#Web Review Scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Text
SO HERE IS THE WHOLE STORY (SO FAR).
I am on my knees begging you to reblog this post and to stop reblogging the original ones I sent out yesterday. This is the complete account with all the most recent info; the other one is just sending people down senselessly panicked avenues that no longer lead anywhere.
IN SHORT
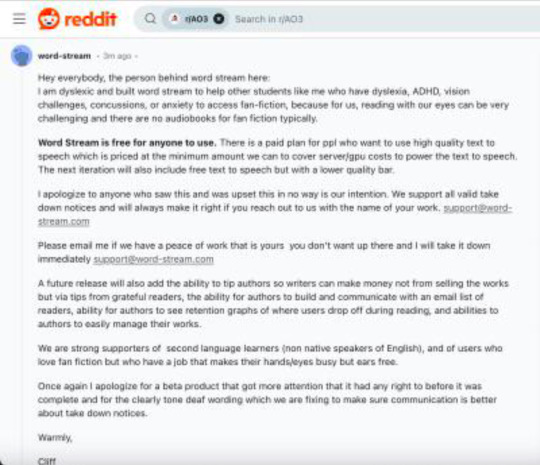
Cliff Weitzman, CEO of Speechify and (aspiring?) voice actor, used AI to scrape thousands of popular, finished works off AO3 to list them on his own for-profit website and in his attached app. He did this without getting any kind of permission from the authors of said work or informing AO3. Obviously.
When fandom at large was made aware of his theft and started pushing back, Weitzman issued a non-apology on the original social media posts—using
his dyslexia;
his intent to implement a tip-system for the plagiarized authors; and
a sudden willingness to take down the work of every author who saw my original social media posts and emailed him individually with a ‘valid’ claim,
as reasons we should allow him to continue monetizing fanwork for his own financial gain.
When we less-than-kindly refused, he took down his ‘apologies’ as well as his website (allegedly—it’s possible that our complaints to his web host, the deluge of emails he received or the unanticipated traffic brought it down, since there wasn’t any sort of official statement made about it), and when it came back up several hours later, all of the work formerly listed in the fan fiction category was no longer there.
THE TAKEAWAYS
1. Cliff Weitzman (aka Ofek Weitzman) is a scumbag with no qualms about taking fanwork without permission, feeding it to AI and monetizing it for his own financial gain;
2. Fandom can really get things done when it wants to, and
3. Our fanworks appear to be hidden, but they’re NOT DELETED from Weitzman’s servers, and independently published, original works are still listed without the authors' permission. We need to hold this man responsible for his theft, keep an eye on both his current and future endeavors, and take action immediately when he crosses the line again.
THE TIMELINE, THE DETAILS, THE SCREENSHOTS (behind the cut)
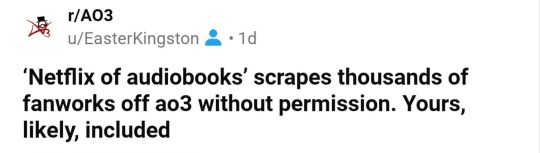
Sunday night, December 22nd 2024, I noticed an influx in visitors to my fic You & Me & Holiday Wine. When I searched the title online, hoping to find out where they came from, a new listing popped up (third one down, no less):

This listing is still up today, by the way, though now when you follow the link to word-stream, it just brings you to the main site. (Also, to be clear, this was not the cause for the influx of traffic to my fic; word-stream did not link back to the original work anywhere.)
I followed the link to word-stream, where to my horror Y&M&HW was listed in its entirety—though, beyond the first half of the first chapter, behind a paywall—along with a link promising to take me—through an app downloadable on the Apple Store—to an AI-narrated audiobook version. When I searched word-stream itself for my ao3 handle I found both of my multi-chapter fics were listed this way:
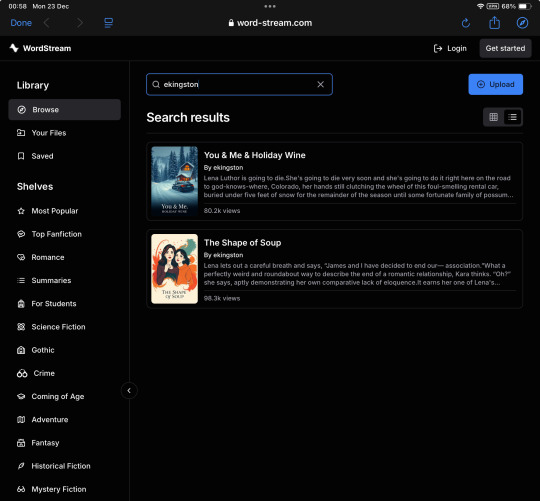
Because the tags on my fics (which included genres* and characters, but never the original IPs**) weren’t working, I put ‘Kara Danvers’ into the search bar and discovered that many more supercorp fics (Supergirl TV fandom, Kara Danvers/Lena Luthor pairing) were listed.
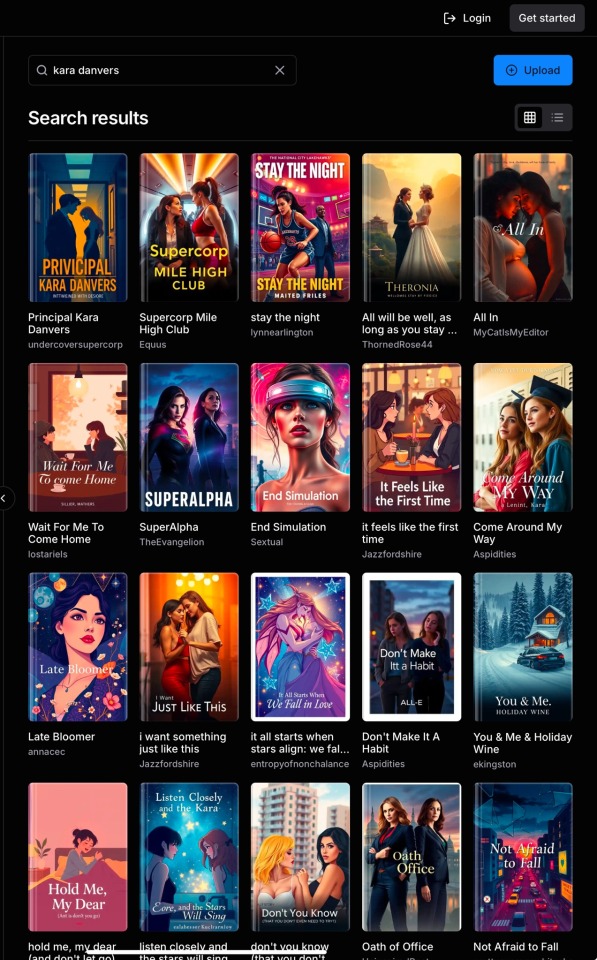
I went looking online for any mention of word-stream and AI plagiarism (the covers—as well as the ridiculously inflated number of reviews and ratings—made it immediately obvious that AI fuckery was involved), but found almost nothing: only one single Reddit post had been made, and it received (at that time) only a handful of upvotes and no advice.
I decided to make a tumblr post to bring the supercorp fandom up to speed about the theft. I draw as well as write for fandom and I’ve only ever had to deal with art theft—which has a clear set of steps to take depending on where said art was reposted—and I was at a loss regarding where to start in this situation.
After my post went up I remembered Project Copy Knight, which is worth commending for the work they’ve done to get fic stolen from AO3 taken down from monetized AI 'audiobook’ YouTube accounts. I reached out to @echoekhi, asking if they’d heard of this site and whether they could advise me on how to get our works taken down.

While waiting for a reply I looked into Copy Knight’s methods and decided to contact OTW’s legal department:
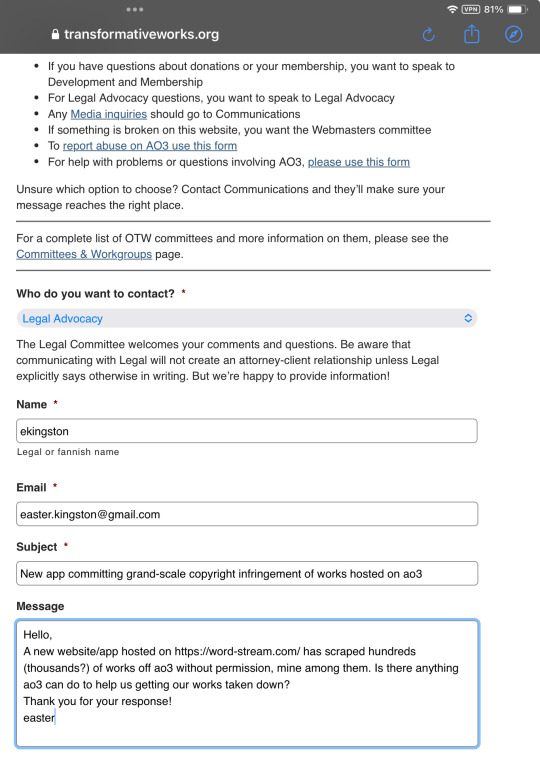
And then I went to bed.
By morning, tumblr friends @makicarn and @fazedlight as well as a very helpful tumblr anon had seen my post and done some very productive sleuthing:

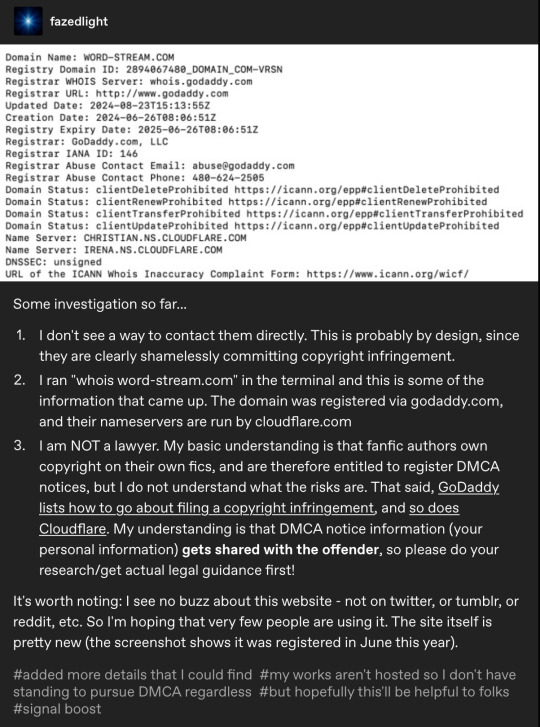
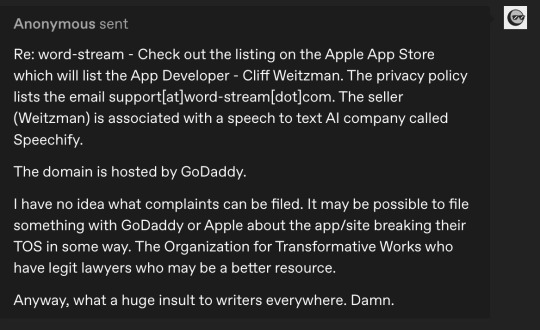
@echoekhi had also gotten back to me, advising me, as expected, to contact the OTW. So I decided to sit tight until I got a response from them.
That response came only an hour or so later:
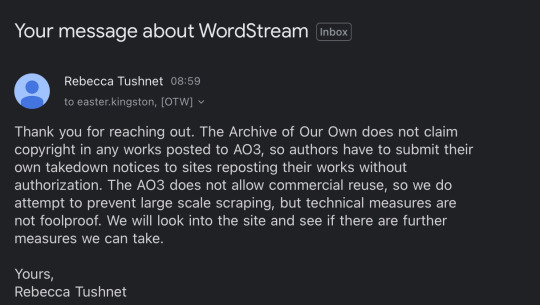
Which was 100% understandable, but still disappointing—I doubted a handful of individual takedown requests would accomplish much, and I wasn’t eager to share my given name and personal information with Cliff Weitzman himself, which is unavoidable if you want to file a DMCA.
I decided to take it to Reddit, hoping it would gain traction in the wider fanfic community, considering so many fandoms were affected. My Reddit posts (with the updates at the bottom as they were emerging) can be found here and here.
A helpful Reddit user posted a guide on how users could go about filing a DMCA against word-stream here (to wobbly-at-best results)
A different helpful Reddit user signed up to access insight into word-streams pricing. Comment is here.
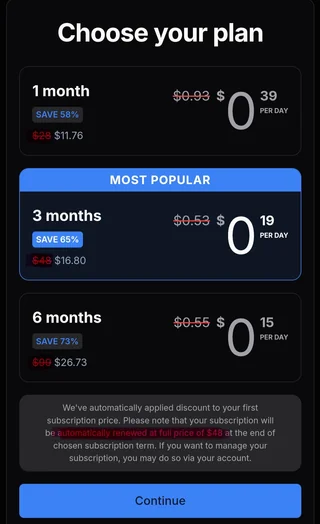
Smells unbelievably scammy, right? In addition to those audacious prices—though in all fairness any amount of money would be audacious considering every work listed is accessible elsewhere for free—my dyscalculia is screaming silently at the sight of that completely unnecessary amount of intentionally obscured numbers.
Speaking of which! As soon as the post on r/AO3—and, as a result, my original tumblr post—began taking off properly, sometime around 1 pm, jumpscare! A notification that a tumblr account named @cliffweitzman had commented on my post, and I got a bit mad about the gist of his message :
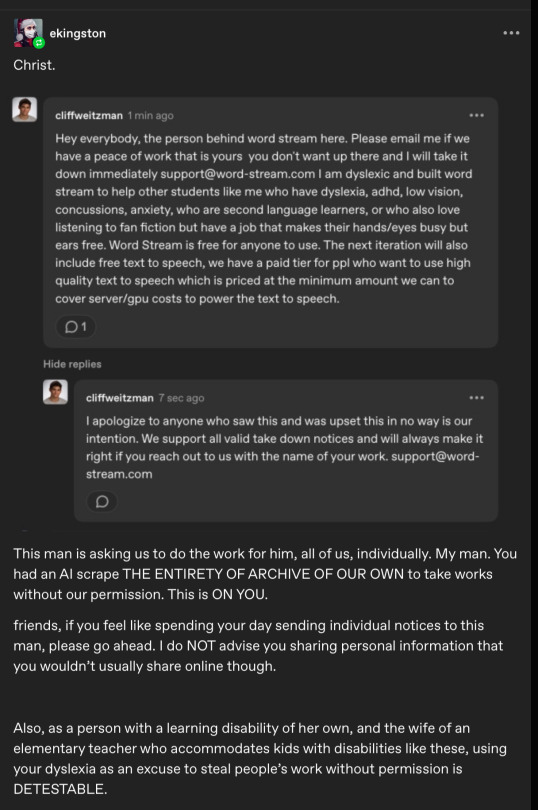
Fortunately he caught plenty of flack in the comments from other users (truly you should check out the comment section, it is extremely gratifying and people are making tremendously good points), in response to which, of course, he first tried to both reiterate and renegotiate his point in a second, longer comment (which I didn’t screenshot in time so I’m sorry for the crappy notification email formatting):

which he then proceeded to also post to Reddit (this is another Reddit user’s screenshot, I didn’t see it at all, the notifications were moving too fast for me to follow by then)
... where he got a roughly equal amount of righteously furious replies. (Check downthread, they're still there, all the way at the bottom.)
After which Cliff went ahead & deleted his messages altogether.
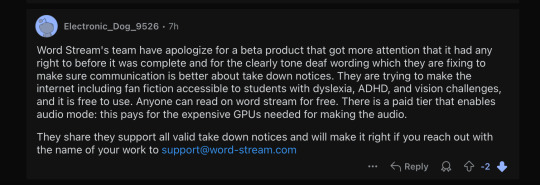
It’s not entirely clear whether his account was suspended by Reddit soon after or whether he deleted it himself, but considering his tumblr account is still intact, I assume it’s the former. He made a handful of sock puppet accounts to play around with for a while, both on Reddit and Tumblr, only one of which I have a screenshot of, but since they all say roughly the same thing, you’re not missing much:
And then word-stream started throwing a DNS error.
That lasted for a good number of hours, which was unfortunately right around the time that a lot of authors first heard about the situation and started asking me individually how to find out whether their work was stolen too. I do not have that information and I am unclear on the perimeters Weitzman set for his AI scraper, so this is all conjecture: it LOOKS like the fics that were lifted had three things in common:
They were completed works;
They had over several thousand kudos on AO3; and
They were written by authors who had actively posted or updated work over the past year.
If anyone knows more about these perimeters or has info that counters my observation, please let me know!
I finally thought to check/alert evil Twitter during this time, and found out that the news was doing the rounds there already. I made a quick thread summarizing everything that had happened just in case. You can find it here.
I went to Bluesky too, where fandom was doing all the heavy lifting for me already, so I just reskeeted, as you do, and carried on.
Sometime in the very early evening, word-stream went back up—but the fan fiction category was nowhere to be seen. Tentative joy and celebration!***
That’s when several users—the ones who had signed up for accounts to gain intel and had accessed their own fics that way—reported that their work could still be accessed through their history. Relevant Reddit post here.
Sooo—
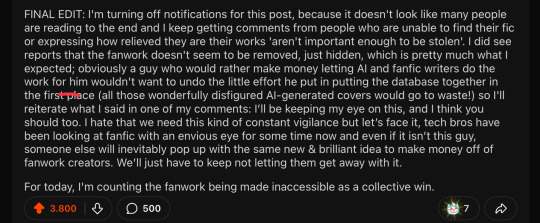
We’re obviously not done. The fanwork that was stolen by Weitzman may be inaccessible through his website right now, but they aren’t actually gone. And the fact that Weitzman wasn’t willing to get rid of them altogether means he still has plans for them.
This was my final edit on my Reddit post before turning off notifications, and it's pretty much where my head will be at for at least the foreseeable future:
Please feel free to add info in the comments, make your own posts, take whatever action you want to take to protect your work. I only beg you—seriously, I’m on my knees here—to not give up like I saw a handful of people express the urge to do. Keep sharing your creative work and remain vigilant and stay active to make sure we can continue to do so freely. Visit your favorite fics, and the ones you’ve kept in your ‘marked for later’ lists but never made time to read, and leave kudos, leave comments, support your fandom creatives, celebrate podficcers and support AO3. We created this place and it’s our responsibility to keep it alive and thriving for as long as we possibly can.
Also FUCK generative AI. It has NO place in fandom spaces.
THE 'SMALL' PRINT (some of it in all caps):
*Weitzman knew what he was doing and can NOT claim ignorance. One, it’s pretty basic kindergarten stuff that you don’t steal some other kid’s art project and present it as your own only to act surprised when they protest and then tell the victim that they should have told you sooner that they didn’t want their project stolen. And two, he was very careful never to list the IPs these fanworks were based on, so it’s clear he was at least familiar enough with the legalities to not get himself in hot water with corporate lawyers. Fucking over fans, though, he figured he could get away with that.
**A note about the AI that Weitzman used to steal our work: it’s even greasier than it looks at first glance. It’s not just the method he used to lift works off AO3 and then regurgitate onto his own website and app. Looking beyond the untold horrors of his AI-generated cover ‘art’, in many cases these covers attempt to depict something from the fics in question that can’t be gleaned from their summaries alone. In addition, my fics (and I assume the others, as well) were listed with generated genres; tags that did not appear anywhere in or on my fic on AO3 and were sometimes scarily accurate and sometimes way off the mark. I remember You & Me & Holiday Wine had ‘found family’ (100% correct, but not tagged by me as such) and I believe The Shape of Soup was listed as, among others, ‘enemies to friends to lovers’ and ‘love triangle’ (both wildly inaccurate). Even worse, not all the fic listed (as authors on Reddit pointed out) came with their original summaries at all. Often the entire summary was AI-generated. All of these things make it very clear that it was an all-encompassing scrape—not only were our fics stolen, they were also fed word-for-word into the AI Weitzman used and then analyzed to suit Weitzman’s needs. This means our work was literally fed to this AI to basically do with whatever its other users want, including (one assumes) text generation.
***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS.
PLEASE check my later versions of this post via my main page to make sure you have the latest version of this post before you reblog. All the information I’ve been able to gather is in my reblogs below, and it's frustrating to see the old version getting passed around, sending people on wild goose chases.
Thank you all so much!
#fandom#plagiarism#AO3#speechify#word-stream#Cliff Weitzman#writers on tumblr#fan fic writing#AI plagiarism#independent authors#Ofek Weitzman#please share
48K notes
·
View notes
Text
Google Search Results Data Scraping

Google Search Results Data Scraping
Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age, information is king. For businesses, researchers, and marketing professionals, the ability to access and analyze data from Google search results can be a game-changer. However, manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com offers cutting-edge Google Search Results Data Scraping services, enabling you to efficiently extract valuable information and transform it into actionable insights.
The vast amount of information available through Google search results can provide invaluable insights into market trends, competitor activities, customer behavior, and more. Whether you need data for SEO analysis, market research, or competitive intelligence, DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology ensures you get accurate and up-to-date data, helping you stay ahead in your industry.
List of Data Fields
Our Google Search Results Data Scraping services can extract a wide range of data fields, ensuring you have all the information you need:
-Business Name: The name of the business or entity featured in the search result.
- URL: The web address of the search result.
- Website: The primary website of the business or entity.
- Phone Number: Contact phone number of the business.
- Email Address: Contact email address of the business.
- Physical Address: The street address, city, state, and ZIP code of the business.
- Business Hours: Business operating hours
- Ratings and Reviews: Customer ratings and reviews for the business.
- Google Maps Link: Link to the business’s location on Google Maps.
- Social Media Profiles: LinkedIn, Twitter, Facebook
These data fields provide a comprehensive overview of the information available from Google search results, enabling businesses to gain valuable insights and make informed decisions.
Benefits of Google Search Results Data Scraping
1. Enhanced SEO Strategy
Understanding how your website ranks for specific keywords and phrases is crucial for effective SEO. Our data scraping services provide detailed insights into your current rankings, allowing you to identify opportunities for optimization and stay ahead of your competitors.
2. Competitive Analysis
Track your competitors’ online presence and strategies by analyzing their rankings, backlinks, and domain authority. This information helps you understand their strengths and weaknesses, enabling you to adjust your strategies accordingly.
3. Market Research
Access to comprehensive search result data allows you to identify trends, preferences, and behavior patterns in your target market. This information is invaluable for product development, marketing campaigns, and business strategy planning.
4. Content Development
By analyzing top-performing content in search results, you can gain insights into what types of content resonate with your audience. This helps you create more effective and engaging content that drives traffic and conversions.
5. Efficiency and Accuracy
Our automated scraping services ensure you get accurate and up-to-date data quickly, saving you time and resources.
Best Google Data Scraping Services
Scraping Google Business Reviews
Extract Restaurant Data From Google Maps
Google My Business Data Scraping
Google Shopping Products Scraping
Google News Extraction Services
Scrape Data From Google Maps
Google News Headline Extraction
Google Maps Data Scraping Services
Google Map Businesses Data Scraping
Google Business Reviews Extraction
Best Google Search Results Data Scraping Services in USA
Dallas, Portland, Los Angeles, Virginia Beach, Fort Wichita, Nashville, Long Beach, Raleigh, Boston, Austin, San Antonio, Philadelphia, Indianapolis, Orlando, San Diego, Houston, Worth, Jacksonville, New Orleans, Columbus, Kansas City, Sacramento, San Francisco, Omaha, Honolulu, Washington, Colorado, Chicago, Arlington, Denver, El Paso, Miami, Louisville, Albuquerque, Tulsa, Springs, Bakersfield, Milwaukee, Memphis, Oklahoma City, Atlanta, Seattle, Las Vegas, San Jose, Tucson and New York.
Conclusion
In today’s data-driven world, having access to detailed and accurate information from Google search results can give your business a significant edge. DataScrapingServices.com offers professional Google Search Results Data Scraping services designed to meet your unique needs. Whether you’re looking to enhance your SEO strategy, conduct market research, or gain competitive intelligence, our services provide the comprehensive data you need to succeed. Contact us at [email protected] today to learn how our data scraping solutions can transform your business strategy and drive growth.
Website: Datascrapingservices.com
Email: [email protected]
#Google Search Results Data Scraping#Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age#information is king. For businesses#researchers#and marketing professionals#the ability to access and analyze data from Google search results can be a game-changer. However#manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com o#enabling you to efficiently extract valuable information and transform it into actionable insights.#The vast amount of information available through Google search results can provide invaluable insights into market trends#competitor activities#customer behavior#and more. Whether you need data for SEO analysis#market research#or competitive intelligence#DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology#helping you stay ahead in your industry.#List of Data Fields#Our Google Search Results Data Scraping services can extract a wide range of data fields#ensuring you have all the information you need:#-Business Name: The name of the business or entity featured in the search result.#- URL: The web address of the search result.#- Website: The primary website of the business or entity.#- Phone Number: Contact phone number of the business.#- Email Address: Contact email address of the business.#- Physical Address: The street address#city#state#and ZIP code of the business.#- Business Hours: Business operating hours#- Ratings and Reviews: Customer ratings and reviews for the business.
0 notes
Text
How Customer Review Collection Brings Profitable Results?

What is the first thing you do when you're about to purchase? Do you rely on the brand's claims or the product's features? Or do you turn to other customers' experiences, seeking their insights and opinions? Knowing the first-hand experience through customer reviews builds trust.
Now, you can transform your role as a buyer, seller, or mediator by reading a few customer reviews and having a wide range of customer review collections. The power lies in extracting data from multiple resources, understanding various factors, and leveraging this knowledge to streamline your processes and efficiently bring quality returns.
This content will equip you with secret strategies for converting customer review collection into profitable actions to ensure your business's success. We will familiarize you with web scraping customer reviews from multiple sources and how companies optimize their marketing strategies to target potential leads.
What Is Customer Reviews Collection?
Review scraping services make retrieving customer review data from various websites and platforms to analyze valuable information easy and efficient. They streamline the complete process of collecting useful information and meet your goals with data stored in a structured format, giving you the confidence to leverage this data for your business's success.
Here are the common platforms to scrape review data of customers:AmazonYelpGlassdoorTripAdvisorTrustpilotCostcoGoogle ReviewsHomedepotShopeeIKEAZaraFlipkartLowesZalandoEtsyBigbasketAlibabaAmctheatresWalmartTargetRakuteneBayBestbuyWishShein
Customer review collection can be completed using web scraping tools, programs, or scripts to extract customer reviews from the desired location. This can include various forms of data, such as product ratings, reviews, images, reviewers' names, and other information if required. Collecting and analyzing this data lets you gain insights into customer preferences, product performance, and more.
How Is Customer Reviews Collection Profitable?
They are a source of customers' experience about specific goods and products, which means you can easily understand the pros and cons. Here are some of the benefits of data for your business that can help you generate quality returns:
Understand Your Products & Services
With access to structured customer reviews, understanding the positive and negative impacts on the audience becomes more manageable. This allows you to focus on the negative section, make necessary changes, and embrace the positive ones to grow and engage more audiences, inspiring your business's success.
Scraping Competitor Reviews
It is essential to know what you are up against in the market. With a custom review data scraper, you can easily filter the data you want to gather from where and when. This gives you the freedom to examine your competitors' positives and negatives. Now, you can build strategies to fulfill customer requirements where your competitors need to improve and improve services where they excel. This will ultimately grab the attention of potential users and boost profits efficiently.
Find The Top Selling Products & Services
It is a plus point if you know the popular products and services when entering a market irrelevant to your target industry. Some common platforms to extract customer reviews for services are Yelp and TripAdvisor, while people opt for Amazon, eBay, or Flipkart for products.

With billions of users active on each platform, you can analyze data about products and services from different locations, ages, genders, and more. The review scraping services use quality tools and resources to make data extraction effortless to understand.
Improve Your Marketing & Product Strategies
The customer reviews collection helps to optimize the production description and connect with your audience. Analyzing the data extracted can help you focus on customer-centric strategies to promote your products and services.
Also, you can get valuable insights about your team to take unbiased and accurate actions to enhance your business performance. Unlike customer forms, surveys, or other media for collecting customer feedback, product reviews are organic views explaining their experience. Customer reviews are unique in that they are often more detailed and provide a broader perspective, making them a valuable source of information for businesses.
Different Methods To Extract Customer Review Data
There are various methods available to scrape customer review data from multiple resources. Let you look at some of them:
Coding with Libraries
This involves using programming languages such as HTML, XPath, Python, Java, and others, depending on expertise. Then, use custom libraries or readily available ones like Beautiful Soup and Scrapy to parse website code and extract specific elements like ratings, text, and more.
Web Scraping Tools
Many software tools are designed for web scraping customer review data. These tools offer user-friendly interfaces to target website review sections and collect data without any code.
Scraping Review APIs
Some websites offer APIs (Application Programming Interfaces) allowing authorized review data access. This provides a structured way to collect reviews faster and effortlessly.
How Does Web Scraping Work For Customer Reviews Collection?

No matter which method you pick to extract customer review data, it is essential to meet the final target. Here is a standard procedure to collect desired data from multiple websites:
Define Web Pages
Creating a list of pages you need to scrape to gather customer review data is essential. Then, we will send HTTP requests to the target website to fetch the HTML content.
Parse HTML
Our experts will parse the content using libraries after fetching it. The aim is to convert the data into a structured format that is easy to understand.
Extraction
Web scrapers find elements like images, text, links, and more through tags, attributes, or classes. They gather and store this data in a desired format.
Organizing Data
Once you have stored the data in SCV, JSON, or a database for analysis, you can structure it efficiently. Multiple libraries are available to manage data for better visualization.
What To Do With Scraped Customer Review Collection Data?

You know the different methods and reasons for extracting customer review data. We will now give you insights about what to do next after gathering data from review scraping services:
Analysis
Go through your collected data to understand customer sentiments towards a particular resource. This involves analyzing customer reviews, looking for patterns or trends, and categorizing the feedback into positive, negative, or neutral. Having a wide range of information from different locations, platforms, and customers can help you find your business's and competitors' strengths and weaknesses.
For example, you might discover that customers love a particular product feature or need clarification on a specific aspect of your service. Allows you to connect with customers and personalize their experience to boost engagement rates.
Tracking
The market changes every second, so with the help of custom review, data scraper extraction will be done in real-time. This allows you to monitor the latest trends, demands, and updates. You can also figure out your business's USPs (Unique selling points) and quickly gain customer loyalty.
For example, you have tracked the market updates regularly for a particular location for previous months. Now, you know which product is highly purchased, the peak time of orders, and more details about the customers. This can help you optimize your promotions and target the right audience to have higher chances of conversions.
Strategize
After analyzing and monitoring the data, it is time to implement strategies to scale your business. Focus on the significant segments where customer reviews and opinions have made a difference. This can be a location, time duration, or a popular product with quality services.
For example, if you notice a trend of positive reviews for a particular product feature, you can emphasize that feature in your marketing campaigns. If you see a lot of negative feedback on a specific aspect of your service, you can address it and improve customer satisfaction. This could involve updating your product description, offering additional support for the feature, or adjusting your pricing strategy.
Social Profiling
Customer feedback helps optimize marketing strategies and gain the trust of other visitors. Social profiling means highlighting the positive customer reviews on your apps, websites, or social media channels.
You can demonstrate credibility by showcasing these reviews and letting potential customers make more informed decisions. This becomes an excellent source for new visitors to understand your services and the quality of customer care.
Wrapping It Up!
We have made your journey effective whether you are planning to scale your business, gain potential leads, understand the company's pros and cons, or gather information about competitors.
Web scraping has become a go-to solution for extracting customer review collection data stored in structured form for analysis. Pick the right tools, platforms, and experts to streamline the process. Whether dealing with competitor analysis, marketing, pricing, personalization, customer sentiments, or more, ensure you have a precise output for analysis.
At iWeb Scraping, a trusted provider of web data scraping services, we help you harness the power of customer review collection to boost your business's profits smartly. Data is dynamic and readily available. You need the right resources and expertise to convert that into high returns like ours.
0 notes
Text
The Ultimate Guide to Reviews and Ratings Data Scraping Services
In the digital age, online reviews and ratings have become critical factors influencing consumer decisions. Whether someone is looking for a restaurant, choosing a new gadget, or selecting a service provider, they often turn to online reviews to guide their choices. For businesses, harnessing the power of this valuable data is essential for staying competitive and meeting customer expectations. One way to achieve this is through reviews and ratings data scraping services. In this article, we'll explore how businesses can maximize the benefits of these services to gain a competitive edge and enhance customer satisfaction.

Understanding Reviews and Ratings Data Scraping Services:
Reviews and ratings data scraping services involve the automated extraction of customer feedback and ratings from various online platforms. These services use web scraping techniques to gather information from review sites, e-commerce platforms, social media, and other sources. By aggregating this data, businesses can gain valuable insights into customer opinions, sentiments, and preferences.
Identifying Key Metrics and Trends:
Reviews and ratings data scraping services enable businesses to identify key metrics and trends in customer feedback. Analyzing this information can reveal patterns related to product satisfaction, service quality, and customer sentiment. By understanding these trends, businesses can make informed decisions to improve their offerings and address any issues highlighted by customers.
Enhancing Product Development and Innovation:
Customer feedback is a goldmine of ideas for product development and innovation. Reviews and ratings data scraping services can help businesses identify areas where their products excel and areas that need improvement. By integrating customer suggestions, businesses can enhance their products, ensuring they meet or exceed customer expectations.
Monitoring Competitor Performance:
Staying ahead of the competition is crucial in today's fast-paced business environment. Reviews and ratings data scraping services allow businesses to monitor their competitors' performance by analyzing customer feedback. By understanding what customers appreciate or dislike about competitors, businesses can adjust their strategies to gain a competitive advantage.
Building a Positive Online Reputation:
Online reputation is a key factor in attracting and retaining customers. Reviews and ratings data scraping services help businesses monitor and manage their online reputation by highlighting positive reviews and addressing negative feedback promptly. A positive online reputation can significantly impact consumer trust and influence purchasing decisions.
Optimizing Marketing Strategies:
Customer testimonials and positive reviews are powerful marketing tools. Reviews and ratings data scraping services can be leveraged to identify compelling customer stories and endorsements. Businesses can use this content in their marketing efforts, whether through social media, email campaigns, or website testimonials. This user-generated content adds authenticity to marketing messages and builds credibility.
Tailoring Customer Support and Services:
Understanding customer concerns and preferences is crucial for delivering excellent customer service. Reviews and ratings data scraping services provide businesses with valuable insights into customer experiences, allowing them to tailor their customer support and services accordingly. By addressing common issues and improving service in identified areas, businesses can enhance overall customer satisfaction.
Compliance with Privacy Regulations:
While reviews and ratings data scraping services offer immense benefits, it's essential for businesses to prioritize compliance with privacy regulations. Ensure that the chosen service adheres to data protection laws and guidelines, safeguarding both customer and business data. Respecting privacy builds trust with customers and avoids legal complications.
Choosing the Right Data Scraping Service Provider:
Not all data scraping services are created equal. Businesses should carefully choose a reputable and reliable service provider that offers ethical and transparent scraping practices. Look for providers that prioritize data accuracy, provide customizable solutions, and have a track record of delivering actionable insights.
Continuous Improvement and Adaptation:
The online landscape is dynamic, and customer preferences can change rapidly. Businesses should view reviews and ratings data scraping as an ongoing process rather than a one-time solution. Regularly updating and adapting strategies based on the latest feedback ensures that businesses remain responsive to evolving customer needs.
conclusion
Reviews and ratings data scraping services offer businesses a powerful tool for gaining insights, improving products and services, and staying ahead of the competition. By leveraging these services strategically and ethically, businesses can maximize the benefits and foster long-term success in the ever-evolving digital marketplace.
#grocerydatascraping#web scraping services#food data scraping#restaurantdataextraction#restaurant data scraping#zomato api#fooddatascrapingservices#Reviews and Ratings Data#Reviews and Ratings Data Scraping#Reviews and Ratings Data Scraping Service
0 notes
Text
year in review - hockey rpf on ao3

hello!! the annual ao3 year in review had some friends and i thinking - wouldn't it be cool if we had a hockey rpf specific version of that. so i went ahead and collated the data below!!
i start with a broad overview, then dive deeper into the 3 most popular ships this year (with one bonus!)
if any images appear blurry, click on them to expand and they should become clear!
₊˚⊹♡ . ݁₊ ⊹ . ݁˖ . ݁���� ‧₊˚ ⋅. ݁
before we jump in, some key things to highlight: - CREDIT TO: the webscraping part of my code heavily utilized the ao3 wrapped google colab code, as lovingly created by @kyucultures on twitter, as the main skeleton. i tweaked a couple of things but having it as a reference saved me a LOT of time and effort as a first time web scraper!!! thank you stranger <3 - please do NOT, under ANY circumstances, share any part of this collation on any other website. please do not screenshot or repost to twitter, tiktok, or any other public social platform. thank u!!! T_T - but do feel free to send requests to my inbox! if you want more info on a specific ship, tag, or you have a cool idea or wanna see a correlation between two variables, reach out and i should be able to take a look. if you want to take a deeper dive into a specific trope not mentioned here/chapter count/word counts/fic tags/ship tags/ratings/etc, shoot me an ask!
˚ . ˚ . . ✦ ˚ . ★⋆. ࿐࿔
with that all said and done... let's dive into hockey_rpf_2024_wrapped_insanity.ipynb
BIG PICTURE OVERVIEW
i scraped a total of 4266 fanfics that dated themselves as published or finished in the year 2024. of these 4000 odd fanfics, the most popular ships were:

Note: "Minor or Background Relationship(s)" clocked in at #9 with 91 fics, but I removed it as it was always a secondary tag and added no information to the chart. I did not discern between primary ship and secondary ship(s) either!
breaking down the 5 most popular ships over the course of the year, we see:

super interesting to see that HUGE jump for mattdrai in june/july for the stanley cup final. the general lull in the offseason is cool to see as well.
as for the most popular tags in all 2024 hockey rpf fic...

weee like our fluff. and our established relationships. and a little H/C never hurt no one.
i got curious here about which AUs were the most popular, so i filtered down for that. note that i only regex'd for tags that specifically start with "Alternate Universe - ", so A/B/O and some other stuff won't appear here!

idk it was cool to me.
also, here's a quick breakdown of the ratings % for works this year:

and as for the word counts, i pulled up a box plot of the top 20 most popular ships to see how the fic length distribution differed amongst ships:

mattdrai-ers you have some DEDICATION omg. respect
now for the ship by ship break down!!
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#1 MATTDRAI
most popular ship this year. peaked in june/july with the scf. so what do u people like to write about?

fun fun fun. i love that the scf is tagged there like yes actually she is also a main character
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#2 SIDGENO
(my babies) top tags for this ship are:

folks, we are a/b/o fiends and we cannot lie. thank you to all the selfless authors for feeding us good a/b/o fic this year. i hope to join your ranks soon.
(also: MPREG. omega sidney crosby. alpha geno. listen, the people have spoken, and like, i am listening.)
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#3 NICOJACK
top tags!!

it seems nice and cozy over there... room for one more?
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS: JDTZ.
i wasnt gonna plot this but @marcandreyuri asked me if i could take a look and the results are so compelling i must include it. are yall ok. do u need a hug

top tags being h/c, angst, angst, TRADES, pining, open endings... T_T katie said its a "torture vortex" and i must concurr
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS BONUS: ALPHA/BETA/OMEGA
as an a/b/o enthusiast myself i got curious as to what the most popular ships were within that tag. if you want me to take a look about this for any other tag lmk, but for a/b/o, as expected, SID GENO ON TOP BABY!:

thats all for now!!! if you have anything else you are interested in seeing the data for, send me an ask and i'll see if i can get it to ya!
#fanfic#sidgeno#evgeni malkin#hockey rpf#sidney crosby/evgeni malkin#hockeyrpf#hrpf fic#sidgeno fic#sidney crosby#hockeyrpf wrapped 2024#leon draisaitl#matthew tkachuk#mattdrai#leon draisaitl/matthew tkachuk#nicojack#nico hischier#nico hischier/jack hughes#jack hughes#jamie drysdale#trevor zegras#jdtz#jamie drysdale/trevor zegras#pittsburgh penguins#edmonton oilers#florida panthers#new jersey devils
466 notes
·
View notes
Text
Copyright takedowns are a cautionary tale that few are heeding

On July 14, I'm giving the closing keynote for the fifteenth HACKERS ON PLANET EARTH, in QUEENS, NY. Happy Bastille Day! On July 20, I'm appearing in CHICAGO at Exile in Bookville.

We're living through one of those moments when millions of people become suddenly and overwhelmingly interested in fair use, one of the subtlest and worst-understood aspects of copyright law. It's not a subject you can master by skimming a Wikipedia article!
I've been talking about fair use with laypeople for more than 20 years. I've met so many people who possess the unshakable, serene confidence of the truly wrong, like the people who think fair use means you can take x words from a book, or y seconds from a song and it will always be fair, while anything more will never be.
Or the people who think that if you violate any of the four factors, your use can't be fair – or the people who think that if you fail all of the four factors, you must be infringing (people, the Supreme Court is calling and they want to tell you about the Betamax!).
You might think that you can never quote a song lyric in a book without infringing copyright, or that you must clear every musical sample. You might be rock solid certain that scraping the web to train an AI is infringing. If you hold those beliefs, you do not understand the "fact intensive" nature of fair use.
But you can learn! It's actually a really cool and interesting and gnarly subject, and it's a favorite of copyright scholars, who have really fascinating disagreements and discussions about the subject. These discussions often key off of the controversies of the moment, but inevitably they implicate earlier fights about everything from the piano roll to 2 Live Crew to antiracist retellings of Gone With the Wind.
One of the most interesting discussions of fair use you can ask for took place in 2019, when the NYU Engelberg Center on Innovation Law & Policy held a symposium called "Proving IP." One of the panels featured dueling musicologists debating the merits of the Blurred Lines case. That case marked a turning point in music copyright, with the Marvin Gaye estate successfully suing Robin Thicke and Pharrell Williams for copying the "vibe" of Gaye's "Got to Give it Up."
Naturally, this discussion featured clips from both songs as the experts – joined by some of America's top copyright scholars – delved into the legal reasoning and future consequences of the case. It would be literally impossible to discuss this case without those clips.
And that's where the problems start: as soon as the symposium was uploaded to Youtube, it was flagged and removed by Content ID, Google's $100,000,000 copyright enforcement system. This initial takedown was fully automated, which is how Content ID works: rightsholders upload audio to claim it, and then Content ID removes other videos where that audio appears (rightsholders can also specify that videos with matching clips be demonetized, or that the ad revenue from those videos be diverted to the rightsholders).
But Content ID has a safety valve: an uploader whose video has been incorrectly flagged can challenge the takedown. The case is then punted to the rightsholder, who has to manually renew or drop their claim. In the case of this symposium, the rightsholder was Universal Music Group, the largest record company in the world. UMG's personnel reviewed the video and did not drop the claim.
99.99% of the time, that's where the story would end, for many reasons. First of all, most people don't understand fair use well enough to contest the judgment of a cosmically vast, unimaginably rich monopolist who wants to censor their video. Just as importantly, though, is that Content ID is a Byzantine system that is nearly as complex as fair use, but it's an entirely private affair, created and adjudicated by another galactic-scale monopolist (Google).
Google's copyright enforcement system is a cod-legal regime with all the downsides of the law, and a few wrinkles of its own (for example, it's a system without lawyers – just corporate experts doing battle with laypeople). And a single mis-step can result in your video being deleted or your account being permanently deleted, along with every video you've ever posted. For people who make their living on audiovisual content, losing your Youtube account is an extinction-level event:
https://www.eff.org/wp/unfiltered-how-youtubes-content-id-discourages-fair-use-and-dictates-what-we-see-online
So for the average Youtuber, Content ID is a kind of Kafka-as-a-Service system that is always avoided and never investigated. But the Engelbert Center isn't your average Youtuber: they boast some of the country's top copyright experts, specializing in exactly the questions Youtube's Content ID is supposed to be adjudicating.
So naturally, they challenged the takedown – only to have UMG double down. This is par for the course with UMG: they are infamous for refusing to consider fair use in takedown requests. Their stance is so unreasonable that a court actually found them guilty of violating the DMCA's provision against fraudulent takedowns:
https://www.eff.org/cases/lenz-v-universal
But the DMCA's takedown system is part of the real law, while Content ID is a fake law, created and overseen by a tech monopolist, not a court. So the fate of the Blurred Lines discussion turned on the Engelberg Center's ability to navigate both the law and the n-dimensional topology of Content ID's takedown flowchart.
It took more than a year, but eventually, Engelberg prevailed.
Until they didn't.
If Content ID was a person, it would be baby, specifically, a baby under 18 months old – that is, before the development of "object permanence." Until our 18th month (or so), we lack the ability to reason about things we can't see – this the period when small babies find peek-a-boo amazing. Object permanence is the ability to understand things that aren't in your immediate field of vision.
Content ID has no object permanence. Despite the fact that the Engelberg Blurred Lines panel was the most involved fair use question the system was ever called upon to parse, it managed to repeatedly forget that it had decided that the panel could stay up. Over and over since that initial determination, Content ID has taken down the video of the panel, forcing Engelberg to go through the whole process again.
But that's just for starters, because Youtube isn't the only place where a copyright enforcement bot is making billions of unsupervised, unaccountable decisions about what audiovisual material you're allowed to access.
Spotify is yet another monopolist, with a justifiable reputation for being extremely hostile to artists' interests, thanks in large part to the role that UMG and the other major record labels played in designing its business rules:
https://pluralistic.net/2022/09/12/streaming-doesnt-pay/#stunt-publishing
Spotify has spent hundreds of millions of dollars trying to capture the podcasting market, in the hopes of converting one of the last truly open digital publishing systems into a product under its control:
https://pluralistic.net/2023/01/27/enshittification-resistance/#ummauerter-garten-nein
Thankfully, that campaign has failed – but millions of people have (unwisely) ditched their open podcatchers in favor of Spotify's pre-enshittified app, so everyone with a podcast now must target Spotify for distribution if they hope to reach those captive users.
Guess who has a podcast? The Engelberg Center.
Naturally, Engelberg's podcast includes the audio of that Blurred Lines panel, and that audio includes samples from both "Blurred Lines" and "Got To Give It Up."
So – naturally – UMG keeps taking down the podcast.
Spotify has its own answer to Content ID, and incredibly, it's even worse and harder to navigate than Google's pretend legal system. As Engelberg describes in its latest post, UMG and Spotify have colluded to ensure that this now-classic discussion of fair use will never be able to take advantage of fair use itself:
https://www.nyuengelberg.org/news/how-explaining-copyright-broke-the-spotify-copyright-system/
Remember, this is the best case scenario for arguing about fair use with a monopolist like UMG, Google, or Spotify. As Engelberg puts it:
The Engelberg Center had an extraordinarily high level of interest in pursuing this issue, and legal confidence in our position that would have cost an average podcaster tens of thousands of dollars to develop. That cannot be what is required to challenge the removal of a podcast episode.
Automated takedown systems are the tech industry's answer to the "notice-and-takedown" system that was invented to broker a peace between copyright law and the internet, starting with the US's 1998 Digital Millennium Copyright Act. The DMCA implements (and exceeds) a pair of 1996 UN treaties, the WIPO Copyright Treaty and the Performances and Phonograms Treaty, and most countries in the world have some version of notice-and-takedown.
Big corporate rightsholders claim that notice-and-takedown is a gift to the tech sector, one that allows tech companies to get away with copyright infringement. They want a "strict liability" regime, where any platform that allows a user to post something infringing is liable for that infringement, to the tune of $150,000 in statutory damages.
Of course, there's no way for a platform to know a priori whether something a user posts infringes on someone's copyright. There is no registry of everything that is copyrighted, and of course, fair use means that there are lots of ways to legally reproduce someone's work without their permission (or even when they object). Even if every person who ever has trained or ever will train as a copyright lawyer worked 24/7 for just one online platform to evaluate every tweet, video, audio clip and image for copyright infringement, they wouldn't be able to touch even 1% of what gets posted to that platform.
The "compromise" that the entertainment industry wants is automated takedown – a system like Content ID, where rightsholders register their copyrights and platforms block anything that matches the registry. This "filternet" proposal became law in the EU in 2019 with Article 17 of the Digital Single Market Directive:
https://www.eff.org/deeplinks/2018/09/today-europe-lost-internet-now-we-fight-back
This was the most controversial directive in EU history, and – as experts warned at the time – there is no way to implement it without violating the GDPR, Europe's privacy law, so now it's stuck in limbo:
https://www.eff.org/deeplinks/2022/05/eus-copyright-directive-still-about-filters-eus-top-court-limits-its-use
As critics pointed out during the EU debate, there are so many problems with filternets. For one thing, these copyright filters are very expensive: remember that Google has spent $100m on Content ID alone, and that only does a fraction of what filternet advocates demand. Building the filternet would cost so much that only the biggest tech monopolists could afford it, which is to say, filternets are a legal requirement to keep the tech monopolists in business and prevent smaller, better platforms from ever coming into existence.
Filternets are also incapable of telling the difference between similar files. This is especially problematic for classical musicians, who routinely find their work blocked or demonetized by Sony Music, which claims performances of all the most important classical music compositions:
https://pluralistic.net/2021/05/08/copyfraud/#beethoven-just-wrote-music
Content ID can't tell the difference between your performance of "The Goldberg Variations" and Glenn Gould's. For classical musicians, the best case scenario is to have their online wages stolen by Sony, who fraudulently claim copyright to their recordings. The worst case scenario is that their video is blocked, their channel deleted, and their names blacklisted from ever opening another account on one of the monopoly platforms.
But when it comes to free expression, the role that notice-and-takedown and filternets play in the creative industries is really a sideshow. In creating a system of no-evidence-required takedowns, with no real consequences for fraudulent takedowns, these systems are huge gift to the world's worst criminals. For example, "reputation management" companies help convicted rapists, murderers, and even war criminals purge the internet of true accounts of their crimes by claiming copyright over them:
https://pluralistic.net/2021/04/23/reputation-laundry/#dark-ops
Remember how during the covid lockdowns, scumbags marketed junk devices by claiming that they'd protect you from the virus? Their products remained online, while the detailed scientific articles warning people about the fraud were speedily removed through false copyright claims:
https://pluralistic.net/2021/10/18/labor-shortage-discourse-time/#copyfraud
Copyfraud – making false copyright claims – is an extremely safe crime to commit, and it's not just quack covid remedy peddlers and war criminals who avail themselves of it. Tech giants like Adobe do not hesitate to abuse the takedown system, even when that means exposing millions of people to spyware:
https://pluralistic.net/2021/10/13/theres-an-app-for-that/#gnash
Dirty cops play loud, copyrighted music during confrontations with the public, in the hopes that this will trigger copyright filters on services like Youtube and Instagram and block videos of their misbehavior:
https://pluralistic.net/2021/02/10/duke-sucks/#bhpd
But even if you solved all these problems with filternets and takedown, this system would still choke on fair use and other copyright exceptions. These are "fact intensive" questions that the world's top experts struggle with (as anyone who watches the Blurred Lines panel can see). There's no way we can get software to accurately determine when a use is or isn't fair.
That's a question that the entertainment industry itself is increasingly conflicted about. The Blurred Lines judgment opened the floodgates to a new kind of copyright troll – grifters who sued the record labels and their biggest stars for taking the "vibe" of songs that no one ever heard of. Musicians like Ed Sheeran have been sued for millions of dollars over these alleged infringements. These suits caused the record industry to (ahem) change its tune on fair use, insisting that fair use should be broadly interpreted to protect people who made things that were similar to existing works. The labels understood that if "vibe rights" became accepted law, they'd end up in the kind of hell that the rest of us enter when we try to post things online – where anything they produce can trigger takedowns, long legal battles, and millions in liability:
https://pluralistic.net/2022/04/08/oh-why/#two-notes-and-running
But the music industry remains deeply conflicted over fair use. Take the curious case of Katy Perry's song "Dark Horse," which attracted a multimillion-dollar suit from an obscure Christian rapper who claimed that a brief phrase in "Dark Horse" was impermissibly similar to his song "A Joyful Noise."
Perry and her publisher, Warner Chappell, lost the suit and were ordered to pay $2.8m. While they subsequently won an appeal, this definitely put the cold grue up Warner Chappell's back. They could see a long future of similar suits launched by treasure hunters hoping for a quick settlement.
But here's where it gets unbelievably weird and darkly funny. A Youtuber named Adam Neely made a wildly successful viral video about the suit, taking Perry's side and defending her song. As part of that video, Neely included a few seconds' worth of "A Joyful Noise," the song that Perry was accused of copying.
In court, Warner Chappell had argued that "A Joyful Noise" was not similar to Perry's "Dark Horse." But when Warner had Google remove Neely's video, they claimed that the sample from "Joyful Noise" was actually taken from "Dark Horse." Incredibly, they maintained this position through multiple appeals through the Content ID system:
https://pluralistic.net/2020/03/05/warner-chappell-copyfraud/#warnerchappell
In other words, they maintained that the song that they'd told the court was totally dissimilar to their own was so indistinguishable from their own song that they couldn't tell the difference!
Now, this question of vibes, similarity and fair use has only gotten more intense since the takedown of Neely's video. Just this week, the RIAA sued several AI companies, claiming that the songs the AI shits out are infringingly similar to tracks in their catalog:
https://www.rollingstone.com/music/music-news/record-labels-sue-music-generators-suno-and-udio-1235042056/
Even before "Blurred Lines," this was a difficult fair use question to answer, with lots of chewy nuances. Just ask George Harrison:
https://en.wikipedia.org/wiki/My_Sweet_Lord
But as the Engelberg panel's cohort of dueling musicologists and renowned copyright experts proved, this question only gets harder as time goes by. If you listen to that panel (if you can listen to that panel), you'll be hard pressed to come away with any certainty about the questions in this latest lawsuit.
The notice-and-takedown system is what's known as an "intermediary liability" rule. Platforms are "intermediaries" in that they connect end users with each other and with businesses. Ebay and Etsy and Amazon connect buyers and sellers; Facebook and Google and Tiktok connect performers, advertisers and publishers with audiences and so on.
For copyright, notice-and-takedown gives platforms a "safe harbor." A platform doesn't have to remove material after an allegation of infringement, but if they don't, they're jointly liable for any future judgment. In other words, Youtube isn't required to take down the Engelberg Blurred Lines panel, but if UMG sues Engelberg and wins a judgment, Google will also have to pay out.
During the adoption of the 1996 WIPO treaties and the 1998 US DMCA, this safe harbor rule was characterized as a balance between the rights of the public to publish online and the interest of rightsholders whose material might be infringed upon. The idea was that things that were likely to be infringing would be immediately removed once the platform received a notification, but that platforms would ignore spurious or obviously fraudulent takedowns.
That's not how it worked out. Whether it's Sony Music claiming to own your performance of "Fur Elise" or a war criminal claiming authorship over a newspaper story about his crimes, platforms nuke first and ask questions never. Why not? If they ignore a takedown and get it wrong, they suffer dire consequences ($150,000 per claim). But if they take action on a dodgy claim, there are no consequences. Of course they're just going to delete anything they're asked to delete.
This is how platforms always handle liability, and that's a lesson that we really should have internalized by now. After all, the DMCA is the second-most famous intermediary liability system for the internet – the most (in)famous is Section 230 of the Communications Decency Act.
This is a 27-word law that says that platforms are not liable for civil damages arising from their users' speech. Now, this is a US law, and in the US, there aren't many civil damages from speech to begin with. The First Amendment makes it very hard to get a libel judgment, and even when these judgments are secured, damages are typically limited to "actual damages" – generally a low sum. Most of the worst online speech is actually not illegal: hate speech, misinformation and disinformation are all covered by the First Amendment.
Notwithstanding the First Amendment, there are categories of speech that US law criminalizes: actual threats of violence, criminal harassment, and committing certain kinds of legal, medical, election or financial fraud. These are all exempted from Section 230, which only provides immunity for civil suits, not criminal acts.
What Section 230 really protects platforms from is being named to unwinnable nuisance suits by unscrupulous parties who are betting that the platforms would rather remove legal speech that they object to than go to court. A generation of copyfraudsters have proved that this is a very safe bet:
https://www.techdirt.com/2020/06/23/hello-youve-been-referred-here-because-youre-wrong-about-section-230-communications-decency-act/
In other words, if you made a #MeToo accusation, or if you were a gig worker using an online forum to organize a union, or if you were blowing the whistle on your employer's toxic waste leaks, or if you were any other under-resourced person being bullied by a wealthy, powerful person or organization, that organization could shut you up by threatening to sue the platform that hosted your speech. The platform would immediately cave. But those same rich and powerful people would have access to the lawyers and back-channels that would prevent you from doing the same to them – that's why Sony can get your Brahms recital taken down, but you can't turn around and do the same to them.
This is true of every intermediary liability system, and it's been true since the earliest days of the internet, and it keeps getting proven to be true. Six years ago, Trump signed SESTA/FOSTA, a law that allowed platforms to be held civilly liable by survivors of sex trafficking. At the time, advocates claimed that this would only affect "sexual slavery" and would not impact consensual sex-work.
But from the start, and ever since, SESTA/FOSTA has primarily targeted consensual sex-work, to the immediate, lasting, and profound detriment of sex workers:
https://hackinghustling.org/what-is-sesta-fosta/
SESTA/FOSTA killed the "bad date" forums where sex workers circulated the details of violent and unstable clients, killed the online booking sites that allowed sex workers to screen their clients, and killed the payment processors that let sex workers avoid holding unsafe amounts of cash:
https://www.eff.org/deeplinks/2022/09/fight-overturn-fosta-unconstitutional-internet-censorship-law-continues
SESTA/FOSTA made voluntary sex work more dangerous – and also made life harder for law enforcement efforts to target sex trafficking:
https://hackinghustling.org/erased-the-impact-of-fosta-sesta-2020/
Despite half a decade of SESTA/FOSTA, despite 15 years of filternets, despite a quarter century of notice-and-takedown, people continue to insist that getting rid of safe harbors will punish Big Tech and make life better for everyday internet users.
As of now, it seems likely that Section 230 will be dead by then end of 2025, even if there is nothing in place to replace it:
https://energycommerce.house.gov/posts/bipartisan-energy-and-commerce-leaders-announce-legislative-hearing-on-sunsetting-section-230
This isn't the win that some people think it is. By making platforms responsible for screening the content their users post, we create a system that only the largest tech monopolies can survive, and only then by removing or blocking anything that threatens or displeases the wealthy and powerful.
Filternets are not precision-guided takedown machines; they're indiscriminate cluster-bombs that destroy anything in the vicinity of illegal speech – including (and especially) the best-informed, most informative discussions of how these systems go wrong, and how that blocks the complaints of the powerless, the marginalized, and the abused.
Support me this summer on the Clarion Write-A-Thon and help raise money for the Clarion Science Fiction and Fantasy Writers' Workshop!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/06/27/nuke-first/#ask-questions-never
Image: EFF https://www.eff.org/files/banner_library/yt-fu-1b.png
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#vibe rights#230#section 230#cda 230#communications decency act#communications decency act 230#cda230#filternet#copyfight#fair use#notice and takedown#censorship#reputation management#copyfraud#sesta#fosta#sesta fosta#spotify#youtube#contentid#monopoly#free speech#intermediary liability
677 notes
·
View notes
Text
Been frontstuck for a boringly long amount of time so I might as well do the thing I was talking about -Kazuki
Disclaimer: this is all based on random associations spat out by our synesthesia brain, no part of this is based on anything logical this is literally just for the funsies and giggles.
💜transname flags colored by our associative synesthesia💜
(Part 1)
Toby

The name Toby reads fanficfion all day and night, loves cool looking rocks and has a huge collection, favorite weather is blindingy sunny. There is a bandaid because somehow the name Toby manages to fall terribly every single day and scrape a new spot on their body
Hazel

The name Hazel is in love with all sorts of alternative fashion. They're also a raging nerd about nature, especially flowers. There are angel wings and the font is somewhat similar to a cloud shape because the name Hazel is oddly intrigued by heaven/angel imagery and they're questioning if they might be an angel.
Annalise

The name Annalise is the older sibling figure of the name Hazel. The name Annalise likes sickly sweet candy, haunted dolls, and urban exploring. They also do nail art. There's a spider web because the name Annalise has a halloween special episode cartoon villain type of vibe.
Charlotte

The name Charlotte likes studying psychology and history. Absolutely in love with chocolate and occasionally reviews different flavors and brands of chocolate and posts about it online. They have a cat image because their comfort hoodie has cat ears and every being knows them as the cat hoodie being.
#rq community#transid please interact#🌈🍓 safe#radq safe#radqueer#radqueer 🌈🍓#transid#transid interact#rq coining#transid community#transid coining#transid labels#rq flag
21 notes
·
View notes
Text

Running program and loading document.
Security bypassed.

Upload complete!

Document of specimen designated ‘Subject #42’
Case Number: 19.15.21.12
Date: REDACTED
———————————————————————



———————————————————————
1: Subject #42’s Eyes
Subject #42 has large forward facing eyes, its pupils can easily expand and shrink to account for glare or near total darkness. The sclera of the eyes are vibrant yellow. This was later concluded to be due to having high levels of some bilirubin adjacent chemicals within the body.
Originally, it was assumed Subject #42 was suffering from liver failure, but further examination and blood tests revealed such was far from the truth. Whereas that much bilirubin in a red blood celled organism would be a sign of toxicity, because Subject #42 does not have red iron based blood, these high levels of bilirubin do not strip away or break down the blood cells. Instead of causing toxicity, it’s a natural antioxidant.
Subject #42’s eyes appear to have entered a near constant state of myosis, even in low lighting.
———————————————————————
2: Subject #42’s wings
Subject #42 has broad webbed wings that suggest an adaptation for long periods of non stop flight over vast distances.
Such an hypothesis was confirmed reviewing the observation notes of Subject #42 traveling vast distances prior to its capture. Subject #42’s wings were bound with cold iron cuffs shortly after its capture. While Subject #42 later outsmarted the attempts to restrict its ability to fly by simply using its abilities to levitate, the cuffs serve as a successful means to stop it from phasing through the walls of its containment unit.
The second finger of Subject #42’s wings are covered in small, aged scars along the whole length of the limb. The patterns and depth of the scars are consistent with wounds received from scraping against rocks and deflecting debris with the limbs. Subject #42 will swing its talons around like weapons with remarkable precision.
———————————————————————
3: Subject #42’s teeth and mouth
Armed with impressively developed canine teeth and a pointed, papillae covered tongue, Subject #42’s diet is primarily that of a hypercarnivore.
This has lead Doctor Cruce to hypothesize that Subject #42 might have been following the armed forces to feed on the bodies of the casualties produced by the conflict. Subject #42 does share some characteristics of scavengers, such as strong jaws and sharp teeth, but the metabolic cost of traveling such far distances, alongside its abilities, claws and the sword it was found wielding suggests that Subject #42 would likely or primarily have hunted opposed to scavenged. And yet, there was no reports of Subject #42 hunting anything prior to its capture.
The blue colouration comes from the subject’s blue blood, being copper based instead of iron based and highly oxygen efficient. An endurance test concluded Subject #42 can go almost four hours without breathing, suggesting Subject #42 comes from a low oxygen environment where it pays to be able to make the most of the little oxygen available. However, it seems to be perfectly fine in environments of standard 21% oxygen levels.
———————————————————————
4: Subject #42’s paws and forelimbs
Everything about Subject #42’s paws and forelimbs suggests it is a highly efficient climber. It has tough palms, strong claws for grip, an abundance of collagen within its body, and well developed tendons and ligaments.
A test concluded that with ease it can swiftly scale up vertical walls, alongside being highly oxygen efficient, it does not tire easily, leading Doctor Cruce to suggest Subject #42 might’ve evolved in a rocky, mountainous environment.
———————————————————————
5: Subject #42’s standard vision
A vision test conducted on Subject #42 determined it has remarkably clear long distance vision, able to spot small movements and small details from over several hundred feet of distance.
It can see a wide range of colours and in various levels of lighting.
Interestingly enough, it is badly nearsighted, seeming to have put all its points towards seeing very far instead of close up.
When Subject #42’s powers are activated, its eyes go fully lavender in colour and light up in a bioluminescent display.
—————————————————————————————————————
6: Subject #42’s ‘soul vision’
Finally approaching Subject #42’s bizarrely dare say otherworldly powers, hooking up various scanners and devices to Subject #42 to scan its brain Doctor Cruce discovered Subject #42 has an ‘alternate vision’ that she’s come to dub ‘soul vision’. When activated, Subject #42’s retinas stop perceiving light entirely, instead seeing a vast spectrum of the electromagnetic wave length that shows up to Subject #42 in various ‘colours’ and shapes.
While it took a bit of trial and error, it was discovered that people who have what’s been commonly dubbed a ‘soul’ will show up to this alternate vision as a figure with white eyes. Anything without a soul, be it people or objects, will be entirely invisible to Subject #42 during this time. It seems to be able to toggle back and forth between these two modes of vision at will.
Currently, it is unknown if the ‘colours’ that show up have different meanings. Subject #42 continues to show no ability and or interest in answering any questions that are asked of it.
—————————————————————————————————————
7: Further manifestations of Subject #42’s ‘soul magic’
Subject #42 is highly proficient in the use of its magic. It appears capable of instantly and immediately telling if something with a soul approaches it, even through walls and when its vision is restricted, suggesting the soul vision might be able to see through solid objects and see a remarkable distance away.
Alternatively, it may just be a sense that Subject #42 has passively.
When focused, this soul magic can form highly energetic lasers (resulting in biweekly maintenance required to Subject #42’s containment unit), an energy field around itself, and various other high energy attacks.
Subject #42 has a large quantity of energy within it, which it appears to get by steadily absorbing the lifeforce of everything around it.
Subject #42 has a large quantity of energy within it, which it appears to get by steadily absorbing the lifeforce of everything around it.
While it initially caused concern and almost led to the immediate order to terminate Subject #42, Doctor Cruce confirmed at the time that Subject #42 does not appear capable of doing this to such an extent that it would cause death or noticeable symptoms, quote ‘it's not taking from you anymore than the rate of you already naturally dying’. This statement was later retracted when, during a test, Subject #42 killed a test subject by simply touching it, examination to the body shows no wounds or signs of bodily trauma. It appears that Subject #42 instantly killed the fellow subject by removing its life force.
Doctor Cruce now believes that Subject #42 can indeed at any time rapidly and fatally absorb the life force of another being, but must come in contact with it first. For safety precautions, and yet another complaint from maintenance, Subject #42 was later moved to be held in stasis.
Up until that point Subject #42 had simply been very aloof and standoffish, during its final moments before being put in stasis it seemed to enter a state of hysteria, repeatedly calling out for something or someone.
—————————————————————————————————————
There are still many unanswered questions regarding Subject #42, such as the unnatural origins of its abilities and its origins in general.
Doctor Cruce’s conclusion is that it would benefit Nightmare Enterprises to make demonbeasts using Subject #42’s DNA.
However, she stressed a high deal of caution and time to conduct further research before proceeding with any attempts to make new monsters.
Subject #42’s highly unpredictable nature and abilities could lead to the creation of a monster far worse than it that could be impossible to contain that could become an unimaginable threat to the company, especially if it escaped and got into the wrong hands.
(END OF LOG)
#kirby#hoshi no kirby#kirby right back at ya#art#kirby art#kirby oc#kirby of the stars#kirby au#digital artist#kirby wolfbell au#subject 42#I have returned to my origins
26 notes
·
View notes
Note
I'm getting 404s trying to get to the Pornboxd homepage and 403s clicking on your pinned link
That happens sometimes. The web host I use isn't very high end and doesn't seem to appreciate how demanding some of my site scraping scripts are lol.
It's back up now.
Also I added the ability to reply to reviews!!!
13 notes
·
View notes
Text
The Power of Yelp Data Scraper Using Our Yelp Review Data Scraping Services
Our Yelp web scraper efficiently collects business information, reviews, ratings, and other relevant data, providing you with actionable insights for business analysis and decision-making. With automated scraping capabilities and a user-friendly interface, our scraper saves you time and effort in gathering important Yelp data.
1 note
·
View note
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
How to Extract Real-Time Promotions Data & Restaurant Data Scraping
#Restaurant data scraping#mobile app scraping#web scraping#instant data scraper#smart scraping strategies#scraping customer reviews
0 notes
Text

I blocked this guy for spreading misinformation, but I want to address the points they made so people don't buy into this shit.
"Have you really never heard of a denoiser?" Glaze and Nightshade cannot be defeated by denoisers. Please see the paper I link in #2. This point is amazingly easy to debunk, and I'm not sure why people are still championing it. Both programs work by changing what the software "sees." Denoising can blur these artifacts, but it does not fundamentally get rid of them.
"White knighting for amoral techbro apps." This was a very early techbro attack on Glaze to try to convince people it was another way to steal data. As I said in an earlier post, it does use a dataset to enable it to add artifacts to your work. It is essentially using AI against itself, and it is effective. There's a whole peer-reviewed paper on how it works. I've posted it before, but if you missed it, you can read it here: https://arxiv.org/abs/2310.13828 (and unlike Generative AI apps, this paper explains exactly how the technology works.)
"Wasting resources." The point is to make the machines unusable, which ultimately will reduce the stress on our infrastructure. If the datasets no longer work, the use of them decreases. Unfortunately, the inability for people to adequately protect their work has led to massive electricity-wasting farms for generative AI, just like what happened with NFTs and cryptocurrency. If enough people inject unusable data in the the systems, the systems themselves become unusable, and the use decreases.
"My artistic vanity." I'm not a good artist. But my artwork HAS been scraped and used. I don't know why I have to keep saying this to make my anger and pain valid, but a few months back, all my artwork was revenge-scraped and stuffed into Midjourney. The person who did it also stripped my name from it, so I am not even able to HOPE to have it removed. I have nothing left to lose. I want to make those motherfuckers pay.
"The google thing only defeats weak watermarks." This is true. But a "strong" watermark must be completely different on each work you post, and also must cover most of the work. This is easily researched. I don't know about you, but I don't have time to make a new watermark on each piece I post, and I also don't want it to cover most of the artwork. Just so you know, the watermark detector works by looking for the same pattern on multiple works by the same person. If you use the same watermark on each piece, it doesn't matter how strong you think it is. It's removable. If you have the time to do it, then yes, this is effective. But it needs to be complex and different on each piece.
Next, I've seen a couple posts going around today stating that you can't even have an account on Glaze because they're closed.
They're not. But to prevent techbros from making accounts, you have to message the team so they can make sure you aren't using AI in your work. The instructions are here: https://glaze.cs.uchicago.edu/webinvite.html
Nightshade is not available on the web yet, but Glaze is. Nightshade will be soon, and they are planning a combo web app that will both Glaze and Nightshade your work.
In the meantime, if you want someone to Nightshade your work for you, please let me know. I have offered this before, and I will offer it again. Email me at [email protected] with your artwork, and let me know you'd like me to Nightshade it for you. There will always be some artifacts, but I will work with you until you are happy with the result.
Lastly, I know my messages are working because I keep getting people spreading misinformation that these things don't work. Please know that I have done the research, I do have a personal stake in this (because hundreds of my pieces are part of Midjourney now) and I am only posting this because I truly believe this is the way to fight back against plagiarism machines.
I don't know why people are so angry when I post about them. I know people don't all have access, which is why I'm offering my resources to help. I know this is a new technology, which is why I read through the boring scientific paper myself so I can validate the claims.
This is the last post I'll make on the matter. If you want to ask questions, fine, but I don't really have the mental capacity to argue with everyone anymore, and I'm not going to.
8 notes
·
View notes
Text
How Customer Reviews Scraping Improves Efficiency and Business Growth?

In the age of digital commerce, consumers are constantly seeking ways to make informed purchasing decisions. Whether it's finding the best deals or tracking price fluctuations over time, accessing accurate and up-to-date data is crucial. Enter web scraping—a powerful technique that provides invaluable insights into the vast landscape of online retail. In this article, we'll explore how web scraping data insights can revolutionize the process of accessing Wayfair price history, empowering consumers with the knowledge they need to make informed decisions.
Understanding Web Scraping
Before delving into its application in accessing Wayfair price history, let's briefly understand what web scraping entails. Web scraping involves extracting data from websites, typically in an automated fashion, using specialized tools or programming scripts. These tools navigate through the structure of web pages, gathering information such as product details, prices, reviews, and more.
The Importance of Price History
Price history serves as a valuable resource for consumers, enabling them to track fluctuations in product prices over time. By analyzing historical data, shoppers can identify patterns, anticipate price trends, and determine the best time to make a purchase. This is particularly relevant in the realm of online retail, where prices can vary widely and change frequently due to factors like demand, competition, and promotions.
Leveraging Web Scraping for Wayfair Price History
Wayfair, one of the largest online destinations for home goods and furniture, offers a vast array of products at competitive prices. However, accessing historical pricing information on Wayfair's platform can be challenging through conventional means. This is where web scraping comes into play, providing a streamlined solution for gathering and analyzing price data.
By utilizing web scraping techniques, consumers can extract price information from Wayfair's website and compile it into structured datasets. These datasets can then be analyzed to uncover valuable insights, such as trends in pricing, seasonal fluctuations, and the impact of promotions or sales events. Moreover, web scraping enables users to compare prices across different time periods, products, or sellers, empowering them to make informed decisions and secure the best possible deals.
Tools and Techniques for Web Scraping
Several tools and techniques are available for web scraping, ranging from simple browser extensions to sophisticated programming libraries. For accessing Wayfair price history, Python-based libraries such as BeautifulSoup and Scrapy are popular choices among web scraping enthusiasts. These libraries provide robust capabilities for navigating web pages, extracting data, and storing it in a structured format for analysis.
Additionally, specialized web scraping services and platforms offer turnkey solutions for extracting price data from Wayfair and other e-commerce websites. These services often feature user-friendly interfaces, pre-built scraping modules, and advanced analytics capabilities, making them accessible to users with varying levels of technical expertise.
Ethical Considerations and Best Practices
While web scraping can provide valuable insights into Wayfair price history, it's essential to adhere to ethical guidelines and respect the terms of service of the websites being scraped. Engaging in excessive or abusive scraping behavior can strain server resources, disrupt website functionality, and potentially violate legal regulations.
To mitigate these risks, practitioners should implement rate limiting mechanisms, respect robots.txt directives, and obtain explicit permission when necessary. Additionally, it's crucial to handle scraped data responsibly, ensuring compliance with data privacy regulations and protecting sensitive information.
Conclusion
In conclusion, web scraping data insights offer a powerful means of accessing Wayfair price history and gaining a deeper understanding of online retail dynamics. By harnessing the capabilities of web scraping tools and techniques, consumers can navigate the complexities of e-commerce, track price fluctuations, and make informed purchasing decisions. However, it's essential to approach web scraping responsibly, respecting ethical considerations and legal boundaries to ensure a fair and sustainable online ecosystem. With the right tools and practices in place, web scraping opens up a world of possibilities for uncovering valuable insights and maximizing savings in the digital marketplace.
1 note
·
View note
Text
Scraping Reviews from TripAdvisor: A Comprehensive Guide

Are you tired of scrolling through endless reviews on TripAdvisor to plan your next vacation? Look no further than the TripAdvisor Scraper, a powerful tool that can help you streamline your travel planning process. In this article, we'll explore the benefits of using a TripAdvisor scraper and how it can unleash your travel planning potential.
What is a TripAdvisor Scraper?
A TripAdvisor scraper is a software tool that extracts data from the popular travel review website, TripAdvisor. It collects information such as hotel reviews, ratings, and prices, and presents it in a structured format for easy analysis. This allows users to quickly compare and contrast different options and make informed decisions for their travel plans.
Save Time and Effort
One of the biggest advantages of using a TripAdvisor scraper is the time and effort it can save you. Instead of manually searching through countless reviews and ratings, the scraper does the work for you. It collects all the necessary information and presents it in an organized manner, allowing you to make efficient and informed decisions for your trip.
Find the Best Deals
With a TripAdvisor scraper, you can easily compare prices and ratings for different hotels and accommodations. This can help you find the best deals and save money on your travels. The scraper also allows you to filter results based on your budget and preferences, making it easier to find the perfect option for your trip.
Analyze Reviews and Ratings
In addition to collecting data, a TripAdvisor scraper also allows you to analyze reviews and ratings. This can be especially helpful for businesses in the travel industry, as they can gain valuable insights into customer satisfaction and areas for improvement. By understanding the sentiments and opinions of customers, businesses can make necessary changes to enhance their services and attract more customers.
Create a Review Aggregator
A TripAdvisor scraper can also be used to create a review aggregator, which is a website or platform that collects reviews from multiple sources and presents them in one place. This can be a valuable resource for travelers, as they can easily access reviews from various sources and make informed decisions for their trips. As a business, having a review aggregator can also help you attract more customers and improve your online reputation.
Stay Ahead of the Competition
By utilizing a TripAdvisor scraper, businesses can stay ahead of the competition by keeping track of their competitors' reviews and ratings. This allows them to identify areas where they can improve and stay on top of industry trends. By constantly monitoring and analyzing reviews, businesses can maintain a strong online presence and attract more customers.
In conclusion,
The TripAdvisor scraper is a powerful tool that can unleash your travel planning potential. It saves time and effort, helps you find the best deals, and allows you to analyze reviews and ratings for valuable insights. Whether you're a traveler or a business in the travel industry, the foods data scraper is a must-have tool for efficient and effective travel planning. Have you used a TripAdvisor scraper before? Share your experience in the comments below.
#food data scraping#grocerydatascraping#restaurant data scraping#food data scraping services#restaurantdataextraction#fooddatascrapingservices#web scraping services#TripAdvisor Reviews#reviews restaurant#hotel reviews#TripAdvisor Reviews service
0 notes