#DBMS vs RDBMS
Text
Dbms Full Form: Enhancing Data Structure And Minimizing Redundancy In DBMS
A dbms full form is a logical collection of data. It includes a set of related tables and index spaces. A database frequently stores all of the data related to a particular application or a group of linked applications. A database or an inventory database could be developed. A database management system (or DBMS) is essentially a computerized data storage system.

#dbms interview questions#dbms javatpoint#dbms notes#dbms definition#dbms vs rdbms#dbms tutorial#database management system#what is database#dbms full form#dbms#normalization in dbms#acid properties in dbms
0 notes
Text
Unraveling the Mysteries of Database Management Systems (DBMS)
In today's digital age, data is critical for any organization's success, and managing data efficiently is essential. A database management system (DBMS) is a software application that allows users to manage and organize large amounts of data. A DBMS serves as an interface between the user and the database, providing a range of features that facilitate data storage, retrieval, and manipulation. In this article, we will explore how a DBMS works and the differences between two main types of DBMS, the relational database management system (RDBMS) and the non-relational database management system (NDBMS).
Understanding DBMS:
A database management system (DBMS) is a software application that enables users to manage and organize large amounts of data. A DBMS serves as an interface between the user and the database, providing a range of features that facilitate data storage, retrieval, and manipulation. A DBMS typically includes a database engine, a query language, a data dictionary, and tools for managing the database.
The database engine is the core component of a DBMS. It is responsible for managing the data storage and retrieval operations. The database engine ensures that the data is stored efficiently and securely and provides mechanisms for accessing and modifying the data.
The query language is the means by which users can interact with the database. A query language allows users to retrieve and manipulate data stored in the database. The most commonly used query language in the industry is SQL (Structured Query Language).
The data dictionary is a catalog of metadata that describes the data stored in the database. The data dictionary includes information such as the names of the tables, the columns in each table, and the relationships between the tables.
Tools for managing the database include utilities for backup and recovery, performance monitoring, and security management.
RDBMS:
A Relational Database Management System (RDBMS) is a type of DBMS that organizes data into tables with columns and rows. Each column represents a specific attribute of the data, and each row represents a record. The relationships between the tables are established through primary and foreign keys.
The RDBMS is designed to provide a structured approach to data management, which makes it ideal for applications that require complex queries and analysis. The RDBMS enforces rules and constraints on data entry, ensuring that the data is consistent. Additionally, RDBMS provides security features, such as access control, encryption, and backup and recovery.
SQL is the most commonly used query language in RDBMS. SQL enables users to perform a range of operations, such as retrieving data, inserting data, updating data, and deleting data. The SQL language is powerful and flexible, allowing users to construct complex queries and perform sophisticated analysis.
NDBMS:
A Non-Relational Database Management System (NDBMS) stores data in a non-tabular format, such as document, graph, or key-value stores. NDBMS offers greater scalability and flexibility than RDBMS. NDBMS is ideal for applications that require horizontal scaling, where data is distributed across multiple servers. NDBMS also offers better performance than RDBMS for applications that require high-speed data retrieval.
NDBMS is designed to provide a more flexible approach to data management. Instead of storing data in a structured format, NDBMS allows users to store data in a format that is more suited to the application's needs. This flexibility makes NDBMS ideal for applications that deal with unstructured data, such as social media data, sensor data, or log files.
Differences Between RDBMS and DBMS:
RDBMS and NDBMS are two types of DBMS, with different approaches to data management. The main differences between RDBMS and DBMS are as follows:
A Relational Database Management System (RDBMS) is a type of DBMS that organizes data into tables with columns and rows. Each column represents a specific attribute of the data, and each row represents a record. The relationships between the tables are established through primary and foreign keys.
The data in RDBMS is organized into tables, which consist of columns and rows. Columns represent the attributes of the data, such as the name, age, and address of a person, while rows represent individual records, such as a specific person's information. The tables in RDBMS are designed to be related to each other through primary and foreign keys, creating a logical structure for the data.
Primary keys are unique identifiers that are used to identify each row in a table. Foreign keys are used to establish relationships between tables, linking the data together. For example, in a customer and order system, the customer table would have a primary key for each customer, and the order table would have a foreign key that references the customer table's primary key DBMS vs RDBMS
The relationship between the tables is essential in RDBMS, as it ensures that the data is consistent and avoids duplication. For example, in the customer and order system, the customer's information is stored in the customer table, and the orders placed by each customer are stored in the order table. By linking the tables using primary and foreign keys, the RDBMS ensures that the orders are associated with the correct customer.
RDBMS also enforces rules and constraints on data entry, ensuring that the data is consistent. For example, a column may be defined to only accept certain types of data or to have a specific format. This ensures that the data is entered correctly and avoids errors that could affect the integrity of the data.
In summary, RDBMS organizes data into tables with columns and rows and establishes relationships between tables through primary and foreign keys. The structure of RDBMS ensures data consistency and avoids duplication, while rules and constraints on data entry ensure data integrity.
RDBMS and DBMS are important tools for managing and processing big data, which refers to large and complex datasets that are difficult to process using traditional data processing techniques. These systems help in big data in the following ways:
Data Management: RDBMS and DBMS provide an efficient and organized way to store and manage large volumes of data. They enable the organization of data into tables, which can be easily searched, filtered, and sorted. This helps in managing the large and complex datasets that are common in big data.
Data Integration: Big data often involves data from multiple sources, such as social media, IoT devices, and enterprise systems. RDBMS and DBMS allow for the integration of this data into a single database, making it easier to analyze and derive insights from.
Data Analysis: RDBMS and DBMS provide a powerful set of tools for analyzing large datasets. They allow for the use of SQL queries, which can be used to extract and manipulate data in various ways. This enables organizations to perform advanced analytics, such as predictive modeling, machine learning, and data mining.
Scalability: RDBMS and DBMS are designed to scale to accommodate large volumes of data. They can handle thousands of concurrent users and terabytes of data, making them ideal for big data processing.
Security: RDBMS and DBMS provide advanced security features to protect sensitive data. They allow for the implementation of access controls, authentication, and encryption, ensuring that data is protected from unauthorized access.
In conclusion, RDBMS and DBMS play a critical role in managing and processing big data. They provide efficient data management, data integration, data analysis, scalability, and security features, making them an essential tool for organizations that deal with large and complex datasets.
A Relational Database Management System (RDBMS) is a type of DBMS that organizes data into tables with columns and rows. Each column represents a specific attribute of the data, and each row represents a record. The relationships between the tables are established through primary and foreign keys.
The data in RDBMS is organized into tables, which consist of columns and rows. Columns represent the attributes of the data, such as the name, age, and address of a person, while rows represent individual records, such as a specific person's information. The tables in RDBMS are designed to be related to each other through primary and foreign keys, creating a logical structure for the data.
Primary keys are unique identifiers that are used to identify each row in a table. Foreign keys are used to establish relationships between tables, linking the data together. For example, in a customer and order system, the customer table would have a primary key for each customer, and the order table would have a foreign key that references the customer table's primary key.
The relationship between the tables is essential in RDBMS, as it ensures that the data is consistent and avoids duplication. For example, in the customer and order system, the customer's information is stored in the customer table, and the orders placed by each customer are stored in the order table. By linking the tables using primary and foreign keys, the RDBMS ensures that the orders are associated with the correct customer.
RDBMS also enforces rules and constraints on data entry, ensuring that the data is consistent. For example, a column may be defined to only accept certain types of data or to have a specific format. This ensures that the data is entered correctly and avoids errors that could affect the integrity of the data.
In summary, RDBMS organizes data into tables with columns and rows and establishes relationships between tables through primary and foreign keys. The structure of RDBMS ensures data consistency and avoids duplication, while rules and constraints on data entry ensure data integrity.
how rdbms and dbms help in big data
RDBMS and DBMS are important tools for managing and processing big data, which refers to large and complex datasets that are difficult to process using traditional data processing techniques. These systems help in big data in the following ways:
Data Management: RDBMS and DBMS provide an efficient and organized way to store and manage large volumes of data. They enable the organization of data into tables, which can be easily searched, filtered, and sorted. This helps in managing the large and complex datasets that are common in big data.
Data Integration: Big data often involves data from multiple sources, such as social media, IoT devices, and enterprise systems. RDBMS and DBMS allow for the integration of this data into a single database, making it easier to analyze and derive insights from.
Data Analysis: RDBMS and DBMS provide a powerful set of tools for analyzing large datasets. They allow for the use of SQL queries, which can be used to extract and manipulate data in various ways. This enables organizations to perform advanced analytics, such as predictive modeling, machine learning, and data mining.
Scalability: RDBMS and DBMS are designed to scale to accommodate large volumes of data. They can handle thousands of concurrent users and terabytes of data, making them ideal for big data processing.
Security: RDBMS and DBMS provide advanced security features to protect sensitive data. They allow for the implementation of access controls, authentication, and encryption, ensuring that data is protected from unauthorized access.
In conclusion, RDBMS and DBMS play a critical role in managing and processing big data. They provide efficient data management, data integration, data analysis, scalability, and security features, making them an essential tool for organizations that deal with large and complex datasets.
Sure, here are some examples of RDBMS and DBMS queries:
SELECT Query: This query is used to retrieve data from a table.Example:SELECT * FROM Employees WHERE department='Sales';This query retrieves all the data from the Employees table where the department is 'Sales'.
INSERT Query: This query is used to insert new data into a table.Example:INSERT INTO Employees (name, age, department) VALUES ('John Doe', 30, 'Marketing');This query inserts a new row into the Employees table with the name 'John Doe', age 30, and department 'Marketing'.
UPDATE Query: This query is used to update existing data in a table.Example:UPDATE Employees SET age=32 WHERE name='John Doe';This query updates the age of the employee with the name 'John Doe' to 32.
DELETE Query: This query is used to delete data from a table.Example:DELETE FROM Employees WHERE name='John Doe';This query deletes the row from the Employees table where the name is 'John Doe'.
JOIN Query: This query is used to combine data from two or more tables.Example:SELECT Orders.order_id, Customers.name, Orders.order_date FROM Orders INNER JOIN Customers ON Orders.customer_id=Customers.customer_id;This query retrieves the order ID, customer name, and order date from the Orders and Customers tables, where the customer ID matches.
GROUP BY Query: This query is used to group data based on a specific column.Example:SELECT department, COUNT(*) as total FROM Employees GROUP BY department;This query groups the employees by department and returns the total number of employees in each department.
These are just a few examples of the many queries that can be used in RDBMS and DBMS systems. Queries are essential for managing and retrieving data from databases, making them an essential tool for data analysts and database administrators.
0 notes
Text
Youtube Short - Difference between RDBMS and NoSQL database | Learn the difference between SQL Vs NoSQL in 1 min
Hi, a short #video on Difference between #rdbms and #nosql #database is published on #codeonedigest #youtube channel. Learn the difference between #sql and nosql in 1 minute.
#sqlvsnosql #nosql #sql #rdbms #database #nosqldatabase #nosqldatabasetutorial
What is RDBMS?
RDBMS stands for Relational Database Management System. RDBMS is a program used to maintain a relational database. RDBMS contains several tables, and each table has its primary key. The RDBMS database uses tables to store data. A table is a collection of related data entries and contains rows and columns to store data. A row of a table is also called a record or tuple. It contains…

