#xml-rpc endpoint
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Link
WordPress Username Enumeration Attacks: Understanding and Prevention
WordPress is without a doubt one of the most widely used content management systems (CMS) in the world, powering over 40% of all websites on the internet. But because of its broad use, it is also a perfect target for bad actors looking to take advantage of security holes for all kinds of evil intents. Among these issues, username enumeration is one that WordPress site owners should be particularly aware of and take proactive measures to prevent...
Learn more here:
https://www.nilebits.com/blog/2024/07/wordpress-username-enumeration-attacks/
0 notes
Text
Using PHP to develop web services
A web service is a software system that provides functionality over the web using HTTP protocols. It is essentially a remote procedure call (RPC) that is invoked by a client application. Web services are typically stateless and highly scalable.
PHP is a popular programming language that can be used to develop web services. It is a server-side language that is well-suited for developing dynamic and interactive web applications.
To develop a web service in PHP, you will need to:
Choose a web service framework. There are a number of PHP web service frameworks available, such as Laravel, Symfony, and Lumen. These frameworks provide a number of features that can help you to develop web services more efficiently, such as routing, authentication, and error handling.
Create a web service endpoint. A web service endpoint is the URL that clients will use to access your web service. You can create a web service endpoint by creating a new PHP file and defining a route for it in your web service framework.
Write the web service code. The web service code is the code that will be executed when a client calls the web service endpoint. This code will typically perform some kind of operation, such as retrieving data from a database or sending an email.
Return the results of the web service call. The results of the web service call can be returned in a variety of formats, such as JSON, XML, or HTML.
Here is a simple example of a PHP web service that returns a list of users:
PHP<?php // Require the Laravel web service framework require 'vendor/autoload.php'; // Define the web service route Route::get('/users', function() { // Get the list of users from the database $users = DB::table('users')->get(); // Return the list of users in JSON format return response()->json($users); });
To call this web service, you would simply make a GET request to the following URL:http://localhost/users
The web service would then return a JSON response containing a list of all of the users in the database.
PHP web services can be used to develop a wide variety of applications, such as:
REST APIs
SOAP APIs
XML-RPC APIs
JSON-RPC APIs
If you want to learn PHP from scratch must checkout e-Tuitions to learn PHP Language online, They can teach you PHP Language and other coding language also they have some of the best teachers for there students and most important thing you can also Book Free Demo for any class just goo and get your free demo.
#php#phpdevelopment#php programming#php script#php framework#learn php#learn coding#coding#learn coding online
0 notes
Text
HTB - Bastard
Another Windows machine down; again, I can’t say this was particularly difficult.
It has a rating of medium but I’m unsure why if I’m honest...Perhaps there’s more resources out on the two attack vectors?
It took me a little longer than I’m happy with but I’m afraid web apps are where I lack at the moment- I spent a considerable amount of time checking for SQL injection, XML-RPC weaknesses and it also doesn’t help that my Kali Linux VM can’t connect to Ruby servers for downloading Ruby libraries (or gems)- after spending some time attempting to solve that issue I simply hopped over to my host to get the bastard rooted. ;P
So, my enum script (since made amendments to this: it wasn’t picking up some files it should have such as robots.txt) and then manual checks:

There are 3 logon forms- one to login, one to register and one for password resets- and some misc web app config files such as CHANGELOG.txt and robots.txt.
CHANGELOG reveals that Drupal is running on version 7.54 while robots shows an array of disallowed URLs.
Firstly, I performed some checks on the present forms and I did discover the existence of user ‘admin’ via the password reset form: existing users can be enumerated as the server will respond with username/email not recognized for non-existent usernames and an error on sending a reset email to valid usernames.
I played around with both this and the login form for a while- tried some classic SQL injection cases and alike; unfortunately for us, we’re temporarily locked out if we enter the incorrect password 5 times.
Now this is a shame for the brute force queen... My first thought with login forms is brute force if there doesn’t seem to be any other vectors present. Taking this as a sign that I was barking up the wrong tree, I moved on to instead seeing if there were any other users on the server by utilizing a username brute force script I have in Bash on the password reset form while I looked around a bit more.
It was around here I ran into drupwn- a Drupal web API enumeration tool written in Python. It’s a bit rubbish to be honest as it has a tendency to hang and requires you to manually stop the running process; it did reveal that my enum script had missed robots.txt and CHANGELOG in it’s execution (since been amended.)
It also revealed the version of Drupal in-use; the script probably just looked through CHANGELOG and grabbed the mentioned version.
I did look into these files but robots had alot of entries that -as an inexperienced web app hacker- would have taken me hours to manually test while CHANGELOG revealed nothing but the version of Drupal in-use.
With the version of Drupal identified, however, this did mean that searching for public exploits was a great deal easier. I took to searchsploit -a native Kali Linux tool- and discovered several Drupal exploits:
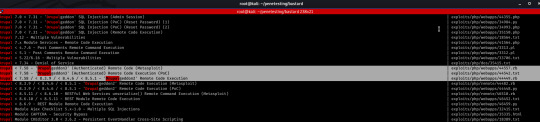
Here we see mentioned Drupalgeddon3 and 2; by process of elimination we know 3 wouldn’t work due to a lack of valid credentials. If any, the vulnerability in question is exploited by Drupalg2.
Drupalgeddon2 (https://github.com/dreadlocked/Drupalgeddon2) is a remote-code execution vulnerability resulting from a lack of input validation on form API AJAX requests. This allows users to inject malicious payloads -in the form of renderable arrays- into the create user form.
In the case of the registration form, this applies to the mail parameter- by setting the values of indexes [#post_render][] to exec, [#type] to markup and ][#markup] to our desired system command we gain RCE (I briefly just tried to exploit this manually but I simply used dev tools within FireFox browser, probably would have succeeded if I’d tried through Burp Proxy or similar!)
It was at this point that I had to switch over to my host to finish up; honestly at this point the bulk of enumeration is complete.
drupalgeddon2>> whoami nt authority\iusr
iusr is essentially Window’s version of an ‘anonymous’ user that is utilized by default by IIS servers in order to access the required system files.
We can grab the user flag from Users/dimitris/Desktop instantly; thankfully there’s further privilege escalation needed for complete admin access!
By following any WIndows privesc cheatsheet, you should check out the privileges on the logged in account and see that we have an interesting one named ‘SeImpersonatePrivilege’- the ability to impersonate a client after authentication.
From previous reading I was aware that this Windows privilege basically means we’re system as there is a well known privesc technique for this called Juicy Potato- the last step is simply seeing how we can download files onto the victim and finding the relevant CISID for our Windows version. Bastard is a Windows 2008 server- as revealed by checking systeminfo.
After some trial and error, I managed to utilize CertUtil:

CertUtil was originally intended to be used to display CA (Certificate Authority) config information and to also make any neccessary alterations to CA components (basically an administrative tool for all things CA related :3)
Part of CertUtil’s functionality includes the ability to download files... Don’t ask me why they thought this was safe. I guess it was in the event of needing third party CA templates (basically pre-config of CA via certificate templates)?
With netcat and JuicyPotato now on our victim, we are able to exploit this privilege for a reverse shell.

This vulnerability is famously named Rotten Potato and -at a simple level- involves tricking AUTHORITY/SYSTEM into authenticating via NTLM to a TCP endpoint under our control.
This authentication process is then captured via a local MITM attack utilizing several Windows API calls. Finally -with one of the relevant privileges- we use the captured token for impersonation, thus gaining the ability to execute commands as SYSTEM.
For those who didn’t guess by the screenshot, a reverse shell is established through our run of jp.exe (I was running a nc listener on port 6969 to receive the connection) and we are able to read root.txt from Administrator’s Desktop directory.
The CLSID I used was obtained from https://github.com/ohpe/juicy-potato/tree/master/CLSID/Windows_Server_2008_R2_Enterprise.
A CLSID is a globally unique identifier that identifies a COM class object.
#hackthebox#bastard#hacking#ctf#OSCP#learning#offensive security#cyber security#windows hacking#drupal RCE#drupal#AJAX#computer science
13 notes
·
View notes
Text
Layman’s Guide to Mass-Exporting Comments from Dreamwidth and LiveJournal
The documentation for this particular feature is piecemeal and scattered over various FAQs, wikis, dev comms, Github repos, etc. No one source quite covers all the bases (basic usage, different URLs for LJ and DW, community export). So here's a writeup of what I’ve pieced together.
Exporting comments, rather than just posts, isn't a "regular user" feature of either site. It’s part of the XML-RPC API intended for programmers, site-to-site communication such as Dreamwidth's importer, and client programs (anyone else remember Semagic?). So following these instructions will get you a giant pile of XML that isn't very pretty or user-friendly. However, it is fairly readable in Firefox and Chrome, which will automatically indent and color-code it for you.
1. Go to LJ or DW and log into the account whose comments you want, if you aren't logged in already. For communities, log in as one of the mods. There's no way to mass-fetch comments from a journal you don't control--you'll just have to set a crawler to slurp them up from flat view.
2. Go to https://www.livejournal.com/export_comments.bml?get=comment_body&startid=0 or http://www.dreamwidth.org/export_comments?get=comment_body&startid=0
3. For communities, add &authas=communityname to the end of the URL.
4. Save as an XML file.
5. This will get you comment texts and timestamps, but only cryptic IDs for accounts and posts. For a map of IDs to usernames, change get=comment_body to get=comment_meta.
6. The comments come back 1000 at a time, so to get the next page of comments, change startid=0 to startid=1000. comment_meta comes back 10,000 at a time.
7. Rinse and repeat until you run out of comments.
8. To back up posts as well, check out LJ's journal export FAQ, which also has instructions on editing the XML file for display. There is probably a way to make the jitemid from the comments XML match up with the ID of the parent post it represents, but I haven't dug that deep yet.
9. Congratulations, you now have a giant pile of (relatively straightforward) XML to work with. Search for a utility that can do what you want with it, or find a friend who's learning to code and tell them you've got a project for them.
Sources: LiveJournal "Exporting Comments" API documentation Dreamwidth's code for importing comments from LJ (see do_authed_comment_fetch) dw_dev post about exporting community comments For developers who want a non-browser-dependent way to authenticate and use the comments endpoint, LJ's XML-RPC Client/Server Protocol documentation has you covered.
111 notes
·
View notes
Text
Xml rpc client error illegal character d83d illegalargu

