#Find the location of data and log files of the databases within a SQL Server instance
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
ORACLE APEX 18.2 DOWNLOAD

Oracle APEX 18.2: Unlocking Low-Code Development (A Download Guide)
Oracle Application Express (APEX) is a powerful, low-code development platform within the Oracle Database. It’s known for creating scalable, secure, and visually appealing web applications with minimal coding effort. While version 18.2 is an older release, it remains relevant for those working with legacy systems or needing specific features from that era. Let’s explore how to download and get started with Oracle APEX 18.2.
Prerequisites
Before you begin your APEX 18.2 adventure, ensure you have these in place:
Oracle Database: Oracle APEX runs within an Oracle Database. You’ll need version 11gR2 or later.
Supported Web Browser: Modern browsers like Chrome, Firefox, or Edge provide the best APEX experience.
Installing Oracle APEX 18.2
The detailed installation process is more involved. Here’s the basic flow:
Extract the Zip File: Unzip the downloaded file to a convenient location on your database server.
Run SQL*Plus: Connect to your Oracle Database as a user with administrative privileges (like SYS).
Execute the Installation Script: Navigate to the extracted folder and run the apexins.sql script. This script will install all the necessary components into your database.
Configure Oracle REST Data Services (ORDS): Instructions for setting up ORDS can be found on the Oracle APEX documentation website (https://docs.oracle.com/database/apex-18.2)
Accessing Your APEX Workspace
Once the installation is complete, you can access your APEX environment:
Determine the URL: The URL format will typically be http://hostname:port/ords/. Replace ‘hostname’ and ‘port’ with the relevant values for your database setup.
Workspace Login: Log in using the ‘ADMIN’ account and the password you defined during installation.
Congratulations! You’ve got Oracle APEX 18.2 up and running.
Important Considerations
Legacy Version: Oracle APEX has evolved significantly. Newer versions have substantial improvements to features, interface, and security. Use 18.2 only if it’s a strict requirement.
Documentation: Thorough installation instructions and helpful resources are available online in the Oracle APEX 18.2 documentation (https://docs.oracle.com/database/apex-18.2).
Let the Low-Code Journey Begin
With Oracle APEX 18.2 at your fingertips, you can embark on rapid web application development. Explore pre-built components, templates, and powerful features to turn your ideas into tangible web forms.
youtube
You can find more information about Oracle Apex in this Oracle Apex Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Oracle Apex Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Oracle Apex here – Oarcle Apex Blogs
You can check out our Best In Class Oracle Apex Details here – Oracle Apex Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
DOWNLOAD ORACLE APEX 22.2

Unlock Low-Code Development Power: Download Oracle APEX 22.2
Oracle Application Express (APEX) is a robust, low-code development framework that lets you rapidly build sophisticated and scalable web applications. Version 22.2 brings a range of exciting improvements and features to enhance your development experience. Let’s learn how to download and start with Oracle APEX 22.2.
Prerequisites
Before diving in, ensure you have the following in place:
Oracle Database: APEX runs within an Oracle Database, so you’ll need a compatible version. Oracle Database 11g Release 2 or later versions are supported. Consult the documentation for the latest compatibility matrix.
Web Server: Oracle REST Data Services (ORDS) or the embedded PL/SQL gateway are common choices for serving your APEX applications.
Installation
The installation process involves the following general steps:
Unzip the Package: Extract the downloaded zip file to a convenient location on your system.
Run SQL*Plus: Connect to your Oracle Database as a user with SYSDBA or SYSASM privileges.
Execute the Installation Script: Navigate to the unzipped apex directory and run the apexins.sql script from SQL*Plus. Follow the on-screen prompts.
Install Images: Run the apxldimg.sql script from the same directory, again using SQL*Plus.
Accessing Your APEX Instance
Once installed, you can access your APEX environment as follows:
APEX Administration Services: To manage your APEX instance, its workspaces, and users, use the Administration Services interface. The URL typically looks like this:
http://hostname:port/ords/apex_admin
APEX Workspace Login: To start developing applications, log in to your designated APEX workspace. The URL will resemble this:
http://hostname:port/ords/apex
Key Features in Oracle APEX 22.2
Here’s a taste of what APEX 22.2 brings to the table:
New Redwood Theme: Modernize your application look with the fresh and accessible Redwood theme.
Faceted Search Enhancements: Create powerful search experiences for your users.
Maps Improvements: Integrate maps more seamlessly into your applications.
Performance and Security Updates: Benefit from various improvements in these crucial areas.
Conclusion
Oracle APEX 22.2 is another excellent step forward in this low-code platform’s evolution. Download it, explore the new features, and unleash the power of rapid application development within your Oracle Database environment.
youtube
You can find more information about Oracle Apex in this Oracle Apex Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Oracle Apex Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Oracle Apex here – Oarcle Apex Blogs
You can check out our Best In Class Oracle Apex Details here – Oracle Apex Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
OWASP - XSS Attacks
It’s important to understand the reason as to why these sort of attacks are possible and what it all boils down - mixing ‘data’ and ‘control’. XSS attacks rely on the fact that web pages served in our browser (i.e. serving data) are also able to run programs at the same (i.e. control). This is achieved through Javascript - the simple “<script></script>” tags embedded within the markup allow an attacker to run malicious code. This means they can potentially:
Modify user cookies - steal sessions, modify data, etc
Read and change browser DOM
Make XMLHttpRequests in the background to send off and receive data
Potentially fiddle with new HTML5 APIs involving webcam, location and file system
Non-Persistent Attacks
The first class of these attacks are non-persistent; they essentially involve serving up a web page which contains the malicious scripts. This can occur when a user enters data into a form which is reflected back to them, without sanitising the input. They also commonly occur when clicking on links through emails or forums; the link will actually go to the correct site, but will execute a script on the side.
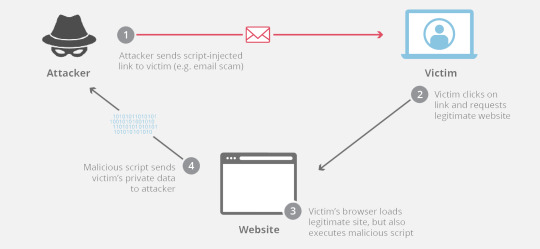
Persistent Attacks
These are the more commonly used and impactful attacks; they rely on a failure of servers to sanitise inputs in forms from Javascript code which results in distributing malicious code to users. For example, let’s say Bob is a regular contributor on the forum SecurityWorld, where you can chat about all things security! After an attack earlier this year, the owner had ramped up security and written a nifty script to parse out any SQL expressions in user input; however it was crappy and hardcoded.
Hacker Mallory comes along and hates the fact that people are spreading ‘useful ways to protect yourself’ when it comes to security; she decides she wants to break into Bob’s account and spread misinformation. The first thing she does is send a DM to Bob; however Mallory is very knowledgeable on XSS attacks and includes a script inside her message. The script fetches all the cookies in the browser and uploads them to a website at www.malloriescookiefactory.com.
The web server doesn’t see anything suss in the input and stores the message in the database. The next time Bob logs in, he accesses the message - the web page then serves him the page with the script included. All his cookies are uploaded to Mallory’s website - Mallory is then able to hijack his session and spread misinformation about the forum.
Protecting Against XSS Attacks
You can find more detailed methods of preventing against XSS attacks in the OWASP cheat sheets here and here. I will summarise the 3 basic concepts however in these protections:
Escaping - rewrite inputs in such a way that nothing is executed if they are served to a user
Validating - prevent special character inputs in forms unless necessary
Sanitising - similar to escaping, except completely removing the problematic characters
In terms of protecting the cookies from being hijacked there are also a number of steps that can be taken as well:
Enable HttpOnly attribute - cookies only submitted to domain of origin
Use Secure attribute - cookies only sent over secure channels
X-XSS protection response headers - feature in the header which prevents pages from loading when they detect an XSS attack
HTTP content security policy headers - allows you to define what and where resources can be loaded from
I also gave a sample attack on HackThisSite - Realistic #9; however the domain used in the injection was fake and only to show the concept.
10 notes
·
View notes
Text
3 THINGS TO EXTEND THE LIFE OF YOUR WEBSITE

There are lots of things that you can do to extend the life of your website from the very beginning; allowing it to run fast and reliably while also being safe from malicious attacks. However, there are three forgotten areas that you should be concerned about when developing a new site; security, stability, and performance.
Let’s discuss some aspects of each area and how they can increase the safety, reliability, and performance of your website.
Security
When most people think about web security, they think about someone hacking into the site and stealing customer data. However, this is not always the case. Sometimes hackers want to use your web server for other types of illegal or unethical practices such as setting up an email server to forward spam, using it to host illegal files or even illegal Bitcoin mining–just to name a few.
There’s nothing worse than having your website infecting your customer’s computers. Not only will Google mark your website as malicious but other filtering and antivirus services will blacklist your website and block their users from visiting it. From being blacklisted as a spammer to having your hosting provider completely shut you down – there’s no good outcome.
The cost of clean up can vary depending on how complicated your website is, the type of infection, and the quality of your backups.
If you are storing customer information, you may need to contact your insurance company and potentially report the breach. It’s a mess no matter how you look at it.
Below are some of the methods you can employ to reduce the risk of your web server being hacked as well as some overall best practices to prevent your server from being misused.
1. Prevent SQL Injection Attacks
If you use a data store that takes advantage of SQL and you use SQL directly in your code, then you could open yourself up to the possibility that a hacker will send malicious code that can cripple your site and/or corrupt your data. The best way to prevent this is to use structured parameters in your Transact SQL code. If you are using Microsoft SQL Server, you can also choose not to use open SQL in your code at all. Instead, you can use stored procedures that use formatted parameters. This will prevent random statements from being executed, and it will also be much faster since your SQL will be precompiled on the server.
2. Avoid Detailed Error Messages
If an error occurs, resist the temptation to use them as debugging tools. Handle the errors gracefully by giving the user a vague error statement and provide them navigation back to the homepage or the page they were on previously. Giving away too much information can give hackers what they need to exploit your site.
3. Prevent Cross-Site Scripting Attacks
Limit and evaluate comments and other forms of input submitted by users to guard against JavaScript injection attacks. You can set attributes through parameterized functions similar to the way you prevent SQL injection attacks. You can also employ the use of Content Security Policy to limit what types of JavaScript that can run in your pages.
4. Use Client and Server-Side Validation
Validate user input on both the client and server levels to make sure that malicious JavaScript wasn’t inserted between when the request was sent from the client to the time it arrives at the server.
5. Use HTTPS
Encrypting the traffic between the user’s browser and the server using SSL is always a good idea when the potential of transmitting sensitive data exists. This will prevent hackers from grabbing and deciphering the data as it is transmitted.
6. Use Two-factor Authentication to Log In
Using two-factor authentication to log into the management area of your website. Two-factor authentication essentially not only a username and password but potentially a continuously changing token/PIN or some sort of additional validation (i.e. a prompt on your cell phone) to verify it is you. Even if someone has your username and password, they can’t get in without the extra piece of information.
7. Keep Your Software Up to Date
In this day and age, you should be using a content management system (CMS). If you have an admin area you log into to manage content, then you are using a CMS. The CMS provider regularly provides updates to their core system, and various vendors provide updates to their plugins. Some updates add functionality, but many of the updates in between are primarily to fix security holes. If you don’t keep your system up to date, you are leaving yourself open to known vulnerabilities.
8. File Change Detection
You can run scripts on your server that notifies you of any changed files. There are some files that shouldn’t change often or at all unless you install an update. If you see that file change, you should be on high alert to find out what changed and who changed it. This is essentially a canary in a coal mine – it’s an early detection system.
9. Limit the Number of Login Attempts
Most systems these days can block an IP address if it has failed multiple authentication requests within a given period. Hackers have scripts that try different combinations to get in. If your website allows someone to continue trying, they may eventually get in. If you limit their ability to try new combinations, you may be able to keep them out. An example ruleset may look like five failed authentication attempts within a three minute period makes the user wait 15 minutes before allowing them to try again. You could even block their IP completely after a certain number of attempts.
10. Think in Layers
Consider someone picking a lock only to be met with another door with another lock. You can protect your website directly, but you should also protect your web server. You can use hardware or software firewalls, DDOS prevention systems, IP filtering, standard port changes, and malware scans to add an extra layer of protection.
Stability
Stability is a hard thing to define. There are lots of things that you should be aware of during development to make your site perform reliably and be more stable, such as cleaning up user sessions, guarding against memory leaks and managing garbage collection. There are also things that you can monitor for stability after the site has been deployed, like:
1. Clean Code
There is no replacement for clean code. Not only will it be more efficient, but it will be easier to track down bugs as well as easier for a new developer to understand. Code with no architecture or “spaghetti code” as we call doesn’t define code in a way that is separate and understandable. Instead, it is all mixed together and potentially duplicated in different areas of the site. There’s not much you can do with a site like this.
2. Load Testing
You should be utilizing cloud-based load testing tools if your website is expected to function under heavy load or heavy load spikes. You can create load simulations to see how your website performs under different scenarios. Make sure your testing environment matches your production environment.
3. Customize Memory Limits
If you have your own server make sure that your site’s memory limit is set to match your sites requirements as well as the resources of your server. You don’t want to make the website run on too little memory, but you also don’t want to allow one connection to use up all of your memory.
4. Cross Browser Testing
Stability is in the eye of the beholder. Make sure you test on the most popular version of Internet Explorer, Edge, Firefox, Chrome, and Safari. There are automated cloud tools to help you but adding manually testing never hurts.
5. Your Web Server
Are you using a dedicated server or a shared server? With a shared server, you are sharing the server’s resources with other websites. Although there should be limits on how many resources one website can use, we have seen servers at bulk hosting providers that may have hundreds of websites on one web server.
Performance
Not only do you want to make sure that your site is reliable and stable, but you also want it to be fast and easy to use. Below are a few of the things that you should monitor to make sure your site performs at its peak potential.
1. Full Page Loading Times
Measure the time it takes to fully load different pages. Especially measure the ones that contain linked content or things such as embedded content, large images or pages that query a database to pull in content. There are many tools out there to measure page speed. There are various factors to review such as first-byte time, DOM load, the overall file size of the website, compression, image optimization, caching, etc.
2. Geography
Try to test your site’s performance from different locations to make sure it isn’t slowing down in specific areas. This may have to do with the number of switches, networks, and servers someone goes through to get to your site. One solution is to use a Content Delivery Network (CDN). A CDN essentially caches copies of your website and places them on POP locations around the world, which then reduces the number of switches and servers your user has to go through to view your content. The network is set to come back to your main website and look for updated content.
3. Dedicated Resources
The cost of dedicated cloud servers has been going down. For the extra amount paid, you are essentially asking your provider to dedicate a certain amount of resources for your web server regardless of whether you are using it or not at that particular time. You are giving your website some breathing room instead of having it compete for resources.
4. Network Latency
Make sure to choose a reputable hosting provider. You can have a beast of a web server, but if their network has high latency or packet loss, your server won’t be the bottleneck.
5. DNS
When a visitor types in your website address or clicks a link on Google, their web browser has to do a DNS lookup. It’s essentially asking what IP address to go to in order to request the website files. Think of it as looking up a phone number. You want to make sure that lookup is as fast as possible. Make sure your DNS servers respond quickly.
6. Caching
In simple terms, caching is storing website data for future use. There are many places along the chain you can utilize caching and various types of caching systems. From server side caching to browser caching, you are essentially telling the server or browser to store pieces of information it will need to access often or information that will not change often. It’s one less lookup or transmission, and they add up.
7. Image optimization
Not all images are created equal. If you are taking a photo that you will print in a brochure and also use on your website, you actually have different requirements. For the brochure, you need high pixel density (DPI), but your screen needs fewer pixels. Additionally, there are file formats that work best for different images. You can choose between vector images or raster images. You have format options such as .jpg, .gif, .svg, and .png. You have compression options such as lossless compression or lossy compression. In short, you have a lot of options and what you use should be determined by the image itself and the display requirements.
8. Javascript Minification and CSS Aggregation
Have you ever received where the box was much larger than the contents? Minification is the same thing; it’s the process of taking out unused characters without changing how it functions. You are making it smaller so that it transmits faster. CSS Aggregation is a bit different, it’s like order five things and having them all come in the same box vs. five different boxes. It just reduces the number of files a browser has to download in order to render your website.
