#x scraper api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
🚀 Top 4 Twitter (X) Scraping APIs in 2025
Looking for the best way to scrape Twitter (X) data in 2025? This article compares 4 top APIs based on speed, scalability, and pricing. A must-read for developers and data analysts!
#web scraping#scrapingdog#web scraping api#twitter scraper#twitter scraper api#x scraper#x scraper api
0 notes
Text
Custom Manufacturing for Multi-Zone Wells in Indonesia’s Offshore Fields

Indonesia’s offshore oil and gas fields are increasingly exploring multi-zone well completions to maximize hydrocarbon recovery in deepwater and shelf basins. These operations require specialized tools that can ensure effective zonal isolation, resist corrosion, and optimize flow across complex reservoir sections. At Parveen Industries, we offer custom-manufactured equipment tailored for the country’s offshore needs.
Our multi-zone packers and retrievable seal bore packers are engineered for high-differential pressure and temperature environments common in Indonesia’s marine formations. These packers ensure precise sealing and allow for selective zone production and stimulation.
For reliable completions, our bridge plugs and cement retainers provide proven performance in high-salinity and H₂S-prone conditions, while equalizing valves maintain downhole pressure integrity and operational flexibility.
To address mechanical reliability in the harsh offshore environment, we supply non-magnetic drill collars and grooved drill collars, supporting optimal bottomhole assembly design and directional stability.
Our coil tubing equipment, including quad BOPs and tubing hangers, supports intervention operations with maximum safety and efficiency.
We also provide a full range of API 6A gate valves and wellhead & X-mas tree assemblies, all designed for harsh offshore pressures and temperatures. Modular wellhead parts, adapters, and casing head spools ensure compatibility with a wide range of Indonesian offshore wells.
For stimulation and flow control, Parveen offers rugged HFP Plug Valves and production testing tools, built to withstand high-pressure circulation and abrasive slurries.
We further support sand control with gravel pack tools and bore maintenance using casing scrappers and non-rotating casing scrapers, minimizing tool wear and improving operational life.
With decades of engineering excellence, Parveen Industries remains a trusted partner for Indonesia’s offshore development needs—delivering precision, performance, and production assurance.
0 notes
Text
How to Use a Twitter Scraper Tool Easily

Why Twitter Scraping Changed My Social Media Game
Let me share a quick story. Last year, I was managing social media for a small tech startup, and we were struggling to create content that resonated with our audience. I was spending 4–5 hours daily just browsing Twitter, taking screenshots, and manually tracking competitor posts. It was exhausting and inefficient.
That’s when I discovered the world of Twitter scraping tool, and honestly, it was a game-changer. Within weeks, I was able to analyze thousands of tweets, identify trending topics in our niche, and create data-driven content strategies that increased our engagement by 300%.
What Exactly is a Twitter Scraper Tool?
Simply put, a Twitter scraping tool is software that automatically extracts data from Twitter (now X) without you having to manually browse and copy information. Think of it as your personal digital assistant that works 24/7, collecting tweets, user information, hashtags, and engagement metrics while you focus on more strategic tasks.
These tools can help you:
Monitor brand mentions and sentiment
Track competitor activities
Identify trending topics and hashtags
Analyze audience behavior patterns
Generate leads and find potential customers
Finding the Best Twitter Scraper Online: My Personal Experience
After testing dozens of different platforms over the years, I’ve learned that the best twitter scraper online isn’t necessarily the most expensive one. Here’s what I look for when evaluating scraping tools:
Key Features That Actually Matter
1. User-Friendly Interface The first time I used a complex scraping tool, I felt like I needed a computer science degree just to set up a basic search. Now, I only recommend tools that my grandmother could use (and she’s not exactly tech-savvy!).
2. Real-Time Data Collection In the fast-paced world of Twitter, yesterday’s data might as well be from the stone age. The best tools provide real-time scraping capabilities.
3. Export Options Being able to export data in various formats (CSV, Excel, JSON) is crucial for analysis and reporting. I can’t count how many times I’ve needed to quickly create a presentation for stakeholders.
4. Rate Limit Compliance This is huge. Tools that respect Twitter’s API limits prevent your account from getting suspended. Trust me, I learned this the hard way.
Step-by-Step Guide: Using an X Tweet Scraper Tool
Based on my experience, here’s the easiest way to get started with any x tweet scraper tool:
Step 1: Define Your Scraping Goals
Before diving into any tool, ask yourself:
What specific data do I need?
How will I use this information?
What’s my budget and time commitment?
I always start by writing down exactly what I want to achieve. For example, “I want to find 100 tweets about sustainable fashion from the past week to understand current trends.”
Step 2: Choose Your Scraping Parameters
Most tweet scraper online tools allow you to filter by:
Keywords and hashtags
Date ranges
User accounts
Geographic location
Language
Engagement levels (likes, retweets, replies)
Step 3: Set Up Your First Scraping Project
Here’s my tried-and-true process:
Start Small: Begin with a narrow search (maybe 50–100 tweets) to test the tool
Test Different Keywords: Use variations of your target terms
Check Data Quality: Always review the first batch of results manually
Scale Gradually: Once you’re confident, increase your scraping volume
My Final Thoughts
Using a twitter scraper tool effectively isn’t just about having the right software — it’s about understanding your goals, respecting platform rules, and continuously refining your approach. The tools I use today are vastly different from what I started with, and that’s okay. The key is to keep learning and adapting.
Whether you’re a small business owner trying to understand your audience, a researcher analyzing social trends, or a marketer looking to stay ahead of the competition, the right scraping approach can provide invaluable insights.
1 note
·
View note
Text
How To Use Python for Web Scraping – A Complete Guide
The ability to efficiently extract and analyze information from websites is critical for skilled developers and data scientists. Web scraping – the automated extraction of data from websites – has become an essential technique for gathering information at scale. As per reports, 73.0% of web data professionals utilize web scraping to acquire market insights and to track their competitors. Python, with its simplicity and robust ecosystem of libraries stands out as the ideal programming for this task. Regardless of your purpose for web scraping, Python provides a powerful yet accessible approach. This tutorial will teach you all you need to know to begin using Python for efficient web scraping. Step-By-Step Guide to Web Scraping with Python
Before diving into the code, it is worth noting that some websites explicitly prohibit scraping. You ought to abide by these restrictions. Also, implement rate limiting in your scraper to prevent overwhelming the target server or virtual machine. Now, let’s focus on the steps –
1- Setting up the environment
- Downlaod and install Python 3.x from the official website. We suggest version 3.4+ because it has pip by default.
- The foundation of most Python web scraping projects consists of two main libraries. These are Requests and Beautiful Soup
Once the environment is set up, you are ready to start building the scraper.
2- Building a basic web scraper
Let us first build a simple scraper that can extract quotes from the “Quotes to Scrape” website. This is a sandbox created specifically for practicing web scraping.
Step 1- Connect to the target URL
First, use the requests libraries to fetch the content of the web page.
import requests

Setting a proper User-agent header is critical, as many sites block requests that don’t appear to come from a browser.
Step 2- Parse the HTML content
Next, use Beautiful Soup to parse the HTML and create a navigable structure.

Beautiful Soup transforms the raw HTML into a parse tree that you can navigate easily to find and extract data.
Step 3- Extract data from the elements
Once you have the parse tree, you can locate and extract the data you want.

This code should find all the div elements with the class “quote” and then extract the text, author and tags from each one.
Step 4- Implement the crawling logic
Most sites have multiple pages. To get extra data from all the pages, you will need to implement a crawling mechanism.

This code will check for the “Next” button, follow the link to the next page, and continue the scraping process until no more pages are left.
Step 5- Export the data to CSV
Finally, let’s save the scraped data to a CSV file.

And there you have it. A complete web scraper that extracts the quotes from multiple pages and saves them to a CSV file.
Python Web Scraping Libraries
The Python ecosystem equips you with a variety of libraries for web scraping. Each of these libraries has its own strength. Here is an overview of the most popular ones –
1- Requests
Requests is a simple yet powerful HTTP library. It makes sending HTTP requests exceptionally easy. Also, it handles, cookies, sessions, query strings, including other HTTP-related tasks seamlessly.
2- Beautiful Soup
This Python library is designed for parsing HTML and XML documents. It creates a parse tree from page source code that can be used to extract data efficiently. Its intuitive API makes navigating and searching parse trees straightforward.
3- Selenium
This is a browser automation tool that enables you to control a web browser using a program. Selenium is particularly useful for scraping sites that rely heavily on JavaScript to load content.
4- Scrapy
Scrapy is a comprehensive web crawling framework for Python. It provides a complete solution for crawling websites and extracting structured data. These include mechanisms for following links, handling cookies and respecting robots.txt files.
5- 1xml
This is a high-performance library for processing XML and HTML. It is faster than Beautiful Soup but has a steeper learning curve.
How to Scrape HTML Forms Using Python?
You are often required to interact with HTML when scraping data from websites. This might include searching for specific content or navigating through dynamic interfaces.
1- Understanding HTML forms
HTML forms include various input elements like text fields, checkboxes and buttons. When a form is submitted, the data is sent to the server using either a GET or POST request.
2- Using requests to submit forms
For simple forms, you can use the Requests library to submit form data
import requests

3- Handling complex forms with Selenium
For more complex forms, especially those that rely on JavaScript, Selenium provides a more robust solution. It allows you to interact with forms just like human users would.

How to Parse Text from the Website?
Once you have retrieved the HTML content form a site, the next step is to parse it to extract text or data you need. Python offers several approaches for this.
1- Using Beautiful Soup for basic text extraction
Beautiful Soup makes it easy to extract text from HTML elements.

2- Advanced text parsing
For complex text extraction, you can combine Beautiful Soup with regular expressions.

3- Structured data extraction
If you wish to extract structured data like tables, Beautiful Soup provides specialized methods.

