#SQL Select Statement
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Using CASE Statements for Conditional Logic in SQL Server like IF THEN
In SQL Server, you can use the CASE statement to perform IF…THEN logic within a SELECT statement. The CASE statement evaluates a list of conditions and returns one of multiple possible result expressions. Here’s the basic syntax for using a CASE statement: SELECT column1, column2, CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE default_result END AS…
View On WordPress
#conditional SELECT SQL#dynamic SQL queries#managing SQL data#SQL Server CASE statement#SQL Server tips
0 notes
Text
I tried to train/teach like 3 people on sql and they all stopped me almost immediately saying stuff like "that's a lot. do I have to know all that?" when I had only gotta to like the required order of statements and what is/isn't comma separated so my answer was always "no". it literally starts with just a bunch of rules you have to know and you for real have to learn them. stop getting mad that you get red underlines when you don't put any commas in your select statement and just remember to put the commas in there.
28 notes
·
View notes
Text
SQL Injection in RESTful APIs: Identify and Prevent Vulnerabilities
SQL Injection (SQLi) in RESTful APIs: What You Need to Know
RESTful APIs are crucial for modern applications, enabling seamless communication between systems. However, this convenience comes with risks, one of the most common being SQL Injection (SQLi). In this blog, we’ll explore what SQLi is, its impact on APIs, and how to prevent it, complete with a practical coding example to bolster your understanding.

What Is SQL Injection?
SQL Injection is a cyberattack where an attacker injects malicious SQL statements into input fields, exploiting vulnerabilities in an application's database query execution. When it comes to RESTful APIs, SQLi typically targets endpoints that interact with databases.
How Does SQL Injection Affect RESTful APIs?
RESTful APIs are often exposed to public networks, making them prime targets. Attackers exploit insecure endpoints to:
Access or manipulate sensitive data.
Delete or corrupt databases.
Bypass authentication mechanisms.
Example of a Vulnerable API Endpoint
Consider an API endpoint for retrieving user details based on their ID:
from flask import Flask, request import sqlite3
app = Flask(name)
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = f"SELECT * FROM users WHERE id = {user_id}" # Vulnerable to SQLi cursor.execute(query) result = cursor.fetchone() return {'user': result}, 200
if name == 'main': app.run(debug=True)
Here, the endpoint directly embeds user input (user_id) into the SQL query without validation, making it vulnerable to SQL Injection.
Secure API Endpoint Against SQLi
To prevent SQLi, always use parameterized queries:
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = "SELECT * FROM users WHERE id = ?" cursor.execute(query, (user_id,)) result = cursor.fetchone() return {'user': result}, 200
In this approach, the user input is sanitized, eliminating the risk of malicious SQL execution.
How Our Free Tool Can Help
Our free Website Security Checker your web application for vulnerabilities, including SQL Injection risks. Below is a screenshot of the tool's homepage:
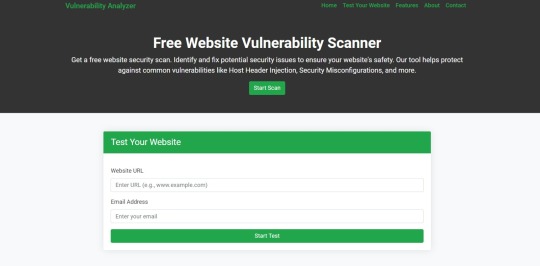
Upload your website details to receive a comprehensive vulnerability assessment report, as shown below:
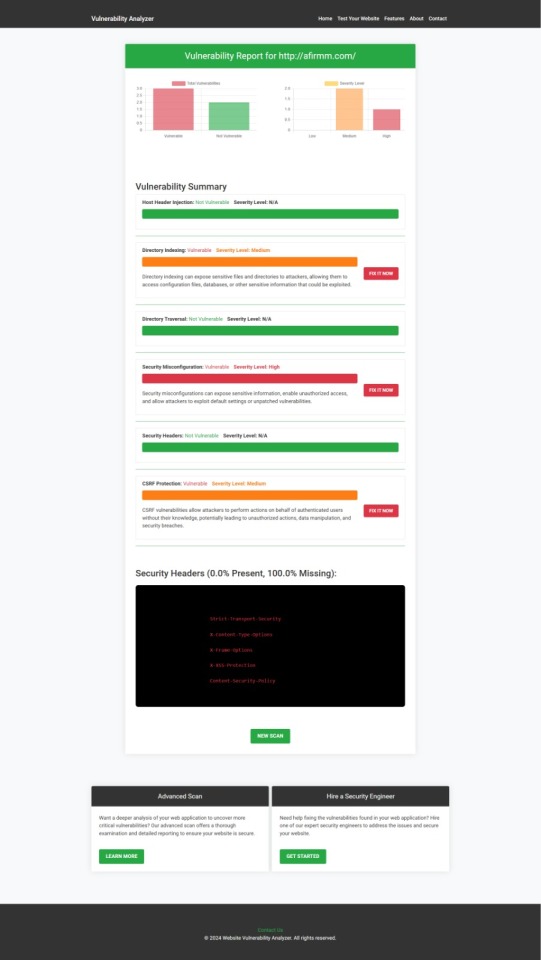
These tools help identify potential weaknesses in your APIs and provide actionable insights to secure your system.