9. Query Optimization
This one is a bit more difficult because it requires experience and finesse. When building a website that relies on a database to function, you can pull that data from the database in many ways. Additionally, you may be pulling from multiple tables in one database to display the content.
For example, in an eCommerce website, you may store the user information in one table and order information in another table. When a user goes to their profile page to see past orders, you would pull data from the user table first and then use information in that query to pull data from another table. Sometimes, you are pulling data from many database tables.
Query optimization is essentially finding the most efficient route to get the information you need. If the query is not designed well, your user may have to wait several seconds for the server to pull up all the information and while that is happening, your server is using up more resources than it should which means it can serve fewer people at once.
Paying special attention to these three areas will help to ensure that your website is always safe, reliable and running at its peak. Designing, developing and deploying a website is only the beginning. If you compromise sensitive user data, your site is always down, or your site is consistently slow then users won’t want to return to your site, and you’ve done all of that hard work for nothing.
Managing and improving your website is an ongoing process. It is a living entity, and it needs to be given every opportunity to flourish. Contact Web designer in Denver, CO today if you want to extend the life of your website by ensuring that it is secure, stable, and performs.
0 notes
Text
300+ TOP FILEMAKER Interview Questions and Answers
FILEMAKER Interview Questions for freshers experienced :-
1.What is FileMaker Pro? FileMaker Pro is a 32 bit, Y2K compliant, cross-platform, fully relational, database program. Similar to Microsoft Access, the current version of FileMaker is a fully relational database development tool that allows one-to-one, one-to-many, many-to-one, and many-to-many relations between files (tables). Another one of FileMaker Pro's advantage is the FileMaker Developer tools that allows us to 'bundle' the form files with the FileMaker Runtime engine that allows our outside customers to use WSDOT forms without requiring them to purchase any additional software. 2.What are the symptoms of a corrupt FileMaker file? Symptoms vary from corruption type and level of corruption. Maybe your FileMaker application freezes when the file is tried to open, or maybe an error message is shown when you click the file to open it. 3.Is it possible to search any FileMaker .fp7 file? FileMaker Recovery Software has an inbuilt option to search FP7 files in a specified location. File properties like modification date, creation date, size, etc. are shown in the search result for accurate selection. 4.How is FileMaker Recovery Software different from other similar products in market? Many features have been included in latest version of FileMaker Recovery Software. Latest version of FileMaker Recovery Software supports File Maker Pro 10/11/Pro/Advance and above. Search option in the preview, selective recovery of a specific table, log summary, etc. make it above other similar software applications in the market. 5.What is FileMaker Recovery Software? FileMaker Recovery Software is used to repair, restore and recover corrupt FileMaker database (.fp7) files. A search feature is provided that helps in searching all the .fp7 files present in a drive or folder. A new FileMaker file is set as target to store the recovered table data. Data of Text, Number, Date, Timestamp, Calculation, Container and Summary data type are recovered back in the repaired database file. 6.Can I repair a FileMaker database for trial and evaluation without payment? Yes, you can download FileMaker Recovery Software absolutely free of cost. Preview is shown in the demo version for customer evaluation. If you are satisfied by the scanned results, you can register the demo version to save the recovered FileMaker database. 7.What is new in FileMaker Pro 6? The best just got better with FileMaker Pro 6 database software. It features digital image capture and import; more than 20 modern and powerful templates for "instant productivity" in business, education and home; many time-saving features like Format Painter and Custom Dialog Boxes for users and developers; and integrated XML support so FileMaker can exchange data with a large and growing number of other applications. FileMaker Pro 6 will jump-start the productivity and creativity of workgroups ranging from entire small businesses to departments within the enterprise. 8.Why is the new FileMaker Pro 6 available before other revised products? FileMaker Pro 6 files share the same file format as FileMaker Pro 5 and 5.5 files. Thus, all three versions may co-exist on the same network. In addition, all versions utilize the current FileMaker Server (now relabeled without a version number) features, enabling large workgroups to share information seamlessly. 9.Is XML import/export support in FileMaker Pro 6 a big deal? Absolutely the widespread support of XML (Extensible Markup Language) standards means FileMaker Pro 6 can exchange data with a large and growing number of other applications without complex and costly converting of data between proprietary formats. A developer can easily empower a workgroup using FileMaker Pro 6 to, for example, find and get data from Websites, import accounting data from QuickBooks, or query corporate databases without using ODBC drivers. With XML export, FileMaker Pro 6 users can share information with users of other applications. For example, users can export formatted FileMaker data in an attachment to an email, into Microsoft Excel, or into document-authoring applications. 10.What's new about XML support in FileMaker Pro 6? In the past, accessing FileMaker data as XML required users to make requests to the FileMaker Web Companion from an external application; in other words, it was "pull" only through the Web Companion. Additionally, processing XSLT style sheets required the user to have installed an XSLT processor on the client machine. With FileMaker Pro 6 the XML capabilities are integrated into the product as import/export menu selections without the need for the Web Companion. Alternatively, the customer can script XML data import and export. Also within FileMaker Pro 6 is an XSLT processor allowing style sheets can be processed without the need for the customer to install their own.

FILEMAKER Interview Questions 11.How hard is it to use XML import/export? Can anyone use it? While the creation of the XSLT style sheets does require a good understanding of XML and XSLT, the benefits of our XML import/export can be enjoyed by all users. Note that a developer can empower an entire workgroup, very efficiently, to enjoy the benefits of XML data-exchange while hiding the plumbing from the users. To further assist our customers with better understanding of XML and XSLT, we ship 8 XSLT style sheet examples with FileMaker Pro 6. Furthermore, customers can visit the FileMaker XSLT Library, which is part of our FileMaker XML Central. The FileMaker XSLT Library is a repository of XML/XSLT examples that are available for download at no charge. 12.Why did FileMaker add integrated XML support in FileMaker Pro 6? XML support is the tool that best accomplishes this task. With the implementation of our XML support, FileMaker Pro 6 users are now able to gather data from more data-sources and share data with more applications.FileMaker Pro 6 customers can benefit from XML import and export. Through the creation of an XSLT style sheet , a workgroup can: Import XML data from a SQL server without the use of ODBC drivers. Share information with other workgroups who don’t even use FileMaker Pro by sending data from FileMaker directly into a formatted Excel file (*.xls) or other text-based file formats. Create charts and graphics (*.svg) to represent FileMaker data. 13. Is there RAIC support for Instant Web Publishing in FileMaker Pro 6? There is no support for RAIC technology in FileMaker Pro 6. Use FileMaker Pro 6 Unlimited to deploy Web-based solutions to an unlimited number of users. It also includes the FileMaker Pro Web Server Connector and support for RAIC, which can increase the performance and scalability of your FileMaker Pro web databases. Toolbars are not supported under Mac OS X. 14.What is FileMaker Pro 5.5 Unlimited? FileMaker Pro 5.5 Unlimited includes all of the powerful desktop database functionality of FileMaker Pro 5.5, plus it allows databases to be hosted via the Web to an unlimited number of unique visitors with unique IP addresses. FileMaker Pro 5.5 Unlimited also includes the Web Server Connector and tools needed to use and access advanced functionalities such as Custom Web Publishing (via CDML), XML, JDBC, Java class libraries, and JavaScript. 15.What is the difference between FileMaker Pro 5.5 and FileMaker Pro 5.5 Unlimited? There are four major differences between FileMaker Pro 5.5 and FileMaker Pro 5.5 Unlimited: The Web Companion that ships with FileMaker Pro 5.5 Unlimited allows access to the Web Companion for an unlimited number of web browsers. The Web Companion that ships with FileMaker Pro 5.5 is limited to 10 IP addresses in a rolling 12 hour period. FileMaker Pro 5.5 Unlimited includes the FileMaker Web Server Connector. Additional copies of FileMaker Pro 5.5 Unlimited can be used to set up a Redundant Array of Inexpensive Computers (RAIC) structure to take advantage of scalable load balancing, and fault tolerance, to increase the performance of FileMaker web enabled databases. Computers running Mac OS X cannot serve as RAIC machines FileMaker Pro 5.5 Unlimited can be used with various CGIs, middleware, and application servers for deployment across the Web. Tools and information needed to implement solutions using advanced functionalities (JDBC driver, Java class library, Custom Web Publishing , Custom Workgroup Portal, XML) are not included in FileMaker Pro 5.5. 16.What is the FileMaker Web Server Connector? The FileMaker Web Server Connector is a Java servlet that is used to connect FileMaker Pro 5.5 Unlimited with powerful web servers. A servlet is a standard Java based mechanism for extending the functionality of a web server. The FileMaker Web Server Connector is used to pass through (or relay) requests received on a web server to FileMaker. The reasons to use the FileMaker Web Server Connector include. To take advantage of other web server plug-ins and features including SSL and server-side includes, provide a Redundant Array of Inexpensive Computers (RAIC) structure to increase throughput and reliability, increase performance by storing static pages and graphic images on the Web server, bypassing the Web Companion for pages that don't involve databases, and provide redundancy to allow for operation through failure situations. 17.Can I use the FileMaker Web Server Connector with FileMaker Pro 5.5? The FileMaker Web Server Connector is designed to work only with FileMaker Pro 5.5 Unlimited, the dedicated web publishing product in our product family. 18.Can I use the FileMaker Pro 5.5 Unlimited Web Server Connector with Instant Web Publishing? No. The improved FileMaker Pro 5.5 Unlimited Web Server Connector is intended for use with Custom Web Publishing. 19.How can I run reports and print labels via browser in databases hosted under FileMaker Pro Unlimited? If you need more functionality than browsing, searching, adding, updating, or deleting records, you will want to access the database using a copy of FileMaker Pro, rather than a browser. 20.How can I set up a Redundant Array of Inexpensive Computers (RAIC) with FileMaker Pro 5.5 Unlimited to increase scalability, performance and robustness? The FileMaker Web Server Connector, included with FileMaker Pro 5.5 Unlimited, lets you set up a RAIC. A RAIC increases the scalability of your web-based FileMaker Pro solutions and helps ensure operation through fail-over situations. To set up a RAIC, an additional copy of FileMaker Pro 5.5 Unlimited is required for each CPU you wish to add to the RAIC. 21.What languages will FileMaker Pro 5.5 Unlimited be available in? FileMaker Pro 5.5 Unlimited in Worldwide English, French, Italian, German, Swedish, Dutch, Japanese and Spanish. 22.What are the price and availability of FileMaker Pro 5.5 Unlimited? FileMaker Pro 5.5 Unlimited is currently available. Estimated retail price in the U.S. is $999. Upgrade price for licensed owners of FileMaker Pro 5 Unlimited is US $499. Volume license pricing is available. 23.Do I have to use the FileMaker Web Server Connector when I install FileMaker Pro 5.5 Unlimited? No. If you want to use FileMaker and simply have more than 10 IP addresses accessing your copy of FileMaker in a rolling 12 hour period and do not need to add scalability and load balancing to your FileMaker web solutions, you can simply install the "unlocked" version of FileMaker Pro 5.5 that ships with FileMaker Pro 5.5 Unlimited. 24.Is FileMaker Pro 5.5 Unlimited certified for Windows 2000? FileMaker Pro 5.5 Unlimited is certified for Windows 2000 Professional. 25.Why did we build FM Starting Point? When we worked with FileMaker, Inc. to rebuild and clean up the “Starter Solution Templates,” a premium was placed on simple functionality that would be easy for brand new FileMaker users to take apart and customize. Of course, with simplicity elevated to such a high degree, overall usefulness of a database can be quite limited. There is, therefore, a genuine need for a more robust FREE starter solution for FileMaker users; this tool meets those needs. 26.What is new in FM Starting Point 2? With the release of FileMaker 11, we decided to update our FM Starting Point template with a few new features. A few of these include Charting throughout the system, inventory tracking between the Invoice and Products module, and hourly rates in the Timesheets module. You will find a brand new Summary tab in the Projects Module that collects information from the Inventory, Expenses, and Timesheets tables to produce graphs showing the current status and profitability of a project. All this and more you will find in the new version. Once again, FM Starting Point 2 is a FREE solution so you can go ahead and download it as soon as you get FileMaker 11. 27.Will FM Starting Point 1 still be available? A new link has be put onto the FM Starting Point website for downloading our last release, FM Starting Point 1.0v15. 28.Is FileMaker Inc. responsible for this Database? No. FM Starting Point was influenced by the redevelopment of FileMaker’s “Starter Solution Templates” which are already included for FREE with each install of FileMaker Pro. FileMaker Inc. has not underwritten this enhanced solution. FMI staff provided feedback for the included features, and we greatly appreciate their assistance. All quality assurance testing was performed by RCC and not FMI. 29.How is this different than Data4Life? Some FileMaker users are aware of another FREE database offered, called Data4Life. Data4Life is designed for personal use, and not business use. FM Starting Point targeted towards small businesses, work groups, and non-profit organizations. 30.Does FM Starting Point connect to QuickBooks? FM Starting Point can connect to QuickBooks (on Windows only) via the use of third party plug-ins. The Mac version of QuickBooks has some limitations that prevent it from communicating with a Plug-in unless you are a FileMaker “power user” then you might need to get some help from a FileMaker developer with this task. 31.Does FM Starting Point connect to iCal or Address book on a Mac? FM Starting Point can connect to these other applications via the use of third party plug-ins. Unless you are a FileMaker “power user” then you might need to get some help from a FileMaker developer with this task. 32.Is there an instruction manual for FM Starting Point? No. There are several instructional on screen help videos to help get users rolling in the new system. We are also commenting on the scripts and various features within the database template. FM Starting Point is design for new users so it is not too complex. Few people read the manuals anyway. They just hack their way through a product. However, if someone wants to write a manual, and then give it away to everyone, let us know and we’ll post it for you. 33.What are the different kinds of Email I can send from FM Starting Point? Primarily, the email capabilities are within the "contacts" modules, where you can shoot off a myriad of different "canned" emails. These will be plain text emails, since that is what the new built in FileMaker 10 feature supports. Email may be sent through a users email client OR use the new “Direct Send” capability of FileMaker Pro 10. 34.When I am reviewing a specific to-do, from the to-do list, and I select a due date, the Window will flash. Why is this? We had to use a script trigger. When the due date is modified, it selects the to-do list window, and causes a refresh to occur. We did this because FileMaker 10’s new sticky sort capability would frequently re-sort the new to-do item off the visible list (above or below), and would confuse the user when the to-do pop up is closed. 35.In the FileMaker 10 Starter Solutions, there is frequent use of "Type Ahead" aka Clairvoyance. Why is this missing from FM Starting Point? Normally, we added functionality to the system, but not in this case. Type ahead causes a performance drain that is very noticeable for medium sized data sets, when accessed over a Wide Area network or Internet connection. We expect a fair number of people to access FMSP, hosted at their offices, or at a Hosting company, and then accessing the database remotely. These people would be highly disappointed by the huge slow down of FileMaker when using “Type Ahead” features. So to prevent nasty phone calls and flaming emails, we dropped this capability out of FMSP. If you run FMSP as a single user, on your local computer, feel free to turn “Type Ahead” back on. 36.What is FREE SuperContainer Hosted Lite? SuperContainer Hosted Lite is a FREE limited version of SuperContainer that is hosted by 360Works and is built specifically into FM Starting Point. The Lite Hosting Plan includes the following: No limit on number of users within your organization. Maximum of 2 megabytes per file. Limit of 10,000 total items. 250 megabytes total storage. Up to 1 gigabyte of download/upload traffic per month. Thumbnails display at a maximum resolution of 300x300. For use exclusively with the FM Starting Point solution. 37.What is SuperContainer Hosted Pro? SuperContainer Hosted Pro is a more powerful version of SuperContainer that is hosted by 360Works and is built specifically into FM Starting Point. The “Hosted Pro” version includes the following: No limit on number of users within your organization. Unlimited file size, total items, and thumbnail resolution. 