#Data Collection and Analysis
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Salisbury Autistic Care - The Sensory Haven Future Homes for Autistic People
Salisbury Autistic Care: Creating Inclusive Communities for Individuals on the Autism Spectrum is putting its best foot forward by designing homes best suited for autistic individuals. Efforts are made to provide an environment where those on the autism spectrum can thrive and feel at ease.
In this discussion, we'll explore how Salisbury's real estate sector is designing homes with the latest innovations that prioritize the safety concerns of these individuals.
Let's discover together how the latest innovative homes are reshaping the landscape of inclusive living.

Smart Home Technology: Real estate is focusing on installing homes with smart home devices that can be controlled remotely or automated to perform tasks autonomously. It includes devices like voice-activated assistants (like Amazon Alexa or Google Home), smart thermostats, lighting systems, and security cameras that can greatly improve the autonomy and comfort of individuals with autism. These technologies can be programmed to adjust environmental factors according to the individual's preferences, providing a sense of control and reducing sensory overload.
Communication Apps and Devices: Many autistic people face trouble in communication. However, integrating communication apps and devices within the property can facilitate effective communication. It will help them by assisting in conveying their message to their caregivers. These may include augmentative and alternative communication (AAC) apps, picture exchange communication systems (PECS), or specialized devices that support speech output.
Safety and Monitoring Solutions: Autistic individuals are not much aware of their safety in the surrounding environment. As a result, they may unintentionally engage in behaviors that could put their well-being at risk. Technology can play a crucial role in ensuring their safety. GPS tracking devices, door alarms, and wearable sensors can alert caregivers if a resident leaves the property or enters restricted areas, allowing for timely intervention. Additionally, smart locks and security systems can enhance overall safety within the property.
Sensory Regulation Tools: Many individuals with autism are sensitive to sensory stimuli. The real estate must focus on designing calming sensory rooms with soft lighting, comfortable seating, tactile objects, soothing music or sounds, and visual projections. Interactive projections or immersive virtual reality experiences can provide engaging and customizable sensory experiences, allowing individuals with autism to explore different sensory inputs in a controlled and therapeutic environment.
Data Collection and Analysis: Homes installed with smart sensors can help in tracking daily behavior patterns like sleep patterns, activity levels, or emotional states, providing valuable insights about the individual. This information can be used to create personalized care plans and interventions.
Educational and Therapeutic Resources: Integrating educational and therapeutic resources within autism care properties empowers residents to engage in meaningful activities and skill-building exercises that support their development and enhance their quality of life. Smart home technology helps them to have access to educational and therapeutic sessions that promote learning, growth, and self-confidence for individuals with autism.
Conclusion
Through these advancements, Salisbury Autistic Care — Most Desirable Areas to Live in is not only addressing the unique needs and challenges faced by autistic individuals but also trying to create surroundings where they can feel safe and comfortable. By prioritizing safety, communication, sensory comfort, and personalized support, these homes are reshaping the landscape of inclusive living and setting a new standard for the integration of technology and compassion in real estate development.
#Educational and Therapeutic Resources#Data Collection and Analysis#Sensory Regulation Tools#Safety and Monitoring Solutions#Smart Home Technology#Future Homes#Sensory Haven:#Salisbury Autistic Care
8 notes
·
View notes
Text

flickr
Algo trading, short for algorithmic trading, is a revolutionary approach to financial markets that leverages computer algorithms to execute trading strategies.
#Algo Trading#financial markets#Algorithm Development#Data Collection and Analysis#Automated Execution
0 notes
Text
i love being a scientist scientist in one field and a citizen scientist in another, lmao. looking at my own research and thesis gives me a crisis, but at least my stress walks and procrastination give bio/enviro people a bunch of photos/observational data for their own work :')
#it's also particularly nice to just collect data and tag it without having to worry about any of the more stressful/difficult part of#research and analysis#zip quips#inaturalist#ebird#citizen science
16 notes
·
View notes
Note
If im not wrong i think those things are kremnos soldiers badge
i see i see. thank you anon
#COLLECTING DATA FOR MYDEI TRAILER ANALYSIS#i have so so many thoughts. i. ohhhhh ohhhhh#yeah#honkai star rail#hsr#hsr mydei
9 notes
·
View notes
Text
going through my tumblr drafts today and the category of posts can be neatly sorted into four categories:
me complaining about chronic illness symptoms
half written media analysis that i give up halfway through because i realize i have no idea what i'm talking about but like. there's something there.
