#Data Lake vs Data Warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Understanding Data Lake vs Data Warehouse: Key Concepts and Applications

In the realm of big data and data analytics, two terms often come up: data lakes and data warehouses. These concepts are essential for managing and analyzing large volumes of data. While they serve similar purposes, they differ significantly in their structure, functionality, and use cases. This blog will delve into the key concepts and applications of data lakes and data warehouses, helping you understand their differences of data lakes vs data warehouses and how to leverage them effectively.
What is a Data Lake?
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to structure it first, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
Key Characteristics of Data Lakes
Flexibility: Data lakes can store any type of data, whether it's structured, semi-structured, or unstructured.
Scalability: They can scale to accommodate petabytes of data.
Cost-Effective: Typically, data lakes use low-cost storage systems.
Data Ingestion: Data can be ingested in real-time or batch mode.
Applications of Data Lakes
Data Exploration and Discovery: Useful for data scientists and analysts who need to explore and understand data before building models.
Machine Learning: Facilitates the training of machine learning models on large datasets.
Big Data Analytics: Ideal for processing large volumes of data to uncover insights and trends.
What is a Data Warehouse?
A data warehouse, on the other hand, is a centralized repository for storing data from multiple sources in a structured format. It is designed for query and analysis, supporting business intelligence activities. Data warehouses typically store historical data, making it easier to perform trend analysis and reporting.
Key Characteristics of Data Warehouses
Structured Data: Data is cleaned, transformed, and organized into a predefined schema.
High Performance: Optimized for complex queries and data analysis.
Data Integration: Consolidates data from various sources.
Historical Data: Stores large volumes of historical data for analysis.
Applications of Data Warehouses
Business Intelligence: Supports reporting, dashboards, and data visualization tools for business users.
Operational Reporting: Facilitates daily, weekly, and monthly reports.
Trend Analysis: Analyzes historical data to identify trends and patterns.
Key Differences Between Data Lake and Data Warehouse
Structure and Schema
Data Lake: Stores raw data in its native format until needed. It supports all data types, including structured, semi-structured, and unstructured data.
Data Warehouse: Stores processed and refined data in a predefined schema, making it suitable for structured data only.
Cost and Performance
Data Lake: Typically more cost-effective due to the use of low-cost storage. Performance can vary depending on the type of analytics performed.
Data Warehouse: Higher cost due to the need for specialized hardware and software, but offers high performance for complex queries.
Use Cases
Data Lake: Ideal for data scientists and engineers who need a flexible, scalable storage solution for large volumes of diverse data.
Data Warehouse: Best for business analysts and decision-makers who need reliable, fast access to historical data for reporting and analysis.
Choosing Between Data Lake and Data Warehouse
When deciding between a data lake and a data warehouse, consider the following factors:
Data Variety: If you need to store and analyze a variety of data types (e.g., logs, sensor data, social media data), a data lake is the better choice.
Data Volume: For large volumes of data that need to be stored cost-effectively, a data lake is suitable.
Query Performance: For high-performance queries on structured data, a data warehouse is more appropriate.
Business Needs: Consider the end-users of the data. Data lakes are typically used by data scientists and engineers, while data warehouses are used by business analysts and decision-makers.
Conclusion
Understanding the key concepts and applications of data lakes and data warehouses is crucial for making informed decisions about data management and analytics. Data lakes offer flexibility and scalability for diverse data types, making them ideal for data exploration and big data analytics. Data warehouses, with their structured data and high-performance capabilities, are perfect for business intelligence and trend analysis. By considering your specific needs and use cases, you can choose the right solution to unlock the full potential of your data.
0 notes
Text
Data Lake vs Data Warehouse: 10 Key difference

Today, we are living in a time where we need to manage a vast amount of data. In today's data management world, the growing concepts of data warehouse and data lake have often been a major part of the discussions. We are mainly looking forward to finding the merits and demerits to find out the details. Undeniably, both serve as the repository for storing data, but there are fundamental differences in capabilities, purposes and architecture.
Hence, in this blog, we will completely pay attention to data lake vs data warehouse to help you understand and choose effectively.
We will mainly discuss the 10 major differences between data lakes and data warehouses to make the best choice.
Data variety: In terms of data variety, data lake can easily accommodate the diverse data types, which include semi-structured, structured, and unstructured data in the native format without any predefined schema. It can include data like videos, documents, media streams, data and a lot more. On the contrary, a data warehouse can store structured data which has been properly modelled and organized for specific use cases. Structured data can be referred to as the data that confirms the predefined schema and makes it suitable for traditional relational databases. The ability to accommodate diversified data types makes data lakes much more accessible and easier.
Processing approach: When it is about the data processing, data lakes follow a schema-on-read approach. Hence, it can ingest raw data on its lake without the need for structuring or modelling. It allows users to apply specific structures to the data while analyzing and, therefore, offers better agility and flexibility. However, for data warehouse, in terms of processing approach, data modelling is performed prior to ingestion, followed by a schema-on-write approach. Hence, it requires data to be formatted and structured as per the predefined schemes before being loaded into the warehouse.
Storage cost: When it comes to data cost, Data Lakes offers a cost-effective storage solution as it generally leverages open-source technology. The distributed nature and the use of unexpected storage infrastructure can reduce the overall storage cost even when organizations are required to deal with large data volumes. Compared to it, data warehouses include higher storage costs because of their proprietary technologies and structured nature. The rigid indexing and schema mechanism employed in the warehouse results in increased storage requirements along with other expenses.
Agility: Data lakes provide improved agility and flexibility because they do not have a rigid data warehouse structure. Data scientists and developers can seamlessly configure and configure queries, applications and models, which enables rapid experimentation. On the contrary, Data warehouses are known for their rigid structure, which is why adaptation and modification are time-consuming. Any changes in the data model or schema would require significant coordination, time and effort in different business processes.
Security: When it is about data lakes, security is continuously evolving as big data technologies are developing. However, you can remain assured that the enhanced data lake security can mitigate the risk of unauthorized access. Some enhanced security technology includes access control, compliance frameworks and encryption. On the other hand, the technologies used in data warehouses have been used for decades, which means that they have mature security features along with robust access control. However, the continuously evolving security protocols in data lakes make it even more robust in terms of security.
User accessibility: Data Lakes can cater to advanced analytical professionals and data scientists because of the unstructured and raw nature of data. While data lakes provide greater exploration capabilities and flexibility, it has specialized tools and skills for effective utilization. However, when it is about Data warehouses, these have been primarily targeted for analytic users and Business Intelligence with different levels of adoption throughout the organization.
Maturity: Data Lakes can be said to be a relatively new data warehouse that is continuously undergoing refinement and evolution. As organizations have started embracing big data technologies and exploring use cases, it can be expected that the maturity level has increased over time. In the coming years, it will be a prominent technology among organizations. However, even when data warehouses can be represented as a mature technology, the technology faces major issues with raw data processing.
Use cases: The data lake can be a good choice for processing different sorts of data from different sources, as well as for machine learning and analysis. It can help organizations analyze, store and ingest a huge volume of raw data from different sources. It also facilitates predictive models, real-time analytics and data discovery. Data warehouses, on the other hand, can be considered ideal for organizations with structured data analytics, predefined queries and reporting. It's a great choice for companies as it provides a centralized representative for historical data.
Integration: When it comes to data lake, it requires robust interoperability capability for processing, analyzing and ingesting data from different sources. Data pipelines and integration frameworks are commonly used for streamlining data, transformation, consumption and ingestion in the data lake environment. Data warehouse can be seamlessly integrated with the traditional reporting platforms, business intelligence, tools and data integration framework. These are being designed to support external applications and systems which enable data collaborations and sharing across the organization.
Complementarity: Data lakes complement data warehouse by properly and seamlessly accommodating different Data sources in their raw formats. It includes unstructured, semi-structured and structured data. It provides a cost-effective and scalable solution to analyze and store a huge volume of data with advanced capabilities like real-time analytics, predictive modelling and machine learning. The Data warehouse, on the other hand, is generally a complement transactional system as it provides a centralized representative for reporting and structured data analytics.
So, these are the basic differences between data warehouses and data lakes. Even when data warehouses and data lakes share a common goal, there are certain differences in terms of processing approach, security, agility, cost, architecture, integration, and so on. Organizations need to recognize the strengths and limitations before choosing the right repository to store their data assets. Organizations who are looking for a versatile centralized data repository which can be managed effectively without being heavy on your pocket, they can choose Data Lakes. The versatile nature of this technology makes it a great decision for organizations. If you need expertise and guidance on data management, experts in Hexaview Technologies will help you understand which one will suit your needs.
0 notes
Text
Data Warehouses Vs Data Lakes Vs Databases – A Detailed Evaluation
Data storage is a major task, especially for organizations handling large amounts of data. For businesses garnering optimal value from big data, you hear about data storage terminologies – ‘Databases’, ‘Data warehouses’, and ‘Data lakes’. They all sound similar. But they aren’t! Each of them has its own unique characteristics that make them stand apart in the data landscape.
Through this detailed article, we attempt to introduce the three terminologies, their salient features and how different are they from each other. Hope it throws some light into how data can be managed and stored with databases, data lakes, and data warehouses.
0 notes
Text
In the rapidly evolving landscape of modern business, the imperative for digital transformation has never been more pronounced, driven by the relentless pressures of competition. Central to this transformational journey is the strategic utilization of data, which serves as a cornerstone for gaining insights and facilitating predictive analysis. In effect, data has assumed the role of a contemporary equivalent to gold, catalyzing substantial investments and sparking a widespread adoption of data analytics methodologies among businesses worldwide. Nevertheless, this shift isn't without its challenges. Developing end-to-end applications tailored to harness data for generating core insights and actionable findings can prove to be time-intensive and costly, contingent upon the approach taken in constructing data pipelines. These comprehensive data analytics applications, often referred to as data products within the data domain, demand meticulous design and implementation efforts. This article aims to explore the intricate realm of data products, data quality, and data governance, highlighting their significance in contemporary data systems. Additionally, it will explore data quality vs data governance in data systems, elucidating their roles and contributions to the success of data-driven initiatives in today's competitive landscape. What are Data Products? Within the domain of data analytics, processes are typically categorized into three distinct phases: data engineering, reporting, and machine learning. Data engineering involves ingesting raw data from diverse sources into a centralized repository such as a data lake or data warehouse. This phase involves executing ETL (extract, transform, and load) operations to refine the raw data and then inserting this processed data into analytical databases to facilitate subsequent analysis in machine learning or reporting phases. In the reporting phase, the focus shifts to effectively visualizing the aggregated data using various business intelligence tools. This visualization process is crucial for uncovering key insights and facilitating better data-driven decision-making within the organization. By presenting the data clearly and intuitively, stakeholders can derive valuable insights to inform strategic initiatives and operational optimizations. Conversely, the machine learning phase is centered around leveraging the aggregated data to develop predictive models and derive actionable insights. This involves tasks such as feature extraction, hypothesis formulation, model development, deployment to production environments, and ongoing monitoring to ensure data quality and workflow integrity. In essence, any software service or tool that orchestrates the end-to-end pipeline—from data ingestion and visualization to machine learning—is commonly referred to as a data product, serving as a pivotal component in modern data-driven enterprises. At this stage, data products streamline and automate the entire process, making it more manageable while saving considerable time. Alongside these efficiencies, they offer a range of outputs, including raw data, processed-aggregated data, data as a machine learning service, and actionable insights. What is Data Quality? Data quality refers to the reliability, accuracy, consistency, and completeness of data within a dataset or system. It encompasses various aspects such as correctness, timeliness, relevance, and usability of the data. In simpler terms, data quality reflects how well the data represents the real-world entities or phenomena it is meant to describe. High-quality data is free from errors, inconsistencies, and biases, making it suitable for analysis, decision-making, and other purposes. The Mission of Data Quality in Data Products In the realm of data products, where decisions are often made based on insights derived from data, ensuring high data quality is paramount. The mission of data quality in data products is multifaceted.
First and foremost, it acts as the foundation upon which all subsequent analyses, predictions, and decisions are built. Reliable data fosters trust among users and stakeholders, encourages the adoption and utilization of data products, and drives innovation, optimization, and compliance efforts. Moreover, high-quality data enables seamless integration, collaboration, and interoperability across different systems and platforms, maximizing the value derived from dataasset What is Data Governance? Data governance is the framework, policies, procedures, and practices that organizations implement to ensure the proper management, usage, quality, security, and compliance of their data assets. It involves defining roles, responsibilities, and decision-making processes related to data management, as well as establishing standards and guidelines for data collection, storage, processing, and sharing. Data governance aims to optimize the value of data assets while minimizing risks and ensuring alignment with organizational objectives and regulatory requirements. The Mission of Data Governance in Data Products In data products, data governance ensures accountability, transparency, and reliability in data management. It maintains data quality and integrity, fostering trust among users. Additionally, data governance facilitates compliance with regulations, enhances data security, and promotes efficient data utilization, driving organizational success through informed decision-making and collaboration. By establishing clear roles, responsibilities, and standards, data governance provides a structured framework for managing data throughout its lifecycle. This framework mitigates errors and inconsistencies, ensuring data remains accurate and usable for analysis. Furthermore, data governance safeguards against data breaches and unauthorized access, while also enabling seamless integration and sharing of data across systems, optimizing its value for organizational objectives. Data Quality vs. Data Governance: A Brief Comparison Data quality focuses on the accuracy, completeness, and reliability of data, ensuring it meets intended use requirements. It guarantees that data is error-free and suitable for analysis and decision-making. Data governance, meanwhile, establishes the framework, policies, and procedures for managing data effectively. It ensures data is managed securely, complies with regulations, and aligns with organizational goals. In essence, data quality ensures the reliability of data, while data governance provides the structure and oversight to manage data effectively. Both are crucial for informed decision-making and organizational success. Conclusion In summary, data quality and data governance play distinct yet complementary roles in the realm of data products. While data quality ensures the reliability and accuracy of data, data governance provides the necessary framework and oversight for effective data management. Together, they form the foundation for informed decision-making, regulatory compliance, and organizational success in the data-driven era.
0 notes
Text

