#api as a service business model
Text
Why has Meta provided the search box and subcategory features exclusively to JioMart on WhatsApp? Why hasn't this feature been officially extended to other WhatsApp Commerce platforms?

0 notes
Text
Multilingual AI on Google Cloud: The Global Reach of Meta’s Llama 3.1 Models
New Post has been published on https://thedigitalinsider.com/multilingual-ai-on-google-cloud-the-global-reach-of-metas-llama-3-1-models/
Multilingual AI on Google Cloud: The Global Reach of Meta’s Llama 3.1 Models
Artificial Intelligence (AI) transforms how we interact with technology, breaking language barriers and enabling seamless global communication. According to MarketsandMarkets, the AI market is projected to grow from USD 214.6 billion in 2024 to USD 1339.1 billion by 2030 at a Compound Annual Growth Rate (CAGR) of 35.7%. One new advancement in this field is multilingual AI models. Meta’s Llama 3.1 represents this innovation, handling multiple languages accurately. Integrated with Google Cloud’s Vertex AI, Llama 3.1 offers developers and businesses a powerful tool for multilingual communication.
The Evolution of Multilingual AI
The development of multilingual AI began in the mid-20th century with rule-based systems relying on predefined linguistic rules to translate text. These early models were limited and often produced incorrect translations. The 1990s saw significant improvements in statistical machine translation as models learned from vast amounts of bilingual data, leading to better translations. IBM’s Model 1 and Model 2 laid the groundwork for advanced systems.
A significant breakthrough came with neural networks and deep learning. Models like Google’s Neural Machine Translation (GNMT) and Transformer revolutionized language processing by enabling more nuanced, context-aware translations. Transformer-based models such as BERT and GPT-3 further advanced the field, allowing AI to understand and generate human-like text across languages. Llama 3.1 builds on these advancements, using massive datasets and advanced algorithms for exceptional multilingual performance.
In today’s globalized world, multilingual AI is essential for businesses, educators, and healthcare providers. It offers real-time translation services that enhance customer satisfaction and loyalty. According to Common Sense Advisory, 75% of consumers prefer products in their native language, underscoring the importance of multilingual capabilities for business success.
Meta’s Llama 3.1 Model
Meta’s Llama 3.1, launched on July 23, 2024, represents a significant development in AI technology. This release includes models like the 405B, 8B, and 70B, designed to handle complex language tasks with impressive efficiency.
One of the significant features of Llama 3.1 is its open-source availability. Unlike many proprietary AI systems restricted by financial or corporate barriers, Llama 3.1 is freely accessible to everyone. This encourages innovation, allowing developers to fine-tune and customize the model to suit specific needs without incurring additional costs. Meta’s goal with this open-source approach is to promote a more inclusive and collaborative AI development community.
Another key feature is its strong multilingual support. Llama 3.1 can understand and generate text in eight languages, including English, Spanish, French, German, Chinese, Japanese, Korean, and Arabic. This goes beyond simple translation; the model captures the nuances and complexities of each language, maintaining contextual and semantic integrity. This makes it extremely useful for applications like real-time translation services, where it provides accurate and contextually appropriate translations, understanding idiomatic expressions, cultural references, and specific grammatical structures.
Integration with Google Cloud’s Vertex AI
Google Cloud’s Vertex AI now includes Meta’s Llama 3.1 models, significantly simplifying machine learning models’ development, deployment, and management. This platform combines Google Cloud’s robust infrastructure with advanced tools, making AI accessible to developers and businesses. Vertex AI supports various AI workloads and offers an integrated environment for the entire machine learning lifecycle, from data preparation and model training to deployment and monitoring.
Accessing and deploying Llama 3.1 on Vertex AI is straightforward and user-friendly. Developers can start with minimal setup due to the platform’s intuitive interface and comprehensive documentation. The process involves selecting the model from the Vertex AI Model Garden, configuring deployment settings, and deploying the model to a managed endpoint. This endpoint can be easily integrated into applications via API calls, enabling interaction with the model.
Moreover, Vertex AI supports diverse data formats and sources, allowing developers to use various datasets for training and fine-tuning models like Llama 3.1. This flexibility is essential for creating accurate and effective models across different use cases. The platform also integrates effectively with other Google Cloud services, such as BigQuery for data analysis and Google Kubernetes Engine for containerized deployments, providing a cohesive ecosystem for AI development.
Deploying Llama 3.1 on Google Cloud
Deploying Llama 3.1 on Google Cloud ensures the model is trained, optimized, and scalable for various applications. The process starts with training the model on an extensive dataset to enhance its multilingual capabilities. The model uses Google Cloud’s robust infrastructure to learn linguistic patterns and nuances from vast amounts of text in multiple languages. Google Cloud’s GPUs and TPUs accelerate this training, reducing development time.
Once trained, the model optimizes performance for specific tasks or datasets. Developers fine-tune parameters and configurations to achieve the best results. This phase includes validating the model to ensure accuracy and reliability, using tools like the AI Platform Optimizer to automate the process efficiently.
Another key aspect is scalability. Google Cloud’s infrastructure supports scaling, allowing the model to handle varying demand levels without compromising performance. Auto-scaling features dynamically allocate resources based on the current load, ensuring consistent performance even during peak times.
Applications and Use Cases
Llama 3.1, deployed on Google Cloud, has various applications across different sectors, making tasks more efficient and improving user engagement.
Businesses can use Llama 3.1 for multilingual customer support, content creation, and real-time translation. For example, e-commerce companies can offer customer support in various languages, which enhances the customer experience and helps them reach a global market. Marketing teams can also create content in different languages to connect with diverse audiences and boost engagement.
Llama 3.1 can help translate papers in the academic world, making international collaboration more accessible and providing educational resources in multiple languages. Research teams can analyze data from different countries, gaining valuable insights that might be missed otherwise. Schools and universities can offer courses in several languages, making education more accessible to students worldwide.
Another significant application area is healthcare. Llama 3.1 can improve communication between healthcare providers and patients who speak different languages. This includes translating medical documents, facilitating patient consultations, and providing multilingual health information. By ensuring that language barriers do not hinder the delivery of quality care, Llama 3.1 can help enhance patient outcomes and satisfaction.
Overcoming Challenges and Ethical Considerations
Deploying and maintaining multilingual AI models like Llama 3.1 presents several challenges. One challenge is ensuring consistent performance across different languages and managing large datasets. Therefore, continuous monitoring and optimization are essential to address the issue and maintain the model’s accuracy and relevance. Moreover, regular updates with new data are necessary to keep the model effective over time.
Ethical considerations are also critical in the development and deployment of AI models. Issues such as bias in AI and the fair representation of minority languages need careful attention. Therefore, developers must ensure that models are inclusive and fair, avoiding potential negative impacts on diverse linguistic communities. By addressing these ethical concerns, organizations can build trust with users and promote the responsible use of AI technologies.
Looking ahead, the future of multilingual AI is promising. Ongoing research and development are expected to enhance these models further, likely supporting more languages and offering improved accuracy and contextual understanding. These advancements will drive greater adoption and innovation, expanding the possibilities for AI applications and enabling more sophisticated and impactful solutions.
The Bottom Line
Meta’s Llama 3.1, integrated with Google Cloud’s Vertex AI, represents a significant advancement in AI technology. It offers robust multilingual capabilities, open-source accessibility, and extensive real-world applications. By addressing technical and ethical challenges and using Google Cloud’s infrastructure, Llama 3.1 can enable businesses, academia, and other sectors to enhance communication and operational efficiency.
As ongoing research continues to refine these models, the future of multilingual AI looks promising, paving the way for more advanced and impactful solutions in global communication and understanding.
#2024#Accessibility#ai#AI development#ai model#AI models#ai platform#AI systems#Algorithms#Analysis#API#applications#approach#artificial#Artificial Intelligence#attention#BERT#Bias#bigquery#billion#Business#challenge#Cloud#cloud services#Collaboration#collaborative#Commerce#communication#Community#Companies
0 notes
Text
the great reddit API meltdown of '23, or: this was always bound to happen
there's a lot of press about what's going on with reddit right now (app shutdowns, subreddit blackouts, the CEO continually putting his foot in his mouth), but I haven't seen as much stuff talking about how reddit got into this situation to begin with. so as a certified non-expert and Context Enjoyer I thought it might be helpful to lay things out as I understand them—a high-level view, surveying the whole landscape—in the wonderful world of startups, IPOs, and extremely angry users.
disclaimer that I am not a founder or VC (lmao), have yet to work at a company with a successful IPO, and am not a reddit employee or third-party reddit developer or even a subreddit moderator. I do work at a startup, know my way around an API or two, and have spent twelve regrettable years on reddit itself. which is to say that I make no promises of infallibility, but I hope you'll at least find all this interesting.
profit now or profit later
before you can really get into reddit as reddit, it helps to know a bit about startups (of which reddit is one). and before I launch into that, let me share my Three Types Of Websites framework, which is basically just a mental model about financial incentives that's helped me contextualize some of this stuff.
(1) website/software that does not exist to make money: relatively rare, for a variety of reasons, among them that it costs money to build and maintain a website in the first place. wikipedia is the evergreen example, although even wikipedia's been subject to criticism for how the wikimedia foundation pays out its employees and all that fun nonprofit stuff. what's important here is that even when making money is not the goal, money itself is still a factor, whether it's solicited via donations or it's just one guy paying out of pocket to host a hobby site. but websites in this category do, generally, offer free, no-strings-attached experiences to their users.
