#Abstract Syntax Tree
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
for some reason the intro to phonology and syntax classes for grad students are also the advanced phonology and syntax classes for undergrads, which means the professors are spouting off dense syntactical theory to undergrads who have already taken the intro class with them, meanwhile there's six of us grad students sitting to the side staring at each other like this

#linguistics blogging#no joke I literally made this face in syntax earlier#the professor was describing contiguity theory and drawing syntax trees I could NOT understand#and an undergrad asked her ''what does this mean for phi-boundaries'' or something like that#and I just looked over at my friends and made this face#only to discover they were all also looking bewildered and/or miserable#I'm so glad it's not just me#because I have literally never taken a phonology or syntax class#and I am SO out of my depth#we did the BARE basics of this stuff in my minor#and definitely no theory#so I have no fucking idea what's going on#luckily out of the six of us only two have an actual linguistics degree before this#the rest of us are pretty new to the field#so we are suffering together#i hate syntax and phonology. god.#these technical fields are NOT for me#this is why I'm a sociolinguist!!!!!#I am not interested in theories about how language works from an abstract perspective#I'm much more interested in WHY language behaves the way it does socially#like. I don't care about the phonological reasons for a particular sound feature#im more interested in the social context. does this sound carry prestige? is it stigmatized? how has the perception of it changed over time#I don't care about the theory behind why certain languages have developed grammatical rules for word order#I'm more interested in what happens when a dialect forms from a community with a different L1#and how their ideas of word order affect their L2 dialect#you know?#the social and historical stuff is where I thrive#not this theory babble#like. the theory is important work. but it's not MY work.
23 notes
·
View notes
Text
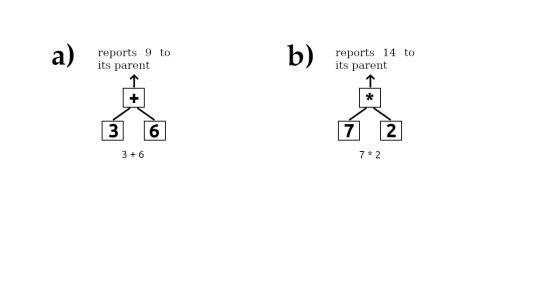
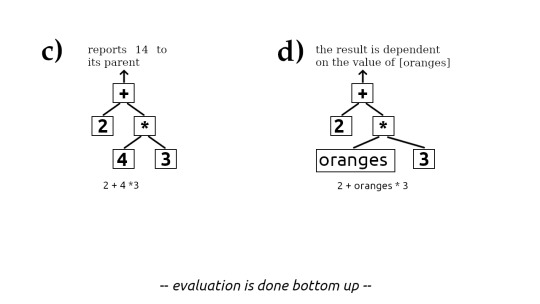
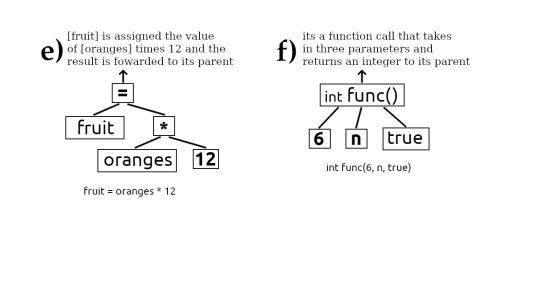
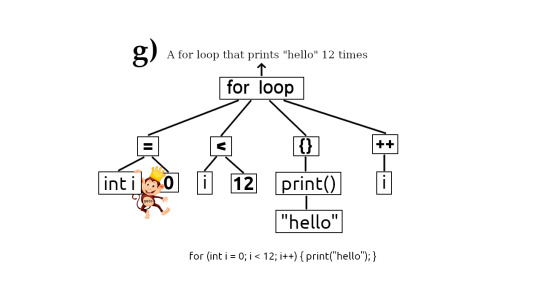
Programs expressed using tree structures
Officially they are called abstract syntax trees. Sometimes referred to as token trees. If you look at the images (a) thru (g) you can see the progression of how code can be represented as tree structures. Evaluating this tree is the same as executing the code.
A compiler parses your code and converts it into these tree structures before generating code. At first compilers would take the approach similar to an assembler. It would go line by line. Converting each line to code before going to the next one. That is a linear path. But then about half a century ago there were debates and discussions about structured programming and restraining the goto statement.
These trees represent the structure in structured programming. They got rid of line numbers and introduced scope rules. Code is better organized this way. One down side was that they had to discourage the use of the goto statement. Because the goto statement is like Neo in the Matrix. Its like a wild monkey that can jump to any branch it wants to. Thus breaking structure.
Anyways the brain loves this structure. For starters you can see the "chunking" right. You can see the "divide and conquer" approach. Encapsulation is also there. Every node in the tree, encapsulates its branches. For example in the example (g) the [for loop] node encapsulates the content of the for loop in its branches.
In our brain Hayakawa's ladder of abstraction is not a linear ladder. Its one of these. Its an abstract syntax tree. Our brain can go up and down these trees with with ease.
2 notes
·
View notes
Text
16^12, a nucleus of worldview (6/?)