View On WordPress
#database#database management system#dbms#difference between sql vs nosql#document database#key value database#mongo database#mysql#nosql#nosql database#nosql database for beginners#nosql database tutorial#nosql training#nosql tutorial#nosql vs sql#oracle#postgres#rdbms#rdbms full course#rdbms tutorial for beginners#relational data model#relational database#relational database design#relational database management system#relational database model#sql#sql database#sql database tutorial#sql training#sql vs nosql
0 notes
Text
Difference Between SQL and MySQL | Key Factors in Database Decision-Making

In the vast landscape of data management, SQL and MySQL stand out as two prominent players. These technologies are often mentioned interchangeably, leading to confusion regarding their distinctions and best-use scenarios. In this blog, we'll dissect the difference between SQL and MySQL, explore their applications, and provide insights into making informed decisions when choosing a database solution.
What is SQL and MySQL?
To begin, let's clarify the basics. A standardized computer language called SQL, or Structured Query Language, is used to manage and work with relational databases. It serves as the foundation for various database management systems (DBMS), allowing users to interact with databases through queries, updates, and modifications.
On the other hand, MySQL is an open-source relational database management system (RDBMS) that utilizes SQL as its querying language. MySQL, created by Oracle Corporation, is well known for its dependability, scalability, and user-friendliness. It powers countless applications and websites worldwide, making it one of the most popular database systems in the industry.
What is SQL used for?
SQL is incredibly versatile, catering to a wide range of data-related tasks. Its primary functions include:
Data Querying: SQL enables users to retrieve specific information from databases using SELECT statements. These queries can filter, sort, and aggregate data based on user-defined criteria, facilitating efficient data retrieval.
Data Manipulation: With SQL, users can insert, update, and delete records within a database. This functionality is essential for maintaining data integrity and keeping information up-to-date.
Schema Modification: SQL allows for the creation, alteration, and deletion of database schema objects such as tables, views, and indexes. This flexibility enables database administrators to adapt to evolving business requirements seamlessly.
Access Control: SQL includes robust security features for managing user access and permissions within a database. Administrators can grant or revoke privileges to ensure data confidentiality and integrity.
What is MySQL used for?
As an RDBMS built on SQL, MySQL inherits many of the same capabilities while offering additional features tailored to specific use cases. Some common applications of MySQL include:
Web Development: MySQL is widely used in web development for storing and retrieving dynamic content. It integrates seamlessly with popular web development frameworks like PHP, Python, and Ruby on Rails, making it an ideal choice for building dynamic websites and web applications.
Enterprise Solutions: Many enterprises leverage MySQL for mission-critical applications such as e-commerce platforms, content management systems, and customer relationship management (CRM) software. Its scalability and high availability make it well-suited for handling large volumes of transactions and concurrent users.
Data Warehousing: MySQL can also serve as a backend database for data warehousing solutions. By aggregating and analyzing vast amounts of data, organizations can gain valuable insights into their business operations and make data-driven decisions.
MySQL vs SQL
It's important to note that MySQL is not an alternative to SQL but rather an implementation of it. When comparing MySQL to SQL, we're essentially comparing a specific RDBMS to the broader SQL language. However, there are key distinctions worth highlighting:
Features and Functionality: MySQL offers additional features beyond the standard SQL language, such as support for transactions, replication, and stored procedures. These features enhance MySQL's capabilities but may not be present in all SQL-compliant databases.
Performance and Scalability: MySQL is renowned for its performance and scalability, particularly in web-based applications with high concurrency. Its optimized query execution and efficient storage engine contribute to faster response times and improved throughput compared to some other SQL-based databases.
Licensing and Support: While SQL is a standardized language with multiple implementations, MySQL is governed by Oracle Corporation, which provides commercial support and services for enterprise users.
However, there are also open-source distributions of MySQL available for users who prefer community-driven development and support.
Best Place to Learn SQL and MySQL
For those interested in mastering SQL and MySQL, there are numerous resources available online.These are some of the places where you can learn both SQL as well as MySQL are mentioned down below:
Online Courses: Platforms like Coursera, Udemy, and Codecademy offer comprehensive courses on SQL and MySQL, catering to learners of all skill levels. These courses typically include video lectures, hands-on exercises, and quizzes to reinforce learning.
Institute and Training Center: There are many institutes which offer SQL and MySQL courses which are actually included in the Data Science course. If you want best career guidance as well as training from experts then do check Milestone Institute of Technology for better learning and placement. They also provide internships as well as personal training if required.
Conclusion
In conclusion, while SQL and MySQL are closely related, they serve distinct purposes within the realm of data management. Understanding their differences and applications is crucial for making informed decisions when selecting a database solution. By leveraging the right technology for the job and investing in continuous learning, individuals and organizations can harness the power of SQL and MySQL to drive innovation and success.
0 notes
Text
Unveiling the Data Storm: MongoDB vs MySQL - The Ultimate Battle for Database