20 gigabytes total storage. Up to 20 gigabytes of download/upload traffic per month. For use with any solution, not just Starting Point. Monthly charge of $49 US. 38.What is SuperContainer Enterprise? SuperContainer Enterprise is for an unlimited number of users and access via the web, running on your own in-house FileMaker Server. The Enterprise version includes the following: No limit on number of users within your organization. Accessible only with a Web Viewer in FileMaker Pro, or via a web browser for viewing and uploading files from the web. Unlimited file size, total items, thumbnail resolution (limited only by space on your server). Unlimited total storage (limited only by space on your server). Unlimited download/upload traffic per month (limited only by bandwidth to your server). Supports SSL encryption. For use with any solution, not just Starting Point. One-time charge of $695 US. 39.What is SuperContainer Workgroup? SuperContainer Workgroup is for up to 10 FileMaker users, running on your own in-house FileMaker Server. The Workgroup version includes the following: Up to 10 users within your organization. Accessible only with a Web Viewer in FileMaker Pro (not via the a web browser). Unlimited file size, total items, thumbnail resolution (limited only by space on your server). Unlimited total storage (limited only by space on your server). Unlimited download/upload traffic per month (limited only by bandwidth to your server). Supports SSL encryption. For use with any solution, not just Starting Point. One-time charge of $195 US. 40.Does FileMaker Work on the iPhone and iPad? Yes! The product is called “FileMaker Go,” and can be installed on either the iPhone or iPad, after being purchased from the App Store. You need this software before you can use FM Starting Point on these devices. Once you have FM Go installed, you have the choice of accessing the database as shared from a FileMaker Server, or as shared from a single desktop with peer to peer sharing turned on. Also, for maximum speed, you can email or otherwise transfer FMSP to your iPhone or iPad and have it run on the device locally. 41.How do I download the iPhone or iPad version of FMSP? The iPhone and iPad version of FMSP are all “rolled together” into a single FileMaker file – the same file that is accessed by the desktop copy of FileMaker Pro. All three versions are in a single file. This way, users with different devices can log onto the same database and share data. 42.Did you make some screens designed just for the iPhone or iPad? We did actually develop some screens specific to these devices. Building an interface for a touchscreen device is somewhat different than for a desktop computer with a mouse. For the iPhone, we built out screens that allow user to find, view, edit and add contacts to FMSP. Plus, if you click the contact's phone number, it will actually dial the number and make the call on the iPhone. For the iPad, we took all the screens and functionality of FMSP and duplicated them. Then we weaked these duplicated screens so they have bigger buttons and fields things you need for a touchscreen device. 43.Does FMSP and FileMaker Go on the iPhone work with the camera built into my iPhone? Unfortunately, no: integration with the iPhone's camera is not supported in this initial release of FileMaker Go. 44.Where did the charts go in FMSP on my iPhone and iPad? Why can't I save as PDF or Print? Charting is not yet a supported feature of FileMaker Go. Same for making PDFs and printing. 45.Can Recovery for FileMaker repair my FileMaker Pro database? The effective way to find out if a FileMaker Pro database is recoverable is to try the demo version of Recovery for FileMaker on it. 46.What limitations does the demo version of Recovery for FileMaker have? Demo version recovers limited number of the database rows. The remaining rows will be blank. Full version will restore demo-limited rows as well. 47.I have tried the demo. How do I decide whether to purchase the full version of Recovery for FileMaker? Evaluating the results of demo recovery can help in making the decision. 48. Why is WSDOT using FileMaker Pro for electronic forms? In October 1992, the department started researching and testing different software packages to develop and deploy electronic forms department wide. None of the software provided all of the features initially defined. FileMaker Pro (version 2.0) was chosen, providing the most features, flexibility, and usability within the WSDOT IT infrastructure. 49.After successful recovery of the original database a new .DBF file is created. What is the procedure for transferring data from this temporary file to a database? You should simply import data from the resulting file in .DBF format into a new database. 50.Will FMTouch support the Apple iPad? Yes, we have already tested and written the new code for FMTouch and the Apple iPad. 51.Will FMTouch work with FileMaker 11? Yes, FMTouch works with FileMaker 11. There was an update to a new plug-in for FMTouch FileMaker 11 support. If you are using FileMaker 11, please make sure you download the new plug-in. 52.Will FMTouch work on both the iPhone and the iPod iTouch? Yes, FMTouch works with both the iPhone and the iPod iTouch. 53.Do I have to be connected to the internet? No, you do not have to be connected to the internet. FMTouch runs locally on your mobile device as a local application. You can sync FMTouch while you have FileMaker running with the sync plug-in - sync once an hour, once a day on your own schedule. 54.Will Runtime solutions run on FMTouch? Yes, runtime solutions work on FMTouch. 55.What versions of FileMaker are supported? FMTouch works with FileMaker version 8-11 and beyond. We will not be releasing versions for FileMaker 7 and below. 56.Do I have to design special layouts or databases? You should make database layouts that would render effectively on the iPhone. Many developers are simply adding iPhone specific layouts. Smaller databases are also faster and take less time to load. 57.Is FMTouch Relational? Yes, and you will find that the ability to use and edit portals is great bonus. You have the ability to have many related tables and many related databases all talking to one another. 58.Can I have multiple layouts? Yes, you can have multiple layouts, and you can easily deselect the layouts that you don't want to display. 59.Can I do scripting and calculations? Scripting and Calculations are supported. 60.Are repeating fields supported? Yes, repeating fields are now supported as are merge fields. As of version 1.23. Note: Repeating fields require FileMaker 9+. 61.Will FMTouch work for both Windows and Macintosh? Yes, FMTouch works equally well with both Macintosh and Windows OS. 62.What versions of FileMaker does FMTouch support? Initially you will need FileMaker Advanced to create your DDR. Once this is generated, FMTouch can be used with FileMaker Pro 8-11. Note: 8.5 is needed for webviewer support. 63.Why do I need FileMaker Advanced? FileMaker Advanced enables you to generate your database DDR. This information is needed to help FMTouch create your database. Once the DDR is created you can use regular FileMaker Pro 8-10. 64.Will enterprise or developer licenses be available? Yes, enterprise licensing is available. 65.I am having problems syncing with my Mac? If you are having problems syncing 99% of the time it is because of a few things. You have a firewall set up - and the correct port is not open. You are trying to sync through the USB cable. You do not have the plug-in correctly installed. 66.I am having problems syncing with my PC? If you are having problems syncing 99% of the time it is because of a few things. You have a firewall set up - and the correct port is not open. You are trying to sync through the USB cable. You do not have the plug-in correctly installed. 67.Do you have an online Forum? Yes 68.Are container fields supported? Yes, beginning with version 1.30 we added container field support. 69.Can I sync to FileMaker Server on Windows and MaC? Yes, check out the user’s guide server section you can sync to both Mac and PC Server with FileMaker Server 9, 10 and 11. 70.What version of FileMaker Pro is the department using? The department is currently using FileMaker Pro 11.0v3. FileMaker Pro is a Level Playing Field software and is installed on all WSDOT workstations. For our downloadable eForms, we are using version 11.0v3 of the FileMaker Pro runtime engine. FileMaker Questions and Answers Pdf Download Read the full article
0 notes
Text
SIEM VERSUS UTM

No, it is not a Boxing fight; these two tech giants don't fight one versus others. The contest is against the threats to cybersecurity. According to the U.K. government’s Cybersecurity Breaches Survey 2019, over 32% of businesses have identified breaches in the last 12 months.
The most commons Cyberattacks nowadays are: Phishing, with its variants: Vishing, Smishing, and Spear Phishing, Ransomware, Distributed Denial of Service (DDoS), Viruses, and Attack Vectors, the main types of attack vectors are: Man-in-the-middle (MITM), Drive-by, SQL Injection, and Zero-day attack.
The ever-growing volume of sophisticated security attacks has impelled sellers of UTM (Unified Threat Management Systems), and SIEM (Security Information and Event Management) to add unique features to their products. A SIEM is an excellent starting point for security analytics, and UTM is the pinnacle.
This comparison addresses the basic and advanced capabilities offered by both security suites.
SIEM
BASIC CAPABILITIES
o Log Collection, Aggregation, and Normalization (CAN): Collection from firewall and network logs, IDS logs, Windows server logs, web server logs, and various Syslog sources.
o Event Correlation: Examines the events to understand their behavior and write correlation rules to identify threats.
o Alerting: Logging for all correlated events and alerting via pager/email/text for those that exceed a given threshold or meet specific alert criteria.
o Reporting: Availability of a variety of reports. The vulnerability reports are classified according to severity levels that are defined by the correlation engines.
ADVANCED CAPABILITIES
o File integrity monitoring: It monitors and initiates alerts when any change is made to the system files. It employs real-time analytics.
o Vulnerability Assessment: It employs heuristic and signature-based scanners built on a robust database to make available a full vulnerabilities report.
o Asset Discovery: It discovers all network assets without impacting the performance functions. Creates and updates an inventory.

UTM BASIC CAPABILITIES
o Firewall
o URL filtering
o IPS
o Web antivirus
o IPsec and SSL
o Virtual private networking (VPN)
o Application control
o User control and Anti-spam
ADVANCED CAPABILITIES
o Data loss prevention: DLP technologies focus on detecting, and blocking attempts to exfiltrate sensitive data from within an organization to external locations
o Sandboxing: A sandbox service provides a safe, isolated environment for running suspicious executables and analyzing its behavior, so the UTM can choose whether to allow or deny the executable.
o Bandwidth management or Quality of Service: It can limit the bandwidth for network services. QoS can be effective at limiting the impact of some distributed denial of service (DDoS) attacks.

Both tools are highly flexible. Many vendors offer solutions that allow deploying the capabilities one at the time. This is convenient for organizations with limited IT budgets. For example, organizations can initially opt for a UTM box with just a firewall and IPS activated by default, so they spend less. SIEM solutions historically focused on large enterprises, but today sellers offer simplified solutions pointed at the SMB (Small and Medium Businesses) space such as Logz.io, UTMStack, Qualys, and ELK.
Among the UTM vendors, we find Stormshield Network Security, Sophos XG Firewall, and Fortinet UTM, which is the clear leader in the Market. You can find more articles about this topic in https://utmstack.com/
If an organization has a SIEM, would it need an UTM?
It depends, of course, on the Organization’s needs. If the main concern is to meet compliance with legal requirements and track access activity, a SIEM provides suitable tools. The UTMs combine multiple network security functions in a single appliance, protecting the web traffic and avoiding the loss of sensitive data. Both SIEM and UTM are excellent options.
0 notes
Text
Step-by-Step Guide to Troubleshoot SQL Connectivity Issues
We all have problems that occur from time to time, where we need to work through some problem-solving steps to identify why or where the problem occurred. In these situations, to uncover the root cause of the problem, you need to act as a Crime Scene Investigator (CSI). No, we're not putting yellow tape of caution around our servers, network cables, and desktop machines. Sometimes, however, we unplug the network cable to avoid further contamination of the machine, in rare cases. Sometimes it's obvious, but not always, what caused the problem. Regardless of the problem, to determine the cause of the problem, you will need to do some forensic analysis. I will cover some of the tools you can use to search for clues in this article, and the steps you may take to help mysql performance improvement.

Problem Solving Tools
You can use a number of different troubleshooting tools. I can't cover, nor do I know of all the tools you might be able to use for troubleshooting, so I'll cover the most common tools available within SQL Server and Windows OS. In most cases, you should be able to find enough information using these tools to provide you with enough clues to determine the cause of the problem.
Here is a list of commonly used tools:
· Notepad
· Event Viewer
· Profiler
It starts a default trace event when SQL Server starts, provided that the default trace is enabled. To review the information captured from the default trace event, Profiler can be used. Exploring the default trace information is amazing what you can find. In addition, creating your own traces while troubleshooting a problem might be useful. Notepad doesn't look like much of a tool; however, different log files can be opened with it. Notepad allows you to perform string searches to quickly locate information in large log files. You may need to use WordPad as an alternative if your log files are too large.
Event records will be written to the Windows event logs sometime when your system has problems. Using the Event Viewer, mysql consulting can browse the events one by one. Events in the event log may provide a quick answer to why your SQL Server instance is not behaving as it should, provided the problem you are trying to solve is associated with event records.
Information Collection Phase
To diagnose an issue, you first need to collect some information about the problem. You also need to review log files to determine what type of system error messages and log records are available to help you diagnose the problem. Below is a set of steps to consider when going through your forensic analysis information gathering phase.
Step 1: Gathering the facts
The first step in any exercise to solve problems is to collect the facts. You need to know what kind of issue is going on. This is where the customer or programmer needs to be interviewed to understand how and when the problem occurs. You need to determine whether it is wide-ranging in the system or more localized to a particular application or application component. You also need to know when the problem occurred and if it is still a problem or not. Besides this, the last time the system worked correctly, you need to know. You need to determine if you have introduced any new system or application changes that could have caused the problem. Armed with some facts about the problem you can start searching for clues to help identify the root cause of the issue.
Step 2: Testing in Different Environments and Machines
If you have them, it's worth testing in various environments. This is an exercise of fact gathering, but I spelled it out as a separate step because many times seasoned staff do not think when they gather facts about performing tests in separate environments.
You may find that only one environment, a set of environments or all environments are affected. If only one environment is affected, the problem with that environment or the other working environments could be a configuration issue. Alternatively, the problem could be caused by the data in the environment. You may also want to try various client machines or application servers. Occasionally, you may find that a different configuration or setup may or may not cause the application to work. You must explore all the different options for setup and configuration and then document those that work and those that don't work.
Step 3: Review the SQL Server Error Log
SQL Server creates the "ERRORLOG" log file. Every time SQL Server starts, a new ERRORLOG file is created. By default, SQL Server keeps six old log files of errors, each with a sequential number. The default ERRORLOG file is stored in the folder "Log" within the folder structure of the standard folder"... Program FilesMicrosoft SQL Server...." Find the log file for which the timeframe is associated when the issue first occurred. Look to see if the messages being issued by SQL Server contain any anomalies. Sometime it will be logged in the ERRORLOG file if SQL Server detects a change or encounters a problem.
Step 4: Review the Event Log
To view the different event log records, you should use the Event Viewer. There are both information warnings and error events in the event log. You should look at all the events that took place shortly before, during and after the identified problem's timeframe. The "Application" and "System" events, as well as the "Security" events, must be reviewed.
Eric Vanier is a mysql database expert who has helped numerous Fortune 500 companies keep their database together with his team of mysql experts. The current database management scenario is very cluttered and requires both championing ability and expertise. Companies are now dependent on a smooth running thanks to him and have experienced improvement in mysql performance.
#mysql database expert#MySql consultant#mysql optimization expert#mysql queries consultant#mysql performance improvement#mysql expert#mysql consulting#mysql query optimization expert#mysql database consultant#mysql performance expert#expert mysql#database optimization expert#MySQL Performance Optimization#mysql queries optimization expert
0 notes
Text
T-SQL: Find the location of data and log files of the databases within a SQL Server instance.
T-SQL: Find the location of data and log files of the databases within a SQL Server instance.
Hi Friends,
Hope, you are doing fine!
