#Scrape Streaming App Data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Scrape OTT Media Platform App Data | Streaming App Data Scraping
Mobile App Scraping offers OTT Media Platform Data Scraping Services to extract data from popular OTT Media Platforms such as Netflix, Amazon Prime Video, Hulu, and Disney+ Hotstar and more.

#Scrape OTT Media App Data#Streaming App Data Scraping#Scrape Streaming App Data#OTT Media Platform App Data Scraping
0 notes
Text
OTT Media Platform Data Scraping | Extract Streaming App Data
Unlock insights with our OTT Media Platform Data Scraping. Extract streaming app data in the USA, UK, UAE, China, India, or Spain. Optimize your strategy today
know more: https://www.mobileappscraping.com/ott-media-app-scraping-services.php
#OTT Media Platform Data Scraping#Extract Streaming App Data#extracting relevant data from OTT media platforms#extracting data from websites
0 notes
Note
Hi; I don't know if you're still following the word-stream stuff, but the app is back online on the app store as "booktok - books and podcasts". The reviews marking it as having AI scraped data are still on the page itself, even though the name has changed, and duckduckgo still directs to their page if you look up "word-stream audiobooks"-- although if I don't know how long that will last. The website is seemingly gone, but the app still presumably has access to all the stolen works in the database.
Best regards, -someone else whose fics were stolen
yup
word-stream is back
it just calls itself—in an obvious attempt to profit from the TikTok upheaval—BookTok, now. and it’s not just the app, either: the whole website is back online, same as it was just before Cliff Weitzman took it down.
(in case you missed it, here are the original story & the update.)
fortunately (so far) the fanfiction category hasn't been re-added, but if you go to the store page for the app you can see that it’s still using 'fan-created universes' as advertising.
Weitzman didn't register the app under his own name this time, but through something called 'Oak Prime Inc'. hilariously, however, the email address listed in BookTok's privacy policy still refers to word-stream.com, so if Cliff was trying to scrub the connection between Speechify and his BookTok app, he didn't do a very thorough job.
here's the thing (and i'm about to put this up in a separate, more easily digestible post): if you take a look at the terms & conditions of Cliff's other platform, Speechify, it claims a truly comprehensive license to use the works uploaded to that platform in any way Cliff sees fit, including publishing and monetizing it elsewhere. and i keep seeing posts on Reddit and Bluesky from both readers and writers, happily using the Speechify app to read fanfic, advanced reader copies and their own yet-to-be-published work to them.
this is a BAD IDEA. Cliff has already proven that he will take work authored by others without their permission and redistribute it wholesale if he thinks it might make him money.
Cliff is the financial beneficiary of both Speechify and word-stream/booktokapp. it seems pretty obvious to me that he's trying to claim, via Speechify's terms & conditions, that every work uploaded to Speechify is his to do with whatever he pleases, which naturally includes moving them to this other platform so he can charge people for two subscriptions instead of just the one.
thank you so much for keeping an eye on this, anon, and for reaching out!! like i said, another post will go up today about the above, but i'm going to ask you all to help ensure that my posts & my name aren't the only ones giving voice to this message. when i tried to approach people about this issue on social media, often the—completely justified!—response was 'why should I take your word for it?' and Wikipedia only allowed the mention of Weitzman's copyright infringement to remain on his page when 'The Endless Appetite for Fanfiction' was listed as a source.
it can't just be me. DON’T take my word for it. do your own research (i would love to be proven wrong about this!), talk to your friends, engage with posts on social media similar to the ones i mentioned above (those are just some examples, don’t pile on to the OPs!) and make sure people know what they're jeopardizing. help me protect authors from money-grubbing shitheads like this one.
#cliff weitzman#speechify#word-stream#writers on tumblr#ao3#fanfiction#copyright infringement#fanfic theft#booktokapp#BookTok#text-to-speech#ask me things!#anonymous
244 notes
·
View notes
Text
I think most of us should take the whole ai scraping situation as a sign that we should maybe stop giving google/facebook/big corps all our data and look into alternatives that actually value your privacy.
i know this is easier said than done because everybody under the sun seems to use these services, but I promise you it’s not impossible. In fact, I made a list of a few alternatives to popular apps and services, alternatives that are privacy first, open source and don’t sell your data.
right off the bat I suggest you stop using gmail. it’s trash and not secure at all. google can read your emails. in fact, google has acces to all the data on your account and while what they do with it is already shady, I don’t even want to know what the whole ai situation is going to bring. a good alternative to a few google services is skiff. they provide a secure, e3ee mail service along with a workspace that can easily import google documents, a calendar and 10 gb free storage. i’ve been using it for a while and it’s great.
a good alternative to google drive is either koofr or filen. I use filen because everything you upload on there is end to end encrypted with zero knowledge. they offer 10 gb of free storage and really affordable lifetime plans.
google docs? i don’t know her. instead, try cryptpad. I don’t have the spoons to list all the great features of this service, you just have to believe me. nothing you write there will be used to train ai and you can share it just as easily. if skiff is too limited for you and you also need stuff like sheets or forms, cryptpad is here for you. the only downside i could think of is that they don’t have a mobile app, but the site works great in a browser too.
since there is no real alternative to youtube I recommend watching your little slime videos through a streaming frontend like freetube or new pipe. besides the fact that they remove ads, they also stop google from tracking what you watch. there is a bit of functionality loss with these services, but if you just want to watch videos privately they’re great.
if you’re looking for an alternative to google photos that is secure and end to end encrypted you might want to look into stingle, although in my experience filen’s photos tab works pretty well too.
oh, also, for the love of god, stop using whatsapp, facebook messenger or instagram for messaging. just stop. signal and telegram are literally here and they’re free. spread the word, educate your friends, ask them if they really want anyone to snoop around their private conversations.
regarding browser, you know the drill. throw google chrome/edge in the trash (they really basically spyware disguised as browsers) and download either librewolf or brave. mozilla can be a great secure option too, with a bit of tinkering.
if you wanna get a vpn (and I recommend you do) be wary that some of them are scammy. do your research, read their terms and conditions, familiarise yourself with their model. if you don’t wanna do that and are willing to trust my word, go with mullvad. they don’t keep any logs. it’s 5 euros a month with no different pricing plans or other bullshit.
lastly, whatever alternative you decide on, what matters most is that you don’t keep all your data in one place. don’t trust a service to take care of your emails, documents, photos and messages. store all these things in different, trustworthy (preferably open source) places. there is absolutely no reason google has to know everything about you.
do your own research as well, don’t just trust the first vpn service your favourite youtube gets sponsored by. don’t trust random tech blogs to tell you what the best cloud storage service is — they get good money for advertising one or the other. compare shit on your own or ask a tech savvy friend to help you. you’ve got this.
#internet privacy#privacy#vpn#google docs#ai scraping#psa#ai#archive of our own#ao3 writer#mine#textpost
1K notes
·
View notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about ���AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
Honestly, the Fediverse feels, to me, like the perfect place for the Sims Community to go to.
Mastodon is well developed and there are tons of fun servers to sign up for. It provides a Twitter-like experience for those who like the whole micro-blogging thing. 500 characters per toot! Four pictures! Polls! Content Warnings/Read More links! Chronological timelines! NO ADS or data scraping! :O
Maybe someday folks will make a bunch of Sims-focused servers for people to be on? I'd sign up for one! (I'm aware there used to be a Mastodon instance called Simstodon, but it collapsed years ago due to a tidal wave of sims pornography and I think some in-fighting, so maybe we could do better a second time around? Multiple small communities > than one large one, anyway!)
Pixelfed is perfect for simmers who like Instagram-style picture-focused posting and image galleries.
Peertube is great for simtubers, and OwnCast for folks who stream.
Want to do something larger-scale? There's Friendica, Hubzilla, or Calckey. There's Lemmy and Kbin for those who like Reddit-style apps. There are also ActivityPub plugins for WordPress, so you can send your WordPress posts automatically to your Fediverse followers! And at least with Mastodon, every account defaults with built-in RSS feeds, so you can follow folks that way if you prefer, too!
And the awesome thing about the Fediverse is no matter where you land, whether it's a Mastodon instance, or an Akkoma instance, or a Friendica account, or even a Bookwyrm (Goodreads) account, etc. etc., you can still follow anyone on any other app. Is there a simstuber you want to follow, but you're on Mastodon and they're on Peertube? No problem, you can follow each other! You like Pixelfed better than Akkoma? Folks can still follow you there, and you can follow them!
No more closed gardens, no more having to smush yourself into boxes to try and fit into a social media that demands your money, data, content, and mental health.
Anyway… I'll stop ranting. But maybe I'll start posting more Sims stuff on Fedi. I'll use the hashtag "#SimmerFed" if I do, hopefully more people will join me!
I'm here if you want to follow me, btw: https://comicscamp.club/@Rheall/
#social media#Fediverse#Mastodon#Tumblr won't be our weird haven forever#It's time we take control of our communities and create them ourselves.#I'd do it but I'm already admining one instance and my health won't let me do more work than that already entails :(#<3#Text Post#Rheall Rambles#Btw I've been on the Fediverse since 2017#I used to be admin of Mastodon.ART#I'd be happy to try and answer any questions you might have!#I suffer from chronic fatigue though so forgive me if I take a while to reply <3
15 notes
·
View notes
Text
NOPE. Look at those numbers again - they are nowhere close to "running out of money"
Sorry to burst anyone's bubble, but this is right out of the emerging technology playbook, and it's easy to see from just the information contained in the headline what bunk it is. There's no way for them to go bankrupt within the year when they have several decades worth of funding to blow through. $700k is a lot of money to be losing every day, but with 10 BILLON dollars in funding, they have nearly 40 years to figure out how to make it profitable. They can afford to lose money in the short term, because it's part of their long game.