Today, data is indispensable to the success of any organization. And, given the enormous amount of data generated daily, it took time to determine which platform would be optimal for managing such large amounts of data while ensuring security. Given the abundance of database options, users typically compare and contrast MongoDB and MySQL to determine which is preferable.
Moreover, in today's world, where trillions of data are readily accessible, it is essential to have a reliable database system that meets all your requirements. However, determining which option is ideal for your company can take time. Various DBMS types are available, but selecting the correct one for your organization is essential. MySQL and MongoDB are two of the most popular alternatives to DBMSs. Both have benefits and drawbacks; your company's decision may hinge on its needs.
Organizations that use a tabular database like MySQL may need help managing and storing data as their needs change. At the same time, new businesses are still trying to figure out which database to use to keep their development pipelines running smoothly.
MySQL is a famous relational database management system (RDBMS) made by Oracle. It is free to use and open source. Like other relational systems, MySQL stores data in tables and rows, checks for referential integrity, and helps you access data using an organized query language (SQL). When individuals want to get data from a MySQL database, they have to make a SQL query that puts together multiple tables to get the view of the data they need.
Predefined database schemas and data models require predefining, and data needs to conform to the schema in order to record it in the database. This rigid approach to data storage provides some security but at the expense of flexibility. Schema migration occurs when a new data type or format must be stored in the database, which can become difficult and costly as the database grows.
MongoDB is also open source and free to use, but it differs from relational databases in its design principles. Often regarded as a "non-relational" or "NoSQL" system, MongoDB uniquely stores data. Instead of tables and rows, it saves data as a collection of JSON-like documents (stored as binary JSON or BSON).
Documents in MongoDB contain various forms of key/value pairs, including arrays and nested documents. The primary distinction is that the format of a collection's key/value pairs can vary between documents. Because documents are self-descriptive, this more flexible method is possible. MongoDB provides enhanced security, reliability, and performance; you can modify the data structure or schema as necessary. Thus, it facilitates achieving the increased speed and storage requirements.
Performance and speed should always be taken into consideration while choosing a database. You must be aware of each database's capabilities and intended application. For busy personnel like developers and administrators, every second counts. Therefore, you should select a database that enables you to be more productive through faster access.
MongoDB is faster than MySQL because it stores many unstructured data and employs a document-based storage technique. MongoDB stores data in a single document per entity, allowing faster read and write operations. MySQL slows down with lots of data. It saves tables ordinarily. You must travel through several tables to edit or remove data from the database. This delays the server. MySQL can be used for transactional activities.
Finally, MongoDB and MySQL have their benefits and drawbacks; thus, picking one over the other will ultimately come down to the requirements of a given project. MySQL may be better if your app needs well-organized data and extensive procedures. MongoDB may be appropriate if your app needs to grow quickly and manage lots of unstructured data. Your project's requirements will determine which to use.
0 notes
Text

#ICYDK: Comparing DBMS vs. RDBMS: Key differences https://www.techtarget.com/searchdatamanagement/answer/What-is-the-difference-between-DBMS-and-RDBMS?utm_source=dlvr.it&utm_medium=tumblr
0 notes
Video
youtube
UGC NET Computer Science | RDBMS vs DBMS vs File System | Puneet Mam | N...
0 notes
Text
Dbms Full Form: Enhancing Data Structure And Minimizing Redundancy In DBMS
A dbms full form is a logical collection of data. It includes a set of related tables and index spaces. A database frequently stores all of the data related to a particular application or a group of linked applications. A database or an inventory database could be developed. A database management system (or DBMS) is essentially a computerized data storage system.

#dbms interview questions#dbms javatpoint#dbms notes#dbms definition#dbms vs rdbms#dbms tutorial#database management system#what is database#dbms full form#dbms#normalization in dbms#acid properties in dbms
1 note
·
View note
Link
Top 15 differences between DBMS and RDBMS
Read full post : http://onlinetutorialhub.blogspot.com/2017/11/dbms-vs-rdbms-sql.html
Follow us on :
#Blog : https://goo.gl/pYVwZ5
#Facebook : https://goo.gl/zLbihL
#twitter : https://goo.gl/dvZFJF
#Google+ : https://goo.gl/MXFsc9
#Pinterest : https://goo.gl/hWgQ2i
#Instagram : https://goo.gl/ovqzMw
#onlinetutorialhub#onlinetutorial#dbms#rdbms#sql#learn sql#database#sql server#ms sql server#online#tutorial#hub#learn#technology#education#study#study material#tech news#technolove#technolife#html#hadoop#python#data
6 notes
·
View notes
Text
SQL vs NoSQL - Confronto, guida e casi d'uso

