
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by brainmentors and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
1
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Single Number | Arrays | Data Structures and Algorithms
Single Number is a problem statement that is based on arrays from Data Structures and Algorithms. In this problem, we can find the single number that occurs an odd number of times in the given array.
The first approach to solve this problem is: Brute Force Algorithm

As you can see we have an array with size 5. To find the single number that occurring the odd number of times in this given array. So, we can traverse from left to right side of the array, one by one select each element and compare it with all the remaining elements of the array. If the selected element is equal to any remaining elements of the array, so for this we keep one variable that is count variable which is used to increment it’s value by 1 each time and If the count variable’s value is odd. It means, it is that single number which occurred the odd number of times in an array.
So the output of this given array is 3.
Let me explain it.
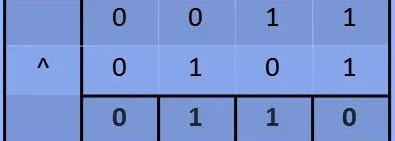
As you can see here, element 1 has occurred 2 times, not an odd number of times in this given array. So it is not a single number. Next, element 3 has occurred 3 times/odd number of times in this given array. That’s why the output is 3 which means it is a single number that occurred the odd number of times in this given array.
By using a brute force algorithm the time complexity is Big O (n2). Because we use two loops. The outer loop is used to select each element one by one from the given array. And the inner loop is used to compare that selected element of an array with all the remaining elements of the array. When the inner loop is completed we can check that the count variable’s value is odd or not.
So can we solve this problem less than Big O(n2)?
So the answer is yes. We can solve this problem using an X-OR based solution.
The second approach to solve this problem is: X-OR Based Solution
So how X-OR works. Let me explain it to you.
X-OR is a very powerful/magical bitwise operator. It is part of bit manipulation. And by using X-OR, we can easily solve this problem in less than Big O(n2). X-OR means an Exclusive OR bitwise operator. Bitwise means it solves the problem bit by bit. The symbol of X-OR is ^. If both the inputs are the same then the output is 0 or exclude it. And if both inputs are different then the output is 1 or any nonzero value.
Read Full Article - Single Number | Arrays | Data Structures and Algorithms
0 notes
Text
What is Recursion? | Concepts of Recursion
Why we need recursion?
Any problem can be solved by a recursive method as well as by the iterative method. But whenever we have a problem that is complex to do just by iterative/looping method. Then we are going to divide the problem into a smaller instance of the same problem that means we solve it by the recursive method.

What is call Stack?
A call stack is a stack data structure that is used to trace the sequence of the function call. When a function called then it’s get pushed inside the stack and when a function returns it popped out from the stack.
Three Concepts of Recursion
Base Case (Terminating Case)
Small Problem
Processing Logic
Types of Recursion:
Tail Recursion:
If a recursive function is calling itself and that recursive call is the last statement in the function. After that call there is nothing, it is not performing anything.
Head Recursion:
If a recursive function is calling itself and that recursive call is the first statement in the function and some operations are performed after the call. The function doesn’t have a processor to perform any operation at the time of calling. It has to do everything at the time of returning.
Linear Recursion:
A linear recursive function is a function that only makes a single call to itself each time the function runs. It has something to process before and after the call.
Read Full Article Here - What is Recursion? | Concepts of Recursion
0 notes
Text
Leaders In An Array – Data Structures & Algorithms
Leaders in an array is an easy problem of arrays from Data Structures and Algorithms. Leaders in the array mean that element is greater than all its right side elements of the array.

So there are two approaches to find the leaders in an array:
- Brute Force Algorithm
- Scan Array from Right
1. Brute Force Algorithm
As you can see, we have an array of size 5. In this approach, we can traverse the array from left to right and each element picks one by one and check with all its right side elements of the array, which is used to checking that it is greater or not than its right side elements of the array. So those are greater than their right side elements of the array, then they become the leaders of this given array.
The rightmost element is always a leader because there is no element to the right side.
So the leaders of this given array are 20, 6, and 5. So let me explain it.