half written media analysis that i give up halfway through because i realize posting my take is a little bit too controversial/overly negative for this blog.
well written opinion pieces on social issues that i spend hours writing before going "eh... i don't want to get hate anons for the controversial opinions that all hatred & bigotry is bad, people are really susceptible to bias & conspiratorial thinking, and the world is much more complicated than anyone thinks"
#there's one post about internet censorship vs moderation that's so good but i am not posting it on the piss on the poor website#anyways there is one big ST analysis post i successfully located and am going to finish by the end of the year bc i did some data#collection that i think is really interesting!!#but have not been in a space to write up a full report/analyze the results for like a year#so i think i'll just finish writing up the raw data stuff and let people look at it#my posts
12 notes
·
View notes
Text
Unlock the other 99% of your data - now ready for AI
New Post has been published on https://thedigitalinsider.com/unlock-the-other-99-of-your-data-now-ready-for-ai/
Unlock the other 99% of your data - now ready for AI
For decades, companies of all sizes have recognized that the data available to them holds significant value, for improving user and customer experiences and for developing strategic plans based on empirical evidence.
As AI becomes increasingly accessible and practical for real-world business applications, the potential value of available data has grown exponentially. Successfully adopting AI requires significant effort in data collection, curation, and preprocessing. Moreover, important aspects such as data governance, privacy, anonymization, regulatory compliance, and security must be addressed carefully from the outset.
In a conversation with Henrique Lemes, Americas Data Platform Leader at IBM, we explored the challenges enterprises face in implementing practical AI in a range of use cases. We began by examining the nature of data itself, its various types, and its role in enabling effective AI-powered applications.
Henrique highlighted that referring to all enterprise information simply as ‘data’ understates its complexity. The modern enterprise navigates a fragmented landscape of diverse data types and inconsistent quality, particularly between structured and unstructured sources.
In simple terms, structured data refers to information that is organized in a standardized and easily searchable format, one that enables efficient processing and analysis by software systems.
Unstructured data is information that does not follow a predefined format nor organizational model, making it more complex to process and analyze. Unlike structured data, it includes diverse formats like emails, social media posts, videos, images, documents, and audio files. While it lacks the clear organization of structured data, unstructured data holds valuable insights that, when effectively managed through advanced analytics and AI, can drive innovation and inform strategic business decisions.
Henrique stated, “Currently, less than 1% of enterprise data is utilized by generative AI, and over 90% of that data is unstructured, which directly affects trust and quality”.
The element of trust in terms of data is an important one. Decision-makers in an organization need firm belief (trust) that the information at their fingertips is complete, reliable, and properly obtained. But there is evidence that states less than half of data available to businesses is used for AI, with unstructured data often going ignored or sidelined due to the complexity of processing it and examining it for compliance – especially at scale.
To open the way to better decisions that are based on a fuller set of empirical data, the trickle of easily consumed information needs to be turned into a firehose. Automated ingestion is the answer in this respect, Henrique said, but the governance rules and data policies still must be applied – to unstructured and structured data alike.
Henrique set out the three processes that let enterprises leverage the inherent value of their data. “Firstly, ingestion at scale. It’s important to automate this process. Second, curation and data governance. And the third [is when] you make this available for generative AI. We achieve over 40% of ROI over any conventional RAG use-case.”
IBM provides a unified strategy, rooted in a deep understanding of the enterprise’s AI journey, combined with advanced software solutions and domain expertise. This enables organizations to efficiently and securely transform both structured and unstructured data into AI-ready assets, all within the boundaries of existing governance and compliance frameworks.
“We bring together the people, processes, and tools. It’s not inherently simple, but we simplify it by aligning all the essential resources,” he said.
As businesses scale and transform, the diversity and volume of their data increase. To keep up, AI data ingestion process must be both scalable and flexible.
“[Companies] encounter difficulties when scaling because their AI solutions were initially built for specific tasks. When they attempt to broaden their scope, they often aren’t ready, the data pipelines grow more complex, and managing unstructured data becomes essential. This drives an increased demand for effective data governance,” he said.
IBM’s approach is to thoroughly understand each client’s AI journey, creating a clear roadmap to achieve ROI through effective AI implementation. “We prioritize data accuracy, whether structured or unstructured, along with data ingestion, lineage, governance, compliance with industry-specific regulations, and the necessary observability. These capabilities enable our clients to scale across multiple use cases and fully capitalize on the value of their data,” Henrique said.
