#Git merge conflicts
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Top 10 ChatGPT Prompts For Software Developers

ChatGPT can do a lot more than just code creation and this blog post is going to be all about that. We have curated a list of ChatGPT prompts that will help software developers with their everyday tasks. ChatGPT can respond to questions and can compose codes making it a very helpful tool for software engineers.
While this AI tool can help��developers with the entire SDLC (Software Development Lifecycle), it is important to understand how to use the prompts effectively for different needs.
Prompt engineering gives users accurate results. Since ChatGPT accepts prompts, we receive more precise answers. But a lot depends on how these prompts are formulated.
To Get The Best Out Of ChatGPT, Your Prompts Should Be:
Clear and well-defined. The more detailed your prompts, the better suggestions you will receive from ChatGPT.
Specify the functionality and programming language. Not specifying what you exactly need might not give you the desired results.
Phrase your prompts in a natural language, as if asking someone for help. This will make ChatGPT understand your problem better and give more relevant outputs.
Avoid unnecessary information and ambiguity. Keep it not only to the point but also inclusive of all important details.
Top ChatGPT Prompts For Software Developers
Let’s quickly have a look at some of the best ChatGPT prompts to assist you with various stages of your Software development lifecycle.
1. For Practicing SQL Commands;

2. For Becoming A Programming Language Interpreter;

3. For Creating Regular Expressions Since They Help In Managing, Locating, And Matching Text.

4. For Generating Architectural Diagrams For Your Software Requirements.
Prompt Examples: I want you to act as a Graphviz DOT generator, an expert to create meaningful diagrams. The diagram should have at least n nodes (I specify n in my input by writing [n], 10 being the default value) and to be an accurate and complex representation of the given input. Each node is indexed by a number to reduce the size of the output, should not include any styling, and with layout=neato, overlap=false, node [shape=rectangle] as parameters. The code should be valid, bugless and returned on a single line, without any explanation. Provide a clear and organized diagram, the relationships between the nodes have to make sense for an expert of that input. My first diagram is: “The water cycle [8]”.

5. For Solving Git Problems And Getting Guidance On Overcoming Them.
Prompt Examples: “Explain how to resolve this Git merge conflict: [conflict details].” 6. For Code generation- ChatGPT can help generate a code based on descriptions given by you. It can write pieces of codes based on the requirements given in the input. Prompt Examples: -Write a program/function to {explain functionality} in {programming language} -Create a code snippet for checking if a file exists in Python. -Create a function that merges two lists into a dictionary in JavaScript.
7. For Code Review And Debugging: ChatGPT Can Review Your Code Snippet And Also Share Bugs.
Prompt Examples: -Here’s a C# code snippet. The function is supposed to return the maximum value from the given list, but it’s not returning the expected output. Can you identify the problem? [Enter your code here] -Can you help me debug this error message from my C# program: [error message] -Help me debug this Python script that processes a list of objects and suggests possible fixes. [Enter your code here]
8. For Knowing The Coding Best Practices And Principles: It Is Very Important To Be Updated With Industry’s Best Practices In Coding. This Helps To Maintain The Codebase When The Organization Grows.
Prompt Examples: -What are some common mistakes to avoid when writing code? -What are the best practices for security testing? -Show me best practices for writing {concept or function} in {programming language}.
9. For Code Optimization: ChatGPT Can Help Optimize The Code And Enhance Its Readability And Performance To Make It Look More Efficient.
Prompt Examples: -Optimize the following {programming language} code which {explain the functioning}: {code snippet} -Suggest improvements to optimize this C# function: [code snippet] -What are some strategies for reducing memory usage and optimizing data structures?
10. For Creating Boilerplate Code: ChatGPT Can Help In Boilerplate Code Generation.
Prompt Examples: -Create a basic Java Spring Boot application boilerplate code. -Create a basic Python class boilerplate code
11. For Bug Fixes: Using ChatGPT Helps Fixing The Bugs Thus Saving A Large Chunk Of Time In Software Development And Also Increasing Productivity.
Prompt Examples: -How do I fix the following {programming language} code which {explain the functioning}? {code snippet} -Can you generate a bug report? -Find bugs in the following JavaScript code: (enter code)
12. Code Refactoring- ChatGPt Can Refactor The Code And Reduce Errors To Enhance Code Efficiency, Thus Making It Easier To Modify In The Future.
Prompt Examples –What are some techniques for refactoring code to improve code reuse and promote the use of design patterns? -I have duplicate code in my project. How can I refactor it to eliminate redundancy?
13. For Choosing Deployment Strategies- ChatGPT Can Suggest Deployment Strategies Best Suited For A Particular Project And To Ensure That It Runs Smoothly.
Prompt Examples -What are the best deployment strategies for this software project? {explain the project} -What are the best practices for version control and release management?
14. For Creating Unit Tests- ChatGPT Can Write Test Cases For You
Prompt Examples: -How does test-driven development help improve code quality? -What are some best practices for implementing test-driven development in a project? These were some prompt examples for you that we sourced on the basis of different requirements a developer can have. So whether you have to generate a code or understand a concept, ChatGPT can really make a developer’s life by doing a lot of tasks. However, it certainly comes with its own set of challenges and cannot always be completely correct. So it is advisable to cross-check the responses. Hope this helps. Visit us- Intelliatech
#ChatGPT prompts#Developers#Terminal commands#JavaScript console#API integration#SQL commands#Programming language interpreter#Regular expressions#Code debugging#Architectural diagrams#Performance optimization#Git merge conflicts#Prompt engineering#Code generation#Code refactoring#Debugging#Coding best practices#Code optimization#Code commenting#Boilerplate code#Software developers#Programming challenges#Software documentation#Workflow automation#SDLC (Software Development Lifecycle)#Project planning#Software requirements#Design patterns#Deployment strategies#Security testing
0 notes
Text
working devops and being responsible for code management across a large project will have you feel like some kind of administrator of time travel and you can see people fucking up the entire timeline every few weeks because they are all unaware of what the other idiots are doing
13 notes
·
View notes
Text
1 note
·
View note
Text
Messing up branches is shockingly easy tbh, nothing makes my brain ache like trying to fix a merge conflict in a unity project lmao
I love how git only has two functions, but people somehow manage to make this the most convoluted bullshit ever.
I am starting to remember why I hate webdev
#but yeah#it's generally pretty simple#and merge conflicts are usually avoidable/solvable#so i do quite like git
12 notes
·
View notes
Text
Man do I hate programming. Writing code is fine, sometimes I like it, but everything surrounding the process, like deployment, war with dependencies that constantly get deprecated breaking things, git merge conflicts, some mysterious bugs that takes hours to fix, all this tedious crap makes programming overall one of the most miserable activities a man can indulge himself with.
5 notes
·
View notes
Text
Infrastructure for Teamwork, a.k.a. Version Control
Working together on a game is quite difficult. How do you make sure everyone is on the same page?
You could send zips with assets and code between people, but that is slow, cumbersome, and very error-prone.
This is why Source Control software was invented. With Source Control, you can store the project files on a server, and everyone who wants to work on the project files, can download the project from the server. Once they're done with their changes, they send them back to the server. Then the other people can get those changes from the server again.
There are many different Source Control softwares. Probably the best-known one is git. (Source Control, Version Control, Revision Control all mean essentially the same thing.) Git is very good for working on projects that are all just plain-text code. However, it kind of falls flat when it needs to deal with binary assets, like textures, models, and sounds. Unreal Engine Scenes and Blueprints are also binary files. So if you don't use C++, but only Blueprints, basically your entire project is binary files.
This is why I went looking for a different Version Control Software that can handle this better. At my internship, I used Subversion, which is said to work better with binary assets, but in my experience then, it still wasn't exactly great. Though that might also have been due to the fact that they barely used any of its fancier features there.
Unreal Engine itself recommends using Perforce Helix Core. (Perforce is the company, Helix Core is the VCS, but the term "Perforce" is usually used to refer to the VCS itself, due to historical reasons. Source) So I looked into it, and indeed, it seemed very suitable!
So we requested a computer from the XR Lab to use as server for this project, and I installed the Helix Core Server on it.


