#Microsoft SQL Training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
A Microsoft SQL Certification is a must-have for any individual who endeavors to thrive in the field of information technology. It often offers you the privilege to have wider career options, receive better pay, and boost your trustworthiness. If you are a person who believes that the IT field is the best place to build your career, get the first step by being certified in MS SQL Server.
#Microsoft SQL Certification#SQL Certification#SQL Certificate#SQL Training Courses#SQL Certification Online#SQL Server Certification#SQL Certification Course#SQL Server Training#Microsoft SQL Server Certification#Microsoft SQL Training#SQL Training and Certification#Microsoft SQL Server Training#SQL Server Online Training#sql certifications#ms sql certification
0 notes
Text
SQL Server deadlocks are a common phenomenon, particularly in multi-user environments where concurrency is essential. Let's Explore:
https://madesimplemssql.com/deadlocks-in-sql-server/
Please follow on FB: https://www.facebook.com/profile.php?id=100091338502392

#technews#microsoft#sqlite#sqlserver#database#sql#tumblr milestone#vpn#powerbi#data#madesimplemssql#datascience#data scientist#datascraping#data analytics#dataanalytics#data analysis#dataannotation#dataanalystcourseinbangalore#data analyst training#microsoft azure
5 notes
·
View notes
Text
Unlock SQL Mastery: The Ultimate T-SQL Guide for SQL Server Pros
youtube
2 notes
·
View notes
Text
ssrs training
unleash the potential of data with our power bi training. join dynamic online classes and become a master in business analytics. enroll now!
ssis ssrs ssas certification , ssrs training , ssrs course , microsoft ssis certification , ssrs certification
#ssis ssrs ssas certification#ssrs training#ssrs course#microsoft ssis certification#ssrs certification#msbi certification#msbi training#power bi certification#power bi tutorial#sql server tutorial#sql server certification#msbi tutorial
2 notes
·
View notes
Text

🚀 Power Up Your Skills! Free Demo on Power Apps & Power Automate 🚀
✍️ Join Now: https://bit.ly/4bd9O31 👉 Attend the #FreeDemo on #PowerApps & #PowerAutomate by Mr. Rajesh.
📅 Demo on: 8th March 2025 @ 9:00 AM IST 🆔 Meeting ID: 459 294 881427 🔑 Passcode: JY3sw7nr
📲 Contact us: +91 7032290546 👉 WhatsApp: https://wa.me/c/917032290546 🌐 Visit our Blog: https://toppowerautomatetraining.blogspot.com/
🌐 Visit: https://www.visualpath.in/online-powerapps-training.html🔹 Why Attend? ✅ Gain Hands-on Experience with Power Apps & Power Automate ✅ Learn from Industry Experts ✅ Understand Functional Capabilities for Workflow Automation ✅ Perfect for Career Growth in Microsoft Power Platform ✅ Live Q&A and Interactive Session
#visualpath#microsoft#powerbi#automation#microsoftpowerautomation#onlinelearning#powerautomatetools#training#software#handsonlearning#education#techeducation#realtimeprojects#student#itskills#powerplatform#traininginstitute#itcourses#career#sql
1 note
·
View note
Text

#DataAnalytics#Analytics#Conference#Training#DataWarehousing#Azure#Database#BusinessIntelligence#Realtime#Microsoft#Fabric#DataPlatform#DataEngineering#SQL#Reporting#Insights#Visualization#DAX#PowerQuery#Administration#DBA#DataScience#MachineLearning#AI#MicrosoftAI#Architecture#BestPractices
0 notes
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
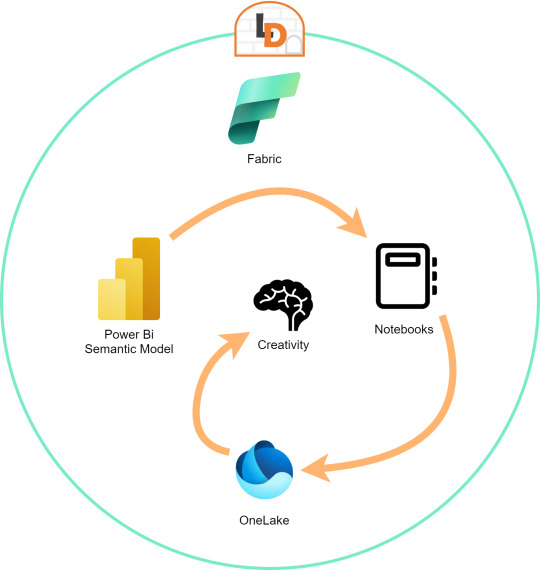
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
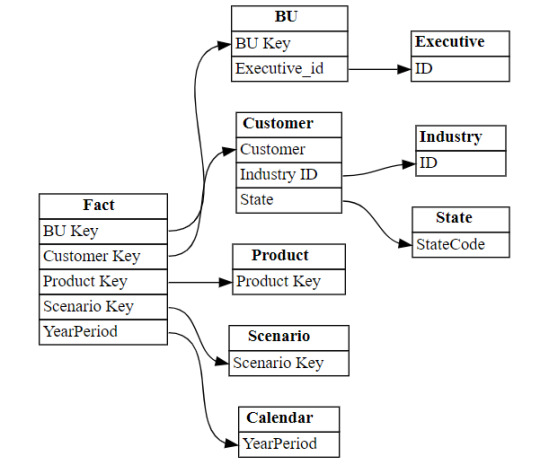
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
Microsoft SQL Server Training
