#Web Data Collection Services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Unleashing the Power of Data: How Web Data Collection Services Can Propel Your Business Forward

Are you looking for a comprehensive guide on restaurant menu scraping? Look no further! In this ultimate guide, we will walk you through the process of scraping restaurant data, providing you with all the necessary tools and techniques to obtain valuable information from restaurant menus.
Restaurants have a wealth of data within their menus, including prices, ingredients, and special dishes. However, manually extracting this data can be time-consuming and tedious. That’s where a restaurant menu scraper comes in handy. With the right scraper, you can quickly and efficiently extract menu data, saving you hours of manual work.
In this article, we will explore different types of restaurant menu scrapers, their features, and how to choose the best one for your needs. We will also dive into the legal and ethical considerations of scraping restaurant menus, ensuring that you stay on the right side of the law while accessing this valuable data.
Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide will equip you with the knowledge and tools you need to successfully scrape restaurant menus. So, let’s get started and unlock the unlimited possibilities of restaurant menu scraping!
Understanding the Benefits of Restaurant Menu Scraping
Scraping restaurant menus offers numerous benefits for both restaurant owners and data enthusiasts. For restaurant owners, menu scraping can provide valuable insights into their competitors’ offerings, pricing strategies, and popular dishes. This information can help them make informed decisions to stay ahead in the market.
Data enthusiasts, on the other hand, can leverage restaurant menu scraping to analyze trends, identify popular ingredients, and even predict customer preferences. This data can be used to develop innovative culinary concepts, create personalized dining experiences, or even build restaurant recommendation systems.
Restaurant menu scraping can also be useful for food bloggers, food critics, and review websites. By extracting data from various menus, they can provide detailed and up-to-date information to their readers, enhancing the overall dining experience.
Common Challenges in Restaurant Menu Scraping
While restaurant menu scraping offers numerous benefits, it is not without its challenges. One of the major challenges is the dynamic nature of restaurant menus. Menus are often updated regularly, with changes in prices, seasonal dishes, and ingredients. This constant change makes it crucial to have a scraper that can adapt and capture the latest data accurately.
Another challenge is the variability in menu layouts and formats. Each restaurant may have a unique menu design, making it difficult to create a one-size-fits-all scraper. Scraping tools need to be flexible and capable of handling different menu structures to ensure accurate data extraction.
Additionally, some restaurants may implement anti-scraping measures to protect their data. These measures can include CAPTCHAs, IP blocking, or even legal action against scrapers. Overcoming these challenges requires advanced scraping techniques and adherence to legal and ethical guidelines.
Step-by-step Guide on How to Scrape Restaurant Data
Now that we understand the benefits and challenges of restaurant menu scraping, let’s dive into the step-by-step process of scraping restaurant data. It is important to note that the exact steps may vary depending on the scraping tool you choose and the specific website you are targeting. However, the general process remains the same.
1. Identify the target restaurant: Start by choosing the restaurant whose menu you want to scrape. Consider factors such as relevance, popularity, and availability of online menus.
2. Select a scraping tool: There are several scraping tools available in the market, ranging from simple web scrapers to sophisticated data extraction platforms. Research and choose a tool that aligns with your requirements and budget.
3. Analyze the target website: Before scraping, familiarize yourself with the structure and layout of the target restaurant’s website. Identify the HTML elements that contain the menu data you want to extract.
4. Set up your scraper: Configure your scraping tool to target the specific HTML elements and extract the desired data. This may involve writing custom scripts, using CSS selectors, or utilizing pre-built scraping templates.
5. Run the scraper: Once your scraper is set up, initiate the scraping process. Monitor the progress and ensure that the scraper is capturing the data accurately. Adjust the scraper settings if necessary.
6. Clean and format the data: After scraping, the raw data may require cleaning and formatting to remove any inconsistencies or unwanted information. Depending on your needs, you may need to convert the data into a structured format such as CSV or JSON.
7. Validate the extracted data: It is important to validate the accuracy of the extracted data by cross-referencing it with the original menu. This step helps identify any errors or missing information that may have occurred during the scraping process.
8. Store and analyze the data: Once the data is cleaned and validated, store it in a secure location. You can then analyze the data using various statistical and data visualization tools to gain insights and make informed decisions.
By following these steps, you can successfully scrape restaurant menus and unlock a wealth of valuable data.
Choosing the Right Tools for Restaurant Menu Scraping
When it comes to restaurant menu scraping, choosing the right tools is crucial for a successful scraping project. Here are some factors to consider when selecting a scraping tool:
1. Scalability: Ensure that the scraping tool can handle large volumes of data and can scale with your business needs. This is especially important if you plan to scrape multiple restaurant menus or regularly update your scraped data.
2. Flexibility: Look for a tool that can handle different menu layouts and formats. The scraper should be able to adapt to changes in the structure of the target website and capture data accurately.
3. Ease of use: Consider the user-friendliness of the scraping tool. Look for features such as a visual interface, pre-built templates, and easy customization options. This will make the scraping process more efficient and accessible to users with varying levels of technical expertise.
4. Data quality and accuracy: Ensure that the scraping tool provides accurate and reliable data extraction. Look for features such as data validation, error handling, and data cleansing capabilities.
5. Support and documentation: Check the availability of support resources such as documentation, tutorials, and customer support. A robust support system can help you troubleshoot issues and make the most out of your scraping tool.
By carefully evaluating these factors, you can choose a scraping tool that meets your specific requirements and ensures a smooth and successful scraping process.
Best Practices for Restaurant Menu Scraping
To ensure a successful restaurant menu scraping project, it is important to follow best practices and adhere to ethical guidelines. Here are some key practices to keep in mind:
1. Respect website terms and conditions: Before scraping, review the terms and conditions of the target website. Some websites explicitly prohibit scraping, while others may have specific guidelines or restrictions. Ensure that your scraping activities comply with these terms to avoid legal consequences.
2. Implement rate limiting: To avoid overwhelming the target website with excessive requests, implement rate limiting in your scraping tool. This helps prevent IP blocking or other anti-scraping measures.
3. Use proxies: Consider using proxies to mask your IP address and distribute scraping requests across multiple IP addresses. Proxies help maintain anonymity and reduce the risk of IP blocking.
4. Monitor website changes: Regularly monitor the target website for any changes in menu structure or layout. Update your scraping tool accordingly to ensure continued data extraction.
5. Be considerate of website resources: Scraping can put a strain on website resources. Be mindful of the impact your scraping activities may have on the target website’s performance. Avoid excessive scraping or scraping during peak hours.
By following these best practices, you can maintain a respectful and ethical approach to restaurant menu scraping.
Legal Considerations When Scraping Restaurant Menus
Scraping restaurant menus raises legal considerations that must be taken seriously. While scraping is not illegal per se, it can potentially infringe upon copyright, intellectual property, and terms of service agreements. Here are some legal factors to consider:
1. Copyright infringement: The content of restaurant menus, including descriptions, images, and branding, may be protected by copyright. It is important to obtain permission from the restaurant or the copyright holder before using or redistributing scraped menu data.
