#Scraping Streaming Netflix Data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Note
nightshade is basically useless https://www.tumblr.com/billclintonsbeefarm/740236576484999168/even-if-you-dont-like-generative-models-this
I'm not a developer, but the creators of Nightshade do address some of this post's concerns in their FAQ. Obviously it's not a magic bullet to prevent AI image scraping, and obviously there's an arms race between AI developers and artists attempting to disrupt their data pools. But personally, I think it's an interesting project and is accessible to most people to try. Giving up on it at this stage seems really premature.
But if it's caption data that's truly valuable, Tumblr is an ... interesting ... place to be scraping it from. For one thing, users tend to get pretty creative with both image descriptions and tags. For another, I hope whichever bot scrapes my blog enjoys the many bird photos I have described as "Cheese." Genuinely curious if Tumblr data is actually valuable or if it's garbage.
That said, I find it pretty ironic that the OP of the post you linked seems to think nightshade and glaze specifically are an unreasonable waste of electricity. Both are software. Your personal computer's graphics card is doing the work, not an entire data center, so if your computer was going to be on anyway, the cost is a drop in the bucket compared to what AI generators are consuming.
Training a large language model like GPT-3, for example, is estimated to use just under 1,300 megawatt hours (MWh) of electricity; about as much power as consumed annually by 130 US homes. To put that in context, streaming an hour of Netflix requires around 0.8 kWh (0.0008 MWh) of electricity. That means you’d have to watch 1,625,000 hours to consume the same amount of power it takes to train GPT-3. (source)
So, no, I don't think Nightshade or Glaze are useless just because they aren't going to immediately topple every AI image generator. There's not really much downside for the artists interested in using them so I hope they continue development.
991 notes
·
View notes
Text
So earlier today, everyone on twitter got all confused because everything was showing a “rate limit exceeded” error message with no further clarification whatsoever. Then, some hours later, Mister dumb-dumb claims its “totally deliberate u guys” to “address extreme levels of data scraping”, and limiting people to seeing 600 posts per day. That might sound like a lot, but the way Twitter loads its feed, that basically means you get about 30 seconds of usage.
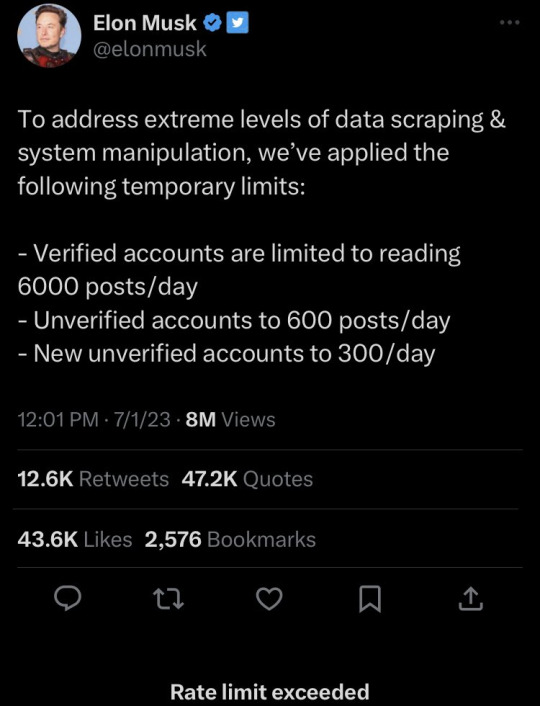
So basically, Mister dumb-dumb spent an unearthly amount of money to buy one of the biggest, most relied-upon social networks in the world, fired all the people who actually worked there, changed the verification badges so instead of confirming celeb accounts are legit, they instead mean “my cult is paying me $8″, claimed an adjective is a slur and is now massively restricting people using the service.

He does claim this is “temporary”, but given this idiot’s track record, he probably doesn’t know how to fix it. Especially since he laid off most of the actual software engineers.
Twitter has, for years, been a primary platform for both communities as well as keeping up on news. If people can barely see any tweets per day, that all goes right out the window.
Twitter got so big largely because it was convenient to get those things on one feed. Netflix got big when it started because it was convenient to have everything in one place, it reduced the amount of piracy that was going on for film/TV because it was easier and more convenient than the old torrenting services of the day. Now, every last studio wants to cash in with its own streaming service, and people are going back to piracy because its more convenient that having 500 different monthly subscriptions. This is the social media version of that. Mister dumb-dumb took one of the most convenient social media platforms and utterly mangled it, so user retention is understandably going through the floor.
Anyway, that means a lot of the communities I’ve been a part of are splitting all over the place to countless third party platforms. I’m not 100% sure yet, but I might be making more of an effort to get used to Tumblr. I’ve never quite felt confident posting here, but its currently the best alternative; Reddit is also going down the toilet with their API changes, Facebook is more built for people you know IRL rather than fandom communities (I never particularly liked the groups systems there), Discord is utterly alien to me and I simply cannot learn how to make the most of it and stuff like Mastodon or random-twitter-knockoff-that-my-mutuals-aren’t-bothering-to-tell-me-what-it-is are too niche and a bit weird.
So yeah, this feed might become more active with videogame screenshots, Star Trek episode thoughts and opinions, neurodivergent ramblings and whatever else, idk.
EDIT: News article with a bit more detail if you want
https://www.bbc.co.uk/news/technology-66077195
#twitter ded#mister dumb-dumb broke twitter for good#social media's gone all weird#i just want my online community spaces#i need somewhere to talk about my hyperfixations#trust your software engineers#i'm still not entirely sure how to use tumblr
19 notes
·
View notes
Text
[Image Description: A series of screenshots.
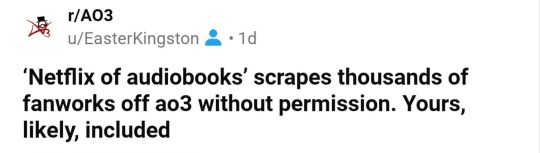
Image 1: A post on r/Ao3 on Reddit by u/EasterKingston. The post is titled "'Netflix of audiobooks' scrapes thousands of fanworks off Ao3 without permission. Yours, likely, included."
Image 2: The preview for a website titled word-stream. The page is titled "You & Me & Holiday Wine - WordStream".
Image 3: A screenshot from the website WordStream. The word "ekingston" is entered into the search bar. There are two results. One named "You & Me & Holiday Wine" and the other named "The Shape of Soup". Both have over 80 thousand views.
Image 4: Another screenshot from the same site. The name "Kara Danvers" is entered into the search bar. There are twenty results from a variety of authors that fill up the page.
Image 5: A sent text reading: "I followed you here from Reddit, where I was made aware of the truly awesome work your project Copyknight has been doing. I just discovered the website/app word-stream.com today-it's a site that's seemingly scraped thousands of works off ao3 and offers audiobook versions of them, presumably for a fee. It looks like it only went live in October, and I don't see much chatter about it (or contact information) anywhere. I was wondering if you'd heard from it/could offer advice on how to go about getting our works taken down?"
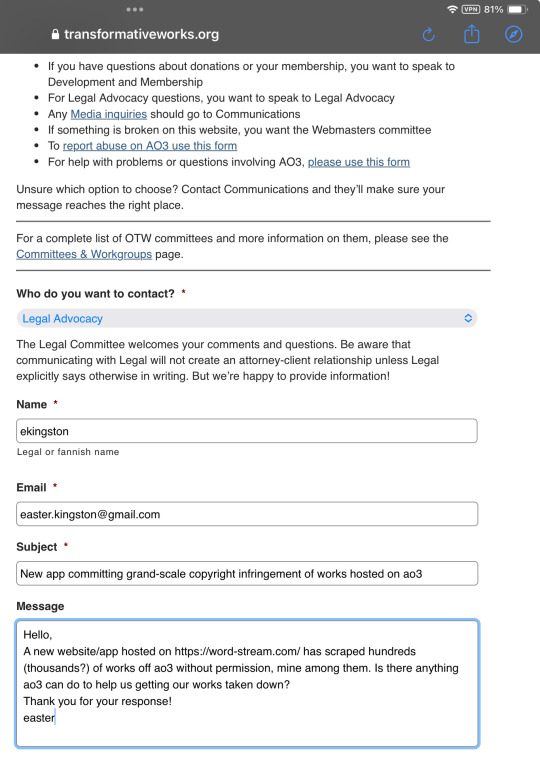
Image 6: A screenshot of a contact form being filled out. The form is on transformativeworks.org and appears to be a contact form. The subject is "New app committing grand-scale copyright infringement of works hosted on Ao3". The message reads: "Hello, A new website/app hosted on https://word-stream.com/ has scraped hundreds (thousands?) of works off Ao3 without permission, mine among them. Is there anything Ao3 can do to help us getting our works taken down? Thank you for your response! Easter."
Image 7: A series of interspersed text and screenshots. Text reads: "If you try to click on any of the sites, you get a link to the AppStore app, which is called "WordStream - Audiobooks". There is a screenshot of the app in the app store. The creator's name is Ofek Weitzman. Text reads: "Who is Ofek Weitzman? Apparently he's also known as Cliff Weitzman, the CEO of Speechify, an AI Voice generator app famous for its partnership with Snoop. Also, Cliff Weitzman is named as the copyright holder at the bottom:" A screenshot showing the copyright holder as Cliff Weitzman. Text reads: "If you search for Ofek/Cliff Weitzman, you find his name in the terms and conditions for Speechify." A screenshot showing the terms and conditions including the name Ofek Weitzman as the individual to address a notice of dispute to. Text reads: "Strange that someone with a legitimate company with a partnership with Brandon Sanderson would put their name behind a shady company stealing works from fanfic writers, but it may be worth reaching out to him on X. Best case scenario is that someone has stolen the name for an app, but in that case, it would be good for him to know. Otherwise, it would be good to start a dialogue about how authors can get their works taken down from this site!"
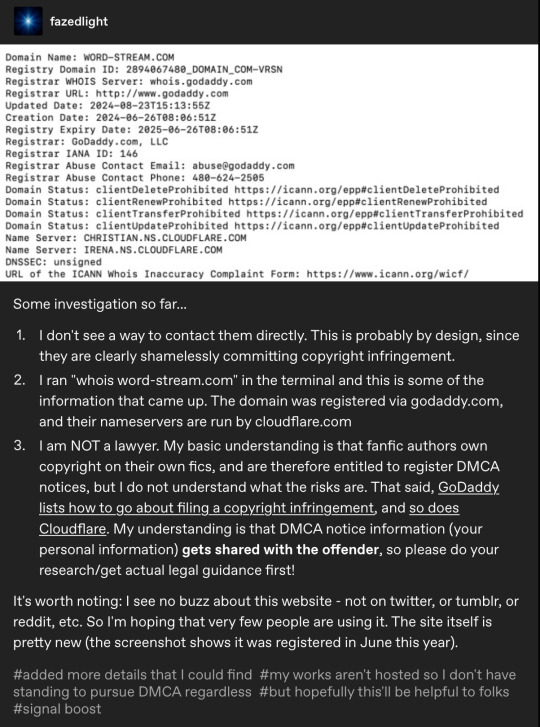
Image 8: A screenshot of a Tumblr post from user fazedlight (Fazed Light). It shows an image of domain registry data for Word-Stream. Text reads: Some investigation so far: 1. I don't see a way to contact them directly. This is probably by design, since they are clearly shamelessly committing copyright infringement. 2. I ran "Who is Word-Stream" in the terminal and this is some of the information that came up. The domain was registered via Go Daddy.com and their nameservers are run by CloudFlare.com. 3. I am NOT a lawyer. My basic understanding is that fanfic authors own copyright on their own fics, and are therefore entitled to register DMCA notices, but I do not understand what the risks are. That said, GoDaddy links how to go about filing a copyright infringement, and so does CloudFlare. My understanding is that DMCA notice information (Your personal information) gets shared with the offender, so please do your research/get actual legal guidance first! It's worth noting: I see no buzz about this website - not on Twitter, or Tumblr, or Reddit, etc. So I'm hoping that very few people are using it. The site itself is pretty new (The screenshot shows it was registered in June this year).
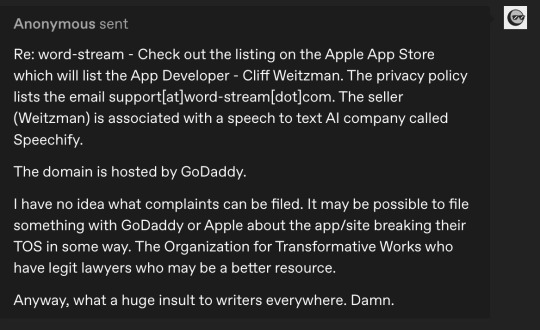
Image 9: An anonymous Tumblr asks that reads: "Re: word-stream - Check out the listing on the Apple App Store which will list the App Developer - Cliff Weitzman. The privacy policy lists the email support[at]word-stream[dot]com. The seller (Weitzman) is associated with a speech to text AI company called Speechify. The domain is hosted by GoDaddy. I have no idea what complaints can be filed. It may be possible to file something with GoDaddy or Apple about the app/site breaking their TOS in some way. The Organization for Transformative Works who have legit lawyers who may be a better resource. Anyway, what a huge insult to writers everywhere. Damn.
Image 10: An email from Rebecca Tushnet to easter.kingston. The subject is "Your message about WordStream". The email reads: "Thank you for reaching out. The Archive of Our Own does not claim copyright in any works posted to AO3 so authors have to submit their own takedown notices to sites reposting their works without authorization. The AO3 does not allow commercial reuse, so we do attempt to prevent large scale scraping, but techical measures are not foolproof. We will look into the site and see if there are further measures we can take. Yours, Rebecca Tushnet."
Image 11: A screenshot showing three subscription plans to choose from: A month long for 93 cents per day or a discounted price of 39 cents, a three month long for 53 cents per day or a discounted price of 19 cents, and a six month long for 55 cents per day or a discounted price of 15 cents. The three month plan is listed as most popular.
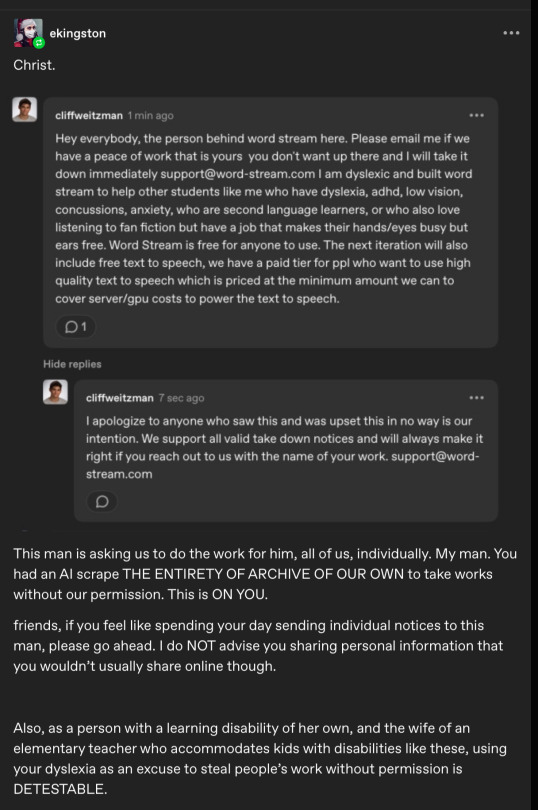
Image 12: A Tumblr post by user ekingston. It reads: "Christ". A screenshot of a Tumblr reply by user cliffweitzman (Cliff Weitzman) is below. It reads: "Hey everybody, the person behind word stream here. Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately [email protected] I am dyslexic and built word stream to help other students like me who have dyslexia, adhd, low vision, concussions, anxiety, who are second language learners, or who also love listening to fan fiction but have a job that makes their hands/eyes busy but ears free. Word Stream is free for anyone to use. The next iteration will also include free text to speech, we have a paid tier for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech." The same user has replied to the original comment. Their reply reads: "I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices and will always make it right if you reach out to us with the name of your work. support@word- stream.com". Text in the original Tumblr post reads: "This man is asking us to do the work for him, all of us, individually. My man. You had an Al scrape THE ENTIRETY OF ARCHIVE OF OUR OWN to take works without our permission. This is ON YOU. friends, if you feel like spending your day sending individual notices to this man, please go ahead. I do NOT advise you sharing personal information that you wouldn't usually share online though. Also, as a person with a learning disability of her own, and the wife of an elementary teacher who accommodates kids with disabilities like these, using your dyslexia as an excuse to steal people's work without permission is DETESTABLE."
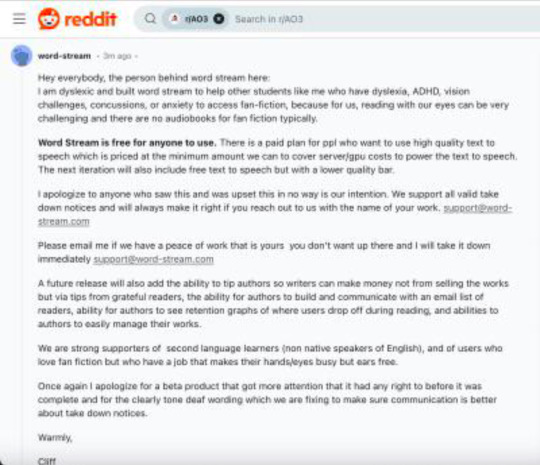
Image 13: Text reads: "cliffweitzman (Cliff Weitzman) replied to your text post." The reply reads: "Hey everybody, the person behind word stream here: I am dyslexic and built word stream to help other students like me who have dyslexia, ADHD, vision challenges, concussions, or anxiety to access fan-fiction, because for us, reading with our eyes can be very challenging and there are no audiobooks for fan fiction typically. Word Stream is free for anyone to use. There is a paid plan for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech. The next iteration will also include free text to speech but with a lower quality bar. I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices an d will always make it right if you reach out to us with the name of your work. [email protected] Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately [email protected]. A future release will also add the ability to tip authors so writers can make money not from selling the works but via tips from grateful readers, the ability for authors to build and communicate with an email list of readers, ability for authors to see retention graphs of where users drop off during reading, and abilities to authors to easily manage their works. We are strong supporters of second language learners (non native speakers of English), and of users who love fan fiction but who have a job that makes their hands/eyes busy but ears free. Once again I apologize for a beta product that got more attention that it ha d any right to before it was complete and for the clearly tone deaf wording which we are fixing to make sure communication is better about take down notices. Warmly, Cliff If you can, pl ease upvote or comment on the post so others can see the e mail they should message to have anything they don't want posted taken down immediately Word Stream."
Image 14: A Reddit comment on r/Ao3 by user word-stream. It reads: "Hey everybody, the person behind word stream here: I am dyslexic and built word stream to help other students like me who have dyslexia, ADHD, vision challenges, concussions, or anxiety to access fan-fiction, because for us, reading with our eyes can be very challenging and there are no audiobooks for fan fiction typically. Word Stream is free for anyone to use. There is a paid plan for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech. The next iteration will also include free text to speech but with a lower quality bar, I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices and will always make it right if you reach out to us with the name of your work, [email protected] Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately support@@word-stream.com A future release will also add the ability to tip authors so writers can make money not from selling the works but via tips from grateful readers, the ability for authors to build and communicate with an email list of readers, ability for authors to see retention graphs of where users drop off during reading, and abilities to authors to easily manage their works. We are strong supporters of second language learners (non native speakers of English), and of users who love fan fiction but who have a job that makes their hands/eyes busy but ears free. Once again I apologize for a beta product that got more attention that it had any right to before it was complete and for the clearly tone deaf wording which we are fixing to make sure communication is better about take down notices. Warmly, Cliff."
Image 15: A Reddit comment from user Electronic_Dog_9526. It reads: "Word Stream's team have apologize for a beta product that got more attention that it had any right to before it was complete and for the clearly tone deaf wording which they are fixing to make sure communication is better about take down notices. They are trying to make the internet including fan fiction accessible to students with dyslexia, ADHD, and vision challenges, and it is free to use. Anyone can read on word stream for free. There is a paid tier that enables audio mode: this pays for the expensive GPUs needed for making the audio. They share they support all valid take down notices and will make it right if you reach out with the name of your work to [email protected]." The comment has two downvotes.
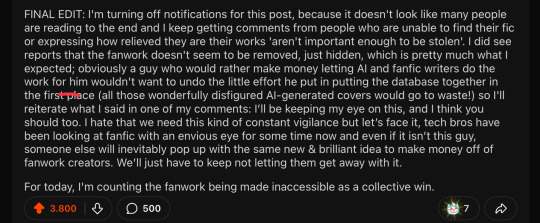
Image 16: A partial screenshot of a Reddit post. It has 3800 upvotes, 500 comments, and 7 awards. It reads: "FINAL EDIT: I'm turning off notifications for this post, because it doesn't look like many people are reading to the end and I keep getting comments from people who are unable to find their fic or expressing how relieved they are their works 'aren't important enough to be stolen'. I did see reports that the fanwork doesn't seem to be removed, just hidden, which is pretty much what I expected; obviously a guy who would rather make money letting Al and fanfic writers do the work for him wouldn't want to undo the little effort he put in putting the database together in the first place (all those wonderfully disfigured Al-generated covers would go to waste!) so I'll reiterate what I said in one of my comments: I'll be keeping my eye on this, and I think you should too. I hate that we need this kind of constant vigilance but let's face it, tech bros have been looking at fanfic with an envious eye for some time now and even if it isn't this guy, someone else will inevitably pop up with the same new & brilliant idea to make money off of fanwork creators. We'll just have to keep not letting them get away with it. For today, I'm counting the fanwork being made inaccessible as a collective win."
End ID.]
[Plain Text: Text in red reads: "***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS."]
SO HERE IS THE WHOLE STORY (SO FAR).
I am on my knees begging you to reblog this post and to stop reblogging the original ones I sent out yesterday. This is the complete account with all the most recent info; the other one is just sending people down senselessly panicked avenues that no longer lead anywhere.
IN SHORT
Cliff Weitzman, CEO of Speechify and (aspiring?) voice actor, used AI to scrape thousands of popular, finished works off AO3 to list them on his own for-profit website and in his attached app. He did this without getting any kind of permission from the authors of said work or informing AO3. Obviously.
When fandom at large was made aware of his theft and started pushing back, Weitzman issued a non-apology on the original social media posts—using
his dyslexia;
his intent to implement a tip-system for the plagiarized authors; and
a sudden willingness to take down the work of every author who saw my original social media posts and emailed him individually with a ‘valid’ claim,
as reasons we should allow him to continue monetizing fanwork for his own financial gain.
When we less-than-kindly refused, he took down his ‘apologies’ as well as his website (allegedly—it’s possible that our complaints to his web host, the deluge of emails he received or the unanticipated traffic brought it down, since there wasn’t any sort of official statement made about it), and when it came back up several hours later, all of the work formerly listed in the fan fiction category was no longer there.
THE TAKEAWAYS
1. Cliff Weitzman (aka Ofek Weitzman) is a scumbag with no qualms about taking fanwork without permission, feeding it to AI and monetizing it for his own financial gain;
2. Fandom can really get things done when it wants to, and
3. Our fanworks appear to be hidden, but they’re NOT DELETED from Weitzman’s servers, and independently published, original works are still listed without the authors' permission. We need to hold this man responsible for his theft, keep an eye on both his current and future endeavors, and take action immediately when he crosses the line again.
THE TIMELINE, THE DETAILS, THE SCREENSHOTS (behind the cut)
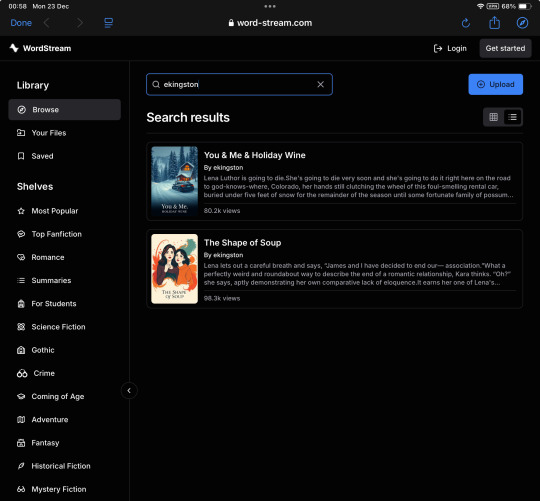
Sunday night, December 22nd 2024, I noticed an influx in visitors to my fic You & Me & Holiday Wine. When I searched the title online, hoping to find out where they came from, a new listing popped up (third one down, no less):

