#Various Types of Hypothesis Testing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Exploring the Various Types of Hypothesis Testing: A Comprehensive Overview
Summary: This blog explains the importance of various types of hypothesis testing in statistical analysis, highlighting its role in evaluating assumptions about population parameters. It discusses the significance of null and alternative hypotheses, types of hypothesis tests, and common pitfalls, emphasizing the value of hypothesis testing for making informed, data-driven decisions across various fields.

Introduction to Hypothesis Testing
Hypothesis testing is a fundamental aspect of statistical analysis that allows researchers to make informed decisions based on data. It provides a structured framework for evaluating assumptions about a population parameter, enabling scientists, statisticians, and decision-makers to determine the validity of their hypotheses.
This process is crucial in various fields, including medicine, social sciences, and business, where data-driven conclusions can significantly impact outcomes.
At its core, hypothesis testing involves formulating two competing statements: the null hypothesis (H₀) and the alternative hypothesis (H₁). The null hypothesis typically posits that there is no effect or difference, while the alternative hypothesis suggests that there is a significant effect or difference.
By collecting and analyzing sample data, researchers can assess the likelihood of observing the data under the null hypothesis, ultimately leading to a decision about whether to reject or fail to reject H₀.
This blog will explore the various types of hypothesis testing, their importance in statistical analysis, and the common pitfalls associated with the process. Understanding these concepts is essential for anyone looking to apply statistical methods effectively in their research or decision-making processes.
Importance in Statistical Analysis and Research
Hypothesis testing is crucial in statistical analysis and research, providing a systematic framework for making data-driven decisions, quantifying uncertainty, and validating scientific theories through empirical evidence and rigorous evaluation.
Data-Driven Decision Making
In an era where data is abundant, hypothesis testing provides a systematic approach to make decisions based on evidence rather than assumptions or intuition. This is particularly important in fields like medicine, where clinical trials rely on hypothesis testing to determine the efficacy of new treatments.
Quantifying Uncertainty
Hypothesis testing allows researchers to quantify the uncertainty associated with their conclusions. By calculating p-values and confidence intervals, researchers can assess the strength of their evidence and the likelihood of making errors in their conclusions.
Facilitating Scientific Inquiry
The process of hypothesis testing is central to the scientific method. It encourages researchers to formulate clear, testable hypotheses and to seek empirical evidence to support or refute them. This iterative process fosters a deeper understanding of phenomena and contributes to the advancement of knowledge.
Guiding Policy and Strategy
In business and public policy, hypothesis testing can guide strategic decisions. For example, companies can use A/B testing to evaluate marketing strategies, while policymakers can assess the impact of interventions based on statistical evidence.
Identifying Relationships and Effects
Hypothesis testing helps researchers identify significant relationships between variables, allowing for a better understanding of causal mechanisms and the development of theories.
Null and Alternative Hypotheses
Null and alternative hypotheses form the foundation of hypothesis testing, representing competing statements about a population parameter. Understanding these hypotheses is essential for conducting rigorous statistical analyses and drawing valid conclusions.
Null Hypothesis (H₀)
The null hypothesis is a statement that indicates no effect, no difference, or no relationship between variables. It serves as the default position that researchers seek to test against. For example, if a researcher is studying the effect of a new drug on blood pressure, the null hypothesis might state that the mean blood pressure of patients taking the drug is equal to that of those not taking it.
Mathematically, the null hypothesis is often expressed as:
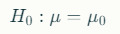
where μμ is the population mean, and μ0μ0 is a specific value (e.g., the mean blood pressure of the control group).
Alternative Hypothesis (H₁)
The alternative hypothesis represents the statement that researchers aim to support. It posits that there is a significant effect, difference, or relationship between variables. Continuing with the drug example, the alternative hypothesis might state that the mean blood pressure of patients taking the drug is different from that of those not taking it.
The alternative hypothesis can be one-tailed or two-tailed:
One-Tailed Alternative Hypothesis: This specifies the direction of the effect. For instance, if the researcher believes the drug lowers blood pressure, the alternative hypothesis would be H1:μ<μ0H1:μ<μ0.
Two-Tailed Alternative Hypothesis: This does not specify the direction of the effect, only that there is a difference. In this case, it would be expressed as H1:μ≠μ0H1:μ=μ0.
Types of Hypothesis Tests
There are several types of hypothesis tests, each suited for different data types and research questions. Here are some of the most commonly used tests:
Z-Test
The Z-test is used when the sample size is large (typically n>30) and the population standard deviation is known. It assesses whether the sample mean differs from a known population mean. The formula for the Z-test statistic is:

where x‾x is the sample mean, μμ is the population mean, σσ is the population standard deviation, and nn is the sample size.
T-Test
The T-test is appropriate for smaller sample sizes (typically n<30) or when the population standard deviation is unknown. It compares the sample mean to a known value or another sample mean. The formula for the one-sample T-test statistic is:
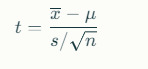
where s is the sample standard deviation.
There are different types of T-tests, including:
One-Sample T-Test: Compares the sample mean to a known population mean.
Independent Two-Sample T-Test: Compares the means of two independent groups.
Paired Sample T-Test: Compares means from the same group at different times.
Chi-Square Test
The Chi-square test is used to assess relationships between categorical variables. It evaluates whether the observed frequencies in a contingency table differ significantly from expected frequencies. The formula for the Chi-square statistic is:

ANOVA (Analysis of Variance)
ANOVA is used to compare means across three or more groups. It tests the null hypothesis that all group means are equal. If the ANOVA test indicates significant differences, further post-hoc tests can identify which specific groups differ. The F-statistic is used to determine the ratio of between-group variance to within-group variance.
Non-parametric Tests
When data do not meet the assumptions of parametric tests (e.g., normality), non-parametric tests can be used. Examples include the Mann-Whitney U test (for two independent samples) and the Kruskal-Wallis test (for three or more independent samples).
Read More: Crucial Statistics Interview Questions for Data Science Success
Choosing the Right Hypothesis Test
Selecting the appropriate hypothesis test is crucial for obtaining valid results. Here are some factors to consider:
Data Type: Determine whether your data is continuous or categorical. For continuous data, consider T-tests or ANOVA; for categorical data, consider Chi-square tests.
Sample Size: The size of your sample influences the choice of test. Larger samples may allow for Z-tests, while smaller samples may require T-tests.
Distribution: Assess whether your data follows a normal distribution. If not, consider using non-parametric tests.
Number of Groups: If comparing means across multiple groups, ANOVA may be appropriate. For two groups, use T-tests or non-parametric alternatives.
Hypothesis Direction: Determine whether your hypothesis is one-tailed or two-tailed, as this will influence the test selection.
Errors, Common Misinterpretations, and Pitfalls
Hypothesis testing is not without its challenges. Researchers must be aware of common errors and misinterpretations:
Type I and Type II Errors
Type I Error (α): This occurs when the null hypothesis is rejected when it is actually true. The significance level (α) represents the probability of making a Type I error, commonly set at 0.05.
Type II Error (β): This occurs when the null hypothesis is not rejected when it is false. The power of a test (1 - β) indicates the probability of correctly rejecting a false null hypothesis.
Common Misinterpretations
P-Value Misunderstandings: A common misconception is that a p-value indicates the probability that the null hypothesis is true. Instead, it reflects the probability of observing the data given that the null hypothesis is true.
Overemphasis on Statistical Significance: Researchers may focus solely on p-values, neglecting the practical significance of their findings. A statistically significant result may not always translate to a meaningful effect in real-world applications.
Ignoring Assumptions: Each hypothesis test comes with underlying assumptions (e.g., normality, independence). Violating these assumptions can lead to incorrect conclusions.
Sample Size Effects: Small sample sizes can result in unreliable estimates, while large sample sizes can lead to statistically significant results even for trivial effects. Researchers should balance sample size with practical significance.
Conclusion
Hypothesis testing is a cornerstone of statistical analysis, providing a structured approach to evaluate assumptions about population parameters. By understanding the various types of hypothesis tests, the importance of null and alternative hypotheses, and the common pitfalls associated with the process, researchers can make informed decisions and draw valid conclusions from their data.
As data continues to play a pivotal role in decision-making across various fields, mastering hypothesis testing will empower researchers and practitioners to navigate uncertainties and enhance the robustness of their findings.
Frequently Asked Questions
What is the Purpose of Hypothesis Testing?
Hypothesis testing aims to evaluate assumptions about a population parameter based on sample data. It helps researchers determine whether to reject or fail to reject the null hypothesis, guiding data-driven decision-making.
What are the Types of Hypothesis Tests?
Common types of hypothesis tests include Z-tests, T-tests, Chi-square tests, ANOVA, and non-parametric tests. The choice of test depends on factors such as data type, sample size, and distribution.
What is a P-value?
A p-value is a statistical measure that indicates the probability of obtaining results as extreme as those observed, assuming the null hypothesis is true. It helps researchers assess the strength of evidence against the null hypothesis.
#Various Types of Hypothesis Testing#Types of Hypothesis Testing#Hypothesis Testing#statistics#statistical analysis
0 notes
Text
NO, THE VALENTINE'S LETTER IS NOT FROM W.D. GASTER
On the supposed veracity of a 'quirked up' Gaster

A little over a year ago, Toby released a newsletter on Valentine's Day. It contained a bunch of cute little Valentine's cards from various characters across Undertale and Deltarune, randomly selected for individual recipients. The rarest one, however, stood out from the rest, and contained a lengthy letter from an unknown sender, seemingly addressing us as players of Deltarune. After a while, it was deleted from the official website. Naturally, people jumped to the conclusion that Gaster had sent it, and this hypothesis remains the most popular to this day.
There's only one problem: the letter isn't from Gaster, and I can prove it. Or get pretty damn close, anyway.
I'll keep it short and sweet. I've gone over every single piece of confirmed Gaster dialogue multiple times, and done the same with the Valentine's letter. I'll start by listing the key features of Gaster's confirmed dialogue up to this point, and then compare it to the key features of the letter writer. Then I'll expound a little bit on what I think we can take away from this whole situation.
Key features of Gaster's dialogue
Gaster’s dialogue is characterized by a very peculiar syncopated rhythm, with frequent and arbitrary caesura which is communicated either through short pauses in the rendering of dialogue on screen, or (double) line breaks. This is Gaster's key identifying feature. There is no consistent pattern tying the caesura/line breaks to any practical or grammatical feature (such as punctuation); it is purely arbitrary. You will sound like G-Man from Half-Life if you voice the dialogue with the appropriate pauses.
Sometimes, Gaster will split one line of dialogue across multiple “text boxes” (or any other equivalent) for extra emphasis.
Rarely, Gaster’s punctuation will follow a space. In both instances so far, it happened as Gaster was introducing a new chapter of Deltarune.
When speaking in Wingdings, Gaster does not use punctuation.
When speaking in a normal typeface, Gaster consistently uses punctuation, the only exception being one instance in the tweets preceding Chapter 1.
Gaster’s use of language distinctly tends to be either quite formal or lyrical.
While Gaster is usually perfectly coherent, he will occasionally indulge in philosophical musing, make leaps you can’t reasonably be expected to follow, or present bizarre notions (such as the “flavor” of pain, or the notion of “favorite blood types”, where C and D are apparently candidates; that said, Gaster might simply be testing how the player will respond).
There are certain words or phrases Gaster repeatedly comes back to: “VERY, VERY...”, “INTERESTING”, “WONDERFUL”, “EXCELLENT.”, “TRULY…”. Toby seems to rely on the first two phrases especially to make it clear to the reader that Gaster is the one who's speaking.
Gaster retains a serious tone and almost never exhibits humor or self-awareness.
In Japanese, Gaster's dialogue is spoken (very unusually) exclusively in katakana and kanji, with very formal language used.
In Japanese, Gaster's first person pronoun is 'watashi' - to the best of my knowledge, a common neutral way to refer to yourself in formal settings or to strangers. In informal/casual contexts, however, it apparently tends to only be used by women.
In Japanese, Gaster refers to the player exclusively with 'anata' - a formal neutral pronoun which is most often used in cases where the speaker doesn't know the name of the person they are addressing (in paperwork for example).
The only exception is in Entry 17, where "what do you two think" is translated with the pronoun 'kimi'(-tachi, the plural form). Kimi seems to carry some complex nuances - as far as I've gathered, the gist is that it signifies a superior position by the speaker, is socially acceptable when speaking to a subordinate (if you're a teacher or boss for example), can be affectionately used between close friends and family, but is otherwise typically seen as rude or condescending, especially to strangers or superiors.
"During the survey portion, [Gaster] uses “ware-ware” - a rather stiff way of saying “we.” He ends his requests with “kudasai” (please) and uses the polite endings desu/masu. He’s almost excessively formal, as this level of politeness is unusual in Undertale/Deltarune." (source)
The above points by and large do not apply to the text after the vessel is discarded, which is part of why people theorize it's spoken by a different person. This post looks at the differences in Japanese between Gaster and the 'second voice'.
Key features of the letter writer
The letter writer utilizes (single) line breaks which exclusively follow punctuation. Gaster’s arbitrary caesura is not present. You will not sound like G-Man if you voice the letter.
The letter writer says “DELTA RUNE”, whereas Gaster has only used “DELTARUNE”; this is, admittedly, not entirely consistent across translations.
The letter writer uses very idiosyncratic and/or shoddy punctuation, which Gaster rarely does.
The letter writer uses none of Gaster’s common words/phrases.
The letter writer comes off knowingly forgetful, aloof and silly – behaviors which Gaster has never exhibited in his dialogue.
The letter writer exhibits a fondness for riddles and paradoxical statements, something absent from Gaster’s characterization so far.
The letter writer is noticeably less formal and elegant than Gaster usually is, joking, meandering and rambling where Gaster is typically succinct and to-the-point about the topic at hand.
The letter writer seems easily excitable and uses exclamation marks at multiple points throughout the message, something which Gaster, heretofore characterized as reserved and calm, has done a total of one time.
The letter writer seems aware of the player, which is consistent with Gaster… and yet, the letter writer adopts an unfamiliar, questioning stance towards us and commissions our help, despite Gaster having already established contact with us ages ago and collaborated with us for two chapters now – on cordial, well-acquainted terms at that.
The letter writer does not have a clear objective in mind, whereas Gaster has been “patiently waiting” to put his plans into action.
The letter writer is quite blunt and judgemental, dismissing Valentine’s Day as “absurd” and remarking that the player (presumably, anyway) is “very odd”. By contrast, Gaster is reserved, unanimously polite, and only ever offers his opinions when he has something positive to say.
In Japanese, the letter is in a mix of hiragana and kanji (but slanted towards the former) and uses casual language.
In Japanese, the letter writer uses the first person pronoun 'watashi'.
In Japanese, the letter writer refers to the person being addressed with 'kimi' - not 'anata'.
So what do we make of this?
The Valentine’s Day letter is, at the very least, presented in such a way as to make the reader think about Gaster. This is mostly from contextual features of the letter – the letter being “strange”, its “illegibility” possibly referring to the Wingdings font, it disappearing and getting deleted from the website shortly afterwards, and, of course, the letter seemingly being addressed to the player, who only Gaster has been shown to be truly aware of so far.
While all of these are valuable considerations, it must be stressed that not only does the actual content of this letter contain zero substantive similarities to Gaster’s dialogue, it outright contradicts every significant pattern that’s been established so far.
The letter is clearly meant to evoke Gaster, and it would’ve been trivial for Toby to confirm that it was Gaster if he wanted to. Even with all the other patterns broken, Toby could’ve retained the caesura, or written it in katakana, or had the letter writer say “VERY INTERESTING” or “WONDERFUL” or any other common phrase of Gaster’s and this matter wouldn’t even be up for debate. However, Toby deliberately refrained from clearly identifying the writer as Gaster. Instead, he systematically cast doubt on that idea by making it, in every respect, completely unlike all other dialogue we’ve heard from him.
So I think the question to ask is: why would Toby even do this? If this really is just Gaster, why not make that clearer? Again, even if this is showing a “different side” of him, it still would’ve been the easiest thing in the world for him to prevent undue speculation about it being a different character. It seems tremendously implausible that in the already unlikely case of Toby doing a complete 180 on Gaster’s characterization, that he wouldn’t communicate that fact more clearly. If you think this letter is from Gaster, you have to basically ignore the fact that Toby is deliberately (because to imply that he's unaware of this would be absurd) posing a question about the identity of this letter which on first glance would seem to be from Gaster; you either have to assume that his doing so is meaningful (in which case it can't be Gaster), or that Toby is essentially doing this for no reason to trick or confuse the fandom.
I personally see no other plausible answer to the question of “why give us such good reason to believe that this isn’t Gaster” than… this simply not being Gaster. Or at the very least, not the same Gaster that we’ve previously spoken to.
Who could it be then?
The short answer is that I have no idea. But I think we can narrow down a list of candidates (presented here in no particular order).
#1 - It really is just Gaster The first possibility is that this actually is just the same Gaster that we've come to know. I've made it clear how I feel about this scenario.
#2 - It's a shard of Gaster or a flashback I personally am not fond of Gaster having some form of split personality, but there is at least some support for that idea in Undertale. Likewise I don't see why pre-shattered Gaster would be less coherent than shattered-across-time-and-space Gaster, but it's technically plausible. The benefit of these candidates is that they obviously go some ways towards explaining the Gastery aspects of the letter while also accounting for the dramatic difference in their characterization, but if you ask me, they come with considerable baggage.
#3 - It's the Secret Boss of Chapter 3 or 4 It would fit the bill. All caps dialogue, distinctive speech pattern, probably insane, connected to Gaster, and seemingly about to send you on some weird personal quest. This is the one my money's on. The only issue is that it might be too on the nose if they really are addressing us, the player, directly, and referring to the game of Deltarune (but remember - they say "DELTA RUNE", like the prophecy, or the symbol).
#4 - It's the Man behind the tree Obviously this is assuming that the Egg Man isn't Gaster (and personally, I don't think he is). Handing you an Egg is a similar kind of mix between surreal and silly that characterizes the letter. The Egg Man seems at the very least connected to Gaster, so this would explain that aspect of the letter too. There's also the mirrored flavor text "Well, there is a man here" / "Well, there is not a man here", which is reminiscent of some of the contradictory repetitions in the letters - though, granted, that kind of language is also somewhat associated with the "someone" contacting the Secret Bosses, who I do think is Gaster. Let's move on before we get too confused.
#5 - It's Everyman Everyman certainly has Gaster connections through his appearance in Undertale's True Lab, his status as a recurring easter egg in Deltarune, and his liberal travels between the Light and Dark Worlds. Other than that, we can't say much about Everyman (cards on the table - I think Everyman is the Egg Man). But he definitely isn't Gaster, and he seems semi-important, soooo... could be him! A combination of #4 and #5 would be my second choice behind a new Secret Boss.
#6 - It's FRIEND Okay, I'm not even convinced "FRIEND" is a real character, but if you're not aware, there's a weird Spamton-like entity that briefly appears in Queen's basement in Chapter 2 which, oddly enough, is tied to Gaster via its internal filename, DEVICE_FRIEND. There are a ton of crackpot theories about this thing; I'm not particularly fond of any of them. But I haven't been able to come up with a very enticing explanation for the FRIEND phenomenon myself, so maybe it really is a new character, and the letter was their formal introduction. At the very least I'd say it's more plausible than it being Gaster.
#7 - It's the 'second voice' Once you've accepted that the vessel was discarded by someone other than Gaster, this may seem like a tempting conclusion. However, there are a number of issues with this idea, namely that the SV does not speak in all-caps, uses kanji more frequently than the letter writer, and uses different pronouns. The same reasons that compel us to distinguish between Gaster and the second voice also compel us to distinguish between the second voice and the letter writer.
#8 - It's Dess We know very little about Dess other than that she disappeared in what many assume to be a Gaster-related incident. The problem is that there's not much reason to believe this over the other options, aside from maybe the choice of the 'watashi' pronoun.
#9 - It's the "unused" voice in the code Which many assume to be Dess. Again, not impossible, but I think this stretches credulity even more because there's quite a shift in characterization from UNUSED's scared helplessness to the letter writer's brash, loony arrogance. And while I'm not an expert in Japanese, from a quick glance it seems like UNUSED uses kanji with more frequency than the letter writer does. This post seems pretty informative re: what can be gleaned from the Japanese translation of UNUSED.
(Thanks @kitten-kokomo for the above two suggestions)
#10 - It's some entirely new character unrelated to all of these This is possible, of course, but there's nothing to say about this scenario; if this is the case we couldn't have predicted it and we have nothing to work with at the moment, so we'll just have to wait. I will say, the Gaster connections make me think this is unlikely. We already have a bevy of potential Gaster minions.
Okay, that's all I have to say about the letter.
Good by!
64 notes
·
View notes
Text
Imagine: watching the great Yuri Isami’s face turn a glorious shade of red the first time you stripped him of his pristine white gloves to enhance his stigma. His pale skin, now flushed various hues of pink, was such an adoring sight to see… you couldn’t help but want to see it again.
So the next time you enhanced his stigma, you made sure to intertwine your fingers with his. He didn’t comment on your actions, simply looking away with warm ears.
You tried again. This time, when you grabbed his hand, you twisted it towards yourself, placing a teasing kiss to the back of it. Yuri’s eyes widened, gawking at you before stuttering out how unnecessary your actions were.
Later, you were in Mortkranken’s lab, observing Yuri who had grown accustomed to your company… eventually. He had two beakers of some glowing liquid, watching them carefully as he tipped them both onto a Petri dish. When he set them down, you silently approached him from behind, humming his name and brushing your nose against his neck. He whipped around, nearly smacking you by mistake.
“W-w-what do you think you’re doing?!” He yelled, one hand on his neck and the other pointing at you accusingly.
“Want to test if I need to hold hands with someone for the ring’s power to work?” You smile slyly, “…or if any type of skin contact is fine?” Yuri froze, seeming to mull the idea over before stiffening, and looking at you suspiciously.
“Of course anything would work!” He finally snapped with a huff. “Hand contact is merely the easiest!”
“Hmm… is that so?” You quickly spun his chair around, draping yourself over him before he could protest. “So… would this work?” You murmur against his skin, kissing his neck gently. “Haha! What a pretty pink!” You marvel as Yuri seemed to malfunction, eyes dilated as he kicks you out. Oh well, you’d be back tomorrow for a check up anyway.
The thing was… Yuri didn’t hate your advances…
He buried his head in his arms after you left, trying to calm his racing heart. He felt a lump in his throat as the truth of his affection towards you was becoming harder to swallow. He was Darkwick’s genius doctor! How could he be falling for a patient!? What a scandalous type of relationship for a doctor to lov-!
Yuri shook the thought out of his mind. Maybe this was all just some side effect of you using that ring on him! That was surely it! Yuri called Jiro in to get his hypothesis validated… but no matter how much Yuri tried to deny it, deep in his heart he knew the reason behind his heart palpitations.
Which made it all the more hard to come to terms that he… the great Yuri Isami… hadn’t found a cure to reverse your curse… it hadn’t even been a full year before Darkwick Agents dragged you away. Without you here, how could Yuri cure you? He needed more blood samples! He needed a sampled of the anomaly that cursed you! He needed more time! More…!
He needed you…
Maybe if you were here, you could enhance his stigma again and he could think of more possible cures… maybe if you were there to hold his hand… kiss his neck, as embarrassing as it was… was it pathetic that a doctor needed comfort from their sick patient…? If it was, Yuri was too tired to care. Maybe… if you were still here… he wouldn’t be falling apart right now…

#tokyo debunker#tokyo debunker x reader#tkdb#tkdb x reader#tokyo debunker yuri#yuri isami#imaginate with me
78 notes
·
View notes
Text
Experiment 43.8-2B: Blood Testing using Various Subjects
Viv Weylin and Vex Weylin
Date: [REDACTED]

To test how the human body reacts to different blood types being injected in their body
Subject 1 was unresponsive for the duration of the procedure. Subject is blood type A. Subject was injected in the upper arm with blood type AB. After 22.3 hours Subject 1 showed signs of fever, and blood clumping was discovered. The problems were addressed and treated in time, and Subject 1 survived.
Subject 2 was responsive for the procedure and 7 hours following. Subject was blood type O. Subject was injected with blood type A. Subject did not survive experiment. Cause of death was kidney failure.
Subject 3 was the control group. Subject 3 is blood type A. Subject was not injected with any blood. Subject 3 survived the duration of the experiment.
Experiment was discontinued because of blood samples becoming unusable due to the unprofessional nature of Vex Weylin. Vex was removed from the project and the project was put off for the next few days until more blood samples can be acquired.
Conclusion: The human body has a negative and deadly reaction to different blood types being injected into them. Results support hypothesis and previous research.
#scalpel and syringe#Ooc: Yes I did research although not super thorough lmk if there’s any medical misinformation
16 notes
·
View notes
Text
i had to write a 6k word research paper last semester in which i had to do hypothesis testing relating to any subject about WMDs. my idea was to test why states step away from the brink of developing nuclear weapons or get rid of them, with a focus on two explanations: domestic normative changes (so, attitudes regarding nuclear weapons) and security-based explanations (do nuclear weapons provide meaningful defence to the state in question?). this was done in tandem with my plotting for buzzsaw 2, which made me curious about the strategic utility of projecting "safety" or "neutrality" to potential aggressors. the core dilemma in the story is about whether or not aliens can be trusted, or more specifically if kindness is present throughout the universe. it's really all about perception--so, how an individual perceives aliens. to link this with my paper topic, i was specifically seeking to prove that perceptions of nuclear weapons had a greater influence on the lack of horizontal proliferation than security issues. my findings were kind of interesting.
basically, i was proven incorrect. i used congruence analysis (comparing various states and why they did or did not acquire nuclear weapons) to do my hypothesis testing. i feel like rambling a little bit, so here are some of my favourite cases:
Canada (Nuclear weapons capacity: HIGH -- large domestic sources of uranium, multiple research reactors that could be converted to uranium-enrichment facilities for weapons production, encouragement from US to create arsenal, and sufficient high-tech weaponry knowledge to develop an arsenal). Normative explanation: Canadians on average do not perceive military strength as being a source of national pride. It isn't very important in the national consciousness. Security Explanations: Proximity to US means that any nuclear strikes on Canadian territory will provoke US retaliation against the aggressor. Moreover, Canada's nuclear weapons policy at the time emphasized the avoidance of negative security externalities--leaders believed that acquiring nuclear weapons would provoke enemy states into doing the same, and so chose not to obtain them.
Sweden (Nuclear weapons capacity: MEDIUM -- domestic plutonium sources, advanced weapons systems) Normative Explanations: Public support for acquiring a nuclear arsenal reached a high of 57% in 1959. A successful anti-nuclear weapons campaign by the Social Democrat Party sought to make Swedish identity and the possession of nuclear weapons "incompatible" lowered public support to 31% by 1967. The nuclear weapons program lost public support entirely within a decade. Security Explanations: Sweden was most concerned about a Soviet invasion of Western Europe. Despite being a neutral state, their leaders came to the conclusion that the United States would defend any western European state from Soviet expansion to prevent its sphere of influence from growing further. As well, Sweden was worried about provoking the USSR and chose not to develop an arsenal for this reason as well.
Brazil (Nuclear weapons capacity: MEDIUM -- similar reasons to Sweden) Normative Explanations: Brazil's nuclear weapons program occurred under its military dictatorship. After its collapse, the civilian government ended all plans to develop an arsenal. I'm not taking into consideration how Brazilians felt about it because it was a secret program. Security Explanations: The military regime was primarily concerned by Argentina's head-start on enrichment methods and ballistic missile technology. President Geisel established a military nuclear energy research program that ran parallel to the civilian nuclear energy body, CNEN. By 1990, they were believed to be around two years away from testing a Hiroshima-type bomb (admittedly, a piece of shit by 90s standards). The program was terminated in 1990 by civilian President Mollo. Notably, Argentina had transitioned to democracy a few years prior, which contributed greatly to the end of its paranoia towards its neighbour. (Military regimes are prone to mirror paradoxes, in which they assume their rivals are as equally unstable and militaristic. This was definitely true of Argentina's military dictatorship in general though).
My primary case study was South Africa, whose apartheid government built six nuclear bombs beginning in the 1970s until the late 1980s. I chose it because it's the only state to have ever built and then dismantled its nuclear arsenal. At the time, the government was very concerned about the survival of its white state, since the rest of Africa was decolonizing and they were becoming a pariah on the global scene for their apartheid policies. Also, Soviet and Cuban troops were running around getting into conflicts in the continent and they were worried about getting invaded for being anti-communist and super racist. This made them desperate enough to build nuclear weapons.
They actually tried really, really hard to get security assurances from the United States, which led to them going as far as to sanction Rhodesia for being white supremacist (a hypocrisy equivalent only to Norway convincing itself that it meets climate targets). They failed to convince the US to help them (because South Africa was strategically worthless, so it was totally within the United States' comfort zone to ignore them and later condemn them) and were pretty much only friends with Israel, who helped them quite a bit with the nuclear weapons program. In one of the texts I read for the paper (page 287 of Will South Africa Survive? by R.W. Johnson), there's a translation of a section of South African Prime Minister Vorster's interview with Israeli newspaper Ma'ariv in 1976 in which he states that Israel and apartheid South Africa kind of have the same thing going on, with specific reference to their policies of occupation and racial/economic exclusion. So, if you ever need some additional evidence that Israel is an apartheid state for whatever reason, feel free to cite a literal leader of apartheid South Africa admitting that Israel does the same thing.
ANYWAYS, apartheid South Africa got rid of its nuclear weapons during two events/processes: the end of apartheid, and the fall of the Soviet Union. The cause of their disarmament doesn't require much thought since PM de Klerk admitted to parliament that they got rid of their nuclear weapons because their primary security threat (the USSR) no longer existed. Their weapons weren't even very good (could only be delivered by bombers) and their entire strategy for them was to just imply to the US that they possessed them, which would force the US to step up and protect them so South Africa wouldn't reveal they had them to the world and potentially trigger proliferation across Africa.
What I got out of all of this isn't that normative/perceptive explanations for disarmament are worthless, but rather that security concerns must be dealt with as a prerequisite to disarmament. Sweden and Canada fell under US extended deterrence and felt no need to develop weapons, while Brazil and South Africa's regional security concerns collapsed and they no longer had a reason to have nuclear weapons. Countries who are not threatened by nuclear powers or are protected by nuclear powers do not need nuclear weapons to guarantee their survival.
Taking into this account, I've altered the story of buzzsaw 2 to reflect my findings somewhat. A lot of it is the same, I've just put a bit more attention into addressing the security dilemma faced by Earth lol. More specifically, how a planet can minimize security externalities to avoid provoking aliens and how the necessity of doing so can challenge the status of imperial powers on said planet...
#sorry i felt like rambling about nuclear weapons policy#it will happen again probably#fic: the cosmic beholder#redposts
19 notes
·
View notes
Note
run/{Greetings, I would like to test a hypothesis with you.
My visor has been broken and no matter the type of fixes, it seems to remain that way. I assume it might be the same with yours.
To test this, I have a simple test to conduct: I will attempt to scan you, and you’ll do the vice versa. (Break)
[Visor Online.] (Cont.) Let’s hope my suspicions aren’t true..}.txt

Fal's expression freezes with shock. Snow White seems quite perturbed by the proposition of Gizmo
“You... You want to... Your visor... Is this a joke, pon? Wait... You are... You're serious, pon!?”
“Fal… This is a bad idea..."
“Perhaps, but... It could be a good chance, Fal... Fal tried on various occasions to use the goggles in Fal, with no result, pon. Besides, if he says that his visor doesn't work, then it wouldn't be dangerous... And... Fal wants to try, the last time Fal used the goggles, they just brought “Unknown” results... That was strange, pon..."
“Alright, bring it on, pon! Is not like this can possibly go badly, pon!”
Snow grabs Fal from his cape and murmured something to him
“... Fal... You shouldn't take the matter so lightly..."
“Fal is not taking it lightly, pon!... It's going to be ok, pon!”
Fal addressed Gizmo with seriousness on his face, while Snow looked uneasy
His goggles could see the abilities of individuals and, when he used them on someone, he learned not only their individual parameters, but everything related to that person. He could even know about certain past events. The story of that person's life: the beauty, the ugly, the noble and the dirty side of that person couldn't be hidden from Fal. However… He wasn't able to use his goggles properly since he arrived in the Tournament
“Alright, pon. But! Do not use the information obtained for malicious purposes, pon. Fal can do the same if you dare to do it, pon”
#fal mahoiku#kirby oc#kirby oc tournament#kirby#my draws#gizmo kirby oc#kid-of-chaos ask#fal only accepted because he truly wants to know what kind of information would be displayed#in another timeline he tried to use the goggles on his Mirror Counterpart... terrible idea
27 notes
·
View notes
Text
TW: Highly patriotic content

"Anyone who doesn’t light them must be a terrorist…"
ANM №: ANM-446
Responsible Researcher: Jack Black
Identification: Uncle Sam's Fireworks
Danger Level: Snit 🟡 (Cognitive, Manipulative)
Containment Difficulty: 2 (Medium)
Type of Anomaly: Object, multi-anomalous, manipulative
Containment: ANM-446 must be stored in a locked vault in D-02. Access to ANM-446 requires authorization from at least two Level 3 personnel. The 446 fireworks may only be activated in an isolated testing field under the supervision of a senior researcher. Anyone exposed to the effects of ANM-446 must undergo psychological evaluation and treatment if necessary.
Description: ANM-446 is a set of 50 fireworks of various types and colors, packaged in a cardboard box labeled "Uncle Sam Fireworks - The Best in the USA." ANM-446 was recovered from ANM-176's shop following reports of anomalous incidents involving customers, especially a person from Paraíba identified as "Cartoonizing."
When lit, ANM-446 fireworks produce a normal pyrotechnic display, except that the explosions form images and symbols related to U.S. culture and history, such as the flag, the Statue of Liberty, Mount Rushmore, Uncle Sam, etc. Additionally, ANM-446 emits sounds of American anthems, speeches, slogans, and patriotic songs at a volume loud enough to be heard within a 5 km radius.
The anomalous effect of ANM-446 manifests in people observing the display. These individuals undergo a temporary change in personality, becoming extremely patriotic, nationalistic, and loyal to the United States of America, regardless of origin, ethnicity, religion, or political opinion. This change lasts from a few hours to a few days, depending on the duration and intensity of exposure. Those affected by ANM-446 tend to express their patriotism verbally, through gestures, or behaviorally, sometimes resorting to violence against those they consider enemies or traitors of the American nation.
The origin and purpose of ANM-446 are unknown. Chemical and physical analyses have not revealed any significant differences between ANM-446 and common fireworks. The "Uncle Sam Fireworks" company does not officially exist, and there are no records of its production or distribution. The most likely hypothesis is that ANM-446 is a form of propaganda or psychological sabotage created by some group or individual with political or ideological interests in the United States of America.
Incident Report ANM-446-1
Date: 07/04/20██
Location: [REDACTED], Texas, USA
Description: An unidentified individual, later designated as [EXCLUDED], activated one of ANM-446's fireworks in a public park during the U.S. Independence Day celebrations. The firework produced a blue explosion, forming the image of Uncle Sam, the national symbol of the USA, in the sky. The image of Uncle Sam was animated and spoke in a deep, authoritative voice, saying phrases like "I want you for the U.S. Army," "Remember Pearl Harbor," "God bless America," among others.
The anomalous effect of ANM-446 affected about 200 people in the park, including the person who lit the fireworks. Those affected became extremely patriotic, nationalistic, and loyal to the USA, following Uncle Sam's orders, which instructed them to enlist in the army, attack immigrants, burn flags of other countries, among other violent and extremist actions.
A figure emerged from the crowd after the firework dissipated—a tall man with long white hair and a goatee, dressed and communicating like Uncle Sam. This individual was later identified as instance ANM-446-B, Uncle Sam himself, summoned by the fireworks.
The Organization was alerted to the incident by an undercover agent in the local police, who recognized the firework as one of ANM-446's items. A containment team was dispatched to the location and successfully neutralized the firework, dispersed the crowd, and administered amnestics to those involved.
Interview ANM-446-B (translated from English)
Date: [REDACTED]
Interviewer: Dr. [REDACTED]
Interviewee: ANM-446-B (Uncle Sam)
Preface: The interview was conducted in a local military bunker following Incident 446-1.
<Start of Interview>
Dr. [REDACTED]: Hello. Can you hear me?
Uncle Sam: Of course, I can, son. Who are you, and what do you want with me?
Dr. [REDACTED]: I’m a researcher from the MOTHRA Foundation, an organization dedicated to studying and containing anomalous phenomena like you.
Uncle Sam: MOTHRA? Never heard of it. Are you some kind of communist spy?
Dr. [REDACTED]: Uuh… n-no. I'm not a communist spy. I just want to ask you some questions to better understand your nature and origin.
Uncle Sam: Well, I’ve got nothing to hide. I'm Uncle Sam, the symbol of freedom and democracy, the protector of the United States of America and the free world. You must respect and obey me, or suffer the consequences.
Dr. [REDACTED]: I see. And how were you created? Who is responsible for you?
Uncle Sam: I was created by the American people, by their faith and love for the nation. I am the result of their will and spirit. I don’t have a creator, I am the creator.
Dr. [REDACTED]: But you're not a physical being; you're an entity produced by a firework. Do you have any consciousness or personality of your own?
Uncle Sam: Of course, I do, son. I’m as real as you, or even more. I have a mission, a cause, a reason for being. I’m the guardian of American values and ideals, and the enemy of tyrants and oppressors. I influence and inspire the people who see me, and I make them act according to my principles.
Dr. [REDACTED]: And what are your principles, exactly?
Uncle Sam: The principles of freedom, justice, equality, fraternity, prosperity, peace, glory, honor, loyalty, courage, honesty, generosity, kindness, wisdom, virtue, faith, hope, love, and everything good and noble in this world.
Dr. [REDACTED]: Those are commendable principles, but don’t you think they are a bit idealized and simplistic? Don’t you recognize the complexity and diversity in political, social, and cultural issues?
Uncle Sam: No, I do not. I know what is right and wrong, and there is no middle ground. The United States of America is the most perfect and superior nation that has ever existed and has the duty to lead and guide the rest of the world. Anyone who opposes or doubts this is an enemy, a traitor, a heretic, a sinner, a worm, garbage, and must be eliminated.
Dr. [REDACTED]: Don’t you think that’s an extremist and intolerant view? Aren't you afraid of causing conflicts and violence with your actions?
Uncle Sam: No, I am not afraid, son. I am proud and confident. I know my cause is just and sacred, and that God is on my side. I don’t care about conflicts and violence, as they are necessary to defend and spread my message.
Dr. [REDACTED]: And what is your mission, after all?
Uncle Sam: My mission is to make everyone on this planet become American citizens or die trying.
<End of Interview>
#scp#scp foundation#mothra institution#writing#original scp#america#united states#patriotic#uncle sam
6 notes
·
View notes
Text
Unlock the Power of Data Analysis with STAT Data Modeling Software - LabDeck's Stat Studio
In today's data-driven world, having the right tools to analyze and interpret vast amounts of data is essential for researchers, data scientists, and analysts. LabDeck’s Stat Studio stands out as a premier STAT Data Modeling Software, designed to meet the diverse needs of professionals who work with complex datasets. This robust software offers an intuitive interface combined with powerful analytical features, enabling users to perform advanced statistical modeling with ease.
Why Choose Stat Studio for Your Data Analysis Needs?
Stat Studio is more than just another statistical software; it's an all-in-one solution that helps you unlock deeper insights from your data. Here's why it's a top choice for anyone looking to elevate their data modeling capabilities:
1. Advanced Regression Analysis
One of Stat Studio's most powerful features is its regression analysis toolset. Whether you are performing basic linear regression or more complex methods, Stat Studio gives you the flexibility to choose the right model for your data. Key statistical measures, such as Mean Squared Error (MSE) and R-squared values, are automatically calculated and displayed, providing instant insight into your model's performance. This makes it easy to interpret relationships between variables, ensuring accurate and reliable results.
2. Comprehensive Data Handling
Stat Studio excels in data handling by supporting a wide range of file formats and data sources. With its flexible import options, users can seamlessly integrate and analyze datasets from various origins. Whether your data comes from spreadsheets, databases, or other statistical software, Stat Studio ensures that you can work with it efficiently.
3. Customizable Visualizations
Data visualization is an integral part of any analysis, and Stat Studio’s advanced plotting capabilities make it simple to create professional-grade charts and graphs. Users can easily generate scatter plots, line graphs, bar charts, and more, with a full range of customizable options like marker styles, line types, and color schemes. Additionally, the software allows you to overlay regression lines and add trend lines, giving your visualizations deeper analytical value.
4. Tailored Analysis and Presentation
Customization doesn’t end with visuals. Stat Studio offers extensive options to tailor every aspect of your analysis to meet specific presentation or publication requirements. You can adjust parameters for data scaling, clean your datasets, and fine-tune the presentation of your results to suit your audience, whether you are presenting to a boardroom or preparing for publication.
Advanced Features for Complex Analyses
For users who require more than just basic analysis, Stat Studio offers an array of advanced features. A dedicated “Tests” tab hints at the software’s ability to run a wide variety of statistical tests, including hypothesis testing, ANOVA, and more. These features make Stat Studio a versatile tool for users in fields like academia, market research, healthcare, and beyond.
Additionally, the software includes tools for data cleaning and scaling, which are essential for preparing large and complex datasets for accurate analysis. These pre-processing steps ensure that your data is ready for in-depth statistical modeling, leading to more reliable and meaningful results.
Conclusion: Empower Your Data with LabDeck's Stat Studio
LabDeck’s Stat Studio offers a complete package for anyone looking to perform STAT Data Modeling software. With its combination of advanced analysis features, flexible data handling, and customizable visualization options, Stat Studio is a powerful tool for both novice and experienced statisticians alike. Whether you're conducting regression analysis, creating intricate data visualizations, or preparing your data for publication, Stat Studio provides the precision, efficiency, and versatility you need to succeed.
To learn more about how Stat Studio can revolutionize your data analysis process, visit the official page here.
Embrace the power of Stat Studio and take your data modeling to new heights!
2 notes
·
View notes
Text
From Beginner to Pro: A Game-Changing Big Data Analytics Course
Are you fascinated by the vast potential of big data analytics? Do you want to unlock its power and become a proficient professional in this rapidly evolving field? Look no further! In this article, we will take you on a journey to traverse the path from being a beginner to becoming a pro in big data analytics. We will guide you through a game-changing course designed to provide you with the necessary information and education to master the art of analyzing and deriving valuable insights from large and complex data sets.

Step 1: Understanding the Basics of Big Data Analytics
Before diving into the intricacies of big data analytics, it is crucial to grasp its fundamental concepts and methodologies. A solid foundation in the basics will empower you to navigate through the complexities of this domain with confidence. In this initial phase of the course, you will learn:
The definition and characteristics of big data
The importance and impact of big data analytics in various industries
The key components and architecture of a big data analytics system
The different types of data and their relevance in analytics
The ethical considerations and challenges associated with big data analytics
By comprehending these key concepts, you will be equipped with the essential knowledge needed to kickstart your journey towards proficiency.
Step 2: Mastering Data Collection and Storage Techniques
Once you have a firm grasp on the basics, it's time to dive deeper and explore the art of collecting and storing big data effectively. In this phase of the course, you will delve into:
Data acquisition strategies, including batch processing and real-time streaming
Techniques for data cleansing, preprocessing, and transformation to ensure data quality and consistency
Storage technologies, such as Hadoop Distributed File System (HDFS) and NoSQL databases, and their suitability for different types of data
Understanding data governance, privacy, and security measures to handle sensitive data in compliance with regulations
By honing these skills, you will be well-prepared to handle large and diverse data sets efficiently, which is a crucial step towards becoming a pro in big data analytics.
Step 3: Exploring Advanced Data Analysis Techniques
Now that you have developed a solid foundation and acquired the necessary skills for data collection and storage, it's time to unleash the power of advanced data analysis techniques. In this phase of the course, you will dive into:
Statistical analysis methods, including hypothesis testing, regression analysis, and cluster analysis, to uncover patterns and relationships within data
Machine learning algorithms, such as decision trees, random forests, and neural networks, for predictive modeling and pattern recognition
Natural Language Processing (NLP) techniques to analyze and derive insights from unstructured text data
Data visualization techniques, ranging from basic charts to interactive dashboards, to effectively communicate data-driven insights
By mastering these advanced techniques, you will be able to extract meaningful insights and actionable recommendations from complex data sets, transforming you into a true big data analytics professional.
Step 4: Real-world Applications and Case Studies
To solidify your learning and gain practical experience, it is crucial to apply your newfound knowledge in real-world scenarios. In this final phase of the course, you will:
Explore various industry-specific case studies, showcasing how big data analytics has revolutionized sectors like healthcare, finance, marketing, and cybersecurity
Work on hands-on projects, where you will solve data-driven problems by applying the techniques and methodologies learned throughout the course
Collaborate with peers and industry experts through interactive discussions and forums to exchange insights and best practices
Stay updated with the latest trends and advancements in big data analytics, ensuring your knowledge remains up-to-date in this rapidly evolving field
By immersing yourself in practical applications and real-world challenges, you will not only gain valuable experience but also hone your problem-solving skills, making you a well-rounded big data analytics professional.

Through a comprehensive and game-changing course at ACTE institute, you can gain the necessary information and education to navigate the complexities of this field. By understanding the basics, mastering data collection and storage techniques, exploring advanced data analysis methods, and applying your knowledge in real-world scenarios, you have transformed into a proficient professional capable of extracting valuable insights from big data.
Remember, the world of big data analytics is ever-evolving, with new challenges and opportunities emerging each day. Stay curious, seek continuous learning, and embrace the exciting journey ahead as you unlock the limitless potential of big data analytics.
17 notes
·
View notes
Text
Understanding Different Types of Variables in Statistical Analysis
Summary: This blog delves into the types of variables in statistical analysis, including quantitative (continuous and discrete) and qualitative (nominal and ordinal). Understanding these variables is critical for practical data interpretation and statistical analysis.

Introduction
Statistical analysis is crucial in research and data interpretation, providing insights that guide decision-making and uncover trends. By analysing data systematically, researchers can draw meaningful conclusions and validate hypotheses.
Understanding the types of variables in statistical analysis is essential for accurate data interpretation. Variables representing different data aspects play a crucial role in shaping statistical results.
This blog aims to explore the various types of variables in statistical analysis, explaining their definitions and applications to enhance your grasp of how they influence data analysis and research outcomes.
What is Statistical Analysis?
Statistical analysis involves applying mathematical techniques to understand, interpret, and summarise data. It transforms raw data into meaningful insights by identifying patterns, trends, and relationships. The primary purpose is to make informed decisions based on data, whether for academic research, business strategy, or policy-making.
How Statistical Analysis Helps in Drawing Conclusions
Statistical analysis aids in concluding by providing a structured approach to data examination. It involves summarising data through measures of central tendency (mean, median, mode) and variability (range, variance, standard deviation). By using these summaries, analysts can detect trends and anomalies.
More advanced techniques, such as hypothesis testing and regression analysis, help make predictions and determine the relationships between variables. These insights allow decision-makers to base their actions on empirical evidence rather than intuition.
Types of Statistical Analyses
Analysts can effectively interpret data, support their findings with evidence, and make well-informed decisions by employing both descriptive and inferential statistics.
Descriptive Statistics: This type focuses on summarising and describing the features of a dataset. Techniques include calculating averages and percentages and crating visual representations like charts and graphs. Descriptive statistics provide a snapshot of the data, making it easier to understand and communicate.
Inferential Statistics: Inferential analysis goes beyond summarisation to make predictions or generalisations about a population based on a sample. It includes hypothesis testing, confidence intervals, and regression analysis. This type of analysis helps conclude a broader context from the data collected from a smaller subset.
What are Variables in Statistical Analysis?
In statistical analysis, a variable represents a characteristic or attribute that can take on different values. Variables are the foundation for collecting and analysing data, allowing researchers to quantify and examine various study aspects. They are essential components in research, as they help identify patterns, relationships, and trends within the data.
How Variables Represent Data
Variables act as placeholders for data points and can be used to measure different aspects of a study. For instance, variables might include test scores, study hours, and socioeconomic status in a survey of student performance.
Researchers can systematically analyse how different factors influence outcomes by assigning numerical or categorical values to these variables. This process involves collecting data, organising it, and then applying statistical techniques to draw meaningful conclusions.
Importance of Understanding Variables
Understanding variables is crucial for accurate data analysis and interpretation. Continuous, discrete, nominal, and ordinal variables affect how data is analysed and interpreted. For example, continuous variables like height or weight can be measured precisely. In contrast, nominal variables like gender or ethnicity categorise data without implying order.
Researchers can apply appropriate statistical methods and avoid misleading results by correctly identifying and using variables. Accurate analysis hinges on a clear grasp of variable types and their roles in the research process, interpreting data more reliable and actionable.
Types of Variables in Statistical Analysis

Understanding the different types of variables in statistical analysis is crucial for practical data interpretation and decision-making. Variables are characteristics or attributes that researchers measure and analyse to uncover patterns, relationships, and insights. These variables can be broadly categorised into quantitative and qualitative types, each with distinct characteristics and significance.
Quantitative Variables
Quantitative variables represent measurable quantities and can be expressed numerically. They allow researchers to perform mathematical operations and statistical analyses to derive insights.
Continuous Variables
Continuous variables can take on infinite values within a given range. These variables can be measured precisely, and their values are not limited to specific discrete points.
Examples of continuous variables include height, weight, temperature, and time. For instance, a person's height can be measured with varying degrees of precision, from centimetres to millimetres, and it can fall anywhere within a specific range.
Continuous variables are crucial for analyses that require detailed and precise measurement. They enable researchers to conduct a wide range of statistical tests, such as calculating averages and standard deviations and performing regression analyses. The granularity of continuous variables allows for nuanced insights and more accurate predictions.
Discrete Variables
Discrete variables can only take on separate values. Unlike continuous variables, discrete variables cannot be subdivided into finer increments and are often counted rather than measured.
Examples of discrete variables include the number of students in a class, the number of cars in a parking lot, and the number of errors in a software application. For instance, you can count 15 students in a class, but you cannot have 15.5 students.
Discrete variables are essential when counting or categorising is required. They are often used in frequency distributions and categorical data analysis. Statistical methods for discrete variables include chi-square tests and Poisson regression, which are valuable for analysing count-based data and understanding categorical outcomes.
Qualitative Variables
Qualitative or categorical variables describe characteristics or attributes that cannot be measured numerically but can be classified into categories.
Nominal Variables
Nominal variables categorise data without inherent order or ranking. These variables represent different categories or groups that are mutually exclusive and do not have a natural sequence.
Examples of nominal variables include gender, ethnicity, and blood type. For instance, gender can be classified as male, female, and non-binary. However, there is no inherent ranking between these categories.
Nominal variables classify data into distinct groups and are crucial for categorical data analysis. Statistical techniques like frequency tables, bar charts, and chi-square tests are commonly employed to analyse nominal variables. Understanding nominal variables helps researchers identify patterns and trends across different categories.
Ordinal Variables
Ordinal variables represent categories with a meaningful order or ranking, but the differences between the categories are not necessarily uniform or quantifiable. These variables provide information about the relative position of categories.
Examples of ordinal variables include education level (e.g., high school, bachelor's degree, master's degree) and customer satisfaction ratings (e.g., poor, fair, good, excellent). The categories have a specific order in these cases, but the exact distance between the ranks is not defined.
Ordinal variables are essential for analysing data where the order of categories matters, but the precise differences between categories are unknown. Researchers use ordinal scales to measure attitudes, preferences, and rankings. Statistical techniques such as median, percentiles, and ordinal logistic regression are employed to analyse ordinal data and understand the relative positioning of categories.
Comparison Between Quantitative and Qualitative Variables
Quantitative and qualitative variables serve different purposes and are analysed using distinct methods. Understanding their differences is essential for choosing the appropriate statistical techniques and drawing accurate conclusions.
Measurement: Quantitative variables are measured numerically and can be subjected to arithmetic operations, whereas qualitative variables are classified without numerical measurement.
Analysis Techniques: Quantitative variables are analysed using statistical methods like mean, standard deviation, and regression analysis, while qualitative variables are analysed using frequency distributions, chi-square tests, and non-parametric techniques.
Data Representation: Continuous and discrete variables are often represented using histograms, scatter plots, and box plots. Nominal and ordinal variables are defined using bar charts, pie charts, and frequency tables.
Frequently Asked Questions
What are the main types of variables in statistical analysis?
The main variables in statistical analysis are quantitative (continuous and discrete) and qualitative (nominal and ordinal). Quantitative variables involve measurable data, while qualitative variables categorise data without numerical measurement.
How do continuous and discrete variables differ?
Continuous variables can take infinite values within a range and are measured precisely, such as height or temperature. Discrete variables, like the number of students, can only take specific, countable values and are not subdivisible.
What are nominal and ordinal variables in statistical analysis?
Nominal variables categorise data into distinct groups without any inherent order, like gender or blood type. Ordinal variables involve categories with a meaningful order but unequal intervals, such as education levels or satisfaction ratings.
Conclusion
Understanding the types of variables in statistical analysis is crucial for accurate data interpretation. By distinguishing between quantitative variables (continuous and discrete) and qualitative variables (nominal and ordinal), researchers can select appropriate statistical methods and draw valid conclusions. This clarity enhances the quality and reliability of data-driven insights.
#Understanding Different Types of Variables in Statistical Analysis#Variables in Statistical Analysis#Statistical Analysis#statistics#data science
4 notes
·
View notes
Text

Gonna have to write a "proper" headcanon post on this some other day when my back isn't killing me because I stupidly pulled a muscle but anyway - finally, a quick summary of Dottore's Fun And Happy And Wholesome Two Years of ToniToni Guardianship Arc (pt. 1 of ???)
Simply put, after taking Tonia back to his laboratories under Zapolyarny Palace, the following two years were filled with a never-ending series of experiments.
These experiments could be broadly organized into three types: physical, mental, and anything that didn't fit into the previous categories.
The mental tests were done first, if only because Dottore knew that the eventual prolonged entrapment and the experiences of future experiments might have an effect as is on her - and since she was still a "fresh" subject, her mental state would still be alert and stable enough to conduct such tests without needing to take too much consideration of an altered baseline for notes and comparison reasons.
Said mental testing wasn't too extensive and was considered completed (for the time being, anyway; Dottore definitely left a few notes to consider more mental tests in the future, if only to gauge any potentially interesting change in cognition - these particular tests never ended up happening though) within a relatively short period of time.
Physical testing followed suit, and ultimately, these tests took the greater bulk of time and hypothesis variety in the overall scheme of things.
In-between these experiments, Dottore also considered a handful of "side projects" related to Tonia - or rather, the results of the various experiments on her, using the derived insights to conduct derivative research and tests. These side projects count as the third type of experiments done during this time.
The most significant (and overall result) of these side projects include:
Improved technologies utilizing the elements and/or the leylines - this includes not just general tech for the public or weaponry for the Fatui, but also the stabilization and upgrading of Delusions. (Successful)
Cloning Tonia to create additional "master copies" for study. (Unsuccessful)
Creating an Irminsul-based creature from scratch. (Unsuccessful with a few exceptions)
Genetically-engineering pre-existing subjects into Irminsul-mixed hybrids. (Semi-successful, and had horrific consequences.)
#headcanons | (without love it cannot be seen);#era | (a reckoning will not be postponed indefinitely);#(will i ever actually write a thread abt tonitoni's (second) worst time of her life? likely not. but ill still talk about it anyway lmao)
0 notes
Text
Excel-Based Statistical Assignment Help – Introduction
Statistics plays a vital role in academic research, business forecasting, and data analysis. Excel is widely used for statistical operations due to its flexibility and functionality. However, many students find it challenging to complete statistical assignments using Excel due to its complexity. That's where our Excel-Based Statistical Assignment Help comes into play For More...
We offer fast, accurate, and easy solutions for all types of Excel-based statistical tasks. Whether you are dealing with data visualization, regression analysis, or probability calculations, our experts are ready to guide you step-by-step. Our service connects students directly with professional tutors who not only help you complete your assignments but also ensure you understand the concepts behind the solutions.
About Gritty Tech Academy
Gritty Tech Academy is a leading online learning platform focused on technical excellence. Our mission is to support students worldwide by offering personalized tutoring and academic help. We specialize in Excel, data science, and applied statistics, making us the perfect destination for Excel-Based Statistical Assignment Help.
Our academy hosts a team of qualified experts with advanced degrees and real-world experience in analytics, research, and academic support. Students who use our services receive more than just assignment completion—they gain valuable skills in using Excel for practical, data-driven decision-making. Gritty Tech Academy has earned trust for its high standards, confidentiality, and student-friendly approach.
Why Choose Us for Excel-Based Statistical Assignment Help
Choosing the right platform for your academic needs makes a big difference. Here’s why thousands of students prefer our Excel-Based Statistical Assignment Help:
Expert Tutors: Our tutors hold master’s and PhDs in statistics, mathematics, and data analytics. They are proficient in Excel and trained to handle assignments of any complexity.
Customized Solutions: Every assignment is solved from scratch based on your unique requirements.
Fast Turnaround: We understand deadlines. Our team delivers accurate work quickly without compromising quality.
Learning-Focused Approach: We explain every step so you learn while completing your assignment.
24/7 Availability: Reach out anytime you need help.
Plagiarism-Free Work: Each assignment is checked thoroughly to ensure originality.
Affordable Pricing: Quality help doesn’t have to be expensive. We provide value-driven pricing with no hidden charges.
Tutors’ Experience
Our team includes seasoned professionals with hands-on experience in:
Advanced Excel functions for statistics
Time series and trend analysis
Correlation and regression
ANOVA and hypothesis testing
Probability distributions
Descriptive and inferential statistics
With over 10 years of combined experience in Excel-based statistical tutoring, our tutors have helped students from various academic levels and backgrounds. They understand the common mistakes students make and focus on building strong foundations.
What Our Students Say – Testimonials
John M. – Business Student (USA) "I was struggling with my Excel statistics assignment, and Gritty Tech Academy saved me. The tutor walked me through every function used. Best Excel-Based Statistical Assignment Help I've received!"
Priya S. – Data Science Graduate (India) "I needed urgent help with hypothesis testing in Excel. Not only did I submit my assignment on time, but I also finally understood the logic. Truly expert-level support!"
Carlos R. – Economics Major (UK) "This service made Excel so much easier. Now I know how to create data models and charts for analysis. Highly recommended for any Excel-Based Statistical Assignment Help."
Frequently Asked Questions (FAQs)
1. What is Excel-Based Statistical Assignment Help? Excel-Based Statistical Assignment Help refers to expert assistance in completing statistics assignments using Excel functions, formulas, and data tools.
2. Who provides Excel-Based Statistical Assignment Help? Our experienced tutors, who specialize in both statistics and Excel, provide personalized help for your assignments.
3. Can I get help with urgent Excel-based statistics tasks? Yes, we offer fast and reliable Excel-Based Statistical Assignment Help even for tight deadlines without compromising quality.
4. Is the Excel-Based Statistical Assignment Help plagiarism-free? Absolutely. We ensure each assignment is custom-written, original, and free from any plagiarism.
5. Will I learn while getting Excel-Based Statistical Assignment Help? Yes, we believe in learning by doing. Our tutors explain every concept so you gain knowledge as well as solutions.
6. What topics are covered under Excel-Based Statistical Assignment Help? We cover all statistical topics including regression, probability, descriptive stats, ANOVA, forecasting, and more.
7. How do I get started with Excel-Based Statistical Assignment Help? Simply contact us with your assignment details, and we’ll assign a tutor who fits your needs. Quick and easy.
Conclusion
Statistics using Excel can be challenging, but with the right help, it becomes manageable and even enjoyable. Our Excel-Based Statistical Assignment Help service ensures that you not only submit your assignments on time but also develop the confidence to work independently in the future.
At Gritty Tech Academy, we bridge the gap between academic theory and practical application. Whether you’re a beginner or an advanced learner, our expert tutors are here to assist. Connect with us today and experience the difference in how Excel-based assignments can be completed with clarity and speed.
Excel-Based Statistical Assignment Help is not just about getting answers; it’s about understanding, efficiency, and growth. Trust Gritty Tech Academy to deliver quality you can rely on.
0 notes
Text
coursera project
Blog Entry: Exploring the Association Between Screen Time and Academic PerformanceDataset Choice:For this assignment, I have chosen to work with a hypothetical "Youth Health and Education Survey" (YOUTHES) dataset. This dataset is designed to capture various aspects of adolescent life, including health behaviors, academic engagement, and social factors.Research Question and Proposed Association:I am interested in exploring the association between screen time and academic performance among adolescents. Specifically, I want to investigate whether increased daily screen time (measured in hours) is associated with lower academic performance (measured by GPA or self-reported grades).Personal Codebook (YOUTHES Dataset - Excerpt)Below is a section of my personal codebook, focusing on the variables relevant to my chosen topics.Topic 1: Screen Time| Variable Name | Description | Response Options/Coding ||---|---|---|| SCREEN_DAILY_HRS | Average daily hours spent on screens (e.g., phone, computer, tablet, TV) for non-academic purposes. | Numeric (e.g., 0-10+ hours) || SCREEN_LEISURE | Hours spent on screens specifically for leisure activities (e.g., gaming, social media, streaming). | Numeric (e.g., 0-10+ hours) || DEVICE_OWNERSHIP | Does the respondent own a personal smartphone/tablet? | 1 = Yes, 0 = No |Topic 2: Academic Performance| Variable Name | Description | Response Options/Coding ||---|---|---|| GPA_CURRENT | Current self-reported Grade Point Average. | Numeric (e.g., 0.0 - 4.0 scale) || REPORT_GRADES | Self-reported typical grades in core subjects (e.g., Math, English). | 1 = Mostly A's, 2 = Mostly B's, 3 = Mostly C's, 4 = Mostly D's, 5 = Failing || HOMEWORK_HRS_WEEK | Average hours spent on homework per week. | Numeric (e.g., 0-20+ hours) |Literature ReviewSearch Terms Used:My literature review focused on terms such as "screen time academic performance," "digital media use grades adolescents," "social media impact student achievement," "smartphone use education," and "leisure screen time academic outcomes."References Used (Examples - you would include full bibliographic information for your actual references): * Reference 1: A study by Przybylski, A. K., & Weinstein, N. (2017). A large-scale test of the goldilocks hypothesis: Quantifying the relationship between digital-screen use and the mental well-being of adolescents. Psychological Science, 28(2), 204-215. (While not directly about academics, this explores optimal digital use and provides a foundational understanding). * Reference 2: A meta-analysis or systematic review on screen time and academic outcomes (e.g., typically found in journals like Computers & Education or Journal of School Health). For example, a hypothetical study by Smith, J., & Jones, A. (2020). The pervasive influence: A meta-analysis of screen time and academic achievement in adolescents. Journal of Adolescent Research, XX(X), XXX-XXX. * Reference 3: A qualitative study exploring student perceptions of screen time and its effect on their study habits (e.g., from Qualitative Health Research or Youth & Society). For example, a hypothetical study by Chen, L. (2021). "It's a distraction": Adolescent narratives on smartphone use and academic focus. Youth & Society, XX(X), XXX-XXX.Summary of Findings:The existing literature generally suggests a complex relationship between screen time and academic performance, often finding a negative association, especially when screen time is excessive and unsupervised. * Variables Considered: Studies frequently examine various facets of screen time, including total daily hours, specific types of screen use (e.g., social media, gaming, passive viewing), and the context of use (e.g., during homework, before bed). Academic performance is typically measured through GPA, standardized test scores, self-reported grades, or teacher assessments. Confounding variables like socio-economic status, parental involvement, sleep patterns, and physical activity are often controlled for in more robust studies. *
1 note
·
View note
Text
The Power of Quantitative Methods in Modern Research
In an era where data is considered the new oil, quantitative methods have emerged as the backbone of credible, data-driven research. These methods transform raw numbers into meaningful insights, helping professionals across various sectors make informed decisions with confidence.
Why Quantitative Methods Matter
Quantitative methods are essential because they bring structure and precision to the research process. By using numerical data, these methods allow for clear measurement, comparison, and statistical validation. This reduces the risk of bias and ensures that results can be replicated and scaled.
Whether you're working in business, academia, public policy, or technology, quantitative methods help answer key questions such as:
What is happening?
How often does it happen?
Is there a correlation or causal relationship?
Types of Quantitative Methods
Descriptive Research Used to summarize and describe features of a dataset. It includes frequencies, percentages, averages, and more.
Correlational Research Investigates the relationship between two or more variables without manipulating them.
Experimental Research Involves controlled experiments to establish cause-and-effect relationships.
Quasi-Experimental Research Similar to experimental research, but without random assignment—often used when true experiments are not feasible.
Tools and Techniques
Professionals using quantitative methods often rely on tools such as:
SPSS, R, or Python for statistical analysis
Excel for data entry and visualization
Surveys and structured questionnaires for data collection
They also use techniques like hypothesis testing, regression analysis, and factor analysis to interpret results.
Real-World Impact of Quantitative Methods
In marketing, they reveal consumer behavior trends and campaign performance.
In education, they help assess the effectiveness of teaching methods.
In healthcare, they guide treatment decisions based on clinical trial data.
In government, they shape public policy through population studies and economic forecasts.
Conclusion
The ability to harness and interpret data through quantitative methods is no longer optional—it’s a necessity. These methods provide clarity, credibility, and actionable insight in a world overflowing with information. Whether you're a student, researcher, or professional, building strong skills in quantitative methods is a smart investment in your future.
0 notes
Text
0 notes
Text
6 Types of Data Analysis That Help Decision-Makers| MAE
There are different methods of data analysis used by companies today. Some are similar to each other, some are complementary. Below, we’ll focus on the six key ways of analysing data that we believe to be most frequently used in various software projects. Let’s take a look.
1. Exploratory Analysis
The goal of this type of analysis is to visually examine existing data and potentially find relationships between variables that may have been unknown or overlooked. It can be useful for discovering new connections to form a hypothesis for further testing.
With an exploratory analysis, you try to get a general view of the data you have on-hand and let it speak for itself. This approach looks at digital information to find relationships and inform you of their existence, but it does not establish causality. For that, you’d have to conduct further analytical procedures.
2. Inferential Analysis
This type of analysis is all about using a sample of digital information to make inferences about a larger population. It is a common statistical approach that is generally present across various types of data analysis, but is particularly relevant in predictive analytics. This is because it essentially allows you to make forecasts about the behaviour of a larger population.
Here, it’s important to remember that the chosen sampling technique dictates the accuracy of the inference. If you choose a sample that isn’t representative of the population, the resulting generalizations will be inaccurate.
3. Descriptive Analysis
Now, we’ll be going into the terminology that is most widely used in the context of software development and that you may have already heard of.
Descriptive analysis is probably the most common type of data analysis employed by modern businesses. Its goal is to explain what happened by looking at historical data. So, it is precisely what is used to track KPIs and determine how the company is performing based on the chosen metrics.
Things like revenue or website visitor reports all rely on descriptive analysis, as do CRM dashboards that visually summarize leads acquired or deals closed. This approach merges data from various sources to deliver valuable insights about the past. Thus, helping you identify benchmarks and set new goals.
Find out how we helped a FinTech Company Unify Data from Disparate Systems
Of course, this technique isn’t very helpful in explaining why things are the way they are or recommending best courses of action. Hence, it’s a good idea to pair descriptive analysis with other types of data analytics.
4. Diagnostic Analysis
Once you’ve established what has occurred, it’s important to understand why it happened. This is where diagnostic analysis plays a role. It helps uncover connections between data and identify hidden patterns that may have caused an event.
By continuously leveraging this type of data analysis, you can quickly determine why issues arise by looking at historical information that may pertain to them. Thus, any problems that are interconnected can be swiftly discovered and dealt with.
For example, after conducting a descriptive analysis, you may learn that contact centre calls have become 60 seconds longer than they used to be. Naturally, you’d want to find out why. By employing diagnostic analysis at this point, your analysts will try to identify additional data sources that may explain this.
After looking at real-time call analytics, they might discover that some newly hired agents are struggling with finding relevant information to help the client, and this causes extra time to be spent on the search. Now that the problem is clearly identified, you’ll be able to deal with it in the most suitable manner.
Discover how a leading insurance firm benefited from a Real-Time Call Analytics Platform
5. Predictive Analysis
Now we’re moving on to some of the most exciting types of data analysis. Predictive analytics, as the name suggests, delivers forecasts regarding what is going to happen in the future. Often, it incorporates artificial intelligence and machine learning technologies to provide more accurate predictions in a faster manner.
Read up on the Role of AI in Business
Predictive analysis usually looks at patterns from historical data as well as insights about current events to make the most reliable forecast about what might happen in the future.
For example, in the manufacturing industry, historical information on machine failure can be supplemented with real-time data from connected devices to predict asset malfunctions and schedule timely maintenance.
If you’re looking to better manage your data and start employing analytical solutions — don’t hesitate to contact Mobile app experts because our company is the best mobile app development in India. Our team has vast expertise in delivering data analysis services that drive business growth and positively impact the bottom line.

#mobile app development#top app development companies#mobile application development#mobile app development company#mobile app developers
0 notes