2. Terms of service agreements: Review the terms of service of the target website to ensure that scraping is not explicitly prohibited. Even if scraping is allowed, there may be specific restrictions on data usage or redistribution.
3. Data privacy laws: Scrapped data may contain personal information, such as customer names or contact details. Ensure compliance with data privacy laws, such as the General Data Protection Regulation (GDPR) in the European Union, by anonymizing or removing personal information from the scraped data.
4. Competitor analysis: While scraping competitor menus can provide valuable insights, be cautious of any anti-competitive behavior. Avoid using scraped data to gain an unfair advantage or engage in price-fixing activities.
To avoid legal complications, consult with legal professionals and ensure that your scraping activities are conducted in accordance with applicable laws and regulations.
Advanced Techniques for Restaurant Menu Scraping
For more advanced scraping projects, you may encounter additional challenges that require specialized techniques. Here are some advanced techniques to consider:
1. Dynamic scraping: Some websites use JavaScript to dynamically load menu content. To scrape such websites, you may need to utilize headless browsers or JavaScript rendering engines that can execute JavaScript code and capture dynamically loaded data.
2. OCR for image-based menus: If the target menu is in image format, you can use Optical Character Recognition (OCR) tools to extract text from the images. OCR technology converts the text in images into machine-readable format, allowing you to extract data from image-based menus.
3. Natural language processing: To gain deeper insights from scraped menu data, consider applying natural language processing (NLP) techniques. NLP can be used to extract key information such as dish names, ingredients, and customer reviews from the scraped text.
4. Machine learning for menu classification: If you have a large collection of scraped menus, you can employ machine learning algorithms to classify menus based on cuisine type, pricing range, or other categories. This can help streamline data analysis and enhance menu recommendation systems.
By exploring these advanced techniques, you can take your restaurant menu scraping projects to the next level and unlock even more valuable insights.
Case Studies of Successful Restaurant Menu Scraping Projects
To illustrate the practical applications of restaurant menu scraping, let’s explore some real-world case studies:
1. Competitor analysis: A restaurant owner wanted to gain a competitive edge by analyzing the menus of their direct competitors. By scraping and analyzing the menus, they were able to identify pricing trends, popular dishes, and unique offerings. This allowed them to adjust their own menu and pricing strategy to attract more customers.
2. Food blog creation: A food blogger wanted to create a comprehensive food blog featuring detailed information about various restaurants. By scraping menus from different restaurants, they were able to provide accurate and up-to-date information to their readers. This increased the blog’s credibility and attracted a larger audience.
3. Data-driven restaurant recommendations: A data enthusiast developed a restaurant recommendation system based on scraped menu data. By analyzing menus, customer reviews, and other factors, the system provided personalized restaurant suggestions to users. This enhanced the dining experience by matching users with restaurants that align with their preferences.
These case studies highlight the diverse applications and benefits of restaurant menu scraping in various industries.
Conclusion: Leveraging Restaurant Menu Scraping for Business Success
Restaurant menu scraping presents a wealth of opportunities for restaurant owners, data enthusiasts, bloggers, and various other stakeholders. By leveraging the power of scraping tools and techniques, you can unlock valuable insights, make data-driven decisions, and stay ahead in the competitive restaurant industry.
In this ultimate guide, we have explored the benefits and challenges of restaurant menu scraping, provided a step-by-step guide on how to scrape restaurant data, discussed the importance of choosing the right tools and following best practices, and highlighted legal considerations and advanced techniques. We have also shared case studies showcasing the practical applications of restaurant menu scraping.
Now it’s your turn to dive into the world of restaurant menu scraping and unlock the unlimited possibilities it offers. Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide has equipped you with the knowledge and tools you need to succeed. So, let’s get scraping and make the most out of restaurant menu data!
Know more : https://medium.com/@actowiz/ultimate-guide-to-restaurant-menu-scraper-how-to-scrape-restaurant-data-a8d252495ab8
#Web Data Collection Services#Data Collection Services#Web Scraping Services#Data Mining Services#Data Extraction Services
0 notes
Text
ok but once again. the small niche userbase needs to be loyal in a way that is profitable or else RadioShackTM goes away anyways in a few years when investors finally get bored of playing hot potato with the money pit. I agree they shouldn't pivot away from their roots and we should be very loud when we don't like the direction of shilling out and copying the Big Stores, but dear god we must understand that they cannot continue to give out capacitors for free
Does anyone remember what happened to Radio Shack?
They started out selling niche electronics supplies. Capacitors and transformers and shit. This was never the most popular thing, but they had an audience, one that they had a real lock on. No one else was doing that, so all the electronics geeks had to go to them, back in the days before online ordering. They branched out into other electronics too, but kept doing the electronic components.
Eventually they realize that they are making more money selling cell phones and remote control cars than they were with those electronic components. After all, everyone needs a cellphone and some electronic toys, but how many people need a multimeter and some resistors?
So they pivoted, and started only selling that stuff. All cellphones, all remote control cars, stop wasting store space on this niche shit.
And then Walmart and Target and Circuit City and Best Buy ate their lunch. Those companies were already running big stores that sold cellphones and remote control cars, and they had more leverage to get lower prices and selling more stuff meant they had more reasons to go in there, and they couldn't compete. Without the niche electronics stuff that had been their core brand, there was no reason to go to their stores. Everything they sold, you could get elsewhere, and almost always for cheaper, and probably you could buy 5 other things you needed while you were there, stuff Radio Shack didn't sell.
And Radio Shack is gone now. They had a small but loyal customer base that they were never going to lose, but they decided to switch to a bigger but more fickle customer base, one that would go somewhere else for convenience or a bargain. Rather than stick with what they were great at (and only they could do), they switched to something they were only okay at... putting them in a bigger pond with a lot of bigger fish who promptly out-competed them.
If Radio Shack had stayed with their core audience, who knows what would have happened? Maybe they wouldn't have made a billion dollars, but maybe they would still be around, still serving that community, still getting by. They may have had a small audience, but they had basically no competition for that audience. But yeah, we only know for sure what would happen if they decided to attempt to go more mainstream: They fail and die. We know for sure because that's what they did.
I don't know why I keep thinking about the story of what happened to Radio Shack. It just keeps feeling relevant for some reason.