The first element is 14 which is not greater than with all its right side elements because 14 is not greater than 20. The second element is 20 which is greater than with all its right side elements. So it is the first leader. The third element is 3 which is not greater than with all its right side elements because 3 is not greater than 6 and 5. The fourth element is 6 which is greater than with all its right side elements. So it is a second leader. Fifth and last element is 5 which is the rightmost element and it is always a leader as there is no element to its right side. And that’s why leaders are: 20, 6, and 5.
By using the brute force approach the Time complexity of Leaders in an array is Big O(n2).
Because In this approach we use two loops
Outer loop is used to traverse the array from 0 to n-1
And pick one by one all the elements of the array from left to right
Then the inner loop is used to compares the picked element with all the elements to its right side
2. Scan Array from Right
As you can see, we have an array of size 5. In this approach, we traverse from right to left side of the array. Keep the one highest variable in it that is used as the highest variable and if we find any element that is greater than this highest variable then we print this element as a leader and update the highest variable with the new value.
So here maxElement is treated as the highest variable with initial value is equal to 0. And if we find any element that is greater than this maxElement then we print this element as a leader and update the maxElement with the new value.
So the leaders of this given array are 5, 6, and 20. So let me explain it.
The first element is 5 which is greater than this maxElement as maxElement is equal to 0. So the first leader is 5 and the updated value of maxElement is 5. The second element is 6 which is greater than maxElement as maxElement is equal to 5. So the second leader is 6. And the updated value of maxElement is 6. The third element is 3 which is not greater than maxElement as maxElement is equal to 6. So it is not a leader. The fourth element is 20 which is greater than maxElement as maxElement is equal to 6. So the third leader is 20. And the updated value of maxElement is 20. The fifth element is 14 which is not greater than maxElement as maxElement is equal to 20. So it is not a leader. And that’s why leaders are: 5, 6, and 20.
Read Full Article Here - Leaders In An Array – Data Structures & Algorithms
youtube
0 notes
Text
Web Crawling in Python 3
Steps Involved in Web Crawling
To perform this tutorial step-by-step with me, you’ll need Python3 already configured on your local development machine. You can set up everything you need before-hand and then come back to continue ahead.
Creating a Basic Web Scraper
Web Scraping is a two-step process:
You send HTTP request and get source code web pages.
You take that source code and extract information from it.
Both these steps can be implemented in numerous ways in various languages. But we will be using request and bs4 packages of python to perform them.
pip install beautifulsoup4
If you want to install BeautifulSoup4 without using pip or you face any issues during installation you can always refer to the official documentation.
Create a new folder 📂 : With bs4 ready to be utilized, let’s create a new folder for our lab inside any code editor you want (I will be using Microsoft Visual Studio Code
Firstly, we import request package from urllib folder (a directory containing multiple packages related to HTTP requests and responses) of Python so that we can use a particular function that the package provides to make an HTTP request to the website, from where we are trying to scrape data, to get complete source code of its webpage.
import urllib.request as req
Import BeautifulSoup4 package
Next, we bring in the bs4 package that we installed using pip. Think of bs4 as a specialized package to read HTML or XML data. Bs4 has methods and behaviours that allow us to extract data from the webpages’ source code we provide to it, but it doesn’t know what data to look for or in which part to look out.
We will help it to gather information from the webpage and return that info back to us.
import bs4
Provide the URL for webpage
Finally, we provide the crawler with URL of the webpage from where we want to start gathering data: https://www.indeed.co.in/python-jobs.
If you paste this URL in your browser, you will reach indeed.com’s search results page, showing the most relevant jobs out of 11K jobs containing Python as a skill required.
Next, we will send an HTTP request to this URL.
