#LLM RAG
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
LLM RAG 擷取增強生成介紹 (3 種 RAG/Self-RAG/CRAG 全解析)
目前的 LLM RAG 解決了什麼問題? 當前的人工智慧技術中,LLM (大型語言模型) 和 RAG (檢索增強生成) 結合是一種強大的應用方式。簡單來說,這是一種將「AI LLM 的智慧」與「資料庫的知識」結合起來的方法。LLM 就像是一位非常聰明的助手,擅長理解和生成自然語言,能回答問題、完成文章,甚至進行創意寫作。但它的知識是來自於訓練過程,並非即時更新,因此可能會有過時或不完整的資訊。RAG 則解決了這個問題,RAG 的核心是利用檢索技術,即在需要的時候,從外部資料庫或知識庫中提取最新、相關的資訊,再將這些資訊傳遞給 LLM,讓它能結合這些資訊生成更準確、更有依據的回答。可以說是有效率的彌補新資訊對於 LLM 訓練時不存在的神經網��參數記憶,大幅度提昇回應能力。 舉個例子:想像你在問一個問題,比如「今年最流行���手機是哪款?」LLM 本身可能無法知道最新的資訊。但通過…
0 notes
Text
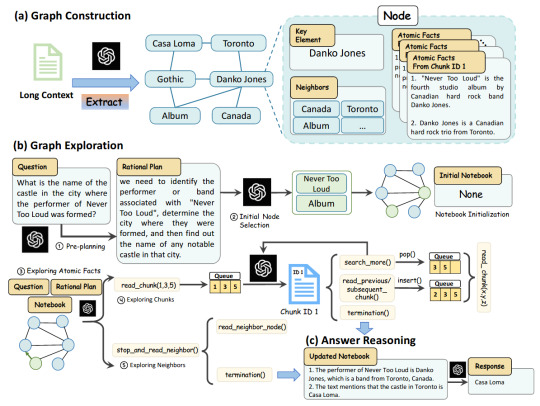
GraphReader approach, consisting of graph construction, graph exploration, andanswer reasoning
2 notes
·
View notes
Text

AI Generation
6 notes
·
View notes
Text
OWASP's LLM AI Security & Governance Checklist: 13 action items for your team

Artificial intelligence is developing at a dizzying pace. And if it's dizzying for people in the field, it's even more so for those outside it, especially security professionals trying to weigh the risks the technology poses to their organizations. That's why the Open Web Application Security Project (OWASP) has introduced a new cybersecurity and governance checklist for those security pros who are striving to protect against the risks of hasty or insecure AI implementations. https://jpmellojr.blogspot.com/2024/04/owasps-llm-ai-security-governance.html
#Checklist#OWASP#LLM#Security#Privacy#ThreatModeling#AIAssets#RiskManagement#Compliance#ModelCards#RAG#RedTeaming#Challenges#Prioritization
2 notes
·
View notes
Video
youtube
🎥 RAG vs Fine-Tuning – Practical Comparison with Voice Prompts on Mobile...
#youtube#RAG FineTuning RetrievalAugmentedGeneration LLMs LanguageModels AIComparison VoicePromptAI MobileAI MachineLearning DeepLearning PromptEngin
0 notes
Text
最小限のRAGアプリケーション
最小限のRAGアプリケーション
0 notes
Text
RAG or LLM—what powers smarter AI?
Understand the difference, spot the strengths, and choose the right fit for your business intelligence.
Read the full blog here!