#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU ZIP FILE#
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU DRIVER#
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU CODE#
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU WINDOWS#
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU CODE#
I have also attached the code we use to extract the XML file. The XML file to the table for this and any other possible Illegal characters that may appear in future. But I need a way to automate this validation and clean up activity each time before loading As of now we are manually validating and removing this character. This character appears as a arrowmark while opening it in Internet Explorer. The specified image file did not contain a resource section.Below is the sample XML file containing the Illegal character in the The server is in use and cannot be unloaded. The name or security ID (SID) of the domain specified is inconsistent with the trust information for that domain. Use your global user account or local user account to access this server. The account used is a server trust account. The account used is an interdomain trust account.
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU DRIVER#
The specified printer driver is already installed. The redirector is in use and cannot be unloaded. The trust relationship between this workstation and the primary domain failed.Ī remote procedure call is already in progress for this thread.Īn attempt was made to logon, but the network logon service was not started. The trust relationship between the primary domain and the trusted domain failed. The security database on the server does not have a computer account for this workstation trust relationship. The workstation does not have a trust secret. The supplied user buffer is not valid for the requested operation. The stub is unable to get the remote procedure call handle.Ī null reference pointer was passed to the stub. The binding handles passed to a remote procedure call do not match. The context handle changed during a remote procedure call. The file containing the character translation table has fewer than 512 bytes.Ī null context handle was passed from the client to the host during a remote procedure call. Unable to open the character translation table file. The list of RPC servers available for the binding of auto handles has been exhausted. The RPC server attempted an integer division by zero.Īn addressing error occurred in the RPC server.Ī floating-point operation at the RPC server caused a division by zero.Ī floating-point underflow occurred at the RPC server.Ī floating-point overflow occurred at the RPC server. No security context is available to allow impersonation.Īn internal error occurred in a remote procedure call (RPC). The requested operation is not supported. There are no more endpoints available from the endpoint mapper. The server endpoint cannot perform the operation. The binding does not contain any authentication information. The maximum number of calls is too small. No network address is available to use to construct a universal unique identifier (UUID). The binding does not contain an entry name. The universal unique identifier (UUID) type is not supported. The transfer syntax is not supported by the RPC server. The remote procedure call failed and did not execute.Ī remote procedure call (RPC) protocol error occurred. There are no remote procedure calls active on this thread. The RPC server is too busy to complete this operation. Not enough resources are available to complete this operation. No protocol sequences have been registered. The type universal unique identifier (UUID) has already been registered. The object universal unique identifier (UUID) has already been registered. The object universal unique identifier (UUID) was not found. The string universal unique identifier (UUID) is invalid. The RPC protocol sequence is not supported. The binding handle is not the correct type. Hold the shift-key and right click in the window. As a result, you should see a folder called AccessChk on your desktop. Click Next when prompted for the Destination.
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU ZIP FILE#
To retrieve the description text for the error in your application, use the FormatMessage function with the FORMAT_MESSAGE_FROM_SYSTEM flag. Save the zip file on your desktop, and extract the file: - Right click on the file, and select Extract All. They are returned by the GetLastError function when many functions fail. The following list describes system error codes for errors 1700 to 3999.
#XML RPC CLIENT ERROR ILLEGAL CHARACTER D83D ILLEGALARGU WINDOWS#
For other errors, such as issues with Windows Update, there is a list of resources on the Error codes page. This information is intended for developers debugging system errors.
0 notes
Photo

An Introduction to REST and RESTful APIs
REST is an acronym for Representational State Transfer — an almost meaningless description of the most-used web service technology! REST is a way for two computer systems to communicate over HTTP in a similar way to web browsers and servers.
Sharing data between two or more systems has always been a fundamental requirement of software development. For example, consider buying motor insurance. Your insurer must obtain information about you and your vehicle so they request data from car registration authorities, credit agencies, banks, and other systems. All this happens transparently in real time to determine whether a policy can be offered.
REST Example
Open the following link in your browser to request a random programming joke:
https://official-joke-api.appspot.com/jokes/programming/random
This is a public API implemented as RESTful web service (it follows REST conventions). Your browser will show an awful JSON-formatted programming joke, such as:
[ { "id": 29, "type": "programming", "setup": "There are 10 types of people in this world...", "punchline": "Those who understand binary and those who don't" } ]
You could request the same URL and get a response using any HTTP client, such as curl:
curl "https://official-joke-api.appspot.com/jokes/programming/random"
HTTP client libraries are available in all popular languages and runtimes including Fetch in JavaScript and file_get_contents() in PHP. A JSON response is machine-readable so it can be parsed and output in HTML or any other format.
REST and the Rest
Various data communication standards have evolved over the years. You may have encountered standards including CORBA, SOAP, or XML-RPC, which usually established strict messaging rules.
REST was defined in 2000 by Roy Fielding and is considerably simpler. It's not a standard but a set of recommendations and constraints for RESTful web services. These include:
Client-Server. SystemA makes an HTTP request to a URL hosted by SystemB, which returns a response.
It's identical to how a browser works. The application makes a request for a specific URL. The request is routed to a web server that returns an HTML page. That page may contain references to images, style sheets, and JavaScript, which incur further requests and responses.
Stateless. REST is stateless: the client request should contain all the information necessary to respond to a request. In other words, it should be possible to make two or more HTTP requests in any order and the same responses will be received.
Cacheable. A response should be defined as cacheable or not.
Layered. The requesting client need not know whether it’s communicating with the actual server, a proxy, or any other intermediary.
Creating a RESTful Web Service
A RESTful web service request contains:
An Endpoint URL. An application implementing a RESTful API will define one or more URL endpoints with a domain, port, path, and/or querystring — for example, https://mydomain/user/123?format=json.
The HTTP method. Differing HTTP methods can be used on any endpoint which map to application create, read, update, and delete (CRUD) operations:
HTTP method CRUD Action GET read returns requested data POST create creates a new record PUT or PATCH update updates an existing record DELETE delete deletes an existing record
Examples:
a GET request to /user/ returns a list of registered users on a system
a POST request to /user/123 creates a user with the ID 123 using the body data
a PUT request to /user/123 updates user 123 with the body data
a GET request to /user/123 returns the details of user 123
a DELETE request to /user/123 deletes user 123
HTTP headers. Information such as authentication tokens or cookies can be contained in the HTTP request header.
Body Data. Data is normally transmitted in the HTTP body in an identical way to HTML <form> submissions or by sending a single JSON-encoded data string.
The Response
The response payload can be whatever is practical: data, HTML, an image, an audio file, and so on. Data responses are typically JSON-encoded, but XML, CSV, simple strings, or any other format can be used. You could allow the return format to be specified in the request — for example, /user/123?format=json or /user/123?format=xml.
An appropriate HTTP status code should also be set in the response header. 200 OK is most often used for successful requests, although 201 Created may also be returned when a record is created. Errors should return an appropriate code such as 400 Bad Request, 404 Not Found, 401 Unauthorized, and so on.
Other HTTP headers can be set including the Cache-Control or Expires directives to specify how long a response can be cached before it’s considered stale.
However, there are no strict rules. Endpoint URLs, HTTP methods, body data, and response types can be implemented as you like. For example, POST, PUT, and PATCH are often used interchangeably so any will create or update a record.
REST "Hello World" Example
The following code creates a RESTful web service using the Node.js Express framework. A single /hello/ endpoint responds to GET requests.
Ensure you have Node.js installed, then create a new folder named restapi. Create a new package.json file within that folder with the following content:
{ "name": "restapi", "version": "1.0.0", "description": "REST test", "scripts": { "start": "node ./index.js" }, "dependencies": { "express": "4.17.1" } }
Run npm install from the command line to fetch the dependencies, then create an index.js file with the following code:
// simple Express.js RESTful API 'use strict'; // initialize const port = 8888, express = require('express'), app = express(); // /hello/ GET request app.get('/hello/:name?', (req, res) => res.json( { message: `Hello ${req.params.name || 'world'}!` } ) ); // start server app.listen(port, () => console.log(`Server started on port ${port}`); );
Launch the application from the command line using npm start and open http://localhost:8888/hello/ in a browser. The following JSON is displayed in response to the GET request:
{ "message": "Hello world!" }
The API also allows a custom name, so http://localhost:8888/hello/everyone/ returns:
{ "message": "Hello everyone!" }
The post An Introduction to REST and RESTful APIs appeared first on SitePoint.
by Craig Buckler via SitePoint https://ift.tt/2S0jtmw
0 notes
Text
300+ TOP SOA Objective Questions and Answers
SOA Multiple Choice Questions :-
1. Which of the following statements does not make sense? A. Intrinsic interoperability is important because it helps increase the quantity of integration projects that may be required to accommodate new business requirements, thereby fostering agility. B. Intrinsic interoperability is important because it enables services to exchange data without having to resort to transformation technologies. C. Intrinsic interoperability is important because it is fundamental to enabling services to be repeatedly composed. D. Intrinsic interoperability is important because one of the goals of service-oriented computing is to increase intrinsic interoperability. Ans: A 2. Which of the following statements is true? A. To apply service-orientation requires the use of Web services. B. Web services are required in order to build service-oriented solutions. C. When discussing SOA and service-oriented computing, the term "Web service" must always be synonymous with (have the same meaning as) the term "service". D. None of these statements are true. Ans: D 3. Which of the following statements is true? A. "Contract first" design is important to SOA because it makes you think about service contract design options at the same time that you are building the underlying service logic. B. "Contract first" design is important to SOA because it forces you to establish standardized service contracts prior to the development of the underlying service logic. C. "Contract first" design is important to SOA because without a contract, services cannot be invoked. However, there is no preference as to when, during the service delivery lifecycle, the contract should be designed or established. D. "Contract first" design is an unproven design technique that is not commonly employed when delivering service-oriented solutions and is therefore not considered important to SOA. Ans: B 4. Which of the following statements is false? A. A service is a unit of logic to which service-orientation has been applied to a meaningful extent. B. Services are designed to increase the need for integration. C. Services are the fundamental building blocks of service-oriented solutions. D. A service composition is comprised of services. Ans: B 5. Which of the following statements accurately describes the strategic benefit of Increased Federation? A. A target state whereby all services are always consistently delivered as Web services. B. A target state in which the entire enterprise has been successfully service-oriented. C. A target state whereby the enterprise has adopted SOA by replacing all legacy environments with custom-developed services. D. A target state whereby standardized service contracts have been established to express a consistent and unified service endpoint layer. Ans: D 6. In order to achieve __________ we have traditionally required __________ projects. With service-orientation, we aim to establish an intrinsic level of __________ within each service so as to reduce the need for __________ effort. A. vendor diversity, integration, vendor diversity, design B. agility, development, scalability, development C. interoperability, integration, interoperability, integration D. autonomy, integration, statelessness, integration Ans: C 7. Below are four statements about business and technology alignment, as it pertains to service-oriented computing. Which of these statements is false? A. Business and technology alignment represents the extent to which an IT enterprise and its automated systems can mirror and evolve in alignment with the business. B. Service-oriented computing promotes the abstraction and accurate encapsulation and expression of business logic in services. This supports business and technology alignment. C. The pursuit of business and technology alignment can be supported by the collaboration of business analysts and technology experts during analysis and modeling phases. D. In order for an IT enterprise to increase business and technology alignment, its business analysts must become more technical and assume the responsibilities of technology experts so that they can independently design quality business services that take both business and technology considerations into account. Ans: D 8. Which of the following is not a benefit of maintaining a vendor-neutral and business-driven context for a service-oriented architecture? A. Establish a technology architecture with a fixed scope and purpose that remains unchanged, regardless of how the business may need to change over time. B. Avoid establishing a technology architecture that will need to be replaced in the near future when it no longer adequately fulfills business requirements. C. Leverage new technological innovation in order to maximize the fulfillment of business requirements. D. Establish a technology architecture that can stay in alignment with how the business may need to change over time. Ans: A 9. Which of the following statements is false? A. The design standardization of service contracts helps increase interoperability between services. B. Design standardization can introduce organizational and cultural challenges because it requires that the design standards be regularly enforced. C. The design standardization of service contracts helps avoid the need for transformation technologies. D. Design standardization is not relevant to the design of service compositions. It is only relevant to the design of individual services. Ans: D 10. Which of the following statements is false? A. The governance burden of services is not impacted by the SOA project delivery approach. B. The bottom-up approach to SOA project delivery results in less up-front impact, but will usually increase the eventual governance burden of services. C. Alternative approaches exist that provide a compromise between bottom-up and top-down SOA project delivery approaches. D. Up-front analysis as part of a top-down SOA project delivery approach helps reduce the eventual governance burden of services. Ans: A