URL = “https://www.indeed.co.in/python-jobs“
Making an HTTP request
Now let’s make a request to indeed.com for the search results page, using HTTP(S) protocol. You typically make this request by using urlopen() from the request package of Python. However, the HTTP response we get is just an object and we cannot make anything useful out it. So, we will handover this object to bs4 to extract the source code and do the needful with it. Send a request to a particular website like this:
response = req.urlopen(URL)
Extracting the source code
Now let’s extract out the source code from the response object. You, generally, will do this by feeding this response object to the BeautifulSoup class present inside bs4 package. However, this source code is very large and it’s a very tedious task to read through it, so we would want to filter the information out of this source code later on. Hand over the response object to BeautifulSoup by writing the following line:
htmlSourceCode = bs4.BeautifulSoup(response)
Testing the crawler
Now let’s test out the code. You can run your Python files by running a command like python <filename> in the integrated terminal of VS Code. Moreover, VS Code has got a graphical play button which can directly run the file which is currently open in the text editor. Still, execute your file by running the following command:
python crawler.py
Read Full Article Here - Web Crawling in Python 3
0 notes
Text
MongoDB – The Inside
What is MongoDB?
It is a DataBase.
Mongo Means Humongous (It can store lots of Data)
MongoDB is NOSQL Based DB , it is Schema Less and it has Less Or No Relationships.
It contains Collections. Inside Collections we have Documents. It is good for Heavy Data , Extensive Read/Write DB Operations.
MongoDB – The Little History
MongoDB was founded in 2007 by Dwight Merriman , Eliot Horowitz and Kevin Ryan – the team behind DoubleClick.
At the Internet advertising company DoubleClick (now owned by Google), the team developed and used many custom data stores to work around the shortcomings of existing databases. The business served 400,000 ads per second, but often struggled with both scalability and agility. Frustrated, the team was inspired to create a database that tackled the challenges it faced at DoubleClick.
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, with offices across North America, Europe, and Asia-Pacific, we are close to where you do business. MongoDB has more than 17,000 customers in more than 100 countries. The MongoDB database platform has been downloaded over 90 million times and there have been more than 1 million MongoDB University registrations.
Now, we will study about collections and documents
MongoDB Structure
Data Base contains Collections ,Collection contains Documents
Note: A Collection of group of
documents . Document contain JSON.
Collection has dynamic schemas.
This means that the documents within a single collection can have any number of different shapes.
Read Full Blog - MongoDB – The Inside | Brain Mentors
0 notes
Text
Concepts of Data Preprocessing
Data pre-processing is a data mining technique which is used to transform raw data into a useful format.
Steps Involved in Data Pre-processing:
1. Data Cleaning
“The idea of imputation is both seductive and dangerous” (R.J.A Little & D.B. Rubin)
One of the most common problems I have faced in Exploratory Analysis is handling the missing values. I feel like that there is NO good way to deal with missing data. There are loads of different solutions for data imputation depending on the kind of problem — Time series Analysis, ML, Regression etc. and it is much more difficult to choose between them. So, let’s explore the most commonly used methods and try to find some solutions that fit our needs.
The data can have many irrelevant and missing parts. To handle this part, data cleaning is done. It involves handling of missing data, noisy data etc.
Missing Data This situation arises when some data is missing in our dataset. Before jumping to the various methods of handling missing data, we have to understand the reason why data goes missing.
Data Goes Missing Randomly : Missing at random means that the case in which a data point is missing, the reason for missing data is not related to the observed dataset.
Data Goes Missing not Randomly : Two possible cases for missing data can be – it depends on the hypothetical value or, it is dependent on some other variable’s values. People with high salaries generally do not want to reveal their incomes in surveys, this can be an example for first case and, we can think that the missing value was actually quite large and can fill it with some hypothetical value. And, an instance for latter case can be, females generally don’t want to reveal their ages! Here, the missing value in age column is impacted by gender column. If data goes missing randomly, it is safe to remove the tuples with occurrences of missing values, while in the other case removing observations with missing values can produce a bias in the model. So we have to be quite bold while removing some tuples. P.S. – Data imputation does not guarantee better results.