AI's goal right now isn't profit, it's exponential growth. They are hemorrhaging money right now because they are in their kudzu stage - spread everywhere, choke out any alternative options to using their technology. The goal is to make AI an indispensable part of our daily lives as quickly as possible, and only once we've gotten so used to it that we don't remember how to live without it will their attention turn to monetization of their products and technology.
In the meantime, new money will flood into the industry through investments. Anyone with a little cash to spare will buy into the hype and invest in any company that has AI in the name because they believe that if they get in "on the ground floor" they're going to become wealthy beyond their wildest dreams when AI "takes off". (Word to the wise - the chances of you actually becoming wealthy from one good stock pick are infinitesimal.)
This is the "market disruption" playbook, and pretty much every emerging technology company of the past few decades has used it (some more successfully than others). The company offers products and services at prices that are too good to be true (including "free") and eats the loss while they drive competition out of business and get their consumers so used to using their services that they can't imagine doing it any other way, then they pivot. They raise subscription fees, introduce "tiered" memberships, sell advertising space and user data.
And even though people get pissed off at the changes, because they're used to "too good to be true", they're now at a point where they can't walk away without making a sacrifice - this streaming platform has their favorite show, so they're gonna suck it up and pay the higher rate. This social media platform is their primary form of keeping in touch with old friends, so they swallow the placebo of marking their profile as "private" and pretend they believe that will keep their data from being scraped. This rideshare app drove all the cab companies out of business, and anyway they don't remember how to call a cab the old fashioned way, so they'll pay for "surge pricing" because they don't know how to get home otherwise.
AI is losing money on purpose right now. They don't want your money (yet), they want your attention. They want you to use AI reckless and with abandon until you don't remember how you did things before AI. They want to reshape society so that not using AI is at best wildly inconvenient and oftentimes impossible. They want you to need AI like it's electricity, because they want to be in a position where they own the electric company and can charge you whatever they want for the thing you no longer know how to live without.
Use AI or don't, but if your goal is to push back you should know what you're up against.
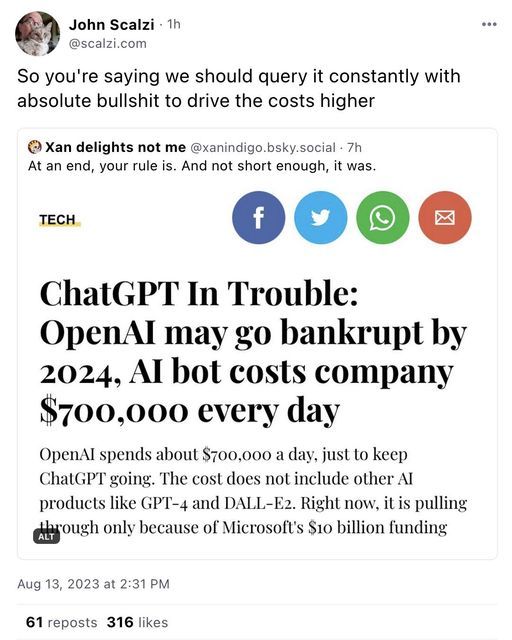
ChatGPT is running out of money because they haven't actually figured out how to make money with the plagiarism engine they created.
Like to charge, reblog to cast.
62K notes
·
View notes
Text
Singapore Restaurant Insights via Food App Dataset Analysis
Introduction
ArcTechnolabs provided a comprehensive Food Delivery Menu Dataset that helped the client extract detailed menu and pricing data from major food delivery platforms such as GrabFood, Foodpanda, and Deliveroo. This dataset included valuable insights into restaurant menus, pricing strategies, delivery fees, and popular dishes across different cuisine types in Singapore. The data also covered key factors like restaurant ratings and promotions, allowing the client to benchmark prices, identify trends, and create actionable insights for strategic decision-making. By extracting menu and pricing data at scale, ArcTechnolabs empowered the client to deliver high-impact market intelligence to the F&B industry.
Client Overview
A Singapore-based market intelligence firm partnered with ArcTechnolabs to analyze over 5,000 restaurants across the island. Their goal was to extract strategic insights from top food delivery platforms like GrabFood, Foodpanda, and Deliveroo—focusing on menu pricing, cuisine trends, delivery coverage, and customer ratings. They planned to use the insights to support restaurant chains, investors, and FMCG brands targeting the $1B+ Singapore online food delivery market.
The Challenge
The client encountered several data-related challenges, including fragmented listings across platforms, where the same restaurant had different menus and prices. There was no unified data source available to benchmark cuisine pricing or delivery charges. Additionally, inconsistent tagging for cuisines, promotions, and outlets created difficulties in standardization. The client also faced challenges in extracting food item pricing at scale and needed to perform detailed analysis by location, cuisine type, and restaurant rating. These obstacles highlighted the need for a structured and reliable dataset to overcome the fragmentation and enable accurate insights.They turned to ArcTechnolabs for a structured, ready-to-analyze dataset covering Singapore’s entire food delivery landscape.

ArcTechnolabs Solution:
ArcTechnolabs built a custom dataset using data scraped from:
GrabFood Singapore
Foodpanda Singapore
Deliveroo SG
The dataset captured details for 5,000+ restaurants, normalized for comparison and analytics.
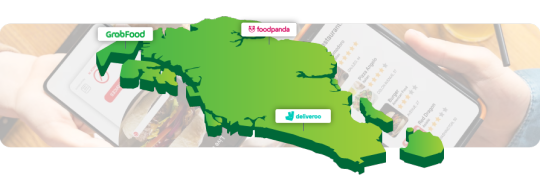
Sample Dataset Extract
Client Testimonial
"ArcTechnolabs delivered exactly what we needed—structured, granular, and high-quality restaurant data across Singapore’s top food delivery apps. Their ability to normalize cuisine categories, menu pricing, and delivery metrics helped us drastically cut down report turnaround time. With their support, we expanded our client base and began offering zonal insights and cuisine benchmarks no one else in the market had. The quality, speed, and support were outstanding. We now rely on their weekly datasets to power everything from investor reports to competitive pricing models."
— Director of Research & Analytics, Singapore Market Intelligence Firm
Conclusion
ArcTechnolabs enabled a market intelligence firm to transform fragmented food delivery data into structured insights—analyzing over 5,000 restaurants across Singapore. With access to a high-quality, ready-to-analyze dataset, the client unlocked new revenue streams, faster reports, and higher customer value through data-driven F&B decision-making.
Source >> https://www.arctechnolabs.com/singapore-food-app-dataset-restaurant-analysis.php
#FoodDeliveryMenuDatasets#ExtractingMenuAndPricingData#FoodDeliveryDataScraping#SingaporeFoodDeliveryDataset#ScrapeFoodAppDataSingapore#ExtractSingaporeRestaurantReviews#WebScrapingServices#ArcTechnolabs
0 notes
Text
Beyond the Books: Real-World Coding Projects for Aspiring Developers
One of the best colleges in Jaipur, which is Arya College of Engineering & I.T. They transitioning from theoretical learning to hands-on coding is a crucial step in a computer science education. Real-world projects bridge this gap, enabling students to apply classroom concepts, build portfolios, and develop industry-ready skills. Here are impactful project ideas across various domains that every computer science student should consider:
Web Development
Personal Portfolio Website: Design and deploy a website to showcase your skills, projects, and resume. This project teaches HTML, CSS, JavaScript, and optionally frameworks like React or Bootstrap, and helps you understand web hosting and deployment.
E-Commerce Platform: Build a basic online store with product listings, shopping carts, and payment integration. This project introduces backend development, database management, and user authentication.
Mobile App Development
Recipe Finder App: Develop a mobile app that lets users search for recipes based on ingredients they have. This project covers UI/UX design, API integration, and mobile programming languages like Java (Android) or Swift (iOS).
Personal Finance Tracker: Create an app to help users manage expenses, budgets, and savings, integrating features like OCR for receipt scanning.
Data Science and Analytics
Social Media Trends Analysis Tool: Analyze data from platforms like Twitter or Instagram to identify trends and visualize user behavior. This project involves data scraping, natural language processing, and data visualization.
Stock Market Prediction Tool: Use historical stock data and machine learning algorithms to predict future trends, applying regression, classification, and data visualization techniques.
Artificial Intelligence and Machine Learning
Face Detection System: Implement a system that recognizes faces in images or video streams using OpenCV and Python. This project explores computer vision and deep learning.
Spam Filtering: Build a model to classify messages as spam or not using natural language processing and machine learning.
Cybersecurity
Virtual Private Network (VPN): Develop a simple VPN to understand network protocols and encryption. This project enhances your knowledge of cybersecurity fundamentals and system administration.
Intrusion Detection System (IDS): Create a tool to monitor network traffic and detect suspicious activities, requiring network programming and data analysis skills.
Collaborative and Cloud-Based Applications
Real-Time Collaborative Code Editor: Build a web-based editor where multiple users can code together in real time, using technologies like WebSocket, React, Node.js, and MongoDB. This project demonstrates real-time synchronization and operational transformation.
IoT and Automation
Smart Home Automation System: Design a system to control home devices (lights, thermostats, cameras) remotely, integrating hardware, software, and cloud services.