This listing is still up today, by the way, though now when you follow the link to word-stream, it just brings you to the main site. (Also, to be clear, this was not the cause for the influx of traffic to my fic; word-stream did not link back to the original work anywhere.)
I followed the link to word-stream, where to my horror Y&M&HW was listed in its entirety—though, beyond the first half of the first chapter, behind a paywall—along with a link promising to take me—through an app downloadable on the Apple Store—to an AI-narrated audiobook version. When I searched word-stream itself for my ao3 handle I found both of my multi-chapter fics were listed this way:
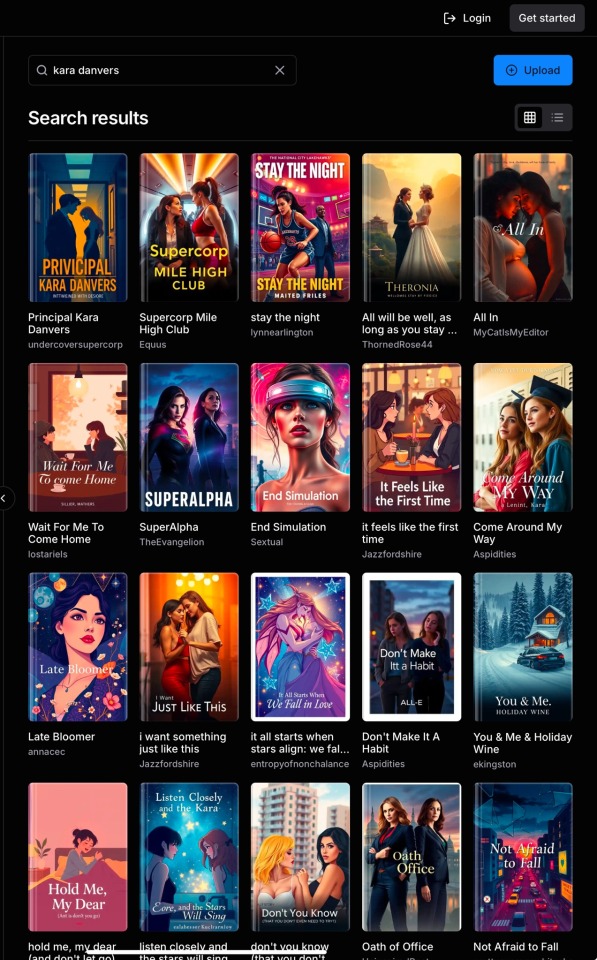
Because the tags on my fics (which included genres* and characters, but never the original IPs**) weren’t working, I put ‘Kara Danvers’ into the search bar and discovered that many more supercorp fics (Supergirl TV fandom, Kara Danvers/Lena Luthor pairing) were listed.
I went looking online for any mention of word-stream and AI plagiarism (the covers—as well as the ridiculously inflated number of reviews and ratings—made it immediately obvious that AI fuckery was involved), but found almost nothing: only one single Reddit post had been made, and it received (at that time) only a handful of upvotes and no advice.
I decided to make a tumblr post to bring the supercorp fandom up to speed about the theft. I draw as well as write for fandom and I’ve only ever had to deal with art theft—which has a clear set of steps to take depending on where said art was reposted—and I was at a loss regarding where to start in this situation.
After my post went up I remembered Project Copy Knight, which is worth commending for the work they’ve done to get fic stolen from AO3 taken down from monetized AI 'audiobook’ YouTube accounts. I reached out to @echoekhi, asking if they’d heard of this site and whether they could advise me on how to get our works taken down.

While waiting for a reply I looked into Copy Knight’s methods and decided to contact OTW’s legal department:
And then I went to bed.
By morning, tumblr friends @makicarn and @fazedlight as well as a very helpful tumblr anon had seen my post and done some very productive sleuthing:

@echoekhi had also gotten back to me, advising me, as expected, to contact the OTW. So I decided to sit tight until I got a response from them.
That response came only an hour or so later:
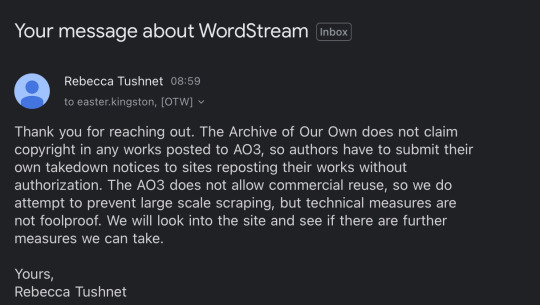
Which was 100% understandable, but still disappointing—I doubted a handful of individual takedown requests would accomplish much, and I wasn’t eager to share my given name and personal information with Cliff Weitzman himself, which is unavoidable if you want to file a DMCA.
I decided to take it to Reddit, hoping it would gain traction in the wider fanfic community, considering so many fandoms were affected. My Reddit posts (with the updates at the bottom as they were emerging) can be found here and here.
A helpful Reddit user posted a guide on how users could go about filing a DMCA against word-stream here (to wobbly-at-best results)
A different helpful Reddit user signed up to access insight into word-streams pricing. Comment is here.
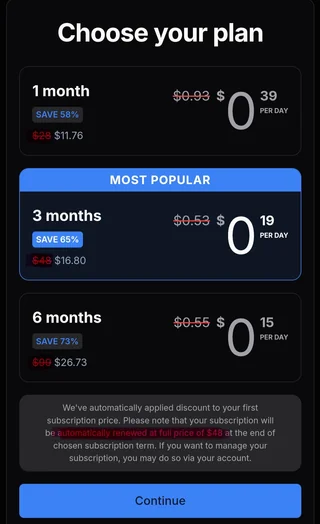
Smells unbelievably scammy, right? In addition to those audacious prices—though in all fairness any amount of money would be audacious considering every work listed is accessible elsewhere for free—my dyscalculia is screaming silently at the sight of that completely unnecessary amount of intentionally obscured numbers.
Speaking of which! As soon as the post on r/AO3—and, as a result, my original tumblr post—began taking off properly, sometime around 1 pm, jumpscare! A notification that a tumblr account named @cliffweitzman had commented on my post, and I got a bit mad about the gist of his message :
Fortunately he caught plenty of flack in the comments from other users (truly you should check out the comment section, it is extremely gratifying and people are making tremendously good points), in response to which, of course, he first tried to both reiterate and renegotiate his point in a second, longer comment (which I didn’t screenshot in time so I’m sorry for the crappy notification email formatting):

