#Web Scraping APIs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
RealdataAPI is the one-stop solution for Web Scraper, Crawler, & Web Scraping APIs for Data Extraction in countries like USA, UK, UAE, Germany, Australia, etc.
1 note
·
View note
Text
When in doubt, scrape it out!
Come find me on TikTok!
#greek tumblr#greek posts#ελληνικο ποστ#ελληνικά#greek post#greek#ελληνικο tumblr#ελληνικο ταμπλρ#ελληνικα#python#python language#python programming#python ninja#python for web scraping#web scraping#web scraping api#python is fun#python is life
2 notes
·
View notes
Text
How to Extract Amazon Product Prices Data with Python 3
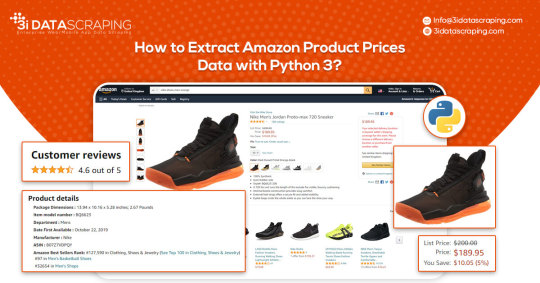
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Kroger Grocery Data Scraping | Kroger Grocery Data Extraction

Shopping Kroger grocery online has become very common these days. At Foodspark, we scrape Kroger grocery apps data online with our Kroger grocery data scraping API as well as also convert data to appropriate informational patterns and statistics.
#food data scraping services#restaurantdataextraction#restaurant data scraping#web scraping services#grocerydatascraping#zomato api#fooddatascrapingservices#Scrape Kroger Grocery Data#Kroger Grocery Websites Apps#Kroger Grocery#Kroger Grocery data scraping company#Kroger Grocery Data#Extract Kroger Grocery Menu Data#Kroger grocery order data scraping services#Kroger Grocery Data Platforms#Kroger Grocery Apps#Mobile App Extraction of Kroger Grocery Delivery Platforms#Kroger Grocery delivery#Kroger grocery data delivery
2 notes
·
View notes
Video
youtube
Zenrows Alternative | ScrapingBypass Web Scraping API Bypass Cloudflare
Are you looking for a Zenrows alternative?
Zenrows is a web scraping API that can bypass Cloudflare, Captcha, and all anti-bot verification. ScrapingBypass is so similar to Zenrows, so you can use it to extract data easily.
👉 Go to ScrapingBypass website: https://www.scrapingbypass.com
#zenrows#zenrows alternative#web scraping#web scraping api#bypass cloudflare#cloudflare bypass#scrapingbypass
2 notes
·
View notes
Video
youtube
ScrapingBypass Web Scraping API Bypass Cloudflare Captcha Verification
ScrapingBypass API can bypass Cloudflare Captcha verification for web scraping using Python, Java, NodeJS, and Curl. $3 for 3-day trial: https://www.scrapingbypass.com/pricing ScrapingBypass: https://scrapingbypass.com Telegram: https://t.me/CloudBypassEN
#scrapingbypass#bypass cloudflare#cloudflare bypass#web scraping api#captcha solver#web scraping#web crawler#extract data
1 note
·
View note
Text
youtube
#web scraping#web scraping api#scrapingdog#instagram scraper#instagram scraper api#instagram scraping#Youtube
0 notes
Text
Custom Data API - Web Scraping API
Get real-time custom data API to automate web data scraping processes, and enhance data integration. Our web scraping APIs collets key data from data sources and deliver in quick time. Access real-time data specific to your needs with our custom APIs.
Know more about Custom Data API
0 notes
Text

E-commerce Web Scraping API for Accurate Product & Pricing Insights
Access structured e-commerce data efficiently with a robust web scraping API for online stores, marketplaces, and retail platforms. This API helps collect data on product listings, prices, reviews, stock availability, and seller details from top e-commerce sites. Ideal for businesses monitoring competitors, following trends, or managing records, it provides consistent and correct results. Built to scale, the service supports high-volume requests and delivers results in easy-to-integrate formats like JSON or CSV. Whether you need data from Amazon, eBay, or Walmart. iWeb Scraping provides unique e-commerce data scraping services. Learn more about the service components and pricing by visiting iWebScraping E-commerce Data Services.
