time.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author

Dawn Anderson is a SEO & Search Digital Marketing Strategist focusing on technical, architectural and database-driven SEO. Dawn is the director of Move It Marketing.
https://www.businesscreatorplus.com/a-deep-dive-into-bert-how-bert-launched-a-rocket-into-natural-language-understanding/
0 notes
Text
steph’s guide to roleplaying
Heyo! Bare with me, for this is a long post.
So, within various fandoms, I have seen a common trend that rubs me the wrong way. People asking, either their followers or blogs they follow, why they aren’t popular/roleplayed with. Or, they ask for advice and do not apply it, for one reason or another.
I have been in the indie Tumblr roleplaying community for over three years now, across three big fandoms (Marvel, Harry Potter, and Fire Emblem) as well as smaller fandoms. I have seen many trends come and go, many popular roleplayers come and go, and more.
It’s hard to get your foot in the RP door on Tumblr. I was there. Your favorite blog that you cry about being so good was there. Everyone was there. It’s a BIG pond, with many fish. Things are ever changing on Tumblr, so this will be reference guide to what you need to get started on your RP blog!
When it comes to edits, whether they are icons, themes, or promos, they are very important to RP blogs. Icons are a staple within the RP community, across fandoms, indie, and group. It may seem hard to get and make graphics without Photoshop, a very expensive program, but there are ways around it. Your graphics do not have to be fancy or hand drawn, but cleanly sized and cropped. There are many image editors out there, but these are my personal favorites.
GIMP- a free and downloadable image editor. it works very similarly to Photoshop, and will work for basic things like cropping, coloring, and resizing images. It does not have all the features of Photoshop, but will work fine for simple things.
Pixlr- a free image editing site that requires no download. Again, it works similarly to Photoshop and Gimp, but more on the basic side. I recommend this if your version of GIMP or Photoshop is acting wonky or broken. If you are iffy about downloading programs, this will be perfect for you.
Photoshop Torrents- While stealing, pirating, and torrenting is wrong and illegal, Photoshop is expensive. You can get older versions of Photoshop through various torrents on the internet (I found mine through tumblr). I like using CS5 because it is a well known version with plenty of tutorials online. I recommend downloading Photoshop Portable, as it can easily be stored on your flash drive.
As for what is actually on the blog and what people like to see on a roleplay blog, there is a few things that people prefer not to see. The number one thing most followers want from a roleplay blog is writing. They may want that through interaction with you as a partner, or they just like reading it as a personal or follower. As for the things that people do not like to see, there are the top few things.
6 Pages of Memes- It is okay to reblog memes. It is how interactions between partners start, and can serve as good ice breakers between new mutuals. However, as someone who has gone through many blogs, six pages of memes with a few RP post in between is not appealing. Just because you may not be getting responses right away, does not mean you should spam your blog and the dash with memes every half hour. People may not be online or interested in that meme. If you like all these memes, queue or schedule them for when people are online more. Also, send some to the people on your dash and focus on making new threads from them.
Short Replies- Before I start, yes, one liners are fun. They are quick, easy, and light, but they should not be the only thing on your blog. Many people like to expand to paragraphs because they are writers. Paragraph responses also show potential followers how you write and if it will click with their style. They may seem intimidating, but take your time on them. Save part of your responses to the drafts and come back to it later. Roleplaying is not about how fast you can respond, but the quality of your writing. This is especially true when you do not use icons. If a blog doesn’t use icons, I look for description in shorter replies rather than dialogue.
Negativity- This monster comes in many shapes or forms. Negativity/guilt tripping, drama with other blogs, and personal posts do not belong on a roleplay blog, though. Instead of guilt tripping and vague posting, talk it out with a friend for a confidence booster or take a tiny 1-hour break from blogging. Keep whatever beef you have with someone private, as well as your personal/political beliefs about an issue. That’s why personal blogs are things.
Lack of Pages- Pages about your blog are very important! It serves as your personal anchor on your blog, as well as people’s knowledge to your and your character prior to following and interacting. If someone does not see pages about your blog on it, they are more than likely to brush your blog aside. A rules page is the first thing people look for. They want to know how you are as a person, and how to interact with you. Besides the general “do not be a jerk” rule that everyone has, many people elaborate on how interaction with them work. An about page also helps people know your character. Do not just link a wiki page, especially if play as a canon divergent canon character. A well thought out about page helps both OCs and canon characters. It gives a personality and base for your muse and sets it apart from others.
Make it this far? Hella! You are almost through that metaphorical door! Now that the basic and bare bones of your blog is out of the way, let’s talk about trends, or what it is more commonly called aesthetics. They constantly change in the rp community. GIFs used to be the common thing, now it is still icons. While the trends may change, the basics of tumblr rp stays the same.
Themes- Right now, as I write this long essay of a post, container themes are all the rage. They were not always, nor are they required of an RP blog. As long as a blog does not have the basic preloaded themes that tumblr offers, most people don’t care too much about what it looks like. A few good theme blogs for RPers are soldierholiic, theme-hunter, and octomoosey. Don’t like any of those? Look at someone’s blog. There is usually a small icon in the bottom corner that links to the theme maker’s blog. My personal favorite is soldierholiic’s sora theme.
Formatting- You do not have to format your post to be considered quality! You do not have to hate formatting to be considered quality! As long as you can use basic grammar and spelling, you are good. Many people use small text because it looks a bit cleaner. The shortcut for small text is ctrl+shift+ -, if that helps. Also, many people expect your posts to be cut, meaning the latest two replies on a post. If you do not want or cannot download x-kit or other extensions, just politely ask your partners either through talking OOC or in your rules, to cut your post for you.