ETL vS. ELT - TERMINOLOGIA DE ENGENHARIA DE DADOS
Uma forma simples de compará-los é usando o exemplo do suco de laranja:
ETL (Extrair -> Transformar -> Carregar)
1. Extrair: Colher laranjas da árvore
(Coletar dados
brutos de bancos de dados, APls ou arquivos);
2. Transformar: Espremer as laranjas em suco antes de armazenar O (Limpar, filtrar e formatar os dados);
3. Carregar: Armazenar o suco pronto na geladeira (Salvar dados estruturados em um data warehouse);
Usado em: Finanças e Saúde (Os dados devem estar
limpos antes do armazenamento)
ELT (Extrair -> Carregar -> Transformar)
1. Extrair: Colher laranjas da árvore
(Coletar dados
brutos de bancos de dados, APIs ou arquivos)
2. Carregar: Armazenar as laranjas inteiras na geladeira primeiro (Salvar dados brutos em um data lake ou armazém na nuvem)
3. Transformar: Fazer suco quando necessário O (Processar e analisar dados posteriormente)
• Usado em: Big Data e Cloud (Transformações mais rápidas e escaláveis)
Stack tecnológica: Snowflake, BigQuery, Databricks,
AWS Redshift
0 notes
Text
Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer: Choose Your Perfect Data Career!

In today’s rapidly evolving tech world, career opportunities in data-related fields are expanding like never before. However, with multiple roles like Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer, newcomers — and even seasoned professionals — often find it confusing to understand how these roles differ.
At Yasir Insights, we think that having clarity makes professional selections more intelligent. We’ll go over the particular duties, necessary abilities, and important differences between these well-liked Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer data positions in this blog.
Also Read: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Introduction to Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
The Data Science and Machine Learning Development Lifecycle (MLDLC) includes stages like planning, data gathering, preprocessing, exploratory analysis, modelling, deployment, and optimisation. In order to effectively manage these intricate phases, the burden is distributed among specialised positions, each of which plays a vital part in the project’s success.
Data Engineer
Who is a Data Engineer?
The basis of the data ecosystem is built by data engineers. They concentrate on collecting, sanitising, and getting data ready for modelling or further analysis. Think of them as mining precious raw materials — in this case, data — from complex and diverse sources.
Key Responsibilities:
Collect and extract data from different sources (APIS, databases, web scraping).
Design and maintain scalable data pipelines.
Clean, transform, and store data in warehouses or lakes.
Optimise database performance and security.
Required Skills:
Strong knowledge of Data Structures and Algorithms.
Expertise in Database Management Systems (DBMS).
Familiarity with Big Data tools (like Hadoop, Spark).
Hands-on experience with cloud platforms (AWS, Azure, GCP).
Proficiency in building and managing ETL (Extract, Transform, Load) pipelines.
Data Analyst
Who is a Data Analyst?
Data analysts take over once the data has been cleansed and arranged. Their primary responsibility is to evaluate data in order to get valuable business insights. They provide answers to important concerns regarding the past and its causes.
Key Responsibilities:
Perform Exploratory Data Analysis (EDA).
Create visualisations and dashboards to represent insights.
Identify patterns, trends, and correlations in datasets.
Provide reports to support data-driven decision-making.
Required Skills:
Strong Statistical knowledge.
Proficiency in programming languages like Python or R.
Expertise in Data Visualisation tools (Tableau, Power BI, matplotlib).
Excellent communication skills to present findings clearly.
Experience working with SQL databases.
Data Scientist
Who is a Data Scientist?
Data Scientists build upon the work of Data Analysts by developing predictive models and machine learning algorithms. While analysts focus on the “what” and “why,” Data Scientists focus on the “what’s next.”
Key Responsibilities:
Design and implement Machine Learning models.
Perform hypothesis testing, A/B testing, and predictive analytics.
Derive strategic insights for product improvements and new innovations.
Communicate technical findings to stakeholders.
Required Skills:
Mastery of Statistics and Probability.
Strong programming skills (Python, R, SQL).
Deep understanding of Machine Learning algorithms.
Ability to handle large datasets using Big Data technologies.
Critical thinking and problem-solving abilities.
Machine Learning Engineer
Who is a Machine Learning Engineer?
Machine Learning Engineers (MLES) take the models developed by Data Scientists and make them production-ready. They ensure models are deployed, scalable, monitored, and maintained effectively in real-world systems.
Key Responsibilities:
Deploy machine learning models into production environments.
Optimise and scale ML models for performance and efficiency.
Continuously monitor and retrain models based on real-time data.
Collaborate with software engineers and data scientists for integration.
Required Skills:
Strong foundations in Linear Algebra, Calculus, and Probability.
Mastery of Machine Learning frameworks (TensorFlow, PyTorch, Scikit-learn).
Proficiency in programming languages (Python, Java, Scala).
Knowledge of Distributed Systems and Software Engineering principles.
Familiarity with MLOps tools for automation and monitoring.
Summary: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Data Engineer
Focus Area: Data Collection & Processing
Key Skills: DBMS, Big Data, Cloud Computing
Objective: Build and maintain data infrastructure
Data Analyst
Focus Area: Data Interpretation & Reporting
Key Skills: Statistics, Python/R, Visualisation Tools
Objective: Analyse data and extract insights
Data Scientist
Focus Area: Predictive Modelling
Key Skills: Machine Learning, Statistics, Data Analysis
Objective: Build predictive models and strategies
Machine Learning Engineer
Focus Area: Model Deployment & Optimisation
Key Skills: ML Frameworks, Software Engineering
Objective: Deploy and optimise ML models in production
Frequently Asked Questions (FAQS)
Q1: Can a Data Engineer become a Data Scientist?
Yes! With additional skills in machine learning, statistics, and model building, a Data Engineer can transition into a Data Scientist role.
Q2: Is coding necessary for Data Analysts?
While deep coding isn’t mandatory, familiarity with SQL, Python, or R greatly enhances a Data Analyst’s effectiveness.
Q3: What is the difference between a Data Scientist and an ML Engineer?
Data Scientists focus more on model development and experimentation, while ML Engineers focus on deploying and scaling those models.
Q4: Which role is the best for beginners?
If you love problem-solving and analysis, start as a Data Analyst. If you enjoy coding and systems, a Data Engineer might be your path.
Published By:
Mirza Yasir Abdullah Baig
Repost This Article and built Your Connection With Others
0 notes
Text
ETL Engineer vs. Data Engineer: Which One Do You Need?

