#DataView
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Note
would you be willing to talk more about how you use dataview to organize data in obsidian? (i am referring to the fact that you kind of mentioned that you do that in this post, but didn't go into any detail about how.) i appreciate your running this blog! 💌💐
hello :) gladly!
i'm still a super beginner with dataview, but i'd be happy to walk through the ways i currently use it with obsidian :)
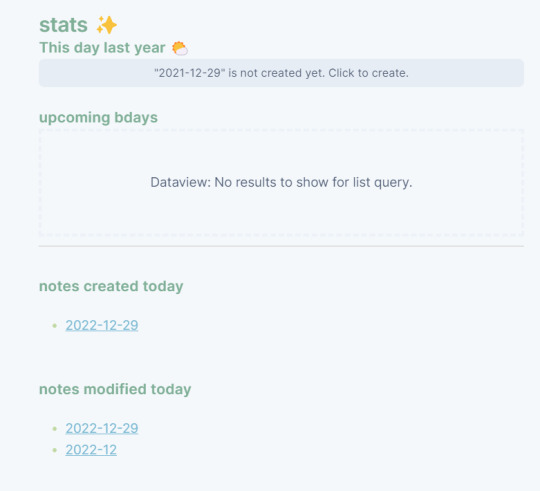
under each daily page, i have a stats section, which is a sort of automatically updating part of my diary.
this day last year: it links me to a diary page from the year previous (i only started using obsidian in the summer so i don't have enough entries for that yet)
upcoming bdays: on pages for my friends / family etc. i have a section on the page's YAML frontmatter for their birthdays - if the birthday is within the month, it'll appear in this section
notes created today: lists all the notes created today
notes modified today: lists all the notes modified today
the only other use of dataview i have atm is that when i create checkboxes like the fofllowing:

i have a page in my vault called 'tasks' that just rounds up all my incomplete tasks in one place so that i can keep all my notes to myself in one spot and to address them later. my rule for this is that these are things / thoughts that i need to process later on, like a short idea for something, or something that needs to be turned into a legit task, etc.
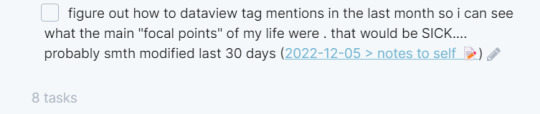
here's a preview of the task page :)
that's honestly it atm - i'd love to incorporate it more into my workflow, but haven't done it yet!
17 notes
·
View notes
Text
oh man oh man oh man oh man

I just learned how to use Dataview plugin with Obsidian.MD to automate these lists of my characters and oh my fucking jesus christ, I am absolutely going BALLISTIC at the possibilities of everything righ tnow, i need to calm down and process the things,
but THIS IS JUST LISTS
NO T EVEN TABLES HOLY FUCK
10 notes
·
View notes
Text
Obsidian Hub is a guide to using Obsidian personal wiki or personal knowledge management (PKM) software. It includes an intro to the Dataview plugin, which I’ve been trying to figure out.
4 notes
·
View notes
Text
Page redone with Dataview


I should not be doing this things at 12:00 when I have to wake up early :((((
1 note
·
View note
Text
How to create a DataView in C#
DataView is special table view which allows you to traverse through rows and columns respectively. C# DataView is an offline data holder as DataSet. What you need is A Database connection object A Data Adapter which configures the data table using SQL query. And a dataset which holds the table information. Create a data view object and initialize it with the dataset tables name as follows…
View On WordPress
1 note
·
View note
Text
This just took me literal hours to figure out, but my new sewing journal in Obsidian will now auto-list the fabric information for each fabric used in a project.
(Note: Every fabric has an assigned ID that is YY000 format).
Inside the dataview lines:
TABLE WITHOUT ID file.link AS "ID", content_percentages as "Content", weight as "Weight"
FLATTEN this.fabric_id as ids
WHERE contains(file.name, ids)
---
Table without ID just means that they don't add a column for file name.
The items after that are my columns: the link to the fabric's page, the content percentages, and the weight. These are all items in the fabric's metadata
Now, fabric_id is a List item in my metadata. Since a project can contain more than one fabric, you have to FLATTEN the list. That way, each fabric is separated onto its own row. Also, the "this." part is very important because queries are looking at your entire vault and not just a section (unless you limit it with 'from' which I didn't here as I wanted to pull from multiple parts of my vault).