Like anything worthwhile in technology implementation, it takes time to put the right processes in place, gravitate to the right tools, and have the necessary vision of how any data solution might need to evolve.
IBM offers enterprises a range of options and tooling to enable AI workloads in even the most regulated industries, at any scale. With international banks, finance houses, and global multinationals among its client roster, there are few substitutes for Big Blue in this context.
To find out more about enabling data pipelines for AI that drive business and offer fast, significant ROI, head over to this page.
#ai#AI-powered#Americas#Analysis#Analytics#applications#approach#assets#audio#banks#Blue#Business#business applications#Companies#complexity#compliance#customer experiences#data#data collection#Data Governance#data ingestion#data pipelines#data platform#decision-makers#diversity#documents#emails#enterprise#Enterprises#finance
2 notes
·
View notes
Text

Sketched out the final part of the growth spurt comic!
Already made up my mind, but out of curiosity. What do you think: Who will end up being the shortest turtle? :)
#Saw comments about both of them sooo… I just have to do some data collection before the last part drops!#And then we can compare twitter tumblr and instagram#some fun data analysis!
10 notes
·
View notes
Text
*remembers that this used to be an ethoslab blog* i have to make. a survey
#i jest but also. all of a sudden i have been possessed by a demon. and her name is data collection and analysis.#by the end of the month* hopefully we will understand the collective fandomized transfem ethoslab.
2 notes
·
View notes
Text
currently working on the early stages (ie. user research) of a spotify user interface redesign as a personal portfolio project and i am ridiculously excited about it
#this is my current hyperfixation#i'm working on designing a survey and interview guide#with luck i will start conducting user interviews next week#my goal is to spend the next two weeks collecting data and then analysis it the following week#then it will be on to defining the problem statements and working on personas and user journeys and other deliverables#also thinking abt using tiktok to get the survey to (hopefully) reach a wider audience and document my process#lots of big things#this is what happens when my literal ux design job does not give me enough tasks to entertain me#antlerknives.txt
2 notes
·
View notes
Text
My Excel knowledge has grown so much in the past 2 months of working at my new job, so I am planning to revamp my Pokémon card spreadsheet. I'm going to start during the long weekend coming up. I am going to make pivot tables and chart up the wazoo. I am going to organize, analyze, and report. You ask me any question about my collection, and I will give you the answer. You wanna know how many stage 2 psychic Pokémon cards I have that are less than 5 years old? I'll tell you. You want a list of trainer item cards that start with the letter D? You got it. You want to know what percentage of basic energy cards are water type? You need only ask.
#pokemon#pokémon#pokemon tcg#autism#collection#collecting#excel#microsoft excel#data analysis#llbtspost
7 notes
·
View notes
Text
it’s crazy like actually insane that i can’t find historical demographic analyses of childlessness rates among women of any time period before the 1800s. that seems like it should be such a interesting illustrative statistic in and of itself but also as an indicator of broader social/economic/religious/political/environmental conditions. it’s a statistic that establishes something entirely distinct from what you get out of an average birth rate...
OK NVM post kind of cancelled i'm finding a couple articles. but nothing that's really what i'm looking for/what i'd be wanting answers to. w/e do i sound insane/is this already obvious
#like they're bringing it up as something that was discussed/understood in the period but not how frequent it was and what factors informed#its presence#like there are time periods in many locations prior to the late modern period that would theoretically have administrative#records/census data collection that you could use to extract this statistic/analysis. i wonder if my jstor/school#library searches just aren't properly describing what i'm thinking of.#sorry. im high#a
4 notes
·
View notes
Text
I dont want to do this dissertation crap anymore actually
#my god i wish i couldve just done primary data collection instead of driving myself mad with document analysis#but the time frame for primary data is so tough to manage
2 notes
·
View notes
Text
Precision Insights: Expert Quantitative Market Research Services
Our Quantitative Market Research Services help you quickly gather insights from our panellists and understand the changing consumer behaviour. Using our comprehensive services, we find the answers to the most of your questions! Follow this link to know more https://insighttellers.com/services/quantitative-research-market

#Quantitative Market Research Services#Qualitative Research#Translation#Survey Programming#Data Collection & Analysis#Secondary Research#Panel Aggregation#Contracted Work
2 notes
·
View notes
Text
Centreoftheselights just shared the new 2024 AO3 stats.