Function>Aesthetics- While having a nice looking blog is...well, nice, if someone can’t read or navigate through it, then they most likely will avoid you. Many experienced blogs are guilty of this too, not just over zealous newer blogs. Make your posts readable, both on the dash and the blog. Make your pages easy and accessible to find, especially for mobile users. Use colors that won’t kill my eyes because I’m reading your reply on your blog.
Graphics pt 2- While many blogs have personalized or hand drawn icons and promos, it’s not a requirement. You can use the icons you find in the tags. You can have icons that don’t match your theme. As long as they are sized correctly (100x100px is the norm), they do not have to be super edited. For promos, many fandoms accept the casual promo, containing an icon and a bit of info about your blog. It’s easy to spread around and learn a bit about the mun/muse. A fancy photoshopped graphic designed promo is not 100% necessary in most fandoms right now.
I know this post is getting very long and boring, but I swear I am almost done. Your blog is set up. You know the basics of roleplaying on tumblr. But everyone seems so scary with their rules, friends, and mains, etc. Many people on here are shy when it comes to new people. You probably are too. This is how you talk to people who seem intimidating.
Be Casual- There is no need to call everyone senpai or quality or perf. That just makes things awkward. Just be casual with people you want to interact with. Talk about your fandom, scream headcanons with them, ask for their name. You do not have to go in with ‘HI DO YOU WANT TO RP WITH ME, [muse name here]-MUN-SENPAI?!!’ That comes off a bit strong and off-putting.
Be Respectful- First off, don’t be a jerk to people. Secondly, just read someone’s rules before messaging them with questions about something. While many are open to answering any questions a follower may have about them, if it something already stated in the rules of that blog, just save you all some trouble by reading them. Also, do not hate on their interpretation of a character. Each blog is different, even if there are 100 duplicates for that character.
Don’t Be Afraid To Ask For Help- Is there something in the reply you don’t understand? Something about their character you don’t understand? Questions about the universe? Feel free to ask a partner for help! They won’t bite if you are respectful about it. Also, if you are close to your partners, they will often be open to help you with graphics if they have experience/time. Just don’t strut into their IMs expecting a theme done before you get there. Ask first! Be okay with their answer, even if you do not like it.
Lastly, roleplaying is a hobby. Do not let it consume your life or stress you out. If that does happen, it is okay to take a break and come back. It is okay to restart your blog from scratch. It is okay to follow new and different people. Just have fun and be yourself.
#long post#reblog okay#tumblr rp#tumblr rp help#indie rp#rp meme#reference#rp reference#make me tumblr famous
136 notes
·
View notes
Text
Spire–The City Must Fall Review
The drow have become a fixture in Dungeons and Dragons, and that brings a lot of baggage to the game, since they live squarely at the corner of “a lot of players like even sentient, free willed beings to be born evil so it’s okay to kill them” and “hey, this thing that was born evil looks a lot like a human being and also happens to have dark skin.” Over the years, there have been several attempts to reconcile this concept, but those attempts just seem to multiply the awkward tropes associated with drow, oddly, without decreasing the overall appeal of them as an element of the game.
Given that most of this baggage is associated with a species that is unique to Dungeons and Dragons, it’s interesting that a game that addresses the politics of occupation and occupiers controlling the narrative of a culture, utilizing elves and drow as examples, comes from a game that isn’t derived from any version of the d20 SRD. In this review, we’re going to look at the game Spire, a unique RPG system that explores what life is like in a drow city occupied by elves, and to what ends your drow will go to make a lasting change to their home. Spire successfully funded on Kickstarter last August and went on sale in March of this year.
The Construction of the Spire
This review is based on the PDF version of the product. The PDF is 220 pages in length, with about five pages of thanks and the names of Kickstarter backers, a character sheet, and a two-page index.
Major sections of the book have full page artwork, which is color line art in washed out colors, highlighting the tone of the work. The artwork consists of bold black lines, and splashes of color are more representative of the emotional impact of the scene being presented than a realistic use of lighting or colors.
Headers are underlined in red, with blue sub-headers and dark grey sidebars. All of this is on blue pages with a light background image of concentric circles. It is a visually striking presentation that helps to convey the tone of the stories the game is trying to tell, but the easily seen headers and sidebars do an excellent job of breaking up the information presented into logical divisions.
Welcome to Spire and The World of Spire
The first image you see in this section is an amazing image of the titular city of Spire with an overlay graphic showing the relationships of the neighborhoods to one another. Welcome to Spire, the first section of the book, gives a high-level pitch about the tone of the game, the dice used, and paragraphs on what it means to be a player and a GM. If you are wondering if this is the kind of RPG that has a “what is an RPG” section, it does, but it’s contained on two pages and interspersed with discussions of tone and expectations for the setting.
The World of Spire section describes the broad status quo of the world. If you already know that drow are elves that live underground, dislike sunlight, and have an affinity for spiders, none of that is subverted. After that, just about everything else is. The core concept is that the players are portraying drow characters that are members of The Ministry, a secret cult/revolutionary organization, trying to reclaim Spire from the Aelfir (high elf) oppressors.
The aelfir can’t feel sadness and may not feel empathy either. According to the aelfir, the drow were once aelfir who were cursed for their evil ways and forced to flee from the sun, although there are drow that believe that drow have always been the way they are now, no curse involved. Spire is a huge, mysterious tower like city, that had plenty of space within it to shield those living in it from the sun.