If your business handles large data volumes you already know how vital it is to have the right talent managing it. But when it comes to scalability or improving your data systems, you must know whether to hire ETL experts or hire data engineers.
While the roles do overlap in some areas, they each have unique skills to bring forth. This is why an understanding of the differences can help you make the right hire. Several tech companies face this question when they are outlining their data strategy. So if you are one of those then let’s break it down and help you decide which experts you should hire.
Choosing the Right Role to Build and Manage Your Data Pipeline
Extract, Transform, Load is what ETL stands for. The duties of an ETL engineer include:
Data extraction from various sources.
Cleaning, formatting, and enrichment.
Putting it into a central system or data warehouse.
Hiring ETL engineers means investing in a person who will make sure data moves accurately and seamlessly across several systems and into a single, usable format.
Businesses that largely rely on dashboards, analytics tools, and structured data reporting would benefit greatly from this position. ETL engineers assist business intelligence and compliance reporting for a large number of tech organizations.
What Does a Data Engineer Do?
The architecture that facilitates data movement and storage is created and maintained by a data engineer. Their duties frequently consist of:
Data pipeline design
Database and data lake management
Constructing batch or real-time processing systems
Developing resources to assist analysts and data scientists
When hiring data engineers, you want someone with a wider range of skills who manages infrastructure, performance optimization, and long-term scalability in addition to using ETL tools.
Remote Hiring and Flexibility
Thanks to cloud platforms and remote technologies, you can now hire remote developers, such as data engineers and ETL specialists, with ease. This strategy might be more economical and gives access to worldwide talent, particularly for expanding teams.
Which One Do You Need?
If your main objective is to use clean, organized data to automate and enhance reporting or analytics, go with ETL engineers.
If you're scaling your current infrastructure or creating a data platform from the ground up, hire data engineers.
Having two responsibilities is ideal in many situations. While data engineers concentrate on the long-term health of the system, ETL engineers manage the daily flow.
Closing Thoughts
The needs of your particular project will determine whether you should hire a data engineer or an ETL. You should hire ETL engineers if you're interested in effectively transforming and transporting data. It's time to hire data engineers if you're laying the framework for your data systems.
Combining both skill sets might be the best course of action for contemporary IT organizations, particularly if you hire remote talent to scale swiftly and affordably. In any case, hiring qualified personnel guarantees that your data strategy fosters expansion and informed decision-making.
0 notes
Text
ETL Pipelines: How Data Moves from Raw to Insights

Introduction
Businesses collect raw data from various sources.
ETL (Extract, Transform, Load) pipelines help convert this raw data into meaningful insights.
This blog explains ETL processes, tools, and best practices.
1. What is an ETL Pipeline?
An ETL pipeline is a process that Extracts, Transforms, and Loads data into a data warehouse or analytics system.
Helps in cleaning, structuring, and preparing data for decision-making.
1.1 Key Components of ETL
Extract: Collect data from multiple sources (databases, APIs, logs, files).
Transform: Clean, enrich, and format the data (filtering, aggregating, converting).
Load: Store data into a data warehouse, data lake, or analytics platform.
2. Extract: Gathering Raw Data
Data sources: Databases (MySQL, PostgreSQL), APIs, Logs, CSV files, Cloud storage.
Extraction methods:
Full Extraction: Pulls all data at once.
Incremental Extraction: Extracts only new or updated data.
Streaming Extraction: Real-time data processing (Kafka, Kinesis).
3. Transform: Cleaning and Enriching Data
Data Cleaning: Remove duplicates, handle missing values, normalize formats.
Data Transformation: Apply business logic, merge datasets, convert data types.
Data Enrichment: Add contextual data (e.g., join customer records with location data).
Common Tools: Apache Spark, dbt, Pandas, SQL transformations.
4. Load: Storing Processed Data
Load data into a Data Warehouse (Snowflake, Redshift, BigQuery, Synapse) or a Data Lake (S3, Azure Data Lake, GCS).
Loading strategies:
Full Load: Overwrites existing data.
Incremental Load: Appends new data.
Batch vs. Streaming Load: Scheduled vs. real-time data ingestion.
5. ETL vs. ELT: What’s the Difference?