My "where" is where I limit so that my table only shows the fabric information for those fabrics in that project. Since my fabrics are all listed by their ID number, I can just match the two using contains (basically, in the file name, look for the id).
At least, that is how I understand what I've done.
0 notes
Text
Blogger data:view List
Data:View normally used with a conditional expression as in to programmatically call something.
0 notes
Text
Obsidian : Data analyst ?
Il y a bientôt 2 ans, j'ai publier un article sur Obsidian. Vu le nombre de messages, j'ai le sentiment que ce logiciel de prise de notes est de plus en plus utilisé. Ce premier article abordait comment ce logiciel peut vous aider à trouver la bonne information le plus rapidement possible. Je vous propose un autre exemple d'analyse de données avec Obsidian.

Je tiens à préciser que pour les exemples décrits, j'ai généré aléatoirement des données sur le site MocKaroo. Il se peut, de façon fortuite, que des données soient réelles mais cela ne peut engager ma responsabilité.
Résumé de la problématique : Supposons que vous ayez récupéré sur le DarkNet un fichier CSV contenant des numéros de téléphones avec des logins/mot de passe :
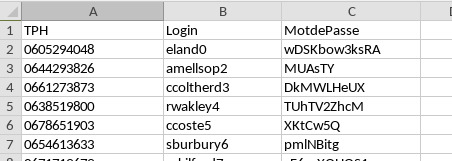
Vous voudriez savoir, l'identité des personnes qui ont ce numéro. Pour cela vous avez en votre possession une base de données sous forme d'un autre fichier CSV :
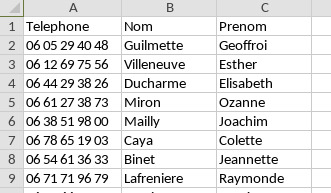
De même vous avez également un fichier CSV qui contient les URLs des sites où sont identifiés des numéros de téléphones :

Comme vous le comprenez, l'idée est à travers les numéros de téléphones (dont le format est différent dans chaque fichier) de pouvoir :
Si vous êtes le responsable d'un site (par exemple wix.com), savoir quelles sont les données qui ont été "dérobées".
Sous forme d'un tableau, connaître les identités des personnes et les sites auxquels ont peut accéder via les login/mot de passe.
Enfin de pouvoir exporter le tableau obtenu dans un et un seul fichier CSV.
D'habitude j'utiliserai un petit script qui ferait office d'ETL ou de DATA pipeline pour obtenir les résultats demandés (il faudra qu'un jour je publie un article là-dessus) mais dans le cadre de cet article nous allons utiliser obsidian.
Voilà ce que nous allons faire :
Importer chaque fichier CSV dans une arborescence différente en transformant chaque ligne par une note.
Lors de la création de cette note, des métadonnées seront insérées comportant les valeurs de chaque colonne d'une ligne du tableau CSV.
Reconstituer des notes avec les résultats souhaités.
Il faut donc dans un premier temps transformer toutes nos lignes de nos différents fichiers CSV en notes Markdown pour qu'elles soient interprétées par obsidian. On pourrait utiliser Pandoc comme on l'a vu dans mon premier article. Mais on va plutôt utiliser un module complémentaire : "JSON/CSV Importer" :
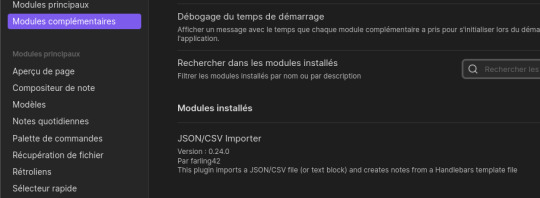
Pour rappel, si vous n'arrivez pas à récupérer le plugin via l'interface d'obsidian (car derrière un firewall), vous pouvez récupérer le plugin sous Github et l'installer manuellement. Pour cela, le dezipper et le mettre dans le répertoire de VotreVault/.obsidian/plugins (créez éventuellement le répertoire plugins). A noter qu'on trouve aussi le répertoire des thèmes contenant les feuilles de style css de chaque thème.

Après avoir récupéré ce plugin et après l'avoir activé, nous allons préparer l'import de nos fichiers.
