#Azure Pipelines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Optimizing Azure Container App Deployments: Best Practices for Pipelines & Security
🚀 Just shared a new blog on boosting Azure Container App deployments! Dive into best practices for Continuous Deployment, choosing the right agents, and securely managing variables. Perfect for making updates smoother and safer!
In the fifth part of our series, we explored how Continuous Deployment (CD) pipelines and revisions bring efficiency to Azure Container Apps. From quicker feature rollouts to minimal downtime, CD ensures that you’re not just deploying updates but doing it confidently. Now, let’s take it a step further by optimizing deployments using Azure Pipelines. In this part, we’ll dive into the nuts and…
#Agent Configuration#app deployment#Azure Container Apps#Azure Pipelines#CI/CD#Cloud Applications#Cloud Security#continuous deployment#Deployment Best Practices#DevOps#microsoft azure#Pipeline Automation#Secure Variables
0 notes
Text
How to Create Self-Hosted Agent for Azure DevOps Pipelines

View On WordPress
#Agent Pool#Azure#Azure DevOps#Azure DevOps Agent#Azure DevOps Pipelines#Azure Pipelines#PowerShell#Self-Hosted Agent#Yaml#Yaml File
0 notes
Text
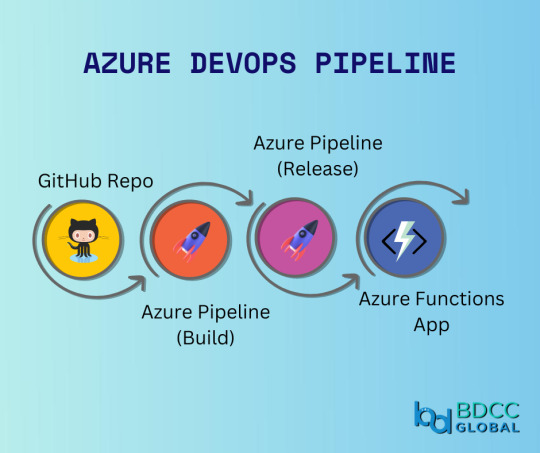
Boost your team's productivity with Azure DevOps pipeline. Automate your development process and focus on what really matters - building great software!
#Azure#DevOps#azuredevOps#pipeline#DevOpspipeline#Automation#developmentprocess#devops consulting services#aws consultants#awspartners#aws#bdccglobal#devopstrends#top aws consulting partners#bdcc#devops consulting
2 notes
·
View notes
Text
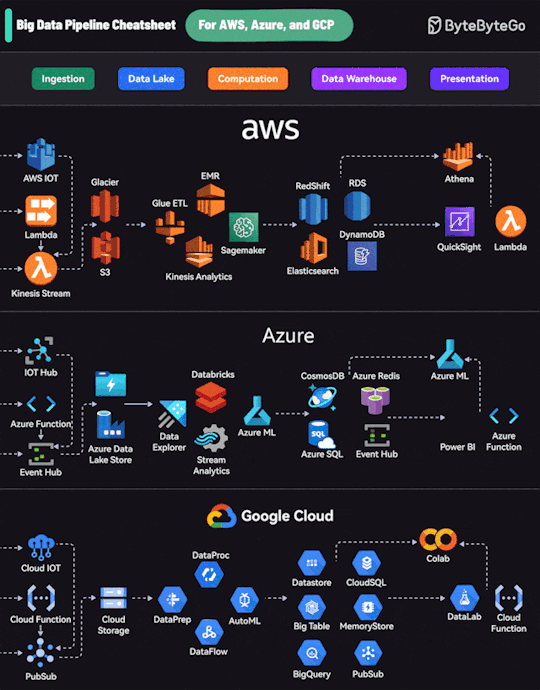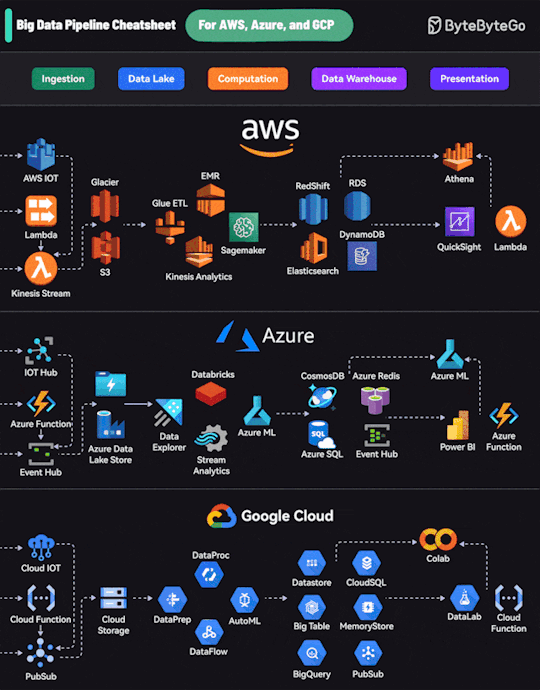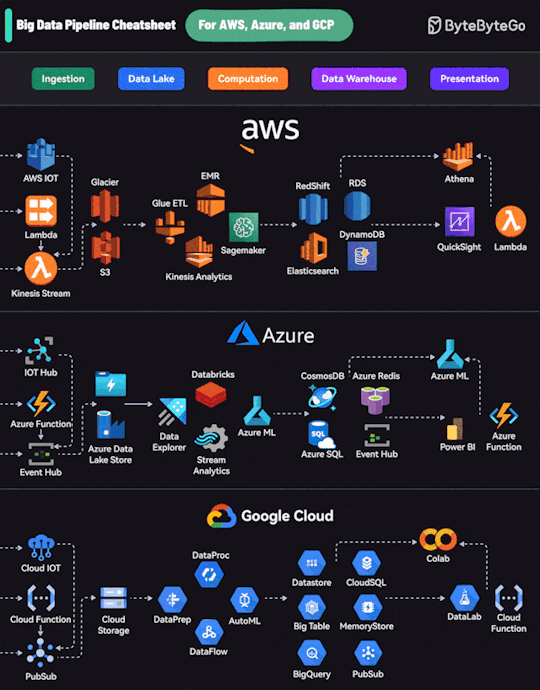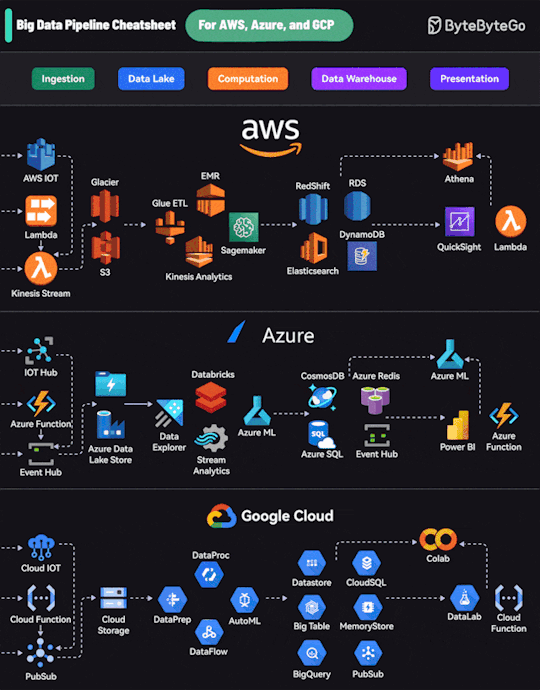
1 note
·
View note
Text
It’s important to note that even though Foulques lives in standard Ava canon hes still very much like. A sidequest ARR NPC who is absolutely not qualified for the shit going on in the MSQ and it shows. He’s Ava’s trophy husband. No one recognizes who he is he wasn’t even an official scion. He’s just kind of along for the ride, it’s not like he has anywhere else to be at this point.
His essential role in the story is to be a tsukkomi.
#He DOES also have the role of helping out with Ava’s azure dragoon duties when she’s stuck saving the world and shit#however. main role is tsukkomi. it’s hard being an ARR NPC in a expac world#Val roars#my posts#the ARR sidequest antag to tsukkomi trophy husband pipeline
0 notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text

Microsoft Azure DevOps
QServices provides expert Microsoft Azure DevOps services to streamline your development processes. From planning and coding to testing and deployment, our team ensures seamless integration and automation for your projects. Boost efficiency and collaboration with QServices Azure DevOps solutions.
0 notes
Text
#python#azure#development#software development#pipeline#machine learning#pipeline orchestration#programming
0 notes
Text
#Azure Data Factory#azure data factory interview questions#adf interview question#azure data engineer interview question#pyspark#sql#sql interview questions#pyspark interview questions#Data Integration#Cloud Data Warehousing#ETL#ELT#Data Pipelines#Data Orchestration#Data Engineering#Microsoft Azure#Big Data Integration#Data Transformation#Data Migration#Data Lakes#Azure Synapse Analytics#Data Processing#Data Modeling#Batch Processing#Data Governance
1 note
·
View note
Text
Setup Mobsfscan in Azure DevOps
Hello everyone! Welcome to pentestguy. In this article we are going to focus on how to setup mobsfscan in azure devops. What does it mean? As we know MobSF is one of the most popular tool use for android app pentesting. and MobSF have a child tool named as mobsfscan which is a static analysis tool that help to find the insecure code patterns in Android and iOS source code. Here we are going to…

View On WordPress
0 notes
Text
How to connect GitHub and Build a CI/CD Pipeline with Vercel
Gone are the days when it became difficult to deploy your code for real-time changes. The continuous integration and continuous deployment process has put a stop to the previous archaic way of deployment. We now have several platforms that you can use on the bounce to achieve this task easily. One of these platforms is Vercel which can be used to deploy several applications fast. You do not need…

View On WordPress
#AWS#Azure CI/CD build Pipeline#cicd#deployment#development#Github#Google#Pipeline#Pipelines#Repository#software#vercel#Windows
0 notes
Text
#🌟 Preparing for an Azure DevOps interview? Here are the top 5 questions you should know:#1️⃣ What is Azure DevOps?#2️⃣ Describe some Azure DevOps tools. 3️⃣ What is Azure Repos?#4️⃣ What are Azure Pipelines?#5️⃣ Why should I use Azure pipelines and CI/CD?#Get ready to impress your interview techquestions#kloudcourseacademy#AzureDevOps#InterviewPrep#TechQuestions
1 note
·
View note
Text
How to publish a multi-page Azure DevOps Wiki to PDF (and pipeline it)
Although you can print a single page of your wiki to a PDF using the browser, it’s problematic when you have a more complex structured multi-page wiki and you need to distribute or archive it as a single file. Fortunately thanks to the great initiative by Max Melcher and his AzureDevOps.WikiPDFExport tool, combined with Richard Fennell’s WIKI PDF Export Tasks, we can not only produce pretty good…
View On WordPress
0 notes
Text
Verfügbare Tools für das Managen von DevOps Prozessen: "Verwenden Sie die neuesten Tools von MHM Digitale Lösungen UG für das effiziente Managen Ihrer DevOps Prozesse"
#DevOps #MHMDigitaleLösungen #VerfügbareTools #EffizientesManagen #Prozesse
DevOps ist ein Prozess, der sich auf die Entwicklung, den Betrieb und die Wartung von Software-Systemen konzentriert. Es hilft, Due Diligence zu leisten, um sicherzustellen, dass Anwendungen reibungslos funktionieren und dass die Entwicklungszyklen so effizient wie möglich sind. Effizientes Management Ihrer DevOps-Prozesse ist eine wichtige Voraussetzung für eine erfolgreiche Implementierung. MHM…
View On WordPress
#Amazon Web Services (AWS)#Ansible#Azure DevOps#Containers#Gitlab#Jenkins Pipeline#Kubernetes#Logstash#Openshift#Splunk.
0 notes
Text
[SimplePBI][CD] Auto Deploy informes de PowerBi con Azure Devops Pipelines
CI/CD, DataOps, Devops y muchos otros nombres han recorrido las redes para referirse al proceso más continuo y automático de deploy. Hoy luego de tanto tiempo de dos herramientas como Azure Devops y PowerBi existen muchos posts y artículos que nos hablan de esto.
¿Qué diferencia este artículo de otro? que haremos el deploy continuo con SimplePBI (librería de python para usar la PowerBi Rest API) dentro de Azure Devops. Solo prácticas de CD. Luego compartiré pensamientos sobre CI. Para esto nos acompañaremos de un repositorio Git en Azure Devops.
No se si llamarle algo “Ops” o simplemente CD PowerBi. Asique sin más charla que dar seguí leyendo si te interesa este mix de temas.
Si hay algo de lo que estoy seguro sobre todo esto de Ops, CI o CD es que tiene un origen y base en software que consiste en facilitar la experiencia del desarrollador. Con ese objetivo vamos a mantener la metodología de un post anterior. El desarrollador no necesita saber más nada. Todo lo siguiente lo configuraría un admin o persona que se dedique a “Ops”.
NOTA: Antes de iniciar aclaro que para que funcione la metodología anterior vamos a quitar el “tracking” del archivo y mantener unicamente el lock. Debemos quitarlo puesto que modifica la metadata guardada en gitattributes y le impide a la API de PowerBi importar el informe. Código: git lfs untrack "Folder/File_name.pbix"
Proceso
Intentando simular metodologías de desarrollo de software es que vamos a plantear este artículo. Cabe aclarar que funcionaría en tradicionales esquemas que siguen el hilo de “Origenes -> Power Bi Desktop -> Power Bi Service”. Nuestro enfoque aquí esta centrado en que los desarrolladores no tengan contacto con Power Bi Service. Su herramienta de desarrollo Desktop y Git serían la diaria. De este modo solo deben preocuparse por tomar la última versión desarrollada, efectuar modificaciones bloqueando el archivo y devolverlo al repositorio modificado y desbloqueado.
La responsabilidad del profesional Ops será la de asegurar que esos desarrollos publicados se disponibilicen en el servicio de PowerBi con flujos automáticos. Con este propósito, y aprovechando nuestro repositorio, vamos a utilizar la herramienta de Azure Devops Pipelines. Para tener acceso a los procesamientos paralelos que nos permiten ejecutar el pipeline, será necesario llenar una encuesta especificada en la documentación de Microsoft como nueva política. Forms y doc para más info en el siguiente link: https://learn.microsoft.com/en-us/azure/devops/pipelines/licensing/concurrent-jobs?view=azure-devops&tabs=ms-hosted
Si bien existen muchas formas y procesos de generar deploys automáticos, la que vamos a generar es la siguiente:
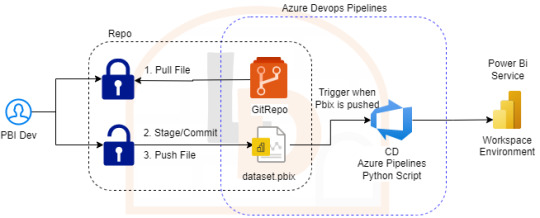
Nos vamos a concentar en importar archivos de PowerBi Desktop ni bien hayan sido pusheados al repositorio. Nuestro enfoque consiste en tener un Pipeline por Área de Trabajo, lo que llevaría a un archivo .yml por area de trabajo. Para mejorar la consistencia de nuestros desarrollos les recomiendo ordenar las carpetas para que coincidan con las areas de trabajo, datasets/reportes o ambientes. Por ejemplo:
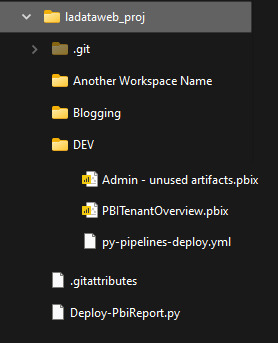
De ese modo podríamos controlar ambientes, shared datasets o simplemente informes con el dataset. Cada quien conoce sus desarrollos para aplicar la complejidad deseada. Vamos a ver el ejemplo con un solo ambiente que tiene informes en areas de trabajo sin separación de shared datasets.
