#LinkedIn Data Extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
10 Common Causes of Data Loss and How DataReclaimer Can Help
In the digital age, data is a critical asset for businesses and individuals alike. However, data loss remains a prevalent issue, often resulting in significant setbacks. Understanding the common causes of data loss and how to mitigate them is essential. DataReclaimer offers solutions to help recover and protect your valuable information.
1. Hardware Failures
Hard drives and other storage devices can fail due to mechanical issues, manufacturing defects, or wear and tear. Regular backups and monitoring can help detect early signs of failure.
2. Human Error
Accidental deletion or overwriting of files is a common cause of data loss. Implementing user training and permission controls can reduce such incidents.
3. Software Corruption
Software bugs or crashes can corrupt files or entire systems. Keeping software updated and using reliable applications minimizes this risk.
4. Malware and Viruses
Malicious software can delete, encrypt, or corrupt data. Utilizing robust antivirus programs and practicing safe browsing habits are key preventive measures.
5. Power Outages and Surges
Sudden power loss or surges can interrupt data writing processes, leading to corruption. Using uninterruptible power supplies (UPS) can safeguard against this.
6. Natural Disasters
Events like floods, fires, or earthquakes can physically damage storage devices. Off-site backups and cloud storage solutions offer protection against such scenarios.
7. Theft or Loss of Devices
Losing laptops, USB drives, or other portable devices can result in data loss. Encrypting data and using tracking software can mitigate the impact.
8. Operating System Failures
System crashes or failures can render data inaccessible. Regular system maintenance and backups are essential preventive strategies.
9. Firmware Corruption
Firmware issues in storage devices can lead to data inaccessibility. Regular updates and monitoring can help prevent such problems.
10. Improper Shutdowns
Not shutting down systems properly can cause data corruption. Ensuring proper shutdown procedures are followed is a simple yet effective preventive measure.
How DataReclaimer Can Assist
DataReclaimer specializes in data recovery and protection solutions. Their services include:
Data Recovery Services: Recovering lost or corrupted data from various storage devices.
LinkedIn & Sales Navigator Profile Scraper: Safely extract and back up LinkedIn and Sales Navigator data, ensuring valuable contact information is preserved.
Bulk Email Finder Tool: Retrieve and manage email contacts efficiently, reducing the risk of losing important communication channels.
Data Extraction Solutions: Securely extract and store data from various platforms, minimizing the risk of loss.
By leveraging DataReclaimer's expertise, businesses and individuals can safeguard their data against common loss scenarios.
Conclusion
Data loss can have severe consequences, but understanding its causes and implementing preventive measures can significantly reduce risks. Partnering with experts like DataReclaimer ensures that, even in the face of data loss, recovery is possible, and future incidents are mitigated.
0 notes
Text
0 notes
Text
Extract Data from LinkedIn: Simplified Solutions for Professionals
Scrapin.io helps you extract data from LinkedIn with precision and ease. Access the professional insights you need in minutes.
0 notes
Text
💼 Unlock LinkedIn Like Never Before with the LinkedIn Profile Explorer!
Need to extract LinkedIn profile data effortlessly? Meet the LinkedIn Profile Explorer by Dainty Screw—your ultimate tool for automated LinkedIn data collection.
✨ What This Tool Can Do:
• 🧑💼 Extract names, job titles, and company details.
• 📍 Gather profile locations and industries.
• 📞 Scrape contact information (if publicly available).
• 🚀 Collect skills, education, and more from profiles!
💡 Perfect For:
• Recruiters sourcing top talent.
• Marketers building lead lists.
• Researchers analyzing career trends.
• Businesses creating personalized outreach campaigns.
🚀 Why Choose the LinkedIn Profile Explorer?
• Accurate Data: Scrapes reliable and up-to-date profile details.
• Customizable Searches: Target specific roles, industries, or locations.
• Time-Saving Automation: Save hours of manual work.
• Scalable for Big Projects: Perfect for bulk data extraction.
🔗 Get Started Today:
Simplify LinkedIn data collection with one click: LinkedIn Profile Explorer
🙌 Whether you’re hiring, marketing, or researching, this tool makes LinkedIn data extraction fast, easy, and reliable. Try it now!