4- Cleaning extracted text
Extracted data is bound to contain unwanted whitespaces, new lines or other characters. Here is how to clean it up –

Conclusion Python web scraping offers a powerful way to automate data collection from websites. Libraries like Requests and Beautiful Soup, for instance, make it easy even for beginners to build effective scrappers with just a few lines of code. For more complex scenarios, the advanced capabilities of Selenium and Scrapy prove helpful. Keep in mind, always scrape responsibly. Respect the website’s terms of service and implement rate limiting so you don’t overwhelm servers. Ethical scraping practices are the way to go! FAQs 1- Is web scraping illegal? No, it isn’t. However, how you use the obtained data may raise legal issues. Hence, always check the website’s terms of service. Also, respect robots.txt files and avoid personal or copyrighted information without permission. 2- How can I avoid getting blocked while scraping? There are a few things you can do to avoid getting blocked – - Use proper headers - Implement delays between requests - Respect robot.txt rules - Use rotating proxies for large-scale scraping - Avoid making too many requests in a short period 3- Can I scrape a website that requires login? Yes, you can. Do so using the Requests library with session handling. Even Selenium can be used to automate the login process before scraping. 4- How do I handle websites with infinite scrolling? Use Selenium when handling sites that have infinite scrolling. It can help scroll down the page automatically. Also, wait until the new content loads before continuing scraping until you have gathered the desired amounts of data.
0 notes
Text
How Scraping LinkedIn Data Can Give You a Competitive Edge Over Your Competitors?

In the era of digital world, data is an important part in any growing business. Apart from extracting core data for investigation, companies believe in the usefulness of open internet data for competitive benefits. There are various data resources, but we consider LinkedIn as the most advantageous data source.
LinkedIn is the largest social media website for professionals and businesses. Also, it is one of the best sources for social media data and job data. Using LinkedIn web scraping, it becomes easy to fetch the data fields to investigate performance.
LinkedIn holds a large amount of data for both businesses and researchers. Along with finding profile information of companies and businesses, it is also possible to get data for profile details of the employees. LinkedIn is the biggest platform for job posting and searching jobs related information.
LinkedIn does not provide an inclusive API that will allow data analysts to access.
How Valuable is LinkedIn Data?
LinkedIn has registered almost 772 million clients among 200 countries. According 2018 data, there is 70% growth in information workers for the LinkedIn platform among 1.25 billion global workers’ population.
There are about 55 million firms, 14 million disclosed job posts, and 36000 skills are mentioned in LinkedIn platform. Hence, it is proved that web data for LinkedIn is extremely important for Business Intelligence.
Which type of Information Is Extracted From LinkedIn Scraping?
Millions of data items are accessible on the platform. There is some useful information for customers and businesses. Here are several data points commonly utilized by LinkedIn extracting services. According to data facts, LinkedIn registers two or more users every second!
Public data
Having 772 million registered user accounts on LinkedIn and increasing, it is not possible to manually tap on the capital of such user information. There are around 100 data opinions available per LinkedIn account. Importantly, LinkedIn’s profile pattern is very reflective where a employer enters entire details of career or study history. Then it possible goes to rebuild an individual’s professional career from their work knowledge in a information.
Below shown is an overview of data points fetched from a personal LinkedIn users.
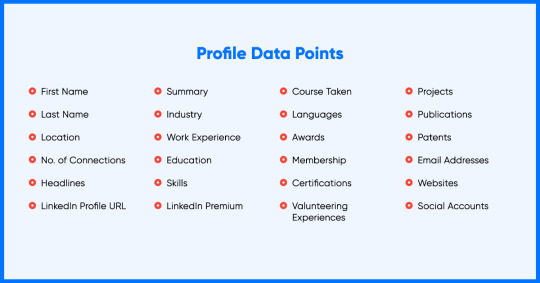
Company Data
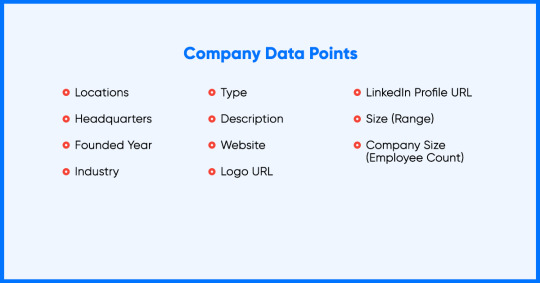
Organizations invest resources for upholding their LinkedIn profile using key firmographic, job data, and public activity. Fetching main firmographic data will enhance companies to remain ahead of the opposite companies and investigate the market site. Firms need to search filters such as industry, business size, and geological location to receive detailed competitive intelligence.
It is possible to scrape company’s data with necessary information as shown below:
Social Listening Information:

Either in research, business discipline, or any other economics, what data a top executive will share on social media platforms is as valuable as statistics with probable business impact. We can capture new market expansion, executive hires, and product failures, M&As, or departures. This is the fact because individuals and companies initiate to be more live on LinkedIn.
The point is to stay updated on those indicators by observing the social actions of the top experts and companies.
One can fetch data from the social actions of LinkedIn by highlighting the below data points.
How Businesses use LinkedIn Data Scraping?

