#Applications of Binary Trees
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
New Post has been published on https://thedigitalinsider.com/lightautoml-automl-solution-for-a-large-financial-services-ecosystem/
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
Although AutoML rose to popularity a few years ago, the ealy work on AutoML dates back to the early 90’s when scientists published the first papers on hyperparameter optimization. It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers. One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machine learning model. Another method commonly implemented by AutoML models is to estimate the probability of a particular hyperparameter being the optimal hyperparameter for a given machine learning model. The model achieves this by implementing Bayesian methods that traditionally use historical data from previously estimated models, and other datasets. In addition to hyperparameter optimization, other methods try to select the best models from a space of modeling alternatives.
In this article, we will cover LightAutoML, an AutoML system developed primarily for a European company operating in the finance sector along with its ecosystem. The LightAutoML framework is deployed across various applications, and the results demonstrated superior performance, comparable to the level of data scientists, even while building high-quality machine learning models. The LightAutoML framework attempts to make the following contributions. First, the LightAutoML framework was developed primarily for the ecosystem of a large European financial and banking institution. Owing to its framework and architecture, the LightAutoML framework is able to outperform state of the art AutoML frameworks across several open benchmarks as well as ecosystem applications. The performance of the LightAutoML framework is also compared against models that are tuned manually by data scientists, and the results indicated stronger performance by the LightAutoML framework.
This article aims to cover the LightAutoML framework in depth, and we explore the mechanism, the methodology, the architecture of the framework along with its comparison with state of the art frameworks. So let’s get started.
Although researchers first started working on AutoML in the mid and early 90’s, AutoML attracted a major chunk of the attention over the last few years, with some of the prominent industrial solutions implementing automatically build Machine Learning models are Amazon’s AutoGluon, DarwinAI, H20.ai, IBM Watson AI, Microsoft AzureML, and a lot more. A majority of these frameworks implement a general purpose AutoML solution that develops ML-based models automatically across different classes of applications across financial services, healthcare, education, and more. The key assumption behind this horizontal generic approach is that the process of developing automatic models remains identical across all applications. However, the LightAutoML framework implements a vertical approach to develop an AutoML solution that is not generic, but rather caters to the needs of individual applications, in this case a large financial institution. The LightAutoML framework is a vertical AutoML solution that focuses on the requirements of the complex ecosystem along with its characteristics. First, the LightAutoML framework provides fast and near optimal hyperparameter search. Although the model does not optimize these hyperparameters directly, it does manage to deliver satisfactory results. Furthermore, the model keeps the balance between speed and hyperparameter optimization dynamic, to ensure the model is optimal on small problems, and fast enough on larger ones. Second, the LightAutoML framework limits the range of machine learning models purposefully to only two types: linear models, and GBMs or gradient boosted decision trees, instead of implementing large ensembles of different algorithms. The primary reason behind limiting the range of machine learning models is to speed up the execution time of the LightAutoML framework without affecting the performance negatively for the given type of problem and data. Third, the LightAutoML framework presents a unique method of choosing preprocessing schemes for different features used in the models on the basis of certain selection rules and meta-statistics. The LightAutoML framework is evaluated on a wide range of open data sources across a wide range of applications.
LightAutoML : Methodology and Architecture
The LightAutoML framework consists of modules known as Presets that are dedicated for end to end model development for typical machine learning tasks. At present, the LightAutoML framework supports Preset modules. First, the TabularAutoML Preset focuses on solving classical machine learning problems defined on tabular datasets. Second, the White-Box Preset implements simple interpretable algorithms such as Logistic Regression instead of WoE or Weight of Evidence encoding and discretized features to solve binary classification tasks on tabular data. Implementing simple interpretable algorithms is a common practice to model the probability of an application owing to the interpretability constraints posed by different factors. Third, the NLP Preset is capable of combining tabular data with NLP or Natural Language Processing tools including pre-trained deep learning models and specific feature extractors. Finally, the CV Preset works with image data with the help of some basic tools. It is important to note that although the LightAutoML model supports all four Presets, the framework only uses the TabularAutoML in the production-level system.
The typical pipeline of the LightAutoML framework is included in the following image.
Each pipeline contains three components. First, Reader, an object that receives task type and raw data as input, performs crucial metadata calculations, cleans the initial data, and figures out the data manipulations to be performed before fitting different models. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets. The third component are the multiple machine learning pipelines stacked and/or blended to get a single prediction. A machine learning pipeline within the architecture of the LightAutoML framework is one of multiple machine learning models that share a single data validation and preprocessing scheme. The preprocessing step may have up to two feature selection steps, a feature engineering step or may be empty if no preprocessing is needed. The ML pipelines can be computed independently on the same datasets and then blended together using averaging (or weighted averaging). Alternatively, a stacking ensemble scheme can be used to build multi level ensemble architectures.
LightAutoML Tabular Preset
Within the LightAutoML framework, TabularAutoML is the default pipeline, and it is implemented in the model to solve three types of tasks on tabular data: binary classification, regression, and multi-class classification for a wide array of performance metrics and loss functions. A table with the following four columns: categorical features, numerical features, timestamps, and a single target column with class labels or continuous value is feeded to the TabularAutoML component as input. One of the primary objectives behind the design of the LightAutoML framework was to design a tool for fast hypothesis testing, a major reason why the framework avoids using brute-force methods for pipeline optimization, and focuses only on efficiency techniques and models that work across a wide range of datasets.
Auto-Typing and Data Preprocessing
To handle different types of features in different ways, the model needs to know each feature type. In the situation where there is a single task with a small dataset, the user can manually specify each feature type. However, specifying each feature type manually is no longer a viable option in situations that include hundreds of tasks with datasets containing thousands of features. For the TabularAutoML Preset, the LightAutoML framework needs to map features into three classes: numeric, category, and datetime. One simple and obvious solution is to use column array data types as actual feature types, that is, to map float/int columns to numeric features, timestamp or string, that could be parsed as a timestamp — to datetime, and others to category. However, this mapping is not the best because of the frequent occurrence of numeric data types in category columns.
Validation Schemes
Validation schemes are a vital component of AutoML frameworks since data in the industry is subject to change over time, and this element of change makes IID or Independent Identically Distributed assumptions irrelevant when developing the model. AutoML models employ validation schemes to estimate their performance, search for hyperparameters, and out-of-fold prediction generation. The TabularAutoML pipeline implements three validation schemes:
KFold Cross Validation: KFold Cross Validation is the default validation scheme for the TabularAutoML pipeline including GroupKFold for behavioral models, and stratified KFold for classification tasks.
Holdout Validation : The Holdout validation scheme is implemented if the holdout set is specified.
Custom Validation Schemes: Custom validation schemes can be created by users depending on their individual requirements. Custom Validation Schemes include cross-validation, and time-series split schemes.
Feature Selection
Although feature selection is a crucial aspect of developing models as per industry standards since it facilitates reduction in inference and model implementation costs, a majority of AutoML solutions do not focus much on this problem. On the contrary, the TabularAutoML pipeline implements three feature selection strategies: No selection, Importance cut off selection, and Importance-based forward selection. Out of the three, Importance cut off selection feature selection strategy is default. Furthermore, there are two primary ways to estimate feature importance: split-based tree importance, and permutation importance of GBM model or gradient boosted decision trees. The primary aim of importance cutoff selection is to reject features that are not helpful to the model, allowing the model to reduce the number of features without impacting the performance negatively, an approach that might speed up model inference and training.
The above image compares different selection strategies on binary bank datasets.