Humans also figure into the story, as a mercenary element crazy enough to dig around ancient cities that predate the modern age, reverse engineering arcane medical procedures, steam-powered devices, and firearms.
There are sidebars that discuss lands beyond Spire, Drow Traditions, and Aelfir Traditions, and while there is a lot more lore coming, this relatively short section already showcases that the game is walking a tight line between recognizable and subverted tropes.
The Rules, Skills and Domains, Equipment, and Bonds
The next sections of the book are The Rules, Skills and Domains, Equipment, and Bonds. While these are all distinct sections, the unified way in which these elements work with one another makes these sections feel like more of an extended explanation of the game.
Characters roll a d10 to resolve an action. If they have a skill that pertains to the roll, they can add a d10. If they have a domain—an area of expertise where they are comfortable operating—that applies to the roll, they can add another d10. Sometimes equipment, circumstances, or character abilities will allow the character to roll with mastery, adding another d10. Since mastery can only be applied once per action, most die rolls will cap at four dice, although some character abilities play with this cap.
More difficult tasks remove a die from the die pool, so that four dice pool, against a difficulty 2 task, only allows the character to roll two dice. The highest die resolves whether the action is a critical failure, a failure, a success at a cost, a success, or a critical success.
Failure usually results in stress, which is tracked under five main resistances (some characters might also have an armor resistance added to the list as well):
Blood (Physical health)
Mind (Mental well-being)
Silver (Wealth and resources)
Shadow (Ability to operate secretly)
Reputation (Social standing)
The stress taken will vary depending on the stakes of the initial action, and might be generated with a d3, d6, or a d8. As soon as a character takes stress, they roll for fallout, which has minor, moderate, and severe levels depending on the total amount of stress the character has taken.
What this means is that some failures don’t have immediate consequences, but every failure starts to add up. It also means that the rules for taking a hit to your personal funds are the same as taking a blow to the body in combat, although the fallout, when it happens, will be different.
Different character types have different actions that allow them to remove stress when they take those actions, which reinforce the theme of that character type. The world makes more sense to a vigilante that can bring transgressors to justice, and someone well versed in commerce is going to set things right by cutting some deals.
Bonds work the same way as resistances, but they have their own list of fallout, and a character doesn’t check for fallout as often as they do for their regular resistances. Most equipment has something it’s very good at doing (which might allow a roll with mastery), and something it’s not suited for (which increases the difficulty). Weapons and armors have their own tags, which have special effects when rolling a 1 or a 10, or allowing stress to be rolled multiple times, keeping the best or worst result.
Characters and Combat
The next sections of the book cover characters and combat. Character creation consists of choosing a durance, a class, and picking a few starting abilities and equipment.
The durance is a period of indentured servitude that the drow serve under the aelfir to “repay” them for what the aelfir contribute to society. Depending on the durance selected, your character might gain more skills, or special boxes they can add to their resistance that doesn’t count against their normal stress.
The character classes available in the core rules are the following:
Azurite (A well connected mercantile priest)
Bound (A vigilante with items that have minor gods dwelling in them, boosting their power)
Carrion-Priest (Death worshippers with pet hyenas)
Firebrand (True believer revolutionaries)
Idol (Famous, well-regarded artists)
Knight (A member of a once proud martial organization that now operates like a gang)
Lajhan (A priest of the moon goddess of the drow)
Masked (A drow that learned subterfuge and espionage while serving under the aelfir)
Midwife (A drow that is part spider and protects the young and the future of drow society)
Vermission Sage (A drow sage that has learned secrets of the city’s extradimensional spaces)
Several of the class abilities grant the character the ability to use magic. Magic in this setting always has a price, and often spells will cause a character to mark stress, usually in a manner that matches the tenor of the religion and the type of spell being cast. A character using their own pain to fuel a spell might take blood stress, while someone sacrificing valuable items may take silver stress, and some spells might require more than one type of stress to be taken.
Each character class has a list of Low, Medium, and High advances, and there is a list of extra advances based on narrative choices the character has made in game. For example, joining the city guard allows for advances other characters may not be able to access, as does getting infected with a magical blood disease that is trying to bring an extra-dimensional being into the world.
Advances are earned by making some kind of change to the city. Small changes earn low advances, moderate changes earn a medium advance, and severe and potentially irreversible changes result in high advances. Characters are expected to gain low advances often, with the other advances gained at the end of major, long term objectives.
Combat is handled as a conversation, a convention that shouldn’t be too difficult for players accustomed to Powered by the Apocalypse or similar games, but for gamers from a more traditional background, this might be a trickier adjustment. Unlike most of those games, however, Spire suggests that you may want to just ask for an action and then move to the next player at the table, unless there is a logical follow up action that would make sense to resolve before moving to the next player and asking them what they are planning.
Districts
There are multiple chapters detailing the districts of the city, and they comprise a large portion of the book. In addition to giving locations, the various sections include example NPCs, organizations, and sidebars that call out more of the setting or potential adventure hooks.
The districts covered in this chapter are:
Districts and Factions of Academia
Districts and Factions of Commerce
Districts and Factions of Crime
Districts and Factions of High Society
Districts and Factions of Low Society
Districts and Factions of the Occult
Districts and Factions of Order
Districts and Factions of Religion
The details on the various characters operating in the different districts reveal a great deal of depth about the setting in an almost incidental, yet memorable way. You find out that some of the aelfir don’t agree with the oppressive ways of their kin, that gnolls, who are portrayed by almost everyone else in the setting as savages, are given to being inquisitive and intellectual, but for various reasons still cultivate their savage reputation. There are intelligent corvids the size of drow, and floating sky whales, and a failed interdimensional sub-way system that may end up causing everything to collapse into an alternate dimension.