#this is me saying: almost no one pays for ad free#i know a lot of tumblr users are BrokeTM#but if you are not broke#please consider paying for this site like you actually want it to keep going#I basically think of it like buying a movie ticket each month#only the movie is like 8 hours a day for the whole month if i want it to be#like they can either sell out or they can sell you a service#but remember the old adage: if something is free then YOU are the product#and tumblr is CLEARLY making good faith attempts to not resort to collecting and selling data#they WANT to sell you a product: their webbed site#instead of selling YOU and your privacy and eyeballs/attention to their investors/advertisers#like buy ad free participate in crab day buy some fuckin shoelaces or a checkmark idc what#but dont pretend that a company that is constantly losing money#is somehow being unreasonable#when they try to make any god damned money#your anticapitalism wont keep the servers running#and even if staff was 100% anticapitalist that wouldn't keep the servers running EITHER#so either buy out the servers and turn tumblr into a crowdfunded fuckin coop or whateverthefuck#or pay them so THEY can deal with running the hellsite moneypit#SORRY for ranting in the tags#i hate the updates as much as yall#but I just. have seen some deeply frustrating attitudes this week
34K notes
·
View notes
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note
Text
Discover the benefits of automated web data collection in cutting down operational costs. This innovative approach harnesses technology to gather and analyze data efficiently, leading to significant cost reductions and improved business insights. Learn how businesses can leverage this method to enhance productivity and make data-driven decisions. Explore strategies and case studies in our detailed blog to understand the potential savings and operational efficiencies achievable through automation.
0 notes
Text
Mastering Virtual Assistant Success: Essential Tips for Efficiency and Productivity
In today's fast-paced digital landscape, virtual assistants (VAs) play a crucial role in supporting businesses and entrepreneurs worldwide. As the demand for remote work continues to surge, mastering the art of virtual assistance has become paramount. Whether you're a seasoned VA or just starting in the field, implementing effective strategies can enhance your efficiency and productivity. Here are some invaluable tips to help you excel as a virtual assistant.

Cultivate Excellent Communication Skills: Effective communication lies at the heart of successful virtual assistance. Clear and concise communication ensures that tasks are understood correctly, deadlines are met, and expectations are managed. Utilize various communication channels such as email, instant messaging platforms, and video conferencing tools to stay connected with your clients. Actively listen to their needs, ask clarifying questions, and provide regular updates on your progress. Building a strong rapport through communication fosters trust and reliability, essential for long-term partnerships.
Embrace Time Management Techniques: Time management is key to juggling multiple tasks and meeting deadlines efficiently. Implement proven techniques like the Pomodoro Technique, time blocking, or using productivity apps to structure your workday effectively. Prioritize tasks based on urgency and importance, allocating sufficient time for each. Set realistic deadlines and strive to deliver quality results within the agreed-upon timeframe. Remember to factor in breaks to prevent burnout and maintain focus throughout the day.
Harness Technology Tools: Take advantage of a plethora of digital tools and software designed to streamline virtual assistance tasks. Project management platforms like Trello, Asana, or Monday.com can help you organize tasks, collaborate with team members, and track progress seamlessly. Use cloud storage services such as Google Drive or Dropbox to store and share files securely. Additionally, leverage automation tools like Zapier or IFTTT to automate repetitive tasks, saving time and increasing efficiency.
Develop Specialized Skills: Continuously expand your skill set to offer specialized services that cater to your clients' specific needs. Whether it's proficiency in graphic design, social media management, content writing, or bookkeeping, acquiring niche skills enhances your value as a virtual assistant. Invest in online courses, attend webinars, and stay updated with industry trends to stay ahead of the curve. Position yourself as an expert in your niche to attract high-paying clients and stand out in a competitive market.
Foster Professionalism and Integrity: Maintain professionalism in all your interactions with clients, colleagues, and stakeholders. Honor confidentiality agreements and handle sensitive information with the utmost discretion. Be transparent about your capabilities, availability, and pricing structure from the outset to avoid misunderstandings later on. Strive to exceed expectations by delivering exceptional work consistently and demonstrating reliability and integrity in your conduct.
Prioritize Self-Care: Amidst the demands of virtual assistance, don't overlook the importance of self-care. Set boundaries between work and personal life to prevent burnout and maintain overall well-being. Engage in regular exercise, practice mindfulness techniques, and allocate time for hobbies and leisure activities to recharge your batteries. Remember that a healthy work-life balance is essential for sustained productivity and job satisfaction.
Becoming a proficient virtual assistant requires a combination of effective communication, time management, technological proficiency, continuous learning, professionalism, and self-care. By implementing these tips, you can enhance your efficiency, productivity, and overall success in the dynamic world of virtual assistance. Embrace the journey of growth and development, and strive to deliver unparalleled value to your clients, forging lasting partnerships built on trust and excellence.
#fiverr#data entry services#data entry projects#virtual assistant#typing#data entry company#data collection#web scraping services
0 notes
Text
1 note
·
View note
Text
Grocery Delivery App Data Scraping - Grocery Delivery App Data Collection Service
Grocery Delivery App Data Scraping - Grocery Delivery App Data Collection Service
Shopping grocery online has become a significant trend. Web scraping grocery delivery data is helpful for retail industries to get business growth in the retail space.Data Scraping, we scrape grocery delivery app data and convert it into appropriate informational patterns and statistics.
https://www.iwebdatascraping.com/img/api-client/new_hp_image-1.png
Our grocery app scraper can quickly extract data from grocery apps, including product full name, SKU, product URL, categories, subcategories, price, discounted price, etc. Our grocery menu data scraping services are helpful for multiple applications or business requirements through different analytics. Leverage the benefits of our grocery app listing data scraping services across USA, UK, India, Australia, Germany, France, UAE, Spain, and Dubai to gather retail data from different applications and use it for market research and data analysis.
#Grocery Delivery App Data Scraping#Grocery Delivery App Data Collection Service#Web scraping grocery delivery data#grocery menu data scraping services
0 notes
Text
What kind of bubble is AI?
My latest column for Locus Magazine is "What Kind of Bubble is AI?" All economic bubbles are hugely destructive, but some of them leave behind wreckage that can be salvaged for useful purposes, while others leave nothing behind but ashes:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Think about some 21st century bubbles. The dotcom bubble was a terrible tragedy, one that drained the coffers of pension funds and other institutional investors and wiped out retail investors who were gulled by Superbowl Ads. But there was a lot left behind after the dotcoms were wiped out: cheap servers, office furniture and space, but far more importantly, a generation of young people who'd been trained as web makers, leaving nontechnical degree programs to learn HTML, perl and python. This created a whole cohort of technologists from non-technical backgrounds, a first in technological history. Many of these people became the vanguard of a more inclusive and humane tech development movement, and they were able to make interesting and useful services and products in an environment where raw materials – compute, bandwidth, space and talent – were available at firesale prices.
Contrast this with the crypto bubble. It, too, destroyed the fortunes of institutional and individual investors through fraud and Superbowl Ads. It, too, lured in nontechnical people to learn esoteric disciplines at investor expense. But apart from a smattering of Rust programmers, the main residue of crypto is bad digital art and worse Austrian economics.
Or think of Worldcom vs Enron. Both bubbles were built on pure fraud, but Enron's fraud left nothing behind but a string of suspicious deaths. By contrast, Worldcom's fraud was a Big Store con that required laying a ton of fiber that is still in the ground to this day, and is being bought and used at pennies on the dollar.