Hyperparameter Tuning
The TabularAutoML pipeline implements different approaches to tune hyperparameters on the basis of what is tuned.
Early Stopping Hyperparameter Tuning selects the number of iterations for all models during the training phase.
Expert System Hyperparameter Tuning is a simple way to set hyperparameters for models in a satisfactory fashion. It prevents the final model from a high decrease in score compared to hard-tuned models.
Tree Structured Parzen Estimation or TPE for GBM or gradient boosted decision tree models. TPE is a mixed tuning strategy that is the default choice in the LightAutoML pipeline. For each GMB framework, the LightAutoML framework trains two models: the first gets expert hyperparameters, the second is fine-tuned to fit into the time budget.
Grid Search Hyperparameter Tuning is implemented in the TabularAutoML pipeline to fine-tune the regularization parameters of a linear model alongside early stopping, and warm start.
The model tunes all the parameters by maximizing the metric function, either defined by the user or is default for the solved task.
LightAutoML : Experiment and Performance
To evaluate the performance, the TabularAutoML Preset within the LightAutoML framework is compared against already existing open source solutions across various tasks, and cements the superior performance of the LightAutoML framework. First, the comparison is carried out on the OpenML benchmark that is evaluated on 35 binary and multiclass classification task datasets. The following table summarizes the comparison of the LightAutoML framework against existing AutoML systems.
As it can be seen, the LightAutoML framework outperforms all other AutoML systems on 20 datasets within the benchmark. The following table contains the detailed comparison in the dataset context indicating that the LightAutoML delivers different performance on different classes of tasks. For binary classification tasks, the LightAutoML falls short in performance, whereas for tasks with a high amount of data, the LightAutoML framework delivers superior performance.
The following table compares the performance of LightAutoML framework against AutoML systems on 15 bank datasets containing a set of various binary classification tasks. As it can be observed, the LightAutoML outperforms all AutoML solutions on 12 out of 15 datasets, a win percentage of 80.
Final Thoughts
In this article we have talked about LightAutoML, an AutoML system developed primarily for a European company operating in the finance sector along with its ecosystem. The LightAutoML framework is deployed across various applications, and the results demonstrated superior performance, comparable to the level of data scientists, even while building high-quality machine learning models. The LightAutoML framework attempts to make the following contributions. First, the LightAutoML framework was developed primarily for the ecosystem of a large European financial and banking institution. Owing to its framework and architecture, the LightAutoML framework is able to outperform state of the art AutoML frameworks across several open benchmarks as well as ecosystem applications. The performance of the LightAutoML framework is also compared against models that are tuned manually by data scientists, and the results indicated stronger performance by the LightAutoML framework.
#ai#Algorithms#Amazon#applications#approach#architecture#Art#Article#Artificial Intelligence#attention#autoML#banking#benchmark#benchmarks#binary#box#Building#change#classes#classical#columns#comparison#continuous#CV#data#data validation#datasets#dates#Decision Tree#Deep Learning
0 notes
Text
╭»»————≪•◦ INTRO POST ◦•≫————««╮
Hello!!! We are the Floral Atom Collective, a non-disordered traumaendo system of over 20. If front isn't specified we collectively go by Atom.
We collectively go by They/It, some headmates are more sensitive to they/them pronouns though /neg [ eg. Two ]
We are bodily a minor with many adults, ageless, and age regressing headmates.

— Our plain pronouns page –>
⋆₊ ..𖥔 ݁ * Link ☆
— Our simple strawpage –>
⋆₊ ..𖥔 ݁ * Link ☆
— A tone tags master list ->
⋆₊ ..𖥔 ݁ * Link ☆
— "Please do NOT argue on our behalf" ->
⋆₊ ..𖥔 ݁ * Link ☆

—Extra Under Cut->
⋆₊ ..𖥔 ݁ * We self diagnose with a handful of things, [ eg. Autism, Chronic Pain ], this is because we don't have access to diagnostic tests in our current situation.
⋆₊ ..𖥔 ݁ * Everything we self diagnose with we have done months of research into. We don't self diagnose for fun, we self diagnose so people understand we are actively struggling to function.
⋆₊ ..𖥔 ݁ * Forewarning - we get really clingy, potentially because of previous trauma. Please explicitly tell us if you want us to leave you alone. We are also quite sensitive to criticism and can/have been dependent on praise.
⋆₊ ..𖥔 ݁ * We have frequent "minor" panic attacks, our limbs often go numb, some headmates struggle with hallucinations, our memory is horrible remind us to do things if applicable please.
⋆₊ ..𖥔 ݁ * We tend to over use or under use tone tags. We often misread our own tone and are worried others might as well. Headmates who don't use tone tags, or use them infrequently, typically come off as rude to ourselves.
⋆₊ ..𖥔 ݁ * Since we are very likely autistic we need a lot of context and explanation for most conversations. Please be patient with us if we ask you to explain something.
⋆₊ ..𖥔 ݁ * We are constantly paranoid that we've upset people or that they pretend to like us for whatever reason. If we ever ask if you are upset at us please answer truthfully. It stresses us out so much more being worried you might lie to us about it.
⋆₊ ..𖥔 ݁ * That being said, if something is genuinely upsetting you let us know and we will try to change our behavior. [ also, if telling us you're upset, please be direct about it and explain why you're upset. If you can't please do your best and tell us how you'd like our behavior to change ]
⋆₊ ..𖥔 ݁ * If for whatever reason we've upset you so much you don't want to interact with us anymore or if our behavior hasn't changed enough [ or we refuse to ], please prioritize yourself and leave.
—HEADMATES-PRONOUNS-AGE->
? = unknown info
Apricot - Paw/Bug [ +he/they for sys members only] - teenage minor
Aspen - She/Bug - 21
Kiwi - It/Its - 19
Sadie - She/They/It - Teenage minor [ frequently regressed ]
Suitcase - He/They/Xey/Fluff - ?
Lightbulb - She/It/Buzz -?
Gaty/Finn - She/Her - ?
Two/Felix - Cake/Show/Green/Two - ?
One/Stella - She/They/Star - ?
Q - She/They - ?
Four - He/They - 47
X - He/She/They/Egg - 47
Liam - He/It/They - ?
Bryce - He/They - ?
Amelia - She/Her - 28
Airy - He/It/They/Xey - ?
Marnie - He/They/Xey - 32
[ Tree, Bottle, Fanny, Black hole, Marker ]
Pillow - She/Fluff/Any - 24
Codey - it/its - 25
Binary - he/any - 25
◇☆◇ - he/they - none of your business..

—TAG NOTES->
//atom system// - general non-reblog tag
Another being says - reblog tag
-[name] - tag version of sign off
[name] replaced with headmate name.

⋆₊ ..𖥔 ݁ * Our interests typically fall under general osc media. We work in a handful of wip shows. Typically in voice acting, background art/design, asset art/design, and occasionally concept art and writing.
⋆₊ ..𖥔 ݁ *Each headmate has their own boundaries, in general we will not hesitate to leave a situation if we feel our boundaries are being crossed.
⋆₊ ..𖥔 ݁ * Link - our post including a brief explanation of plurality along with some examples and resources.
⋆₊ ..𖥔 ݁ * Link - our post about our relatively messy and drawn out syscovery

⋆₊ ..𖥔 ݁ * Link ☆ << our userboxes
all userboxes were made ourselves
[ None of the userboxes have image ID's! ]
Requests for userboxes are open at @floral-atom-gives
#//atom system//#Friend tags >#friend from the stars#A state fueled system#The silliest gizmo#friendly edible pancake#ryan-the-not-loser's friendship bracelet#Frequently shifting yapper#cat shaped ecko and her dorit#grape sodium#The yuri is so evil here
33 notes
·
View notes
Note
could we get a pack for a frag that’s a pallas cat hybrid and untamed one (role) ? they’re persecutory externally, hold paranoia, but are a comforter to other headmates. all add-ons pls :} ty !