Using all the available data, how will business effectively utilize the data to compete in the market. To learn this, there are few common use cases for information.
Research
Having the capability of rebuilding whole careers for creating a LinkedIn profile, one can only think how broad it is in the research arena.
Research institutions and top academic are initiating to explore the power of information and are even starting to integrate LinkedIn in their publications as a reference.
We can choose an example as fetching all the profiles corporated with company X from 2012 to 2018 and collecting data items such like skills, and interacting to the sales presentation of the company X. It can be assumed that few abilities found in workers would result in an outstanding company.
Human Resources
Human resources are all about people, and LinkedIn is a database record of experts across the globe. One creates a competitive advantage that goes to any recruiter, HR technical SaaS, or any service provider. It is obvious that searching them physically on LinkedIn is not that extensible, but it is valuable when you have all the data with you.
Alternative Information For Finance
Financial organizations are looking forward for data to calculate better investment capability of the company. That is where people’s data play an important role and drives the presentation of the company.
The capability of LinkedIn User information of all the employees cannot be judged. Organizations can utilize this information to monitor business hierarchies, educational backgrounds, functional compositions, and more. Furthermore, gathering the information will provide insights like key departures/ executive hires, talent acquisition policies, and geographical market expansions.
Ways to Extract LinkedIn Data
Looking forward to reader’s advantage, web data scraping for LinkedIn is a method that will use computer programming to enhance data fetching from several sources like sites, digital media platforms, e-commerce, and webpages business platforms. If someone is professional enough to build the scraper, then you can build it. But, extracting LinkedIn information has its challenges with a huge figure of information and social media platform control.
There are various LinkedIn data scraping tools available in the marketplace with distinguishing factors such as data points, data quality, and aggregation scale. Selecting the perfect data partner according to your company’s requirement is quite difficult.
Here at iWeb Scraping, our data collecting methods are continuously evolving in providing LinkedIn extracting service delivering scraping results with well-formatted complete data points, datasets, and even first-class data.
Conclusions
LinkedIn is a far-reaching and filter-after data source from public and company information. This is predictable for more growth as the company continues to utilize more employers. The possibility of using the volume of data is boundless and business firms might start capitalization for this opportunity.
Unless you know the effective methods for scraping, it is better to use LinkedIn scrapers developed by experts. Also, you can ping us for more assistance regarding LinkedIn data web scraping.
https://www.iwebscraping.com/how-scraping-linkedin-data-can-give-you-a-competitive-edge-over-your-competitors.php
6 notes
·
View notes
Text
9 herramientas de Web Scraping Gratuitas que No Te Puedes Perder en 2021
¿Cuánto sabes sobre web scraping? No te preocupe, este artículo te informará sobre los conceptos básicos del web scraping, cómo acceder a una herramienta de web scraping para obtener una herramienta que se adapte perfectamente a tus necesidades y por último, pero no por ello menos importante, te presentará una lista de herramientas de web scraping para tu referencia.
Web Scraping Y Como Se Usa
El web scraping es una forma de recopilar datos de páginas web con un bot de scraping, por lo que todo el proceso se realiza de forma automatizada. La técnica permite a las personas obtener datos web a gran escala rápidamente. Mientras tanto, instrumentos como Regex (Expresión Regular) permiten la limpieza de datos durante el proceso de raspado, lo que significa que las personas pueden obtener datos limpios bien estructurados en un solo lugar.
¿Cómo funciona el web scraping?
En primer lugar, un robot de raspado web simula el acto de navegación humana por el sitio web. Con la URL de destino ingresada, envía una solicitud al servidor y obtiene información en el archivo HTML.
A continuación, con el código fuente HTML a mano, el bot puede llegar al nodo donde se encuentran los datos de destino y analizar los datos como se ordena en el código de raspado.
Por último, (según cómo esté configurado el bot de raspado) el grupo de datos raspados se limpiará, se colocará en una estructura y estará listo para descargar o transferir a tu base de datos.
Cómo Elegir Una Herramienta De Web Scraping
Hay formas de acceder a los datos web. A pesar de que lo has reducido a una herramienta de raspado web, las herramientas que aparecieron en los resultados de búsqueda con todas las características confusas aún pueden hacer que una decisión sea difícil de alcanzar.
Hay algunas dimensiones que puedes tener en cuenta antes de elegir una herramienta de raspado web:
Dispositivo: si eres un usuario de Mac o Linux, debes asegurarte de que la herramienta sea compatible con tu sistema.
Servicio en la nube: el servicio en la nube es importante si deseas acceder a tus datos en todos los dispositivos en cualquier momento.
Integración: ¿cómo utilizarías los datos más adelante? Las opciones de integración permiten una mejor automatización de todo el proceso de manejo de datos.
Formación: si no sobresales en la programación, es mejor asegurarte de que haya guías y soporte para ayudarte a lo largo del viaje de recolección de datos.
Precio: sí, el costo de una herramienta siempre se debe tener en cuenta y varía mucho entre los diferentes proveedores.
Ahora es posible que desees saber qué herramientas de raspado web puedes elegir:
Tres Tipos De Herramientas De Raspado Web
Cliente Web Scraper
Complementos / Extensión de Web Scraping
Aplicación de raspado basada en web
Hay muchas herramientas gratuitas de raspado web. Sin embargo, no todo el software de web scraping es para no programadores. Las siguientes listas son las mejores herramientas de raspado web sin habilidades de codificación a un bajo costo. El software gratuito que se enumera a continuación es fácil de adquirir y satisfaría la mayoría de las necesidades de raspado con una cantidad razonable de requisitos de datos.
Software de Web Scraping de Cliente
1. Octoparse
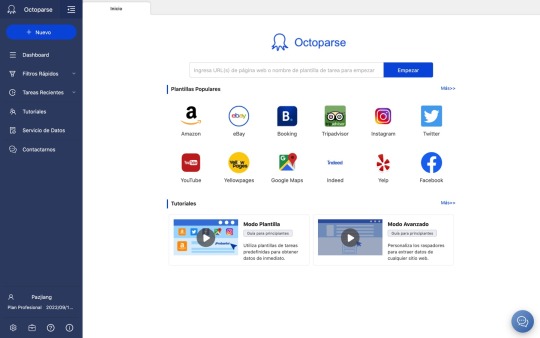
Octoparse es una herramienta robusta de web scraping que también proporciona un servicio de web scraping para empresarios y empresas.
Dispositivo: como se puede instalar tanto en Windows como en Mac OS, los usuarios pueden extraer datos con dispositivos Apple.
Datos: extracción de datos web para redes sociales, comercio electrónico, marketing, listados de bienes raíces, etc.
Función:
- manejar sitios web estáticos y dinámicos con AJAX, JavaScript, cookies, etc.
- extraer datos de un sitio web complejo que requiere inicio de sesión y paginación.
- tratar la información que no se muestra en los sitios web analizando el código fuente.
Casos de uso: como resultado, puedes lograr un seguimiento automático de inventarios, monitoreo de precios y generación de leads al alcance de tu mano.
Octoparse ofrece diferentes opciones para usuarios con diferentes niveles de habilidades de codificación.
El Modo de Plantilla de Tareas Un usuario con habilidades básicas de datos scraping puede usar esta nueva característica que convirte páginas web en algunos datos estructurados al instante. El modo de plantilla de tareas solo toma alrededor de 6.5 segundos para desplegar los datos detrás de una página y te permite descargar los datos a Excel.
El modo avanzado tiene más flexibilidad comparando los otros dos modos. Esto permite a los usuarios configurar y editar el flujo de trabajo con más opciones. El modo avanzado se usa para scrape sitios web más complejos con una gran cantidad de datos.
La nueva función de detección automática te permite crear un rastreador con un solo clic. Si no estás satisfecho con los campos de datos generados automáticamente, siempre puedes personalizar la tarea de raspado para permitirte raspar los datos por ti.
Los servicios en la nube permiten una gran extracción de datos en un corto período de tiempo, ya que varios servidores en la nube se ejecutan simultáneamente para una tarea. Además de eso, el servicio en la nube te permitirá almacenar y recuperar los datos en cualquier momento.
2.
ParseHub
Parsehub es un raspador web que recopila datos de sitios web que utilizan tecnologías AJAX, JavaScript, cookies, etc. Parsehub aprovecha la tecnología de aprendizaje automático que puede leer, analizar y transformar documentos web en datos relevantes.
Dispositivo: la aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux, o puedes usar la extensión del navegador para lograr un raspado instantáneo.
Precio: no es completamente gratuito, pero aún puedes configurar hasta cinco tareas de raspado de forma gratuita. El plan de suscripción paga te permite configurar al menos 20 proyectos privados.
Tutorial: hay muchos tutoriales en Parsehub y puedes obtener más información en la página de inicio.
3.
Import.io
Import.io es un software de integración de datos web SaaS. Proporciona un entorno visual para que los usuarios finales diseñen y personalicen los flujos de trabajo para recopilar datos. Cubre todo el ciclo de vida de la extracción web, desde la extracción de datos hasta el análisis dentro de una plataforma. Y también puedes integrarte fácilmente en otros sistemas.
Función: raspado de datos a gran escala, captura de fotos y archivos PDF en un formato factible
Integración: integración con herramientas de análisis de datos
Precios: el precio del servicio solo se presenta mediante consulta caso por caso
Complementos / Extensión de Web Scraping1.
Data Scraper (Chrome)
Data Scraper puede extraer datos de tablas y datos de tipo de listado de una sola página web. Su plan gratuito debería satisfacer el scraping más simple con una pequeña cantidad de datos. El plan pagado tiene más funciones, como API y muchos servidores proxy IP anónimos. Puede recuperar un gran volumen de datos en tiempo real más rápido. Puede scrapear hasta 500 páginas por mes, si necesitas scrapear más páginas, necesitas actualizar a un plan pago.
2.
Web scraper
El raspador web tiene una extensión de Chrome y una extensión de nube.
Para la versión de extensión de Chrome, puedes crear un mapa del sitio (plan) sobre cómo se debe navegar por un sitio web y qué datos deben rasparse.
La extensión de la nube puede raspar un gran volumen de datos y ejecutar múltiples tareas de raspado al mismo tiempo. Puedes exportar los datos en CSV o almacenarlos en Couch DB.
3.
Scraper (Chrome)
El Scraper es otro raspador web de pantalla fácil de usar que puede extraer fácilmente datos de una tabla en línea y subir el resultado a Google Docs.
Simplemente selecciona un texto en una tabla o lista, haz clic con el botón derecho en el texto seleccionado y elige "Scrape similar" en el menú del navegador. Luego obtendrás los datos y extraerás otro contenido agregando nuevas columnas usando XPath o JQuery. Esta herramienta está destinada a usuarios de nivel intermedio a avanzado que saben cómo escribir XPath.
4.
Outwit hub(Firefox)
Outwit hub es una extensión de Firefox y se puede descargar fácilmente desde la tienda de complementos de Firefox. Una vez instalado y activado, puedes extraer el contenido de los sitios web al instante.
Función: tiene características sobresalientes de "Raspado rápido", que rápidamente extrae datos de una lista de URL que ingresas. La extracción de datos de sitios que usan Outwit Hub no requiere habilidades de programación.
Formación: El proceso de raspado es bastante fácil de aprender. Los usuarios pueden consultar sus guías para comenzar con el web scraping con la herramienta.
Outwit Hub also offers services of tailor-making scrapers.Outwit Hub también ofrece servicios de raspadores a medida.
Aplicación de raspado basada en web1.
Dexi.io (anteriormente conocido como raspado de nubes)
Dexi.io está destinado a usuarios avanzados que tienen habilidades de programación competentes. Tiene tres tipos de robots para que puedas crear una tarea de raspado - Extractor, Crawler, y Pipes. Proporciona varias herramientas que te permiten extraer los datos con mayor precisión. Con su característica moderna, podrás abordar los detalles en cualquier sitio web. Sin conocimientos de programación, es posible que debas tomarte un tiempo para acostumbrarte antes de crear un robot de raspado web. Consulta su página de inicio para obtener más información sobre la base de conocimientos.
El software gratuito proporciona servidores proxy web anónimos para raspar la web. Los datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de ser archivados, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios de pago para satisfacer tus necesidades de obtención de datos en tiempo real.
2.
Webhose.io
Webhose.io te permite obtener datos en tiempo real de raspar fuentes en línea de todo el mundo en varios formatos limpios. Incluso puedes recopilar información en sitios web que no aparecen en los motores de búsqueda. Este raspador web te permite raspar datos en muchos idiomas diferentes utilizando múltiples filtros y exportar datos raspados en formatos XML, JSON y RSS.
El software gratuito ofrece un plan de suscripción gratuito para que puedas realizar 1000 solicitudes HTTP por mes y planes de suscripción pagados para realizar más solicitudes HTTP por mes para satisfacer tus necesidades de raspado web.
0 notes
Link
Introduction
Let’s observe how we may extract Amazon’s Best Sellers Products with Python as well as BeautifulSoup in the easy and sophisticated manner.
The purpose of this blog is to solve real-world problems as well as keep that easy so that you become aware as well as get real-world results rapidly.
So, primarily, we require to ensure that we have installed Python 3 and if not, we need install that before making any progress.
Then, you need to install BeautifulSoup with:
pip3 install beautifulsoup4
We also require soupsieve, library's requests, and LXML for extracting data, break it into XML, and also utilize the CSS selectors as well as install that with:.
pip3 install requests soupsieve lxml
Whenever the installation is complete, open an editor to type in:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
After that, go to the listing page of Amazon’s Best Selling Products and review data that we could have.
See how it looks below.
After that, let’s observe the code again. Let’s get data by expecting that we use a browser provided there :
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml')
Now, it’s time to save that as scrapeAmazonBS.py.
If you run it
python3 scrapeAmazonBS.py
You will be able to perceive the entire HTML page.
Now, let’s use CSS selectors to get the necessary data. For doing that, let’s utilize Chrome again as well as open the inspect tool.
We have observed that all the individual products’ information is provided with the class named ‘zg-item-immersion’. We can scrape it using CSS selector called ‘.zg-item-immersion’ with ease. So, the code would look like :
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.zg-item-immersion'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('')
This would print all the content with all elements that hold products’ information.
Here, we can select classes within the rows that have the necessary data.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.zg-item-immersion'): try: print('----------------------------------------') print(item) print(item.select('.p13n-sc-truncate')[0].get_text().strip()) print(item.select('.p13n-sc-price')[0].get_text().strip()) print(item.select('.a-icon-row i')[0].get_text().strip()) print(item.select('.a-icon-row a')[1].get_text().strip()) print(item.select('.a-icon-row a')[1]['href']) print(item.select('img')[0]['src']) except Exception as e: #raise e print('')
If you run it, that would print the information you have.
That’s it!! We have got the results.
If you want to use it in production and also want to scale millions of links then your IP will get blocked immediately. With this situation, the usage of rotating proxies for rotating IPs is a must. You may utilize services including Proxies APIs to route your calls in millions of local proxies.
If you want to scale the web scraping speed and don’t want to set any individual arrangement, then you may use RetailGators’ Amazon web scraper for easily scraping thousands of URLs at higher speeds.
source code: https://www.retailgators.com/scraping-amazon-best-seller-lists-with-python-and-beautifulsoup.php
0 notes
Text
Web Scraping Amazon Grocery Data using X-Byte Cloud?
Having over 350 million products across product types and activities, Amazon acquired 45% of the US e-commerce market share in 2020. It is one of the world's largest online marketplaces. By using the Amazon scraping tool to scrape grocery delivery information will assist you to easily study your competition, keeping a record of important product information like prices and ratings, and spot emerging market trends.
Below are the Steps for Scraping Amazon Grocery Delivery Data
Creating an account on X-byte Cloud.
Selecting the Amazon scraping tool for instance Amazon search results Scraper.
Enter the list of input URLs.
Execute the crawler, and download the required data.
X-Byte Cloud's pre-built scrapers allow you to extract publicly available data from Google, retail websites, social media, financial websites, and more. X-Byte’s cloud-based web crawlers make web scraping simple. Furthermore, no extra software is required to organize a scraping job. You can use your browser to access the scraper at any moment, enter the required input URLs, and the data will be delivered to you.
Data Fields Scraped from Amazon Grocery Delivery Data
Using Amazon search result scraper, we can extract the below-given data fields:
Product name
Category
Price
Reviews
Ratings
Descriptions
ASIN
Seller information
How to Scrape Amazon Grocery Delivery Data?
The Amazon Search Results Scraper from X-Byte Cloud is simple to use and allows you to safeguard data in the most efficient way possible. The required data and information can be collected from Amazon's food search results page.
Step 1: Creating an X-Byte cloud Account for using Amazon Scraping Tool
Sign up on X-Byte Cloud by signing up using an email address and other details. https://www.xbyte.io/amazon-product-search.php
Before subscribing to X-Byte Cloud, you can try scraping 20-25 pages for free. A thorough explanation of how to execute the Amazon Search Results Scraper, which is available on X-Byte Cloud, can be seen below.
Step 2: Add the Amazon Search Result Crawler to Account and Provide with Necessary Requirements.
After making an account on X-Byte Cloud, go to the Crawlers tab and add the Amazon Search Results Scraper.
After that, select ‘Add this crawler to my account.' The main basic page, as shown under the ‘Input' tab, has all data fields:
1. Crawler Name:
Providing a name to your crawlers may help you distinguish between scraping operations. Fill in the chosen name in the input field and save your changes at the end of the screen by clicking the ‘Save Settings' button.
2. Domain
You may extract comprehensive product information from categories or search engine results on Amazon US, Amazon Canada, and Amazon UK with X-Byte’s Amazon Search Result Scraper. Simply type in the domain you want to scrape into the input field and the scraper will handle the rest.
3. Search Result URLs
Then, throughout this data field, enter your target URLs. We recommend utilizing no more than three input URLs if you're on the free plan. If you currently have an X-Byte Cloud subscription, you can add an unlimited number of URLs for the Amazon Search Results Scraper to extract the data.
If you want to scrape more than one URL, enter them one after the other, separated by a new line (press Enter key). The URLs for the search results can be obtained from Amazon's website in the following way:
Select an Amazon Fresh category now. You can also use filters to narrow down your search results if necessary. Then, the Search Results URLs data field will work as follow:
4. Keywords
Users must enter a list of keywords that they'd like to scrape Amazon grocery data for in this area. Keywords such as 'organic apples,' 'fresh apples,' and 'fresh Honeycrisp apples,' can be used.
If you're not sure what keywords to use, you can use the desired search results URL as input instead.
5. Brand Name
Thousands of brands can be found on Amazon's marketplace. Scraping can be accelerated by including the names of your competitors' brands.
6. Number of Pages to Scrape
On Amazon, you can choose the amount of search results pages to scrape. You can select from the following options:
You can enter the required number of documents in the ‘Custom number of pages' data section below if you have special needs.
Step 3: Running the Amazon Search Results Scraper
After you've filled in all of the information, click 'Save Settings' to save your changes.
To get started, go to the top of the page and click on ‘Gather Data.'
Under the tasks tab, you can check the status of the Amazon scraping program. The status of the scraper may be found there.
If the status is set to ‘Running,' your data is being collected.
If the status is ‘Finished,' it means the crawler has completed the task.
Step 4: Download the Scraped Information
Finally, select ‘View Data' to see the collected data, or ‘Download' to save the results to your computer in Excel, CSV, or JSON format.
The below image shows the scraped grocery information in CSV format.
Features of the X-Byte Cloud Amazon Search Results Scraper
Scheduling the Scraping Process
You can schedule your data crawling using X-Byte Cloud at your convenience.
Generating API Key:
API keys allow the user to create the crawlers and improve the efficiency of the operation. This key can be found on the Integrations tab.
Immediate data Delivery to Dropbox account – You can upload all of the obtained data to a Dropbox account if you pay for an X-Byte cloud subscription. This way, anyone can read the system whenever and anywhere they choose. This feature can be found under the Integrations tab.
Gathering Solutions to Scrape Amazon Data
Of course, Amazon has one of the largest publicly accessible data collections. Customer preferences, market trends, product reviews, ratings, product descriptions, and other information can all be included in the data. Web scraping is a fantastic solution because it eliminates the need to manually search through all of Amazon's data. X-Byte Cloud ensures that you do have instant access to this structured and reliable data.
While you concentrate on other key business activities, then Amazon Search Results Crawler may retrieve crucial grocery delivery information and more. Scraping for grocery data with the Amazon Search Results Crawler on X-Byte Cloud is only the effective way to extract the required information.
Looking for Scraping Amazon Grocery Delivery Data, Contact X-Byte Enterprise Crawling Now!!
For more visit: https://www.xbyte.io/web-scraping-amazon-grocery-data-using-x-byte-cloud.php
#Web Scraping Amazon Grocery Data#amazon scraping tool#amazon search results crawler#Scraping grocery data
0 notes
Text
How To Extract Alibaba Product Data Using Python And Beautiful Soup?