In less than two days their post has already received 16 MILLION views and 80 THOUSAND retweets/quote tweets, with every comment I've seen taking the data at face value and using it to draw conclusions, much to my horror.
While OP did change the title of the "new works" column to "works gained" so that they're at least not blatantly lying now (the bare minimum), the wording is still very misleading. More importantly though they continue to use the same extremely flawed methodology and continue to bury and obfuscate those flaws and what the data actually represents. Nowhere on the chart or the details provided on the main page does it even say that only publicly available works are counted... and that's not even the biggest problem!
This data is, yet again, garbage and absolutely should not be used to determine the current size and popularity of a fandom (inarguably the main reason for it existing).
AO3 Ship Stats: Year In Bad Data
You may have seen this AO3 Year In Review.

It hasn’t crossed my tumblr dash but it sure is circulating on twitter with 3.5M views, 10K likes, 17K retweets and counting. Normally this would be great! I love data and charts and comparisons!
Except this data is GARBAGE and belongs in the TRASH.
I first noticed something fishy when I realized that Steve/Bucky – the 5th largest ship on AO3 by total fic count – wasn’t on this Top 100 list anywhere. I know Marvel’s popularity has fallen in recent years, but not that much. Especially considering some of the other ships that made it on the list. You mean to tell me a femslash HP ship (Mary MacDonald/Lily Potter) in which one half of the pairing was so minor I had to look up her name because she was only mentioned once in a single flashback scene beat fandom juggernaut Stucky? I call bullshit.
Now obviously jumping to conclusions based on gut instinct alone is horrible practice... but it is a good place to start. So let’s look at the actual numbers and discover why this entire dataset sits on a throne of lies.
Here are the results of filtering the Steve/Bucky tag for all works created between Jan 1, 2023 and Dec 31, 2023:
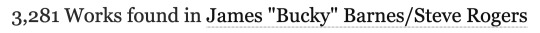
Not only would that place Steve/Bucky at #23 on this list, if the other counts are correct (hint: they're not), it’s also well above the 1520-new-work cutoff of the #100 spot. So how the fuck is it not on the list? Let’s check out the author’s FAQ to see if there’s some important factor we’re missing.
The first thing you’ll probably notice in the FAQ is that the data is being scraped from publicly available works. That means anything privated and only accessible to logged-in users isn’t counted. This is Sin #1. Already the data is inaccurate because we’re not actually counting all of the published fics, but the bots needed to do data collection on this scale can't easily scrape privated fics so I kinda get it. We’ll roll with this for now and see if it at least makes the numbers make more sense:
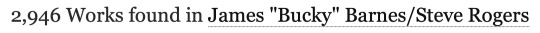
Nope. Logging out only reduced the total by a couple hundred. Even if one were to choose the most restrictive possible definition of "new works" and filter out all crossovers and incomplete fics, Steve/Bucky would still have a yearly total of 2,305. Yet the list claims their total is somewhere below 1,500? What the fuck is going on here?
Let’s look at another ship for comparison. This time one that’s very recent and popular enough to make it on the list so we have an actual reference value for comparison: Nick/Charlie (Heartstopper). According to the list, this ship sits at #34 this year with a total of 2630 new works. But what’s AO3 say?
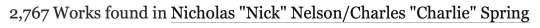
Off by a hundred or so but the values are much closer at least!
If we dig further into the FAQ though we discover Sin #2 (and the most egregious): the counting method. The yearly fic counts are NOT determined by filtering for a certain time period, they’re determined by simply taking a snapshot of the total number of fics in a ship tag at the end of the year and subtracting the previous end-of-year total. For example, if you check a ship tag on Jan 1, 2023 and it has 10,000 fics and check it again on Jan 1, 2024 and it now has 12,000 fics, the difference (2,000) would be the number of "new works" on this chart.
At first glance this subtraction method might seem like a perfectly valid way to count fics, and it’s certainly the easiest way, but it can and did have major consequences to the point of making the entire dataset functionally meaningless. Why? If any older works are deleted or privated, every single one of those will be subtracted from the current year fic count. And to make the problem even worse, beginning at the end of last year there was a big scare about AI scraping fics from AO3, which caused hundreds, if not thousands, of users to lock down their fics or delete them.
The magnitude of this fuck up may not be immediately obvious so let’s look at an example to see how this works in practice.