(I do want push back against the retrospective nostalgia of "everything on the internet used to be this way" because I don't think that was ever really true—look at AOL, the dotcom boom, the rise of banner ads. I distinctly remember that neopets had multiple corporate sponsors, including a cookie crisp-themed flash game. yahoo bought geocities for $3.6 billion; money's always been trading hands, obvious or not. it's indisputable that the internet is simply different now than it was ten or twenty years ago, and that monetization models themselves have largely changed as well (I have thoughts about this as it relates to web 1.0 vs web 2.0 and their associated costs/scale/etc.), but I think the only time people weren't trying to squeeze the internet for all the dimes it can offer was when the internet was first conceived as a tool for national defense.)
(2) website/software that exists to make money now: the type that requires the least explanation. mostly non-startup apps and services, including any random ecommerce storefront, mobile apps that cost three bucks to download, an MMO with a recurring subscription, or even a news website that runs banner ads and/or offers paid subscriptions. in most (but not all) cases, the "make money now" part is obvious, so these things don't feel free to us as users, even to the extent that they might have watered-down free versions or limited access free trials. no one's shocked when WoW offers another paid expansion packs because WoW's been around for two decades and has explicitly been trying to make money that whole time.
(3) website/software that exists to make money later: this is the fun one, and more common than you'd think. "make money later" is more or less the entire startup business model—I'll get into that in the next section—and is deployed with the expectation that you will make money at some point, but not always by means as obvious as "selling WoW expansions for forty bucks a pop."
companies in this category tend to have two closely entwined characteristics: they prioritize growth above all else, regardless of whether this growth is profitable in any way (now, or sometimes, ever), and they do this by offering users really cool and awesome shit at little to no cost (or, if not for free, then at least at a significant loss to the company).
so from a user perspective, these things either seem free or far cheaper than their competitors. but of course websites and software and apps and [blank]-as-a-service tools cost money to build and maintain, and that money has to come from somewhere, and the people supplying that money, generally, expect to get it back...
just not immediately.
startups, VCs, IPOs, and you
here's the extremely condensed "did NOT go to harvard business school" version of how a startup works:
(1) you have a cool idea.
(2) you convince some venture capitalists (also known as VCs) that your idea is cool. if they see the potential in what you're pitching, they'll give you money in exchange for partial ownership of your company—which means that if/when the company starts trading its stock publicly, these investors will own X numbers of shares that they can sell at any time. in other words, you get free money now (and you'll likely seek multiple "rounds" of investors over the years to sustain your company), but with the explicit expectations that these investors will get their payoff later, assuming you don't crash and burn before that happens.
during this phase, you want to do anything in your power to make your company appealing to investors so you can attract more of them and raise funds as needed. because you are definitely not bringing in the necessary revenue to offset operating costs by yourself.
it's also worth nothing that this is less about projecting the long-term profitability of your company than it's about its perceived profitability—i.e., VCs want to put their money behind a company that other people will also have confidence in, because that's what makes stock valuable, and VCs are in it for stock prices.
(3) there are two non-exclusive win conditions for your startup: you can get acquired, and you can have an IPO (also referred to as "going public"). these are often called "exit scenarios" and they benefit VCs and founders, as well as some employees. it's also possible for a company to get acquired, possibly even more than once, and then later go public.
acquisition: sell the whole damn thing to someone else. there are a million ways this can happen, some better than others, but in many cases this means anyone with ownership of the company (which includes both investors and employees who hold stock options) get their stock bought out by the acquiring company and end up with cash in hand. in varying amounts, of course. sometimes the founders walk away, sometimes the employees get laid off, but not always.
IPO: short for "initial public offering," this is when the company starts trading its stocks publicly, which means anyone who wants to can start buying that company's stock, which really means that VCs (and employees with stock options) can turn that hypothetical money into real money by selling their company stock to interested buyers.
drawing from that, companies don't go for an IPO until they think their stock will actually be worth something (or else what's the point?)—specifically, worth more than the amount of money that investors poured into it. The Powers That Be will speculate about a company's IPO potential way ahead of time, which is where you'll hear stuff about companies who have an estimated IPO evaluation of (to pull a completely random example) $10B. actually I lied, that was not a random example, that was reddit's valuation back in 2021 lol. but a valuation is basically just "how much will people be interested in our stock?"
as such, in the time leading up to an IPO, it's really really important to do everything you can to make your company seem like a good investment (which is how you get stock prices up), usually by making the company's numbers look good. but! if you plan on cashing out, the long-term effects of your decisions aren't top of mind here. remember, the industry lingo is "exit scenario."
if all of this seems like a good short-term strategy for companies and their VCs, but an unsustainable model for anyone who's buying those stocks during the IPO, that's because it often is.
also worth noting that it's possible for a company to be technically unprofitable as a business (meaning their costs outstrip their revenue) and still trade enormously well on the stock market; uber is the perennial example of this. to the people who make money solely off of buying and selling stock, it literally does not matter that the actual rideshare model isn't netting any income—people think the stock is valuable, so it's valuable.
this is also why, for example, elon musk is richer than god: if he were only the CEO of tesla, the money he'd make from selling mediocre cars would be (comparatively, lol) minimal. but he's also one of tesla's angel investors, which means he holds a shitload of tesla stock, and tesla's stock has performed well since their IPO a decade ago (despite recent dips)—even if tesla itself has never been a huge moneymaker, public faith in the company's eventual success has kept them trading at high levels. granted, this also means most of musk's wealth is hypothetical and not liquid; if TSLA dropped to nothing, so would the value of all the stock he holds (and his net work with it).
what's an API, anyway?
to move in an entirely different direction: we can't get into reddit's API debacle without understanding what an API itself is.
an API (short for "application programming interface," not that it really matters) is a series of code instructions that independent developers can use to plug their shit into someone else's shit. like a series of tin cans on strings between two kids' treehouses, but for sending and receiving data.
APIs work by yoinking data directly from a company's servers instead of displaying anything visually to users. so I could use reddit's API to build my own app that takes the day's top r/AITA post and transcribes it into pig latin: my app is a bunch of lines of code, and some of those lines of code fetch data from reddit (and then transcribe that data into pig latin), and then my app displays the content to anyone who wants to see it, not reddit itself. as far as reddit is concerned, no additional human beings laid eyeballs on that r/AITA post, and reddit never had a chance to serve ads alongside the pig-latinized content in my app. (put a pin in this part—it'll be relevant later.)
but at its core, an API is really a type of protocol, which encompasses a broad category of formats and business models and so on. some APIs are completely free to use, like how anyone can build a discord bot (but you still have to host it yourself). some companies offer free APIs to third-party developers can build their own plugins, and then the company and the third-party dev split the profit on those plugins. some APIs have a free tier for hobbyists and a paid tier for big professional projects (like every weather API ever, lol). some APIs are strictly paid services because the API itself is the company's core offering.
reddit's financial foundations
okay thanks for sticking with me. I promise we're almost ready to be almost ready to talk about the current backlash.
reddit has always been a startup's startup from day one: its founders created the site after attending a startup incubator (which is basically a summer camp run by VCs) with the successful goal of creating a financially successful site. backed by that delicious y combinator money, reddit got acquired by conde nast only a year or two after its creation, which netted its founders a couple million each. this was back in like, 2006 by the way. in the time since that acquisition, reddit's gone through a bunch of additional funding rounds, including from big-name investors like a16z, peter thiel (yes, that guy), sam altman (yes, also that guy), sequoia, fidelity, and tencent. crunchbase says that they've raised a total of $1.3B in investor backing.
in all this time, reddit has never been a public company, or, strictly speaking, profitable.
APIs and third-party apps
reddit has offered free API access for basically as long as it's had a public API—remember, as a "make money later" company, their primary goal is growth, which means attracting as many users as possible to the platform. so letting anyone build an app or widget is (or really, was) in line with that goal.
as such, third-party reddit apps have been around forever. by third-party apps, I mean apps that use the reddit API to display actual reddit content in an unofficial wrapper. iirc reddit didn't even have an official mobile app until semi-recently, so many of these third-party mobile apps in particular just sprung up to meet an unmet need, and they've kept a small but dedicated userbase ever since. some people also prefer the user experience of the unofficial apps, especially since they offer extra settings to customize what you're seeing and few to no ads (and any ads these apps do display are to the benefit of the third-party developers, not reddit itself.)
