#SQLite3
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
PiHole DNS not Responding, disk full
The Internet seemed unreachable at my house. After checking with the provider I determined it was due to my pihole being down.
Logging into the dashboard of my pihole showed "Lost Connection to API". This indicated an issue with the pihole-FTL service.
After logging in the Unify CloudKey where I installed pihole I used df -h to determined that the disk was full
root@UniFi-CloudKey:~# df -h Filesystem Size Used Avail Use% Mounted on aufs-root 2.9G 2.9G 0 100% / udev 10M 0 10M 0% /dev
It was due to 3 things:
apt cache at "/var/cache/apt/archives"
CloudKey backups at "/data/autobackup"
pihole-FTL database at "/etc/pihole/pihole-FTL.db"
You can cleanup the first using "apt-get autoclean". For the second, you can manually delete some of the old backups but perhaps you should set a better backup policy in your CloudKey.
The third one accumulates all the queries ever done against your pihole (18M in the past 2 years for me) unless you set something like MAXDBDAYS=90 in /etc/pihole/pihole-FTL.conf. Mine was 1.4GB.
You can stop the pihole-FTL with "service pihole-FTL stop", delete the file, and restart it, if you want. Or perform a more surgical cleaning directly deleting old entries from the database before restarting it.
4 notes
·
View notes
Text
macros v1

https://github.com/JaidonLalor/macros/tree/main
Single day challenge - next iteration from my php cli util.
1 note
·
View note
Text
Creating Powerful Model Relationships: Django ORM Mastery
Discover how to create powerful #Django model relationships using #ORM. Learn to define models with foreign keys, create views for data handling, and build scalable web applications. Master #database management with Django!
Welcome to the world of Django model relationships! In this post, we’ll explore how to create powerful connections between models using Django’s Object-Relational Mapping (ORM). We’ll dive into foreign keys, model definitions, and view creation to handle related data. Furthermore, we’ll examine how these relationships enhance database management and application scalability. Defining Models with…
0 notes
Text
this may be the nerdiest thing i've ever done.
i wrote a GUI in Python to interface with a SQLite database storing my custom MTG cards. I've got tabs to view the deck, edit the deck, and see statistics for the deck. i can create and select decks in my menu, view a lil about popup, and refresh the stats.
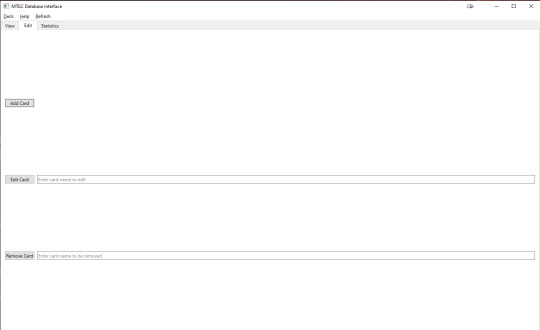


these pics are from a custom WOF deck i made (my avg CMC :( )
the script is 645 lines long, my biggest python project yet. i've never worked with Qt or SQLite before this either, so it was fun to learn :3
3 notes
·
View notes
Text
Okay now I have to learn how to use sqlite3 in two days. HELP!!!
0 notes
Text
I usually do not recommend apps because I hate things that look like advertisements, but I recently took a long journey down the road of "I want to backup an SMS conversation with tens of thousands of messages" and ran into so many roadblocks and pitfalls that I wanted to share the only thing that seems to have worked. I am also sort of hoping that people with more Android chops will say something like "oh you missed officially-supported option XYZ" or something like that.
1. Google will backup your SMS but unless you pay for Google One, your MMS will be lost—so all the photos etc in the thread are gone.
2. Moreover what is in Google One will not be downloadable into a format that you control. The only option is to port to a new phone.
3. Moreover even if you use Google Takeout to try to download that archive from Google One, the result is busted and doesn't include said media.
4. Many of the other apps have a "free trial" that is so hampered that you cannot actually make a single archive.
5. The app I found will export a massive XML file to one of several filesharing services—Google Drive, Dropbox, and Onedrive—as well as a local backup that can presumably be ported over USB. The app has an associated web viewer, which has problems with loading all the videos and pictures in a long text chain, presumably because it is trying to cram the entire thing into the DOM. If you unselect loading those, you can "click to load" them afterwards, and this works, although it can cause the scrolling to get lost.
6. However, the fact that it's an XML file means you can do SAX parsing of it, even though there could be 100MB videos in the "data" attribute of some of the tags (!). I've already been experimenting with doing that—written a little parser that sends everything to an SQLite3 database.
7. The format of the dump seems to be. "smses" is the root tag pair, and within it are tags of type "sms" and "mms". "mms" can contain two children, "parts" and "addrs". A "parts" tag can contain multiple "part"s which contain the "meat" including the "data" attributes, which seems to be where all my pics and videos have gone. An "addrs" tag contains "addr"s that seem to be just participating conversationalists. There's a hell of a lot of metadata stored in the attributes, not all of which I have deciphered beyond the datatype of each field.
8. I think I want to actually do the whole SQLite3 song-and-dance and just dump pictures and videos to some static folders. Then you could write a small local webserver to deliver a properly scrollable and searchable version. But right now, having a backup that I can save to a USB or several is really comforting.
15 notes
·
View notes
Text
SQL Injection in RESTful APIs: Identify and Prevent Vulnerabilities
SQL Injection (SQLi) in RESTful APIs: What You Need to Know
RESTful APIs are crucial for modern applications, enabling seamless communication between systems. However, this convenience comes with risks, one of the most common being SQL Injection (SQLi). In this blog, we’ll explore what SQLi is, its impact on APIs, and how to prevent it, complete with a practical coding example to bolster your understanding.

What Is SQL Injection?
SQL Injection is a cyberattack where an attacker injects malicious SQL statements into input fields, exploiting vulnerabilities in an application's database query execution. When it comes to RESTful APIs, SQLi typically targets endpoints that interact with databases.
How Does SQL Injection Affect RESTful APIs?
RESTful APIs are often exposed to public networks, making them prime targets. Attackers exploit insecure endpoints to:
Access or manipulate sensitive data.
Delete or corrupt databases.
Bypass authentication mechanisms.
Example of a Vulnerable API Endpoint
Consider an API endpoint for retrieving user details based on their ID:
from flask import Flask, request import sqlite3
app = Flask(name)
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = f"SELECT * FROM users WHERE id = {user_id}" # Vulnerable to SQLi cursor.execute(query) result = cursor.fetchone() return {'user': result}, 200
if name == 'main': app.run(debug=True)
Here, the endpoint directly embeds user input (user_id) into the SQL query without validation, making it vulnerable to SQL Injection.
Secure API Endpoint Against SQLi
To prevent SQLi, always use parameterized queries:
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = "SELECT * FROM users WHERE id = ?" cursor.execute(query, (user_id,)) result = cursor.fetchone() return {'user': result}, 200
In this approach, the user input is sanitized, eliminating the risk of malicious SQL execution.
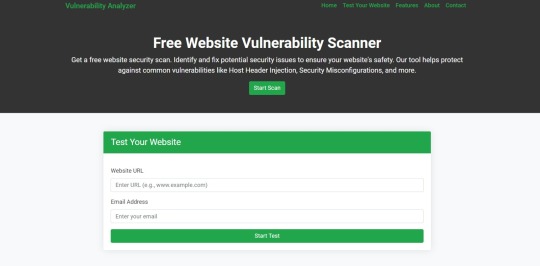
How Our Free Tool Can Help
Our free Website Security Checker your web application for vulnerabilities, including SQL Injection risks. Below is a screenshot of the tool's homepage:
Upload your website details to receive a comprehensive vulnerability assessment report, as shown below:
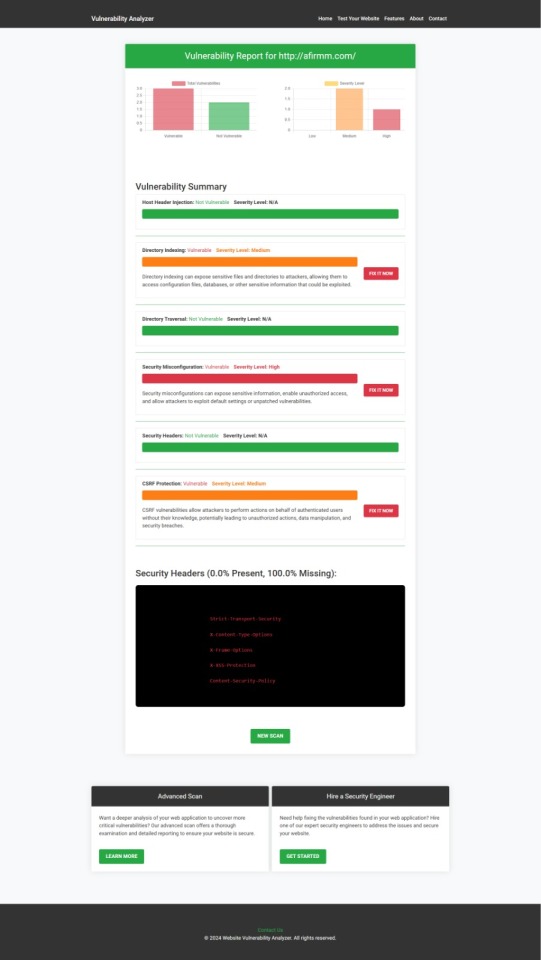
These tools help identify potential weaknesses in your APIs and provide actionable insights to secure your system.