There is an amazing depth of setting lore touched upon in these chapters, almost always in a way that makes you want to use that lore at the table. Each district has several easy to grasp plot hooks that almost write themselves if the PCs only wander into the district.
Running the Game
The earlier sections of the book make it clear that there can be several difficult topics in the game. It’s based on resisting an oppressive force, and characters are assumed to be members of a revolutionary organization that can easily fall into terrorist tactics. Several of the character types are borderline nihilistic. This tone is addressed in this section, and right at the beginning of the chapter there are discussions about lines and veils and the X Card, as well as the importance of checking in with players.
There is also discussion about turning the dials up and down in the game. While characters may always have to make hard choices to fight for a better future, they may attempt to be more heroic or at least compassionate about their actions. GMs are instructed to consider how evil, alien, or just out of touch they want their aelfir to be.
There are several places where expectations are broken into different stages, such as the usual progression of a story arc, or the questions you should ask when designing a villain. I especially like the sidebar that details what kind of story elements you might expect to be introduced if players pick certain character classes.
Appendices
There are various appendices in the book detailing new gods, random items and events, a glossary of city slang and terminology, ancient cities that humans have found and what they salvaged from them, antagonists, suggested media, and the best appendix of all, goats native to Spire.
Much like the information in the district chapters, there is a lot of implied setting detail on the random lists, in what special words exist in the setting, and the fact that there are very specific, special goats in the city (some of them are just bursting in arcane energies and are great to sacrifice, and others are really big and probably not good eating).
The section on new gods also provides advances for followers of those gods, allowing for more customization for players that want to go that route. Antagonist don’t provide specific stats (most NPCs just have a set amount of stress they can absorb before being removed from the scene), but there are random tables to see what other factions might get involved in a mission when the PCs are operating on the streets or effecting city level change.
Side Note—Introductory Adventures
I am a huge fan of introductory adventures in core rulebooks. I can’t say that I’m always likely to run them, but I think just seeing the structure of an adventure, as laid out by the game’s creators, often shows a lot about how the game should run.
Spire doesn’t contain an introductory adventure, but there are several products referred to as “campaign frames” available as “pay what you want” digital products at the One Book Shelf sites. The titles currently available are Kings of Silver, Blood and Dust, and Eidolon Sky.
Revolution!
The lore is compelling and delivered in gameable sized chunks that make it easy to digest.
Share1
Tweet1
+11
Reddit1
Email
There is a ton of lore in this book that is just familiar enough to feel comfortable, and then quickly subverts that comfort zone to make the setting its own unique place. The lore is compelling and delivered in gameable sized chunks that make it easy to digest. The mechanics are new and engaging, but, like the lore involved, the mechanics feel just familiar enough, until they go their own directions. It can be a huge boon to be able to introduce a system where everything, from combat to social climbing to buying and selling, can be introduced in a unified system.
Counter-Insurgency
The book has a well-placed and well-written safety section, but topics like cannibalism, terrorism, and oppression may override the wondrous weirdness of potentially living cities, sky whales, and god powered ropes. While the text does a great job of breaking down elements that might be introduced when different character classes are in play, I think a little more discussion of what classes work best together to create different campaign frames may have been helpful as well.
Strongly Recommended—This product is exceptional, and may contain content that would interest you even if the game or genre covered is outside of your normal interests.
I think if you have even a passing interest in fantasy settings, the information in this book is going to make for a solid purchase, even if you never use the ruleset. I would never advocate for someone to push themselves into territory where they feel unsafe, but if the themes discussed in this review are within your tolerance, exploring the setting is going to be a joy.
Additionally, the mechanics of stress and fallout are both familiar and combined in a new and exciting fashion, and I think that even people that are a little burned out on fantasy may want to keep an eye on these mechanics and how they managed to promote and resolve story elements.
What are some of the most refreshing fantasy games that you have encountered? What games managed to redefine genres for you? Are you a fan of games that find a way to resolve very different actions in a unified fashion? Let us know below! We would love to hear from you.
Spire–The City Must Fall Review published first on https://medium.com/@ReloadedPCGames
0 notes
Text
Spire–The City Must Fall Review
The drow have become a fixture in Dungeons and Dragons, and that brings a lot of baggage to the game, since they live squarely at the corner of “a lot of players like even sentient, free willed beings to be born evil so it’s okay to kill them” and “hey, this thing that was born evil looks a lot like a human being and also happens to have dark skin.” Over the years, there have been several attempts to reconcile this concept, but those attempts just seem to multiply the awkward tropes associated with drow, oddly, without decreasing the overall appeal of them as an element of the game.
Given that most of this baggage is associated with a species that is unique to Dungeons and Dragons, it’s interesting that a game that addresses the politics of occupation and occupiers controlling the narrative of a culture, utilizing elves and drow as examples, comes from a game that isn’t derived from any version of the d20 SRD. In this review, we’re going to look at the game Spire, a unique RPG system that explores what life is like in a drow city occupied by elves, and to what ends your drow will go to make a lasting change to their home. Spire successfully funded on Kickstarter last August and went on sale in March of this year.
The Construction of the Spire
This review is based on the PDF version of the product. The PDF is 220 pages in length, with about five pages of thanks and the names of Kickstarter backers, a character sheet, and a two-page index.
Major sections of the book have full page artwork, which is color line art in washed out colors, highlighting the tone of the work. The artwork consists of bold black lines, and splashes of color are more representative of the emotional impact of the scene being presented than a realistic use of lighting or colors.
Headers are underlined in red, with blue sub-headers and dark grey sidebars. All of this is on blue pages with a light background image of concentric circles. It is a visually striking presentation that helps to convey the tone of the stories the game is trying to tell, but the easily seen headers and sidebars do an excellent job of breaking up the information presented into logical divisions.
Welcome to Spire and The World of Spire
The first image you see in this section is an amazing image of the titular city of Spire with an overlay graphic showing the relationships of the neighborhoods to one another. Welcome to Spire, the first section of the book, gives a high-level pitch about the tone of the game, the dice used, and paragraphs on what it means to be a player and a GM. If you are wondering if this is the kind of RPG that has a “what is an RPG” section, it does, but it’s contained on two pages and interspersed with discussions of tone and expectations for the setting.
The World of Spire section describes the broad status quo of the world. If you already know that drow are elves that live underground, dislike sunlight, and have an affinity for spiders, none of that is subverted. After that, just about everything else is. The core concept is that the players are portraying drow characters that are members of The Ministry, a secret cult/revolutionary organization, trying to reclaim Spire from the Aelfir (high elf) oppressors.
The aelfir can’t feel sadness and may not feel empathy either. According to the aelfir, the drow were once aelfir who were cursed for their evil ways and forced to flee from the sun, although there are drow that believe that drow have always been the way they are now, no curse involved. Spire is a huge, mysterious tower like city, that had plenty of space within it to shield those living in it from the sun.
Humans also figure into the story, as a mercenary element crazy enough to dig around ancient cities that predate the modern age, reverse engineering arcane medical procedures, steam-powered devices, and firearms.
There are sidebars that discuss lands beyond Spire, Drow Traditions, and Aelfir Traditions, and while there is a lot more lore coming, this relatively short section already showcases that the game is walking a tight line between recognizable and subverted tropes.
The Rules, Skills and Domains, Equipment, and Bonds
The next sections of the book are The Rules, Skills and Domains, Equipment, and Bonds. While these are all distinct sections, the unified way in which these elements work with one another makes these sections feel like more of an extended explanation of the game.
Characters roll a d10 to resolve an action. If they have a skill that pertains to the roll, they can add a d10. If they have a domain—an area of expertise where they are comfortable operating—that applies to the roll, they can add another d10. Sometimes equipment, circumstances, or character abilities will allow the character to roll with mastery, adding another d10. Since mastery can only be applied once per action, most die rolls will cap at four dice, although some character abilities play with this cap.
More difficult tasks remove a die from the die pool, so that four dice pool, against a difficulty 2 task, only allows the character to roll two dice. The highest die resolves whether the action is a critical failure, a failure, a success at a cost, a success, or a critical success.
Failure usually results in stress, which is tracked under five main resistances (some characters might also have an armor resistance added to the list as well):
Blood (Physical health)
Mind (Mental well-being)
Silver (Wealth and resources)
Shadow (Ability to operate secretly)
Reputation (Social standing)
The stress taken will vary depending on the stakes of the initial action, and might be generated with a d3, d6, or a d8. As soon as a character takes stress, they roll for fallout, which has minor, moderate, and severe levels depending on the total amount of stress the character has taken.
What this means is that some failures don’t have immediate consequences, but every failure starts to add up. It also means that the rules for taking a hit to your personal funds are the same as taking a blow to the body in combat, although the fallout, when it happens, will be different.
Different character types have different actions that allow them to remove stress when they take those actions, which reinforce the theme of that character type. The world makes more sense to a vigilante that can bring transgressors to justice, and someone well versed in commerce is going to set things right by cutting some deals.
Bonds work the same way as resistances, but they have their own list of fallout, and a character doesn’t check for fallout as often as they do for their regular resistances. Most equipment has something it’s very good at doing (which might allow a roll with mastery), and something it’s not suited for (which increases the difficulty). Weapons and armors have their own tags, which have special effects when rolling a 1 or a 10, or allowing stress to be rolled multiple times, keeping the best or worst result.
Characters and Combat
The next sections of the book cover characters and combat. Character creation consists of choosing a durance, a class, and picking a few starting abilities and equipment.
The durance is a period of indentured servitude that the drow serve under the aelfir to “repay” them for what the aelfir contribute to society. Depending on the durance selected, your character might gain more skills, or special boxes they can add to their resistance that doesn’t count against their normal stress.
The character classes available in the core rules are the following:
Azurite (A well connected mercantile priest)
Bound (A vigilante with items that have minor gods dwelling in them, boosting their power)
Carrion-Priest (Death worshippers with pet hyenas)
Firebrand (True believer revolutionaries)
Idol (Famous, well-regarded artists)
Knight (A member of a once proud martial organization that now operates like a gang)
Lajhan (A priest of the moon goddess of the drow)
Masked (A drow that learned subterfuge and espionage while serving under the aelfir)
Midwife (A drow that is part spider and protects the young and the future of drow society)
Vermission Sage (A drow sage that has learned secrets of the city’s extradimensional spaces)
Several of the class abilities grant the character the ability to use magic. Magic in this setting always has a price, and often spells will cause a character to mark stress, usually in a manner that matches the tenor of the religion and the type of spell being cast. A character using their own pain to fuel a spell might take blood stress, while someone sacrificing valuable items may take silver stress, and some spells might require more than one type of stress to be taken.
Each character class has a list of Low, Medium, and High advances, and there is a list of extra advances based on narrative choices the character has made in game. For example, joining the city guard allows for advances other characters may not be able to access, as does getting infected with a magical blood disease that is trying to bring an extra-dimensional being into the world.
Advances are earned by making some kind of change to the city. Small changes earn low advances, moderate changes earn a medium advance, and severe and potentially irreversible changes result in high advances. Characters are expected to gain low advances often, with the other advances gained at the end of major, long term objectives.
Combat is handled as a conversation, a convention that shouldn’t be too difficult for players accustomed to Powered by the Apocalypse or similar games, but for gamers from a more traditional background, this might be a trickier adjustment. Unlike most of those games, however, Spire suggests that you may want to just ask for an action and then move to the next player at the table, unless there is a logical follow up action that would make sense to resolve before moving to the next player and asking them what they are planning.
Districts
There are multiple chapters detailing the districts of the city, and they comprise a large portion of the book. In addition to giving locations, the various sections include example NPCs, organizations, and sidebars that call out more of the setting or potential adventure hooks.
The districts covered in this chapter are:
Districts and Factions of Academia
Districts and Factions of Commerce
Districts and Factions of Crime
Districts and Factions of High Society
Districts and Factions of Low Society
Districts and Factions of the Occult
Districts and Factions of Order
Districts and Factions of Religion
The details on the various characters operating in the different districts reveal a great deal of depth about the setting in an almost incidental, yet memorable way. You find out that some of the aelfir don’t agree with the oppressive ways of their kin, that gnolls, who are portrayed by almost everyone else in the setting as savages, are given to being inquisitive and intellectual, but for various reasons still cultivate their savage reputation. There are intelligent corvids the size of drow, and floating sky whales, and a failed interdimensional sub-way system that may end up causing everything to collapse into an alternate dimension.
There is an amazing depth of setting lore touched upon in these chapters, almost always in a way that makes you want to use that lore at the table. Each district has several easy to grasp plot hooks that almost write themselves if the PCs only wander into the district.
Running the Game
The earlier sections of the book make it clear that there can be several difficult topics in the game. It’s based on resisting an oppressive force, and characters are assumed to be members of a revolutionary organization that can easily fall into terrorist tactics. Several of the character types are borderline nihilistic. This tone is addressed in this section, and right at the beginning of the chapter there are discussions about lines and veils and the X Card, as well as the importance of checking in with players.
There is also discussion about turning the dials up and down in the game. While characters may always have to make hard choices to fight for a better future, they may attempt to be more heroic or at least compassionate about their actions. GMs are instructed to consider how evil, alien, or just out of touch they want their aelfir to be.
There are several places where expectations are broken into different stages, such as the usual progression of a story arc, or the questions you should ask when designing a villain. I especially like the sidebar that details what kind of story elements you might expect to be introduced if players pick certain character classes.
Appendices
There are various appendices in the book detailing new gods, random items and events, a glossary of city slang and terminology, ancient cities that humans have found and what they salvaged from them, antagonists, suggested media, and the best appendix of all, goats native to Spire.
Much like the information in the district chapters, there is a lot of implied setting detail on the random lists, in what special words exist in the setting, and the fact that there are very specific, special goats in the city (some of them are just bursting in arcane energies and are great to sacrifice, and others are really big and probably not good eating).
The section on new gods also provides advances for followers of those gods, allowing for more customization for players that want to go that route. Antagonist don’t provide specific stats (most NPCs just have a set amount of stress they can absorb before being removed from the scene), but there are random tables to see what other factions might get involved in a mission when the PCs are operating on the streets or effecting city level change.
Side Note—Introductory Adventures
I am a huge fan of introductory adventures in core rulebooks. I can’t say that I’m always likely to run them, but I think just seeing the structure of an adventure, as laid out by the game’s creators, often shows a lot about how the game should run.
Spire doesn’t contain an introductory adventure, but there are several products referred to as “campaign frames” available as “pay what you want” digital products at the One Book Shelf sites. The titles currently available are Kings of Silver, Blood and Dust, and Eidolon Sky.
Revolution!
The lore is compelling and delivered in gameable sized chunks that make it easy to digest.
Share1
Tweet1
+11
Reddit1
Email
There is a ton of lore in this book that is just familiar enough to feel comfortable, and then quickly subverts that comfort zone to make the setting its own unique place. The lore is compelling and delivered in gameable sized chunks that make it easy to digest. The mechanics are new and engaging, but, like the lore involved, the mechanics feel just familiar enough, until they go their own directions. It can be a huge boon to be able to introduce a system where everything, from combat to social climbing to buying and selling, can be introduced in a unified system.
Counter-Insurgency
The book has a well-placed and well-written safety section, but topics like cannibalism, terrorism, and oppression may override the wondrous weirdness of potentially living cities, sky whales, and god powered ropes. While the text does a great job of breaking down elements that might be introduced when different character classes are in play, I think a little more discussion of what classes work best together to create different campaign frames may have been helpful as well.
Strongly Recommended—This product is exceptional, and may contain content that would interest you even if the game or genre covered is outside of your normal interests.
I think if you have even a passing interest in fantasy settings, the information in this book is going to make for a solid purchase, even if you never use the ruleset. I would never advocate for someone to push themselves into territory where they feel unsafe, but if the themes discussed in this review are within your tolerance, exploring the setting is going to be a joy.
