#what is data pipeline architecture
Text
What is a Data Pipeline? | Data Pipeline Explained in 60 Seconds
If you've been curious about data pipelines but don't know what they are, this video is for you! Data pipelines are a powerful way to manage and process data, and in this video, we'll explain them in 60 seconds.
If you're looking to learn more about data pipelines, or want to know what they are used for, then this video is for you! We'll walk you through the data pipeline architecture and share some of the uses cases for data pipelines.
By the end of this video, you'll have a better understanding of what a data pipeline is and how it can help you with your data management needs!
#data pipelines#data#data science#data analyses#data integration#data replication#data virtualization#business intelligence#data mining#etl#extract transform load#machine learning#batch processing#what is data pipeline architecture#data pipeline#big data#data pipeline data science#data warehouse#what is data pipeline#batch vs stream processing#data pipeline explained#real time data processing
2 notes
·
View notes
Text
What is Data Observability - Concept, Metrics & Architecture
It is the practice of understanding the internal state or condition of a data-centric system by carefully monitoring and analyzing the data, logs and signals emitted by the system. Learn more about Data observability in this article
#observability data#data pipeline observability#limitations of data observability#data observability metrics#data observability architecture#data observability definition#what is data observability#data observability
0 notes
Note
I've had a semi irrational fear of continer software (docker, cubernates etc) for a while, and none of my self hosting needs have needed more than a one off docker setup occasionally but i always ditch it fairly quickly. Any reason to use kubernates you wanna soap box about? (Features, use cases, stuff u've used it for, anything)
the main reasons why i like Kubernetes are the same reasons why i like NixOS (my Kubernetes addiction started before my NixOS journey)
both are declarative, reproducible and solve dependency hell
i will separate this a bit,
advantages of container technologies (both plain docker but also kubernetes):
every container is self-contained which solves dependency problems and "works on my machine" problems. you can move a docker container from one computer to another and as long as the container version and the mounted files stay the same and it will behave in the same way
advantages of docker-compose and kubernetes:
declarativeness. the standard way of spinning up a container with `docker run image:tag` is in my opinion an anti pattern and should be avoided. it makes updating the container difficult and more painful than it needs to be. instead docker compose allows you to write a yaml file instead which configures your container. like this:
```
version: "3"
services:
myService:
image: "image:tag"
```
you can then start up the container with this config with `docker compose up`. with this you can save the setup for all your docker containers in config files. this already makes your setup quite portable which is very cool. it increases your reliability by quite a bit since you only need to run `docker compose up -d` to configure everything for an application. when you also have the config files for that application stored somewhere it's even better.
kubernetes goes even further. this is what a simple container deployment looks like: (i cut out some stuff, this isn't enough to even expose this app)
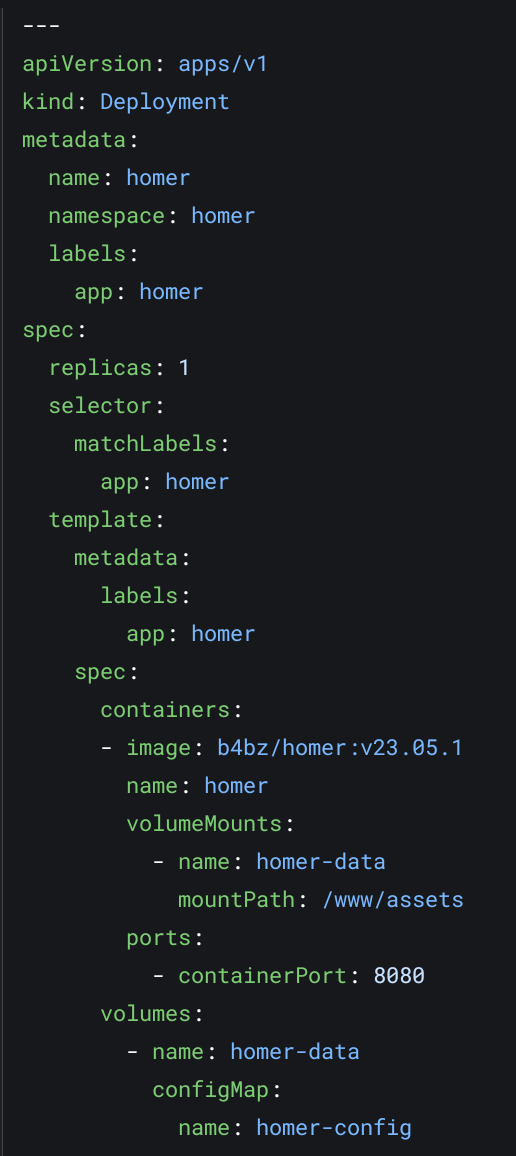
this sure is a lot of boilerplate, and it can get much worse. but this is very powerful when you want to make everything on your server declarative.
for example, my grafana storage is not persistent, which means whenever i restart my grafana container, all config data gets lost. however, i am storing my dashboards in git and have SSO set up, so kubernetes automatically adds the dashboards from git
the main point why i love kubernetes so much is the combination of a CI/CD pipeline with a declarative setup.
there is a software called ArgoCD which can read your kubernetes config files from git, check if the ones that you are currently using are identical to the ones in git and automatically applies the state from git to your kubernetes.
i completely forgot to explain of the main features of kubernetes:
kubernetes is a clustered software, you can use one or two or three or 100 computers together with it and use your entire fleet of computers as one unit with kubernetes. i have currently 3 machines and i don't even decide which machine runs which container, kubernetes decides that for me and automatically maintains a good resource spread. this can also protect from computer failures, if one computer fails, the containers just get moved to another host and you barely use any uptime. this works even better with clustered storage, where copies of your data are distributed around your cluster. this is also useful for updates, as you can easily reboot a server for updates without causing any downtime.
also another interesting design pattern is the architecture of how containers are managed. to create a new container, you usually create a deployment, which is a higher-level resource than a container and which creates containers for you. and the deployment will always make sure that there are enough containers running so the deployment specifications are met. therefore, to restart a container in kubernetes, you often delete it and let the deployment create a new one.
so for use cases, it is mostly useful if you have multiple machines. however i have run kubernetes on a singular machine multiple times, the api and config is just faaaaaaar too convenient for me. you can run anything that can run in docker on kubernetes, which is (almost) everything. kubernetes is kind of a data center operating system, it makes stuff which would require a lot of manual steps obsolete and saves ops people a lot of time. i am managing ~150 containers with one interface with ease. and that amount will grow even more in the future lol
i hope this is what you wanted, this came straight from my kubernetes-obsessed brain. hope this isn't too rambly or annoying
it miiiiiiiight be possible to tell that this is my main interest lol
6 notes
·
View notes
Text
Exploring Career Paths After Mastering AWS
In today’s digital era, cloud computing has transformed how businesses operate, and Amazon Web Services (AWS) stands at the forefront of this evolution. With its extensive suite of services, AWS has become an industry standard, leading to a surge in demand for skilled professionals. If you’ve recently learned AWS, you’re likely wondering what career opportunities await you. Let’s delve into some exciting roles you can pursue in the ever-expanding cloud landscape.
If you want to advance your career at the AWS Course in Pune, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

1. Architecting the Cloud: Cloud Architect
Cloud Architects play a pivotal role in shaping an organization’s cloud strategy. They are tasked with designing, deploying, and managing cloud infrastructure that meets business requirements. This role requires a comprehensive understanding of AWS services, as well as expertise in security and scalability.
Essential Skills:
Proficiency in AWS architecture and services
Understanding of cloud networking and security protocols
Skills in cost management and optimization techniques
2. Bridging Development and Operations: DevOps Engineer
DevOps Engineers focus on streamlining the software development lifecycle. They leverage AWS tools to automate deployment processes and enhance collaboration between development and operations teams. Mastery of CI/CD practices is critical in this role.
Essential Skills:
Familiarity with CI/CD tools like AWS CodePipeline
Knowledge of Infrastructure as Code (IaC) using AWS CloudFormation
Experience with monitoring tools such as AWS CloudWatch
3. Innovating Applications: Cloud Developer
Cloud Developers are responsible for creating applications that utilize cloud infrastructure. They often work with serverless architectures and microservices, utilizing AWS services to build scalable solutions. Strong programming skills are essential for success in this role.
Essential Skills:
Proficient in programming languages (e.g., Python, Java, Node.js)
Experience with AWS Lambda and serverless computing
Skills in API design and development
4. Managing Data Flows: Data Engineer
Data Engineers are crucial in managing and optimizing data pipelines. They ensure efficient data movement from various sources to storage and analytics systems, often utilizing AWS data services like Amazon Redshift and AWS Glue.
Essential Skills:
Expertise in data warehousing and ETL processes
Proficient in SQL and database technologies
Familiarity with AWS data management services
To master the intricacies of AWS and unlock its full potential, individuals can benefit from enrolling in the AWS Online Training.

5. Securing the Cloud: Cloud Security Specialist
With increasing cloud adoption, the need for Cloud Security Specialists has never been higher. These professionals focus on safeguarding cloud infrastructures, ensuring compliance, and implementing robust security measures. A solid understanding of AWS security features is paramount.
Essential Skills:
Knowledge of AWS Identity and Access Management (IAM)
Familiarity with security best practices and compliance frameworks
Skills in incident response and risk assessment
6. Designing Tailored Solutions: Solutions Architect
Solutions Architects take on the challenge of designing customized cloud solutions that align with client needs. They work closely with stakeholders to understand their requirements and guide them through the implementation process.
Essential Skills:
Strong customer engagement and requirement analysis
Exceptional problem-solving capabilities
In-depth knowledge of AWS service offerings
7. Strategic Guidance: Cloud Consultant
Cloud Consultants provide strategic advice to organizations on cloud adoption and implementation. They assess existing IT environments, recommend appropriate AWS solutions, and assist in the migration process, blending technical acumen with strategic insight.
Essential Skills:
Expertise in cloud strategy and migration frameworks
Strong communication and presentation skills
Experience in project management methodologies
Conclusion
Mastering AWS opens the door to a plethora of career opportunities in the tech industry. Whether you aspire to be an architect, engineer, developer, or consultant, AWS skills are valuable assets that can enhance your professional journey. By pursuing AWS certifications and gaining hands-on experience, you can position yourself as a competitive candidate in the thriving cloud job market.
0 notes
Text
Data Engineering Services Explained: What Lies Ahead for the Industry
In an era where data shapes every aspect of business decision-making, organizations are turning to data engineering to harness its full potential. As data volumes and complexities escalate, the demand for specialized data engineering services has surged. This article delves into the core components of data engineering services and offers insights into the evolving future of this critical field.