I database NoSQL sono una realtà consolidata ormai da molti anni e godono di una grande diffusione a tutti i livelli: la maggior parte dei provider di servizi cloud (Amazon, Google, Microsoft, etc.) fornisce soluzioni NoSQL in modalità as-a-service per la gestione dei dati, utilizzate ad oggi da milioni di utenti in tutto il mondo anche a livello enterprise. In questo articolo cercheremo di far luce sulle principali caratteristiche di questa soluzione, sottolineandone le similarità e differenze rispetto ai database relazionali, con l'obiettivo di comprenderne al meglio i principali ambiti di utilizzo e individuare gli scenari in cui - perlomeno a nostro avviso - non rappresentano ad oggi la soluzione ottimale.
L'obiettivo di questo contributo è quello di rendere DBA e sviluppatori in grado di fare una scelta consapevole quando si deve prendere in considerazione l'utilizzo di una determinata base dati (RDBMS o NoSQL) all’interno di un progetto.
Definizione
SQL, acronimo di Structured Query Language, è un linguaggio volto all’interrogazione di dati altamente strutturati per mezzo di una sintassi grossomodo standardizzata, cosa che rende possibile migrare agevolmente da un sistema all’altro. L’approccio NoSQL, alternativo al precedente a partire dal nome, nasce dall’esigenza di dover rappresentare dati per loro natura eterogenei, per i quali ha poco senso (o sarebbe troppo oneroso) forzare una struttura.
Applicabilità
Da un punto di vista teorico, l’approccio SQL si rivela applicabile alla maggior parte dei contesti, in quanto la standardizzazione dei dati costituisce quasi sempre un obiettivo primario dello sviluppo software nella quasi totalità dei progetti IT: al tempo stesso, la versatilità dell’approccio NoSQL si sposa bene con un approccio iterativo ed evolutivo (tipico delle metodologie Agile), in quanto si prevede che ci sarà spesso bisogno di molte iterazioni, feedback e refactoring prima di poter raggiungere una standardizzazione effettiva della base dati.
Entrambe le argomentazioni sono ragionevoli e facilmente verificabili: di conseguenza, non esiste una soluzione “migliore” o “peggiore” in assoluto, ma entrambe possono essere più o meno adatte a seconda delle singole circostanze e scenari implementativi. Di seguito si propone un confronto tra i due sistemi, declinato nelle principali caratteristiche funzionali che ci si aspetta da un DBMS.
Transazioni
Il supporto delle transazioni ACID (Atomicity, Consistency, Isolation, Durability) è un punto di forza dei RDBMS; i DB NoSQL hanno un approccio diverso, basato sulla atomicità della singola istruzione, che però non è sufficiente a garantire una consistenza su una pluralità eterogenea di inserimenti a meno di non gestirla a livello applicativo (manualmente o con middleware ad hoc). Di conseguenza, se il supporto transazionale è importante, l’utilizzo di un RDBS è raccomandato.
Performance
I DB NoSQL garantiscono spesso prestazioni migliori e sono generalmente considerati più efficienti; i RDBMS più moderni sono in grado di garantire performance paragonabili, a patto di disegnare il database in modo efficiente, utilizzando gli indici in modo opportuno e strutturando le Query nel modo corretto e senza commettere errori: si tratta certamente di un lavoro più complesso, in assenza del quale i DB NoSQL risultano superiori.
Cache
Il punto di forza dei DB NoSQL è quando vengono utilizzati come cache, in quanto i datastore utilizzati a tale scopo (key-value pair, generalmente su standard Redis) sono estremamente veloci ed efficienti. Si tratta del resto di uno degli utilizzi più diffusi dei DB NoSQL, anche perché è compatibile con l’utilizzo di un RDBMS che operi “dietro” alla cache.
Data Normalization
La normalizzazione (o tipizzazione) dei dati è un altro punto di forza dei RDBMS, ma è spesso anche una debolezza a livello applicativo perché costringe a operare con query complesse (JOIN, MERGE etc.) qualora il Data Model presenti molteplici livelli di relazione. I DB NoSQL non hanno questo problema in quanto, lavorando in un contesto destrutturato e privo di un DB Schema definito a priori, supportano nativamente liste, nested entities e strutture relazionali.
Il “costo” di questo approccio porta però alla frequente duplicazione dei dati, che aumenta le dimensioni del DB e complica le cose in caso di aggiornamenti orizzontali dei dati “annidati” (oltre a rallentare le prestazioni). Questo problema, nelle versioni più recenti dei motori NoSQL più diffusi, viene risolto con l’implementazione dei “riferimenti”, che però a ben vedere altro non sono che relazioni.
Quando usare cosa?
Sulla base di quanto detto, cerchiamo di tirare le somme e individuare degli ambiti di utilizzo reali per i due approcci che abbiamo descritto.
In termini generali, potremmo affermare che l'utilizzo di un RDBMS è a tut'oggi preferibile in caso di dati strutturati, facili da rappresentare e con numero ridotto di relazioni, oltre che in tutti i casi in cui è importante garantire l’integrità dei dati in senso “ACID”.
Viceversa, l'approccio NoSQL risulta convincente in caso di dati “polimorfi”, ovvero dotati di una struttura estremamente variabile e tendenzialmente mutevole o soggetta a cambiamenti frequenti e/o imprevedibili; inoltre, si tratta di una modalità di storage e accesso ai dati che risulta estremamente efficace in tutte le situazioni legate al caching dei dati e alla gestione di informazioni destrutturate (o parzialmente strutturate) contraddistinte da una persistenza temporanea e variabile nel corso del tempo: HTTP session management, key-value pair, etc..
Read the full article
0 notes
Text
“Data” is not simple as we think!
After a short period of time,hello again my friends!
Today in our seventh blog article we will be talking about data
controlling and few more new topics.

First lets learn what data and information is.Data is naturally unsorted things.
Data becomes information when they are sorted.That is when it becomes
useful.
Data can come in various formats like,
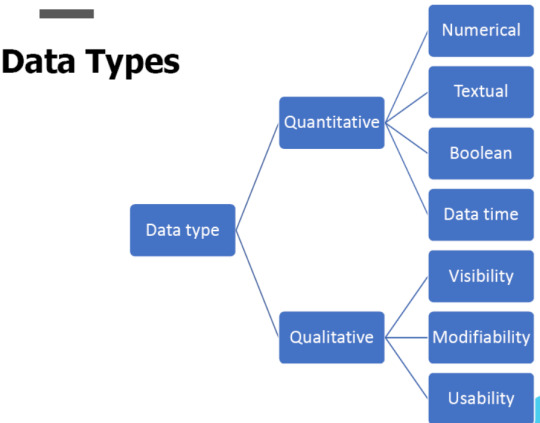
So data can can be stored, read, updated/modified,
and deleted as we need to and thereby they can be organized in a
useful manner.
At run time of software systems, data is stored in main memory, which is volatile
Therefore data should be stored in non-volatile storage for persistence.
There are two main ways of storing data
• Files
•Databases