0 notes
Link
看看網頁版全文 ⇨ 雜談:到底要怎麼使用RAGFlow呢? / TALK: RAGFlow Drained All My Resources https://blog.pulipuli.info/2025/03/talk-ragflow-drained-all-my-resources.html 由於這次RAGFlow看起來又無法順利完成任務了,我還是來記錄一下目前的狀況吧。 ---- # 專注做好RAG的RAGFlow / RAGFlow: Focusing on RAG。 https://ragflow.io/ 在眾多LLM DevOps的方案中,RAGFlow也絕對可以算得上是重量級的那邊。 相較於其他方案,RAGFlow一直積極加入各種能夠改進RAG的特殊技術,使得它在RAG的應用方面出類拔萃。 RAGFlow的主要特色包括了: 1. 文件複雜排版分析功能:能夠解讀表格,甚至能分析PDF裡面圖片的文字。 2. 分層摘要RAPTOR。能改善RAG用分段(chunking)切斷資訊的問題。 3. 結合知識圖譜的GraphRAG跟LightRAG。讓回答著重與命名實體,而且還可能找到詞彙之間的隱含關係。 4. 能作為Dify外部知識庫使用。 不過,除了第四點之外,要做到前三項功能,目前看起來還有很多問題需要克服。 # 硬體要求 / Hardware Requirements。 由於運作RAGFlow會使用OCR來分析文件的排版,記憶體最好是給到16GB之多,硬碟空間也需要準備50GB。 這真的是重量級的方案。 如果這些準備好的話,要做到分析複雜排版文件的這件事情就不是很難了。 只要做到這個程度,RAGFlow就能在回答引用時顯示來源的文件位置。 這樣幫助就很大了呢。 # 大量請求的難題 / The Challenge of Numerous Requests。 相較於排版分析是RAGFlow組件中的功能,RAPTOR跟Knowledge Graph都要搭配大型語言模型才能解析跟查詢資料。 而RAGFlow在處理資料的時候會在短時間內發送大量的API請求,很容易就被rate limit限流。 既然直接連接LLM API會因為太多請求而被限流,我就試著改轉接到Dify上,並在API請求的時候加上排隊等候的機制。 Dify裡面雖然可以寫程式碼,但他其實也是在沙盒裡面運作的程式,還是有著不少的限制。 其中一個限制就是不能讓我直接修改系統上的檔案。 因此如果要在Dify內用程式讀寫資料,用HTTP請求傳送可能是比較好的做法。 這些做法花了很多時間調整。 調整了老半天,總算能夠讓它正常運作。 不過過了一陣子,LLM API連回應沒有反應了。 我猜想可能是連接的Gemini API已經超過用量而被禁止吧。 ---- 繼續閱讀 ⇨ 雜談:到底要怎麼使用RAGFlow呢? / TALK: RAGFlow Drained All My Resources https://blog.pulipuli.info/2025/03/talk-ragflow-drained-all-my-resources.html
0 notes
Text
Paper page - DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
0 notes
Text
This custom AI app uses Retrieval-Augmented Generation (RAG) to create document-specific embeddings (*cough* LORA), layered on top of a locally running Llama 3.2 4B model. The goal? To answer targeted questions about the documents I converted - ALL LOCALLY.
1 note
·
View note
Text
The Mistral AI New Model Large-Instruct-2411 On Vertex AI