AI is definitely a bubble. As I write in the column, if you fly into SFO and rent a car and drive north to San Francisco or south to Silicon Valley, every single billboard is advertising an "AI" startup, many of which are not even using anything that can be remotely characterized as AI. That's amazing, considering what a meaningless buzzword AI already is.
So which kind of bubble is AI? When it pops, will something useful be left behind, or will it go away altogether? To be sure, there's a legion of technologists who are learning Tensorflow and Pytorch. These nominally open source tools are bound, respectively, to Google and Facebook's AI environments:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
But if those environments go away, those programming skills become a lot less useful. Live, large-scale Big Tech AI projects are shockingly expensive to run. Some of their costs are fixed – collecting, labeling and processing training data – but the running costs for each query are prodigious. There's a massive primary energy bill for the servers, a nearly as large energy bill for the chillers, and a titanic wage bill for the specialized technical staff involved.
Once investor subsidies dry up, will the real-world, non-hyperbolic applications for AI be enough to cover these running costs? AI applications can be plotted on a 2X2 grid whose axes are "value" (how much customers will pay for them) and "risk tolerance" (how perfect the product needs to be).
Charging teenaged D&D players $10 month for an image generator that creates epic illustrations of their characters fighting monsters is low value and very risk tolerant (teenagers aren't overly worried about six-fingered swordspeople with three pupils in each eye). Charging scammy spamfarms $500/month for a text generator that spits out dull, search-algorithm-pleasing narratives to appear over recipes is likewise low-value and highly risk tolerant (your customer doesn't care if the text is nonsense). Charging visually impaired people $100 month for an app that plays a text-to-speech description of anything they point their cameras at is low-value and moderately risk tolerant ("that's your blue shirt" when it's green is not a big deal, while "the street is safe to cross" when it's not is a much bigger one).
Morganstanley doesn't talk about the trillions the AI industry will be worth some day because of these applications. These are just spinoffs from the main event, a collection of extremely high-value applications. Think of self-driving cars or radiology bots that analyze chest x-rays and characterize masses as cancerous or noncancerous.
These are high value – but only if they are also risk-tolerant. The pitch for self-driving cars is "fire most drivers and replace them with 'humans in the loop' who intervene at critical junctures." That's the risk-tolerant version of self-driving cars, and it's a failure. More than $100b has been incinerated chasing self-driving cars, and cars are nowhere near driving themselves:
https://pluralistic.net/2022/10/09/herbies-revenge/#100-billion-here-100-billion-there-pretty-soon-youre-talking-real-money
Quite the reverse, in fact. Cruise was just forced to quit the field after one of their cars maimed a woman – a pedestrian who had not opted into being part of a high-risk AI experiment – and dragged her body 20 feet through the streets of San Francisco. Afterwards, it emerged that Cruise had replaced the single low-waged driver who would normally be paid to operate a taxi with 1.5 high-waged skilled technicians who remotely oversaw each of its vehicles:
https://www.nytimes.com/2023/11/03/technology/cruise-general-motors-self-driving-cars.html
The self-driving pitch isn't that your car will correct your own human errors (like an alarm that sounds when you activate your turn signal while someone is in your blind-spot). Self-driving isn't about using automation to augment human skill – it's about replacing humans. There's no business case for spending hundreds of billions on better safety systems for cars (there's a human case for it, though!). The only way the price-tag justifies itself is if paid drivers can be fired and replaced with software that costs less than their wages.
What about radiologists? Radiologists certainly make mistakes from time to time, and if there's a computer vision system that makes different mistakes than the sort that humans make, they could be a cheap way of generating second opinions that trigger re-examination by a human radiologist. But no AI investor thinks their return will come from selling hospitals that reduce the number of X-rays each radiologist processes every day, as a second-opinion-generating system would. Rather, the value of AI radiologists comes from firing most of your human radiologists and replacing them with software whose judgments are cursorily double-checked by a human whose "automation blindness" will turn them into an OK-button-mashing automaton:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
The profit-generating pitch for high-value AI applications lies in creating "reverse centaurs": humans who serve as appendages for automation that operates at a speed and scale that is unrelated to the capacity or needs of the worker:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
But unless these high-value applications are intrinsically risk-tolerant, they are poor candidates for automation. Cruise was able to nonconsensually enlist the population of San Francisco in an experimental murderbot development program thanks to the vast sums of money sloshing around the industry. Some of this money funds the inevitabilist narrative that self-driving cars are coming, it's only a matter of when, not if, and so SF had better get in the autonomous vehicle or get run over by the forces of history.
Once the bubble pops (all bubbles pop), AI applications will have to rise or fall on their actual merits, not their promise. The odds are stacked against the long-term survival of high-value, risk-intolerant AI applications.
The problem for AI is that while there are a lot of risk-tolerant applications, they're almost all low-value; while nearly all the high-value applications are risk-intolerant. Once AI has to be profitable – once investors withdraw their subsidies from money-losing ventures – the risk-tolerant applications need to be sufficient to run those tremendously expensive servers in those brutally expensive data-centers tended by exceptionally expensive technical workers.
If they aren't, then the business case for running those servers goes away, and so do the servers – and so do all those risk-tolerant, low-value applications. It doesn't matter if helping blind people make sense of their surroundings is socially beneficial. It doesn't matter if teenaged gamers love their epic character art. It doesn't even matter how horny scammers are for generating AI nonsense SEO websites:
https://twitter.com/jakezward/status/1728032634037567509
These applications are all riding on the coattails of the big AI models that are being built and operated at a loss in order to be profitable. If they remain unprofitable long enough, the private sector will no longer pay to operate them.
Now, there are smaller models, models that stand alone and run on commodity hardware. These would persist even after the AI bubble bursts, because most of their costs are setup costs that have already been borne by the well-funded companies who created them. These models are limited, of course, though the communities that have formed around them have pushed those limits in surprising ways, far beyond their original manufacturers' beliefs about their capacity. These communities will continue to push those limits for as long as they find the models useful.
These standalone, "toy" models are derived from the big models, though. When the AI bubble bursts and the private sector no longer subsidizes mass-scale model creation, it will cease to spin out more sophisticated models that run on commodity hardware (it's possible that Federated learning and other techniques for spreading out the work of making large-scale models will fill the gap).
So what kind of bubble is the AI bubble? What will we salvage from its wreckage? Perhaps the communities who've invested in becoming experts in Pytorch and Tensorflow will wrestle them away from their corporate masters and make them generally useful. Certainly, a lot of people will have gained skills in applying statistical techniques.
But there will also be a lot of unsalvageable wreckage. As big AI models get integrated into the processes of the productive economy, AI becomes a source of systemic risk. The only thing worse than having an automated process that is rendered dangerous or erratic based on AI integration is to have that process fail entirely because the AI suddenly disappeared, a collapse that is too precipitous for former AI customers to engineer a soft landing for their systems.
This is a blind spot in our policymakers debates about AI. The smart policymakers are asking questions about fairness, algorithmic bias, and fraud. The foolish policymakers are ensnared in fantasies about "AI safety," AKA "Will the chatbot become a superintelligence that turns the whole human race into paperclips?"
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
But no one is asking, "What will we do if" – when – "the AI bubble pops and most of this stuff disappears overnight?"

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/12/19/bubblenomics/#pop
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
tom_bullock (modified) https://www.flickr.com/photos/tombullock/25173469495/
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/
4K notes
·
View notes
Text
"For over a decade, the Yosemite toad has been recognized as a federally threatened species, after experiencing a 50% population decline during the Rim Fire of 2013.
The wildfire, which encompassed a mass of land near Yosemite National Park, made the amphibian species especially vulnerable in its home habitat.
Native to the Sierra Nevada, the toads play a key role in the area’s ecosystem — and conservationists stepped in to secure their future.
In 2017, the San Francisco Zoo’s conservation team began working with the National Park Service, Yosemite Conservancy, U.S. Fish & Wildlife Service, California Department of Fish & Wildlife, and the U.S. Geological Survey.
The goal of all of these stakeholders? To raise their own Yosemite toads, re-establishing a self-sustaining population in the wild.

“Over the past several years, SF Zoo’s conservation team has been busily raising hundreds of these small but significant amphibians from tadpole stage, a species found only in the Sierra Nevada, for the purpose of reintroducing them to an area of Yosemite National Park where it was last seen 11 years ago,” the zoo shared on social media.
By 2022, a group of toads were deemed ready for release — and at the end of June of this year [2024], 118 toads were flown via helicopter back to their habitat.
“It’s the first time anyone has ever raised this species in captivity and released them to the wild,” Rochelle Stiles, field conservation manager at the San Francisco Zoo, told SFGATE. “It’s just incredible. It makes what we do at the zoo every day worthwhile.”
Over the past two years, these toads were fed a diet of crickets and vitamin supplements and were examined individually to ensure they were ready for wildlife release.
Zoo team members inserted a microchip into each toad to identify and monitor its health. In addition, 30 of the toads were equipped with radio transmitters, allowing their movements to be tracked using a radio receiver and antenna.
The project doesn’t end with this single wildlife release; it’s slated to take place over the next five years, as conservationists continue to collect data about the toads’ breeding conditions and survivability in an ever-changing climate. They will also continue to raise future toad groups at the zoo’s wellness and conservation center...
While the future of the Yosemite toad is still up in the air — and the uncertainty of climate change makes this a particularly audacious leap of faith — the reintroduction of these amphibians could have positive ripple effects for all of Yosemite.
Their re-entry could restore the population balance of invertebrates and small vertebrates that the toads consume, as well as balance the food web, serving as prey for snakes, birds, and other local predators.
“Zoo-reared toads can restore historic populations,” Nancy Chan, director of communications at the San Francisco Zoo, told SFGATE.
Stiles continued: “This is our backyard, our home, and we want to bring native species back to where they belong.”
-via GoodGoodGood, July 11, 2024
#yosemite#yosemite national park#california#united states#amphibian#frogs and toads#frogblr#frogposting#toadblr#toad#endangered species#wild animals#biodiversity#wildlife conservation#wildlife#good news#hope
1K notes
·
View notes
Note
Hi there! Firstly, wanna say a huge thank you: your blog has inspired me to become more educated about cybersecurity and nutrition, and it’s the reason my brother and I now use Firefox! I came across this article and… it seemed to raise a lot of valid points about Mozilla, but I have no idea if they are true or not since I’m not that knowledgeable about tech, and they go against everything I’ve ever heard about Firefox. Wanted to ask if you wouldn’t mind giving it a quick read, if that’s not too much trouble, and explaining why it’s false/true? If you can, ofc, I realise that is a weird request, and I promise it&: not something I’d usually ask someone. I just thought I’d ask since you’re the only sort of ‘tech’ person I can think of whom I’d trust to know stuff about this. https://digdeeper.neocities.org/articles/mozilla
So this is a great example of someone reading a ToS uncharitably and extracting the most paranoid bullshit possible.
Aside from the absolute classic "oh noes they are storing info about what devices you use" (if you use firefox logged in mozilla will collect information about what device and OS you use to connect; they do this for a lot of reasons like figuring out what stuff the bulk of their users are using but also because *they can't display on your device without that data*) I want to zoom in on this as an example:

BTW, there is one really funny thing inside the account ToS (MozArchive) that I just have to mention: "We may suspend or terminate your access to the Services at any time for any reason, including [...] our provision of the Services to you is no longer commercially viable." The fuck? If you stop bringing them profit, you're gone. They really said that! To me, this is a roundabout admission that your data is being sold. And if it's not worth much (for whatever reason), then you get kicked out.
This person is highlighting the idea that they may cut you off from services if the provision of those services is no longer commercially viable. This author is saying "FIREFOX WILL BOOT YOU WHEN YOU STOP BEING A PROFITABLE LITTLE PAYPIG FOR THEM"
But. Okay. Let's go look at that section of the ToS:

These Terms will continue to apply until ended by either you or Mozilla. You can choose to end them at any time for any reason by deleting your Mozilla account, discontinuing your use of the Services, and if applicable, unsubscribing from our emails. We may suspend or terminate your access to the Services at any time for any reason, including, but not limited to, if we reasonably believe: (i) you have violated these Terms, (ii) you create risk or possible legal exposure for us; or (iii) our provision of the Services to you is no longer commercially viable. We will make reasonable efforts to notify you by the email address associated with your Mozilla account or the next time you attempt to access the Services. In all such cases, these Terms shall terminate, including, without limitation, your license to use the Services, except that the following sections shall continue to apply: Indemnification, Disclaimer; Limitation of Liability, Miscellaneous.
Bud. This says "we are not obligated to provide services to you and we may stop providing services that cost us more money to maintain than is viable." This isn't about selling your data, this is about backwards compatibility and sunsetting projects. They don't have to keep providing access to services they're no longer developing nor bend over backwards to make sure that you can keep running a version of the browser that uses the extensions they dropped support for ten years ago.
Ugh. I got to the section where they talk about cucking for manifest3 and jesus this asshole. Manifest 3 is a defacto set of web standards that are changing because google has so much market share as a browser that if they do something everybody else has to follow or they're going to break basic functionality; if they don't make these changes eventually a shitload of websites just will not work on firefox. WAY more than currently experience this problem. Nobody is happy about manifest 3 and the fact that mozilla put out a press release about coming manifest 3 changes (that was not positive!) doesn't mean they're happy about getting dragged along by the nose; this blogger would prefer something like them refusing to adopt those standards, but all that would happen is that they'd lose more users because less shit would work on firefox browsers since people write their sites for chrome first and anything else second if at all.
This writer also gripes a lot about things like "mozilla took away this functionality for the sake of security and SURE you can change that by going into the configurations but it should be an option right in the first panel of the settings what are they really trying to hide???" and they're not trying to hide anything bud they're trying to make a functional browser with intuitive menus for people who aren't power users.
