#ai and data science
Text
Know about AI in full detailed.
#machine learning#ai art#popular#ai creativity#artificial intelligence#ai and data science#about ai#ai#art by artificail intelligence#artists on tumblr#digital artist#ai technology#generative ai#ai tools#ai music#ai music composer#ai cover
2 notes
·
View notes
Text
AI and Data Science: Synergies in the Digital Age
In today’s rapidly evolving digital landscape, the fields of Artificial Intelligence (AI) and Data Science have emerged as key drivers of innovation and transformation. The convergence of these two disciplines has created powerful synergies, enabling organizations to extract valuable insights from vast amounts of data and develop intelligent algorithms and models. This article explores the…

View On WordPress
#ai#ai and data science#artificial intelligence#artificial intelligence and data science#data science#data science of ai
2 notes
·
View notes
Text

0 notes
Text

Discover the groundbreaking ways AI and data science are revolutionizing the banking and finance sector, from personalized customer experiences to predictive analytics. https://bit.ly/3PFGfgW
0 notes
Text
#artificial intelligence#AI and Data Science#AI services#Data Science solution#Data science services
0 notes
Text
Artificial Islands; Forest City in Malaysia, what to hope before 2030?
Artificial Islands; Forest City in Malaysia, what to hope before 2030?
Artificial Islands are man-made land areas. Most of this man-made land is used for commercial activities. In earlier times artificial islands are built as floating structures by wood megalithic structures in shallow water. The floating island in Lake Titicaca and Scotland and Ireland’s ceremonial centers are historical man-made Islands.
In modern times artificial islands are formed by land…

View On WordPress
#ai#ai and data science#ai and machine learning#ai companies#ai in business#ai in education#ai learning#ai machine learning#ai systems#ai tech#ai technology#ai types#alcatraz island#alcatraz prison#artificial intelligence#artificial intelligence and data science#artificial intelligence and machine learning#artificial intelligence article#artificial intelligence companies#artificial intelligence engineering#artificial intelligence in business#artificial intelligence in education#artificial intelligence is#artificial intelligence robot#artificial intelligence technology#artificial intelligence with python#caribbean islands#coco bodu hithi#greek islands#island
0 notes
Text
AI and Data Science Services Company in India
In the era of continuous technology innovation driving the business, it is important for enterprises to leverage the right technology tools to stay ahead of the competition. krtrimaIQ helps enterprises deliver a great customer experience and become intelligent by implementing AI and data science in every aspect of business operations. We at krtrimaIQ build an intelligent enterprise by leveraging cognitive, big data engineering, data analytics, and intelligent automation tools. Our practices, solutions, and services enhance customer experience, unlock profitable growth and build an immortal business. Our AI services include Big Data Engineering, Business Intelligence solutions, NLP/NLG, computer vision applications, conversational AI(digital assistants, chatbots), etc.
Unleash the potential of AI technology with our team of experts who understand the requirements of clients and meet their needs. Contact us through the website: https://www.krtrimaiq.ai/, and email: [email protected].

1 note
·
View note
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
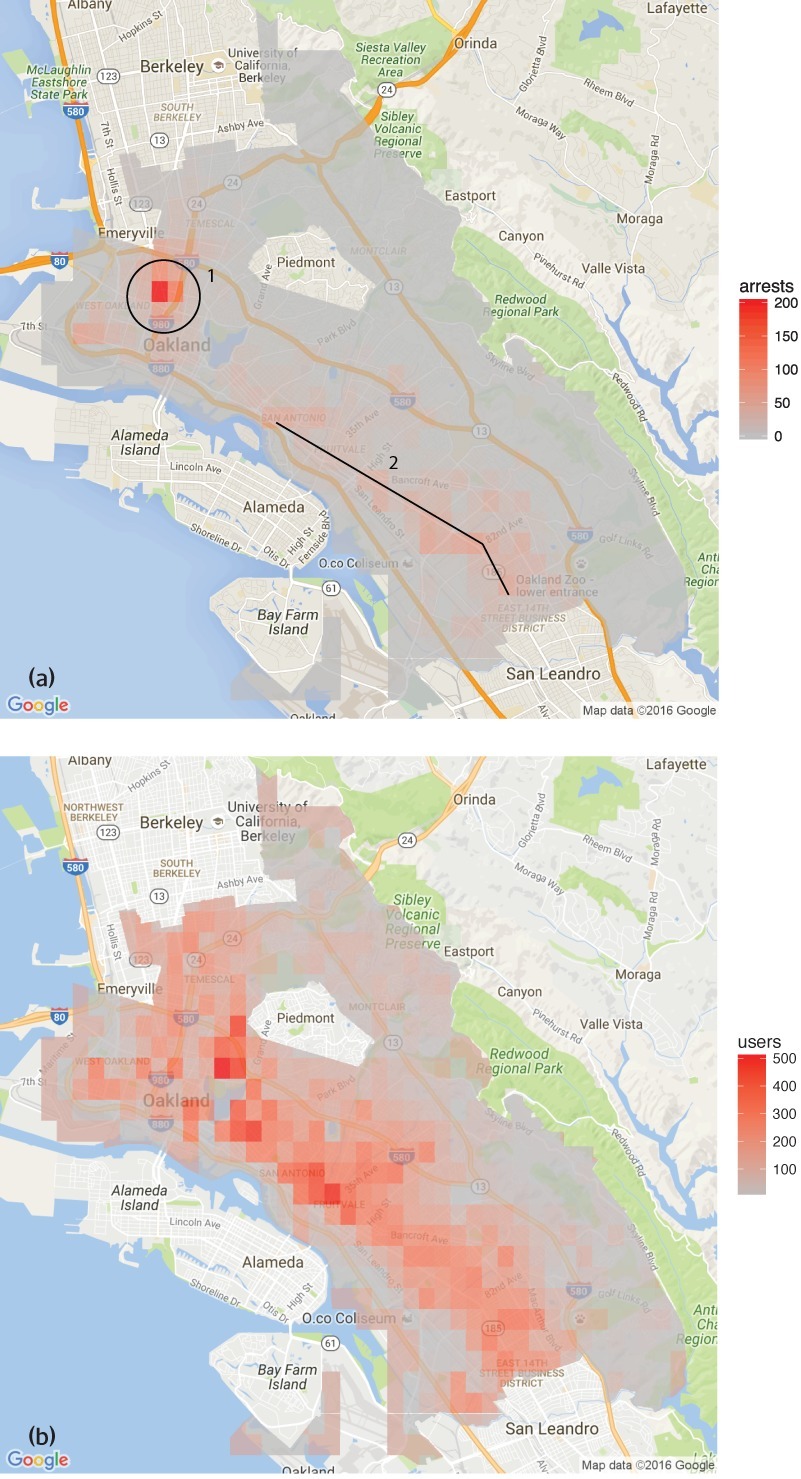
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified)
https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0
https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified)
https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified)
https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0
https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
830 notes
·
View notes
Text
Artificial intelligence in everyday
What is AI?
Man-made consciousness (artificial intelligence) refers to the re-enactment of human insight processes through a PC framework. These processes include learning, reasoning, problem solving, comprehension, and language comprehension. Read More
#about ai#ai#ai and data science#ai art#artificial intelligence#ai generated#ai image#machine learning#technology#ai artwork#ai art gallery
2 notes
·
View notes
Text
robot / AI characters in media are always my favorite and idk why?? even if theyre “evil” i still find them the most interesting. im always drawn towards books, games, and film that have robotic main characters.
#hal 9000#am allied mastercomputer#inscryption p03#data soong#wall e#i robot#science fiction#robots#ai
83 notes
·
View notes
Link
InstaDeep and BioNTech scientists introduced ChatNT, a multimodal conversational agent that has an advanced understanding of biological sequences like DNA, RNA, and proteins. ChatNT opens up biological data analysis and modeling capabilities to a wider user base via its conversational nature.
After examining a lengthy segment of DNA, have you ever thought about what secrets might be hidden within it? What about the elaborate ballet performed by proteins and RNA that directs all life’s processes? Typically, this has been the work of highly trained scientists who crack these codes of life. But what if you could have a conversation with your DNA, asking it to reveal its function in a way anyone can understand?