Introducing the Mistral AI New Model Large-Instruct-2411 on Vertex AI from Mistral AI
Mistral AI’s models, Codestral for code generation jobs, Mistral Large 2 for high-complexity tasks, and the lightweight Mistral Nemo for reasoning tasks like creative writing, were made available on Vertex AI in July. Google Cloud is announcing that the Mistral AI new model is now accessible on Vertex AI Model Garden: Mistral-Large-Instruct-2411 is currently accessible to the public.
Large-Instruct-2411 is a sophisticated dense large language model (LLM) with 123B parameters that extends its predecessor with improved long context, function calling, and system prompt. It has powerful reasoning, knowledge, and coding skills. The approach is perfect for use scenarios such as big context applications that need strict adherence for code generation and retrieval-augmented generation (RAG), or sophisticated agentic workflows with exact instruction following and JSON outputs.
The new Mistral AI Large-Instruct-2411 model is available for deployment on Vertex AI via its Model-as-a-Service (MaaS) or self-service offering right now.
With the new Mistral AI models on Vertex AI, what are your options?
Using Mistral’s models to build atop Vertex AI, you can:
Choose the model that best suits your use case: A variety of Mistral AI models are available, including effective models for low-latency requirements and strong models for intricate tasks like agentic processes. Vertex AI simplifies the process of assessing and choosing the best model.
Try things with assurance: Vertex AI offers fully managed Model-as-a-Service for Mistral AI models. Through straightforward API calls and thorough side-by-side evaluations in its user-friendly environment, you may investigate Mistral AI models.
Control models without incurring extra costs: With pay-as-you-go pricing flexibility and fully managed infrastructure built for AI workloads, you can streamline the large-scale deployment of the new Mistral AI models.
Adjust the models to your requirements: With your distinct data and subject expertise, you will be able to refine Mistral AI’s models to produce custom solutions in the upcoming weeks.
Create intelligent agents: Using Vertex AI’s extensive toolkit, which includes LangChain on Vertex AI, create and coordinate agents driven by Mistral AI models. To integrate Mistral AI models into your production-ready AI experiences, use Genkit’s Vertex AI plugin.
Construct with enterprise-level compliance and security: Make use of Google Cloud’s integrated privacy, security, and compliance features. Enterprise controls, like the new organization policy for Vertex AI Model Garden, offer the proper access controls to guarantee that only authorized models are accessible.
Start using Google Cloud’s Mistral AI models
Google Cloud’s dedication to open and adaptable AI ecosystems that assist you in creating solutions that best meet your needs is demonstrated by these additions. Its partnership with Mistral AI demonstrates its open strategy in a cohesive, enterprise-ready setting. Many of the first-party, open-source, and third-party models offered by Vertex AI, including the recently released Mistral AI models, can be provided as a fully managed Model-as-a-service (MaaS) offering, giving you enterprise-grade security on its fully managed infrastructure and the ease of a single bill.
Mistral Large (24.11)
The most recent iteration of the Mistral Large model, known as Mistral Large (24.11), has enhanced reasoning and function calling capabilities.
Mistral Large is a sophisticated Large Language Model (LLM) that possesses cutting-edge knowledge, reasoning, and coding skills.
Intentionally multilingual: English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, Polish, Arabic, and Hindi are among the dozens of languages that are supported.
Multi-model capability: Mistral Large 24.11 maintains cutting-edge performance on text tasks while excelling at visual comprehension.
Competent in coding: Taught more than 80 coding languages, including Java, Python, C, C++, JavaScript, and Bash. Additionally, more specialized languages like Swift and Fortran were taught.
Agent-focused: Top-notch agentic features, including native function calls and JSON output.
Sophisticated reasoning: Cutting-edge reasoning and mathematical skills.
Context length: 128K is the most that Mistral Large can support.
Use cases
Agents: Made possible by strict adherence to instructions, JSON output mode, and robust safety measures
Text: Creation, comprehension, and modification of synthetic text
RAG: Important data is preserved across lengthy context windows (up to 128K tokens).
Coding includes creating, finishing, reviewing, and commenting on code. All popular coding languages are supported.
Read more on govindhtech.com
#MistralAI#ModelLarge#VertexAI#MistralLarge2#Codestral#retrievalaugmentedgeneration#RAG#VertexAIModelGarden#LargeLanguageModel#LLM#technology#technews#news#govindhtech
0 notes
Text
Vectorize: NEW RAG Engine - Semantic Search, Embeddings, Vector Search, & More!
In the age of information overload, the need for effective search and retrieval systems has never been more critical. Traditional keyword-based search methods often fall short when it comes to understanding the context and nuances of language. Enter Vectorize, a groundbreaking new Retrieval-Augmented Generation (RAG) engine that revolutionizes the way we approach semantic search, embeddings, and…
0 notes
Text
RAG vs Fine-Tuning: Choosing the Right Approach for Building LLM-Powered Chatbots

Imagine having an ultra-intelligent assistant ready to answer any question. Now, imagine making it even more capable, specifically for tasks you rely on most. That’s the power—and the debate—behind Retrieval-Augmented Generation (RAG) and Fine-Tuning. These methods act as “training wheels,” each enhancing your AI’s capabilities in unique ways.
RAG brings in current, real-world data whenever the model needs it, perfect for tasks requiring constant updates. Fine-Tuning, on the other hand, ingrains task-specific knowledge directly into the model, tailoring it to your exact needs. Selecting between them can dramatically influence your AI’s performance and relevance.
Whether you’re building a customer-facing chatbot, automating tailored content, or optimizing an industry-specific application, choosing the right approach can make all the difference.
This guide will delve into the core contrasts, benefits, and ideal use cases for RAG and Fine-Tuning, helping you pinpoint the best fit for your AI ambitions.
Key Takeaways:
Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful techniques for enhancing Large Language Models (LLMs) with distinct advantages.
RAG is ideal for applications requiring real-time information updates, leveraging external knowledge bases to deliver relevant, up-to-date responses.
Fine-Tuning excels in accuracy for specific tasks, embedding task-specific knowledge directly into the model’s parameters for reliable, consistent performance.
Hybrid approaches blend the strengths of both RAG and Fine-Tuning, achieving a balance of real-time adaptability and domain-specific accuracy.
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced technique in natural language processing (NLP) that combines retrieval-based and generative models to provide highly relevant, contextually accurate responses to user queries. Developed by OpenAI and other leading AI researchers, RAG enables systems to pull information from extensive databases, knowledge bases, or documents and use it as part of a generated response, enhancing accuracy and relevance.
How RAG Works?