What are Data Engineering Services?
Data engineering involves the design, construction, and maintenance of systems and infrastructure that allow for the collection, storage, processing, and analysis of data. Data engineering services encompass a variety of tasks and functions that ensure data is accessible, reliable, and usable for data scientists, analysts, and business stakeholders. Key components of data engineering services include:
1. Data Architecture
Data engineers are responsible for designing data architectures that define how data is collected, stored, and accessed. This includes selecting appropriate databases, data lakes, and data warehouses to optimize performance and scalability.
2. Data Integration
Data often comes from multiple sources, including transactional systems, external APIs, and sensor data. Data engineering services involve creating ETL (Extract, Transform, Load) processes that integrate data from these various sources into a unified format.
3. Data Quality and Governance
Ensuring data quality is critical for accurate analysis. Data engineers implement data validation and cleansing processes to identify and rectify errors. They also establish governance frameworks to maintain data integrity and compliance with regulations.
4. Data Pipeline Development
Data pipelines automate the flow of data from its source to storage and processing systems. Data engineering services focus on building efficient pipelines that can handle large volumes of data while ensuring minimal latency.
5. Performance Optimization
As organizations scale, performance becomes a crucial consideration. Data engineers optimize databases and pipelines for speed and efficiency, enabling faster data retrieval and processing.
6. Collaboration with Data Teams
Data engineers work closely with data scientists, analysts, and other stakeholders to understand their data needs. This collaboration ensures that the data infrastructure supports analytical initiatives effectively.
The Future of Data Engineering
As the field of data engineering evolves, several trends are shaping its future:
1. Increased Automation
Automation is set to revolutionize data engineering. Tools and platforms are emerging that automate repetitive tasks such as data cleansing, pipeline management, and monitoring. This will allow data engineers to focus on more strategic initiatives rather than manual processes.
2. Real-time Data Processing
With the rise of IoT devices and streaming applications, the demand for real-time data processing is growing. Future data engineering services will increasingly incorporate technologies like Apache Kafka and Apache Flink to facilitate real-time data ingestion and analytics.
3. Cloud-based Solutions
Cloud computing is becoming the norm for data storage and processing. Data engineering services will continue to leverage cloud platforms like AWS, Google Cloud, and Azure, offering greater scalability, flexibility, and cost-effectiveness.
4. DataOps
DataOps is an emerging discipline that applies agile methodologies to data management. It emphasizes collaboration, continuous integration, and automation in data pipelines. As organizations adopt DataOps, the role of data engineers will shift toward ensuring seamless collaboration across data teams.
5. Focus on Data Security and Privacy
With growing concerns about data security and privacy, data engineers will play a vital role in implementing security measures and ensuring compliance with regulations like GDPR and CCPA. Future services will prioritize data protection as a foundational element of data architecture.
6. Integration of AI and Machine Learning
Data engineering will increasingly intersect with artificial intelligence and machine learning. Data engineers will need to build infrastructures that support machine learning models, ensuring they have access to clean, structured data for training and inference.
Conclusion
Data engineering services are essential for organizations seeking to harness the power of data. As technology continues to advance, the future of data engineering promises to be dynamic and transformative. With a focus on automation, real-time processing, cloud solutions, and security, data engineers will be at the forefront of driving data strategy and innovation. Embracing these trends will enable organizations to make informed decisions, optimize operations, and ultimately gain a competitive edge in their respective industries.
#Data Engineering Services#Data Security#Data Privacy#Future of Data Engineering#Data Architecture#Data Governance
0 notes
Text
Unlocking the Power of Data: Ecorfy’s Innovative Data Engineering Solutions
Introduction:
In today’s fast-paced digital landscape, data is more than just a byproduct of business operations; it is the foundation of decision-making, strategy, and growth. Organizations generate vast amounts of data daily, but the real challenge lies in managing, processing, and transforming this data into actionable insights. This is where Ecorfy’s Data Engineering services come into play, offering businesses a comprehensive solution to streamline their data management and harness its true potential. Whether you're looking for data engineering services in Texas or data engineering solutions in California, Ecorfy delivers top-tier results to clients across the USA.
What is Data Engineering?
Data engineering is the process of designing, building, and maintaining the infrastructure that allows for the collection, storage, and analysis of large datasets. It serves as the backbone of data-driven organizations, ensuring that data is accessible, reliable, and usable across various platforms. From designing efficient pipelines to ensuring data integrity, data engineering is critical for enabling advanced analytics, machine learning, and artificial intelligence applications. Ecorfy’s data engineering consultants in the USA are experts in optimizing this process, ensuring that businesses get the most from their data.
Ecorfy’s Approach to Data Engineering
Ecorfy understands the complexities associated with managing large datasets, and their team of experts is equipped to handle every aspect of the data engineering lifecycle. Their solutions are designed to help businesses scale efficiently by building robust data architectures that support long-term growth and agility.
1. Data Integration
Ecorfy’s data engineering team excels at integrating data from disparate sources into a unified platform. Whether it's cloud data, structured databases, or unstructured data from various sources like social media and IoT devices, Ecorfy’s integration techniques ensure that businesses have a single source of truth for all their data-related needs. This integrated approach enhances data quality, making analytics more precise and decision-making more informed. Their big data engineering services in New York stand out as a benchmark for real-time and high-volume data management.
2. Data Pipeline Creation
Ecorfy specializes in creating seamless data pipelines that automate the flow of data from multiple sources into a central data repository. This enables businesses to handle real-time data processing and ensure that data is available for immediate use by analytics and business intelligence tools. The automation reduces human errors, enhances efficiency, and ensures that data remains consistent and up-to-date. With big data consultants in New York, Ecorfy provides robust solutions that make real-time data processing effortless.
3. Data Storage and Architecture
Proper storage and efficient data architecture are crucial for handling large datasets. Ecorfy ensures that businesses have the right storage solutions in place, whether on-premise or in the cloud. Their team also ensures that data is stored in ways that optimize retrieval speed and accuracy, implementing the best database management systems that are scalable and secure. Their data engineering solutions in California offer a diverse range of options suited to different business needs.
5. Big Data Handling and Real-Time Processing
With the rise of big data, businesses often struggle to process and analyze large volumes of data quickly. Ecorfy offers cutting-edge solutions for handling big data and real-time analytics, allowing companies to gain insights and respond to business needs without delays. From implementing technologies like Apache Hadoop to optimizing data workflows, Ecorfy makes big data accessible and manageable. Their big data consultants in New York offer specialized expertise to ensure that your big data projects are handled with precision and foresight.
Conclusion
In the data-driven era, effective data management is critical for business success. Ecorfy’s Data Engineering services offer businesses the tools they need to unlock the full potential of their data. By providing seamless integration, optimized data pipelines, scalable architecture, and real-time processing, Ecorfy helps organizations stay ahead of the competition in an increasingly data-centric world. Whether you're seeking data engineering consultants in the USA or industry-leading data engineering services in Texas and California, Ecorfy is your go-to partner for comprehensive, scalable data solutions.
0 notes
Text
What is Software Engineering? Career Paths and Opportunities

Software engineering is a dynamic field that has become an integral part of almost every industry. With the rise of technology and its applications across different sectors, the demand for skilled software engineers has increased tremendously. But what exactly is software engineering? It’s the process of designing, developing, testing, and maintaining software systems. Software engineers work to create reliable, efficient, and user-friendly programs that meet the needs of both businesses and consumers.
One of the appealing aspects of software engineering is the variety of career paths it offers. Whether you're interested in developing web applications, building operating systems, or working on artificial intelligence, there’s a role for you. A software engineer can specialize in areas like front-end development, back-end development, mobile app development, or systems architecture. With each specialization, engineers contribute to the overall process of delivering high-quality software.
Career Opportunities in Software Engineering
The opportunities in software engineering are vast. Some of the most common roles in the field include:
Full-Stack Developer: Full-stack developers are proficient in both front-end and back-end technologies, making them versatile contributors to any development team. They can build entire web applications from scratch and ensure that both the client-facing interface and server-side logic are functional.
Data Engineer: Data engineers design and manage large-scale data systems that allow organizations to process and analyze data effectively. They work closely with data scientists and analysts to build pipelines that gather, store, and process big data, contributing to strategic business decisions.
DevOps Engineer: DevOps engineers focus on automating processes, improving collaboration between development and operations teams, and ensuring that the software development lifecycle is efficient. They work to streamline the deployment and scaling of software applications in cloud environments.
Mobile App Developer: Mobile app developers specialize in creating applications for mobile devices, such as smartphones and tablets. With the continuous growth of mobile technology, this role is crucial for companies looking to engage with their customers through mobile platforms.
Security Engineer: Security engineers are responsible for protecting software systems from cyberattacks. They design security protocols, identify vulnerabilities, and ensure that software is safe from external threats, which is especially important in today’s data-driven world.
The Growing Demand for Software Engineers
As industries continue to digitalize their operations, the demand for software engineers shows no signs of slowing down. According to industry reports, software development roles are expected to grow by 22% over the next decade. This makes software engineering one of the most in-demand professions globally. Companies are increasingly seeking individuals who not only possess technical skills but also have the ability to adapt to new technologies and methodologies.
In addition to job security, software engineers enjoy competitive salaries. The average salary for a software engineer varies depending on location, experience, and specialization, but it is generally well above the national average for most industries. For instance, experienced engineers in fields like artificial intelligence and machine learning can command even higher salaries due to the specialized knowledge required.
Conclusion
Software engineering is a promising career path that offers diverse opportunities for growth and development. Whether you're passionate about solving complex problems or building cutting-edge applications, there’s a role for you in this ever-evolving field. If you want to explore more about the career paths and opportunities in software engineering, you can find detailed insights in our article: What is Software Engineering? Career Paths and Opportunities.
0 notes
Text
Essential Guide to Web Application Development in Simple Terms

