#Image Data collection
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text

Explore the power of image data collection and its role in transforming raw visuals into actionable intelligence.
#artificial intelligence#machinelearning#aitraining#image data collection#Image Data Transformation#AI Image Processing#Data to Intelligence
0 notes
Text
0 notes
Photo

(via Vending machine error reveals secret face image database of college students | Ars Technica)
Canada-based University of Waterloo is racing to remove M&M-branded smart vending machines from campus after outraged students discovered the machines were covertly collecting facial-recognition data without their consent.
The scandal started when a student using the alias SquidKid47 posted an image on Reddit showing a campus vending machine error message, "Invenda.Vending.FacialRecognitionApp.exe," displayed after the machine failed to launch a facial recognition application that nobody expected to be part of the process of using a vending machine.
"Hey, so why do the stupid M&M machines have facial recognition?" SquidKid47 pondered.
The Reddit post sparked an investigation from a fourth-year student named River Stanley, who was writing for a university publication called MathNEWS.
Stanley sounded alarm after consulting Invenda sales brochures that promised "the machines are capable of sending estimated ages and genders" of every person who used the machines without ever requesting consent.
This frustrated Stanley, who discovered that Canada's privacy commissioner had years ago investigated a shopping mall operator called Cadillac Fairview after discovering some of the malls' informational kiosks were secretly "using facial recognition software on unsuspecting patrons."
Only because of that official investigation did Canadians learn that "over 5 million nonconsenting Canadians" were scanned into Cadillac Fairview's database, Stanley reported. Where Cadillac Fairview was ultimately forced to delete the entire database, Stanley wrote that consequences for collecting similarly sensitive facial recognition data without consent for Invenda clients like Mars remain unclear.
Stanley's report ended with a call for students to demand that the university "bar facial recognition vending machines from campus."
what the motherfuck
#m&m vending machine#secret face image database#college students#massive invasion of privacy#tech#collecting facial-recognition data without consent
474 notes
·
View notes
Note

You really did leave this in the tags and go. OP, I NEED that essay asap. 😭. Would help a lot in fics.
Also, the idea that Shidou's playstyle is reminiscent of Young Rin's "free" playstyle before he started copying Sae and U-20 Rin. So the implications of Sae choosing someone so similar to him, narratively it hurts.
Shidou's past is so interesting to me, bcz his answers seem to be so melancholy in his interview. I saw this plausible hc of him living with his grandparents. Can't wait till manga reveals that.
I just...gsqvsjskjajkksksnns, I want to look at Sae, Shidou and Rin's relationship thru a microscope fr. Plz try to write that essay. You'll be doing the world a favor.
I love ur blog!💙💜💙
🥹🥹🥹🥹 (AAAa it never fails to make me happy to know that someone reads the nonsense that I write in tags)
Thank you!!! I actually have that essay mostly written and sitting in my drafts, but every time I look at it I think "This is completely insane" and never finish it. But you know what, maybe I should, I love talking about these characters. And Sae especially is constantly rotating in my mind at most hours of the day like a warm rotisserie chicken.
I do really want to wait to see what's happening in PxG though to get more insight into how Shidou's and Rin's relationship has developed, and also simply to get more information on Shidou as a standalone character and player.
((( I also have a lot of ideas about Shidou's backstory (I actly talked abt it here ))))
and thank you for saying that and sending this i appreciate it a lot !!!!(O.O)7
#AAAAA#*INSERT THAT ONE GTA IMAGE* HERE WE GO AGAIN#i feel my brain tuning into sae/shidou/rin frequency once again aaaaaaaa i won't be able to think abt anything else again aaaaaaaa#ty for sending this hehe#u get me i want to put the 3 of them in a beaker and run experiments and observe and collect data and
6 notes
·
View notes
Text

Join our global work-from-home opportunities: varied projects, from short surveys to long-term endeavors. Utilize your social media interest, mobile device proficiency, linguistics degree, online research skills, or passion for multimedia. Find the perfect fit among our diverse options.
#image collection jobs#Data Annotation Jobs#Freelance jobs#Text Data Collection job#Speech Data Collection Jobs#Translation jobs online#Data annotation specialist#online data annotation jobs#image annotation online jobs
0 notes
Text
Image Datasets for Machine Learning: An In-Depth Overview

Introduction:
In the field Image Dataset for Machine Learning especially within computer vision, the presence of high-quality image datasets is of paramount importance. These datasets form the cornerstone for training algorithms, validating models, and ensuring their performance in practical applications. Regardless of whether one is a novice or a seasoned professional in machine learning, grasping the importance and intricacies of image datasets is essential. This article will delve into the fundamentals of image datasets, their significance, and the avenues available for sourcing or creating them for machine learning endeavors.