Additionally, the mechanics of stress and fallout are both familiar and combined in a new and exciting fashion, and I think that even people that are a little burned out on fantasy may want to keep an eye on these mechanics and how they managed to promote and resolve story elements.
What are some of the most refreshing fantasy games that you have encountered? What games managed to redefine genres for you? Are you a fan of games that find a way to resolve very different actions in a unified fashion? Let us know below! We would love to hear from you.
Spire–The City Must Fall Review published first on https://supergalaxyrom.tumblr.com
0 notes
Text
Game 303: Die Dunkle Dimension (1989)
Die Dunkle Dimension "The Dark Dimension" Germany German Design Group (developer and publisher) Released in 1989 for Commodore 64 Date Started: 29 August 2018 When I decided my master list would include foreign games, as long as they were in a language I could easily type into a translator, I expected that I'd be translating a two-paragraph backstory, a one-screen ending, and a bunch of repetitive stuff like "you miss the skeleton!" in between. I wasn't counting on games that were so text-heavy, like Antares, Die Drachen von Laas, or Nippon. Now here comes another one, Die Dunkle Dimension ("The Dark Dimension"), in which I accomplished over four hours what would have taken me 35 minutes in an English title. Dunkle is a German Ultima IV clone, and unlike the author of most clones, the developer here did a good job retaining most of what makes Ultima IV so special, including the keyword-based dialogue system, the sense of exploring a large world, and the tactical combat screen. It lacks the virtue system, of course, and you control only one party member throughout the game. Still, it's a better clone than most. The setup even sounds like Ultima IV in its beginning: You, a person in the "real world," decide to take a walk on a warm summer day. You soon stumble upon a crystalline shard in the grass. Picking it up, you quickly learn that it's some kind of portkey, and within a few minutes, you're warped through time and space to another dimension. You splash down into a lake and swim to shore, just avoiding the jaws of a giant serpent. At first, you think you're in the past looking at a dinosaur, but then the dinosaur breathes fire, and you realize you're in another world. (Although: are we sure that dinosaurs didn't breathe fire? That would be pretty rad.) You set out to find out where you are and how to get home.
Character creation sure has a lot of text to translate.
Character creation is a simple and unnecessarily wordy process of specifying a name and then identifying a primary attribute from among four choices: strength, skill, wisdom, and charisma (I chose strength). You get to specify a difficulty level (I chose "medium"), and whether you favor attacking or defense (attacking). The game then determines your final attribute scores.
Gameplay begins where the story left off: on the shores of a lake with a serpent lurking nearby. You have to get away from the shore before he closes and attacks.
Arriving in a new world.
The interface is much like an Ultima title. Movement is with the bracket-semicolon-apostrophe-slash cluster (on a PC keyboard anyway; their analogues on a C64 are a little different), and actions are performed with single letters, such as (A)ttack, (K)ommunicate, (I)nventory, and (R)eady armor. The specific list varies a little depending on whether you're outside, inside, or in combat. In any event, it's relatively easy to master.
The game came with a map. I believe the starting area is at the lake slightly southwest of center.
Near the starting point is a cottage, so naturally I entered it. It turned out to be the home of a druid named Cerfak. Conversation with NPCs proceeds exactly as in Ultima IV except that you only type the first four letters of your keyword. All NPCs respond to NAME (same in both languages), GESUndheit (health), and BERUf (occupation). The rest of their responses are from keywords that they feed you or that other NPCs tell you to ask them. Occasionally, they ask you something that requires a (J)a or (N)ein response. Cerfak was extremely wordy, and he left me terrified that all NPCs would have as much to say. Fortunately, that isn't the case, because it took me almost an hour just to transcribe his conversation. It was important, because it includes a lot about the backstory and quest.
Name: I am Cerfak
Health: I am exhausted. Are you OK?
Yes: I'm happy for you
Job: I am a druid.
Druid: We druids are wise old magicians, but closer to nature than sorcerers. We see, we heal, and we help.
See: I see how evil conquers our world.
Heal: let me heal you (heals me)
Help: Ask what you want to know. I know a lot.
World: Evil has destroyed the balance of our world.
Balance: Are you from another world?
Yes: Once upon a time, our world was beautiful and bright. The people lived in peace and were happy. But the Evil One brought eternal darkness over us, and the creatures of darkness came out of their holes and overflowed the land. The sun will never rise again, because the crystal is broken.
Crystal: The Crystal of Light that kept the balance of our world. Carried by fire and air, it floats above the lava of the great volcano. But the Evil One struck with all its cruel power, and the crystal shattered. A splinter broke off. The crystal turned black. With it went the sun [thus explaining the game's name]. The splinter broke out of the upper right corner of the crystal. Remember this point! The Evil One built an impregnable fortress in the form of a huge skull around the crystal. There he lurks and sends out doom. The splinter was cast into another dimension. When you touched it, a spell broke and the splinter and you were teleported here. Do you have the splinter?
No: (At least it's not listed in my inventory.) Go and find it; otherwise our world is lost forever. Go northeast. There you will come to the castle of the king. There, they will help you.
Splinter: The crystal and the splinter must be united!
Bye: My prayers go with you.
The druid has a lot to say.
The bit about the crystal, shard, lava, and mountain seem to be influenced by The Dark Eye tabletop RPG published by Schmidt Spiele in 1984 (on which the later CRPG Realms of Arkania was based). I don't know the game well enough to determine if the developer of Dunkle took any other inspiration. The character starts with no weapons or armor, and there's no obvious place nearby to obtain any. It's not long before robbers, zombies, forest demons, and goblins come wandering out of the nearby woods and start attacking. Fortunately, the character is capable of beating most of these combatants to death with his bare hands. He takes a large hit point loss doing so, but the druid heals for free.