Today, please find below the T-SQL script tip to find the location of the data & log files available within a SQL Server instance. The script is as below:
T-SQL:
SELECT name AS NameOfFile, physical_name AS FileLocation FROM sys.master_files
Snapshot:
Happy Coding :)
View On WordPress
#Find the location of data and log files of the databases within a SQL Server instance#MS SQL Server#sys.master_files#T-SQL Scripts
0 notes
Text
Deceive in order to detect
http://cyberparse.co.uk/2017/01/19/deceive-in-order-to-detect/ https://i0.wp.com/cyberparse.co.uk/wp-content/uploads/2016/04/security-binary-pd-898757.jpg?fit=3888%2C2592
Interactivity is a security system feature that implies interaction with the attacker and their tools as well as an impact on the attack scenario depending on the attacker’s actions. For example, introducing junk search results to confuse the vulnerability scanners used by cybercriminals is interactive. As well as causing problems for the cybercriminals and their tools, these methods have long been used by researchers to obtain information about the fraudsters and their goals. There is a fairly clear distinction between interactive and “offensive” protection methods. The former imply interaction with attackers in order to detect them inside the protected infrastructure, divert their attention and lead them down the wrong track. The latter may include all the above plus exploitation of vulnerabilities on the attackers’ own resources (so-called “hacking-back”). Hacking-back is not only against the law in many countries (unless the defending side is a state organization carrying out law enforcement activities) it may also endanger third parties, such as users’ computers compromised by cybercriminals. The use of interactive protection methods that don’t break the law and that can be used in an organization’s existing IT security processes make it possible not only to discover if there is an intruder inside the infrastructure but also to create a threat profile. One such approach is Threat Deception – a set of methods, specialized solutions and processes that have long been used by researchers to analyze threats. In our opinion, this approach can also be used to protect valuable data inside the corporate network from targeted attacks. Characteristics of targeted attacks Despite the abundance of technology and specialized solutions to protect corporate networks, information security incidents continue to occur even in large organizations that invest lots of money to secure their information systems. Part of the reason for these incidents is the fact that the architecture of automated security solutions, based on identifying patterns in general traffic flows or monitoring a huge number of endpoints, will sooner or later fail to recognize an unknown threat or a criminal stealing valuable data from the infrastructure. This may occur, for example, if the attacker has studied the specific features of a corporate security system in advance and identified a way of stealing valuable data that will go unnoticed by security solutions and will be lost among the legitimate operations of other users. nother reason is the fact that APT attacks differ from other types of attacks: in terms of target selection and pinpoint execution, they are similar to surgical strikes, rather than the blanket bombing of mass attacks. The organizers of targeted attacks carefully study the targeted infrastructure, identifying gaps in configuration and vulnerabilities that can be exploited during an attack. With the right budget, an attacker can even deploy the products and solutions that are installed in the targeted corporate network on a testbed. Any vulnerabilities or flaws identified in the configuration may be unique to a specific victim. This allows cybercriminals to go undetected on the network and steal valuable data for long periods of time. To protect against an APT, it is necessary not only to combat the attacker’s tools (utilities to analyze security status, malicious code, etc.) but to use specific behavioral traits on the corporate network to promptly detect their presence and prevent any negative consequences that may arise from their actions. Despite the fact that the attacker usually has enough funds to thoroughly examine the victim’s corporate network, the defending side still has the main advantage – full physical access to its network resources. And it can use this to create its own rules on its own territory for hiding valuable data and detecting an intruder. After all, “locks only keep an honest person honest,” but with a motivated cybercriminal a lock alone is not enough – a watchdog is required to notify the owner about a thief before he has time to steal something. Interactive games with an attacker In our opinion, in addition to the obligatory conventional methods and technologies to protect valuable corporate information, the defensive side needs to build interactive security systems in order to get new sources of information about the attacker who, for one reason or another, has been detected inside the protected corporate network. Interactivity in a security system implies a reaction to the attacker’s actions. That reaction, for instance, may be the inclusion of the attacker’s resources to a black list (e.g. the IP address of the workstations from which the attack is carried out) or the isolation of compromised workstations from other network resources. An attacker who is looking for valuable data within a corporate network may be deliberately misled, or the tools used by the attacker, such as vulnerability scanners, could be tricked into leading them in the wrong direction. Let’s assume that the defending side has figured out all the possible scenarios where the corporate network can be compromised and sets traps on the protected resource: a special tool capable of deceiving automated vulnerability scanners and introducing all sorts of “junk” (information about non-existent services or vulnerabilities, etc.) in reports; a web scenario containing a vulnerability that, when exploited, leads the attacker to the next trap (described below); a pre-prepared section of the web resource that imitates the administration panel and contains fake documents. How can these traps help? Below is a simple scenario showing how a resource with no special security measures can be compromised: The attacker uses a vulnerability scanner to find a vulnerability on the server side of the protected infrastructure, for example, the ability to perform an SQL injection in a web application. The attacker successfully exploits this vulnerability on the server side and gains access to the closed zone of the web resource (the administration panel). The attacker uses the gained privileges to study the inventory of available resources, finds documents intended for internal use only and downloads them. Let’s consider the same scenario in the context of a corporate network where the valuable data is protected using an interactive system: The attacker searches for vulnerabilities on the server side of the protected infrastructure using automated means (vulnerability scanner and directory scanner). Because the defending side has pre-deployed a special tool to deceive scanning tools, the attacker has to spend time analyzing the scan results, after which the attacker finds a vulnerability – the trap on the server side of the protected infrastructure. The attacker successfully exploits the detected vulnerability and gains access to the closed zone of the web resource (the administration panel). The attempt to exploit the vulnerability is recorded in the log file, and a notification is sent to the security service team. The attacker uses the gained privileges to study the inventory of available resources, finds the fake documents and downloads them. The downloaded documents contain scripts that call the servers controlled by the defending side. The parameters of the call (source of the request, time, etc.) are recorded in the log file. This information can then be used for attacker attribution (what type of information they are interested in, where the workstations used in the attack are located, the subnets, etc.) and to investigate the incident. Detecting an attack by deceiving the attacker Currently, in order to strengthen protection of corporate networks the so-called Threat Deception approach is used. The term ‘deception’ comes from the military sphere, where it refers to a combination of measures aimed at misleading the enemy about one’s presence, location, actions and intentions. In IT security, the objective of this interactive system of protection is to detect an intruder inside the corporate network, identifying their attributes and ultimately removing them from the protected infrastructure. The threat deception approach involves the implementation of interactive protection systems based on the deployment of traps (honeypots) in the corporate network and exploiting specific features of the attacker’s behavior. In most cases, honeypots are set to divert the attacker’s attention from the truly valuable corporate resources (servers, workstations, databases, files, etc.). The use of traps also makes it possible to get information about any interaction between the attacker and the resource (the time interactions occur; types of data attracting the attacker’s attention, toolset used by the attacker, etc.). However, it’s often the case that a poorly deployed trap inside a corporate network will not only be successfully detected and bypassed by the attackers but can serve as an entry point to genuine workstations and servers containing valuable information.
Incorrect implementation of a honeypot in the corporate network can be likened to building a small house next to a larger building containing valuable data. The smaller house is unlikely to divert the attention of the attacker; they will know where the valuable information is and where to look for the “key” to access it. Simply installing and configuring honeypots is not enough to effectively combat cybercriminals; a more nuanced approach to developing scenarios to detect targeted attacks is required. At the very least, it is necessary to carry out an expert evaluation of the attacker’s potential actions, to set honeypots so that the attacker cannot determine which resources (workstations, files on workstations and servers, etc.) are traps and which are not, and to have a plan for dealing with the detected activity. Correct implementation of traps and a rapid response to any events related to them make it possible to build an infrastructure where almost any attacker will lose their way (fail to find the protected information and reveal their presence). Forewarned is forearmed Getting information about a cybercriminal in the corporate network enables the defending side to take measures to protect their valuable data and eliminate the threat: to send the attacker in the wrong direction (e.g., to a dedicated subnet), and thereby concealing valuable resources from their field of view, as well as obtaining additional information about the attacker and their tools, which can be used to investigate the incident further; to identify compromised resources and take all necessary measures to eliminate the threat (e.g., to isolate infected workstations from the rest of the resources on the corporate network); to reconstruct the chronology of actions and movements of the attacker inside the corporate network and to define the entry points so that they can be eliminated. Conclusion The attacker has an advantage over the defender, because they have the ability to thoroughly examine their victim before carrying out an attack. The victim doesn’t know where the attack will come from or what the attacker is interested in, and so has to protect against all possible attack scenarios, which requires a significant amount of time and resources. Implementation of the Threat Deception approach gives the defending side an additional source of information on threats thanks to resource traps. The approach also minimizes the advantage enjoyed by the attacker due to both the early detection of their activity and the information obtained about their profile that enables timely measures to be taken to protect valuable data. It is not necessary to use prohibited “offensive security” methods, which could make the situation worse for the defending side if law enforcement agencies get involved in investigating the incident. Interactive security measures that are based on deceiving the attacker will only gain in popularity as the number of incidents in the corporate and public sector increases. Soon, systems based on the Threat Deception approach will become not just a tool of the researchers but an integral part of a protected infrastructure and yet another source of information about incidents for security services. If you’re interested in implementing the Threat Deception concept described in the post on your corporate network, please complete the form below:
2 notes
·
View notes
Text
Framework "CakePHP": An Introduction & Installation Setup
CakePHP framework: An Overview
This remarkable PHP framework "CakePHP" is an open-source for generating the major web applications. It lets you develop such applications much quicker and also executes your task more manageable by depreciating the necessity of building your application from scratch.
Using PHP framework, the developers are enabled to work in a structured and speedy manner, without losing compliance. A foremost advantage of CakePHP is the appearance of an active developer team and a solid community of users.
About Latest Version:
As per https://cakephp.org/ CakePHP 4.0.0 is as tasty as other major CakePHP releases but will now require you to use PHP 7.2. With a refreshed application skeleton design, CakePHP 4.0.0 comes with a streamlined API making your development and application faster.
While 4.0 contains a number of breaking changes we have prepared an exhaustive migration guide covering all the deprecated and removed features as well as highlighting the shiny new features.
Prerequisites
Before you continue with this tutorial, we hope that you have experience of HTML, Core PHP, and Advance PHP. If you have knowledge about these advanced essentials then learn about CakePHP's installation process in the below section:
How to install CakePHP?
Before we proceed, it is best that you install XAMPP first, which contains PHP, Apache, and MySQL. Let’s get cracking then!
1: Download XAMPP and CakePHP
Download XMPP XAMPPand
And download CakePHP
2: Install XAMPP
Once you have installed XAMPP (version 1.7.3) on your Windows with the default option, all your files will be located in the C:/xampp folder.
3: Mod Rewrite Module
Once XAMPP is installed as the local server, you can then proceed to enable mod_rewrite. To do so, you will have to open the httpd.conf file that is located in C:/xampp/apacheconf and uncomment by removing # from the following line: # LoadModule rewrite_module modules/mod_rewrite.so.
4: Place CakePHP Files in a New Folder
Extract the CakePHP (version 1.3.8) zip file and copy all its contents to your local web server, which in this instance is C:/xampp/htdocs/jack. I have decided to name the CakePHP folder as jack and in it, you will find many files and folders for the framework, including app, cake, docs, vendors, .htaccess, and index.php.
5: Set Up Virtual Host Open the httpd-vhosts.conf file from the C:/xampp/apacheconf/extra in order to set up a new virtual host that can run your CakePHP application. You will have to add the following lines in order to run the application:
<strong>NameVirtualHost *:80 <VirtualHost *:80> ServerAdmin webmaster@localhost DocumentRoot C:/xampp/htdocs/jack ServerName local.jack.com <Directory "C:/xampp/htdocs/jack"> Options Indexes FollowSymLinks Includes ExecCGI AllowOverride All Order allow,deny Allow from all </Directory>
<VirtualHost *:80> ServerAdmin webmaster@localhost DocumentRoot C:/xampp/htdocs/xampp ServerName localhost <Directory "C:/xampp/htdocs/xampp"> Options Indexes FollowSymLinks Includes ExecCGI AllowOverride All Order allow,deny Allow from all </Directory>
```
The httpd-vhosts.conf file will have the aforementioned configuration for virtual hosts to run CakePHP and other php applications. I have decided to choose local.jack.com as the server name, and likewise, we will have to add it to the C:/Windows/System32/drivers/etchosts file as mentioned below:
# LOCALHOST NAME RESOLUTION IS HANDLED WITHIN DNS ITSELF.
127.0.0.1 LOCALHOST
127.0.0.1 LOCAL.JACK.COM
# ::1 LOCALHOST
If your web server is already running, restart it so that you can access the new CakePHP installation by growing to http://local.jack.com through your browser.
6: Setting Up Database Connection
Start off setting up your database connection by renaming the database configuration file to database.php file from database.php.default file, as found in the C:/xampp/htdocs/razib/appconfig folder. Now open the database.php file and enter a username, password, and database name to the ‘$default’ connection variable:
VAR $DEFAULT = ARRAY (
'DRIVER' => 'MYSQL' ,
'PERSISTENT' => FALSE
'HOST' => 'LOCALHOST' ,
'LOGIN' => 'ROOT' ,
'PASSWORD' => ' ' ,
'DATABASE' => 'JACK' ,
'PREFIX' => ' ' ,
);
7: Run CakePHP
Open http://local.jack.com on any browser and CakePHP can now access the database configuration file!
How to change database settings?
1. Open app.php file from config folder.
2. Then Find Datasources array in the file.
'DATASOURCES' => [
'DEFAULT' => [
'CLASSNAME' => 'CAKE\DATABASE\CONNECTION',
'DRIVER' => 'CAKE\DATABASE\DRIVER\MYSQL',
'PERSISTENT' => FALSE,
'HOST' => 'LOCALHOST',
/**
* CAKEPHP WILL USE THE DEFAULT DB PORT BASED ON THE DRIVER SELECTED
* MYSQL ON MAMP USES PORT 8889, MAMP USERS WILL WANT TO UNCOMMENT
* THE FOLLOWING LINE AND SET THE PORT ACCORDINGLY
*/
//'PORT' => 'NON_STANDARD_PORT_NUMBER',
'USERNAME' => 'ROOT',
'PASSWORD' => '',
'DATABASE' => 'MYDATABASE',
'ENCODING' => 'UTF8',
'TIMEZONE' => 'UTC',
'FLAGS' => [],
'CACHEMETADATA' => TRUE,
'LOG' => FALSE,
/**
* SET IDENTIFIER QUOTING TO TRUE IF YOU ARE USING RESERVED WORDS OR
* SPECIAL CHARACTERS IN YOUR TABLE OR COLUMN NAMES. ENABLING THIS
* SETTING WILL RESULT IN QUERIES BUILT USING THE QUERY BUILDER HAVING
* IDENTIFIERS QUOTED WHEN CREATING SQL. IT SHOULD BE NOTED THAT THIS
* DECREASES PERFORMANCE BECAUSE EACH QUERY NEEDS TO BE TRAVERSED AND
* MANIPULATED BEFORE BEING EXECUTED.
*/
'QUOTEIDENTIFIERS' => FALSE,
/**
* DURING DEVELOPMENT, IF USING MYSQL
< 5.6, UNCOMMENTING THE
* FOLLOWING LINE COULD BOOST THE SPEED AT WHICH SCHEMA METADATA IS
* FETCHED FROM THE DATABASE. IT CAN ALSO BE SET DIRECTLY WITH THE
* MYSQL CONFIGURATION DIRECTIVE 'INNODB_STATS_ON_METADATA =
0'
* WHICH IS THE RECOMMENDED VALUE IN PRODUCTION ENVIRONMENTS
*/
//'INIT' =>
['SET GLOBAL INNODB_STATS_ON_METADATA = 0'],
'URL' => ENV('DATABASE_URL', NULL),
],
Why is CakePHP best for Web App development?
Nowadays, there are several open-source alternatives that are simply convenient for many of the companies only to build up their web applications. Moreover, CakePHP is an extreme and exceptional PHP development system that completely allows developers to build site and web applications rapidly. The Web Service of Cakephp additionally provides an essential structure for sorting out records and database table names.
Now look at the few reasons that explain why CakePHP is worldwide popular in Web Application:
Easy and Quick: CakePHP underpins viable and fast methods for the documentation. Consequently, it is very easy to do the documentation for the designers without wasting excessive time for this procedure.
Friendly & Supportive: CakePHP Development which is uniformly developed to share data and expand from each other with such immense numbers of subscribers, it is usually friendly and supportive for the software engineers to quickly acquire the latest instruments and highlights of the CakePHP.
Manageable for data administration: Database administration is totally easy and manageable with the support of CRUD combination highlight. This component provides more additional functionalities to the swift and successful database administration work.
Advantages of CakePHP
CakePHP one can easily install and operate software tools
A brilliant file manager
There are multiple language options in CakePHP
This PHP framework can also be used for e-commerce websites and blog sites.
Manage content and Themes
User management features
Helps reduce web application development cost & time considerably.
RSS feeds and comments
Have customized fields and templates
Disadvantages of CakePHP
One-way routing in CakePHP often proves to be a disadvantage when compared with frameworks such as Ruby on Rails.
While using CakePHP, one needs to update the default routes for creating Fancy URLs. If compared with other frameworks such as Symfony, CakePHP loses battle in this case.
Many still believe that CakePHP is easier to learn. But they haven’t come across frameworks such as CodeIgniter which make learning all the easier!
The documentation for CakePHP definitely needs some work.
Bottom Line
CakePHP has proved to be a very valuable tool and we can say that it has become a favourite among developers. With its amazing features for translating, caching, validating and authenticating, it is the most competent choice for developing a comprehensive content management system. So what are you waiting for? Get out there and build something!