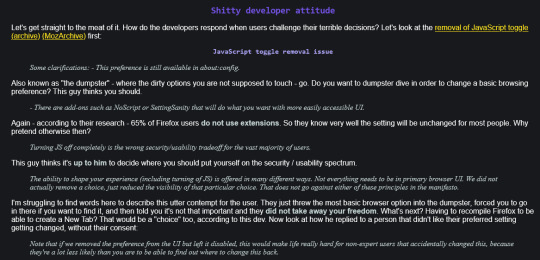
Like they want to be able to do everything they want and they want to be able to see the option in front of them at all times. It's a weird combination of "I know how to configure everything about this browser" and "if a setting is ever hidden behind a readmore it's a dark pattern and is an attack on user privacy." Like they gripe a lot about privacy and then link to a bunch of pages on mozilla where they explain their privacy settings and link to tutorials on how to hide the data that they just explained they collect.

Yeah this is someone I would walk away from in order to avoid getting into a fistfight.
"FOSS licenses are nice but they don't ensure quality" nobody said they did.
"FOSS licensed softwares don't always accept user participation in development" nobody said they did
"I can't change the actual code of firefox to remove things that I don't like don't tell me to fork it it has to be all or nothing mozilla specifically has to do what I want or it's user hostile" I can see why it would be hostile to you as a user fuck you dude this is why forks *exist* (also the "spyware" discussed is basic browser tracking stuff, the realistic necessities of how email work that make it not private by default like the PROTOCOLS are not private you can't get around that, and a lot of the stuff is opt out but improves functionality for day to day users, AND a lot of the tracking is specifically for people with logged-in accounts which are not necessary to use firefox like if you hate pocket don't use it my friend! I also hate pocket it is quite simple to never use it thanks)
"There's no justification for making the source code unavailable" my dude. https://hg.mozilla.org/mozilla-central/
"If they really cared about an open internet they'd work toward killing capitalism." Friend. I think there's very little more that a web browser could do to undermine the capitalist nature of huge chunks of the web and maintain a broad userbase than what firefox is doing.
I'm reminded of the time that I saw someone losing their shit about a linux distro that included chrome as *a* browser - not the default browser, but *a* browser.
It is an unpleasant fact that a lot of firefox's funding comes from google. That's part of why google is still the default search engine in Firefox and I read some similar articles decrying mozilla's residence firmly in Google's pocket a few years ago. I don't think there's anyone at mozilla who is genuinely pleased that their cheques are signed by google, but there are a ton of people at mozilla who are happy they can keep the lights on because getting paid by google means that they can do as much as they possibly can to create a functional browser that has a significant interest in privacy by default and that can be made *VERY* private by a dedicated user.
Anyway a lot of the stuff on this post is things like "a certificate expired five years ago and broke extensions and that means that mozilla is incompetent and hates users" or "eleven years ago there was a slapfight in the bug reporting forums between a user and a mod and the fact that the user was kicked after repeatedly being told his fix wasn't going to get made is censorship."
The big beefs at the center of this post are:
Mozilla collects data on users
Mozilla limits functionality that should be up to the users
Mozilla takes money from google
and my refutations are:
it does, and it is less than any other mainstream browser and is much much more transparent about what data is collected and how to prevent that data from being collected
A lot of the functionality they're discussing is still there and the stuff that isn't is allowing unsigned extensions which, dude, put a fork in it. They're not going to budge on unsigned extensions but the bar you have to clear to get signed is really really low; like this guy is LITERALLY saying "allow the installation of malicious extensions."
Yep. They do. This point reminds me of a lot of the people on tumblr who hate ads but also hate it when people pay for tumblr. As it turns out making things costs money, and making things used by millions of people costs *A LOT* of money.
I mean FFS one of the things this writer complains about is that Mozilla has a YouTube page.
This isn't just letting perfect be the enemy of good, it's letting perfect be the enemy of *functionally existing as a large organization in the modern world.*
Anyway, I'm glad you enjoy my blog, thank you for letting me know!
405 notes
·
View notes
Text
Mozilla Firefox has started sharing and selling your data and has now implemented a terms of service.
TL;DR: Mozilla has done the following to Firefox (edit)
They removed from their FAQ a statement that they'd never sell or collect your data. (So much for "never")
For the first time ever, they added a Terms of Use for Firefox which includes the ability to bar you from using Firefox for any reason by adding a Termination clause to their new Terms of Use.
Mozilla claims that there they're changing the language of 'selling of data' to avoid potential lawsuits due to "the broad and vague language of 'data selling'"; which could legitimately be true.
Alternatives
If you want a good alternative that doesn't do that, try out LibreWolf, a more private fork of Firefox, or LadyBird, which doesn't include clode from other browser.
Librewolf:
Ladybird
#librewolf#firefox#terms of service#new firefox update#data privacy#privacy#ladybird browser#ladybird#Terms of use
41 notes
·
View notes
Text
NO AI
TL;DR: almost all social platforms are stealing your art and use it to train generative AI (or sell your content to AI developers); please beware and do something. Or don’t, if you’re okay with this.
Which platforms are NOT safe to use for sharing you art:
Facebook, Instagram and all Meta products and platforms (although if you live in the EU, you can forbid Meta to use your content for AI training)
Reddit (sold out all its content to OpenAI)
Twitter
Bluesky (it has no protection from AI scraping and you can’t opt out from 3rd party data / content collection yet)
DeviantArt, Flikr and literally every stock image platform (some didn’t bother to protect their content from scraping, some sold it out to AI developers)
Here’s WHAT YOU CAN DO:
1. Just say no:
Block all 3rd party data collection: you can do this here on Tumblr (here’s how); all other platforms are merely taking suggestions, tbh
Use Cara (they can’t stop illegal scraping yet, but they are currently working with Glaze to built in ‘AI poisoning’, so… fingers crossed)
2. Use art style masking tools:
Glaze: you can a) download the app and run it locally or b) use Glaze’s free web service, all you need to do is register. This one is a fav of mine, ‘cause, unlike all the other tools, it doesn’t require any coding skills (also it is 100% non-commercial and was developed by a bunch of enthusiasts at the University of Chicago)
Anti-DreamBooth: free code; it was originally developed to protect personal photos from being used for forging deepfakes, but it works for art to
Mist: free code for Windows; if you use MacOS or don’t have powerful enough GPU, you can run Mist on Google’s Colab Notebook
(art style masking tools change some pixels in digital images so that AI models can’t process them properly; the changes are almost invisible, so it doesn’t affect your audiences perception)
3. Use ‘AI poisoning’ tools
Nightshade: free code for Windows 10/11 and MacOS; you’ll need GPU/CPU and a bunch of machine learning libraries to use it though.
4. Stay safe and fuck all this corporate shit.
75 notes
·
View notes
Text
Re: 8tracks
HUGE UPDATE:
As I said on my earlier post today the CTO of 8tracks answered some questions on the discord server of mixer.fm
IF YOU'RE INTERESTED IN INFORMATION ABOUT 8TRACKS AND THE ANSWERS THE CTO OF 8TRACKS GAVE, PLEASE, KEEP READING THIS POST BECAUSE IT'S A LOT BUT YOU WON'T REGRET IT.