Configuración
Para iniciarnos en este camino abrimos dev.azure.com y creamos un proyecto. El proyecto trae muchos componentes. De momento a nosotros nos interesan dos. Repos y Pipelines. Asumiendo que saben de lo que hablo y ya tienen un repositorio en esta tecnología o Github, procedemos a crear el pipeline eligiendo el repo:
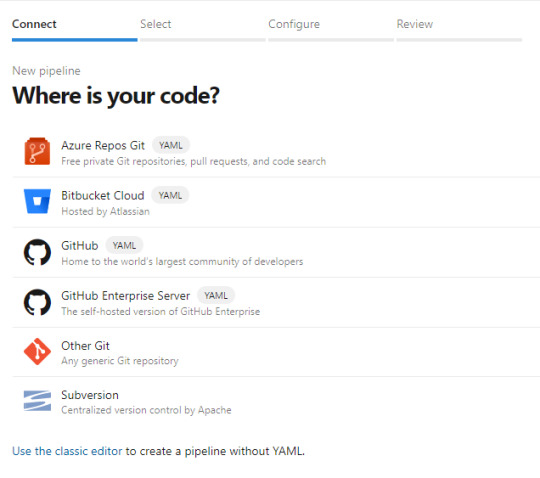
Luego nos preguntará si tenemos una acción concreta de creación incial para nuestro archivo yaml (archivos de configuración de pipelines que orientan el proceso). Podemos elegir iniciar en blanco e ir completando o descarguen el código que veremos en el artículo, ponganlo en el repositorio y creen el pipeline a partir de un archivo existente
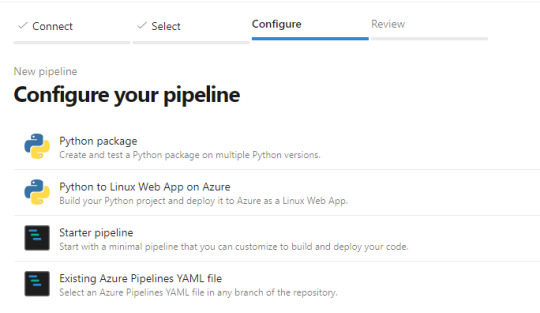
Ahora si tendremos nuestro archivo yml en el repositorio listo para modificarlo. Veamos como hacemos la configuración.
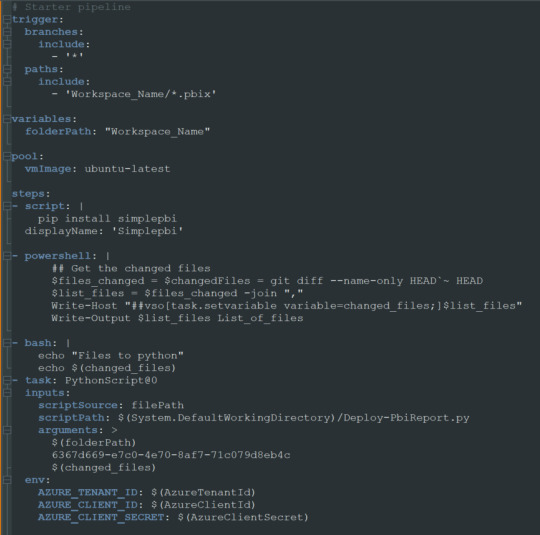
Enlace de github del archivo.
Nuestro pequeño pipeline cuenta con una serie de pasos.
Trigger
Variables
Pool
Steps
NOTA: Estos son un mínimo viable para correr una automatización. Si desean leer más y conocer mayor profundidad puede adentrarse en la documentación de microsoft: https://learn.microsoft.com/es-es/azure/devops/pipelines/yaml-schema/?view=azure-pipelines
Trigger nos mencionará en que parte del repositorio y sobre que branch tiene que prestar atención. En nuestro caso dijimos cualquier branch del path con carpeta “Workspace_Name” y al modificar cualquier archivo PBIX de dicha carpeta. Eso significa que al realizar un commit y push de un archivo de Power Bi Desktop dentro de esa carpeta, se ejecutará el pipeline.