0 notes
Text
Data Scraping Made Simple: What It Really Means
Data Scraping Made Simple: What It Really Means
In the digital world, data scraping is a powerful way to collect information from websites automatically. But what exactly does that mean—and why is it important?
Let’s break it down in simple terms.
What Is Data Scraping?
Data scraping (also called web scraping) is the process of using bots or scripts to extract data from websites. Instead of copying and pasting information manually, scraping tools do the job automatically—much faster and more efficiently.
You can scrape product prices, news headlines, job listings, real estate data, weather reports, and more.
Imagine visiting a website with hundreds of items. Now imagine a tool that can read all that content and save it in a spreadsheet in seconds. That’s what data scraping does.
Why Is It So Useful?
Businesses, researchers, and marketers use data scraping to:
Track competitors' prices
Monitor customer reviews
Gather contact info for leads
Collect news for trend analysis
Keep up with changing market data
In short, data scraping helps people get useful information without wasting time.
Is Data Scraping Legal?
It depends. Public data (like product prices or news articles) is usually okay to scrape, but private or copyrighted content is not. Always check a website’s terms of service before scraping it.
Tools for Data Scraping
There are many tools that make data scraping easy:
Beautiful Soup (for Python developers)
Octoparse (no coding needed)
Scrapy (for advanced scraping tasks)
SERPHouse APIs (for SEO and search engine data)
Some are code-based, others are point-and-click tools. Choose what suits your need and skill level.
Final Thoughts
What is data scraping? It’s the smart way to extract website content for business, research, or insights. With the right tools, it saves time, increases productivity, and opens up access to valuable online data.
Just remember: scrape responsibly.
#serphouse#google serp api#serp scraping api#google search api#seo#api#google#bing#data scraping#web scraping
0 notes
Text
How to Scrape Data from Chinese Sellers on MercadoLibre MX FBM
Introduction
The eCommerce industry in Latin America has seen massive growth, with MercadoLibre Mexico emerging as one of the largest online marketplaces. Among the various sellers operating on the platform, Chinese Sellers on MercadoLibre Mexico have gained a significant market share due to their competitive pricing, diverse product offerings, and strategic use of FBM (Fulfillment by Merchant). These sellers bypass local fulfillment centers, shipping products directly from China, allowing them to maintain lower costs and high-profit margins.
With this increasing competition, businesses need Web Scraping MercadoLibre Mexico Sellers to track seller data, pricing trends, and inventory insights. Extracting real-time marketplace data helps brands, retailers, and competitors stay ahead by understanding product availability, discount strategies, and customer preferences.
This blog explores how to Scrape Data from Chinese Sellers on MercadoLibre, why businesses should monitor seller trends, and how MercadoLibre FBM Web Scraping can help in gathering actionable insights.
Growing Presence of Chinese Sellers on MercadoLibre Mexico
The eCommerce landscape in Latin America has witnessed a surge in international sellers, with Chinese vendors dominating a significant portion of MercadoLibre Mexico. Due to the platform’s vast customer base and cross-border selling opportunities, more Chinese businesses are leveraging MercadoLibre FBM (Fulfillment by Merchant) to ship products directly from their warehouses. This strategy helps them avoid local fulfillment costs and maintain competitive pricing. According to 2025 statistics, over 40% of new electronics and gadget listings on MercadoLibre MX come from Chinese sellers. Their competitive pricing, fast shipping partnerships, and broad product variety have made them major players in Mexico’s online retail market

Importance of MercadoLibre FBM Web Scraping for Tracking Seller Data
With the rising competition in the Latin American eCommerce market, businesses must leverage MercadoLibre FBM Web Scraping to track Chinese seller activities, pricing trends, and inventory strategies. Web Scraping MercadoLibre Mexico Sellers allows companies to extract critical insights such as:
Product Listings – Track new product additions and category trends.
Pricing Strategies – Analyze price fluctuations and discount offers.
Seller Ratings & Feedback – Understand customer sentiment and service quality.
Shipping & Delivery – Monitor estimated delivery times and logistics efficiency.
By implementing Scrape Data from Chinese Sellers on MercadoLibre, businesses can make data-backed decisions, optimize pricing strategies, and enhance their marketplace performance.