This is where ChatNT comes into play. A groundbreaking AI model that’s changing the game for bioinformatics. It acts as an interface between human language and complex biological sequences like never before seen. Just think of having an AI biologist on speed dial in your pocket, ready to answer any question about DNA, RNA, or proteins in plain English!
Continue Reading
32 notes
·
View notes
Text
Cornell quantum researchers have detected an elusive phase of matter, called the Bragg glass phase, using large volumes of X-ray data and a new machine learning data analysis tool. The discovery settles a long-standing question of whether this almost–but not quite–ordered state of Bragg glass can exist in real materials.
The paper, "Bragg glass signatures in PdxErTe3 with X-ray diffraction Temperature Clustering (X-TEC)," is published in Nature Physics. The lead author is Krishnanand Madhukar Mallayya, a postdoctoral researcher in the Department of Physics in the College of Arts and Sciences (A&S). Eun-Ah Kim, professor of physics (A&S), is the corresponding author. The research was conducted in collaboration with scientists at Argonne National Laboratory and at Stanford University.
Continue Reading.
42 notes
·
View notes
Text
Perish (love how Tumblr decided that not only is it the queer site that constantly suppresses queer people, but now they’re happy to get desperate users (many of which are minors) to get their data harvested just like that koko one! Oh how they care.) I can’t wait to see the lawsuits.
#expedite your meeting with god posthaste whoever came up with this#are you harvesting data like the koko one does :]#I can’t wait until they’re sued into oblivion and this also includes current tumblr staff#vena vents#not art#trying to get mentally unwell people who cannot evaluate the situation or aren’t aware enough about the therapy shit#including minors I’m sure which I;m pretty sure is illegal#any kind of new ai that;s not simulating or performing some task for science and whatnot are on the shitlist until proven innocent#but this is insidious and I don’t fucking care if it;s actually queer owned advertising this is predatory
89 notes
·
View notes
Text
How ChatGPT Is Trained (Source: OpenAI)

