#Extract API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Top E-commerce Websites Scraping API | Extract API from eCommerce Website
In the world of e-commerce, data is power. Whether you're tracking market trends, monitoring competitor pricing, or keeping an eye on your supply chain, having access to real-time data is essential. This is where scraping APIs come into play. In this blog, we'll dive into the top e-commerce websites scraping APIs and explore how they can help you extract valuable data from e-commerce websites efficiently and effectively.
What is an E-commerce Website Scraping API?
An e-commerce website scraping API is a tool that allows you to extract data from e-commerce websites. This data can include product information, pricing, availability, reviews, and more. Scraping APIs can automate the process of gathering data from multiple websites, making it easier to analyze market trends and gain insights.
Why Use an E-commerce Website Scraping API?
Market Research: Understand the trends and demands in your industry by tracking data from various e-commerce websites.
Competitive Analysis: Monitor your competitors' pricing, product offerings, and customer reviews to stay ahead of the game.
Dynamic Pricing: Keep your pricing strategy agile by adjusting prices based on real-time data from other e-commerce platforms.
Product Discovery: Find new products and suppliers by exploring different e-commerce websites.
Inventory Management: Track product availability and update your inventory in real-time to avoid stockouts.
Top E-commerce Websites Scraping APIs
Scrapy: A popular open-source web crawling framework, Scrapy provides a flexible and efficient way to extract data from e-commerce websites. It supports custom spiders and pipelines for processing data.
ParseHub: ParseHub offers an easy-to-use visual scraping interface, allowing you to create scraping projects without any coding knowledge. It supports advanced features such as pagination and dynamic content handling.
Octoparse: Octoparse is a no-code scraping tool that offers a visual editor to create web scraping tasks. It supports cloud extraction, scheduling, and automated data parsing.
Diffbot: Diffbot provides advanced AI-powered scraping with pre-built APIs for product data extraction. It offers real-time data updates and can handle complex websites.
Bright Data: Bright Data (formerly Luminati Networks) offers a scraping API that supports a wide range of use cases, including e-commerce data extraction. It provides residential and data center proxies for high-quality scraping.
Extracting Data from E-commerce Websites
When using a scraping API, you can extract data from e-commerce websites such as:
Product Information: Extract product names, descriptions, prices, images, and categories.
Pricing: Monitor competitor pricing and dynamic pricing changes.
Availability: Track product availability and stock levels.
Reviews: Gather customer reviews and ratings for products.
Categories: Analyze product categories and subcategories for trends.
Best Practices for Web Scraping
Respect Website Terms of Service: Always adhere to the terms of service of the websites you are scraping to avoid legal issues.
Rate Limiting: Respect the rate limits of websites to avoid overwhelming their servers.
Rotate Proxies: Use proxy servers to avoid getting blocked and to maintain anonymity.
Data Accuracy: Validate the data you collect to ensure its accuracy and reliability.
Conclusion
E-commerce websites scraping APIs are powerful tools for gaining insights into the competitive landscape and staying ahead in the market. By leveraging these APIs, you can automate the process of gathering data and make data-driven decisions for your business. Just remember to follow best practices and respect the websites you're scraping to maintain a positive online presence.
0 notes
Text
i just went through and turned off the sharing setting on all my main/side blogs each, and here's my thoughts on the whole thing:
it's likely that anything public could have been scraped by the feckless scumbags building most ai systems. however, information regarding tumblr's data sale is rumored to include private, personal, deleted, and/or otherwise illegal data; if for whatever goddamn reason they actually contractually hold themselves to not accessing that data, then that is not nothing. (and, for example, if they are barred from accessing non-public data because of this, that is a big deal actually) (yes, i know, it's complicated. these are bullet points)
if Tumblr Corporate or one of the AI companies is running numbers on this, it's in everyone's favor to count in the "don't scrape me" pile (if for nothing else, then to support advocates on staff telling execs what a bad idea it all is)
there absolutely has to be some fuckery afoot with Tumblr being desperate for income and AIs being desperate for data they may have already scraped, which is to say i think it's in your best interests to have it on record you Do Not Consent.