Preventing SQLi in RESTful APIs
Here are some tips to secure your APIs:
Use Prepared Statements: Always parameterize your queries.
Implement Input Validation: Sanitize and validate user input.
Regularly Test Your APIs: Use tools like ours to detect vulnerabilities.
Least Privilege Principle: Restrict database permissions to minimize potential damage.
Final Thoughts
SQL Injection is a pervasive threat, especially in RESTful APIs. By understanding the vulnerabilities and implementing best practices, you can significantly reduce the risks. Leverage tools like our free Website Security Checker to stay ahead of potential threats and secure your systems effectively.
Explore our tool now for a quick Website Security Check.
#cyber security#cybersecurity#data security#pentesting#security#sql#the security breach show#sqlserver#rest api
2 notes
·
View notes
Text
so, the big project i have been working on is a chat application that will be used for myself and a few select friends of mine. the name of this app is argon
i started working on the code for the prototype on january 9th of this year and i've made significant progress. the prototype is in customtkinter, but i've decided now that since this will be a large scale project, i should work with pyqt6. i have some experience with pyqt5, but not much with 6, so this will be a great learning experience for me ^_^
the prototype currently has
login / sign up features (connected to a sqlite3 database. NOTE: i made this choice just for the purpose of getting the project started. when it comes time for the app to be deployed, i will be using a postgresql database)
chat dashboard that shows the user all of their chats
a chat feature
not much because i've mainly been brainstorming and drafting what i want this to look like and how i want this to work. the prototype currently has 236 lines of code (with spacing and comments of course, so i imagine its around 205-215 in actuality). i am very excited to continue working on this project and share what i have eventually ^_^
7 notes
·
View notes
Text
Password Manager Part 1
So the other day I was thinking about what else I could do to make my cyber life safer. So I started to looking into a Password Manager. Now you can buy a subscription to a password manager service and there are some good sites out there, but the problem is two things the subscription and security.
By security I mean you look around and you see leaks every where. Corporations getting hacked or they use the info to sale your info and all the user data is under there control. All it would take is someone to hack the password manages and then all the passwords could be out there and your rushing to change everything before they get in.
I don't have the money to do something like that, so I started to dig into making my own Password Manager using Python.I started looking into what I would need.
First would be encryption, one of the standards of the cybersecurity world. Using a mix of hashing through the SHA256 algorithm, and always salting your hashes you can make your stored passwords even more secure.
The code
# Setting up crytogtaphy from cryptography.hazmat.primitives import hashes from cryptography.hazmat.primitives.kdf.pbkdf2 import PBKDF2HMAC from cryptography.hazmat.backends import defult_backend import base64
def derive_encryption_key(master_password, salt): kdf = PBKDF2HMAC( algorithm=hashes.SHA256(), length=32, salt=salt, iterations=100000, backend=defult_backend() ) key = base64.urlsafe_b64encode(kdf.derive(master_oasswird.encode())) return key
Then encryption and decryption, the method of the program will use to keep the passwords encrypted and then decryption when they need to be executed. Writing this code was more challenging but there some amazing resources out there. With quick google searches you can find them.