Pour l'import des CVS (qui sont des tableaux), nous allons utiliser un template afin de définir la mise en forme de la note en utilisant les métadonnées des notes. Pour rappel, afin de créer des métadonnées, il vous suffit d'ajouter trois tirets tout en haut de la note puis de saisir dans une ligne vide la syntaxe "clé: valeur". Répéter l'opération pour ajouter autant de valeurs de métadonnées que vous le souhaitez. Enfin, terminez cette section avec trois tirets, encore une fois.
On va donc utiliser un template dans lequel la partie métadonnées va contenir les noms des colonnes (clé) et la valeur d'une ligne du tableau. Lors de l'import un mécanisme d'association du template défini et des données du fichier CSV permet de générer les notes dans le format voulu. L'avantage du plugin est de personnaliser via un langage de templates (handlebars) les notes générées par l'import du fichier CSV.
Nous allons, à travers les exemples aboter quelques syntaxes de ce langage de template. Vous pouvez en découvrir plus sur ce site que j'utilise :
Maintenant place à l'exercice. Dans un premier temps nous allons créer sous Obsdian l’arborescence suivante :
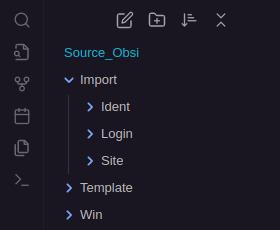
Sous Import nous avons créé 3 dossiers qui vont recevoir les notes générés par les 3 fichiers csv. Un répertoire Template qui va contenir nos templates d'import et un mystérieux répertoire Win... Positionnez vous dans le répertoire Template. Nous allons créer une première note modèle avec des métadonnées pour les imports. Par exemple, pour le fichier cvs contenant les sites nous allons créer les métadonnées suivante :
--- TPH: {{replace Telephon "-" ""}} Entreprise: {{uppercase Entreprise}} Domaine: {{URL}} ---
On retrouve le nom de nos colonnes (Telephon, Entreprise et URL). Le mot replace va permettre de supprimer le caractère "-" en le remplaçant par rien. uppercase permet de tout mettre en majuscule. Maintenant qu'on a créé les métadonnées, il ne reste plus qu'à définir l'affichage de la note. Personnellement je vais utiliser des "callouts" dans un block mais libre à vous de soigner la présentation. Par contre il faute obligatoirement définir un lien vers le numéro de téléphone. J'ai ajouté aussi un lien externe vers le site web.
>[!Note] Téléphone : [[{{replace Telephon "-" ""}}]] URL : [{{Entreprise}}]({{URL}})
On va procéder à l'import, cliquez sur la petite loupe dans la barre de gauche. Un popup s'ouvre :
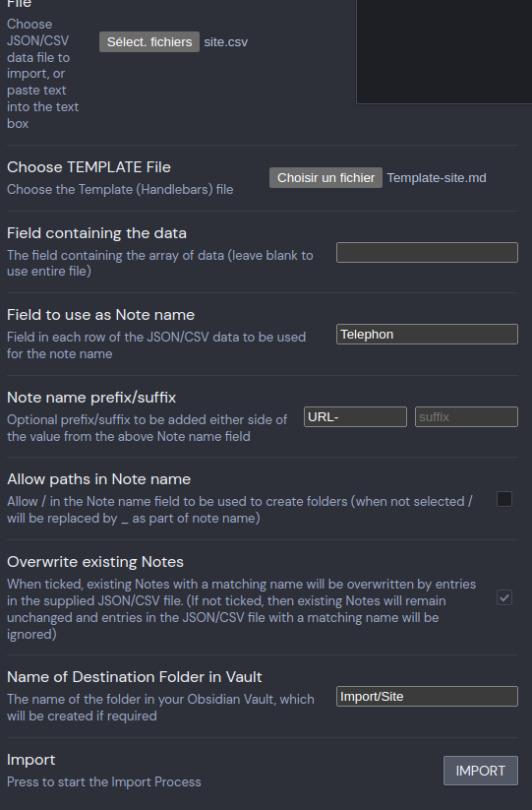
Sélectionnez votre fichier csv, puis votre fichier template que nous avons créé. Il faut ensuite définir le champ qui va servir de nom de la note. Celui-ci doit être unique, on va donc utiliser le champ "Telephon" auquel on va ajouter un prefix. Enfin on spécifie la destination dans notre arborescence. Cliquez sur Import. Et le résultat est immédiat :

On retrouve toutes les notes créées dans le répertoire Site. En se positionnant sur une note je vois bien mes métadonnées (Attention, vérifiez bien que vous être en mode source et passer en édition => Ctrl E), la vue graphique est encore plus claire. Faites la même chose avec les 2 autres fichiers CSV. Voici les templates que j'utilise :
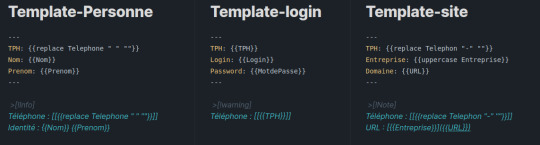
Il ne reste plus qu'à faire les imports comme vu précédemment. Vous devez obtenir le résultat suivant :

Remarquez le lien identique vers le numéro de téléphone. C'est notre "index" qui va pouvoir nous permettre d'effectuer nos recherches.