ETL is best for structured data and compliance-focused workflows.
ELT is ideal for cloud-native analytics, handling massive datasets efficiently.
6. Best Practices for ETL Pipelines
✅ Optimize Performance: Use indexing, partitioning, and parallel processing. ✅ Ensure Data Quality: Implement validation checks and logging. ✅ Automate & Monitor Pipelines: Use orchestration tools (Apache Airflow, AWS Glue, Azure Data Factory). ✅ Secure Data Transfers: Encrypt data in transit and at rest. ✅ Scalability: Choose cloud-based ETL solutions for flexibility.
7. Popular ETL Tools
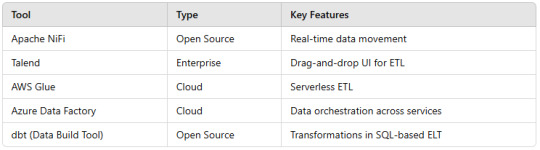
Conclusion
ETL pipelines streamline data movement from raw sources to analytics-ready formats.
Choosing the right ETL/ELT strategy depends on data size, speed, and business needs.
Automated ETL tools improve efficiency and scalability.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Data Warehousing vs. Data Lakes: Choosing the Right Approach for Your Organization
As a solution architect, my journey into data management has been shaped by years of experience and focused learning. My turning point was the data analytics training online, I completed at ACTE Institute. This program gave me the clarity and practical knowledge I needed to navigate modern data architectures, particularly in understanding the key differences between data warehousing and data lakes.
Both data warehousing and data lakes have become critical components of the data strategies for many organizations. However, choosing between them—or determining how to integrate both—can significantly impact how an organization manages and utilizes its data.
What is a Data Warehouse?
Data warehouses are specialized systems designed to store structured data. They act as centralized repositories where data from multiple sources is aggregated, cleaned, and stored in a consistent format. Businesses rely on data warehouses for generating reports, conducting historical analysis, and supporting decision-making processes.
Data warehouses are highly optimized for running complex queries and generating insights. This makes them a perfect fit for scenarios where the primary focus is on business intelligence (BI) and operational reporting.
Features of Data Warehouses:
Predefined Data Organization: Data warehouses rely on schemas that structure the data before it is stored, making it easier to analyze later.
High Performance: Optimized for query processing, they deliver quick results for detailed analysis.
Data Consistency: By cleansing and standardizing data from multiple sources, warehouses ensure consistent and reliable insights.
Focus on Business Needs: These systems are designed to support the analytics required for day-to-day business decisions.
What is a Data Lake?
Data lakes, on the other hand, are designed for flexibility and scalability. They store vast amounts of raw data in its native format, whether structured, semi-structured, or unstructured. This approach is particularly valuable for organizations dealing with large-scale analytics, machine learning, and real-time data processing.
Unlike data warehouses, data lakes don’t require data to be structured before storage. Instead, they use a schema-on-read model, where the data is organized only when it’s accessed for analysis.
Features of Data Lakes:
Raw Data Storage: Data lakes retain data in its original form, providing flexibility for future analysis.
Support for Diverse Data Types: They can store everything from structured database records to unstructured video files or social media content.
Scalability: Built to handle massive amounts of data, data lakes are ideal for organizations with dynamic data needs.
Cost-Effective: Data lakes use low-cost storage options, making them an economical solution for large datasets.
Understanding the Differences
To decide which approach works best for your organization, it’s essential to understand the key differences between data warehouses and data lakes:
Data Structure: Data warehouses store data in a structured format, whereas data lakes support structured, semi-structured, and unstructured data.
Processing Methodology: Warehouses follow a schema-on-write model, while lakes use a schema-on-read approach, offering greater flexibility.
Purpose: Data warehouses are designed for business intelligence and operational reporting, while data lakes excel at advanced analytics and big data processing.
Cost and Scalability: Data lakes tend to be more cost-effective, especially when dealing with large, diverse datasets.
How to Choose the Right Approach
Choosing between a data warehouse and a data lake depends on your organization's goals, data strategy, and the type of insights you need.
When to Choose a Data Warehouse:
Your organization primarily deals with structured data that supports reporting and operational analysis.
Business intelligence is at the core of your decision-making process.
You need high-performance systems to run complex queries efficiently.
Data quality, consistency, and governance are critical to your operations.

