#cloud data warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
A diverse landscape unfolds in the realm of major Cloud Data Warehouse vendors—Amazon Redshift, Google BigQuery, Microsoft Synapse, Snowflake, and Databricks. Amazon Redshift offers robust scalability; Google BigQuery excels in real-time analytics; Microsoft Synapse integrates seamlessly with the Microsoft ecosystem; Snowflake boasts elasticity and ease of use, while Databricks specializes in data science and machine learning integration.
0 notes
Text
6 Justifications for A Data Warehouse in The Cloud
Some organizations find data warehouses difficult to manage and have problems with issues such as file types, storage and visibility. Here are six reasons why moving to a cloud-based data warehouse can solve these problems and deliver a range of benefits. Modern data warehouses allow you to collect information from different sources, analyze it and act on it. The ability to quickly process the…

View On WordPress
0 notes
Text
Why Data Warehouse Assessment is Necessary for Successful Cloud Migration Migrating to the cloud often brings challenges, starting with how to begin and what objects to migrate. Many organizations face difficulties when identifying the necessary data objects, especially with large and complex databases. Datametica’s innovative solution, Eagle, The Planner, addresses these common issues by intelligently scanning logs to establish relationships between database objects, identify access patterns, and build migration plans.
Eagle visualizes the complexity of ETL/ELT processes, pinpointing problem areas and optimizing migration efforts. It also groups objects into manageable migration clusters for iterative migration, reducing time and cost by nearly 50%. This approach enables organizations to plan more effectively and ensures smoother migrations with minimal disruption. Supported technologies include Teradata, Netezza, Oracle, and more, with continuous updates.
0 notes
Text
BigQuery: Definition, Meaning, Uses, Examples, History, and More
Explore a comprehensive dictionary-style guide to BigQuery—its definition, pronunciation, synonyms, history, examples, grammar, FAQs, and real-world applications in cloud computing and data analytics. BigQuery Pronunciation: /ˈbɪɡˌkwɪəri/Syllables: Big·Que·ryPart of Speech: NounPlural: BigQueriesCapitalization: Always capitalized (Proper noun)Field of Usage: Computing, Data Science, Cloud…
#BigQuery#BigQuery antonyms#BigQuery article#BigQuery data warehouse#BigQuery definition#BigQuery etymology#BigQuery examples#BigQuery FAQ#BigQuery for beginners#BigQuery Google Cloud#BigQuery grammar#BigQuery in sentences#BigQuery kids definition#BigQuery machine learning#BigQuery meaning#BigQuery medical definition#BigQuery pricing#BigQuery pronunciation#BigQuery rhymes#BigQuery SQL#BigQuery synonyms#BigQuery usage#BigQuery use cases#Google BigQuery#history of BigQuery#what is BigQuery
0 notes
Text
Looking for data content? Check out Hoyt Emerson's page.
0 notes
Text
0 notes
Text
UltiHash’s Sustainable Data Infrastructure Tackles AI Storage Challenges
New Post has been published on https://thedigitalinsider.com/ultihashs-sustainable-data-infrastructure-tackles-ai-storage-challenges/
UltiHash’s Sustainable Data Infrastructure Tackles AI Storage Challenges
UltiHash, a provider of high-performance and eco-friendly data storage solutions, has launched its object storage platform to address critical issues in AI data storage. This development aims to resolve mounting challenges in the AI industry related to infrastructure costs and environmental sustainability. The new platform enhances performance for data-heavy applications, including generative AI and advanced analytics, offering scalable and sustainable solutions for data management.
As the AI industry grows, projected to reach $407 billion by 2027 according to Forbes, the demand for data storage has surged. AI model training, which relies on massive datasets, often strains current storage infrastructure due to inefficiency, leading to high costs and a significant environmental footprint. UltiHash’s new platform is designed to solve these issues, providing high-performance storage while reducing both operational expenses and environmental impact.
Key Features of UltiHash’s Platform
UltiHash’s platform introduces several key innovations, including:
Advanced Deduplication: Reducing data volumes by up to 60% by eliminating redundant data at the byte level, minimizing storage needs and bandwidth usage.
Scalability: Built for organizations with rapidly growing data needs, the platform scales easily to petabytes and beyond, supporting continuous data expansion.
Enhanced Performance: With 250% faster read speeds compared to AWS S3, the platform improves data throughput for both read and write operations, essential for high-performance applications.
Interoperability: Fully compatible with S3 APIs and designed for seamless integration with both cloud and on-premises infrastructures, including Kubernetes-native environments.
Data Resiliency: Built-in erasure coding ensures data is protected even during hardware failures, safeguarding against system disruptions.
These features position UltiHash as a critical player in the AI data storage landscape, especially for organizations adopting data lakehouse architectures. By combining the scalability of data lakes with the query efficiency of data warehouses, the platform supports diverse data formats while optimizing performance and resource usage.
Building on Recent Success: $2.5M Pre-Seed Funding
UltiHash’s latest announcement follows its successful $2.5 million pre-seed funding round in December 2023, led by Inventure, alongside investors like PreSeedVentures, Tiny VC, and Sequoia Capital-affiliated angel investors. The funding supports UltiHash’s efforts to enhance its platform and accelerate market entry.
The company’s entry into the market comes as data growth reaches unprecedented levels. IDC projects that global digital data will hit 175 zettabytes by 2025, each zettabyte contributing the carbon footprint of approximately two million people annually. This rapid increase in data generation presents both operational and environmental challenges, with existing storage solutions often requiring significant cost outlays and energy consumption. UltiHash’s platform aims to break this cycle by reducing the overall storage demand while maintaining high performance.
A Future of Sustainable, High-Performance Storage
By reducing the data stored through advanced deduplication, UltiHash enables companies to scale their data operations sustainably. This technology addresses the core issue of balancing scalability with affordability, which has traditionally constrained data-driven industries, including AI, telecom, manufacturing, and automotive.
“The AI revolution is generating data at an unprecedented rate, and traditional storage solutions are struggling to keep pace,” says Tom Lüdersdorf, Co-Founder and CEO of UltiHash. “The future of storage will make it possible to avoid ballooning data costs without compromising on speed.”
As data continues to fuel innovation in AI and other industries, UltiHash‘s platform is poised to play a crucial role in enabling sustainable data growth. Its focus on reducing both the environmental toll and the financial burden of large-scale data storage could reshape how organizations approach data infrastructure.
#2023#250#ai#ai model#Analytics#APIs#applications#approach#Artificial Intelligence#automotive#AWS#billion#Building#Byte#carbon#carbon footprint#CEO#Cloud#coding#Companies#continuous#Critical Issues#data#data lakehouse#data lakes#Data Management#data storage#data storage solutions#data warehouses#data-driven
0 notes
Text
Find out which cloud data warehouse is superior—Azure Synapse Analytics or AWS Redshift. Compare features, cost efficiency, and data integration capabilities.
0 notes
Text
Data Lake vs Data Warehouse: 10 Key difference

Today, we are living in a time where we need to manage a vast amount of data. In today's data management world, the growing concepts of data warehouse and data lake have often been a major part of the discussions. We are mainly looking forward to finding the merits and demerits to find out the details. Undeniably, both serve as the repository for storing data, but there are fundamental differences in capabilities, purposes and architecture.
Hence, in this blog, we will completely pay attention to data lake vs data warehouse to help you understand and choose effectively.
We will mainly discuss the 10 major differences between data lakes and data warehouses to make the best choice.
Data variety: In terms of data variety, data lake can easily accommodate the diverse data types, which include semi-structured, structured, and unstructured data in the native format without any predefined schema. It can include data like videos, documents, media streams, data and a lot more. On the contrary, a data warehouse can store structured data which has been properly modelled and organized for specific use cases. Structured data can be referred to as the data that confirms the predefined schema and makes it suitable for traditional relational databases. The ability to accommodate diversified data types makes data lakes much more accessible and easier.
Processing approach: When it is about the data processing, data lakes follow a schema-on-read approach. Hence, it can ingest raw data on its lake without the need for structuring or modelling. It allows users to apply specific structures to the data while analyzing and, therefore, offers better agility and flexibility. However, for data warehouse, in terms of processing approach, data modelling is performed prior to ingestion, followed by a schema-on-write approach. Hence, it requires data to be formatted and structured as per the predefined schemes before being loaded into the warehouse.
Storage cost: When it comes to data cost, Data Lakes offers a cost-effective storage solution as it generally leverages open-source technology. The distributed nature and the use of unexpected storage infrastructure can reduce the overall storage cost even when organizations are required to deal with large data volumes. Compared to it, data warehouses include higher storage costs because of their proprietary technologies and structured nature. The rigid indexing and schema mechanism employed in the warehouse results in increased storage requirements along with other expenses.