Out of these two types databases have proved to be much efficient.
This is due to the advantages that are observed in databases.
Data independence –application programs are independent of the way the data is structured and stored.
Efficient data access
Enforcing integrity–provide capabilities to define and enforce constraints
Ex: Data type for a name should be string
Restricting unauthorized access
Providing backup and recovery
Concurrent access
There are many formats for storing data
•Plain-text, XML, JSON, tables, text files, images,
etc…
Digging more upto "data" related terms,lets take a brief look at the
terms
Database and Database Management System.
A database is a place where data is stored.More accurately a database
is a collection of related data.Whereas a database management
systems (DBMS) is a general-purpose software system that
facilitates the processes of defining, constructing, manipulating,
and sharing databases among various users and applications.
Also DBMSs are used to connect to the DB servers and manage
the DBs and data in them
•PHPMyAdmin
•MySQL Workbench
In databases data can be arranged in the following manners..
•Un-structured
Semi-structured data is data that has not been organized into a
specialized repository, such as a database, but that nevertheless has associated information, such as metadata,
that makes it more amenable to processing than raw data.
•Semi-structured
Structured data is data that has been organized into a formatted repository,
typically a database, so that its elements can be made addressable for more effective processing and analysis.
•Structured
Unstructured data is information, in many different forms, that
doesn't hew to conventional data models and thus typically isn't a good fit for a mainstream relational database.
*SQL-Structered Query Language
SQL-Structered Query Language is used to process data in a databases.
Furthermore SQL can be categorized as DDL and DML.
DDL-Data definition language
CRUD databases
DML-Data manipulation language
CRUD data in databases
•Hierarchical databases
•Network databases
•Relational databases
•Non-relational databases (NoSQL)
•Object-oriented databases
•Graph databases
•Document databases are the types of databases to be found.
** Data warehouse and Big data
Data warehouse and Big data have become two popular topics in the
new world.

Data warehouse a system used for reporting and data analysis,
and is considered a core component of business intelligence.
Big data is a field that treats ways to analyze, systematically extract
information from, or otherwise deal with data sets that are too large
or complex to be dealt with by traditional data-processing application software.
Big data was originally associated with three key concepts:
volume, variety, and velocity.
So how do we use databases in day to day life?
To process data in DB we use,
•SQL statements
•Prepared statements
•Callable statements


Connection statement codes
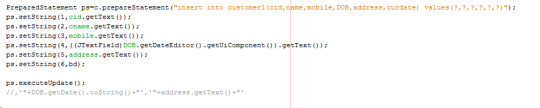
Prepared statement codes
3.Callable statements
CallableStatement cstmt = con.prepareCall("{call
anyProcedure(?, ?, ?)}");
cstmt.execute();
Other useful objects are,
•Connection
•Statement
•Reader
•Result set
**ORM
The mapping of relational objects (ORM, O / RM and O / R) in
computer science is a programming technique for converting
data between incompatible writing systems using object-oriented programming languages.
ORM implementations in JAVA
• Java Beans
• JPA
POJO stands for Plain Old Java Object, and would be used to describe the same things as a "Normal Class" whereas a JavaBean follows a set of rules.
Most commonly Beans use getters and setters to protect their member
variables, which are typically set to private and have a no-argument
public constructor.
POJO stands for Plain Old Java Object, and would be used to describe
the same things as a "Normal Class" whereas a JavaBean follows a set
of rules. Most commonly Beans use getters and setters to protect their
member variables, which are typically set to private and have a
no-argument public constructor.
Beans
Beans are special type of Pojos. There are some restrictions on POJO to be a bean.
POJO Vs Beans
All JavaBeans are POJOs but not all POJOs are JavaBeans. A JavaBean
is a Java object that satisfies certain programming conventions: the JavaBean class must implement either Serializable or Externalizable; ... all JavaBean properties must have public setter and getter methods (as appropriate).
* Java Persistence API (JPA)
Java Persistence API is a collection of classes and methods to persistently
store the vast amounts of data into a database which is provided by
the Oracle Corporation.
JPA can be used to reduce the burden of writing codes for
relational object management.
A programmer follows the ‘JPA Provider’ framework, which allows easy
interaction with database instance. Here the required framework is
taken over by JPA.
JPA is an open source API.Some of the products are,
Eclipselink,Toplink,Hibernate.
**NoSQL
SQL databases are commonly known as Relational databases(RDBMs),while
NoSQL databases are called non-relational databases or distributed
databases.
NoSQL comes in to need when semi-structured and un-structured data are
needed to be processed.
It is advantageous to use NoSQL databases as they have high performance,
supports both semi-structured and un-structured data,scalability.
MongoDB, BigTable, Redis, RavenDB Cassandra, HBase, Neo4j and CouchDB
are examples of NoSQL databases.
You can find more by this link..
https://searchdatamanagement.techtarget.com/definition/NoSQL-Not-Only-SQL
**Hadoop
Hadoop is an open source framework implmented by Apache.It is Java
based.It is used to process large datasets across clusters
of computers distributedly.Hadoop is designed to scale up from single server
to thousands of machines, each offering local computation and storage.
Hadoop is consisted of two major layers,
1.Processing/Computation layer (MapReduce), and
2.Storage layer (Hadoop Distributed File System).
Finally we'll turn into the topic Information retrieval (IR).
This is the activity of obtaining information system resources
relevant to an information need from a collection. Searches can be based on
full-text or other content-based indexing.

For better results, IR should have the following characteristics.
1. Fast/performance
2. Scalablitiy
3. Efficient
4. Reliable/Correct
References
[1] Wikipedia.com. “ Hadoop ”. [Accessed: April 10, 2019].
[2] TutorialsPoint.com. “JPA”. [Accessed: April 10 , 2019]
[3] TutorialsPoint.com. “Hadoop”. [Accessed: April 10 , 2019].
0 notes
Text