In today's digital era, web applications have become a vital part of our daily lives. They power our favorite social networks, streamline online shopping, and even assist our productivity. Developing these web applications requires a blend of technical skills and creativity. This article will walk you through the essentials of web application development in a straightforward manner, suitable for anyone interested in learning about this fascinating field.
What is Web Application Development?
Web application development involves creating application programs that run on remote servers and are delivered to users over the internet through web browsers. Unlike traditional software that needs to be installed on a local device, web applications can be accessed online, making them versatile and easily updatable.
Key Components of Web Applications
Web applications are built using three primary components:
1. Front-End (Client-Side)
This is the visual part of the application that users interact with.
Technologies Used: HTML for structure, CSS for styling, and JavaScript for interactivity.
Frameworks and Libraries: Popular tools like React, Angular, and Vue.js help developers create dynamic interfaces.
2. Back-End (Server-Side)
This component handles the server, application logic, and database.
Languages and Frameworks: Common choices include Node.js, Python (with Django or Flask), Ruby on Rails, Java (Spring), and PHP (Laravel).
Database Management: Databases such as MySQL, PostgreSQL, and MongoDB play a crucial role in storing data.
3. API (Application Programming Interface)
APIs facilitate communication between different software components.
Types of APIs: RESTful APIs and GraphQL are widely used for developing robust and scalable APIs.
Steps to Develop a Web Application
Let's break down the web application development process into several key steps:
1. Gather Requirements
Stakeholder Interviews: Talk to those who have a stake in the project to understand its goals.
User Stories: Detail what users need and expect from the application.
Feasibility Analysis: Ensure the project can be completed within time and budget constraints.
2. Design Phase
Wireframes and Mockups: Create simple sketches or models of the application's layout.
Prototyping: Build interactive prototypes to test user interface (UI) and user experience (UX).
System Architecture: Plan how different parts of the application will interact.
3. Development Phase
Front-End Development: Use HTML, CSS, and JavaScript to build the user interface.
Back-End Development: Write code for the server, application logic, and database integration.
Integration: Ensure seamless communication between the front-end and back-end components.
4. Testing Phase
Unit Testing: Test individual pieces of code to ensure they work correctly.
Integration Testing: Check if different modules work together without issues.
System Testing: Test the entire application as a whole.
User Acceptance Testing (UAT): Let real users trial the application to identify any usability issues.
5. Deployment Phase
Hosting: Choose a reliable hosting service like AWS, Heroku, or Azure.
CI/CD Pipelines: Implement Continuous Integration/Continuous Deployment to streamline the release process.
Monitoring: Use tools to keep track of application performance and detect any issues promptly.
6. Maintenance and Updates
Performance Optimization: Regularly check and improve the application’s speed and efficiency.
Security Updates: Keep the application secure by applying the latest patches.
Feature Enhancements: Continuously add new features based on user feedback.
Emerging Trends in Web Application Development
To stay ahead in web development, it's essential to be aware of the latest trends:
Progressive Web Apps (PWAs): Combining the best of web and mobile apps, PWAs offer offline access and fast load times.
Serverless Architecture: This approach allows developers to focus on writing code without worrying about server management.
Artificial Intelligence (AI) and Machine Learning (ML): Integrating AI and ML can enhance user experiences with personalized content and advanced analytics.
Microservices: Breaking down applications into smaller, independent services makes them easier to manage and scale.
Conclusion
Web application development is an exciting and evolving field that requires a mix of technology write for us creativity and technical know-how. By understanding the components of web applications and following a structured development process
0 notes
Text
What is Data Architecture? Key Components and Their Importance