(let me add this preemptively: one solution I've seen proposed to the paid API backlash is that reddit should have third-party developers display reddit's ads in those third-party apps, but this isn't really possible or advisable due to boring adtech reasons I won't inflict on you here. source: just trust me bro)
in addition to mobile apps, there are also third-party tools that don’t replace the Official Reddit Viewing Experience but do offer auxiliary features like being able to mass-delete your post history, tools that make the site more accessible to people who use screen readers, and tools that help moderators of subreddits moderate more easily. not to mention a small army of reddit bots like u/AutoWikibot or u/RemindMebot (and then the bots that tally the number of people who reply to bot comments with “good bot” or “bad bot).
the number of people who use third-party apps is relatively small, but they arguably comprise some of reddit’s most dedicated users, which means that third-party apps are important to the people who keep reddit running and the people who supply reddit with high-quality content.
unpaid moderators and user-generated content
so reddit is sort of two things: reddit is a platform, but it’s also a community.
the platform is all the unsexy (or, if you like python, sexy) stuff under the hood that actually makes the damn thing work. this is what the company spends money building and maintaining and "owns." the community is all the stuff that happens on the platform: posts, people, petty squabbles. so the platform is where the content lives, but ultimately the content is the reason people use reddit—no one’s like “yeah, I spend time on here because the backend framework really impressed me."
and all of this content is supplied by users, which is not unique among social media platforms, but the content is also managed by users, which is. paid employees do not govern subreddits; unpaid volunteers do. and moderation is the only thing that keeps reddit even remotely tolerable—without someone to remove spam, ban annoying users, and (god willing) enforce rules against abuse and hate speech, a subreddit loses its appeal and therefore its users. not dissimilar to the situation we’re seeing play out at twitter, except at twitter it was the loss of paid moderators; reddit is arguably in a more precarious position because they could lose this unpaid labor at any moment, and as an already-unprofitable company they absolutely cannot afford to implement paid labor as a substitute.
oh yeah? spell "IPO" backwards
so here we are, June 2023, and reddit is licking its lips in anticipation of a long-fabled IPO. which means it’s time to start fluffing themselves up for investors by cutting costs (yay, layoffs!) and seeking new avenues of profit, however small.
this brings us to the current controversy: reddit announced a new API pricing plan that more or less prevents anyone from using it for free.
from reddit's perspective, the ostensible benefits of charging for API access are twofold: first, there's direct profit to be made off of the developers who (may or may not) pay several thousand dollars a month to use it, and second, cutting off unsanctioned third-party mobile apps (possibly) funnels those apps' users back into the official reddit mobile app. and since users on third-party apps reap the benefit of reddit's site architecture (and hosting, and development, and all the other expenses the site itself incurs) without “earning” money for reddit by generating ad impressions, there’s a financial incentive at work here: even if only a small percentage of people use third-party apps, getting them to use the official app instead translates to increased ad revenue, however marginal.
(also worth mentioning that chatGPT and other LLMs were trained via tools that used reddit's API to scrape post and content data, and now that openAI is reaping the profits of that training without giving reddit any kickbacks, reddit probably wants to prevent repeats of this from happening in the future. if you want to train the next LLM, it's gonna cost you.)
of course, these changes only benefit reddit if they actually increase the company’s revenue and perceived value/growth—which is hard to do when your users (who are also the people who supply the content for other users to engage with, who are also the people who moderate your communities and make them fun to participate in) get really fucking pissed and threaten to walk.
pricing shenanigans
under the new API pricing plan, third-party developers are suddenly facing steep costs to maintain the apps and tools they’ve built.
most paid APIs are priced by volume: basically, the more data you send and receive, the more money it costs. so if your third-party app has a lot of users, you’ll have to make more API requests to fetch content for those users, and your app becomes more expensive to maintain. (this isn’t an issue if the tool you’re building also turns a profit, but most third-party reddit apps make little, if any, money.)
which is why, even though third-party apps capture a relatively small portion of reddit’s users, the developer of a popular third-party app called apollo recently learned that it would cost them about $20 million a year to keep the app running. and apollo actually offers some paid features (for extra in-app features independent of what reddit offers), but nowhere near enough to break even on those API costs.
so apollo, any many apps like it, were suddenly unable to keep their doors open under the new API pricing model and announced that they'd be forced to shut down.
backlash, blackout
plenty has been said already about the current subreddit blackouts—in like, official news outlets and everything—so this might be the least interesting section of my whole post lol. the short version is that enough redditors got pissed enough that they collectively decided to take subreddits “offline” in protest, either by making them read-only or making them completely inaccessible. their goal was to send a message, and that message was "if you piss us off and we bail, here's what reddit's gonna be like: a ghost town."
but, you may ask, if third-party apps only captured a small number of users in the first place, how was the backlash strong enough to result in a near-sitewide blackout? well, two reasons:
first and foremost, since moderators in particular are fond of third-party tools, and since moderators wield outsized power (as both the people who keep your site more or less civil, and as the people who can take a subreddit offline if they feel like it), it’s in your best interests to keep them happy. especially since they don’t get paid to do this job in the first place, won’t keep doing it if it gets too hard, and essentially have nothing to lose by stepping down.
then, to a lesser extent, the non-moderator users on third-party apps tend to be Power Users who’ve been on reddit since its inception, and as such likely supply a disproportionate amount of the high-quality content for other users to see (and for ads to be served alongside). if you drive away those users, you’re effectively kneecapping your overall site traffic (which is bad for Growth) and reducing the number/value of any ad impressions you can serve (which is bad for revenue).
also a secret third reason, which is that even people who use the official apps have no stake in a potential IPO, can smell the general unfairness of this whole situation, and would enjoy the schadenfreude of investors getting fucked over. not to mention that reddit’s current CEO has made a complete ass of himself and now everyone hates him and wants to see him suffer personally.
(granted, it seems like reddit may acquiesce slightly and grant free API access to a select set of moderation/accessibility tools, but at this point it comes across as an empty gesture.)
"later" is now "now"
TL;DR: this whole thing is a combination of many factors, specifically reddit being intensely user-driven and self-governed, but also a high-traffic site that costs a lot of money to run (why they willingly decided to start hosting video a few years back is beyond me...), while also being angled as a public stock market offering in the very near future. to some extent I understand why reddit’s CEO doubled down on the changes—he wants to look strong for investors—but he’s also made a fool of himself and cast a shadow of uncertainty onto reddit’s future, not to mention the PR nightmare surrounding all of this. and since arguably the most important thing in an IPO is how much faith people have in your company, I honestly think reddit would’ve fared better if they hadn’t gone nuclear with the API changes in the first place.
that said, I also think it’s a mistake to assume that reddit care (or needs to care) about its users in any meaningful way, or at least not as more than means to an end. if reddit shuts down in three years, but all of the people sitting on stock options right now cashed out at $120/share and escaped unscathed... that’s a success story! you got your money! VCs want to recoup their investment—they don’t care about longevity (at least not after they’re gone), user experience, or even sustained profit. those were never the forces driving them, because these were never the ultimate metrics of their success.
and to be clear: this isn’t unique to reddit. this is how pretty much all startups operate.
I talked about the difference between “make money now” companies and “make money later” companies, and what we’re experiencing is the painful transition from “later” to “now.” as users, this change is almost invisible until it’s already happened—it’s like a rug we didn’t even know existed gets pulled out from under us.
the pre-IPO honeymoon phase is awesome as a user, because companies have no expectation of profit, only growth. if you can rely on VC money to stay afloat, your only concern is building a user base, not squeezing a profit out of them. and to do that, you offer cool shit at a loss: everything’s chocolate and flowers and quarterly reports about the number of signups you’re getting!
...until you reach a critical mass of users, VCs want to cash in, and to prepare for that IPO leadership starts thinking of ways to make the website (appear) profitable and implements a bunch of shit that makes users go “wait, what?”
I also touched on this earlier, but I want to reiterate a bit here: I think the myth of the benign non-monetized internet of yore is exactly that—a myth. what has changed are the specific market factors behind these websites, and their scale, and the means by which they attempt to monetize their services and/or make their services look attractive to investors, and so from a user perspective things feel worse because the specific ways we’re getting squeezed have evolved. maybe they are even worse, at least in the ways that matter. but I’m also increasingly less surprised when this occurs, because making money is and has always been the goal for all of these ventures, regardless of how they try to do so.
8K notes
·
View notes
Text
/r/Sonic goes dark in protest of Reddit's controversial API changes

Fans will not be able to view the unofficial Sonic the Hedgehog community on Reddit due to a massive site-wide protest.
/r/SonicTheHedgehog and thousands of Reddit communities went dark on Monday in protest against the platform's planned changes to their app programming interface, or API.
Why is this happening?
Reddit's interface allowed third party services and the platform to communicate with each other. Protestors claimed that the site's motivation to monetize access will threaten to shut down off-site applications, drastically affect moderator tools, limit accessibility-focused programs, and alter the ability to impartially access content.
One popular iOS cilent already announced plans to shut down, as it would cost around $20 million USD per year if it were to continue under the new agreement.
Reddit CEO Steve Huffman defended the changes in a ask-me-anything thread, and claimed that the platform "can no longer subsidize commercial entities that require large-scale data use."
The changes were similarly compared to Twitter's controversial plan to cut off third-party access to its interface in early 2023, which saw many long-standing third-party clients forced to shut down.
The response
As a result, more than 6,000 subreddits elected to go dark in protest of the changes. Users either saw subreddits in a "read-only" state, which meant that there was no ability to create new comments or posts; or in a "private" state, which meant it cannot be viewed in public at all.
The protests were expected to generally last to a minimum of 48 hours; however, a seemingly defensive rebuke from Reddit managed to escalate numerous communities to extend their outage to an indefinite period.
Affecting you

The Sonic the Hedgehog subreddit went dark just before midnight Eastern time on Monday.
Tails' Channel understands that the blackout will last for a minimum of 48 hours, but it could extend to an undetermined period of time "based on the general climate" of the situation, according to the subreddit's head moderator, @andtails.
"Reddit's entire business model is predicated on the use of free labor to run their communities, so the only way we send a powerful message to their higher ups that what they're doing isn't okay is to strike," said the moderator in a public post.
The statement continued, "even if you are not directly impacted by Reddit's corporate decision-making now, their decision to charge for API access may set a precedence for future corporate decisions down the line that will increasingly hurt the user experience on this platform."
Subreddit users were encouraged to "take a break from Reddit" and submit complaints during the indefinite outage, as the mod argued that the planned changes will fundamentally hurt the platform.
#sonic the hedgehog#reddark#/r/sonic#/r/sonicthehedgehog#reddit#sonic#sega#gaming#gaming news#sonic news
333 notes
·
View notes
Text
What Are the Key Benefits of Scraping Zepto Grocery Data for Your Business?

In the rapidly evolving world of e-commerce, quick commerce or q-commerce is gaining significant traction, particularly in the grocery sector. Zepto, a prominent player in this space, is redefining how consumers shop for groceries by offering ultra-fast delivery services. Scraping Zepto grocery data is essential for businesses aiming to harness insights, optimize operations, and stay ahead in the competitive landscape. This article explores the significance of extracting Zepto grocery data, the methods involved, and the potential applications of this information.
Understanding Zepto and Quick Commerce
Zepto is a critical player in the quick commerce (q-commerce) sector, providing rapid grocery delivery services to meet the growing demand for convenience. With a promise of delivering groceries in as little as 10 minutes, Zepto operates in a highly competitive market where speed and efficiency are paramount. As a result, the platform handles a vast amount of data related to inventory, prices, customer preferences, and order patterns.
Quick commerce is a subset of e-commerce focused on delivering products within a short time frame, often under 30 minutes. This model requires real-time inventory management, dynamic pricing strategies, and agile logistics. Scraping quick commerce data offers invaluable insights into these aspects, enabling businesses to adapt and thrive in this fast-paced environment.
Why Scrape Zepto Grocery Data?
Scraping Zepto grocery data is crucial for gaining insights into market trends, optimizing inventory, and refining pricing strategies. By analyzing this data, businesses can enhance their competitive edge, tailor their offerings to consumer preferences, and drive operational efficiency.
Market Analysis and Competitive Intelligence: Zepto grocery data scraping services provide a window into the competitive landscape. Businesses can gain insights into market trends and competitor strategies by analyzing Zepto’s product offerings, pricing strategies, and inventory levels. This information is crucial for positioning your products and services effectively.
Consumer Behavior Insights: Understanding consumer preferences and buying patterns is essential for tailoring marketing strategies and optimizing product offerings. Scraping data on popular items, purchase frequency, and customer reviews from Zepto helps businesses identify trends and adapt to changing consumer demands.
Pricing Strategy Optimization: Dynamic pricing is critical to the quick commerce model. By scraping pricing data from Zepto, businesses can monitor price fluctuations, track promotions, and adjust their pricing strategies accordingly. This ensures competitiveness and maximizes revenue potential.
Inventory Management: Real-time inventory data is crucial for effective supply chain management. Scraping Zepto inventory data allows businesses to monitor stock levels, track product availability, and optimize inventory management practices to avoid overstocking or stockouts.
Product Development and Innovation: Insights gained from Zepto data scraper can drive product development and innovation. Analyzing popular products and customer feedback helps businesses identify gaps in the market and develop new products that cater to emerging trends.
Methods for Scraping Zepto Grocery Data
Scraping Zepto grocery data involves collecting relevant information from the platform’s website or app. There are several methods to accomplish this, each with its advantages and challenges:
HTML Parsing: This traditional method involves downloading the HTML content of Zepto’s web pages and using parsing libraries to extract data. Tools like BeautifulSoup (Python) or Cheerio (JavaScript) can be employed. While effective, HTML parsing may face challenges with dynamic content and frequent website updates.
APIs: If Zepto provides an API (Application Programming Interface), it offers a structured and reliable way to access data. APIs are generally more stable and less prone to breaking than HTML parsing. Checking for available APIs or contacting Zepto for API access can simplify the data extraction.
Web Scraping Tools: Several commercial and open-source web scraping tools, such as Scrapy, Selenium, or Puppeteer, are available. These tools can automate data extraction processes, handle dynamic content, and efficiently manage large-scale scraping tasks.
Browser Automation: For sites that use JavaScript extensively to load content, browser automation tools like Selenium or Puppeteer can simulate user interactions and extract data. These tools help scrape dynamic content but may require more resources and setup than straightforward methods.
Web Scraping Services: There are dedicated web scraping services and platforms that offer pre-built scrapers for various e-commerce sites, including grocery platforms. These services can save time and resources, providing ready-to-use data extraction solutions.
Challenges and Considerations
Scraping data from Zepto presents challenges related to legal compliance, data accuracy, and server load. Ethical considerations also include respecting privacy and avoiding excessive strain on the website. Addressing these challenges ensures responsible and effective data extraction practices.
Legal and Ethical Issues: Scraping data from Quick Commerce websites must comply with legal regulations and terms of service. Some sites explicitly prohibit scraping, and violating these terms can result in legal consequences. It is essential to review Zepto’s terms and seek permission if required.
Data Accuracy and Quality: Maintaining data accuracy is crucial for practical analysis. Websites frequently update their content, which can impact scraping tools. Regular monitoring and updating of scraping scripts are necessary to ensure data quality.
Rate Limiting and Load: Excessive scraping activity can significantly load Zepto’s servers, potentially affecting the site’s performance for other users. Implementing rate limiting and respecting the site’s bandwidth can mitigate this issue and ensure ethical scraping practices.
Data Privacy: Scraping user-generated content, such as reviews or ratings, requires careful handling of personal data. Adhering to data protection regulations and ensuring that scraped data is stored and processed securely is crucial to maintaining user privacy.
Applications of Scraped Zepto Grocery Data
Scraped Zepto grocery data can be applied to enhance business intelligence, optimize supply chains, and personalize marketing efforts. Analyzing imthis data helps identify trends, benchmark performance, and improve inventory management, driving strategic decisions and operational efficiency.
Business Intelligence: craped data can be analyzed to generate actionable insights for strategic decision-making. Businesses can create dashboards, reports, and visualizations to track performance metrics, identify trends, and make data-driven decisions.
Competitive Benchmarking: By comparing scraped data from Zepto with data from other grocery platforms, businesses can benchmark their performance and identify areas for improvement. This competitive analysis can guide strategy and operational adjustments.
Personalization and Marketing: Insights from scraped data can inform personalized marketing campaigns and product recommendations. Understanding customer preferences and purchase patterns allows businesses to tailor their marketing efforts and improve customer engagement.
Supply Chain Optimization: Real-time inventory data helps businesses optimize their supply chain operations, ensuring that popular products are adequately stocked and reducing the risk of overstocking or stockouts.
Trend Identification: Analyzing data on popular products and customer reviews helps businesses identify emerging trends and adapt their product offerings to meet changing consumer demands.
Conclusion :
Scrape Zepto grocery data to offer businesses a wealth of opportunities to gain insights, optimize operations, and stay competitive in the dynamic, quick commerce landscape. Businesses can make informed decisions, enhance their marketing strategies, and improve overall performance by leveraging data on product offerings, pricing, inventory, and consumer behavior. However, it is crucial to approach data scraping with a strong understanding of legal, ethical, and technical considerations. With careful planning and execution, scraping Zepto grocery data can provide valuable advantages and drive success in the fast-paced world of quick commerce.
Transform your retail operations with Retail Scrape Company's data-driven solutions. Harness real-time data scraping to understand consumer behavior, fine-tune pricing strategies, and outpace competitors. Our services offer comprehensive pricing optimization and strategic decision support. Elevate your business today and unlock maximum profitability. Reach out to us now to revolutionize your retail operations!!
Source : https://www.retailscrape.com/benefits-of-scraping-zepto-grocery-data.php
#ScrapeZeptoGroceryData#ZeptoGroceryDataScrapingServices#WebScrapingZeptoGroceryData#ZeptoGroceryDataExtraction#ZeptoGroceryDataCollection#ZeptoGroceryDatasets#ZeptoGroceryScrapingAPI#ZeptoGroceryDataScraper
2 notes
·
View notes
Text
A really long, excellent post about what's happening with Reddit and why, including how LLM companies scraping its hosted material has massively increased server costs for the company, but the way Reddit has chosen to solve the issue is just the worst option.
And also this:
Reddit is the only major social media company that relies almost entirely on unpaid, volunteer moderators to enforce the rules of its site. On the one hand, it’s an example of a multibillion-dollar corporation getting free labor. On the other hand, Reddit is such a good, human-feeling website because it relies on an moderation model more reminiscent of old internet forums where moderators are entrenched in their communities and, rather than simply enforcing a set of uniform rules handed down from a giant corporation, are helping to grow and shape the communities that they're a part of.
Even if many moderators like what they do and enjoy some of the power that comes with moderating and guiding a community, they bring unmistakeable monetary value to Reddit the corporation. Li was the lead author of a paper published last year that found Reddit moderators work at least a collective 466 hours per day, which would cost Reddit a minimum of $3.4 million a year at a wage of $20/hour.