Dropping Observations Tuple deletion removes all data for an observation that has one or more missing values. If the missing data is limited to a small number of observations, you may just opt to eliminate those cases from the dataset. However, in most cases, it can produce bias in the analysis because we can never be totally sure that the data has gone missing randomly. mydata.dropna(inplace=True)
Dropping Variables The better choice always is keep data than discarding it. Sometimes you can drop variables (columns) if the data for that particular column is missing for more than 60% rows but only if that column is insignificant. But, still, dropping tuples is always preferred choice over dropping columns. del mydata.column_name mydata.drop(‘column_name’, axis=1, inplace=True)
Fill the missing values There are various ways to do this task. You can choose to fill the missing values manually, by using mean, mode or median. Utilising the overall mean, median or mode is a very straight-forward imputation method. It is quite fast to perform, but has clear disadvantages, one of them being that mean imputation reduces variance in the dataset. from sklearn.preprocessing import Imputer values = mydata.values imputer = Imputer(missing_values=’NaN’, strategy=’mean’) transformed_values = imputer.fit_transform(values) # strategy can be changed to “median” and “most_frequent”
Regression: Data can be made smooth by fitting it into a regression function. The regression used can be linear (having one independent variable) or multiple (having multiple independent variables). To start, most significant variables are identified using a correlation matrix. They are used as independent variables in a regression equation. The dependent variable is the one which has got missing values. Tuples having complete data are used to generate the regression equation; the equation is then used to predict missing values for dependent variable. It provides good estimates for missing values. However, there are several disadvantages of this model which tend to overshadow the advantages. First, since the inserted values were predicted from other variables they fit together very easily and so standard error becomes biased. Another one, we also assume that there is a linear relationship between the variables used in the regression equation when there may not be one.
KNN (K Nearest Neighbours) In this method, k neighbours are chosen based on some distance measure and their average is used as an hypothetical value which can be used to fill up the missing data. KNN can predict both discrete values (most frequent value among the k nearest neighbours) and continuous values (mean among the k nearest neighbours) Different formulas / concepts are used for calculating distance according to the type of data:
Continuous Data: Most commonly used distance formulas are – Euclidean, Manhattan and Cosine
Categorical Data: Hamming distance is generally used for categorical imputation. It iterates through all the categorical attributes and for each, counts one if the value is not the same between two tuples for that variable. The number of attributes for which the value was different is considered as the Hamming distance. One of the drawbacks of the KNN algorithm is that it becomes time-consuming when we try to analyse large datasets because it searches for similar instances through the entire dataset. Moreover, if we are dealing with high-dimensional data, KNN’s accuracy can severely have a downfall because there seems to be little difference between the nearest and farthest neighbour in multiple dimensions. from fancyimpute import KNN # Use 5 nearest rows which have a feature to fill in each row’s missing features knnOutput = KNN(k=5).complete(mydata)
Read Full Article Here - Concepts of Data Preprocessing
0 notes
Text
Flutter vs React Native – What to Choose?
As mobile hardware is progressing, the demand for mobile apps has started increasing. Software developers were looking for a platform that could make mobile apps fast.
Today we are going to talk about React-Native and Flutter.

Flutter
Flutter is an open source UI (SDK) created by Google. The first version of Flutter was known as codename “Sky”. Flutter framework written in C, C++, and Dart Language. Flutter used to develop mobile app, desktop app and web app. flutter initial release was Alpha(v0.0.6)/May 2017 and now currently stable version of Flutter is (v1.17.0)/May 6 2020. Flutter uses single codebase for Android and iOS platforms.
Features of Flutter
Flutter is for developers that want a faster way to build beautiful apps, or a way to reach more users with a single investment.
Flutter is also for designers that want their original design visions delivered consistently, with high fidelity, to all users. In fact, CodePen now supports Flutter.
Flutter is approachable to programmers familiar with object-oriented concepts (classes, methods, variables, etc) and imperative programming concepts (loops, conditionals, etc).
You can build full-featured apps with Flutter, including camera, geolocation, network, storage, 3rd-party SDKs, and more.
What makes Flutter unique
Flutter is different than most other options for building mobile apps because Flutter uses neither WebView nor the OEM widgets that shipped with the device. Instead, Flutter uses its own high-performance rendering engine to draw widgets.
Flutter is different because it only has a thin layer of C/C++ code. Flutter implements most of its system (compositing, gestures, animation, framework, widgets, etc.) in Dart (a modern, concise, object-oriented language) that developers can easily approach read, change, replace, or remove.
React Native
React Native is an open-source JavaScript framework developed by Facebook in 2015. It is used for developing a real, native mobile application for both Android and iOS platforms. It is a JavaScript framework that builds upon the React library to create mobile apps with a single codebase.
Read Full Blog Here - Flutter vs React Native – What to Choose?
0 notes
Text
Introduction to Natural Language Processing
NLP short for Natural Language Processing is one of the major areas of Data Science. When it comes to text processing or when you send or receive some sort of data in any text format whether it is a mail or a message or anything else then just think about it that how you are going to apply machine learning on it. A lot of applications are using NLP like Apple Siri, Windows Cortona, Amazon Alex, etc.
In this blog we are going to cover :
Usage of NLP
Text Processing Approach
Convert Text document to vector form
Implementation using Python and NLTK
Usage of NLP
Let’s understand the use of NLP with the help of a few examples :
Gmail (Spam Classification)
When you receive a mail on Gmail then how Gmail finds out whether this mail will go to your inbox or the spam box.
Sentiment Analysis
When you watch a movie and review it on any website then how my machine learning model will predict that the review is positive or negative. This kind of feature is used on online shopping websites or Google Play Store. When we write a review for any product or an app then it is classified as positive or negative based on the text or words I have used in my review.
Similarly, Gmail keeps track of each mail that what sort of text or words are used. For example :
Chatbots
Chatbots have killed a lot of jobs and introduced a new way of tackling the customers. When you call at customer care centers than there are 90% chances that you will be talking to a chatbot rather than a human. With the help of chatbots, AI has become more powerful. Earlier it was a job of humans to listen to the complaints or queries and then process them and they took a salary for that. But now the same task is done by bots without any salary. A Lot of companies like Google, Apple, Microsoft, or Facebook are using these kinds of chatbots.
So, these were the few examples of NLP that how companies are using this technique to process the text data and apply machine learning to it. We need to understand how to make our machines understand the text and convert it into vector form.
Read Full Article Here - Introduction to Natural Language Processing
0 notes
Text
R Programming Vs Python Programming
What do you want to become :
Perfect Data Analyst or,
Full Stack Data Scientist ?
First, understand the difference between the jobs here. If you just want to become a Data Analyst with few concepts of machine learning as well, then you can just go with R Programming without any second thought. But if you want to become a full stack data scientist with deep knowledge of machine learning and deep learning and then how to deploy them or integrate your models into some web or desktop applications then go for Python programming.

In this blog we will learn :
R Programming Definition
Python Definition
Usability
Popularity Comparison
Jobs and Salary Comparison
Features Comparison
Libraries and Packages
Syntax Comparison
R Programming
R is one of the most popular languages in data science. But we need to understand the usage and limitations of it. R programming is designed in such a way that even a non-programmer can easily understand it. R is a programming language as well as it is considered as a tool for data analysis. R is mainly designed to fulfill your statistical needs. It is primarily used in academics and research and it is the best tool/programming to perform EDA (Exploratory Data Analysis). It could be used in finance, marketing, media, etc.
Python Programming
Python has become one of the most popular languages in data science as well as in other domains like web development or security. Python is considered as a general-purpose language, it means you can use Python for multiple tasks like software development, web development, networking or security, and data science. Using Python programming you can explore a whole new level of data science. Machine Learning and Deep learning could be easily done using python.
Read Full Articel Here - R Programming Vs Python Programming
0 notes
Text
Essential Python Print Statement Tips and Tricks for Every Programmer
Learn various tips and tricks based on print()
Various Tips and Tricks:
To perform this tutorial step-by-step with me, you’ll need Python3 already configured on your local development machine. You can set up everything you need before-hand and then come back to continue ahead.
1. Printing sum of two numbers
Printing sum of two numbers is a two-step process:
Define two variables, say a and b and store their sum in third variable, say c.
Print out the sum stored in the third variable, i.e., c.
Both these steps can be implemented in numerous ways in various languages. But we will be using the most basic syntax available with Python’s print statement.
print(“Sum of”, a, “and”, b, “is”, c)
If you want to use more easier syntaxes for doing the same task or this syntax seems difficult to write when you have loads of variables then you can follow on for more better tricks to use with python( ).
C-inspired syntax 😉 : Most of us are already acquainted with print statement of C-language. So, let’s see the same thing in action in Python (we will still need to take care of data types of variables). Here’s the screenshot for this statement:
str.format( ) 🧐 : We can use format( ) available with each String object in Python. It is used to format the string at runtime, i.e., fill in the values just like last syntax did, we just use { } (curly braces) instead of %d or %s. But, the benefit we get is that we don’t need to worry about commas, ‘+’ signs and even data types. str.format( ) allows us to format strings effortlessly.
str.format( ) with a twist 🐍 : In the above syntax, you can use a little variation. Instead of writing variables in a order in which they should replace curly braces, you can write names of variables inside format( ) in any order, and use indexes inside curly braces to select a particular variable whose value should replace that particular curly braces. Keep in mind, the numbering of variables start from because they act like a tuple. This syntax is very helpful when you have got loads of { } to fill up. You can use this variation like this:
We’ll move forward after these 3 syntaxes to look at the latest and easiest print syntax released in Python 3.7. To do that, we need to
Use f-strings instead of format( ), which are nothing but an improvement over it. For that, we need to write ‘f’ just before our string begins to indicate Python that we want to use f-strings
Use { } containing names of variables, instead of empty curly braces, and omit the format( ) part, which makes the complete statement quite shorter.
Read Full Article Here - Essential Python Print Statement Tips and Tricks for Every Programmer
3 notes
·
View notes
Text
What is Deno? Will it replace NodeJS – Node vs Deno
Deno is a simple, modern and secure runtime for JavaScript and TypeScript that uses Chromium V8 Engine and is built in Rust Programming Language.
Installing Deno
Go to deno.land
Now click on install menu in the deno.land’s menubar
Now, based on Your OS , you can install by using listed commands.Suppose , you have Mac OS , So Copy the command as listed for Mac OS ,then open the terminal and pass the command you copy ,then press enter
Now , you have to set path ,So ,open your bash_profile by typing nano .bash_profile, then press ENTER , Then copy these two lines to your .bash_profile given below:
Now , Hit ctrl + X to save the .bash_profile
Now , You have successfully added the deno path
Now , You can verify your deno Installation by typing deno –version in the terminal to check your current deno’s version.
Also , you can type demo –help in the terminal to check all the deno commands
Also, you can open the deno shell in the terminal by just typing deno and then just press enter.Then you can execute any demo’s Code there.
Now, Lets Start with first Deno’s Program
For this , you have to install vs code through https://code.visualstudio.com/
Now, Open VS Code , goto extension , then install deno plugin as shown :
Now, create a new folder named as Deno where we will write our first program.
Deno has a supports of JavaScript an TypeScript. So you can either write JS or TS. So, we will create a file named as one.ts
Now, lets write code in our one.ts file.This is our type script code :
Now , we have to run this code , so open terminal in vs code by right clicking on file (one.ts) , then navigate to terminal :
Now, terminal will be opened in the bottom of the VS Code.
Read Full Article Here - What is Deno? Will it replace NodeJS – Node vs Deno
0 notes
Text
Templates in C++ with Examples
Templates are a very powerful feature in C++ because templates allow you to write generic programs. It means we can only write one program that is used for different types of data.
C++ is an object-oriented programming language (OOPs). Because C++ programming language viewing the problems in terms of objects rather than the functions/procedures for doing this. C++ also a free form programming language because it supports procedural programming, object-oriented programming, and generic programming. And that’s why using templates we can easily perform the generic programming in C++.
Object-oriented paradigm provides many concepts such as Classes and Objects, Inheritance, Abstraction, Encapsulation, Polymorphism, etc.
Why use Templates?
A single program accepts different types of data. That means, it also provides the concept of reusability and flexibility in C++. And most important C++ templates are used for generic programming. Generic means generalization and generalization means that based on the data type that you can write on the code which can work for any type of data.
There are two types of Templates available in C++ are as follows:
- Function Templates
- Class Templates
Function Templates
Function templates are very similar to a normal function but with one difference. In Function Templates, a function can use for different (more than one) data types at once whereas, in normal Function, a function can use only for one data type at once.
Function templates concept is the same as function overloading but function overloading’s count of lines of code is more than function templates. As function templates are easy to implement and provides generic programming features in C++, the count of lines of code is less than function overloading.
Syntax of Function Template:
Template
T function_name(T x, T y)
{
//Block of Statements
}
Example: 1. Create a simple program for addition by using Function Templates, so that means a single function takes different types of data:
First create a simple addition program by using normal function for different types of data.
Output :
As you see in above program we used three functions to create simple addition program for different types of data. But by using function templates it can be implemented in a single function.
Output:
Example: 2. Create a program to implement swapping between two numbers by using Function Templates, so that means a single function takes different types of data:
Read Full Article Here - Templates in C++ with Examples
0 notes
Text
Interface Overview Blender 3D 2.80 – Brain Mentors
Blender is a free to use and open-source 3D graphics software used for creating animated films, visual effects, 3D printed models, motion graphics, interactive 3D applications, and computer games.
WHY BLENDER ?
There are many softwares like maya , 3D’s Max but why blender can be a better option?
For using 3D’s Max and Maya you have to purchase their tools. But good thing about blender is that it is open source (free to use).
INSTALLING BLENDER
Go to https://www.blender.org/
Then goto download menu in the topbar
Then download a version suitable for your OS (MAC/WINDOWS/LINUX)
After Downloading , double click to install
Now, Congrats, You have successfully installed Blender.
Now ,Lets get your hands dirty with Blender
When you open blender for the first time,the UI of it will look like this as shown :
Now, lets understand the options and Menus in the Blender
The screen showing with a 3 cube in it is called 3D ViewPort.
Inside 3D ViewPort, There are many components like cube , camera and light
Cube is a shape / mesh .
Camera provides the view for our scene.
Light provides lightening in our scene.
Read Full Articel Here - Interface Overview Blender 3D 2.80 – Brain Mentors
0 notes
Text
Introduction to Data Science – Brain Mentors
Data Science has become a hub of opportunities now a days. It is taking care of each domain of the industry whether it is IT, Electronics, Mechanical, Medical or research. Anyone from any background can go for data science today. Data Science is a combination of programming and mathematics. You don’t need to be an expert in mathematics, but you should know basics of it. These are the prerequisite that you must see before going into the detail of data science:
- Math
Linear Algebra
Statistics and Probability
Calculus (Partial Derivatives)
- Programming (Any One)
Python
R Programming
MATLAB

Mathematics is one of the most beautiful subjects in this world. If you are eager to learn these topics of mathematics and a little bit of any of the programming, then only you can go for Data Science. You might be learning mathematics from your school time, but did you ever thought about the real time use case of the topics that you learn in math. In data science you will understand the real meaning of math that how it is helping to make your software and applications more and more smart.
In this blog we are going to see the life cycle of a data scientist. Data Scientist job is considered as one of the most highly paid job in industry today. But there are lot of domains inside a data science life cycle. You could become any one of them or you could be a full fledge data scientist as well. So let’s see the life cycle of data science first :
Here, I am using very basic terms to make you understand the life cycle of data science. And you might find few different life cycles on internet as well. But the meaning is almost same everywhere. I have divided data science into 5 major parts. Let’s talk about each and every part of life cycle in detail :
Data Collection
This is the first phase of data science life cycle. Before doing anything the first thing you need is data. So how and from where you will get the dataset ?
Data Collection means to collect the data and being a data science engineer, it becomes your responsibility to gather data from different resources. And you should be aware of the different techniques to gather data.
Data could be available on any website or in database or a file or it could be an API.
Techniques of data collection :
So these are the few techniques which are used to gather data and you cannot rely on a single technique because data could be available on any website or it might be stored in database or some web services are providing you the dataset.
Read Full Article Here - Introduction to Data Science – Brain Mentors
0 notes
Text
5 New JavaScript Features in ES 2020 – Brain Mentors
In this Blog we are going to learn ES 2020 Key Features.ES2020 released on Start of this year.
Here we are going to learn some really cool features of ES 2020
Let’s start with Feature 1 : Nullish coalescing
Use when the value is missing (undefined or null (It doesn’t work with NaN , ‘’, 0)).
The undefined and null are the nullish value , and you want to handle it then we use nullish coalescing operator.