In the modern digital landscape, organizations are constantly seeking ways to harness and manage vast amounts of data. Data architecture plays a pivotal role in structuring, organizing, and managing data effectively. It serves as a blueprint for collecting, storing, processing, and utilizing data in a way that aligns with business goals. This blog explores what is data architecture, its key components, and why it's crucial for businesses.
What is Data Architecture?
Data architecture refers to the design and structure of an organization's data management systems. It provides a framework that defines how data is collected, stored, transformed, and accessed across various applications and platforms. Data architecture ensures that data is managed consistently and securely while enabling efficient data flow and integration across different systems.
In essence, data architecture is the backbone of any data-driven organization. It allows businesses to understand where their data is coming from, how it is being used, and how it can be leveraged to make informed decisions.
Key Components of Data Architecture
Data architecture consists of several key components that work together to ensure seamless data management and utilization. Understanding these components is essential for building an effective data architecture strategy.
1. Data Sources
Data sources are the origin points of data within an organization. They can include various forms of data, such as transactional data from business applications, customer data from CRM systems, external data from third-party sources, and unstructured data like social media feeds and emails.
Managing multiple data sources efficiently is critical for organizations to create a comprehensive and accurate data ecosystem. Data architects need to ensure that the data from these sources is clean, structured, and ready for further processing.
2. Data Storage
Data storage refers to the method of storing data within an organization. Depending on the volume, type, and usage of data, organizations may use different storage solutions such as databases, data warehouses, and data lakes.
Databases: Designed to store structured data in tables, databases are optimized for transactional data processing and are commonly used in applications where quick access to specific data points is required.
Data Warehouses: These are large repositories designed to store historical data, often structured and used for reporting and analysis.
Data Lakes: Data lakes store vast amounts of raw, unstructured data, allowing for flexibility in processing and analyzing data at a later stage.
Choosing the right storage solution is a critical aspect of data architecture, as it influences how quickly and efficiently data can be accessed and utilized.
3. Data Integration
Data integration is the process of combining data from different sources into a unified view. Organizations often deal with data from various departments and systems, which makes it challenging to analyze data comprehensively. Data integration tools ensure that data flows smoothly between different systems, eliminating data silos and inconsistencies.
Common data integration methods include ETL (Extract, Transform, Load) processes, APIs (Application Programming Interfaces), and data pipelines. Efficient data integration allows for seamless data sharing, improving decision-making and enabling real-time analytics.
4. Data Processing
Once data is collected and stored, it must be processed to extract meaningful insights. Data processing involves cleaning, transforming, and aggregating data to prepare it for analysis. Organizations use data processing tools and frameworks to handle large datasets, ensuring data quality and consistency.
Data processing can take place in real-time (streaming) or in batches, depending on the business requirements. Proper data processing is vital to ensure that the data is accurate and relevant before it is used for analysis or reporting.
5. Data Governance
Data governance refers to the policies, procedures, and standards that ensure the proper management, security, and compliance of data within an organization. It involves defining who has access to data, how it should be used, and how data quality is maintained.
Strong data governance is crucial to protect sensitive information, maintain data integrity, and ensure compliance with regulations such as GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act).
6. Data Security
Data security focuses on protecting data from unauthorized access, breaches, and cyberattacks. Given the growing concerns around data privacy and security, organizations must implement robust data security measures, including encryption, authentication, and access controls.
An effective data architecture ensures that sensitive data is encrypted both at rest and in transit, and that access to data is restricted based on user roles and responsibilities.
Importance of Data Architecture
A well-designed data architecture is crucial for several reasons:
Improved Data Quality: Data architecture ensures that data is clean, consistent, and accurate, which is essential for making reliable business decisions.
Data Accessibility: By organizing data effectively, data architecture makes it easier for users to access the information they need in a timely manner.
Enhanced Data Security: A solid data architecture ensures that sensitive data is protected through encryption, access controls, and compliance with regulations.
Scalability: As organizations grow, their data needs will expand. A robust data architecture provides the flexibility to scale data storage, processing, and integration without major disruptions.
Cost Efficiency: Effective data architecture helps organizations optimize their data storage and processing strategies, reducing costs and improving operational efficiency.
Conclusion
Data architecture is a critical aspect of modern business operations, enabling organizations to manage their data efficiently and securely. With the right components in place—data sources, storage, integration, processing, governance, and security—businesses can unlock the full potential of their data and drive informed decision-making.
By understanding and implementing a strong data architecture, organizations can ensure that their data infrastructure is prepared for future growth and innovation.
0 notes
Text
Mastering Data Flow in GCP: A Complete Guide
1. Introduction
Overview of Data Flow in GCP
In the modern digital age, the volume of data generated by businesses and applications is growing at an unprecedented rate. Managing, processing, and analyzing this data in real-time or in batch jobs has become a key factor in driving business insights and competitive advantages. Google Cloud Platform (GCP) offers a suite of tools and services to address these challenges, with Dataflow standing out as one of the most powerful tools for building and managing data pipelines.
Data Flow in GCP refers to the process of collecting, processing, and analyzing large volumes of data in a streamlined and scalable way. This process is critical for businesses that require fast decision-making, accurate data analysis, and the ability to handle both real-time streams and batch processing. GCP Dataflow provides a fully-managed, cloud-based solution that simplifies this entire data processing journey.
As part of the GCP ecosystem, Dataflow integrates seamlessly with other services like Google Cloud Storage, BigQuery, and Cloud Pub/Sub, making it an integral component of GCP's data engineering and analytics workflows. Whether you need to process real-time analytics or manage ETL pipelines, GCP Dataflow enables you to handle large-scale data workloads with efficiency and flexibility.
What is Dataflow?
At its core, Dataflow is a managed service for stream and batch processing of data. It leverages the Apache Beam SDK to provide a unified programming model that allows developers to create robust, efficient, and scalable data pipelines. With its serverless architecture, Dataflow automatically scales up or down depending on the size of the data being processed, making it ideal for dynamic and unpredictable workloads.
Dataflow stands out for several reasons:
It supports streaming data processing, which allows you to handle real-time data in an efficient and low-latency manner.
It also excels in batch data processing, offering powerful tools for running large-scale batch jobs.
It can be used to build ETL pipelines that extract, transform, and load data into various destinations, such as BigQuery or Google Cloud Storage.
Its integration with GCP services ensures that you have a complete ecosystem for building data-driven applications.
The importance of Data Flow in GCP is that it not only provides the infrastructure for building data pipelines but also handles the complexities of scaling, fault tolerance, and performance optimization behind the scenes.
2. What is Dataflow in GCP?
Dataflow Overview
GCP Dataflow is a cloud-based, fully-managed service that allows for the real-time processing and batch processing of data. Whether you're handling massive streaming datasets or processing huge data volumes in batch jobs, Dataflow offers an efficient and scalable way to transform and analyze your data. Built on the power of Apache Beam, Dataflow simplifies the development of data processing pipelines by providing a unified programming model that works across both stream and batch processing modes.
One of the key advantages of Dataflow is its autoscaling capability. When the workload increases, Dataflow automatically provisions additional resources to handle the load. Conversely, when the workload decreases, it scales down resources, ensuring you only pay for what you use. This is a significant cost-saving feature for businesses with fluctuating data processing needs.
Key Features of GCP Dataflow
Unified Programming Model: Dataflow utilizes the Apache Beam SDK, which provides a consistent programming model for stream and batch processing. Developers can write their code once and execute it across different environments, including Dataflow.
Autoscaling: Dataflow automatically scales the number of workers based on the current workload, reducing manual intervention and optimizing resource utilization.
Dynamic Work Rebalancing: This feature ensures that workers are dynamically assigned tasks based on load, helping to maintain efficient pipeline execution, especially during real-time data processing.
Fully Managed: Dataflow is fully managed, meaning you don’t have to worry about infrastructure, maintenance, or performance tuning. GCP handles the heavy lifting of managing resources, freeing up time to focus on building and optimizing pipelines.
Integration with GCP Services: Dataflow integrates seamlessly with other Google Cloud services such as BigQuery for data warehousing, Cloud Pub/Sub for messaging and ingestion, and Cloud Storage for scalable storage. This tight integration ensures that data flows smoothly between different stages of the processing pipeline.
Comparison with Other GCP Services
While Dataflow is primarily used for processing and analyzing streaming and batch data, other GCP services also support similar functionalities. For example, Cloud Dataproc is another option for data processing, but it’s specifically designed for running Apache Hadoop and Apache Spark clusters. BigQuery, on the other hand, is a data warehousing service but can also perform real-time analytics on large datasets.
In comparison, GCP Dataflow is more specialized for streamlining data processing tasks with minimal operational overhead. It provides a superior balance of ease of use, scalability, and performance, making it ideal for both developers and data engineers who need to build ETL pipelines, real-time data analytics solutions, and other complex data processing workflows
3. Data Flow Architecture in GCP
Key Components of Dataflow Architecture
The architecture of GCP Dataflow is optimized for flexibility, scalability, and efficiency in processing both streaming and batch data. The key components in a Dataflow architecture include:
Pipeline: A pipeline represents the entire data processing workflow. It is composed of various steps, such as transformations, filters, and aggregations, that process data from source to destination.
Workers: These are virtual machines provisioned by Dataflow to execute the tasks defined in the pipeline. Workers process the data in parallel, allowing for faster and more efficient data handling. GCP Dataflow automatically scales the number of workers based on the complexity and size of the job.
Sources: The origin of the data being processed. This can be Cloud Pub/Sub for real-time streaming data or Cloud Storage for batch data.
Transforms: These are the steps in the pipeline where data is manipulated. Common transforms include filtering, mapping, grouping, and windowing.
Sinks: The destination for the processed data. This can be BigQuery, Cloud Storage, or any other supported output service. Sinks are where the final processed data is stored for analysis or further use.
How Dataflow Works in GCP
GCP Dataflow simplifies data pipeline management by taking care of the underlying infrastructure, autoscaling, and resource allocation. The process of setting up and running a data pipeline on Dataflow typically follows these steps:
Pipeline Creation: A pipeline is created using the Apache Beam SDK, which provides a unified model for both batch and stream data processing. Developers define a pipeline using a high-level programming interface that abstracts away the complexity of distributed processing.
Ingesting Data: The pipeline starts by ingesting data from sources like Cloud Pub/Sub for streaming data or Cloud Storage for batch data. GCP Dataflow can handle both structured and unstructured data formats, making it versatile for different use cases.
Applying Transformations: Dataflow pipelines apply a series of transformations to the ingested data. These transformations can include data filtering, aggregation, joining datasets, and more. For example, you might filter out irrelevant data or aggregate sales data based on location and time.
Processing the Data: Once the pipeline is set, Dataflow provisions the necessary resources and begins executing the tasks. It automatically scales up resources when data volume increases and scales down when the load decreases, ensuring efficient resource usage.
Outputting Data: After processing, the transformed data is written to its final destination, such as a BigQuery table for analytics, Cloud Storage for long-term storage, or even external databases. Dataflow supports multiple sink types, which makes it easy to integrate with other systems in your architecture.
Understanding Apache Beam in Dataflow
Apache Beam is an open-source, unified programming model for defining both batch and stream data processing pipelines. Beam serves as the foundation for GCP Dataflow, enabling users to write pipelines that can be executed across multiple environments (including Dataflow, Apache Flink, and Apache Spark).
Key concepts of Apache Beam used in GCP Dataflow pipelines:
PCollections: This is a distributed data set that represents the data being processed by the pipeline. PCollections can hold both bounded (batch) and unbounded (stream) data.
Transforms: Operations that modify PCollections, such as filtering or grouping elements.
Windowing: A technique for segmenting unbounded data streams into discrete chunks based on time. This is particularly useful for stream processing, as it allows for timely analysis of real-time data.
Triggers: Controls when windowed results are output based on event time or data arrival.
By leveraging Apache Beam, developers can write pipelines once and execute them in multiple environments, allowing for greater flexibility and easier integration.
4. Stream Processing with GCP Dataflow
What is Stream Processing?
Stream processing refers to the real-time analysis and processing of data as it is generated. Unlike batch processing, which processes data in chunks at scheduled intervals, stream processing analyzes data continuously as it arrives. This capability is particularly useful for applications that require immediate responses to new information, such as real-time analytics, fraud detection, or dynamic pricing models.
Stream Processing in GCP Dataflow allows users to build pipelines that handle unbounded data streams. This means that data flows into the pipeline continuously, and the processing happens in near real-time. GCP Dataflow's ability to manage low-latency processing and dynamically scale resources based on data volume makes it an ideal tool for stream processing applications.
Implementing Stream Processing on Dataflow
Stream processing in GCP Dataflow can be implemented using the Apache Beam SDK, which supports stream data sources like Cloud Pub/Sub. Here's how stream processing works in Dataflow:
Data Ingestion: Data from real-time sources such as IoT devices, social media platforms, or transaction systems is ingested through Cloud Pub/Sub. These sources continuously produce data, which needs to be processed immediately.
Windowing and Aggregation: In stream processing, it’s common to group data into windows based on time. For example, you might group all transactions within a 5-minute window for real-time sales reporting. Windowing allows Dataflow to create discrete chunks of data from an otherwise continuous stream, facilitating easier analysis and aggregation.
Transformation and Filtering: Streamed data is often noisy or contains irrelevant information. Dataflow pipelines apply transformations to clean, filter, and aggregate data in real-time. For example, you can filter out irrelevant logs from a monitoring system or aggregate clicks on a website by geographical location.
Real-Time Analytics: Processed data can be sent to real-time analytics systems like BigQuery. This enables businesses to gain immediate insights, such as detecting fraudulent transactions or generating marketing insights from user behavior on a website.
Advantages of Stream Processing in Dataflow
Real-Time Decision Making: With stream processing, businesses can react to events as they happen. This is crucial for applications like fraud detection, stock market analysis, and IoT monitoring, where quick decisions are essential.
Scalability: Dataflow automatically scales up or down based on the volume of incoming data. This ensures that your pipeline remains performant even as data volumes spike.
Unified Programming Model: Since Dataflow is built on Apache Beam, you can use the same codebase for both stream and batch processing. This simplifies development and reduces maintenance overhead.
5. Batch Processing with GCP Dataflow
What is Batch Processing?
Batch processing is the processing of a large volume of data in a scheduled, defined period. Unlike stream processing, which handles unbounded, continuous data, batch processing deals with bounded data sets that are processed in chunks. This approach is useful for tasks like ETL (Extract, Transform, Load), where data is processed periodically rather than continuously.
Batch processing pipelines in GCP Dataflow allow you to handle large-scale data transformations efficiently, whether for periodic reporting, aggregating data from multiple sources, or building machine learning models. The batch processing mode is especially suited for workloads that do not require real-time processing but need to handle vast amounts of data.
Implementing Batch Jobs on Dataflow
Batch processing in Dataflow involves reading data from sources such as Google Cloud Storage, processing it with the desired transformations, and then outputting the results to a destination like BigQuery or another storage solution. Here's a typical workflow:
Data Ingestion: For batch jobs, data is typically read from static sources such as Cloud Storage or a database. For example, you might pull in a week's worth of sales data for analysis.
Transformation: The batch data is then processed using various transformations defined in the pipeline. These might include filtering out irrelevant data, joining multiple datasets, or performing aggregations such as calculating the total sales for each region.
Batch Execution: Dataflow processes the batch job and automatically provisions the necessary resources based on the size of the dataset. Since batch jobs typically involve processing large datasets at once, Dataflow’s ability to scale workers to meet the workload demands is critical.
Output to Sink: After the data has been processed, the results are written to the designated sink, such as a BigQuery table for analysis or Cloud Storage for long-term storage.
Advantages of Batch Processing in Dataflow
Cost Efficiency: Since batch jobs are processed periodically, resources are only used when necessary, making batch processing a cost-effective solution for tasks like reporting, ETL, and data aggregation.
Scalability: Dataflow handles large-scale batch jobs efficiently by scaling resources to process large volumes of data without impacting performance.
Integration with Other GCP Services: Like stream processing, batch processing in Dataflow integrates seamlessly with BigQuery, Cloud Storage, and other GCP services, enabling you to build robust data pipelines.
6. Key Use Cases for Dataflow in GCP
GCP Dataflow is a versatile service with applications across various industries and use cases. By offering real-time stream processing and scalable batch processing, it provides critical infrastructure for modern data-driven organizations. Here are some key use cases where Dataflow in GCP excels:
Real-Time Analytics
In today's fast-paced business environment, gaining insights from data as soon as it's generated is essential. Real-time analytics enables companies to respond to events and make data-driven decisions immediately. Dataflow's stream processing capabilities make it an ideal choice for real-time analytics pipelines.
Marketing and Customer Engagement: In digital marketing, real-time analytics can be used to track user behavior and engagement in real-time. For example, e-commerce websites can use Dataflow to process clickstream data, track customer interactions, and make instant product recommendations or personalized offers based on user behavior.
Fraud Detection: Financial institutions rely heavily on real-time data processing to detect fraud. Dataflow can process financial transactions as they happen, analyze patterns for anomalies, and trigger alerts if suspicious activities are detected. The low-latency nature of Dataflow stream processing ensures that businesses can act on fraudulent activities in real-time.
IoT Analytics: The Internet of Things (IoT) generates massive amounts of data from connected devices, often requiring real-time analysis. GCP Dataflow can ingest and process this data from devices such as sensors, wearables, and industrial machines, enabling real-time monitoring, predictive maintenance, and anomaly detection.
ETL (Extract, Transform, Load) Pipelines
ETL pipelines are a fundamental part of data engineering, enabling organizations to move data from various sources, transform it into a usable format, and load it into a data warehouse or other destination. GCP Dataflow simplifies the ETL process, making it easy to build pipelines that scale with your data needs.
Data Warehousing: Dataflow can be used to extract data from different sources, transform it by cleansing and aggregating the data, and load it into BigQuery for analysis. For example, an organization might collect sales data from various regional databases and then use Dataflow to aggregate and load this data into a central data warehouse for reporting and analysis.
Data Transformation: As part of the ETL process, GCP Dataflow can perform complex data transformations, such as joining datasets, filtering out irrelevant data, or applying machine learning models to enrich the data before it is loaded into the destination system.
Data Migration: For companies moving to the cloud, GCP Dataflow can be a key tool for migrating large datasets from on-premises systems to the cloud. Whether it's migrating data from legacy databases to Google Cloud Storage or BigQuery, Dataflow ensures smooth and efficient data transfers.
Data Lakes and Warehousing
A data lake is a storage repository that holds vast amounts of raw data in its native format, while a data warehouse stores structured, processed data that can be queried for business insights. Dataflow plays a vital role in the creation and management of both data lakes and data warehouses within GCP.
Data Lakes: Dataflow can process large volumes of raw, unstructured data and store it in Cloud Storage, creating a data lake that can be used for future data exploration and analytics. This allows businesses to store data at scale without the need for immediate structure or format.
Data Warehousing: BigQuery is GCP’s fully-managed, scalable data warehouse, and GCP Dataflow can act as a powerful ETL tool to load structured and transformed data into BigQuery. For example, Dataflow might be used to preprocess transactional data before loading it into BigQuery for real-time analytics.
Machine Learning Pipelines
Machine learning models often require vast amounts of historical data for training and real-time data for continuous learning and inference. GCP Dataflow is ideal for building machine learning data pipelines, whether it’s for preprocessing data for model training or applying real-time models to incoming data.
Preprocessing Data for ML Models: Dataflow can be used to cleanse, transform, and prepare raw data for training machine learning models in AI Platform or Vertex AI. For instance, you might use Dataflow to normalize and structure data before feeding it into a model to predict customer churn.
Real-Time Predictions: Once a machine learning model is deployed, Dataflow can ingest real-time data from Cloud Pub/Sub, run predictions using the trained model, and output the results to BigQuery or another storage system. This enables businesses to make predictions based on incoming data, such as recommending products in real-time or detecting anomalies in IoT sensor data.
7. Best Practices for Using Dataflow in GCP
To get the most out of GCP Dataflow, there are several best practices to consider when building and managing your data pipelines:
Optimizing Dataflow Pipelines
Efficiency is key when designing Dataflow pipelines to minimize costs and ensure optimal performance. Here are some tips for optimizing your pipelines:
Avoid Large Batches in Stream Processing: When processing real-time data streams, it's important to avoid waiting too long before processing data (i.e., accumulating large batches). Use smaller time windows to ensure timely processing and to avoid latency issues.
Use Windowing for Stream Processing: For streaming data, windowing is an essential tool to group unbounded data into discrete chunks. Use appropriate windowing strategies (e.g., fixed windows, sliding windows, or session windows) depending on your use case. For example, session windows are great for tracking user activity on a website over a period of time.
Efficient Data Partitioning: When working with batch jobs, partition your data properly to ensure that each worker processes a reasonable chunk of data. This avoids hotspots where certain workers are overloaded while others are idle.
Security and Compliance
Data security is critical when dealing with sensitive information, and GCP Dataflow provides several features to ensure data privacy and regulatory compliance:
Encryption: All data processed by GCP Dataflow is encrypted at rest and in transit by default. For sensitive data, ensure that you configure custom encryption keys to meet your organization's security standards.
Compliance: GCP Dataflow is compliant with several regulatory standards, including GDPR, HIPAA, and SOC 2. When building data pipelines that process personal data, ensure that your pipeline adheres to these regulations and implements data masking, tokenization, or other privacy-enhancing techniques.
Scaling and Performance Tuning
GCP Dataflow automatically scales to accommodate your data processing needs, but there are a few things you can do to improve performance:
Autoscaling: By default, Dataflow uses autoscaling to adjust the number of workers based on workload. However, in cases where you have a predictable workload, you can manually adjust the number of workers to optimize performance and reduce costs.
Worker Selection: Dataflow allows you to choose different machine types for your workers, depending on your workload. If you're processing large datasets with intensive transformations, consider using higher-tier machine types to improve performance.
Fusion Optimization: Dataflow applies a technique called fusion to combine steps in a pipeline where possible, reducing the overhead of processing multiple steps separately. Make sure that your pipeline is structured in a way that allows Dataflow to apply fusion optimally.
8. Dataflow Pricing in GCP
How GCP Dataflow Pricing Works
GCP Dataflow pricing is based on the resources used by the pipeline, including the number of vCPU, memory, and storage required for the processing tasks. The cost structure involves:
Compute Time: The primary cost comes from the compute resources (i.e., vCPU and memory) used by the workers in your pipeline. You’re charged based on the amount of time your workers are active.
Data Processing Volume: If you are working with large volumes of data, the amount of data processed by the workers also influences the cost.
Autoscaling and Optimization: Since Dataflow supports autoscaling, you only pay for the resources you use, ensuring cost-efficiency for varying workloads. Optimizing pipelines and reducing unnecessary data processing steps can lead to cost savings.
Comparing Costs with Other GCP Services
Compared to other data processing services in GCP, such as Cloud Dataproc or BigQuery, Dataflow offers flexibility for stream and batch processing with real-time autoscaling and advanced data transformations. While BigQuery is more suitable for structured data warehousing tasks, Dataflow excels at building dynamic data pipelines, especially for ETL jobs and real-time streaming applications.
Cost Optimization Strategies
To reduce costs while using GCP Dataflow, consider the following strategies:
Use Preemptible Workers: For batch jobs that can tolerate interruptions, you can use preemptible VMs, which cost significantly less than standard VMs.
Optimize Pipeline Steps: Ensure that your pipeline is optimized to reduce the amount of data that needs to be processed, thereby reducing compute and storage costs.
Batch Processing for Large Jobs: If real-time processing is not required, consider using batch processing instead of streaming. Batch jobs tend to be less resource-intensive and can be scheduled during off-peak hours to further save costs.
9. Alternatives to GCP Dataflow
While GCP Dataflow is a powerful and flexible solution for real-time stream processing and batch data pipelines, other alternatives exist in the data processing landscape. Here, we explore some of the top alternatives to Dataflow, focusing on their features, pros, and cons.
1. Apache Spark on Dataproc
Apache Spark is a popular open-source distributed data processing engine known for its speed and ease of use in big data workloads. When deployed on Google Cloud Dataproc, Spark becomes a compelling alternative to Dataflow.
Key Features:
Provides in-memory data processing, making it suitable for high-performance data analytics.
Supports a wide range of data types, including structured, unstructured, and semi-structured data.
Integrates seamlessly with Hadoop, Hive, and other big data ecosystems.
Supports batch, real-time (through Spark Streaming), and machine learning workflows.
Pros:
In-memory processing offers higher speed than disk-based alternatives.
Broad community support and extensive libraries.
Flexibility to handle diverse workloads, including streaming, batch, machine learning, and SQL queries.
Cons:
Requires more hands-on management, including cluster provisioning and resource optimization.
Lacks the autoscaling capabilities of Dataflow, meaning resource allocation needs to be managed more carefully.
Stream processing in Spark Streaming is often less efficient compared to Dataflow’s native streaming capabilities.
2. Amazon Kinesis
Amazon Kinesis is a fully managed service on AWS designed for real-time data streaming. It is a strong alternative for organizations already using AWS services and looking for real-time data processing capabilities.
Key Features:
Kinesis enables real-time data ingestion from various sources, such as IoT devices, logs, and application events.
Supports integration with other AWS services like Lambda, S3, and Redshift for further data processing and analysis.
Offers Kinesis Data Analytics for real-time analytics on streaming data using SQL queries.
Pros:
Seamless integration with the AWS ecosystem.
Optimized for real-time, low-latency processing.
Managed service, removing the burden of infrastructure management.
Cons:
Less flexibility for complex transformations compared to Dataflow.
Pricing models can become costly for high-throughput data streams.
Lacks a unified framework for handling both batch and streaming pipelines like Dataflow provides with Apache Beam.
3. Azure Stream Analytics
Azure Stream Analytics is a real-time analytics service offered by Microsoft Azure. It is designed for low-latency stream processing and is often used for IoT applications, real-time analytics, and anomaly detection.
Key Features:
Integrates well with Azure IoT Hub, Event Hubs, and other Azure services for real-time data ingestion.
Offers SQL-based query language, allowing users to write real-time queries easily.
Built-in machine learning models for tasks such as predictive analytics and anomaly detection.
Pros:
Easy integration with other Azure services, making it ideal for organizations using the Azure cloud ecosystem.
Managed service with auto-scaling and fault-tolerance built-in.
Streamlined user experience with a simple SQL-like query language for real-time processing.
Cons:
Limited flexibility in terms of complex data transformations and processing compared to Dataflow and Apache Beam.
Batch processing capabilities are not as robust, making it less suitable for workloads that require both batch and stream processing.
4. Apache Flink
Apache Flink is another open-source stream processing framework with advanced features for real-time, stateful computation. Flink is known for its performance in low-latency processing and support for complex event processing (CEP).
Key Features:
Supports true low-latency, real-time stream processing.
Offers event time processing, making it ideal for use cases where the timing of events is critical (e.g., IoT and financial transactions).
Stateful processing capabilities allow for complex event pattern recognition and real-time decision making.
Pros:
Best-in-class stream processing with stateful processing and event time handling.
Flexible support for both batch and stream processing.
High fault tolerance through distributed checkpoints.
Cons:
More complex to set up and manage compared to Dataflow, requiring manual provisioning of infrastructure.
Less user-friendly for developers new to stream processing.
Smaller community compared to Apache Spark and Beam.
5. Apache NiFi
Apache NiFi is a data flow management system that provides an intuitive interface for designing data pipelines. It is especially useful for managing complex, distributed data flows, often across hybrid cloud and on-premise environments.
Key Features:
Provides a visual, drag-and-drop interface for building data pipelines.
Ideal for data ingestion from multiple sources, including IoT devices, web servers, and databases.
Supports both stream and batch processing, with real-time monitoring of data flows.
Pros:
User-friendly, making it accessible to non-developers.
Flexible, allowing for complex routing, transformation, and integration of data across multiple environments.
Well-suited for hybrid cloud and multi-cloud environments.
Cons:
While NiFi is powerful for managing data flows, it is not optimized for high-throughput data processing tasks like Dataflow or Spark.
Stream processing capabilities are limited in comparison to dedicated stream processing systems like Flink or Dataflow.
10. Conclusion
In conclusion, GCP Dataflow is a robust, flexible, and scalable tool for processing both real-time streaming and batch data. With its integration with Apache Beam, Dataflow provides a unified model that allows developers to write pipelines once and execute them across both batch and streaming environments, greatly simplifying the process of managing complex data workflows.
For real-time data processing, Dataflow's stream processing capabilities, combined with tools like Cloud Pub/Sub, offer low-latency, scalable solutions for use cases such as real-time analytics, IoT monitoring, and fraud detection. On the batch processing side, Dataflow provides an efficient way to handle large-scale ETL jobs, data aggregation, and data warehousing tasks, integrating seamlessly with services like BigQuery and Cloud Storage.
While GCP Dataflow excels in many areas, it’s important to weigh it against other tools in the market, such as Apache Spark, Amazon Kinesis, and Azure Stream Analytics. Each of these alternatives has its own strengths and weaknesses, and the choice of tool will depend on your specific use case, cloud provider, and data processing needs.
By following best practices in pipeline optimization, scaling, and security, you can maximize the value of your Dataflow pipelines while keeping costs under control. Additionally, with the built-in autoscaling and fault tolerance features of GCP Dataflow, businesses can ensure that their data pipelines remain resilient and performant even as workloads fluctuate.
In an era where data is increasingly seen as the lifeblood of modern organizations, tools like GCP Dataflow enable companies to harness the power of both real-time and historical data to drive insights, optimize operations, and deliver more value to customers. Whether you are building ETL pipelines, analyzing real-time data streams, or developing machine learning models, GCP Dataflow provides the infrastructure and flexibility needed to meet today’s data challenges. GCP Masters is the best training institute in Hyderabad.
1 note
·
View note
Text
DevSecOps Flow: Integrating Security in Every Step of the Development Pipeline
As organizations increasingly adopt digital transformation and cloud-native technologies, the demand for secure, rapid, and efficient software development processes has never been more critical. This is where DevSecOps plays a pivotal role. DevSecOps involves the integration of security into every phase of the DevOps pipeline, ensuring that applications are constructed, tested, and deployed with security as a primary focus. In an era marked by rising cyber threats, it is imperative that security is considered not merely as an afterthought but as an essential component of the development process.
This blog will delve into the DevSecOps flow, elucidating how security can be seamlessly integrated throughout the development lifecycle, from code creation to production deployment.
What is DevSecOps?
DevSecOps represents the integration of Development, Security, and Operations. It is a culture and practice that incorporates security checks and protocols into the traditional DevOps workflow. The primary objective is to ensure that security considerations are addressed early and continually throughout the software development lifecycle (SDLC), rather than postponing them until after development is completed.
Historically, security measures were often applied as a final checkpoint prior to release, a practice that frequently resulted in delays, vulnerabilities, and increased costs. By shifting security left—closer to the beginning of the development process—DevSecOps enables teams to identify and mitigate risks before they escalate into significant issues.
Key Phases of the DevSecOps Flow
Planning and Design
During the planning phase, security considerations begin with the application's design. This involves defining security requirements, comprehending compliance needs, and performing risk assessments. Security teams collaborate closely with developers and operations teams to identify potential threats and vulnerabilities at an early stage.
Threat modeling is frequently employed in this phase to analyze possible attack vectors and establish measures to protect the application architecture.
2. Code Development
During the development phase, security practices are seamlessly integrated into the coding process. Developers are encouraged to write code with security best practices in mind, adhering to secure coding guidelines to mitigate common vulnerabilities such as SQL injection and cross-site scripting (XSS).
Static Application Security Testing (SAST) tools play a crucial role in scanning the code for vulnerabilities as it is being written, providing developers with immediate feedback to rectify security issues prior to code commitment.
3. Build and Continuous Integration (CI)
Once the code is completed, it transitions into the build phase of the pipeline. At this stage, automated security tests are executed as part of the Continuous Integration (CI) process. These tests encompass automated static analysis, dependency checking, and unit testing to ensure the application is devoid of vulnerabilities and adheres to security policies.
Effective dependency management is vital at this juncture, as many security vulnerabilities arise from third-party libraries. Tools like OWASP Dependency-Check are employed to scan dependencies for known vulnerabilities.
3. Testing and Continuous Testing (CT)
The testing phase introduces Dynamic Application Security Testing (DAST) and Interactive Application Security Testing (IAST). These assessments evaluate the running application for security concerns, including misconfigurations, improper authentication, and unauthorized data access.
Security testing is conducted not only in isolated environments but also throughout the CI/CD pipeline, allowing for the identification of real-world vulnerabilities that could impact production. Penetration testing and fuzz testing are also utilized to simulate malicious attacks and uncover weaknesses.
4. Release and Continuous Delivery (CD)
In the release phase, security is verified one final time before the application is deployed. Security gates are integrated into the Continuous Delivery (CD) pipeline to ensure that the application satisfies all security requirements prior to deployment.
Should critical vulnerabilities be identified, the release process is halted until these issues are resolved. Automating this step guarantees that no vulnerable code is deployed into production, thereby enhancing the organization's overall security posture.
5. Deployment and Continuous Monitoring
Once deployed, security efforts continue unabated. Continuous monitoring tools such as AWS CloudWatch, Prometheus, and Splunk are utilized to detect any anomalous behavior, potential breaches, or policy violations in real time.
Runtime Application Self-Protection (RASP) technologies may be implemented to provide real-time defenses against attacks. By monitoring the application during runtime, these tools assist in detecting and blocking suspicious activities.
6. Feedback and Incident Response
The final phase of the DevSecOps flow focuses on collecting feedback from monitoring systems and incorporating it back into the development cycle. If any security incidents or vulnerabilities are detected, an immediate response is initiated to address them.
Incident response plans are established to ensure that teams can react swiftly to breaches or vulnerabilities. Post-mortem analyses are conducted to ascertain the root cause of any security issues and to implement measures that prevent recurrence.
Benefits of DevSecOps
Accelerated Time to Market with Security Assurance
By incorporating security measures at every stage, DevSecOps facilitates quicker development cycles without compromising security. Automated security testing detects vulnerabilities early, thereby minimizing delays associated with last-minute fixes.
2. Decreased Risk of Breaches
Proactive detection and continuous monitoring significantly lower the likelihood of breaches. By integrating security practices throughout the development lifecycle, organizations can effectively prevent the exploitation of vulnerabilities.
3. Cost Efficiency
Addressing security vulnerabilities during the development phase is considerably more cost-effective than rectifying them post-deployment. DevSecOps aids in reducing technical debt and lessening the financial ramifications of security incidents.
4. Regulatory Compliance
DevSecOps ensures that applications adhere to security and compliance standards, which are vital for industries such as finance, healthcare, and e-commerce. By automating security checks, organizations can effortlessly maintain compliance.
Conclusion
DevSecOps represents the future of secure software development, merging development, security, and operations into a cohesive process. By integrating security practices early in the DevOps pipeline, organizations can create robust, secure applications that withstand modern cyber threats. As businesses increasingly embrace cloud-native technologies and expedite their development cycles, DevSecOps becomes essential for preserving security while fostering speed and innovation.
0 notes
Text
Sun Technologies DevOps-As-A-Service and Testing Centers of Excellence (CoE)