Now we will see how to Extract Alibaba Product data using Python and BeautifulSoup in a simple and elegant manner.
The purpose of this blog is to start solving many problems by keeping them simple so you will get familiar and get practical results as fast as possible Alibaba Product Data Scraper is useful for taking profitable business desicion in e-commerce sector.
Initially, you need to install Python 3. If you haven’t done, then please install Python 3 before you continue.
You can mount Beautiful Soup with:
pip3 install beautifulsoup4
We also require the library's needs soup sieve, lxml, and to catch data, break down to XML, and utilize CSS selectors.
pip3 install requests soupsieve lxml
Once it is installed you need to open the editor and type in:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
Now go to the Alibaba list page and look over the details we need to get.
Get back to code. Let’s acquire and try that information by imagining we are also a browser like this:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml')
Save this as scrapeAlibaba.py
If you run it.
python3 scrapeAlibaba.py
You will be able to see the entire HTML side.
Now, let’s utilize CSS selectors to get the data you require. To ensure that you need to go to Chrome and open the review tool.
We observe all the specific product data contains a class ‘organic-gallery-offer-outter’. We scrape this with the CSS selector ‘. organic-gallery-offer-outter’ effortlessly. Here is the code, let’s see how it will look like:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml')#print(soup.select('[data-lid]')) for item in soup.select('.organic-gallery-offer-outter'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('')
This will print all the remaining content in every container that clutches the product information.
We can choose the classes inside the given row that holds the information we require.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651'response=requests.get(url,headers=headers)soup=BeautifulSoup(response.content,'lxml')#print(soup.select('[data-lid]')) for item in soup.select('.organic-gallery-offer-outter'): try: print('----------------------------------------') print(item) print(item.select('.organic-gallery-title__content')[0].get_text().strip()) print(item.select('.gallery-offer-price')[0].get_text().strip()) print(item.select('.gallery-offer-minorder')[0].get_text().strip()) print(item.select('.seb-supplier-review__score')[0].get_text().strip()) print(item.select('[flasher-type=supplierName]')[0].get_text().strip()) print(item.select('.seb-img-switcher__imgs img')[0]['src']) except Exception as e: #raise e print('')
Once it is run, it will print all the information.
If you need to use this product and want to scale millions of links, then you will see that your IP is getting blocked by Copy Blogger. In this situation use a revolving proxy service to rotate IPs is necessary. You can use a service like Proxies API to track your calls via millions of inhabited proxies.
If you need to measure the crawling pace or you don’t need to set up your structure, you can easily utilize our Cloud base crawler. So that you can easily crawl millions of URLs at a high pace from crawlers.
If you are looking for Alibaba Product Data Scraping Services, then you can contact Web Screen Scraping for all your queries.
0 notes
Text
High-Performance Well Control Equipment for Shale and Tight Oil Formations in the U.S.