0 notes
Text
Openerp Server Download

OpenERP as a multitenant three-tiers architecture¶
Openerp Server 6.1 Download
Openerp Server Download Pc
Openerp Client
Openerp Server Download Free
This section presents the OpenERP architecture along with technology detailsof the application. The tiers composing OpenERP are presented. Communicationmeans and protocols between the application components are also presented.Some details about used development languages and technology stack are then summarized.
OpenERP is a multitenant, three-tiers architecture:database tier for data storage, application tier for processing and functionalitiesand presentation tier providing user interface. Those are separate layersinside OpenERP. The application tier itself is written as a core; multipleadditional modules can be installed in order to create a particular instanceof OpenERP adapted to specific needs and requirements. Moreover, OpenERPfollows the Model-View-Controller (MVC) architectural pattern.
# The file where the server pid will be stored (default False). #pidfile = /var/run/openerp.pid # The file where the server log will be stored (default False). Logfile = /var/log/openerp-server.log # The unix account on behalf openerp is running. Processuser = zg # The IP address on which the server will bind.
Download OpenERP for free. Insignis OpenERP is driven by the urge to create a multi-layered, platform and programming language independent environment for the development of database driven custom made business applications, all within a 'standard' application environment.
The PostgreSQL download page lists the available installation methods. Choose the one that best suits your needs. You can now start OpenERP Server. You will probably need to modify the OpenERP configuration file according to your needs which is normally located in /.openerprc. Odoo which was previously known as OpenERP was founded in 2005 and since then it got re-branded various times few names previously was TinyERP. The biggest advantage of using Odoo is that it offers you with more than 4000+ apps that can be covered for various business needs and requirements.
A typical deployment of OpenERP is shown on Figure 1. This deployment iscalled Web embedded deployment. As shown, an OpenERP system consists ofthree main components:
a PostgreSQL database server which contains all OpenERP databases.Databases contain all application data, and also most of the OpenERPsystem configuration elements. Note that this server can possibly bedeployed using clustered databases.
the OpenERP Server, which contains all the enterprise logic and ensuresthat OpenERP runs optimally. One layer of the server is dedicated tocommunicate and interface with the PostgreSQL database, the ORM engine.Another layer allows communications between the server and a web browser,the Web layer. Having more than one server is possible, for example inconjunction with a load balancing mechanism.
the client running in the a web browser as javascript application.
The database server and the OpenERP server can be installed on the samecomputer, or distributed onto separate computer servers, for example forperformance considerations.
OpenERP 6.1 architecture for embedded web deployment
The next subsections give details about the different tiers of the OpenERParchitecture.
PostgreSQL database¶

The data tier of OpenERP is provided by a PostgreSQL relational database.While direct SQL queries can be executed from OpenERP modules, most accessesto the relational database are done through the server Object RelationalMapping layer.
Databases contain all application data, and also most of the OpenERP systemconfiguration elements. Note that this server can possibly be deployed usingclustered databases.
OpenERP server¶
OpenERP provides an application server on which specific business applicationscan be built. It is also a complete development framework, offering a rangeof features to write those applications. Among those features, the OpenERPORM provides functionalities and an interface on top of the PostgreSQL server.The OpenERP server also features a specific layer designed to communicatewith the web browser-based client. This layer connects users using standardbrowsers to the server.
Openerp Server 6.1 Download
From a developer perspective, the server acts both as a library which bringsthe above benefits while hiding the low-level details, and as a simple wayto install, configure and run the written applications. The server also containsother services, such as extensible data models and view, workflow engine orreports engine. However, those are OpenERP services not specifically relatedto security, and are therefore not discussed in details in this document.
Server - ORM
The Object Relational Mapping ORM layer is one of the salient features ofthe OpenERP Server. It provides additional and essential functionalitieson top of PostgreSQL server. Data models are described in Python and OpenERPcreates the underlying database tables using this ORM. All the benefits ofRDBMS such as unique constraints, relational integrity or efficient queryingare used and completed by Python flexibility. For instance, arbitrary constraintswritten in Python can be added to any model. Different modular extensibilitymechanisms are also afforded by OpenERP.
It is important to understand the ORM responsibility before attempting toby-pass it and to access directly the underlying database via raw SQL queries.When using the ORM, OpenERP can make sure the data remains free of any corruption.For instance, a module can react to data creation in a particular table.This behavior can occur only if queries go through the ORM.
The services granted by the ORM are among other :
consistency validation by powerful validity checks,
providing an interface on objects (methods, references, ...) allowingto design and implement efficient modules,
row-level security per user and group; more details about users and usergroups are given in the section Users and User Roles,
complex actions on a group of resources,
inheritance service allowing fine modeling of new resources
Server - Web
The web layer offers an interface to communicate with standard browsers.In the 6.1 version of OpenERP, the web-client has been rewritten and integratedinto the OpenERP server tier. This web layer is a WSGI-compatible applicationbased on werkzeug. It handles regular http queries to server static file ordynamic content and JSON-RPC queries for the RPC made from the browser.
Modules
By itself, the OpenERP server is a core. For any enterprise, the value ofOpenERP lies in its different modules. The role of the modules is to implementany business requirement. The server is the only necessary component toadd modules. Any official OpenERP release includes a lot of modules, andhundreds of modules are available thanks to the community. Examples ofsuch modules are Account, CRM, HR, Marketing, MRP, Sale, etc.
Clients¶
As the application logic is mainly contained server-side, the client isconceptually simple. It issues a request to the server, gets data backand display the result (e.g. a list of customers) in different ways(as forms, lists, calendars, ...). Upon user actions, it sends queriesto modify data to the server.
The default client of OpenERP is an JavaScript application running in thebrowser that communicates with the server using JSON-RPC.
Setup a PostgreSQL user for OpenERP¶
When the installations of the required software are done, you must create aPostgreSQL user. This user must be the same as your system user. OpenERP will use this user toconnect to PostgreSQL.
Figure demonstrating how OpenERP uses the PostgreSQL user to interact with it
Tip
Database
Without creating and configuring a PostgreSQL user for OpenERP as described below, you cannot create a database using OpenERP Client.
First Method¶
The default superuser for PostgreSQL is called postgres. You may need to login as thisuser first.
Now create PostgreSQL user openerp using the following command:
Openerp Server Download Pc
Make this new user a superuser. Only then you can create a database using OpenERP Client.In short, openerp is the new user created in PostgreSQL for OpenERP. This user is the ownerof all the tables created by OpenERP Client.
Now check the list of databases created in PostgreSQL using the following command:
You can find the database template1, run the following command to use this database:
To apply access rights to the role openerp for the database which will be created from OpenERP Client,use the following command:
Second Method¶
Another option to create and configure a PostgreSQL user for OpenERP is shown below:
Note
Password
Note that the password is postgres.
Option explanations:
--createdb : the new user will be able to create new databases
--usernamepostgres : createuser will use the postgres user (superuser)
--no-createrole : the new user will not be able to create new users
--pwprompt : createuser will ask you the new user’s password
openerp : the new user’s name
To access your database using pgAdmin III, you must configure the database connection as shown in the following figure:
You can now start OpenERP Server. You will probably need to modify theOpenERP configuration file according to your needs which is normallylocated in ~/.openerprc.
Tip
Openerp Client
Developer Book
Openerp Server Download Free
You can find information on configuration files in the Developer Book, section Configuration
0 notes
Text
How To Build Your Own Comment System Using Firebase
How To Build Your Own Comment System Using Firebase
Aman Thakur
2020-08-24T10:30:00+00:00 2020-08-24T12:31:29+00:00
A comments section is a great way to build a community for your blog. Recently when I started blogging, I thought of adding a comments section. However, it wasn’t easy. Hosted comments systems, such as Disqus and Commento, come with their own set of problems:
They own your data.
They are not free.
You cannot customize them much.
So, I decided to build my own comments system. Firebase seemed like a perfect hosting alternative to running a back-end server.
First of all, you get all of the benefits of having your own database: You control the data, and you can structure it however you want. Secondly, you don’t need to set up a back-end server. You can easily control it from the front end. It’s like having the best of both worlds: a hosted system without the hassle of a back end.
In this post, that’s what we’ll do. We will learn how to set up Firebase with Gatsby, a static site generator. But the principles can be applied to any static site generator.
Let’s dive in!
What Is Firebase?
Firebase is a back end as a service that offers tools for app developers such as database, hosting, cloud functions, authentication, analytics, and storage.
Cloud Firestore (Firebase’s database) is the functionality we will be using for this project. It is a NoSQL database. This means it’s not structured like a SQL database with rows, columns, and tables. You can think of it as a large JSON tree.
Introduction to the Project
Let’s initialize the project by cloning or downloading the repository from GitHub.
I’ve created two branches for every step (one at the beginning and one at the end) to make it easier for you to track the changes as we go.
Let’s run the project using the following command:
gatsby develop
If you open the project in your browser, you will see the bare bones of a basic blog.
(Large preview)
The comments section is not working. It is simply loading a sample comment, and, upon the comment’s submission, it logs the details to the console.
Our main task is to get the comments section working.
How the Comments Section Works
Before doing anything, let’s understand how the code for the comments section works.
Four components are handling the comments sections:
blog-post.js
Comments.js
CommentForm.js
Comment.js
First, we need to identify the comments for a post. This can be done by making a unique ID for each blog post, or we can use the slug, which is always unique.
The blog-post.js file is the layout component for all blog posts. It is the perfect entry point for getting the slug of a blog post. This is done using a GraphQL query.
export const query = graphql` query($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html frontmatter { title } fields { slug } } } `
Before sending it over to the Comments.js component, let’s use the substring() method to get rid of the trailing slash (/) that Gatsby adds to the slug.
const slug = post.fields.slug.substring(1, post.fields.slug.length - 1) return ( ) }
The Comments.js component maps each comment and passes its data over to Comment.js, along with any replies. For this project, I have decided to go one level deep with the commenting system.
The component also loads CommentForm.js to capture any top-level comments.
const Comments = ({ comments, slug }) => { return (
Join the discussion
) }
Let’s move over to CommentForm.js. This file is simple, rendering a comment form and handling its submission. The submission method simply logs the details to the console.
const handleCommentSubmission = async e => { e. preventDefault() let comment = { name: name, content: content, pId: parentId ∣∣ null, time: new Date(), } setName("") setContent("") console.log(comment) }
The Comment.js file has a lot going on. Let’s break it down into smaller pieces.
First, there is a SingleComment component, which renders a comment.
I am using the Adorable API to get a cool avatar. The Moment.js library is used to render time in a human-readable format.
const SingleComment = ({ comment }) => (
{comment.name} says
{comment.time} &&((moment(comment.time.toDate()).calendar()})}
{comment.content}
)
Next in the file is the Comment component. This component shows a child comment if any child comment was passed to it. Otherwise, it renders a reply box, which can be toggled on and off by clicking the “Reply” button or “Cancel Reply” button.
const Comment = ({ comment, child, slug }) => { const [showReplyBox, setShowReplyBox] = useState(false) return (
Now that we have an overview, let’s go through the steps of making our comments section.
1. Add Firebase
First, let’s set up Firebase for our project.
Start by signing up. Go to Firebase, and sign up for a Google account. If you don’t have one, then click “Get Started”.
Click on “Add Project” to add a new project. Add a name for your project, and click “Create a project”.
(Large preview)
Once we have created a project, we’ll need to set up Cloud Firestore.
In the left-side menu, click “Database”. Once a page opens saying “Cloud Firestore”, click “Create database” to create a new Cloud Firestore database.
(Large preview)
When the popup appears, choose “Start in test mode”. Next, pick the Cloud Firestore location closest to you.
(Large preview)
Once you see a page like this, it means you’ve successfully created your Cloud Firestore database.
(Large preview)
Let’s finish by setting up the logic for the application. Go back to the application and install Firebase:
yarn add firebase
Add a new file, firebase.js, in the root directory. Paste this content in it:
import firebase from "firebase/app" import "firebase/firestore" var firebaseConfig = 'yourFirebaseConfig' firebase.initializeApp(firebaseConfig) export const firestore = firebase.firestore() export default firebase
You’ll need to replace yourFirebaseConfig with the one for your project. To find it, click on the gear icon next to “Project Overview” in the Firebase app.
(Large preview)
This opens up the settings page. Under your app’s subheading, click the web icon, which looks like this:
(Large preview)
This opens a popup. In the “App nickname” field, enter any name, and click “Register app”. This will give your firebaseConfig object.
Copy just the contents of the firebaseConfig object, and paste it in the firebase.js file.
Is It OK to Expose Your Firebase API Key?
Yes. As stated by a Google engineer, exposing your API key is OK.
The only purpose of the API key is to identify your project with the database at Google. If you have set strong security rules for Cloud Firestore, then you don’t need to worry if someone gets ahold of your API key.
We’ll talk about security rules in the last section.
For now, we are running Firestore in test mode, so you should not reveal the API key to the public.
How to Use Firestore?
You can store data in one of two types:
collection A collection contains documents. It is like an array of documents.
document A document contains data in a field-value pair.
Remember that a collection may contain only documents and not other collections. But a document may contain other collections.
This means that if we want to store a collection within a collection, then we would store the collection in a document and store that document in a collection, like so:
{collection-1}/{document}/{collection-2}
How to Structure the Data?
Cloud Firestore is hierarchical in nature, so people tend to store data like this:
blog/{blog-post-1}/content/comments/{comment-1}
But storing data in this way often introduces problems.
Say you want to get a comment. You’ll have to look for the comment stored deep inside the blog collection. This will make your code more error-prone. Chris Esplin recommends never using sub-collections.
I would recommend storing data as a flattened object:
blog-posts/{blog-post-1} comments/{comment-1}
This way, you can get and send data easily.
How to Get Data From Firestore?
To get data, Firebase gives you two methods:
get() This is for getting the content once.
onSnapshot() This method sends you data and then continues to send updates unless you unsubscribe.
How to Send Data to Firestore?
Just like with getting data, Firebase has two methods for saving data:
set() This is used to specify the ID of a document.
add() This is used to create documents with automatic IDs.
I know, this has been a lot to grasp. But don’t worry, we’ll revisit these concepts again when we reach the project.
2. Create Sample Date
The next step is to create some sample data for us to query. Let’s do this by going to Firebase.
Go to Cloud Firestore. Click “Start a collection”. Enter comments for the “Collection ID”, then click “Next”.
(Large preview)
For the “Document ID”, click “Auto-ID. Enter the following data and click “Save”.
(Large preview)
While you’re entering data, make sure the “Fields” and “Types” match the screenshot above. Then, click “Save”.
That’s how you add a comment manually in Firestore. The process looks cumbersome, but don’t worry: From now on, our app will take care of adding comments.
At this point, our database looks like this: comments/{comment}.
3. Get the Comments Data
Our sample data is ready to query. Let’s get started by getting the data for our blog.
Go to blog-post.js, and import the Firestore from the Firebase file that we just created.
import {firestore} from "../../firebase.js"
To query, we will use the useEffect hook from React. If you haven’t already, let’s import it as well.
useEffect(() => { firestore .collection(`comments`) .onSnapshot(snapshot => { const posts = snapshot.docs .filter(doc => doc.data().slug === slug) .map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) }, [slug])
The method used to get data is onSnapshot. This is because we also want to listen to state changes. So, the comments will get updated without the user having to refresh the browser.
We used the filter and map methods to find the comments whose slug matches the current slug.
One last thing we need to think about is cleanup. Because onSnapshot continues to send updates, this could introduce a memory leak in our application. Fortunately, Firebase provides a neat fix.
useEffect(() => { const cleanUp = firestore .doc(`comments/${slug}`) .collection("comments") .onSnapshot(snapshot => { const posts = snapshot.docs.map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) return () => cleanUp() }, [slug])
Once you’re done, run gatsby develop to see the changes. We can now see our comments section getting data from Firebase.
(Large preview)
Let’s work on storing the comments.
4. Store Comments
To store comments, navigate to the CommentForm.js file. Let’s import Firestore into this file as well.
import { firestore } from "../../firebase.js"
To save a comment to Firebase, we’ll use the add() method, because we want Firestore to create documents with an auto-ID.
Let’s do that in the handleCommentSubmission method.
firestore .collection(`comments`) .add(comment) .catch(err => { console.error('error adding comment: ', err) })
First, we get the reference to the comments collection, and then add the comment. We’re also using the catch method to catch any errors while adding comments.
At this point, if you open a browser, you can see the comments section working. We can add new comments, as well as post replies. What’s more amazing is that everything works without our having to refresh the page.