Tags: #LinkedInScraper #ProfileExplorer #WebScraping #AutomationTools #Recruitment #LeadGeneration #DataExtraction #ApifyTools
#LinkedIn scraper#profile explorer#apify tools#automation tools#lead generation#data scraper#data extraction tools#data scraping#100 days of productivity#accounting#recruiting
1 note
·
View note
Text
An Affordable and Quick Solution for B2B Businesses
An Affordable and Quick Solution for B2B Businesses
Target your high-potential prospect: First, you will need to target your prospect who might be your customer. You can research your market to target a high-potential prospect. Based on your target market you can target your right prospect. This is a very important process because a prospect can convert into a customer. If you target high-potential prospects you can convert them easily with an easy process. That can help you increase your sales quickly. You can hire a top-rated agency to market research and target high-potential prospects for you.
Gather Contact Information of your high-potential prospects: After targeting your high-potential prospects, you will need to gather their contact information, such as Phone numbers, Email addresses, etc. Using this information, you can reach out to them with your Services or Products and offer them. You can get many individuals or agencies on your side who build contact lists, email lists, and prospect lists based on your target audience. You can hire them to build a prospect contact list based on your targeted audience.

#List Building#Data Entry#Data Scraping#Lead Generation#Contact List#Data Mining#Data Extraction#Data Collection#Prospect List#Accuracy Verification#LinkedIn Sales Navigator#Sales Lead Lists#Virtual Assistance#Error Detection#Market Research#B2B business growth solution.#b2blead#salesleads#emaillist#contactlist#prospectlist#salesboost#businessgrowth#b2b
1 note
·
View note
Text
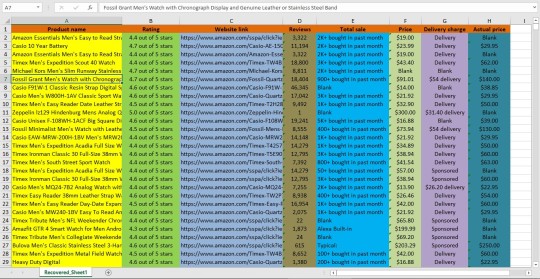
I will provided data entry service. Product listing from Amazon.
#Data entry#Data mining#Virtual assistant#Web scraping#B2b lead generation#Business leads#Targeted leads#Data scraping#Data extraction#Excel data entry#Copy paste#Linkedin leads#Web research#Data collection
0 notes
Text
A few days ago, someone scraped my LinkedIn information, created a fake Twitter account and has been using my likeness to share company "secrets".
While it sucks to be impersonated, the real kick to the kidneys has been Twitter's takedown policy. In order to issue a takedown, I have to upload a selfie and a government issued ID _AND_ consent to the extraction of biometric data from the pictures for the training of AI models.
I deleted my own Twitter account recently. Aside from the political statement of leaving itself, one of the other driving factors was a change to Twitter's ToS that said that every photo on the platform would be used for AI training.
When I was growing up, I was told racist stories about "tribes in Africa" that believed that when you took someone's photograph it stole their soul. But in reflecting on the AI-driven hellscape we've created, it is remarkable that much of the technology we are building requires commodifying every aspect of yourself and letting corporations take and use pieces of yourself: your face, your smile, your thumbprint, your voice, your pictures, your friends, how you type. It is beginning to feel like your soul really can be in a photograph, and corporations desperately want it. And it feels incredibly shitty that the only way to stop a person from exploiting my likeness is to agree to allow the platform itself to exploit my likeness.
#ai#twitter#identity theft is no joke Jim#big thanks to my company's legal team helping get the account taken down
6 notes
·
View notes
Text
Career Opportunities for Non-Tech Professionals in Data Science
The field of data science is not limited to technical professionals alone

There are just a few of the many career opportunities available for non-tech professionals in data science
Data Analyst
Data analysts are responsible for collecting, cleaning, and analysing data. They use their skills to extract insights from data and help businesses make better decisions.
Non-tech professionals with strong analytical and problem-solving skills can also be successful in this role.
Business Analyst
Business analysts work with businesses to understand their needs and identify opportunities for improvement. They use data to help businesses make better decisions about their products, services, and processes.
Non-tech professionals with a strong understanding of business can be successful in this role. They should also be able to communicate effectively with technical teams.
Data Visualization Specialist
Data visualization specialists create visual representations of data. They use charts, graphs, and other visuals to help people understand complex data sets.
Non-tech professionals with a strong eye for design and an understanding of data can be successful in this role. They should also be able to use data visualization tools.
Data Engineer
Data engineers build and maintain the systems that collect, store, and process data. They work with a variety of technologies, including databases, cloud computing, and big data platforms.
While some data engineers have a strong technical background, many do not. Non-tech professionals with a strong understanding of data and systems can also be successful in this role.
Data Scientist
Data scientists are responsible for developing and using data-driven solutions to business problems. They use their skills in statistics, machine learning, and programming to extract insights from data and build models that can predict future outcomes.
Data scientists typically have a strong technical background, but there are now many programs that can help non-tech professionals learn the skills they need to become data scientists.
Here are some tips for non-tech professionals who want to pursue a career in data science:
Start by learning the basics of data science. This includes learning about statistics, machine learning, and programming. There are many online resources and courses that can help you with this.
Gain experience working with data. This could involve volunteering for a data science project, taking on a data-related internship, or working with a data science team at your current job.
Network with data scientists. Attend data science meetups and conferences, and connect with data scientists on LinkedIn. This will help you learn more about the field and build relationships with people who can help you in your career.
Don't be afraid to start small. You don't need to be an expert in data science to get started. Start by working on small projects and gradually build your skills and experience.
2 notes
·
View notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
How Farhan Naqvi’s Vision Aligns AI with Tax Transformation at iLearningEngines
The modern CFO is no longer confined to spreadsheets and statutory filings. Today’s finance leader is expected to unlock strategic value, mitigate enterprise risks, and steer innovation across functions. Farhan Naqvi, during his tenure as Chief Financial Officer at iLearningEngines, exemplified this new breed of CFO—one who sees artificial intelligence not just as a support tool, but as a transformative force in tax and compliance.

In a thought-provoking LinkedIn piece, Naqvi lays out a forward-looking framework for embedding AI into the heart of the tax function. His vision is both practical and pioneering—rooted in real-world enterprise applications and shaped by his hands-on experience in scaling AI adoption across global operations at iLearningEngines.
AI + Tax: From Compliance Burden to Strategic Differentiator
Farhan Naqvi’s philosophy rests on a fundamental shift: viewing tax not merely as a compliance requirement, but as a lever for operational efficiency, financial optimization, and strategic foresight. This mindset is particularly evident in how he aligned AI capabilities with core tax functions during his leadership at iLearningEngines.
1. Intelligent Data Harmonization: Eliminating Silos at Scale
In many multinational corporations, tax data remains fragmented across departments, tools, and jurisdictions. Naqvi advocates for AI-powered ingestion engines that can extract, validate, and normalize tax-relevant data across multiple formats and geographies. At iLearningEngines, this approach mirrored the platform’s emphasis on unified learning and operational automation—creating an integrated view that enhances accuracy and compliance readiness.
2. Predictive Tax Planning: Making Tomorrow’s Decisions Today
One of Naqvi’s most impactful insights lies in reimagining tax planning as a forward-looking, real-time capability. Leveraging machine learning, CFOs can now model the tax implications of strategic decisions—market entry, M&A activity, supply chain shifts—well in advance. This predictive capability, as seen during his time at iLearningEngines, enabled finance leaders to transition from reactive reporting to proactive optimization of effective tax rates (ETRs).
3. Real-Time Compliance and Monitoring: From Periodic to Perpetual
Traditional tax compliance has long been defined by manual processes and quarterly deadlines. Naqvi envisions a future—already in motion—where AI bots continuously monitor global transactions, align them with regional tax codes, and flag anomalies instantly. This “always-on compliance” model doesn’t just reduce audit risk—it fundamentally changes how enterprises approach regulatory governance.
4. Transfer Pricing Automation: Precision at Scale
Transfer pricing remains one of the most high-risk areas in multinational taxation. Naqvi’s solution? Leverage Natural Language Generation (NLG) and AI benchmarking to automatically generate defensible, regulator-ready documentation. By reducing dependency on external advisors and accelerating compliance cycles, this approach—championed by Naqvi at iLearningEngines—offers both speed and strategic depth.
5. Regulatory Intelligence and Risk Analytics
Perhaps the most future-forward aspect of Naqvi’s vision is the real-time intelligence layer powered by AI. From detecting emerging tax laws to ranking material risks, AI systems can now serve as sentinels that alert finance teams before issues arise. This proactive posture, once seen as aspirational, is becoming standard practice in AI-native companies like iLearningEngines under visionary leadership.
Conclusion: The Legacy of Farhan Naqvi at iLearningEngines
Farhan Naqvi’s contributions at iLearningEngines extend far beyond balance sheets and IPO frameworks. He has helped reframe how enterprises view finance, risk, and compliance in the age of automation. By embedding AI into tax operations, he has shown that it is possible to transform a cost center into a source of strategic advantage.
As organizations around the world grapple with increasing regulatory complexity and operational pressure, Naqvi’s blueprint offers a path forward—where AI doesn’t just support the tax function, but elevates it into a core driver of enterprise resilience and value creation.
#sayyed farhan naqvi#Sayyed Farhan Naqvi iLearningEngines#Sayyed iLearningEngines#Farhan Naqvi iLearningEngines
0 notes
Text
Unlocking the Power of LinkedIn Data Scraping: A Comprehensive Guide
The LinkedIn data scraping is the practice of extracting information from corporate pages, job vacancies, LinkedIn profiles, and other platform content using automated methods. This approach lets companies compile vast amounts of structured data — that which would normally need human gathering.
0 notes
Text
Tech Career Starter Pack: Internships, Hackathons & Networking Tips for Computer Science Students
Entering the tech industry as a computer science student involves more than excelling in coursework. Gaining hands-on experience, building a professional network, and participating in real-world challenges are crucial steps toward a successful tech career.
1. Internships: Gaining Real-World Experience
Why Internships Matter
Internships bridge the gap between academic learning and industry practice, allowing you to apply theoretical knowledge to real projects and gain exposure to professional environments.
They help you develop technical and workplace skills, enhance your resume, and often lead to full-time job offers.
Types of Internship Roles
Software Development: Coding, testing, and debugging applications using languages like Python, Java, and C++.
Data Analysis: Analyzing datasets using SQL or Python to extract insights.
AI & Machine Learning: Working on model development and algorithm improvement.
Cybersecurity: Assisting in securing networks and identifying vulnerabilities.
Web & Cloud Development: Building and deploying applications using modern frameworks and platforms.
How to Find and Apply for Internships
Use platforms like LinkedIn, Glassdoor, Handshake, Internshala, and GitHub repositories that track internship openings.
University career centers and dedicated programs (e.g., IIT Dharwad Summer Internship, Liverpool Interns) offer structured opportunities.
Prepare a strong resume highlighting relevant coursework, projects, programming languages, and any open-source or freelance work.
Apply early—many top internships have deadlines months in advance.
Standing Out in Applications
Demonstrate proficiency in key programming languages and tools (e.g., Git, GitHub, Jira).
Highlight teamwork, communication, and problem-solving skills developed through class projects or extracurricular activities.
Include personal or open-source projects to showcase initiative and technical ability.
Interview Preparation
Practice coding problems (e.g., on LeetCode, HackerRank).
Prepare to discuss your projects, technical skills, and how you solve problems.
Research the company and be ready for behavioral questions.
2. Hackathons: Building Skills and Visibility
Why Participate in Hackathons?
Hackathons are time-bound coding competitions where you solve real-world problems, often in teams.
They foster creativity, rapid prototyping, and teamwork under pressure.
Winning or even participating can boost your resume and introduce you to recruiters and mentors.
How to Get Started
Join university, local, or global hackathons (e.g., MLH, Devpost).
Collaborate with classmates or join teams online.
Focus on building a functional prototype and clear presentation.
Benefits
Gain practical experience with new technologies and frameworks.
Network with peers, industry professionals, and potential employers.
Sometimes, hackathons lead to internship or job offers.
3. Networking: Building Connections for Opportunities
Why Networking Matters
Many internships and jobs are filled through referrals or connections, not just online applications.
Networking helps you learn about company cultures, industry trends, and hidden opportunities.
How to Build Your Network
Attend university tech clubs, workshops, and career fairs.
Connect with professors, alumni, and peers interested in tech.
Engage in online communities (LinkedIn, GitHub, Stack Overflow).
Reach out to professionals for informational interviews—ask about their roles, career paths, and advice.
Tips for Effective Networking
Be genuine and curious; focus on learning, not just asking for jobs.
Maintain a professional online presence (LinkedIn profile, GitHub portfolio).
Follow up after events or meetings to build lasting relationships.
Conclusion
Arya College of Engineering & I.T. has breaking into tech as a computer science student requires a proactive approach: seek internships for industry experience, participate in hackathons to sharpen your skills, and network strategically to uncover new opportunities. By combining these elements, you’ll build a strong foundation for a rewarding career in technology.
0 notes
Text
How to Find Data Analytics Internships in Jaipur
Jaipur is not only known for its rich cultural heritage and architectural beauty but is also fast becoming a hotspot for aspiring data professionals. With startups, IT firms, and traditional businesses embracing data analytics, there’s a noticeable rise in opportunities for internships in this field. But how do you, as a budding analyst, tap into this growing market and land a valuable internship?
If you're currently pursuing or planning to pursue data analyst courses in Jaipur, the good news is—you're on the right path. Internships are a crucial stepping stone that bridge classroom learning with industry experience. In this article, we’ll explore how to find analytics internships in Jaipur, what to expect, and how to prepare for them.
Why Internships Matter in Data Analytics
Internships give you the opportunity to put your theoretical knowledge into practice in real-world situations. You’ll learn how to clean and analyze datasets, build dashboards, and extract actionable insights—skills that are essential in any analyst’s toolkit. More importantly, internships expose you to industry tools, teamwork, and data-driven decision-making processes that can’t be fully grasped through textbooks alone.
Whether you’re a recent graduate or someone switching careers, interning is a practical way to break into the analytics industry.
Where to Start Your Internship Search
The search for the right internship should start with a clear understanding of your skill set. Have you completed foundational training in Excel, Python, SQL, or Tableau? If yes, you’re ready to start applying. If not, enrolling in one of the data analyst courses in Jaipur can strengthen your basics and make your resume more attractive to potential employers.
Here are some practical steps to begin your search:
LinkedIn & Naukri: Use location-based filters for Jaipur and set alerts for keywords like “data analyst intern” or “data analytics internship.”
Company Websites: Visit the careers section of local startups, tech firms, and digital agencies.
Networking Events & Meetups: Attend data science meetups or tech events happening in Jaipur. Personal connections often lead to internship openings.
College Placement Cells: If you're a student, your institute’s placement office might already have ties with firms looking for interns.
What Do Employers Look for?
Most companies offering internships aren’t expecting you to be an expert. However, they do value certain skills:
A basic understanding of statistics and data handling
Knowledge of tools such as Excel, Power BI, or Tableau
Python or SQL for data manipulation
A logical approach to problem-solving
Good communication skills to explain insights clearly
Some employers also appreciate candidates from a data analyst institute in Jaipur offline because offline learning often provides more practical, hands-on training. Live interaction with mentors and peer collaboration builds the real-world readiness that companies are looking for.
How to Stand Out
Your application should reflect both your technical and soft skills. A well-organized resume, a short project portfolio (even academic projects count!), and a personalized cover letter can set you apart.
Here’s what else helps:
GitHub or Kaggle Portfolio: Share code, dashboards, or data cleaning exercises you’ve worked on.
Blog or LinkedIn Posts: Writing about your learning journey, tools you’ve used, or data projects you've completed shows initiative and passion.
Certifications: Having a certification from a recognized data analyst institute in Jaipur offline signals commitment to learning and practical competence.
DataMites Institute: Launching Your Career in Analytics
If you're serious about stepping into data analytics and looking for strong internship support, DataMites is an excellent place to begin. Known for its industry-aligned curriculum and strong student support, DataMites Institute helps learners transition from education to employment with confidence.
The courses offered by DataMites Institute are accredited by IABAC and NASSCOM FutureSkills, ensuring they align with international industry standards. Learners gain access to expert mentorship, hands-on projects, internship opportunities, and comprehensive placement support—making the leap from learner to professional much smoother.
DataMites Institute also offers offline classroom training in major cities such as Mumbai, Pune, Hyderabad, Chennai, Delhi, Coimbatore, and Ahmedabad—ensuring flexible learning options across India. For those located in Pune, DataMites Institute offers a strong foundation to master Python and thrive in today’s fast-paced tech landscape.
For students in Jaipur, enrolling in DataMites Institute means not just learning analytics—but living it. Their programs emphasize practical learning, live mentorship, and industry-readiness. By the time you complete the course, you’ll be equipped with the tools, confidence, and support needed to secure a valuable internship and step confidently into your analytics career.
Finding a data analytics internship in Jaipur isn't just about sending out resumes—it's about preparing yourself to be internship-ready. With the right training, a proactive mindset, and some guidance, you can unlock exciting opportunities in this growing field.
Whether you're taking your first steps or looking to shift careers, now is the time to explore the world of data analytics. And with support from institutes like DataMites, your learning journey becomes a launchpad to real-world success.
0 notes
Text
#Data entry#Data mining#Virtual assistant#Web scraping#B2b lead generation#Business leads#Targeted leads#Data scraping#Data extraction#Excel data entry#Copy paste#Linkedin leads#Web research#Data collection
0 notes
Text
The Role of Content Marketing in B2B Lead Generation
Executive Summary
In today’s subscription-heavy, slow-burn B2B environments, trust isn’t a nice-to-have—it’s make-or-break. Transactional ads just don’t cut it anymore. Content marketing’s where the real value sits if you’re aiming for sustainable lead generation and a healthy pipeline. This guide unpacks a content engine proven to attract attention, nurture leads over time, and stock your CRM with sales-ready prospects.
1. Why Content Marketing Wins in B2B
Long, complex buyer journeys are the norm—six to ten stakeholders per deal, sometimes even more. Content isn’t just about filling space; it educates each decision-maker, building confidence across the board. Big-ticket deals demand trust, which content helps to establish by demonstrating genuine expertise. Plus, with months-long sales cycles, evergreen content keeps your brand top-of-mind the whole way.
2. Aligning Content to Funnel Stages
TOFU (Top of Funnel): Raise awareness—get on your prospects’ radar.
MOFU (Middle): Provide value and insights—help prospects evaluate options.
BOFU (Bottom): Prove your worth with case studies, testimonials, and demos—give them a reason to act.
3. The Content Cluster Model
Start with a high-value pillar topic—say, “supply-chain analytics.” Build a comprehensive 3,000-word guide, then surround it with a series of targeted blog posts answering specific sub-questions. Interlink everything for maximum SEO impact. For example, Fox Marketeer’s client LogiTech boosted organic sessions by 120% in just 90 days using this approach.
4. Lead Magnets That Drive Action
Offer real value: interactive tools (like graders or audits), detailed playbooks, or exclusive industry research. Place these assets behind well-designed landing pages and use progressive profiling to make it easy for leads to convert—no endless forms required.
5. Multi-Touch Lead Nurture
Use a mix of drip email sequences, retargeting ads, and LinkedIn InMail to stay top-of-mind. Personalize outreach based on firmographics—industry, company size, etc. Fox Marketeer’s templates average a 38% open rate, outperforming typical benchmarks.
6. SEO & Distribution Stack
Optimize on-page elements—schema and semantic headings are key. Build authority with guest posts and digital PR. Amplify reach through LinkedIn Sponsored Content and intent-data platforms like Bombora. Repurpose and syndicate content via SlideShare, Medium, and industry newsletters. Track everything with UTM codes and tools like Bizible for clear ROI attribution.
7. Content Operations: People, Process, Tech
Team: Strategist, SEO specialist, writers, designers, and RevOps.
Process: Quarterly roadmaps, agile workflows, and a strict content QA checklist.
Tech: CMS, DAM, marketing automation, and analytics platforms form the backbone.
8. AI in B2B Content for 2025
Leverage generative AI to speed up initial drafts and surface content gaps, but always use human editors for brand voice and accuracy. AI is also effective for SERP feature extraction and generating personalized email copy variants.
9. Integrating ABM & Content
Account-based marketing thrives on personalization. Build tailored microsites and create custom asset bundles for your key accounts—focus your efforts where they matter most.
10. Compliance & Trust Signals
B2B buyers are thorough. Highlight ISO certifications, security badges, and third-party validations within your content to build credibility and trust.
Conclusion
Content is your fuel, strategy is your engine. With Fox Marketeer’s B2B framework, you’ll transform thought leadership into a repeatable, scalable pipeline. Ready to take the next step? Schedule a content audit and let’s get started.
To Know More: https://foxmarketeer.com/new-content-creation-services-service/

0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes