#best vector database for large-scale AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
#best vector database for large-scale AI#Deep learning data management#How vector databases work in AI#Personalization using vector databases#role of vector search in semantic AI#vector database for AI
0 notes
Text
What Are the Key Technologies Behind Successful Generative AI Platform Development for Modern Enterprises?
The rise of generative AI has shifted the gears of enterprise innovation. From dynamic content creation and hyper-personalized marketing to real-time decision support and autonomous workflows, generative AI is no longer just a trend—it’s a transformative business enabler. But behind every successful generative AI platform lies a complex stack of powerful technologies working in unison.

So, what exactly powers these platforms? In this blog, we’ll break down the key technologies driving enterprise-grade generative AI platform development and how they collectively enable scalability, adaptability, and business impact.
1. Large Language Models (LLMs): The Cognitive Core
At the heart of generative AI platforms are Large Language Models (LLMs) like GPT, LLaMA, Claude, and Mistral. These models are trained on vast datasets and exhibit emergent abilities to reason, summarize, translate, and generate human-like text.
Why LLMs matter:
They form the foundational layer for text-based generation, reasoning, and conversation.
They enable multi-turn interactions, intent recognition, and contextual understanding.
Enterprise-grade platforms fine-tune LLMs on domain-specific corpora for better performance.
2. Vector Databases: The Memory Layer for Contextual Intelligence
Generative AI isn’t just about creating something new—it’s also about recalling relevant context. This is where vector databases like Pinecone, Weaviate, FAISS, and Qdrant come into play.
Key benefits:
Store and retrieve high-dimensional embeddings that represent knowledge in context.
Facilitate semantic search and RAG (Retrieval-Augmented Generation) pipelines.
Power real-time personalization, document Q&A, and multi-modal experiences.
3. Retrieval-Augmented Generation (RAG): Bridging Static Models with Live Knowledge
LLMs are powerful but static. RAG systems make them dynamic by injecting real-time, relevant data during inference. This technique combines document retrieval with generative output.
Why RAG is a game-changer:
Combines the precision of search engines with the fluency of LLMs.
Ensures outputs are grounded in verified, current knowledge—ideal for enterprise use cases.
Reduces hallucinations and enhances trust in AI responses.
4. Multi-Modal Learning and APIs: Going Beyond Text
Modern enterprises need more than text. Generative AI platforms now incorporate multi-modal capabilities—understanding and generating not just text, but also images, audio, code, and structured data.
Supporting technologies:
Vision models (e.g., CLIP, DALL·E, Gemini)
Speech-to-text and TTS (e.g., Whisper, ElevenLabs)
Code generation models (e.g., Code LLaMA, AlphaCode)
API orchestration for handling media, file parsing, and real-world tools
5. MLOps and Model Orchestration: Managing Models at Scale
Without proper orchestration, even the best AI model is just code. MLOps (Machine Learning Operations) ensures that generative models are scalable, maintainable, and production-ready.
Essential tools and practices:
ML pipeline automation (e.g., Kubeflow, MLflow)
Continuous training, evaluation, and model drift detection
CI/CD pipelines for prompt engineering and deployment
Role-based access and observability for compliance
6. Prompt Engineering and Prompt Orchestration Frameworks
Crafting the right prompts is essential to get accurate, reliable, and task-specific results from LLMs. Prompt engineering tools and libraries like LangChain, Semantic Kernel, and PromptLayer play a major role.
Why this matters:
Templates and chains allow consistency across agents and tasks.
Enable composability across use cases: summarization, extraction, Q&A, rewriting, etc.
Enhance reusability and traceability across user sessions.
7. Secure and Scalable Cloud Infrastructure
Enterprise-grade generative AI platforms require robust infrastructure that supports high computational loads, secure data handling, and elastic scalability.
Common tech stack includes:
GPU-accelerated cloud compute (e.g., AWS SageMaker, Azure OpenAI, Google Vertex AI)
Kubernetes-based deployment for scalability
IAM and VPC configurations for enterprise security
Serverless backend and function-as-a-service (FaaS) for lightweight interactions
8. Fine-Tuning and Custom Model Training
Out-of-the-box models can’t always deliver domain-specific value. Fine-tuning using transfer learning, LoRA (Low-Rank Adaptation), or PEFT (Parameter-Efficient Fine-Tuning) helps mold generic LLMs into business-ready agents.
Use cases:
Legal document summarization
Pharma-specific regulatory Q&A
Financial report analysis
Customer support personalization
9. Governance, Compliance, and Explainability Layer
As enterprises adopt generative AI, they face mounting pressure to ensure AI governance, compliance, and auditability. Explainable AI (XAI) technologies, model interpretability tools, and usage tracking systems are essential.
Technologies that help:
Responsible AI frameworks (e.g., Microsoft Responsible AI Dashboard)
Policy enforcement engines (e.g., Open Policy Agent)
Consent-aware data management (for HIPAA, GDPR, SOC 2, etc.)
AI usage dashboards and token consumption monitoring
10. Agent Frameworks for Task Automation
Generative AI platform Development are evolving beyond chat. Modern solutions include autonomous agents that can plan, execute, and adapt to tasks using APIs, memory, and tools.
Tools powering agents:
LangChain Agents
AutoGen by Microsoft
CrewAI, BabyAGI, OpenAgents
Planner-executor models and tool calling (OpenAI function calling, ReAct, etc.)
Conclusion
The future of generative AI for enterprises lies in modular, multi-layered platforms built with precision. It's no longer just about having a powerful model—it’s about integrating it with the right memory, orchestration, compliance, and multi-modal capabilities. These technologies don’t just enable cool demos—they drive real business transformation, turning AI into a strategic asset.
For modern enterprises, investing in these core technologies means unlocking a future where every department, process, and decision can be enhanced with intelligent automation.
0 notes
Text
The Ultimate Guide to AI Agent Development for Enterprise Automation in 2025
In the fast-evolving landscape of enterprise technology, AI agents have emerged as powerful tools driving automation, efficiency, and innovation. As we step into 2025, organizations are no longer asking if they should adopt AI agents—but how fast they can build and scale them across workflows.
This comprehensive guide unpacks everything you need to know about AI agent development for enterprise automation—from definitions and benefits to architecture, tools, and best practices.

🚀 What Are AI Agents?
AI agents are intelligent software entities that can autonomously perceive their environment, make decisions, and act on behalf of users or systems to achieve specific goals. Unlike traditional bots, AI agents can reason, learn, and interact contextually, enabling them to handle complex, dynamic enterprise tasks.
Think of them as your enterprise’s digital co-workers—automating tasks, communicating across systems, and continuously improving through feedback.
🧠 Why AI Agents Are Key to Enterprise Automation in 2025
1. Hyperautomation Demands Intelligence
Gartner predicts that by 2025, 70% of organizations will implement structured automation frameworks, where intelligent agents play a central role in managing workflows across HR, finance, customer service, IT, and supply chain.
2. Cost Reduction & Productivity Gains
Enterprises using AI agents report up to 40% reduction in operational costs and 50% faster task completion rates, especially in repetitive and decision-heavy processes.
3. 24/7 Autonomy and Scalability
Unlike human teams, AI agents work round-the-clock, handle large volumes of data, and scale effortlessly across cloud-based environments.
🏗️ Core Components of an Enterprise AI Agent
To develop powerful AI agents, understanding their architecture is key. The modern enterprise AI agent typically includes:
Perception Layer: Integrates with sensors, databases, APIs, or user input to observe its environment.
Reasoning Engine: Uses logic, rules, and LLMs (Large Language Models) to make decisions.
Planning Module: Generates action steps to achieve goals.
Action Layer: Executes commands via APIs, RPA bots, or enterprise applications.
Learning Module: Continuously improves via feedback loops and historical data.
🧰 Tools and Technologies for AI Agent Development in 2025
Developers and enterprises now have access to an expansive toolkit. Key technologies include:
🤖 LLMs (Large Language Models)
OpenAI GPT-4+, Anthropic Claude, Meta Llama 3
Used for task understanding, conversational interaction, summarization
🛠️ Agent Frameworks
LangChain, AutoGen, CrewAI, MetaGPT
Enable multi-agent systems, memory handling, tool integration
🧩 Integration Platforms
Zapier, Make, Microsoft Power Automate
Used for task automation and API-level integrations
🧠 RAG (Retrieval-Augmented Generation)
Enables agents to access external knowledge sources, ensuring context-aware and up-to-date responses
🔄 Vector Databases & Memory
Pinecone, Weaviate, Chroma
Let agents retain long-term memory and user-specific knowledge
🛠️ Steps to Build an Enterprise AI Agent in 2025
Here’s a streamlined process to develop robust AI agents tailored to your enterprise needs:
1. Define the Use Case
Start with a clear objective. Popular enterprise use cases include:
IT support automation
HR onboarding and management
Sales enablement
Invoice processing
Customer service response
2. Choose Your Agent Architecture
Decide between:
Single-agent systems (for simple tasks)
Multi-agent orchestration (for collaborative, goal-driven tasks)
3. Select the Right Tools
LLM provider (OpenAI, Anthropic)
Agent framework (LangChain, AutoGen)
Vector database for memory
APIs or RPA tools for action execution
4. Develop & Train
Build prompts or workflows
Integrate APIs and data sources
Train agents to adapt and improve from user feedback
5. Test and Deploy
Run real-world scenarios
Monitor behavior and adjust reasoning logic
Ensure enterprise-grade security, compliance, and scalability
🛡️ Security, Privacy, and Governance
As agents operate across enterprise systems, security and compliance must be integral to your development process:
Enforce role-based access control (RBAC)
Use private LLMs or secure APIs for sensitive data
Implement audit trails and logging for transparency
Regularly update models to prevent hallucinations or bias
📊 KPIs to Measure AI Agent Performance
To ensure ongoing improvement and ROI, track:
Task Completion Rate
Average Handling Time
Agent Escalation Rate
User Satisfaction (CSAT)
Cost Savings Per Workflow
🧩 Agentic AI: The Future of Enterprise Workflows
2025 marks the beginning of agentic enterprises, where AI agents become core building blocks of decision-making and operations. From autonomous procurement to dynamic scheduling, businesses are building systems where humans collaborate with agents, not just deploy them.
In the near future, we’ll see:
Goal-based agents with autonomy
Multi-agent systems negotiating outcomes
Cross-department agents driving insights
🏁 Final Thoughts: Start Building Now
AI agents are not just another automation trend—they are the new operating layer of enterprises. If you're looking to stay competitive in 2025 and beyond, investing in AI agent development is not optional. It’s strategic.
Start small, scale fast, and always design with your users and business outcomes in mind.
📣 Ready to Develop Your AI Agent?
Whether you're automating workflows, enhancing productivity, or creating next-gen customer experiences, building an AI agent tailored to your enterprise is within reach.
Partner with experienced AI agent developers to move from concept to implementation with speed, security, and scale.
0 notes
Text
When choosing between a knowledge graph and a vector database for smart data handling, it's essential to grasp the advantages and applications of each. Each technology provides effective methods for handling and searching data, yet they are designed for various purposes and situations. Knowledge Graphs: Structured Relationships Knowledge graphs are highly effective at capturing and querying relationships between entities. They organize data into nodes (representing entities) and edges (representing relationships), creating a graph-based structure. This arrangement supports intricate queries that can explore relationships, making knowledge graphs particularly well-suited for situations where the connections between data points are as crucial as the data itself. For example, in a knowledge graph, you might have nodes representing people, organizations, and events. The edges between these nodes can represent relationships like "works for," "attended," or "founded." This allows for queries like "Which people attended events hosted by a specific organization?" to be executed efficiently. Knowledge graphs are particularly powerful in domains like recommendation systems, fraud detection, and knowledge management. They are also widely used in semantic search engines, where understanding the meaning behind search queries requires a deep understanding of the relationships between concepts. Vector Databases: Managing Unstructured Data Vector databases are specifically built to manage unstructured data, including text, images, and audio. They represent data as high-dimensional vectors, which mathematically capture the essence or meaning of the data. This enables similarity searches, allowing you to find data points that are "close" to each other in vector space, even if they are not exactly the same. In a vector database, text can be transformed into a vector that captures its underlying meaning. These vectors can then be compared to identify similar texts, even when the words used differ. This makes vector databases particularly useful for tasks such as semantic search, recommendation systems, and natural language processing. Vector databases are increasingly being used in applications that involve AI and machine learning. They are well-suited for managing large-scale, unstructured data where traditional databases might struggle. Choosing the Right Technology When deciding on a knowledge graph or a vector database, the key consideration is the nature of your data and the type of queries you need to perform. Data Structure If your data is highly structured, with clear entities and relationships, a knowledge graph is likely the better choice. Knowledge graphs are optimized for handling structured data and can efficiently execute complex queries that involve multiple relationships. Query Requirements If your queries involve traversing relationships or understanding the connections between data points, a knowledge graph is more suitable. For example, if you need to find all individuals connected to a specific entity through multiple relationships, a knowledge graph can handle this with ease. Unstructured Data If your data is largely unstructured, such as text, images, or audio, and you need to perform similarity searches, a vector database is the better option. Vector databases are designed to handle the challenges of unstructured data and can perform searches based on the meaning or content of the data rather than exact matches. Scalability Non functional requirement scalability is important for your application. Knowledge graphs can scale well for structured data, but they may require significant computational resources as the complexity of the graph increases. Vector databases, on the other hand, are designed to handle large-scale unstructured data and can scale more easily for applications involving AI and machine learning. Integration with AI If your application involves AI or machine
learning, especially tasks like recommendation systems or natural language processing, a vector database is likely the better fit. Vector databases can easily integrate with AI models and handle the high-dimensional data that these models generate. Use Cases for Knowledge Graphs Knowledge graphs are best for applications where it's important for the stakeholders to understand and navigate relationships between data points. Here are some common use cases below: Recommendation Systems: Knowledge graphs can enhance personalized recommendations by analyzing the relationships between users, products, and their preferences. Fraud Detection: In financial services, knowledge graphs can help identify suspicious patterns by analyzing the relationships between transactions, accounts, and individuals. Knowledge Management: Organizations use knowledge graphs to organize and retrieve information efficiently, making it easier for employees to find relevant data. Supply Chain Management: Knowledge graphs can help track and optimize supply chain processes by mapping relationships between suppliers, manufacturers, and distribution networks. Use Cases for Vector Databases Vector databases are best suited for applications involving unstructured data and similarity searches. Common use cases include: Semantic Search: Vector databases can enhance search engines by allowing them to understand the meaning behind queries and find relevant results, even if they don't contain the exact keywords. Recommendation Engines: By comparing user preferences and behavior, vector databases can recommend similar items, even if the user hasn't explicitly searched for them. Natural Language Processing: Vector databases can store and query the vectors generated by language models, enabling applications like chatbots, sentiment analysis, and machine translation. Image and Video Retrieval: Vector databases can search and retrieve similar images or videos based on content, enabling applications like visual search and media recommendation systems. Conclusion Choosing between a knowledge graph and a vector database hinges on what your application requires. Knowledge graphs are more appropriate for organized data and intricate queries about relationships, whereas vector databases are more effective at managing unorganized data and searching for similarities. Grasping the characteristics of your data and the demands of your queries will assist you in selecting the appropriate technology for smart data handling. By selecting the appropriate technology, you can ensure that your data management strategy is aligned with your business goals, enabling more effective decision-making and better insights from your data.
0 notes
Text
Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen – A Comprehensive Guide