SOA MCQs 11. What is wrong with this statement: "We delivered two services last year. Even though each service was delivered by a separate project team in a different location and at a different time, I am confident that the services will be reasonably interoperable because each project team was asked to use the same design standards." A. The statement is incorrect because services should never be delivered by different project teams. B. The statement is incorrect because services rely on post-implementation integration effort in order to achieve interoperability, not design standards. C. The statement is incorrect because SOA delivery projects require that services be created at exactly the same time in order to guarantee interoperability. D. There is nothing wrong with this statement. Ans: D 12. Which of the following statements is false? A. Industry standards are usually produced by standards organizations. B. Industry standards are usually created by standards committees so that they do not favor any one vendor or organization. C. The use of industry standards alone automatically results in fully standardized service-oriented solutions. D. XML is an example of an industry standard. Ans: C 13. You can create __________ or __________ service inventories. A. process-specific, process-wide B. domain, enterprise C. domain, process-specific D. enterprise, process-specific Ans: B 14. __________ and __________ are used to classify and organize services within a service inventory. A. service compositions, service-oriented solutions B. service capabilities, service compositions C. service models, service layers D. service contracts, service capabilities Ans: C 15. The standardization of services within a service inventory supports the repeated __________ of services, thereby increasing their potential reuse. A. integration B. composition C. definition D. expression Ans: B 16. Solution logic is classified as "service-oriented" after: A. it has been built using Web services B. it has been built using RPC technologies C. it has been performance tested to a meaningful extent D. service-orientation has been applied to a meaningful extent Ans: D 17. A __________ can be part of a/an __________ which can be assembled from __________ within a/an __________. A. component, object, enterprises, service B. service inventory, service, enterprises, service composition C. service, service composition, services, service inventory D. service inventory, service, service compositions, enterprise Ans: C 18. Two common, yet opposing SOA delivery approaches are: A. bottom-up and upside-down B. top-down and left-to-right C. upside-down and left-to-right D. none of the above Ans: D 19. When designing service-oriented architectures, it is important to take the strategic goal of Increased Vendor Diversity Options into account, because this goal: A. encourages you to commit to one vendor platform and stick with that platform, which fosters long-term flexibility B. encourages you to retain the constant option of using proprietary vendor features and extensions so that they can be entrenched into your service-oriented architectures for long-term flexibility C. encourages you to retain the constant option to extend or replace parts of your service-oriented architectures with different vendor technologies or products, which fosters long-term flexibility D. encourages you to bridge disparity between vendor platforms by using modern transformation technologies for long-term flexibility Ans: C 20. Services can be referred to as __________ because of the enterprise-centric design considerations of service-orientation and SOA. A. enterprise architectures B. enterprise resources C. enterprise definitions D. enterprise-centric business models Ans: B 21. A service inventory is considered to have normalized services when: A. its scope does not overlap with any existing databases B. service boundaries within the service inventory do not overlap with each other C. each service within the service inventory is not used by more than one service composition D. legacy systems within the service inventory boundary do not overlap with each other Ans: B 22. Service metadata can be centrally registered within a __________ for discoverability purposes. A. service inventory B. service composition C. service registry D. service model Ans: C 23. When planning a transition toward SOA, we are usually required to balance the __________ goals with the __________ requirements. A. strategic (long-term), tactical (short-term) B. strategic (long-term), unimportant (low priority) C. tactical (short-term), unimportant (low priority) D. unimportant (low priority), important (high priority) Ans: A 24. Services are ideally designed to be: A. agnostic and reusable B. unidirectional and semi-granular C. linear and logistically decomposable D. returnable and non-standardized Ans: A 25. The ROI (return on investment) potential of services is increased by: A. increasing the amount of agnostic services within an inventory B. increasing the amount of non-agnostic services within an inventory C. increasing the amount of legacy systems within an enterprise D. decreasing the scope of a service inventory Ans: A 26. Which of the following is not the result of achieving the strategic goal of Reduced IT Burden? A. a reduction in waste and redundancy among automation solutions (compared to a traditional silo-based IT enterprise) B. a reduction in the quantity of services (compared to a traditional silo-based IT enterprise) C. a reduction in the overhead associated with IT governance and evolution (compared to a traditional silo-based IT enterprise) D. a reduction in size and operational cost of IT as a whole (compared to a traditional silo-based IT enterprise) Ans: B 27. Which of the following statements is true? A. Organizational agility can be viewed as the ability of IT to rapidly produce new legacy applications on-demand. B. Organizational agility can be viewed as a state whereby the organization increases its responsiveness with the support of a more agile IT enterprise. C. Organizational agility can be viewed as a tactical benefit that empowers the organization to respond to new business requirements by building new applications from scratch each time. D. Organizational agility can be viewed as the ability of IT project managers to rapidly replace slow performing programmers without jeopardizing project delivery schedules. Ans: B 28. To qualify as a service composition, at least __________ participating services need to be present. Otherwise, the service interaction only represents a point-to-point exchange. A. two B. four C. six D. eight Ans: A 29. There are two basic types of service-oriented solution logic: __________ and __________. A. services, service registries B. services, service compositions C. service candidates, service registries D. top-down service models, bottom-up service models Ans: B 30. Which of the following statements is false? A. Service-orientation is a design paradigm that must be applied on an enterprise-wide basis in order to be successful. B. Service-orientation is a design paradigm comprised of a set of design principles. C. Service-orientation is an evolutionary design paradigm that has been influenced by older, established IT paradigms and platforms. D. Service-orientation is applied to logic in order to create service-oriented logic. Ans: A 31. When an organization cannot implement a single enterprise service inventory, it has the option to organize collections of services into multiple service inventories referred to as __________. A. domain service inventories B. sub-inventories C. sectional service inventories D. service inventory subsets Ans: A 32. A part of a service contract that is commonly standardized is the __________. A. data model B. service agent C. service registry D. data agent Ans: A 33. Service-oriented computing advocates a concept based on the creation of a service layer with standardized and unified endpoints (service contracts) while allowing individual service implementations to remain disparate and independently governed. This concept is known as: A. interoperability B. transformation C. federation D. isolation Ans: C 34. Service-oriented computing aims to increase an organization's responsiveness by allowing it to adapt to change more efficiently and effectively. This is known as: A. organizational diversity B. organizational agility C. organizational federation D. organizational interoperability Ans: B 35. One of the fundamental characteristics of service-oriented architecture is: A. business-driven B. integration-centric C. inventory-neutral D. silo-driven Ans: A 36. By applying a __________ strategic scope to the technology architecture, it can be kept in constant synch with how the business evolves over time. A. consistently decreasing B. middleware-centric C. vendor-driven D. None of the above answers correctly complete this sentence. Ans: D 37. Why is it recommended to establish a service-oriented architectural model that is vendor-neutral? A. Because a vendor-neutral architectural model provides you with the opportunity to fully leverage and form dependencies on proprietary (vendor-specific) vendor features. B. Because a vendor-neutral architectural model provides you with the opportunity to build service-oriented solutions only with open source technologies, thereby avoiding the use of vendor technologies altogether. C. Because a vendor-neutral architectural model provides you with the freedom to diversify its implementation by leveraging multiple vendor technologies as required. D. A vendor-neutral service-oriented architectural model is not recommended. Ans: C 38. Service Autonomy, Service Statelessness, and Service Loose Coupling are examples of: A. service-oriented architecture types B. service-orientation design principles C. service models D. none of the above Ans: B 39. Which of the following statements is true? A. Service-orientation is a revolutionary design paradigm comprised solely of new design techniques and practices never before used in IT's history. B. The only known historical influence of the service-orientation design paradigm is procedural programming. C. The service-orientation design paradigm has been influenced by several established design paradigms and platforms. D. None of the above statements are true. Ans: C 40. When enterprise-wide standardization is unattainable, multiple domain service inventories may need to be created instead of: A. multiple enterprise service inventories B. a single enterprise service inventory C. multiple enterprise service registries D. a single enterprise service registry Ans: D 41. The use of __________ services tends to __________ the size of service compositions. A. autonomous, increase B. stateless, decrease C. scalable, decrease D. agnostic, increase Ans: B 42. The distinct ownership and governance requirements introduced by agnostic services can introduce the need for more __________ staff and less __________ staff. A. management-centric, administration-centric B. development-centric, quality assurance-centric C. enterprise-centric, project-centric D. development-centric, communication-centric Ans: C 43. XML and XML Schema are examples of: A. custom design standards commonly used by service-oriented solutions B. custom design characteristics commonly found in service-oriented solutions C. industry standards commonly used by service-oriented solutions D. industry characteristics commonly found in service-oriented solutions Ans: C 44. A product or technology that is key to facilitating service discovery and service governance in general is a: A. visual service development tool B. business analysis tool C. service registry D. none of the above Ans: C 45. Administering, maintaining, and evolving the services and service inventories that you build and own can be broadly referred to as: A. federated SOA ownership B. SOA standardization C. SOA governance D. SOA enforcement Ans: C 46. "A primary focus of service modeling is the encapsulation and abstraction of business logic in support of defining business service candidates." What is wrong with this statement? A. Service modeling is a phase dedicated to defining non-business service logic only. B. There is no such thing as a business service when creating service-oriented solutions. C. The service modeling process results in the implementation of services, not the definition of service candidates. D. There is nothing wrong with this statement. Ans: D 47. Which of the following statements is true? A. Integration is the effort required to enable interoperability. A goal of service-oriented computing is to increase intrinsic integration, thereby reducing the need for interoperability. B. Interoperability is the effort required to enable integration. A goal of service-oriented computing is to increase intrinsic integration, thereby reducing the need for interoperability. C. Integration is the effort required to enable interoperability. A goal of service-oriented computing is to increase intrinsic interoperability, thereby reducing the need for integration. D. Interoperability is the effort required to enable integration. A goal of service-oriented computing is to increase intrinsic interoperability, thereby reducing the need for integration. Ans: C 48. Project Team Alpha delivers Service A for Solution 1. Project Team Beta delivers Service B for Solution 2. Some time later, Project Team Omega wants to reuse Service A and Service B for its new Solution 3. How would Services A and B need to have been designed in order for Project Team Omega to successfully reuse these services without having to resort to a major integration project? A. Services always require the use of transformation technologies in order to communicate. Therefore, major integration effort is unavoidable in this scenario. B. Services A and B need to reside on the same physical server or workstation, thereby allowing them to be reused without the need for major integration effort. C. Services A and B need to be standardized and designed with an emphasis on intrinsic interoperability so that they are compatible regardless of when or by which project team they are delivered. D. Service A needs to be designed using a different vendor platform than ServiceB. This enables vendor diversity, thereby guaranteeing interoperability. Ans: C 49. A fundamental means of achieving business and technology alignment in support of service-oriented computing is: A. through the use of a service registry because this allows business and technology-centric services to be located in the same place B. through the creation of business services because this enables services to encapsulate and express business logic C. through the use of a business registry because this allows for the centralized registration of business analysts D. through the creation of a vendor-specific architecture because this supports both the vendor-neutral and business-driven SOA characteristics Ans: B 50. Complete the following statement with the correct text: "The objective of organizational agility is to dramatically reduce the time and effort required to fulfill new or changed business requirements... A. ...as long as the business requirements don't change too often." B. ...once legacy integration has been broadly achieved." C. ...once a collection of mature agnostic services is available." D. ...as long as the organization can continually outsource its IT projects." Ans: D SOA Questions and Answers pdf Download Read the full article
0 notes
Text
Top 5 WordPress Malware Removal Plugins Of 2020