Defining Image Datasets
An image dataset refers to an organized compilation of images, frequently accompanied by metadata or labels, utilized for training and evaluating machine learning models. Such datasets enable algorithms to discern patterns, identify objects, and generate predictions. For instance, a dataset designed for facial recognition might comprise thousands of labeled images of human faces, each annotated with specific attributes such as age, gender, or emotional expression.
The Significance of Image Datasets in Machine Learning
Model Development: Image datasets serve as the foundational data necessary for training machine learning models, allowing them to identify patterns and generate predictions.
Enhanced Performance: The effectiveness of a model is significantly influenced by the quality and variety of the dataset. A well-rounded dataset enables the model to perform effectively across a range of situations.
Algorithm Assessment: Evaluating algorithms using labeled datasets is crucial for determining their accuracy, precision, and overall reliability.
Specialization for Targeted Applications: Image datasets designed for specific sectors or applications facilitate more precise and efficient model development.
Categories of Image Datasets
Labeled Datasets: These datasets include annotations or labels that detail the content of each image (such as object names, categories, or bounding boxes), which are vital for supervised learning.
Unlabeled Datasets: These consist of images that lack annotations and are utilized in unsupervised or self-supervised learning scenarios.
Synthetic Datasets: These datasets are artificially created using techniques like Generative Adversarial Networks (GANs) to enhance the availability of real-world data.
Domain-Specific Datasets: These datasets concentrate on particular industries or fields, including medical imaging, autonomous driving, or agriculture.
Attributes of a Quality Image Dataset
An effective image dataset should exhibit the following attributes:
Variety: The images should encompass a range of lighting conditions, angles, backgrounds, and subjects to enhance robustness.
Volume: Larger datasets typically yield improved model performance, assuming the data is both relevant and varied.
Annotation Precision: If the dataset is labeled, the annotations must be precise and uniform throughout.
Relevance: The dataset should be closely aligned with the goals of your machine learning initiative.
Equitable Distribution: The dataset should evenly represent various categories or classes to mitigate bias.
Notable Image Datasets for Machine Learning
The following are some commonly utilized image datasets:
ImageNet: A comprehensive dataset featuring over 14 million labeled images, extensively employed in object detection and classification endeavors.
COCO (Common Objects in Context): Comprises over 300,000 images annotated for object detection, segmentation, and captioning tasks.
MNIST: A user-friendly dataset containing 70,000 grayscale images of handwritten digits, frequently used for digit recognition applications.
CIFAR-10 and CIFAR-100: These datasets include 60,000 color images categorized into 10 and 100 classes, respectively, for object classification purposes.
Open Images Dataset: A large-scale collection of 9 million images annotated with image-level labels and bounding boxes.
Kaggle Datasets: An extensive repository of datasets for various machine learning applications, contributed by the global data science community.
Medical Datasets: Specialized collections such as LUNA (for lung cancer detection) and ChestX-ray14 (for pneumonia detection).
Creating a Custom Image Dataset
When existing datasets do not fulfill your specific requirements, you have the option to develop a personalized dataset. The following steps outline the process:
Data Collection: Acquire images from diverse sources, including cameras, online platforms, or public databases. It is essential to secure the necessary permissions for image usage.
Data Cleaning: Eliminate duplicates, low-resolution images, and irrelevant content to enhance the overall quality of the dataset.
Annotation: Assign appropriate labels and metadata to the images. Utilizing tools such as LabelImg, RectLabel, or VGG Image Annotator (VIA) can facilitate this task.
Organizing the Dataset: Arrange the dataset into structured folders or adopt standardized formats like COCO or Pascal VOC.
Data Augmentation: Improve the dataset's diversity by applying transformations such as rotation, scaling, flipping, or color modifications.
Guidelines for Managing Image Datasets
Assess Your Project Requirements: Choose or create a dataset that aligns with the goals of your machine learning initiative.
Image Preprocessing: Resize, normalize, and standardize images to maintain consistency and ensure compatibility with your model.