When to Choose a Data Lake:
You work with diverse data types, including unstructured and semi-structured data.
Advanced analytics, machine learning, or big data solutions are part of your strategy.
Scalability and cost-efficiency are essential for managing large datasets.
You need a flexible solution that can adapt to emerging data use cases.
Combining Data Warehouses and Data Lakes
In many cases, organizations find value in adopting a hybrid approach that combines the strengths of data warehouses and data lakes. For example, raw data can be ingested into a data lake, where it’s stored until it’s needed for specific analytical use cases. The processed and structured data can then be moved to a data warehouse for BI and reporting purposes.
This integrated strategy allows organizations to benefit from the scalability of data lakes while retaining the performance and reliability of data warehouses.
My Learning Journey with ACTE Institute
During my career, I realized the importance of mastering these technologies to design efficient data architectures. The data analytics training in Hyderabad program at ACTE Institute provided me with a hands-on understanding of both data lakes and data warehouses. Their comprehensive curriculum, coupled with practical exercises, helped me bridge the gap between theoretical knowledge and real-world applications.
The instructors at ACTE emphasized industry best practices and use cases, enabling me to apply these concepts effectively in my projects. From understanding how to design scalable data lakes to optimizing data warehouses for performance, every concept I learned has played a vital role in my professional growth.
Final Thoughts
Data lakes and data warehouses each have unique strengths, and the choice between them depends on your organization's specific needs. With proper planning and strategy, it’s possible to harness the potential of both systems to create a robust and efficient data ecosystem.
My journey in mastering these technologies, thanks to the guidance of ACTE Institute, has not only elevated my career but also given me the tools to help organizations make informed decisions in their data strategies. Whether you're working with structured datasets or diving into advanced analytics, understanding these architectures is crucial for success in today’s data-driven world.
#machinelearning#artificialintelligence#digitalmarketing#marketingstrategy#adtech#database#cybersecurity#ai
0 notes
Text
Data Warehouses Vs Data Lakes Vs Databases – A Detailed Evaluation
Data storage is a major task, especially for organizations handling large amounts of data. For businesses garnering optimal value from big data, you hear about data storage terminologies – ‘Databases’, ‘Data warehouses’, and ‘Data lakes’. They all sound similar. But they aren’t! Each of them has its own unique characteristics that make them stand apart in the data landscape.
Through this detailed article, we attempt to introduce the three terminologies, their salient features and how different are they from each other. Hope it throws some light into how data can be managed and stored with databases, data lakes, and data warehouses.
0 notes
Text
Microsoft Fabric data warehouse
Microsoft Fabric data warehouse
What Is Microsoft Fabric and Why You Should Care?
Unified Software as a Service (SaaS), offering End-To-End analytics platform
Gives you a bunch of tools all together, Microsoft Fabric OneLake supports seamless integration, enabling collaboration on this unified data analytics platform
Scalable Analytics
Accessibility from anywhere with an internet connection
Streamlines collaboration among data professionals
Empowering low-to-no-code approach
Components of Microsoft Fabric
Fabric provides comprehensive data analytics solutions, encompassing services for data movement and transformation, analysis and actions, and deriving insights and patterns through machine learning. Although Microsoft Fabric includes several components, this article will use three primary experiences: Data Factory, Data Warehouse, and Power BI.
Lake House vs. Warehouse: Which Data Storage Solution is Right for You?
In simple terms, the underlying storage format in both Lake Houses and Warehouses is the Delta format, an enhanced version of the Parquet format.
Usage and Format Support
A Lake House combines the capabilities of a data lake and a data warehouse, supporting unstructured, semi-structured, and structured formats. In contrast, a data Warehouse supports only structured formats.
When your organization needs to process big data characterized by high volume, velocity, and variety, and when you require data loading and transformation using Spark engines via notebooks, a Lake House is recommended. A Lakehouse can process both structured tables and unstructured/semi-structured files, offering managed and external table options. Microsoft Fabric OneLake serves as the foundational layer for storing structured and unstructured data Notebooks can be used for READ and WRITE operations in a Lakehouse. However, you cannot connect to a Lake House with an SQL client directly, without using SQL endpoints.
On the other hand, a Warehouse excels in processing and storing structured formats, utilizing stored procedures, tables, and views. Processing data in a Warehouse requires only T-SQL knowledge. It functions similarly to a typical RDBMS database but with a different internal storage architecture, as each table’s data is stored in the Delta format within OneLake. Users can access Warehouse data directly using any SQL client or the in-built graphical SQL editor, performing READ and WRITE operations with T-SQL and its elements like stored procedures and views. Notebooks can also connect to the Warehouse, but only for READ operations.
An SQL endpoint is like a special doorway that lets other computer programs talk to a database or storage system using a language called SQL. With this endpoint, you can ask questions (queries) to get information from the database, like searching for specific data or making changes to it. It’s kind of like using a search engine to find things on the internet, but for your data stored in the Fabric system. These SQL endpoints are often used for tasks like getting data, asking questions about it, and making changes to it within the Fabric system.
Choosing Between Lakehouse and Warehouse
The decision to use a Lakehouse or Warehouse depends on several factors:
Migrating from a Traditional Data Warehouse: If your organization does not have big data processing requirements, a Warehouse is suitable.
Migrating from a Mixed Big Data and Traditional RDBMS System: If your existing solution includes both a big data platform and traditional RDBMS systems with structured data, using both a Lakehouse and a Warehouse is ideal. Perform big data operations with notebooks connected to the Lakehouse and RDBMS operations with T-SQL connected to the Warehouse.
Note: In both scenarios, once the data resides in either a Lakehouse or a Warehouse, Power BI can connect to both using SQL endpoints.
A Glimpse into the Data Factory Experience in Microsoft Fabric
In the Data Factory experience, we focus primarily on two items: Data Pipeline and Data Flow.
Data Pipelines
Used to orchestrate different activities for extracting, loading, and transforming data.
Ideal for building reusable code that can be utilized across other modules.
Enables activity-level monitoring.
To what can we compare Data Pipelines ?
microsoft fabric data pipelines Data Pipelines are similar, but not the same as:
Informatica -> Workflows
ODI -> Packages
Dataflows
Utilized when a GUI tool with Power Query UI experience is required for building Extract, Transform, and Load (ETL) logic.
Employed when individual selection of source and destination components is necessary, along with the inclusion of various transformation logic for each table.
To what can we compare Data Flows ?
Dataflows are similar, but not same as :
Informatica -> Mappings
ODI -> Mappings / Interfaces
Are You Ready to Migrate Your Data Warehouse to Microsoft Fabric?
Here is our solution for implementing the Medallion Architecture with Fabric data Warehouse:
Creation of New Workspace
We recommend creating separate workspaces for Semantic Models, Reports, and Data Pipelines as a best practice.
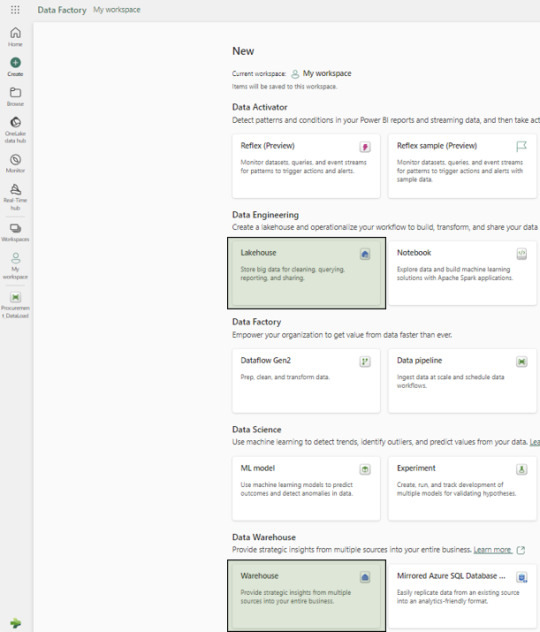
Creation of Warehouse and Lakehouse
Follow the on-screen instructions to setup new Lakehouse and a Warehouse:
Configuration Setups
Create a configurations.json file containing parameters for data pipeline activities:
Source schema, buckets, and path
Destination warehouse name
Names of warehouse layers bronze, silver and gold – OdsStage,Ods and Edw
List of source tables/files in a specific format
Source System Id’s for different sources
Below is the screenshot of the (config_variables.json) :

File Placement
Place the configurations.json and SourceTableList.csv files in the Fabric Lakehouse.
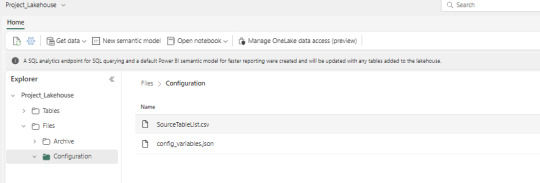
SourceTableList will have columns such as – SourceSystem, SourceDatasetId, TableName, PrimaryKey, UpdateKey, CDCColumnName, SoftDeleteColumn, ArchiveDate, ArchiveKey
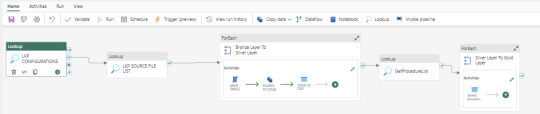
Data Pipeline Creation
Create a data pipeline to orchestrate various activities for data extraction, loading, and transformation. Below is the screenshot of the Data Pipeline and here you can see the different activities like – Lookup, ForEach, Script, Copy Data and Stored Procedure
Bronze Layer Loading
Develop a dynamic activity to load data into the Bronze Layer (OdsStage schema in Warehouse). This layer truncates and reloads data each time.
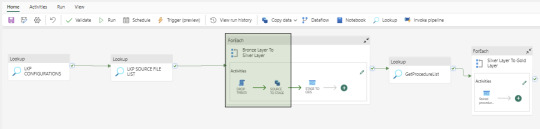
We utilize two activities in this layer: Script Activity and Copy Data Activity. Both activities receive parameterized inputs from the Configuration file and SourceTableList file. The Script activity drops the staging table, and the Copy Data activity creates and loads data into the OdsStage table. These activities are reusable across modules and feature powerful capabilities for fast data loading.
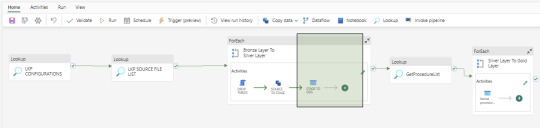
Silver Layer Loading
Establish a dynamic activity to UPSERT data into the Silver layer (Ods schema in Warehouse) using a stored procedure activity. This procedure takes parameterized inputs from the Configuration file and SourceTableList file, handling both UPDATE and INSERT operations. This stored procedure is reusable. At this time, MERGE statements are not supported by Fabric Warehouse. However, this feature may be added in the future.
Control Table Creation
Create a control table in the Warehouse with columns containing Sequence Numbers and Procedure Names to manage dependencies between Dimensions, Facts, and Aggregate tables. And finally fetch the values using a Lookup activity.
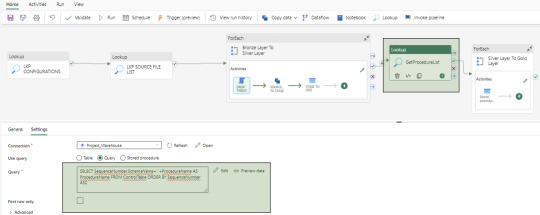
Gold Layer Loading
To load data into the Gold Layer (Edw schema in the warehouse), we develop individual stored procedures to UPSERT (UPDATE and INSERT) data for each dimension, fact, and aggregate table. While Dataflow can also be used for this task, we prefer stored procedures to handle the nature of complex business logic.

Dashboards and Reporting
Fabric includes the Power BI application, which can connect to the SQL endpoints of both the Lakehouse and Warehouse. These SQL endpoints allow for the creation of semantic models, which are then used to develop reports and applications. In our use case, the semantic models are built from the Gold layer (Edw schema in Warehouse) tables.
Upcoming Topics Preview
In the upcoming articles, we will cover topics such as notebooks, dataflows, lakehouse, security and other related subjects.
Conclusion
microsoft Fabric data warehouse stands as a potent and user-friendly data manipulation platform, offering an extensive array of tools for data ingestion, storage, transformation, and analysis. Whether you’re a novice or a seasoned data analyst, Fabric empowers you to optimize your workflow and harness the full potential of your data.
We specialize in aiding organizations in meticulously planning and flawlessly executing data projects, ensuring utmost precision and efficiency.
Curious and would like to hear more about this article ?
Contact us at [email protected] or Book time with me to organize a 100%-free, no-obligation call
Follow us on LinkedIn for more interesting updates!!
DataPlatr Inc. specializes in data engineering & analytics with pre-built data models for Enterprise Applications like SAP, Oracle EBS, Workday, Salesforce to empower businesses to unlock the full potential of their data. Our pre-built enterprise data engineering models are designed to expedite the development of data pipelines, data transformation, and integration, saving you time and resources.
Our team of experienced data engineers, scientists and analysts utilize cutting-edge data infrastructure into valuable insights and help enterprise clients optimize their Sales, Marketing, Operations, Financials, Supply chain, Human capital and Customer experiences.
0 notes
Text
Data Lake vs. Data Warehouse: What Works Best for Your Business?
Data Lake vs. Data Warehouse: Understand the key differences and when to use each for your data strategy. This blog breaks down the features, benefits, and challenges of both data lakes and data warehouses, helping businesses choose the right solution for their needs.
Learn how each can streamline data management, improve analytics, and support business growth in a data-driven world.
0 notes
Text
Data Lake VS Data Warehouse - Understanding the difference
Data Warehouse & Data Lake

Before we jump into discussing Data Warehouse & Data Lakes let us understand a little about Data. The term Data is all about information or we could say data & information are words that are used interchangeably, but there is still a difference between both of them. So what exactly does it mean ??
Data are "small chunks" of information that do not have value until and unless it is structured, but information is a set of Data that is addressing a value from the words itself.
Now that we understand the concept of Data, let's look forward to learning about Data Warehouse & Data Lake. From the name itself we could get the idea that there is data that is maintained like how people keep things in a warehouse, and how the rivers join together to meet and build a lake.
So to understand technically Data Warehouses & Data Lakes both of the terms are used to introduce the process of storing Data.
Data Warehouse
A Data Warehouse is a storage place where different sets of databases are stored. Before the process of transferring data into a warehouse from any source or medium it is processed and cleaned and containerized into a database. It basically has summarized data which is later used for reporting and analytical purposes.
For an example, let us consider an e-commerce platform. They maintain a structured database containing customer details, product details, purchase history. This data is then cleaned, aggregated and organized in a data warehouse using ETL or ELT process.
Later this Data Warehouse is used to generate reports by analysts to make an informed data driven decision for a business.
Data Lake
A data lake is like a huge storage pool where you can dump all kinds of data—structured (like tables in a database), semi-structured (like JSON files), and unstructured (like images, videos, and text documents)—in their raw form, without worrying about organizing it first.
Imagine a Data Lake as a big, natural lake where you can pour in water from different sources— rivers, rain, streams, etc. Just like the water in a lake comes from different places and mixes together, a data lake stores all kinds of data from various sources.
Store Everything as It Is. In a data lake, you don’t need to clean, organize, or structure the data before storing it. You can just dump it in as it comes. This is useful because you might not know right away how you want to use the data, so you keep it all and figure that out later.
Since the data is stored in its raw form, you can later decide how to process or analyze it. Data scientists and analysts can use the data in whatever way they need, depending on the problem they’re trying to solve.
What is the connection between Data-warehouse and Data-lakes?
Data Lake: Think of it as the first stop for all your raw data. A data lake stores everything as it comes in—whether it’s structured, semi-structured, or unstructured—without much processing. It’s like a big, unfiltered collection of data from various sources.
Data Warehouse: After the data is in the lake, some of it is cleaned, organized, and transformed to make it more useful for analysis. This processed and structured data is then moved to a data warehouse, where it’s ready for specific business reports and queries
Together, they form a data ecosystem where the lake feeds into the warehouse, ensuring that raw data is preserved while also providing clean, actionable insights for the business.
1 note
·
View note
Text
Top Data Ingestion Techniques for Modern Businesses

Welcome to the world of data ingestion, a pivotal process in modern data architecture. Data ingestion seamlessly transfers data from diverse sources such as databases, files, streaming platforms, and IoT devices to centralised repositories like cloud data lakes or warehouses. This critical process ensures that raw data is efficiently moved to a landing zone, ready for transformation and analysis.
Data ingestion occurs in two primary modes: real-time and batch processing. In real-time ingestion, data items are continuously imported as they are generated, ensuring up-to-the-moment analytics capability. Conversely, batch processing imports data periodically, optimising resource utilisation and processing efficiency.
Adequate data ingestion begins with prioritising data sources, validating individual files, and routing data items to their designated destinations. This foundational step ensures that downstream data science, business intelligence, and analytics systems receive timely, complete, and accurate data.
What is Data Ingestion?