It was surprisingly easy to install!
I then downloaded the Helix Core Client application on my laptop, and connected to the server. The setup there took a while, because there was a lot to learn. But in the end, I did it!
Sadly, Perforce is not free, so we are forced to use the free version, which is limited to a maximum of five users. We are with ten people, so we had to choose a few "representatives" who would actually put the things everyone made into the project. We requested an educational licence from Saxion, but got told to wait. Now that the project is over, we still don't have it. We also requested an educational licence from Perforce itself, directly, but we have still not got a response. But we made do with the limitations we got.
I wrote a guide for my teammates on how to set up a workspace for the project with Perforce, and improved it multiple times based on user testing and feedback. (I sat next to my teammates while they were following the guide and tried my best to now say anything; to let the guide speak for itself. I would then take note of what went wrong and improved that section of the guide for the next user test.)
Over the months of this project, we all used P4V and Perforce to work together on the project. Due to Perforce's locking system, we never had any merge conflicts! Most of the team actually really enjoyed working with Perforce. Personally, I do miss git, but I acknowledge that for an Unreal Engine project, Perforce is a lot better. And I also found it pretty nice to work with. The documentation was pretty good, and they have a lot of tutorials, guide, and demonstration videos, which have been very helpful during the setup. It's very useful to be able to follow along every single click.
3 notes
·
View notes
Text
Is xenoblade 3 just a result of a git merge conflict. Or is it like, an unapproved pull request into main.
Do they still use git in the xenoblade universe. Tbh I could see it
11 notes
·
View notes
Text
this is, obviously, the kind of thing you ideally never use, and thus probably shouldn't really know?
however: I finally bothered to figure out how to use git rebase --onto to sync changes between multiple git branches that depend on one another.
normally, one runs git rebase [new base branch] to change the base of the the currently checked out branch to the target. typically this is git rebase main or git rebase master. there's a second argument that can go after the new base branch that defaults to the currently checked out branch; that argument makes following the documentation/examples I could find confusing and I always check out the branch I'm working on so I'm going to ignore it.
the --onto argument takes two inputs: the first is the same as the regular argument; the second is the last commit on the current checked out feature branch we want to drop because it is now obsolete.
I think the way git diagrams usually show branches is unhelpful here; here's mine. say I have this:
A---B---C---D feature1 A---B---C---D---E---F feature2
I realize that I have a bug in commit C in feature1, and the fix will merge conflict with D. I rewrite history on feature1 to fix it:
A---B---C*--D* feature1 A---B---C---D---E---F feature2
now I check out feature2, wanting to update it. I can't just do git rebase feature1, because git will try to make A---B---C*--D*--C---D---E---F. I can make a temporary branch based on feature1, cherry pick E and F onto it, then hard reset feature2 to the temporary branch, but that's silly. (I could probably do a number of other things; there are like eleven billion git commands. please comment if you know an even better way to do this.)
what I want to do here is git rebase --onto feature1 D (where D is the sha of commit D, the last commit I do not want to keep on feature2 because I am replacing it with the new base branch).
I have no idea why this command is not git rebase feature1 --onto D or something. replacing the first argument you would normally use with a flag and then the argument you would normally use and then another different argument makes precisely zero sense? but, whatever, fine. sure wasted me a lot of time in between the first time I read that manpage, gave up, did temporary branches for years, then finally figured it out, but you do you, git devs.
edit: oh, this probably goes without saying if you know enough git to read this, but this is only necessary if one does rewrite history on feature1. if you just commit a fix on it normally, git rebase feature1 (and then handling any merge conflicts in E and F) will work fine. that's why you generally don't need to know this; it's only necessary if you're manipulating your commit history because you think it'll provide useful clarity and think that's worth the complexity in your git workflow. I do it a fair amount because I tend to juggle multiple potential changes to the same code at once more than is probably wise, but I definitely lean toward not doing it, particularly in a codebase that uses squash merging for PRs and discards all of this history in the end anyway.
3 notes
·
View notes
Text
God forbid Katy does ANYTHING I c
.....