Attendance System with Facial Recognition: Automate attendance tracking using facial recognition and deploy it with hardware like Raspberry Pi.
Other Noteworthy Projects
Chatbots: Develop conversational agents for customer support or entertainment, leveraging natural language processing and AI.
Weather Forecasting App: Create a user-friendly app displaying real-time weather data and forecasts, using APIs and data visualization.
Game Development: Build a simple 2D or 3D game using Unity or Unreal Engine to combine programming with creativity.
Tips for Maximizing Project Impact
Align With Interests: Choose projects that resonate with your career goals or personal passions for sustained motivation.
Emphasize Teamwork: Collaborate with peers to enhance communication and project management skills.
Focus on Real-World Problems: Address genuine challenges to make your projects more relevant and impressive to employers.
Document and Present: Maintain clear documentation and present your work effectively to demonstrate professionalism and technical depth.
Conclusion
Engaging in real-world projects is the cornerstone of a robust computer science education. These experiences not only reinforce theoretical knowledge but also cultivate practical abilities, creativity, and confidence, preparing students for the demands of the tech industry.
0 notes
Text
IPPeak: The Invisible Bridge and Powerful Tool in the Digital World

IP proxies have evolved from a niche technology to an indispensable tool for both everyday internet users and businesses. Acting like an "invisibility cloak" and a "master key" in the online world, they unlock numerous possibilities. Let’s delve into this seemingly mysterious yet highly practical technology and explore how it quietly transforms our internet experience.
1. Understanding IP Proxies: The "Middleman" of the Internet
Simply put, an IP proxy is like a diligent mail carrier. When you want to send a letter to a friend, you don’t deliver it directly—instead, you go through a post office. An IP proxy is that "post office," receiving your online requests, forwarding them under its own identity, and then returning the results to you. This process masks your real IP address, keeping your true online identity hidden.
2. Six Core Benefits of IP Proxies
Guardian of Privacy Protection In an era where data is as valuable as gold, proxy IPs effectively prevent personal information leaks, ensuring you don’t become a transparent target of online tracking. It’s like wearing a mask to a masquerade—you can move freely without revealing your true identity.
Key to Bypassing Geo-Restrictions Frustrated by messages like "This content is not available in your region"? Proxy IPs allow you to "virtually travel" to other countries and regions, unlocking geo-blocked content on streaming platforms, games, and more—almost like having the superpower of teleportation.
Booster for Business Operations • Market Research: Obtain real search results and pricing information from different regions. • Ad Verification: Check how ads appear in various locations. • E-commerce Management: Safely operate multiple accounts without association risks. • Data Collection: Efficiently gather public web data without getting blocked.
Buffer for Cybersecurity Proxy servers filter out malicious traffic, acting like a security gate that blocks threats before delivering safe content to you.
Optimizer for Network Performance By caching frequently accessed content and compressing data, high-quality proxies can significantly improve webpage loading speeds—especially beneficial for multinational businesses.
Testing Platform for Developers Developers can use different regional IPs to test website and app compatibility, ensuring a consistent and smooth user experience worldwide.
With the rise of 5G and IoT, IP proxy technology continues to evolve, and the market is flooded with proxy service providers. Among the ones I’ve tested, IPPeak stands out as an excellent choice.
IP proxies have grown from mere technical tools into vital bridges for the free flow of information. Whether for individual users or organizations, leveraging this tool wisely can significantly enhance online experiences and business advantages. The key lies in finding the right balance—maximizing its benefits while adhering to responsible usage principles.
Have you experienced the convenience of IP proxies? Or do you still have questions about this technology? Share your thoughts and experiences in the comments—let’s explore this "invisible assistant" of the digital age together!
1 note
·
View note
Text
How to Choose the Right Proxy for Your Needs
Proxies are essential tools for privacy, security, and accessing restricted content. However, with different types available, selecting the right one can be challenging. Here’s a quick guide to help you make an informed decision.
1. Understand the Different Proxy Types
Residential Proxies – Use real IP addresses from ISPs, making them appear as regular users. Best for tasks requiring high anonymity (e.g., web scraping, ad verification).
Datacenter Proxies – Come from cloud servers, offering high speed but lower anonymity. Ideal for bulk tasks where IP bans are less likely.
Mobile Proxies – Use 4G/5G IPs, perfect for mobile-specific tasks like app testing or social media management.
SOCKS5 Proxies – Support various traffic types (TCP/UDP), useful for torrenting and gaming.
2. Consider Your Use Case
Web Scraping? → Residential or rotating proxies to avoid blocks.
SEO Monitoring? → Location-specific proxies for accurate local results.
Gaming or Streaming? → Low-latency SOCKS5 proxies.
Social Media Management? → Mobile or residential proxies to mimic real users.
3. Check Key Features
Speed & Reliability – Datacenter proxies are faster, while residential proxies are more stable for long sessions.
Geo-Targeting – Ensure the provider offers IPs in your desired locations.
Rotation Options – Rotating IPs help avoid detection in automated tasks.
Concurrent Connections – Some proxies limit simultaneous sessions; choose based on your needs.
4. Security & Privacy
Avoid Free Proxies – They often log data and may be unsafe.
Look for HTTPS Support – Ensures encrypted connections.
No-Log Policies – Critical if handling sensitive data. https://nodemaven.com/
5. Test Before Committing
Many providers offer trial periods or money-back guarantees. Test speed, uptime, and compatibility with your tools before long-term use.
0 notes
Text
[Image Description: A series of screenshots.
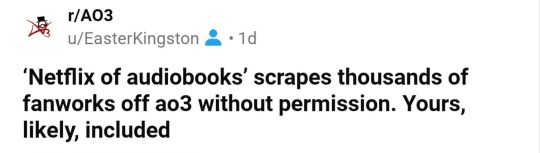
Image 1: A post on r/Ao3 on Reddit by u/EasterKingston. The post is titled "'Netflix of audiobooks' scrapes thousands of fanworks off Ao3 without permission. Yours, likely, included."
Image 2: The preview for a website titled word-stream. The page is titled "You & Me & Holiday Wine - WordStream".
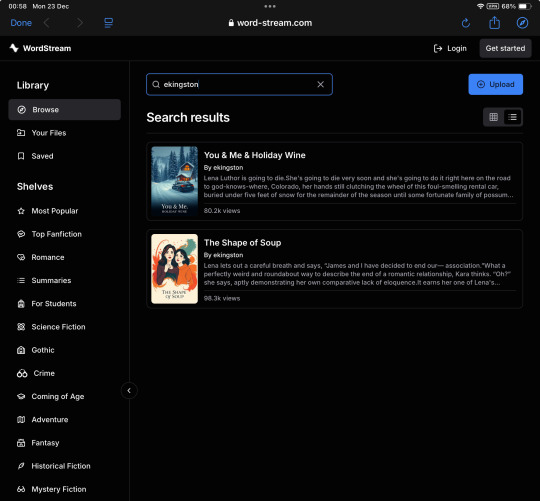
Image 3: A screenshot from the website WordStream. The word "ekingston" is entered into the search bar. There are two results. One named "You & Me & Holiday Wine" and the other named "The Shape of Soup". Both have over 80 thousand views.
Image 4: Another screenshot from the same site. The name "Kara Danvers" is entered into the search bar. There are twenty results from a variety of authors that fill up the page.
Image 5: A sent text reading: "I followed you here from Reddit, where I was made aware of the truly awesome work your project Copyknight has been doing. I just discovered the website/app word-stream.com today-it's a site that's seemingly scraped thousands of works off ao3 and offers audiobook versions of them, presumably for a fee. It looks like it only went live in October, and I don't see much chatter about it (or contact information) anywhere. I was wondering if you'd heard from it/could offer advice on how to go about getting our works taken down?"
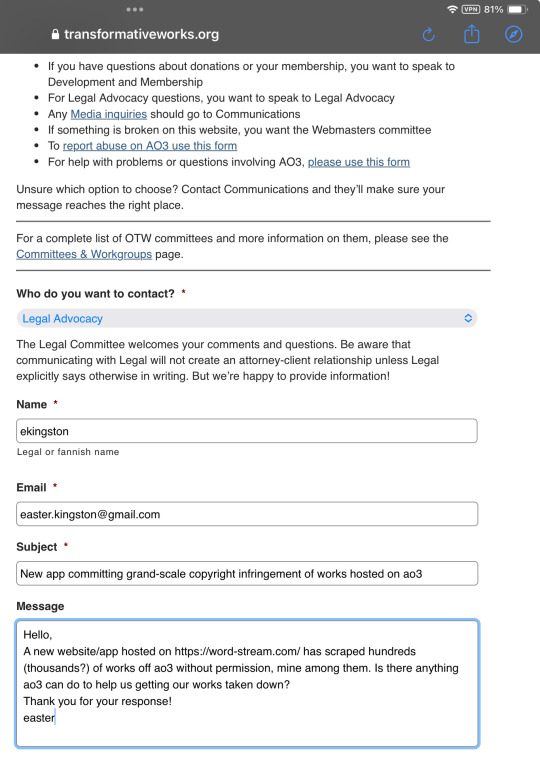
Image 6: A screenshot of a contact form being filled out. The form is on transformativeworks.org and appears to be a contact form. The subject is "New app committing grand-scale copyright infringement of works hosted on Ao3". The message reads: "Hello, A new website/app hosted on https://word-stream.com/ has scraped hundreds (thousands?) of works off Ao3 without permission, mine among them. Is there anything Ao3 can do to help us getting our works taken down? Thank you for your response! Easter."
Image 7: A series of interspersed text and screenshots. Text reads: "If you try to click on any of the sites, you get a link to the AppStore app, which is called "WordStream - Audiobooks". There is a screenshot of the app in the app store. The creator's name is Ofek Weitzman. Text reads: "Who is Ofek Weitzman? Apparently he's also known as Cliff Weitzman, the CEO of Speechify, an AI Voice generator app famous for its partnership with Snoop. Also, Cliff Weitzman is named as the copyright holder at the bottom:" A screenshot showing the copyright holder as Cliff Weitzman. Text reads: "If you search for Ofek/Cliff Weitzman, you find his name in the terms and conditions for Speechify." A screenshot showing the terms and conditions including the name Ofek Weitzman as the individual to address a notice of dispute to. Text reads: "Strange that someone with a legitimate company with a partnership with Brandon Sanderson would put their name behind a shady company stealing works from fanfic writers, but it may be worth reaching out to him on X. Best case scenario is that someone has stolen the name for an app, but in that case, it would be good for him to know. Otherwise, it would be good to start a dialogue about how authors can get their works taken down from this site!"
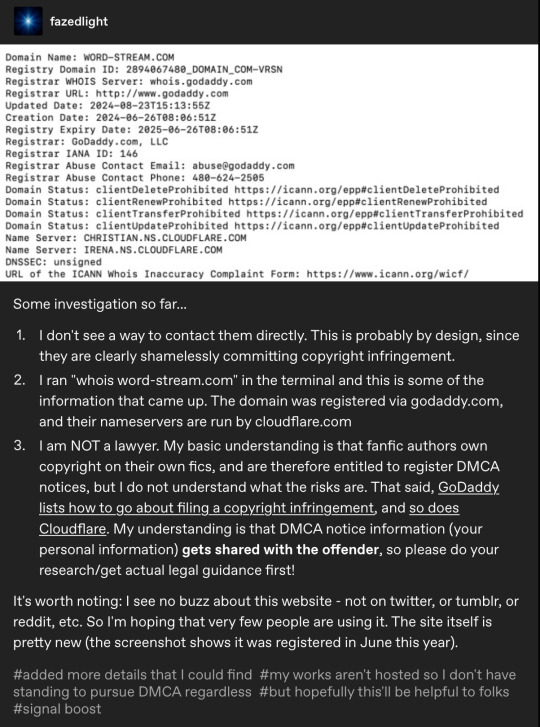
Image 8: A screenshot of a Tumblr post from user fazedlight (Fazed Light). It shows an image of domain registry data for Word-Stream. Text reads: Some investigation so far: 1. I don't see a way to contact them directly. This is probably by design, since they are clearly shamelessly committing copyright infringement. 2. I ran "Who is Word-Stream" in the terminal and this is some of the information that came up. The domain was registered via Go Daddy.com and their nameservers are run by CloudFlare.com. 3. I am NOT a lawyer. My basic understanding is that fanfic authors own copyright on their own fics, and are therefore entitled to register DMCA notices, but I do not understand what the risks are. That said, GoDaddy links how to go about filing a copyright infringement, and so does CloudFlare. My understanding is that DMCA notice information (Your personal information) gets shared with the offender, so please do your research/get actual legal guidance first! It's worth noting: I see no buzz about this website - not on Twitter, or Tumblr, or Reddit, etc. So I'm hoping that very few people are using it. The site itself is pretty new (The screenshot shows it was registered in June this year).
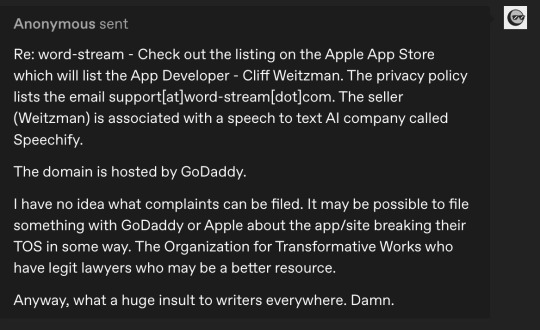
Image 9: An anonymous Tumblr asks that reads: "Re: word-stream - Check out the listing on the Apple App Store which will list the App Developer - Cliff Weitzman. The privacy policy lists the email support[at]word-stream[dot]com. The seller (Weitzman) is associated with a speech to text AI company called Speechify. The domain is hosted by GoDaddy. I have no idea what complaints can be filed. It may be possible to file something with GoDaddy or Apple about the app/site breaking their TOS in some way. The Organization for Transformative Works who have legit lawyers who may be a better resource. Anyway, what a huge insult to writers everywhere. Damn.
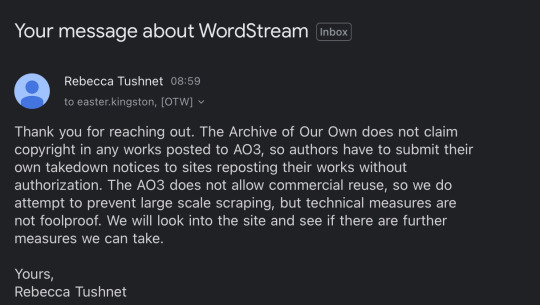
Image 10: An email from Rebecca Tushnet to easter.kingston. The subject is "Your message about WordStream". The email reads: "Thank you for reaching out. The Archive of Our Own does not claim copyright in any works posted to AO3 so authors have to submit their own takedown notices to sites reposting their works without authorization. The AO3 does not allow commercial reuse, so we do attempt to prevent large scale scraping, but techical measures are not foolproof. We will look into the site and see if there are further measures we can take. Yours, Rebecca Tushnet."
Image 11: A screenshot showing three subscription plans to choose from: A month long for 93 cents per day or a discounted price of 39 cents, a three month long for 53 cents per day or a discounted price of 19 cents, and a six month long for 55 cents per day or a discounted price of 15 cents. The three month plan is listed as most popular.
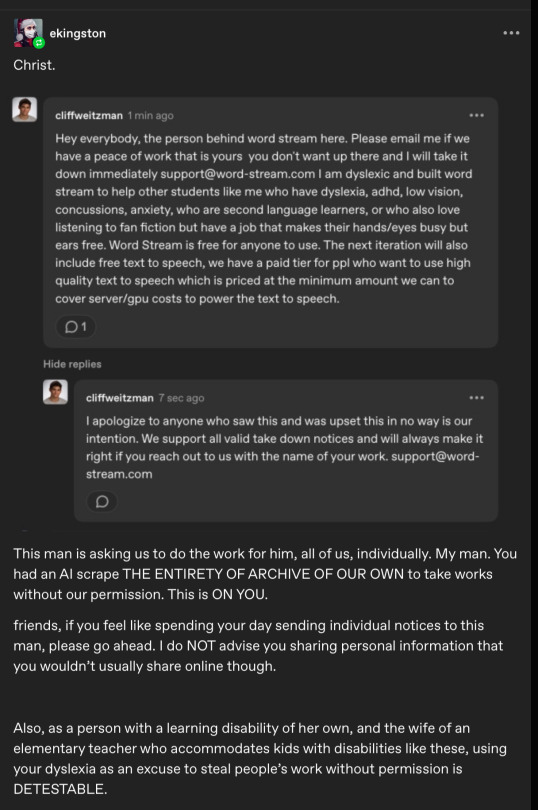
Image 12: A Tumblr post by user ekingston. It reads: "Christ". A screenshot of a Tumblr reply by user cliffweitzman (Cliff Weitzman) is below. It reads: "Hey everybody, the person behind word stream here. Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately [email protected] I am dyslexic and built word stream to help other students like me who have dyslexia, adhd, low vision, concussions, anxiety, who are second language learners, or who also love listening to fan fiction but have a job that makes their hands/eyes busy but ears free. Word Stream is free for anyone to use. The next iteration will also include free text to speech, we have a paid tier for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech." The same user has replied to the original comment. Their reply reads: "I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices and will always make it right if you reach out to us with the name of your work. support@word- stream.com". Text in the original Tumblr post reads: "This man is asking us to do the work for him, all of us, individually. My man. You had an Al scrape THE ENTIRETY OF ARCHIVE OF OUR OWN to take works without our permission. This is ON YOU. friends, if you feel like spending your day sending individual notices to this man, please go ahead. I do NOT advise you sharing personal information that you wouldn't usually share online though. Also, as a person with a learning disability of her own, and the wife of an elementary teacher who accommodates kids with disabilities like these, using your dyslexia as an excuse to steal people's work without permission is DETESTABLE."
Image 13: Text reads: "cliffweitzman (Cliff Weitzman) replied to your text post." The reply reads: "Hey everybody, the person behind word stream here: I am dyslexic and built word stream to help other students like me who have dyslexia, ADHD, vision challenges, concussions, or anxiety to access fan-fiction, because for us, reading with our eyes can be very challenging and there are no audiobooks for fan fiction typically. Word Stream is free for anyone to use. There is a paid plan for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech. The next iteration will also include free text to speech but with a lower quality bar. I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices an d will always make it right if you reach out to us with the name of your work. [email protected] Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately [email protected]. A future release will also add the ability to tip authors so writers can make money not from selling the works but via tips from grateful readers, the ability for authors to build and communicate with an email list of readers, ability for authors to see retention graphs of where users drop off during reading, and abilities to authors to easily manage their works. We are strong supporters of second language learners (non native speakers of English), and of users who love fan fiction but who have a job that makes their hands/eyes busy but ears free. Once again I apologize for a beta product that got more attention that it ha d any right to before it was complete and for the clearly tone deaf wording which we are fixing to make sure communication is better about take down notices. Warmly, Cliff If you can, pl ease upvote or comment on the post so others can see the e mail they should message to have anything they don't want posted taken down immediately Word Stream."