corollary to fuckery being afoot, even if it comes down to just being demonstrative politically of the rejection of the way capitalism sucks down and spits out every single goddamned thing in its path, i think that the rejection is necessary morally and ethically. sometimes you just have to do something for yourself, even if no one else will see it.
exploitation and manipulation rely on weaseling their way in. despair and apathy falls in their favor. privacy can be "easy" to give up but nearly impossible to reclaim. do not consent in advance until you know what you are consenting to. we do not.
i'm sure i had other thoughts but i'll have to come back to it when i'm more coherent
#tech#tumblr#current events#plagiarism#crapitalism#poison pill blogs are probably too late if they extract pre-2021 data using the API but it would still be funny to bee movie them to death
5 notes
·
View notes
Text
How to Extract Amazon Product Prices Data with Python 3
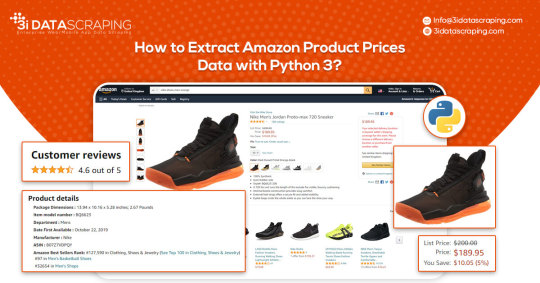
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text

"Barnswarmers"
Created in conjunction with Tom Beaton, winner of the MassBee custom comic raffle.
#beeingapis#bees#comic#honeybee#humor#beekeeping#apis#beeing#bee#beecomic#cutouts#extraction#abscond#barnswarmers
2 notes
·
View notes
Text
Kroger Grocery Data Scraping | Kroger Grocery Data Extraction

Shopping Kroger grocery online has become very common these days. At Foodspark, we scrape Kroger grocery apps data online with our Kroger grocery data scraping API as well as also convert data to appropriate informational patterns and statistics.
#food data scraping services#restaurantdataextraction#restaurant data scraping#web scraping services#grocerydatascraping#zomato api#fooddatascrapingservices#Scrape Kroger Grocery Data#Kroger Grocery Websites Apps#Kroger Grocery#Kroger Grocery data scraping company#Kroger Grocery Data#Extract Kroger Grocery Menu Data#Kroger grocery order data scraping services#Kroger Grocery Data Platforms#Kroger Grocery Apps#Mobile App Extraction of Kroger Grocery Delivery Platforms#Kroger Grocery delivery#Kroger grocery data delivery
2 notes
·
View notes
Video
youtube
ScrapingBypass Web Scraping API Bypass Cloudflare Captcha Verification
ScrapingBypass API can bypass Cloudflare Captcha verification for web scraping using Python, Java, NodeJS, and Curl. $3 for 3-day trial: https://www.scrapingbypass.com/pricing ScrapingBypass: https://scrapingbypass.com Telegram: https://t.me/CloudBypassEN
#scrapingbypass#bypass cloudflare#cloudflare bypass#web scraping api#captcha solver#web scraping#web crawler#extract data
1 note
·
View note
Text
there are potential spreadsheets everywhere for those with the eyes to see
#relevant to nothing I just looooove data and automation and processing and dashboards :)#lee speaks#adding your smile to my spreadsheet. extracting this beautiful sunny day using an api. etc etc
1 note
·
View note
Text
Why Agentic Document Extraction Is Replacing OCR for Smarter Document Automation
New Post has been published on https://thedigitalinsider.com/why-agentic-document-extraction-is-replacing-ocr-for-smarter-document-automation/
Why Agentic Document Extraction Is Replacing OCR for Smarter Document Automation

For many years, businesses have used Optical Character Recognition (OCR) to convert physical documents into digital formats, transforming the process of data entry. However, as businesses face more complex workflows, OCR’s limitations are becoming clear. It struggles to handle unstructured layouts, handwritten text, and embedded images, and it often fails to interpret the context or relationships between different parts of a document. These limitations are increasingly problematic in today’s fast-paced business environment.