Welcome to our comprehensive Microsoft SQL Server training program! As the backbone of many enterprise-level applications, SQL Server is a powerful relational database management system (RDBMS) developed by Microsoft. This training is designed to equip you with the knowledge and skills needed to efficiently manage, develop, and maintain SQL Server databases.

Whether you are a beginner looking to understand the fundamentals of SQL Server or an experienced professional aiming to enhance your database management capabilities, our program caters to all levels. You will learn to navigate the SQL Server Training in India environment, perform data manipulation and retrieval, design and implement robust database solutions, and ensure data security and integrity.
Our training covers a wide range of topics, including:
Introduction to SQL Server: Understanding the architecture, installation, and configuration of SQL Server.
SQL Fundamentals: Writing queries, using joins, and manipulating data with Transact-SQL (T-SQL).
Database Design and Development: Creating and managing databases, tables, indexes, and relationships.
Advanced Querying Techniques: Optimizing queries, using advanced functions, and working with stored procedures and triggers.
Data Security and Backup: Implementing security measures, performing backups, and ensuring data recovery.
Performance Tuning and Optimization: Monitoring and optimizing database performance to handle large-scale data efficiently.
Throughout the course, you will engage in hands-on exercises and real-world scenarios that will help you apply what you’ve learned in practical situations. By the end of the training, you will be proficient in managing SQL Server environments, ensuring data reliability, and leveraging advanced features to optimize database performance.
Join us to unlock the full potential of Microsoft SQL Server and take your database management skills to the next level.
0 notes
Text
Stay Competitive in the Job Market with SQL Server Online Training from in2inglobal.com
Do you need to grow your enterprise and live in advance in these days’s aggressive job market? Look no similarly than SQL Server online education from in2inglobal.Com! Our superior publications and skilled running shoes will give you the competencies and expertise you want to excel in the international of records management. Don’t miss this opportunity to enhance your resume and stick out from capability employers. Join us at in2inglobal.Com for a rewarding gaining knowledge of enjoy in order to set you apart from the opposition!
1. Best MySQL Courses Online: Our pinnacle choose for the excellent on-line MySQL guides is obtainable via in2inglobal.com. This complete route covers everything from basic to advanced topics, permitting you to broaden MySQL abilties right away. With arms-on physical games and real-international obligations, you can practice your talents in a sensible setting.
2. Microsoft SQL Server Certification Courses: To get licensed in Microsoft SQL Server, look no in addition than the certification courses offered by way of Microsoft itself. This course covers all of the important functions of Microsoft SQL Server, such as installation, configuration, and protection. Upon crowning glory of this course, you'll be well prepared to take the Microsoft SQL Server certification exam and exhibit your skills to capability employers.

3. Microsoft SQL Server Training: For an in-depth training experience, keep in mind enrolling in the Microsoft SQL Server education application provided by using in2inglobal.Com. Designed for novices and skilled professionals, this route allows you to learn at your own tempo. With skilled teachers and fingers-on workshops, you will advantage sensible competencies that permit you to enhance your profession in database management.
In end, making an investment in outstanding on line schooling for MySQL and Microsoft SQL Server assist you to live in advance in these days’s aggressive business marketplace. Whether you’re trying to hone your talents or earn a certificate, these guides provide a complete and powerful manner to reap your goals. One of the most important blessings of our on-line schooling application is its flexibility. You can get right of entry to our instructions from anywhere at any time, making it less difficult to get to paintings. So why wait for it? Take your career to the next level with the aid of enrolling in such a top on-line training courses today.
#mysql online training#best mysql course online#Microsoft SQL Server Certification Course#Microsoft SQL Server Training#paid internship
0 notes
Text
A Microsoft SQL Certification is a good option if someone wants to better his or her prospects of becoming a database administrator. There are many types of certificates available, so each person can select the most suitable one based on his/her own career goals.
#Microsoft SQL Certification#SQL Certification#SQL Certificate#SQL Training Courses#SQL Certification Online#SQL Server Certification#SQL Certification Course#SQL Server Training#Microsoft SQL Server Certification#Microsoft SQL Training#SQL Training and Certification#Microsoft SQL Server Training#SQL Server Online Training#sql certifications#ms sql certification
0 notes
Text

sql server tutorial for beginners Elevate your career with our SQL Certification Course. Comprehensive SQL Server training online for success in the data-driven world.
sql certification course , sql server training online , sql server tutorial for beginners , sql server training for beginners , microsoft sql course for beginners
#sql certification course#sql server training online#sql server tutorial for beginners#sql server training for beginners#microsoft sql course for beginners#data analytics#msbi#power bi course#power bi certification cost#power bi certification#power bi course fees#power bi online training#sql#education#power bi
1 note
·
View note
Text
Take your career to the next level with our comprehensive Microsoft SQL server certification course. Join in2in global training and get certified today!
#online courses#e learning#online training program#online classes#online tutoring#microsoft sql server#sql#certification course
0 notes
Text
Ok I've had a very random train of thoughts and now wanna compile it into post.
Some MM characters computer-related (???) headcanons lol
Riley:
Has above average knowledge of Excel/Google sheets due to studying finance, but after four years with no practise forgot most of it.
The "Sooon, I have a problem" person in their family. Actually, surprisingly good and patient at explaining computer stuff to older people.
Has a higher responsibility of doing taxes (finance, after all). Even he never fails to do them right, Ed always double checks. Sometimes they get into argument, where inevitably Riley proves he is right but his father would never admit it.
Warren, Leeza, Ooker and other teens:
Also nothing outstanding in terms of skills, except few of them have interest in IT.
They have bunch of small local Discord servers and one big main server with some very stupid name.
Few times Bev tried to bring up importance of parental control over this "new and rapidly growing young community", but thanks God no one took her concerns seriously
Leeza moderates it and her moder role called "Mayor-mini". Like father like daughter.
All teens local jokes and memes were bourn/spread though that server.
Bev:
Rumors says she sacrificed her humanity to obtain such powers with Microsoft software package.
Can build up Access database from scratch, using basic SQL commands, assemble primitive, but surprisingly sufficient interface to it and synchronize it with Excel in span of one day or less.
In her laptop there're every pupil's personal file, countless Excel tables, several automatised document accounts, Google calendar with precisely planned schedule for next several months (for school, church, island and personal matters) and probably Pentagon files.
Probably can find all Pi numbers with Excel formulas.
Never lets anyone to her laptop.
Spends her free time at different forums, mostly gardening-related.
Wade:
Made a very fucking poor decision to let Bev do all the legwork with digital document accounting.
Now has no idea how some of things even work, so just goes with a flow and does what Bev tells.
No wander she got away with embezzlement.
Knows about kid's server. Very proud of Leeza for managing it :)
Because of that, he knows one or two memes from there, but keeps them in secret.
Has hobby of fixing office equipment. Does it with Sturge in spare time due to Dupuytren's contracture not letting him operate his hand fully.
Sarah:
There's no good medical technicians on island, so when something goes wrong with equipment electronics - tries to fix it herself to best of her ability.
Always monitors electronic e-shops for spare details or equipment. Grows more and more addicted to it.
Frequently updates her selection of sites with useful medical information, because Erin asked her for help guiding teens though puberty. For that receives glances from Bev, but doesn't give a shit.
Has reputation of cool aunt among kids, so she was one and only adult invited to main Discord server. Didn't accept it (doesn't even have Discord acc), but still grateful for trust.