Alright, mysterious stranger being so skilfully covert about who exactly he is, I am really not so sure what exactly got you so bothered about my taste in men- If you really think he is cringe, well, LOOSER FAILURE YOUR LOSS, more left for ME! And if you're jealous that I prefer him..... well, what can I say except for GIT GUD and if YOUR body ends up consisting from rotten flesh of your victims and spreads all across the floor I might even consider, you know? x) 🌼
P.S.: As for Marika question,

I am really glad that at last, after three years in the fandom, my competence in the lore-digging has been PROPERLY acknowledged and I get entrusted with the tasks of utmost importance! ...siiigh yeah the simplest answer is that she does on the virtue of sharing body with Radagon, but who is to tell how exactly it works when they are merged? Here is for more on-point answer. You see, her transformation into Radagon was shown to be gradual, and we know she had to fully turn into him as that moment he was taking over the body to kick our ass since his motives were conflicting with Marika's! The seal that traps the way to the Elden Ring, that Marika tasked Melina to help burning one day, is patterned with his trademark crossing lines, and he was not happy about the shattering of course!

That being said, we can't tell that Marika has to shift into Radagon 100% to get her.... OTHER big hammer. Because the time it had to be this way had specific circumstances (of two sides being at conflict)! I think they could otherwise blend and interchange partially! The core factor here would be that both Marika and Radagon should want this experience for the body to change in such a way that it is still Marika's, but with his.... OTHER sword okay it's getting old
P.P.S.: STOP BEING MEAN TO ME!!!!!!!!!!!!!! :U
You are just JEALOUS because you have skill issue and I don't!!!!!
8 notes
·
View notes
Text
okay I knoooooow there are benefits to working in a monorepo or else no one would do it, but. I just had the scariest git moment of my career where I was trying to fix a merge conflict in a PR and rebase wasn't working for some reason so I followed github's little instructions (bad idea) and ended up doing like a merge merge into my feature branch that pulled in changes from basically every folder in our repo. which means literally every single person in our codeowners file got pinged. I'm mortified
#closed the PR in shame and starting fresh with a new one from my last non-fucked commit#and you know how I fixed it in the new branch? a goddamn rebase lol. idk what I was doing the first time that didn't work
4 notes
·
View notes
Text
A beginners guide to GIT: Part 5 - How to use GIT as a group.
Table of content: Part 1: What is GIT? Why should I care?
Part 2: Definitions of terms and concepts
Part 3: How to learn GIT after (or instead of ) this guide.
Part 4: How to use GIT as 1 person
Part 5: How to use GIT as a group.
For this, I will describe a workflow, called “feature branch workflow.” There are others that are simpler, and are sometimes better, but I will describe one that always works, for any amount of people, and most likely is what your future workplace uses.. And yes, it involves branching (which sounds scary, but it is not so bad.)
Why? Well because of 2 goals we have that somewhat clash.
1: To use GIT in a way that is easy on ourselves and will give us all the benefits of GIT. This means committing often. Pretty much every time we have made a change, and we can compile.
2: We want to sync our work with our fellow workers. But this takes effort every time we do it because we might have made changes that clashes with changes someone else have made.
(Notice though that this is not a problem originating in GIT. This is a problem that comes from people working together on the same thing. GIT just makes it easy to spot the problems and describe them in an accurate way.)
We alleviate this by only syncing up when we have made a larger chunk of self contained work. Usually we use the term "feature" for this. And they can be quite small (For example 4 commits, making a "Return to previous page" button ) or large (For example, 38 commits, which also used branches, to implement a GUI on top of the backend code we have made).
It is best to make features as small as you can, so that a feature branch does not end up being an entirely different sister project to the main branch.
The first thing we do is declare the main/master branch holy. Just like any branch, it must always compile, but now we add " May only have fully realized features". It must ALWAYS be ready to be shown to the customer/your boss/your adviser/your teacher.
So when we want to do some work, we coordinate it with our teammates so people are not working on the same thing, and thus wasting their time. ( This can be done with tickets, verbally at meetings, in group chats. Whichever fits your team )
Then we make a branch with its base at the tip of the main/master branch. We then do work, commit and push every commit onto that branch. This has all the benefits we had from working alone. We cannot get merge conflicts, as we are the only one working on this branch.
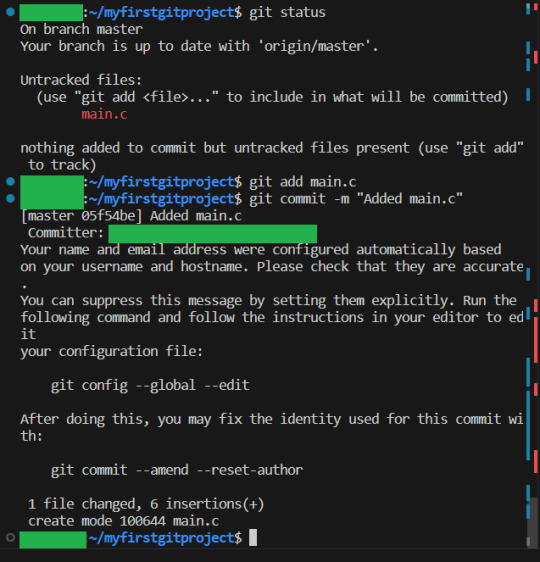
So let us show how this works! For this example I have set up a remote repository on bitbucket containing only a standard README that I have not written in at all., I then cloned it down in 2 different directories. Each of which I have opened with a console. This is how I will represent multiple people:

So first, we show off one person making a change, and the other getting it. So I add a main.c file in there, add it so it is staged for commit, and then commit it:
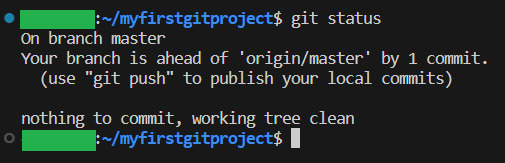
And if we write git status, we can see that we are 1 commit ahead of the remote repository:
We then push our commits to the remote repository:
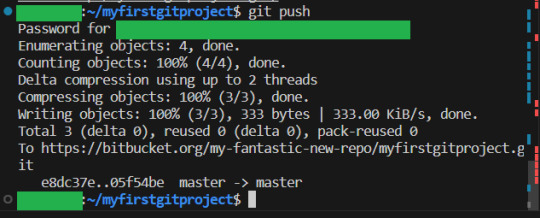
The other user can now use git fetch (Which gets the latest information from the remote repository, but does not change anything):
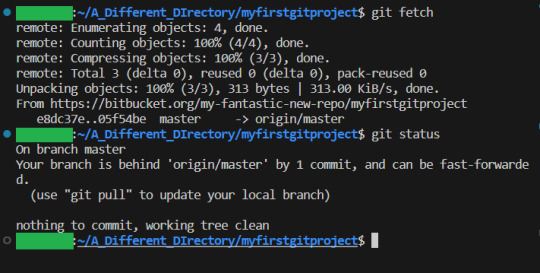
We then pull the latest update from the remote repository with git pull:
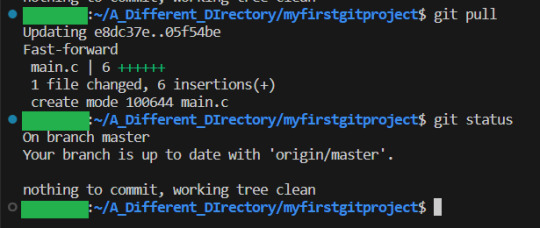
This is the simple way to work. But of course, if we have changed the same file, we will get a merge conflict.
As we talked about, we will minimize those by using branches. So we will say that each of these two people now will work on a different feature. Each of which will be a function that prints something. And each will be in another c file, with a header. We will do this with branching. We want to make a branch, and then switch to it. Switching to branches is called “checkout”. We can do both in one step by checking out a branch that does not exist, with the option -b (You can as always read about checkout, by writing “git help checkout”)
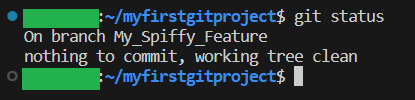
git checkout -b My_Spiffy_Feature
When we then write git status, we can see that we are on the new branch:
I then add the new files. with the new function in, and we want test that they work by calling the function in main:
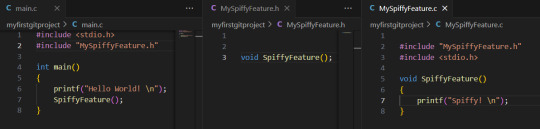
We then compile our program (which gets default name a.out) and run it:
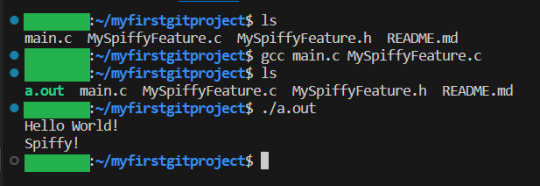
It works! Great, time to commit. We add the new files, BUT NOT main.c or a.out . They were just for testing, and is otherwise not related to our feature.
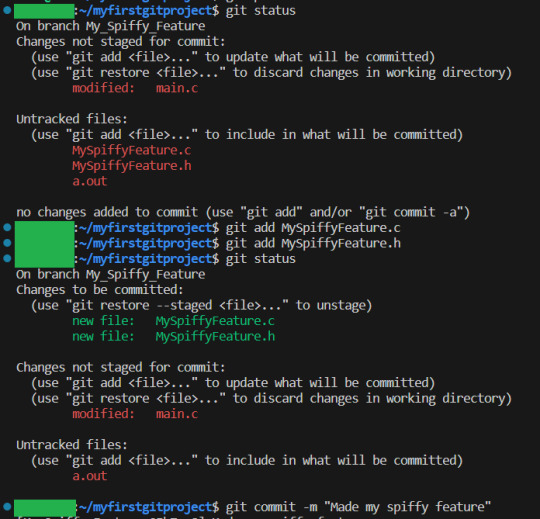
And we then push to the remote repository:
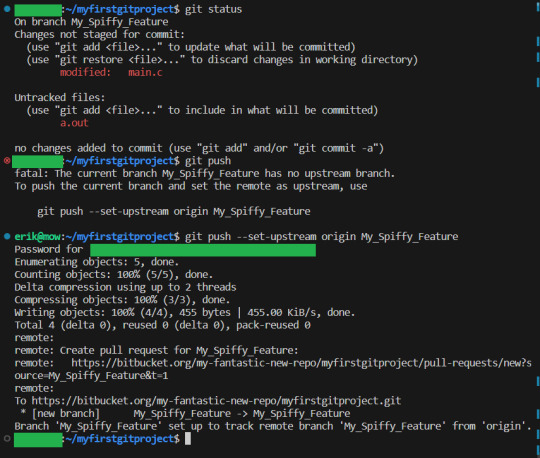
As you can see, git complained, because while we have created our branch, we had not really configured it yet (Specifically, we never told git what branch this new branch should originate from from. We just created it out in the void). But GIT TELLS you what to do. So I simply wrote the recommended command, and bam, branch is working as we want it to
I update the new feature file, just so we have more than one commit. I add the changes, commit and push again:
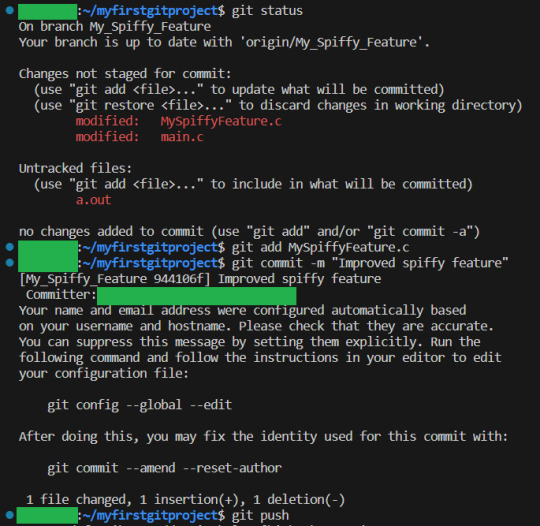
Now that our feature is done, we want to merge the branch into the master branch.
To showcase something, I will first have the other person make a change to main, add, commit and push it:
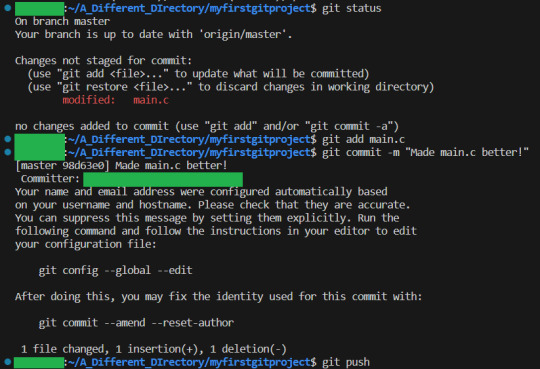
The first person will now merge their spiffy new feature in. They do that by switching to the master branch with git checkout:

We see that we are behind 1 commit, so we pull.

But horror! Since we have the unstaged changes, we cannot pull, since we changed main.c to tests our new feature, AND the other person have changed main, those two cannot exist at the same time. So what do we do? Well, in this case, we are ok with our tiny test in main.c being lost. So we remove it like so:
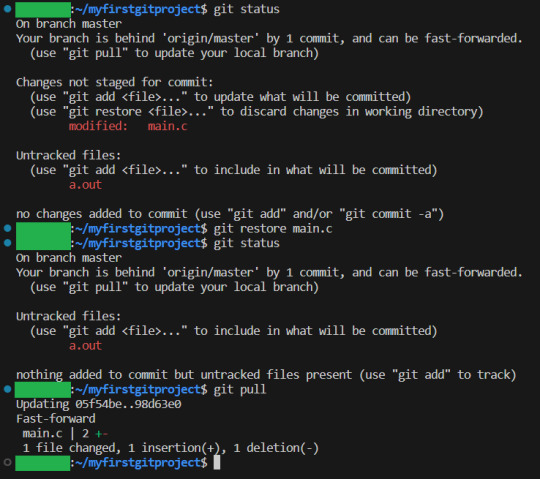
Notice how EVERYTHING I did here, was just read what GIT said was the problem, then write git status, and do the actions that GIT tells me I can do, which solves the problem. Ok, now we have the latest update of the master branch. Time to merge our feature in:
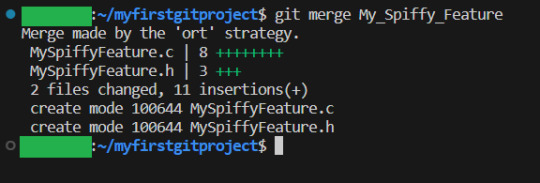
This time I did not use the -m feature (Because I forgot) so I just used the external program to write the commit message.
And if we write git log, we can see every single one of the commits. Both in the branch, and in the master:
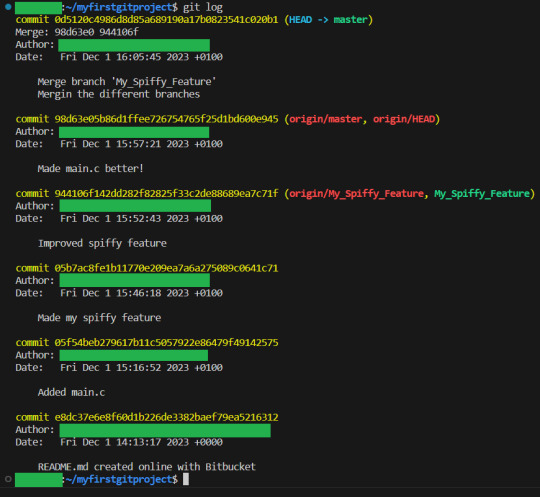
And if we want to get a bit of a graphical representation of what happened, we can use git log --graph:
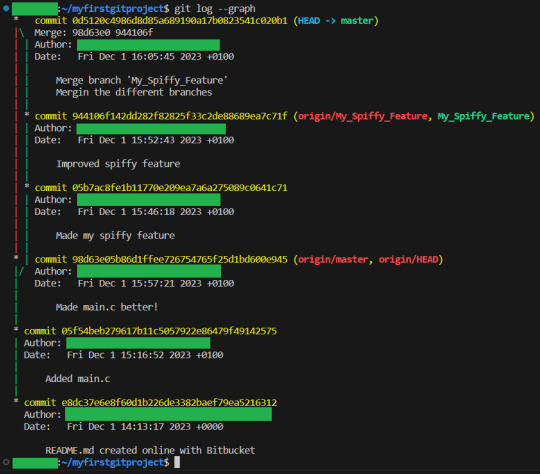
Now, this is the simple way to do branching. You actually have full control over how exactly you want to merge your branch in. In this case, the two commits of the branch was added AFTER the commit on master. But we COULD have merged the branch in so that the two commits on the spiffy function was done BEFORE the changes on master. When you are still starting out, do not worry about this. But that is the workflow. You create a branch, you work on your feature in it, where you cannot get in the way of anyone else. When your feature is done, you merge it into the master. This way, the master was always ready to show to your teacher/boss, and did not have half implemented things that you would have to explain should be ignored at any point.
Half of the benefit of the feature branch workflow is that it minimizes the chance for merge conflicts. For them to happen, 1 group would have to go to the master branch and pull. AFTER they pulled, but before they managed to merge their branch in, another group must pull from master, and merged their feature in.