In recent years, the world of artificial intelligence and data science has seen remarkable growth, particularly with advancements in retrieval-augmented generation (RAG) models. Among the most cutting-edge topics in this space are the use of Vector to Graph RAG LangChain Neo4j AutoGen, which has created waves in transforming the way we approach information retrieval, data structuring, and knowledge generation.
In this blog, we’ll dive into what Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen is all about, explore its core components, and why it’s crucial for developers and businesses looking to leverage AI-based solutions for more accurate and scalable applications.
Introduction to Advanced RAG
The concept of Retrieval-Augmented Generation (RAG) combines the best of both worlds: retrieval-based models and generative models. RAG leverages the power of large-scale pre-trained models and enhances them by including a retrieval component. This ensures that instead of generating responses purely from learned data, the model retrieves relevant information, leading to more accurate and contextually sound outputs.
At the heart of the Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen approach is the seamless integration between vector representations and graph databases such as Neo4j. In simple terms, this method allows data to be stored, retrieved, and represented as a graph structure while incorporating the benefits of LangChain for natural language processing and AutoGen for automatic data generation.
Vector to Graph RAG: A Powerful Shift
The transformation from vectors to graphs is a significant evolution in the RAG landscape. Vector embeddings are widely used in machine learning and AI to represent data in a high-dimensional space. These embeddings capture the semantic essence of text, images, and other types of data. However, vectors on their own don’t capture relationships between entities as well as graph structures do.
Graph RAG, on the other hand, enables us to represent data not only based on the content but also based on the relationships between various entities. For instance, in a customer service chatbot application, it’s important not just to retrieve the most relevant answer but to understand how different pieces of knowledge are connected. This is where Neo4j, a leading graph database, plays a pivotal role. By utilizing Neo4j, Vector to Graph RAG LangChain Neo4j AutoGen creates a rich knowledge network that enhances data retrieval and generative capabilities.
Why Neo4j?
Neo4j is one of the most popular graph databases used today, known for its ability to store and manage highly interconnected data. Its flexibility and performance in handling relationship-based queries make it ideal for graph RAG models. When used alongside LangChain, which excels in handling large language models (LLMs), and AutoGen, which automates the generation of relevant data, the synergy between these tools opens up a new frontier in AI.
Neo4j is particularly beneficial because:
Enhanced Relationships: Unlike traditional databases, Neo4j captures the rich connections between data points, offering a deeper layer of insights.
Scalability: It can scale horizontally, making it perfect for handling large amounts of data.
Real-Time Querying: With its graph-based querying system, Neo4j can retrieve data faster than conventional systems when relationships are involved.
LangChain’s Role in Advanced RAG
LangChain is a framework designed to work with large language models (LLMs) to simplify the process of combining language generation with external knowledge retrieval. In the context of Advanced RAG, LangChain adds significant value by serving as a bridge between the LLMs and the retrieval mechanism.
Imagine a scenario where a model needs to generate a customer support response. Instead of relying solely on pre-trained knowledge, LangChain can retrieve relevant data from Neo4j based on the query and use the LLM to generate a coherent, contextually appropriate answer. This combination boosts both the accuracy and relevance of the responses, addressing many of the limitations that come with generative-only models.
LangChain offers key advantages such as:
Seamless integration with LLMs: By utilizing Vector to Graph RAG LangChain Neo4j AutoGen, the generated content is more contextually aware and grounded in real-world data.
Modular framework: LangChain allows developers to customize components like retrieval mechanisms and data sources, making it a flexible solution for various AI applications.
AutoGen: The Future of AI-Generated Content
The final pillar in the Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen framework is AutoGen, which, as the name suggests, automates the generation of data. AutoGen allows for real-time generation of both text-based and graph-based data, significantly reducing the time it takes to build and scale AI models.
With AutoGen, developers can automate the process of building and updating knowledge graphs in Neo4j, thereby keeping the data fresh and relevant. This is particularly useful in dynamic industries where information changes rapidly, such as healthcare, finance, and e-commerce.
Applications of Vector to Graph RAG LangChain Neo4j AutoGen
The combination of Vector to Graph RAG LangChain Neo4j AutoGen has far-reaching applications. Here are a few real-world examples:
Customer Support Chatbots: By using this system, businesses can enhance their customer support services by not only retrieving the most relevant information but also understanding the relationship between customer queries, products, and services, ensuring more personalized and effective responses.
Recommendation Engines: Graph-based RAG models can improve the accuracy of recommendation systems by understanding the relationships between user behavior, preferences, and product offerings.
Healthcare Knowledge Graphs: In healthcare, creating and maintaining up-to-date knowledge graphs using Neo4j can significantly enhance diagnosis and treatment recommendations based on relationships between medical conditions, treatments, and patient data.
Optimizing SEO for “Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen”
To make sure this blog ranks well on search engines, we have strategically included related keywords like:
Retrieval-Augmented Generation (RAG)
Graph-based RAG models
LangChain integration with Neo4j
Vector embeddings
Neo4j for AI
AutoGen for automated graph generation
Advanced AI frameworks
By using variations of the keyphrase Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen and related terms, this blog aims to rank for multiple keywords across the board. Ensuring keyphrase density throughout the blog and placing the keyphrase in the introduction gives this content the SEO boost it needs to rank on SERPs.
Conclusion: Why Adopt Advanced RAG?
The landscape of AI is evolving rapidly, and methods like Advanced RAG: Vector to Graph RAG LangChain Neo4j AutoGen are pushing the boundaries of what’s possible. For developers, data scientists, and businesses looking to harness the power of AI for more accurate, scalable, and contextually aware solutions, this combination offers an incredible opportunity.
By integrating vector embeddings, graph databases like Neo4j, and frameworks like LangChain and AutoGen, organizations can create more robust systems for knowledge retrieval and generation. Whether you’re building the next-generation chatbot, recommendation engine, or healthcare solution, this advanced RAG model offers a scalable and powerful path forward.
0 notes
Text
Your guide to LLMOps
New Post has been published on https://thedigitalinsider.com/your-guide-to-llmops/
Your guide to LLMOps

Navigating the field of large language model operations (LLMOps) is more important than ever as businesses and technology sectors intensify utilizing these advanced tools.
LLMOps is a niche technical domain and a fundamental aspect of modern artificial intelligence frameworks, influencing everything from model design to deployment.
Whether you’re a seasoned data scientist, a machine learning engineer, or an IT professional, understanding the multifaceted landscape of LLMOps is essential for harnessing the full potential of large language models in today’s digital world.
In this guide, we’ll cover:
What is LLMOps?
How does LLMOps work?
What are the benefits of LLMOps?
LLMOps best practices
What is LLMOps?
Large language model operations, or LLMOps, are techniques, practices, and tools that are used in operating and managing LLMs throughout their entire lifecycle.
These operations comprise language model training, fine-tuning, monitoring, and deployment, as well as data preparation.
What is the current LLMops landscape?
LLMs. What opened the way for LLMOps.
Custom LLM stack. A wider array of tools that can fine-tune and implement proprietary solutions from open-source regulations.
LLM-as-a-Service. The most popular way of delivering closed-based models, it offers LLMs as an API through its infrastructure.
Prompt execution tools. By managing prompt templates and creating chain-like sequences of relevant prompts, they help to improve and optimize model output.
Prompt engineering tech. Instead of the more expensive fine-tuning, these technologies allow for in-context learning, which doesn’t use sensitive data.
Vector databases. These retrieve contextually relevant data for specific commands.
The fall of centralized data and the future of LLMs
Gregory Allen, Co-Founder and CEO at Datasent, gave this presentation at our Generative AI Summit in Austin in 2024.
What are the key LLMOps components?
Architectural selection and design
Choosing the right model architecture. Involving data, domain, model performance, and computing resources.
Personalizing models for tasks. Pre-trained models can be customized for lower costs and time efficiency.
Hyperparameter optimization. This optimizes model performance as it finds the best combination. For example, you can use random search, grid research, and Bayesian optimization.
Tweaking and preparation. Unsupervised pre-training and transfer learning lower training time and enhance model performance.
Model assessment and benchmarking. It’s always good practice to benchmark models against industry standards.
Data management
Organization, storing, and versioning data. The right database and storage solutions simplify data storage, retrieval, and modification during the LLM lifecycle.
Data gathering and processing. As LLMs run on diverse, high-quality data, models might need data from various domains, sources, and languages. Data needs to be cleaned and pre-processed before being fed into LLMs.
Data labeling and annotation. Supervised learning needs consistent and reliable labeled data; when domain-specific or complex instances need expert judgment, human-in-the-loop techniques are beneficial.
Data privacy and control. Involves pseudonymization, anonymization techniques, data access control, model security considerations, and compliance with GDPR and CCPA.
Data version control. LLM iteration and performance improvement are simpler with a clear data history; you’ll find errors early by versioning models and thoroughly testing them.
Deployment platforms and strategies
Model maintenance. Showcases issues like model drift and flaws.
Optimizing scalability and performance. Models might need to be horizontally scaled with more instances or vertically scaled with additional resources within high-traffic settings.
On-premises or cloud deployment. Cloud deployment is flexible, easy to use, and scalable, while on-premises deployment could improve data control and security.