Address Imbalanced Data: Implement strategies such as oversampling, under sampling, or synthetic data generation to achieve a balanced dataset.
Dataset Partitioning: Split the dataset into training, validation, and testing subsets, typically following a 70:20:10 distribution.
Prevent Overfitting: Mitigate the risk of overfitting by ensuring the dataset encompasses a broad range of scenarios and images.
Challenges Associated with Image Datasets
Data Privacy: Adhere to data privacy regulations when handling sensitive images.
Complexity of Annotation: Labeling extensive datasets can be labor-intensive and susceptible to inaccuracies.
Bias in Datasets: Imbalanced or unrepresentative datasets may result in biased models.
Storage and Computational Demands: Large datasets necessitate considerable storage capacity and processing power.
Conclusion
Image datasets serve as the fundamental component of machine learning initiatives within the realm of computer vision. Whether obtained from publicly accessible sources or developed independently, the importance of a well-organized and high-quality dataset cannot be overstated in the creation of effective models. By gaining insight into the various categories of image datasets and mastering their management, one can establish a solid groundwork for successful machine learning applications. Investing the necessary effort to carefully curate or choose the appropriate dataset will significantly enhance the prospects of achieving success in your machine learning projects. Image datasets are the foundation of machine learning applications in fields such as computer vision, medical diagnostics, and autonomous systems. Their quality and design directly influence the performance and generalizability of machine learning models. Large-scale datasets like ImageNet have propelled advancements in deep learning, but small, domain-specific datasets curated by experts—such as Globose Technology Solutions are equally vital.
0 notes
Text
Explore the power of image data collection and its role in transforming raw visuals into actionable intelligence. Learn how AI and machine learning are revolutionizing industries, from healthcare to autonomous vehicles, and shaping a smarter, data-driven future.
#artificial intelligence#machinelearning#aitraining#image data collection#AI Image Processing#Data to Intelligence#Image Recognition#Image Annotation
0 notes
Text
The Importance of Speech Datasets in the Advancement of Voice AI:

Introduction:
Voice AI is Speech Datasets revolutionizing human interaction with technology, encompassing virtual assistants like Siri and Alexa, automated transcription services, and real-time language translation. Central to these innovations is a vital component: high-quality speech datasets. This article examines the significance of speech datasets in the progression of voice AI and their necessity for developing precise, efficient, and intelligent speech recognition systems.
The Significance of Speech Datasets in AI Development
Speech datasets consist of collections of recorded human speech that serve as foundational training resources for AI models. These datasets are crucial for the creation and enhancement of voice-driven applications, including:
Speech Recognition: Facilitating the conversion of spoken language into written text by machines.
Text-to-Speech: Enabling AI to produce speech that sounds natural.
Speaker Identification: Differentiating between various voices for purposes of security and personalization.
Speech Translation: Providing real-time translation of spoken language to enhance global communication.
Essential Characteristics of High-Quality Speech Datasets
To create effective voice AI applications, high-quality speech datasets must encompass:
Diverse Accents and Dialects: Ensuring that AI models can comprehend speakers from various linguistic backgrounds.
Varied Noise Conditions: Training AI to function effectively in real-world settings, such as environments with background noise or multiple speakers.
Multiple Languages: Facilitating multilingual capabilities in speech recognition and translation.
Comprehensive Metadata: Offering contextual details, including speaker demographics, environmental factors, and language specifics.
Prominent Speech Datasets for AI Research
Numerous recognized speech datasets play a crucial role in the development of voice AI, including:
Speech: A comprehensive collection of English speech sourced from audiobooks.
Common Voice: An open-source dataset created by Mozilla, compiled from contributions by speakers worldwide.
VoxCeleb: A dataset focused on speaker identification, containing authentic recordings from various contexts.
Speech Commands: A dataset specifically designed for recognizing keywords and commands.