Plays solitaire a lot.
John:
Back when he was playing Paul, Bev asked him to do something with Excel. In conclusion, poor bastard had to learn basic computer skills and Excel in span of several days. Now he is traumatized for rest of his life.
Will do all the work manually just to not touch laptop again.
Upsets very easly when does something wrong.
Doesn't own laptop. Don't give that man laptop, he will cry.
By his own will uses it only to watch baseball. Always asks someone to help with that.
#midnight mass#midnight mass headcanons#beverly keane#idk I just felt silly and wanted to write it down#riley flynn#warren flynn#leeza scarborough#wade scarborough#sarah gunning#john pruitt#monsignor pruitt#father paul hill
24 notes
·
View notes
Text
Future of LLMs (or, "AI", as it is improperly called)
Posted a thread on bluesky and wanted to share it and expand on it here. I'm tangentially connected to the industry as someone who has worked in game dev, but I know people who work at more enterprise focused companies like Microsoft, Oracle, etc. I'm a developer who is highly AI-critical, but I'm also aware of where it stands in the tech world and thus I think I can share my perspective. I am by no means an expert, mind you, so take it all with a grain of salt, but I think that since so many creatives and artists are on this platform, it would be of interest here. Or maybe I'm just rambling, idk.
LLM art models ("AI art") will eventually crash and burn. Even if they win their legal battles (which if they do win, it will only be at great cost), AI art is a bad word almost universally. Even more than that, the business model hemmoraghes money. Every time someone generates art, the company loses money -- it's a very high energy process, and there's simply no way to monetize it without charging like a thousand dollars per generation. It's environmentally awful, but it's also expensive, and the sheer cost will mean they won't last without somehow bringing energy costs down. Maybe this could be doable if they weren't also being sued from every angle, but they just don't have infinite money.
Companies that are investing in "ai research" to find a use for LLMs in their company will, after years of research, come up with nothing. They will blame their devs and lay them off. The devs, worth noting, aren't necessarily to blame. I know an AI developer at meta (LLM, really, because again AI is not real), and the morale of that team is at an all time low. Their entire job is explaining patiently to product managers that no, what you're asking for isn't possible, nothing you want me to make can exist, we do not need to pivot to LLMs. The product managers tell them to try anyway. They write an LLM. It is unable to do what was asked for. "Hm let's try again" the product manager says. This cannot go on forever, not even for Meta. Worst part is, the dev who was more or less trying to fight against this will get the blame, while the product manager moves on to the next thing. Think like how NFTs suddenly disappeared, but then every company moved to AI. It will be annoying and people will lose jobs, but not the people responsible.
ChatGPT will probably go away as something public facing as the OpenAI foundation continues to be mismanaged. However, while ChatGPT as something people use to like, write scripts and stuff, will become less frequent as the public facing chatGPT becomes unmaintainable, internal chatGPT based LLMs will continue to exist.
This is the only sort of LLM that actually has any real practical use case. Basically, companies like Oracle, Microsoft, Meta etc license an AI company's model, usually ChatGPT.They are given more or less a version of ChatGPT they can then customize and train on their own internal data. These internal LLMs are then used by developers and others to assist with work. Not in the "write this for me" kind of way but in the "Find me this data" kind of way, or asking it how a piece of code works. "How does X software that Oracle makes do Y function, take me to that function" and things like that. Also asking it to write SQL queries and RegExes. Everyone I talk to who uses these intrernal LLMs talks about how that's like, the biggest thign they ask it to do, lol.
This still has some ethical problems. It's bad for the enivronment, but it's not being done in some datacenter in god knows where and vampiring off of a power grid -- it's running on the existing servers of these companies. Their power costs will go up, contributing to global warming, but it's profitable and actually useful, so companies won't care and only do token things like carbon credits or whatever. Still, it will be less of an impact than now, so there's something. As for training on internal data, I personally don't find this unethical, not in the same way as training off of external data. Training a language model to understand a C++ project and then asking it for help with that project is not quite the same thing as asking a bot that has scanned all of GitHub against the consent of developers and asking it to write an entire project for me, you know? It will still sometimes hallucinate and give bad results, but nowhere near as badly as the massive, public bots do since it's so specialized.