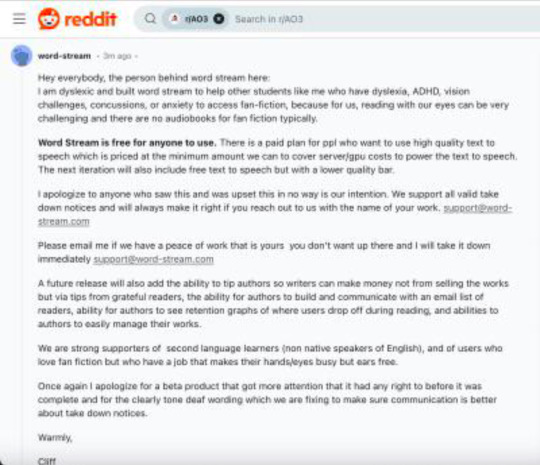
Image 14: A Reddit comment on r/Ao3 by user word-stream. It reads: "Hey everybody, the person behind word stream here: I am dyslexic and built word stream to help other students like me who have dyslexia, ADHD, vision challenges, concussions, or anxiety to access fan-fiction, because for us, reading with our eyes can be very challenging and there are no audiobooks for fan fiction typically. Word Stream is free for anyone to use. There is a paid plan for ppl who want to use high quality text to speech which is priced at the minimum amount we can to cover server/gpu costs to power the text to speech. The next iteration will also include free text to speech but with a lower quality bar, I apologize to anyone who saw this and was upset this in no way is our intention. We support all valid take down notices and will always make it right if you reach out to us with the name of your work, [email protected] Please email me if we have a peace of work that is yours you don't want up there and I will take it down immediately support@@word-stream.com A future release will also add the ability to tip authors so writers can make money not from selling the works but via tips from grateful readers, the ability for authors to build and communicate with an email list of readers, ability for authors to see retention graphs of where users drop off during reading, and abilities to authors to easily manage their works. We are strong supporters of second language learners (non native speakers of English), and of users who love fan fiction but who have a job that makes their hands/eyes busy but ears free. Once again I apologize for a beta product that got more attention that it had any right to before it was complete and for the clearly tone deaf wording which we are fixing to make sure communication is better about take down notices. Warmly, Cliff."
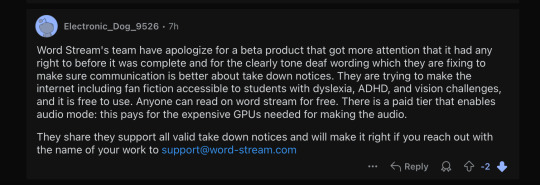
Image 15: A Reddit comment from user Electronic_Dog_9526. It reads: "Word Stream's team have apologize for a beta product that got more attention that it had any right to before it was complete and for the clearly tone deaf wording which they are fixing to make sure communication is better about take down notices. They are trying to make the internet including fan fiction accessible to students with dyslexia, ADHD, and vision challenges, and it is free to use. Anyone can read on word stream for free. There is a paid tier that enables audio mode: this pays for the expensive GPUs needed for making the audio. They share they support all valid take down notices and will make it right if you reach out with the name of your work to [email protected]." The comment has two downvotes.
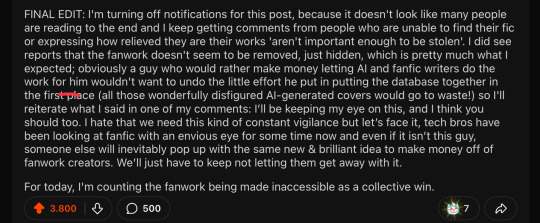
Image 16: A partial screenshot of a Reddit post. It has 3800 upvotes, 500 comments, and 7 awards. It reads: "FINAL EDIT: I'm turning off notifications for this post, because it doesn't look like many people are reading to the end and I keep getting comments from people who are unable to find their fic or expressing how relieved they are their works 'aren't important enough to be stolen'. I did see reports that the fanwork doesn't seem to be removed, just hidden, which is pretty much what I expected; obviously a guy who would rather make money letting Al and fanfic writers do the work for him wouldn't want to undo the little effort he put in putting the database together in the first place (all those wonderfully disfigured Al-generated covers would go to waste!) so I'll reiterate what I said in one of my comments: I'll be keeping my eye on this, and I think you should too. I hate that we need this kind of constant vigilance but let's face it, tech bros have been looking at fanfic with an envious eye for some time now and even if it isn't this guy, someone else will inevitably pop up with the same new & brilliant idea to make money off of fanwork creators. We'll just have to keep not letting them get away with it. For today, I'm counting the fanwork being made inaccessible as a collective win."
End ID.]
[Plain Text: Text in red reads: "***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS."]
SO HERE IS THE WHOLE STORY (SO FAR).
I am on my knees begging you to reblog this post and to stop reblogging the original ones I sent out yesterday. This is the complete account with all the most recent info; the other one is just sending people down senselessly panicked avenues that no longer lead anywhere.
IN SHORT
Cliff Weitzman, CEO of Speechify and (aspiring?) voice actor, used AI to scrape thousands of popular, finished works off AO3 to list them on his own for-profit website and in his attached app. He did this without getting any kind of permission from the authors of said work or informing AO3. Obviously.
When fandom at large was made aware of his theft and started pushing back, Weitzman issued a non-apology on the original social media posts—using
his dyslexia;
his intent to implement a tip-system for the plagiarized authors; and
a sudden willingness to take down the work of every author who saw my original social media posts and emailed him individually with a ‘valid’ claim,
as reasons we should allow him to continue monetizing fanwork for his own financial gain.
When we less-than-kindly refused, he took down his ‘apologies’ as well as his website (allegedly—it’s possible that our complaints to his web host, the deluge of emails he received or the unanticipated traffic brought it down, since there wasn’t any sort of official statement made about it), and when it came back up several hours later, all of the work formerly listed in the fan fiction category was no longer there.
THE TAKEAWAYS
1. Cliff Weitzman (aka Ofek Weitzman) is a scumbag with no qualms about taking fanwork without permission, feeding it to AI and monetizing it for his own financial gain;
2. Fandom can really get things done when it wants to, and
3. Our fanworks appear to be hidden, but they’re NOT DELETED from Weitzman’s servers, and independently published, original works are still listed without the authors' permission. We need to hold this man responsible for his theft, keep an eye on both his current and future endeavors, and take action immediately when he crosses the line again.
THE TIMELINE, THE DETAILS, THE SCREENSHOTS (behind the cut)
Sunday night, December 22nd 2024, I noticed an influx in visitors to my fic You & Me & Holiday Wine. When I searched the title online, hoping to find out where they came from, a new listing popped up (third one down, no less):

This listing is still up today, by the way, though now when you follow the link to word-stream, it just brings you to the main site. (Also, to be clear, this was not the cause for the influx of traffic to my fic; word-stream did not link back to the original work anywhere.)
I followed the link to word-stream, where to my horror Y&M&HW was listed in its entirety—though, beyond the first half of the first chapter, behind a paywall—along with a link promising to take me—through an app downloadable on the Apple Store—to an AI-narrated audiobook version. When I searched word-stream itself for my ao3 handle I found both of my multi-chapter fics were listed this way:
Because the tags on my fics (which included genres* and characters, but never the original IPs**) weren’t working, I put ‘Kara Danvers’ into the search bar and discovered that many more supercorp fics (Supergirl TV fandom, Kara Danvers/Lena Luthor pairing) were listed.
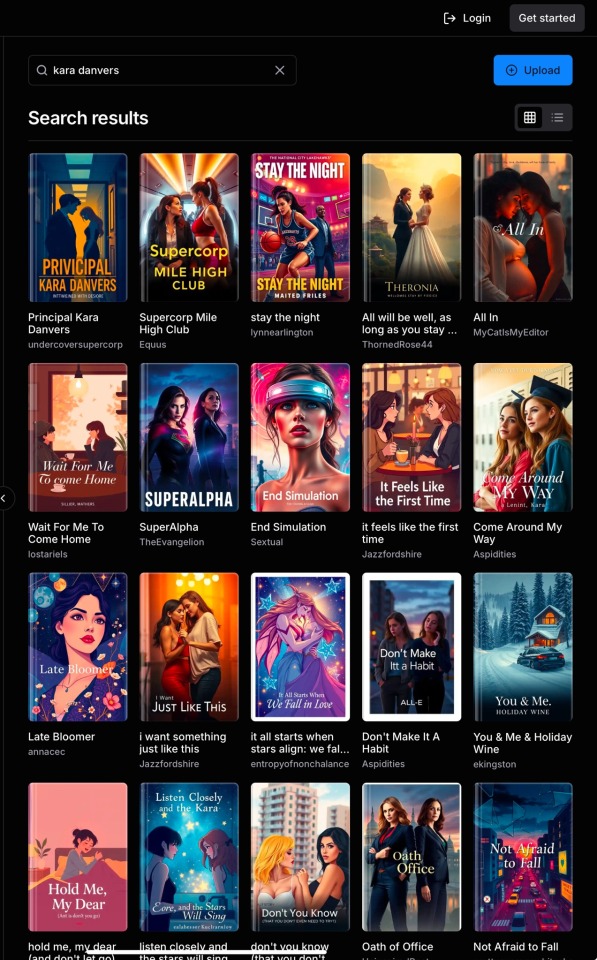
I went looking online for any mention of word-stream and AI plagiarism (the covers—as well as the ridiculously inflated number of reviews and ratings—made it immediately obvious that AI fuckery was involved), but found almost nothing: only one single Reddit post had been made, and it received (at that time) only a handful of upvotes and no advice.
I decided to make a tumblr post to bring the supercorp fandom up to speed about the theft. I draw as well as write for fandom and I’ve only ever had to deal with art theft—which has a clear set of steps to take depending on where said art was reposted—and I was at a loss regarding where to start in this situation.
After my post went up I remembered Project Copy Knight, which is worth commending for the work they’ve done to get fic stolen from AO3 taken down from monetized AI 'audiobook’ YouTube accounts. I reached out to @echoekhi, asking if they’d heard of this site and whether they could advise me on how to get our works taken down.

While waiting for a reply I looked into Copy Knight’s methods and decided to contact OTW’s legal department:
And then I went to bed.
By morning, tumblr friends @makicarn and @fazedlight as well as a very helpful tumblr anon had seen my post and done some very productive sleuthing:

@echoekhi had also gotten back to me, advising me, as expected, to contact the OTW. So I decided to sit tight until I got a response from them.
That response came only an hour or so later:
Which was 100% understandable, but still disappointing—I doubted a handful of individual takedown requests would accomplish much, and I wasn’t eager to share my given name and personal information with Cliff Weitzman himself, which is unavoidable if you want to file a DMCA.
I decided to take it to Reddit, hoping it would gain traction in the wider fanfic community, considering so many fandoms were affected. My Reddit posts (with the updates at the bottom as they were emerging) can be found here and here.
A helpful Reddit user posted a guide on how users could go about filing a DMCA against word-stream here (to wobbly-at-best results)
A different helpful Reddit user signed up to access insight into word-streams pricing. Comment is here.
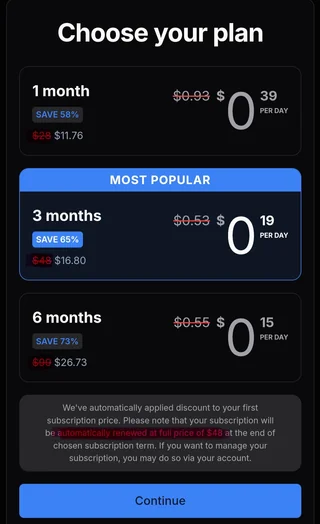
Smells unbelievably scammy, right? In addition to those audacious prices—though in all fairness any amount of money would be audacious considering every work listed is accessible elsewhere for free—my dyscalculia is screaming silently at the sight of that completely unnecessary amount of intentionally obscured numbers.
Speaking of which! As soon as the post on r/AO3—and, as a result, my original tumblr post—began taking off properly, sometime around 1 pm, jumpscare! A notification that a tumblr account named @cliffweitzman had commented on my post, and I got a bit mad about the gist of his message :
Fortunately he caught plenty of flack in the comments from other users (truly you should check out the comment section, it is extremely gratifying and people are making tremendously good points), in response to which, of course, he first tried to both reiterate and renegotiate his point in a second, longer comment (which I didn’t screenshot in time so I’m sorry for the crappy notification email formatting):

which he then proceeded to also post to Reddit (this is another Reddit user’s screenshot, I didn’t see it at all, the notifications were moving too fast for me to follow by then)
... where he got a roughly equal amount of righteously furious replies. (Check downthread, they're still there, all the way at the bottom.)
After which Cliff went ahead & deleted his messages altogether.
It’s not entirely clear whether his account was suspended by Reddit soon after or whether he deleted it himself, but considering his tumblr account is still intact, I assume it’s the former. He made a handful of sock puppet accounts to play around with for a while, both on Reddit and Tumblr, only one of which I have a screenshot of, but since they all say roughly the same thing, you’re not missing much:
And then word-stream started throwing a DNS error.
That lasted for a good number of hours, which was unfortunately right around the time that a lot of authors first heard about the situation and started asking me individually how to find out whether their work was stolen too. I do not have that information and I am unclear on the perimeters Weitzman set for his AI scraper, so this is all conjecture: it LOOKS like the fics that were lifted had three things in common:
They were completed works;
They had over several thousand kudos on AO3; and
They were written by authors who had actively posted or updated work over the past year.
If anyone knows more about these perimeters or has info that counters my observation, please let me know!
I finally thought to check/alert evil Twitter during this time, and found out that the news was doing the rounds there already. I made a quick thread summarizing everything that had happened just in case. You can find it here.
I went to Bluesky too, where fandom was doing all the heavy lifting for me already, so I just reskeeted, as you do, and carried on.
Sometime in the very early evening, word-stream went back up—but the fan fiction category was nowhere to be seen. Tentative joy and celebration!***
That’s when several users—the ones who had signed up for accounts to gain intel and had accessed their own fics that way—reported that their work could still be accessed through their history. Relevant Reddit post here.
Sooo—
We’re obviously not done. The fanwork that was stolen by Weitzman may be inaccessible through his website right now, but they aren’t actually gone. And the fact that Weitzman wasn’t willing to get rid of them altogether means he still has plans for them.
This was my final edit on my Reddit post before turning off notifications, and it's pretty much where my head will be at for at least the foreseeable future:
Please feel free to add info in the comments, make your own posts, take whatever action you want to take to protect your work. I only beg you—seriously, I’m on my knees here—to not give up like I saw a handful of people express the urge to do. Keep sharing your creative work and remain vigilant and stay active to make sure we can continue to do so freely. Visit your favorite fics, and the ones you’ve kept in your ‘marked for later’ lists but never made time to read, and leave kudos, leave comments, support your fandom creatives, celebrate podficcers and support AO3. We created this place and it’s our responsibility to keep it alive and thriving for as long as we possibly can.
Also FUCK generative AI. It has NO place in fandom spaces.
THE 'SMALL' PRINT (some of it in all caps):
*Weitzman knew what he was doing and can NOT claim ignorance. One, it’s pretty basic kindergarten stuff that you don’t steal some other kid’s art project and present it as your own only to act surprised when they protest and then tell the victim that they should have told you sooner that they didn’t want their project stolen. And two, he was very careful never to list the IPs these fanworks were based on, so it’s clear he was at least familiar enough with the legalities to not get himself in hot water with corporate lawyers. Fucking over fans, though, he figured he could get away with that.
**A note about the AI that Weitzman used to steal our work: it’s even greasier than it looks at first glance. It’s not just the method he used to lift works off AO3 and then regurgitate onto his own website and app. Looking beyond the untold horrors of his AI-generated cover ‘art’, in many cases these covers attempt to depict something from the fics in question that can’t be gleaned from their summaries alone. In addition, my fics (and I assume the others, as well) were listed with generated genres; tags that did not appear anywhere in or on my fic on AO3 and were sometimes scarily accurate and sometimes way off the mark. I remember You & Me & Holiday Wine had ‘found family’ (100% correct, but not tagged by me as such) and I believe The Shape of Soup was listed as, among others, ‘enemies to friends to lovers’ and ‘love triangle’ (both wildly inaccurate). Even worse, not all the fic listed (as authors on Reddit pointed out) came with their original summaries at all. Often the entire summary was AI-generated. All of these things make it very clear that it was an all-encompassing scrape—not only were our fics stolen, they were also fed word-for-word into the AI Weitzman used and then analyzed to suit Weitzman’s needs. This means our work was literally fed to this AI to basically do with whatever its other users want, including (one assumes) text generation.
***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS.
PLEASE check my later versions of this post via my main page to make sure you have the latest version of this post before you reblog. All the information I’ve been able to gather is in my reblogs below, and it's frustrating to see the old version getting passed around, sending people on wild goose chases.
Thank you all so much!
#fandom culture#fanfic culture#ao3 culture#ai in fandom#described#image description#described by me(at)
48K notes
·
View notes
Text
How can real-time updates and scores be integrated into fantasy baseball app development?
Fantasy baseball has become a highly engaging and competitive industry, requiring real-time updates and scores to enhance user experience. Integrating these features into a fantasy baseball app can improve user retention, increase engagement, and provide players with up-to-the-minute insights on their selected teams. This article explores the various methods and technologies used to integrate real-time updates and scores into fantasy baseball app development.
1. Importance of Real-Time Updates in Fantasy Baseball
Real-time updates and live scoring are crucial for fantasy baseball apps as they provide users with instant feedback on player performances. Key benefits include:
Enhanced User Engagement: Real-time scoring keeps users actively involved in their teams.
Competitive Edge: Apps with faster updates attract more users.
Strategic Decision Making: Players can make timely changes based on live statistics.
2. Data Sources for Real-Time Updates
To ensure accurate real-time updates, fantasy baseball apps need reliable data sources, such as:
Official MLB APIs – Major League Baseball provides APIs with real-time game stats and player performance data.
Third-Party Sports Data Providers – Companies like Sportradar, STATS Perform, and FantasyData offer real-time feeds.
Web Scraping Techniques – In some cases, apps use web scraping to extract live scores from sports websites.