The Code
# Encryption and Decrptions from cryptography.fernet import Fernet
def encrypt_password(password, key): fernet = Fernet(key) encrypted_password = fernet.encrypt(password.encode()) return encrypted_password
def decrypt_password(encrytped_password, key): fernet = fernet(key) decrypt_password = fernet.decrypt(encrypted_password).decode() return decrypted_password
Next up I wanted Random Password generation, at least 12 chars long, with letters, numbers and special chars.
The Code
# password generation import string import random
def generate_secure_password(length=12): char_pool = string.ascii_letters + string.digits + string.punctuation password = ''.join(random.choice(char_pool) for _ in range(length)) return password
Finally it would be needing a data base to store the passwords. Through googling, and research. I would need to set up a SQL Data base. This would be something new for me. But first I could set up the code and the key for the user. Later I will add the SQL data base.
Now part of this would be setting up a Master Password and user name. This worried me abet, because anybody could just hop in and take a look at the code and see the Master Password and then get access to all my passwords and such. So to keep your code safe, it is all about restricting your code. Location, keep your code in a safe locked files, away from prying eyes and encrypted, and access to the source code should be restricted to just you and who ever you trust.
The Code
# Seting up SQL database. def setup_database(): conn = sqlite3.connect('users.db') c = conn.cursor() c.execute('''CREATE TABLE IF NOT EXISTS Uer_keys (user_id TEXT PRIMARY KEY, key BLOB)''') conn.comit() conn.close()
def main(): # setup database setup_database()
#create a key for the user master_password = input("Enter your master password: ") salt = b' some_salt' # Generate secure salt for each user key = derive_encryption_key(master_password, salt)
#Simulate user intreaction user_id = "[email protected]" #user ID user_password = "Password1234" #user password to encrypt
# Encrypt the users password encrypt_password = encrypt_password(user_password, key) print(f"decrypted password for {user_id}; {decrypt_password}")
# Placeholder for intrgrtating the password storage and retriecal logic # This would inculde calls to interact with the SQL database.
if __name__ == "__main__": main()
Now I have much more to do to the program, I need to set up a SQL data base for storage this will be its own can of worms. Learning SQL will be a new challenge for me.
Also I wanted to add more features to the program, I was thinking about setting up an auto fill feature. Now the program will just display the requested password and you have to manually put it in. I want to see if there will be a way to auto fill it.
So stay tuned as I do more research.
2 notes
·
View notes
Text
tumblr-backup and datasette
I've been using tumblr_backup, a script that replicates the old Tumblr backup format, for a while. I use it both to back up my main blog and the likes I've accumulated; they outnumber posts over two to one, it turns out.
Sadly, there isn't an 'archive' view of likes, so I have no idea what's there from way back in 2010, when I first really heavily used Tumblr. Heck, even getting back to 2021 is hard. Pulling that data to manipulate it locally seems wise.
I was never quite sure it'd backed up all of my likes, and it turns out that a change to the API was in fact limiting it to the most recent 1,000 entries. Luckily, someone else noticed this well before I did, and a new version, tumblr-backup, not only exists, but is a Python package, which made it easy to install and run. (You do need an API key.)
I ran it using this invocation, which saved likes (-l), didn't download images (-k), skipped the first 1,000 entries (-s 1000), and output to the directory 'likes/full' (-O):
tumblr-backup -j -k -l -s 1000 blech -O likes/full
This gave me over 12,000 files in likes/full/json, one per like. This is great, but a database is nice for querying. Luckily, jq exists:
jq -s 'map(.)' likes/full/json/*.json > likes/full/likes.json
This slurps (-s) in every JSON file, iterates over them to make a list, and then saves it in a new JSON file, likes.json. There was a follow-up I did to get it into the right format for sqlite3:
jq -c '.[]' likes/full/likes.json > likes/full/likes-nl.json
A smart reader can probably combine those into a single operator.
Using Simon Willison's sqlite-utils package, I could then load all of them into a database (with --alter because the keys of each JSON file vary, so the initial column setup is incomplete):
sqlite-utils insert likes/full/likes.db lines likes/full/likes-nl.json --nl --alter
This can then be fed into Willison's Datasette for a nice web UI to query it:
datasette serve --port 8002 likes/full/likes.d
There are a lot of columns there that clutter up the view: I'd suggest this is a good subset (it also shows the post with most notes (likes, reblogs, and comments combined) at the top):
select rowid, id, short_url, slug, blog_name, date, timestamp, liked_timestamp, caption, format, note_count, state, summary, tags, type from lines order by note_count desc limit 101
Happy excavating!
2 notes
·
View notes
Text

July 2nd, 2023
I started working on a new project today: A discord game bot that lets you buy monsters, and battle with other players, and it also has game currency :3.
Today I want to focus on a very confusing concept for me - Databases. I need to set up database for this bot, and I'm using sqlite3 to do it.
All tips regarding the topic are welcome :D
🎧 long story short - Taylor Swift
14 notes
·
View notes
Text
How to (Probably) Save Those Fanfictions You LOVED That Were Deleted
I know I'm not the only one who has experienced this, so I wanted to explain how I was able to recover a fanfiction from a deleted account.
Obviously there is no guarantee 100% that this will work, but I'm fairly confident you'll find most old fanfictions. With the caveat here that you know some concrete detail about that fanfic (i.e. you need to know who the author was or what the title was, ideally the fanfic's ID # or upload/update date). You can search without it, but it's going to take quite a long time.
So, oh no! The Fanfiction that you read 5 years ago that you LOVED is no longer on FF.net/AO3/Etc. What are you going to do (besides weep hysterically)?
Go here: https://www.reddit.com/r/DataHoarder/comments/b6ut3j/fanfic_just_all_of_it/ (Reddit user nerdguy1138 deserves ALL the kudos and coffee and praise for this, because this would literally NOT be possible without their efforts (yes, ongoing)).
On that link you'll find multiple archives for various popular fanfiction sites over the years. Importantly, there are MULTIPLE FF.NET ones. If I remember correctly the 2nd link (updateablefanfic) is the more recent of the two. The one below that is old and is everything up to 2016. The second link is after 2016 and is ongoing. The key information here you need to know: 1. where was the fanfic you're looking for originally posted? 2. When was it created/last updated? The fanfic I wanted was finished at the end of 2017 and so I went with the updateablefanfic link.
Once you know which archive to go to, you're going to have to search for your file. You could do it the old-fashioned way and open up the preview and search with CTRL+F. But I'm going to tell you from experience that it sucks, takes forever, and can 100% be inaccurate (not because the data is inaccurate, but because there is SO MUCH data there that your browser is trying to load that it simply cannot handle it all, and if it can't load it, you can't search it). So. Instead, what you're going to do is look for the appropriate file for your fandom/work. You may not know it. Sometimes the data is sorted by Fandom letter (i.e. Pride and Prejudice is under the "P" file), other times it's sorted by username of the author(s) or the actual fic ID or name. If you know some or all of that, it will help immensely. If you know what you're looking for you can find the appropriate file pretty easily. For example the one I was looking for was in the "P" file. So I just had to look there. If you don't know any of the specifics you're going to want to repeat the below couple of steps for each file until you're able to find what you're after.
DON'T just download the giant zipped file for that letter. Let's do the simpler thing and search first. You'll also have to do this step if you don't know the ID/Name/Author, and it's a good thing to know how to do anyway. Go find the files ending with SQLITE/SQLITE3 under the ALL FILES section on the right. Download the file(s).
Paste https://sqliteviewer.app/#/metadata122.sqlite/table/metadata/ into another browser window. Click the "Open File" button on the top left and add in the file(s) you are trying to search through that you just downloaded. Give it a second to load and you'll be able to search the file for the author name/ID/Title/Fandom/Update Date, etc. etc. If the file exists in that list then it exists in the corresponding Zip file. If it doesn't, try another file. (I'm not sure if you can load multiple of the SQLITE files at once, but I kinda doubt it).
Okay, once you have located the name of the ZIP File you need - DON'T just click download. Trust me, your computer WILL hate you for it. Mine did. A lot. Instead, look and see what program was used to Zip the files. Most of the time it'll probably be 7zip. Now, go to: https://www.7-zip.org/ (or other appropriate zipping tool and download). You're going to use the program that was used to zip the file to unzip the file. It WILL go a LOT faster and your computer will hate you a (smidge) less. These files are still MASSIVE and WILL eat your memory like crazy. (I actually used a good chunk of my external 1 TB hard drive to get some extra memory for the duration of the download - I did the first option on this page: https://www.partitionwizard.com/partitionmanager/use-usb-as-ram.html page - you should also consider clearing your cache, but at these sizes I'm not sure how truly effective that will be). Anyway, download the 7zip/etc program and install. Now go and download the zip file. Once the zipped file is downloaded to your computer, right click, More options - 7zip and THEN click "Open Archive" Do NOT extract everything. You will literally be extracting hundreds of thousands of files, and while you may want more than one of them, I can guarantee you you probably don't want ALL of them. So, open archive. Search for the specific file(s) you're looking to get and extract JUST those by highlighting and clicking EXTRACT.
Okay, now the files you want will be downloaded to your desktop. But you'll notice that they are .txt only files. No more rich text. I can walk everyone through a tutorial of how I reformatted the files I pulled, but I don't want to do that on this post. I'll create a follow up on that, but with the plain .txt version you can paste it into word/google doc/notepad, whatever floats your boat and you can READ it.
An important lesson for us all: if you loved it - SAVE IT.
Hope this helps anyone who may be/has been in a similar situation to what I was in.
1 note
·
View note
Text
Discord Bot: Devlog #0
I've never done done anything like this before but I just wanted to share some of the things I've been learning about. This is also like my second tumblr post so please bear with me.
I've recently been working on this discord bot that lets users earn points and such. It's very basic, but I'm using it to learn a little SQL and JavaScript (even though I hate it).
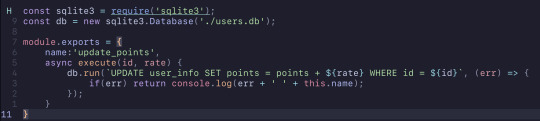
I had written this little piece of code that updates the amount of points a user has by the provided rate. However, a problem will of course occur if the user doesn't exist in the table.
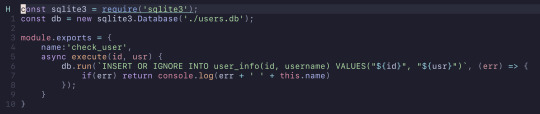
So I created this verifier to check if the user exists in the table, and if they don't it would insert them into the table.

Put together, this is what it looks like. Both functions were wrapped in sqlite3's serialize function to ensure that they would execute the queries to the db sequentially. However, this did not work as intended. Sqlite3's serialize function doesn't really "extend" into each of the function and it would simply just run asynchronously like normal. This meant that if the user didn't exist, it would sometimes (most of the time) try to update the non-existent user's points and then it would check and insert the user into the table.
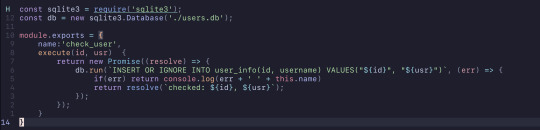
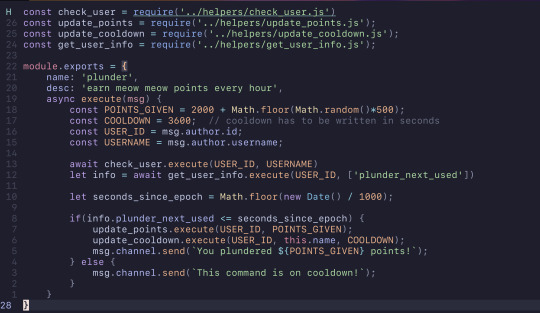
Ignoring all of the extra features added, this was fixed using async/await with promises. The check_user function now returns a promise and in combination of using await in the now async function, plunder, it works perfectly. The function has to wait for the promise that check_user returns to resolve before moving forward with the code. The update_points function didn't need to be asynchronous as nothing else in the function really relied on it.
I just wanted to share me learning about async/await and promises in JavaScript. Thanks for reading!