#ICYMI: Comparing DBMS vs. RDBMS: Key differences https://www.techtarget.com/searchdatamanagement/answer/What-is-the-difference-between-DBMS-and-RDBMS?utm_source=dlvr.it&utm_medium=tumblr
0 notes
Text
Tute 8
PERSISTENT DATA
The opposite of dynamic—it doesn’t change and is not accessed very frequently.
Core information, also known as dimensional information in data warehousing. Demographics of entities—customers, suppliers,orders.
Master data that’s stable.
Data that exists from one instance to another. Data that exists across time independent of the systems that created it. Now there’s always a secondary use for data, so there’s more persistent data. A persistent copy may be made or it may be aggregated. The idea of persistence is becoming more fluid.
Stored in actual format and stays there versus in-memory where you have it once, close the file and it’s gone. You can retrieve persistent data again and again. Data that’s written to the disc; however, the speed of the discs is a bottleneck for the database. Trying to move to memory because it’s 16X faster.
Every client has their own threshold for criticality (e.g. financial services don’t want to lose any debits or credits). Now, with much more data from machines and sensors, there is greater transactionality. The meta-data is as important as Now, with much more data from machines and sensors, there is greater transactionality. The meta-data is as important as the data itself. Meta-data must be transactional.
Non-volatile. Persists in the face of a power outage.
Any data stored in a way that it stays stored for an extended period versus in-memory data. Stored in the system modeled and structured to endure power outages. Data doesn’t change at all.
Data considered durable at rest with the coming and going of hardware and devices. There’s a persistence layer at which you hold your data at risk.Data that is set and recoverable whether in flash or memory backed.
With persistent data, there is reasonable confidence that changes will not be lostand the data will be available later. Depending on the requirements, in-cloud or in-memory systems can qualify. We care most about the “data” part. If it’s data, we want to enable customers to read, query, transform, write, add-value, etc.
A way to persist data to disk or storage. Multiple options to do so with one replica across data centers in any combination with and without persistence. Snapshot data to disk or snapshot changes. Write to disk every one second or every write. Users can choose between all options. Persistence is part of a high availability suite which provides replication and instant failover. Registered over multiple clouds. Host thousands of instances over multiple data centers with only two node failures per day. Users can choose between multiple data centers and multiple geographies. We are the company behind Redis. Others treat as a cache and not a database. Multiple nodes – data written to disks. You can’t do that with regular open source. If you don’t do high availability, like recommended, you can lose your data.
Anything that goes to a relational or NoSQL database in between.
DATA
All information systems require the input of data in order to perform organizational activities. Data, as described by Stair and Reynolds (2006), is made up of raw facts such as employee information, wages, and hours worked, barcode numbers, tracking numbers or sale numbers.
The scope of data collected depends on what information needs to be extrapolated for maximum efficiency. Kumar and Palvia (2001) state that: “ Data plays a vital role in organizations, and in recent years companies have recognized the significance of corporate data as an organizational asset” (¶ 4). Raw data on it’s own however, has no representational value (Stair and Reynolds, 2006). Data is collected in order to create information and knowledge about particular subjects that interest any given organization in order for that organization to make better management decisions.
DATABASE
A database (DB), in the most general sense, is an organized collection of data. More specifically, a database is an electronic system that allows data to be easily accessed, manipulated and updated.
In other words, a database is used by an organization as a method of storing, managing and retrieving information.
Modern databases are managed using a database management system (DBMS).
DATABASE SERVER
The term database server may refer to both hardware and software used to run a database, according to the context. As software, a database server is the back-end portion of a database application, following the traditional client-server model. This back-end portion is sometimes called the instance. It may also refer to the physical computer used to host the database. When mentioned in this context, the database server is typically a dedicated higher-end computer that hosts the database.
Note that the database server is independent of the database architecture. Relational databases, flat files, non-relational databases: all these architectures can be accommodated on database servers.
DATABASE MANAGEMENT SYSTEM
Database Management System (also known as DBMS) is a software for storing and retrieving users’ data by considering appropriate security measures. It allows users to create their own databases as per their requirement.
It consists of a group of programs which manipulate the database and provide an interface between the database. It includes the user of the database and other application programs.
The DBMS accepts the request for data from an application and instructs the operating system to provide the specific data.
In large systems, a DBMS helps users and other third-party software to store and retrieve data.
DBMS vs FILES
Multi-user access-It does not support multi-user access
Design to fulfill the need for small and large businesses-It is only limited to smaller DBMS system.
Remove redundancy and Integrity-Redundancy and Integrity issues
Expensive. But in the long term Total Cost of Ownership is cheap-It’s cheaper
Easy to implement complicated transactions-No support for complicated transactions
Pros of the File System
Performance can be better than when you do it in a database. To justify this, if you store large files in DB, then it may slow down the performance because a simple query to retrieve the list of files or filename will also load the file data if you used Select * in your query. In a files ystem, accessing a file is quite simple and light weight.
Saving the files and downloading them in the file system is much simpler than it is in a database since a simple “Save As” function will help you out. Downloading can be done by addressing a URL with the location of the saved file.
Migrating the data is an easy process. You can just copy and paste the folder to your desired destination while ensuring that write permissions are provided to your destination.
It’s cost effective in most cases to expand your web server rather than pay for certain databases.
It’s easy to migrate it to cloud storage i.e. Amazon S3, CDNs, etc. in the future.
Cons of the File System
Loosely packed. There are no ACID (Atomicity, Consistency, Isolation, Durability) operations in relational mapping, which means there is no guarantee. Consider a scenario in which your files are deleted from the location manually or by some hacking dudes. You might not know whether the file exists or not. Painful, right?
Low security. Since your files can be saved in a folder where you should have provided write permissions, it is prone to safety issues and invites trouble, like hacking. It’s best to avoid saving in the file system if you cannot afford to compromise in terms of security.
Pros of Database
ACID consistency, which includes a rollback of an update that is complicated when files are stored outside the database.
Files will be in sync with the database and cannot be orphaned, which gives you the upper hand in tracking transactions.
Backups automatically include file binaries.
It’s more secure than saving in a file system.
Cons of Database
You may have to convert the files to blob in order to store them in the database.
Database backups will be more hefty and heavy.
Memory is ineffective. Often, RDBMSs are RAM-driven, so all data has to go to RAM first. Yeah, that’s right. Have you ever thought about what happens when an RDBMS has to find and sort data? RDBMS tracks each data page — even the lowest amount of data read and written — and it has to track if it’s in-memory or if it’s on-disk, if it’s indexed or if it’s sorted physically etc.
TYPES OF DATABASE
Depending upon the usage requirements, there are following types of databases available in the market:
Centralised database.
Distributed database.
Personal database.
End-user database.
Commercial database.
NoSQL database.
Operational database.
Relational database.
Cloud database.
Object-oriented database.
Graph database.
But we ca conseder the following databases as main databases.
1.Relational Database
The relational database is the most common and widely used database out of all. A relational database stores different
data in the form of a data table.
2.Operational Database
Operational database, which has garnered huge popularity from different organizations, generally includes customer database, inventory database, and personal database.
3.Data Warehouse
There are many organizations that need to keep all their important data for a long span of time. This is where the importance of the data warehouse comes into play.
4.Distributed Database
As its name suggests, the distributed databases are meant for those organizations that have different workplace venues and need to have different databases for each location.
5.End-user Database
To meet the needs of the end-users of an organization, the end-user database is used.
key terms of different types of database users
application programmer: user who implements specific application programs to access the stored data
application user: accesses an existing application program to perform daily tasks.
database administrator (DBA): responsible for authorizing access to the database, monitoring its use and managing all the resources to support the use of the entire database system
end user: people whose jobs require access to a database for querying, updating and generating reports
sophisticated user: those who use other methods, other than the application program, to access the database
STATEMENT VS PREPARED STATEMENT VS CALLABLE STATEMENT IN JAVA
JDBC API provides 3 different interfaces to execute different SQL Queries. They are:
Statement: Statement interface is used to execute normal SQL Queries.
PreparedStatement: It is used to execute dynamic or parametrized SQL Queries.
CallableStatement: It is used to execute the Stored Procedure.
STATEMENT
In JDBC Statement is an Interface. By using Statement object we can send our SQL Query to Database. At the time of creating a Statement object, we are not required to provide any Query. Statement object can work only for static query.
PREPARED STATEMENT
PreparedStatement is an interface, which is available in java.mysql package. It extends the Statement interface.
Benefits of Prepared Statement:
It can be used to execute dynamic and parametrized SQL Query.
Prepared Statement is faster then Statement interface. Because in Statement Query will be compiled and execute every time, while in case of Prepared Statement Query won’t be compiled every time just executed.
It can be used for both static and dynamic query.
In case of Prepared Statement no chance of SQL Injection attack. It is some kind of problem in database programming.
CALLABLE STATEMENT
CallableStatement in JDBC is an interface present in a java.sql package and it is the child interface of Prepared Statement. Callable Statement is used to execute the Stored procedure and functions. Similarly to method stored procedure has its own parameters. Stored Procedure has 3 types of parameters.
IN PARAMETER : IN parameter is used to provide input values.
OUT PARAMETER : OUT parameter is used to collect output values.
IN OUT PARAMETER : It is used to provide input and to collect output values.
The driver software vendor is responsible for providing the implementations for Callable statement interface. If Stored Procedure has OUT parameter then to hold that output value we should register every OUT parameter by using registerOutParameter() method of CallableStatement. CallableStatement interface is better then Statement and PreparedStatement because its call the stored procedure which is already compiled and stored in the database.