How Speech Datasets Enhance AI Performance
Speech datasets empower AI models to:
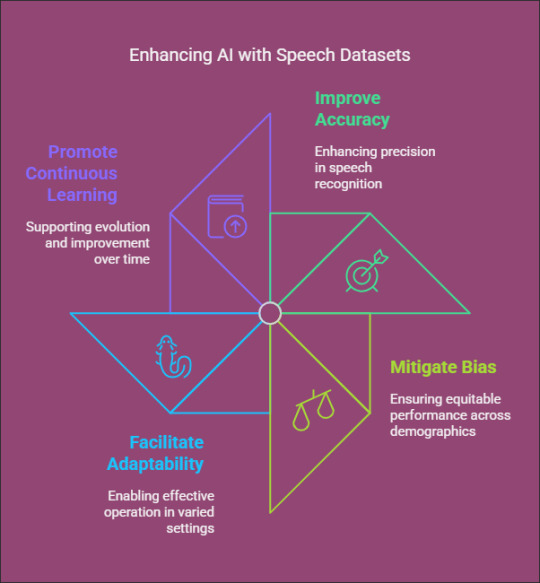
Improve Accuracy: Training on a variety of datasets enhances the precision of speech recognition.
Mitigate Bias: Incorporating voices from diverse demographics helps to eliminate AI bias and promotes equitable performance.
Facilitate Adaptability: AI models trained on a wide range of datasets can operate effectively across different settings and applications.
Promote Continuous Learning: Regular updates to datasets enable AI systems to evolve and improve over time.
Challenges in Collecting Speech Data
Despite their significance, the collection of speech datasets presents several challenges, including:
Data Privacy and Ethics: Adhering to regulations and ensuring user anonymity is essential.
High Annotation Costs: The process of labeling and transcribing speech data demands considerable resources.
Noise and Variability: Obtaining high-quality data in various environments can be challenging.
Conclusion
Speech datasets play Globose Technology Solutions a critical role in the advancement of voice AI, providing the foundation for speech recognition, synthesis, and translation technologies. By leveraging diverse and well-annotated datasets, AI researchers and developers can create more accurate, inclusive, and human-like voice AI systems.
0 notes
Text
How to Develop a Video Text-to-Speech Dataset for Deep Learning

Introduction:
In the swiftly advancing domain of deep learning, video-based Text-to-Speech (TTS) technology is pivotal in improving speech synthesis and facilitating human-computer interaction. A well-organized dataset serves as the cornerstone of an effective TTS model, guaranteeing precision, naturalness, and flexibility. This article will outline the systematic approach to creating a high-quality video TTS dataset for deep learning purposes.
Recognizing the Significance of a Video TTS Dataset
A video Text To Speech Dataset comprises video recordings that are matched with transcribed text and corresponding audio of speech. Such datasets are vital for training models that produce natural and contextually relevant synthetic speech. These models find applications in various areas, including voice assistants, automated dubbing, and real-time language translation.
Establishing Dataset Specifications
Prior to initiating data collection, it is essential to delineate the dataset’s scope and specifications. Important considerations include:
Language Coverage: Choose one or more languages relevant to your application.
Speaker Diversity: Incorporate a range of speakers varying in age, gender, and accents.
Audio Quality: Ensure recordings are of high fidelity with minimal background interference.
Sentence Variability: Gather a wide array of text samples, encompassing formal, informal, and conversational speech.
Data Collection Methodology
a. Choosing Video Sources
To create a comprehensive dataset, videos can be sourced from:
Licensed datasets and public domain archives
Crowdsourced recordings featuring diverse speakers
Custom recordings conducted in a controlled setting
It is imperative to secure the necessary rights and permissions for utilizing any third-party content.
b. Audio Extraction and Preprocessing
After collecting the videos, extract the speech audio using tools such as MPEG. The preprocessing steps include:
Noise Reduction: Eliminate background noise to enhance speech clarity.
Volume Normalization: Maintain consistent audio levels.
Segmentation: Divide lengthy recordings into smaller, sentence-level segments.
Text Alignment and Transcription
For deep learning models to function optimally, it is essential that transcriptions are both precise and synchronized with the corresponding speech. The following methods can be employed:
Automatic Speech Recognition (ASR): Implement ASR systems to produce preliminary transcriptions.
Manual Verification: Enhance accuracy through a thorough review of the transcriptions by human experts.
Timestamp Alignment: Confirm that each word is accurately associated with its respective spoken timestamp.
Data Annotation and Labeling
Incorporating metadata significantly improves the dataset's functionality. Important annotations include:
Speaker Identity: Identify each speaker to support speaker-adaptive TTS models.
Emotion Tags: Specify tone and sentiment to facilitate expressive speech synthesis.
Noise Labels: Identify background noise to assist in developing noise-robust models.
Dataset Formatting and Storage
To ensure efficient model training, it is crucial to organize the dataset in a systematic manner:
Audio Files: Save speech recordings in WAV or FLAC formats.