En passant en vue graphique on voit clairement les liens s'établir (j'ai volontairement limité le nombre de données pour pouvoir travailler sur des échantillons).

Maintenant on va tout de suite, répondre à notre première question. Quelles sont les données provenant du site WIX ? Rien de plus simple il suffit d'utiliser le champ de recherche :
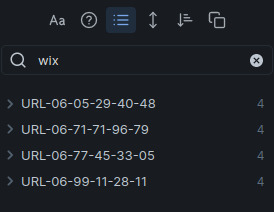
Puis de copier le résultat dans une note qu'on va créer (par exemple WIXID) sous Import/Win et afficher la vue graphique de cette note (Ctrl+G). Par ce système visuel, on peut facilement naviguer de note en note pour retrouver les renseignements "intéressants".
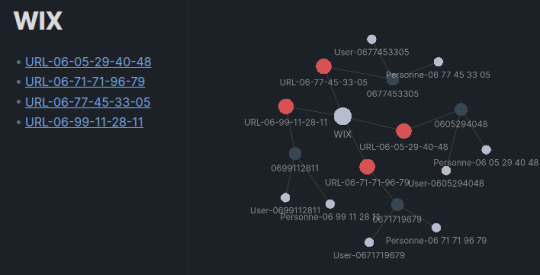
Pour la deuxième question, nous allons avoir besoin d'un autre module complémentaire. Il s'agit de "Dataview". Grace à cette autre extension, et aux métadonnées mises dans nos notes, nous allons pouvoir créer des requêtes comme en SQL. Je ne vais pas détailler dans cet article toutes les commandes possibles de Dataview. Cet outil est très puissant, je vous invite plutôt à lire la documentation disponible ici. Mais nous allons à travers notre exercice comprendre le fonctionnement de ce module.
Une fois installé, nous allons recréer une nouvelle note sous Import/Win. Cette nouvelle note qu'on va appeler "RESULTAT" va nous servir à construire notre requête DQL (Dataview Query Langage). Commencez par saisir 3 backticks (le symbole sous le chiffre 7) qui permet de définir le début d'un bloc de code. Automatiquement obsidian ajoute 3 autres backticks pour indiquer la fin du bloc. Il faut alors coller le mot "dataview" à côté des premiers backticks comme ci-dessous :
```dataview ```
Dans cette zone de code on va saisir notre requête. Comme on veut un tableau, on va saisir le mot clef "TABLE" et indiquer par la suite les champs de cette table.
```dataview TABLE Nom, Prenom, Login, Password, Domaine FROM "Import" ```
Le FROM permet de définir la zone de recherche, ici le répertoire Import et les sous répertoires.