How Businesses Can Benefit from Extracting Accurate and Real-Time Marketplace Insights?
By using Extract MercadoLibre Seller Information, businesses can unlock crucial insights to improve sales strategies and outperform competitors. Key benefits include:
A. Competitive Pricing Strategies
Track Chinese seller pricing and adjust prices accordingly.
Identify seasonal discount patterns and promotional campaigns.
Use Track Chinese Seller Prices on MercadoLibre to maintain a competitive edge.
B. Trend Analysis & Market Research
Discover top-selling categories and emerging trends.
Analyze product demand based on customer preferences.
Scrape MercadoLibre Product Listings to monitor newly launched items.
C. Inventory & Stock Optimization
Monitor product availability and restocking patterns.
Identify potential stock shortages and supply chain issues.
Ensure optimal inventory levels to meet market demand.

How to Scrape Data from Chinese Sellers on MercadoLibre?
Businesses can leverage Web Scraping for Cross-Border eCommerce Data to gain critical marketplace insights and stay competitive. By extracting data from global marketplaces, companies can track pricing trends, monitor competitors, and optimize their sales strategy.
Key Steps in Web Scraping for eCommerce Insights
Identifying Targeted Seller Data – Businesses can collect essential details such as product names, prices, ratings, and reviews from various online platforms. This data helps in understanding competitor pricing strategies and customer preferences.
Setting Up Automated Scrapers – Utilizing advanced web scraping tools, businesses can efficiently extract structured data without manual effort. Automation ensures consistency and scalability, making data collection seamless.
Filtering & Analyzing Data – Once data is extracted, it is essential to organize and analyze it for competitor benchmarking and pricing analysis. This helps businesses adjust their pricing strategies and enhance product offerings based on real market trends.
Monitoring Real-Time Updates – The eCommerce landscape is dynamic, requiring businesses to stay updated. Automated scrapers can be set to perform daily or weekly data extraction to track changing trends, stock availability, and price fluctuations.
MercadoLibre FBM Web Scraping for Enhanced Market Intelligence
For businesses targeting Latin American markets, MercadoLibre FBM Web Scraping is a game-changer. By automating data collection from MercadoLibre, companies can gain real-time insights into competitor pricing, top-selling products, and customer sentiment. This ensures accurate and up-to-date marketplace intelligence, enabling data-driven decision-making.

Challenges in Scraping MercadoLibre & How to Overcome Them
While Extracting MercadoLibre Seller Information offers valuable insights, businesses face challenges such as:
CAPTCHAs & Anti-Scraping Mechanisms – Implement Web Scraping API Services for seamless data extraction.
Large Data Volumes – Use Automated Data Extraction from MercadoLibre for scalability.
Dynamic Pricing & Real-Time Updates – Ensure frequent data collection to track price fluctuations accurately.

How Actowiz Solutions Can Help?
Actowiz Solutions specializes in MercadoLibre Seller Analytics with Web Scraping, providing:
Custom Web Scraping Solutions – Tailored tools for tracking seller data.
Real-Time Price & Inventory Monitoring – Keep up with market changes.
Competitor Benchmarking – Compare pricing strategies and product listings.
Scalable & Automated Scraping – Extract large datasets without restrictions.
Our expertise in Scrape Data from Chinese Sellers on MercadoLibre ensures accurate, real-time insights that drive business growth.
Conclusion
The increasing presence of Chinese Sellers on MercadoLibre Mexico presents both opportunities and challenges for businesses. To stay competitive, companies must leverage Web Scraping MercadoLibre Mexico Sellers for data-driven insights on pricing, inventory, and seller strategies. By implementing MercadoLibre FBM Web Scraping, businesses can optimize pricing, track competitors, and enhance their overall marketplace performance.
Ready to extract real-time data from MercadoLibre? Contact Actowiz Solutions for powerful Web Scraping Services today!
Learn More
#Web Scraping MercadoLibre#Web Scraping to track Chinese seller#web scraping tools#Web Scraping API Services
0 notes
Text
Tapping into Fresh Insights: Kroger Grocery Data Scraping
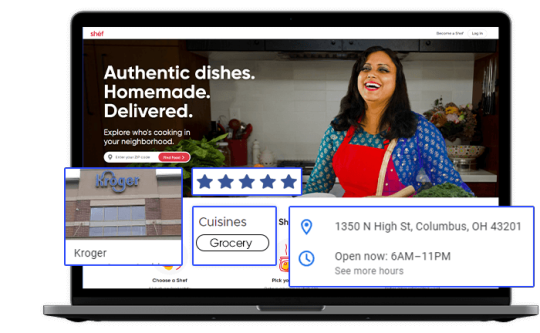
In today's data-driven world, the retail grocery industry is no exception when it comes to leveraging data for strategic decision-making. Kroger, one of the largest supermarket chains in the United States, offers a wealth of valuable data related to grocery products, pricing, customer preferences, and more. Extracting and harnessing this data through Kroger grocery data scraping can provide businesses and individuals with a competitive edge and valuable insights. This article explores the significance of grocery data extraction from Kroger, its benefits, and the methodologies involved.
The Power of Kroger Grocery Data
Kroger's extensive presence in the grocery market, both online and in physical stores, positions it as a significant source of data in the industry. This data is invaluable for a variety of stakeholders:
Kroger: The company can gain insights into customer buying patterns, product popularity, inventory management, and pricing strategies. This information empowers Kroger to optimize its product offerings and enhance the shopping experience.
Grocery Brands: Food manufacturers and brands can use Kroger's data to track product performance, assess market trends, and make informed decisions about product development and marketing strategies.
Consumers: Shoppers can benefit from Kroger's data by accessing information on product availability, pricing, and customer reviews, aiding in making informed purchasing decisions.
Benefits of Grocery Data Extraction from Kroger
Market Understanding: Extracted grocery data provides a deep understanding of the grocery retail market. Businesses can identify trends, competition, and areas for growth or diversification.
Product Optimization: Kroger and other retailers can optimize their product offerings by analyzing customer preferences, demand patterns, and pricing strategies. This data helps enhance inventory management and product selection.
Pricing Strategies: Monitoring pricing data from Kroger allows businesses to adjust their pricing strategies in response to market dynamics and competitor moves.
Inventory Management: Kroger grocery data extraction aids in managing inventory effectively, reducing waste, and improving supply chain operations.
Methodologies for Grocery Data Extraction from Kroger
To extract grocery data from Kroger, individuals and businesses can follow these methodologies:
Authorization: Ensure compliance with Kroger's terms of service and legal regulations. Authorization may be required for data extraction activities, and respecting privacy and copyright laws is essential.
Data Sources: Identify the specific data sources you wish to extract. Kroger's data encompasses product listings, pricing, customer reviews, and more.
Web Scraping Tools: Utilize web scraping tools, libraries, or custom scripts to extract data from Kroger's website. Common tools include Python libraries like BeautifulSoup and Scrapy.
Data Cleansing: Cleanse and structure the scraped data to make it usable for analysis. This may involve removing HTML tags, formatting data, and handling missing or inconsistent information.
Data Storage: Determine where and how to store the scraped data. Options include databases, spreadsheets, or cloud-based storage.
Data Analysis: Leverage data analysis tools and techniques to derive actionable insights from the scraped data. Visualization tools can help present findings effectively.
Ethical and Legal Compliance: Scrutinize ethical and legal considerations, including data privacy and copyright. Engage in responsible data extraction that aligns with ethical standards and regulations.
Scraping Frequency: Exercise caution regarding the frequency of scraping activities to prevent overloading Kroger's servers or causing disruptions.
Conclusion
Kroger grocery data scraping opens the door to fresh insights for businesses, brands, and consumers in the grocery retail industry. By harnessing Kroger's data, retailers can optimize their product offerings and pricing strategies, while consumers can make more informed shopping decisions. However, it is crucial to prioritize ethical and legal considerations, including compliance with Kroger's terms of service and data privacy regulations. In the dynamic landscape of grocery retail, data is the key to unlocking opportunities and staying competitive. Grocery data extraction from Kroger promises to deliver fresh perspectives and strategic advantages in this ever-evolving industry.