Is Your WordPress Website Really Hacked? WordPress Malware Removal plugins are one of the most crucial plugins that you need to have for your WordPress site. It helps you to keep malware and specific threats away from your WordPress site.Select any WordPress Malware Scanner from the following list for WordPress Security:
1. WordFence:

Protect your websites with the best WordPress security available.Wordfence includes an endpoint firewall and malware scanner that was built from the ground up to protect WordPress. Our Threat Defense Feed arms Wordfence with the newest firewall rules, malware signatures and malicious IP addresses it needs to keep your website safe. Rounded out by a suite of additional features, Wordfence is the most comprehensive security option available.
2. MalCare:
The simplest WordPress Security plugin with Instant Malware Removal that doesn’t need any technical knowledge. You can get set and ready in just 50 secs.

Clean your malware in less than 60 seconds. Our safe malware removal technology ensures that your website never breaks.
MalCare comes with an inbuilt smart and powerful Firewall for real-time protection from Hackers and bots.
3. Sucuri Security:

We Clean and Protect Websites
Gain peace of mind by securing all your websites. We fix hacks and prevent future attacks. A cloud-based platform for every site
4. Anti-Malware Security :
- Run a Complete Scan to automatically remove known security threats and backdoor scripts.
- Firewall blocks SoakSoak and other malware from exploiting Revolution Slider and other plugins with known vulnerabilities.
- Upgrade vulnerable versions of Tim thumb scripts.
- Download Definition Updates to protect against new threats.

5. Cerber Security & Anti-Spam:
Defends WordPress against hacker attacks, spam, trojans, and malware.
Mitigates brute force attacks by limiting the number of login attempts through the login form, XML-RPC / REST API requests or using auth cookies.
Tracks user and bad actors activity with flexible email, mobile and desktop notifications.
Stops spam by using a specialized Cerber’s anti-spam engine and Google reCAPTCHA to protect registration, contact and comments forms.
Advanced malware scanner, integrity checker and file monitor.

Hardening WordPress with a set of flexible security rules and sophisticated security algorithms.
Restricts access with Black and White IP Access Lists.
0 notes
Text
Web Servers
Web services is a standardized way or medium to propagate communication between the client and server applications on the World Wide Web. This course will give a detailed insight into various components of web services like SOAP, WSDL, REST, and how they operate. Web services are server side application components. Which provides set of services. The services of the web service are exposed via an API. modular, well-defined, encapsulated interfaces are used for loosely coupled integration between applications or systems. Loosely coupled architecture, and interacts with client-side components via the API. Multiple types of clients can communicate with the web-service via the API.Browser-based clients, non-browser-based clients (mobile apps), other web services.