Agility: Data lakes provide improved agility and flexibility because they do not have a rigid data warehouse structure. Data scientists and developers can seamlessly configure and configure queries, applications and models, which enables rapid experimentation. On the contrary, Data warehouses are known for their rigid structure, which is why adaptation and modification are time-consuming. Any changes in the data model or schema would require significant coordination, time and effort in different business processes.
Security: When it is about data lakes, security is continuously evolving as big data technologies are developing. However, you can remain assured that the enhanced data lake security can mitigate the risk of unauthorized access. Some enhanced security technology includes access control, compliance frameworks and encryption. On the other hand, the technologies used in data warehouses have been used for decades, which means that they have mature security features along with robust access control. However, the continuously evolving security protocols in data lakes make it even more robust in terms of security.
User accessibility: Data Lakes can cater to advanced analytical professionals and data scientists because of the unstructured and raw nature of data. While data lakes provide greater exploration capabilities and flexibility, it has specialized tools and skills for effective utilization. However, when it is about Data warehouses, these have been primarily targeted for analytic users and Business Intelligence with different levels of adoption throughout the organization.
Maturity: Data Lakes can be said to be a relatively new data warehouse that is continuously undergoing refinement and evolution. As organizations have started embracing big data technologies and exploring use cases, it can be expected that the maturity level has increased over time. In the coming years, it will be a prominent technology among organizations. However, even when data warehouses can be represented as a mature technology, the technology faces major issues with raw data processing.
Use cases: The data lake can be a good choice for processing different sorts of data from different sources, as well as for machine learning and analysis. It can help organizations analyze, store and ingest a huge volume of raw data from different sources. It also facilitates predictive models, real-time analytics and data discovery. Data warehouses, on the other hand, can be considered ideal for organizations with structured data analytics, predefined queries and reporting. It's a great choice for companies as it provides a centralized representative for historical data.
Integration: When it comes to data lake, it requires robust interoperability capability for processing, analyzing and ingesting data from different sources. Data pipelines and integration frameworks are commonly used for streamlining data, transformation, consumption and ingestion in the data lake environment. Data warehouse can be seamlessly integrated with the traditional reporting platforms, business intelligence, tools and data integration framework. These are being designed to support external applications and systems which enable data collaborations and sharing across the organization.
Complementarity: Data lakes complement data warehouse by properly and seamlessly accommodating different Data sources in their raw formats. It includes unstructured, semi-structured and structured data. It provides a cost-effective and scalable solution to analyze and store a huge volume of data with advanced capabilities like real-time analytics, predictive modelling and machine learning. The Data warehouse, on the other hand, is generally a complement transactional system as it provides a centralized representative for reporting and structured data analytics.
So, these are the basic differences between data warehouses and data lakes. Even when data warehouses and data lakes share a common goal, there are certain differences in terms of processing approach, security, agility, cost, architecture, integration, and so on. Organizations need to recognize the strengths and limitations before choosing the right repository to store their data assets. Organizations who are looking for a versatile centralized data repository which can be managed effectively without being heavy on your pocket, they can choose Data Lakes. The versatile nature of this technology makes it a great decision for organizations. If you need expertise and guidance on data management, experts in Hexaview Technologies will help you understand which one will suit your needs.
0 notes
Text

Data Warehouse Services in Basking Ridge NJ
#quellsoft#Data Warehouse Services in Basking Ridge NJ#Data Warehouse Services#Cloud Applications in Basking Ridge NJ#Data Integration in Basking Ridge NJ#Cloud Computing in Basking Ridge NJ#Cloud Data Warehousing in Basking Ridge NJ
0 notes
Text
Cloud vs On-Prem Data Warehouse: Making the Right Choice for Your Business
In today's data-driven world, businesses face a critical decision when it comes to choosing the right data warehouse solution. The debate between cloud and on-premise data warehouses has been ongoing, with each option offering distinct advantages and challenges. This article will delve into the practical differences between cloud and on-premise data warehouses, offering real-world examples and data-driven insights to help you make an informed decision.

What is a Cloud Data Warehouse?