[Brought to you by: Mods Venn, Vyvian, and Klaus!]
🪨 HEADMATE TEMPLATE 🏔️
✦ Name(s): Boulder, Snowy, Rocky ✦ Pronouns: they/them, it/its, x/xs/xself, et/ets/etself, paw/paws/pawself, cat/cats/catself, snow/snows/snowself, 🪨/🪨s/🪨self, 🏔️/🏔️s/🏔️self ✦ Species: human/Pallas's cat hybrid ✦ Age: 35 ✦ Role(s): untamed one, persecutor, janusian, protector, paranoia holder, comforter, caretaker, anger holder, naturalist ✦ Labels: gaybian, catgender, librandrogynous, proxvir, juxera, aporine, wilderic, florauna ✦ Xenos: snow, trees, cats ✦ Likes: mountains, books, gemstones ✦ Dislikes: most people ✦ Music taste: folk pop, lowercase music, deathdream ✦ Aesthetic(s): naturecore, flat design, Frutiger Aero ✦ Objectum attraction(s): vehicles, buildings, rocks ✦ Kins: boulders, oak trees, beetles ✦ Color palette: muted dark brown, muted green, dark gray, medium gray, tan ✦ Personality traits: misanthropic, caring, angry ✦ Interests: natural sciences, botany ✦ Hobbies: hiking, reading ✦ Preferences: bitter over sweet, direct over subtle ✦ Heart emoji: (opt-in) ✦ Emoji proxy: 🪨🏔️ ✦ Details:
Boulder is mostly human with the ears and tails of a Pallas's cat, and its hair is the same color as a Pallas's cat's fur. They can be antagonistic towards external people but are comforting to its headmates.
✦ Role performance:
Boulder is prone to anger, and it often lashes out at people because of it. It also doesn't like people who remind it of anyone who has mistreated the system, so it antagonizes them as well. However, it cares a lot about the other members of its system, especially the ones who identify as or with animals. Paw frequently acts in an animalistic way and encourages other headmates to do the same.
✦ Personality:
Boulder identifies much more with being an animal than being a human, and they hold some disdain for humanity, as well as general paranoia. Some of this is informed by any negative experiences with humans the system may have had in the past. However, it is caring and protective towards its own headmates.
✦ Identity:
Boulder mostly doesn't identify with binary gender, but they feel slightly connected to genders that are adjacent to being male and to being female. Its gender is more informed by animals and nature. X is simultaneously a gay man and a lesbian.
✦ Interests and hobbies:
Boulder loves being out in nature, going hiking and camping and visiting local wildlife sanctuaries and zoos if applicable. It also likes books, particularly non-fiction about the natural sciences.
[These can be edited and changed as needed, and headmates will almost definitely not turn out EXACTLY as described.]
#templatepost#alter packs#headmate packs#build an alter#build a headmate#create an alter#create a headmate#source: request#adult themes: no#species: hybrid#age: adult#roles: untamed one#roles: persecutor#roles: janusian#roles: protector#roles: paranoia holder#roles: holder#roles: comforter#roles: caretaker#roles: anger holder#roles: emotion holder#roles: naturalist#themes: animals#themes: nature
2 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
3 notes
·
View notes
Note
explain binary search trees
okay I've been saving the one I'm fairly sure I can actually answer for last. I'm not entirely sure how coherent it's going to be because I'm used to explaining things verbally which gives a bit more feedback on whether people are confused or I've forgotten something.
I'll start by saying that binary search trees are a type of data structure. Data structures in CS are a way to organize and think about your data so that you're able to do things you'd like to do with your data more easily or faster than others. For example, accessing the value of a particular piece of data, or sorting your data, etc.
Trees are a data structure in which data is stored such that a given piece of data also "points to" another piece of data. We usually call these pieces nodes. A binary tree's node "points to" up to two other nodes, hence "binary".
A binary search tree is a special kind of tree organized such that if you traverse the tree in order you will end up with a sorted list. What "in order" means may vary by your application, but for the purposes of this example I'll say integers least to greatest.
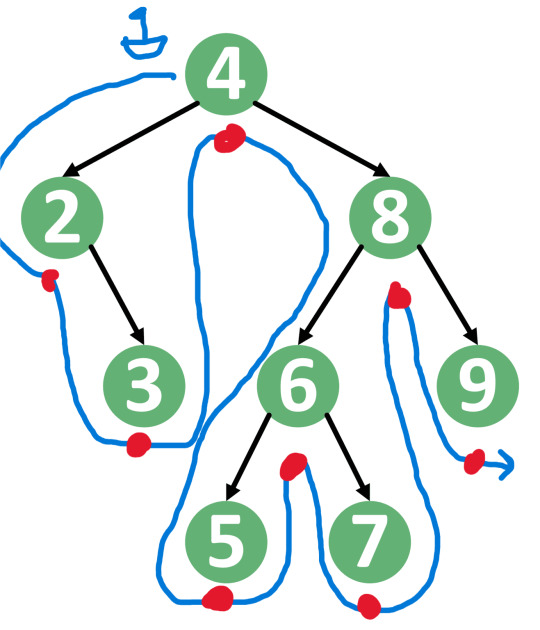
A tree traversal looks like this: imagine a little boat (or whatever you'd like) that goes around your tree counterclockwise starting from the root node, which is at the top. This is the blue squiggly arrow I've drawn. The in order traversal is when you announce the number whenever the boat is at the bottom of the node, where I've drawn the red dots. You'll notice that this produces all the numbers in the tree in sorted order, 2 - 9.
A binary search tree is so called because it's really easy to search when you know the tree will be sorted like this. You can go left or right simply based on whether the number you're looking for is greater or less than what you're looking for.
Say for example you're searching for the number 7.
7 > 4, so go right
7 < 8, so go left
7 > 6, so go right
7 = 7!
This is much much faster and simpler than with an unsorted tree, where you'd have to visit every single node searching for your value.
3 notes
·
View notes
Text
Advanced C Programming: Mastering the Language
Introduction
Advanced C programming is essential for developers looking to deepen their understanding of the language and tackle complex programming challenges. While the basics of C provide a solid foundation, mastering advanced concepts can significantly enhance your ability to write efficient, high-performance code.
1. Overview of Advanced C Programming
Advanced C programming builds on the fundamentals, introducing concepts that enhance efficiency, performance, and code organization. This stage of learning empowers programmers to write more sophisticated applications and prepares them for roles that demand a high level of proficiency in C.
2. Pointers and Memory Management
Mastering pointers and dynamic memory management is crucial for advanced C programming, as they allow for efficient use of resources. Pointers enable direct access to memory locations, which is essential for tasks such as dynamic array allocation and manipulating data structures. Understanding how to allocate, reallocate, and free memory using functions like malloc, calloc, realloc, and free can help avoid memory leaks and ensure optimal resource management.
3. Data Structures in C
Understanding advanced data structures, such as linked lists, trees, and hash tables, is key to optimizing algorithms and managing data effectively. These structures allow developers to store and manipulate data in ways that improve performance and scalability. For example, linked lists provide flexibility in data storage, while binary trees enable efficient searching and sorting operations.
4. File Handling Techniques
Advanced file handling techniques enable developers to manipulate data efficiently, allowing for the creation of robust applications that interact with the file system. Mastering functions like fopen, fread, fwrite, and fclose helps you read from and write to files, handle binary data, and manage different file modes. Understanding error handling during file operations is also critical for building resilient applications.
5. Multithreading and Concurrency
Implementing multithreading and managing concurrency are essential skills for developing high-performance applications in C. Utilizing libraries such as POSIX threads (pthreads) allows you to create and manage multiple threads within a single process. This capability can significantly enhance the performance of I/O-bound or CPU-bound applications by enabling parallel processing.
6. Advanced C Standard Library Functions
Leveraging advanced functions from the C Standard Library can simplify complex tasks and improve code efficiency. Functions for string manipulation, mathematical computations, and memory management are just a few examples. Familiarizing yourself with these functions not only saves time but also helps you write cleaner, more efficient code.
7. Debugging and Optimization Techniques
Effective debugging and optimization techniques are critical for refining code and enhancing performance in advanced C programming. Tools like GDB (GNU Debugger) help track down bugs and analyze program behavior. Additionally, understanding compiler optimizations and using profiling tools can identify bottlenecks in your code, leading to improved performance.
8. Best Practices in Advanced C Programming
Following best practices in coding and project organization helps maintain readability and manageability of complex C programs. This includes using consistent naming conventions, modularizing code through functions and header files, and documenting your code thoroughly. Such practices not only make your code easier to understand but also facilitate collaboration with other developers.
9. Conclusion
By exploring advanced C programming concepts, developers can elevate their skills and create more efficient, powerful, and scalable applications. Mastering these topics not only enhances your technical capabilities but also opens doors to advanced roles in software development, systems programming, and beyond. Embrace the challenge of advanced C programming, and take your coding skills to new heights!
#C programming#C programming course#Learn C programming#C programming for beginners#Online C programming course#C programming tutorial#Best C programming course#C programming certification#Advanced C programming#C programming exercises#C programming examples#C programming projects#Free C programming course#C programming for kids#C programming challenges#C programming course online free#C programming books#C programming guide#Best C programming tutorials#C programming online classes
2 notes
·
View notes
Text

( jes tom, twenty-nine, non-binary, they/them ) ☼ congratulations, beau sun, you’ve been accepted as a visitor center staff at central hazel in grand hazel national park this summer! we could tell from your application that you are chatty and personable, so we are so pleased to welcome you from huntington, west virginia for your first summer on staff. hopefully you can check flirting with some cute visitors, learning about every corner of the park, and petting a wild animal (just kidding. maybe) off your bucket list. please consult your employee handbook with questions!
background
Beau grew up right in the middle of five children. No one ever listened to them talk so they might as well talk about everything and anything, right? Beau is always talking. Whether it’s an appropriate time or not, whether they even know who they’re talking to, whether or not they even know what they’re talking about.
They left home right at 18 to make their own way in life, and after all manners of odd jobs and strange living situations, now at 29 they have found themself very happily submitting an application to Grand Hazel National Park.
about them
Beau loves love. They have been in some very happy monogamous relationships and polyamorous relationships. They believe in romance in all its (consensual, appropriate) forms. They are pansexual.
They absolutely love to talk. Talk to visitors, talk to themself... oh yeah, talk to their peers too.
They love the outdoors but are scatter-brained enough to forget some safety rules. Watch out for this one, they’re a bit of a danger to themself.
Self-admitted energy drink fanatic. (Please drink more water.)
Beau will defend their friends with their life.
They're really hoping that Disney movies haven't lied to them, and they really want to pet a wild animal. (Don’t let them.)
looking for
lots and lots of friends!!
friends to explore some hidden parts of the park with
friends to go on an early morning hike with to watch the sun rise above the trees
friends to talk with about the cute visitors that come by ;)
a romantic fling here and there
(possibly a serious relationship?)
helpful coworkers to make this whole job smoother
cowokers that will make sure Beau does NOT pet a wild animal
a tour guide or two to help introduce them to the area, they're new here
someone to talk conspiracy theories with -- who here has seen Bigfoot??
if anyone has any other ideas I'm totally open to chat!! ☼
5 notes
·
View notes
Text
Common (Lisp) gaslighting
TLDR I am a fucking noob and I wasted a lot of time on Lisp.
Also Tumblr has terrible text markup.
Common Lisp has many implementations, but
More like many incompatible implementations - they may implement all, but have different ideas about non-standards like FFI, threads, and what not
Libraries like Bordeaux-Threads, CFFI, Closer-MOP actually tries to provide a baseline for ALL implementations, just look at all the #+ in the code - reading the libraries feels like reading how every implementation does things
When they say there's a lot of libraries, this is not what I have in mind - if standardising features across implementations is a library, then I have nothing much to say
If you are creating an application (not designing a library), the libs above are actually not helpful as they are another layer on top of the implementation itself
Other implementations are problematic
https://www.reddit.com/r/Common_Lisp/comments/15maush/clozure_cl_1122/
https://gitlab.com/gnu-clisp/clisp no Windows binary release since 2010, developer refuses to support MingW 64bit, GPL program
On Lispworks
Lispworks has GUI, tree shaker, ability to create shared libraries, and good support, but..
It costs way too much - USD 3,000 for 64-bit Windows, or about MYR 14,000. Daylight robbery. If I want a great GUI designer, there is JFormDesigner, one time purchase of USD 179. Intellij reaches price parity at 29 years.. the entire Jetbrains suite reaches price parity at 17 years..
Lispworks have Hobbyist starting at USD 750.. but anyone trying to justify that other hobbies also cost this much is missing a huge point - most hobby allows them to resell their stuffs, and you can even do commercial stuffs with it. I am pretty sure that you cannot sell back your license, and can only upgrade, which is paying another USD 2250..
Whereas Jetbrains has Intellij and PyCharm community edition - awesome products, free, and can be used for commercial purposes
All Lisp follows a standard, so it is portable/stable/etc
More like dead. No one bothers to standardise threads, C ffi, etc
The language has a lot of unnecessary nesting thanks to let/flet and friends - I can also use https://quickdocs.org/serapeum and use the macro local, but this library pulls 19 libraries, one of them Slime, which is used for .. I actually don't know why it is needed, isn't Slime used for interacting with Emacs???
https://portability.cl/ doesn't seem portable to me
Library situation is still bad
No implementation comes with GUI. Quite bad considering how having many implementations is considered a good thing (actually there are ABCL but that's cheating)
I am looking for https://docs.python.org/3/library/cmd.html, I see that https://github.com/vindarel/replic is a good library, and is MIT licensed. But it uses GNU Readline, which is definitely GPL. replic depends on cl-readline, which is GPL. So.. isn't replic supposed to be GPL because of its dependency on GNU Readline? The author owns the code for replic and cl-readline, but not GNU Readline
Out of the box, almost all the implementations doesn't come with batteries. (Racket included, as a user say it comes with a retrofittable fusion battery pack)
When I think of batteries included, I think of this.
I am looking for game development
I see xelf, it asks for SDL.dll, and a bunch of other dlls, which I have to supply. SDL1 last update was around 2013
This is one where "stable" or "will work for decades" fails badly
I see SDL2, it asks for SDL2.dll
I see raylib, it wants to compile C stuffs (which I did not install). Why??
I see Trial, I see the docs, I feel dumb
On the other hand
pip install pygame-ce, look at docs, viola
pip install raylib, copy starter code, viola
Download gdx-liftoff, generate project, open in Intellij, viola
The docs for these game libs are so easy to read, and all of them includes the DLLs required
Why don't Common Lisp stuffs include the DLLs? You expect me to put it in the Systems folder? Expect me to use Linux and apt install sdl/whatever? The idea that I "use Linux for easy development and then compile using Wine" is insane
And best practices..
https://google.github.io/styleguide/lispguide.xml
I might as well use C++ and read http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines, even Lisps programs eventually need to interface C stuffs, and Python can use nanobind with great effect
As to why I say C++ when talking about interfacing C, it is because these days, the world is built in C++
And more links
https://news.ycombinator.com/item?id=29017710
https://news.ycombinator.com/item?id=26065511
https://news.ycombinator.com/item?id=28040351
https://news.ycombinator.com/item?id=37458188
Please don’t assume Lisp is only useful for Animation and Graphics, AI, Bio-informatics, B2B and Ecommerce, Data Mining, EDA/Semiconductor applications, Expert Systems, Finance, Intelligent Agents, Knowledge Management, Mechanical CAD, Modeling and Simulation, Natural Language, Optimization, Research, Risk Analysis, Scheduling, Telecom, and Web Authoring just because these are the only things they happened to list. – Kent Pitman
Where?? Please show me where it is. Otherwise it feels like gas lighting.
2 notes
·
View notes
Text

Why Do MLM Companies Need Software?
1. Complex Commission Structures
MLM businesses operate using various commission and bonus models. Manual calculation is time-consuming and error-prone. Software automates the process, ensuring accuracy and timely payouts.
2. User Management
With potentially thousands of users in a growing network, it’s critical to have an organized system for user data, genealogy trees, and performance tracking.
3. Compliance & Security
Regulatory compliance and data security are crucial in MLM. Custom software ensures these aspects are covered with audit logs, secure payment gateways, and privacy protection.
4. Real-Time Analytics
MLM software provides dashboards for real-time tracking of sales, recruitment, income, and overall network performance.
Key Features of MLM Software
1. Customizable Compensation Plans
MLM software supports various plans like:
Binary Plan
Unilevel Plan
Matrix Plan
Board Plan
Hybrid Plan
Australian and Monoline Plans
Flexibility to customize or combine these plans is essential.
2. E-Wallet Integration
Users and admins benefit from integrated e-wallets that support deposits, withdrawals, transfers, and transaction histories.
3. Genealogy Tree View
A graphical representation of the downline structure helps users understand their network and strategize better.
4. Automated Commission Calculations
Daily, weekly, or monthly commissions can be automatically calculated and disbursed according to company policies.
5. User and Admin Dashboards
Separate dashboards offer relevant insights and functionalities, such as new sign-ups, top performers, sales graphs, and activity logs.
6. Replicated Websites
For branding and recruitment, each distributor can have a personal website linked to the central system.
7. Multi-Currency and Multi-Language Support
To support international expansion, MLM software often includes multi-language interfaces and currency converters.
8. Mobile App Integration
Having mobile-friendly access or dedicated mobile apps enhances user engagement and accessibility.
Steps in MLM Software Development
1. Requirement Gathering
Understand the business model, compensation structure, and specific operational needs of the MLM company.
2. Plan Selection and Customization
Choose the appropriate MLM plan or a hybrid model based on business goals.
3. Software Architecture Design
Decide on the tech stack (e.g., Laravel, Node.js, React, MySQL) and software architecture—cloud-based or on-premises.
4. Development and Testing
Build the application with modular code, integrate third-party services, and conduct rigorous testing (unit, integration, user acceptance).
5. Deployment and Maintenance
After launching the software, continuous support and updates ensure scalability and bug resolution.
Challenges in MLM Software Development
1. Scalability
Handling thousands or millions of users requires a highly scalable backend system.
2. Data Security
With sensitive financial and personal data, encryption, role-based access control, and secure APIs are mandatory.
3. Regulatory Compliance
MLM is often scrutinized for unethical practices. The software must be developed in accordance with the legal frameworks of various countries.
4. Customization vs. Standardization
Balancing client-specific customization with the need to keep the core product standardized and maintainable is a common challenge.
Technologies Used in MLM Software
Frontend: React, Vue.js, Angular
Backend: Laravel, Node.js, Django
Databases: MySQL, PostgreSQL, MongoDB
Mobile: Flutter, React Native, Swift (iOS), Kotlin (Android)
Hosting: AWS, Google Cloud, Microsoft Azure
Security Tools: SSL, OAuth2, JWT, AES encryption
Benefits of Using MLM Software
Automation of repetitive tasks
Improved accuracy in calculations
Enhanced user experience with mobile/web dashboards
Better scalability with cloud integration
Transparency in transactions and reporting
Future Trends in MLM Software
1. Blockchain Integration
Ensures transparency and decentralization in transactions and commission tracking.
2. AI & Machine Learning
Can be used for lead scoring, network behavior prediction, and performance forecasting.
3. AR/VR for Training
MLM companies are beginning to use immersive technologies for onboarding and training.
4. Gamification
Increases user engagement by incorporating leaderboards, rewards, and levels.
5. Smart Contracts
Automating commissions using Ethereum-based smart contracts is being explored by progressive MLM startups.
Choosing the Right MLM Software Development Company
When selecting a developer or agency:
Check their experience with different compensation plans
Ask for live demos or case studies
Ensure post-deployment support
Verify security protocols
Consider cost versus scalability
Conclusion
MLM software development is at the heart of modern network marketing operations. It transforms the complexities of MLM into manageable, efficient systems that empower businesses to grow, engage users, and stay compliant. As technology continues to evolve, MLM software is becoming smarter, more transparent, and user-friendly—paving the way for the future of ethical and scalable network marketing.
www.mlmgig.com
#mlm software#mlm software development#software#mlm software in Patna#custom software development#custom website design
0 notes
Text
What is SPIR-V? How SYCL Expands C++ Virtual Functions

Discover SPIR-V and how it lets SYCL support heterogeneous C++ virtual functions. This post covers two notions that take SYCL in different directions.
At the 13th IWOCL International Workshop on OpenCL and SYCL, Intel's Alexey Sachiko presented several experimental ideas to expand SYCL's use and scope as a cross-architecture framework for accelerated computing from edge to cloud and AI PC to supercomputer.
Virtual functions are discussed first. SYCL aims to make C++ to multiarchitecture computing a smooth transition. Virtual functions can be redefined in derived classes to offload kernels, so expanding them is consistent.
The second concept is abstraction, although not of base class functions. Increased SPIR-V backend abstraction support will help SYCL's low-level implementation interface with the wide range of hardware architectures and custom accelerators available. The purpose is to improve SYCL LLVM-SPIR-V collaboration.
In many ways, SYCL is becoming more general. SYCL abstraction, from low-level hardware abstraction to C++ virtual function objects, will be discussed as its development continues.
SYCL Virtual Functions
Virtual functions have been used in C++ program development since its inception. Popular backend abstractions like the Kokkos C++ performance portability interface, used in high-speed scientific computing, require it.
Even though the SYCL standard allows one-definition rule (ODR) virtual inheritance, device functions cannot invoke virtual member functions, making code migration difficult.
Alexey begins his talk with a simple base class with a few virtual methods, direct classes with overrides, and offload kernels.
Easy oneAPI kernel property addition for virtual class inheritance.
The experimental indirectly callable function properties from the sycl_ext_oneapi_kernel_properties GitHub sandbox are included first. A function or offload kernel can be identified as a device function and invoked indirectly.
Why do virtual functions need this?