Here’s how we are helping top Fortune 500 Companies to automate application testing & CI/CD: Build, Deploy, Test & Commit.
Powering clients with the right DevOps talent for the following: Continuous Development | Continuous Testing | Continuous Integration|Continuous Delivery | Continuous Monitoring
How Our Testing and Deployment Expertise Ensures Zero Errors
Test
Dedicated Testing Team: Prior to promoting changes to production, the product goes through a series of automated vulnerability assessments and manual tests
Proven QA Frameworks: Ensures architectural and component level modifications don’t expose the underlying platform to security weaknesses
Focus on Security: Design requirements stated during the Security Architecture Review are validated against what was built
Deploy
User-Acceptance Environments: All releases first pushed into user-acceptance environments and then, when it’s ready, into production
No-Code Release Management: Supports quick deployment of applications by enabling non-technical Creators and business users
No-Code platform orientation and training: Helps release multiple deploys together, increasing productivity while reducing errors
Our approach to ensure seamless deployments at scale
Testing Prior to Going Live: Get a secure place to test and prepare major software updates and infrastructural changes.
Creating New Live Side: Before going all in, we will first make room to test changes on small amounts of production traffic.
Gradual Deployments at Scale: Rolls deployment out to production by gradually increasing the percentage served to the new live side.
Arriving at the best branching and version control strategy that delivers the highest-quality software quickly and reliably?
Discovery assessment to evaluate existing branching strategies: Git Flow, GitHub Flow, Trunk-Based Development, GitLab Flow
Sun DevOps teams use a library that allows developers to test their changes: For example, tested in Jenkins without having to commit to trunk.
Sun’s deployment team uses a one-button web-based deployment: Makes code deployment as easy and painless as possible.
The deployment pipeline passes through our staging environment: Before going into production. It uses data stores, networks, and production resources.
Config flags (feature flags) are an integral part of our deployment process: Leverages an internal A/B testing tool and API builder to test new features.
New features are made live for a certain percentage of users: We will understand its behavior before making it live on a global scale.
Case Study: How Sun Technologies helped CI/CD Pipelines Implementation for a Leading Bank of USA
Customer Challenges:
Legacy Systems: The bank grappled with legacy systems and traditional software development methodologies, hindering agility and slowing down the delivery of new features and updates.
Regulatory Compliance: The financial industry is highly regulated, requiring strict adherence to compliance standards and rigorous testing processes, which often led to delays in software releases.
Customer Expectations: With the rise of digital banking and fintech startups, customers increasingly expect seamless and innovative banking experiences. The bank faced pressure to meet these expectations while ensuring the security and reliability of its software systems.
Our Solution:
Automated Build and Integration: Automated the build and integration process to trigger automatically upon code commits, ensuring that new features and bug fixes are integrated and tested continuously.
Automated Testing: Integrated automated testing into the pipeline, including unit tests, integration tests, and security tests, to detect and address defects early in the development cycle and ensure compliance with regulatory standards.
Continuous Deployment: Implemented continuous deployment to automate the deployment of validated code changes to production and staging environments, reducing manual effort and minimizing the risk of deployment errors.
Monitoring and Logging: Integrated monitoring and logging tools into the pipeline to track performance metrics, monitor system health, and detect anomalies in real-time, enabling proactive problem resolution and continuous improvement
Compliance and Security Checks: Incorporated security scanning tools and compliance checks into the pipeline to identify and remediate security vulnerabilities and ensure compliance with regulatory requirements before software releases
Tools and Technologies Used:
Jenkins, Bitbucket, Jfrog Artifactory, Sonarqube, Ansbile,Vault
Engagement Highlights:
Employee Training and Adoption: The bank invested in comprehensive training programs to upskill employees on CI/CD practices and tools, fostering a culture of continuous learning and innovation.
Cross-Functional Collaboration: The implementation of DevOps practices encouraged collaboration between development, operations, and security teams, breaking down silos and promoting shared ownership of software delivery and quality.
Feedback and Improvement Loop: The bank established feedback mechanisms to gather input from stakeholders, including developers, testers, and end-users, enabling continuous improvement of the CI/CD pipeline and software development processes
Impact:
Accelerated Delivery: CI/CD pipelines enabled swift deployment of new features, keeping the bank agile and competitive.
Enhanced Quality: Automated testing and integration processes bolstered software quality, reducing errors and boosting satisfaction.
Improved Security and Compliance: Integrated checks ensured regulatory adherence, fostering trust with customers and regulators.
Cost Efficiency: Automation curtailed manual tasks, slashing costs and optimizing resources.
Competitive Edge: CI/CD adoption facilitated innovation and agility, positioning the bank as a market leader.
0 notes
Text
Unlocking Precision: The Power of 3D Laser Scanning
In today’s world of advanced technology, 3D laser scanning has become an indispensable tool across multiple industries. From construction and architecture to manufacturing and heritage preservation, this cutting-edge technology allows for detailed and accurate digital representations of objects and environments. In this article, we will delve into the fundamentals of 3D laser scanning, its applications, and how it is transforming various sectors by enhancing precision, efficiency, and overall productivity.