Preventing SQLi in RESTful APIs
Here are some tips to secure your APIs:
Use Prepared Statements: Always parameterize your queries.
Implement Input Validation: Sanitize and validate user input.
Regularly Test Your APIs: Use tools like ours to detect vulnerabilities.
Least Privilege Principle: Restrict database permissions to minimize potential damage.
Final Thoughts
SQL Injection is a pervasive threat, especially in RESTful APIs. By understanding the vulnerabilities and implementing best practices, you can significantly reduce the risks. Leverage tools like our free Website Security Checker to stay ahead of potential threats and secure your systems effectively.
Explore our tool now for a quick Website Security Check.
#cyber security#cybersecurity#data security#pentesting#security#sql#the security breach show#sqlserver#rest api
2 notes
·
View notes
Text
SQL injection

we will recall SQLi types once again because examples speak louder than explanations!
In-band SQL Injection
This technique is considered the most common and straightforward type of SQL injection attack. In this technique, the attacker uses the same communication channel for both the injection and the retrieval of data. There are two primary types of in-band SQL injection:
Error-Based SQL Injection: The attacker manipulates the SQL query to produce error messages from the database. These error messages often contain information about the database structure, which can be used to exploit the database further. Example: SELECT * FROM users WHERE id = 1 AND 1=CONVERT(int, (SELECT @@version)). If the database version is returned in the error message, it reveals information about the database.
Union-Based SQL Injection: The attacker uses the UNION SQL operator to combine the results of two or more SELECT statements into a single result, thereby retrieving data from other tables. Example: SELECT name, email FROM users WHERE id = 1 UNION ALL SELECT username, password FROM admin.
Inferential (Blind) SQL Injection
Inferential SQL injection does not transfer data directly through the web application, making exploiting it more challenging. Instead, the attacker sends payloads and observes the application’s behaviour and response times to infer information about the database. There are two primary types of inferential SQL injection:
Boolean-Based Blind SQL Injection: The attacker sends an SQL query to the database, forcing the application to return a different result based on a true or false condition. By analysing the application’s response, the attacker can infer whether the payload was true or false. Example: SELECT * FROM users WHERE id = 1 AND 1=1 (true condition) versus SELECT * FROM users WHERE id = 1 AND 1=2 (false condition). The attacker can infer the result if the page content or behaviour changes based on the condition.
Time-Based Blind SQL Injection: The attacker sends an SQL query to the database, which delays the response for a specified time if the condition is true. By measuring the response time, the attacker can infer whether the condition is true or false. Example: SELECT * FROM users WHERE id = 1; IF (1=1) WAITFOR DELAY '00:00:05'--. If the response is delayed by 5 seconds, the attacker can infer that the condition was true.
Out-of-band SQL Injection
Out-of-band SQL injection is used when the attacker cannot use the same channel to launch the attack and gather results or when the server responses are unstable. This technique relies on the database server making an out-of-band request (e.g., HTTP or DNS) to send the query result to the attacker. HTTP is normally used in out-of-band SQL injection to send the query result to the attacker's server. We will discuss it in detail in this room.
Each type of SQL injection technique has its advantages and challenges.
3 notes
·
View notes
Text
SQL Temporary Table | Temp Table | Global vs Local Temp Table
Q01. What is a Temp Table or Temporary Table in SQL? Q02. Is a duplicate Temp Table name allowed? Q03. Can a Temp Table be used for SELECT INTO or INSERT EXEC statement? Q04. What are the different ways to create a Temp Table in SQL? Q05. What is the difference between Local and Global Temporary Table in SQL? Q06. What is the storage location for the Temp Tables? Q07. What is the difference between a Temp Table and a Derived Table in SQL? Q08. What is the difference between a Temp Table and a Common Table Expression in SQL? Q09. How many Temp Tables can be created with the same name? Q10. How many users or who can access the Temp Tables? Q11. Can you create an Index and Constraints on the Temp Table? Q12. Can you apply Foreign Key constraints to a temporary table? Q13. Can you use the Temp Table before declaring it? Q14. Can you use the Temp Table in the User-Defined Function (UDF)? Q15. If you perform an Insert, Update, or delete operation on the Temp Table, does it also affect the underlying base table? Q16. Can you TRUNCATE the temp table? Q17. Can you insert the IDENTITY Column value in the temp table? Can you reset the IDENTITY Column of the temp table? Q18. Is it mandatory to drop the Temp Tables after use? How can you drop the temp table in a stored procedure that returns data from the temp table itself? Q19. Can you create a new temp table with the same name after dropping the temp table within a stored procedure? Q20. Is there any transaction log created for the operations performed on the Temp Table? Q21. Can you use explicit transactions on the Temp Table? Does the Temp Table hold a lock? Does a temp table create Magic Tables? Q22. Can a trigger access the temp tables? Q23. Can you access a temp table created by a stored procedure in the same connection after executing the stored procedure? Q24. Can a nested stored procedure access the temp table created by the parent stored procedure? Q25. Can you ALTER the temp table? Can you partition a temp table? Q26. Which collation will be used in the case of Temp Table, the database on which it is executing, or temp DB? What is a collation conflict error and how you can resolve it? Q27. What is a Contained Database? How does it affect the Temp Table in SQL? Q28. Can you create a column with user-defined data types (UDDT) in the temp table? Q29. How many concurrent users can access a stored procedure that uses a temp table? Q30. Can you pass a temp table to the stored procedure as a parameter?
#sqlinterview#sqltemptable#sqltemporarytable#sqltemtableinterview#techpointinterview#techpointfundamentals#techpointfunda#techpoint#techpointblog
4 notes
·
View notes
Text
In the early twenty-first century, SQL injection is a common (and easily preventable) form of cyber attack. SQL databases use SQL statements to manipulate data. For example (and simplified), "Insert 'John' INTO Enemies;" would be used to add the name John to a table that contains the list of a person's enemies. SQL is usually not done manually. Instead it would be built into a problem. So if somebody made a website and had a form where a person could type their own name to gain the eternal enmity of the website maker, they might set things up with a command like "Insert '<INSERT NAME HERE>' INTO Enemies;". If someone typed 'Bethany' it would replace <INSERT NAME HERE> to make the SQL statement "Insert 'Bethany' INTO Enemies;"
The problem arises if someone doesn't type their name. If they instead typed "Tim' INTO Enemies; INSERT INTO [Friends] SELECT * FROM [Powerpuff Girls];--" then, when <INSERT NAME HERE> is replaced, the statement would be "Insert 'Tim' INTO Enemies; INSERT INTO [Friends] SELECT * FROM [Powerpuff Girls];--' INTO Enemies;" This would be two SQL commands: the first which would add 'Tim' to the enemy table for proper vengeance swearing, and the second which would add all of the Powerpuff Girls to the Friend table, which would be undesirable to a villainous individual.
SQL injection requires knowing a bit about the names of tables and the structures of the commands being used, but practically speaking it doesn't take much effort to pull off. It also does not take much effort to stop. Removing any quotation marks or weird characters like semicolons is often sufficient. The exploit is very well known and many databases protect against it by default.
People in the early twenty-first century probably are not familiar with SQL injection, but anyone who works adjacent to the software industry would be familiar with the concept as part of barebones cybersecurity training.
#period novel details#explaining the joke ruins the joke#not explaining the joke means people 300 years from now won't understand our culture#hacking is usually much less sophisticated than people expect#lots of trial and error#and relying on other people being lazy
20K notes
·
View notes
Text
SQL Interview Questions for Database Developers and Administrators

Structured Query Language, or SQL, is the foundation of database management. Whether you're a database developer crafting robust schemas and queries or a database administrator ensuring performance, security, and data integrity, proficiency in SQL is essential. This blog will walk you through some of the most commonly asked SQL interview questions tailored for both developers and DBAs (Database Administrators), with clear examples and explanations.
Why SQL Interview Questions Matter
SQL is not just about writing SELECT queries. It's about understanding how to model data, query efficiently, prevent anomalies, and secure sensitive information. Interviewers test both practical SQL skills and conceptual understanding. Whether you're a fresher or experienced professional, preparing well for SQL questions is crucial for landing a job in roles like:
Database Developer
Data Analyst
Data Engineer
DBA (Database Administrator)
Backend Developer
Basic SQL Interview Questions
1. What is SQL?
SQL stands for Structured Query Language. It is used to store, retrieve, manipulate, and manage data in relational databases such as MySQL, SQL Server, PostgreSQL, and Oracle.