In the demanding landscape of U.S. shale and tight oil fields, equipment must perform under high pressures, corrosive fluids, and variable formation depths. At Parveen Industries, our U.S. operations through parveenoilfield.com offer API-certified, field-proven solutions tailored for these exacting environments.
Advanced Well Control Starts with API-Certified Gear
Our engineering team understands the unique challenges posed by unconventional reservoirs. That’s why our portfolio includes Choke and Kill Manifolds, Slab-Type Gate Valves, and Surface-Controlled Subsurface Safety Valves (SSSVs) that meet or exceed API 6A requirements.
These units regulate flow, protect surface and subsurface assets, and provide dependable shut-in capabilities during kick or blowout scenarios—critical for both drilling and production phases.
Downhole Integrity with Proven Bridge Plug Technology
Efficient zonal isolation in multi-stage fracturing requires reliable Bridge Plugs and Cement Retainers. We offer wireline and tubing set options that are compatible with diverse casing sizes and well geometries.
Pair these with our Multi-Stage Setting Tools and Hydraulic Setting Tools to ensure fast deployment and long-term anchoring in shale zones.
Precision Pressure Control at the Surface
Our Quick Test Subs and Treating Irons are designed for swift pressure testing, minimizing downtime between fracturing and flowback operations.
For production testing or early-stage reservoir evaluation, our Production Testing Equipment supports accurate flow rate analysis, pressure measurements, and well productivity studies.
Robust Surface & Subsurface Hardware
Parveen’s U.S.-grade wellheads—including Wellhead Flange Adapters and Tubing Head Spools—integrate seamlessly with our Wellhead & X-Mas Tree Assemblies for safe, modular deployment.
To ensure safe mechanical retrieval and chemical injection, tools like the Equalizing Valve Assemblies and Chemical Injection Subs are available in corrosion-resistant variants for tight oil formations.
Hole Cleaning and Integrity Maintenance
Our high-efficiency Casing Scrappers and Non-Rotating Casing Scrapers remove scale and debris, preparing casing surfaces for effective cementing and plug setting.
Pair them with Drill Collars for directional stability and torque transmission in extended-reach horizontal sections.
Partner with Parveen Industries for U.S. Shale Excellence
With decades of engineering heritage and a strong U.S. footprint, Parveen Industries is enabling operators to drill deeper, complete faster, and produce more safely across the shale plays of Texas, Pennsylvania, North Dakota, and beyond.
Explore our full U.S. offering at parveenoilfield.com
0 notes
Text
PlayStation 5 Scalpers Aren’t Happy With Their Public Image