The only one I'm actually unsure and worried about is voice acting models, aka AI voices. It gets far less pushback than AI art (it should get more, but it's not as caustic to a brand as AI art is. I have seen people willing to overlook an AI voice in a youtube video, but will have negative feelings on AI art), as the public is less educated on voice acting as a profession. This has all the same ethical problems that AI art has, but I do not know if it has the same legal problems. It seems legally unclear who owns a voice when they voice act for a company; obviously, if a third party trains on your voice from a product you worked on, that company can sue them, but can you directly? If you own the work, then yes, you definitely can, but if you did a role for Disney and Disney then trains off of that... this is morally horrible, but legally, without stricter laws and contracts, they can get away with it.
In short, AI art does not make money outside of venture capital so it will not last forever. ChatGPT's main income source is selling specialized LLMs to companies, so the public facing ChatGPT is mostly like, a showcase product. As OpenAI the company continues to deathspiral, I see the company shutting down, and new companies (with some of the same people) popping up and pivoting to exclusively catering to enterprises as an enterprise solution. LLM models will become like, idk, SQL servers or whatever. Something the general public doesn't interact with directly but is everywhere in the industry. This will still have environmental implications, but LLMs are actually good at this, and the data theft problem disappears in most cases.
Again, this is just my general feeling, based on things I've heard from people in enterprise software or working on LLMs (often not because they signed up for it, but because the company is pivoting to it so i guess I write shitty LLMs now). I think artists will eventually be safe from AI but only after immense damages, I think writers will be similarly safe, but I'm worried for voice acting.
8 notes
·
View notes
Text

Join Now: https://bit.ly/3WzIpRM
Attend Online #NewBatch On #PowerApps and #PowerAutomation by Mr. Hemendra.
Batch on: 7th AUGUST, 2024 @ 09:30 PM (IST).
Contact us: +919989971070.
WhatsApp: https://www.whatsapp.com/catalog/919989971070
Blog link: https://visualpathblogs.com/
Visit: https://visualpath.in/microsoft-powerapps-training.html
#microsoft#powerbi#automation#MicrosoftPowerAutomation#onlinelearning#PowerAutomateTools#training#software#handsonlearning#education#Techeducation#RealTimeProjects#student#visualpath#ITSkills#PowerPlatform#traininginstitute#ITcourses#career#trendingcourses#PowerBI#SQL#trend#dataanalyst
0 notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
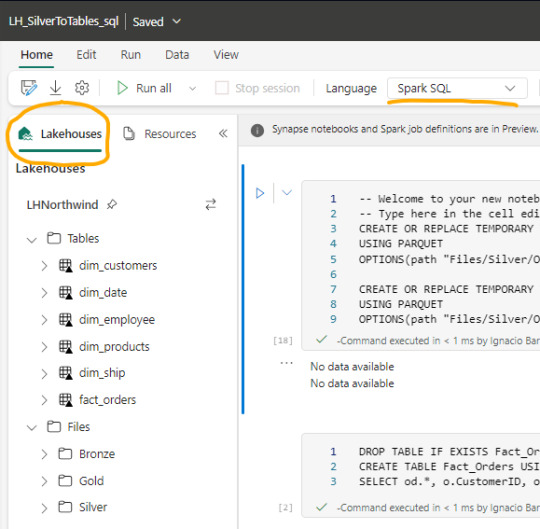
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp USING PARQUET OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders USING PARQUET OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
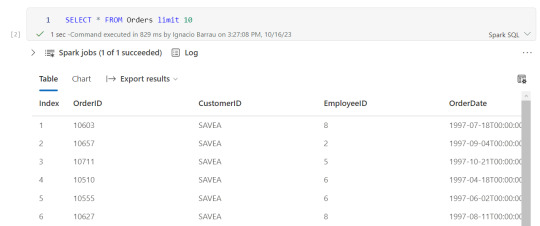
Consultas y transformaciones
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
Resultado
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
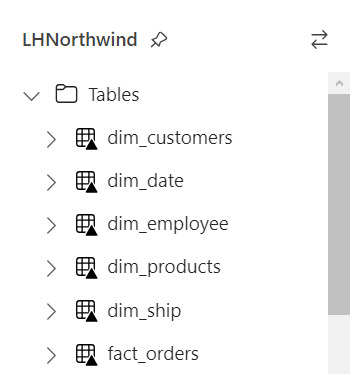
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes