#Web Scraper API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
E-commerce Web Scraping | Data Scraping for eCommerce
Are you in need of data scraping for eCommerce industry? Get expert E-commerce web scraping services to extract real-time data. Flat 20%* off on ecommerce data scraping.
0 notes
Text
youtube
#web scraping#web scraping api#scrapingdog#instagram scraper#instagram scraper api#instagram scraping#Youtube
0 notes
Text

E-commerce Web Scraping API for Accurate Product & Pricing Insights
Access structured e-commerce data efficiently with a robust web scraping API for online stores, marketplaces, and retail platforms. This API helps collect data on product listings, prices, reviews, stock availability, and seller details from top e-commerce sites. Ideal for businesses monitoring competitors, following trends, or managing records, it provides consistent and correct results. Built to scale, the service supports high-volume requests and delivers results in easy-to-integrate formats like JSON or CSV. Whether you need data from Amazon, eBay, or Walmart. iWeb Scraping provides unique e-commerce data scraping services. Learn more about the service components and pricing by visiting iWebScraping E-commerce Data Services.
0 notes
Text
RealdataAPI is the one-stop solution for Web Scraper, Crawler, & Web Scraping APIs for Data Extraction in countries like USA, UK, UAE, Germany, Australia, etc.
1 note
·
View note
Text
Best Zomato Web Scraping Services by ReviewGators
Our online Zomato web scraping service makes it easy for you to get all the information you need to focus on providing value to your customers. We develop our Zomato Review Scraper API with no contracts, no setup fees, and no upfront costs to satisfy the needs of our clients. Customers have the option to make payments as needed. You can efficiently and accurately scrape Zomato data about reviews and ratings from the Zomato website using our Zomato Scraper.
1 note
·
View note
Text
Foodpanda API will extract and download Foodpanda data, including restaurant details, menus, reviews, ratings, etc. Download the data in the required format, such as CSV, Excel, etc.
#food data scraping services#web scraping services#restaurantdataextraction#zomato api#grocerydatascraping#food data scraping#restaurant data scraping#grocerydatascrapingapi#fooddatascrapingservices#Foodpanda API#Restaurant Scraper
1 note
·
View note
Video
youtube
Google SERP Scraping With Python
The video shows a easy Google SERP scraping process with Python. 👉 Go to ScrapingBypass website: https://www.scrapingbypass.com Google SERP scraping code: https://www.scrapingbypass.com/tutorial/google-serp-scraping-with-python
#serp scraping#serp scraper#google serp scraping#bypass cloudflare#cloudflare bypass#web scraping#scrapingbypass#web scraping api
0 notes
Note
there is a dip in the fic count of all fandoms between february 26 and march 3, is there a reason for that? just something I noticed while looking at the dashboard
So I finally had time to look into this properly - at first I couldn't figure it out, because I didn't make any changes to my workflow around that time.
However, I had a hunch and checked everyone's favorite RPF fandom (Hockey RPF) and the drop was wayyy more dramatic there. This confirmed my theory that my stats were no longer including locked works (since RPF fandoms tend to have a way higher percentage of locked fics).
It looks AO3 made some changes to how web scrapers can interact with their site, likely due to the DDOS attacks / AI scrapers they've been dealing with. That change caused my scraper to pull all fic counts as if it was a guest and not a member, which caused the drop.
~
The good news: I was able to leverage the login code from the unofficial python AO3 api to fix it, so future fic counts should be accurate.
The bad news: I haven't figured out what to do about the drop in old data. I can either leave it or I can try to write some math-based script that estimates how many fics there were on those old dates (using the data I do have and scaling up based on that fandom's percentage of locked fics). This wouldn't be a hundred percent accurate, but neither are the current numbers, so we'll see.
~
Thanks Nonny so much for pointing this out! I wish I would've noticed & had a chance to fix earlier, but oh well!
37 notes
·
View notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
25 Python Projects to Supercharge Your Job Search in 2024

Introduction: In the competitive world of technology, a strong portfolio of practical projects can make all the difference in landing your dream job. As a Python enthusiast, building a diverse range of projects not only showcases your skills but also demonstrates your ability to tackle real-world challenges. In this blog post, we'll explore 25 Python projects that can help you stand out and secure that coveted position in 2024.
1. Personal Portfolio Website
Create a dynamic portfolio website that highlights your skills, projects, and resume. Showcase your creativity and design skills to make a lasting impression.
2. Blog with User Authentication
Build a fully functional blog with features like user authentication and comments. This project demonstrates your understanding of web development and security.
3. E-Commerce Site
Develop a simple online store with product listings, shopping cart functionality, and a secure checkout process. Showcase your skills in building robust web applications.
4. Predictive Modeling
Create a predictive model for a relevant field, such as stock prices, weather forecasts, or sales predictions. Showcase your data science and machine learning prowess.
5. Natural Language Processing (NLP)
Build a sentiment analysis tool or a text summarizer using NLP techniques. Highlight your skills in processing and understanding human language.
6. Image Recognition
Develop an image recognition system capable of classifying objects. Demonstrate your proficiency in computer vision and deep learning.
7. Automation Scripts
Write scripts to automate repetitive tasks, such as file organization, data cleaning, or downloading files from the internet. Showcase your ability to improve efficiency through automation.
8. Web Scraping
Create a web scraper to extract data from websites. This project highlights your skills in data extraction and manipulation.
9. Pygame-based Game
Develop a simple game using Pygame or any other Python game library. Showcase your creativity and game development skills.
10. Text-based Adventure Game
Build a text-based adventure game or a quiz application. This project demonstrates your ability to create engaging user experiences.
11. RESTful API
Create a RESTful API for a service or application using Flask or Django. Highlight your skills in API development and integration.
12. Integration with External APIs
Develop a project that interacts with external APIs, such as social media platforms or weather services. Showcase your ability to integrate diverse systems.
13. Home Automation System
Build a home automation system using IoT concepts. Demonstrate your understanding of connecting devices and creating smart environments.
14. Weather Station
Create a weather station that collects and displays data from various sensors. Showcase your skills in data acquisition and analysis.
15. Distributed Chat Application
Build a distributed chat application using a messaging protocol like MQTT. Highlight your skills in distributed systems.
16. Blockchain or Cryptocurrency Tracker
Develop a simple blockchain or a cryptocurrency tracker. Showcase your understanding of blockchain technology.
17. Open Source Contributions
Contribute to open source projects on platforms like GitHub. Demonstrate your collaboration and teamwork skills.
18. Network or Vulnerability Scanner
Build a network or vulnerability scanner to showcase your skills in cybersecurity.
19. Decentralized Application (DApp)
Create a decentralized application using a blockchain platform like Ethereum. Showcase your skills in developing applications on decentralized networks.
20. Machine Learning Model Deployment
Deploy a machine learning model as a web service using frameworks like Flask or FastAPI. Demonstrate your skills in model deployment and integration.
21. Financial Calculator
Build a financial calculator that incorporates relevant mathematical and financial concepts. Showcase your ability to create practical tools.
22. Command-Line Tools
Develop command-line tools for tasks like file manipulation, data processing, or system monitoring. Highlight your skills in creating efficient and user-friendly command-line applications.
23. IoT-Based Health Monitoring System
Create an IoT-based health monitoring system that collects and analyzes health-related data. Showcase your ability to work on projects with social impact.
24. Facial Recognition System
Build a facial recognition system using Python and computer vision libraries. Showcase your skills in biometric technology.
25. Social Media Dashboard
Develop a social media dashboard that aggregates and displays data from various platforms. Highlight your skills in data visualization and integration.
Conclusion: As you embark on your job search in 2024, remember that a well-rounded portfolio is key to showcasing your skills and standing out from the crowd. These 25 Python projects cover a diverse range of domains, allowing you to tailor your portfolio to match your interests and the specific requirements of your dream job.
If you want to know more, Click here:https://analyticsjobs.in/question/what-are-the-best-python-projects-to-land-a-great-job-in-2024/
#python projects#top python projects#best python projects#analytics jobs#python#coding#programming#machine learning
2 notes
·
View notes
Text
#trying to find a maintained api for ao3 is lowkey impossible#esp one that doesnt require an existing list of work ids#trying to scrape some data for a fannish project and i’m thinking i either have to vm dowload fics onto a server or a container#and then parse thru pdf files for raw data that way#or build a webscraper from scratch#the problem with both of these is that i don’t wanna strain ao3’s servers lol#altho the fandom is small so i might just be able to do this without threading#altho at that point why not just do it manually#AAAAAAAAA#can we pls have an api i know we won’t get one bc of app-gate but :(
ok this has the vibe of someone talking to themselves so you probably didn't expect me to respond but... it is my post. so anyway
ao3downloader actually has an option to save work stats as a csv (or just the plain links in a .txt file) instead of downloading the files, so you may be able to use it for your project as-is (depending on which stats you need - it doesn't currently include kudos/hits/bookmark counts, and anything that requires clicking into the work - as opposed to just looking at the list view - is also not included)
if you do decide to download files and then parse them offline, please for the love of god don't download them as pdfs? why. why would you hurt yourself in that way. do html, or even epub, or really anything other than pdf. have you ever tried to programmatically parse a pdf? if so, and you're still sane, I'd like to know your secrets. if not: DON'T.
ao3 is rate-limited so you are very very unlikely to hit on a way of accidentally ddosing them with a hobby web scraper. like as long as you're not deliberately on purpose doing hacker/botnet type shit to get around the rate limit, you're fine. I mean, do make an effort to not spam request after you get a retry later since that's just polite, but even if you accidentally do it's still fine.
also because of the rate limit, I strongly advise against trying to parallelize your scraper (should you decide to roll your own). it won't speed anything up and it will cause race conditions.
as far as I know app gate isn't the blocker for an ao3 api, they've been dragging their feet on the api since well before any app scandals occurred. the reason we don't have an api is because the devs just simply aren't interested in making one. and, to an extent I can understand that. sometimes shit is just outside of the realm of what you're trying to accomplish as a developer. it's frustrating for me personally but well so it goes.
purely out of curiosity, what's the project you're working on?
Well folks I've been sitting on this little script for ages and finally decided to just go ahead and publish it. What does it do?
you can enter any ao3 link - for example, to your bookmarks or an author's works page - and automatically download all the works and series that are linked from that page in the format of your choice
if your format of choice is epub (sorry, this part doesn't work for other file formats), you can check your fanfic-savin' folder for unfinished fics and automatically update them if there are new chapters
if you're a dinosaur who uses Pinboard, you can back up all the Pinboard bookmarks you have that link to ao3
don't worry about crashing ao3 with this! this baby takes forever to run, guaranteed. anyway ao3 won't let me make more than one request per second even if I wanted to so it's quite safe
I've been working on this for about two years and it's finally in a state where it does everything I want and isn't breaking every two seconds, so I thought it was time to share! I hope y'all get some use out of it.
note: this is a standalone desktop app that DOES NOT DO ANYTHING aside from automate clicking on buttons on the ao3 website. Everything this script does, can be done by hand using ao3's regular features. It is just a utility to facilitate personal backups for offline reading - there's no website or server, I have no access to or indeed interest in the fics other people download using this. No plagiarism is happening here, please don't come after me.
14K notes
·
View notes
Text
🚀 Top 4 Twitter (X) Scraping APIs in 2025
Looking for the best way to scrape Twitter (X) data in 2025? This article compares 4 top APIs based on speed, scalability, and pricing. A must-read for developers and data analysts!
#web scraping#scrapingdog#web scraping api#twitter scraper#twitter scraper api#x scraper#x scraper api
0 notes
Text
Uncover the hidden potential of data scraping to propel your startup's growth to new heights. Learn how data scraping can supercharge your startup's success.
0 notes
Text
Overcoming Bot Detection While Scraping Menu Data from UberEats, DoorDash, and Just Eat
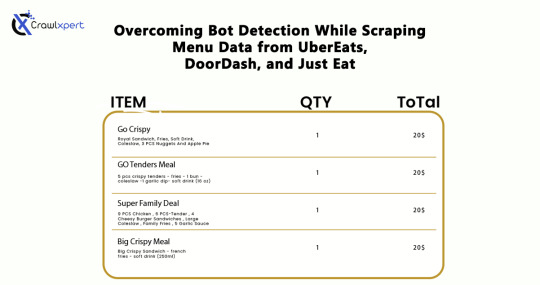
Introduction
In industries where menu data collection is concerned, web scraping would serve very well for us: UberEats, DoorDash, and Just Eat are the some examples. However, websites use very elaborate bot detection methods to stop the automated collection of information. In overcoming these factors, advanced scraping techniques would apply with huge relevance: rotating IPs, headless browsing, CAPTCHA solving, and AI methodology.
This guide will discuss how to bypass bot detection during menu data scraping and all challenges with the best practices for seamless and ethical data extraction.
Understanding Bot Detection on Food Delivery Platforms
1. Common Bot Detection Techniques
Food delivery platforms use various methods to block automated scrapers:
IP Blocking – Detects repeated requests from the same IP and blocks access.
User-Agent Tracking – Identifies and blocks non-human browsing patterns.
CAPTCHA Challenges – Requires solving puzzles to verify human presence.
JavaScript Challenges – Uses scripts to detect bots attempting to load pages without interaction.
Behavioral Analysis – Tracks mouse movements, scrolling, and keystrokes to differentiate bots from humans.
2. Rate Limiting and Request Patterns
Platforms monitor the frequency of requests coming from a specific IP or user session. If a scraper makes too many requests within a short time frame, it triggers rate limiting, causing the scraper to receive 403 Forbidden or 429 Too Many Requests errors.
3. Device Fingerprinting
Many websites use sophisticated techniques to detect unique attributes of a browser and device. This includes screen resolution, installed plugins, and system fonts. If a scraper runs on a known bot signature, it gets flagged.
Techniques to Overcome Bot Detection
1. IP Rotation and Proxy Management
Using a pool of rotating IPs helps avoid detection and blocking.
Use residential proxies instead of data center IPs.
Rotate IPs with each request to simulate different users.
Leverage proxy providers like Bright Data, ScraperAPI, and Smartproxy.
Implement session-based IP switching to maintain persistence.
2. Mimic Human Browsing Behavior
To appear more human-like, scrapers should:
Introduce random time delays between requests.
Use headless browsers like Puppeteer or Playwright to simulate real interactions.
Scroll pages and click elements programmatically to mimic real user behavior.
Randomize mouse movements and keyboard inputs.
Avoid loading pages at robotic speeds; introduce a natural browsing flow.
3. Bypassing CAPTCHA Challenges
Implement automated CAPTCHA-solving services like 2Captcha, Anti-Captcha, or DeathByCaptcha.
Use machine learning models to recognize and solve simple CAPTCHAs.
Avoid triggering CAPTCHAs by limiting request frequency and mimicking human navigation.
Employ AI-based CAPTCHA solvers that use pattern recognition to bypass common challenges.
4. Handling JavaScript-Rendered Content
Use Selenium, Puppeteer, or Playwright to interact with JavaScript-heavy pages.
Extract data directly from network requests instead of parsing the rendered HTML.
Load pages dynamically to prevent detection through static scrapers.
Emulate browser interactions by executing JavaScript code as real users would.
Cache previously scraped data to minimize redundant requests.
5. API-Based Extraction (Where Possible)
Some food delivery platforms offer APIs to access menu data. If available:
Check the official API documentation for pricing and access conditions.
Use API keys responsibly and avoid exceeding rate limits.
Combine API-based and web scraping approaches for optimal efficiency.
6. Using AI for Advanced Scraping
Machine learning models can help scrapers adapt to evolving anti-bot measures by:
Detecting and avoiding honeypots designed to catch bots.
Using natural language processing (NLP) to extract and categorize menu data efficiently.
Predicting changes in website structure to maintain scraper functionality.
Best Practices for Ethical Web Scraping
While overcoming bot detection is necessary, ethical web scraping ensures compliance with legal and industry standards:
Respect Robots.txt – Follow site policies on data access.
Avoid Excessive Requests – Scrape efficiently to prevent server overload.
Use Data Responsibly – Extracted data should be used for legitimate business insights only.
Maintain Transparency – If possible, obtain permission before scraping sensitive data.
Ensure Data Accuracy – Validate extracted data to avoid misleading information.
Challenges and Solutions for Long-Term Scraping Success
1. Managing Dynamic Website Changes
Food delivery platforms frequently update their website structure. Strategies to mitigate this include:
Monitoring website changes with automated UI tests.
Using XPath selectors instead of fixed HTML elements.
Implementing fallback scraping techniques in case of site modifications.
2. Avoiding Account Bans and Detection
If scraping requires logging into an account, prevent bans by:
Using multiple accounts to distribute request loads.
Avoiding excessive logins from the same device or IP.
Randomizing browser fingerprints using tools like Multilogin.
3. Cost Considerations for Large-Scale Scraping
Maintaining an advanced scraping infrastructure can be expensive. Cost optimization strategies include:
Using serverless functions to run scrapers on demand.
Choosing affordable proxy providers that balance performance and cost.
Optimizing scraper efficiency to reduce unnecessary requests.
Future Trends in Web Scraping for Food Delivery Data
As web scraping evolves, new advancements are shaping how businesses collect menu data:
AI-Powered Scrapers – Machine learning models will adapt more efficiently to website changes.
Increased Use of APIs – Companies will increasingly rely on API access instead of web scraping.
Stronger Anti-Scraping Technologies – Platforms will develop more advanced security measures.
Ethical Scraping Frameworks – Legal guidelines and compliance measures will become more standardized.
Conclusion
Uber Eats, DoorDash, and Just Eat represent great challenges for menu data scraping, mainly due to their advanced bot detection systems. Nevertheless, if IP rotation, headless browsing, solutions to CAPTCHA, and JavaScript execution methodologies, augmented with AI tools, are applied, businesses can easily scrape valuable data without incurring the wrath of anti-scraping measures.
If you are an automated and reliable web scraper, CrawlXpert is the solution for you, which specializes in tools and services to extract menu data with efficiency while staying legally and ethically compliant. The right techniques, along with updates on recent trends in web scrapping, will keep the food delivery data collection effort successful long into the foreseeable future.
Know More : https://www.crawlxpert.com/blog/scraping-menu-data-from-ubereats-doordash-and-just-eat
#ScrapingMenuDatafromUberEats#ScrapingMenuDatafromDoorDash#ScrapingMenuDatafromJustEat#ScrapingforFoodDeliveryData
0 notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Text
How To Extract 1000s of Restaurant Data from Google Maps?

In today's digital age, having access to accurate and up-to-date data is crucial for businesses to stay competitive. This is especially true for the restaurant industry, where trends and customer preferences are constantly changing. One of the best sources for this data is Google Maps, which contains a wealth of information on restaurants around the world. In this article, we will discuss how to extract thousands of restaurant data from Google Maps and how it can benefit your business.
Why Extract Restaurant Data from Google Maps?
Google Maps is the go-to source for many customers when searching for restaurants in their area. By extracting data from Google Maps, you can gain valuable insights into the current trends and preferences of customers in your target market. This data can help you make informed decisions about your menu, pricing, and marketing strategies. It can also give you a competitive edge by allowing you to stay ahead of the curve and adapt to changing trends.
How To Extract Restaurant Data from Google Maps?
There are several ways to extract restaurant data from Google Maps, but the most efficient and accurate method is by using a web scraping tool. These tools use automated bots to extract data from websites, including Google Maps, and compile it into a usable format. This eliminates the need for manual data entry and saves you time and effort.
To extract restaurant data from Google Maps, you can follow these steps:
Choose a reliable web scraping tool that is specifically designed for extracting data from Google Maps.
Enter the search criteria for the restaurants you want to extract data from, such as location, cuisine, or ratings.
The tool will then scrape the data from the search results, including restaurant names, addresses, contact information, ratings, and reviews.
You can then export the data into a spreadsheet or database for further analysis.
Benefits of Extracting Restaurant Data from Google Maps
Extracting restaurant data from Google Maps can provide numerous benefits for your business, including:
Identifying Trends and Preferences
By analyzing the data extracted from Google Maps, you can identify current trends and preferences in the restaurant industry. This can help you make informed decisions about your menu, pricing, and marketing strategies to attract more customers.
Improving SEO
Having accurate and up-to-date data on your restaurant's Google Maps listing can improve your search engine optimization (SEO). This means that your restaurant will appear higher in search results, making it easier for potential customers to find you.
Competitive Analysis
Extracting data from Google Maps can also help you keep an eye on your competitors. By analyzing their data, you can identify their strengths and weaknesses and use this information to improve your own business strategies.
conclusion:
extracting restaurant data from Google Maps can provide valuable insights and benefits for your business. By using a web scraping tool, you can easily extract thousands of data points and use them to make informed decisions and stay ahead of the competition. So why wait? Start extracting restaurant data from Google Maps today and take your business to the next level.
#food data scraping services#restaurant data scraping#restaurantdataextraction#food data scraping#zomato api#fooddatascrapingservices#web scraping services#grocerydatascraping#grocerydatascrapingapi#Google Maps Scraper#google maps scraper python#google maps scraper free#web scraping service#Scraping Restaurants Data#Google Maps Data
0 notes