LLMOps vs. MLOps: What’s the difference?
Machine learning operations, or MLOps, are practices that simplify and automate machine learning workflows and deployments. MLOps are essential for releasing new machine learning models with both data and code changes at the same time.
There are a few key principles of MLOps:
1. Model governance
Managing all aspects of machine learning to increase efficiency, governance is vital to institute a structured process for reviewing, validating, and approving models before launch. This also includes considering ethical, fairness, and ethical concerns.
2. Version control
Tracking changes in machine learning assets allows you to copy results and roll back to older versions when needed. Code reviews are part of all machine learning training models and code, and each is versioned for ease of auditing and reproduction.
3. Continuous X
Tests and code deployments are run continuously across machine learning pipelines. Within MLOps, ‘continuous’ relates to four activities that happen simultaneously whenever anything is changed in the system:
Continuous integration
Continuous delivery
Continuous training
Continuous monitoring
4. Automation
Through automation, there can be consistency, repeatability, and scalability within machine learning pipelines. Factors like model training code changes, messaging, and application code changes can initiate automated model training and deployment.
MLOps have a few key benefits:
Improved productivity. Deployments can be standardized for speed by reusing machine learning models across various applications.
Faster time to market. Model creation and deployment can be automated, resulting in faster go-to-market times and reduced operational costs.
Efficient model deployment. Continuous delivery (CI/CD) pipelines limit model performance degradation and help to retain quality.
LLMOps are MLOps with technology and process upgrades tuned to the individual needs of LLMs. LLMs change machine learning workflows and requirements in distinct ways:
1. Performance metrics
When evaluating LLMs, there are several different standard scoring and benchmarks to take into account, like recall-oriented understudy for gisting evaluation (ROUGE) and bilingual evaluation understudy (BLEU).
2. Cost savings
Hyperparameter tuning in LLMs is vital to cutting the computational power and cost needs of both inference and training. LLMs start with a foundational model before being fine-tuned with new data for domain-specific refinements, allowing them to deliver higher performance with fewer costs.
3. Human feedback
LLM operations are typically open-ended, meaning human feedback from end users is essential to evaluate performance. Having these feedback loops in KKMOps pipelines streamlines assessment and provides data for future fine-tuning cycles.
4. Prompt engineering
Models that follow instructions can use complicated prompts or instructions, which are important to receive consistent and correct responses from LLMs. Through prompt engineering, you can lower the risk of prompt hacking and model hallucination.
5. Transfer learning
LLM models start with a foundational model and are then fine-tuned with new data, allowing for cutting-edge performance for specific applications with fewer computational resources.
6. LLM pipelines
These pipelines integrate various LLM calls to other systems like web searches, allowing LLMs to conduct sophisticated activities like a knowledge base Q&A. LLM application development tends to focus on creating pipelines, not new ones.
3 learnings from bringing AI to market
Drawing from experience at Salesforce, Mike Kolman shares three essential learnings to help you confidently navigate the AI landscape.

How does LLMOps work?
LLMOps involve a few important steps:
1. Selection of foundation model
Foundation models, which are LLMs pre-trained on big datasets, are used for downstream operations. Training models from scratch can be very expensive and time-consuming; big companies often develop proprietary foundation models, which are larger and have better performance than open-source ones. They do, however, have more expensive APIs and lower adaptability.
Proprietary model vendors:
OpenAI (GPT-3, GPT-4)
AI21 Labs (Jurassic-2)
Anthropic (Claude)
Open-source models:
LLaMA
Stable Diffusion
Flan-T5
2. Downstream task adaptation
After selecting the foundation model, you can use LLM APIs, which don’t always say what input leads to what output. It might take iterations to get the LLM API output you need, and LLMs can hallucinate if they don’t have the right data. Model A/B testing or LLM-specific evaluation is often used to test performance.
You can adapt foundation models to downstream activities:
Model assessment
Prompt engineering
Using embeddings
Fine-tuning pre-trained models
Using external data for contextual information
3. Model deployment and monitoring
LLM-powered apps must closely monitor API model changes, as LLM deployment can change significantly across different versions.
What are the benefits of LLMOps?
Scalability
You can achieve more streamlined management and scalability of data, which is vital when overseeing, managing, controlling, or monitoring thousands of models for continuous deployment, integration, and delivery.
LLMOps does this by enhancing model latency for more responsiveness in user experience. Model monitoring with a continuous integration, deployment, and delivery environment can simplify scalability.
LLM pipelines often encourage collaboration and reduce speed release cycles, being easy to reproduce and leading to better collaboration across data teams. This leads to reduced conflict and increased release speed.
LLMOps can manage large amounts of requests simultaneously, which is important in enterprise applications.
Efficiency
LLMOps allow for streamlined collaboration between machine learning engineers, data scientists, stakeholders, and DevOps – this leads to a more unified platform for knowledge sharing and communication, as well as model development and employment, which allows for faster delivery.
You can also cut down on computational costs by optimizing model training. This includes choosing suitable architectures and using model pruning and quantization techniques, for example.
With LLMOps, you can also access more suitable hardware resources like GPUs, allowing for efficient monitoring, fine-tuning, and resource usage optimization. Data management is also simplified, as LLMOps facilitate strong data management practices for high-quality dataset sourcing, cleaning, and usage in training.
With model performance able to be improved through high-quality and domain-relevant training data, LLMOps guarantees peak performance. Hyperparameters can also be improved, and DaraOps integration can ease a smooth data flow.
You can also speed up iteration and feedback loops through task automation and fast experimentation.
3. Risk reduction
Advanced, enterprise-grade LLMOps can be used to enhance privacy and security as they prioritize protecting sensitive information.
With transparency and faster responses to regulatory requests, you’ll be able to comply with organization and industry policies much more easily.
Other LLMOps benefits
Data labeling and annotation
GPU acceleration for REST API model endpoints
Prompt analytics, logging, and testing
Model inference and serving
Data preparation
Model review and governance
Superintelligent language models: A new era of artificial cognition
The rise of large language models (LLMs) is pushing the boundaries of AI, sparking new debates on the future and ethics of artificial general intelligence.

LLMOps best practices
These practices are a set of guidelines to help you manage and deploy LLMs efficiently and effectively. They cover several aspects of the LLMOps life cycle:
Exploratory Data Analysis (EDA)
Involves iteratively sharing, exploring, and preparing data for the machine learning lifecycle in order to produce editable, repeatable, and shareable datasets, visualizations, and tables.
Stay up-to-date with the latest practices and advancements by engaging with the open-source community.
Data management
Appropriate software that can handle large volumes of data allows for efficient data recovery throughout the LLM lifecycle. Making sure to track changes with versioning is essential for seamless transitions between versions. Data must also be protected with access controls and transit encryption.
Data deployment
Tailor pre-trained models to conduct specific tasks for a more cost-effective approach.
Continuous model maintenance and monitoring
Dedicated monitoring tools are able to detect drift in model performance. Real-world feedback for model outputs can also help to refine and re-train the models.
Ethical model development
Discovering, anticipating, and correcting biases within training model outputs to avoid distortion.
Privacy and compliance
Ensure that operations follow regulations like CCPA and GDPR by having regular compliance checks.
Model fine-tuning, monitoring, and training
A responsive user experience relies on optimized model latency. Having tracking mechanisms for both pipeline and model lineage helps efficient lifecycle management. Distributed training helps to manage vast amounts of data and parameters in LLMs.
Model security
Conduct regular security tests and audits, checking for vulnerabilities.
Prompt engineering
Make sure to set prompt templates correctly for reliable and accurate responses. This also minimizes the probability of prompt hacking and model hallucinations.
LLM pipelines or chains
You can link several LLM external system interactions or calls to allow for complex tasks.
Computational resource management
Specialized GPUs help with extensive calculations on large datasets, allowing for faster and more data-parallel operations.
Disaster redundancy and recovery
Ensure that data, models, and configurations are regularly backed up. Redundancy allows you to handle system failures without any impact on model availability.
Propel your career in AI with access to 200+ hours of video content, a free in-person Summit ticket annually, a members-only network, and more.
Sign up for a Pro+ membership today and unlock your potential.
AI Accelerator Institute Pro+ membership
Unlock the world of AI with the AI Accelerator Institute Pro Membership. Tailored for beginners, this plan offers essential learning resources, expert mentorship, and a vibrant community to help you grow your AI skills and network. Begin your path to AI mastery and innovation now.

#2024#access control#ai#ai skills#ai summit#AI21#amp#Analysis#Analytics#anthropic#API#APIs#application development#applications#approach#apps#architecture#artificial#Artificial General Intelligence#Artificial Intelligence#assessment#assets#automation#benchmark#benchmarking#benchmarks#career#ccpa#CEO#change
0 notes
Text
Vultr Partners with SQream to Enhance Data Analytics through GPU Acceleration and Improved Scalability

Modern hyperscaler Vultr, who is often mentioned on LowEndBox, is excited to announce its new partnership with SQream as part of the Vultr Cloud Alliance, aimed to provide greater efficiency in data processing and a reduction in cloud and AI costs. Vultr, renowned as one of the largest privately-owned cloud computing platforms, has recently welcomed SQream, a prominent data and analytics acceleration platform, to its Vultr Cloud Alliance. This alliance is designed to foster a network of leading solution providers that deliver versatile cloud services. This collaboration harnesses the high-performance cloud computing capabilities of Vultr, enhanced by NVIDIA GPUs, alongside SQream's innovative, patented GPU-powered data processing technology. This partnership promises to expedite data analysis and machine learning projects for AI-driven enterprises, surpassing traditional data processing challenges. The advanced data analytics solutions provided by Vultr and SQream tackle the issues related to handling large and complex datasets that are essential for propelling forward AI advancements. This robust tool addresses key issues such as sluggish data processing, elevated operational costs, and the challenges of extracting timely insights from extensive datasets. Utilizing progressive GPU acceleration allows for complex queries and analytics at remarkable speeds, cuts down on infrastructure expenses, and enables deeper insights for faster, data-based decision-making. The cooperation ensures effortless scalability, sturdy data ingestion, and effective data transformation. "The collaboration with Vultr via its Cloud Alliance will transform the way companies tackle data analytics and machine learning initiatives," stated Ittai Bareket, Chief Alliance Officer at SQream. "With multi-layer parallel processing, extensive big data lifecycle management, and superior data processing features, Vultr and SQream facilitate organizations to obtain quicker insights, manage extensive and intricate analytics with seamless scalability, and maintain unmatched flexibility and control. This enhancement helps businesses swiftly develop sophisticated AI applications while advancing the frontiers of AI innovation." The Vultr Cloud Alliance permits enterprises to tailor their infrastructure with a composable strategy, effortlessly putting together and enlarging their modern cloud and AI operations as needed, eliminating concerns over vendor lock-in. SQream is joined in the alliance by other members such as Qdrant, who offers a high-performance vector database featuring retrieval-augmented generation; Console Connect, which provides private, high-speed networking ensuring secure, low-latency data transmissions; DDN for sophisticated AI storage solutions; and Run:ai, a cutting-edge AI workload orchestration platform. “Vultr continues to grow its Cloud Alliance to give customers easy access to all the best-in-class technology and tools they need to build and scale their cloud- and AI-native operations,” said Kevin Cochrane, CMO of Vultr. “This latest partnership between SQream and Vultr marks a significant step forward. By making it easier, faster, and less costly to analyze large and complex data sets, SQream and Vultr are clearing the way for a new wave of AI-driven innovation and transformation across industries.” The partnership between SQream and Vultr opens up a world of possibilities for enterprises across financial services, telecom, healthcare & life sciences, retail, manufacturing, and other sectors. Such industry applications and use cases include: The Vultr-SQream partnership follows a steady stream of industry innovations delivered by Vultr within the half year to enable modern AI enterprise, including industry-specific cloud computing solutions that help companies meet industry-specific needs and regulatory requirements, Sovereign Cloud and Private Cloud to bring digital autonomy to nations and enterprises worldwide, and Cloud Inference for serverless Inference-as-a-Service across Vultr’s 32 locations around the globe. If you haven't already, check out the Vultr Cloud Alliance. About Sqream: SQream delivers cutting-edge data processing and analytics acceleration, transforming how companies handle big data analytics and AI/ML workloads with its proprietary GPU SQL engine. Designed for businesses dealing with large or complicated datasets, SQream's solutions provide unmatched performance, scalability, and cost-effectiveness. Covering every aspect of the data lifecycle from ingestion to complex analytics, SQream enables companies to derive actionable insights from their data swiftly and efficiently. About Vultr: Vultr stands as the world’s foremost privately-held cloud computing platform, celebrated for its simplicity, performance, cost-effectiveness, and extensive reach. With 1.5 million customers spread across 185 countries, Vultr is a prime alternative hyperscaler, catering to high-stake sectors including financial services, telecommunications, healthcare & life sciences, retail, media & entertainment, manufacturing, and more. Vultr offers a wide array of cloud solutions such as Cloud Compute, Cloud GPU, Bare Metal, Managed Kubernetes, Managed Databases, Cloud Storage, and Networking functionalities, providing global access and superior performance. LowEndBox is a go-to resource for those seeking budget-friendly hosting solutions. This editorial focuses on syndicated news articles, delivering timely information and insights about web hosting, technology, and internet services that cater specifically to the LowEndBox community. With a wide range of topics covered, it serves as a comprehensive source of up-to-date content, helping users stay informed about the rapidly changing landscape of affordable hosting solutions. Read the full article
0 notes
Text
NVIDIA NeMo Retriever Microservices Improves LLM Accuracy
NVIDIA NIM inference microservices
AI, Get Up! Businesses can unleash the potential of their business data with production-ready NVIDIA NIM inference microservices for retrieval-augmented generation, integrated into the Cohesity, DataStax, NetApp, and Snowflake platforms. The new NVIDIA NeMo Retriever Microservices Boost LLM Accuracy and Throughput.
Applications of generative AI are worthless, or even harmful, without accuracy, and data is the foundation of accuracy.
NVIDIA today unveiled four new NVIDIA NeMo Retriever NIM inference microservices, designed to assist developers in quickly retrieving the best proprietary data to produce informed responses for their AI applications.
NeMo Retriever NIM microservices, when coupled with the today-announced NVIDIA NIM inference microservices for the Llama 3.1 model collection, allow enterprises to scale to agentic AI workflow, where AI applications operate accurately with minimal supervision or intervention, while delivering the highest accuracy retrieval-augmented generation, or RAG.
Nemo Retriever
With NeMo Retriever, businesses can easily link bespoke models to a variety of corporate data sources and use RAG to provide AI applications with incredibly accurate results. To put it simply, the production-ready microservices make it possible to construct extremely accurate AI applications by enabling highly accurate information retrieval.
NeMo Retriever, for instance, can increase model throughput and accuracy for developers building AI agents and chatbots for customer support, identifying security flaws, or deriving meaning from intricate supply chain data.
High-performance, user-friendly, enterprise-grade inferencing is made possible by NIM inference microservices. The NeMo Retriever NIM microservices enable developers to leverage all of this while leveraging their data to an even greater extent.
Nvidia Nemo Retriever
These recently released NeMo Retriever microservices for embedding and reranking NIM are now widely accessible:
NV-EmbedQA-E5-v5, a well-liked embedding model from the community that is tailored for text retrieval questions and answers.
Snowflake-Arctic-Embed-L, an optimized community model;
NV-RerankQA-Mistral4B-v3, a popular community base model optimized for text reranking for high-accuracy question answering;
NV-EmbedQA-Mistral7B-v2, a well-liked multilingual community base model fine-tuned for text embedding for correct question answering.
They become a part of the group of NIM microservices that are conveniently available via the NVIDIA API catalogue.
Model Embedding and Reranking
The two model types that make up the NeMo Retriever microservices embedding and reranking have both open and commercial versions that guarantee dependability and transparency.
With the purpose of preserving their meaning and subtleties, an embedding model converts a variety of data types, including text, photos, charts, and video, into numerical vectors that can be kept in a vector database. Compared to conventional large language models, or LLMs, embedding models are quicker and less expensive computationally.
After ingesting data and a query, a reranking model ranks the data based on how relevant it is to the query. These models are slower and more computationally complex than embedding models, but they provide notable improvements in accuracy.Image Credit To Nvidia
NeMo Retriever microservices offers advantages over other options. Developers utilising NeMo Retriever microservices may create a pipeline that guarantees the most accurate and helpful results for their company by employing an embedding NIM to cast a wide net of data to be retrieved, followed by a reranking NIM to cut the results for relevancy.
Developers can create the most accurate text Q&A retrieval pipelines by using the state-of-the-art open, commercial models available with NeMo NIM Retriever. NeMo Retriever microservices produced 30% less erroneous responses for enterprise question answering when compared to alternative solutions.Image Credit To Nvidia
NeMo Retriever microservices Principal Use Cases
NeMo Retriever microservices drives numerous AI applications, ranging from data-driven analytics to RAG and AI agent solutions.
With the help of NeMo Retriever microservices, intelligent chatbots with precise, context-aware responses can be created. They can assist in the analysis of enormous data sets to find security flaws. They can help glean insights from intricate supply chain data. Among other things, they can improve AI-enabled retail shopping advisors that provide organic, tailored shopping experiences.
For many use cases, NVIDIA AI workflows offer a simple, supported beginning point for creating generative AI-powered products.
NeMo Retriever NIM microservices are being used by dozens of NVIDIA data platform partners to increase the accuracy and throughput of their AI models.
NIM microservices
With the integration of NeMo Retriever integrating NIM microservices in its Hyper-Converged and Astra DB systems, DataStax is able to provide customers with more rapid time to market with precise, generative AI-enhanced RAG capabilities.
With the integration of NVIDIA NeMo Retriever microservices with Cohesity Gaia, the AI platform from Cohesity will enable users to leverage their data to drive smart and revolutionary generative AI applications via RAG.
Utilising NVIDIA NeMo Retriever, Kinetica will create LLM agents that can converse naturally with intricate networks in order to react to disruptions or security breaches faster and translate information into prompt action.
In order to link NeMo Retriever microservices to exabytes of data on its intelligent data infrastructure, NetApp and NVIDIA are working together. Without sacrificing data security or privacy, any NetApp ONTAP customer will be able to “talk to their data” in a seamless manner to obtain proprietary business insights.
Services to assist businesses in integrating NeMo Retriever NIM microservices into their AI pipelines are being developed by NVIDIA’s global system integrator partners, which include Accenture, Deloitte, Infosys, LTTS, Tata Consultancy Services, Tech Mahindra, and Wipro, in addition to their service delivery partners, Data Monsters, EXLService (Ireland) Limited, Latentview, Quantiphi, Slalom, SoftServe, and Tredence.
Nvidia NIM Microservices
Utilize Alongside Other NIM Microservices
NVIDIA Riva NIM microservices, which boost voice AI applications across industries increasing customer service and enlivening digital humans, can be used with NeMo Retriever microservices.
The record-breaking NVIDIA Parakeet family of automatic speech recognition models, Fastpitch and HiFi-GAN for text-to-speech applications, and Metatron for multilingual neural machine translation are among the new models that will soon be available as Riva NIM microservices.
The modular nature of NVIDIA NIM microservices allows developers to create AI applications in a variety of ways. To give developers even more freedom, the microservices can be connected with community models, NVIDIA models, or users’ bespoke models in the cloud, on-premises, or in hybrid settings.
Businesses may use NIM to implement AI apps in production by utilising the NVIDIA AI Enterprise software platform.
NVIDIA-Certified Systems from international server manufacturing partners like Cisco, Dell Technologies, Hewlett Packard Enterprise, Lenovo, and Supermicro, as well as cloud instances from Amazon Web Services, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure, can run NIM microservices on customers’ preferred accelerated infrastructure.
Members of the NVIDIA Developer Program will soon have free access to NIM for
Read more on govindhtech.com
#NVIDIANeMo#RetrieverMicroservices#generativeAI#ImprovesLLMAccuracy#NVIDIANIMinferencemicroservices#Llama31model#AIapplications#AIagents#supplychain#NVIDIAAPI#llargelanguagemodels#text#NVIDIAAI#AmazonWebServices#MicrosoftAzure#NVIDIAmodels#GoogleCloud#technews#technology#news#govindhtech
0 notes
Text
What are the challenges of retrieval augmented generation?
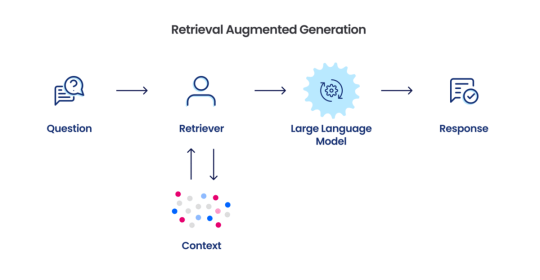
Retrieval Augmented Generation (RAG) represents a cutting-edge technique in the field of artificial intelligence, blending the prowess of generative models with the vast storage capacity of retrieval systems.
This method has emerged as a promising solution to enhance the quality and relevance of generated content. However, despite its significant potential, RAG faces numerous challenges that can impact its effectiveness and applicability in real-world scenarios.
Understanding the Complexity of Integration
One of the primary challenges of implementing RAG systems is the complexity associated with integrating two fundamentally different approaches: generative models and retrieval mechanisms.
Generative models, like GPT (Generative Pre-trained Transformer), are designed to predict and produce sequences of text based on learned patterns and contexts. Conversely, retrieval systems are engineered to efficiently search and fetch relevant information from a vast database, typically structured for quick lookup.