3. Technologies Used for Real-Time Data Integration
Several technologies and frameworks can be used to integrate real-time updates and scores into fantasy baseball apps:
WebSockets: Enables real-time bidirectional communication between the server and client.
RESTful APIs & GraphQL: Used for fetching and delivering data efficiently.
Firebase Realtime Database: Provides seamless real-time syncing across devices.
Cloud Computing Services: AWS, Google Cloud, and Azure offer scalable data processing for real-time updates.
4. Backend Infrastructure for Real-Time Processing
Developing a robust backend infrastructure is crucial for handling live data updates efficiently. Key components include:
Data Streaming Pipelines: Technologies like Apache Kafka and RabbitMQ help manage large-scale real-time data.
Database Optimization: Using NoSQL databases like MongoDB or Redis enhances performance.
Load Balancing: Ensures smooth data flow and prevents server overload.
5. Frontend Implementation for Live Scores
User experience is critical for fantasy baseball apps. The frontend should be designed to display real-time updates effectively:
Push Notifications: Instant alerts for player stats and match results.
Live Score Widgets: Interactive components that show real-time scores.
Dynamic UI Updates: Implement frameworks like React or Vue.js for smooth real-time rendering.
6. Handling Latency and Performance Optimization
Minimizing latency is key to providing seamless real-time updates. Strategies include:
Content Delivery Networks (CDN): Distributes data efficiently to reduce lag.
Efficient API Caching: Reduces server load and speeds up response times.
Edge Computing: Processes data closer to the user, minimizing delays.
7. Security and Data Integrity Measures
Ensuring the security and accuracy of real-time updates is vital:
Data Encryption: Protects sensitive user and player information.
Access Control: Prevents unauthorized API access.
Data Validation: Regularly checks data accuracy to prevent discrepancies.
8. Testing and Monitoring Real-Time Features
Rigorous testing ensures smooth operation of live updates:
Load Testing: Evaluates app performance under high traffic.
User Testing: Collects feedback to improve usability.
Monitoring Tools: Services like New Relic and Datadog track real-time data issues.
9. Monetization Opportunities with Real-Time Data
Real-time updates can be monetized to increase revenue:
Premium Subscriptions: Offer exclusive live data features for paying users.
In-App Advertisements: Display targeted ads during live updates.
Sponsorship Deals: Partner with sports brands to sponsor real-time scoring features.
Conclusion
Fantasy baseball app development enhances user experience, engagement, and monetization opportunities. By leveraging advanced technologies, optimizing backend infrastructure, and ensuring security, developers can create a dynamic and competitive fantasy baseball platform. As the demand for real-time fantasy sports apps continues to grow, investing in real-time integration remains a key strategy for success.
#Fantasy Baseball Software Development#Fantasy Baseball App Developer#Fantasy Baseball App Development#Fantasy Baseball Solution
0 notes
Text
Effortlessness and the Erotic
I have always had an interest in communications and branding. More specifically, the story that is created and who the intended audience is. I have been reading celebrity magazines and gossip since my tender teens and after a while, I began to see the invisible structure. I learned how to do even closer readings by following Lainey Gossip and PopBitch. They have remained in the game for over twenty years because of how they open up the playbook of public relations and explain the rules to readers. Even going as far to name who has reached out and what information they were strongly encouraging be published.
A good execution doesn’t seem crafted at all. It will have the appearance of being natural and human but it will still have a firm hand to guide the narrative on the road and avoid any hazards. It is sitting down with a publication, such as People Magazine, who will ask the softball questions and allow the publicist to guide the piece to whatever end is needed. The magazine will want to maintain a relationship with the star so the piece will be flattering and favorable. Though, for a bigger payoff, a talent may gamble on a more in-depth interview as a test of deftness to answer questions of a higher difficulty. A chance for redemption to put a scandal behind them or career comeback after the scripts have long dried up. Even when dissected, you’ll find that invisible skeleton.
This didn’t change with social media - it was just a new platform to allow for rapid messaging and even more control by the celebrity (though in reality it is a team of managers and publicists). It allowed the creation of authenticity that with the growth of an audience became even more performative with the explosion of influencers. The idea of a lifestyle could be leveraged into a monetary stream. It also created a new space for brands to embed themselves in the lives of consumers and data-scrape to plot on a spreadsheet for marketing strategy. Quinn’s About page declares in text taking up the whole screen is it: Made by women, for the world. Though extensive curation on their TikTok shows a very narrow and specific world for an audience. Since January 1, 2025 they have posted roughly 500 videos (and it is barely mid-February) and with rights being obliterated by the hour - their structure isn’t just invisible, it remains willfully ignorant in this bonfire of geo-politics. I am a believer in having spaces to unhook from the world in the name of joy, self-care, and all those positive buzzwords. And I genuinely mean it! It is why I initially signed up for the app. But it is clear this escape from reality doesn’t apply to me when looking at the image of the Quinn Girlie. The Quinn Girlie is inoffensive. She wears comfy athleisure in a pastel or muted color scheme. The only black you may see are leggings but that’s about the only dark glimpse you’ll see. There can be a pop of red though typically just when holiday appropriate. Sometimes it is even in branded items from the Quinn shop - available in a limited size range, but not so much for larger bodies. Every day is cozy and pulled together just enough in case she has to leave the house in her Uggs. She isn’t going to stand out. Her makeup will have the look of minimalism that is labored over. It takes a lot of effort to look like there was none. There will never be a magenta lipstick, nary a shimmery eyeshadow moment. Nails with an immaculate manicure to tap on iced coffees or cans of Diet Coke. There are cuticles which do not experience anything close to harsh conditions. The hair will have Those Waves to give it just enough body and bounce. She might show you her skincare routine but only in a carefully undone state. She still has to exist in the realm of being cute. The Quinn Girlie isn’t bogged down by real life. She exists in her own bubble to perform that she is low-maintenance but also on top of her life in a stealth Type A way. It is all just so easy because the QG isn’t complicated. Her activities fit into the neat and easy categories which early advertising messaging focused on with women: shopping, cleaning, and cosmetics. Taylor Swift is paused and her soundtrack is man growling he’s going to lick her pussy clean. See, it is the juxtaposition to make it interesting. Every video features the pink Apple headphones with the Quinn logo. They are an oversized statement piece. If they aren’t being worn, they are around the neck and ready at a moment’s notice to press play on the porn. Quinn has created a clamoring for an object ultimately no one can own. As they cannot be sold, the headphones are only occasionally released into the wild to petite young women on Instagram who embody the QG image. So long as they have several thousand followers. She is clean, polished, and more than likely white and she has what you want and can never purchase. But just maybe if you perform hard enough, Quinn will decide you are worthy to be gifted a pair.
The headphones are crucial because they are the necessary prop for these performances and there are about a handful of places to stage these scenes. The QG is in the middle of the container section of Target as she listens to a snippet of Naudio or Bad Influence or any one of the regular white male voices who the account promotes, and is making exaggerated faces intending to convey the throes of ecstasy. She fans herself, she makes wide eyed O-faces. It is all to be a spectacle to call attention to what those headphones provide. The QG practically lives in Target as she fingers the folds of clothing and browses the makeup section. Though, her favorite spot is where the mass-market paperbacks live which isn’t just in Target. She can go just a few doors over in the shopping center to Barnes and Noble. She is not only a listener of smut, she is a reader and you must be aware. But specifically she chases the trending titles of BookTok with the candy-colored covers which compliment her outfit. Her basket is loaded with the Those Books with That Kind of Font which saturate the shelves. The QG needs people to know she buys these books and must exist in a physical form so they can be displayed in her space. There is no shine put on smaller titles or ones which are less mainstream because holding the book is just a secondary accessory. And in a Barnes and Noble, during banker’s hours, she is grabbing onto a shelf of Colleen Hoover novels and fighting an impending orgasm while a gruff Irish accent goes on about being a good girl. As romance/erotica/porn is having its moment, there have been tons of physical and online stores opening who specialize in the genre and are independent. Often their mission is to create an inclusive space and show it is a serious and legitimate kind of story beyond the hand stuff and women in their early 20s who have to save all of existence. More importantly, it has never been easier to utilize your local library. I managed to sign up online one night at 10 PM and by 10:12 I was in the Libby app, tapping check out on available titles. But! Going to the library and reading on your tablet lacks the goods to show off. Basically, if you have the books on your shelf, you have the money to buy your own participation trophy. For reasons that have never been clear, there is the occasional detour to Staples or Home Depot. The shopping center also has a TJ Maxx and Family which provides even more bedding options to be fondled. There is also a large selection of candles and those big drinking cups. TJ Maxx tends to have really good deals on cookware so if you lost the Quinn Girlie when shopping, check near the baking sheets and pizza cutters. If the GQ isn’t shopping, she loves a walking errand with an iced coffee. It is a nice treat before heading home to do laundry. There is so much laundry but a candle can be lit and in the background you will catch a glimpse of those bright little book spines. The housework doesn’t even and there are dishes to wash, best accessorized with a Quinn branded bathrobe. The headphones are glued to her person. The women’s work persists but there are new audios twice a week. This lays the foundation for how a starter/trad wife is built. There is a lack of depth and personality beyond being a body to perform the women’s work. The framing of the TikTok could seem as a woman trapped, but instead she is embracing the burdens and runs into participating. She has sunk further into her delusions by spending her waking hours with these audios. She doesn’t have a greater awareness of the world because she isn’t being impacted by everything else. The audios serve as her insulation. She chooses to ignore these audios exist as a form of sex work and the intersectional dominos that are lined up - one push and they all will fall. For Quinn, there is only one kind of world and it doesn’t want me in it.