Variables nos permite definir un texto que podremos reutilizar más adelante. En este caso el path de la carpeta. Si bien es una sola carpeta, la práctica de la variable puede ser útil si queremos usar paths más largos. IMPORTANTE: los nombres de carpetas en la variable path no pueden contener espacios dado que la captura de python posterior los reconoce como argumentos separados. Recomiendo usar “_” en lugar de espacios.
Pool viene por defecto y es el trasfondo que correrá el pipeline. Recomiendo dejarlo en ubuntu-latest.
Steps aquí estan los pasos ejecutables de nuestro pipeline. La plataforma nos permite ayudarnos a escribir esta parte cuando elegimos basarnos de la ayuda del wizard. En este caso podemos basarnos en lo que proveemos en ladataweb. Hablemos más de estos pasos.
Detalle de Steps
Primero haremos la instalación de la librería de Python que nos permite utilizar la Power Bi Rest API de manera sencilla en el paso Script.
El paso powershell puesto que nos permite jugar con una consola directa sobre el repositorio. Aqui aprovecharemos para ejecutar un comando git que nos informe cuales fueron los últimos archivos afectados entre el commit anteriores y el actual. Tengamos en cuenta que para poder realizar esta comparación necesitamos cambiar el shallow fetch de nuestro repositorio. Esto significa la memoria de cambio reciente que normalmente viene resguardando 1 commit “más reciente”. Para realizar este cambio necesitamos guardar el pipeline. Luego lo editamos nuevamente y nos dirigimos a triggers:

Una vez allí en la pestaña Yaml podremos encontrar la siguiente opción que igualaremos a 3 como el mínimo necesario para la comparativa.
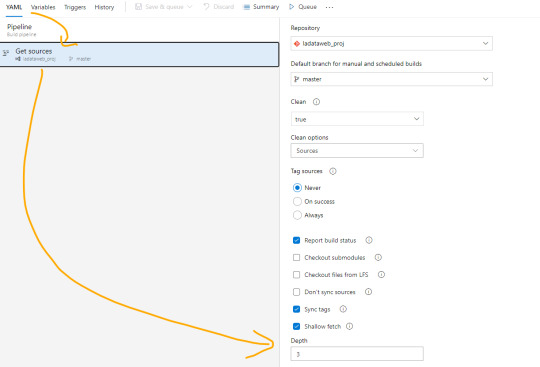
Esta operación también se puede realizar con un Bach de Git local, pero este modo me parece más simple y visual. Para más información pueden leer aqui: https://learn.microsoft.com/es-es/azure/devops/pipelines/repos/azure-repos-git?view=azure-devops&tabs=yaml#shallow-fetch
El paso bash es simplemente para mostrarnos en la consola los archivos que reconoció el script y estan listos para pasar entre pasos.
El paso crítico es Task que llamará a un python script. Para ser más ordenado vamos a llamar a un archivo en el repositorio que nos permita leer un código que cambie con unos parámetros que envía el pipeline para no estar reescribiendolo en cada pipeline de cada workspace/carpeta. Aqui completamos que en script source del file path definido podemos encontrar el script path hasta el archivo puntual que usuará los siguientes tres argumentos. La lista de argumentos refiere al path de los archivos pbix, el id del workspace en donde publicaremos y los archivos que se modificaron según el último commit. Cierra definiendo unas variables de entorno para garantizar la seguridad del script evitando la exposición de la autenticación de la API. En el menú superior derecho veremos la posibilidad de agregar variables:

Sugiero mantener oculto el secret del cliente y visible el id del cliente. Visible este segundo para reconocer con que App Registrada de Azure AD nos estamos conectado a usar la Power Bi Rest API.
Ya definido nuestro Pipeline creemos el script de python que hará la operación de publicar el archivo. En nuestro script lo dejé en la Raíz del repositorio $(System.DefaultWorkingDirectory)/Deploy-PbiReport.py para reutilizarlo en los pipelines de las carpetas/workspaces. Veamos el script

Enlace de github del archivo.
Primero importaremos simplepbi y otras dos librerías. OS para reconocer las variables del entorno y SYS para recibir argumentos.