Attacking a forest demon in forested terrain. A zombie approaches.
Combat is again much like Ultima IV. When it begins, the action transitions to a tactical map based on the terrain you were standing on. You can use environmental obstacles to block and funnel enemies. You and enemies exchange turns, and during your turn you can attack, cast a spell, or switch weapons (I naturally have no spells or weapons yet). When hit, enemies progress from barely scratched (kaum angekratzt) to lightly wounded (leicht verletzt), wounded (verwundet), seriously injured (schwer verletzt), fleeing (auf der flucht), and then death. If an enemy successfully flees (which happens to my weaponless character most of the time), you get his gold but no experience points. If you flee, you lose some experience points. Animals provide no experience, which echoes Ultima IV's system by which it was unvirtuous to kill them.
I made some money hanging around the druid's hut, but I noticed my food depleting (you start with 50 rations) and I figured I'd better stake out for a town or the king's castle, as recommended by Cerfak. It took me a few false starts in which I was killed by an accumulation of combats on the way. Fortunately, you can save anywhere outdoors and reload.
Arriving at the castle.
The king's castle was a small, one-level structure with about a dozen NPCs. Collectively, they had only about as much text as Cerfak by himself, but it still took a long time to translate. Of course, there was a Chuckles analogue (calling himself a "harlequin") waiting for me in the courtyard. This was his joke:
Q: Do you know the difference between a king and a hippopotamus?
A: The hippopotamus bathes more often!
I'm not sure how that's supposed to be any kind of an insult considering a hippopotamus basically lives in water. I mean, you could bathe twice a day and a hippo would probably still bathe more often than you.
Chuckles somehow has the power to annoy me across universes.
Anyway, among the NPCs the king and queen had the most dialogue. King Casiodorus said he'd heard of my exploits even though I haven't done much. After a quick pause, he encouraged me to come back when I had more experience--clearly, I go to him to level up. Between him and the distraught queen, they related that there's a terrible dragon (lindwurm) who lives in the mountains to the east. Twice a year, always at solstice, he gets hungry for human flesh. To avoid him razing the countryside, the nation made a deal with him to supply him with virgins twice a year, their names drawn by lottery from all the eligible young women in the kingdom. Unfortunately, Princess Sheila's name came up in the last drawing and she'll soon have to be sacrificed. The king implored me to find a way to defeat the dragon. Not only is this the plot of 1981's Dragonslayer (in which Peter MacNicol is weirdly miscast as the hero), but the king's name is taken from that film. The forthcoming rescue seems to be what's depicted on the title screen.
The king introduces himself.
Torquill, the king's sheriff, also told me to ask the king about a thieving band that lives in a lair called Mubrak. The king is eager to wipe them out. So I left the castle with two quests which may be side quests or somehow related to the main quest.
Other NPCs included Chancellor Helmut Kohl, who had nothing to say; Dakteon the bard, who told me that no one can pronounce the name of the Evil One without burning alive, but that I'd somehow need to do it; Antonius the priest, who admitted that he doesn't believe in God, but "you have to make a living somehow"; and Theodorus the geographer, who asked if I wanted maps of all the game's dungeons and towns and, when I said yes, told me to send money to the German Design Group and gave me the address.
A random maid asks if I'm there to save the world.
In a corner, a swordmaster named Ator (from the Italian series of Conan-inspired films) said he could train me when I was more experienced. When you level up, you must get the ability to raise your attributes.
Unfortunately, there was no place to buy weapons or armor in the castle, so I left unsure what to do next. I ultimately made my way back to the familiar territory of the druid's hut, and I'll have to explore outward from there.
The druid heals me for free as I slowly build my gold and experience around his hut.
Other notes:
Magic, which I haven't had any chance to investigate yet, is apparently divided into white magic (healing and protection spells) and black magic (damage spells), a division that we'll see later in the German Dragonflight (1990). Casting them requires reagents, just like Ultima IV.
Also making an appearance from Ultima IV are bridge trolls (they have a random chance of attacking when you cross bridges) and patches of swamp that poison the character.
Bridge trolls are a little too tough for an unarmed character.
Enemies can move and attack on the diagonal but you can't. This makes it impossible to outrun enemies.
From the manual's descriptions, horses, ships, and aircraft are due to make appearances.
The king's castle has something you don't find in most RPGs: bathrooms.
There's even a toilet paper roll holder and a toilet brush.
The primary author of Die Dunkle Dimension seems to be one Hendrik Belitz, who went by the pseudonyms "Silent Shadow" and "The Dark One." Belitz had a web site dedicated to the game as recently as a few years ago, but he seems to have lost the domain. I was able to retrieve it from the Internet Archive and get the files that were offered on it, including the game manual and map. Scanning the site and the documentation, I found it more than a little irksome that the author didn't provide any credit to Ultima, from which he'd clearly taken so many of the game's concepts. I never criticize clones for being clones, but I sure do criticize them for not acknowledging that they're clones. We'll talk more about the author, company, and legacy of the game in the final entry.
I'm nowhere near having translated the entire manual yet; I'm just consulting bits and pieces as I need it. This one seems like it's going to be slow-going but perhaps enjoyable in its own way.
source http://crpgaddict.blogspot.com/2018/09/game-303-die-dunkle-dimension-1989.html
0 notes