3 notes
·
View notes
Text
Django Models: Defining and Exporting Data Structures
Discover the power of #Django models! Learn how to define, export, and manage data structures in your Django projects. Boost your web development skills and create efficient, scalable applications. #DjangoModels #WebDev
Django models serve as the backbone of data management in Django applications. They define the structure of your database tables and provide an intuitive way to interact with your data. In this post, we’ll explore how to define and export it effectively. Understanding Django Models Django models are Python classes that represent database tables. They encapsulate the fields and behaviors of the…
0 notes
Text
assuming i put together some actual posts for it, roadtrip could theoretically ‘soft open’ as a thing i run locally any time. like i think the minimum operational stuff for making tumblr posts and archiving them in a sqlite db is all there. that’s terrifying
i think my next project is working on a decent web admin panel for myself (and like, a create post page that isn’t just a bunch of form elements shat into an empty document). then i have to decide whether i get a blog working first, or figure out remote deployment first and then do the blog. i’m looking forward to neither but remote deployment is scarier
also i’ve had another core compsci project experience. which is that after about 20 hours of assorted infrastructure fucking around, using the sqlite nodejs library that my webdev class told us to use, i heard someone mention ‘better-sqlite3′, which. is literally just that library but better in every possible way, but with different enough syntax that migrating would be a Project. boy i really wish i had known this 20 hours of code ago
#realistically i should try and get it to start posting soon because i know there's going to be weird bugs i didn't catch#i did some testing obviously but There's Always Fucking Something
2 notes
·
View notes
Text

Deploying SQLite for Local Data Storage in Industrial IoT Solutions
Introduction
In Industrial IoT (IIoT) applications, efficient data storage is critical for real-time monitoring, decision-making, and historical analysis. While cloud-based storage solutions offer scalability, local storage is often required for real-time processing, network independence, and data redundancy. SQLite, a lightweight yet powerful database, is an ideal choice for edge computing devices like ARMxy, offering reliability and efficiency in industrial environments.
Why Use SQLite for Industrial IoT?
SQLite is a self-contained, serverless database engine that is widely used in embedded systems. Its advantages include:
Lightweight & Fast: Requires minimal system resources, making it ideal for ARM-based edge gateways.
No Server Dependency: Operates as a standalone database, eliminating the need for complex database management.
Reliable Storage: Supports atomic transactions, ensuring data integrity even in cases of power failures.
Easy Integration: Compatible with various programming languages and industrial protocols.
Setting Up SQLite on ARMxy
To deploy SQLite on an ARMxy Edge IoT Gateway, follow these steps:
1. Installing SQLite
Most Linux distributions for ARM-based devices include SQLite in their package manager. Install it with:
sudo apt update
sudo apt install sqlite3
Verify the installation:
sqlite3 --version
2. Creating and Managing a Database
To create a new database:
sqlite3 iiot_data.db
Create a table for sensor data storage:
CREATE TABLE sensor_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP,
sensor_id TEXT,
value REAL
);
Insert sample data:
INSERT INTO sensor_data (sensor_id, value) VALUES ('temperature_01', 25.6);
Retrieve stored data:
SELECT * FROM sensor_data;
3. Integrating SQLite with IIoT Applications
ARMxy devices can use SQLite with programming languages like Python for real-time data collection and processing. For instance, using Python’s sqlite3 module:
import sqlite3
conn = sqlite3.connect('iiot_data.db')
cursor = conn.cursor()
cursor.execute("INSERT INTO sensor_data (sensor_id, value) VALUES (?, ?)", ("pressure_01", 101.3))
conn.commit()
cursor.execute("SELECT * FROM sensor_data")
rows = cursor.fetchall()
for row in rows:
print(row)
conn.close()
Use Cases for SQLite in Industrial IoT
Predictive Maintenance: Store historical machine data to detect anomalies and schedule maintenance.
Energy Monitoring: Log real-time power consumption data to optimize usage and reduce costs.
Production Line Tracking: Maintain local records of manufacturing process data for compliance and quality control.
Remote Sensor Logging: Cache sensor readings when network connectivity is unavailable and sync with the cloud later.
Conclusion
SQLite is a robust, lightweight solution for local data storage in Industrial IoT environments. When deployed on ARMxy Edge IoT Gateways, it enhances real-time processing, improves data reliability, and reduces cloud dependency. By integrating SQLite into IIoT applications, industries can achieve better efficiency and resilience in data-driven operations.
0 notes