The simple, joyful, act of buying the latest console – a twice-decade dopamine hit like no other – has become a rage-inducing misery in 2020 and 2021.
Why? Because of scalpers who employ fast-buying bots to scoop up hundreds of consoles in the time it takes for your finger to press “order”.
They are using increasingly sophisticated bots to do this and becoming more organised to spot opportunities, often working in large groups. For regular gamers who want to buy a console, this has caused huge frustration and anger towards scalpers who are profiting from reselling consoles at huge markups.
But scalpers I’ve spoken with say their intentions are misunderstood and their negative public image isn’t justified.
“There seems to be A LOT of bad press on this incredibly valuable industry and I do not feel that it is justified, all we are acting as is a middleman for limited quantity items.” said Jordan, who co-founded The Lab, a private group that advises paying users on how to scalp (known as a “cook group”).
Jordan claims to have secured 25 PlayStation 5 units in January and resold them for £700. The most expensive recommended retail price for the PS5 is £450. This, he feels, is no different to how any other business operates.
“Essentially every business resells their products. Tesco, for example, buys milk from farmers for 26p or so per litre and sells it on for upwards of 70p per litre. No one ever seems to complain to the extent as they are currently doing towards ourselves.” The backlash from angry gamers has led to death threats, Jordan claims, which have been reported to police.
I put Jordan’s analogy to some frustrated gamers who have been trying to buy the Sony console for weeks. One, who didn’t want to be named, said “he is deluded. He doesn’t get he’s another layer of profiteering in his own Tesco analogy. He’s not Robin Hood.”
Bypassing security checks
Jordan’s success has been replicated by other users in The Lab. Jordan’s business partner, Regan, shared images of mass purchases of in-demand Supreme gear using a bot called Velox.
The screenshots show that not only is the bot fast at checking out (the fastest is 2.3 seconds for a Supreme x Smurfs Skateboard), but it also manages to bypass 3D Secure to make the transaction happen.
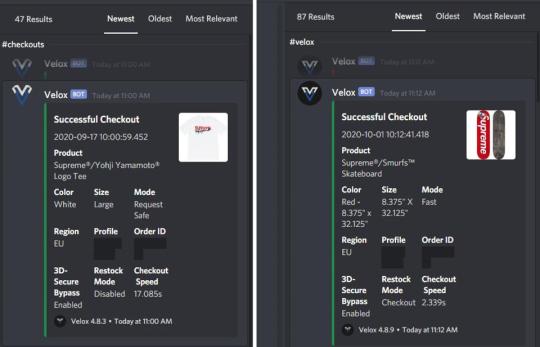
3D Secure is an additional layer of security which verifies that the buyer is the legitimate card owner. It is a requirement in the UK for all websites processing card payments (if the payment card supports it). This usually redirects buyers to another site, which is owned by the bank, for authentication. But the Velox bot used for these supreme purchases bypasses the protocol for a faster checkout.
I asked web security and performance consultant, Edward Spencer, how this bypass this works.
“I suspect the 3D Secure payments page is being by passed by using a card that has not had 3D Secure enabled. Generally, all cards provided by EU banks must have 3D Secure enabled. If you called your bank and requested that 3D Secure was disabled for your card, they’d refuse. So I would guess that they are using cards associated with banks that are from outside of the EU, and are probably pre-paid. The shops could probably thwart these guys by banning all non-3d Secure transactions”.
But there’s more to scalper success then bypassing 3D Secure. Another person I spoke with, who only wanted to be quoted as “Alex”, attempted to build his own bot to buy a PS5. But his was a website scraper that automated purchases, which, as Alex explains, isn’t quick enough.
“There are bots that interact with servers, and there are bots that interact with the web browser – mine interacted with a web browser. So it can only go as fast as a website will let you go. It works faster than a normal human, but there are other bots that, you know, people would be selling for thousands of dollars that will beat my bot every time.”
He continued: “so I know, for Walmart, there was an open API for their stock. Some of these bots could add a PS5 to their shopping cart, and then they could purchase it from there.”
Alex is right that scalpers and cook groups are finding innovative ways to get stock before anyone else. On January 25th cook group Express Notify found a way to buy PlayStation 5 units from UK retailer Argos a full day before the official stock drop, ordering several consoles. Argos eventually shut down the loophole.
Exactly how these bots bypass safeguards, or “interact with servers”, as Alex put it is a bit of a mystery. Spencer speculates that the creators of these bots have “sniffed” the web traffic between the web browser or mobile app of an online store, and the servers.
“Right now I can open Google Chrome and go to any online store, press F12 and I’ll get the developer tools up. All I’ve got to do is go to the network tab, and then maybe add a product into my cart , and observe how my browser is talking to the server that hosts the website. There will typically be network calls to an API running on the server that reveals information – in a computer and human readable way – about products and stock levels.
“So this API isn’t intended to be used by 3rd party developers, but a 3rd party developer could use it if they worked out how. It’s reverse engineering the online store’s API. This isn’t exactly sophisticated. Sites can mitigate this with tried and tested anti-request forgery techniques but unfortunately many sites just don’t bother.”
I contacted several bot makers and cook groups to ask how their tech works, but none were forthcoming apart from those quoted in this story. If you have any information you’re willing to share, then get in contact.
Impossible competition
The scalpers I did speak with operate as a business, in some cases with full time staff. Because of the potential money on the table, the scalpers employ a lot of techniques to gain an advantage over regular buyers and other bot users. Jordan explained that because of bot competition, he has to be vigilant of opportunities.
“Our group monitors hundreds of websites waiting to notify members of restocks. The website I was able to get checkouts from was GAME, which the monitors notified us at around 10am GMT that PS5 stock had been loaded onto the backend of the website.
“It is pretty simple to set up as all the top tier bots have in-depth guides or really simple interfaces. All I needed was the product ID, a few unique billing profiles and proxies (proxies allow us access websites from different locations whether it be country or city specific). We have this all in place ready before any restocks happen to give us the best chances of purchasing. If you are slow, even with a bot, you will miss out on the product.”
GAME issued the following statement in reply to Jordan’s claim.
“PlayStation 5s continue to be in very high demand and that demand far outweighs current supply. We have strong measures in place to help ensure that our “1 per customer” statement is maintained to allow for as many individual customers to successfully purchase as possible.
“All pre-orders are subject to automatic checks and order updates such as cancellations following these checks take place after a customer will have received a valid order confirmation email.”
Jordan didn’t want to name the bot they used to complete the purchases, but they did say that “ you will have seen it plastered amongst the media recently due to the PS5 shortage.” In late January, the team behind a bot called Carnage boasted about helping users secure 2000 PS5s. The Carnage bot team could not be reached for comment.
Both Regan and Jordan say that they are, ultimately, helping people by giving them financial opportunities to resell consoles at an inflated price. “I mainly just try and help others now, that’s all that really matters to me. The whole group came about near the start of the first UK lockdown and it makes me so happy that I can help people make some extra money for themselves.
“We do a lot for charity as well. I myself or collectively as a group donate to charity almost monthly at this point. Most notably over the past month we donated a large portion of our membership fees to a foodbank local to me.” I asked for details of the food bank to confirm Regan’s donation but he didn’t provide their information.
Employing the use of bots doesn’t guarantee a purchase of any hot ticket item, but it can massively improve your chances. What this means for the consumer is that the already limited pool of available product – which has been exacerbated by supply chain issues related to Covid – shrinks even further. Regan says this means average buyers will always struggle.
“Your average person who just wants one of the consoles to use struggles to get close. A lot of these sites have very minimal or easy to bypass bot protection. They often release stocks at stupid times or without any form of schedule. A retailer I won’t name released stock of the PlayStation 5s in the extremely early hours of the morning. Which shows the lack of care on their part. The only people who will have known about those restocks will have been people with monitors inside of cook groups.”
The post PlayStation 5 Scalpers Aren’t Happy With Their Public Image appeared first on RyLi Gaming Solutions.
0 notes
Link
For just $15.18 Soap making molds come in various shapes, sizes and materials. It’s crucial to consider what kind of mold you’ll be using when designing a soapy project. WHY SILICONE? -- Silicone molds are extremely popular due to their ease of use. Sturdy yet flexible, silicone molds make unmolding both cold process and melt and pour soap easy. EASY OPERATION -- The key is to break the airlock by gently pulling away the sides of the mold from the soap. If you experience any resistance when removing cold process soap, stop and give it a few more days in the mold. It’s not worth it to tear the sides or bottom of your project! HOW TO STORE? -- After removing your soap from the mold, hand wash the silicone mold with hot water and dish soap. Allow to dry and the mold is ready to use next time. FREEDOM TO MATCH -- can customize the Handmade soap any way you like with colors, fragrance and the skin-loving oils and butters. and the cutter and The Wavy & Scraper can easy to cut your handmade soap. B0258 -- Silicone mold size: 14 x 13 x 7.3 cm /5.5 x 5.1 x 2.9'' Mold inner size(Finished product size): 10.1 x 8.8 x 7 cm /3.9 x 3.5 x 2.8'' B0260 -- Silicone mold size:29.2 x 12.8 x 6.6 cm /11.5 x 5 x 2.6'' Mold inner size(Finished product size): 25.3 x 8.8 x 6.3 cm /10 x 3.5 x 2.5'' B0261 -- Silicone mold size: 34.5 x 9.8 x 8.6 cm /13.6 x 3.9 x 3.4'' Mold inner size(Finished product size): 30.6 x 8.3 x 5.7 cm /12 x 3.3 x 2.2'' B0264 -- Silicone mold size: 19.1 x 19.1 x 8.7cm /7.5 x 7.5 x 8.4'' Mold inner size(Finished product size): 15.2 x 15.2 x 4.8cm /6 x 6 x 1.9'' D0031 -- Silicone mold size: 23.9 x 12.9 x 11.9cm /9.4 x 5 x 4.7'' Mold inner size(Finished product size): 20 x 9 x 8cm /7.9 x 3.5 x 3.1'' D0037 -- Silicone mold size: 31.4cm(L) x 28.4cm(H) x 12.9cm(Top width), 10.9cm (Bottom width) /12.4''(L) x 11.2''(H) x 5.1''(Top width), 4.3''(Bottom width) Mold inner size(Finished product size): 27.5cm(L) x 7.3cm(H) x 9cm (Top width), 7cm (Bottom width) /10.8''(L) x 2...
#RectangularSoap#WoodSoapMold#DiySoapMold#HomeSoapMaking#LoafSoapMold#MoldsForSoap#SoapSiliconeMolds#SoapMoldsSilicon#RenderingMould#SoapMaking
0 notes
Video
youtube
Gerador de Token - Facebook Extractor 9.0 - Simpel Audiens 9.0 - Filtro Separador - WhatsApp Sender - Kit WhatsApp Marketing - Download Grátis - Baixar Grátis
https://marketing-toolsbr.com/kit-whatsapp-marketing.html
#simpelaudiens #facebookextractor #kitwhatsappmarketing #whatsappmarketing kit whatsapp marketing whatsapp marketing simpel audiens simpel audience facebook extractor whatsApp spam whatsapp envios segmentado WhatsApp em massa envios de Whats App Sistema de envios de mensagens Mensagens via WhatsApp Whats em massa propaganda via WHats whats app em massa enviando via Whats App programa de envios de whatsapp tags: Postador de grupos de WHATSAPP 2018 postador de grupos de whatsapp como adicionar varios grupos na minha conta de whatsapp software de postagens de whatsapp whatsapp marketing ferramenta de postagens em grupos de whatsapp como postar em grupos de whatsapp como vender pelo whatsapp como faturar pelo whatsapp hotmart monetize eduzz lomande zanox afilio como ganhar dinheiro no whatsapp como ganhar dinheiro na internet com o whatsapp Programa de whatsapp gerador de numeros de whatsapp como filtrar listas de numeros para whatsapp whatsapp programa de envios de sms listas de contatos de todo o brasil sms marketing whatsapp marketinh mmn ganhar dinheiro na internet WappBulk Filtro para números de Whatsapp 2017 whatsapp software sistema de envio sistema de marketing google facebook instagram plataforma whatsapp whatsapp marketing software whatsapp zap marketing programa de envios enviar whats whatsapp em massa programa whatsapp whatsapp software whatsapp sender marketing Software WhatsApp Marketing Google Chrome Programa de Envios em MASSA de Whatsapp Marketing / Software WhatsApp Marketing programa de envios de whatsapp em massa envios de mensagens via whatsapp aplicativo de whatsapp para envios em massa programa de envios de whatsapp Programa de Envios em MASSA de Whatsapp Marketing Софт для массовых рассылок Whatsapp Софт для массовых рассылок | рассылка по Whatsapp Как сделать рассылку на WhatsApp? WhatsApp Channel Finder Turbo WART (WhatsApp Registration Tool) 5 حيل خفيّة لا تعرفها عن واتس اب قد توقع بك فى ورطه 5 حيل خفيّة لا تعرفها عن واتس اب قد توقع بك فى ورطه يُعد تطبيق واتس اب، أكثر تطبيقات المُحادثات الفورية شهرة، إذ يضم أكثر من مليار مُستخدمًا حول العالم. وإذا كُنت واحدًا من مُحبّي التطبيق، فعليك أن تكون مُلمًا ببعض المزايا التي ربما تكون غير شائعة لدى أغلب المُستخدمين. whatsapp for pc, whatsapp web, whatsapp sniffer, whatsapp plus, whatsapp sniffer شرح, whatsapp spy, whatsapp tricks, whatsapp sound effect, whatsapp hacker, whatsapp plus 2016, whatsapp hack, whatsapp android, whatsapp adjust date problem, whatsapp android to iphone, whatsapp app, whatsapp android to ios, whatsapp api java, whatsapp ad, whatsapp accident videos, whatsapp api, whatsapp audio tamil, a musica whatsapp, whatsapp backup, whatsapp bulk sender, whatsapp backup iphone, whatsapp broadcast, whatsapp bluestacks, whatsapp backup restore android, whatsapp backup google drive, whatsapp beta, whatsapp bot, whatsapp block, plan b whatsapp, whatsapp channel, whatsapp chat, whatsapp chat backup, whatsapp channel generator, whatsapp call, whatsapp conversations, whatsapp chat backup from android to iphone simpel audiens v4 , simpel audiens token , simpel audiens 4 , simpel audiens login , simpel audiens x , simpel audiens v3 , simpel audiens v4 cracked , simpel audiens review , simpel audiens, simpel audiens v4.0 , simpel audiens 2017 (fb scraper) cracked , simpel audiens v4, simple audience ratakan, simpel audiens crack, simple audience software, simpelaudiens com cari, simpel audiens free, simple audiens 2017 (fb scraper) cracked, simpel audiens login, simpel audiens craqueado, simpel audiens cracked, simpel audiens crack simpel audiens setup, simpel audiens install, simpel audiens rar, simpel audiens zip, crack simpel audiens, serial simpel audiens extrator facebook, scraper facebook, GET Simpel Audiens, simpel audiens X version, simple audience pro, crack simple audience pro, crack simple audience, simple audience, crack audience, simpel audiens crack, token simpel audiens, token simple audiens, token simple audiens, token facebook extractor, crack token facebook extractor pro, facebook extractor, facebook extractor pro, simpelaudiens, simpel audiens 2019, facebook extractor 2019, simpel update, audiens facebook, facebook audiens, leads facebook, extract leads," /> <meta name="description" content="simpel audiens , simpel audiens v4 , simpel audiens token , simpel audiens 4 , simpel audiens login , simpel audiens x , simpel audiens v3 , simpel audiens v4 cracked , simpel audiens review , simpel audiens, simpel audiens v4.0 , simpel audiens 2017 (fb scraper) cracked , simpel audiens v4, simple audience ratakan, simpel audiens crack, simple audience software, simpelaudiens com cari, simpel audiens free, simple audiens 2017 (fb scraper) cracked, simpel audiens login, simpel audiens craqueado, simpel audiens cracked, simpel audiens crack simpel audiens setup, simpel audiens install, simpel audiens rar, simpel audiens zip, crack simpel audiens, serial simpel audiens extrator facebook, scraper facebook, GET Simpel Audiens, simpel audiens X version, simple audience pro, crack simple audience pro, crack simple audience, simple audience, crack audience, simpel audiens crack, token simpel audiens, token simple audiens, token simple audiens, token facebook extractor, crack token facebook extractor pro, facebook extractor, facebook extractor pro, simpelaudiens, simpel audiens 2019, facebook extractor 2019, simpel update, audiens facebook, facebook audiens, leads facebook, extract leads
0 notes
Text
Las 20 Mejores Herramientas de Web Scraping para 2021
Herramienta Web Scraping (también conocido como extracción de datos de la web, web crawling) se ha aplicado ampliamente en muchos campos hoy en día. Antes de que una herramienta de scraping llegue al público, es la palabra mágica para personas normales sin habilidades de programación. Su alto umbral sigue bloqueando a las personas fuera de Big Data. Una herramienta de web scraping es la tecnología de captura automatizada y cierra la brecha entre Big Data y cada persona.
Enumeré 20 MEJORES web scrapers incluyen sus caracterísiticas y público objetivo para que tomes como referencia. ¡Bienvenido a aprovecharlo al máximo!
Tabla de Contenidos
¿Cuáles son los beneficios de usar técnicas de web scraping?
20 MEJORES web scrapers
Octoparse
Cyotek WebCopy
HTTrack
Getleft
Scraper
OutWit Hub
ParseHub
Visual Scraper
Scrapinghub
Dexi.io
Webhose.io
Import. io
80legs
Spinn3r
Content Grabber
Helium Scraper
UiPath
Scrape.it
WebHarvy
ProWebScraper
Conclusión
¿Cuáles son los beneficios de usar técnicas de web scraping?
Liberar tus manos de hacer trabajos repetitivos de copiar y pegar.
Colocar los datos extraídos en un formato bien estructurado que incluye, entre otros, Excel, HTML y CSV.
Ahorrarte tiempo y dinero al obtener un analista de datos profesional.