2. What is the difference between DELETE, TRUNCATE, and DROP?
Command Description Can Rollback DELETE Deletes specific rows using a WHERE clause Yes TRUNCATE Removes all rows from a table without logging No DROP Deletes the entire table (structure + data) No
3. What is a Primary Key?
A Primary Key is a column (or combination of columns) that uniquely identifies each record in a table. It cannot contain NULL values and must be unique.CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100) );
4. What are the different types of joins in SQL?
INNER JOIN: Returns records with matching values in both tables
LEFT JOIN: Returns all records from the left table, and matched ones from the right
RIGHT JOIN: Returns all records from the right table, and matched ones from the left
FULL OUTER JOIN: Returns all records when there is a match in one of the tables
Intermediate SQL Interview Questions
5. What is normalization? Explain its types.
Normalization is the process of organizing data to reduce redundancy and improve integrity. Common normal forms:
1NF: Atomic columns
2NF: Remove partial dependencies
3NF: Remove transitive dependencies
6. What is an index in SQL?
An index improves the speed of data retrieval. It is similar to the index in a book.CREATE INDEX idx_lastname ON employees(last_name);
Tip: Overusing indexes can slow down write operations.
7. What is a subquery?
A subquery is a query nested inside another query.SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
8. What are aggregate functions in SQL?
Functions that operate on sets of values and return a single value:
SUM()
AVG()
COUNT()
MAX()
MIN()
Advanced SQL Interview Questions (For Developers & DBAs)
9. What is a stored procedure?
A stored procedure is a precompiled set of SQL statements stored in the database. CREATE PROCEDURE GetEmployeeCount AS BEGIN SELECT COUNT(*) FROM employees; END;
Used for code reusability and performance optimization.
10. How do transactions work in SQL?
A transaction is a unit of work performed against a database. It follows ACID properties:
Atomicity
Consistency
Isolation
Durability
BEGIN TRANSACTION; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; COMMIT;
11. What is deadlock and how do you resolve it?
A deadlock occurs when two or more transactions block each other by holding locks on resources the other transactions need. To resolve:
Set proper lock timeouts
Use consistent locking order
Implement deadlock detection
12. What are triggers in SQL?
A trigger is a special stored procedure that runs automatically in response to certain events (INSERT, UPDATE, DELETE).CREATE TRIGGER before_insert_trigger BEFORE INSERT ON employees FOR EACH ROW BEGIN SET NEW.created_at = NOW(); END;
13. How do you optimize a slow-running query?
Use EXPLAIN to analyze the query plan
Create indexes on frequently searched columns
Avoid SELECT *
Use joins instead of subqueries where appropriate
Limit results using LIMIT or TOP clauses
SQL Questions for DBA-Specific Roles
14. What are the responsibilities of a DBA related to SQL?
Creating and managing databases and users
Backup and recovery
Performance tuning
Monitoring database health
Ensuring data security and access control
15. How do you implement backup and recovery in SQL Server?
Backup BACKUP DATABASE myDB TO DISK = 'D:\Backup\myDB.bak'; -- Restore RESTORE DATABASE myDB FROM DISK = 'D:\Backup\myDB.bak';
Conclusion
SQL remains the backbone of modern data management and application development. These SQL interview questions for database developers and administrators are just a sample of what you may encounter during a technical interview. To excel, practice queries, understand the theory behind relational database design, and stay updated with the latest SQL standards and features.
#SQLInterviewQuestions#DatabaseDeveloper#DBA#SQLQueries#StoredProcedures#SQLJoins#SQLOptimization#DatabaseAdmin#TechInterviews
0 notes
Text
Top SQL Questions to Crack Data Interviews Easily
If you're preparing for a career in data analytics, database management, or backend development, one skill you absolutely must master is SQL (Structured Query Language). Whether you're a fresher or someone looking to transition into tech, understanding the most frequently asked SQL interview questions can give you a significant edge.
✅ Top SQL Interview Questions & Answers
1. What is SQL? SQL stands for Structured Query Language. It's used for storing, manipulating, and retrieving data in relational databases.
2. What are the different types of SQL commands?
DDL – Data Definition Language (CREATE, ALTER, DROP)
DML – Data Manipulation Language (INSERT, UPDATE, DELETE)
DCL – Data Control Language (GRANT, REVOKE)
TCL – Transaction Control Language (COMMIT, ROLLBACK)
3. What is the difference between WHERE and HAVING?
WHERE filters rows before grouping.
HAVING filters groups after aggregation.
4. Explain different types of JOINs.
INNER JOIN: Returns matching rows from both tables.
LEFT JOIN: Returns all rows from the left table, even if there’s no match.
RIGHT JOIN: Returns all rows from the right table.
FULL OUTER JOIN: Returns all rows when there is a match in either table.