Say we have two ships. Ship A is more than a decade old with a large fanbase. Ship B is only a couple years old but gaining traction. On Jan 1, 2023, Ship A had a catalog of 50,000 fics and ship B had 5,000. Both ships have 3,000 new works published in 2023. However, 4% of the older works in each fandom were either privated or deleted during that same time (this percentage is was just chosen to make the math easy but it’s close to reality).
Ship A: 50,000 x 4% = 2,000 removed works Ship B: 5,000 x 4% = 200 removed works
Ship A: 3,000 - 2,000 = 1,000 "new" works Ship B: 3,000 - 200 = 2,800 "new" works
This gives Ship A a net gain of 1,000 and Ship B a net gain of 2,800 despite both fandoms producing the exact same number of new works that year. And neither one of these reported counts are the actual new works count (3,000). THIS explains the drastic difference in ranking between a ship like Steve/Bucky and Nick/Charlie.
How is this a useful measure of anything? You can't draw any conclusions about the current size and popularity of a fandom based on this data.
With this system, not only is the reported "new works" count incorrect, the older, larger fandom will always be punished and it’s count disproportionately reduced simply for the sin of being an older, larger fandom. This example doesn’t even take into account that people are going to be way more likely to delete an old fic they're no longer proud of in a fandom they no longer care about than a fic that was just written, so the deletion percentage for the older fandom should theoretically be even larger in comparison.
And if that wasn't bad enough, the author of this "study" KNEW the data was tainted and chose to present it as meaningful anyway. You will only find this if you click through to the FAQ and read about the author’s methodology, something 99.99% of people will NOT do (and even those who do may not understand the true significance of this problem):


The author may try to argue their post states that the tags "which had the greatest gain in total public fanworks” are shown on the chart, which makes it not a lie, but a error on the viewer’s part in not interpreting their data correctly. This is bullshit. Their chart CLEARLY titles the fic count column “New Works” which it explicitly is NOT, by their own admission! It should be titled “Net Gain in Works” or something similar.
Even if it were correctly titled though, the general public would not understand the difference, would interpret the numbers as new works anyway (because net gain is functionally meaningless as we've just discovered), and would base conclusions on their incorrect assumptions. There’s no getting around that… other than doing the counts correctly in the first place. This would be a much larger task but I strongly believe you shouldn’t take on a project like this if you can’t do it right.
To sum up, just because someone put a lot of work into gathering data and making a nice color-coded chart, doesn’t mean the data is GOOD or VALUABLE.
#please keep spreading this post#and for the love of god please do not spread these 'studies'#every time someone trusts their data and uses it in any kind of fandom analysis I die a little bit inside#16 MILLION VIEWS!#it should be illegal to spread misinformation to that many people#I will not rest until OP learns how to collect and present data correctly#ao3#ao3 stats#fandom
4K notes
·
View notes
Text
Creative uses for Discogs Collection data
I have more than 80% of my CDs listed on Discogs, and now routinely add new acquisitions. The others are listed on a spreadsheet because they’re editions or releases not included in the Discogs database. With more than 8500 albums, I wondered how to use that data. My Discogs collection data represents a rich archaeological record of my musical journey, containing layers of metadata that can be…
0 notes
Text
GridCARE Emerges from Stealth with $13.5M to Solve AI’s Power Crisis with Generative Grid Intelligence
New Post has been published on https://thedigitalinsider.com/gridcare-emerges-from-stealth-with-13-5m-to-solve-ais-power-crisis-with-generative-grid-intelligence/
GridCARE Emerges from Stealth with $13.5M to Solve AI’s Power Crisis with Generative Grid Intelligence

GridCARE, a pioneering grid intelligence company, has officially emerged from stealth with a $13.5 million seed round, aiming to solve one of artificial intelligence’s most pressing bottlenecks: access to reliable power. The oversubscribed round was led by Xora, a deep tech venture firm backed by Temasek, with participation from a coalition of climate, AI, and infrastructure-focused investors.
The timing couldn’t be more urgent. The global AI market is projected to reach $757.6 billion by 2025 and grow to $3.68 trillion by 2034, according to Precedence Research. This explosive trajectory is placing unprecedented strain on the world’s power grids. The International Energy Agency (IEA) forecasts that electricity demand from data centers will more than double by 2030, with AI leading the charge. The U.S. alone is expected to see data centers account for nearly half of all new electricity demand growth, soon surpassing the energy use of entire heavy industries like steel, cement, and chemicals.