(Large preview)
You can also check Firestore to see that it is storing the data.
(Large preview)
Finally, let’s talk about one crucial thing in Firebase: security rules.
5. Tighten Security Rules
Until now, we’ve been running Cloud Firestore in test mode. This means that anybody with access to the URL can add to and read our database. That is scary.
To tackle that, Firebase provides us with security rules. We can create a database pattern and restrict certain activities in Cloud Firestore.
In addition to the two basic operations (read and write), Firebase offers more granular operations: get, list, create, update, and delete.
A read operation can be broken down as:
get Get a single document.
list Get a list of documents or a collection.
A write operation can be broken down as:
create Create a new document.
update Update an existing document.
delete Delete a document.
To secure the application, head back to Cloud Firestore. Under “Rules”, enter this:
service cloud.firestore { match /databases/{database}/documents { match /comments/{id=**} { allow read, create; } } }
On the first line, we define the service, which, in our case, is Firestore. The next lines tell Firebase that anything inside the comments collection may be read and created.
If we had used this:
allow read, write;
… that would mean that users could update and delete existing comments, which we don’t want.
Firebase’s security rules are extremely powerful, allowing us to restrict certain data, activities, and even users.
On To Building Your Own Comments Section
Congrats! You have just seen the power of Firebase. It is such an excellent tool to build secure and fast applications.
We’ve built a super-simple comments section. But there’s no stopping you from exploring further possibilities:
Add profile pictures, and store them in Cloud Storage for Firebase;
Use Firebase to allow users to create an account, and authenticate them using Firebase authentication;
Use Firebase to create inline Medium-like comments.
A great way to start would be to head over to Firestore’s documentation.
Finally, let’s head over to the comments section below and discuss your experience with building a comments section using Firebase.
Smashing Newsletter
Every week, we send out useful front-end & UX techniques. Subscribe and get the Smart Interface Design Checklists PDF delivered to your inbox.
Front-end, design and UX. Sent 2× a month. You can always unsubscribe with just one click.
(ra, yk, al, il)
via Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/3hBcASM
0 notes
Text
How To Build Your Own Comment System Using Firebase
About The Author
Aman is a software developer and a student. He codes, writes, and runs a lot. He usually finds time to study when he is not doing any of those. More about Aman …
Ever wanted to have a comments section for your blog, but were overwhelmed by the high cost and maintenance solutions? Firebase can be your savior. In this guide, we’ll learn how to add a comments section to your blog with Firebase, while learning the basics of Firebase on the way.
A comments section is a great way to build a community for your blog. Recently when I started blogging, I thought of adding a comments section. However, it wasn’t easy. Hosted comments systems, such as Disqus and Commento, come with their own set of problems:
They own your data.
They are not free.
You cannot customize them much.
So, I decided to build my own comments system. Firebase seemed like a perfect hosting alternative to running a back-end server.
First of all, you get all of the benefits of having your own database: You control the data, and you can structure it however you want. Secondly, you don’t need to set up a back-end server. You can easily control it from the front end. It’s like having the best of both worlds: a hosted system without the hassle of a back end.
In this post, that’s what we’ll do. We will learn how to set up Firebase with Gatsby, a static site generator. But the principles can be applied to any static site generator.
Let’s dive in!
What Is Firebase?
Firebase is a back end as a service that offers tools for app developers such as database, hosting, cloud functions, authentication, analytics, and storage.
Cloud Firestore (Firebase’s database) is the functionality we will be using for this project. It is a NoSQL database. This means it’s not structured like a SQL database with rows, columns, and tables. You can think of it as a large JSON tree.
Introduction to the Project
Let’s initialize the project by cloning or downloading the repository from GitHub.
I’ve created two branches for every step (one at the beginning and one at the end) to make it easier for you to track the changes as we go.
Let’s run the project using the following command:
gatsby develop
If you open the project in your browser, you will see the bare bones of a basic blog.
(Large preview)
The comments section is not working. It is simply loading a sample comment, and, upon the comment’s submission, it logs the details to the console.
Our main task is to get the comments section working.
Before doing anything, let’s understand how the code for the comments section works.
Four components are handling the comments sections:
blog-post.js
Comments.js
CommentForm.js
Comment.js
First, we need to identify the comments for a post. This can be done by making a unique ID for each blog post, or we can use the slug, which is always unique.
The blog-post.js file is the layout component for all blog posts. It is the perfect entry point for getting the slug of a blog post. This is done using a GraphQL query.
export const query = graphql` query($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html frontmatter { title } fields { slug } } } `
Before sending it over to the Comments.js component, let’s use the substring() method to get rid of the trailing slash (/) that Gatsby adds to the slug.
const slug = post.fields.slug.substring(1, post.fields.slug.length - 1) return ( <Layout> <div className="container"> <h1>{post.frontmatter.title}</h1> <div dangerouslySetInnerHTML= /> <Comments comments={comments} slug={slug} /> </div> </Layout> ) }
The Comments.js component maps each comment and passes its data over to Comment.js, along with any replies. For this project, I have decided to go one level deep with the commenting system.
The component also loads CommentForm.js to capture any top-level comments.
const Comments = ({ comments, slug }) => { return ( <div> <h2>Join the discussion</h2> <CommentForm slug={slug} /> <CommentList> {comments.length > 0 && comments .filter(comment => !comment.pId) .map(comment => { let child if (comment.id) { child = comments.find(c => comment.id === c.pId) } return ( <Comment key={comment.id} child={child} comment={comment} slug={slug} /> ) })} </CommentList> </div> ) }
Let’s move over to CommentForm.js. This file is simple, rendering a comment form and handling its submission. The submission method simply logs the details to the console.
const handleCommentSubmission = async e => { e. preventDefault() let comment = { name: name, content: content, pId: parentId ∣∣ null, time: new Date(), } setName("") setContent("") console.log(comment) }
The Comment.js file has a lot going on. Let’s break it down into smaller pieces.
First, there is a SingleComment component, which renders a comment.
I am using the Adorable API to get a cool avatar. The Moment.js library is used to render time in a human-readable format.
const SingleComment = ({ comment }) => ( <div> <div className="flex-container"> <div className="flex"> <img src="https://api.adorable.io/avazars/65/[email protected]" alt="Avatar" /> </div> <div className="flex"> <p className="comment-author"> {comment.name} <span>says</span> </p> {comment.time} &&(<time>(moment(comment.time.toDate()).calendar()}</time>)} </div> </div> </p>{comment.content}</p> </div> )
Next in the file is the Comment component. This component shows a child comment if any child comment was passed to it. Otherwise, it renders a reply box, which can be toggled on and off by clicking the “Reply” button or “Cancel Reply” button.
const Comment = ({ comment, child, slug }) => { const [showReplyBox, setShowReplyBox] = useState(false) return ( <CommentBox> <SingleComment comment={comment} /> {child && ( <CommentBox child className=comment-reply"> <SingleComment comment={child} /> </CommentBox> )} {!child && ( <div> {showReplyBox ? ( <div> <button className="btn bare" onClick={() => setShowReplyBoy(false)} > Cancel Reply </button> <CommentForm parentId={comment.id} slug={slug} /> </div> ) : ( <button className="btn bare" onClick={() => setShowReplyBox(true)}> Reply </button> )} </div> )} </div> )} </CommentBox>
Now that we have an overview, let’s go through the steps of making our comments section.
1. Add Firebase
First, let’s set up Firebase for our project.
Start by signing up. Go to Firebase, and sign up for a Google account. If you don’t have one, then click “Get Started”.
Click on “Add Project” to add a new project. Add a name for your project, and click “Create a project”.
(Large preview)
Once we have created a project, we’ll need to set up Cloud Firestore.
In the left-side menu, click “Database”. Once a page opens saying “Cloud Firestore”, click “Create database” to create a new Cloud Firestore database.
(Large preview)
When the popup appears, choose “Start in test mode”. Next, pick the Cloud Firestore location closest to you.
(Large preview)
Once you see a page like this, it means you’ve successfully created your Cloud Firestore database.
(Large preview)
Let’s finish by setting up the logic for the application. Go back to the application and install Firebase:
yarn add firebase
Add a new file, firebase.js, in the root directory. Paste this content in it:
import firebase from "firebase/app" import "firebase/firestore" var firebaseConfig = 'yourFirebaseConfig' firebase.initializeApp(firebaseConfig) export const firestore = firebase.firestore() export default firebase
You’ll need to replace yourFirebaseConfig with the one for your project. To find it, click on the gear icon next to “Project Overview” in the Firebase app.
(Large preview)
This opens up the settings page. Under your app’s subheading, click the web icon, which looks like this:
(Large preview)
This opens a popup. In the “App nickname” field, enter any name, and click “Register app”. This will give your firebaseConfig object.
<!-- The core Firebase JS SDK is always required and must be listed first --> <script src="https://www.gstatic.com/firebasejs/7.15.5/firebase-app.js"></script> <!-- TODO: Add SDKs for Firebase products that you want to use https://firebase.Google.com/docs/web/setup#available-libraries --> <script> // Your web app’s Firebase configuration var firebaseConfig = { ... }; // Initialize Firebase firbase.initializeApp(firebaseConfig); </script>
Copy just the contents of the firebaseConfig object, and paste it in the firebase.js file.
Is It OK to Expose Your Firebase API Key?
Yes. As stated by a Google engineer, exposing your API key is OK.
The only purpose of the API key is to identify your project with the database at Google. If you have set strong security rules for Cloud Firestore, then you don’t need to worry if someone gets ahold of your API key.
We’ll talk about security rules in the last section.
For now, we are running Firestore in test mode, so you should not reveal the API key to the public.
How to Use Firestore?
You can store data in one of two types:
collection A collection contains documents. It is like an array of documents.
document A document contains data in a field-value pair.
Remember that a collection may contain only documents and not other collections. But a document may contain other collections.
This means that if we want to store a collection within a collection, then we would store the collection in a document and store that document in a collection, like so:
{collection-1}/{document}/{collection-2}
How to Structure the Data?
Cloud Firestore is hierarchical in nature, so people tend to store data like this:
blog/{blog-post-1}/content/comments/{comment-1}
But storing data in this way often introduces problems.
Say you want to get a comment. You’ll have to look for the comment stored deep inside the blog collection. This will make your code more error-prone. Chris Esplin recommends never using sub-collections.
I would recommend storing data as a flattened object:
blog-posts/{blog-post-1} comments/{comment-1}
This way, you can get and send data easily.
How to Get Data From Firestore?
To get data, Firebase gives you two methods:
get() This is for getting the content once.
onSnapshot() This method sends you data and then continues to send updates unless you unsubscribe.
How to Send Data to Firestore?
Just like with getting data, Firebase has two methods for saving data:
set() This is used to specify the ID of a document.
add() This is used to create documents with automatic IDs.
I know, this has been a lot to grasp. But don’t worry, we’ll revisit these concepts again when we reach the project.
2. Create Sample Date
The next step is to create some sample data for us to query. Let’s do this by going to Firebase.
Go to Cloud Firestore. Click “Start a collection”. Enter comments for the “Collection ID”, then click “Next”.
(Large preview)
For the “Document ID”, click “Auto-ID. Enter the following data and click “Save”.
(Large preview)
While you’re entering data, make sure the “Fields” and “Types” match the screenshot above. Then, click “Save”.
That’s how you add a comment manually in Firestore. The process looks cumbersome, but don’t worry: From now on, our app will take care of adding comments.
At this point, our database looks like this: comments/{comment}.
Our sample data is ready to query. Let’s get started by getting the data for our blog.
Go to blog-post.js, and import the Firestore from the Firebase file that we just created.
import {firestore} from "../../firebase.js"
To query, we will use the useEffect hook from React. If you haven’t already, let’s import it as well.
useEffect(() => { firestore .collection(`comments`) .onSnapshot(snapshot => { const posts = snapshot.docs .filter(doc => doc.data().slug === slug) .map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) }, [slug])
The method used to get data is onSnapshot. This is because we also want to listen to state changes. So, the comments will get updated without the user having to refresh the browser.
We used the filter and map methods to find the comments whose slug matches the current slug.
One last thing we need to think about is cleanup. Because onSnapshot continues to send updates, this could introduce a memory leak in our application. Fortunately, Firebase provides a neat fix.
useEffect(() => { const cleanUp = firestore .doc(`comments/${slug}`) .collection("comments") .onSnapshot(snapshot => { const posts = snapshot.docs.map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) return () => cleanUp() }, [slug])
Once you’re done, run gatsby develop to see the changes. We can now see our comments section getting data from Firebase.
(Large preview)
Let’s work on storing the comments.
To store comments, navigate to the CommentForm.js file. Let’s import Firestore into this file as well.
import { firestore } from "../../firebase.js"
To save a comment to Firebase, we’ll use the add() method, because we want Firestore to create documents with an auto-ID.
Let’s do that in the handleCommentSubmission method.
firestore .collection(`comments`) .add(comment) .catch(err => { console.error('error adding comment: ', err) })
First, we get the reference to the comments collection, and then add the comment. We’re also using the catch method to catch any errors while adding comments.
At this point, if you open a browser, you can see the comments section working. We can add new comments, as well as post replies. What’s more amazing is that everything works without our having to refresh the page.
(Large preview)
You can also check Firestore to see that it is storing the data.
(Large preview)
Finally, let’s talk about one crucial thing in Firebase: security rules.
5. Tighten Security Rules
Until now, we’ve been running Cloud Firestore in test mode. This means that anybody with access to the URL can add to and read our database. That is scary.
To tackle that, Firebase provides us with security rules. We can create a database pattern and restrict certain activities in Cloud Firestore.
In addition to the two basic operations (read and write), Firebase offers more granular operations: get, list, create, update, and delete.
A read operation can be broken down as:
get Get a single document.
list Get a list of documents or a collection.
A write operation can be broken down as:
create Create a new document.
update Update an existing document.
delete Delete a document.
To secure the application, head back to Cloud Firestore. Under “Rules”, enter this:
service cloud.firestore { match /databases/{database}/documents { match /comments/{id=**} { allow read, create; } } }
On the first line, we define the service, which, in our case, is Firestore. The next lines tell Firebase that anything inside the comments collection may be read and created.
If we had used this:
allow read, write;
… that would mean that users could update and delete existing comments, which we don’t want.
Firebase’s security rules are extremely powerful, allowing us to restrict certain data, activities, and even users.
Congrats! You have just seen the power of Firebase. It is such an excellent tool to build secure and fast applications.
We’ve built a super-simple comments section. But there’s no stopping you from exploring further possibilities:
Add profile pictures, and store them in Cloud Storage for Firebase;
Use Firebase to allow users to create an account, and authenticate them using Firebase authentication;
Use Firebase to create inline Medium-like comments.
A great way to start would be to head over to Firestore’s documentation.
Finally, let’s head over to the comments section below and discuss your experience with building a comments section using Firebase.
(ra, yk, al, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/how-to-build-your-own-comment-system-using-firebase/ source https://scpie.tumblr.com/post/627344381619372032
0 notes
Text
How To Build Your Own Comment System Using Firebase
About The Author
Aman is a software developer and a student. He codes, writes, and runs a lot. He usually finds time to study when he is not doing any of those. More about Aman …
Ever wanted to have a comments section for your blog, but were overwhelmed by the high cost and maintenance solutions? Firebase can be your savior. In this guide, we’ll learn how to add a comments section to your blog with Firebase, while learning the basics of Firebase on the way.
A comments section is a great way to build a community for your blog. Recently when I started blogging, I thought of adding a comments section. However, it wasn’t easy. Hosted comments systems, such as Disqus and Commento, come with their own set of problems:
They own your data.
They are not free.
You cannot customize them much.
So, I decided to build my own comments system. Firebase seemed like a perfect hosting alternative to running a back-end server.
First of all, you get all of the benefits of having your own database: You control the data, and you can structure it however you want. Secondly, you don’t need to set up a back-end server. You can easily control it from the front end. It’s like having the best of both worlds: a hosted system without the hassle of a back end.
In this post, that’s what we’ll do. We will learn how to set up Firebase with Gatsby, a static site generator. But the principles can be applied to any static site generator.
Let’s dive in!
What Is Firebase?
Firebase is a back end as a service that offers tools for app developers such as database, hosting, cloud functions, authentication, analytics, and storage.