Continuation upon this loose thread.

I got a new dream onto the intertextual implications, history doctorate-tier narrative components & overall intrigue of my books' narrative. And it boils down to something somewhat similar to Tolkien's works as a nuanced, mysterious, profound but yet optimistic, empowering & introspective complete cosmic-scale GLOSS* history epic about the cycle of life versus entropy, coming-of-age, constructing meaning in bleak times & about all sorts of """autistic""" patterns.
What that means is that I have a clearer perspective & direction of what plot points could be around the core series of books and how to reuse what other good things come from what I shall write soon. And while still taking into account some key world building parameters to keep this narrative realm timeless-ly useful, I now know what overall intrigue for the core duo of characters (aka "Kate" the human INTJ historian lady & "Valenz" the ENFP synthetic-tier android social assistant + syndicalist vigilante) is gonna feel like (a escalation of power, of worldly understanding & of individual self-control);
And while they still have to overcome systemic issues & bring forth constructive change, I think adding this very spiritually metaphysical, honest nuanced yet hopeful, constructive & affirmative aspect will really enrich the paracosm long-term appeal & the intertextual relations derived from such, especially considering all the historical & mythological heritage that I am tying it with (such as the Bronze Age period, World War 1, Thirty Years War, Abrahamic Mythos...) going both backwards, forwards and sideways in time.
Granted, I do have some personal worldview values to transmit, some opinionated tools to use & so much additional research & iterative work left to be done in order to reach the one planet cyclic universal history scope thing I am onto, but rest assured I will find S.M.A.R.T ways to distribute the risks & rewards of this endeavor into edible chunks of data as well as leave a decent share of open space / mystery to do as you please (within ethical consensus bounds) inside that paracosm framework of ours.
Very abstract, ain't it? Well, I will pace more specific explanations for it out in due time as I figure things out as the open book I really am inside. Farewell to soon!

#maskutchew#16^12#worldbuilding#actually autistic#red instead#far far away cosmic future at the edge of time#bronze age solarpunk as time period mood?#epic track record of a open source abstract syntax tree of Lisp meta-patterns...
0 notes
Text
Calculus is ruining my fucking life. Every time I see a thing inside another thing, I can't help but wonder how to apply the chain rule. It started with abstract things like syntax trees, but I got jumpscared by a banner ad showing penis-in-vagina sex and all I could think about was derivatives. v'(p(x)) * p'(x), where v(x) is vagina and p(x) is penis. Now, how to find v'(x) and p'(x). . . ?
Everything is secretly about sex, except sex, which is secretly about calculus.
576 notes
·
View notes
Text
I think every programming language is stupid and full of syntax "sugar" that isn't even sugar. Random bullshit that violates the established conventions of how the language works without actually making anything simpler or easier. Look, I'm not a coder. But I just learned that JS has a variable declaration thingy
var <variable name> = <value>
that automatically moves the variable declaration to the top of the scope, as opposed to
let <variable name> = <value>
which doesn't. Ok, why have that? Why have that. That's so fucking dumb. Maybe they differ in some other way that actually makes sense, idk, but even if they do why add this additional difference.
Where's what I think. A programing language should have exactly one way to do everything. Maybe a couple if there's a really good reason in terms of convenience/readability. If you do not have a really good reason, only have one. Furthermore, a programming language should make the underlying program tree as transparent as possible. A written program should be, to the greatest extent possible, in complete isomorphism with the program logic. It should have the same order, the same nesting, the same everything. I should be able to see the logic just by glancing at it.
Everything else is stupid.
There are competing needs that matter: technical fidelity (written code clearly represents what is actually happening when a computer executes a program) and mathematical fidelity (written code clearly represents the abstract mathematical structure of a program). I get that these sometimes trade off against each other, and that's fair. It's reasonable to draw that line in different places. But everything else? Stupid, absolutely stupid. Concessions not to nature but to man. Needless frivolity.
87 notes
·
View notes
Note
how do u make ur own programming language??
PERSISTENCE .
if youre making an interpreted language it's 2 major parts: the compiler (which is tied to the lexer and its abstract syntax tree), and the virtual machine (which may also include a garbage collector). I started with what syntax and features i wanted the language to be at its core and built the AST / lexer to fit it. Then from there the compiler + virtual machine were built piece by piece based on what was needed. Then finally the garbage collector was made.