Transcriptions: Keep aligned text files in JSON or CSV formats.
Metadata Files: Provide speaker information and timestamps for reference.
Quality Assurance and Data Augmentation
Prior to finalizing the dataset, it is important to perform comprehensive quality assessments:
Verify Alignment: Ensure that text and speech are properly synchronized.
Assess Audio Clarity: Confirm that recordings adhere to established quality standards.
Augmentation: Implement techniques such as pitch shifting, speed variation, and noise addition to enhance model robustness.
Training and Testing Your Dataset
Ultimately, utilize the dataset to train deep learning models such as Taco Tron, Fast Speech, or VITS. Designate a segment of the dataset for validation and testing to assess model performance and identify areas for improvement.
Conclusion
Creating a video TTS dataset is a detailed yet fulfilling endeavor that establishes a foundation for sophisticated speech synthesis applications. By Globose Technology Solutions prioritizing high-quality data collection, accurate transcription, and comprehensive annotation, one can develop a dataset that significantly boosts the efficacy of deep learning models in TTS technology.
0 notes
Text
pausing the niche-interest podcast-style interview to process the bizarre connection my brain had just made was not enough
going back and re-listening to the section that had made my brain go "oh? oh." was not enough
the flurry of google and wikipedia and reddit searches to track down bits of corroborating evidence about that one innocuous background-information section of the interview was not enough
pacing around my house while I tried to grapple with this strange, possibly true, frightening-if-true bit of information was not enough
no, I needed a solid 30 minutes of mindlessly scrolling my Tumblr dash to just let that information sit, and now I might, maybe be ready to listen to the rest of the interview
#or maybe I'll go watch Mumbo's new Hermitcraft episode and come back to the interview in a bit#the worst part is that I don't know if I'm right#it's like a constellation. I was presented with the data points and my brain turned it into an image that _might_ be true#but that has really odd implications if it _is_ true#and my impromptu research only led to one piece of information that sways me away from seeing that image from that collection of data point#and a bunch of other bits of information that make me lean more towards believing that my sudden insight is true#this is 'there's a djinn-shaped hole in Kim Philby's life' kind of thing#only. you know. not djinn. or anything else supernatural#but rather the very real-world sort of read-between-the-lines thing that my family background raised me to recognize#this wouldn't be the first time I've made this connection about someone and I know in at least one of those instances I was right#but this is just weird enough that I absolutely cannot talk about it#I just wanted this post for my tag:#2025 mood#so I can come back and think about this later hopefully with the benefit of more information#I might need to pace around my house again for a bit#tagged for future reference#DAP-HSCA#?v=ID-urPx7tOM#dear future self: hopefully you can figure out what that means
0 notes
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note
Text
Capture, Upload, Earn: The Simplicity of Image Data Collection Jobs

Introduction:
If you’re seeking a flexible, remote opportunity that allows you to contribute to the advancement of artificial intelligence, consider exploring image data collection jobs. These positions involve capturing and curating images to train AI and machine learning models, playing a crucial role in the development of technologies like facial recognition, autonomous vehicles, and smart assistants.
📸 What Is Image Data Collection?
Image data collection entails gathering photographs that serve as training material for AI systems. These images can range from everyday objects and environments to specific themes or scenarios, depending on the project’s requirements. The collected data helps AI models learn to recognize patterns, objects, and contexts, enhancing their accuracy and functionality. dash.gts.ai
💼 Why Consider Image Data Collection Jobs?
Remote Flexibility: Work from the comfort of your home or any location of your choice.
No Specialized Equipment Needed: A basic camera or smartphone is sufficient for most projects.
Diverse Projects: Engage in various assignments, from capturing urban landscapes to documenting specific objects.
Contribute to AI Development: Your work directly impacts the improvement of AI technologies used globally.
🛠️ Getting Started
To begin your journey in image data collection:
Sign Up: Register on platforms that offer image data collection projects.
Select Projects: Choose assignments that align with your interests and schedule.
Capture Images: Follow the project’s guidelines to collect the required images.
Submit Work: Upload your images through the platform’s submission system.
Receive Compensation: Payments are typically processed upon project completion, with details provided upfront. dash.gts.ai
🔗 Explore Opportunities
For more information on available projects and to sign up, visit: https://dash.gts.ai/image-data-collection
Embark on a rewarding path that combines creativity with technology, all while enjoying the convenience of remote work.
0 notes