Retrieval Step
When a query is received, the system searches through a pre-indexed database or corpus to find relevant documents or passages. This retrieval process typically uses dense embeddings, which are vector representations of text that help identify the most semantically relevant information.
Generation Step
The retrieved documents are then passed to a generative model, like GPT or a similar transformer-based architecture. This model combines the query with the retrieved information to produce a coherent, relevant response. The generative model doesn’t just repeat the content but rephrases and contextualizes it for clarity and depth.
Combining Outputs
The generative model synthesizes the response, ensuring that the answer is not only relevant but also presented in a user-friendly way. The combined information often makes RAG responses more informative and accurate than those generated by standalone generative models.
Advantages of RAG

Improved Relevance
By incorporating external, up-to-date sources, RAG generates more contextually accurate responses than traditional generative models alone.
Reduced Hallucination
One of the significant issues with purely generative models is “hallucination,” where they produce incorrect or fabricated information. RAG mitigates this by grounding responses in real, retrieved content.
Scalability
RAG can integrate with extensive knowledge bases and adapt to vast amounts of information, making it ideal for enterprise and research applications.
Enhanced Context Understanding
By pulling from a wide variety of sources, RAG provides a richer, more nuanced understanding of complex queries.
Real-World Knowledge Integration
For companies needing up-to-date or specialized information (e.g., medical databases, and legal documents), RAG can incorporate real-time data, ensuring the response is as accurate and current as possible.
Disadvantages of RAG

Computational Intensity
RAG requires both retrieval and generation steps, demanding higher processing power and memory, making it more expensive than traditional NLP models.
Reliance on Database Quality
The accuracy of RAG responses is highly dependent on the quality and relevance of the indexed knowledge base. If the corpus lacks depth or relevance, the output can suffer.
Latency Issues
The retrieval and generation process can introduce latency, potentially slowing response times, especially if the retrieval corpus is vast.
Complexity in Implementation
Setting up RAG requires both an effective retrieval system and a sophisticated generative model, increasing the technical complexity and maintenance needs.
Bias in Retrieved Data
Since RAG relies on existing data, it can inadvertently amplify biases or errors present in the retrieved sources, affecting the quality of the generated response.
What is Fine-Tuning?

Fine-tuning is a process in machine learning where a pre-trained model (one that has been initially trained on a large dataset) is further trained on a more specific, smaller dataset. This step customizes the model to perform better on a particular task or within a specialized domain. Fine-tuning adjusts the weights of the model so that it can adapt to nuances in the new data, making it highly relevant for specific applications, such as medical diagnostics, legal document analysis, or customer support.
How Fine-Tuning Works?

Pre-Trained Model Selection
A model pre-trained on a large, general dataset (like GPT trained on a vast dataset of internet text) serves as the foundation. This model already understands a wide range of language patterns, structures, and general knowledge.
Dataset Preparation
A specific dataset, tailored to the desired task or domain, is prepared for fine-tuning. This dataset should ideally contain relevant and high-quality examples of what the model will encounter in production.
Training Process
During fine-tuning, the model is retrained on the new dataset with a lower learning rate to avoid overfitting. This step adjusts the pre-trained model’s weights so that it can capture the specific patterns, terminology, or context in the new data without losing its general language understanding.
Evaluation and Optimization
The fine-tuned model is tested against a validation dataset to ensure it performs well. If necessary, hyperparameters are adjusted to further optimize performance.
Deployment
Once fine-tuning yields satisfactory results, the model is ready for deployment to handle specific tasks with improved accuracy and relevancy.
Advantages of Fine-Tuning

Enhanced Accuracy
Fine-tuning significantly improves the model’s performance on domain-specific tasks since it adapts to the unique vocabulary and context of the target domain.
Cost-Effectiveness
It’s more cost-effective than training a new model from scratch. Leveraging a pre-trained model saves computational resources and reduces time to deployment.
Task-Specific Customization
Fine-tuning enables customization for niche applications, like customer service responses, medical diagnostics, or legal document summaries, where specialized vocabulary and context are required.
Reduced Data Requirements
Fine-tuning typically requires a smaller dataset than training a model from scratch, as the model has already learned fundamental language patterns from the pre-training phase.
Scalability Across Domains
The same pre-trained model can be fine-tuned for multiple specialized tasks, making it highly adaptable across different applications and industries.
Disadvantages of Fine-Tuning

Risk of Overfitting
If the fine-tuning dataset is too small or lacks diversity, the model may overfit, meaning it performs well on the fine-tuning data but poorly on new inputs.
Loss of General Knowledge
Excessive fine-tuning on a narrow dataset can lead to a loss of general language understanding, making the model less effective outside the fine-tuned domain.
Data Sensitivity
Fine-tuning may amplify biases or errors present in the new dataset, especially if it’s not balanced or representative.
Computation Costs
While fine-tuning is cheaper than training from scratch, it still requires computational resources, which can be costly for complex models or large datasets.
Maintenance and Updates
Fine-tuned models may require periodic retraining or updating as new domain-specific data becomes available, adding to maintenance costs.
Key Difference Between RAG and Fine-Tuning

Key Trade-Offs to Consider

Data Dependency
RAG’s dynamic data retrieval means it’s less dependent on static data, allowing accurate responses without retraining.
Cost and Time
Fine-tuning is computationally demanding and time-consuming, yet yields highly specialized models for specific use cases.
Dynamic Vs Static Knowledge
RAG benefits from dynamic, up-to-date retrieval, while fine-tuning relies on stored static knowledge, which may age.
When to Choose Between RAG and Fine-Tuning?
RAG shines in applications needing vast and frequently updated knowledge, like tech support, research tools, or real-time summarization. It minimizes retraining requirements but demands a high-quality retrieval setup to avoid inaccuracies. Example: A chatbot using RAG for product recommendations can fetch real-time data from a constantly updated database.
Fine-tuning excels in tasks needing domain-specific knowledge, such as medical diagnostics, content generation, or document reviews. While demanding quality data and computational resources, it delivers consistent results post-training, making it well-suited for static applications. Example: A fine-tuned AI model for document summarization in finance provides precise outputs tailored to industry-specific language.
the right choice is totally depended on the use case of your LLM chatbot. Take the necessary advantages and disadvantages in the list and choose the right fit for your custom LLM development.
Hybrid Approaches: Leveraging RAG and Fine-Tuning Together
Rather than favoring either RAG or fine-tuning, hybrid approaches combine the strengths of both methods. This approach fine-tunes the model for domain-specific tasks, ensuring consistent and precise performance. At the same time, it incorporates RAG’s dynamic retrieval for real-time data, providing flexibility in volatile environments.
Optimized for Precision and Real-Time Responsiveness

With hybridization, the model achieves high accuracy for specialized tasks while adapting flexibly to real-time information. This balance is crucial in environments that require both up-to-date insights and historical knowledge, such as customer service, finance, and healthcare.
Fine-Tuning for Domain Consistency: By fine-tuning, hybrid models develop strong, domain-specific understanding, offering reliable and consistent responses within specialized contexts.
RAG for Real-Time Adaptability: Integrating RAG enables the model to access external information dynamically, keeping responses aligned with the latest data.
Ideal for Data-Intensive Industries: Hybrid models are indispensable in fields like finance, healthcare, and customer service, where both past insights and current trends matter. They adapt to new information while retaining industry-specific precision.
Versatile, Cost-Effective Performance
Hybrid approaches maximize flexibility without extensive retraining, reducing costs in data management and computational resources. This approach allows organizations to leverage existing fine-tuned knowledge while scaling up with dynamic retrieval, making it a robust, future-proof solution.
Conclusion
Choosing between RAG and Fine-Tuning depends on your application’s requirements. RAG delivers flexibility and adaptability, ideal for dynamic, multi-domain needs. It provides real-time data access, making it invaluable for applications with constantly changing information.
Fine-Tuning, however, focuses on domain-specific tasks, achieving greater precision and efficiency. It’s perfect for tasks where accuracy is non-negotiable, embedding knowledge directly within the model.
Hybrid approaches blend these benefits, offering the best of both. However, these solutions demand thoughtful integration for optimal performance, balancing flexibility with precision.
At TechAhead, we excel in delivering custom AI app development around specific business objectives. Whether implementing RAG, Fine-Tuning, or a hybrid approach, our expert team ensures AI solutions drive impactful performance gains for your business.
Source URL: https://www.techaheadcorp.com/blog/rag-vs-fine-tuning-difference-for-chatbots/
0 notes
Text
Think Smarter, Not Harder: Meet RAG