This $3.4 million number isn’t an estimate of the actual value those moderators bring to Reddit, however. Li wrote that these moderators essentially make Reddit a “viable” website and business. Notably, the company was valued at more than $10 billion in 2021.
“There’s this question of what is a fair value exchange between online volunteers and companies that might rely only on volunteer cases,” Li said. “We traditionally think of all this volunteer work as a labor of love. But at the same time, this is really valuable labor for companies, and the moderators go through so much stress and pressure, and trauma to do this work.”
The only reason Reddit is able to sell any ads at all is because their moderators and the communities they've created prevent (most) of the site from becoming a cesspool.
What Reddit is doing with its API is somewhat hypocritical, then. Huffman says that Reddit is not profitable. He also says that third party companies should not be able to make money from Reddit while Reddit itself subsidizes them in the form of API access. This may be the case with AI companies that make billions and do not add any value to Reddit. But with third-party apps and mod tools, this argument breaks down.
Some third-party apps make money, but they also bring Reddit more users and increase the company’s cultural relevancy and strengthen its communities. There is no guarantee that people who previously used third-party apps will suddenly start using the clunky official app once those apps go away. More importantly, apps like Apollo make moderating Reddit easier because of the moderation tools that have been built on top of it. In this sense, Apollo is providing a service to Reddit by making life easier for its moderators who, again, are unpaid.
Reddit makes money from user content, volunteer moderators, and third party apps make it easier for them to make money. So of course, they are shitting on users, moderators, and third party app makers :(
So, so stupid.
22 notes
·
View notes
Text
Journey to AWS Proficiency: Unveiling Core Services and Certification Paths
Amazon Web Services, often referred to as AWS, stands at the forefront of cloud technology and has revolutionized the way businesses and individuals leverage the power of the cloud. This blog serves as your comprehensive guide to understanding AWS, exploring its core services, and learning how to master this dynamic platform. From the fundamentals of cloud computing to the hands-on experience of AWS services, we'll cover it all. Additionally, we'll discuss the role of education and training, specifically highlighting the value of ACTE Technologies in nurturing your AWS skills, concluding with a mention of their AWS courses.

The Journey to AWS Proficiency:
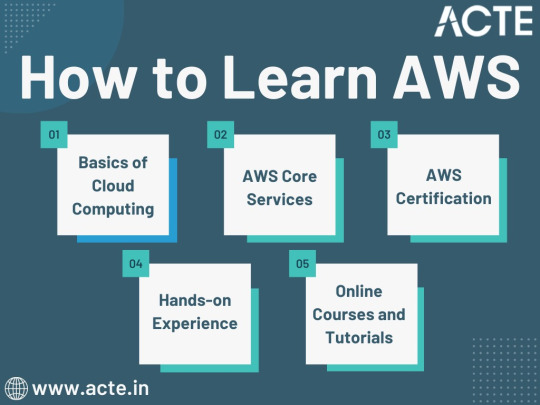
1. Basics of Cloud Computing:
Getting Started: Before diving into AWS, it's crucial to understand the fundamentals of cloud computing. Begin by exploring the three primary service models: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Gain a clear understanding of what cloud computing is and how it's transforming the IT landscape.
Key Concepts: Delve into the key concepts and advantages of cloud computing, such as scalability, flexibility, cost-effectiveness, and disaster recovery. Simultaneously, explore the potential challenges and drawbacks to get a comprehensive view of cloud technology.
2. AWS Core Services:
Elastic Compute Cloud (EC2): Start your AWS journey with Amazon EC2, which provides resizable compute capacity in the cloud. Learn how to create virtual servers, known as instances, and configure them to your specifications. Gain an understanding of the different instance types and how to deploy applications on EC2.
Simple Storage Service (S3): Explore Amazon S3, a secure and scalable storage service. Discover how to create buckets to store data and objects, configure permissions, and access data using a web interface or APIs.
Relational Database Service (RDS): Understand the importance of databases in cloud applications. Amazon RDS simplifies database management and maintenance. Learn how to set up, manage, and optimize RDS instances for your applications. Dive into database engines like MySQL, PostgreSQL, and more.
3. AWS Certification:
Certification Paths: AWS offers a range of certifications for cloud professionals, from foundational to professional levels. Consider enrolling in certification courses to validate your knowledge and expertise in AWS. AWS Certified Cloud Practitioner, AWS Certified Solutions Architect, and AWS Certified DevOps Engineer are some of the popular certifications to pursue.
Preparation: To prepare for AWS certifications, explore recommended study materials, practice exams, and official AWS training. ACTE Technologies, a reputable training institution, offers AWS certification training programs that can boost your confidence and readiness for the exams.
4. Hands-on Experience:
AWS Free Tier: Register for an AWS account and take advantage of the AWS Free Tier, which offers limited free access to various AWS services for 12 months. Practice creating instances, setting up S3 buckets, and exploring other services within the free tier. This hands-on experience is invaluable in gaining practical skills.
5. Online Courses and Tutorials:
Learning Platforms: Explore online learning platforms like Coursera, edX, Udemy, and LinkedIn Learning. These platforms offer a wide range of AWS courses taught by industry experts. They cover various AWS services, architecture, security, and best practices.
Official AWS Resources: AWS provides extensive online documentation, whitepapers, and tutorials. Their website is a goldmine of information for those looking to learn more about specific AWS services and how to use them effectively.
Amazon Web Services (AWS) represents an exciting frontier in the realm of cloud computing. As businesses and individuals increasingly rely on the cloud for innovation and scalability, AWS stands as a pivotal platform. The journey to AWS proficiency involves grasping fundamental cloud concepts, exploring core services, obtaining certifications, and acquiring practical experience. To expedite this process, online courses, tutorials, and structured training from renowned institutions like ACTE Technologies can be invaluable. ACTE Technologies' comprehensive AWS training programs provide hands-on experience, making your quest to master AWS more efficient and positioning you for a successful career in cloud technology.
8 notes
·
View notes
Text
In which Arilin says pointed things about open source, open data, and social media
N.B.: As I was writing this, an entirely different kerfluffle started about Meta, Facebook's parent company, working on their own ActivityPub-compatible microblogging service. While that may be a field of land mines topic worth writing about, it's a topic for a different day.
Cohost's recent financial update revealing they are running on fumes can't help but bring to my mind what I wrote back in December:
[Cohost is] still a centralized platform, and that represents a single point of failure. If Cohost takes off, it's going to require a lot more money to run than they have right now, and it's hard to know if "Cohost Plus" will be enough to offset those costs.
I have a few friends who are Cohost partisans. While its "cram posts into 40% of the browser window width" aesthetic is claws on a chalkboard to me, it's easy to see why people like the service. They have the nice things from Twitter and Tumblr, but without the ads and the NSFW policies and the right-wing trolls and the Elons. They don't have the annoying things from Mastodon---the nerdy fiddliness around "instances" endemic to any such service, and the prickly, change-resistant and mansplainy culture endemic to Mastodon in particular. They even have a manifesto! (Who doesn't like a good manifesto?) Unfortunately, what they don't have is a business model---and unlike the vast majority of Mastodon instances, they need one.
To the degree I've become a social media partisan, it's for Mastodon, despite its cultural and technical difficulties. I'm not going to beat the federation drum again, though---not directly. Instead, I'd like to discuss "silos": services whose purpose is to share user-generated content, from tweets to photos to furry porn, but that largely lock that data in.
Let's pick two extremes that aren't social media: the blogging engine WordPress, and the furry story/image archive site Fur Affinity.
WordPress itself is open source. You can put up your own WordPress site or use any number of existing commercial hosts if you like.
WordPress has export and import tools: when you change WordPress hosts, you can bring everything with you.
WordPress has open APIs: you can use a variety of other tools to make and manage your posts, not just WordPress's website.
Fur Affinity is not open source. If FA goes away, there won't be another FA, unless they transfer the assets to someone else.
You can't move from another archive site to FA or move from FA to another archive site without doing everything manually. You can't even export lists of your social graph to try to rebuild it on another site.
FA has no API, so there's no easy way for anyone else to build third-party tools to work with it.*
Cohost is, unfortunately, on the FA side of the equation. It has no official, complete API, no data export function, no nothing. If it implodes, it's taking your data down with it.
Mastodon, for all of its faults, is open-source software built on an open protocol. Anyone with sufficient know-how and resources can spin up a Mastodon (or Mastodon-compatible) server, and if you as a user need to move to a different instance for any reason, you can. And I know there are a lot of my readers who don't dig Mastodon ready to point out all the asterisks there, the sharp edges, the failures in practice. But if you as a user need to move to a different Cohost instance for any reason, there is only one asterisk there and the asterisk is "sorry, you're fucked".
I've often said that I'm more interested in open data than open source, and that's largely true: since I write nearly everything in plain text with Markdown, my writing won't be trapped in a proprietary format if the people who make my closed-source editors go under or otherwise stop supporting them. But, I'm not convinced that a server for a user-generated content site doesn't ultimately need both data and source to be open. A generation ago, folks abandoning LiveJournal who wanted to keep using an LJ-like system could migrate to Dreamwidth nearly effortlessly. Dreamwidth was a fork of LJ's open-source server, and LJ had a well-documented API for posting, reading, importing, and exporting.
To be clear, I hope Cohost pulls out of their current jam. They seem to have genuinely good motivations. But even the best of intentions can't guarantee…well, anything. Small community-driven sites have moderation faceplants all the damn time. And sites that get big enough that they can no longer be run as a hobby will need revenue. If they don't have a plan to get that revenue, they're going to be in trouble; if they do have a plan, they face the danger of enshittification. Declaring your for-profit company to be proudly anti-capitalist is not, in the final analysis, a solution to this dilemma.
And yet. I can't help but read that aspirational "against all things Silicon Valley" manifesto, look at the closed source, closed data, super-siloed service they actually built in practice, and wonder just how those two things can be reconciled. At the end of the day, there's little more authentically Silicon Valley than lock-in.
------
*I know you're thinking "what about PostyBirb"; as far as I know, PostyBirb is basically brute-forcing it by "web scraping". This works, but it's highly fragile; a relatively small change on FA's front end, even a purely aesthetic one, might break things until PostyBirb can figure out how to brute-force the new design.
13 notes
·
View notes
Text
Extract Valuable Data with Our Ecommerce Data Scraping Services and Stay Ahead of Competitors
Experience seamless data extraction with APISCRAPY's Ecommerce Scraper, a cutting-edge solution designed for businesses seeking efficient information gathering. Streamline your decision-making process with precision and efficiency by effortlessly analyzing critical data. Elevate your data extraction experience to new heights with the Ecommerce Scraper.
Explore more at https://apiscrapy.com/ecommerce-data-scraping/
About AIMLEAP – Apiscrapy
Apiscrapy is a division of Aimleap. Aimleap is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered IT & digital transformation projects, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
An ISO 9001:2015 and ISO/IEC 27001:2013 certified
Served 750+ customers
11+ Years of industry experience
98% client retention
Great Place to Work® certified
Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI-driven web scraping & workflow automation platform
APYSCRAPY is an AI-driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, processing data, automate workflows, classify data and integrate ready-to-consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution
AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services
On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution
An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub
APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations:
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
Email: [email protected]
2 notes
·
View notes
Text
Best data extraction services in USA
In today's fiercely competitive business landscape, the strategic selection of a web data extraction services provider becomes crucial. Outsource Bigdata stands out by offering access to high-quality data through a meticulously crafted automated, AI-augmented process designed to extract valuable insights from websites. Our team ensures data precision and reliability, facilitating decision-making processes.
For more details, visit: https://outsourcebigdata.com/data-automation/web-scraping-services/web-data-extraction-services/.
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered IT & digital transformation projects, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
-An ISO 9001:2015 and ISO/IEC 27001:2013 certified
-Served 750+ customers
-11+ Years of industry experience
-98% client retention
-Great Place to Work® certified
-Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform
APISCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution
AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services
On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution
An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub
APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations:
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
Email: [email protected]
2 notes
·
View notes
Text
Navigating the Cloud Landscape: Unleashing Amazon Web Services (AWS) Potential
In the ever-evolving tech landscape, businesses are in a constant quest for innovation, scalability, and operational optimization. Enter Amazon Web Services (AWS), a robust cloud computing juggernaut offering a versatile suite of services tailored to diverse business requirements. This blog explores the myriad applications of AWS across various sectors, providing a transformative journey through the cloud.

Harnessing Computational Agility with Amazon EC2
Central to the AWS ecosystem is Amazon EC2 (Elastic Compute Cloud), a pivotal player reshaping the cloud computing paradigm. Offering scalable virtual servers, EC2 empowers users to seamlessly run applications and manage computing resources. This adaptability enables businesses to dynamically adjust computational capacity, ensuring optimal performance and cost-effectiveness.
Redefining Storage Solutions
AWS addresses the critical need for scalable and secure storage through services such as Amazon S3 (Simple Storage Service) and Amazon EBS (Elastic Block Store). S3 acts as a dependable object storage solution for data backup, archiving, and content distribution. Meanwhile, EBS provides persistent block-level storage designed for EC2 instances, guaranteeing data integrity and accessibility.
Streamlined Database Management: Amazon RDS and DynamoDB
Database management undergoes a transformation with Amazon RDS, simplifying the setup, operation, and scaling of relational databases. Be it MySQL, PostgreSQL, or SQL Server, RDS provides a frictionless environment for managing diverse database workloads. For enthusiasts of NoSQL, Amazon DynamoDB steps in as a swift and flexible solution for document and key-value data storage.
Networking Mastery: Amazon VPC and Route 53
AWS empowers users to construct a virtual sanctuary for their resources through Amazon VPC (Virtual Private Cloud). This virtual network facilitates the launch of AWS resources within a user-defined space, enhancing security and control. Simultaneously, Amazon Route 53, a scalable DNS web service, ensures seamless routing of end-user requests to globally distributed endpoints.
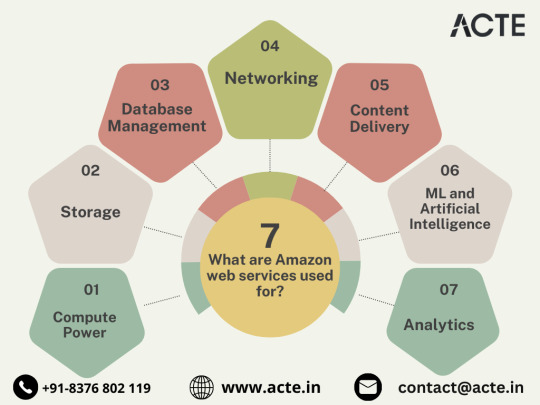
Global Content Delivery Excellence with Amazon CloudFront
Amazon CloudFront emerges as a dynamic content delivery network (CDN) service, securely delivering data, videos, applications, and APIs on a global scale. This ensures low latency and high transfer speeds, elevating user experiences across diverse geographical locations.
AI and ML Prowess Unleashed
AWS propels businesses into the future with advanced machine learning and artificial intelligence services. Amazon SageMaker, a fully managed service, enables developers to rapidly build, train, and deploy machine learning models. Additionally, Amazon Rekognition provides sophisticated image and video analysis, supporting applications in facial recognition, object detection, and content moderation.
Big Data Mastery: Amazon Redshift and Athena
For organizations grappling with massive datasets, AWS offers Amazon Redshift, a fully managed data warehouse service. It facilitates the execution of complex queries on large datasets, empowering informed decision-making. Simultaneously, Amazon Athena allows users to analyze data in Amazon S3 using standard SQL queries, unlocking invaluable insights.
In conclusion, Amazon Web Services (AWS) stands as an all-encompassing cloud computing platform, empowering businesses to innovate, scale, and optimize operations. From adaptable compute power and secure storage solutions to cutting-edge AI and ML capabilities, AWS serves as a robust foundation for organizations navigating the digital frontier. Embrace the limitless potential of cloud computing with AWS – where innovation knows no bounds.
3 notes
·
View notes
Text
What Are the Major Impact Of The Salesforce Marketing Cloud? - A Guide To Implementing And Utilizing The Tool

Salesforce Marketing Cloud is a suite of tools to streamline the digital marketing process. With this tool, you can engage, measure, and track audience engagement across all digital channels. The Salesforce Marketing Cloud has numerous benefits for businesses. This article covers the maximum impact of using this tool and how you can begin using it immediately. Before implementing it in your business, keep reading to learn more about its features, implementation details, and other key considerations.
What is Salesforce Marketing Cloud?
The Salesforce Marketing Cloud is a suite of tools that helps businesses manage their marketing strategy. The Marketing Cloud Service is a tool that simplifies managing digital campaigns.
The marketing cloud provides marketing teams with tools to improve customer satisfaction and increase sales. In addition, the marketing cloud offers various tools that enable brands to communicate more effectively with their customers. With the assistance of a Salesforce Marketing Cloud Consultant, marketers can access a wide range of insights regarding the right time and channel to communicate with customers (mobile, social media advertising, email, and so on). In addition, real-time decision-making is made simple by the presence of a Salesforce Marketing Cloud Consultant.
Also Read: How To Integrate Salesforce Marketing Cloud’s Journey Builder For A Seamless Experience?
Key benefits of using Salesforce Marketing Cloud
Data Management
Marketing Cloud’s data management capabilities are tied to data extensions (a table) that can be linked to a relational database. This ensures that any data stored in SFMC can be organized into a custom data model. Because of this, SFMC is better equipped to handle and manage a wider range of data and can create unique audiences. In addition, because of its ability to store various data types and construct a unique data model, SFMC is better positioned to handle and target a more diverse audience, which makes it one of the reasons it’s important.
Integration Capabilities
Salesforce Marketing Cloud is equipped with extensive integration capabilities that let you combine data from various sources (yet another reason why data management features are so valuable). Besides connecting to Salesforce’s Sales and Service Clouds through the Marketing Cloud Connect feature, SFMC also has various APIs. These include REST and SOAP APIs. Here are a few ways they might be used: importing content, updating contact information, and triggering automatic notifications.
Third-Party Applications
Salesforce Marketing Cloud has a lot of third-party applications available, including those from the Salesforce AppExchange, to extend its functionality and tailor it to your specific business needs. The AppExchange is like the Apple App Store or Google Play Store for other Salesforce Clouds (and it is the same for other Salesforce Clouds). Beyond the AppExchange, other fantastic third-party applications from Salesforce partners integrate with SFMC to improve its performance and value.