What is a WDSL???
WSDL is an XML vocabulary for describing web services that allows developers to describe web services and their capabilities as a standard. standard format to describe a Web Service.In here specifies three fundamental properties:
What a service does -operations (methods) provided by the service.
In this way, WSDL describes the public interface to the Web service. WSDL is often used in combination with SOAP and an XML Schema to provide Web services over the Internet. A client program connecting to a Web service can read the WSDL file to determine what operations are available on the server.
How a service is accessed -data format and protocol details.
WSDL is often used in combination with SOAP and an XML Schema to provide Web services over the Internet. A client program connecting to a Web service can read the WSDL file to determine what operations are available on the server. Any special datatypes used are embedded in the WSDL file in the form of XML Schema.
Where a service is located -Address (URL) details.
Abstract. WSDL is an XML format for describing network services as a set of endpoints operating on messages containing either document-oriented or procedure-oriented information. The operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint.
The document written in WSDL is also simple called a WSDL. WSDL is a contract between the XML(SOAP) Web service and the client who wishes to use this service. The service provides the WSDL document and the Web service client uses the WSDL document to create the stub.
<definitions name = "HelloService"
targetNamespace = "http://www.examples.com/wsdl/HelloService.wsdl"
xmlns = "http://schemas.xmlsoap.org/wsdl/"
xmlns:soap = "http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns = "http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd = "http://www.w3.org/2001/XMLSchema">
<message name = "SayHelloRequest">
<part name = "firstName" type = "xsd:string"/>
</message>
<message name = "SayHelloResponse">
<part name = "greeting" type = "xsd:string"/>
</message>
<portType name = "Hello_PortType">
<operation name = "sayHello">
<input message = "tns:SayHelloRequest"/>
<output message = "tns:SayHelloResponse"/>
</operation>
</portType>
<binding name = "Hello_Binding" type = "tns:Hello_PortType">
<soap:binding style = "rpc"
transport = "http://schemas.xmlsoap.org/soap/http"/>
<operation name = "sayHello">
<soap:operation soapAction = "sayHello"/>
<input>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice"
use = "encoded"/>
</input>
<output>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice"
use = "encoded"/>
</output>
</operation>
</binding>
<service name = "Hello_Service">
<documentation>WSDL File for HelloService</documentation>
<port binding = "tns:Hello_Binding" name = "Hello_Port">
<soap:address
location = "http://www.examples.com/SayHello/" />
</port>
</service>
</definitions>
The WSDL specification provides an XML format for documents for this purpose. WSDL is often used in combination with SOAP and an XML Schema to provide Web services over the Internet. A client program connecting to a Web service can read the WSDL file to determine what operations are available on the server.

abstraction interface section
like in traditional IDL, it defines the signatures of procedures (RPC-style) or messages (document-style)
deployment section
defines the service location and the supported transport protocols

WDSL Element Types
use the XML schema language to declare complex data types and elements that are used elsewhere in the WSDL document. serve as a container for defining any data types that are not described by the XML schema builtin types: complex types and custom simple types, the data types and elements defined in the types element are used by message definitions when declaring the parts (payloads) of messages.
A WSDL document contains the following elements −
Definition − It is the root element of all WSDL documents. It defines the name of the web service, declares multiple namespaces used throughout the remainder of the document, and contains all the service elements described here.
Data types − The data types to be used in the messages are in the form of XML schemas.
Message − It is an abstract definition of the data, in the form of a message presented either as an entire document or as arguments to be mapped to a method invocation.
Operation − It is the abstract definition of the operation for a message, such as naming a method, message queue, or business process, that will accept and process the message.
Port type − It is an abstract set of operations mapped to one or more end-points, defining the collection of operations for a binding; the collection of operations, as it is abstract, can be mapped to multiple transports through various bindings.
Binding − It is the concrete protocol and data formats for the operations and messages defined for a particular port type.
Port − It is a combination of a binding and a network address, providing the target address of the service communication.
Service − It is a collection of related end-points encompassing the service definitions in the file; the services map the binding to the port and include any extensibility definitions.
In addition to these major elements, the WSDL specification also defines the following utility elements −
Documentation − This element is used to provide human-readable documentation and can be included inside any other WSDL element.
Import − This element is used to import other WSDL documents or XML Schemas.
The WSDL Document Structure
The main structure of a WSDL document looks like this
<definitions>
<types>
definition of types........
</types>
<message>
definition of a message....
</message>
<portType>
<operation>
definition of a operation.......
</operation>
</portType>
<binding>
definition of a binding....
</binding>
<service>
definition of a service....
</service>
</definitions>
WDSL Elements Message
The <message> element describes the data being exchanged between the web service providers and the consumers.
Each Web Service has two messages: input and output.
The input describes the parameters for the web service and the output describes the return data from the web service.
Each message contains zero or more <part> parameters, one for each parameter of the web service function.
Each <part> parameter associates with a concrete type defined in the <types> container element.
Here, two message elements are defined. The first represents a request message SayHelloRequest, and the second represents a response message SayHelloResponse.
Each of these messages contains a single part element. For the request, the part specifies the function parameters; in this case, we specify a single firstName parameter. For the response, the part specifies the function return values; in this case, we specify a single greeting return value.
WDSL Element Port Type
The <portType> element combines multiple message elements to form a complete one-way or round-trip operation.
For example, a <portType> can combine one request and one response message into a single request/response operation. This is most commonly used in SOAP services. A portType can define multiple operations.
<portType name = "Hello_PortType">
<operation name = "sayHello">
<input message = "tns:SayHelloRequest"/>
<output message = "tns:SayHelloResponse"/>
</operation>
</portType>
The portType element defines a single operation, called sayHello.
The operation consists of a single input message SayHelloRequest and an
output message SayHelloResponse.
WSDL Elements Binding
The <binding> element provides specific details on how a portType operation will actually be transmitted over the wire.
The bindings can be made available via multiple transports including HTTP GET, HTTP POST, or SOAP.
The bindings provide concrete information on what protocol is being used to transfer portType operations.
The bindings provide information where the service is located.
For SOAP protocol, the binding is <soap:binding>, and the transport is SOAP messages on top of HTTP protocol.
You can specify multiple bindings for a single portType.
The binding element has two attributes: name and type attribute.
<binding name = "Hello_Binding" type = "tns:Hello_PortType">
The name attribute defines the name of the binding, and the type attribute points to the port for the binding, in this case the "tns:Hello_PortType" port.
<binding name =" Hello_Binding" type = "tns:Hello_PortType">
<soap:binding style = "rpc"
transport = "http://schemas.xmlsoap.org/soap/http"/>
<operation name = "sayHello">
<soap:operation soapAction = "sayHello"/>
<input>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice" use = "encoded"/>
</input>
<output>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice" use = "encoded"/>
</output>
</operation>
</binding>
WSDL Elements Service
The <service> element defines the ports supported by the web service. For each of the supported protocols, there is one port element. The service element is a collection of ports.
Web service clients can learn the following from the service element −
Ø where to access the service,
Ø through which port to access the web service, and
Ø how the communication messages are defined.
The service element includes a documentation element to provide human-readable documentation.
Here is a piece of code from the Example chapter –
<service name = "Hello_Service">
<documentation>WSDL File for HelloService</documentation>
<port binding = "tns:Hello_Binding" name = "Hello_Port">
<soap:address
location = "http://www.examples.com/SayHello/">
</port>
</service>
SOAP
SOAP message structure
The container of SOAP message information is referred to as a SOAP envelope. Let's open it and take a brief look at the underlying structure of a typical SOAP message. The root Envelope element that frames the message document consists of a mandatory body section and an optional header area.
A skeleton envelope construct
The SOAP header is expressed using the Header construct, which can contain one or more sections or blocks.

The Header construct with a header block

Common uses of header blocks include:
· implementation of (predefined or application-specific) SOAP extensions, such as those introduced by second-generation specifications
· identification of target SOAP intermediaries
· providing supplementary meta information about the SOAP message
While a SOAP message progresses along a message path, intermediaries may add, remove, or process information in SOAP header blocks. Although an optional part of a SOAP message, the use of the header section to carry header blocks is commonplace when working with second-generation Web services specifications.
The one part of a SOAP message that is not optional is the body. As represented by the Body construct, this section acts as a container for the data being delivered by the SOAP message. Data within the SOAP body is often referred to as the payload or payload data.
The Body construct

The Body construct can also be used to host exception information within nested Fault elements. Although fault sections can reside alongside standard data payloads, this type of information is often sent separately in response messages that communicate error conditions. The Fault construct consists of a series of system elements used to identify characteristics of the exception.
A sample fault construct providing error information

SOAP messages may have one or more attachments. Each Attachment Part object has a MIME header to indicate the type of data it contains. it may also have additional MIME headers to identify
it or to give its location, which can be useful when there are multiple attachments .when a SOAP message has one or more .Attachment Part objects, its SOAP Part object may or may not contain message content.
0 notes
Text
Talking About Your Own Work
Talking about your own work can be surprisingly difficult. Sometimes you don’t think to question why something is done a certain way until you have to explain it to someone else, at which point you realize you don’t fully understand what you were doing. Or, more commonly, you have an understanding of the nitty-gritty of a certain framework or library you were using but you aren’t practiced in giving a high-level overview of its purpose, pros and cons, and alternatives to someone who hasn’t worked with it extensively. This is why I love to teach -- and why I like to write blog posts ;) Both require you to put your thoughts into full sentences that give you a more complete and precise understanding of a topic you thought you already understood.
So, I’m going to write about about my previous work at Houzz to practice just that!
Houzz has two codebases: it was originally built in PHP and jQuery, but has been migrating to an in-house frontend framework that uses Node and React. This frontend framework still makes service calls to the PHP codebase to fetch data, but has its own logic for routing, middleware, etc. Service calls are made using ApacheThrift, which no matter HOW MANY TIMES I explain to someone, I cannot remember a good one-sentence summary of.
Ok, I looked it up for the 849th time, so here it is:
Apache Thrift is an interface definition language and binary communication protocol developed by Facebook for “scalable cross-language services development”. (Source)
In other words, Thrift allowed our JavaScript frontend talk to our PHP backend and do type checking on the data that was passed back and forth. It also has the advantage of allowing for binary serialization, in addition to traditional options like JSON and XML. Binary encoding is much faster, making it an ideal choice when transferring data over internal networks (as we are when we make a service call to the backend). Overall, Thrift was a good choice for us because we needed to interface between two codebases in different languages, and speed was a priority.
Thrift can also be described as an RPC (remote procedure call) framework, but there was hardly room in the definition for that so I am tacking it on now. What does that mean? RPC is a specification for how to interact a server, just like REST is. SOAP (Simple Object Access Protocol) is one implementation you may know that’s frequently juxtaposed with REST. RPC frameworks emphasize operations over resources. This table with some example RPC vs REST endpoints illustrates the point nicely (source):