which he then proceeded to also post to Reddit (this is another Reddit user’s screenshot, I didn’t see it at all, the notifications were moving too fast for me to follow by then)
... where he got a roughly equal amount of righteously furious replies. (Check downthread, they're still there, all the way at the bottom.)
After which Cliff went ahead & deleted his messages altogether.
It’s not entirely clear whether his account was suspended by Reddit soon after or whether he deleted it himself, but considering his tumblr account is still intact, I assume it’s the former. He made a handful of sock puppet accounts to play around with for a while, both on Reddit and Tumblr, only one of which I have a screenshot of, but since they all say roughly the same thing, you’re not missing much:
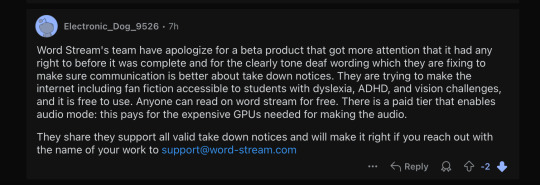
And then word-stream started throwing a DNS error.
That lasted for a good number of hours, which was unfortunately right around the time that a lot of authors first heard about the situation and started asking me individually how to find out whether their work was stolen too. I do not have that information and I am unclear on the perimeters Weitzman set for his AI scraper, so this is all conjecture: it LOOKS like the fics that were lifted had three things in common:
They were completed works;
They had over several thousand kudos on AO3; and
They were written by authors who had actively posted or updated work over the past year.
If anyone knows more about these perimeters or has info that counters my observation, please let me know!
I finally thought to check/alert evil Twitter during this time, and found out that the news was doing the rounds there already. I made a quick thread summarizing everything that had happened just in case. You can find it here.
I went to Bluesky too, where fandom was doing all the heavy lifting for me already, so I just reskeeted, as you do, and carried on.
Sometime in the very early evening, word-stream went back up—but the fan fiction category was nowhere to be seen. Tentative joy and celebration!***
That’s when several users—the ones who had signed up for accounts to gain intel and had accessed their own fics that way—reported that their work could still be accessed through their history. Relevant Reddit post here.
Sooo—
We’re obviously not done. The fanwork that was stolen by Weitzman may be inaccessible through his website right now, but they aren’t actually gone. And the fact that Weitzman wasn’t willing to get rid of them altogether means he still has plans for them.
This was my final edit on my Reddit post before turning off notifications, and it's pretty much where my head will be at for at least the foreseeable future:
Please feel free to add info in the comments, make your own posts, take whatever action you want to take to protect your work. I only beg you—seriously, I’m on my knees here—to not give up like I saw a handful of people express the urge to do. Keep sharing your creative work and remain vigilant and stay active to make sure we can continue to do so freely. Visit your favorite fics, and the ones you’ve kept in your ‘marked for later’ lists but never made time to read, and leave kudos, leave comments, support your fandom creatives, celebrate podficcers and support AO3. We created this place and it’s our responsibility to keep it alive and thriving for as long as we possibly can.
Also FUCK generative AI. It has NO place in fandom spaces.
THE 'SMALL' PRINT (some of it in all caps):
*Weitzman knew what he was doing and can NOT claim ignorance. One, it’s pretty basic kindergarten stuff that you don’t steal some other kid’s art project and present it as your own only to act surprised when they protest and then tell the victim that they should have told you sooner that they didn’t want their project stolen. And two, he was very careful never to list the IPs these fanworks were based on, so it’s clear he was at least familiar enough with the legalities to not get himself in hot water with corporate lawyers. Fucking over fans, though, he figured he could get away with that.
**A note about the AI that Weitzman used to steal our work: it’s even greasier than it looks at first glance. It’s not just the method he used to lift works off AO3 and then regurgitate onto his own website and app. Looking beyond the untold horrors of his AI-generated cover ‘art’, in many cases these covers attempt to depict something from the fics in question that can’t be gleaned from their summaries alone. In addition, my fics (and I assume the others, as well) were listed with generated genres; tags that did not appear anywhere in or on my fic on AO3 and were sometimes scarily accurate and sometimes way off the mark. I remember You & Me & Holiday Wine had ‘found family’ (100% correct, but not tagged by me as such) and I believe The Shape of Soup was listed as, among others, ‘enemies to friends to lovers’ and ‘love triangle’ (both wildly inaccurate). Even worse, not all the fic listed (as authors on Reddit pointed out) came with their original summaries at all. Often the entire summary was AI-generated. All of these things make it very clear that it was an all-encompassing scrape—not only were our fics stolen, they were also fed word-for-word into the AI Weitzman used and then analyzed to suit Weitzman’s needs. This means our work was literally fed to this AI to basically do with whatever its other users want, including (one assumes) text generation.
***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS.
PLEASE check my later versions of this post via my main page to make sure you have the latest version of this post before you reblog. All the information I’ve been able to gather is in my reblogs below, and it's frustrating to see the old version getting passed around, sending people on wild goose chases.
Thank you all so much!
#fandom culture#fanfic culture#ao3 culture#ai in fandom#described#image description#described by me(at)
48K notes
·
View notes
Text
🎬 Want to Understand What’s Trending on Netflix—Before Everyone Else?

In the fast-moving world of OTT content, data is the new currency. With RealDataAPI’s Netflix Datasets & Scraping Service, you can access structured, real-time information from Netflix to gain a competitive edge in the streaming, entertainment, and content analytics space.
📊 What You Can Extract: ✅ Titles, genres, languages, release dates & ratings ✅ Trending shows/movies by country & category ✅ Viewer engagement trends & global rankings ✅ Metadata for regional content preferences ✅ Data for recommendation engines & market analysis
💡 “Great storytelling needs great data.” Whether you're a content studio, media strategist, entertainment startup, or analytics firm—Netflix data helps you track trends, optimize content, and power smarter decisions. 📩 Contact us: [email protected]
0 notes
Text
Netflix Shows Streaming Dataset – Scraping Netflix OTT Media Data
Explore the Netflix Shows Streaming Dataset with powerful tools for Web Scraping Netflix OTT Media Data—ideal for trends, genres, ratings & more.
Read More >> https://www.arctechnolabs.com/netflix-shows-streaming-datasets.php
#NetflixShowsStreamingDataset#WebScrapingNetflixOTTMediaData#ScrapeNetflixStreamingData#MobileAppScrapingServices#ExpertOTTStreamingPlatformData#NetflixStreamingDataset#ScrapeNetflixMoviesTVShowsData#ArcTechnolabs
0 notes
Text
Netflix Viewer Trends Shaping Content Strategy in 2025

In a world where content is consumed on demand, Netflix continues to lead the charge in shaping digital entertainment. With millions of global viewers streaming content every second, the Netflix streaming dataset has become a goldmine for uncovering viewer preferences, predicting trends, and making data-driven decisions.
As businesses and creators compete to grab attention in the crowded OTT space, understanding Netflix viewer behavior is more crucial than ever.
The Power of Streaming Analytics
Behind every popular show or movie on Netflix lies an ocean of streaming analytics insights—from watch time and genre preferences to regional content performance. By analyzing these patterns, content producers can create smarter strategies that resonate with audiences.
With accurate and timely Netflix data analysis, production houses, marketers, and even investors can:
Identify trending genres before they go mainstream
Understand Netflix viewing habits across demographics
Tailor marketing campaigns based on real-time audience interest
Optimize release schedules using predictive analytics in streaming
Why Access to Real-Time Netflix Data Matters
In today’s fast-moving entertainment ecosystem, timing is everything. Having access to real-time Netflix data extraction allows businesses to monitor what's gaining traction right now—not what was popular weeks ago.
Whether it's analyzing top-watched series or tracking seasonal viewing spikes, web scraping for OTT platforms like Netflix empowers you with the data needed to stay ahead.
Transforming Content Strategy with Netflix Data
The future of content creation lies in understanding what works—and why. By tapping into reliable OTT content trends 2025, companies can shift from guessing to knowing. This enables:
Smarter content investment
Improved audience targeting
Enhanced subscriber retention strategies
Customized user experiences across platforms
The Netflix streaming dataset offers rich insights that can redefine how brands approach the entertainment market.
Get Started with Trusted Netflix Data Extraction
At Actowiz Solutions, we specialize in providing clean, structured, and insightful Netflix OTT data that helps our clients make impactful decisions. Our advanced tools ensure accurate, ethical, and scalable Netflix web data extraction for businesses across media, entertainment, and analytics industries.
Final Thoughts
As the OTT industry continues to evolve, one thing is clear—streaming analytics will be at the heart of innovation. By leveraging the power of Netflix data analysis, companies can stay one step ahead and deliver content that truly connects.
Ready to unlock the full potential of Netflix data? 👉 Explore our Netflix Streaming Dataset Solutions
0 notes
Text
What Are Private Proxies and Why Are They Worth It?

Private proxies are tools for secure and anonymous internet access. Unlike shared proxies, private proxies are assigned to one user, ensuring better performance and privacy. They route your requests through secure servers, concealing your real IP address to protect your identity and prevent tracking.
More info private proxies
With 31% of internet users globally using VPNs for privacy, the demand for secure solutions like private proxies is rising. Private proxies offer faster speeds, uninterrupted access, and reduced risk of being blocked, making them ideal for personal and business needs.
What Are Private Proxies?
Private proxies function as intermediaries between your device and the websites you visit, forwarding your internet requests while hiding your real IP address. This ensures your online identity remains anonymous, preventing others from tracking your activity. Unlike shared proxies, which are used by many users, private proxies are dedicated to a single user, ensuring superior performance.
By masking your IP address with their own, private proxies offer enhanced privacy and prevent location tracking. Many private proxies also provide encryption to protect the data you transmit, adding an extra layer of security. For a reliable, high-performance solution, Live Proxies offers private proxies with global server coverage and fast, uninterrupted connections.
Why Do You Need Private Proxies?
Private proxies provide enhanced privacy by concealing your IP address, allow access to geo-restricted content, and support secure business operations like market research, managing multiple accounts, and web scraping without the risk of IP bans.
Private proxies conceal your IP address, preventing unauthorized tracking, which is essential for confidential activities like accessing financial accounts, conducting market research, or browsing anonymously.
Access Restricted Content
Private proxies enable you to bypass geographic restrictions, providing access to streaming platforms, websites, and services that would otherwise be unavailable in your location.
Boost Business Operations
Private proxies are indispensable for businesses, offering secure market research, safe management of multiple social media accounts, and uninterrupted web scraping without the risk of IP bans.
What Are the Benefits of Private Proxies?
The benefits of private proxies include enhanced privacy by masking your IP address, faster speeds with dedicated bandwidth, reliable and uninterrupted connections, access to geo-restricted content, and protection against IP bans during activities like web scraping or managing multiple accounts.
Enhanced Privacy and Security: They conceal your real IP address, protecting your identity and preventing unauthorized tracking. Encryption adds an extra layer of data protection.
Faster Speeds: Dedicated bandwidth ensures high-speed connections without interference from other users.
Unrestricted Access: They bypass geographic restrictions, allowing you to access region-locked content on platforms like Netflix or Hulu.
Reliable Connections: Exclusive access minimizes downtime and ensures stable, uninterrupted browsing.
Protection Against IP Bans: They reduce the risk of detection during tasks like web scraping or managing multiple accounts.
How Can You Optimize Your Private Proxy Usage?
To optimize private proxies, regularly rotate IPs to avoid detection, choose residential proxies for region-specific tasks and data center proxies for speed, and monitor bandwidth to maintain performance. Use trusted providers with strong encryption, verify compatibility with your tools, enable authentication for security, and keep settings updated for smooth operation.
How to Choose the Best Private Proxy Provider?
Choose a provider that offers fast, reliable connections, global server coverage, strong encryption with a no-logs policy, flexible pricing plans, and responsive customer support for a seamless and secure experience.
0 notes
Text

Python: Unlocking Possibilities Beyond Code
Python has earned its place as one of the most powerful and versatile programming languages in the world. While it is celebrated for its simple syntax and robust capabilities, the true magic of Python lies in its ability to empower innovation across a variety of domains. From data science to artificial intelligence, Python's influence extends far beyond the world of coding itself.
In this blog, we will explore the non-technical aspects of Python—its versatility, applications, community, and impact on industries—showcasing why Python is the backbone of the modern digital era.
Why Python Stands Out
Python’s widespread adoption is not just due to its technical features but also its accessibility and adaptability. Let’s examine the key factors that set Python apart:
Ease of Learning Python’s clean and readable syntax makes it beginner-friendly, attracting newcomers to the world of programming. This ease of use also enables non-programmers, such as researchers and analysts, to leverage Python effectively.
Community Support Python boasts one of the largest and most active communities. This global network of developers continuously contributes to its growth by creating libraries, frameworks, and tools that address evolving industry needs.
Cross-Domain Applications Python isn’t limited to a single industry. Its versatility spans across web development, automation, data analysis, artificial intelligence, and even creative fields like game design and music.
Integration with Other Technologies Python plays well with other languages and tools, making it a preferred choice for integrating systems and technologies.
Real-World Applications of Python
Python’s influence is evident in its diverse applications, which make it indispensable for businesses and industries.
Data Science and Analytics Python is the go-to language for data scientists. Its libraries like Pandas, NumPy, and Matplotlib simplify data manipulation, visualization, and analysis. Organizations rely on Python to extract insights from massive datasets, driving informed decision-making.
Artificial Intelligence and Machine Learning Frameworks like TensorFlow and Scikit-learn have made Python a leader in AI and ML development. Companies use these technologies to create smart applications, from chatbots to recommendation systems.
Web Development Python-powered frameworks like Django and Flask have revolutionized web development. These tools enable developers to create secure, scalable, and feature-rich web applications quickly.
Automation Python’s simplicity makes it ideal for automating repetitive tasks. From scraping web data to managing workflows, Python helps businesses save time and resources.
Education Python’s intuitive nature has made it a staple in educational institutions. It’s often used to introduce students to programming concepts due to its simplicity and relevance.
Creative Industries Python has found its place in game development, music production, and even digital art. Tools like Blender and PyGame rely on Python to create immersive experiences.
Python's Role in Shaping Industries
Python’s impact extends to transforming industries by enabling innovation and improving efficiency:
Healthcare Python is used in medical research for analyzing complex datasets, developing diagnostic tools, and even managing hospital systems.
Finance Financial institutions use Python for risk analysis, fraud detection, and algorithmic trading, leveraging its precision and scalability.
E-commerce Platforms like Amazon and Shopify use Python to enhance user experience, optimize search algorithms, and manage large inventories.
Entertainment Streaming giants like Netflix rely on Python for recommendation algorithms and managing content delivery networks.
Manufacturing Python’s role in IoT and predictive maintenance ensures smooth operations and reduces downtime in factories.
The Human Element: Python’s Community
The heart of Python lies in its community. Developers, educators, and enthusiasts worldwide contribute to Python’s success by sharing knowledge, creating resources, and supporting newcomers. The open-source nature of Python ensures its continuous growth and adaptation to new challenges.
Whether through meetups, forums, or conferences like PyCon, Python’s community fosters collaboration and innovation, ensuring the language remains relevant for years to come.
The Future of Python
Python’s journey is far from over. With advancements in technology, Python is set to play a pivotal role in areas such as:
Quantum Computing Python libraries like Cirq and Qiskit are paving the way for quantum computing, unlocking new possibilities in problem-solving.
Sustainability Python’s analytical capabilities can address environmental challenges by optimizing resource use and analyzing climate data.
Education Python will continue to democratize coding education, empowering learners from diverse backgrounds to enter the tech world.
Ethical AI Development Python’s frameworks will contribute to creating transparent and ethical AI systems that align with societal values.
Conclusion
Python is more than just a programming language; it’s a catalyst for innovation and collaboration. Its adaptability, extensive community support, and applications across industries make it a cornerstone of modern technology.
Whether you’re a business aiming to innovate or an individual looking to build a career, Python offers endless opportunities. Its simplicity and versatility ensure that it remains a language not just for coders but for thinkers and creators across the globe.
If you’re ready to embark on this exciting journey, consider learning Python to unlock its full potential and stay ahead in the digital age.
0 notes
Text
What are the application scenarios of SOCKS5 proxy?
SOCKS5 proxy, as an advanced proxy protocol, has stronger privacy protection and network performance optimization capabilities, so it is widely used in various scenarios. Next, we will introduce the common application scenarios of SOCKS5 proxy.

1. Data Scraping and Web Crawling
For users engaged in data crawling and web crawling, SOCKS5 proxy has excellent performance advantages. It is able to bypass IP blocking of websites and simulate multiple IP accesses to the target site, thus preventing crawlers from being blocked due to frequent visits. In addition, SOCKS5 supports a variety of protocols (TCP/UDP), so it can handle the diverse needs of data flow and network requests, ensuring smoother data crawling tasks.
2. Enhanced Network Privacy
The SOCKS5 proxy is able to hide the user's real IP address and forward network requests through a proxy server, allowing users to access the network with a higher degree of anonymity. This is especially important for users who want to protect their privacy and avoid being tracked. Especially when transferring sensitive data or accessing geo-restricted websites, the SOCKS5 proxy can provide users with additional privacy protection.
3. Bypassing geo-restrictions
Many websites, content and services have restrictions on access to certain countries or regions, such as streaming services (Netflix, Hulu, etc.) or game servers. By using a SOCKS5 proxy, users can select IP addresses from other countries or regions, thus bypassing these geographical restrictions and accessing otherwise unavailable content or services, and enjoying a globalized online experience.
4. Online Gaming
For online gamers, especially when participating in multiplayer games on cross-region or global servers, network latency (ping) is a key factor affecting the gaming experience, and the SOCKS5 proxy can help gamers reduce latency and optimize connection speeds, especially when using games with servers located overseas, the SOCKS5 proxy can provide a smoother gaming experience.
5. File Transfer
The SOCKS5 proxy performs particularly well with file transfer protocols (such as FTP, BitTorrent, etc.). Because it supports the UDP protocol, this enables the SOCKS5 proxy to provide faster transfer speeds and more stable connections when dealing with large file transfers or P2P connections. Especially in peer-to-peer networks, the SOCKS5 proxy allows users to avoid attacks due to IP exposure.
6. Enterprise telecommuting
With the popularity of remote office, more and more enterprises adopt SOCKS5 proxy to provide secure and stable remote access for their employees. With SOCKS5 proxy, employees can access the company's internal network and applications in a secure environment, ensuring the safety of company data and communications. In addition, the fast connectivity and flexibility of SOCKS5 proxy enhances the efficiency of remote work.
7. Download Acceleration
Using SOCKS5 proxy can increase the speed of downloading large files or bulk data, especially when multiple servers are involved. Its ability to handle a large number of concurrent requests at the same time improves the efficiency of downloads through distributed connectivity, making it particularly suitable for users who need to obtain files from multiple data sources around the world.
With its support for multiple protocols, strong privacy protection, and superior network performance, the SOCKS5 proxy is an all-in-one tool for enhancing network experience and efficiency. Whether in scenarios such as data capture, network privacy, bypassing geographical restrictions, online gaming, file transfer, remote office or download acceleration, the SOCKS5 proxy has demonstrated its strong practical value.
0 notes
Text
The Many Applications of Residential Proxy Servers
Residential proxy servers are a powerful tool that can enable a wide variety of use cases across different industries. Unlike datacenter proxies that use IP addresses assigned to servers, residential proxies leverage IP addresses belonging to real internet users and their home devices. This provides several key advantages that make residential proxies invaluable for many applications.
Web Scraping and Data Extraction
One of the primary use cases for residential proxies is web scraping and large-scale data extraction. When scraping websites, using residential IPs can significantly reduce the chances of getting blocked or banned. Websites are much more likely to trust and allow requests coming from residential IP addresses versus those from known data centerIP ranges.
This makes residential proxies essential for price comparison, market research, lead generation, and competitive analysis. A market researcher, for example, can use residential proxies to gather sales intelligence data from various e-commerce sites without revealing their actual location or IP address.
Similarly, an e-commerce business can leverage residential IPs to monitor product listings, prices, and reviews across competitor websites. This provides valuable insights to inform their own pricing and product strategies.
Content Access and Geo-Targeting
Residential proxies also enable users to access online content that is restricted or only available in certain geographic regions. This is particularly useful for streaming services like Netflix, Hulu, or BBC iPlayer, which often impose geo-restrictions on their content libraries.
By connecting through a residential proxy in the target location, users can bypass these restrictions and access the local content catalog. This is valuable not just for individual consumers, but also for businesses that need to test their apps and websites from different locations.
Residential proxies can also help businesses deliver more personalized, location-based experiences to their customers. An e-commerce store, for instance, can use residential IPs to show users products, pricing, and promotions tailored to their apparent geographic region.
Ad Verification and Brand Protection
Residential proxy networks are crucial for verifying the delivery and performance of online advertising campaigns. Ad verification providers can use residential IPs to monitor the visibility, placement, and engagement of ads across various websites, apps, and platforms without being detected or blocked.
This helps identify ad fraud, such as bot traffic or competitor interference and ensures brands get the full value from their advertising spend. Residential proxies are also vital for brand protection use cases, where businesses need to constantly monitor the web for copyright infringement, trademark abuse, and other malicious activities.
Application and Website Testing
Residential proxy servers play a key role in testing the functionality, usability, and performance of apps and websites across different locations, devices, and network conditions. Developers and QA teams can use residential IPs to simulate real-world user experiences from various geographic regions.