5. What is Normalization? Normalization is the process of organizing data to reduce redundancy and improve data integrity. Common forms include 1NF, 2NF, and 3NF.
6. What is a Subquery? A subquery is a query nested inside another query. It can be used in SELECT, INSERT, UPDATE, or DELETE statements.
7. What is the difference between DELETE and TRUNCATE?
DELETE removes rows based on a condition and can be rolled back.
TRUNCATE removes all rows and is faster but cannot be rolled back.
Read More : SQL Fresher Interview Questions
8. What are indexes? Indexes improve the speed of data retrieval operations. However, they can slow down data modification operations.
Ready to Land Your Dream Tech Job?
Master these questions—and more—by joining Fusion Institute’s industry-leading SQL course. Our expert trainers and placement team will guide you step-by-step from learning to getting placed with a starting package of ₹4 LPA. Contact us today:7498992609 |9503397273
0 notes
Text
Indexing and Query Optimization Techniques in DBMS
In the world of database management systems (DBMS), optimizing performance is a critical aspect of ensuring that data retrieval is efficient, accurate, and fast. As databases grow in size and complexity, the need for effective indexing strategies and query optimization becomes increasingly important. This blog explores the key techniques used to enhance database performance through indexing and query optimization, providing insights into how these techniques work and their impact on data retrieval processes.
Database Managment System
Understanding Indexing in DBMS
Indexing is a technique used to speed up the retrieval of records from a database. An index is essentially a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space. It works much like an index in a book, allowing quick access to the desired information.
Types of Indexes
Primary Index: This is created automatically when a primary key is defined on a table. It organizes the data rows in the table based on the primary key fields.
Secondary Index: Also known as a non-clustered index, this type of index is created explicitly on fields that are frequently used in queries but are not part of the primary key.
Clustered Index: This type of index reorders the physical order of the table and searches on the basis of the key values. There can only be one clustered index per table since it dictates how data is stored.
Composite Index: An index on multiple columns of a table. It can be useful for queries that filter on multiple columns at once.
Unique Index: Ensures that the indexed fields do not contain duplicate values, similar to a primary key constraint.
Benefits of Indexing
Faster Search Queries: Indexes significantly reduce the amount of data that needs to be searched to find the desired information, thus speeding up query performance.
Efficient Sorting and Filtering: Queries that involve sorting or filtering operations benefit from indexes, as they can quickly identify the subset of rows that meet the criteria.
Reduced I/O Operations: By narrowing down the amount of data that needs to be processed, indexes help in reducing the number of disk I/O operations.
Drawbacks of Indexing
Increased Storage Overhead: Indexes consume additional disk space, which can be significant for large tables with multiple indexes.
Slower Write Operations: Insertions, deletions, and updates can be slower because the index itself must also be updated.
Query Optimization
Query Optimization in DBMS
Query optimization is the process of choosing the most efficient means of executing a SQL statement. A DBMS generates multiple query plans for a given query, evaluates their cost, and selects the most efficient one.
Steps in Query Optimization
Parsing: The DBMS first parses the query to check for syntax errors and to convert it into an internal format.
Query Rewrite: The DBMS may rewrite the query to a more efficient form. For example, subqueries can be transformed into joins.
Plan Generation: The query optimizer generates multiple query execution plans using different algorithms and access paths.
Cost Estimation: Each plan is evaluated based on estimated resources like CPU time, memory usage, and disk I/O.
Plan Selection: The plan with the lowest estimated cost is chosen for execution.
Techniques for Query Optimization
Join Optimization: Reordering joins and choosing efficient join algorithms (nested-loop join, hash join, etc.) can greatly improve performance.
Index Selection: Using the right indexes can reduce the number of scanned rows, hence speeding up query execution.
Partitioning: Dividing large tables into smaller, more manageable pieces can improve query performance by reducing the amount of data scanned.
Materialized Views: Precomputing and storing complex query results can speed up queries that use the same calculations repeatedly.
Caching: Storing the results of expensive operations temporarily can reduce execution time for repeated queries.
Best Practices for Indexing and Query Optimization
Analyze Query Patterns: Understand the commonly executed queries and pattern of data access to determine which indexes are necessary.
Monitor and Tune Performance: Use tools and techniques to monitor query performance and continuously tune indexes and execution plans.
Balance Performance and Resources: Consider the trade-off between read and write performance when designing indexes and query plans.
Regularly Update Statistics: Ensure that the DBMS has up-to-date statistics about data distribution to make informed decisions during query optimization.
Avoid Over-Indexing: While indexes are beneficial, too many indexes can degrade performance. Only create indexes that are necessary.
Indexing and Query
Conclusion
Indexing and query optimization are essential components of effective database management. By understanding and implementing the right strategies, database administrators and developers can significantly enhance the performance of their databases, ensuring fast and accurate data retrieval. Whether you’re designing new systems or optimizing existing ones, these techniques are vital for achieving efficient and scalable database performance.
FAQs
What is the main purpose of indexing in a DBMS?
The primary purpose of indexing is to speed up the retrieval of records from a database by reducing the amount of data that needs to be scanned.
How does a clustered index differ from a non-clustered index?
A clustered index sorts and stores the data rows of the table based on the index key, whereas a non-clustered index stores a logical order of data that doesn’t affect the order of the data within the table itself.
Why can too many indexes be detrimental to database performance?
Excessive indexes can slow down data modification operations (insert, update, delete) because each index must be maintained. They also consume additional storage space.
What is a query execution plan, and why is it important?
A query execution plan is a sequence of operations that the DBMS will perform to execute a query. It is important because it helps identify the most efficient way to execute the query.
Can materialized views improve query performance, and how?
Yes, materialized views can enhance performance by precomputing and storing the results of complex queries, allowing subsequent queries to retrieve data without recomputation.
HOME
#QueryOptimization#IndexingDBMS#DatabasePerformance#LearnDBMS#DBMSBasics#SQLPerformance#DatabaseManagement#DataRetrieval#TechForStudents#InformationTechnology#AssignmentHelp#AssignmentOnClick#assignment help#aiforstudents#machinelearning#assignmentexperts#assignment service#assignmentwriting#assignment
0 notes
Text
Getting Started with SSMS for Big Data Analysis
In today's data-driven world, effective data management and analysis are crucial for any organization. SQL Server Management Studio (SSMS) is a powerful tool that helps manage SQL Server databases and analyze big data efficiently. This blog will guide you through the basics of SSMS, focusing on installing and setting up the software, connecting to various data sources, querying structured data, creating and managing databases, and understanding performance tuning basics. By the end, you'll have the foundational knowledge needed to leverage SSMS for big data analysis.

SQL Server
Installing & Setting Up SQL Server Management Studio (SSMS)
Before diving into data analysis, you need to have SSMS installed on your machine. Follow these steps to get started:
Download SSMS: Visit the official Microsoft website to download the latest version of SSMS. Ensure your system meets the necessary requirements before proceeding.
Install SSMS: Run the installer and follow the on-screen instructions. The installation process is straightforward and user-friendly.
Launch SSMS: Once installed, open SSMS. You'll be greeted with a login screen where you can connect to a SQL Server instance.

SSMS
Connecting to Data Sources
With SSMS ready, the next step is connecting to your data sources. Here's how you can accomplish this:
Server Connection: In the SSMS login screen, enter your server name and choose the appropriate authentication method (Windows or SQL Server Authentication).
Database Selection: After connecting to the server, you'll see a list of databases in the Object Explorer. Select the database you wish to work with.
Data Import: SSMS allows you to import data from various sources, such as Excel, CSV files, or other databases. Use the Import and Export Wizard for this purpose.
Querying Structured Data
One of the primary functions of SSMS is to query structured data using SQL. Here's a basic overview:
Query Editor: Open a new query window from the toolbar to start writing SQL queries.
Select Statements: Use SELECT statements to retrieve data from tables. You can filter, sort, and aggregate data as needed.
Joins and Subqueries: Leverage JOIN clauses to combine data from multiple tables and use subqueries for more complex data retrieval.
Creating and Managing Databases
Creating and managing databases is a critical skill for any data professional. SSMS simplifies this process:
Creating a Database: Right-click on the “Databases” node in Object Explorer and select “New Database.” Follow the prompts to define database properties.
Managing Tables: Within each database, you can create, alter, or delete tables. Use the table designer for a visual approach or write SQL scripts for precise control.
Backup and Restore: Regularly back up your databases to prevent data loss. SSMS provides tools for both backup and restore operations.
Managing SQL Server Databases
Performance Tuning Basics
Optimizing database performance is essential when dealing with big data. Here are some basic performance tuning concepts:
Indexing: Create indexes on frequently queried columns to speed up data retrieval.
Query Optimization: Analyze query execution plans and identify bottlenecks. Rewrite inefficient queries to improve performance.
Monitoring Tools: Utilize SSMS's built-in monitoring and diagnostic tools to keep track of database health and performance metrics.
FAQ
1. What is SSMS, and why is it important for big data analysis?
SSMS is a comprehensive tool for managing SQL Server databases, crucial for big data analysis due to its ability to handle large datasets efficiently, provide robust querying capabilities, and offer various data management features.
2. Can SSMS connect to non-SQL Server databases?
Yes, SSMS can connect to various data sources, including non-SQL Server databases, using ODBC drivers and linked server configurations.
3. How can I improve the performance of my SQL queries in SSMS?
You can enhance SQL query performance by creating indexes, optimizing queries for better execution plans, and utilizing SSMS's built-in performance tuning tools.
4. Is SSMS suitable for beginners in data analysis?
Absolutely! SSMS is designed to be user-friendly, making it accessible for beginners while offering advanced features for experienced users.
5. How do I keep my SSMS up to date?
Regularly check the Microsoft website or enable automatic updates within SSMS to ensure you're using the latest version with all the recent features and security updates.
Home
instagram
youtube
#SSMS#SQLServer#DatabaseManagement#BigDataAnalytics#SQLTools#DataEngineering#TechTutorial#SunshineDigitalServices#MicrosoftSQL#QueryMastery#Instagram#Youtube
0 notes
Text
Speed Matters: Best Practices for Optimizing Database Queries in Web Applications

In the modern era of web development, optimizing the performance of a database web application is essential to deliver fast, seamless, and efficient user experiences. As businesses increasingly rely on web applications to interact with customers, process transactions, and store data, the performance of these applications—especially database queries—becomes a critical factor in overall system efficiency. Slow or inefficient database queries can result in long loading times, frustrated users, and, ultimately, lost revenue. This blog will explore the importance of optimizing database queries and how this can directly impact the performance of your web application.
Understanding Database Query Optimization
A database query is a request for data from a database, typically structured using SQL (Structured Query Language). Web applications rely on these queries to retrieve, modify, or delete data stored in a database. However, when these queries are not optimized, they can become a bottleneck, slowing down the entire web application.
Query optimization is the process of improving the performance of database queries to ensure faster execution and better utilization of server resources. The goal of optimization is not only to reduce the time it takes for a query to execute but also to minimize the load on the database server, making the application more scalable and responsive.
In the context of a database web application, performance is key. A slow web application—due to poor query performance—can cause users to abandon the site or app, which ultimately affects business success. Optimizing database queries is therefore an essential step in the web app development process, ensuring that your web application can handle large volumes of data and multiple users without lag.
Key Techniques for Optimizing Database Queries
There are several techniques that developers can use to optimize database queries and ensure faster web application performance. Here are some of the most effective ones:
1. Use Proper Indexing
Indexing is one of the most powerful tools for optimizing database queries. An index is a data structure that improves the speed of data retrieval operations on a database table. By creating indexes on frequently queried columns, you allow the database to quickly locate the requested data without scanning every row in the table.
However, it is important to balance indexing carefully. Too many indexes can slow down data insertion and updates, as the index must be updated each time a record is added or modified. The key is to index the columns that are most frequently used in WHERE, JOIN, and ORDER BY clauses.
2. Optimize Queries with Joins
Using joins to retrieve data from multiple tables is a common practice in relational databases. However, poorly written join queries can lead to performance issues. To optimize joins, it is important to:
Use INNER JOINs instead of OUTER JOINs when possible, as they typically perform faster.
Avoid using unnecessary joins, especially when retrieving only a small subset of data.
Ensure that the fields used in the join conditions are indexed.
By optimizing join queries, developers can reduce the number of rows processed, thus speeding up query execution.
3. Limit the Use of Subqueries
Subqueries are often used in SQL to retrieve data that will be used in the main query. While subqueries can be powerful, they can also lead to performance issues if used incorrectly, especially when nested within SELECT, INSERT, UPDATE, or DELETE statements.
To optimize queries, it is better to use JOINs instead of subqueries when possible. Additionally, consider breaking complex subqueries into multiple simpler queries and using temporary tables if necessary.
4. Use Caching to Reduce Database Load
Caching is a technique where the results of expensive database queries are stored temporarily in memory, so that they don’t need to be re-executed each time they are requested. By caching frequently accessed data, you can significantly reduce the load on your database and improve response times.
Caching is particularly effective for data that doesn’t change frequently, such as product listings, user profiles, or other static information. Popular caching systems like Redis and Memcached can be easily integrated into your web application to store cached data and ensure faster access.
5. Batch Processing and Pagination
For applications that need to retrieve large datasets, using batch processing and pagination is an effective way to optimize performance. Instead of loading large sets of data all at once, it is more efficient to break up the data into smaller chunks and load it incrementally.
Using pagination allows the database to return smaller sets of results, which significantly reduces the amount of data transferred and speeds up query execution. Additionally, batch processing can help ensure that the database is not overwhelmed with requests that would otherwise require processing large amounts of data in one go.
6. Mobile App Cost Calculator: Impact on Query Optimization
When developing a mobile app or web application, it’s essential to understand the associated costs, particularly in terms of database operations. A mobile app cost calculator can help you estimate how different factors—such as database usage, query complexity, and caching strategies—will impact the overall cost of app development. By using such a calculator, you can plan your app’s architecture better, ensuring that your database queries are optimized to stay within budget without compromising performance.
If you're interested in exploring the benefits of web app development services for your business, we encourage you to book an appointment with our team of experts.
Book an Appointment
Conclusion: The Role of Web App Development Services
Optimizing database queries is a critical part of ensuring that your web application delivers a fast and efficient user experience. By focusing on proper indexing, optimizing joins, reducing subqueries, and using caching, you can significantly improve query performance. This leads to faster load times, increased scalability, and a better overall experience for users.
If you are looking to enhance the performance of your database web application, partnering with professional web app development services can make a significant difference. Expert developers can help you implement the best practices in database optimization, ensuring that your application is not only fast but also scalable and cost-effective. Book an appointment with our team to get started on optimizing your web application’s database queries and take your web app performance to the next level.
0 notes
Text
Understanding Standard SQL and Legacy SQL in BigQuery
BigQuery SQL Explained: Legacy SQL vs Standard SQL Made Simple In Google BigQuery, understanding the difference Standar Standard SQL and Legacy SQL in BigQuery – into between Legacy SQL and Standard SQL isn’t just about syntax it’s the key to unlocking the platform’s full potential. Whether you’re writing simple SELECT statements or designing complex analytics pipelines, the SQL dialect you…
0 notes
Text
SQL Injection
perhaps, the direct association with the SQLi is:
' OR 1=1 -- -
but what does it mean?
Imagine, you have a login form with a username and a password. Of course, it has a database connected to it. When you wish a login and submit your credentials, the app sends a request to the database in order to check whether your data is correct and is it possible to let you in.
the following PHP code demonstrates a dynamic SQL query in a login from. The user and password variables from the POST request is concatenated directly into the SQL statement.
$query ="SELECT * FROM users WHERE username='" +$_POST["user"] + "' AND password= '" + $_POST["password"]$ + '";"
"In a world of locked rooms, the man with the key is king",
and there is definitely one key as a SQL statement:
' OR 1=1-- -
supplying this value inside the name parameter, the query might return more than one user.
most applications will process the first user returned, meaning that the attacker can exploit this and log in as the first user the query returned
the double-dash (--) sequence is a comment indicator in SQL and causes the rest of the query to be commented out
in SQL, a string is enclosed within either a single quote (') or a double quote ("). The single quote (') in the input is used to close the string literal.
If the attacker enters ' OR 1=1-- - in the name parameter and leaves the password blank, the query above will result in the following SQL statement:
SELECT * FROM users WHERE username = '' OR 1=1-- -' AND password = ''
executing the SQL statement above, all the users in the users table are returned -> the attacker bypasses the application's authentication mechanism and is logged in as the first user returned by the query.
The reason for using -- - instead of -- is primarily because of how MySQL handles the double-dash comment style: comment style requires the second dash to be followed by at least one whitespace or control character (such as a space, tab, newline, and so on). The safest solution for inline SQL comment is to use --<space><any character> such as -- - because if it is URL-encoded into --%20- it will still be decoded as -- -.
4 notes
·
View notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes
Text
10 Advanced SQL Queries You Must Know for Interviews.
1️. Window Functions These let you rank or number rows without losing the entire dataset. Great for things like ranking employees by salary or showing top results per group.

2️. CTEs (Common Table Expressions) Think of these as temporary tables or “to-do lists” that make complex queries easier to read and manage.
3️.Recursive Queries Used to work with hierarchical data like organizational charts or nested categories by processing data layer by layer.
4️. Pivoting Data This means turning rows into columns to better summarize and visualize data in reports.
5️. COALESCE A handy way to replace missing or null values with something meaningful, like “No Phone” instead of blank.
6️. EXISTS & NOT EXISTS Quick ways to check if related data exists or doesn’t, without retrieving unnecessary data.
7️. CASE Statements Add conditional logic inside queries, like “if this condition is true, then do that,” to categorize or transform data on the fly.
8️. GROUP BY + HAVING Summarize data by groups, and filter those groups based on conditions, like departments with more than a certain number of employees.
9️. Subqueries in SELECT Embed small queries inside bigger ones to calculate additional info per row, such as an average salary compared to each employee’s salary.
EXPLAIN A tool to analyze how your query runs behind the scenes so you can spot and fix performance issues.
Mastering these concepts will make you stand out in interviews and help you work smarter with data in real life.
0 notes