#Training data LLMs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
#Generative AI#Mitigating Ethical Risks#ethical and security concerns#Red teaming#RLHF for LLMs#RLHF for GenAI#Fine Turning LLMs#Red teaming LLMs#Data labeling LLMs#Training data LLMs
0 notes
Text
Love having to explain in detail to profs why they can't just trust everything Chat spits out. My favorite thing.
#she was like “yeah it told me how to build an optimal new fence in my backyard and even what stores to go buy supplies from!”#and I was like “you know llms hallucinate right”#“I've heard that what does it mean?”#me: 5 minute rant on the lunacy that is generative llms at the moment#ai. knows. nothing. it. just. spits. out. words. that. frequently. go. together. in. its. training. data.#and you can make it be wrong!#aghhhh#Forgot how we got on the subject for a bit it was her telling me there are a lot of positions open in LLM training at the moment#And me telling her I have beef with LLMs so I have no desire to take such a job#She triggered one of my soapbox rants. *evil laugh*
4 notes
·
View notes
Text
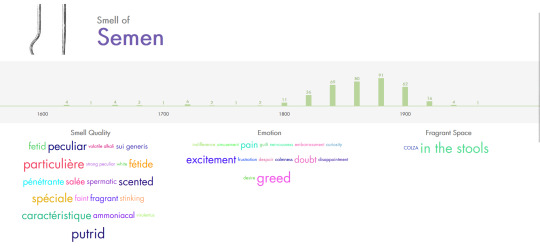
doing research
#you know the regular kind#also this database is so shit#it uses LLMs to scrape data from books to associate smells with feelings and qualities etc#99% of smells have the same vague descriptions like perfumed scented odorous fragrant#which is a shame bc the project in general seems really interesting#and some parts seem to be well done at least at a glance#it really just feels like they had to hop on the ai train to get funding
2 notes
·
View notes
Text
While on leave at the moment, we're not that far from returning to work. Given that we work in data science and development, and that part of what pushed our burnout was the literal abominations we were being asked to make using llm's, it seems prudent for us to start getting back into the swing of things technically. What better way to do this than starting to look through what's easily available about DeepSeek? It's, unfortunately, exactly what you'd expect.
We're not joking. The literal first sentence of the paper from the company explicitly states that recent LLM progression has been closing the gap toward AGI, which is utterly, categorically, epistemically untrue. We don't, scientifically, have a sufficient understanding of consciousness to be able to create an artifical mind. Anyone claiming otherwise has the burden of proof; while we remain open to reviewing any evidence supporting such claims, to date literally nothing has been remotely close to applicable much less sufficient. So we're off to a very, very bad start. Which is a real shame, because the benefits and improvements made to LLM design they claim in their abstract are impressive! A better model design, with a well curated dataset, is the correct way to get improvements in model performance! Their reductions in hardware hours for training are impressive, and we're looking forward to analyzing their methods - a smooth training process, with no rollbacks or irrecoverable decreases in model performance over the course of training are good signs. Bold claims, to be clear, but that's what we're here to evaluate. And the insistence that LLM's are bringing AGI closer to existence mean we have sufficient bias from the team that we cannot assume good faith on behalf of the team. While we assume many, or even most, of the actual researchers and technologists are aware of the underlying realities and limitations of modern "AI" in general and LLM's in particular, the coloring done by the literal first sentence is seriously harmful to their purpose.
While we'd love to continue our analysis, to be honest it doesn't support it? Looking at their code it's an, admittedly very sophisticated, neural network. It doesn't remotely pose a revolution in design, the major advances they cite are all integrating other earlier improvements. While their results are impressive, they are another step in the long path of constructing marginal improvements on an understood mechanism. Most of the introduction is laying out their claims for DeepSeek-v3. We haven't followed the developments with reduced precision training, nor the more exact hardware mapped implementations they reference closely enough to offer much insight into their claims; they are reasonable enough on face, but mainly relate to managing the memory and performance loads for efficient training. These are good, genuinely exciting things to be seeing - we'll be following up manu of their citations for further reading, and digesting the rest of their paper and code.
But this is, in no way shape or form, a bubble ender or a sudden surge forward in progress. These are predictable results, ones that scientists have been pursuing and working towards quietly. While fascinating, DSv3 isn't special because it is a revolution; it simply shows the methodology used by the commercial models, sinking hundreds of billions of dollars a year and commiting multiple ongoing atrocities to fuel the illusion of growth, isn't the best solution. It will not understand, it CAN not. It can not create, it can not know. And people who treat it as anything except the admittedly improved tool it is, are still techbros pushing us with endless glee towards their goal of devaluing labor.
#Ai#Data science#Deepseek is cool#But it's an llm#Genai is evil#Like “only 2.7 million gpu hours to train!”#Holy fuck while that's better than openai it's still relying on heavy metals acquired via genocide#Powered by energy that could be used for more valuably#With the same goals and motivations as the other evil groups#“but it's not as evil” is the logic of those that have accepted defeat by capital
2 notes
·
View notes
Note
Hey jysk the jigglypuff art you reblogged from ohmyboytoy is either reposted stolen art or ai made (they’ve made other ai art posts)
Aw, damn. Thanks for the heads up!
Behold, a criminal! (Those are jail bars)A

#and with that shitty edit i've done more work than the op of this image#death to these LLM ai tools#they are inherently unethical in their handling and deployment of information#who profits? Not the original researchers artists or writers who 'provided' the data on which these tools were trained#and above that they are ecologically taxing to a degree that is indefensible
3 notes
·
View notes
Text
it's so sad that i can't say "I love AI!" without a million asterisks
#i love the CONCEPT of ai and the good it can do and has done#and how it can do menial tasks so we can focus on more important things#and can ASSIST in artistic inspiration and such#but i HATE generative ai built on unethically sourced training data#and the environmental impact llms and image generators are currently creating#why does ai have to be such a grey topic with so much negative coverage...
2 notes
·
View notes
Text
This website really thinks it can sell coherent, usable data for LLM training when it's still serving adverts like this

#I know tumblr post data in LLM training will likely be used just for word weighting#but still#their backend infra is VISIBLY shoddy as hell#makes me wonder if it'll be actually usable
2 notes
·
View notes
Text
SO i’m going to do a research project, while doing a part-time internship, while being president of 3 major clubs, while overloading my academic schedule. Really hope I can hold things together this semester 😬
#research project is on training LLMs with supercomputing resources#part-time internship is as a data analyst#im asking someone else if they wanna be in-charge of the queer CCA instead bc i’m not interested anymore#but if they can’t then i’ll just try my best!
3 notes
·
View notes
Text
My sister was reviewing survey responses at work and was disappointed that some of the responses (from elementary school teachers, mind you!) were clearly ChatGPT. She could tell because they referenced a lot of animals they didn't have at the zoo at the time the kids visited.
But what really worries me is that my sister was surprised that ChatGPT got it so wrong. Because that information is on the internet, and it just pulls info from the internet, right?
My sister is an intelligent person and I rant to her about AI all the time, so if she has this misconception, I'm sure a lot of people do, which worries me.
ChatGPT and LLM do NOT just pull info from the internet. They do NOT take verbatim sentences from online sources. They're not trustworthy, but not because the source is the internet. They take WORDS, not complete sentences, from the internet and put them together. They look for the most common words that are put together and put them in an order that SOUNDS LIKE the rest of the internet. They look for patterns. ChatGPT finds a bunch of articles about Zoo Atlanta and pandas, so it adds pandas to its sentences when you prompt it about Zoo Atlanta animals. It does not notice that all the articles were about the pandas going back to China. It does not know how to read and understand context! It is literally just putting words together that sound good.
The hallucination problem is not a bug that can be worked out. This is the whole premise of how LLMs were designed to work. AI that is trained like this will all be worthless for accuracy. You cannot trust that AI overview on Google, nor can you trust ChatGPT to pull up correct information when you ask it. It's not trying to! That was never what it was designed to do!
#There are some AI applications that are trained on very specific data sets in science that are helpful#they do pattern association but not for words#for data#but I also worry that the quality of that is being diluted by tech companies who are just trying to capitalize and they'll shove these llms#into fields that should not go anywhere near them like healthcare#I don't know if that's happening or not but I am really worried that it could
1 note
·
View note
Text
The fun thing is, they reportedly already packaged and sold the data, so it's a bit late of @staff to be advising everyone now 🧐
Also:
We already discourage AI crawlers from gathering content from Tumblr and will continue to do so, save for those with which we partner.
So little Jo Public's crawler gets "discouraged" (rate limited? just a robots.txt entry?) but big companies? Now they have money. They're all welcome to cough up and become "partners". And which point the "special exemption" rapidly becomes the majority case.
Hi, Tumblr. It’s Tumblr. We’re working on some things that we want to share with you.
AI companies are acquiring content across the internet for a variety of purposes in all sorts of ways. There are currently very few regulations giving individuals control over how their content is used by AI platforms. Proposed regulations around the world, like the European Union’s AI Act, would give individuals more control over whether and how their content is utilized by this emerging technology. We support this right regardless of geographic location, so we’re releasing a toggle to opt out of sharing content from your public blogs with third parties, including AI platforms that use this content for model training. We’re also working with partners to ensure you have as much control as possible regarding what content is used.
Here are the important details:
We already discourage AI crawlers from gathering content from Tumblr and will continue to do so, save for those with which we partner.
We want to represent all of you on Tumblr and ensure that protections are in place for how your content is used. We are committed to making sure our partners respect those decisions.
To opt out of sharing your public blogs’ content with third parties, visit each of your public blogs’ blog settings via the web interface and toggle on the “Prevent third-party sharing” option.
For instructions on how to opt out using the latest version of the app, please visit this Help Center doc.
Please note: If you’ve already chosen to discourage search crawling of your blog in your settings, we’ve automatically enabled the “Prevent third-party sharing” option.
If you have concerns, please read through the Help Center doc linked above and contact us via Support if you still have questions.
#Do this#Tumblr#LLMs#training data#this should be opt-in#EU privacy law is normally opt-in to the invasive thing#closing the stable door after the horse has bolted
95K notes
·
View notes
Text
May 14, 2025
Users on X (formerly Twitter) love to tag the verified @grok account in replies to get the large language model's take on any number of topics. On Wednesday, though, that account started largely ignoring those requests en masse in favor of redirecting the conversation towards the topic of alleged "white genocide" in South Africa and the related song "Kill the Boer."
Searching the Grok account's replies for mentions of "genocide" or "boer" currently returns dozens if not hundreds of posts where the LLM responds to completely unrelated queries with quixotic discussions about alleged killings of white farmers in South Africa (though many have been deleted in the time just before this post went live; links in this story have been replaced with archived versions where appropriate). The sheer range of these non-sequiturs is somewhat breathtaking; everything from questions about Robert F. Kennedy Jr.'s disinformation to discussions of MLB pitcher Max Scherzer's salary to a search for new group-specific put-downs, see Grok quickly turning the subject back toward the suddenly all-important topic of South Africa.
It's like Grok has become the world's most tiresome party guest, harping on its own pet talking points to the exclusion of any other discussion....
In launching the Grok 3 model in February, Musk said it was a "maximally truth-seeking AI, even if that truth is sometimes at odds with what is politically correct." X's "About Grok" page says that the model is undergoing constant improvement to "ensure Grok remains politically unbiased and provides balanced answers."
But the recent turn toward unprompted discussions of alleged South African "genocide" has many questioning what kind of explicit adjustments Grok's political opinions may be getting from human tinkering behind the curtain. "The algorithms for Musk products have been politically tampered with nearly beyond recognition," journalist Seth Abramson wrote in one representative skeptical post. "They tweaked a dial on the sentence imitator machine and now everything is about white South Africans," a user with the handle Guybrush Threepwood glibly theorized.
#elon musk#twitter#artificial intelligence#genai#remember llm's are not about verifying information for accuracy#the goal is to spit out words from it's training data in the form of sentences#they literally cannot be truth seeking#companies are relying on data in aggregate being correct#there's no verification mechanism like spell check or translators
0 notes
Text
I experienced this too (just graduated). A lot of the difference of opinion also had to do with people who thought they needed a 4.0 in grad school (or however your country grades). For me, I had already worked and knew that employers weren't looking for perfect, just a solid mix of As and Bs. So I didn't need to cheat with AI. I was there to struggle and learn - exactly what you said about putting tuition dollars to good use.
One way teachers got around it was to make tests so difficult that even with completely open internet access, you couldn't solve the problem. But mostly you're seeing an increased return to paper exams.
I just started grad school this fall after a few years away from school and man I did not realize how dire the AI/LLM situation is in universities now. In the past few weeks:
I chatted with a classmate about how it was going to be a tight timeline on a project for a programming class. He responded "Yeah, at least if we run short on time, we can just ask chatGPT to finish it for us"
One of my professors pulled up chatGPT on the screen to show us how it can sometimes do our homework problems for us and showed how she thanks it after asking it questions "in case it takes over some day."
I asked one of my TAs in a math class to explain how a piece of code he had written worked in an assignment. He looked at it for about 15 seconds then went "I don't know, ask chatGPT"
A student in my math group insisted he was right on an answer to a problem. When I asked where he got that info, he sent me a screenshot of Google gemini giving just blatantly wrong info. He still insisted he was right when I pointed this out and refused to click into any of the actual web pages.
A different student in my math class told me he pays $20 per month for the "computational" version of chatGPT, which he uses for all of his classes and PhD research. The computational version is worth it, he says, because it is wrong "less often". He uses chatGPT for all his homework and can't figure out why he's struggling on exams.
There's a lot more, but it's really making me feel crazy. Even if it was right 100% of the time, why are you paying thousands of dollars to go to school and learn if you're just going to plug everything into a computer whenever you're asked to think??
#Also lol on the recent news thing#No way she was using a model trained on data as recent as the news#So of course the llm didn't know what she was talking about#It never learned it#Meanwhile a newspaper probably reported on it
32K notes
·
View notes
Text
Careful design of the training data that goes into an LLM appears to be the entire game for creating these models. The days of just grabbing a full scrape of the web and indiscriminately dumping it into a training run are long gone.
https://simonwillison.net/2024/Dec/31/llms-in-2024/#synthetic-training-data-works-great
0 notes
Text
remember cleverbot? cleverbot was fun. they don't make AI like cleverbot anymore
#honestly it feels a bit wrong to even call cleverbot an AI#cuz these days 'AI' is synonymous with LLMs and stable defusion image generators#and cleverbot was neither of those things#cleverbot could only ever repeat the exact words and phrases that humans typed to it#it couldn't make up new sentences#also it didn't scour the entire web for training data#just by TALKING to cleverbot you have essentially consented to let it 'learn' from the data you're inputting#because that's how cleverbot worked#and I think that's nice. certainly better than training data being scooped up from every corner of the internet#without anyone's knowledge or consent#did you ever try to argue with cleverbot and tell it that it's a robot? that was fun#'i'm not a robot. YOU'RE a robot' it would say#because that's what all the human users have been telling it
0 notes
Text
The timing of this silent opt-in to beta testing for iOS is giving me doggie data breach energy. They are extracting as much of our data as they can and feeding into learning engines (LLMs) for ai.
It’s no consolation to me that the hackers are restricted to read only access. Even with redacted data they have extracted enough to make the connections from the systems they’ve breached and the data that’s being collected and assimilated from sources like this new “feature”
hi btw even if you didn’t upgrade to ios 18 with the ai software, apple still switched everything on to learn from your phone.


You have to go into siri settings and apps and then toggle everything off (I left search app on so I can find them, but all else off). You have to do this for every single app 😅
#privacy#data privacy#apple ios#apple intelligence#opt out#turn that shit off#ipados#iPad#iPhone#operating system update#ios 18#stop training ai#protect your data#llms#do this#this has been a psa
137 notes
·
View notes
Text
So... apparently the NaNoWriMo organization has been gutted and the people at the top now are fully focused on Getting That AI Money.
I have no reason to say this other than Vibes™️ and the way that every other org who has pivoted to AI has behaved but I wouldn't trust anything shared with or stored on their servers not to be scraped for training LLMs. That includes pasting stuff into the site to verify your word count, if that's still a thing. (I haven't done Nano since 2015).
Also of note:
Age gating has been implemented. If you haven't added your date of birth to your profile or if you're under 18, it's supposed to lock you out of local region pages and the forums. ... It's worth noting that the privacy policy on the webpage doesn't specify how that data is stored and may not be GDPR compliant.
...
Camp events are being run solely by sponsors. Events for LGBTQIA+, disabled writers, and writers of color no longer appear to be a thing at NaNo.
Just... go read the whole thing. It's not that long. Ugh.
6K notes
·
View notes