Agentic Document Extraction, however, represents a significant advancement. By employing AI technologies such as Machine Learning (ML), Natural Language Processing (NLP), and visual grounding, this technology not only extracts text but also understands the structure and context of documents. With accuracy rates above 95% and processing times reduced from hours to just minutes, Agentic Document Extraction is transforming how businesses handle documents, offering a powerful solution to the challenges OCR cannot overcome.
Why OCR is No Longer Enough
For years, OCR was the preferred technology for digitizing documents, revolutionizing how data was processed. It helped automate data entry by converting printed text into machine-readable formats, streamlining workflows across many industries. However, as business processes have evolved, OCR’s limitations have become more apparent.
One of the significant challenges with OCR is its inability to handle unstructured data. In industries like healthcare, OCR often struggles with interpreting handwritten text. Prescriptions or medical records, which often have varying handwriting and inconsistent formatting, can be misinterpreted, leading to errors that may harm patient safety. Agentic Document Extraction addresses this by accurately extracting handwritten data, ensuring the information can be integrated into healthcare systems, improving patient care.
In finance, OCR’s inability to recognize relationships between different data points within documents can lead to mistakes. For example, an OCR system might extract data from an invoice without linking it to a purchase order, resulting in potential financial discrepancies. Agentic Document Extraction solves this problem by understanding the context of the document, allowing it to recognize these relationships and flag discrepancies in real-time, helping to prevent costly errors and fraud.
OCR also faces challenges when dealing with documents that require manual validation. The technology often misinterprets numbers or text, leading to manual corrections that can slow down business operations. In the legal sector, OCR may misinterpret legal terms or miss annotations, which requires lawyers to intervene manually. Agentic Document Extraction removes this step, offering precise interpretations of legal language and preserving the original structure, making it a more reliable tool for legal professionals.
A distinguishing feature of Agentic Document Extraction is the use of advanced AI, which goes beyond simple text recognition. It understands the document’s layout and context, enabling it to identify and preserve tables, forms, and flowcharts while accurately extracting data. This is particularly useful in industries like e-commerce, where product catalogues have diverse layouts. Agentic Document Extraction automatically processes these complex formats, extracting product details like names, prices, and descriptions while ensuring proper alignment.
Another prominent feature of Agentic Document Extraction is its use of visual grounding, which helps identify the exact location of data within a document. For example, when processing an invoice, the system not only extracts the invoice number but also highlights its location on the page, ensuring the data is captured accurately in context. This feature is particularly valuable in industries like logistics, where large volumes of shipping invoices and customs documents are processed. Agentic Document Extraction improves accuracy by capturing critical information like tracking numbers and delivery addresses, reducing errors and improving efficiency.
Finally, Agentic Document Extraction’s ability to adapt to new document formats is another significant advantage over OCR. While OCR systems require manual reprogramming when new document types or layouts arise, Agentic Document Extraction learns from each new document it processes. This adaptability is especially valuable in industries like insurance, where claim forms and policy documents vary from one insurer to another. Agentic Document Extraction can process a wide range of document formats without needing to adjust the system, making it highly scalable and efficient for businesses that deal with diverse document types.
The Technology Behind Agentic Document Extraction
Agentic Document Extraction brings together several advanced technologies to address the limitations of traditional OCR, offering a more powerful way to process and understand documents. It uses deep learning, NLP, spatial computing, and system integration to extract meaningful data accurately and efficiently.
At the core of Agentic Document Extraction are deep learning models trained on large amounts of data from both structured and unstructured documents. These models use Convolutional Neural Networks (CNNs) to analyze document images, detecting essential elements like text, tables, and signatures at the pixel level. Architectures like ResNet-50 and EfficientNet help the system identify key features in the document.
Additionally, Agentic Document Extraction employs transformer-based models like LayoutLM and DocFormer, which combine visual, textual, and positional information to understand how different elements of a document relate to each other. For example, it can connect a table header to the data it represents. Another powerful feature of Agentic Document Extraction is few-shot learning. It allows the system to adapt to new document types with minimal data, speeding up its deployment in specialized cases.