Cloud Firestore (Firebase’s database) is the functionality we will be using for this project. It is a NoSQL database. This means it’s not structured like a SQL database with rows, columns, and tables. You can think of it as a large JSON tree.
Introduction to the Project
Let’s initialize the project by cloning or downloading the repository from GitHub.
I’ve created two branches for every step (one at the beginning and one at the end) to make it easier for you to track the changes as we go.
Let’s run the project using the following command:
gatsby develop
If you open the project in your browser, you will see the bare bones of a basic blog.
(Large preview)
The comments section is not working. It is simply loading a sample comment, and, upon the comment’s submission, it logs the details to the console.
Our main task is to get the comments section working.
Before doing anything, let’s understand how the code for the comments section works.
Four components are handling the comments sections:
blog-post.js
Comments.js
CommentForm.js
Comment.js
First, we need to identify the comments for a post. This can be done by making a unique ID for each blog post, or we can use the slug, which is always unique.
The blog-post.js file is the layout component for all blog posts. It is the perfect entry point for getting the slug of a blog post. This is done using a GraphQL query.
export const query = graphql` query($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html frontmatter { title } fields { slug } } } `
Before sending it over to the Comments.js component, let’s use the substring() method to get rid of the trailing slash (/) that Gatsby adds to the slug.
const slug = post.fields.slug.substring(1, post.fields.slug.length - 1) return ( <Layout> <div className="container"> <h1>{post.frontmatter.title}</h1> <div dangerouslySetInnerHTML= /> <Comments comments={comments} slug={slug} /> </div> </Layout> ) }
The Comments.js component maps each comment and passes its data over to Comment.js, along with any replies. For this project, I have decided to go one level deep with the commenting system.
The component also loads CommentForm.js to capture any top-level comments.
const Comments = ({ comments, slug }) => { return ( <div> <h2>Join the discussion</h2> <CommentForm slug={slug} /> <CommentList> {comments.length > 0 && comments .filter(comment => !comment.pId) .map(comment => { let child if (comment.id) { child = comments.find(c => comment.id === c.pId) } return ( <Comment key={comment.id} child={child} comment={comment} slug={slug} /> ) })} </CommentList> </div> ) }
Let’s move over to CommentForm.js. This file is simple, rendering a comment form and handling its submission. The submission method simply logs the details to the console.
const handleCommentSubmission = async e => { e. preventDefault() let comment = { name: name, content: content, pId: parentId ∣∣ null, time: new Date(), } setName("") setContent("") console.log(comment) }
The Comment.js file has a lot going on. Let’s break it down into smaller pieces.
First, there is a SingleComment component, which renders a comment.
I am using the Adorable API to get a cool avatar. The Moment.js library is used to render time in a human-readable format.
const SingleComment = ({ comment }) => ( <div> <div className="flex-container"> <div className="flex"> <img src="https://api.adorable.io/avazars/65/[email protected]" alt="Avatar" /> </div> <div className="flex"> <p className="comment-author"> {comment.name} <span>says</span> </p> {comment.time} &&(<time>(moment(comment.time.toDate()).calendar()}</time>)} </div> </div> </p>{comment.content}</p> </div> )
Next in the file is the Comment component. This component shows a child comment if any child comment was passed to it. Otherwise, it renders a reply box, which can be toggled on and off by clicking the “Reply” button or “Cancel Reply” button.
const Comment = ({ comment, child, slug }) => { const [showReplyBox, setShowReplyBox] = useState(false) return ( <CommentBox> <SingleComment comment={comment} /> {child && ( <CommentBox child className=comment-reply"> <SingleComment comment={child} /> </CommentBox> )} {!child && ( <div> {showReplyBox ? ( <div> <button className="btn bare" onClick={() => setShowReplyBoy(false)} > Cancel Reply </button> <CommentForm parentId={comment.id} slug={slug} /> </div> ) : ( <button className="btn bare" onClick={() => setShowReplyBox(true)}> Reply </button> )} </div> )} </div> )} </CommentBox>
Now that we have an overview, let’s go through the steps of making our comments section.
1. Add Firebase
First, let’s set up Firebase for our project.
Start by signing up. Go to Firebase, and sign up for a Google account. If you don’t have one, then click “Get Started”.
Click on “Add Project” to add a new project. Add a name for your project, and click “Create a project”.
(Large preview)
Once we have created a project, we’ll need to set up Cloud Firestore.
In the left-side menu, click “Database”. Once a page opens saying “Cloud Firestore”, click “Create database” to create a new Cloud Firestore database.
(Large preview)
When the popup appears, choose “Start in test mode”. Next, pick the Cloud Firestore location closest to you.
(Large preview)
Once you see a page like this, it means you’ve successfully created your Cloud Firestore database.
(Large preview)
Let’s finish by setting up the logic for the application. Go back to the application and install Firebase:
yarn add firebase
Add a new file, firebase.js, in the root directory. Paste this content in it:
import firebase from "firebase/app" import "firebase/firestore" var firebaseConfig = 'yourFirebaseConfig' firebase.initializeApp(firebaseConfig) export const firestore = firebase.firestore() export default firebase
You’ll need to replace yourFirebaseConfig with the one for your project. To find it, click on the gear icon next to “Project Overview” in the Firebase app.
(Large preview)
This opens up the settings page. Under your app’s subheading, click the web icon, which looks like this:
(Large preview)
This opens a popup. In the “App nickname” field, enter any name, and click “Register app”. This will give your firebaseConfig object.
<!-- The core Firebase JS SDK is always required and must be listed first --> <script src="https://www.gstatic.com/firebasejs/7.15.5/firebase-app.js"></script> <!-- TODO: Add SDKs for Firebase products that you want to use https://firebase.Google.com/docs/web/setup#available-libraries --> <script> // Your web app’s Firebase configuration var firebaseConfig = { ... }; // Initialize Firebase firbase.initializeApp(firebaseConfig); </script>
Copy just the contents of the firebaseConfig object, and paste it in the firebase.js file.
Is It OK to Expose Your Firebase API Key?
Yes. As stated by a Google engineer, exposing your API key is OK.
The only purpose of the API key is to identify your project with the database at Google. If you have set strong security rules for Cloud Firestore, then you don’t need to worry if someone gets ahold of your API key.
We’ll talk about security rules in the last section.
For now, we are running Firestore in test mode, so you should not reveal the API key to the public.
How to Use Firestore?
You can store data in one of two types:
collection A collection contains documents. It is like an array of documents.
document A document contains data in a field-value pair.
Remember that a collection may contain only documents and not other collections. But a document may contain other collections.
This means that if we want to store a collection within a collection, then we would store the collection in a document and store that document in a collection, like so:
{collection-1}/{document}/{collection-2}
How to Structure the Data?
Cloud Firestore is hierarchical in nature, so people tend to store data like this:
blog/{blog-post-1}/content/comments/{comment-1}
But storing data in this way often introduces problems.
Say you want to get a comment. You’ll have to look for the comment stored deep inside the blog collection. This will make your code more error-prone. Chris Esplin recommends never using sub-collections.
I would recommend storing data as a flattened object:
blog-posts/{blog-post-1} comments/{comment-1}
This way, you can get and send data easily.
How to Get Data From Firestore?
To get data, Firebase gives you two methods:
get() This is for getting the content once.
onSnapshot() This method sends you data and then continues to send updates unless you unsubscribe.
How to Send Data to Firestore?
Just like with getting data, Firebase has two methods for saving data:
set() This is used to specify the ID of a document.
add() This is used to create documents with automatic IDs.
I know, this has been a lot to grasp. But don’t worry, we’ll revisit these concepts again when we reach the project.
2. Create Sample Date
The next step is to create some sample data for us to query. Let’s do this by going to Firebase.
Go to Cloud Firestore. Click “Start a collection”. Enter comments for the “Collection ID”, then click “Next”.
(Large preview)
For the “Document ID”, click “Auto-ID. Enter the following data and click “Save”.
(Large preview)
While you’re entering data, make sure the “Fields” and “Types” match the screenshot above. Then, click “Save”.
That’s how you add a comment manually in Firestore. The process looks cumbersome, but don’t worry: From now on, our app will take care of adding comments.
At this point, our database looks like this: comments/{comment}.
Our sample data is ready to query. Let’s get started by getting the data for our blog.
Go to blog-post.js, and import the Firestore from the Firebase file that we just created.
import {firestore} from "../../firebase.js"
To query, we will use the useEffect hook from React. If you haven’t already, let’s import it as well.
useEffect(() => { firestore .collection(`comments`) .onSnapshot(snapshot => { const posts = snapshot.docs .filter(doc => doc.data().slug === slug) .map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) }, [slug])
The method used to get data is onSnapshot. This is because we also want to listen to state changes. So, the comments will get updated without the user having to refresh the browser.
We used the filter and map methods to find the comments whose slug matches the current slug.
One last thing we need to think about is cleanup. Because onSnapshot continues to send updates, this could introduce a memory leak in our application. Fortunately, Firebase provides a neat fix.
useEffect(() => { const cleanUp = firestore .doc(`comments/${slug}`) .collection("comments") .onSnapshot(snapshot => { const posts = snapshot.docs.map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) return () => cleanUp() }, [slug])
Once you’re done, run gatsby develop to see the changes. We can now see our comments section getting data from Firebase.
(Large preview)
Let’s work on storing the comments.
To store comments, navigate to the CommentForm.js file. Let’s import Firestore into this file as well.
import { firestore } from "../../firebase.js"
To save a comment to Firebase, we’ll use the add() method, because we want Firestore to create documents with an auto-ID.
Let’s do that in the handleCommentSubmission method.
firestore .collection(`comments`) .add(comment) .catch(err => { console.error('error adding comment: ', err) })
First, we get the reference to the comments collection, and then add the comment. We’re also using the catch method to catch any errors while adding comments.
At this point, if you open a browser, you can see the comments section working. We can add new comments, as well as post replies. What’s more amazing is that everything works without our having to refresh the page.
(Large preview)
You can also check Firestore to see that it is storing the data.
(Large preview)
Finally, let’s talk about one crucial thing in Firebase: security rules.
5. Tighten Security Rules
Until now, we’ve been running Cloud Firestore in test mode. This means that anybody with access to the URL can add to and read our database. That is scary.
To tackle that, Firebase provides us with security rules. We can create a database pattern and restrict certain activities in Cloud Firestore.
In addition to the two basic operations (read and write), Firebase offers more granular operations: get, list, create, update, and delete.
A read operation can be broken down as:
get Get a single document.
list Get a list of documents or a collection.
A write operation can be broken down as:
create Create a new document.
update Update an existing document.
delete Delete a document.
To secure the application, head back to Cloud Firestore. Under “Rules”, enter this:
service cloud.firestore { match /databases/{database}/documents { match /comments/{id=**} { allow read, create; } } }
On the first line, we define the service, which, in our case, is Firestore. The next lines tell Firebase that anything inside the comments collection may be read and created.
If we had used this:
allow read, write;
… that would mean that users could update and delete existing comments, which we don’t want.
Firebase’s security rules are extremely powerful, allowing us to restrict certain data, activities, and even users.
Congrats! You have just seen the power of Firebase. It is such an excellent tool to build secure and fast applications.
We’ve built a super-simple comments section. But there’s no stopping you from exploring further possibilities:
Add profile pictures, and store them in Cloud Storage for Firebase;
Use Firebase to allow users to create an account, and authenticate them using Firebase authentication;
Use Firebase to create inline Medium-like comments.
A great way to start would be to head over to Firestore’s documentation.
Finally, let’s head over to the comments section below and discuss your experience with building a comments section using Firebase.
(ra, yk, al, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/how-to-build-your-own-comment-system-using-firebase/
0 notes
Text
How To Build Your Own Comment System Using Firebase
About The Author
Aman is a software developer and a student. He codes, writes, and runs a lot. He usually finds time to study when he is not doing any of those. More about Aman …
Ever wanted to have a comments section for your blog, but were overwhelmed by the high cost and maintenance solutions? Firebase can be your savior. In this guide, we’ll learn how to add a comments section to your blog with Firebase, while learning the basics of Firebase on the way.
A comments section is a great way to build a community for your blog. Recently when I started blogging, I thought of adding a comments section. However, it wasn’t easy. Hosted comments systems, such as Disqus and Commento, come with their own set of problems:
They own your data.
They are not free.
You cannot customize them much.
So, I decided to build my own comments system. Firebase seemed like a perfect hosting alternative to running a back-end server.
First of all, you get all of the benefits of having your own database: You control the data, and you can structure it however you want. Secondly, you don’t need to set up a back-end server. You can easily control it from the front end. It’s like having the best of both worlds: a hosted system without the hassle of a back end.
In this post, that’s what we’ll do. We will learn how to set up Firebase with Gatsby, a static site generator. But the principles can be applied to any static site generator.
Let’s dive in!
What Is Firebase?
Firebase is a back end as a service that offers tools for app developers such as database, hosting, cloud functions, authentication, analytics, and storage.
Cloud Firestore (Firebase’s database) is the functionality we will be using for this project. It is a NoSQL database. This means it’s not structured like a SQL database with rows, columns, and tables. You can think of it as a large JSON tree.
Introduction to the Project
Let’s initialize the project by cloning or downloading the repository from GitHub.
I’ve created two branches for every step (one at the beginning and one at the end) to make it easier for you to track the changes as we go.
Let’s run the project using the following command:
gatsby develop
If you open the project in your browser, you will see the bare bones of a basic blog.
(Large preview)
The comments section is not working. It is simply loading a sample comment, and, upon the comment’s submission, it logs the details to the console.
Our main task is to get the comments section working.
Before doing anything, let’s understand how the code for the comments section works.
Four components are handling the comments sections:
blog-post.js
Comments.js
CommentForm.js
Comment.js
First, we need to identify the comments for a post. This can be done by making a unique ID for each blog post, or we can use the slug, which is always unique.
The blog-post.js file is the layout component for all blog posts. It is the perfect entry point for getting the slug of a blog post. This is done using a GraphQL query.
export const query = graphql` query($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html frontmatter { title } fields { slug } } } `
Before sending it over to the Comments.js component, let’s use the substring() method to get rid of the trailing slash (/) that Gatsby adds to the slug.
const slug = post.fields.slug.substring(1, post.fields.slug.length - 1) return ( <Layout> <div className="container"> <h1>{post.frontmatter.title}</h1> <div dangerouslySetInnerHTML= /> <Comments comments={comments} slug={slug} /> </div> </Layout> ) }
The Comments.js component maps each comment and passes its data over to Comment.js, along with any replies. For this project, I have decided to go one level deep with the commenting system.
The component also loads CommentForm.js to capture any top-level comments.
const Comments = ({ comments, slug }) => { return ( <div> <h2>Join the discussion</h2> <CommentForm slug={slug} /> <CommentList> {comments.length > 0 && comments .filter(comment => !comment.pId) .map(comment => { let child if (comment.id) { child = comments.find(c => comment.id === c.pId) } return ( <Comment key={comment.id} child={child} comment={comment} slug={slug} /> ) })} </CommentList> </div> ) }
Let’s move over to CommentForm.js. This file is simple, rendering a comment form and handling its submission. The submission method simply logs the details to the console.
const handleCommentSubmission = async e => { e. preventDefault() let comment = { name: name, content: content, pId: parentId ∣∣ null, time: new Date(), } setName("") setContent("") console.log(comment) }
The Comment.js file has a lot going on. Let’s break it down into smaller pieces.
First, there is a SingleComment component, which renders a comment.
I am using the Adorable API to get a cool avatar. The Moment.js library is used to render time in a human-readable format.
const SingleComment = ({ comment }) => ( <div> <div className="flex-container"> <div className="flex"> <img src="https://api.adorable.io/avazars/65/[email protected]" alt="Avatar" /> </div> <div className="flex"> <p className="comment-author"> {comment.name} <span>says</span> </p> {comment.time} &&(<time>(moment(comment.time.toDate()).calendar()}</time>)} </div> </div> </p>{comment.content}</p> </div> )
Next in the file is the Comment component. This component shows a child comment if any child comment was passed to it. Otherwise, it renders a reply box, which can be toggled on and off by clicking the “Reply” button or “Cancel Reply” button.
const Comment = ({ comment, child, slug }) => { const [showReplyBox, setShowReplyBox] = useState(false) return ( <CommentBox> <SingleComment comment={comment} /> {child && ( <CommentBox child className=comment-reply"> <SingleComment comment={child} /> </CommentBox> )} {!child && ( <div> {showReplyBox ? ( <div> <button className="btn bare" onClick={() => setShowReplyBoy(false)} > Cancel Reply </button> <CommentForm parentId={comment.id} slug={slug} /> </div> ) : ( <button className="btn bare" onClick={() => setShowReplyBox(true)}> Reply </button> )} </div> )} </div> )} </CommentBox>
Now that we have an overview, let’s go through the steps of making our comments section.