What is 3D Laser Scanning?
3D laser scanning is a process that captures the shape of physical objects or environments through laser beams. The technology operates by emitting laser pulses towards a surface and measuring the time it takes for the laser to bounce back. The result is a collection of data points, known as a point cloud, that forms a precise 3D representation of the scanned object or area.
The scanners can capture intricate details, from the complex textures of small objects to expansive environments like construction sites or entire buildings. Unlike traditional surveying methods, 3D laser scanning is fast, non-intrusive, and highly accurate, making it a go-to solution for many industries seeking exact measurements.
Key Applications of 3D Laser Scanning
Architecture and Construction
One of the most significant applications of 3D laser scanning is in the field of architecture and construction. The technology is used to create highly accurate digital models of buildings, construction sites, and other structures. These models assist architects, engineers, and construction teams in design, planning, and renovation processes. By scanning existing conditions, teams can reduce errors, ensure precise alignment, and avoid costly rework.
Moreover, construction sites benefit from continuous monitoring through 3D laser scans, allowing project managers to track progress, inspect quality, and ensure adherence to design plans. It also helps identify any discrepancies between the actual site and design models, reducing delays.
Manufacturing and Quality Control
In manufacturing, precision is critical, especially when dealing with complex parts and systems. 3D laser scanning helps manufacturers assess whether components meet design specifications by comparing them to digital models. It is also widely used in reverse engineering, where existing parts or products are scanned to create a 3D model for reproduction or modification.
Quality control processes also benefit from 3D laser scanning, as it allows for the detection of defects, deformities, or inconsistencies in products. This ensures that only high-quality components make it to market.
Heritage Preservation
For historical preservation, 3D laser scanning plays a vital role in documenting and conserving cultural heritage. This technology enables precise digital reconstructions of ancient structures, artifacts, and monuments, many of which may be at risk of deterioration due to time or environmental factors. The scanned models can be used for restoration projects, virtual exhibitions, or educational purposes, ensuring that historical treasures are preserved for future generations.
Oil and Gas Industry
In the oil and gas sector, 3D laser scanning is used for plant and facility management, as well as maintenance. Detailed 3D scans of oil rigs, pipelines, and refineries help engineers plan upgrades or repairs while minimizing downtime and avoiding hazards. Additionally, the scans assist in monitoring the wear and tear of equipment, ensuring safety and compliance with regulations.
Benefits of 3D Laser Scanning
The advantages of 3D laser scanning go beyond its ability to produce accurate digital models. Its non-invasive nature ensures minimal disruption to the surrounding environment, whether it’s a bustling construction site or a delicate archaeological dig. The speed at which it captures data drastically reduces the time needed for surveys and inspections, making it a cost-effective solution in the long run.
Furthermore, 3d Laser Scan To Cad promotes better collaboration between different stakeholders by providing an exact visual reference, which can be shared digitally. This improves communication and reduces the likelihood of misunderstandings during project execution.
0 notes
Text
Observability data: Secret To Successful Data Integration