Thrift is an RPC framework because you interact with the server via operations (e.g., getVisitorHomepagePhotos), as opposed to interacting via resources and HTTP verbs (e.g., GET /photos?type=visitorHomepage).
So there you have it! I spent a while in the previous posts talking about GraphQL in comparison to REST, but my own work was actually integrating it with an RPC framework.
0 notes
Text
ClassicPress: Alternative to WordPress without Gutenberg & React.js
There’s a major shift in WordPress with Gutenberg. It’s an ambitious project lead mostly by the people at Automattic to change the WordPress TinyMCE editor, in a radical way. It brings a new paradigm – a so-called “Block” to WordPress. Each component such as Paragraph, Image, or Headings is now a block built with React.js.


However, the use of React.js has sparked some hot debates within the WordPress community, highlighting problems like licensing in which many argue that it’s not compatible with GPL, hence urge to use an alternative.
So, in this post, I am going to introduce you to ClassicPress, a great alternative to WordPress without Gutenberg and React.js. Let’s read on to know more.
Read Also: Gutenberg: All You Need to Know About WordPress’ Latest Editor
Why do we need a WordPress Alternative anyway?
React.js and the Block concept will spread across the WordPress administration area, even though React.js’ learning curve is quite steep. At the moment, it is only replacing the classic TinyMCE editor. Next, this change is going to replace the Customizer as well as the Admin interface entirely.
For developers, businesses, and indie developers, this change is going to affect in a big way. They’ll need to spend a huge budget to retraining their clients as well as regularly update their themes or plugins to be compatible with Gutenberg.
The entry-level developers are going to be hit the hardest. What was once an easy change and fix with a few lines of a snippet, will soon require a leveled up skill in JavaScript to do the same in WordPress.
These are just a few among many frustrations stemmed by the Gutenberg push. In response to this, some people in the WordPress community have taken a quite strong action seeking out a new platform.
Introducing ClassicPress
ClassicPress is an initiative led by Scott Bowler and a handful of contributors as an alternative to WordPress without Gutenberg and React.js, (at least for the moment). In fact, ClassicPress team has already planned version 2.0.0 of the project where it’ll begin to roll out new changes and features.