ORM
ORMs have some nice features. They can handle much of the dog-work of copying database columns to object fields. They usually handle converting the language’s date and time types to the appropriate database type. They generally handle one-to-many relationships pretty elegantly as well by instantiating nested objects. I’ve found if you design your database with the strengths and weaknesses of the ORM in mind, it saves a lot of work in getting data in and out of the database. (You’ll want to know how it handles polymorphism and many-to-many relationships if you need to map those. It’s these two domains that provide most of the ‘impedance mismatch’ that makes some call ORM the ‘vietnam of computer science’.)
For applications that are transactional, i.e. you make a request, get some objects, traverse them to get some data and render it on a Web page, the performance tax is small, and in many cases ORM can be faster because it will cache objects it’s seen before, that otherwise would have queried the database multiple times.
For applications that are reporting-heavy, or deal with a large number of database rows per request, the ORM tax is much heavier, and the caching that they do turns into a big, useless memory-hogging burden. In that case, simple SQL mapping (LinQ or iBatis) or hand-coded SQL queries in a thin DAL is the way to go.
Pros of ORM:
Portable: ORM is used so that you write your structure once and ORM layer will handle the final statement that is suitable for the configured DBMS. This is an excellent advantage as simple operation like limit is added as ‘limit 0,100’ at the end of select statement in MySQL, while it is ‘select top 100 from table’ in MS SQL.
Nesting of data: in case of relationships, the ORM layer will pull the data automatically for you.
Single language: you don’t to know SQL language to deal the database only your development language.
Adding is like modifying: most ORM layers treat adding new data (SQL insert) and updating data (SQL Update) in the same way, these makes writing and maintaining code a piece of cake.
Cons of ORM
Slow: if you compare the performance between writing raw SQL or using ORM, you will find raw much faster as there is no translation layer.
Tuning: if you know SQL language and your default DBMS well, then you can use your knowledge to make queries faster but this is not the same when using ORM.
Complex Queries: some ORM layers have limitations especially when executing queries so sometimes you will find yourself writing raw SQL.
Studying: in case you are working in a big data project and you are not happy with the performance, you will find yourself studying the ORM layer so that you can minimize the DBMS hits.
JAVA ORM TOOLSHibernate
Hibernate is an object-relational mapping (ORM) library for the Java language, providing a framework for mapping an object-oriented domain model to a traditional relational database. Hibernate solves object-relational impedance mismatch problems by replacing direct persistence-related database accesses with high-level object handling functions.
Hibernate’s primary feature is mapping from Java classes to database tables (and from Java data types to SQL data types). Hibernate also provides data query and retrieval facilities. Hibernate generates the SQL calls and attempts to relieve the developer from manual result set handling and object conversion and keep the application portable to all supported SQL databases with little performance overhead.
IBatis / MyBatis
iBATIS is a persistence framework which automates the mapping between SQL databases and objects in Java, .NET, and Ruby on Rails. In Java, the objects are POJOs (Plain Old Java Objects). The mappings are decoupled from the application logic by packaging the SQL statements in XML configuration files. The result is a significant reduction in the amount of code that a developer needs to access a relational database using lower level APIs like JDBC and ODBC.
Other persistence frameworks such as Hibernate allow the creation of an object model (in Java, say) by the user, and create and maintain the relational database automatically. iBATIS takes the reverse approach: the developer starts with an SQL database and iBATIS automates the creation of the Java objects. Both approaches have advantages, and iBATIS is a good choice when the developer does not have full control over the SQL database schema.
For example, an application may need to access an existing SQL database used by other software, or access a new database whose schema is not fully under the application developer’s control, such as when a specialized database design team has created the schema and carefully optimized it for high performance.
Toplink
In computing, TopLink is an object-relational mapping (ORM) package for Java developers. It provides a framework for storing Java objects in a relational database or for converting Java objects to XML documents.
TopLink Essentials is the reference implementation of the EJB 3.0 Java Persistence API (JPA) and the open-source community edition of Oracle’s TopLink product. TopLink Essentials is a limited version of the proprietary product. For example, TopLink Essentials doesn’t provide cache synchronization between clustered applications, some cache invalidation policy, and query Cache.
.NET ORM TOOLSLinqConnect
LinqConnect is a fast, lightweight, and easy to use LINQ to SQL compatible ORM solution, supporting SQL Server, Oracle, MySQL, PostgreSQL, and SQLite. It allows you to use efficient and powerful data access for your .NET Framework, Metro, Silverlight, or Windows Phone applications supporting Code-First, Model-First, Database-First or mixed approaches.
NHibernate
Entity Developer for NHibernate, being the best NHibernate designer to-date, allows you to create NHibernate models fastly in a convenient GUI environment.
Devart has almost ten-year experience of developing visual ORM model designers for LINQ to SQL and Entity Framework and there is a number of satisfied LINQ to SQL and Entity Framework developers that use Entity Developer. Our extensive experience and skills have become the soundest cornerstone of our NHibernate designer.
Entity Framework 6
Entity Framework 6 (EF6) is a tried and tested object-relational mapper (O/RM) for .NET with many years of feature development and stabilization.
As an O/RM, EF6 reduces the impedance mismatch between the relational and object-oriented worlds, enabling developers to write applications that interact with data stored in relational databases using strongly-typed .NET objects that represent the application’s domain, and eliminating the need for a large portion of the data access “plumbing” code that they usually need to write.
NOSQL
NoSql solves the problem of scalability and availability against that of atomicity or consistency. So According to CAP(Consistency, Availability and Tolerance to network partitions) theorem for shared-data systems, only two can be achieved at any time.
NoSql approach to store data and querying is quite better :
Schemaless data representation:Most of them offer schemaless data representation & allow storing semi-structured data.Can continue to evolve over time— including adding new fields or even nesting the data, for example, in case of JSON representation.
Development time: No complex SQL queries. No JOIN statements.
Speed:Very High speed delivery & Mostly in-built entity-level caching
Plan ahead for scalability:Avoiding rework
Why do we need NoSQL
NoSQL offers a simpler data model in other words, it motivates to use the concepts of embedding and indexing your data rather than using the concept of joining the data.
If a developer wants to do rapid development of the application then NoSQL will be useful.
NoSQL provides high scaling out capability.
NoSQL allows you to add any kind of data in your database because it is flexible.
It also provides distributed storage and high availability of the data.
Streaming is also accepted by NoSQL because it can handle a high volume of data which is stored in your database.
It offers real-time analysis, and redundancy so as to replicate your data on more than one servers.
As mentioned earlier, it is highly scalable therefore it can be implemented with a very low budget.
Types of NoSQL databases
There are 4 basic types of NoSQL databases:
Key-Value Store – It has a Big Hash Table of keys & values {Example- Riak, Amazon S3 (Dynamo)}
Document-based Store- It stores documents made up of tagged elements. {Example- CouchDB}
Column-based Store- Each storage block contains data from only one column, {Example- HBase, Cassandra}
Graph-based-A network database that uses edges and nodes to represent and store data. {Example- Neo4J}
HADOOPWhat is Hadoop:
Hadoop is an open-source tool from theApache Software Foundation.
It provides an efficient framework for running jobs on multiple nodes of clusters.
Hadoop consists of three key parts :
HADOOP Distributed file system (HDFS) – It is the storage layer of Hadoop.
Map Reduce – It is the data processing layer of Hadoop.
YARN – It is the resource management layer of Hadoop.
Why Hadoop
Hadoop is still the backbone of all the Big Data Applications, following characteristics of Hadoop make it a unique platform:
Open Source
Distributed Processing
Fault Tolerance
Reliability
High Availability
Scalability
Economic
Easy to use
Data Locality
HDFS Key Features
HDFS is a fault-tolerant and self-healing distributed filesystem designed to turn a cluster of industry-standard servers into a massively scalable pool of storage. Developed specifically for large-scale data processing workloads where scalability, flexibility, and throughput are critical, HDFS accepts data in any format regardless of schema, optimizes for high-bandwidth streaming, and scales to proven deployments of 100PB and beyond.
Hadoop Scalable:
HDFS is designed for massive scalability, so you can store unlimited amounts of data in a single platform. As your data needs grow, you can simply add more servers to linearly scale with your business.
Flexibility:
Store data of any type — structured, semi-structured, unstructured — without any upfront modeling. Flexible storage means you always have access to full-fidelity data for a wide range of analytics and use cases.
Reliability:
Automatic, tunable replication means multiple copies of your data are always available for access and protection from data loss. Built-in fault tolerance means servers can fail but your system will remain available for all workloads.
MapReduce Key FeaturesAccessibility:
Supports a wide range of languages for developers, including C++, Java, or Python, as well as high-level language through Apache Hive and Apache Pig.
Flexibility:
Process any and all data, regardless of type or format — whether structured, semi-structured, or unstructured. Original data remains available even after batch processing for further analytics, all in the same platform.
Reliability:
Built-in job and task trackers allows processes to fail and restart without affecting other processes or workloads. Additional scheduling allows you to prioritize processes based on needs such as SLAs.
Hadoop Scalable:
MapReduce is designed to match the massive scale of HDFS and Hadoop, so you can process unlimited amounts of data, fast, all within the same platform where it’s stored.
While MapReduce continues to be a popular batch-processing tool, Apache Spark’s flexibility and in-memory performance make it a much more powerful batch execution engine. Cloudera has been working with the community to bring the frameworks currently running on MapReduce onto Spark for faster, more robust processing.
MapReduce is designed to process unlimited amounts of data of any type that’s stored in HDFS by dividing workloads into multiple tasks across servers that are run in parallel.
YARN Key Features
YARN provides open source resource management for Hadoop, so you can move beyond batch processing and open up your data to a diverse set of workloads, including interactive SQL, advanced modeling, and real-time streaming.
Hadoop Scalable:
YARN is designed to handle scheduling for the massive scale of Hadoop so you can continue to add new and larger workloads, all within the same platform.
Dynamic Multi-tenancy:
Dynamic resource management provided by YARN supports multiple engines and workloads all sharing the same cluster resources. Open up your data to users across the entire business environment through batch, interactive, advanced, or real-time processing, all within the same platform so you can get the most value from your Hadoop platform.
0 notes
Photo