1. Add Firebase
First, let’s set up Firebase for our project.
Start by signing up. Go to Firebase, and sign up for a Google account. If you don’t have one, then click “Get Started”.
Click on “Add Project” to add a new project. Add a name for your project, and click “Create a project”.
(Large preview)
Once we have created a project, we’ll need to set up Cloud Firestore.
In the left-side menu, click “Database”. Once a page opens saying “Cloud Firestore”, click “Create database” to create a new Cloud Firestore database.
(Large preview)
When the popup appears, choose “Start in test mode”. Next, pick the Cloud Firestore location closest to you.
(Large preview)
Once you see a page like this, it means you’ve successfully created your Cloud Firestore database.
(Large preview)
Let’s finish by setting up the logic for the application. Go back to the application and install Firebase:
yarn add firebase
Add a new file, firebase.js, in the root directory. Paste this content in it:
import firebase from "firebase/app" import "firebase/firestore" var firebaseConfig = 'yourFirebaseConfig' firebase.initializeApp(firebaseConfig) export const firestore = firebase.firestore() export default firebase
You’ll need to replace yourFirebaseConfig with the one for your project. To find it, click on the gear icon next to “Project Overview” in the Firebase app.
(Large preview)
This opens up the settings page. Under your app’s subheading, click the web icon, which looks like this:
(Large preview)
This opens a popup. In the “App nickname” field, enter any name, and click “Register app”. This will give your firebaseConfig object.
<!-- The core Firebase JS SDK is always required and must be listed first --> <script src="https://www.gstatic.com/firebasejs/7.15.5/firebase-app.js"></script> <!-- TODO: Add SDKs for Firebase products that you want to use https://firebase.Google.com/docs/web/setup#available-libraries --> <script> // Your web app’s Firebase configuration var firebaseConfig = { ... }; // Initialize Firebase firbase.initializeApp(firebaseConfig); </script>
Copy just the contents of the firebaseConfig object, and paste it in the firebase.js file.
Is It OK to Expose Your Firebase API Key?
Yes. As stated by a Google engineer, exposing your API key is OK.
The only purpose of the API key is to identify your project with the database at Google. If you have set strong security rules for Cloud Firestore, then you don’t need to worry if someone gets ahold of your API key.
We’ll talk about security rules in the last section.
For now, we are running Firestore in test mode, so you should not reveal the API key to the public.
How to Use Firestore?
You can store data in one of two types:
collection A collection contains documents. It is like an array of documents.
document A document contains data in a field-value pair.
Remember that a collection may contain only documents and not other collections. But a document may contain other collections.
This means that if we want to store a collection within a collection, then we would store the collection in a document and store that document in a collection, like so:
{collection-1}/{document}/{collection-2}
How to Structure the Data?
Cloud Firestore is hierarchical in nature, so people tend to store data like this:
blog/{blog-post-1}/content/comments/{comment-1}
But storing data in this way often introduces problems.
Say you want to get a comment. You’ll have to look for the comment stored deep inside the blog collection. This will make your code more error-prone. Chris Esplin recommends never using sub-collections.
I would recommend storing data as a flattened object:
blog-posts/{blog-post-1} comments/{comment-1}
This way, you can get and send data easily.
How to Get Data From Firestore?
To get data, Firebase gives you two methods:
get() This is for getting the content once.
onSnapshot() This method sends you data and then continues to send updates unless you unsubscribe.
How to Send Data to Firestore?
Just like with getting data, Firebase has two methods for saving data:
set() This is used to specify the ID of a document.
add() This is used to create documents with automatic IDs.
I know, this has been a lot to grasp. But don’t worry, we’ll revisit these concepts again when we reach the project.
2. Create Sample Date
The next step is to create some sample data for us to query. Let’s do this by going to Firebase.
Go to Cloud Firestore. Click “Start a collection”. Enter comments for the “Collection ID”, then click “Next”.
(Large preview)
For the “Document ID”, click “Auto-ID. Enter the following data and click “Save”.
(Large preview)
While you’re entering data, make sure the “Fields” and “Types” match the screenshot above. Then, click “Save”.
That’s how you add a comment manually in Firestore. The process looks cumbersome, but don’t worry: From now on, our app will take care of adding comments.
At this point, our database looks like this: comments/{comment}.
Our sample data is ready to query. Let’s get started by getting the data for our blog.
Go to blog-post.js, and import the Firestore from the Firebase file that we just created.
import {firestore} from "../../firebase.js"
To query, we will use the useEffect hook from React. If you haven’t already, let’s import it as well.
useEffect(() => { firestore .collection(`comments`) .onSnapshot(snapshot => { const posts = snapshot.docs .filter(doc => doc.data().slug === slug) .map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) }, [slug])
The method used to get data is onSnapshot. This is because we also want to listen to state changes. So, the comments will get updated without the user having to refresh the browser.
We used the filter and map methods to find the comments whose slug matches the current slug.
One last thing we need to think about is cleanup. Because onSnapshot continues to send updates, this could introduce a memory leak in our application. Fortunately, Firebase provides a neat fix.
useEffect(() => { const cleanUp = firestore .doc(`comments/${slug}`) .collection("comments") .onSnapshot(snapshot => { const posts = snapshot.docs.map(doc => { return { id: doc.id, ...doc.data() } }) setComments(posts) }) return () => cleanUp() }, [slug])
Once you’re done, run gatsby develop to see the changes. We can now see our comments section getting data from Firebase.
(Large preview)
Let’s work on storing the comments.
To store comments, navigate to the CommentForm.js file. Let’s import Firestore into this file as well.
import { firestore } from "../../firebase.js"
To save a comment to Firebase, we’ll use the add() method, because we want Firestore to create documents with an auto-ID.
Let’s do that in the handleCommentSubmission method.
firestore .collection(`comments`) .add(comment) .catch(err => { console.error('error adding comment: ', err) })
First, we get the reference to the comments collection, and then add the comment. We’re also using the catch method to catch any errors while adding comments.
At this point, if you open a browser, you can see the comments section working. We can add new comments, as well as post replies. What’s more amazing is that everything works without our having to refresh the page.
(Large preview)
You can also check Firestore to see that it is storing the data.
(Large preview)
Finally, let’s talk about one crucial thing in Firebase: security rules.
5. Tighten Security Rules
Until now, we’ve been running Cloud Firestore in test mode. This means that anybody with access to the URL can add to and read our database. That is scary.
To tackle that, Firebase provides us with security rules. We can create a database pattern and restrict certain activities in Cloud Firestore.
In addition to the two basic operations (read and write), Firebase offers more granular operations: get, list, create, update, and delete.
A read operation can be broken down as:
get Get a single document.
list Get a list of documents or a collection.
A write operation can be broken down as:
create Create a new document.
update Update an existing document.
delete Delete a document.
To secure the application, head back to Cloud Firestore. Under “Rules”, enter this:
service cloud.firestore { match /databases/{database}/documents { match /comments/{id=**} { allow read, create; } } }
On the first line, we define the service, which, in our case, is Firestore. The next lines tell Firebase that anything inside the comments collection may be read and created.
If we had used this:
allow read, write;
… that would mean that users could update and delete existing comments, which we don’t want.
Firebase’s security rules are extremely powerful, allowing us to restrict certain data, activities, and even users.
Congrats! You have just seen the power of Firebase. It is such an excellent tool to build secure and fast applications.
We’ve built a super-simple comments section. But there’s no stopping you from exploring further possibilities:
Add profile pictures, and store them in Cloud Storage for Firebase;
Use Firebase to allow users to create an account, and authenticate them using Firebase authentication;
Use Firebase to create inline Medium-like comments.
A great way to start would be to head over to Firestore’s documentation.
Finally, let’s head over to the comments section below and discuss your experience with building a comments section using Firebase.
(ra, yk, al, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/how-to-build-your-own-comment-system-using-firebase/ source https://scpie1.blogspot.com/2020/08/how-to-build-your-own-comment-system.html
0 notes
Link
Challenge
While a plethora of information on changes made to a database is recorded in transaction log files, SQL Server transaction log reading has always been a big challenge for all SQL Server users since Microsoft never offered a built-in solution which would allow users to immerse themselves and explore the depths of transaction log files. Furthermore, lack of in-house features that would help understand, process, or analyze information within the transaction log files practically made it mandatory for users to turn towards 3rd party solutions.
In this article, the most important SQL Server transaction log reading features and requirements will be discussed, which will help find and pick the best solution for requirements at hand as well as offer powerful overall auditing and recovery capabilities.
Data sources
When SQL Server transaction log reading is considered, it is important to first and foremost understand that there are different types of transaction log files which can be used as an auditing data source:
Online transaction log (LDF) – currently active transaction log files which store latest database changes
Transaction log and full database backups – backups of ‘old’ transaction log files which are most often created automatically on a pre-determined schedule
Detached transaction log – online log files which can be detached from the SQL Server for the purpose of migration or similar
3rd party tool solution
With the above in mind, finding the tool that will be able to handle all transaction log types and produce maximum results is a prime pick. ApexSQL Log, a SQL Server transaction log reading tool, can handle all the above-mentioned transaction log types. As long as *some* transaction log files are available, auditing will be possible, and so will be other related features based on gathering and processing transaction log data information.
The most important take from this is that the nature of SQL Server transaction log reading allows users two separate types of auditing:
On-demand and continuous auditing – where auditing can be performed on a regular basis and audited data stored in various output formats, including SQL database, SQL script, XML, HTML and more
Forensic auditing – which is ideal for post-disaster or ‘point in time’ auditing jobs when there is a requirement to audit operations which occurred sometime in the past, including the time before the auditing tool was even introduced in the production environment
What is audited
SQL Server transaction log reading should always yield results rich in information on audited events.
First and foremost, it is important to ensure that all DML and DDL operations are audited. This includes:
DML: Insert, Update, Delete
DDL: Create, Alter, Drop, Other
As well as being able to extract these operations over various objects, such as: Tables, Views, Schemas, Procedures, Triggers, Primary keys, Foreign keys, Indexes, Permissions, Functions, Sequences, Defaults, Check constraints, Rules, Statistic and more:
Next, once SQL Server transaction log reading is performed, the auditing tool should be able to extract various information on transactions and operations (from the t-log files), including the name and ID of the user that performed the operation, operation state, schema, time, LSN and more. Here is an example of standard information shown in the previously mentioned ApexSQL Log:
In a similar manner, various operation details and important information can be seen on each audited event/operation:
Operation details – including exact information on ‘what has been changed’ – for example – details on what was changed by the DML operation. An important extension here is the auditing of exact field values on update/delete operations – auditing the field values before the change and after the change is an important feature for any SQL Server transaction log reading solution since it not only allows users to see the original (and new) state of the data in the table field but also sets foundations for manual and automatic recovery as well:
Row history – complete historical information on the specified row, from the initial insert, all the way to the final update/delete
Individual scripts to roll the operation back/forward
A comprehensive overview of audited data
Any data audited via any type of tool or tool brand is as good as its ability to quickly and in an easy way display the results to the user and allow them to analyze and process it without much effort.
If the attention is moved to the Grid overview in ApexSQL Log, it shows a great example of displaying a vast amount of information in a comprehensive and easy to use grid where each operation/event can be individually analyzed and investigated:
Furthermore, when dealing with vast amounts of audited data, having at hand many different filters that can be used to narrow down the results is a powerful tool for any analyst and DBA as well. SQL Server transaction log reading is way easier when tools allow filtering by operation, object, users, transactions, table field values, Server process IDs, Transaction descriptions, and more:
Reporting and saving/exporting audited data
Analyzing data gathered using SQL Server transaction log reading is very important for immediate insight into ‘who changed what’ in the SQL Server databases. Reporting, on the other hand, must allow different users to comply with auditing requirements to create comprehensive and highly focused reports in various formats. ApexSQL Log, for example, allows reports exporting into various formats, including SQL script or SQL bulk files, XML, HTML, CSV, or directly into an existing SQL Server database. Furthermore, different auditing/reporting jobs can be run to focus on only specific events, users, or time frames using different filters mentioned above:
Remote auditing
Many production environments span across a large number of servers, which may host dozens or even hundreds of individual SQL Servers. For these environments, it is particularly important to ensure that auditing can be centralized from the main GUI, and all remotely located SQL Server instances can be accessed and audited remotely with minimal intrusion.
In this example, ApexSQL Log utilizes a simple Windows service called ‘server-side components’, which allows the tool to remotely access SQL Server and all related log files after installing it in the production. No components go on the SQL Server itself, so production intrusion is kept at the bare minimum.
Continuous (unattended) auditing, automation and Command line support
Another quality of life feature in high demand is the tool’s ability to allow unattended continuous auditing. This means that the auditing will run on a pre-determined frequency (e.g., every 10 minutes) and generate auditing output as per configured details. Also, since many different transaction log backups may be included in the job, it is important to ensure that no data is missed, as well as there are no duplicate data entries to ensure a high-quality auditing trail, which is easy to work with. ApexSQL Log fully supports command line interface, and all options available in the GUI are available in full in CLI as well – and these are the strong foundations for any automation using PowerShell or batch files. To further simplify this, ApexSQL Log allows users to create their auditing configuration in GUI and then automatically creates PowerShell/batch files with all corresponding CLI switches for all GUI options.
Bonus features
Now that we’ve looked at those prime features to aim at when eyeing SQL Server transaction log reading solution, let’s look at some of the additional features which can tilt the scale and allow users to opt for the best potential solution which plethora of features for auditing, and for a couple of additional key areas which open up after digging deep into the secrets of transaction log files.
Disaster recovery
Yes! Disaster recovery by reading from transaction log files is indeed possible, and with a simple effort to add. ApexSQL Log demonstrates and allows recovery from malicious or inadvertent changes by first reading the operation information from the transaction logs file, and then allows users to create “undo” or “rollback” scripts which reverse the operation back and bring the data or structure back to the original state. E.g., if a set of data is deleted, ApexSQL Log will undo this by inserting the data back to the table. Same for updates – table fields that were updated to a new value can be again updated to the ‘old’ value, reverting the state of data (or structure in some cases) back to how it was.
Replication
High demand for replicating changes in SQL Server environments is all-present on the IT scene. While some built-in replication mechanisms are available in SQL Server itself, most of them lack many important features, are poorly implemented, or have big flaws/limitations. Alternatively, ApexSQL Log, as our solution of choice, has a strong replication potential and capabilities. Similar to the recovery mechanism mentioned above, instead of creating a rollback script, ApexSQL Log can create a “replay” script which will mimic the change and create a script that can be executed on another database/table to keep them in sync. Pair this feature with the before-mentioned automation, and the replication solution is born.
Support plan
Auditing, as well as aforementioned recovery and replication, are tedious tasks, which leave no room for mistakes or setbacks. Even with the strong solution in place, environment hazards should always be taken into consideration and planning ahead for these moments, which can put entire production to a halt, has and will always be a prime concern for DBAs. So will the ability to keep any downtime at a minimum. Here, a strong support plan and availability of support tech is crucial to be able to get ahold of them promptly and ensure the resolution is quick and effective may be the one to tip the scale. Taking ApexSQL Log into consideration, support plans allow users 24/7, 365-day access to the support techs to jump in and assist with critical tasks.
Final words
As seen above, when choosing the best possible SQL Server transaction log reading solution, it is important to pay attention to the following:
Ability to read from different data sources (logs, backups, LDF)
Ability to audit different DML and DDL operations
Ability to audit different SQL Servers across the network/domain from a central point and minimal production intrusion
Ease of use and easy, yet powerful, analytical access to the audited data
Multiple reporting options and QOL features
Unattended auditing
Bonus/additional features which open up new perspectives and add additional important transaction log reading based solutions like replication or recovery
While not all of these features will be mandatory/important to all those that intend to perform SQL Server transaction log reading, they do offer a strong foundation and advise on how to evaluate best potential solution for the auditing requirement at hand and decide on how to meet compliance requirements as well.
0 notes