How do RAG make machines think like you?
Imagine a world where your AI assistant doesn't only talk like a human but understands your needs, explores the latest data, and gives you answers you can trust—every single time. Sounds like science fiction? It's not.
We're at the tipping point of an AI revolution, where large language models (LLMs) like OpenAI's GPT are rewriting the rules of engagement in everything from customer service to creative writing. here's the catch: all that eloquence means nothing if it can't deliver the goods—if the answers aren't just smooth, spot-on, accurate, and deeply relevant to your reality.
The question is: Are today's AI models genuinely equipped to keep up with the complexities of real-world applications, where context, precision, and truth aren't just desirable but essential? The answer lies in pushing the boundaries further—with Retrieval-Augmented Generation (RAG).
While LLMs generate human-sounding copies, they often fail to deliver reliable answers based on real facts. How do we ensure that an AI-powered assistant doesn't confidently deliver outdated or incorrect information? How do we strike a balance between fluency and factuality? The answer is in a brand new powerful approach: Retrieval-Augmented Generation (RAG).
What is Retrieval-Augmented Generation (RAG)?
RAG is a game-changing technique to increase the basic abilities of traditional language models by integrating them with information retrieval mechanisms. RAG does not only rely on pre-acquired knowledge but actively seek external information to create up-to-date and accurate answers, rich in context. Imagine for a second what could happen if you had a customer support chatbot able to engage in a conversation and draw its answers from the latest research, news, or your internal documents to provide accurate, context-specific answers.
RAG has the immense potential to guarantee informed, responsive and versatile AI. But why is this necessary? Traditional LLMs are trained on vast datasets but are static by nature. They cannot access real-time information or specialized knowledge, which can lead to "hallucinations"—confidently incorrect responses. RAG addresses this by equipping LLMs to query external knowledge bases, grounding their outputs in factual data.
How Does Retrieval-Augmented Generation (RAG) Work?
RAG brings a dynamic new layer to traditional AI workflows. Let's break down its components:
Embedding Model
Think of this as the system's "translator." It converts text documents into vector formats, making it easier to manage and compare large volumes of data.
Retriever
It's the AI's internal search engine. It scans the vectorized data to locate the most relevant documents that align with the user's query.
Reranker (Opt.)
It assesses the submitted documents and score their relevance to guarantee that the most pertinent data will pass along.
Language Model
The language model combines the original query with the top documents the retriever provides, crafting a precise and contextually aware response. Embedding these components enables RAG to enhance the factual accuracy of outputs and allows for continuous updates from external data sources, eliminating the need for costly model retraining.
How does RAG achieve this integration?
It begins with a query. When a user asks a question, the retriever sifts through a curated knowledge base using vector embeddings to find relevant documents. These documents are then fed into the language model, which generates an answer informed by the latest and most accurate information. This approach dramatically reduces the risk of hallucinations and ensures that the AI remains current and context-aware.
RAG for Content Creation: A Game Changer or just a IT thing?
Content creation is one of the most exciting areas where RAG is making waves. Imagine an AI writer who crafts engaging articles and pulls in the latest data, trends, and insights from credible sources, ensuring that every piece of content is compelling and accurate isn't a futuristic dream or the product of your imagination. RAG makes it happen.
Why is this so revolutionary?
Engaging and factually sound content is rare, especially in today's digital landscape, where misinformation can spread like wildfire. RAG offers a solution by combining the creative fluency of LLMs with the grounding precision of information retrieval. Consider a marketing team launching a campaign based on emerging trends. Instead of manually scouring the web for the latest statistics or customer insights, an RAG-enabled tool could instantly pull in relevant data, allowing the team to craft content that resonates with current market conditions.
The same goes for various industries from finance to healthcare, and law, where accuracy is fundamental. RAG-powered content creation tools promise that every output aligns with the most recent regulations, the latest research and market trends, contributing to boosting the organization's credibility and impact.
Applying RAG in day-to-day business
How can we effectively tap into the power of RAG? Here's a step-by-step guide:
Identify High-Impact Use Cases
Start by pinpointing areas where accurate, context-aware information is critical. Think customer service, marketing, content creation, and compliance—wherever real-time knowledge can provide a competitive edge.
Curate a robust knowledge base
RAG relies on the quality of the data it collects and finds. Build or connect to a comprehensive knowledge repository with up-to-date, reliable information—internal documents, proprietary data, or trusted external sources.
Select the right tools and technologies
Leverage platforms that support RAG architecture or integrate retrieval mechanisms with existing LLMs. Many AI vendors now offer solutions combining these capabilities, so choose one that fits your needs.
Train your team
Successful implementation requires understanding how RAG works and its potential impact. Ensure your team is well-trained in deploying RAG&aapos;s technical and strategic aspects.
Monitor and optimize
Like any technology, RAG benefits from continuous monitoring and optimization. Track key performance indicators (KPIs) like accuracy, response time, and user satisfaction to refine and enhance its application.
Applying these steps will help organizations like yours unlock RAG's full potential, transform their operations, and enhance their competitive edge.
The Business Value of RAG
Why should businesses consider integrating RAG into their operations? The value proposition is clear:
Trust and accuracy
RAG significantly enhances the accuracy of responses, which is crucial for maintaining customer trust, especially in sectors like finance, healthcare, and law.
Efficiency
Ultimately, RAG reduces the workload on human employees, freeing them to focus on higher-value tasks.
Knowledge management
RAG ensures that information is always up-to-date and relevant, helping businesses maintain a high standard of knowledge dissemination and reducing the risk of costly errors.
Scalability and change
As an organization grows and evolves, so does the complexity of information management. RAG offers a scalable solution that can adapt to increasing data volumes and diverse information needs.
RAG vs. Fine-Tuning: What's the Difference?
Both RAG and fine-tuning are powerful techniques for optimizing LLM performance, but they serve different purposes:
Fine-Tuning
This approach involves additional training on specific datasets to make a model more adept at particular tasks. While effective for niche applications, it can limit the model's flexibility and adaptability.
RAG
In contrast, RAG dynamically retrieves information from external sources, allowing for continuous updates without extensive retraining, which makes it ideal for applications where real-time data and accuracy are critical.
The choice between RAG and fine-tuning entirely depends on your unique needs. For example, RAG is the way to go if your priority is real-time accuracy and contextual relevance.
Concluding Thoughts
As AI evolves, the demand for RAG AI Service Providers systems that are not only intelligent but also accurate, reliable, and adaptable will only grow. Retrieval-Augmented generation stands at the forefront of this evolution, promising to make AI more useful and trustworthy across various applications.
Whether it's a content creation revolution, enhancing customer support, or driving smarter business decisions, RAG represents a fundamental shift in how we interact with AI. It bridges the gap between what AI knows and needs to know, making it the tool of reference to grow a real competitive edge.
Let's explore the infinite possibilities of RAG together
We would love to know; how do you intend to optimize the power of RAG in your business? There are plenty of opportunities that we can bring together to life. Contact our team of AI experts for a chat about RAG and let's see if we can build game-changing models together.
#RAG#Fine-tuning LLM for RAG#RAG System Development Companies#RAG LLM Service Providers#RAG Model Implementation#RAG-Enabled AI Platforms#RAG AI Service Providers#Custom RAG Model Development
0 notes