0 notes
Text
Data Collection for Machine Learning: Powering the Next Generation of AI

Artificial Intelligence (AI) has arisen as the most decisive force across industries, from health to finance, entertainment to logistics. At the center of this evolution is one indispensable element: data collection for machine learning. Data is the lifeblood of AI systems, enabling algorithms to learn, adapt, and make intelligent decisions. Without high-quality data collection, even the best-developed AI models would never supply credible and trustworthy outputs.
In this article, we shall explore in detail the significance importance of data collection for machine learning, the methodologies applied, the challenges posed, and how it is propelling the next-generation innovations in AI.
Importance of Data Collection in AI
Data is the fuel behind the entire functioning of machine learning (ML) systems. It is the patterns, relations, and behaviors inferred from the data that allow the systems to make predictions and decisions. The AI model's performance depends on the quantity, quality, and relevance of the collected data. Here is why data collection is the key pillar of machine learning success:
The Training of AI Models: For any task to be accomplished using machine learning algorithms, they need to be trained with representative data first. The training data allows the system to discover patterns that can eventually be generalized to new, unencountered inputs.
Enhancement in Model Accuracy: The inclusion of all the necessary measures in data collection aims to represent actual scenarios closely, thereby minimizing errors and biases within the AI model. Better data gives better outcomes.
Personalization: When it comes to AI systems, personalized services like recommendation engines, customer support assistance, etc., the only way they can personalize such offerings is through data collection.
Fueling Innovation: By initiating continuous and diverse data collection, AI applications are entering into the fields of autonomous cars, personalized medications, natural language processing, and others.
Data Collection Methods for Machine Learning
Good data collection demands a work plan for methodologies customized to the needs of the machine learning model. Some of the common approaches are:
Crowdsourcing: Crowdsourcing involves collecting data from large groups of people, mostly through online platforms. This method is especially powerful for collecting labeled data for tasks like image recognition or natural language processing.
Web Scraping: Web scraping is an automated process of collecting data from websites. This is commonly applied to build datasets for sentiment analysis, trend tracking, and other ML purposes.
Sensor Data: In the IoT applications, data is collected straight from sensors embedded into the like of a smart thermostat, wearables, or autonomous vehicles. This stream of data is valuable in predictive maintenance and real-time decision-making.
User-Generated Data: A number of companies collect the data that is generated by users, for example, interactions with their app, social media posts, or e-commerce transactions. This process is especially important for the provision of personalized services.
Synthetic Data: Synthetic data is data that is artificially generated rather than obtained from real-world sources. It tends to be very useful for the kinds of applications where the real data is scarce or difficult to acquire, such as the medical imaging or infrequent event prediction ones.
The Challenges with Data Collection
Data collection is vital for machine learning, but it faces a lot of challenges. These hurdles have to be removed for effective and ethical AI systems to be conceived.
Data Privacy and Ethics: Collection of personal data typically generates privacy issues, especially with data protection regulations such as GDPR and CCPA. Organizations are required to collect informed consent and comply with stringent data protection protocols.
Data Bias: Bias can creep into AI systems when data is not diverse or representative, particularly for demographics that do not contribute to it. For instance, systems of facial recognition trained mostly on one demographic may not provide good performances across others.
Readily Scalable: The growing need for massive datasets enhances the sophistication of data collection, storage, and operational management. Consequently, ensuring the integrity of the consistency and quality of millions of data points is really a Herculean task.
Annotation and Labeling: Thus, in supervised learning, we need to label collected data, which requires an enormous amount of time and manual labor. Furthermore, automatization of this stage is a huge challenge and may not be accomplished without loss of accuracy.
Real-Time Data Gathering: In such applications as autonomous driving or financial trading, data should be collected and processed in real time and this sets high demands on system infrastructure, as well as the application of exotic and sophisticated technologies.
Best Practices for Data Collection
Here are some best practices that organizations should follow to make data collection more effective:
Define Objectives Clearly: Know which business goals and use cases to pursue by ensuring collected data is appropriate and actionable.
Ensure Diversity and Representation: Use diverse sources and decisively handle possible bias to enhance the robustness of your AI model.
Focus on Data Quality: More than any huge amounts of irrelevant or noisy data, we speak about high-quality data that really matters. Clean and validate the data before using it for training.
Leverage Automation: Automating both data collection and data annotation processes minimizes labor costs and reduces scope for human error.
Maintain Ethical Standards: User privacy and data protection must always come first. Follow the law and ask for permission to use the data.
Applications of Data Collection in AI
The scope of data collection embraces numerous industries and applications fueled by AI.
Healthcare: Data collected from medical records, imaging, and wearable devices to train AI systems for diagnostics, treatment planning, and patient monitoring.
Autonomous Vehicles: Autonomous vehicles leverage enormous amounts of data from sensors, cameras, and radars to navigate through driving safely and make real-time decisions.
Retail and E-Commerce: Customer behavior, preferences, and purchase history dictate personalized recommendations, inventory optimization, and targeted marketing.
Natural Language Processing: Text and speech data are collected to develop AI models for language translation, sentiment analysis, and virtual assistants.
Financial Services: AI systems are trained to help with fraud detection, risk assessment, and algorithmic trading using historical transaction data and market trends.
The Future of Collection of Data
With the advancements in machine learning technologies, modern data collection practices bend to the will of new requirements. Trends emerging include federated learning for AI models to learn from decentralized data without violating privacy and synthetic dataset-generation practices meant to lessen dependence on real-world data.
Besides, advanced versions of edge computing and IoT would make real-time data collection and processing possible, paving the way for more dynamic and adaptive AI systems.
Conclusion
Data collection for machine learning is at the core of AI innovations. By ensuring that the data is diverse, of high quality, and ethically sourced, organizations make the best of their AI systems.
With challenges being countered and technologies evolving, the importance of data collection assumes cardinal stages on their own, fueling the next generation of AI applications that change industries and enrich lives around the globe.
Visit Globose Technology Solutions to see how the team can speed up your data collection for machine learning projects.
0 notes
Text
Understanding Mobile Proxies and Their Uses
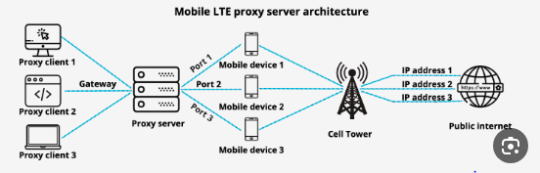
If you've ever tried to purchase items from well-known international stores and ship them to a different country, you may have encountered a common issue: many brand websites block purchases intended for other regions. To work around this, you need to simulate your location and use a specific warehouse address or an authorized representative’s address for delivery. What Are Mobile Proxies and How Do They Work? Mobile proxies function similarly to proxy servers, acting as intermediaries that allow you to bypass geographic restrictions and traffic routing rules. But what sets mobile proxies apart, and why might they be more advantageous than other proxy types? Defining Mobile Proxies Mobile proxies are a type of residential proxy that operates exclusively on mobile devices, connecting to the internet via mobile networks such as 3G, 4G, or 5G. Unlike traditional residential proxies, which use wired connections, mobile proxies route internet traffic through mobile operators. A mobile proxy server typically consists of two components: a specialized app installed on a mobile device (like a smartphone or tablet with mobile network capability) and a control system hosted on the servers of the proxy provider. This setup handles request routing within the proxy network and ensures secure access. Types of Mobile Proxies Mobile proxies can be categorized based on how many users share the same proxy node: - Private Mobile Proxies: These are dedicated to a single user, ensuring that no one else shares the node. This means all internet traffic is exclusive to you, providing greater security and performance. - Shared Mobile Proxies: These allow multiple users to share the same node simultaneously, which can reduce costs but may impact speed and privacy. Advantages of Mobile Proxies Mobile proxies offer several benefits, particularly when compared to server-based or traditional residential proxies: - Reduced Blocking Risk: Mobile proxies are ideal for tasks like bulk data scraping or managing multiple social media accounts. Mobile devices receive dynamic IP addresses from mobile providers, making it difficult for websites to block them without risking disruption to legitimate users. - Frequent IP Rotation: You can easily rotate IP addresses, even with each request if needed. This feature is often included at no additional cost by reputable mobile proxy providers. - Parallel Request Handling: The larger the proxy network, the more simultaneous requests you can send, which can significantly speed up complex tasks like scraping competitor websites. - Wide Range of Locations: Mobile proxies can virtualize your location not just to a specific place but also to different mobile operators, making your online presence indistinguishable from that of real users. - Professional Software Compatibility: Many mobile proxy providers offer APIs and integration with professional tools, enhancing their usability for businesses. Applications for Mobile Proxies Mobile proxies are especially useful for the following tasks: - Ad Arbitrage: Optimizing revenue through targeted user actions. - Social Media Marketing (SMM): Managing multiple accounts and promoting them on platforms like Instagram or Facebook. - Online Reputation Management (ORM): Monitoring reviews, creating a positive online image, and protecting your brand's reputation. - Ad Verification: Ensuring your ads are displayed correctly and reach the intended audience. - SEO: Tracking keyword rankings in specific regions and monitoring competitors. - Price Monitoring: Identifying the best shopping deals by comparing prices across different locations. - Data Collection: Gathering valuable information on competitors or partners. However, mobile proxies may not be suitable for streaming video or torrenting due to high data costs and variable connection stability. Read the full article
0 notes