The NLP capabilities of Agentic Document Extraction go beyond simple text extraction. It uses advanced models for Named Entity Recognition (NER), such as BERT, to identify essential data points like invoice numbers or medical codes. Agentic Document Extraction can also resolve ambiguous terms in a document, linking them to the proper references, even when the text is unclear. This makes it especially useful for industries like healthcare or finance, where precision is critical. In financial documents, Agentic Document Extraction can accurately link fields like “total_amount” to corresponding line items, ensuring consistency in calculations.
Another critical aspect of Agentic Document Extraction is its use of spatial computing. Unlike OCR, which treats documents as a linear sequence of text, Agentic Document Extraction understands documents as structured 2D layouts. It uses computer vision tools like OpenCV and Mask R-CNN to detect tables, forms, and multi-column text. Agentic Document Extraction improves the accuracy of traditional OCR by correcting issues such as skewed perspectives and overlapping text.
It also employs Graph Neural Networks (GNNs) to understand how different elements in a document are related in space, such as a “total” value positioned below a table. This spatial reasoning ensures that the structure of documents is preserved, which is essential for tasks like financial reconciliation. Agentic Document Extraction also stores the extracted data with coordinates, ensuring transparency and traceability back to the original document.
For businesses looking to integrate Agentic Document Extraction into their workflows, the system offers robust end-to-end automation. Documents are ingested through REST APIs or email parsers and stored in cloud-based systems like AWS S3. Once ingested, microservices, managed by platforms like Kubernetes, take care of processing the data using OCR, NLP, and validation modules in parallel. Validation is handled both by rule-based checks (like matching invoice totals) and machine learning algorithms that detect anomalies in the data. After extraction and validation, the data is synced with other business tools like ERP systems (SAP, NetSuite) or databases (PostgreSQL), ensuring that it is readily available for use.
By combining these technologies, Agentic Document Extraction turns static documents into dynamic, actionable data. It moves beyond the limitations of traditional OCR, offering businesses a smarter, faster, and more accurate solution for document processing. This makes it a valuable tool across industries, enabling greater efficiency and new opportunities for automation.
5 Ways Agentic Document Extraction Outperforms OCR
While OCR is effective for basic document scanning, Agentic Document Extraction offers several advantages that make it a more suitable option for businesses looking to automate document processing and improve accuracy. Here’s how it excels:
Accuracy in Complex Documents
Agentic Document Extraction handles complex documents like those containing tables, charts, and handwritten signatures far better than OCR. It reduces errors by up to 70%, making it ideal for industries like healthcare, where documents often include handwritten notes and complex layouts. For example, medical records that contain varying handwriting, tables, and images can be accurately processed, ensuring critical information such as patient diagnoses and histories are correctly extracted, something OCR might struggle with.
Context-Aware Insights
Unlike OCR, which extracts text, Agentic Document Extraction can analyze the context and relationships within a document. For instance, in banking, it can automatically flag unusual transactions when processing account statements, speeding up fraud detection. By understanding the relationships between different data points, Agentic Document Extraction allows businesses to make more informed decisions faster, providing a level of intelligence that traditional OCR cannot match.
Touchless Automation
OCR often requires manual validation to correct errors, slowing down workflows. Agentic Document Extraction, on the other hand, automates this process by applying validation rules such as “invoice totals must match line items.” This enables businesses to achieve efficient touchless processing. For example, in retail, invoices can be automatically validated without human intervention, ensuring that the amounts on invoices match purchase orders and deliveries, reducing errors and saving significant time.
Scalability
Traditional OCR systems face challenges when processing large volumes of documents, especially if the documents have varying formats. Agentic Document Extraction easily scales to handle thousands or even millions of documents daily, making it perfect for industries with dynamic data. In e-commerce, where product catalogs constantly change, or in healthcare, where decades of patient records need to be digitized, Agentic Document Extraction ensures that even high-volume, varied documents are processed efficiently.
Future-Proof Integration
Agentic Document Extraction integrates smoothly with other tools to share real-time data across platforms. This is especially valuable in fast-paced industries like logistics, where quick access to updated shipping details can make a significant difference. By connecting with other systems, Agentic Document Extraction ensures that critical data flows through the proper channels at the right time, improving operational efficiency.