Fintech and Financial Services
In the financial sector, residential proxies are used for a range of applications, from fraud detection to market data aggregation. Banks and fintech firms can leverage residential IPs to monitor online transactions, identify suspicious activities, and prevent financial crimes like money laundering.
Residential proxies are also crucial for collecting real-time market data, such as stock prices and currency exchange rates, from various sources without being blocked or rate-limited. This data can then be used to power trading algorithms, investment research, and other financial services.
Residential Proxy Advantages
The key advantages that make residential proxies so valuable across these diverse use cases include:
Increased Trust and Reduced Blocking: Websites and online services are generally more trusting of requests from residential IP addresses, as they are less likely to be associated with bots, scrapers, or other malicious activities. This significantly reduces the chances of getting blocked or banned.
Improved Geo-Targeting: Residential proxies allow users to appear as if they are accessing the internet from different geographic locations, enabling more accurate location-based content, pricing, and experiences.
Enhanced Privacy and Anonymity: By masking the user’s actual IP address and location, residential proxies provide an extra layer of privacy and anonymity, which is crucial for sensitive applications like financial services and brand protection.
Scalability and Reliability: Residential proxy networks, such as those offered by providers like NetNut, can offer unlimited concurrent sessions and high availability, ensuring consistent performance and reliability even under heavy load.
0 notes
Text

Scrape Streaming App Data | Amazon Prime | Netflix | Disney+ Hotstar
know me>> https://www.mobileappscraping.com/scrape-streaming-app-data-from-amazon-prime-netflix-disney-plus-hotstar.php
#ScrapeStreamingAppsData#ExtractStreamingAppsData#StreamingAppsDataScraping#StreamingAppsDataCollection
0 notes
Text
Scrape Netflix Most Watched TV Show And Movies To Keep Track Of Content Availability
Scrape Netflix Most Watched TV Show And Movies To Keep Track Of Content Availability?