The integration requires a seamless interplay between these components, where the retrieval model first provides relevant context or factual information which the generative model then uses to produce coherent and contextually appropriate responses.
This dual-process necessitates sophisticated algorithms to manage the flow of information and ensure that the output is not only accurate but also maintains a natural language quality that meets user expectations.
Scalability and Computational Efficiency
Another significant hurdle is scalability and computational efficiency. RAG systems need to process large volumes of data rapidly to retrieve relevant information before generation. The "best embedding model" used in these systems must efficiently encode and compare vectors to find the best matches from the database.
This process, especially when scaled to larger databases or more complex queries, can become computationally expensive and slow, potentially limiting the practicality of RAG systems for applications requiring real-time responses.
Moreover, as the size of the data and the complexity of the tasks increase, the computational load can become overwhelming, necessitating more powerful hardware or optimized software solutions that can handle these demands without compromising performance.
Data Quality and Relevance
The effectiveness of a RAG system heavily relies on the quality and relevance of the data within the retrieval database. Inaccuracies, outdated information, or biases in the data can lead to inappropriate or incorrect outputs from the generative model.
Ensuring the database is regularly updated and curated to reflect accurate and unbiased information poses a considerable challenge, especially in dynamically changing fields such as news or scientific research.
Balancing Creativity and Fidelity
A unique challenge in RAG systems is balancing creativity with fidelity. While generative models are valued for their ability to create fluent and novel text, the addition of a retrieval system focuses on providing accurate and factual content.
Striking the right balance where the model remains creative but also adheres strictly to retrieved facts requires fine-tuning and continuous calibration of the model's parameters.
Ethical and Privacy Concerns
With the ability to retrieve and generate content based on vast amounts of data, RAG systems raise ethical and privacy concerns. The use of personal data or sensitive information within the retrieval database must be handled with strict adherence to data protection laws and ethical guidelines.
Ensuring that these systems do not perpetuate biases or misuse personal information is a challenge that developers and users alike must navigate carefully.
Conclusion
Retrieval-Augmented Generation represents a significant advancement in the field of AI, offering the potential to create more accurate, relevant, and context-aware systems. However, the challenges it faces—from integration complexity and scalability to ethical concerns—require ongoing attention and innovative solutions. As research and technology continue to evolve, the future of RAG looks promising, albeit demanding, as it paves the way for more intelligent and capable AI systems.
1 note
·
View note
Text
Important libraries for data science and Machine learning.
Python has more than 137,000 libraries which is help in various ways.In the data age where data is looks like the oil or electricity .In coming days companies are requires more skilled full data scientist , Machine Learning engineer, deep learning engineer, to avail insights by processing massive data sets.
Python libraries for different data science task:
Python Libraries for Data Collection
Beautiful Soup
Scrapy
Selenium
Python Libraries for Data Cleaning and Manipulation
Pandas
PyOD
NumPy
Spacy
Python Libraries for Data Visualization
Matplotlib
Seaborn
Bokeh
Python Libraries for Modeling
Scikit-learn
TensorFlow
PyTorch
Python Libraries for Model Interpretability
Lime
H2O
Python Libraries for Audio Processing
Librosa
Madmom
pyAudioAnalysis
Python Libraries for Image Processing
OpenCV-Python
Scikit-image
Pillow
Python Libraries for Database
Psycopg
SQLAlchemy
Python Libraries for Deployment
Flask
Django
Best Framework for Machine Learning:
1. Tensorflow :
If you are working or interested about Machine Learning, then you might have heard about this famous Open Source library known as Tensorflow. It was developed at Google by Brain Team. Almost all Google’s Applications use Tensorflow for Machine Learning. If you are using Google photos or Google voice search then indirectly you are using the models built using Tensorflow.
Tensorflow is just a computational framework for expressing algorithms involving large number of Tensor operations, since Neural networks can be expressed as computational graphs they can be implemented using Tensorflow as a series of operations on Tensors. Tensors are N-dimensional matrices which represents our Data.
2. Keras :
Keras is one of the coolest Machine learning library. If you are a beginner in Machine Learning then I suggest you to use Keras. It provides a easier way to express Neural networks. It also provides some of the utilities for processing datasets, compiling models, evaluating results, visualization of graphs and many more.
Keras internally uses either Tensorflow or Theano as backend. Some other pouplar neural network frameworks like CNTK can also be used. If you are using Tensorflow as backend then you can refer to the Tensorflow architecture diagram shown in Tensorflow section of this article. Keras is slow when compared to other libraries because it constructs a computational graph using the backend infrastructure and then uses it to perform operations. Keras models are portable (HDF5 models) and Keras provides many preprocessed datasets and pretrained models like Inception, SqueezeNet, Mnist, VGG, ResNet etc
3.Theano :
Theano is a computational framework for computing multidimensional arrays. Theano is similar to Tensorflow , but Theano is not as efficient as Tensorflow because of it’s inability to suit into production environments. Theano can be used on a prallel or distributed environments just like Tensorflow.
4.APACHE SPARK:
Spark is an open source cluster-computing framework originally developed at Berkeley’s lab and was initially released on 26th of May 2014, It is majorly written in Scala, Java, Python and R. though produced in Berkery’s lab at University of California it was later donated to Apache Software Foundation.
Spark core is basically the foundation for this project, This is complicated too, but instead of worrying about Numpy arrays it lets you work with its own Spark RDD data structures, which anyone in knowledge with big data would understand its uses. As a user, we could also work with Spark SQL data frames. With all these features it creates dense and sparks feature label vectors for you thus carrying away much complexity to feed to ML algorithms.
5. CAFFE:
Caffe is an open source framework under a BSD license. CAFFE(Convolutional Architecture for Fast Feature Embedding) is a deep learning tool which was developed by UC Berkeley, this framework is mainly written in CPP. It supports many different types of architectures for deep learning focusing mainly on image classification and segmentation. It supports almost all major schemes and is fully connected neural network designs, it offers GPU as well as CPU based acceleration as well like TensorFlow.
CAFFE is mainly used in the academic research projects and to design startups Prototypes. Even Yahoo has integrated caffe with Apache Spark to create CaffeOnSpark, another great deep learning framework.
6.PyTorch.
Torch is also a machine learning open source library, a proper scientific computing framework. Its makers brag it as easiest ML framework, though its complexity is relatively simple which comes from its scripting language interface from Lua programming language interface. There are just numbers(no int, short or double) in it which are not categorized further like in any other language. So its ease many operations and functions. Torch is used by Facebook AI Research Group, IBM, Yandex and the Idiap Research Institute, it has recently extended its use for Android and iOS.
7.Scikit-learn
Scikit-Learn is a very powerful free to use Python library for ML that is widely used in Building models. It is founded and built on foundations of many other libraries namely SciPy, Numpy and matplotlib, it is also one of the most efficient tool for statistical modeling techniques namely classification, regression, clustering.
Scikit-Learn comes with features like supervised & unsupervised learning algorithms and even cross-validation. Scikit-learn is largely written in Python, with some core algorithms written in Cython to achieve performance. Support vector machines are implemented by a Cython wrapper around LIBSVM.
Below is a list of frameworks for machine learning engineers:
Apache Singa is a general distributed deep learning platform for training big deep learning models over large datasets. It is designed with an intuitive programming model based on the layer abstraction. A variety of popular deep learning models are supported, namely feed-forward models including convolutional neural networks (CNN), energy models like restricted Boltzmann machine (RBM), and recurrent neural networks (RNN). Many built-in layers are provided for users.
Amazon Machine Learning is a service that makes it easy for developers of all skill levels to use machine learning technology. Amazon Machine Learning provides visualization tools and wizards that guide you through the process of creating machine learning (ML) models without having to learn complex ML algorithms and technology. It connects to data stored in Amazon S3, Redshift, or RDS, and can run binary classification, multiclass categorization, or regression on said data to create a model.
Azure ML Studio allows Microsoft Azure users to create and train models, then turn them into APIs that can be consumed by other services. Users get up to 10GB of storage per account for model data, although you can also connect your own Azure storage to the service for larger models. A wide range of algorithms are available, courtesy of both Microsoft and third parties. You don’t even need an account to try out the service; you can log in anonymously and use Azure ML Studio for up to eight hours.
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license. Models and optimization are defined by configuration without hard-coding & user can switch between CPU and GPU. Speed makes Caffe perfect for research experiments and industry deployment. Caffe can process over 60M images per day with a single NVIDIA K40 GPU.
H2O makes it possible for anyone to easily apply math and predictive analytics to solve today’s most challenging business problems. It intelligently combines unique features not currently found in other machine learning platforms including: Best of Breed Open Source Technology, Easy-to-use WebUI and Familiar Interfaces, Data Agnostic Support for all Common Database and File Types. With H2O, you can work with your existing languages and tools. Further, you can extend the platform seamlessly into your Hadoop environments.
Massive Online Analysis (MOA) is the most popular open source framework for data stream mining, with a very active growing community. It includes a collection of machine learning algorithms (classification, regression, clustering, outlier detection, concept drift detection and recommender systems) and tools for evaluation. Related to the WEKA project, MOA is also written in Java, while scaling to more demanding problems.
MLlib (Spark) is Apache Spark’s machine learning library. Its goal is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as lower-level optimization primitives and higher-level pipeline APIs.
mlpack, a C++-based machine learning library originally rolled out in 2011 and designed for “scalability, speed, and ease-of-use,” according to the library’s creators. Implementing mlpack can be done through a cache of command-line executables for quick-and-dirty, “black box” operations, or with a C++ API for more sophisticated work. Mlpack provides these algorithms as simple command-line programs and C++ classes which can then be integrated into larger-scale machine learning solutions.
Pattern is a web mining module for the Python programming language. It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and visualization.
Scikit-Learn leverages Python’s breadth by building on top of several existing Python packages — NumPy, SciPy, and matplotlib — for math and science work. The resulting libraries can be used either for interactive “workbench” applications or be embedded into other software and reused. The kit is available under a BSD license, so it’s fully open and reusable. Scikit-learn includes tools for many of the standard machine-learning tasks (such as clustering, classification, regression, etc.). And since scikit-learn is developed by a large community of developers and machine-learning experts, promising new techniques tend to be included in fairly short order.
Shogun is among the oldest, most venerable of machine learning libraries, Shogun was created in 1999 and written in C++, but isn’t limited to working in C++. Thanks to the SWIG library, Shogun can be used transparently in such languages and environments: as Java, Python, C#, Ruby, R, Lua, Octave, and Matlab. Shogun is designed for unified large-scale learning for a broad range of feature types and learning settings, like classification, regression, or explorative data analysis.
TensorFlow is an open source software library for numerical computation using data flow graphs. TensorFlow implements what are called data flow graphs, where batches of data (“tensors”) can be processed by a series of algorithms described by a graph. The movements of the data through the system are called “flows” — hence, the name. Graphs can be assembled with C++ or Python and can be processed on CPUs or GPUs.
Theano is a Python library that lets you to define, optimize, and evaluate mathematical expressions, especially ones with multi-dimensional arrays (numpy.ndarray). Using Theano it is possible to attain speeds rivaling hand-crafted C implementations for problems involving large amounts of data. It was written at the LISA lab to support rapid development of efficient machine learning algorithms. Theano is named after the Greek mathematician, who may have been Pythagoras’ wife. Theano is released under a BSD license.
Torch is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation. The goal of Torch is to have maximum flexibility and speed in building your scientific algorithms while making the process extremely simple. Torch comes with a large ecosystem of community-driven packages in machine learning, computer vision, signal processing, parallel processing, image, video, audio and networking among others, and builds on top of the Lua community.
Veles is a distributed platform for deep-learning applications, and it’s written in C++, although it uses Python to perform automation and coordination between nodes. Datasets can be analyzed and automatically normalized before being fed to the cluster, and a REST API allows the trained model to be used in production immediately. It focuses on performance and flexibility. It has little hard-coded entities and enables training of all the widely recognized topologies, such as fully connected nets, convolutional nets, recurent nets etc.
1 note
·
View note
Text
Cyber Security in 2020: What Do You Need to Know?

As an ecommerce site, technology is at the heart of your business. Cybersecurity and data protection rank among the top priorities for businesses that rely on technology to function. The 2019 Cost of Data Breach Report highlights that the average cost of data breaches in the US is $3.92 million. The Global Information Security Survey finds that your customer data tends to be the number one target. It’s valuable for attackers because they can use it for a range of criminal enterprises, or sell it to others. If your business experiences a data breach, it’s not just about the cost of the data itself, but the reputational cost to your business too. Besides data breaches, as an ecommerce business you should be vigilant against cyber attacks that seek to take down your website. Malware (malicious software) can hijack the functionality of your website, hold it for ransom, or even take it down altogether. Like anything else technology-related, cybersecurity threats move and change rapidly. It can seem like a game of cyber whack-a-mole at times, as new threats raise their heads. For ecommerce businesses and any others heavy on technology, this means that your best bet is to stay ahead of the game as much as possible. Here are some of the top cybersecurity trends heading into 2020:
The role of AI

AI (artificial intelligence) has seen rapid development over recent years. Expert predictions for 2020 are that we’ll see it playing more of a role in cybersecurity attacks: “AI won’t only enable malware to move stealthily across businesses without requiring a human’s hands on the keyboard, but attackers will also use AI in other malicious ways, including determining their targets, conducting reconnaissance, and scaling their attacks.” -Marcus Fowler, Darktrace Use of AI voice technology has already seen fraud committed using “deepfake”—where the fraudster uses AI to impersonate the voice of a real person. It is expected that this might open the door for the next wave of identity fraud, including phishing attacks. As business owners, it’s important to recognize this not only to protect your own business, but also to protect your customers. Another potential avenue for AI attacks is the spread of disinformation. Most people will be familiar with this idea in a political sense, but there is vast potential for this to be used against businesses and other organizations too: “In 2020, we will see more of the terrifying reality that deep learning algorithms can bring about in generating fake, but seemingly realistic images and videos. This application of AI will be a catalyst for large scale disinformation campaigns that are targeted and individualized to the behavioral and psychological profiles of each victim, furthering reach and impact.” -Pascal Geenens, Radware On the flipside of this are companies that are merging AI into their cybersecurity measures to protect against threats. In 2020, it is expected that more companies will use predictive, proactive AI to help beat cybersecurity threats.
Data encryption advancements
As cyber attacks become more sophisticated, how we encrypt our data has had to become more advanced to stay ahead of the game. Ecommerce stores are no different—you should have (or your platform provider should have) an advanced strategy for encrypting data. It’s not just about protecting your business and reputation, but complying with any laws that apply where you do business, too. Recent advances in data encryption include: Distributed ledger technologies: You may have heard of distributed ledger in relation to digital currencies. It's a digital system for recording the transaction of assets in which the transactions and their details are recorded in multiple places at the same time. This means there is no centralized database or administration role. Each node of the network holds data, which creates a system that is difficult to successfully attack.Zero-knowledge encryption: In a nutshell, “zero-knowledge” means that no one but you has the keys to your data. This means no passwords are kept anywhere for backup in case you forget your password. Of course, this also means that if you’re likely to forget your password, zero-knowledge is probably not the best choice for you as you’ll be locked out from your data. The point of encryption is as “insurance” if your data does get stolen. If it has been well-encrypted, your hope is that whoever stole it won’t be able to read it. This may sound like a bit of a cynical approach, but the fact is, it’s difficult to protect data from any hacker that is skilled and determined enough to access it. Even the NSA has been hacked previously.
Malware infections on devices
As we consider what to expect in the cybersecurity world in 2020, it pays to look at what we’ve already experienced in 2019. Kaspersky’s IT Security Economics in 2019 report reveals that around half of organizations endured a malware infection on company-owned devices. If your company has employees doing any sort of work from their own devices, it’s also worth noting that the report found around half also had malware infections on employee-owned devices. Cyber attacks targeting mobile phones, in particular, rose by over 50% in 2019. These included attacks such as credential-theft, surveillance, and malicious advertising. Given that many companies now allow employees to use their own devices, enabling remote work and flexibility, there is legitimate concern over device attacks being used as a backdoor into companies. Where does this leave your ecommerce business? It’s important to give careful thought to your policies for device use and your methods for protecting company-owned devices. It’s attractive for cyber attackers to target personal devices because they’re often not as well-protected as company-owned devices. This also means they don’t have the more difficult task of trying to target company accounts directly. "Users need to protect their devices with a holistic solution that blocks malware and network attacks, and prevents data leakage and credentials theft, without affecting the user experience." -Danny Palmer, ZDNet
5G and IoT Data impacts
The adoption of 5G is becoming more and more widespread as infrastructure is added to enable it. The expected impacts of 5G rollouts include more connected IoT (Internet of Things) devices and a vaster array of data being collected. For example, healthcare apps are looking at collecting real-time data from users, and connected cars may monitor our movements. This adds more possible vectors of cyber attack. IoT devices are already a known weak link—it’s possible that a hacker could be using your smart home to access data from your ecommerce business. Some experts believe that the adoption of 5G will give rise to the first public disclosures of data breaches due to a mobile phone. 5G may result in gaps in traditional network security that hackers will look to exploit.
Cyber Insurance
The purpose of cyber insurance is to provide protection for businesses or individual users from internet-based and IT infrastructure-based risks. For an ecommerce business, cyber insurance can help with business continuation in the event of a cyber attack, or compensation for loss (such as via business interruption insurance). There are different types of cyber insurance on the market, and with the growth of cyber threats, these insurance policies are becoming a necessity for businesses and other organizations that operate online. Cyber insurance policies are predicted to morph and grow to account for the changing landscape of cyber threats. You only have to consider what it might cost you if your ecommerce store were taken down by malware for a few days, or if you were held up by ransomware. A technology failure could also take you out for a period of time until it is able to be fixed. As it stands, the digital economy tends to be severely under-insured against these cyber threats. It is predicted that more digital businesses will take up cyber insurance as knowledge of it expands.
Final Thoughts
Without wanting to sound all doom and gloom, cybersecurity threats are still an ever-present danger to businesses in 2020. It’s important that companies look to take a preventative approach, over and above a detection-focused approach as getting ahead is your best defense. Read the full article
0 notes
Text
Data Cleaning and Preprocessing for Beginners

When our team’s project scored first in the text subtask of this year’s CALL Shared Task challenge, one of the key components of our success was careful preparation and cleaning of data. Data cleaning and preparation is the most critical first step in any AI project. As evidence shows, most data scientists spend most of their time — up to 70% — on cleaning data.
In this blog post, we’ll guide you through these initial steps of data cleaning and preprocessing in Python, starting from importing the most popular libraries to actual encoding of features.
Data cleansing or data cleaning is the process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. //Wikipedia
Step 1. Loading the data set

Importing libraries
The absolutely first thing you need to do is to import libraries for data preprocessing. There are lots of libraries available, but the most popular and important Python libraries for working on data are Numpy, Matplotlib, and Pandas. Numpy is the library used for all mathematical things. Pandas is the best tool available for importing and managing datasets. Matplotlib (Matplotlib.pyplot) is the library to make charts.
To make it easier for future use, you can import these libraries with a shortcut alias:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Loading data into pandas
Once you downloaded your data set and named it as a .csv file, you need to load it into a pandas DataFrame to explore it and perform some basic cleaning tasks removing information you don’t need that will make data processing slower.
Usually, such tasks include:
Removing the first line: it contains extraneous text instead of the column titles. This text prevents the data set from being parsed properly by the pandas library:
my_dataset = pd.read_csv(‘data/my_dataset.csv’, skiprows=1, low_memory=False)
Removing columns with text explanations that we won’t need, url columns and other unnecessary columns:
my_dataset = my_dataset.drop([‘url’],axis=1)
Removing all columns with only one value, or have more than 50% missing values to work faster (if your data set is large enough that it will still be meaningful):
my_dataset = my_dataset.dropna(thresh=half_count,axis=1)
It’s also a good practice to name the filtered data set differently to keep it separate from the raw data. This makes sure you still have the original data in case you need to go back to it.
Step 2. Exploring the data set

Understanding the data
Now you have got your data set up, but you still should spend some time exploring it and understanding what feature each column represents. Such manual review of the data set is important, to avoid mistakes in the data analysis and the modelling process.
To make the process easier, you can create a DataFrame with the names of the columns, data types, the first row’s values, and description from the data dictionary.
As you explore the features, you can pay attention to any column that:
is formatted poorly,
requires more data or a lot of pre-processing to turn into useful a feature, or
contains redundant information,since these things can hurt your analysis if handled incorrectly.
You should also pay attention to data leakage, which can cause the model to overfit. This is because the model will be also learning from features that won’t be available when we’re using it to make predictions. We need to be sure our model is trained using only the data it would have at the point of a loan application.
Deciding on a target column
With a filtered data set explored, you need to create a matrix of dependent variables and a vector of independent variables. At first you should decide on the appropriate column to use as a target column for modelling based on the question you want to answer. For example, if you want to predict the development of cancer, or the chance the credit will be approved, you need to find a column with the status of the disease or loan granting ad use it as the target column.
For example, if the target column is the last one, you can create the matrix of dependent variables by typing:
X = dataset.iloc[:, :-1].values
That first colon (:) means that we want to take all the lines in our dataset. : -1 means that we want to take all of the columns of data except the last one. The .values on the end means that we want all of the values.
To have a vector of independent variables with only the data from the last column, you can type
y = dataset.iloc[:, -1].values
Step 3. Preparing the Features for Machine Learning