Okay, so he first talked about how they were involved in buying 8tracks, then how everything failed because of money and issues with the plataform then he talked about this new app called MixerFM they developed that works with web3 (8tracks is a web2 product), that if they get to launch it they'll get to launch 8tracks too because both apps will work with the same data.
Here is what they have already done in his own words:
*Built a multitenant backend system that supports both MIXER and 8tracks
*Fully rebuilt the 8tracks web app
*Fixed almost all legacy issues
*Developed iOS and Android apps for MIXER
What is next?
They need to migrate the 8tracks database from the old servers to the new environment. That final step costs about $50,000 and on his own words "I am personally committed to securing the funds to make it happen. If we pull this off since there is a time limit , we will have an chance to launch both 8tracks and MIXER. … so for all you community members that are pinging me to provide more details on X and here on discord, here it is"
Here the screenshots of his full statement:





NOW THE QUESTIONS HE ANSWERED:
*I transcribed them*
1. "What's the status of the founding right now?"
"Fundraising, for music its difficult"
2. "Our past data, is intact, isn't?"
"All data still exists from playlist 1"
3. "Will we be able to access our old playlists?"
"All playlists if we migrate the data will be saved. If we dont all is lost forever"
4. "How will the new 8tracks relaunch and MIXER be similar, and how will they be different?"
"8tracks / human created / mix tape style as it was before
mixer - ai asiated mix creation, music quest where people earn crypto for work they provode to music protocol ( solve quests earn money for providing that service )"
5. "Why is 8tracks being relaunched when they could just launch MIXER with our 8tracks database?"
"One app is web2 ( no crypto economy and incentives / ) mixer is web3 ( economy value exchange between users, artists, publishers, labels, advertisers) value (money) is shared between stakeholders and participants of app. Company earns less / users / artist earn more."
6. "Will we need to create a separate account for mixer? Or maybe a way to link our 8tracks to mixer?"
"New account no linking planned"
7. "What do you mean by fixed almost all legacy issues and fully rebuilt the 8tracks web app?"
"We have rebuilt most of 8tracks from scratch i wish could screen record a demo. In Last year we have rebuilt whole 8tracks ! No more issues no more bugs no more hacked comments"
8. "Will the song database be current and allow new songs? For example if someone makes a K pop playlist theres the capability for new songs and old not just all songs are from 2012. There will be songs from 2020 onwards to today?"
"Current cut of date is 2017, we have planed direct label deals to bring music DB up to speed with all new songs until 2025. This means no more song uploads"
9. "The apps would be available for android and outside USA?"
"USA + Canada + Germany + UK + Sweden + Italy + Greece + Portugal + Croatia in my personal rollout plan / but usa canada croatia would be top priority"
10. "Will 8tracks have a Sign in with Apple option?"
"It will have nothing if we don’t migrate the database but yes if we do it will have it"
11. ""Will Collections return?"
"Ofc If we save the database its safe to assume collections will return"
12. "Will the 8tracks forums return?"
"No that one i will deleted People spending too much time online"
13. "No more songs uploads forever or no more songs until…?"
"Idk, this really depends on do we save database or no. Maybe we restart the process of song uploads to rebuild the and create a worlds first open music database If anyone has any songs to upload that is
We operate under different license"
14. "What is your time limit? for the funding, I mean"
"Good question I think 2-3 months"
15. "From now?"
"Correct"
16. "When is the release date for Mixer?"
"Mixer would need 2-3 more months of work to be released Maybe even less of we would use external database services and just go with minimum features"
17. "Do you have the link for it?"
"Not if we dont secure the database that is number one priority"
*That was the end of the questions and answers*
Then he said:
"You need to act bring here (discord) people and help me set up go fund me camping of investor talks fail so we secure the database and migrate data so we can figure out whats next"
He also said he'll talk with the CEO about buying him the idea of community funding, that all who participate should have a lifetime subscription and "some more special thing", we suggested a message on the 8tracks official accounts (twitter, their blog, tumblr) and he was okay with the idea but he said they need to plan it carefully since the time is limited.
Okay, guys, that's so far what he said, I hope this information helps anyone, I don't know if they get to do a community funding but take in consideration it's a plausible option and that what they want from us is to participate in any way like for example spreading the message, if most people know about it the best, they also want you to join their server so here's the link to the website of mixerfm and where you can join the server:
Keep tagging few people who were discussing about this:
@junket-bank, @haorev, @americanundead, @eatpandulce, @throwupgirl, @avoid-avoidance, @rodeokid, @shehungthemoon, @promostuff-art @tumbling-and-tchaikovsky
#8tracks
17 notes
·
View notes
Text
Discover how the web data collection function can help in boosting business productivity. Visit this blog to explore how businesses can maximize efficiency through effective data collection methods. Stay informed and stay ahead in today's competitive landscape. Unlock the potential of web data collection to streamline processes and drive growth for your business.
0 notes
Text

LETTERS FROM AN AMERICAN
January 18, 2025
Heather Cox Richardson
Jan 19, 2025
Shortly before midnight last night, the Federal Trade Commission (FTC) published its initial findings from a study it undertook last July when it asked eight large companies to turn over information about the data they collect about consumers, product sales, and how the surveillance the companies used affected consumer prices. The FTC focused on the middlemen hired by retailers. Those middlemen use algorithms to tweak and target prices to different markets.
The initial findings of the FTC using data from six of the eight companies show that those prices are not static. Middlemen can target prices to individuals using their location, browsing patterns, shopping history, and even the way they move a mouse over a webpage. They can also use that information to show higher-priced products first in web searches. The FTC found that the intermediaries—the middlemen—worked with at least 250 retailers.
“Initial staff findings show that retailers frequently use people’s personal information to set targeted, tailored prices for goods and services—from a person's location and demographics, down to their mouse movements on a webpage,” said FTC chair Lina Khan. “The FTC should continue to investigate surveillance pricing practices because Americans deserve to know how their private data is being used to set the prices they pay and whether firms are charging different people different prices for the same good or service.”
The FTC has asked for public comment on consumers’ experience with surveillance pricing.
FTC commissioner Andrew N. Ferguson, whom Trump has tapped to chair the commission in his incoming administration, dissented from the report.
Matt Stoller of the nonprofit American Economic Liberties Project, which is working “to address today’s crisis of concentrated economic power,” wrote that “[t]he antitrust enforcers (Lina Khan et al) went full Tony Montana on big business this week before Trump people took over.”
Stoller made a list. The FTC sued John Deere “for generating $6 billion by prohibiting farmers from being able to repair their own equipment,” released a report showing that pharmacy benefit managers had “inflated prices for specialty pharmaceuticals by more than $7 billion,” “sued corporate landlord Greystar, which owns 800,000 apartments, for misleading renters on junk fees,” and “forced health care private equity powerhouse Welsh Carson to stop monopolization of the anesthesia market.”