A cloud data warehouse is a scalable and flexible data storage solution hosted on cloud platforms like AWS, Google Cloud, or Microsoft Azure. Unlike traditional on-premise data warehouses, cloud data warehouses eliminate the need for physical infrastructure, offering businesses the ability to store and manage data with ease and efficiency.
On-Premise Data Warehouse: A Legacy Approach
An on-premise data warehouse is a traditional data storage solution where the data is hosted on local servers within a company's own data center. This model offers complete control over the data and the infrastructure but comes with significant upfront costs and ongoing maintenance requirements.
Key Differences Between Cloud and On-Premise Data Warehouses
1. Cost Efficiency
Cloud Data Warehouse:
Pros: The pay-as-you-go model allows businesses to scale resources up or down based on demand, reducing unnecessary costs. There is no need for significant capital investment in hardware or software.
Cons: Long-term costs can add up if not managed properly, especially with increasing data volumes and computational needs.
On-Premise Data Warehouse:
Pros: Once the initial investment is made, ongoing costs can be more predictable. No recurring subscription fees.
Cons: High upfront costs for hardware, software, and skilled IT personnel. Ongoing maintenance, power, and cooling expenses add to the total cost of ownership (TCO).
2. Scalability
Cloud Data Warehouse:
Pros: Cloud solutions offer almost infinite scalability. Businesses can adjust their storage and processing power according to their needs without physical limitations.
Cons: Rapid scaling can lead to unexpectedly high costs if usage is not carefully monitored.
On-Premise Data Warehouse:
Pros: Customizable to specific business needs. Scaling is possible but requires additional hardware and can be time-consuming.
Cons: Scaling is limited by the physical infrastructure, often requiring significant time and financial investment.
3. Performance
Cloud Data Warehouse:
Pros: Advanced cloud architectures are optimized for performance, offering faster query processing and better data handling capabilities.
Cons: Performance can be affected by network latency and bandwidth limitations.
On-Premise Data Warehouse:
Pros: Performance is highly controlled, with low latency since data is processed on-site.
Cons: Performance improvements require hardware upgrades, which can be costly and time-consuming.
4. Security and Compliance
Cloud Data Warehouse:
Pros: Leading cloud providers offer robust security features, including encryption, access controls, and compliance with industry standards like GDPR, HIPAA, and SOC 2.
Cons: Data security in the cloud is a shared responsibility. Organizations must ensure that they implement proper security measures on their end.
On-Premise Data Warehouse:
Pros: Complete control over security policies and compliance with regulatory requirements. Data remains within the company's own environment.
Cons: Higher responsibility for maintaining security, requiring dedicated IT staff and resources.
Live Examples: Cloud vs On-Premise in Action
Cloud Data Warehouse: Netflix
Netflix is a prime example of a company leveraging cloud data warehouses to manage its massive data volumes. By using AWS Redshift, Netflix can analyze petabytes of data in real-time, optimizing its recommendation algorithms and improving user experience. The scalability and performance of cloud data warehouses allow Netflix to handle peak loads, such as during new content releases, without compromising speed or reliability.
On-Premise Data Warehouse: Bank of America
Bank of America relies on an on-premise data warehouse to maintain full control over its sensitive financial data. By keeping data in-house, the bank ensures that all security and compliance requirements are met without relying on external cloud providers. While the costs and complexity of managing an on-premise solution are higher, the bank prioritizes control and security over the flexibility offered by cloud solutions.
Data-Driven Insights: Market Trends and Future Outlook
Market Growth: According to a report by MarketsandMarkets, the global cloud data warehouse market is expected to grow from $4.7 billion in 2021 to $12.9 billion by 2026, at a CAGR of 23.8%. This growth is driven by the increasing adoption of cloud technologies, the need for real-time analytics, and the flexibility offered by cloud solutions.
Hybrid Approaches: Many organizations are adopting hybrid models, combining both cloud and on-premise data warehouses to balance the benefits of both. For instance, sensitive data may be stored on-premise, while less critical data is managed in the cloud.
AI and Machine Learning Integration: Cloud data warehouses are increasingly integrating AI and machine learning tools to enhance data processing capabilities. This trend is expected to accelerate, with cloud providers offering more advanced analytics and automation features.
Making the Right Choice: Key Considerations
Business Needs: Assess your organization’s specific needs, including data volume, security requirements, budget, and long-term goals.