Challenges and Considerations in Implementing Agentic Document Extraction
Agentic Document Extraction is changing the way businesses handle documents, but there are important factors to consider before adopting it. One challenge is working with low-quality documents, like blurry scans or damaged text. Even advanced AI can have trouble extracting data from faded or distorted content. This is primarily a concern in sectors like healthcare, where handwritten or old records are common. However, recent improvements in image preprocessing tools, like deskewing and binarization, are helping address these issues. Using tools like OpenCV and Tesseract OCR can improve the quality of scanned documents, boosting accuracy significantly.
Another consideration is the balance between cost and return on investment. The initial cost of Agentic Document Extraction can be high, especially for small businesses. However, the long-term benefits are significant. Companies using Agentic Document Extraction often see processing time reduced by 60-85%, and error rates drop by 30-50%. This leads to a typical payback period of 6 to 12 months. As technology advances, cloud-based Agentic Document Extraction solutions are becoming more affordable, with flexible pricing options that make it accessible to small and medium-sized businesses.
Looking ahead, Agentic Document Extraction is evolving quickly. New features, like predictive extraction, allow systems to anticipate data needs. For example, it can automatically extract client addresses from recurring invoices or highlight important contract dates. Generative AI is also being integrated, allowing Agentic Document Extraction to not only extract data but also generate summaries or populate CRM systems with insights.
For businesses considering Agentic Document Extraction, it is vital to look for solutions that offer custom validation rules and transparent audit trails. This ensures compliance and trust in the extraction process.
The Bottom Line
In conclusion, Agentic Document Extraction is transforming document processing by offering higher accuracy, faster processing, and better data handling compared to traditional OCR. While it comes with challenges, such as managing low-quality inputs and initial investment costs, the long-term benefits, such as improved efficiency and reduced errors, make it a valuable tool for businesses.
As technology continues to evolve, the future of document processing looks bright with advancements like predictive extraction and generative AI. Businesses adopting Agentic Document Extraction can expect significant improvements in how they manage critical documents, ultimately leading to greater productivity and success.
#Agentic AI#Agentic AI applications#Agentic AI in information retrieval#Agentic AI in research#agentic document extraction#ai#Algorithms#anomalies#APIs#Artificial Intelligence#audit#automation#AWS#banking#BERT#Business#business environment#challenge#change#character recognition#charts#Cloud#CNN#Commerce#Companies#compliance#computer#Computer vision#computing#content
0 notes
Text
We scraped thousands of posts from popular subreddits to uncover real opinions, pros, and cons of moving to New York. Here's what the data tells us.
0 notes
Text
Efficient Data Extraction with LinkedIn Data Scraping Tools
LinkedIn data holds immense potential for businesses. A LinkedIn data extraction tool can help you harness this potential by extracting relevant data efficiently. This data can then be used to enhance various business functions. Additionally, automated tools can reduce manual effort and increase accuracy.
linkedin data extraction tool
0 notes
Text
Google Flight API - Easy Real-Time Data Extraction

In today's fast-paced travel industry, the ability to access real-time flight data is essential for businesses and travelers alike. Whether you’re a travel agent, an airline, a developer, or simply a tech enthusiast, Google Flight API provides a powerful tool to obtain real-time flight information. This blog will delve into how you can harness the Google Flight API for easy real-time data extraction, highlighting its benefits, applications, and a step-by-step guide to get you started.
What is Google Flight API?
Google Flight API is an interface that allows developers to access and manipulate flight data provided by Google Flights. This includes information about flight schedules, prices, availability, and more. The API enables seamless integration of this data into applications, websites, and other platforms, allowing for real-time updates and a more dynamic user experience.
Benefits of Using Google Flight API
Real-Time Data: The API provides up-to-the-minute information on flight schedules, delays, and cancellations. This is crucial for travel agencies and airlines to keep their customers informed and to make timely decisions.
Wide Coverage: Google Flights covers a vast number of airlines and routes worldwide. This extensive database ensures that users have access to comprehensive flight information.
Cost-Effective: Using the API can be more cost-effective than purchasing data from third-party vendors. It reduces the need for manual data collection and entry, saving time and resources.
Customizable: The API allows for customization to fit the specific needs of your application. You can filter results based on parameters such as price range, airlines, layovers, and more.