It sued Pepsi for conspiring to give Walmart exclusive discounts that made prices higher at smaller stores, “[l]eft a roadmap for parties who are worried about consolidation in AI by big tech by revealing a host of interlinked relationships among Google, Amazon and Microsoft and Anthropic and OpenAI,” said gig workers can’t be sued for antitrust violations when they try to organize, and forced game developer Cognosphere to pay a $20 million fine for marketing loot boxes to teens under 16 that hid the real costs and misled the teens.
The Consumer Financial Protection Bureau “sued Capital One for cheating consumers out of $2 billion by misleading consumers over savings accounts,” Stoller continued. It “forced Cash App purveyor Block…to give $120 million in refunds for fostering fraud on its platform and then refusing to offer customer support to affected consumers,” “sued Experian for refusing to give consumers a way to correct errors in credit reports,” ordered Equifax to pay $15 million to a victims’ fund for “failing to properly investigate errors on credit reports,” and ordered “Honda Finance to pay $12.8 million for reporting inaccurate information that smeared the credit reports of Honda and Acura drivers.”
The Antitrust Division of the Department of Justice sued “seven giant corporate landlords for rent-fixing, using the software and consulting firm RealPage,” Stoller went on. It “sued $600 billion private equity titan KKR for systemically misleading the government on more than a dozen acquisitions.”
“Honorary mention goes to [Secretary Pete Buttigieg] at the Department of Transportation for suing Southwest and fining Frontier for ‘chronically delayed flights,’” Stoller concluded. He added more results to the list in his newsletter BIG.
Meanwhile, last night, while the leaders in the cryptocurrency industry were at a ball in honor of President-elect Trump’s inauguration, Trump launched his own cryptocurrency. By morning he appeared to have made more than $25 billion, at least on paper. According to Eric Lipton at the New York Times, “ethics experts assailed [the business] as a blatant effort to cash in on the office he is about to occupy again.”
Adav Noti, executive director of the nonprofit Campaign Legal Center, told Lipton: “It is literally cashing in on the presidency—creating a financial instrument so people can transfer money to the president’s family in connection with his office. It is beyond unprecedented.” Cryptocurrency leaders worried that just as their industry seems on the verge of becoming mainstream, Trump’s obvious cashing-in would hurt its reputation. Venture capitalist Nick Tomaino posted: “Trump owning 80 percent and timing launch hours before inauguration is predatory and many will likely get hurt by it.”
Yesterday the European Commission, which is the executive arm of the European Union, asked X, the social media company owned by Trump-adjacent billionaire Elon Musk, to hand over internal documents about the company’s algorithms that give far-right posts and politicians more visibility than other political groups. The European Union has been investigating X since December 2023 out of concerns about how it deals with the spread of disinformation and illegal content. The European Union’s Digital Services Act regulates online platforms to prevent illegal and harmful activities, as well as the spread of disinformation.
Today in Washington, D.C., the National Mall was filled with thousands of people voicing their opposition to President-elect Trump and his policies. Online speculation has been rampant that Trump moved his inauguration indoors to avoid visual comparisons between today’s protesters and inaugural attendees. Brutally cold weather also descended on President Barack Obama’s 2009 inauguration, but a sea of attendees nonetheless filled the National Mall.
Trump has always understood the importance of visuals and has worked hard to project an image of an invincible leader. Moving the inauguration indoors takes away that image, though, and people who have spent thousands of dollars to travel to the capital to see his inauguration are now unhappy to discover they will be limited to watching his motorcade drive by them. On social media, one user posted: “MAGA doesn’t realize the symbolism of [Trump] moving the inauguration inside: The billionaires, millionaires and oligarchs will be at his side, while his loyal followers are left outside in the cold. Welcome to the next 4+ years.”
Trump is not as good at governing as he is at performance: his approach to crises is to blame Democrats for them. But he is about to take office with majorities in the House of Representatives and the Senate, putting responsibility for governance firmly into his hands.
Right off the bat, he has at least two major problems at hand.
Last night, Commissioner Tyler Harper of the Georgia Department of Agriculture suspended all “poultry exhibitions, shows, swaps, meets, and sales” until further notice after officials found Highly Pathogenic Avian Influenza, or bird flu, in a commercial flock. As birds die from the disease or are culled to prevent its spread, the cost of eggs is rising—just as Trump, who vowed to reduce grocery prices, takes office.
There have been 67 confirmed cases of the bird flu in the U.S. among humans who have caught the disease from birds. Most cases in humans are mild, but public health officials are watching the virus with concern because bird flu variants are unpredictable. On Friday, outgoing Health and Human Services secretary Xavier Becerra announced $590 million in funding to Moderna to help speed up production of a vaccine that covers the bird flu. Juliana Kim of NPR explained that this funding comes on top of $176 million that Health and Human Services awarded to Moderna last July.
The second major problem is financial. On Friday, Secretary of the Treasury Janet Yellen wrote to congressional leaders to warn them that the Treasury would hit the debt ceiling on January 21 and be forced to begin using extraordinary measures in order to pay outstanding obligations and prevent defaulting on the national debt. Those measures mean the Treasury will stop paying into certain federal retirement accounts as required by law, expecting to make up that difference later.
Yellen reminded congressional leaders: “The debt limit does not authorize new spending, but it creates a risk that the federal government might not be able to finance its existing legal obligations that Congresses and Presidents of both parties have made in the past.” She added, “I respectfully urge Congress to act promptly to protect the full faith and credit of the United States.”
Both the avian flu and the limits of the debt ceiling must be managed, and managed quickly, and solutions will require expertise and political skill.
Rather than offering their solutions to these problems, the Trump team leaked that it intended to begin mass deportations on Tuesday morning in Chicago, choosing that city because it has large numbers of immigrants and because Trump’s people have been fighting with Chicago mayor Brandon Johnson, a Democrat. Michelle Hackman, Joe Barrett, and Paul Kiernan of the Wall Street Journal, who broke the story, reported that Trump’s people had prepared to amplify their efforts with the help of right-wing media.
But once the news leaked of the plan and undermined the “shock and awe” the administration wanted, Trump’s “border czar” Tom Homan said the team was reconsidering it.
LETTERS FROM AN AMERICAN
HEATHER COX RICHARDSON
#Consumer Financial Protection Bureau#consumer protection#FTC#Letters From An American#heather cox richardson#shock and awe#immigration raids#debt ceiling#bird flu#protests#March on Washington
30 notes
·
View notes
Text
Grocery Delivery App Data Scraping - Grocery Delivery App Data Collection Service
Get reliable grocery app listing data scraping services from iWeb Data Scraping for websites like Big Basket, Zepto, and more. Contact us for grocery app data collection services.
know more:
#Grocery Delivery App Data Scraping#Grocery Delivery App Data Collection Service#Web scraping grocery delivery data#grocery menu data scraping services
0 notes