Go look at the source for Lua and Duktape (the open source embeddable JS implementation); they were my inspirations
Also the hardest part by far was the garbage collector. It's on rewrite number 6 and I hope i never have to touch it again
8 notes
·
View notes
Text
it's like. i have the capacity to understand how an interpreter can parse source code into tokens and then turn tokens into an abstract syntax tree and then execute it, i've done this before, but i don't Currently have that knowledge in my head and i would have to shuffle things around and forget some things on order to learn it again. but some day i wanna keep making a compiler
8 notes
·
View notes
Photo

Source “Enjoy! Sudoku” by asie (2020) Published by: Abstract Syntax Tree [SUDOKU.ZZT] - “$. = { ENJOY! SUDOKU } = .” Play This World Online
5 notes
·
View notes
Text
diary397
10/23/24
wendesday
tomorrow, we go to a pumpkin patch with friends.
and believe it or not, i've just done a bit of writing. transcribing from the notes app but that's always like, rather involved because i go, what was i trying to get at, then i reverse engineer it, something better comes out usually. so i need to do that, i've got about 44 notes to go through, which is probably gonna be about 30 extra pages. whew! terrible maybe. but then i get to just start assembling more, i get to move past this middle in the hump as everything before is essentially laid out. a new list to get through... this makes it really manageable honestly, having the number down and now i'll just run run run thru it. it feels good to have this now. i guess i'm like dumb in some way for feeling like a list is going to make writing something easier but i suppose that's how these things might go. it's long as it is so anything to make it less abstract. being less abstract... wow! it can happen and if it can happen that means it could end up out there in the world.
i also ought to work with the tiny thing, what i really need to do is go into the section i wrote forever ago and change the tense, which will also be additional editing when i come across awkward syntax. but whatever... i need to bite the bullet. just doesn't feel like a lot of time for this.
between these two things, i also really need to force myself to sit down and read. i'm just so tired lately, i keep waking up too early for no reason. or. some reason, it's just bright when my gf turns lights on, and a little loud when she moves around. i don't blame her, it just sucks broadly. but whatever. i'm super tired now so i feel like i will sleep better at least.
i didn't start the drawing of daan, i doubt tomorrow will be the day but you never know, i did a little thing with music today also, but nothing for a main project, just having fun writing weird things. odd chords that move weird, it's almost incoherent, but i like it. maybe i can make it make more sense when i get to it another time. maybe the not really making sense is actually a positive. who knows.
oh, the other day, i used the word daub incorrectly, i feel idiotic for that. less so now that i admit the failure. i feel good about that.
errands were very fast today, since my gf's mom is clearly not supposed to be so mobile right now.
i snapped a little, for starving, i was very hungry today, i can be irritable, but i think it was just kind of funny how it happened, my gf made some offhanded joke, i was like, i'm hungry, fuck you, but she didn't care at all, i think because she's similar to that she just understood. it's not good to be that way but i guess everybody is like that sometimes, because they are hungry and had to do a bunch of things. it's interesting how being hungry can make you be something you normally are not. i feel bad that i can be like that at all, honestly, it makes me worry i'm really evil, and a bad presence in anybody's life, and i don't know how to tell if i am or am not. when i ask, everyone says, what do you mean you think you're evil, my gf says it makes her think of happy tree friends when i say things like that. like some kind of cartoon squirrel that's too cute or something to really do anything. which is reassuring to put in words here. it's not about how i look, it's that i guess, there's some line that i can't cross, because my line for being awful is being grouchy when i'm hungry or overstimulated. it really didn't mean anything to her, or her mother, or they were a little shocked since normally i don't ever talk back... i don't know, i feel bad, and it didn't mean anything to either of them, so ultimately, it doesn't matter. but i want to be a better person, or, not mean to people.
i should try and think of concrete ways to do that... maybe i talk about it too much.
i ought to sleep soon, but my friend who has traveled to brazil and will be there for many more months is messaging me, his journey is incredible, one of the coolest things i've seen, to make the effort to go be out there, with a girl i think he is together with, you know, like, i suppose to make solid the relationship in that way, to be with her for 6 months basically, that's really moving to me. making sure to make it strong i guess. and to go so far out of his comfort zone, he's a very cool person. it is nice to think about, from what he's been through, and how he hasn't let it get him to give up you know.
here's an all timer:
youtube
oooh woo ooh ooh ooh oohwooo
perfect song. nothing else to say really except it always blows me away, such a slinky and mysterious thing, a puddle on a grey day without any rain, staring at it, waiting, sad nothing comes, climbing a fence and running around a playground at a school, walking back home.
i will sleep now,
so,
byebye!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
3 notes
·
View notes
Text
The Process:
So like, in this little game I'm making, if I want to be able to script entity behavior on a coarser scale than individual frames, I'm gonna need to set up some kinda state machine right? Like say a "Currently Moving To X,Y" state that takes the entity closer to X,Y each frame until it's there and then moves on to the next thing
So I'll need to come up with a bunch of like primitive actions/states of that kind. And then what, a "script" is just an array of those kinds of things or something?
What if I wanna have conditionals in scripts? That's gonna start being some kinda tedious types
It would be nice to be able to write actual code for scripts, especially if they're gonna be at all complex. Otherwise "writing a script" basically amounts to manually building an abstract syntax tree, that'll get tedious as hell
Will I need to like actually come up with and implement a proper scripting language for this? I mean that'd be fun but also a lot of work
...
.... wait
....... wait hold up, rust async code literally just already compiles to state machines
Wait I think I can make a fuckin async runtime that just does exactly this with normal-ass rust futures
Huh
14 notes
·
View notes
Text
Code Embedding: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/code-embedding-a-comprehensive-guide/
Code Embedding: A Comprehensive Guide
Code embeddings are a transformative way to represent code snippets as dense vectors in a continuous space. These embeddings capture the semantic and functional relationships between code snippets, enabling powerful applications in AI-assisted programming. Similar to word embeddings in natural language processing (NLP), code embeddings position similar code snippets close together in the vector space, allowing machines to understand and manipulate code more effectively.