Also Read: What Impact Can Salesforce Marketing Cloud Have On Your Business
Application of Artificial Intelligence
Some interesting applications of Salesforce’s artificial intelligence technology, known as Einstein, are found within SFMC:
1. Message engagement scoring to predict who will interact with messaging.
2. A message’s sent time optimization to indicate the best time to send it to each individual so it is most likely to be opened.
3. Message engagement frequency to determine how many messages to send each individual.
Conclusion
Salesforce Marketing Cloud has the potential to have a major impact on a business's marketing efforts. The tool offers a wide range of features such as email marketing, social media marketing, and customer journey management, which can help businesses increase engagement, improve customer relationships, and drive revenue. Implementing and utilizing the Salesforce Marketing Cloud can be challenging, it's important to have a well-defined strategy and a clear understanding of the tool's capabilities before getting started. However, with the right approach and the expertise of a reputable Salesforce CRM Silver consulting partner service provider like GetonCRM, businesses can successfully implement and leverage the full potential of Salesforce Marketing Cloud to achieve their business objectives.
#marketingcloud#CRM#salesforce#SalesforceCRM#cloud#Business#uk#SalesforceConsultant#Consulting#consulting services
9 notes
·
View notes
Text
Generative AI, innovation, creativity & what the future might hold - CyberTalk
New Post has been published on https://thedigitalinsider.com/generative-ai-innovation-creativity-what-the-future-might-hold-cybertalk/
Generative AI, innovation, creativity & what the future might hold - CyberTalk

Stephen M. Walker II is CEO and Co-founder of Klu, an LLM App Platform. Prior to founding Klu, Stephen held product leadership roles Productboard, Amazon, and Capital One.
Are you excited about empowering organizations to leverage AI for innovative endeavors? So is Stephen M. Walker II, CEO and Co-Founder of the company Klu, whose cutting-edge LLM platform empowers users to customize generative AI systems in accordance with unique organizational needs, resulting in transformative opportunities and potential.
In this interview, Stephen not only discusses his innovative vertical SaaS platform, but also addresses artificial intelligence, generative AI, innovation, creativity and culture more broadly. Want to see where generative AI is headed? Get perspectives that can inform your viewpoint, and help you pave the way for a successful 2024. Stay current. Keep reading.
Please share a bit about the Klu story:
We started Klu after seeing how capable the early versions of OpenAI’s GPT-3 were when it came to common busy-work tasks related to HR and project management. We began building a vertical SaaS product, but needed tools to launch new AI-powered features, experiment with them, track changes, and optimize the functionality as new models became available. Today, Klu is actually our internal tools turned into an app platform for anyone building their own generative features.
What kinds of challenges can Klu help solve for users?
Building an AI-powered feature that connects to an API is pretty easy, but maintaining that over time and understanding what’s working for your users takes months of extra functionality to build out. We make it possible for our users to build their own version of ChatGPT, built on their internal documents or data, in minutes.
What is your vision for the company?
The founding insight that we have is that there’s a lot of busy work that happens in companies and software today. I believe that over the next few years, you will see each company form AI teams, responsible for the internal and external features that automate this busy work away.
I’ll give you a good example for managers: Today, if you’re a senior manager or director, you likely have two layers of employees. During performance management cycles, you have to read feedback for each employee and piece together their strengths and areas for improvement. What if, instead, you received a briefing for each employee with these already synthesized and direct quotes from their peers? Now think about all of the other tasks in business that take several hours and that most people dread. We are building the tools for every company to easily solve this and bring AI into their organization.
Please share a bit about the technology behind the product:
In many ways, Klu is not that different from most other modern digital products. We’re built on cloud providers, use open source frameworks like Nextjs for our app, and have a mix of Typescript and Python services. But with AI, what’s unique is the need to lower latency, manage vector data, and connect to different AI models for different tasks. We built on Supabase using Pgvector to build our own vector storage solution. We support all major LLM providers, but we partnered with Microsoft Azure to build a global network of embedding models (Ada) and generative models (GPT-4), and use Cloudflare edge workers to deliver the fastest experience.
What innovative features or approaches have you introduced to improve user experiences/address industry challenges?
One of the biggest challenges in building AI apps is managing changes to your LLM prompts over time. The smallest changes might break for some users or introduce new and problematic edge cases. We’ve created a system similar to Git in order to track version changes, and we use proprietary AI models to review the changes and alert our customers if they’re making breaking changes. This concept isn’t novel for traditional developers, but I believe we’re the first to bring these concepts to AI engineers.
How does Klu strive to keep LLMs secure?
Cyber security is paramount at Klu. From day one, we created our policies and system monitoring for SOC2 auditors. It’s crucial for us to be a trusted partner for our customers, but it’s also top of mind for many enterprise customers. We also have a data privacy agreement with Azure, which allows us to offer GDPR-compliant versions of the OpenAI models to our customers. And finally, we offer customers the ability to redact PII from prompts so that this data is never sent to third-party models.
Internally we have pentest hackathons to understand where things break and to proactively understand potential threats. We use classic tools like Metasploit and Nmap, but the most interesting results have been finding ways to mitigate unintentional denial of service attacks. We proactively test what happens when we hit endpoints with hundreds of parallel requests per second.
What are your perspectives on the future of LLMs (predictions for 2024)?
This (2024) will be the year for multi-modal frontier models. A frontier model is just a foundational model that is leading the state of the art for what is possible. OpenAI will roll out GPT-4 Vision API access later this year and we anticipate this exploding in usage next year, along with competitive offerings from other leading AI labs. If you want to preview what will be possible, ChatGPT Pro and Enterprise customers have access to this feature in the app today.
Early this year, I heard leaders worried about hallucinations, privacy, and cost. At Klu and across the LLM industry, we found solutions for this and we continue to see a trend of LLMs becoming cheaper and more capable each year. I always talk to our customers about not letting these stop your innovation today. Start small, and find the value you can bring to your customers. Find out if you have hallucination issues, and if you do, work on prompt engineering, retrieval, and fine-tuning with your data to reduce this. You can test these new innovations with engaged customers that are ok with beta features, but will greatly benefit from what you are offering them. Once you have found market fit, you have many options for improving privacy and reducing costs at scale – but I would not worry about that in the beginning, it’s premature optimization.
LLMs introduce a new capability into the product portfolio, but it’s also an additional system to manage, monitor, and secure. Unlike other software in your portfolio, LLMs are not deterministic, and this is a mindset shift for everyone. The most important thing for CSOs is to have a strategy for enabling their organization’s innovation. Just like any other software system, we are starting to see the equivalent of buffer exploits, and expect that these systems will need to be monitored and secured if connected to data that is more important than help documentation.
Your thoughts on LLMs, AI and creativity?
Personally, I’ve had so much fun with GenAI, including image, video, and audio models. I think the best way to think about this is that the models are better than the average person. For me, I’m below average at drawing or creating animations, but I’m above average when it comes to writing. This means I can have creative ideas for an image, the model will bring these to life in seconds, and I am very impressed. But for writing, I’m often frustrated with the boring ideas, although it helps me find blind spots in my overall narrative. The reason for this is that LLMs are just bundles of math finding the most probable answer to the prompt. Human creativity —from the arts, to business, to science— typically comes from the novel combinations of ideas, something that is very difficult for LLMs to do today. I believe the best way to think about this is that the employees who adopt AI will be more productive and creative— the LLM removes their potential weaknesses, and works like a sparring partner when brainstorming.
You and Sam Altman agree on the idea of rethinking the global economy. Say more?
Generative AI greatly changes worker productivity, including the full automation of many tasks that you would typically hire more people to handle as a business scales. The easiest way to think about this is to look at what tasks or jobs a company currently outsources to agencies or vendors, especially ones in developing nations where skill requirements and costs are lower. Over this coming decade you will see work that used to be outsourced to global labor markets move to AI and move under the supervision of employees at an organization’s HQ.
As the models improve, workers will become more productive, meaning that businesses will need fewer employees performing the same tasks. Solo entrepreneurs and small businesses have the most to gain from these technologies, as they will enable them to stay smaller and leaner for longer, while still growing revenue. For large, white-collar organizations, the idea of measuring management impact by the number of employees under a manager’s span of control will quickly become outdated.
While I remain optimistic about these changes and the new opportunities that generative AI will unlock, it does represent a large change to the global economy. Klu met with UK officials last week to discuss AI Safety and I believe the countries investing in education, immigration, and infrastructure policy today will be best suited to contend with these coming changes. This won’t happen overnight, but if we face these changes head on, we can help transition the economy smoothly.
Is there anything else that you would like to share with the CyberTalk.org audience?
Expect to see more security news regarding LLMs. These systems are like any other software and I anticipate both poorly built software and bad actors who want to exploit these systems. The two exploits that I track closely are very similar to buffer overflows. One enables an attacker to potentially bypass and hijack that prompt sent to an LLM, the other bypasses the model’s alignment tuning, which prevents it from answering questions like, “how can I build a bomb?” We’ve also seen projects like GPT4All leak API keys to give people free access to paid LLM APIs. These leaks typically come from the keys being stored in the front-end or local cache, which is a security risk completely unrelated to AI or LLMs.