Data observability platforms
In the past, creating data pipelines has frequently taken precedence over thorough monitoring and alerting for data engineers. The timely and cost-effective completion of projects frequently took precedence over the long-term integrity of data. Subtle indicators like regular, inexplicable data spikes, slow performance decline, or irregular data quality are typically overlooked by data engineers.
These were perceived as singular occurrences rather than widespread problems. A larger picture becomes visible with improved Observability Data. Uncovered bottlenecks are exposed, resource allocation is optimized, data lineage gaps are found, and firefighting is eventually turned into prevention.
Data engineer
There weren’t many technologies specifically for Data observability accessible until recently. Data engineers frequently turned to creating unique monitoring solutions, which required a lot of time and resources. Although this method worked well in less complicated settings, Observability Data has become an essential part of the data engineering toolbox due to the growing complexity of contemporary data architectures and the growing dependence on data-driven decision-making.
It’s critical to recognize that things are shifting quickly in this situation. According to projections made by Gartner, “by 2026, up from less than 20% in 2024, 50% of enterprises implementing distributed data architectures will have adopted data observability tools toincrease awareness of the current status of the data landscape.”
Data observability is becoming more and more important as data becomes more crucial to company success. Data engineers are now making Observability Data a top priority and a fundamental part of their jobs due to the development of specialized tools and a rising realization of the costs associated with low-quality data.
what is data observability
The process of keeping an eye on and managing data to guarantee its availability, dependability, and quality throughout an organization’s many systems, pipelines, and processes is known as Observability Data. It gives teams a thorough insight of the condition and healthcare of the data, empowering them to see problems early and take preventative action.
Data observability vs Data quality
Dangers lurking in your data pipeline
The following indications indicate whether your data team requires a Observability Data tool:
The high frequency of inaccurate, inconsistent, or missing data can be ascribed to problems with data quality. Finding the source of the data quality problem becomes difficult, even if you can identify the problem. To help ensure data accuracy, data teams frequently need to adhere to a manual method.
Another clue could be long-term outages in data processing operations that keep happening. When data is inaccessible for protracted periods of time, it indicates problems with the reliability of the data pipeline, which undermines trust among downstream consumers and stakeholders.
Understanding data dependencies and relationships presents difficulties for data teams.
If you find yourself using a lot of manual checks and alarms and are unable to handle problems before they affect downstream systems, it may be time to look at observability tools.
The entire data integration process may become more challenging to manage if complex data processing workflows with several steps and a variety of data sources are not well managed.
Another warning flag could be trouble managing the data lifecycle in accordance with compliance guidelines and data privacy and security laws.
A Observability Data tool can greatly enhance your data engineering procedures and the general quality of your data if you’re having any of these problems. Through the provision of data pipeline visibility, anomaly detection, and proactive issue resolution, these technologies can assist you in developing more dependable and effective data systems.
Neglecting the indicators that suggest Observability Data is necessary might have a domino effect on an organization’s undesirable outcomes. Because certain effects are intangible, it might be difficult to accurately estimate these losses; however, they can identify important areas of potential loss.
Data inaccuracies can cause faulty business decisions, lost opportunities, and client attrition, costing money. False data can damage a company’s brand and customers’ trust in its products and services. Although they are hard to measure, the intangible effects on customer trust and reputation can have long-term effects.
Put observability first to prevent inaccurate data from derailing your efforts
Data observability gives data engineers the ability to become data stewards rather than just data movers. You are adopting a more comprehensive, strategic strategy rather than merely concentrating on the technical issues of transferring data from diverse sources into a consolidated repository. You may streamline impact management, comprehend dependencies and lineage, and maximize pipeline efficiency using observability. These advantages all contribute to improved governance, economical resource usage, and reduced expenses.
Data quality becomes a quantifiable indicator that is simple to monitor and enhance with Observability Data. It is possible to anticipate possible problems in your data pipelines and datasets before they become major ones. This methodology establishes a robust and effective data environment.
Observability becomes essential when data complexity increases because it helps engineers to create solid, dependable, and trustworthy data foundations, which ultimately speeds up time-to-value for the entire company. You may reduce these risks and increase the return on investment (ROI) of your data and AI initiatives by making investments in Observability Data.
To put it simply, data observability gives data engineers the ability to create and manage solid, dependable, and high-quality data pipelines that add value to the company.
Read more on govindhtech.com
#Observabilitydata#SuccessfulDataIntegration#datapipelines#Dataengineers#datasyste#datasets#data#DataPrivacy#DataSecurity#technology#Dataobservabilityplatforms#technews#news#govindhtech
0 notes
Text
Kubernetes Consulting Services | Streamlining Your Cloud-Native Journey