Finally, it’s time to do the preparatory work to feed the features for ML algorithms. To clean the data set, you need to handle missing values and categorical features, because the mathematics underlying most machine learning models assumes that the data is numerical and contains no missing values. Moreover, the scikit-learn library returns an error if you try to train a model like linear regression and logistic regression using data that contain missing or non-numeric values.
Dealing with Missing Values
Missing data is perhaps the most common trait of unclean data. These values usually take the form of NaN or None.
here are several causes of missing values: sometimes values are missing because they do not exist, or because of improper collection of data or poor data entry. For example, if someone is under age, and the question applies to people over 18, then the question will contain a missing value. In such cases, it would be wrong to fill in a value for that question.
There are several ways to fill up missing values:
you can remove the lines with the data if you have your data set is big enough and the percentage of missing values is high (over 50%, for example);
you can fill all null variables with 0 is dealing with numerical values;
you can use the Imputer class from the scikit-learn library to fill in missing values with the data’s (mean, median, most_frequent)
you can also decide to fill up missing values with whatever value comes directly after it in the same column.
These decisions depend on the type of data, what you want to do with the data, and the cause of values missing. In reality, just because something is popular doesn’t necessarily make it the right choice. The most common strategy is to use the mean value, but depending on your data you may come up with a totally different approach.
Handling categorical data
Machine learning uses only numeric values (float or int data type). However, data sets often contain the object data type than needs to be transformed into numeric. In most cases, categorical values are discrete and can be encoded as dummy variables, assigning a number for each category. The simplest way is to use One Hot Encoder, specifying the index of the column you want to work on:
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features = [0])X = onehotencoder.fit_transform(X).toarray()
Dealing with inconsistent data entry
Inconsistency occurs, for example, when there are different unique values in a column which are meant to be the same. You can think of different approaches to capitalization, simple misprints and inconsistent formats to form an idea. One of the ways to remove data inconsistencies is by to remove whitespaces before or after entry names and by converting all cases to lower cases.
If there is a large number of inconsistent unique entries, however, it is impossible to manually check for the closest matches. You can use the Fuzzy Wuzzy package to identify which strings are most likely to be the same. It takes in two strings and returns a ratio. The closer the ratio is to 100, the more likely you will unify the strings.
Handling Dates and Times
A specific type of data inconsistency is inconsistent format of dates, such as dd/mm/yy and mm/dd/yy in the same columns. Your date values might not be in the right data type, and this will not allow you effectively perform manipulations and get insight from it. This time you can use the datetime package to fix the type of the date.
Scaling and Normalization
Scaling is important if you need to specify that a change in one quantity is not equal to another change in another. With the help of scaling you ensure that just because some features are big they won’t be used as a main predictor. For example, if you use the age and the salary of a person in prediction, some algorithms will pay attention to the salary more because it is bigger, which does not make any sense.
Normalization involves transforming or converting your dataset into a normal distribution. Some algorithms like SVM converge far faster on normalized data, so it makes sense to normalize your data to get better results.
There are many ways to perform feature scaling. In a nutshell, we put all of our features into the same scale so that none are dominated by another. For example, you can use the StandardScaler class from the sklearn.preprocessing package to fit and transform your data set:
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)As you don’t need to fit it to your test set, you can just apply transformation.sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)
Save to CSV
To be sure that you still have the raw data, it is a good practice to store the final output of each section or stage of your workflow in a separate csv file. In this way, you’ll be able to make changes in your data processing flow without having to recalculate everything.
As we did previously, you can store your DataFrame as a .csv using the pandas to_csv() function.
my_dataset.to_csv(“processed_data/cleaned_dataset.csv”,index=False)
Conclusion
These are the very basic steps required to work through a large data set, cleaning and preparing the data for any Data Science project. There are other forms of data cleaning that you might find useful. But for now we want you to understand that you need to properly arrange and tidy up your data before the formulation of any model. Better and cleaner data outperforms the best algorithms. If you use a very simple algorithm on the cleanest data, you will get very impressive results. And, what is more, it is not that difficult to perform basic preprocessing!
0 notes
Text
First Step to Become Data Scientist
#ICYDK: Do you want to become a ‘Data Scientist’? If yes, then the first step is to understand the basic terms and their usage. A – Brief History Data Science is not a new field as the statisticians were doing the job even before the computer invention. Though, the evolution of modern computing technologies empowered statisticians to solve a wide variety of practical problems with heavy number crunching and massive data storage. The terms ‘knowledge discovery’ and ‘data mining’ came widely in use in the late 1980’s after the invention of the database management system and the relational database management system. Later ‘Big data’ term published in the ACM Digital Library in 1997 after the database industry noticed the explosion of business data. In the late 1990’s, the term ‘Data Science’ inspired researchers and professionals and interchangeably replaced the word ‘statistician’. B- Basic Concept I- Big Data, Data Science & Machine Learning Any data with three V’s i.e. Volume, Variety and Velocity is considered as Big Data. Big Data can’t be handled with conventional ways of data analysis and processing. Data science deals with Big Data and brings out meaningful insights. Due to its large scale, Data Science now depends on algorithms that try numerous possibilities to provide the best solution, here comes the Machine Learning. II- Data Mining & Data Analytics Machine Learning acts as a tool to identify unknown patterns in the Big Data and the process is called Data Mining, unlike Data analytics where the process starts with a specific hypothesis. III- Big Data Analytics The approach to breaking down a task into smaller pieces and assigned to different processors which could be geographically dispersed is called ‘Distributed Computing’. Big data analytics leverages distributed computing technologies to overcome computational challenges. C- Technologies that Enable Data Science Into Reality – Data Infrastructure: It supports data sharing, processing, and consumption. Distributed computing and cloud computing is most popular these days. – Data Management: DBMS plays an important role to store structured and unstructured data sets. Since a majority of business-related data is structured, SQL knowledge is still invaluable. – Visualization: It is very important to communicate newly acquired insights to the leadership and rest of the organization so data visualization technologies play an equally important role. D- Data Science Applications Data Science can be applied where ever ‘Big Data’ is involved. Following are only a few examples: * Fraud detection * Social Media Analytics * Online matchmaking or dating services * Weather forecast * Simulation * Network Security…etc. E- Must Have Skills for Data Scientist I- Statistics Developing a reasonable understanding of statistics is a must for a data scientist as it lays the foundation of data science. At a minimum, a data scientist needs to be proficient with concepts such as probability, correlation, variables, distributions, regression, null hypothesis significance tests, confidence intervals, t-test, ANOVA, and chi-square. At an advanced stage, Data Scientist needs concepts and algorithms such as logistic regression, support vector machines (SVMs) and Bayesian method. Common statistical analysis tools such as Excel, R and SAS are very famous among Data Scientist. II- Data mining * Classification – Labelling a group of data objects into a specific category. * Prediction – Building a model that produces continuous or ordered values that form a trend. * Clustering – Grouping similar data objects into a class…etc. * Natural Language Processing – NLP refers to different ways for a computer to interact with humans through a natural language. Computer science, Artificial Intelligence (AI), Computer linguistics and Human-computer interaction (HCI) are different areas of NLP. Some of the NLP aspects which are specifically related to Data Science are Tokenization, parsing, sentence, segmentation and named entity recognition. Python programming language is very famous and a recommended tool for having well-developed NLP tools. * Tokenization and Parsing: Isolate each symbol from a text and conduct a grammatical analysis * Sentence segmentation: Separates one sentence from the other in a text. * Named entity recognition: Identifies which text symbol maps to what types of proper names * Machine Learning (Supervised & Unsupervised) * Visualization – Softwares are already available in the market that offers comprehensive visualization tools for data scientist such as Tableau. But it is important to remember that Data Scientist always acts as a middleman between data pile up and decision makers. F- Roles and Responsibilities Data Scientist or Engineer A data scientist can work in any organization who is having data and willing to analyze its performance and future prediction. The role is more of a generalist instead of a specialist. A data scientist works with other data science specialist such as machine learning specialist. Machine Learning Specialist It’s a highly creative and independent role where you need the discipline to follow through and meet deadlines. Paying attention to details and quality is critical. Math and IT skills are essential as they form the foundations of the machine learning scientist. Deep knowledge of statistics and probability, ability to develop and validate a mathematical model, translating a model into an algorithm, proficiency in the programming language (Python, C++, Java, R…etc.), understanding of distributed computing are essential skills for a Machine Learning Specialist. G- Related Certifications * MCSE Business Intelligence Certification * Cloudera Certified Professional or CCP data scientist * Cloudera Certified Developer for Apache Hadoop or CCDH * Cloudera Certified Administrator for Apache Hadoop or CCAH * Cloudera Certified Specialist in Apache HBase or CCSHB * EMC Data Science Associate (EMCDSA) * EMC Data Center Architect or EMCDCA * EMC Cloud Architect or EMCCA * Oracle BI Implementation Specialist …etc. H- Final Words * Data Scientist must keep refreshing their knowledge to stay up to date. Attending conferences, workshops, peer networking and continuing education are ways to stay updated. * Cloud vendors like Amazon, IBM, and Google …etc. makes it cheaper for companies to use cloud computing facilities instead of private in housed resources, which in turn increases the demand for Data Scientists. Even Data Scientist no longer worries about data infrastructure and management problems due to emerging online services. * The importance of Machine Learning is growing especially deep learning taking advantage of neural networking is getting more traction. For reference and details visit: First Step To Become a Data Scientist About me: I am a professional engineer, enthusiast programmer, passionate data scientist and machine learning student. You can contact me through [email protected] or visit https://engmrk.com https://goo.gl/DZEihE #DataScience #Cloud
0 notes
Text
The use of AI for retail players can be a decisive factor in their business recovery
30-second summary:
Marketing is likely to be one of the first collateral economic victims of this crisis with an obligation to significantly adjust all spending (media, agencies, platforms, etc…) and a priority focused on commercial efficiency.
Predictive marketing is revolutionary in that it statistically predicts the best suspect customers for a campaign. Marketers will then be able to focus only on “ROI operations”, with ROI being simply the difference between the fixed and variable costs of a campaign and the incremental revenue generated by that campaign.
From inventory management to customer experience, AI automates tasks that are almost impossible for people to perform on a large scale and enables them to be more efficient in their core business, where they can add the most value.
Simplifying the execution of an omnichannel campaign (data transfer, variation testing, automatic management of options, automated product recommendations, setting up control groups, performance measurement…), thanks to the assistance of the AI, facilitates the daily work of the teams.
By relying on AI, retailers can generate ROI as soon as they are integrated and on a long-term basis. A real springboard to ensure the most efficient recovery possible.
Despite an increase in ecommerce activity since the quarantine measure was introduced, retailers, placed in a state of economic emergency, are facing sharp drops in sales. In a global context of cost control, marketing today is under pressure to quickly generate traffic and in-store sales, while reducing costs. The contribution of Artificial Intelligence (AI) in these processes is now a crucial lever to maintain commercial efficiency while considerably increasing productivity.
Leveraging predictive models to identify the best suspects
As a result of the crisis, store closures, and the difficulty in securing workstations in supply chains have led to a drop in sales in stores and ecommerce.
With no sales or cash flow, brands have no choice but to act on two priority performance levers. Retailers must first reduce their operating costs in the short and medium term and tightly control their working capital requirements.
As a result, marketing is likely to be one of the first collateral economic victims of this crisis with an obligation to significantly adjust all spending (media, agencies, platforms, etc…) and a priority focused on commercial efficiency.
To do this, the brands will have to arbitrate and choose to allocate their resources where they will have a rapid and sustainable return on investment.
The so-called Pareto’s Law suggests that 20% of the causes are responsible for 80% of the effects. This theory is obviously a misleading simplification, and may even lead to strategic errors such as focusing loyalty only on very good customers.
However, this theory reminds us that for a marketing campaign all suspects, i.e. all the recipients of an operation, do not have the same potential. Obviously, depending on the objective of the operation (promotions, clearance, novelties, etc…), the right suspects are not always the same.
The challenge for marketing teams will, therefore, be to identify suspects that can potentially generate a higher ROI according to a precise objective, in order to significantly reduce mailing costs while maintaining a high level of performance.
This is where predictive marketing comes into play. Exploiting customer data (offline and online), predictive models now make it possible to quickly detect the best suspects according to a marketing objective.
Predictive marketing is revolutionary in that it statistically predicts the best suspect customers for a campaign. Marketers will then be able to focus only on “ROI operations”, with ROI being simply the difference between the fixed and variable costs of a campaign and the incremental revenue generated by that campaign.
On the one hand, we drastically reduce volumes and therefore expenses, on the other hand, we maintain performance, a real contribution to the service of marketers.
Integrating new AI assisted practices to boost productivity
In sales forecasting, logistics, and even after-sales service, AI is a vector of performance and productivity throughout the value chain and now represents an undeniable competitive advantage for any company.
From inventory management to customer experience, AI automates tasks that are almost impossible for people to perform on a large scale and enables them to be more efficient in their core business, where they can add the most value.
Marketing is no exception to this productivity issue. As it stands, the majority of teams are structurally limited and are unable to contemplate a scale-up of operations.
Processes rely solely on people, teams are fragmented, resources are scarce, technical expertise and data science are not or barely present at the service of the business, and the multidisciplinary skills and agility required are not yet found in the organization.
For example, one of the key elements of marketing performance is being able to communicate to the right people and where they are most likely to receive feedback from suspects.
In other words, setting up an omnichannel plan (email, SMS, Facebook, Google, Display…) is a key element of success. But deploying an omnichannel plan requires too much time and coordination in the current state, and industrialization, although crucial, is not foreseeable.
Today, AI is beginning to provide answers to these productivity challenges.
Simplifying the execution of an omnichannel campaign (data transfer, variation testing, automatic management of options, automated product recommendations, setting up control groups, performance measurement…), thanks to the assistance of the AI, facilitates the daily work of the teams.
They are then gradually freed from operational constraints and can concentrate on high value-added subjects.
The world is changing, the consumer is changing, and marketing must evolve with these changes. Yesterday’s marketer is no longer today’s marketer, and he or she must now integrate the technological (r)evolutions that enable him or her to respond to current and future societal changes.
The current crisis context is pushing companies to reinvent themselves and to integrate technologies in which they did not have the nerve to go through with.
By relying on AI, retailers can generate ROI as soon as they are integrated and on a long-term basis. A real springboard to ensure the most efficient recovery possible.
Olivier Marc is the founder and president of Advalo. Prior to this, Olivier was the co-founder and CTO of Conexance, leader in shared databases, acquired by the WPP group. Before embarking on entrepreneurship, he notably spent 7 years at Google to arouse his digital and technological curiosity. Olivier holds a master’s degree in computer science and a master’s degree in finance.
The post The use of AI for retail players can be a decisive factor in their business recovery appeared first on ClickZ.
source http://wikimakemoney.com/2020/06/24/the-use-of-ai-for-retail-players-can-be-a-decisive-factor-in-their-business-recovery/
0 notes
Text
5 Amazing Machine Learing Course For Beginners