What are Code Embeddings?
Code embeddings convert complex code structures into numerical vectors that capture the meaning and functionality of the code. Unlike traditional methods that treat code as sequences of characters, embeddings capture the semantic relationships between parts of the code. This is crucial for various AI-driven software engineering tasks, such as code search, completion, bug detection, and more.
For example, consider these two Python functions:
def add_numbers(a, b): return a + b
def sum_two_values(x, y): result = x + y return result
While these functions look different syntactically, they perform the same operation. A good code embedding would represent these two functions with similar vectors, capturing their functional similarity despite their textual differences.
Vector Embedding
How are Code Embeddings Created?
There are different techniques for creating code embeddings. One common approach involves using neural networks to learn these representations from a large dataset of code. The network analyzes the code structure, including tokens (keywords, identifiers), syntax (how the code is structured), and potentially comments to learn the relationships between different code snippets.
Let’s break down the process:
Code as a Sequence: First, code snippets are treated as sequences of tokens (variables, keywords, operators).
Neural Network Training: A neural network processes these sequences and learns to map them to fixed-size vector representations. The network considers factors like syntax, semantics, and relationships between code elements.
Capturing Similarities: The training aims to position similar code snippets (with similar functionality) close together in the vector space. This allows for tasks like finding similar code or comparing functionality.
Here’s a simplified Python example of how you might preprocess code for embedding:
import ast def tokenize_code(code_string): tree = ast.parse(code_string) tokens = [] for node in ast.walk(tree): if isinstance(node, ast.Name): tokens.append(node.id) elif isinstance(node, ast.Str): tokens.append('STRING') elif isinstance(node, ast.Num): tokens.append('NUMBER') # Add more node types as needed return tokens # Example usage code = """ def greet(name): print("Hello, " + name + "!") """ tokens = tokenize_code(code) print(tokens) # Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
This tokenized representation can then be fed into a neural network for embedding.
Existing Approaches to Code Embedding
Existing methods for code embedding can be classified into three main categories:
Token-Based Methods
Token-based methods treat code as a sequence of lexical tokens. Techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and deep learning models like CodeBERT fall into this category.
Tree-Based Methods
Tree-based methods parse code into abstract syntax trees (ASTs) or other tree structures, capturing the syntactic and semantic rules of the code. Examples include tree-based neural networks and models like code2vec and ASTNN.
Graph-Based Methods
Graph-based methods construct graphs from code, such as control flow graphs (CFGs) and data flow graphs (DFGs), to represent the dynamic behavior and dependencies of the code. GraphCodeBERT is a notable example.
TransformCode: A Framework for Code Embedding
TransformCode: Unsupervised learning of code embedding
TransformCode is a framework that addresses the limitations of existing methods by learning code embeddings in a contrastive learning manner. It is encoder-agnostic and language-agnostic, meaning it can leverage any encoder model and handle any programming language.
The diagram above illustrates the framework of TransformCode for unsupervised learning of code embedding using contrastive learning. It consists of two main phases: Before Training and Contrastive Learning for Training. Here’s a detailed explanation of each component:
Before Training
1. Data Preprocessing:
Dataset: The initial input is a dataset containing code snippets.
Normalized Code: The code snippets undergo normalization to remove comments and rename variables to a standard format. This helps in reducing the influence of variable naming on the learning process and improves the generalizability of the model.
Code Transformation: The normalized code is then transformed using various syntactic and semantic transformations to generate positive samples. These transformations ensure that the semantic meaning of the code remains unchanged, providing diverse and robust samples for contrastive learning.
2. Tokenization:
Train Tokenizer: A tokenizer is trained on the code dataset to convert code text into embeddings. This involves breaking down the code into smaller units, such as tokens, that can be processed by the model.
Embedding Dataset: The trained tokenizer is used to convert the entire code dataset into embeddings, which serve as the input for the contrastive learning phase.
Contrastive Learning for Training
3. Training Process:
Train Sample: A sample from the training dataset is selected as the query code representation.
Positive Sample: The corresponding positive sample is the transformed version of the query code, obtained during the data preprocessing phase.
Negative Samples in Batch: Negative samples are all other code samples in the current mini-batch that are different from the positive sample.
4. Encoder and Momentum Encoder:
Transformer Encoder with Relative Position and MLP Projection Head: Both the query and positive samples are fed into a Transformer encoder. The encoder incorporates relative position encoding to capture the syntactic structure and relationships between tokens in the code. An MLP (Multi-Layer Perceptron) projection head is used to map the encoded representations to a lower-dimensional space where the contrastive learning objective is applied.
Momentum Encoder: A momentum encoder is also used, which is updated by a moving average of the query encoder’s parameters. This helps maintain the consistency and diversity of the representations, preventing the collapse of the contrastive loss. The negative samples are encoded using this momentum encoder and enqueued for the contrastive learning process.