#chatgpt#openai#coding#programming#programmer#developer#artificial intelligence#machine learning#data science#deep learning#computer science#nlp#ai#algorithms#tech#technology
222 notes
·
View notes
Text
The real AI fight

Tonight (November 27), I'm appearing at the Toronto Metro Reference Library with Facebook whistleblower Frances Haugen.
On November 29, I'm at NYC's Strand Books with my novel The Lost Cause, a solarpunk tale of hope and danger that Rebecca Solnit called "completely delightful."

Last week's spectacular OpenAI soap-opera hijacked the attention of millions of normal, productive people and nonsensually crammed them full of the fine details of the debate between "Effective Altruism" (doomers) and "Effective Accelerationism" (AKA e/acc), a genuinely absurd debate that was allegedly at the center of the drama.
Very broadly speaking: the Effective Altruists are doomers, who believe that Large Language Models (AKA "spicy autocomplete") will someday become so advanced that it could wake up and annihilate or enslave the human race. To prevent this, we need to employ "AI Safety" – measures that will turn superintelligence into a servant or a partner, nor an adversary.
Contrast this with the Effective Accelerationists, who also believe that LLMs will someday become superintelligences with the potential to annihilate or enslave humanity – but they nevertheless advocate for faster AI development, with fewer "safety" measures, in order to produce an "upward spiral" in the "techno-capital machine."
Once-and-future OpenAI CEO Altman is said to be an accelerationists who was forced out of the company by the Altruists, who were subsequently bested, ousted, and replaced by Larry fucking Summers. This, we're told, is the ideological battle over AI: should cautiously progress our LLMs into superintelligences with safety in mind, or go full speed ahead and trust to market forces to tame and harness the superintelligences to come?
This "AI debate" is pretty stupid, proceeding as it does from the foregone conclusion that adding compute power and data to the next-word-predictor program will eventually create a conscious being, which will then inevitably become a superbeing. This is a proposition akin to the idea that if we keep breeding faster and faster horses, we'll get a locomotive:
https://locusmag.com/2020/07/cory-doctorow-full-employment/
As Molly White writes, this isn't much of a debate. The "two sides" of this debate are as similar as Tweedledee and Tweedledum. Yes, they're arrayed against each other in battle, so furious with each other that they're tearing their hair out. But for people who don't take any of this mystical nonsense about spontaneous consciousness arising from applied statistics seriously, these two sides are nearly indistinguishable, sharing as they do this extremely weird belief. The fact that they've split into warring factions on its particulars is less important than their unified belief in the certain coming of the paperclip-maximizing apocalypse:
https://newsletter.mollywhite.net/p/effective-obfuscation
White points out that there's another, much more distinct side in this AI debate – as different and distant from Dee and Dum as a Beamish Boy and a Jabberwork. This is the side of AI Ethics – the side that worries about "today’s issues of ghost labor, algorithmic bias, and erosion of the rights of artists and others." As White says, shifting the debate to existential risk from a future, hypothetical superintelligence "is incredibly convenient for the powerful individuals and companies who stand to profit from AI."
After all, both sides plan to make money selling AI tools to corporations, whose track record in deploying algorithmic "decision support" systems and other AI-based automation is pretty poor – like the claims-evaluation engine that Cigna uses to deny insurance claims:
https://www.propublica.org/article/cigna-pxdx-medical-health-insurance-rejection-claims
On a graph that plots the various positions on AI, the two groups of weirdos who disagree about how to create the inevitable superintelligence are effectively standing on the same spot, and the people who worry about the actual way that AI harms actual people right now are about a million miles away from that spot.
There's that old programmer joke, "There are 10 kinds of people, those who understand binary and those who don't." But of course, that joke could just as well be, "There are 10 kinds of people, those who understand ternary, those who understand binary, and those who don't understand either":
https://pluralistic.net/2021/12/11/the-ten-types-of-people/
What's more, the joke could be, "there are 10 kinds of people, those who understand hexadecenary, those who understand pentadecenary, those who understand tetradecenary [und so weiter] those who understand ternary, those who understand binary, and those who don't." That is to say, a "polarized" debate often has people who hold positions so far from the ones everyone is talking about that those belligerents' concerns are basically indistinguishable from one another.
The act of identifying these distant positions is a radical opening up of possibilities. Take the indigenous philosopher chief Red Jacket's response to the Christian missionaries who sought permission to proselytize to Red Jacket's people:
https://historymatters.gmu.edu/d/5790/
Red Jacket's whole rebuttal is a superb dunk, but it gets especially interesting where he points to the sectarian differences among Christians as evidence against the missionary's claim to having a single true faith, and in favor of the idea that his own people's traditional faith could be co-equal among Christian doctrines.