“Power is the new kingmaker in the AI arms race,” said Amit Narayan, CEO and founder of GridCARE. “Companies that secure reliable energy fastest will dominate the next generation of AI. GridCARE gives our partners that critical speed advantage.”
AI-Powered Grid Analysis to Accelerate Data Center Buildouts
Rather than waiting five to seven years for new substations and interconnections, GridCARE enables developers to bring AI infrastructure online in just 6–12 months. The company’s platform uses Generative AI and grid physics modeling to pinpoint underutilized electricity capacity across thousands of utility networks.
This “time-to-power” optimization allows developers to deploy GPUs and CPUs faster—essential in a competitive landscape where the AI model arms race is defined not just by the best algorithms, but by who can run them at scale first.
GridCARE acts as a bridge between utility companies and hyperscalers, simplifying complex, fragmented processes around grid access. Developers can offload the burden of power acquisition while utilities gain new revenue opportunities and better utilization of existing assets.
“GridCARE uncovers previously invisible grid capacity,” said Peter Freed, former Director of Energy Strategy at Meta and now a partner at New Horizon Group. “It opens a new fast track to power, enabling power-first AI data center development.”
From Stanford to the Smart Grid Frontier
GridCARE’s team is steeped in experience at the intersection of energy, AI, and sustainability. CEO Amit Narayan holds a PhD from UC Berkeley and previously founded AutoGrid, a climate-AI company acquired by Schneider Electric. He began applying chip-level signal optimization techniques to the electric grid over a decade ago while collaborating with Stanford’s Precourt Energy Institute.
Co-founders include:
Ram Rajagopal, Stanford professor and AI-for-energy systems expert
Liang Min, Director at Stanford’s Bits & Watts initiative
Arun Majumdar, Founding Dean of Stanford’s Doerr School of Sustainability and former VP of Energy at Google
Their collective mission: to unlock strategic flexibility from the grid without building new fossil-fuel infrastructure.
Utilities Embrace GridCARE for Smarter Infrastructure Planning
GridCARE isn’t just popular with developers—it’s quickly gaining traction among utilities like Portland General Electric (PGE) and Pacific Gas & Electric (PG&E).
“The rise of AI presents the biggest new electricity demand surge we’ve seen in decades,” said Larry Bekkedahl, SVP at PGE. “Collaborating with GridCARE enables faster, more confident infrastructure decisions.”
PG&E’s EVP Jason Glickman echoed this sentiment: “Smarter use of the infrastructure we already have is one of the most promising solutions to AI’s energy demands. GridCARE helps us unlock that potential.”
GridCARE also promotes a forward-looking concept known as Power Caching—a localized energy strategy akin to edge computing. Just as edge networks bring frequently accessed data closer to users to reduce latency, power caching co-locates energy generation near AI data centers to reduce grid stress and transmission losses.
By supporting localized generation at the site of consumption, Power Caching improves resilience and eliminates long-distance power congestion—an increasingly common issue in gigawatt-scale AI clusters.
Strategic Backing and Vision for Scale
GridCARE’s backers include:
Breakthrough Energy (founded by Bill Gates)
Sherpalo Ventures
WovenEarth
Clearvision
Clocktower Ventures
AI and energy visionaries like Tom Steyer, Ram Shriram, Balaji Prabhakar, and Gokul Rajaram
Their involvement reflects growing recognition that solving AI’s power crisis will define the next decade of innovation.
“GridCARE has found a solution to AI’s most limiting constraint: energy,” said Phil Inagaki, CIO of Xora. “Their generative AI platform has the potential to reshape how we think about grid access and scale.”
Powering the AI Revolution Starts with Reimagining the Grid
As generative AI reshapes everything from search engines to scientific discovery, the race to scale these models hinges not just on algorithms, but on electricity. GridCARE is stepping in where others are stuck—transforming how power is sourced, modeled, and delivered for the AI age.
With deep tech roots, a founding team shaped by Stanford’s sustainability mission, and a platform that turns gigawatt-scale grid complexity into actionable opportunity, GridCARE isn’t just accelerating infrastructure—it’s laying the foundation for AI’s next leap forward.
#2025#acquisition#ai#AI data centers#AI Infrastructure#ai model#ai platform#AI-powered#Algorithms#amp#Analysis#arms race#artificial#Artificial Intelligence#assets#billion#bridge#Building#cement#CEO#chemicals#chip#cio#climate#clusters#Collective#Companies#complexity#computing#data
0 notes