5. Contrastive Learning Objective:
Compute InfoNCE Loss (Similarity): The InfoNCE (Noise Contrastive Estimation) loss is computed to maximize the similarity between the query and positive samples while minimizing the similarity between the query and negative samples. This objective ensures that the learned embeddings are discriminative and robust, capturing the semantic similarity of the code snippets.
The entire framework leverages the strengths of contrastive learning to learn meaningful and robust code embeddings from unlabeled data. The use of AST transformations and a momentum encoder further enhances the quality and efficiency of the learned representations, making TransformCode a powerful tool for various software engineering tasks.
Key Features of TransformCode
Flexibility and Adaptability: Can be extended to various downstream tasks requiring code representation.
Efficiency and Scalability: Does not require a large model or extensive training data, supporting any programming language.
Unsupervised and Supervised Learning: Can be applied to both learning scenarios by incorporating task-specific labels or objectives.
Adjustable Parameters: The number of encoder parameters can be adjusted based on available computing resources.
TransformCode introduces A data-augmentation technique called AST transformation, applying syntactic and semantic transformations to the original code snippets. This generates diverse and robust samples for contrastive learning.
Applications of Code Embeddings
Code embeddings have revolutionized various aspects of software engineering by transforming code from a textual format to a numerical representation usable by machine learning models. Here are some key applications:
Improved Code Search
Traditionally, code search relied on keyword matching, which often led to irrelevant results. Code embeddings enable semantic search, where code snippets are ranked based on their similarity in functionality, even if they use different keywords. This significantly improves the accuracy and efficiency of finding relevant code within large codebases.
Smarter Code Completion
Code completion tools suggest relevant code snippets based on the current context. By leveraging code embeddings, these tools can provide more accurate and helpful suggestions by understanding the semantic meaning of the code being written. This translates to faster and more productive coding experiences.
Automated Code Correction and Bug Detection
Code embeddings can be used to identify patterns that often indicate bugs or inefficiencies in code. By analyzing the similarity between code snippets and known bug patterns, these systems can automatically suggest fixes or highlight areas that might require further inspection.
Enhanced Code Summarization and Documentation Generation
Large codebases often lack proper documentation, making it difficult for new developers to understand their workings. Code embeddings can create concise summaries that capture the essence of the code’s functionality. This not only improves code maintainability but also facilitates knowledge transfer within development teams.
Improved Code Reviews
Code reviews are crucial for maintaining code quality. Code embeddings can assist reviewers by highlighting potential issues and suggesting improvements. Additionally, they can facilitate comparisons between different code versions, making the review process more efficient.
Cross-Lingual Code Processing
The world of software development is not limited to a single programming language. Code embeddings hold promise for facilitating cross-lingual code processing tasks. By capturing the semantic relationships between code written in different languages, these techniques could enable tasks like code search and analysis across programming languages.
Choosing the Right Code Embedding Model
There’s no one-size-fits-all solution for choosing a code embedding model. The best model depends on various factors, including the specific objective, the programming language, and available resources.
Key Considerations:
Specific Objective: For code completion, a model adept at local semantics (like word2vec-based) might be sufficient. For code search requiring understanding broader context, graph-based models might be better.
Programming Language: Some models are tailored for specific languages (e.g., Java, Python), while others are more general-purpose.
Available Resources: Consider the computational power required to train and use the model. Complex models might not be feasible for resource-constrained environments.
Additional Tips:
Experimentation is Key: Don’t be afraid to experiment with a few different models to see which one performs best for your specific dataset and use case.
Stay Updated: The field of code embeddings is constantly evolving. Keep an eye on new models and research to ensure you’re using the latest advancements.
Community Resources: Utilize online communities and forums dedicated to code embeddings. These can be valuable sources of information and insights from other developers.
The Future of Code Embeddings
As research in this area continues, code embeddings are poised to play an increasingly central role in software engineering. By enabling machines to understand code on a deeper level, they can revolutionize the way we develop, maintain, and interact with software.
References and Further Reading
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
GraphCodeBERT: Pre-trained Code Representation Learning with Data Flow
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
Transformers: Attention Is All You Need
Contrastive Learning for Unsupervised Code Embedding
#Abstract Syntax Tree#ai#Analysis#applications#approach#Artificial Intelligence#attention#Behavior#bug#bugs#Capture#code#Code Embedding#Code embeddings#Code Review#Code Search#Code2vec#CodeBERT#coding#Community#comprehensive#computing#continuous#contrastive learning#data#Deep Learning#detection#developers#development#diversity
0 notes
Text
Techmindz: Leading Java Courses in Ernakulam to Kickstart Your IT Career
In today’s rapidly evolving tech landscape, Java continues to be one of the most sought-after programming languages for software development. Whether you are a fresh graduate or a professional looking to enhance your skills, enrolling in a Java course in Ernakulam can open the doors to numerous career opportunities in the world of IT.
Techmindz, located in the heart of Infopark, Kochi, offers industry-centric Java courses designed to help you master the fundamentals and advanced concepts of Java programming. Let’s take a closer look at why Techmindz is the perfect choice for your Java learning journey.