Enhanced User Experience: Integrating real-time flight data into your platform can significantly enhance the user experience. Users can search for flights, compare prices, and make bookings without leaving your site or app.
Applications of Google Flight API
Travel Booking Platforms: Websites and apps that facilitate flight bookings can use the API to display the latest flight options, prices, and availability to their users.
Travel Agencies: Agencies can automate the process of fetching flight data, providing clients with real-time information and recommendations.
Airlines: Airlines can use the API to update their own systems and customer interfaces with the latest flight schedules and status updates.
Travel Planning Tools: Apps that help users plan their trips can integrate the API to provide accurate flight information, helping users to make informed decisions.
Data Analysis: Researchers and analysts can use the API to gather flight data for various analytical purposes, such as studying travel trends, pricing strategies, and more.
Getting Started with Google Flight API
Accessing the API: Currently, Google Flight API is not publicly available as a standalone service. However, there are ways to access similar data through other means, such as third-party APIs or scraping Google Flights with web scraping tools. Alternatively, you can explore Google's QPX Express API, which provides flight search capabilities, though it has limited availability.
API Key: If you’re using an official API or a third-party service, you’ll need to obtain an API key. This key authenticates your requests and tracks your usage.
Setting Up Your Environment: Ensure you have a development environment set up with the necessary libraries and tools for making HTTP requests and handling JSON data. Popular choices include Python with libraries like requests and json, or JavaScript with axios and fetch.
Making Requests: Use the API documentation to understand the endpoints and parameters available. Construct your HTTP requests to fetch the data you need. For example, a typical request might look like this in Python:pythonCopy codeimport requests url = "https://api.example.com/flights" params = { "origin": "JFK", "destination": "LAX", "departure_date": "2024-07-20" } headers = { "Authorization": "Bearer YOUR_API_KEY" } response = requests.get(url, headers=headers, params=params) data = response.json() print(data)
Parsing the Data: Once you receive the response, parse the JSON data to extract the information you need. This could include flight numbers, departure and arrival times, prices, and more.
Integrating the Data: Integrate the parsed data into your application or website. This might involve updating the UI with the latest flight information, storing data in a database, or performing additional processing.
Conclusion
Google Flight API, or similar services, offers a robust solution for accessing real-time flight data. Whether you’re building a travel booking platform, enhancing an airline’s digital presence, or developing a travel planning tool, the ability to fetch and display accurate flight information is invaluable. By understanding the benefits, applications, and steps to get started, you can leverage this powerful tool to create more dynamic and user-friendly experiences in the travel industry.
0 notes
Text
RealdataAPI is the one-stop solution for Web Scraper, Crawler, & Web Scraping APIs for Data Extraction in countries like USA, UK, UAE, Germany, Australia, etc.
1 note
·
View note
Text
How to Build a Web Scraping API Looking for an easy guide to scraping web data? Learn how to create a Web Scraping API using Java, Spring Boot, and Jsoup! Perfect for developers at any level.
0 notes
Text
Learn the art of web scraping with Python! This beginner-friendly guide covers the basics, ethics, legal considerations, and a step-by-step tutorial with code examples. Uncover valuable data and become a digital explorer.
#API#BeautifulSoup#Beginner’s Guide#Data Extraction#Data Science#Ethical Hacking#Pandas#Python#Python Programming#Requests#Tutorial#Web Crawler#web scraping
1 note
·
View note
Text
#AWS#Amazon Textract#AI#Machine Learning#API#AWS SDK#Extraction#Detection#Optical Character Recognition#OCR#Textract
0 notes
Text
OCR technology has revolutionized data collection processes, providing many benefits to various industries. By harnessing the power of OCR with AI, businesses can unlock valuable insights from unstructured data, increase operational efficiency, and gain a competitive edge in today's digital landscape. At Globose Technology Solutions, we are committed to leading innovative solutions that empower businesses to thrive in the age of AI.
#OCR Data Collection#Data Collection Compnay#Data Collection#image to text api#pdf ocr ai#ocr and data extraction#data collection company#datasets#ai#machine learning for ai#machine learning
0 notes