#grocerydatascraping#restaurant data scraping#food data scraping services#food data scraping#fooddatascrapingservices#zomato api#web scraping services#grocerydatascrapingapi#restaurantdataextraction
4 notes
·
View notes
Text
Enhance Your Data Scraping Speed with Powerful API Proxies
Web data scraping has become an important means for enterprises to obtain market intelligence, analyze user behavior and optimize product strategies. However, with the increasing complexity of the network environment, the anti-crawler mechanism of the target website has become more and more stringent, making data scraping more and more difficult. In order to effectively meet this challenge, API proxy has become a key tool to improve the efficiency of web data crawling with its unique advantages.
1. Basic concepts of API proxy
API proxy, that is, application programming interface proxy, is a technology that forwards and processes network requests through a proxy server. It allows crawlers to use the IP address of the proxy server instead of the real IP when accessing the target website, thereby effectively hiding the identity of the crawler and reducing the risk of being blocked.
2. The principle of API proxy to improve scraping efficiency
IP rotation and anonymity: API proxy usually provides a large number of proxy IP address pools, and crawlers can use these IP addresses in turn to make requests to avoid a single IP being blocked due to frequent access. At the same time, the anonymity of the proxy IP also protects the true identity of the crawler, making it more difficult to be identified by the target website.
Request distribution and load balancing: Through API proxy, a large number of crawling requests can be distributed to multiple proxy servers to achieve load balancing and avoid the performance degradation of a single server due to too many requests. This distribution mechanism not only improves the crawling efficiency, but also ensures the stability of crawling.
Bypass restrictions and access acceleration: Some target websites may restrict access from specific regions or specific IP segments. Using API proxy can bypass these restrictions, allowing crawlers to access and crawl data smoothly. At the same time, proxy servers are usually deployed in multiple nodes around the world. By selecting the nearest node for access, latency can be significantly reduced and crawling speed can be increased.
3. How to improve scraping efficiency through API proxy
Choose a suitable API proxy service: First, you need to choose a stable and reliable API proxy service provider. Consider factors such as the number, quality, distribution range and service price of its proxy IPs, and choose the proxy service that best suits your scraping needs.
Optimize crawler program: Integrate API proxy function in the crawler program and configure it accordingly according to the characteristics of the proxy service. For example, set the rotation strategy of the proxy IP, customize the request header, and the exception handling mechanism. Ensure that the crawler can scrape efficiently and stably through the proxy server.
Reasonably control the scraping frequency: Although API proxy can reduce the risk of being banned, overly frequent scraping may still alert the target website. Therefore, it is necessary to reasonably control the scraping frequency according to the anti-crawler mechanism of the target website to avoid triggering alarms.
Monitoring and adjustment: During the scraping process, continuously monitor the scraping efficiency and the use of the proxy IP. Once an abnormality or a decrease in efficiency is found, adjust the scraping strategy or change the proxy IP in time to ensure the smooth progress of the scraping task.
Utilize multi-threading and asynchronous requests: Implementing multi-threading or asynchronous requests in the crawler program can handle multiple scraping tasks at the same time, further improving the scraping efficiency. However, it should be noted that multi-threading and asynchronous requests will increase the pressure on the proxy server, so it is necessary to ensure that the performance and stability of the proxy service can support this high-concurrency scraping demand.
Conclusion
Improving the efficiency of web data scraping through API proxy is a systematic project, which requires comprehensive consideration of multiple aspects such as the selection of proxy services, the optimization of crawler programs, the control of scraping frequency, and monitoring and adjustment. Only by combining these factors organically can we give full play to the advantages of API proxy and achieve efficient and stable web data scraping. With the continuous changes in the network environment and the continuous advancement of technology, the application prospects of API proxy in web data scraping will be broader.
0 notes
Text
Web scraping API

A web scraping API is a tool that allows businesses to automate the process of extracting data from websites using a simple, programmable interface. These APIs enable developers to access and scrape large volumes of data from various online sources without worrying about complex coding or infrastructure. By offering features like proxy rotation, CAPTCHA solving, data parsing, and real-time extraction, a web scraping API helps businesses gather structured data for market research, competitive analysis, price monitoring, and more. With scalability, flexibility, and ease of use, web scraping APIs simplify the data collection process and provide valuable insights quickly.
youtube
0 notes
Text
4 Best Proxycurl Alternatives for LinkedIn Data Scraping
Explore top-rated alternatives to Proxycurl for extracting LinkedIn profile and company data at scale. Ideal for recruiters, marketers, and SaaS builders.
0 notes