Example:

In above example , country is not there so it does show undefined And I want to print some meaningful result
Before ES 2020 we use truthy and falsy

It just checks if the first value is true then don’t go to the second value ,
if first is false (undefined or null ) then go to the second value.
Instead of PIPE Now Use Nullish Operator from ES 2020

Feature 2 : Optional Chaining Operator
Nested Object Property access can be dangerous , if any of the property is null or undefined.
Example :

Read Full Article Here - 5 New JavaScript Features in ES 2020 – Brain Mentors
0 notes
Text
Learn Top 20 Tricks of Python in just 20 minutes
Python is the most popular language among developers as well as non-developers. Its simple syntax and one-liners take this programming to the next level. In this blog, we are going to cover the top 20 python tips and tricks that you must know.
These tricks will be covered :
Swapping of 2 numbers
Pattern Program using a single for loop
Max of 3 in a single statement (Chaining)
Walrus with the while loop
List, Tuples and Dictionary comprehension
Map
Filter
Sorting a List of dictionary in a single statement
The Prime number using for else
Reverse of string
Functions Annotations
Open any website on the browser
Print Calendar
Zip
Is vs ==
Packing Unpacking
Permutation and Combination
Check ASCII from Character or Character from ASCII
Image Downloader
Play music
Read Full Article Here - Learn Top 20 Tricks of Python in just 20 minutes
0 notes
Text
What’s New in Python 3.8? – Python Guide for Beginners
So, python 3.8 has been around a while now, October 14th, 2019 to be accurate. But it is still not used across the board because most people don’t know about the feature-set it brings to the table.
Some of the contemporary features are as follows:
• The Walrus Operator (:=)
It’s called so because the operator symbol resembles a “walrus”.This operator is used to assign and return a value in the same expression. Generally the assignment and retrieval of a value took two statements, but python 3.8 has made it more convenient.
Lets look a few examples:
Simple Print:-
3.7
3.8
While Loops:-
3.7
3.8
• Simpler use of F strings
It is basically used for string replacement as can seen in the given example:
New:-
In Python 3.8 , you can use assignment operators.
New Specifier:
Using this specifier , you can print both the text as well as the value of the variable using only this simple syntax.
You can also add spaces after ‘=’ and use the format specifier.
• New Module importlib.metadata
Through this module, you can access information about installed packages in your pc on python.
• Positional Only Arguments
New parameter syntax ‘/’ is used . It is used to specify that some parameters must be specified positionally according to function needs.
Here more than required positional arguments were given.
Here only ‘name’ is a positional only argument while ‘greet’ is a regular argument that is why in the third iteration the output gives an error.
• New Statistics Functions
Prod function -used to simply multiply numbers.
isqrt function- used to find only the integral value of a square root.
No modulus operator need be used.
Dist function- used to find the distance between the two points
Hypot function – used to find the length of a vector
statistics.fmean()– used to find the mean of float numbers
statistics.geometric_mean()- used to find the geometric mean of float numbers
statistics.multimode()- used to find most frequently occurring values
statistics.quantiles()- used to cut points for dividing data into n continuous intervals with equal probability.
• ‘Finally’ and ‘Continue’ statements
In python 3.7 , you cannot use the ‘continue’ keyword in a ‘finally’ clause, as shown below:
But now in the new version it is supported, the same code in the new shell:
• New Optimizations
Some new optimizations to reduce ‘run’ timings and reduce memory usage.
Saving memory on initializing lists.
3.7
3.8
So, the real question is “Should you upgrade to version 3.8?”
Well , if you want to try out the new features you should absolutely upgrade to it.
About moving your projects from ver- 3.7 to ver- 3.8, Django and anaconda have both made it easy to switch between multiple versions. So switch as you like.
Ultimately it comes to you , if you think you can utilize the interesting but subtle features , try it out . Otherwise Python version 3.6 has become the base and most libraries and packages can be used on it without much problem.
END
These were some of the many features of this new version that I thought were easy to understand & interesting enough to share. For more detailed information check the python official web site:
https://docs.python.org/3/whatsnew/3.8.html
0 notes