Le résultat est un peu décevant : On a un premier champ qui reprend le nom de chaque nom. Pour le supprimer il faut taper les mots "WITHOUT ID" après TABLE :
```dataview TABLE WITHOUT ID Nom, Prenom, Login, Password, Domaine FROM "Import" ```
Cette fois-ci on a bien les résultats mais les uns après les autres. On va essayer de les trier par ordre de numéros de téléphones :
```dataview TABLE WITHOUT ID TPH,Nom, Prenom, Login, Password, Domaine FROM "Import" SORT TPH ASC ```
On a ajouté, le champ TPH qui correspond au téléphone et on a effectué un tri "SORT" sur ce numéro de téléphone de façon croissant (ASC). C'est déjà mieux mais on peut mieux faire en regroupant les résultats par téléphone (au lieu d'avoir 3 lignes). On va donc taper :
```dataview TABLE WITHOUT ID TPH,Nom, Prenom, Login, Password, Domaine FROM "Import" SORT TPH ASC GROUP BY TPH ```
Catastrophe ! on n'a plus aucun résultat... Sauf les numéro de téléphones. Il faut savoir quand on regroupe des notes (ici via le champ de metadonnées TPH), on créé un nouvel objet. Il s'agit d'une liste imbriquée de toutes les valeurs possibles d'un champ de métadonnées pour le critère de regroupement. Dans notre exercice, si on considère une valeur pour TPH, celui-ci est présent au maximum dans 3 notes (exemple avec le n° 0605294048) :
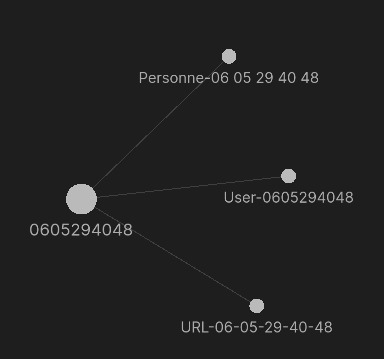
Le système va donc construire un tableau de 3 lignes avec les colonnes : TPH, Nom, Prenom, Login, Password et Domaine. Ainsi dans la colonne Nom on va avoir sur une ligne la métadonnée du fichier Personne-060005294048, donc le nom de la personne mais dans les autres lignes une valeur "null". Idem pour les autres champs :
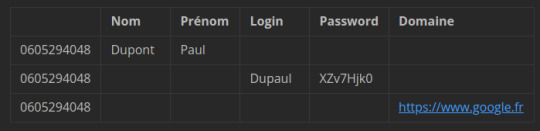
L'objet "Nom" aura donc 3 valeurs possibles si on regroupe par numéro de téléphone. il faut donc demander d'afficher toutes les lignes (rows en anglais) de l'objet Nom ainsi que des autres objets.
```dataview TABLE WITHOUT ID TPH,rows.Nom, rows.Prenom, rows.Login, rows.Password, rows.Domaine FROM "Import" SORT TPH ASC GROUP BY TPH ```
Si vous ne voyez plus toutes les colonnes, c'est que vous êtes en mode édition. Passez en mode lecture (Ctrl+E) pour voir toutes les colonnes puis revenez en mode édition (Ctrl+E). Cette affichage vous permet de bien voir les lignes du tableau. Mais le nom des colonnes n'est plus très explicite on va utiliser le mot "AS" pour renommer correctement les libellés des colonnes.
```dataview TABLE WITHOUT ID TPH,rows.Nom AS Nom, rows.Prenom AS Prenom, rows.Login AS User, rows.Password AS MdP, rows.Domaine AS URL FROM "Import" SORT TPH ASC GROUP BY TPH ```
On y est presque...
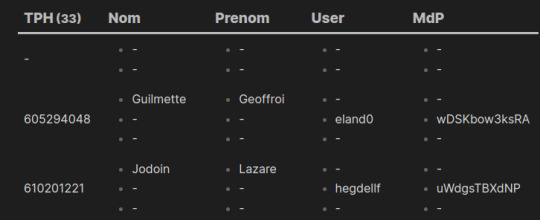
Par contre on voudrait, qu'au lieu d'avoir 3 lignes, on ne trouve qu'une ligne et que les valeurs null matérialisées par le symbole "-" disparaissent. Pour ce dernier cas, il suffit d'aller dans les préférences du modules Dataview et de supprimer la valeur par défaut.