Why Choose Techmindz for Java Courses in Ernakulam?
Techmindz has established itself as a premier institution for tech training in Kerala, known for its comprehensive and hands-on approach to learning. The institution offers a range of Java courses that cater to both beginners and experienced developers. Here's why you should choose Techmindz for your Java learning:
Industry-Aligned Curriculum Techmindz’s Java course is designed with input from industry experts, ensuring that the content is up-to-date and aligned with the needs of the modern job market. You’ll learn not just basic Java syntax, but also how to build real-world applications using Java frameworks like Spring, Hibernate, and more.
Experienced Trainers The trainers at Techmindz are seasoned professionals with years of experience in Java development. They bring a wealth of knowledge, real-world insights, and practical tips, making the learning experience highly valuable.
Hands-On Learning At Techmindz, theoretical knowledge is paired with practical application. Students work on live projects, coding challenges, and problem-solving sessions, ensuring that they gain the skills needed to excel in real-world Java development.
Placement Assistance Techmindz provides excellent placement support, helping students connect with top companies in Ernakulam and beyond. With a network of hiring partners, Techmindz ensures that graduates are job-ready and well-prepared to face interviews.
Flexible Batch Options Understanding that students have different schedules, Techmindz offers both weekday and weekend batches for its Java courses in Ernakulam. Whether you are a student or a working professional, you can choose the batch that fits your schedule.
What Will You Learn in Techmindz’s Java Courses?
Techmindz’s Java course in Ernakulam covers everything from basic to advanced topics. Here’s an overview of the key concepts you’ll learn:
Core Java Concepts: Learn the fundamentals of Java programming including variables, loops, conditionals, and functions.
Object-Oriented Programming (OOP): Understand the four pillars of OOP – encapsulation, inheritance, polymorphism, and abstraction – to write modular and reusable code.
Data Structures and Algorithms: Gain proficiency in key data structures like arrays, linked lists, stacks, queues, and trees, and understand the algorithms used to solve common programming problems.
Java Collections Framework: Dive deep into collections like lists, sets, maps, and queues, which are essential for building efficient Java applications.
Exception Handling: Learn how to handle errors and exceptions effectively to make your Java applications robust.
Java Development Tools: Get hands-on experience with Java IDEs like Eclipse and IntelliJ IDEA, as well as build automation tools like Maven and Gradle.
Database Integration: Learn how to work with databases using Java Database Connectivity (JDBC) to create data-driven applications.
Frameworks and Technologies: Explore popular Java frameworks like Spring and Hibernate for building enterprise-level applications.
Course Duration and Delivery Modes
Techmindz’s Java course is designed to accommodate both full-time and part-time learners. The duration of the course typically ranges from 2 to 3 months, depending on your chosen batch and learning pace. The delivery modes include:
Classroom Sessions: Engage in interactive sessions with industry experts at Techmindz's modern campus in Infopark, Ernakulam.
Online Classes: For those who are unable to attend in person, Techmindz offers live online classes with the same quality of instruction.
Self-Paced Learning: You’ll also have access to recorded sessions, allowing you to learn at your own pace.
Who Should Enroll in Java Courses at Techmindz?
Techmindz’s Java courses in Ernakulam are suitable for:
Beginners: If you are new to programming or coming from a non-technical background, Techmindz’s beginner-friendly curriculum will guide you step-by-step through the concepts of Java.
Experienced Programmers: If you already have basic programming knowledge and want to deepen your Java skills, Techmindz’s advanced modules will prepare you for complex real-world scenarios.
Professionals Seeking Career Change: If you are a working professional looking to shift into Java development, this course provides the necessary skills and knowledge to transition smoothly.
Start Your Journey Today!
The demand for skilled Java developers is at an all-time high, and enrolling in Techmindz’s Java course in Ernakulam can provide you with the expertise you need to succeed in this competitive field. With expert trainers, a practical curriculum, and excellent placement support, Techmindz is the ideal place to take your Java skills to the next level.
To get started, visit Techmindz and book your spot in the next batch. You can also walk into our Ernakulam or Infopark campus for personalized counseling. Don’t miss out on the opportunity to enhance your skills and build a successful career as a Java developer!
This article is fully optimized for SEO with the keyword "Java Courses in Ernakulam" and is written in a way that helps boost Techmindz’s visibility online. Let me know if you would like any changes or further optimizations!
0 notes
Text
Ultimate Guide to Python Compiler

When diving into the world of Python programming, understanding how Python code is executed is crucial for anyone looking to develop, test, or optimize their applications. This process involves using a Python compiler, a vital tool for transforming human-readable Python code into machine-readable instructions. But what exactly is a Python compiler, how does it work, and why is it so important? This guide will break it all down for you in detail, covering everything from the basic principles to advanced usage.
What is a Python Compiler?
A Python compiler is a software tool that translates Python code (written in a human-readable form) into machine code or bytecode that the computer can execute. Unlike languages like C or Java, Python is primarily an interpreted language, which means the code is executed line by line by an interpreter. However, Python compilers and interpreters often work together to convert the source code into something that can run on your system.