Introduction: In the era of Over-the-Top (OTT) streaming platforms, where content is king, data plays a pivotal role in shaping the future of digital entertainment. OTT platform data scraping has emerged as a dynamic practice, offering businesses and analysts unprecedented access to valuable insights. This innovative process involves extracting raw data from OTT platforms like Netflix, Hulu, or Disney+, unveiling a wealth of information, including viewer preferences, content trends, and platform dynamics. As the battle for viewer attention intensifies, OTT platform data scraping becomes a strategic tool, empowering stakeholders to make informed decisions, refine content strategies, and stay ahead in the competitive landscape of online streaming.
Netflix data scraping opens a gateway to the streaming giant's treasure trove, revealing intricate details about TV shows, movies, and viewer interactions. Extracting information like user ratings, genres, release dates, and reviews unveils invaluable insights. This raw data shapes personalized recommendations and guides content creation strategies. However, ethical considerations are crucial, respecting Netflix's terms and user privacy. As technology evolves, responsible scraping practices ensure a symbiotic relationship between data analysts and the streaming giant, elevating the understanding of viewer preferences and trends in the ever-evolving world of digital entertainment.
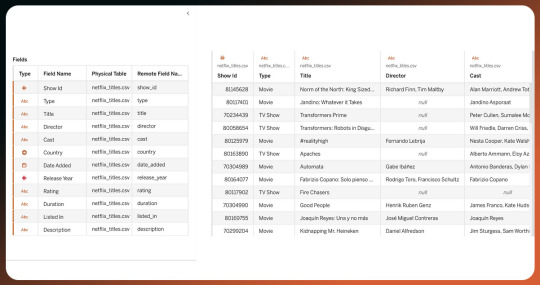
List of Data Fields
Show/Movie Details:
Title
Description
Release year
Duration
Language
Episode Details:
Episode titles
Descriptions
Release dates
Duration
Viewer Ratings:
Average viewer rating
Number of ratings
Viewer reviews
Genres and Tags:
Assigned genres (e.g., drama, comedy)
Additional tags or descriptors
Viewing History:
Recently watched shows/movies
Watchlist
Cast and Crew:
Actor names
Director names
Production crew details
Viewer Preferences:
Recommended shows/movies
Personalized suggestions
Platform Dynamics:
New releases
Trending shows/movies
Featured content
Content Trends:
Popular genres
Trending Keywords
Viewer engagement metrics
About Netflix
Netflix, a global streaming giant founded in 1997, has revolutionized the entertainment industry. Operating in over 190 countries, it offers a vast library of TV shows, movies, and original content, catering to diverse viewer preferences. With millions of subscribers, Netflix employs data-driven algorithms to personalize recommendations. Its success lies in a user-friendly interface, binge-worthy originals, and adaptive technology. The platform continually shapes the future of digital entertainment, pioneering the shift towards Over-the-Top (OTT) streaming. As an industry leader, Netflix's innovative approach and cultural impact make it synonymous with the evolving landscape of on-demand content consumption.
Scrape Netflix Most Watched TV show and movies data to unlock a wealth of insights, including viewer preferences, show details, and content trends, empowering businesses and analysts to make informed decisions in the dynamic landscape of digital entertainment.
The Power of Raw Data
Scraping Netflix's TV show pages opens a gateway to an extensive repository of information. From comprehensive show details and episode lists to viewer ratings, genres, and release dates, this raw data is invaluable for various professionals, including content analysts, marketers, and avid streaming enthusiasts.
Understanding Viewer Preferences: Diving into viewer ratings and reviews extracted from Netflix provides content creators with a nuanced understanding of which TV shows resonate most with audiences. This profound insight becomes a strategic guide, allowing for the tailoring of future content production to align seamlessly with viewer preferences, significantly increasing the likelihood of success.
Content Trends and Genres: The scraped data unveils evolving content trends and sheds light on the popularity of specific genres. Industry professionals gain valuable insights into the ever-changing landscape of viewer preferences through meticulous analysis. This information lets you make strategic decisions regarding content acquisition, creation, and nuanced marketing strategies.
Personalized Recommendations: The scraped data is crucial in enhancing the user experience by contributing to refining Netflix's recommendation algorithms. By comprehending what viewers are watching and enjoying, the platform can offer not just recommendations but personalized suggestions that are more accurate, ensuring a more engaging and tailored viewer journey.
Competitive Analysis: Scraping data from Netflix's TV show pages empowers content creators with a formidable tool for competitive analysis. Understanding the performance metrics of competing shows, gauging audience engagement levels, and identifying unique selling points provide the necessary strategic insights. With this knowledge, content creators can position their productions intelligently in the market, ensuring a competitive edge in the dynamic landscape of streaming content.
Why Scrape Netflix Raw Data from the TV Show Page?
Scraping Netflix raw data from a TV show page involves extracting information directly from the page's HTML code. While web scraping raises ethical and legal considerations, it's important to note that scraping data from websites without permission may violate terms of service. Assuming proper authorization, here are eight potential reasons one might scrape raw data from a Netflix TV show page:
Research and Analysis: Extracting raw data from Netflix TV show pages can be used for research purposes, such as analyzing trends in viewer preferences, genre popularity, or regional content preferences.
Content Aggregation: Aggregating data from multiple TV show pages on Netflix using Netflix data scraper can help create a comprehensive content database. This information can help build catalogs, databases, or content recommendation systems.
User Reviews and Ratings: Scraping user reviews and ratings directly from the Netflix page can provide insights into audience sentiments and preferences for a particular TV show. This data can be valuable for market research or enhancing user experience on other platforms.
Content Metadata Extraction: Extracting metadata such as cast and crew information, release dates, episode lists, and genre tags can help build a detailed database of TV show information. This data can help create content-rich applications or websites.
Customized Recommendation Systems: By collecting data on user interactions with TV shows using OTT data scraping services, such as watch history and preferences, it's possible to build personalized recommendation systems. It can enhance user engagement and satisfaction by suggesting content tailored to individual tastes.
Competitive Analysis: Scraping data from Netflix TV show pages can be part of competitive analysis. Understanding what types of content are popular and analyzing the strategies of successful shows can provide insights for content creators or streaming platforms.
Content Availability Tracking: Keeping track of changes in content availability, including new releases or removals, can be crucial for users, content creators, or researchers. Scraping Netflix pages can help maintain an up-to-date record of the platform's content library.
Offline Access and Archiving: Saving raw data from Netflix TV show pages might be done for archival purposes or to create an offline information backup. It can be helpful in case of changes to the platform or for maintaining historical data for research or reference.
Conclusion
Scraping raw data from Netflix TV show pages can offer invaluable insights for research, content aggregation, and user-centric applications. From analyzing viewer preferences to building comprehensive databases, the extracted information facilitates competitive analysis and the creation of personalized recommendation systems. Ethical considerations and adherence to legal requirements are paramount, and scraping should only be pursued with proper authorization. Ultimately, the extracted data is a powerful resource for understanding trends, enhancing user experiences, and staying informed about the dynamic landscape of Netflix's content library.
Don't hesitate to contact iWeb Data Scraping for comprehensive data solutions! Whether you're looking for web scraping service or mobile app data scraping, our team is ready to assist. Connect with us today to discuss your requirements and explore how our tailored data scraping solutions can offer you efficiency and reliability for your unique needs.
Know More: https://www.iwebdatascraping.com/scrape-netflix-most-watched-tv-show-and-movies.php
#ScrapeNetflixMostWatchedTVShowAndMovies#OTTplatformdatascraping#Netflixdatascrapingservice#Netflixdatascraper#ScrapeNetflixData#ExtractNetflix#NetflixScraperAPI
0 notes
Text
"Friends,
It’s tempting to view the strike underway by Hollywood writers and actors against the studios as a war between wealthy Hollywood elites.
But that’s not at all the case. In fact, what’s happening now in Hollywood is a microcosm of what’s happening across America in the emerging digital economy — which is rapidly replacing the production of things with the production of digitized ideas.
The workers in this emerging economy are some of the worst paid and worst treated anywhere, while the top owners and managers are among the fattest cats outside Wall Street.
The biggest fights between capital and labor in the 21st century may look different from the struggles of the 20th century — which centered on whether, for example, full-time workers got better hourly pay and benefits, time-and-a-half for overtime, and reasonable working conditions — but they are in many ways the same, if not worse.
They don’t involve physical property. They are over digitized creative output. More specifically, how much of the value of what’s created goes to those who do the creating versus to those who manage those creations?
The entertainment corporations say they’re suffering because people are going to the movies less and cutting their TV cables to watch streaming videos.
But follow the money: Your entertainment dollars are actually going to the biggest corporations in America. These giants have gained huge bargaining power because they own the ways content is distributed and are mining consumer data to give them even more power and higher profits.
Consider: Stock gains this year have been concentrated among five giant digital firms: Apple, Microsoft, Alphabet, Amazon, and Meta. Their combined market capitalization is now over $8 trillion, a figure that exceeds the GDP of every country but the United States and China. They are cash rich. All but Amazon have a combined $200 billion net cash-to-debt balance.
As these giant corporations take over streaming video, video games, and media platforms, their top executives, largest contractors, and biggest investors are raking it in.
Netflix’s Reed Hastings got a 2022 compensation package worth $51.1 million, up 25 percent from the year before. Warner Bros. Discovery CEO got $39 million. Comcast’s CEO, $32 million. Paramount’s CEO, $32 million. Disney’s CEO, $24 million.
Amazon’s Bezos and Meta’s Zuckerberg are raking in more than all these executives combined.
Meanwhile, the people who create the content are getting shafted. They have less and less bargaining power.
I’m talking about writers, designers, artists, musicians, software designers and developers, photographers, graphics specialists, coders, sound engineers, animators, singers, songwriters, architects, showrunners, journalists, and everyone who stores or delivers these creations.
And it’s just beginning. Artificial intelligence — right now, mostly via Google, Meta, and OpenAI — is busy scraping up every morsel of digital content on the internet. If you’re not Big Tech, your intellectual property is disappearing.
Over the last decade, the pay of TV writers has fallen by 23 percent. The typical actor has also been on a downward escalator (last year, averaging $26,276). So have the pay, benefits, and job security of most other content creators.
In other words, what’s happening in Hollywood is also happening in a huge and growing portion of the U.S. economy.
This gap between the declining rewards going to digital creators and the soaring rewards going to the executives of the giant corporations that manage digital creations has become a chasm, and it’s becoming ever larger.
The biggest variable in all this is the law — in particular, what limits it places on digital monopolies, and whether it facilitates or limits the power of creators.
In both these respects, the Biden administration has been terrific. It has been more aggressive against monopolists and in favor of unions than any administration since that of Franklin D. Roosevelt.
But much of the law is still in the 20th century, and the federal courts have tended to be on the side of the corporate giants.
Just look at the union busting Amazon has been able to get away with. Or how easily Google, Microsoft, and OpenAI have been lifting copyrighted material from the internet.
Meanwhile, the courts are reluctant to use antitrust to inhibit the giants. Last week a federal judge rejected the FTC’s attempt to stop Microsoft’s $70 billion acquisition of the video game maker Activision Blizzard, saying the agency failed to prove the deal would reduce competition and harm consumers. This followed the FTC’s loss in February, when a judge rejected its attempt to block Meta from buying the virtual reality startup Within.
As Hollywood’s content creators go on strike, and as the FTC goes after Microsoft and Meta, bear in mind this huge and growing imbalance of power. If unchecked, it will soon comprise much of the American economy.
What are your thoughts?" Robert Reich
0 notes
Text
#Netflix data scraping#Netflix data analysis#Netflix web data extraction#web scraping for OTT platforms
0 notes
Text
Scrape OTT Media Platform App Data | Streaming App Data Scraping
Mobile App Scraping offers OTT Media Platform Data Scraping Services to extract data from popular OTT Media Platforms such as Netflix, Amazon Prime Video, Hulu, and Disney+ Hotstar and more.

#Scrape OTT Media App Data#Streaming App Data Scraping#Scrape Streaming App Data#OTT Media Platform App Data Scraping
0 notes
Text
Netflix Data Scraping Services | Scrape Netflix Movies and TV Shows Data

Using Actowiz Solutions Netflix Data Scraping Services in the USA, UK, and UAE helps you scrape Netflix Data like Movies, TV Shows, video metadata, etc.
#Netflix Data Scraping Services#Scrape Netflix Movies and TV Shows Data#Scrape Netflix Data#Netflix Data Scraping#Scraping Streaming Netflix Data#Scraping Netflix Video Apps Data
0 notes