Iniciarmos recibiendo los argumentos de pipeline con sys.argv en el orden correspondiente. Como la recepción de python lee los argumentos separados por espacios como distintos, vamos a asumir que el parámetro 3 o más se unan separados por espacios (puesto que llegaron como argumentos separados. Luego tomamos la lista de archivos en cadena de texto para construir una lista de python que nos permita recorrerla. En este proceso aprovecharemos para quitar archivos modificados en el commit que no pertenezcan a la carpeta/workspace deseada y sean de extensión “.pbix”. Leemos las variables de entorno para loguear nuestro Power Bi Rest API y todo lo siguiente es mágia de SimplePBI. Pedimos el token para nuestra operaciones, hacemos un for de archivos a importar y realizamos la importación con cuidados de capturas de excepciones y condiciones. Todos los prints nos ayudarán a ver los mensajes al termino de la ejecución para reconocer alguna eventualidad. Esto apunta a no cortar si uno de los archivos falla en publicar no corte al resto. Sino que seguirá y al finalizar podremos lanzar la excepción para que falle el pipeline general a pesar que tal vez corrieran 4/5. Por supuesto que esta decisión podría cambiarse a que si uno falla ninguno continue, o que siga pero al final lanzar una excepción
NOTA: Claro que si es la primera vez que colocamos el archivo.pbix en el repositorio no bastará solo con la importación automática. Será necesario ir a ingresar las credenciales para las actualizaciones manualmente. De momento eso no es posible hacerlo automáticamente.
Para ejecutar la prueba solo bastaría con modificar un archivo .pbix dentro de la carpeta del repo, commit y push. Ese debería ejecutar la acción y publicar el archivo.
De ese modo el desarrollador solo se enfoca en desarrollar con Power Bi Desktop de manera apropiada contra un repositorio y nada más. Un profesional Ops y Administrador serían quienes tendrían licencias PRO que administren el entorno de Áreas de trabajo, apps y distribución de audiencias y permisos.
Demo final commiteando con visual studio code:
Conclusión
Estas posibilidades llevan no solo a buenas prácticas en desarrollo sino también a mantener una linea de desarrolladores que no necesitarían licencias pro a menos que querramos que tengan más responsabilidades en el servicio.
Todo este ejemplo puede expandirse mucho más. Podríamos desarrollar los informes con Parametros para apuntar a distintas bases de datos y tener ambientes de desarrollo. Los desarrolladores no cambiarían más que agregar parametros y tal vez tener otro branch o repositorio. Los profesionales Ops podrían incorporar en el script de importación el cambio del parámetro en service. Incluso podrían efectuarse prácticas de CI moviendo automáticamente versiones estables de un repo a otro. Hablar de CI no me gusta porque no podemos hacer build ni correr tests, pero dejen volar su imaginación. Cada día las prácticas de desarrollo son más posibles y cercanas en proyectos de datos.
En ese archivo python podríamos usar todo el poder de SimplePBI para ajustar nuestro escenario a la práctica Ops deseada.
#powerbi#power bi#power bi devops#power bi cicd#azure devops#azure devops pipelines#power bi tips#power bi tutorial#power bi training#power bi versioning#simplepbi#ladataweb#power bi jujuy#power bi argentina#power bi cordoba#power bi rest api
0 notes
Text
Maximizing Collaboration and Productivity: Azure DevOps and Databricks Pipelines
Data is the backbone of modern businesses, and processing it efficiently is critical for success. However, as data projects grow in complexity, managing code changes and deployments becomes increasingly difficult. That's where Continuous Integration and C
Data is the backbone of modern businesses, and processing it efficiently is critical for success. However, as data projects grow in complexity, managing code changes and deployments becomes increasingly difficult. That’s where Continuous Integration and Continuous Delivery (CI/CD) come in. By automating the code deployment process, you can streamline your data pipelines, reduce errors, and…

View On WordPress
#Azure#Azure DevOps#Build Pipeline#CD/CD#Databricks#GitHub Repo#microsoft azure#Python#Python Testing#Release Pipeline
0 notes