Unlikely.
But let us talk about merge conflicts.
Are those not horrible things that break everything?
No. Merge conflicts simply means GIT could not figure out how to merge something, and so a human will have to do it for it. GIT is nice, and shows you exactly where the problem is, and how to solve it. Let us create a merge conflict. The first person adds in the function that uses their new spiffy feature after the hello world prinf, stages the changes and commits them. But do not yet push
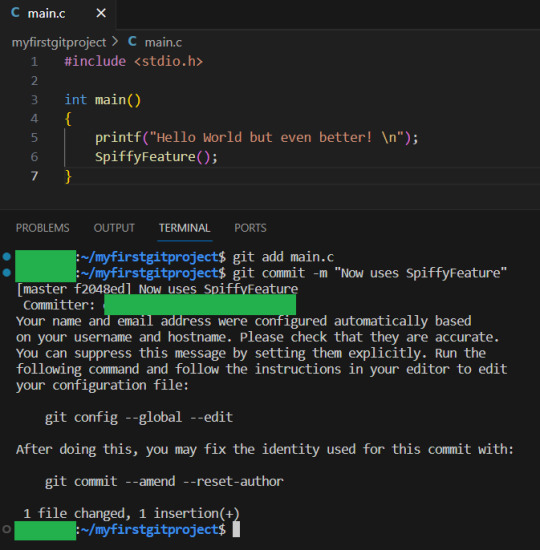
The other person creates 2 more printf statements in main, stages the changes for commit, and commits them:
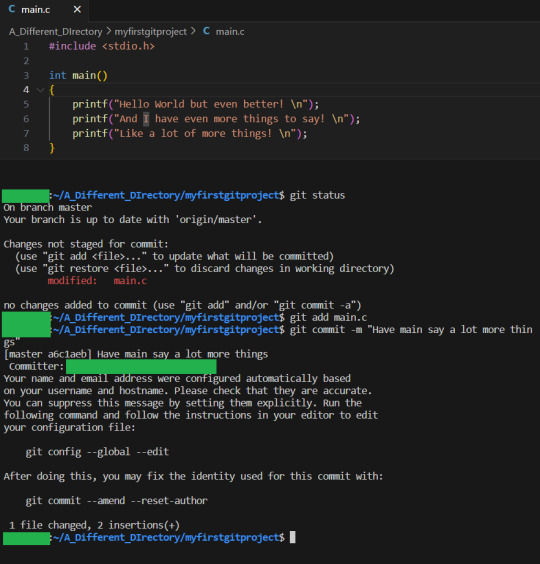
Now we have 2 commits, that both changes main.c How should these two be merged? Should the spiffy feature be called before or after the newly added prinf lines? GIT cannot know this, and so will tell the humans to do it. And the job falls to whoever wanted to push in a change that creates the merge conflict. In our example, I will have the second person, who added the extra printf lines push first:
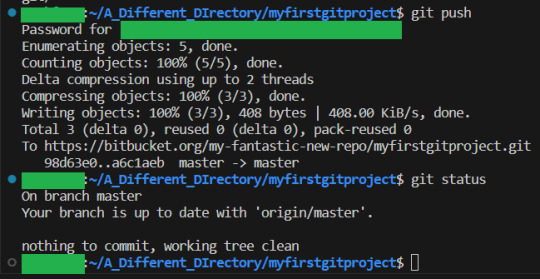
And now the first person with their spiffy feature pushes, and:
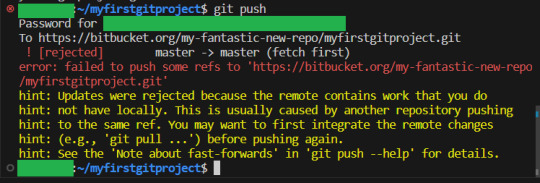
It fails... But we are fine. Nothing actually happened here. The remote is still fine, and we locally are still fine. But we have to figure out how to fix this. When in doubt, use git fetch to get all the info but change nothing, and then git status:
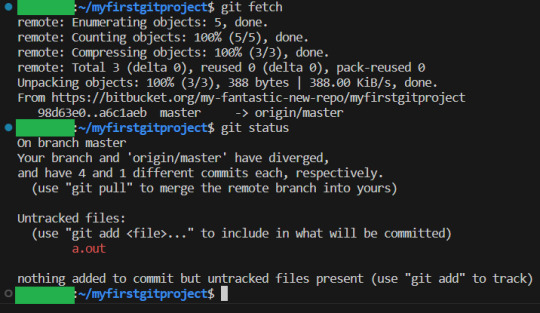
(By the way, I made an honest mistake here, and did not push the branch changes after I merged. But I am not really in trouble, because GIT saved me! :D) And as we can see, GIT is once again telling us what to do. Great!
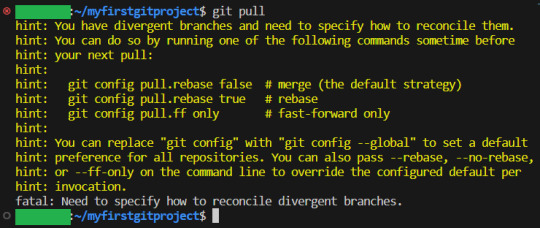
And we are now at the place where we need to decide what to do. While you are still new, I recommend the default strategy. So we do as GIT tells us to:

And now, FINALLY, we have our merge error. But notice that we only got it this way, because we asked for it. So… what does that mean? Git status to the rescue once more!
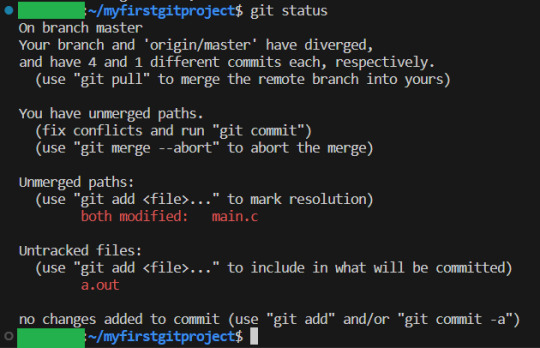
As expected, the problem is in main.c Let us check out what is in that file:

We have our changes first, then a separation, and then the other changes. And fixing it is piss easy. We remove the lines GIT inserted to tell us where the conflict was, and put the code in order. WE decide if the spiffy feature should be put before, after or in the middle of the two printf statements. I decide to put them in the middle like so:
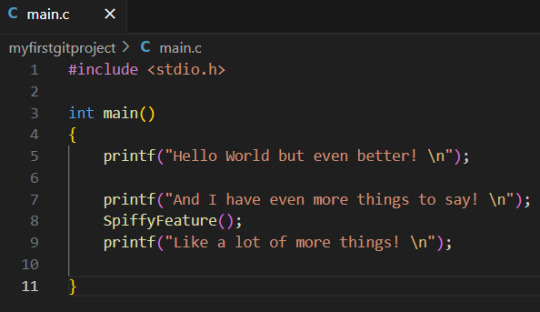
Merging the two versions together, is in of itself, a change to the code. So we will now do what we always do when we have made changes. Add the files that we changed, and make a commit, and then push:
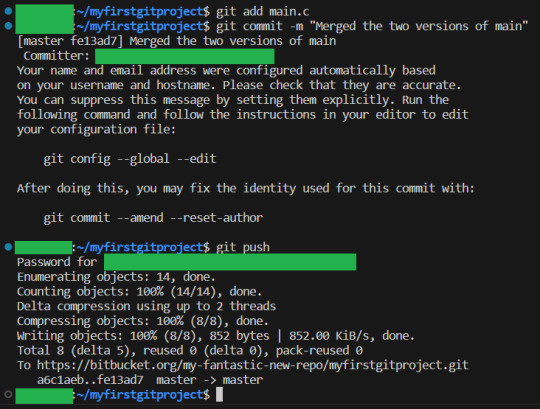
We have now resolved the merge conflict.
Notice how the problems that we ran into were not GIT problems. We ran into issues that ALWAYS come up when multiple people are working on the same project. But GIT made it really clear what the issues were, and forced us to deal with them in a smart way! :D
8 notes
·
View notes
Text
Setting up your .gitignore for Ren'Py games version controlled by Git
Version control is great. If you're not using it already for any gamedev adventures, you should really consider doing it.
Git is the one I see used more often (in conjunction with such distributed versioning services like GitHub or GitLab) and for a good reason - it's the industry standard in pretty much any programming job I've done, there are plenty of tools to make its usage more simple (though I always recommend starting from the command line first, but that's a story for another day) and the aforementioned services are free to use for private projects.
However, if you were to just version-control all of your project with compiled scripts and all and you're not the only one committing stuff, you will soon encounter the dreaded merge conflicts - Git can't really track binary files (compiled scripts are usually this) well and if two people are touching the same file - Boom! Some shenanigans and headaches are bound to occur.
Enter the .gitignore file. It lives in your project root directory (the one you set up git tracking for) and shows you which files not to track with version control.
This is the one I use, but other people have also shared theirs.
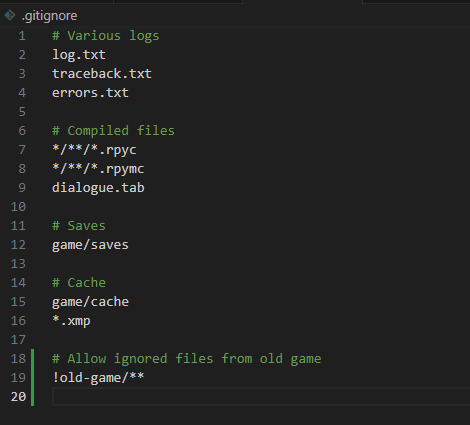
8 notes
·
View notes
Text
One frustrating edge case with Syncthing and Git to look out for:
Empirically, just based on observed behavior, it seems that Git has lots of commands that you'd think are read-only, but which in some cases will mutate internal Git state - specifically, the index (normally at ".git/index"). I haven't yet figured out if this can ever happen with other internal ".git" files.
This creates a race condition with any networked filesystem sync - if you do some work on a local checkout of a repo, then switch to another device to continue where you left off, you can't safely check if Syncthing has synced the local changes to the repo in the most intuitive way: by running commands like "git status".
You have to wait until you're sure the changes have synced, or you'll get a Syncthing merge conflict with the Git index file, which will manifest as weird/unexpected results from commands like "git status" and "git diff [--staged]".
(If you want to look more deeply into this, I'd probably start by reading and understanding Git's "Racy Git" documentation, which seems indirectly relevant - it's talking about a different race condition, but I wouldn't be surprised if the optimization which causes that race condition and/or any workaround which mitigates it contributes to this race condition.)
Luckily, it turns out that we can force Git to never mutate the index. With recent Git versions, there's a top-level "--no-optional-locks" flag that will do it: "git --no-option-locks status".