Es la cura para comercializador, vendedores, periodistas, YouTubers, investigadores y muchos otros que carecen de habilidades técnicas.
1. Octoparse
Octoparse es un web scraper para extraer casi todo tipo de datos que necesitas en los sitios web. Puedes usar Octoparse para extraer datos de la web con sus amplias funcionalidades y capacidades. Tiene dos tipos de modo de operación: Modo Plantilla de tarea y Modo Avanzado, para que los que no son programadores puedan aprender rápidamente. La interfaz fácil de apuntar y hacer clic puede guiarte a través de todo el proceso de extracción. Como resultado, puedes extraer fácilmente el contenido del sitio web y guardarlo en formatos estructurados como EXCEL, TXT, HTML o sus bases de datos en un corto período de tiempo.
Además, proporciona una Programada Cloud Extracción que tle permite extraer datos dinámicos en tiempo real y mantener un registro de seguimiento de las actualizaciones del sitio web.
También puedes extraer la web complejos con estructuras difíciles mediante el uso de su configuración incorporada de Regex y XPath para localizar elementos con precisión. Ya no tienes que preocuparte por el bloqueo de IP. Octoparse ofrece Servidores Proxy IP que automatizarán las IP y se irán sin ser detectados por sitios web agresivos.
Octoparse debería poder satisfacer las necesidades de rastreo de los usuarios, tanto básicas como avanzadas, sin ninguna habilidad de codificación.
2. Cyotek WebCopy
WebCopy es un web crawler gratuito que te permite copiar sitios parciales o completos localmente web en tu disco duro para referencia sin conexión.
Puedes cambiar su configuración para decirle al bot cómo deseas capturar. Además de eso, también puedes configurar alias de dominio, cadenas de agente de usuario, documentos predeterminados y más.
Sin embargo, WebCopy no incluye un DOM virtual ni ninguna forma de análisis de JavaScript. Si un sitio web hace un uso intensivo de JavaScript para operar, es más probable que WebCopy no pueda hacer una copia verdadera. Es probable que no maneje correctamente los diseños dinámicos del sitio web debido al uso intensivo de JavaScript
3. HTTrack
Como programa gratuito de rastreo de sitios web, HTTrack proporciona funciones muy adecuadas para descargar un sitio web completo a su PC. Tiene versiones disponibles para Windows, Linux, Sun Solaris y otros sistemas Unix, que cubren a la mayoría de los usuarios. Es interesante que HTTrack pueda reflejar un sitio, o más de un sitio juntos (con enlaces compartidos). Puedes decidir la cantidad de conexiones que se abrirán simultáneamente mientras descarga las páginas web en "establecer opciones". Puedes obtener las fotos, los archivos, el código HTML de su sitio web duplicado y reanudar las descargas interrumpidas.
Además, el soporte de proxy está disponible dentro de HTTrack para maximizar la velocidad.
HTTrack funciona como un programa de línea de comandos, o para uso privado (captura) o profesional (espejo web en línea). Dicho esto, HTTrack debería ser preferido por personas con habilidades avanzadas de programación.
4. Getleft
Getleft es un web spider gratuito y fácil de usar. Te permite descargar un sitio web completo o cualquier página web individual. Después de iniciar Getleft, puedes ingresar una URL y elegir los archivos que deseas descargar antes de que comience. Mientras avanza, cambia todos los enlaces para la navegación local. Además, ofrece soporte multilingüe. ¡Ahora Getleft admite 14 idiomas! Sin embargo, solo proporciona compatibilidad limitada con Ftp, descargará los archivos pero no de forma recursiva.
En general, Getleft debería poder satisfacer las necesidades básicas de scraping de los usuarios sin requerir habilidades más sofisticadas.
5. Scraper
Scraper es una extensión de Chrome con funciones de extracción de datos limitadas, pero es útil para realizar investigaciones en línea. También permite exportar los datos a las hojas de cálculo de Google. Puedes copiar fácilmente los datos al portapapeles o almacenarlos en las hojas de cálculo con OAuth. Scraper puede generar XPaths automáticamente para definir URL para scraping.
No ofrece servicios de scraping todo incluido, pero puede satisfacer las necesidades de extracción de datos de la mayoría de las personas.
6. OutWit Hub
OutWit Hub es un complemento de Firefox con docenas de funciones de extracción de datos para simplificar sus búsquedas en la web. Esta herramienta de web scraping puede navegar por las páginas y almacenar la información extraída en un formato adecuado.
OutWit Hub ofrece una interfaz única para extraer pequeñas o grandes cantidades de datos por necesidad. OutWit Hub te permite eliminar cualquier página web del navegador. Incluso puedes crear agentes automáticos para extraer datos.
Es una de las herramientas de web scraping más simples, de uso gratuito y te ofrece la comodidad de extraer datos web sin escribir código.
7. ParseHub
Parsehub es un excelente web scraper que admite la recopilación de datos de la web que utilizan tecnología AJAX, JavaScript, cookies, etc. Sutecnología de aprendizaje automático puede leer, analizar y luego transformar documentos web en datos relevantes.
La aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux. Incluso puedes usar la aplicación web que está incorporado en el navegador.
Como programa gratuito, no puedes configurar más de cinco proyectos públicos en Parsehub. Los planes de suscripción pagados te permiten crear al menos 20 proyectos privados para scrape sitios web.
ParseHub está dirigido a prácticamente cualquier persona que desee jugar con los datos. Puede ser cualquier persona, desde analistas y científicos de datos hasta periodistas.
8. Visual Scraper
Visual Scraper es otro gran web scraper gratuito y sin codificación con una interfaz simple de apuntar y hacer clic. Puedes obtener datos en tiempo real de varias páginas web y exportar los datos extraídos como archivos CSV, XML, JSON o SQL. Además de SaaS, VisualScraper ofrece un servicio de web scraping como servicios de entrega de datos y creación de servicios de extracción de software.
Visual Scraper permite a los usuarios programar un proyecto para que se ejecute a una hora específica o repetir la secuencia cada minuto, día, semana, mes o año. Los usuarios pueden usarlo para extraer noticias, foros con frecuencia.
9. Scrapinghub
Scrapinghub es una Herramienta de Extracción de Datos basada Cloud que ayuda a miles de desarrolladores a obtener datos valiosos. Su herramienta de scraping visual de código abierto permite a los usuarios raspar sitios web sin ningún conocimiento de programación.
Scrapinghub utiliza Crawlera, un rotador de proxy inteligente que admite eludir las contramedidas de robots para rastrear fácilmente sitios enormes o protegidos por robot. Permite a los usuarios rastrear desde múltiples direcciones IP y ubicaciones sin la molestia de la administración de proxy a través de una simple API HTTP.
Scrapinghub convierte toda la página web en contenido organizado. Su equipo de expertos está disponible para obtener ayuda en caso de que su generador de rastreo no pueda cumplir con sus requisitos
10. Dexi.io
Como web scraping basado en navegador, Dexi.io te permite scrapear datos basados en su navegador desde cualquier sitio web y proporcionar tres tipos de robots para que puedas crear una tarea de scraping: extractor, rastreador y tuberías.
El software gratuito proporciona servidores proxy web anónimos para tu web scraping y tus datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de que se archiven los datos, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios pagos para satisfacer tus necesidades de obtener datos en tiempo real.
11. Webhose.io
Webhose.io permite a los usuarios obtener recursos en línea en un formato ordenado de todo el mundo y obtener datos en tiempo real de ellos. Este web crawler te permite rastrear datos y extraer palabras clave en muchos idiomas diferentes utilizando múltiples filtros que cubren una amplia gama de fuentes
Y puedes guardar los datos raspados en formatos XML, JSON y RSS. Y los usuarios pueden acceder a los datos del historial desde su Archivo. Además, webhose.io admite como máximo 80 idiomas con sus resultados de crawling de datos. Y los usuarios pueden indexar y buscar fácilmente los datos estructurados rastreados por Webhose.io.
En general, Webhose.io podría satisfacer los requisitos elementales de web scraping de los usuarios.
12. Import. io
Los usuarios pueden formar sus propios conjuntos de datos simplemente importando los datos de una página web en particular y exportando los datos a CSV.
Puede scrapear fácilmente miles de páginas web en minutos sin escribir una sola línea de código y crear más de 1000 API en función de sus requisitos. Las API públicas han proporcionado capacidades potentes y flexibles, controla mediante programación Import.io para acceder automáticamente a los datos, Import.io ha facilitado el rastreo integrando datos web en su propia aplicación o sitio web con solo unos pocos clics.
Para satisfacer mejor los requisitos de rastreo de los usuarios, también ofrece una aplicación gratuita para Windows, Mac OS X y Linux para construir extractores y rastreadores de datos, descargar datos y sincronizarlos con la cuenta en línea. Además, los usuarios pueden programar tareas de rastreo semanalmente, diariamente o por hora.
13. 80legs
80legs es una poderosa herramienta de web crawling que se puede configurar según los requisitos personalizados. Admite la obtención de grandes cantidades de datos junto con la opción de descargar los datos extraídos al instante. 80legs proporciona un rastreo web de alto rendimiento que funciona rápidamente y obtiene los datos requeridos en solo segundos.
80legs es utilizado por una amplia variedad de empresas. Cualquier empresa que necesite datos extraídos de la web puede usar 80legs para sus necesidades.
14. Spinn3r
Spinn3r te permite obtener datos completos de blogs, noticias y sitios de redes sociales y RSS y ATOM. Spinn3r se distribuye con un firehouse API que gestiona el 95% del trabajo de indexación. Ofrece protección avanzada contra spam, que elimina spam y los usos inapropiados del lenguaje, mejorando así la seguridad de los datos.
Spinn3r indexa contenido similar a Google y guarda los datos extraídos en archivos JSON. El web scraper escanea constantemente la web y encuentra actualizaciones de múltiples fuentes para obtener publicaciones en tiempo real. Su consola de administración te permite controlar los scraping y la búsqueda de texto completo permite realizar consultas complejas sobre datos sin procesar.
15. Content Grabber
Content Grabber es un software de web crawler dirigido a empresas. Te permite crear agentes de rastreo web independientes. Puedes extraer contenido de casi cualquier sitio web y guardarlo como datos estructurados en el formato que elijes, incluidos los informes de Excel, XML, CSV y la mayoría de las bases de datos.
Es más adecuado para personas con habilidades avanzadas de programación, ya que proporciona muchas potentes de edición de guiones y depuración de interfaz para aquellos que lo necesitan. Los usuarios pueden usar C # o VB.NET para depurar o escribir scripts para controlar la programación del proceso de scraping. Por ejemplo, Content Grabber puede integrarse con Visual Studio 2013 para la edición de secuencias de comandos, la depuración y la prueba de unidad más potentes para un rastreador personalizado avanzado y discreto basado en las necesidades particulares de los usuarios.
16. Helium Scraper
Helium Scraper es un software visual de datos web scraping que funciona bastante bien cuando la asociación entre elementos es pequeña. No es codificación, no es configuración. Y los usuarios pueden obtener acceso a plantillas en línea basadas en diversas necesidades de web scraping.
Básicamente, podría satisfacer las necesidades de web scraping de los usuarios dentro de un nivel elemental.
17. UiPath
UiPath es un software robótico de automatización de procesos para capturar automáticamente una web. Puede capturar automáticamente datos web y de escritorio de la mayoría de las aplicaciones de terceros. Si lo ejecutas en Windows, puedes instalar el software de automatización de proceso. Uipath puede extraer tablas y datos basados en patrones en múltiples páginas web.
Uipath proporciona herramientas incorporados para un mayor web scraping. Este método es muy efectivo cuando se trata de interfaces de usuario complejas. Screen Scraping Tool puede manejar elementos de texto individuales, grupos de texto y bloques de texto, como la extracción de datos en formato de tabla.
Además, no se necesita programación para crear agentes web inteligentes, pero el .NET hacker dentro de ti tendrá un control completo sobre los datos.
18. Scrape.it
Scrape.it es un software node.js de web scraping. Es una herramienta de extracción de datos web basada en la nube. Está diseñado para aquellos con habilidades avanzadas de programación, ya que ofrece paquetes públicos y privados para descubrir, reutilizar, actualizar y compartir código con millones de desarrolladores en todo el mundo. Su potente integración te ayudará a crear un rastreador personalizado según tus necesidades.
19. WebHarvy
WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. WebHarvy puede scrapear automáticamente Texto, Imágenes, URL y Correos Electrónicos de sitios web, y guardar el contenido raspado en varios formatos. También proporciona un programador incorporado y soporte proxy que permite el rastreo anónimo y evita que el software de web crawler sea bloqueado por servidores web, tiene la opción de acceder a sitios web objetivo a través de servidores proxy o VPN.
Los usuarios pueden guardar los datos extraídos de las páginas web en una variedad de formatos. La versión actual de WebHarvy Web Scraper te permite exportar los datos raspados como un archivo XML, CSV, JSON o TSV. Los usuarios también pueden exportar los datos raspados a una base de datos SQL.
20. ProWebScraper
ProWebScraper es un web scraper automatizado diseñado para la extracción de contenido web a escala empresarial que necesita una solución a escala empresarial. Los usuarios comerciales pueden crear fácilmente agentes de extracción en tan solo unos minutos, sin ninguna programación. La API REST de Prowebscraper puede extraer datos de páginas web para ofrecer respuestas instantáneas en segundos.
Los usuarios pueden crear fácilmente agentes de extracción simplemente apuntando y haciendo clic.
Conclusión
Este artículo primero dio una idea sobre Web Scraping en general. Luego enumeró 20 de las mejores herramientas de raspado web del mercado, considerando una serie de factores. La principal conclusión de este artículo, por lo tanto, es que al final, un usuario debe elegir las herramientas de raspado web que se adapten a sus necesidades.
Deseo que este artículo te ayude a tomar una decisión informada con respecto a la mejor herramienta de raspado web para tu negocio o trabajo.
0 notes
Quote
Introduction In this blog, we will show you how we Extract Wayfair product utilizing BeautifulSoup and Python in an elegant and simple manner. This blog targets your needs to start on a practical problem resolving while possession it very modest, so you need to get practical and familiar outcomes fast as likely. So the main thing you need to check that we have installed Python 3. If don’t, you need to install Python 3 before you get started. pip3 install beautifulsoup4 We also require the library's lxml, soupsieve, and requests to collect information, fail to XML, and utilize CSS selectors. Mount them utilizing. pip3 install requests soupsieve lxml When installed, you need to open the type in and editor. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests Now go to Wayfair page inspect and listing page the details we can need. It will look like this. wayfair-screenshot Let’s get back to the code. Let's attempt and need data by imagining we are a browser like this. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') Save scraper as scrapeWayfais.py If you route it python3 scrapeWayfair.py The entire HTML page will display. Now, let's utilize CSS selectors to acquire the data you need. To peruse that, you need to get back to Chrome and review the tool. wayfair-code We observe all the separate product details are checked with the period ProductCard-container. We scrape this through the CSS selector '.ProductCard-container' effortlessly. So here you can see how the code will appear like. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('') This will print out all the substance in all the fundamentals that contain the product information. code-1 We can prefer out periods inside these file that comprise the information we require. We observe that the heading is inside a # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') #print(item) print(item.select('.ProductCard-name')[0].get_text().strip()) print(item.select('.ProductCard-price--listPrice')[0].get_text().strip()) print(item.select('.ProductCard-price')[0].get_text().strip()) print(item.select('.pl-ReviewStars-reviews')[0].get_text().strip()) print(item.select('.pl-VisuallyHidden')[2].get_text().strip()) print(item.select('.pl-FluidImage-image')[0]['src']) except Exception as e: #raise e print('') If you route it, it will publish all the information. code-2 Yeah!! We got everything. If you need to utilize this in creation and need to scale millions of links, after that you need to find out that you will need IP blocked effortlessly by Wayfair. In such case, utilizing a revolving service proxy to replace IPs is required. You can utilize advantages like API Proxies to mount your calls via pool of thousands of inhabited proxies. If you need to measure the scraping speed and don’t need to fix up infrastructure, you will be able to utilize our Cloud-base scraper RetailGators.com to effortlessly crawl millions of URLs quickly from our system. If you are looking for the best Scraping Wayfair Products with Python and Beautiful Soup, then you can contact RetailGators for all your queries.
source code: https://www.retailgators.com/scraping-wayfair-products-with-python-and-beautiful-soup.php
#Scraping Wayfair Products with Python and Beautiful Soup#Scraping Wayfair Products with Python#Extract Wayfair product utilizing BeautifulSoup and Python
0 notes
Text
How to Scrape Google Play Review Data?