The split that White identifies isn't a split about whether AI tools can be useful. Plenty of us AI skeptics are happy to stipulate that there are good uses for AI. For example, I'm 100% in favor of the Human Rights Data Analysis Group using an LLM to classify and extract information from the Innocence Project New Orleans' wrongful conviction case files:
https://hrdag.org/tech-notes/large-language-models-IPNO.html
Automating "extracting officer information from documents – specifically, the officer's name and the role the officer played in the wrongful conviction" was a key step to freeing innocent people from prison, and an LLM allowed HRDAG – a tiny, cash-strapped, excellent nonprofit – to make a giant leap forward in a vital project. I'm a donor to HRDAG and you should donate to them too:
https://hrdag.networkforgood.com/
Good data-analysis is key to addressing many of our thorniest, most pressing problems. As Ben Goldacre recounts in his inaugural Oxford lecture, it is both possible and desirable to build ethical, privacy-preserving systems for analyzing the most sensitive personal data (NHS patient records) that yield scores of solid, ground-breaking medical and scientific insights:
https://www.youtube.com/watch?v=_-eaV8SWdjQ
The difference between this kind of work – HRDAG's exoneration work and Goldacre's medical research – and the approach that OpenAI and its competitors take boils down to how they treat humans. The former treats all humans as worthy of respect and consideration. The latter treats humans as instruments – for profit in the short term, and for creating a hypothetical superintelligence in the (very) long term.
As Terry Pratchett's Granny Weatherwax reminds us, this is the root of all sin: "sin is when you treat people like things":
https://brer-powerofbabel.blogspot.com/2009/02/granny-weatherwax-on-sin-favorite.html
So much of the criticism of AI misses this distinction – instead, this criticism starts by accepting the self-serving marketing claim of the "AI safety" crowd – that their software is on the verge of becoming self-aware, and is thus valuable, a good investment, and a good product to purchase. This is Lee Vinsel's "Criti-Hype": "taking press releases from startups and covering them with hellscapes":
https://sts-news.medium.com/youre-doing-it-wrong-notes-on-criticism-and-technology-hype-18b08b4307e5
Criti-hype and AI were made for each other. Emily M Bender is a tireless cataloger of criti-hypeists, like the newspaper reporters who breathlessly repeat " completely unsubstantiated claims (marketing)…sourced to Altman":
https://dair-community.social/@emilymbender/111464030855880383
Bender, like White, is at pains to point out that the real debate isn't doomers vs accelerationists. That's just "billionaires throwing money at the hope of bringing about the speculative fiction stories they grew up reading – and philosophers and others feeling important by dressing these same silly ideas up in fancy words":
https://dair-community.social/@emilymbender/111464024432217299
All of this is just a distraction from real and important scientific questions about how (and whether) to make automation tools that steer clear of Granny Weatherwax's sin of "treating people like things." Bender – a computational linguist – isn't a reactionary who hates automation for its own sake. On Mystery AI Hype Theater 3000 – the excellent podcast she co-hosts with Alex Hanna – there is a machine-generated transcript:
https://www.buzzsprout.com/2126417
There is a serious, meaty debate to be had about the costs and possibilities of different forms of automation. But the superintelligence true-believers and their criti-hyping critics keep dragging us away from these important questions and into fanciful and pointless discussions of whether and how to appease the godlike computers we will create when we disassemble the solar system and turn it into computronium.
The question of machine intelligence isn't intrinsically unserious. As a materialist, I believe that whatever makes me "me" is the result of the physics and chemistry of processes inside and around my body. My disbelief in the existence of a soul means that I'm prepared to think that it might be possible for something made by humans to replicate something like whatever process makes me "me."
Ironically, the AI doomers and accelerationists claim that they, too, are materialists – and that's why they're so consumed with the idea of machine superintelligence. But it's precisely because I'm a materialist that I understand these hypotheticals about self-aware software are less important and less urgent than the material lives of people today.
It's because I'm a materialist that my primary concerns about AI are things like the climate impact of AI data-centers and the human impact of biased, opaque, incompetent and unfit algorithmic systems – not science fiction-inspired, self-induced panics over the human race being enslaved by our robot overlords.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Image:
Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#criti-hype#ai doomers#doomers#eacc#effective acceleration#effective altruism#materialism#ai#10 types of people#data science#llms#large language models#patrick ball#ben goldacre#trusted research environments#science#hrdag#human rights data analysis group#red jacket#religion#emily bender#emily m bender#molly white
288 notes
·
View notes
Text
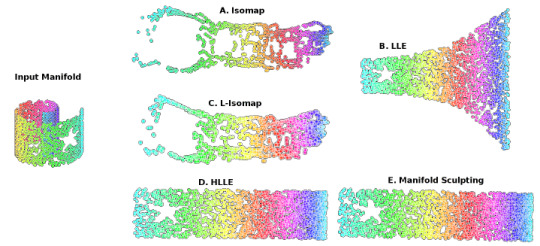
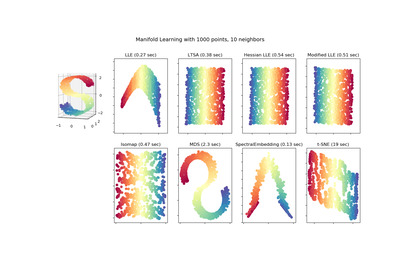
Locally Linear Embedding (LLE) approaches
#gradschool#light academia#data visualization#science#math#mathblr#studybrl#machine learning#ai#python#topology
45 notes
·
View notes
Last Seen Blogs


joohcoco
❣️C O C O❣️

thememedaddy
memes to show your therapist

ure-a-sunflower
🌻Red✨

benjiedrawings
🐰 Benjie's Art 🐰