Difference Between Compiler and Interpreter
Before we delve deeper into Python compilers, it’s important to understand the distinction between a compiler and an interpreter. A compiler translates the entire source code into a machine-readable format at once, before execution begins. Once compiled, the program can be executed multiple times without needing to recompile.
On the other hand, an interpreter processes the source code line by line, converting each line into machine code and executing it immediately. Python, as a high-level language, uses both techniques: it compiles the Python code into an intermediate form (called bytecode) and then interprets that bytecode.
How Does the Python Compiler Work?
The Python compiler is an essential part of the Python runtime environment. When you write Python code, it first undergoes a compilation process before execution. Here’s a step-by-step look at how it works:
1. Source Code Parsing
The process starts when the Python source code (.py file) is written. The Python interpreter reads this code, parsing it into a data structure called an Abstract Syntax Tree (AST). The AST is a hierarchical tree-like representation of the Python code, breaking it down into different components like variables, functions, loops, and classes.
2. Compilation to Bytecode
After parsing the source code, the Python interpreter uses a compiler to convert the AST into bytecode. This bytecode is a lower-level representation of the source code that is platform-independent, meaning it can run on any machine that has a Python interpreter. Bytecode is not human-readable and acts as an intermediate step between the high-level source code and the machine code that runs on the hardware.
The bytecode generated is saved in .pyc (Python Compiled) files, which are stored in a special directory named __pycache__. When you run a Python program, if a compiled .pyc file is already available, Python uses it to speed up the startup process. If not, it re-compiles the source code.
3. Execution by the Python Virtual Machine (PVM)
After the bytecode is generated, it is sent to the Python Virtual Machine (PVM), which executes the bytecode instructions. The PVM is an interpreter that reads and runs the bytecode, line by line. It communicates with the operating system to perform tasks such as memory allocation, input/output operations, and managing hardware resources.
This combination of bytecode compilation and interpretation is what allows Python to run efficiently on various platforms, without needing separate versions of the program for different operating systems.
Why is a Python Compiler Important?
Using a Python compiler offers several benefits to developers and users alike. Here are a few reasons why a Python compiler is so important in the programming ecosystem:
1. Portability
Since Python compiles to bytecode, it’s not tied to a specific operating system or hardware. This allows Python programs to run on different platforms without modification, making it an ideal language for cross-platform development. Once the code is compiled into bytecode, the same .pyc file can be executed on any machine that has a compatible Python interpreter installed.
2. Faster Execution
Although Python is an interpreted language, compiling Python code to bytecode allows for faster execution compared to direct interpretation. Bytecode is more efficient for the interpreter to execute, reducing the overhead of processing the raw source code each time the program runs. It also helps improve performance for larger and more complex applications.
3. Error Detection
By using a Python compiler, errors in the code can be detected earlier in the development process. The compilation step checks for syntax and other issues, alerting the developer before the program is even executed. This reduces the chances of runtime errors, making the development process smoother and more reliable.
4. Optimizations
Some compilers provide optimizations during the compilation process, which can improve the overall performance of the Python program. Although Python is a high-level language, there are still opportunities to make certain parts of the program run faster. These optimizations can include techniques like constant folding, loop unrolling, and more.
Types of Python Compilers
While the official Python implementation, CPython, uses a standard Python compiler to generate bytecode, there are alternative compilers and implementations available. Here are a few examples:
1. CPython
CPython is the most commonly used Python implementation. It is the default compiler for Python, written in C, and is the reference implementation for the language. When you install Python from the official website, you’re installing CPython. This compiler converts Python code into bytecode and then uses the PVM to execute it.
2. PyPy
PyPy is an alternative implementation of Python that features a Just-In-Time (JIT) compiler. JIT compilers generate machine code at runtime, which can significantly speed up execution. PyPy is especially useful for long-running Python applications that require high performance. It is highly compatible with CPython, meaning most Python code runs without modification on PyPy.
3. Cython
Cython is a superset of Python that allows you to write Python code that is compiled into C code. Cython enables Python programs to achieve performance close to that of C while retaining Python’s simplicity. It is commonly used when optimizing computationally intensive parts of a Python program.
4. Jython
Jython is a Python compiler written in Java that allows Python code to be compiled into Java bytecode. This enables Python programs to run on the Java Virtual Machine (JVM), making it easier to integrate with Java libraries and tools.
5. IronPython
IronPython is an implementation of Python for the .NET framework. It compiles Python code into .NET Intermediate Language (IL), enabling it to run on the .NET runtime. IronPython allows Python developers to access .NET libraries and integrate with other .NET languages.
Python Compiler vs. Interpreter: What’s the Difference?
While both compilers and interpreters serve the same fundamental purpose—turning source code into machine-executable code—there are distinct differences between them. Here are the key differences:
Compilation Process
Compiler: Translates the entire source code into machine code before execution. Once compiled, the program can be executed multiple times without recompilation.
Interpreter: Translates and executes source code line by line. No separate executable file is created; execution happens on the fly.
Execution Speed
Compiler: Generally faster during execution, as the code is already compiled into machine code.
Interpreter: Slower, as each line is parsed and executed individually.