Scrape Google Play Reviews Scraper and downloads them for datasets including name, text information, and date. Input the ID or URL of the apps as well as get information for all the reviews.
GET STARTED NOW
WE HAVE DONE 90% OF THE WORK ALREADY!
It's as easy as Copy and Paste
Start
Google Play Reviews Scraper and downloads them for datasets including name, text information, and date. Input the ID or URL of the apps as well as get information for all the reviews.
Download
Just download the data in CSV, Excel, or JSON formats. Just link the Dropbox for storing data.
Schedule
Just schedule the crawlers on hourly, weekly, or daily to have the newest posts on Dropbox.

SAMPLE DATA
ExcelJson
#
URL
Title
Company Name
Category
Description
Star Rating
Review Count
Updated
Size
Installs
Current Version
Requires Android
Content rating
Interactive Elements
In-app Products
Offered By
Developer
Privacy Policy

1
https://play.google.com/store/apps/details?id=com.whatsapp
WhatsApp Messenger
WhatsApp LLC
Communication
WhatsApp from Facebook is a FREE messaging and video calling app. It’s used by over 2B people in more than 180 countries. It’s simple, reliable, and private, so you can easily keep in touch with your friends and family. WhatsApp works across mobile and desktop even on slow connections, with no subscription fees*.
4.1
137396140
25-05-2021
Varies with device
5,000,000,000+
2.21.10.16
4.1 and up
Rated for 3+
Users interact, Digital purchases
-
WhatsApp LLC
Visit website [email protected] Privacy Policy 1601 Willow Road Menlo Park, CA 94025
outside of where you live for the purposes as described in this Privacy Policy. WhatsApp uses Facebook’s global infrastructure and data centers, including in the United States. These transfers are necessary to provide the global Services set forth in our Terms. Please keep in mind that the countries or territories to which your information is transferred may have different privacy laws and protections than what you have in your home country or territory.
2
https://play.google.com/store/apps/details?id=com.instagram.android
Instagram
-
Social
Instagram (from Facebook) brings you closer to the people and things you love. Connect with friends, share videos and photos of what you’re up to, or see what's new from others all over the world. Explore your social community where you can feel free to be yourself and share everything from your daily moments to life's highlights.
3.8
119518219
25-05-2021
Varies with device
1,000,000,000+
Varies with device
Varies with device
Rated for 12+ Parental guidance recommended
Users interact, Shares info, Shares location
₹85.00 – ₹450.00 per item
Instagram
Visit website [email protected] Privacy Policy Facebook, Inc. 1601 Willow Rd Menlo Park, CA 94025 United States
We use the information we have (including information from research partners we collaborate with) to conduct and support research and innovation on topics such as general social welfare, technological development, public interest, health and well-being . Looking. For example, we analyze the information we have for ways to evacuate during times of emergency to assist in relief operations . Learn more about our research program.

SCRAPE GOOGLE PLAY REVIEWS LISTINGS DATA
Our Google Play Reviews Scraper is mainly designed for scraping complete data from Google Play Store. The extracted data includes:
· Title
· App ID
· URL
· Description
· Summary
· Summary HTML
· Installs
· Min Installs
· Score
· Ratings
· Reviews
· Original Price
· Sales
· Sales Text
· Sales Time
AMONG THE MOST ADVANCED GOOGLE PLAY REVIEWS SCRAPERS ACCESSIBLE
· Best Option of Google Reviews API
· Scrape Unlimited Reviews from Businesses or Places
· Extract Google Reviews with No Rate-Limits
· Built-In Option for Extracting the Newest, Most Appropriate, Lowest, and Highest Ratings Reviews
GET REVIEWS IN A FEW MINUTES
Our Google Play Reviews Scraper is mainly designed for scraping complete data from Google Play Store. The extracted data includes:
You can get different Google reviews for a particular place or business within minutes using X-Byte’s Google Play Reviews Scraper.
Just provide Google Review Links or Place IDs to begin data scraping. Besides, you can choose the reviews variety filter if you need special reviews.
· Scrape competitor reviews using some clicks
· Collect and offer data occasionally to Dropbox

FIND GOOGLE PLACE IDS
You can also utilize X-Byte’s Google Play Reviews Scraper to collect information like Place IDs for businesses and places. Instead, you could use the authorized Google’s Place ID finder tool to get place IDs.
0 notes