Program objects have virtual class overrides tables. For each virtual function call, a pointer from this table is loaded to call the relevant derived function.
In the Base function, SYCL device code limitations are violated when foo throws an exception and allocates memory.
The indirectly_callable feature makes the virtual function a device function with all its limitations, like the SYCL_EXTERNAL macro.
For the same reason, assume_indirect_calls properties_tag is needed. Kernel virtual calls without this property fail.
Alexey then discusses more advanced topics and future projects like optional kernel feature support and reqd_sub_group_size.
Considering Implementation
When designing an app with this new functionality, consider these high-level factors:
SYCL applications with virtual function support should separate each virtual function set into a device image. If you use optional kernel features, duplicate with empty functions. This provides all link stage symbols without speculative compilation.
For kernel-equipped device images, connect all images with the same virtual function sets.
When targeting SPIR-V, this happens runtime. Otherwise, it happens during build link.
See the for more on technology implementation.
Ext_intel_virtual_functions is in Intel's LLVM GitHub.
Test cases for sycl_ext_oneapi_virtual_functions extension in the same source code tree.
Improve SYCL Code using Virtual Functions
Recent versions of the Intel DPC++ Compatibility Tool 2025.1 and the Intel oneAPI DPC++/C++ Compiler include experimental and evolving virtual function functionality.
SPIR-V Backend SYCL Application
SPIR-V, a binary intermediate language for compute kernels and graphical-shader stages, was specified by the Khronos Group, which regulates SYCL. Its portable format unifies intermediate representation and programming interface for heterogeneous accelerators.
A varied language and API environment supports it
This creates a duality of intermediate abstracted hardware backend representation for C++ compilers based on LLVM and LLVM Intermediate Representation, as with all CLANG project compilers.
The SPIR-V to LLVM Translator provides bidirectional translation, however it is not updated as part of the LLVM project tree, making it prone to rare incompatibilities and disconnects.
To remedy this, Intel's compiler development team recommends SPIR-V as a normal LLVM code generation target, like other hardware target runtimes. Thus, the LLVM project includes an SPIR-V backend to ensure thorough integration testing and allow it to be used with OpenAI Triton backends, graphics-oriented programming models like Vulkan or HLSL, and heterogeneous computing with OpenCL or SYCL.
With extensive documentation, an active and growing LLVM SPIR-V working group supports and maintains the Backend:
SPIR-V Target User Guide
Clang SPIR-V Support
Intel compiler developers help resolve LLVM IR semantics and specifications to SPIR-V mapping difficulties as part of Intel's commitment to the open source community.
In his presentation, Alexey Sachkov details them and Intel's solution.
Is Spir-V?
SPIR-V, a high-level binary intermediate language, defines compute kernels and graphics shaders. It was created by Khronos Group, an OpenGL, Vulkan, and OpenCL organisation.
What that means and why it matters:
IR: GPU assembly language universal. Developers utilise GLSL or HLSL instead of writing shader code for each GPU architecture, which is complicated. Compilers create SPIR-V from this source code.
SPIR-V comes as compiled binary, not source code. This has numerous benefits:
Application startup and shader loading are faster when drivers don't parse and compile text-based shader code.
IP Protection: Shader source code is hidden, making algorithm reverse-engineering harder.
Closer Hardware: SPIR-V's lower-level representation allows more direct control and performance adjustment than high-level languages.
Standard and Portable: Before SPIR-V, each graphics API (like OpenGL or DirectX) handled shaders differently, requiring several compilers and duplication. SPIR-V is a royalty-free, open standard for graphics and computing APIs.
New, low-overhead graphics API Vulkan leverages SPIR-V shaders.
Although optional, OpenGL 4.6 and later support SPIR-V.
OpenCL: GPU/processor parallelism.
In Shader Model 7.0, Microsoft aims to replace DXIL with SPIR-V for Direct3D interoperability. Important for graphics ecosystem unity.
SYCL Code Compilation Target: SPIR-V
The SPIR-V Backend for LLVM is still being developed, however it has been a project target since January 2025. Try it and comment on the LLVM project RFC page.
Use SPIR-V, oneAPI, and SYCL Now
To learn about these and other new features in LLVM-based C++ compilers and toolchains with SYCL support, see the Intel oneAPI DPC++ C++ Compiler and oneAPI Overview landing page.
#SPIRV#VirtualFunctionsinSYCL#SYCL#SYCLCode#LLVM#SPIRVbackend#SPIRVtool#technology#technews#technologynews#news#govindhtech
0 notes
Text
OpenAI GPTs: Building Your Own ChatGPT-Powered Conversational AI
New Post has been published on https://thedigitalinsider.com/openai-gpts-building-your-own-chatgpt-powered-conversational-ai/
OpenAI GPTs: Building Your Own ChatGPT-Powered Conversational AI
What are GPTs?
GPTs, introduced by OpenAI in November 2023, are customizable versions of the ChatGPT model. They represent a significant shift from general-purpose AI chatbots to specialized, purpose-driven AI assistants. GPTs can be tailored for specific tasks, making them more effective and efficient in various domains, from education and gaming to business and creative arts.
OpenAI new GPT Builder (GPTs)
Key Features and Capabilities
Customization Without Coding: One of the most groundbreaking aspects of GPTs is that they require no coding skills to build. This makes it accessible to a broader audience.
Wide Range of Applications: GPTs can be designed for myriad uses, such as teaching math, assisting in game rules interpretation, or creating digital content like stickers.
Integration of Extra Knowledge: Users can feed additional information into GPTs, enhancing their ability to handle specialized tasks.
Functional Flexibility: GPTs can incorporate capabilities like web searching, image creation, and data analysis, depending on the user’s needs.
Creating a Custom GPT: Simplicity and Efficiency
Creating your personalized GPT app is a straightforward process that requires no coding knowledge, making it accessible for anyone with an idea. Here’s a simplified guide on how to bring your custom GPT to life:
Step-by-Step Guide to Creating Your Personalized GPTs App
Login and Navigate: First, log into your ChatGPT account. Look for the “Explore” section, which is usually located on the top left of your screen. This is where you’ll find all the GPT applications you have access to.
OpenAI ChatGPT
Create Your GPT: Click on ‘Create My GPT’. You’ll be taken to a new screen. Here, you’ll be prompted to describe what your GPT should do.
GPTs Interface
Set Your Prompt: Input your prompt with clarity and purpose. For our example we created a “Code Mentor” by entering a prompt: “Create an AI that provides clear explanations and guides users through algorithms and data structures, capable of facilitating real-time problem-solving sessions.”
Building a Coding Mentor with GPTs
Refinement: ChatGPT may ask follow-up questions to refine your concept. This step ensures your GPT is aligned with your vision and is capable of performing its intended functions efficiently.
Testing and Customization: Once created, your GPT appears on the right side of the screen. Here you can test its capabilities and fine-tune its functions. For the “Code Mentor” you might test it with queries like “Explain the concept of dynamic programming” or “Guide me through implementing a binary search tree.”
Save and Share: After you’re satisfied with your GPT, you can save your settings. Then, take advantage of the option to share your GPT with others. This is done through a link, making collaboration easy and promoting a community-oriented approach to AI development.
Remember, while Plus users have immediate access to use the GPTs via shared links, the creators won’t have access to the chats others have with their GPTs,.
Open AI mentioned that Privacy and safety are at the heart of GPTs. Chats with GPTs remain private, not shared with builders, and users have full control over whether data is sent to third-party APIs. Additionally, builders can decide if interactions with their GPT should contribute to model training, giving users and builders alike control over data usage and privacy.
Connecting GPTs to Real-World Applications
Beyond explanations, these GPTs can connect to external data sources or perform actions in the real-world. For instance, you could create a “Shopping Assistant” GPT that helps with e-commerce orders, or a “Travel Planner” GPT that integrates with a travel listings database.
Empowering Enterprises with Custom GPTs
Enterprises can take advantage of internal-only GPTs for specific use cases. This could range from a “Marketing Assistant” that helps draft brand-aligned materials to a “Support Helper” that aids in customer service. These GPTs can be deployed securely within a company’s workspace, with full administrative control over sharing and external GPT usage.
5 custom GPT applications that users have created
Conclusion
The evolution of AI technology with OpenAI’s GPT-4 Turbo and the introduction of customizable GPTs represent a significant leap forward in the field of artificial intelligence. GPT-4 Turbo’s enhanced context window and integration with visual and auditory capabilities mark a new era of conversational AI that is more accurate, detailed, and versatile. The GPTs, with their user-friendly customization options, open up endless possibilities for personal and professional use, democratizing AI technology and making it accessible to a wider audience.
#2023#ai#AI Tools 101#Algorithms#Analysis#APIs#app#applications#approach#artificial#Artificial Intelligence#Arts#binary#Binary Search#Binary Search Tree#Building#Business#chatbot#chatbots#chatGPT#code#coding#Collaboration#Commerce#Community#conversational ai#creators#customer service#dall-e#data
0 notes
Text
Understanding Algorithms and Data Structures

Algorithms and data structures are fundamental concepts in computer science and programming. Understanding these concepts is crucial for writing efficient code and solving complex problems. This guide will introduce you to the basics of algorithms and data structures and why they matter.
What Is an Algorithm?
An algorithm is a step-by-step procedure for solving a specific problem or performing a task. It takes an input, processes it, and produces an output. Algorithms are essential for tasks such as searching, sorting, and data manipulation.
Characteristics of a Good Algorithm
Correctness: The algorithm produces the correct output for all valid inputs.
Efficiency: The algorithm runs in a reasonable amount of time and uses resources effectively.
Finiteness: The algorithm terminates after a finite number of steps.
Generality: The algorithm can be applied to a broad set of problems.
Common Types of Algorithms
Sorting Algorithms: Organize data in a specific order (e.g., Quick Sort, Merge Sort, Bubble Sort).
Searching Algorithms: Find specific data within a structure (e.g., Binary Search, Linear Search).
Graph Algorithms: Work with graph structures (e.g., Dijkstra's Algorithm, Depth-First Search).
Dynamic Programming: Solve complex problems by breaking them down into simpler subproblems.
What Are Data Structures?
A data structure is a way to organize and store data in a computer so that it can be accessed and modified efficiently. Choosing the right data structure is crucial for optimizing the performance of algorithms.
Common Data Structures
Arrays: A collection of elements identified by index or key.
Linked Lists: A linear collection of elements, where each element points to the next.
Stacks: A collection that follows the Last In First Out (LIFO) principle.
Queues: A collection that follows the First In First Out (FIFO) principle.
Trees: A hierarchical structure with nodes connected by edges (e.g., binary trees).
Graphs: A collection of nodes connected by edges, used to represent networks.
Hash Tables: A data structure that stores key-value pairs for efficient retrieval.
Choosing the Right Data Structure
Choosing the right data structure depends on the problem you're trying to solve. Consider the following factors:
Type of data: Is it linear or hierarchical?
Operations needed: Will you need to search, insert, delete, or traverse data?
Memory constraints: How much memory do you have available?
Performance requirements: What are the time complexities for different operations?
Time and Space Complexity
Understanding the efficiency of algorithms is crucial. Two important concepts are:
Time Complexity: Measures the time an algorithm takes to complete as a function of the input size (e.g., O(n), O(log n)).
Space Complexity: Measures the amount of memory an algorithm uses as a function of the input size.
Conclusion
Algorithms and data structures are essential tools for every programmer. Mastering these concepts will enable you to write efficient code, solve complex problems, and build robust applications. Start by practicing simple algorithms and data structures, and gradually work your way up to more advanced topics.
0 notes
Text
Importance of Data Structures in Computer Science

Introduction
The importance of data structures in computer science lies in their role in the efficient storage and management of data. Understanding data structures is crucial for both new and expert programmers to write optimized and scalable code. TCCI-Tririd Computer Coaching Institute emphasizes the essential nature of learning data structures to build a strong foundation in programming and problem-solving skills.
What Are Data Structures?
A data structure is a way of organizing and storing data in such a way that operations on the data can be performed in an efficient manner. These data structures define ways through which data is accessed, modified, and manipulated in a computer system.
Types of Data Structures
1. Linear Data Structures
Are:
Arrays
Linked Lists
Stacks
Queues
2. Non-Linear Data Structures
Trees (Binary Trees, Binary Search Trees, AVL Trees, etc.)
Graphs (Directed, Undirected, Weighted, etc.)
Hash Tables
Why Are Data Structures Important in Computer Science?
1. Efficient Data Management
Good data structures help organize and quickly retrieve data, which improves performance and decreases execution time.
2. Optimized Algorithm Performance
Data structures play a key role in any algorithm. The choice of a data structure directly affects the speed and efficiency of an algorithm.
3. Scalability
Scalable applications that can accommodate loads of data without degrading in performance would require optimized structures.
4. Memory Optimization
An appropriate data structure ensures that memory is utilized optimally so that there is no wastage.
Real-Time Applications of Data Structures
1. Database Management Systems
Databases use B-Trees and Hash Tables for indexing data and efficient searching of data.
2. Operating Systems
Operating systems use queues for process scheduling and stacks for memory management.
3. Artificial Intelligence and Machine Learning
Most tree and network structures are based on graphs, heavily relied upon by AI and machine learning algorithms.
4. Web Development
Hash tables and graphs are often used for efficient searching, sorting, and recommendation systems on websites.
Data Structures Course at TCCI-Tririd Computer Coaching Institute
At TCCI-Tririd Computer Coaching Institute, we provide high-grade data structures training for both students and professionals. The courses offered include:
Basic concepts of data structures
Extensive hands-on coding sessions
Examples of real-life applications
Interview and competitive programming preparations
Conclusion
Data structures are a backbone of computer science and therefore are mandatory for anyone who is interested in pursuing software development. Getting to learn data structures from TCCI-Tririd Computer Coaching Institute would prepare you with the skills needed to solve difficult problems efficiently and develop durable applications.
Location: Bopal & Iskon-Ambli Ahmedabad, Gujarat
Call now on +91 9825618292
Get information from: tccicomputercoaching.wordpress.com
FAQ
1: Why learn data structures?
Learning data structures improves your coding efficiency and propelling abilities making you a better programmer.
2: What is the best way to learn data structures for the practice?
If you are looking for websites to practice coding problems on, check out LeetCode, CodeChef, and HackerRank that'll help you master your data structures.
3: Data Structures- Are they really important to job interviews?
Indeed, data structures and algorithms are generally discussed in most technical job interviews.
4: Do I need programming skills to learn Data Structures?
It is best to have at least a minimal programming knowledge before you jump into data structures but TCCI-Tririd Computer Coaching Institute offers various entry point courses for getting into these things.
5: How long does it take to learn data structures?
One can build a good grasp on data structures within 2-3 months if consistently practiced.
#Best computer courses near me#Data Structures in Computer Science#Diploma Tuition Classes in Ahmedabad#TCCI - Tririd Computer Coaching Institute#Top Computer Institute Iskcon-Ambli Road Ahmedabad
0 notes
Text
Understanding JavaScript log2: Computing Logarithm Base 2
JavaScript provides a variety of mathematical functions to help developers perform complex calculations efficiently. One such function is Math.log2(), which computes the logarithm of a number with base 2. Understanding how Math.log2() works is essential for applications that involve binary computations, data science, cryptography, and performance optimization.
What is Math.log2()?
The Math.log2() function in javascript log2 returns the base-2 logarithm of a given number. In mathematical terms, the base-2 logarithm of a number x is the exponent y such that:
2^y = x
For example, Math.log2(8) returns 3 because 2^3 = 8.
Syntax
The syntax for using Math.log2() is straightforward
Math.log2(x)
Here, x is the positive number for which you want to compute the logarithm. If x is negative or zero, the function returns NaN (Not-a-Number).
Examples of Math.log2() Usage
Let’s look at a few examples of how Math.log2() works in JavaScript:
console.log(Math.log2(1)); // Output: 0 console.log(Math.log2(2)); // Output: 1 console.log(Math.log2(4)); // Output: 2 console.log(Math.log2(8)); // Output: 3 console.log(Math.log2(16)); // Output: 4
For non-power-of-two numbers:
console.log(Math.log2(10)); // Output: ~3.3219 console.log(Math.log2(100)); // Output: ~6.6438
Handling Edge Cases
While using Math.log2(), it's essential to consider edge cases:
Math.log2(0) returns -Infinity.
Math.log2(-1) and any other negative number return NaN.
Math.log2(NaN) returns NaN.
Example:
console.log(Math.log2(0)); // Output: -Infinity console.log(Math.log2(-5)); // Output: NaN console.log(Math.log2(NaN)); // Output: NaN
Alternative Methods to Compute log2
If Math.log2() is not available in your JavaScript environment, you can use Math.log() with a base change formula:
function log2(x) { return Math.log(x) / Math.log(2); } console.log(log2(8)); // Output: 3
Applications of Math.log2()
Data Compression: Logarithms are used in entropy calculations for data compression algorithms.
Binary Tree Depth Calculation: Helps determine tree depth in binary search algorithms.
Cryptography: Used in key length calculations.
Performance Optimization: Helps estimate algorithm complexity in Big-O notation.
Conclusion
The Math.log2() function in JavaScript is a powerful tool for working with base-2 logarithms, essential in computing and algorithm optimization. Understanding its usage, limitations, and applications can help developers efficiently implement mathematical calculations in their JavaScript programs.
0 notes
Text
### **Understanding Algorithms: The Backbone of Computing**
An **algorithm** is a step-by-step procedure or a set of rules designed to solve a specific problem or perform a task. Algorithms form the foundation of computer science and are used in various fields, including mathematics, artificial intelligence, data processing, and automation.
### **Importance of Algorithms**
Algorithms are crucial because they provide efficient solutions to complex problems. In computing, they help process data, optimize search results, and automate tasks. From simple operations like sorting a list to complex functions like machine learning and encryption, algorithms play a vital role in making technology work seamlessly.
### **Types of Algorithms**
1. **Sorting Algorithms** – Organize data in a specific order (e.g., Bubble Sort, Quick Sort, Merge Sort).
2. **Search Algorithms** – Find specific data within a dataset (e.g., Binary Search, Linear Search).
3. **Graph Algorithms** – Solve network-related problems (e.g., Dijkstra’s Algorithm for shortest path).
4. **Machine Learning Algorithms** – Enable AI to learn from data (e.g., Neural Networks, Decision Trees).
5. **Encryption Algorithms** – Secure data transmission (e.g., RSA, AES).
### **Real-World Applications**
- **Google Search** uses ranking algorithms to deliver relevant results.
- **Social Media** platforms use recommendation algorithms to suggest content.
- **E-commerce** websites use algorithms for personalized shopping experiences.
- **Healthcare** uses AI-driven algorithms for disease prediction and diagnosis.
### **Conclusion**
Algorithms are the building blocks of modern technology, driving efficiency and innovation across industries. Understanding them is essential for anyone in computing, as they enable problem-solving, automation, and decision-making in today’s digital world.
0 notes
Text
Top Machine Learning Algorithms Every Beginner Should Know

Machine Learning (ML) is one of the most transformative technologies of the 21st century. From recommendation systems to self-driving cars, ML algorithms are at the heart of modern innovations. Whether you are an aspiring data scientist or just curious about AI, understanding the fundamental ML algorithms is crucial. In this blog, we will explore the top machine learning algorithms every beginner should know while also highlighting the importance of enrolling in Machine Learning Course in Kolkata to build expertise in this field.
1. Linear Regression
What is it?
Linear Regression is a simple yet powerful algorithm used for predictive modeling. It establishes a relationship between independent and dependent variables using a best-fit line.
Example:
Predicting house prices based on features like size, number of rooms, and location.
Why is it important?
Easy to understand and implement.
Forms the basis of many advanced ML algorithms.
2. Logistic Regression
What is it?
Despite its name, Logistic Regression is a classification algorithm. It predicts categorical outcomes (e.g., spam vs. not spam) by using a logistic function to model probabilities.
Example:
Email spam detection.
Why is it important?
Widely used in binary classification problems.
Works well with small datasets.
3. Decision Trees
What is it?
Decision Trees are intuitive models that split data based on decision rules. They are widely used in classification and regression problems.
Example:
Diagnosing whether a patient has a disease based on symptoms.
Why is it important?
Easy to interpret and visualize.
Handles both numerical and categorical data.
4. Random Forest
What is it?
Random Forest is an ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting.
Example:
Credit risk assessment in banking.
Why is it important?
More accurate than a single decision tree.
Works well with large datasets.
5. Support Vector Machines (SVM)
What is it?
SVM is a powerful classification algorithm that finds the optimal hyperplane to separate different classes.
Example:
Facial recognition systems.
Why is it important?
Effective in high-dimensional spaces.
Works well with small and medium-sized datasets.
6. k-Nearest Neighbors (k-NN)
What is it?
k-NN is a simple yet effective algorithm that classifies data points based on their nearest neighbors.
Example:
Movie recommendation systems.
Why is it important?
Non-parametric and easy to implement.
Works well with smaller datasets.
7. K-Means Clustering
What is it?
K-Means is an unsupervised learning algorithm used for clustering similar data points together.
Example:
Customer segmentation for marketing.
Why is it important?
Great for finding hidden patterns in data.
Used extensively in marketing and image recognition.
8. Gradient Boosting Algorithms (XGBoost, LightGBM, CatBoost)
What is it?
These are powerful ensemble learning techniques that build strong predictive models by combining multiple weak models.
Example:
Stock market price prediction.
Why is it important?
Highly accurate and efficient.
Widely used in data science competitions.
Why Enroll in Machine Learning Classes in Kolkata?
Learning ML algorithms on your own can be overwhelming. Enrolling in Machine Learning Classes in Kolkata can provide structured guidance, real-world projects, and mentorship from industry experts. Some benefits include:
Hands-on training with real-world datasets.
Learning from experienced professionals.
Networking opportunities with peers and industry leaders.
Certification that boosts career opportunities.
Conclusion
Understanding these top ML algorithms is the first step toward mastering machine learning. Whether you’re looking to build predictive models or dive into AI-driven applications, these algorithms are essential. To truly excel, consider enrolling in a Machine Learning Course in Kolkata to gain practical experience and industry-relevant skills.
0 notes