Error Detection
Compiler: Detects syntax and other errors before the program starts executing. All errors must be fixed before running the program.
Interpreter: Detects errors as the code is executed. Errors can happen at any point during execution.
Conclusion
The Python compiler plays a crucial role in the Python programming language by converting source code into machine-readable bytecode. Whether you’re using the default CPython implementation, exploring the performance improvements with PyPy, or enhancing Python with Cython, understanding how compilers work is essential for optimizing and running Python code effectively.
The compilation process, which includes parsing, bytecode generation, and execution, offers various benefits like portability, faster execution, error detection, and optimizations. By choosing the right compiler and understanding how they operate, you can significantly improve both the performance and efficiency of your Python applications.
Now that you have a comprehensive understanding of how Python compilers work, you’re equipped with the knowledge to leverage them in your development workflow, whether you’re a beginner or a seasoned developer.
0 notes
Text
Chunking and how is it relevant in programming languages.
"If it is said that a picture is worth a thousand words can it not be said that a visual code construct can be worth a thousand lines of code"
That is one of my catch phrases that I use to promote the idea of visual or graphical programming languages. Unfortunately there is a flaw in that catch phrase. Its the reason why writing with pictures didn't take off.
The reality is that words, more specifically vocabulary, are quite effective. The reality is that a single vocabulary word is also capable of being worth a thousand words by itself. That is because words are used to define words. In a sense abstraction.
The reason writing in pictures didn't take off is because it is a lot easier to write a word then it is to draw a picture and yet a single word can be just as powerful.
Anyways this post is about importing the ideas behind chunking into programming languages. Chunking is just another angle of looking at abstraction. The divide and conquer paradigm. Its all related.
I came across chunking while watching a video called "Learning to Learn in 25 mins" by Tina Huang. And what she doing is summarizing is a whole Coursera course.
To summarize chunking. We start out with an alphabet of sounds. We express them as letters. Then we "chunk" them letters together into words. We do it again, we "chunk" them words into sentences. We do it again and "chunk" them sentences into conceptual meaning. Then we go recursive. We "chunk" that conceptual meaning into a single word. And we repeat again and again. Hence a single term like biology is worth a thousand other words. I say the word biology is worth millions and millions of words. In fact you might not be able to draw a picture that encompasses the word biology as a whole in all its glory.
Anyways, We do this in computer programming also. If you studied recursive descent. Its pretty clear. I've included a pic of Apple Pascal's Syntax Diagram. A computer program can be represented by a tree structure (A post for another day). Syntax diagrams are the rules that govern how those trees are created. Syntax diagrams is basically chunking at play. If you don't see it visually you can see it textually. Syntax diagrams is just a visual representation of Backus-Naur Form. If you take a look at Backus-Naur Form definition of a language you will see the chunking.
Everyday, ordinary computer programmers also do chunking. The idea of a function call is chunking. A function is essentially a bunch of code "chunked" together into a single identifier. Chunking is nature's manifestation of the Divide and Conquer paradigm.

1 note
·
View note
Text
CPSC 326: Homework 4
The goal of this assignment is to modify your Parser implementation for HW-3 to generate an abstract syntax tree (AST). To complete the assignment, finish the following steps. Note that you should get started on this assignment early to give yourself enough time to ask questions (and receive a response) before the due date. If you wait until the last minute and have issues, you will likely have…
0 notes
Text
Introduction to JavaScript Compilers
JavaScript is one of the most widely used programming languages, powering web applications, servers, and even mobile apps. But how does JavaScript code transform from human-readable text into executable instructions? The answer lies in the JavaScript compiler.
A JavaScript compiler translates high-level JavaScript code into optimized machine code or bytecode, improving performance and efficiency. In this article, we’ll explore how JavaScript compilers work, their key components, and their role in modern web development.
What Is a JavaScript Compiler?
A compiler is a software tool that converts source code written in a high-level programming language (like JavaScript) into a lower-level representation (such as machine code or bytecode). Unlike interpreters, which execute code line by line, compilers process the entire codebase at once, optimizing it for better performance.
JavaScript engines like V8 (Chrome), SpiderMonkey (Firefox), and JavaScriptCore (Safari) use Just-In-Time (JIT) compilation to execute JavaScript efficiently.
How Does a JavaScript Compiler Work?
The JavaScript compilation process involves several stages:
1. Parsing (Lexical Analysis & Syntax Tree Generation)
The compiler first breaks down the code into tokens (keywords, variables, operators).
It then constructs an Abstract Syntax Tree (AST), a structured representation of the code’s logic.
2. Compilation (Bytecode or Machine Code Generation)
Modern JavaScript engines use JIT compilation, which combines interpretation and compilation.
The engine converts the AST into bytecode (an intermediate low-level code) or directly into machine code for execution.
3. Optimization (Inlining, Dead Code Elimination, etc.)
The compiler applies optimizations like:
Inline Caching: Speeds up property access.
Hidden Classes: Optimizes object property access.
Dead Code Elimination: Removes unused code.
4. Execution
The optimized code runs in the browser or Node.js environment.
1 note
·
View note