Machine Learning is an impressive field to supervise, it is flooding with fun and if you are one who is proposing to learn ML, by then you are at the right spot, here today I'll show presumably the best machine learning course that won't simply put aside your money yet it will in like manner offer you quality bearing.
Moreover, the delight part is that you don't have to leave your room, basically plunk down on your chain, pull the work area closer, take a scratch pad and pen in end get the most basic thing, some coffee and go unbending it.
This all machine learning courses in Delhi are impeccably organized and withdrawn into an instructive program that will take you from an inside and out understudy to an authority in Machine Learning, who perceives how to make affirmed exercises.
From the recorded machine learning course, you will become acquainted with the stray pieces and basics of Machine Learning, how it works inside, how to set up a model and likewise how to comprehend the data that you will get.
This all machine learning courses are eminently engineered and apportioned into an educational program that will take you from a by a long shot understudy to a master in Machine Learning, who perceives how to create genuine undertakings.
From the recorded machine learning course, you will get settled with the drifter pieces and stray pieces of Machine Learning, how it works inside, how to set up a model and furthermore how to execute the data that you will get.
For a general idea, these machine learning courses will set you up about various different contemplations like parameter learning, chose fall away from the confidence model, neural frameworks, utilization of neural structures, cost limit, and backpropagation and extensively more.
Some different option from what's normal is that all the machine learning course that we are going to see here are on a very basic level singled out the chance of substance, language straightforwardness, and open reviews.
The standard fundamentals that are required for this all machine learning courses are the little understanding and data on programming lingos like R and Python and little rudiments about number rearranging.
That been imparted, let us start our outing. Try to check the prize.
1. Programming Language
In case you have starting at now virtuoso or learning a programming language that overwhelmingly going to contribute in making Machine Learning based stuff, by then you can really move to the going with point, yet in case you are new here, by then screen things I have a lurch for you.
A reasonable mind is for each condition outstanding as it is freed from dissipate, in case you haven't taken in any language yet, by then at this right moment starting with Python or with R or with JavaScript, I'll propose you Python.
I by and large propose adolescents go with Python for Machine Learning, the prime clarification for this is Python is lively, speedy and clear and learn.
Medium has an exceptional article on Why Python is the most prominent language used for Machine Learning, I'm so wild for Python that I can take a gander at it for the length of the day, regardless, to keep the article short you can head over this article and can clear asks for and requests, you can similarly ask them in underneath comment box.
In like way, in case I talk about R, by then R is helpful for off the cuff appraisal and inquisitive about data sets, R has a perilous learning turn, regardless, people without programming experience, feel that it's wavering.
R in like manner don't have loads of libraries that Python really offers, also the course of action of Python is humongous, so you can without a lot of a stretch find someone who can help you in your goofs.
In the long run the startling that I talk as of now.
In case you are thinking to learn R or Python, by then underneath are the relationship from where you can download the most striking and solid books for Python and R unfathomably.
This book will help you with working inside foundation on which you can learn influenced contemplations at a powerfully noteworthy speed.
Mechanize the Boring Stuff with Python
Programming with R
2. Master in Machine Learning Course From Madrid Software Trainings
The clearness in contemplations is a level out need when you are learning something, especially when it is Machine Learning. Madrid Software Trainings Intro to Machine Learning is the best machine learning Institute in Delhi that will educate and will give you what machine learning truly is.
Another clarification that I propose this machine learning course is that I many time saw that the understudies have their some pre-suppositions, disarray, and demands on machine learning, Madrid Software Trainings this course will give you an unrivaled valuation for ML.
This course is around 10-weeks long and it will show you the all the way the strategy of investigating data through a machine learning reason for intermixing.
It will uncover to you the best way to deal with oust and see consistent features that best area your data, the most colossal machine learning figurings, and how to evaluate the exhibit of your machine learning counts.
I in like manner grasp you to take the basic Intro to Data Science course which manages Data Manipulation, Data Analysis, Data Communication with Information Visualization, and Data at Scale, this will request that you understand machine learning considerations substantially more with no issue.
Prelude to Machine Learning will be told by Industry Experts, the educators anticipate that the apprentices should know head quantifiable thoughts and Python.
3. Stanford Machine Learning Course
This machine learning course is an unprecedented course, as it is told by Andrew Y. Ng (my supernatural article), Andrew is an acclaimed name in the field of machine learning. He is a prime supporter of Coursera, Baidu's Chief Scientist and a past head of Google Brain.
Starting at now course, you will locate a couple of arrangements concerning the best machine learning systems.
You will locate a couple of arrangements concerning some of Silicon Valley's endorsed structures being made by ML and AI. This course gives a wide preamble to machine learning, data mining, and authentic model affirmation.
Subjects that these machine learning course will cover include:
(I) Supervised learning, parametric and non-parametric counts, support vector machines, neural structures.
(ii) Unsupervised learning gathering, dimensionality rot, recommender structures, immense learning.
(iii) Best practices in machine learning — inclination/change speculation, the improvement strategy in machine learning and AI.
This machine learning course besides offers various steady assessments and applications with the objective that you'll see how to use ML counts to building keen robots (understanding, control), content appreciation (web search, finding a way to spam), PC vision, clinical informatics, sound, database mining, and various zones.
In the wake of doing this course, you will get limits like Logistic Regression, Artificial Neural Network, and Machine Learning. Read More
0 notes
Text
Spanner Controls Huge Generative AI and Similarity Search

Spanner Features
With a 99.999% availability SLA, Spanner, a fully managed, highly available distributed database service from Google Cloud, offers relational semantics and almost infinite horizontal scalability for both relational and non-relational workloads. Customers want scaling as data volumes increase and applications place more demands on their operational databases. Recently, Google introduced support for exact closest neighbor (KNN) search in preview for vector embeddings, enabling enterprises to develop generative AI at almost infinite scale. Because Spanner has all of these features, you can do vector search on your transactional data without transferring it to a different database, keeping things operationally simple.
Google explains in this blog post how vector search may improve general artificial intelligence applications and how the underlying architecture of Spanner allows for very large-scale vector search deployments. They also go over the many operational advantages of using Spanner as opposed to a specialized vector database.
Vector embeddings and generative AI
Numerous new applications are being made possible by generative AI, such as individualized conversational virtual assistants and the ability to create original material just by texting suggestions. The foundation of generative AI is pre-trained large language models (LLMs), which make it possible for developers with less experience in machine learning to create gen AI apps with ease. However, as LLMs may sometimes have hallucinations and provide false information, integrating LLMs with operational databases and vector search can aid in the development of Gen AI applications that are based on real-time, contextual, and domain-specific data, resulting in high-quality AI-assisted user experiences.
Suppose a financial institution employs a virtual assistant to assist clients with account-related inquiries, handle accounts, and suggest financial solutions that best suit each client’s particular requirements. The customer’s decision-making process may take place across many chat sessions with the virtual assistant in complicated settings. The virtual assistant may locate the most pertinent material by using vector search across the discussion history, resulting in a high-caliber, highly relevant, and educational chat experience. Utilizing vector embeddings—numerical representations of text, image, or video produced by embedding models—vector search assists the gen AI application in determining the most pertinent information to include in LLM prompts, allowing for the customization and enhancement of the LLM’s responses. The distance between vector embeddings may be used to do vector search. The content of the embeddings is increasingly similar the closer they are in the vector space.
With Spanner, you may virtually expand the scale of vector search
Vector workloads, such as the financial virtual assistant example mentioned above, may readily grow to extremely high sizes when they are required to service a large number of customers. Both a vast number of vectors (more than 10 billion, for example) and queries per second (more than millions of QPS) may be found in large-scale vector search workloads. It should come as no surprise that many database systems may find this difficult.
However, a large number of these searches are highly partitionable, meaning that each search is limited to the data that is connected to a certain person. Because Spanner effectively shrinks the search area to provide precise, timely results with little latency, these workloads are well suited for Spanner KNN search. Spanner supports vector search on trillions of vectors for highly partitionable workloads thanks to its horizontally scalable design.
To keep the application simple, Spanner also allows you to query and filter vector embeddings using SQL. It is simple to combine regular searches with vector search and to integrate vector embeddings with operational data using SQL. For instance, before doing a vector search, you may effectively filter rows of interest using secondary indexes. Like any other query on your operational data, Spanner’s vector search queries deliver new, real-time data as soon as transactions are committed.
Spanner offers resource efficiency and operational simplicity
Additionally, Google Spanner in-database vector search features streamline your operational process by removing the expense and complexity of maintaining a separate vector database. Vector embeddings can take advantage of all of Spanner features, such as high 99.999% availability, managed backups, point-in-time recovery (PITR), security and access control features, and change streams, because they are stored and managed in the same manner as operational data in Spanner. Better resource usage and cost reductions are made possible by the sharing of compute resources between operational and vector queries. Furthermore, Spanner’s PostgreSQL interface supports these features as well, providing customers transitioning from PostgreSQL with a recognizable and portable interface.
Additionally, Spanner integrates with well-known AI development tools like Document Loader, Memory, and LangChain Vector Store, making it simple for developers to create AI applications using the tools of their choice.
Beginning
Vector search skills have gained renewed attention with the emergence of Gen AI. Spanner is well suited to handle your large-scale vector search requirements on the same platform that you currently depend on for your demanding, distributed workloads, thanks to its nearly infinite scalability and support for KNN vector search.
Read more on govindhtech.com
#spannercontrols#spanner#generativeai#spannerfeatures#artificialintelligence#technews#technology#govindhtech
0 notes