ClassicPress practices a more democratic way of letting the community decide the project’s direction. There are a few interesting ideas proposed by the community, for example:
WordPress was started when PHP was still at Version 4 and OOP (Object Oriented Programming) only existed in PHP5. If you dig into the source code you will find it full of legacy code. Given the size of the project and the number of users, it won’t be easy for WordPress to drop support for the older PHP versions.
ClassicPress, being a new project, has plenty of flexibility for change. In fact, it has already set PHP5.6 as the minimum PHP to support. Supporting newer PHP versions will provide ClassicPress a performance boost, a better security, as well as an interesting differentiator from the developer’s point of view.
A great idea taken from a modern dependency manager such as Composer and NPM. This feature will allow developers to define dependency for their plugins and themes. So, for example, when a user installs a theme, it will automatically install the other plugins that the theme depends on.
XML-RPC is an outdated specification that allows outside applications such as a mobile and desktop app to interact with WordPress. WordPress now has its own JSON API that makes using XML-RPC irrelevant. On top of that, the xmlrpc.php endpoint poses some vulnerabilities.
Another interesting thing I found in ClassicPress is that you can find or submit new features proposals as well as vote for them in the Petitions page and the active community will surely respond to your suggestions.
What’s next?
ClassicPress, at the moment, is still in its early stage. The team and the contributors are currently developing version 1.0.0 and already have a plan for version 2.0.0. The development is done with Git and published as a Github repository.
As compared to SVN, which WordPress is still using to manage the Core project repository, using Git will make it easier for developers to contribute to the project with “Pull Request”, just like the way to contribute to a modern open source project these days.
Being a fork and inheriting a familiarity from the most popular CMS, ClassicPress has the potential to be as popular as WordPress in the days to come. It can also grow to be its own entity by introducing its own features that may never happen in WordPress.
It’s nice to have a useful alternative to WordPress and I will be watching the project closely.
via Hongkiat https://ift.tt/2Sz67f9
0 notes
Text
How Our CEQL Compares to SQL Queries
ICYDK: Our Elements are the root of what we do but don't call them Connectors, it doesn't do them justice. Their job is to provide a standard way to connect to endpoints, regardless of the nuances of each given endpoint, and frankly, is not as easy as it sounds. One of these subtleties is with the query language required to filter data when retrieving it from an endpoint using API resources - it ranges from slight variations of SQL queries to OData or XML RPC filter queries. Some endpoints have their own, modified version of SQL queries (e.g. Bullhorn) in order to meet their specific search use cases, others use specialized query languages like SPARQL (e.g. Docustore). https://goo.gl/XSDxdK #DataIntegration #ML
0 notes
Text
How to Incorporate External APIs in Your WordPress Theme or Plugin
APIs can help you to add functionality to your WordPress plugins and themes. In this tutorial I will show you how to use any API (whether it be from Flickr, Google, Twitter, and so on) with WordPress. You will learn how to connect, collect data, store and render–everything you need to know to extend your plugin or theme with new functionality!
We will use Flickr as an example, creating a simple widget that displays the latest Flickr images in order of username.
Wait, What’s an API?
“API” stands for Application Programming Interface; an intermediary between applications, allowing them to communicate, sending information back and forth in real time. We’ll be using a Web API, one which uses HTTP to fetch data from a remote location on the internet somewhere.
“APIs are used by software applications in much the same way that interfaces for apps and other software are used by humans.” – David Berlind, ProgrammableWeb
If you want to get an even clearer idea of what APIs are before we dive into our tutorial, here are some more resources to help you:
News
The Increasing Importance of APIs in Web Development
Janet Wagner
WordPress
Use the WooCommerce API to Customize Your Online Store
Rachel McCollin
API WordPress Plugins on Envato Market
If you’d like to see what other WordPress developers are building with APIs, check out this collection of plugins on Envato Market–plenty of API goodness to get stuck into!
API WordPress plugins on Envato Market
1. Organize Your Working Environment
Let’s begin by organizing our working environment. Start by downloading the Postman app, which provides an API development environment that makes it easy to connect, test, and develop any API. For individuals and small teams it’s completely free.
We’re going to build a widget in a simple WordPress plugin, so make sure you have WordPress installed.
2. Code the Plugin Basics
To start let’s create a simple plugin called flickr-widget. Create a folder with that name and create a flickr-widget.php file in it. At the top of the file place the following code (feel free to change the Author and URIs with your own details):
/* Plugin Name: Flickr widget Plugin URI: https://www.enovathemes.com Description: Display recent Flickr images Author: Enovathemes Version: 1.0 Author URI: http://enovathemes.com */ if ( ! defined( 'ABSPATH' ) ) { exit; // Exit if accessed directly }
Note: this is rudimentary plugin, so I won’t load a language file or create any additional parameters.
Put the freshly created plugin folder inside your WordPress install: wp-content > plugins. You can now activate it from within the WordPress admin dashboard > plugins. You won’t see any changes to your WordPress because we haven’t actually added any functional code.
A Note on Using APIs
Before we go any further, let me quickly mention API use. Any service whose API you want to use will have documentation; I highly recommend you look closely at it. You can use APIs with all kinds of development languages and often get data back in any format you need: PHP, JSON, Java etc. Good documentation will contain detailed information on how to connect to the API, with instructions for each language, and also the main API endpoints (an endpoint is one end of a communication channel).
Web APIs are typically categorized as being either SOAP or REST. SOAP relies solely on XML to provide messaging services, while REST offers a more lightweight method, using URLs in most cases to receive or send information. In our example we will use a REST API.
Programming Fundamentals
What Does REST Mean?
Matthew Machuga
3. Configure and Test API with Postman
So, here is our plan:
Configure and test API with Postman
Connect, collect, and format data from Flickr REST API
Cache the data with WordPress transients
Let’s refer to the Flickr API documentation. Under the Request Formats section you have REST, XML-RPC, SOAP. We need the REST. Click it and you will see an example of a general Flickr REST API Endpoint: https://www.flickr.com/services/rest/.
With the Flickr REST API we can GET, POST, and DELETE any Flickr data we want. Copy the sample endpoint and paste it into Postman (make sure your request type is set to GET).
Click the Send button and... error!
The sample request included the compulsory Flickr API method, but we didn’t specify the API key that is required in order to connect (keys are used to track and control how an API is being used, for example to prevent malicious use or abuse of the API as defined perhaps by terms of service).
4. Get API Key
Having established that we need an API key, let’s go and get one. In order to create one you will first need to have a Flickr/Yahoo account. Once you’ve entered the API dashboard click on the link create your first:
After that click on the Request an API Key. Many API providers have their own specific terms on API usage. Some limit access, others have light and pro versions, or commercial and non-commercial. Sometimes API keys are provided after manual approval; it depends entirely on the API provider. I have chosen Flickr, because it has simple API requirements. For example, Twitter requires a detailed description of the app you want to build before providing an API key, and this is then reviewed by the review team.
That said, click on the Apply for a non-commercial key button and provide some basic info on the app name.
Once you’ve submitted the request you will get the API key (which identifies you) and secret code (which proves you are who you say you are) immediately. Keep these details safe!
5. Set the Request Parameters
Now we will need a method to request data. From the Flickr API documentation we can see that Flickr has tons to choose from. Some methods, like image posting, or deleting, require authentication. Flickr uses OAuth for this; an open, simple, and secure protocol that enables applications to authenticate users and interact with API providers on their behalf. The end user’s information is securely transferred without revealing the identity of the user.
For now, we’ll use simple methods that don’t require oAuth. Click on flickr.photos.getRecent method to see what’s required. This method does not need authentication, but it does take several arguments: api_key (required), extras, per_page, page. Let’s make a simple request in Postman using our parameters:
API general endpoint - https://flickr.com/services/rest
API key - f49df4a290d8f224ecd56536af51FF77 (this is a sample API key which you’ll need to replace with your own)
Method - flickr.photos.getRecent
It will look like this:
https://www.flickr.com/services/rest/?api_key=f49df4a290d8f224ecd56536af51FF77&method=flickr.photos.getRecent
This will return the list of recent public images from Flickr in XML format.
XML format
I always set data format to auto to let Postman decide what format the data is. With Postman you have several data format options: JSON (my favorite), XML, HTML and Text. Flickr returns data in XML format, but this is not a problem for us, as we can add an additional parameter to get data in JSON &format=json:
JSON format
6. Connect, Collect, and Format Data
Now we know how to request data using the REST API, let’s build our WordPress Flickr widget. In the plugin’s main PHP file paste the widget code. I won’t cover the specifics of WordPress widget creation in this tutorial as our focus is different. We have a learning guide Introduction to Creating Your First WordPress Widget by Rachel McCollin which should get you up to speed if you need it.
In the WordPress admin navigate to Appearance > Widgets and add the “Photos from Flickr” widget to a widget area. Now if you go to the front-end you will see the widget title, but no results just yet.
Back in our plugin PHP file, here we render the widget output itself. We have our API key, and the method, and the format we’re looking for. Now we will need to make sure the Flickr user id is provided, and the number of photos the user wants to fetch. These are are gathered from the widget settings.
Note: to get a Flickr user id use this service. I am using envato as the username, and the id is 52617155@N08. Enter the following code inside IF statement:
$url = 'https://www.flickr.com/services/rest/'; $arguments = array( 'api_key' => 'f49df4a290d8f224ecd56536af51FF77', 'method' => 'flickr.people.getPublicPhotos', 'format' => 'json', 'user_id' => $user_id, 'per_page'=> $photos_number, ); $url_parameters = array(); foreach ($arguments as $key => $value){ $url_parameters[] = $key.'='.$value; } $url = $url.implode('&', $url_parameters);
At this point we can knit together the final REST API endpoint url with all the arguments we’ve collected.
Now we’ll make an API request with the file_get_contents() php function:
$response = file_get_contents($url); if ($response) { print_r($response); }
If you now go to the front-end you will something like this outputted:
jsonFlickrApi({"photos":{"page":1,"pages":1033,"perpage":1,"total":"1033","photo":[{"id":"15647274066","owner":"52617155@N08","secret":"2ee48c3fe9","server":"3940","farm":4,"title":"Halloween 2014 at Envato in Melbourne","ispublic":1,"isfriend":0,"isfamily":0}]},"stat":"ok"})
Our request was successful and returned useful data, so now let’s decode and format it. We’ll begin by cleaning up the JSON string–first by removing the wrapper (jsonFlickrApi({...});) with a str_replace. Then we’ll decode the JSON url:
$response = str_replace('jsonFlickrApi(', '', $response); $response = str_replace('})', '}', $response); $response = json_decode($response,true);
Now if we print our results we will see an associative array with data. When we’re ready we can loop through that array and create the data output structure. But first, take a closer look at the small parameter stat. According to the Flickr documentation this indicates the response status. So, before creating the structure of the widget let’s use this status to make sure we have the correct data. Add an IF statement:
if ($response['stat'] == 'ok') { // code here… }
Create an empty array before the IF statement. This array will then be used to contain the collected data:
$response_results = array();
Your foreach loop should now look like this:
if ($response['stat'] == 'ok') { foreach ($response['photos']['photo'] as $photo) { $response_results[$photo['id']]['link'] = esc_url('//flickr.com/photos/'.$photo["owner"].'/'.$photo["id"]); $response_results[$photo['id']]['url'] = esc_url('//farm'.$photo["farm"].'.staticflickr.com/'.$photo["server"].'/'.$photo["id"].'_'.$photo["secret"].'_s.jpg'); $response_results[$photo['id']]['alt'] = esc_attr($photo["title"]); } }
Here we loop through each photo object in the photos array from our response data. Our widget needs the following information to function properly:
Image absolute URL
Image link to Flickr
Image description/alt text
Examine this page and you will understand why I used the given structure. Here you will find the detailed information on how to create the image path and image link.
Create Widget Output
Now our $response_results array contains the exact data we need to create our widget:
if (!empty($response_results)) { $output = ''; $output .= '<ul class="widget-flickr-list">'; foreach ($response_results as $photo) { $output .= '<li>'; $output .= '<a href="'.$photo['link'].'" target="_blank">'; $output .= '<img src="'.$photo['url'].'" alt="'.$photo['alt'].'" />'; $output .= '</a>'; $output .= '</li>'; } $output .= '</ul>'; echo $output; }
We begin by making sure our response is not empty. After that we create an unordered list, storing it in $output, then loop through each image, adding a wrapper link, all the other details, and finally outputting the whole thing with echo;.
If you now go to the site front-end you will see a list of images!
Let’s add some basic styling with CSS to make it look better.
Create an empty flickr-widget.css file in the root plugin folder. In the top of the plugin file paste the following code:
if ( ! defined( 'ABSPATH' ) ) { exit; // Exit if accessed directly } function register_script(){ wp_register_style('widget-flickr', plugins_url('/widget-flickr.css', __FILE__ )); } add_action( 'wp_enqueue_scripts', 'register_script' );
Then, inside the IF statement at the very top add the code:
if (!empty($response_results)) { wp_enqueue_style('widget-flickr');
Inside the css file add basic styling:
.widget-flickr-list { list-style: none; margin:0 -4px 0 -4px; padding: 0; } .widget-flickr-list:after { content: ""; clear: both; } .widget-flickr-list li { display: block; float: left; width: 25%; margin:0; padding: 4px; }
Now it looks much better!
Bonus: Cache the Data with WordPress Transients
At this stage we’ve finished the widget, but there is one more little thing that will take our development to the next level: caching.
Any API request uses your site’s resources and increases load time. Each browser reload will send an API request, which could be multiple users at the same time. What if for some reason your API provider host is down? Your site will suffer load difficulties. The solution is to cache the results and update at a give time interval. So the first time a user visits our page the API request will be sent, but the next time, or with another user, we won’t need to send an API request but instead fetch the results from our site cache.
Let’s modify the widget code to cache results:
if (!empty($flickr_id)) { $api_key = 'f49df4a290d8f224ecd56536af51FF77'; $transient_prefix = esc_attr($flickr_id . $api_key); if (false === ($response_results = get_transient('flickr-widget-' . $transient_prefix))) { $url = 'https://www.flickr.com/services/rest/'; $arguments = array( 'api_key' => $api_key, 'method' => 'flickr.people.getPublicPhotos', 'format' => 'json', 'user_id' => $flickr_id, 'per_page' => $photos_number, ); $url_parameters = array(); foreach ($arguments as $key => $value) { $url_parameters[] = $key . '=' . $value; } $url .= '?' . implode('&', $url_parameters); $response = file_get_contents($url); if ($response) { $response = str_replace('jsonFlickrApi(', '', $response); $response = str_replace('})', '}', $response); $response = json_decode($response, true); $response_results = array(); if ($response['stat'] == 'ok') { foreach ($response['photos']['photo'] as $photo) { $response_results[$photo['id']]['link'] = esc_url('//flickr.com/photos/' . $photo["owner"] . '/' . $photo["id"]); $response_results[$photo['id']]['url'] = esc_url('//farm' . $photo["farm"] . '.staticflickr.com/' . $photo["server"] . '/' . $photo["id"] . '_' . $photo["secret"] . '_s.jpg'); $response_results[$photo['id']]['alt'] = esc_attr($photo["title"]); } if (!empty($response_results)) { $response_results = base64_encode(serialize($response_results)); set_transient('flickr-widget-' . $transient_prefix, $response_results, apply_filters('null_flickr_cache_time', HOUR_IN_SECONDS * 2)); } } } else { return new WP_Error('flickr_error', esc_html__('Could not get data', 'your-text-domain')); } } if (!empty($response_results)) { $response_results = unserialize(base64_decode($response_results)); wp_enqueue_style('widget-flickr'); $output = ''; $output .= '<ul class="widget-flickr-list">'; foreach ($response_results as $photo) { $output .= '<li>'; $output .= '<a href="' . $photo['link'] . '" target="_blank">'; $output .= '<img src="' . $photo['url'] . '" alt="' . $photo['alt'] . '" />'; $output .= '</a>'; $output .= '</li>'; } $output .= '</ul>'; echo $output; } }
I won’t describe what the transient is and how it works, just what it does. Any time the widget is rendered we first check if the transient is in place; if it is present we fetch results from transient, but if not, we make an API request. And each two hours our transient expires, in order to keep our latest Flickr images actual and up to date.
With the WordPress plugin Transients Manager you can even see what your cached Flickr API request results look like:
And the final touch here is to remove transient for every widget update. For example, if you want to change the number of images displayed, or change the username, you’d need to make a new API request. This can be done with the widget_update_callback WordPress filter, or the widget class public function update:
public function update($new_instance, $old_instance) { $instance = $old_instance; $instance['title'] = strip_tags($new_instance['title']); $instance['photos_number'] = strip_tags($new_instance['photos_number']); $instance['flickr_id'] = strip_tags($new_instance['flickr_id']); $api_key = 'f49df4a290d8f224ecd56536af51FF77'; $transient_name = 'flickr-widget-' . esc_attr($instance['flickr_id'] . $api_key); delete_transient($transient_name); return $instance; }
Conclusion
That was a lot of effort, but now you know how to work with WordPress and APIs! If you enjoyed this post and would like to see additional tutorials on APIs or transients, let me know in the comments section.
To grab the widget sample files head over to the GitHub repository.
0 notes
Text
2019/06/17-23
*NASA、サイバー攻���で機密データ流出 侵入口は無許可接続の「Raspberry Pi」 https://www.itmedia.co.jp/news/articles/1906/23/news012.html >攻撃者の侵入口はJPLのネットワークに無許可で接続していた >Raspberry Pi端末だった。
>管理者の1人はOIGに対し、新たに端末を接続する際はセキュリティ >データベースに手動で登録することになっているが、更新機能が >うまく動かないことがあり、そのまま登録を忘れることがあると >語ったという。
>OIGはNASAのセキュリティ体制の問題点を多数挙げている。例えば >ITシステムにセキュリティ脆弱性が見つかっても、180日以上放置 >していることがあった。また、JPLはその性格上、外部パートナー >にもネットワークへのアクセスを許可しているが、ネットワーク >を分離して機密データへのアクセス制限を適宜設定していない。
*【レポート】AWSome Day at Tokyoその3:AWSのセキュリティの基本#AWSSummit https://dev.classmethod.jp/cloud/awsome-day-at-tokyo-3/ >AWS IAMのベストプラクティス > > AWSアカウントの(ルート)アクセスキーがある場合は削除 > 個々のIAMユーザーの作成 > グループを使用してIAMユーザーに権限を割り当てる > 最小権限を付与 > 強力なパスワードポリシーを設定する > 権限のあるユーザーに対してMFAを有効にする
*WordPress侵入対策まとめ:ブルートフォースアタック編 https://www.jtrustsystem.co.jp/2019/06/21/wordpress-anti-penetration/ >以下のようなURLにアクセスしてみてください。 >サイトドメイン/?author=1 > >URLはリダイレクトされ、以下のようになるかと思います。 >サイトドメイン/author/admin/ > >たったこれで、管理者IDがURLに出てきてしまいます。みなさんのサイト >ではどうだったでしょうか。 > >author=の後ろの数字を増やしていくことで、登録された全ユーザが >見えてしまうと思います。
>これを防ぐには、ユーザ用のslugを変更する必要がありますが、素の >WordPressでは変更する手段がありません。 > >「Edit Author Slug」プラグインはこのユーザ用slugを変更すること >ができます。
>それでも繰り返し試行されたら、例えばブラックリストに登録して永久 >にアクセス禁止としても良いですし、半日ロックアウトでも良いかもし >れません。そんな事を可能とするプラグインが、これです。 > >「Limit Login Attempts Reloaded」プラグインです。
>URLが変われば、そもそも攻撃先がわかりませんから、かなり安心する >ことができますね。 > >それを可能とするのがこちら、「SiteGuard WP Plugin」です。
>WordPressにはXML-RPCという外部のサービスと連携するためのAPIが >存在します。ピンバック(Pingback)やトラックバック(Trackback)で >使われています。そのAPIの中に認証機能を持つものもあるため、 >攻撃者がパスワードを探り当てるためにこちらをブルートフォース >攻撃に使うケースが増えています。
>対策で一番簡単なのは、XML-RPCを停止する方法です。これであれば >悪用しようがなくなります。.htaccessを使うのが一番確実でしょうか。 > >RewriteBase / >RewriteRule ^xmlrpc\.php$ "http\:\/\/0\.0\.0\.0\/" [R=301,L]
*Amazon RDS now supports Storage Auto Scaling https://aws.amazon.com/jp/about-aws/whats-new/2019/06/rds-storage-auto-scaling/
*Firefoxに危険度最高の脆弱性、最新版「Firefox 67.0.3」へのアップデートを https://internet.watch.impress.co.jp/docs/news/1191275.html
*歴史的なイベントから得られる5つの教訓とは? https://gigazine.net/news/20190618-five-lessons-from-history/ >◆1:予期せぬ困難に苦しむ人々は以前と大きく考えを転換させる >◆2:平均への回帰は「成長させる力」の持ち主が「維持する力」を > 持たないことによって起きる >◆3:持続不可能な出来事も意外と長く続く >◆4:進歩に人々が気づくのは遅いが失敗は一気に広がる >◆5:傷は治癒しても傷跡は残る
*AWS Clinet VPNを分かりやすく解説してみる http://blog.serverworks.co.jp/tech/2019/06/10/awsclientvpn/ > - VPC上に Client VPN Endpoint を作成することで、クライアント > (普通のPCなど)とVPCの間でVPNを張ることができる > > - OpenVPN (オープンソースのVPNソフトウェア)を利用 > > - 認証には “Active Directoryによるアカウント管理“, > “サーバ証明書・クライアント証明書による相互認証“, > “その両方” を利用できる
>Client VPN Endpoint (①)を作成し、VPCのサブネット(1つまたは複数) >に紐づけます。 > >認証に利用するサーバ証明書・クライアント証明書を AWS Certificate >Manager (②)、通称 ACM に登録しておきます。 >クライアント(③)にはOpenVPNクライアントをインストールし、クライア >ント証明書を配置します。
>なおClient VPN経由でVPC内のリソースにアクセスするとき、接続元IPは >Client VPN EndpointのENIのものになります。つまりクライアントからの >通信は Client VPN Endpoint でいったんNATされているということ。
*Amazon CloudWatchでWindowsのプロセス監視をしてみた https://dev.classmethod.jp/cloud/aws/monitoring-windows-process-using-cloudwatch/ >EC2インスタンスにアタッチするIAMロールは以下。 > > - AmazonSSMManagedInstanceCore : SSM用 > - CloudWatchAgentServerPolicy : CloudWatch Agent用
>ファイルパスについてJSONでは\をエスケープする必要があるので >\\区切りとしています。
0 notes
Text
Clean up WordPress Theme HEAD Section and Unneeded JS & CSS Files
WordPress core ads quite a lot of code in site’s HTML head section whether you want it or not. That code is far from useless and serves a purpose on most sites. However, if you are a clean-code freak or using WordPress to power a SaaS you’ll want to clean up the HTML. As with most things in WP, it’s just a matter of removing a few actions and filters. Why would I remove those tags in HEAD, CSS or JS files? There are a couple of reasons. Some people like to keep their code and sites as tidy as possible. Why have a line of code in HTML if you know you don’t need it and know how to remove it. No reason what so ever. Same goes for extra CSS and JS files. If you’re not using emojis on your site why would you include that JS on every page? Then there’s security. There are a few pieces of HTML that WordPress automatically adds do show URLs that have been exploited in the past. I have to stress out that these URLs (XML RPC endpoint in particular) are not a secret. They should be public. But, changing them to something custom, and hiding them is a known practice. In that case, it’s obvious you don’t want those URLs in your HTML. Speed is also a from ManageWP.org https://managewp.org/articles/17836/clean-up-wordpress-theme-head-section-and-unneeded-js-css-files
0 notes
Text
Clean up WordPress Theme HEAD Section and Unneeded JS & CSS Files
WordPress core ads quite a lot of code in site’s HTML head section whether you want it or not. That code is far from useless and serves a purpose on most sites. However, if you are a clean-code freak or using WordPress to power a SaaS you’ll want to clean up the HTML. As with most things in WP, it’s just a matter of removing a few actions and filters. Why would I remove those tags in HEAD, CSS or JS files? There are a couple of reasons. Some people like to keep their code and sites as tidy as possible. Why have a line of code in HTML if you know you don’t need it and know how to remove it. No reason what so ever. Same goes for extra CSS and JS files. If you’re not using emojis on your site why would you include that JS on every page? Then there’s security. There are a few pieces of HTML that WordPress automatically adds do show URLs that have been exploited in the past. I have to stress out that these URLs (XML RPC endpoint in particular) are not a secret. They should be public. But, changing them to something custom, and hiding them is a known practice. In that case, it’s obvious you don’t want those URLs in your HTML. Speed is also a Source: https://managewp.org/articles/17836/clean-up-wordpress-theme-head-section-and-unneeded-js-css-files
from Willie Chiu's Blog https://williechiu40.wordpress.com/2018/09/04/clean-up-wordpress-theme-head-section-and-unneeded-js-css-files/
0 notes