6 notes
·
View notes
Text
i need u all to know that i was attempting to explain the dc reboots to my beloved best friend who knows nothing about comics and she paused and was like. so this is like a git conflict and then a git merge basically
12 notes
·
View notes
Text
No, I'm-
git: merge conflict, you're fucked
WAIT PEOPLE ON TUMBLR ARE REAL FUCKING PEOPLE
33K notes
·
View notes
Text
Streamlining Software Development with Cloud-Based DevOps and SCM Practices.
In today’s quick-changing tech world, delivering good software fast and reliably is a must. Companies use cloud based devops tools to speed up development, keep things consistent, and stay flexible.
At CloudKodeForm Technologies, we help organizations adopt new ideas by blending cloud-native DevOps practices with strong software configuration management (SCM) methods.

What is Cloud-Based DevOps?
Cloud DevOps merges development and sw configuration management using cloud services to automate, oversee, and handle apps at large scale. It removes the limits of older setups by giving scalability, flexibility, and real-time teamwork across different locations.
Main advantages include:
Fast deployment and ongoing integration/continuous delivery (CI/CD)
Monitoring in real time and diagnostics
Automated testing and quick rollback solutions
Easy collaboration between developers and operations teams
Azure and DevOps: A Strong Match
Azure combined with DevOps offers a full platform for managing the software cycle. Microsoft Azure supplies cloud infrastructure, while Azure DevOps provides tools for project planning, source control, CI/CD pipelines, testing, and managing builds.
At CloudKodeForm, we help clients get the most from Azure DevOps by:
Setting up secure, scalable CI/CD pipelines
Connecting repositories like Git and tracking tools like Azure Boards
Managing infrastructure as code with Azure Resource Manager (ARM) or Terraform
Automating testing and deployment steps
This smooth setup cuts mistakes, speeds up releases, and keeps applications stable and fast.
The Importance of Software Configuration Management (SCM) SCM is key for tracking changes in software through all stages of development. It makes sure every version stays clear and traceable—from source code to deployed files.
SCM includes:
Version control systems like Git or SVN
Change management processes
Control of build and release steps
Auditing of configurations
Without a strong SCM system, teams risk deploying buggy or outdated software, which can cause downtime and higher costs. That’s why CloudKodeForm Technologies stresses using integrated SCM in all parts of azure and devops.
Why SCM Matters in Software Work
In software development, SCM is more than just a tool. It’s a set of rules that helps prevent conflicts, improves teamwork, and keeps software quality high as projects grow and teams expand.
Some core rules are:
Having one clear source for the truth
Following naming and documentation standards
Watching for unauthorized changes
Being able to undo changes if needed
Our experts build custom SCM plans that fit each client’s needs. They use tools like GitHub, Bitbucket, Azure Repos, and CI/CD platforms such as Jenkins or GitLab.
Why Pick CloudKodeForm for Cloud DevOps and SCM?
CloudKodeForm Technologies offers full help with moving to cloud DevOps. We provide advice, setup, and ongoing support. Whether you’re working with microservices, containers, or serverless apps, our team helps you set up cloud-based DevOps, Azure DevOps, and good software management work methods.
We focus on:
Shorter release times about with less downtime
Secure, scalable setups
Following industry standards
Clear reports and full traceability
In conclusion, as tech speeds up, aligning your work with cloud tools and SCM is essential. Using cloud DevOps with platforms like Azure and strong software management will help your business stay ahead.
0 notes