Total Cost of Ownership (TCO): Consider both the short-term and long-term costs associated with each solution, including maintenance, upgrades, and scalability.
Security and Compliance: Ensure that your chosen solution meets all regulatory requirements and provides the necessary security features to protect your data.
Scalability and Performance: Evaluate the scalability and performance needs of your organization, and choose a solution that can grow with your business.
Conclusion
Choosing between a cloud and an on-premise data warehouse is a decision that requires careful consideration of various factors, including cost, scalability, performance, and security. While cloud data warehouses offer flexibility, scalability, and advanced analytics, on-premise solutions provide greater control and security. By understanding your organization’s unique needs and long-term goals, you can make an informed decision that will support your data management strategy for years to come.
#Cloud Data Warehouse#On Premise Data Warehouse#Data Storage#Data Management#Cloud Computing#Enterprise Data#Hybrid Cloud#Data Analytics#Data Security#Digital Transformation#Data Infrastructure#Business Intelligence
0 notes
Text
Unleash the power of the cloud. Our cloud consulting strategy helps you design a secure, scalable, and cost-effective cloud roadmap aligned with your business goals.
#cloud transformation service#cloud transformation consulting#cloud transformation strategy#cloud services#cloud transformation#cloud based services#cloud solutions#cloud company#cloud consulting companies#cloud consulting#Cloud Data Warehouse Services Provider#GCP data Engieer#AWS data engineer
0 notes
Text
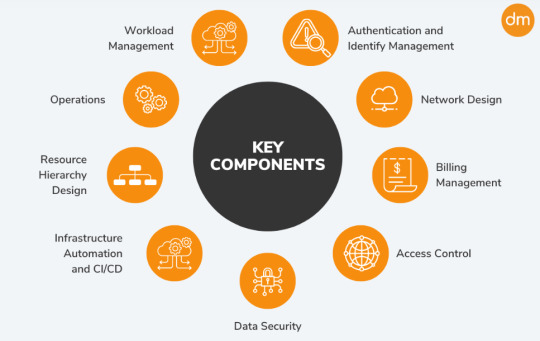
Setting up the Right Foundation for a Successful Cloud Journey
Embarking on a cloud journey requires a robust foundation to ensure success. At DataMetica, we specialize in laying this groundwork through comprehensive assessment and meticulous planning. Our approach starts with evaluating your current infrastructure and understanding your specific needs. This helps data warehouse migration tailor a strategic cloud migration plan that aligns with your business goals. We then implement the migration with minimal disruption, leveraging best practices to optimize performance and cost-efficiency. Post-migration, our focus shifts to continuous optimization and management to ensure that your cloud environment remains agile, secure, and cost-effective. By partnering with DataMetica, you gain a strategic ally dedicated to setting up a strong cloud foundation, driving innovation, and achieving long-term success in the cloud.
Contact us to start your Cloud optimisation services with confidence!
#cloud optimisation services#data warehouse migration#google cloud migration#Cloud Data migration tools
0 notes
Text

Explore the advantages of Airbyte in fintech! Learn how this platform automates data integration, provides real-time insights, scales seamlessly, and is cost-effective for startups. Discover how Airbyte simplifies data workflows for timely decision-making in the fintech industry.
Know more at: https://bit.ly/3UbqGyT
#data#data warehouse#data integration#technology#fintech#data analytics#data engineering#airbyte#ETL#ELt#Cloud data Management#Cloud Data
0 notes
Text
Data warehousing has become a trending avenue for enterprises to better manage large volumes of data. Leveraging it with the latest capabilities will help you stay relevant and neck-to-neck with the competition. Here are a few data warehousing trends that you should keep in mind for 2024 for your data warehousing requirements.
#Data warehousing#cloud Data warehousing#cloud data#data warehouse#2024#trends 2024#data warehousing trends
0 notes
Text
Discover SAP Data Warehouse Cloud: Your Key to Data Transformation!

Hello, Step into the world of SAP Data Warehouse Cloud (SAP DWC) and unlock a new era of data management excellence. Our latest blog post provides an in-depth exploration of SAP DWC's architecture, core components, and features, showcasing how this platform is reshaping the future of data analytics.
Curious to learn more? Explore our blog post now and uncover how SAP DWC can revolutionize the way you manage and leverage your organization's data. Blog Link: (https://www.kaartech.com/sap-data-warehouse-cloud-architecture/)
1 note
·
View note