@javacodegeeks : DBMS vs RDBMS: Comparison and Differences between DBMS and RDBMS - Software Development Databases, DBMS, DBMS vs RDBMS, RDBMS https://t.co/wtEkbXYfkW
0 notes
Text
Difference between SQL and NoSQL
Here you will learn about difference between sql and nosql or sql vs nosql.
Both are a complete different concept, which could be better understood by the following explanation.
SQL
SQL or the Structured Query Language is a Database language for storing, retrieving and accessing database. SQL stores data in the form of data-tables i.e. SQL is a relational database system (RDBMS). It contains queries like commands through which we can get to access, retrieve and manipulate our data.
Also Read: Difference between DBMS and RDBMS
These commands are standardized for the making the migration of projects easy from one system to the other.
For instance: The SELECT command is used to select particular records from the given or designated table. It is used to select only those records which we need to perform any action on. The selected records are then stored in the result-set and any action (if required) is performed on only those records.
Likewise, many more commands are available with the SQL which makes us communicate with our database easily and thus in a way handles our database for us.
SQL is used to build complex databases which have the capability to handle large amount of data in structured format.
Some of the SQL database management systems are:
MySQL
Oracle
Sqlite
PostgreSQL
NoSQL
As the name suggests “NoSQL” is just the opposite of SQL. All the features are reversed in NoSQL.
NoSQL on the other hand is a non-relational database management system. NoSQL is used for developing database for companies with low budget and small amount of data to work on. NoSQL has greater flexibility than SQL because it stores data in the form of graphs, charts, objects ad offers a room for new data entries to be accommodated easily in the database despite of their uniqueness.
But database researchers seek this flexibility as a misguiding feature when it comes to cross platform migration of such databases.
One more point of difference is the lack of standardization of the database query formats. This is another issue that needs to be solved to popularize NoSQL. With this, NoSQL also requires a documentation rich community for problem solving and with easy to learn tutorials to guide new developers take the advantage of this emerging technology.
Some of the NoSQL database management systems are:
MongoDB
BigTable
Redis
RavenDB
Cassandra
Image Source
Difference between SQL and NoSQL
SQL NoSQL SQL is Relational Database Management System (RDBMS). NoSQL is Non-relational database system. SQL databases require a schema to be developed in advance and all the data is stored according to that schema. NoSQL databases have dynamic schema. In SQL data is stored in forms of tables in the database. In NoSQL, data stores data in from of objects, documents, graphs, key-value pairs etc. SQL uses standardized SQL Syntax commands to query the data. NoSQL uses non-standardized query formats to retrieve the data. SQL databases are used when data to be stored is huge and complex database is required. NoSQL databases are used when data to be stored is less and budget is low.
Comment below if you have queries regarding difference between sql and nosql.
The post Difference between SQL and NoSQL appeared first on The Crazy Programmer.
0 notes
Last Seen Blogs

drsabrontosaurio
TheBestVKera

dazzledmind
Whatever you are, be a good one

dude-im-a-witch
Paganism, Probably

kouatl
Ejekatl Miktlan Kouatl

spunky-89
All the Fandoms