As businesses increasingly migrate to cloud-native environments, Kubernetes has emerged as the go-to solution for container orchestration. With its powerful capabilities to automate deployment, scaling, and management of containerized applications, Kubernetes helps organizations achieve agility, scalability, and resilience. However, implementing and managing Kubernetes can be complex, requiring specialized expertise and experience. This is where Kubernetes consulting services come in.
What Are Kubernetes Consulting Services?
Kubernetes consulting services provide businesses with expert guidance to effectively design, implement, and manage Kubernetes environments. These services help companies navigate the complexities of Kubernetes to optimize their cloud-native strategies, whether they are just starting with Kubernetes or looking to scale their existing infrastructure.
Key offerings in Kubernetes consulting services typically include:
Architecture Design and Implementation: Tailored guidance on designing and deploying Kubernetes clusters that align with your business requirements.
Security and Compliance: Ensuring your Kubernetes environment is secure and compliant with industry standards and regulations.
Performance Optimization: Fine-tuning Kubernetes deployments for maximum efficiency and performance, including monitoring and troubleshooting.
Migration Services: Seamless migration of applications from legacy systems or other container platforms to Kubernetes.
DevOps Integration: Integrating Kubernetes with your existing DevOps workflows and CI/CD pipelines to enhance automation and collaboration.
Why You Need Kubernetes Consulting Services
Accelerated Deployment: A Kubernetes consultant can expedite the deployment process, reducing time-to-market for your applications.
Cost Efficiency: By optimizing resources and minimizing misconfigurations, consulting services help in reducing operational costs associated with Kubernetes management.
Enhanced Security: Consultants ensure your Kubernetes clusters are set up with best-in-class security practices, protecting your data and applications.
Scalability and Flexibility: Expert guidance enables you to build a scalable Kubernetes architecture that adapts to changing business needs.
Continuous Support: Beyond initial deployment, consultants provide ongoing support to manage updates, troubleshoot issues, and optimize performance.
How Feathersoft Info Solutions Can Help
At feathersoft info solutions, we provide comprehensive Kubernetes consulting services to help you navigate the complexities of container orchestration. Our team of certified Kubernetes experts will work closely with your IT team to design, deploy, and manage a Kubernetes environment that aligns with your strategic objectives. We offer end-to-end services, from initial assessment and architecture design to ongoing support and optimization, ensuring your Kubernetes deployment is efficient, secure, and scalable.
Benefits of Choosing Feathersoft Info Solutions for Kubernetes Consulting
Tailored Solutions: We customize our approach to meet your unique business requirements and cloud strategy.
Expert Team: Our consultants are seasoned professionals with extensive experience in deploying and managing Kubernetes in diverse environments.
Proven Methodologies: We follow industry best practices to ensure your Kubernetes implementation is robust, secure, and compliant.
Continuous Support: Our services don’t end with deployment; we offer ongoing support to ensure your Kubernetes environment continues to perform optimally.
Conclusion
Kubernetes consulting services are essential for businesses looking to unlock the full potential of cloud-native technologies. By partnering with experts like feathersoft info solutions, you can ensure a smooth Kubernetes adoption, optimize performance, and stay ahead in today’s fast-paced digital landscape. Don’t let the complexities of Kubernetes slow down your innovation—invest in professional consulting services and accelerate your cloud-native journey.
#Kubernetes#CloudNative#DevOps#ContainerOrchestration#CloudComputing#KubernetesConsulting#ITConsulting#DigitalTransformation#Microservices#CloudStrategy#KubernetesSecurity#TechSolutions#CloudInfrastructure
0 notes
Text
Jason Knight is Co-founder and VP of ML at OctoAI – Interview Series
New Post has been published on https://thedigitalinsider.com/jason-knight-is-co-founder-and-vp-of-ml-at-octoai-interview-series/
Jason Knight is Co-founder and VP of ML at OctoAI – Interview Series
Jason Knight is Co-founder and Vice President of Machine Learning at OctoAI, the platform delivers a complete stack for app builders to run, tune, and scale their AI applications in the cloud or on-premises.
OctoAI was spun out of the University of Washington by the original creators of Apache TVM, an open source stack for ML portability and performance. TVM enables ML models to run efficiently on any hardware backend, and has quickly become a key part of the architecture of popular consumer devices like Amazon Alexa.
Can you share the inspiration behind founding OctoAI and the core problem you aimed to solve?
AI has traditionally been a complex field accessible only to those comfortable with the mathematics and high-performance computing required to make something with it. But AI unlocks the ultimate computing interfaces, that of text, voice, and imagery programmed by examples and feedback, and brings the full power of computing to everyone on Earth. Before AI, only programmers were able to get computers to do what they wanted by writing arcane programming language texts.
OctoAI was created to accelerate our path to that reality so that more people can use and benefit from AI. And people, in turn, can use AI to create yet more benefits by accelerating the sciences, medicine, art, and more.
Reflecting on your experience at Intel, how did your previous roles prepare you for co-founding and leading the development at OctoAI?
Intel and the AI hardware and biotech startups before it gave me the perspective to see how hard AI is for even the most sophisticated of technology companies, and yet how valuable it can be to those who have figured out how to use it. And seeing that the gap between those benefiting from AI compared to those who aren’t yet is primarily one of infrastructure, compute, and best practices—not magic.
What differentiates OctoStack from other AI deployment solutions available in the market today?
OctoStack is the industry’s first complete technology stack designed specifically for serving generative AI models anywhere. It offers a turnkey production platform that provides highly optimized inference, model customization, and asset management at an enterprise scale.
OctoStack allows organizations to achieve AI autonomy by running any model in their preferred environment with full control over data, models, and hardware. It also delivers unmatched performance and cost efficiency, with savings of up to 12X compared to other solutions like GPT-4.
Can you explain the advantages of deploying AI models in a private environment using OctoStack?
Models these days are ubiquitous, but assembling the right infrastructure to run those models and apply them with your own data is where the business-value flywheel truly starts to spin. Using these models on your most sensitive data, and then turning that into insights, better prompt engineering, RAG pipelines, and fine-tuning is where you can get the most value out of generative AI. But it’s still difficult for all but the most sophisticated companies to do this alone, which is where a turnkey solution like OctoStack can accelerate you and bring the best practices together in one place for your practitioners.
Deploying AI models in a private environment using OctoStack offers several advantages, including enhanced security and control over data and models. Customers can run generative AI applications within their own VPCs or on-premises, ensuring that their data remains secure and within their chosen environments. This approach also provides businesses with the flexibility to run any model, be it open-source, custom, or proprietary, while benefiting from cost reductions and performance improvements.
What challenges did you face in optimizing OctoStack to support a wide range of hardware, and how were these challenges overcome?
Optimizing OctoStack to support a wide range of hardware involved ensuring compatibility and performance across various devices, such as NVIDIA and AMD GPUs and AWS Inferentia. OctoAI overcame these challenges by leveraging its deep AI systems expertise, developed through years of research and development, to create a platform that continuously updates and supports additional hardware types, GenAI use cases, and best practices. This allows OctoAI to deliver market-leading performance and cost efficiency.
Additionally, getting the latest capabilities in generative AI, such as multi-modality, function calling, strict JSON schema following, efficient fine-tune hosting, and more into the hands of your internal developers will accelerate your AI takeoff point.
OctoAI has a rich history of leveraging Apache TVM. How has this framework influenced your platform’s capabilities?
We created Apache TVM to make it easy for sophisticated developers to write efficient AI libraries for GPUs and accelerators more easily. We did this because getting the most performance from GPU and accelerator hardware was critical for AI inference then as it is now.
We’ve since leveraged that same mindset and expertise for the entire Gen AI serving stack to deliver automation for a broader set of developers.
Can you discuss any significant performance improvements that OctoStack offers, such as the 10x performance boost in large-scale deployments?
OctoStack offers significant performance improvements, including up to 12X savings compared to other models like GPT-4 without sacrificing speed or quality. It also provides 4X better GPU utilization and a 50 percent reduction in operational costs, enabling organizations to run large-scale deployments efficiently and cost-effectively.
Can you share some notable use cases where OctoStack has significantly improved AI deployment for your clients?
A notable use case is Apate.ai, a global service combating telephone scams using generative conversational AI. Apate.ai leveraged OctoStack to efficiently run their suite of language models across multiple geographies, benefiting from OctoStack’s flexibility, scale, and security. This deployment allowed Apate.ai to deliver custom models supporting multiple languages and regional dialects, meeting their performance and security-sensitive requirements.
In addition, we serve hundreds of fine-tunes for our customer OpenPipe. Were they to spin up dedicated instances for each of these, their customers’ use cases would be infeasible as they grow and evolve their use cases and continuously re-train their parameter-efficient fine-tunes for maximum output quality at cost-effective prices.
Thank you for the great interview, readers who wish to learn more should visit OctoAI.
#accelerators#ai#ai inference#AI models#AI systems#alexa#Amazon#amd#Apache#app#applications#approach#architecture#Art#automation#AWS#biotech#Business#Cloud#Companies#computers#computing#conversational ai#cost efficiency#creators#data#deploying#deployment#developers#development
0 notes
Last Seen Blogs

living-the-dreampy
Lettore

letmeseethemtoesgirl
Untitled

whathehe11-writes
Whathehe11 Writes

houseofrumpus
house of rumpus

redeyezx
Untitled