Pour regrouper les 3 lignes, il suffit d'utiliser la commande "JOIN" en spécifiant aucun séparateur "" :
```dataview TABLE WITHOUT ID TPH,join(rows.Nom,"") AS Nom,join(rows.Prenom,"") AS Prenom,join(rows.Login,"") AS User,join(rows.Password,"") AS MdP,join(rows.Domaine,"") AS URL FROM "Import" SORT TPH ASC GROUP BY TPH ```
YES ! on y est... Pas tout à fait, car là on a toutes les valeurs hors on veut filtrer de façon à n'avoir que les renseignements complets :

On va utiliser une clause WHERE. Comme on sait que pour avoir tous les renseignements, il faut qu'un numéro de téléphone soit présent dans 3 notes, c'est à dire que le "tableau" contienne 3 lignes par metadonnée. On va donc spécfier qu'il faut 3 lignes pour un champ :
```dataview TABLE WITHOUT ID TPH,join(rows.Nom,"") AS Nom,join(rows.Prenom,"") AS Prenom,join(rows.Login,"") AS User,join(rows.Password,"") AS MdP,join(rows.Domaine,"") AS URL FROM "Import" SORT TPH ASC GROUP BY TPH WHERE length(rows.Nom)=3 ```
Cette fois c'est bon...

Nous avons vu à travers cet exercice qu'une petite partie des possibilités du plugin Dataview et du langage DQL. Si vous ne vous sentez pas capable de créer des requêtes, il existe un petit utilitaire open source : https://s-blu.github.io/basic-dataview-query-builder/ Cet outil vous permettra à travers des questions (en anglais) de créer la bonne requête.
Bon maintenant, et pour répondre à notre 3ème challenge, il ne reste plus qu'à exporter le résultat... A l'aide d'un module complémentaire ! Nous allons utiliser Table to CSV Exporter. Une fois le plugin activé, il suffit de vous rendre sur la page RESULTAT que nous avons créée préalablement puis de faire CTRL+P afin d'ouvrir le panneau de commande puis de commencer à saisir : export...

Sélectionnez "Table to CSV Exporter..." et validez. Un petit popup vous signale qu'un fichier .csv a été créé dans le répertoire de votre Vault. Sous votre gestionnaire de fichier, récupérez le document que vous pouvez ensuite ouvrir :

On retrouve bien les données de notre note RESULTAT.
Comme annoncé, cela fait 2 ans que j'utilise Obsidian, mais pas réellement comme un logiciel de prise de notes mais plus comme un programme d'analyse de données. J'utilise plus facilement MarkText pour prendre des notes en markdown où je prends soin d'ajouter des métadonnées. Il est ensuite plus facile de structurer toutes ces notes dans obsidian. N'hésitez pas à laisser un commentaire pour décrire vos utilisations.
Mon Avis : Je dis souvent qu'Obsidian est devenu le Wordpress de la gestion de notes. En 2 ans le nombre de plugins ou modules complémentaires n'a fait que grandir. A l'heure où j'écris cet article plus de 600 sont disponibles. Tout comme wordpress, il devient difficile et chronophage de rechercher le meilleur module pour notre besoin (Je ne parle même pas des thèmes...). J'ai ainsi vu des jeux utilisant Obsidian comme moteur, ou encore un système de programmation comme Jupyter NoteBook. Ces nombreuses options, plugins et thèmes font que chacun a une utilisation personnelle de l'outil, c'est peut-être le succès de cette solution.
0 notes
Link
#vr#virtual reality#dataview#dataview vr#interestingengineering#Andy Maggio#maggio#author: Susan Fourtané#Fourtané#march 2019#2019#Artificial Intelligence#ai#AI-driven#multi-dimensional analysis tools#financial industry#data visualization#The Glimpse Group#Virtual Reality-based workspace#HyperDesk#Morgan Stanley
0 notes
Text
How to use dataView rowfilter for searching rows in C#.Net
You can simply use SQL query statements to retrieve desired data from database server with C# and ADO.Net. But there are plenty of ways to search your localized version of data which is stored in dataSet and dataView. We already learn how to use Find and Findrow methods for searching data in Visual Studio App. This post will show how to use row filter property of DataView for sorting data rows.…
View On WordPress
#.Net#C#C DataView Filter#Database#DataView#Filter#howto#postaweek#row Filter#tutorial#Visual Basic#Windows
0 notes
Text
How to fetch data rows from a data view in C#
Data View is a representation of data table which can be used to access rows in a table. In Database programming sometimes we need to search and extract/copy rows which meet some criteria/condition. C# and .Net framework allows you to do this using rich set of objects available in Visual Studio.
In our example we have a table Groups which is used to store various accounting groups. I want to…
View On WordPress
0 notes