#2024#ai#AI-powered#Amazon#animations#API#APIs#app#apps#Art#artificial#Artificial Intelligence#Arts#audio#automation#azure#Building#Business#cache#CEO#chatGPT#Cloud#cloud providers#cloudflare#Companies#Creative Ideas#creativity#cutting#cyber#cyber criminals
2 notes
·
View notes
Text
The Power of AI and Human Collaboration in Media Content Analysis

In today’s world binge watching has become a way of life not just for Gen-Z but also for many baby boomers. Viewers are watching more content than ever. In particular, Over-The-Top (OTT) and Video-On-Demand (VOD) platforms provide a rich selection of content choices anytime, anywhere, and on any screen. With proliferating content volumes, media companies are facing challenges in preparing and managing their content. This is crucial to provide a high-quality viewing experience and better monetizing content.
Some of the use cases involved are,
Finding opening of credits, Intro start, Intro end, recap start, recap end and other video segments
Choosing the right spots to insert advertisements to ensure logical pause for users
Creating automated personalized trailers by getting interesting themes from videos
Identify audio and video synchronization issues
While these approaches were traditionally handled by large teams of trained human workforces, many AI based approaches have evolved such as Amazon Rekognition’s video segmentation API. AI models are getting better at addressing above mentioned use cases, but they are typically pre-trained on a different type of content and may not be accurate for your content library. So, what if we use AI enabled human in the loop approach to reduce cost and improve accuracy of video segmentation tasks.
In our approach, the AI based APIs can provide weaker labels to detect video segments and send for review to be trained human reviewers for creating picture perfect segments. The approach tremendously improves your media content understanding and helps generate ground truth to fine-tune AI models. Below is workflow of end-2-end solution,
Raw media content is uploaded to Amazon S3 cloud storage. The content may need to be preprocessed or transcoded to make it suitable for streaming platform (e.g convert to .mp4, upsample or downsample)
AWS Elemental MediaConvert transcodes file-based content into live stream assets quickly and reliably. Convert content libraries of any size for broadcast and streaming. Media files are transcoded to .mp4 format
Amazon Rekognition Video provides an API that identifies useful segments of video, such as black frames and end credits.
Objectways has developed a Video segmentation annotator custom workflow with SageMaker Ground Truth labeling service that can ingest labels from Amazon Rekognition. Optionally, you can skip step#3 if you want to create your own labels for training custom ML model or applying directly to your content.
The content may have privacy and digitial rights management requirements and protection. The Objectway’s Video Segmentaton tool also supports Digital Rights Management provider integration to ensure only authorized analyst can look at the content. Moreover, the content analysts operate out of SOC2 TYPE2 compliant facilities where no downloads or screen capture are allowed.
The media analysts at Objectways’ are experts in content understanding and video segmentation labeling for a variety of use cases. Depending on your accuracy requirements, each video can be reviewed or annotated by two independent analysts and segment time codes difference thresholds are used for weeding out human bias (e.g., out of consensus if time code differs by 5 milliseconds). The out of consensus labels can be adjudicated by senior quality analyst to provide higher quality guarantees.
The Objectways Media analyst team provides throughput and quality gurantees and continues to deliver daily throughtput depending on your business needs. The segmented content labels are then saved to Amazon S3 as JSON manifest format and can be directly ingested into your Media streaming platform.
Conclusion
Artificial intelligence (AI) has become ubiquitous in Media and Entertainment to improve content understanding to increase user engagement and also drive ad revenue. The AI enabled Human in the loop approach outlined is best of breed solution to reduce the human cost and provide highest quality. The approach can be also extended to other use cases such as content moderation, ad placement and personalized trailer generation.
Contact [email protected] for more information.
2 notes
·
View notes
Text
Amazon Web Service & Adobe Experience Manager:- A Journey together (Part-1)
In the world of digital marketing today, providing a quick, secure, and seamless experience is crucial. A quicker time to market might be a differentiation, and it is crucial to reach a larger audience across all devices. Businesses are relying on cloud-based solutions to increase corporate agility, seize new opportunities, and cut costs.
Managing your marketing content and assets is simple with AEM. There are many advantages to using AWS to run AEM, including improved business agility, better flexibility, and lower expenses.
AEM & AWS a Gift for you:-
We knows about AEM as market leader in the Digital marketing but AWS is having answer for almost all the Architectural concerns like global capacity, security, reliability, fault tolerance, programmability, and usability.
So now AEM become more powerful with the power of AWS and gaining more popularity than the on-premises infrastructure.
Limitless Capacity
This combination gives full freedom to scale all AEM environments speedily in cost effective manner, addition is now more easy,
In peak traffic volume where requests are very huge or unknown then AEM instance need more power or scaling . Here friend AWS come in to picture for rescue as the on-demand feature allows to scale all workloads. In holiday season, sporting events and sale events like thanks giving etc. AWS is holding hand of AEM and say
"Hey don't worry I am here for you, i will not left you alone in these peak scenario"
When AEM require upgrade but worried about other things like downtime backup etc then also AWS as friend come and support greatly with its cloud capability. It streamlines upgrades and deployments of AEM.
Now it become easy task with AWS. Parallel environment is cake walk now, so migration and testing is much easier without thinking of the infrastructure difficulties.
Performance testing from the QA is much easier without disturbing production. It can be done in AEM production-like environment. Performing the actual production upgrade itself can then be as simple as the change of a domain name system (DNS) entry.
Sky is no limit for AEM with AWS features and Capabilities :
As a market leader AEM is used by customers as the foundation of their digital marketing platform. AWS and AEM can provide a lot of third part integration opportunity such as blogs, and providing additional tools for supporting mobile delivery, analytics, and big data management.
A new feature can be generated with AWS & AEM combination.Many services like Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), and AWS Lambda, AEM functionality easily integrated with third-party APIs in a decoupled manner. AWS can provide a clean, manageable, and auditable approach to decoupled integration with back-end systems such as CRM and e-commerce systems.
24*7 Global Availability of AEM with Buddy AWS
A more Agile and Innovative requirement can fulfill by cloud transition. How innovation and how much Agile, in previous on-premise environment for any innovation need new infrastructure and more capital expenditure (Capex). Here again the golden combination of AWS and AEM will make things easier and agile. The AWS Cloud model gives you the agility to quickly spin up new instances on AWS, and the ability to try out new services
without investing in large and upfront costs. One of the feature of AWS pay-for-what-you-use pricing model is become savior in these activities.
AWS Global Infrastructure available across 24
geographic regions around the globe, so enabling customers to deploy on a global footprint quickly and easily.
Major Security concerns handled with High-Compliance
Security is the major concern about any AEM website. AWS gifts these control and confidence for secure environment. AWS ensure that you will gain the control and confidence with safety and flexibility in secure cloud computing environment .
AWS, provides way to improve ability to meet core security and compliance requirements with a comprehensive set of services and features. Compliance certifications and attestations are assessed by a third-party, independent auditor.
Running AEM on AWS provides customers with the benefits of leveraging the compliance and security capabilities of AWS, along with the ability to monitor and audit access to AEM using AWS Security, Identity and Compliance services.
Continue in part-2.......
2 notes
·
View notes
Text
GPT-4 will hunt for trends in medical records thanks to Microsoft and Epic

Enlarge / An AI-generated image of a pixel art hospital with empty windows.
Benj Edwards / Midjourney
On Monday, Microsoft and Epic Systems announced that they are bringing OpenAI's GPT-4 AI language model into health care for use in drafting message responses from health care workers to patients and for use in analyzing medical records while looking for trends.
Epic Systems is one of America's largest health care software companies. Its electronic health records (EHR) software (such as MyChart) is reportedly used in over 29 percent of acute hospitals in the United States, and over 305 million patients have an electronic record in Epic worldwide. Tangentially, Epic's history of using predictive algorithms in health care has attracted some criticism in the past.
In Monday's announcement, Microsoft mentions two specific ways Epic will use its Azure OpenAI Service, which provides API access to OpenAI's large language models (LLMs), such as GPT-3 and GPT-4. In layperson's terms, it means that companies can hire Microsoft to provide generative AI services for them using Microsoft's Azure cloud platform.
The first use of GPT-4 comes in the form of allowing doctors and health care workers to automatically draft message responses to patients. The press release quotes Chero Goswami, chief information officer at UW Health in Wisconsin, as saying, "Integrating generative AI into some of our daily workflows will increase productivity for many of our providers, allowing them to focus on the clinical duties that truly require their attention."
The second use will bring natural language queries and "data analysis" to SlicerDicer, which is Epic's data-exploration tool that allows searches across large numbers of patients to identify trends that could be useful for making new discoveries or for financial reasons. According to Microsoft, that will help "clinical leaders explore data in a conversational and intuitive way." Imagine talking to a chatbot similar to ChatGPT and asking it questions about trends in patient medical records, and you might get the picture.
GPT-4 is a large language model (LLM) created by OpenAI that has been trained on millions of books, documents, and websites. It can perform compositional and translation tasks in text, and its release, along with ChatGPT, has inspired a rush to integrate LLMs into every type of business, whether appropriate or not.
2 notes
·
View notes
Last Seen Blogs

beeneandcosalon-blog
Beene and Company Salon

njamilstore
Graphic designer



cravingcraze
Just a dork posting here. Don’t mind me