Data ingestion, often facilitated through specialised data ingestion tools or services, refers to collecting and importing data from various types of sources into a storage or computing system. This is crucial for subsequent analysis, storage, or processing. Types of data ingestion vary widely, encompassing structured data from databases, unstructured data from documents, and real-time data streams from IoT devices.
Data ingestion vs data integration focuses on importing data into a system, while data integration comes with combining data from different sources to provide a unified view. An example of data ingestion could be pulling customer data from social media APIs, logs, or real-time sensors to improve service offerings.
Automated data ingestion tools streamline this process, ensuring data is promptly available for analytics or operational use. In business management software services, efficient data integration ensures that diverse data sets, such as sales figures and customer feedback, can be harmoniously combined for comprehensive business insights.
Why Is Data Ingestion Important?

1. Providing flexibility
Data ingestion is pivotal in aggregating information from various sources in today’s dynamic business environment. Businesses utilise data ingestion services to gather data, regardless of format or structure, enabling a comprehensive understanding of operations, customer behaviours, and market trends.
This process is crucial as it allows companies to adapt to the evolving digital landscape, where new data sources constantly emerge. Moreover, data ingestion tools facilitate the seamless integration of diverse data types, managing varying volumes and speeds of data influx. For instance, automated data ingestion ensures efficiency by continuously updating information without manual intervention.
This capability distinguishes from traditional data integration, focusing more on comprehensively merging datasets. Ultimately, flexible empowers businesses to remain agile and responsive amid technological advancements.
2. Enabling analytics
Data ingestion is the foundational process in analytics, acting as the conduit through which raw data enters analytical systems. Efficient facilitates the collection of vast data volumes and ensures that this data is well-prepared for subsequent analysis.
Businesses, including those seeking to optimise their operations through business growth consultancy, rely on robust services and tools to automate and streamline this crucial task.
For instance, a retail giant collects customer transaction data from thousands of stores worldwide. Automated data ingestion tools seamlessly gather, transform, and load this data into a centralised analytics platform. This process enhances operational efficiency and empowers decision-makers with timely insights.
3. Enhancing data quality
Data ingestion, primarily through automated services and tools, enhances data quality. First, various checks and validations are executed during data ingestion to ensure data consistency and accuracy. This process includes data cleansing, where corrupt or irrelevant data is identified, corrected, or removed.
Furthermore, data transformation occurs wherein data is standardised, normalised, and enriched. Data enrichment, for instance, involves augmenting datasets with additional relevant information, enhancing their context and overall value. Consider a retail company automating from multiple sales channels.
Here, data ingestion ensures accurate sales data collection and integrates customer feedback seamlessly. This capability is vital for optimising business intelligence services and driving informed decision-making.
Types of Data Ingestion

1. Batch Processing
Batch processing, a fundamental data ingestion method, involves gathering data over a specific period and processing it all at once. However, this approach is particularly beneficial for tasks that do not necessitate real-time updates.
Instead, data can be processed during off-peak hours, such as overnight, to minimise impact on system performance. Common examples include generating daily sales reports or compiling monthly financial statements. Batch processing is valued for its reliability and simplicity in efficiently handling large volumes of data.
However, it may not meet the needs of modern applications that demand real-time data updates, such as those used in fraud detection or stock trading platforms.
2. Real-time Processing
In contrast, real-time processing revolves around ingesting data immediately as it is generated. This method allows instantaneous analysis and action, making it essential for time-sensitive applications like monitoring systems, real-time analytics, and IoT applications.
Real-time processing enables swift decision-making by providing up-to-the-moment insights. Nevertheless, it requires substantial computing power and network bandwidth resources. Additionally, a robust data infrastructure is essential to effectively manage the continuous influx of data.
3. Micro-batching
Micro-batching represents a balanced approach between batch and real-time data processing methods. It facilitates frequent data ingestion in small batches, which enhances near-real-time updates.
This approach is crucial for businesses seeking timely data integration without overburdening their resources with continuous real-time processing demands. Micro-batching finds its niche in scenarios where maintaining data freshness is vital, yet full-scale real-time processing could be more practical.
The Data Ingestion Process

1. Data discovery
Data discovery is the initial step in the lifecycle, where organisations seek to explore, comprehend, and access data from diverse sources. It serves the crucial purpose of identifying available data, its origins, and its potential utility within the organisation.
This exploratory phase is pivotal for understanding the data landscape comprehensively, including its structure, quality, and usability. During data discovery, the primary goal is to uncover insights into the nature of the data and its relevance to organisational objectives.
This process involves scrutinising various sources such as databases, APIs, spreadsheets, and physical documents. By doing so, businesses can ascertain the data’s potential value and strategise its optimal utilisation. Organisations often rely on project management services to streamline and efficiently coordinate these data discovery efforts.
2. Data acquisition
Data acquisition, also known as data ingestion, follows data discovery. It entails the act of gathering identified data from diverse sources and integrating it into the organisation’s systems. This phase is crucial for maintaining data integrity and harnessing its full potential.
Despite the challenges posed by different data formats, volumes, and quality issues, adequate ensures that the data is accessible and usable for analytics, decision-making, and operational efficiency. Automating data ingestion using specialised tools or services further streamlines this process, reducing manual effort and improving accuracy. Examples include ETL (Extract, Transform, Load) tools and cloud-based platforms for seamless data integration.
3. Data Validation
In data ingestion, the initial phase is data validation, a critical step in guaranteeing the reliability of acquired data. Here, the data undergoes rigorous checks for accuracy and consistency. Various validation techniques are applied, including data type validation, range checks, and ensuring data uniqueness. These measures ensure the data is clean and correct, preparing it for subsequent processing steps.
4. Data Transformation
Once validated, the data moves to the transformation phase. This step involves converting the data from its original format into a format conducive to analysis and interpretation. Techniques such as normalisation and aggregation are applied to refine the data, making it more understandable and meaningful for insights. Data transformation is crucial as it prepares the data to be utilised effectively for decision-making purposes.
5. Data Loading
Following transformation, the processed data is loaded into a data warehouse or another designated destination for further utilisation. This final step in the process ensures that the data is readily available for analysis or reporting. Depending on requirements, data loading can occur in batches or in real-time, facilitating immediate access to updated information for decision support.
Conclusion
In conclusion, data ingestion is a cornerstone of modern data-driven enterprises, enabling the normal flow of information from diverse sources to centralised repositories. This pivotal process ensures that businesses can harness the full potential of their data for strategic decision-making, operational efficiency, and actionable insights.
By adopting efficient techniques through real-time, batch processing, or micro-batching—organisations can maintain agility in adapting to market demands and technological development.
Automated tools further enhance this capability by streamlining collection, validation, transformation, and loading, thereby minimising manual effort and improving accuracy.
Moreover, data ingestion enhances quality through validation and transformation and facilitates timely access to critical information for analytics and reporting. Source: Data Ingestion Techniques
0 notes